【中大厂面试题】腾讯 后端 校招 最新面试题
操作系统
进程和线程的区别
-
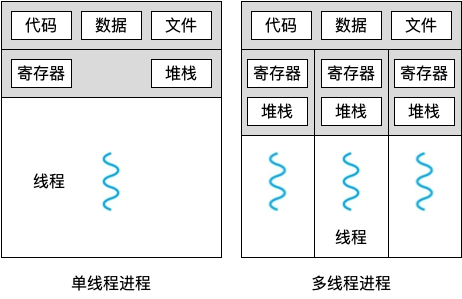
本质区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
-
在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小
-
稳定性方面:进程中某个线程如果崩溃了,可能会导致整个进程都崩溃。而进程中的子进程崩溃,并不会影响其他进程。
-
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源
-
包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程
为什么进程崩溃不会对其他进程产生很大影响
主要是因为:
-
进程隔离性:每个进程都有自己独立的内存空间,当一个进程崩溃时,其内存空间会被操作系统回收,不会影响其他进程的内存空间。这种进程间的隔离性保证了一个进程崩溃不会直接影响其他进程的执行。
-
进程独立性:每个进程都是独立运行的,它们之间不会共享资源,如文件、网络连接等。因此,一个进程的崩溃通常不会对其他进程的资源产生影响。
数据结构
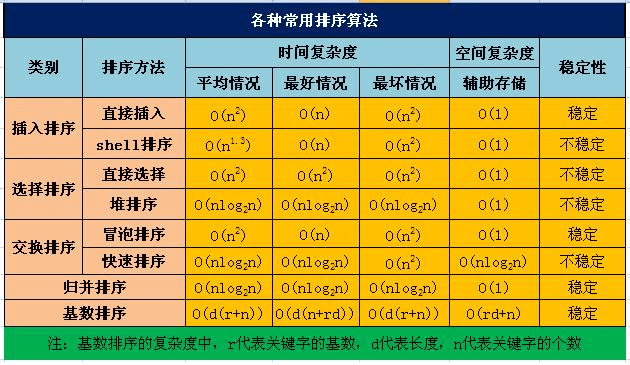
知道哪些排序算法,时间复杂度
-
冒泡排序:通过相邻元素的比较和交换,每次将最大(或最小)的元素逐步“冒泡”到最后(或最前)。时间复杂度:最好情况下O(n),最坏情况下O(n^2),平均情况下O(n^2)。,空间复杂度:O(1)。
-
插入排序:将待排序元素逐个插入到已排序序列的合适位置,形成有序序列。时间复杂度:最好情况下O(n),最坏情况下O(n^2),平均情况下O(n^2),空间复杂度:O(1)。
-
选择排序:通过不断选择未排序部分的最小(或最大)元素,并将其放置在已排序部分的末尾(或开头)。时间复杂度:最好情况下O(n^2),最坏情况下O(n^2),平均情况下O(n^2)。空间复杂度:O(1)。
-
快速排序:通过选择一个基准元素,将数组划分为两个子数组,使得左子数组的元素都小于(或等于)基准元素,右子数组的元素都大于(或等于)基准元素,然后对子数组进行递归排序。时间复杂度:最好情况下O(nlogn),最坏情况下O(n^2),平均情况下O(nlogn)。空间复杂度:最好情况下O(logn),最坏情况下O(n)。
-
归并排序:将数组不断分割为更小的子数组,然后将子数组进行合并,合并过程中进行排序。时间复杂度:最好情况下O(nlogn),最坏情况下O(nlogn),平均情况下O(nlogn)。空间复杂度:O(n)。
-
堆排序:通过将待排序元素构建成一个最大堆(或最小堆),然后将堆顶元素与末尾元素交换,再重新调整堆,重复该过程直到排序完成。时间复杂度:最好情况下O(nlogn),最坏情况下O(nlogn),平均情况下O(nlogn)。空间复杂度:O(1)。
归并排序和快速排序的使用场景
-
归并排序是稳定排序算法,适合排序稳定的场景;
-
快速排序是不稳定排序算法,不适合排序稳定的场景,快速排序是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
排序稳定是什么意思?
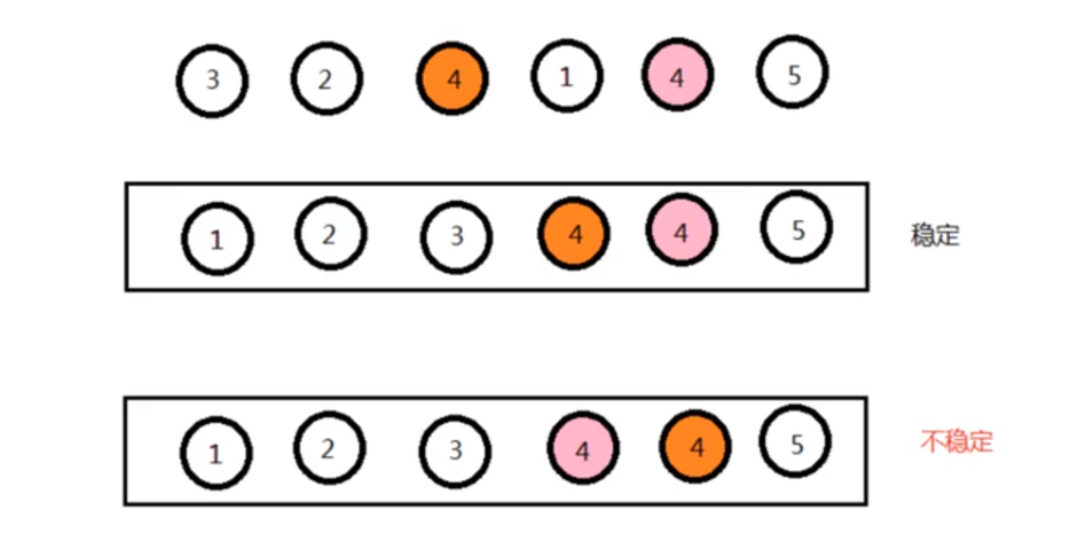
排序稳定指的是在排序过程中,对于具有相同排序关键字的元素,在排序后它们的相对位置保持不变。
换句话说,如果在排序前两个元素 A 和 B 的值相等,并且 A 在 B 的前面,那么在排序后 A 仍然在 B 的前面,这样的排序就是稳定排序。稳定排序保持了相同元素之间的顺序关系,适用于需要保持原始顺序的场景。
稳定和不稳定排序算法有什么特点?
稳定排序算法的特点:
-
相同元素的相对位置不会改变,排序后仍然保持原始顺序。
-
适用于需要保持元素间相对顺序关系的场景,如按照年龄排序后按姓名排序。
不稳定排序算法的特点:
-
相同元素的相对位置可能会改变,排序后不保证原始顺序。
-
可能会更快,但不适用于需要保持元素间相对顺序关系的场景。
MySQL
MySQL 的存储引擎有哪些?为什么常用InnoDB?
MySQL 的存储引擎常用的主要有 3 个:
-
InnoDB存储引擎:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
-
MyISAM存储引擎:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比 较低,也可以使用。如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率
-
MEMORY存储引擎:所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果
常用InnoDB的原因是支持事务,且最小锁的粒度是行级锁。
B+ 树和 B 树的比较
B 树和 B+ 都是通过多叉树的方式,会将树的高度变矮,所以这两个数据结构非常适合检索存于磁盘中的数据。
但是 MySQL 默认的存储引擎 InnoDB 采用的是 B+ 作为索引的数据结构,原因有:
-
B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。
-
B+ 树有大量的冗余节点(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化;
-
B+ 树叶子节点之间用链表连接了起来,有利于范围查询,而 B 树要实现范围查询,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。
除了聚簇索引,还有什么索引?
还有二级索引、联合索引、前缀索引、唯一索引等。
二级索引存放的有哪些数据?
索引又可以分成聚簇索引和非聚簇索引(二级索引),它们区别就在于叶子节点存放的是什么数据:
-
聚簇索引的叶子节点存放的是实际数据,所有完整的用户记录都存放在聚簇索引的叶子节点;
-
二级索引的叶子节点存放的是主键值,而不是实际数据。
索引失效的情况
索引失效的情况:
-
当我们使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效; -
当我们在查询条件中对索引列使用函数,就会导致索引失效。
-
当我们在查询条件中对索引列进行表达式计算,也是无法走索引的。
-
MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。如果字符串是索引列,而条件语句中的输入参数是数字的话,那么索引列会发生隐式类型转换,由于隐式类型转换是通过 CAST 函数实现的,等同于对索引列使用了函数,所以就会导致索引失效。
-
联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
事务隔离级别有哪些?
四个隔离级别如下:
-
读未提交,指一个事务还没提交时,它做的变更就能被其他事务看到;
-
读提交,指一个事务提交之后,它做的变更才能被其他事务看到;
-
可重复读,指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQL InnoDB 引擎的默认隔离级别;
-
串行化;会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行;
按隔离水平高低排序如下:
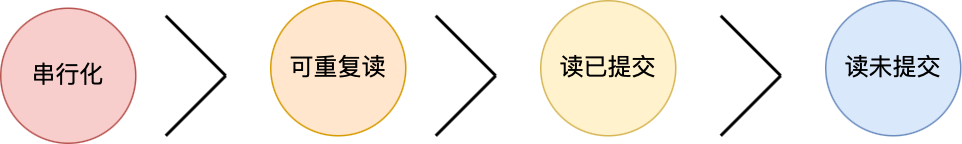
什么情况下会出现幻读?
在一个事务内多次查询某个符合查询条件的「记录数量」,如果出现前后两次查询到的记录数量不一样的情况,就意味着发生了「幻读」现象。
举个栗子。
假设有 A 和 B 这两个事务同时在处理,事务 A 先开始从数据库查询账户余额大于 100 万的记录,发现共有 5 条,然后事务 B 也按相同的搜索条件也是查询出了 5 条记录。
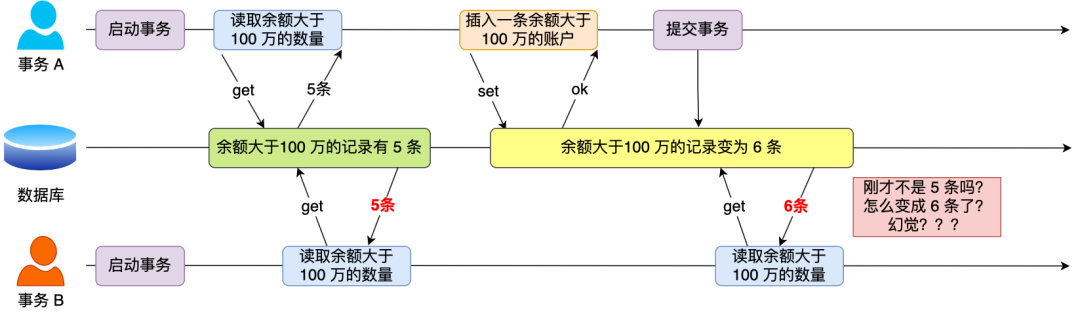
接下来,事务 A 插入了一条余额超过 100 万的账号,并提交了事务,此时数据库超过 100 万余额的账号个数就变为 6。
然后事务 B 再次查询账户余额大于 100 万的记录,此时查询到的记录数量有 6 条,发现和前一次读到的记录数量不一样了,就感觉发生了幻觉一样,这种现象就被称为幻读。
事务的 MVCC 是怎么实现的?
对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同:
-
「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
-
「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,这样就保证了在事务期间读到的数据都是事务启动前的记录。
这两个隔离级别实现是通过「事务的 Read View 里的字段」和「记录中的两个隐藏列」的比对,来控制并发事务访问同一个记录时的行为,这就叫 MVCC(多版本并发控制)。
在创建 Read View 后,我们可以将记录中的 trx_id 划分这三种情况:
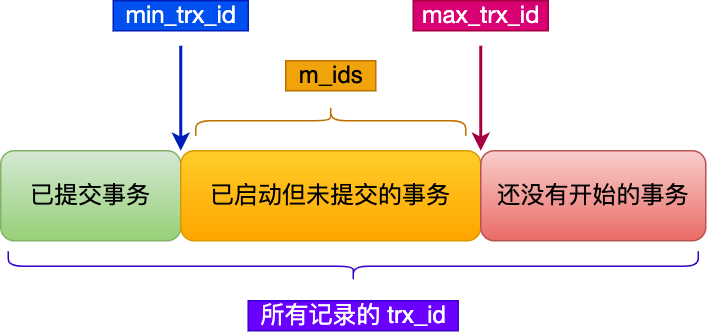
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
-
如果记录的 trx_id 值小于 Read View 中的
min_trx_id值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。 -
如果记录的 trx_id 值大于等于 Read View 中的
max_trx_id值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。 -
如果记录的 trx_id 值在 Read View 的
min_trx_id和max_trx_id之间,需要判断 trx_id 是否在 m_ids 列表中:-
如果记录的 trx_id 在
m_ids列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。 -
如果记录的 trx_id 不在
m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
-
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
事务之间怎么避免脏读的?
针对不同的隔离级别,并发事务时可能发生的现象也会不同。
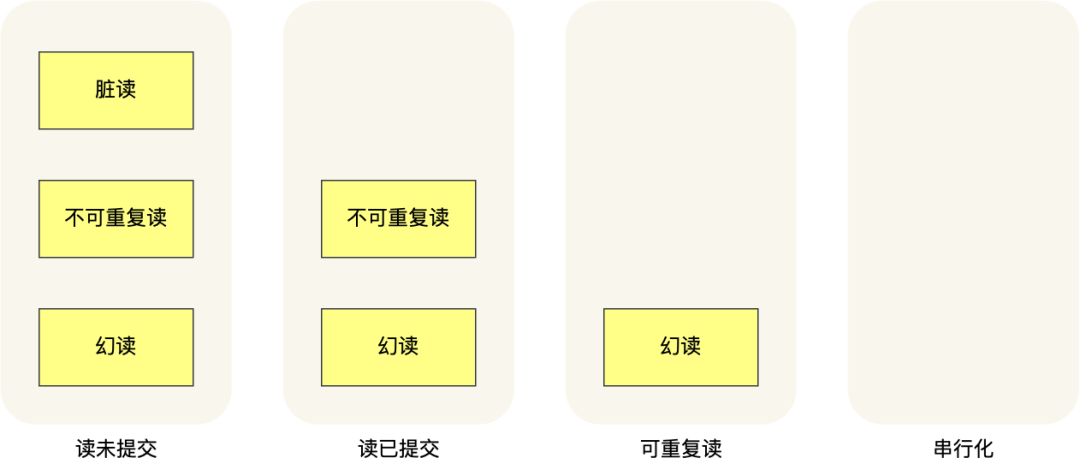
也就是说:
-
在「读未提交」隔离级别下,可能发生脏读、不可重复读和幻读现象;
-
在「读提交」隔离级别下,可能发生不可重复读和幻读现象,但是不可能发生脏读现象;
-
在「可重复读」隔离级别下,可能发生幻读现象,但是不可能脏读和不可重复读现象;
-
在「串行化」隔离级别下,脏读、不可重复读和幻读现象都不可能会发生。
所以,要解决脏读现象,就要升级到「读提交」以上的隔离级别,这样事务只能读到其他事务已经提交完成的数据,而不会读到未提交事务的数据,就避免脏读的问题。
Redis
Redis 支持哪几种数据类型?
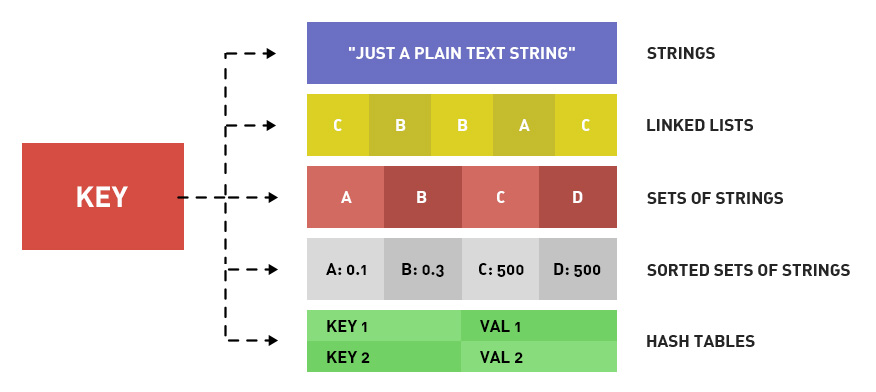
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
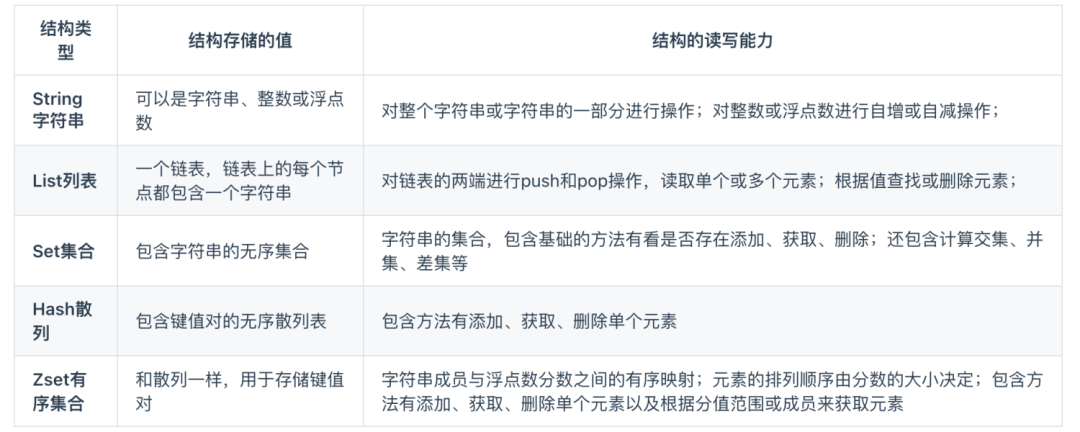
img
随着 Redis 版本的更新,后面又支持了四种数据类型:BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。Redis 五种数据类型的应用场景:
-
String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
-
List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
-
Hash 类型:缓存对象、购物车等。
-
Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
-
Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
-
BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
-
HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
-
GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
-
Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
热 key 是什么?怎么解决?
Redis热key是指被频繁访问的key,可能会导致单个key的访问量过大,影响系统性能。解决方法包括:
-
开启内存淘汰机制,并选择使用LRU算法来淘汰不常用的key,保证内存中存储的是最热门的数据。
-
设置key的过期时间,确保key在一段时间后自动删除,防止长时间占用内存。
-
对热点key进行分片,将数据分散存储在不同的节点上,减轻单个key的压力。
String 是使用什么存储的?为什么不用 c 语言中的字符串?
Redis 的 String 字符串是用 SDS 数据结构存储的。
下图就是 Redis 5.0 的 SDS 的数据结构:

结构中的每个成员变量分别介绍下:
-
len,记录了字符串长度。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。
-
alloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过
alloc - len计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。 -
flags,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,后面在说明区别之处。
-
buf[],字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。
总的来说,Redis 的 SDS 结构在原本字符数组之上,增加了三个元数据:len、alloc、flags,用来解决 C 语言字符串的缺陷。
O(1)复杂度获取字符串长度
C 语言的字符串长度获取 strlen 函数,需要通过遍历的方式来统计字符串长度,时间复杂度是 O(N)。
而 Redis 的 SDS 结构因为加入了 len 成员变量,那么获取字符串长度的时候,直接返回这个成员变量的值就行,所以复杂度只有 O(1)。
二进制安全
因为 SDS 不需要用 “\0” 字符来标识字符串结尾了,而是有个专门的 len 成员变量来记录长度,所以可存储包含 “\0” 的数据。但是 SDS 为了兼容部分 C 语言标准库的函数, SDS 字符串结尾还是会加上 “\0” 字符。
因此, SDS 的 API 都是以处理二进制的方式来处理 SDS 存放在 buf[] 里的数据,程序不会对其中的数据做任何限制,数据写入的时候时什么样的,它被读取时就是什么样的。
通过使用二进制安全的 SDS,而不是 C 字符串,使得 Redis 不仅可以保存文本数据,也可以保存任意格式的二进制数据。
不会发生缓冲区溢出
C 语言的字符串标准库提供的字符串操作函数,大多数(比如 strcat 追加字符串函数)都是不安全的,因为这些函数把缓冲区大小是否满足操作需求的工作交由开发者来保证,程序内部并不会判断缓冲区大小是否足够用,当发生了缓冲区溢出就有可能造成程序异常结束。
所以,Redis 的 SDS 结构里引入了 alloc 和 len 成员变量,这样 SDS API 通过 alloc - len 计算,可以算出剩余可用的空间大小,这样在对字符串做修改操作的时候,就可以由程序内部判断缓冲区大小是否足够用。
而且,当判断出缓冲区大小不够用时,Redis 会自动将扩大 SDS 的空间大小,以满足修改所需的大小。
Java
编译型语言和解释型语言的区别?
编译型语言和解释型语言的区别在于:
-
编译型语言:在程序执行之前,整个源代码会被编译成机器码或者字节码,生成可执行文件。执行时直接运行编译后的代码,速度快,但跨平台性较差。
-
解释型语言:在程序执行时,逐行解释执行源代码,不生成独立的可执行文件。通常由解释器动态解释并执行代码,跨平台性好,但执行速度相对较慢。
-
典型的编译型语言如C、C++,典型的解释型语言如Python、JavaScript。
动态数组的实现有哪些?
ArrayList和Vector都支持动态扩容,都属于动态数组。
ArrayList 和 Vector 的比较
-
线程安全性:Vector是线程安全的,ArrayList不是线程安全的。
-
扩容策略:ArrayList在底层数组不够用时在原来的基础上扩展0.5倍,Vector是扩展1倍。
HashMap 的扩容条件是什么?
Java7 的 HashMap 扩容必须满足两个条件:
-
当前数据存储的数量(即size())大小必须大于等于阈值
-
当前加入的数据是否发生了hash冲突
因为上面这两个条件,所以存在下面这些情况:
-
第一种情况,就是hashmap在存值的时候(默认大小为16,负载因子0.75,阈值12),可能达到最后存满16个值的时候,再存入第17个值才会发生扩容现象,因为前16个值,每个值在底层数组中分别占据一个位置,并没有发生hash碰撞。
-
第二种情况,有可能存储更多值(超多16个值,最多可以存26个值)都还没有扩容。原理:前11个值全部hash碰撞,存到数组的同一个位置(虽然hash冲突,但是这时元素个数小于阈值12,并没有同时满足扩容的两个条件。所以不会扩容),后面所有存入的15个值全部分散到数组剩下的15个位置(这时元素个数大于等于阈值,但是每次存入的元素并没有发生hash碰撞,也没有同时满足扩容的两个条件,所以也不会扩容),前面11+15=26,所以在存入第27个值的时候才同时满足上面两个条件,这时候才会发生扩容现象。
Java8 不再像 Java7中那样需要满足两个条件,Java8中扩容只需要满足一个条件:
-
当前存放新值的时候已有元素的个数大于等于阈值
MQ
用的什么消息队列,消息队列怎么选型的?
项目用的是 RocketMQ 消息队列。选择RocketMQ的原因是:
-
开发语言优势。RocketMQ 使用 Java 语言开发,比起使用 Erlang 开发的 RabbitMQ 来说,有着更容易上手的阅读体验和受众。在遇到 RocketMQ 较为底层的问题时,大部分熟悉 Java 的同学都可以深入阅读其源码,分析、排查问题。
-
社区氛围活跃。RocketMQ 是阿里巴巴开源且内部在大量使用的消息队列,说明 RocketMQ 是的确经得起残酷的生产环境考验的,并且能够针对线上环境复杂的需求场景提供相应的解决方案。
-
特性丰富。根据 RocketMQ 官方文档的列举,其高级特性达到了
12 种,例如顺序消息、事务消息、消息过滤、定时消息等。顺序消息、事务消息、消息过滤、定时消息。RocketMQ 丰富的特性,能够为我们在复杂的业务场景下尽可能多地提供思路及解决方案。
有没有消息积压的问题
导致消息积压突然增加,最粗粒度的原因,只有两种:要么是发送变快了,要么是消费变慢了。
要解决积压的问题,可以通过扩容消费端的实例数来提升总体的消费能力。
如果短时间内没有足够的服务器资源进行扩容,没办法的办法是,将系统降级,通过关闭一些不重要的业务,减少发送方发送的数据量,最低限度让系统还能正常运转,服务一些重要业务。
RocketMQ 消息可靠性怎么保证?
使用一个消息队列,其实就分为三大块:生产者、中间件、消费者,所以要保证消息就是保证三个环节都不能丢失数据。
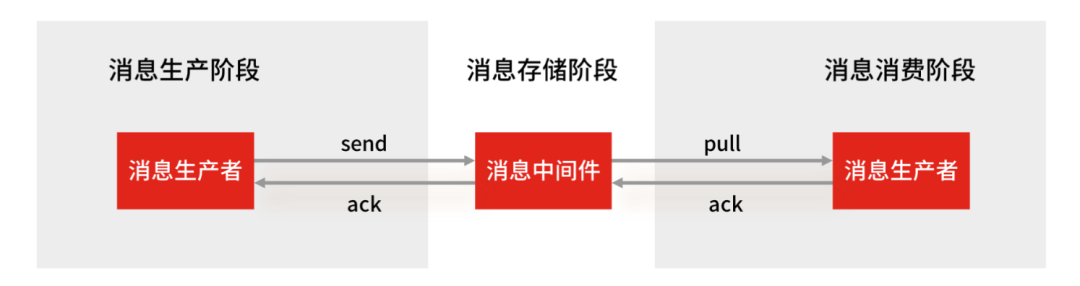
-
消息生产阶段:生产者会不会丢消息,取决于生产者对于异常情况的处理是否合理。从消息被生产出来,然后提交给 MQ 的过程中,只要能正常收到 ( MQ 中间件) 的 ack 确认响应,就表示发送成功,所以只要处理好返回值和异常,如果返回异常则进行消息重发,那么这个阶段是不会出现消息丢失的。
-
消息存储阶段:RabbitMQ 或 Kafka 这类专业的队列中间件,在使用时是部署一个集群,生产者在发布消息时,队列中间件通常会写「多个节点」,也就是有多个副本,这样一来,即便其中一个节点挂了,也能保证集群的数据不丢失。
-
消息消费阶段:消费者接收消息+消息处理之后,才回复 ack 的话,那么消息阶段的消息不会丢失。不能收到消息就回 ack,否则可能消息处理中途挂掉了,消息就丢失了。
Kafka 和 RocketMQ 消息确认机制有什么不同?
Kafka的消息确认机制有三种:0,1,-1:
-
ACK=0:这是最不可靠的模式。生产者在发送消息后不会等待来自服务器的确认。这意味着消息可能会在发送之后丢失,而生产者将无法知道它是否成功到达服务器。
-
ACK=1:这是默认模式,也是一种折衷方式。在这种模式下,生产者会在消息发送后等待来自分区领导者(leader)的确认,但不会等待所有副本(replicas)的确认。这意味着只要消息被写入分区领导者,生产者就会收到确认。如果分区领导者成功写入消息,但在同步到所有副本之前宕机,消息可能会丢失。
-
ACK=-1:这是最可靠的模式。在这种模式下,生产者会在消息发送后等待所有副本的确认。只有在所有副本都成功写入消息后,生产者才会收到确认。这确保了消息的可靠性,但会导致更长的延迟。
RocketMQ 提供了三种消息发送方式:同步发送、异步发送和单向发送:
-
同步发送:是指消息发送方发出一条消息后,会在收到服务端同步响应之后才发下一条消息的通讯方式。应用场景非常广泛,例如重要通知邮件、报名短信通知、营销短信系统等。
-
异步发送:是指发送方发出一条消息后,不等服务端返回响应,接着发送下一条消息的通讯方式,但是需要实现异步发送回调接口(SendCallback)。消息发送方在发送了一条消息后,不需要等待服务端响应即可发送第二条消息。发送方通过回调接口接收服务端响应,并处理响应结果。适用于链路耗时较长,对响应时间较为敏感的业务场景,例如,视频上传后通知启动转码服务,转码完成后通知推送转码结果等。
-
单向发送:发送方只负责发送消息,不等待服务端返回响应且没有回调函数触发,即只发送请求不等待应答。此方式发送消息的过程耗时非常短,一般在微秒级别。适用于某些耗时非常短,但对可靠性要求并不高的场景,例如日志收集。
Kafka 和 RocketMQ 的 broker 架构有什么区别
-
Kafka 的 broker 架构:Kafka 的 broker 架构采用了分布式的设计,每个 Kafka broker 是一个独立的服务实例,负责存储和处理一部分消息数据。Kafka 的 topic 被分区存储在不同的 broker 上,实现了水平扩展和高可用性。
-
RocketMQ 的 broker 架构:RocketMQ 的 broker 架构也是分布式的,但是每个 RocketMQ broker 有主从之分,一个主节点和多个从节点组成一个 broker 集群。主节点负责消息的写入和消费者的拉取,从节点负责消息的复制和消费者的负载均衡,提高了消息的可靠性和可用性。
其他
-
手撕:字符串乘法,输出 2 的 1000 次方
-
反问:流程,业务
相关文章:

【中大厂面试题】腾讯 后端 校招 最新面试题
操作系统 进程和线程的区别 本质区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位 在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销&am…...
 -图)
数据结构第六章(一) -图
数据结构第六章(一) 图一、图的基本概念1.图的分类、度、权等2.路径、回路、连通等3.连通分量、生成树等 二、几种特殊的图1.完全图2.稠密图、稀疏图3.树、有向树 三、常见考点总结 图 一、图的基本概念 感觉要想怎么定义图,图就是顶点和边组…...
)
【技术白皮书】外功心法 | 第三部分 | 数据结构与算法基础(常用的数据结构)
数据结构与算法基础 什么是算法?算法效率查询和排序为什么排序如此重要?思考问题如何确定复杂性数据结构连续或链接的数据结构链表的优点数组的优点数组集合Set 声明的一些方法有Multiset多元集合栈和队列何时使用栈和队列数据字典字典Hash的实现时间复杂度对时间的影响什么是…...

spark简介和安装
spark概念 Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎 spark核心模块 Spark Core Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib 都是在 …...

如何在 CentOS 7 系统上以容器方式部署 GitLab,使用 ZeroNews 通过互联网访问 GitLab 私有仓库,进行代码版本发布与更新
第 1 步: 部署 GitLab 容器 在开始部署 GitLab 容器之前,您需要创建本地目录来存储 GitLab 数据、配置和日志: #创建本地目录 mkdir -p /opt/docker/gitlab/data mkdir -p /opt/docker/gitlab/config mkdir -p /opt/docker/gitlab/log#gi…...

springboot Filter实现请求响应全链路拦截!完整日志监控方案
一、为什么你需要这个过滤器? 日志痛点: 🚨 请求参数散落在各处? 🚨 响应数据无法统一记录? 🚨 日志与业务代码严重耦合? 解决方案: 一个Filter同时拦截请…...

spring mvc 在拦截器、控制器和视图中获取和使用国际化区域信息的完整示例
在拦截器、控制器和视图中获取和使用国际化区域信息的完整示例 1. 核心组件代码示例 1.1 配置类(Spring Boot) import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.spring…...

docker部署jenkins并成功自动化部署微服务
一、环境版本清单: docker 26.1.4JDK 17.0.28Mysql 8.0.27Redis 6.0.5nacos 2.5.1maven 3.8.8jenkins 2.492.2 二、服务架构:有gateway,archives,system这三个服务 三、部署步骤 四、安装linux 五、在linux上安装redis&#…...
)
android 14.0 工厂模式 测试音频的一些问题(高通)
1之前用tinycap,现在得用agmcap 执行----agmcap /data/test.wav -D 100 -d 101 -i CODEC_DMA-LPAIF_RXTX-TX-3 -T 3 报错1 agmcap data/test.wav -D 100 -d 101 -i CODEC_DMA-LPAIF_RXTX-TX-3 -T 3 Failed to open xml file name /vendor/etc/backend_co…...

vue:前端预览 / chrome浏览器设置 / <iframe> 方法预览 doc、pdf / vue-pdf 预览pdf
一、本文目标 <iframe> 方法预览 pdf 、word vue-pdf 预览pdf 二、<iframe> 方法 2.1、iframe 方法预览需要 浏览器 设置为: chrome:设置-隐私设置和安全性-网站设置-更多内容设置-PDF文档 浏览器访问: chrome://settings/co…...

Axure疑难杂症:详解横向菜单左右拖动效果及阈值说明
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! 课程主题:横向菜单左右拖动 主要内容:菜单设计、拖动效果、阈值设计 应用场景:APP横向菜单栏、台账菜单栏、功能选择栏等 案例展示: 案例视频: 横向菜单左右拖动效果 正文内容: 最近很多粉丝私信我,横向…...

多视图几何--立体校正--Bouguet方法
Bouguet算法的数学原理详解 Bouguet算法的核心目标是实现双目相机的极线校正,使左右图像的对应点位于同一水平线上,从而简化立体匹配。其数学原理围绕旋转矩阵分解、极线约束构造和重投影优化展开,以下是分步推导: 一、坐标系定义…...

debian12 mysql完全卸载
MySQL 的数据目录通常是 /var/lib/mysql,配置文件通常在 /etc/mysql 目录下。使用以下命令删除这些目录: sudo rm -rf /var/lib/mysql sudo rm -rf /etc/mysql清理残留文件 sudo find / -name "mysql*" -exec rm -rf {} \; 2>/dev/null验…...

随机动作指令活体检测技术的广泛应用,为人脸识别安全保驾护航
随着人脸识别技术在金融支付、门禁系统、手机解锁等领域的广泛应用,攻击手段也日益多样化,如照片、视频回放、3D面具等伪造方式对系统安全构成严重威胁。传统的人脸识别技术难以区分真实人脸与伪造攻击,正是在这样的背景下,随机动…...
更新内容)
Chrome 135 版本开发者工具(DevTools)更新内容
Chrome 135 版本开发者工具(DevTools)更新内容 一、性能(Performance)面板改进 1. 性能面板中的配置文件和函数调用现已显示来源和脚本链接 Performance > Summary(性能 > 概览)选项卡现在会显示配…...

《算法:以三种算法思想及两种优化策略解决Fibonacci数》
文章目录 0.题目:red_circle:一.递归记忆化搜索**a.普通递归****b.记忆化搜索(优化)**算法讲解: :red_circle:二.前缀和a.算法讲解b.代码示例 :red_circle:三.动态规划滚动数组a.算法讲解b.普通动规代码示例c.滚动数组优化 作者的个人gitee 作者的算法讲…...

定制开发开源AI智能名片S2B2C商城小程序源码中的产品运营协同进化机制研究
摘要 在数字化产品发展进程中,产品经理与运营人员的协同工作机制对产品迭代方向具有决定性作用。本文以定制开发开源AI智能名片S2B2C商城小程序源码为研究对象,通过分析其技术架构中的智能推荐系统、三级账户体系及社交裂变引擎等创新模块,揭…...

Colmap的安装和使用
Colmap 网站: https://colmap.github.io/GitHub: https://github.com/colmap/colmap 安装 Windows 从 GitHub发布页 GitHub Releases 下载预编译的二进制, 区分带CUDA和不带CUDA的版本. Ubuntu 在 Ubuntu 22.04 下可以通过apt install colmap安装, 但是这样安装的是不带C…...

Springboot框架—单元测试操作
Springboot单元测试的操作步骤: 1.添加依赖spring-boot-starter-test 在pom.xml中添加依赖spring-boot-starter-test 2.在src/test/java下新建java class 3.单元测试入口代码结构 import org.junit.Test; import org.junit.runner.RunWith; import org.springfra…...

Elasticearch数据流向
Elasticearch数据流向 数据流向图 --- config: layout: elk look: classic theme: mc --- flowchart LR subgraph s1["图例"] direction TB W["写入流程"] R["读取流程"] end A["Logstash Pipeline"] -- 写入请求 --> B["Elas…...

dB,dBi, dBd, dBc,dBm,dBw释义及区别
贝尔(B) 贝尔(B)最初用于表示音量功率10与1的比值,亚历山大.格拉汉姆.贝尔的名字命名。因此,1B表示功率比10:1,这是一种对数的关系,底数为10,100:12B,1000:13B。即lg(P2/P1)。 可以看出B是一个较大的单位…...

CRM是企业AI Agent应用的关键切入点
CRM(Customer Relationship Management,客户关系管理)是一套用于系统化管理企业与客户交互的技术、策略和流程,旨在优化客户体验、提升忠诚度并驱动业务增长。其核心功能包括客户数据整合(如联系信息、交易记录、行为轨…...
 codepipeline-build-deploy-github-manual)
aws(学习笔记第三十八课) codepipeline-build-deploy-github-manual
文章目录 aws(学习笔记第三十八课) codepipeline-build-deploy-github-manual学习内容:1. 整体架构1.1 代码链接1.2 全体处理架构 2. 代码分析2.1 创建ImageRepo,并设定给FargateTaskDef2.2 创建CodeBuild project2.3 对CodeBuild project赋予权限&#…...
)
【数据分享】1999—2023年地级市市政公用事业和邮政、电信业发展情况相关指标(Shp/Excel格式)
在之前的文章中,我们分享过基于2000-2024年《中国城市统计年鉴》整理的1999-2023年地级市的人口相关数据、染物排放和环境治理相关数据、房地产投资情况和商品房销售面积相关指标数据、社会消费品零售总额和年末金融机构存贷款余额、各类用地面积、地方一般公共预算…...

vscode 跳转失败之c_cpp_properties.json解析
{"configurations": [{"name": "Linux", // 配置名称,对应当前平台,VS Code 中可选"includePath": ["${workspaceFolder}/**", // 包含当前工作区下所有文件夹的头文件(递归&…...

批量将图片转换为 jpg/png/Word/PDF/Excel 等其它格式
图片的格式种类非常的多,常见的图片格式就有 jpg、png、webp、bmp 等等,我们在工作当中经常会碰到需要将一种格式的图片转换为其他格式的需求。今天就给大家介绍一种方法,可以实现批量转换图片格式,支持各种格式的图片之间相互转换…...

MCP+Blender创建电力塔
MCP(Model Context Protocol)与Blender的结合是当前AI与3D建模领域的热门技术,它通过协议化的方式让Claude等AI模型直接控制Blender,实现自动化3D建模。 1. 功能与原理 • 核心能力:用户通过自然语言指令(…...

kafka存储原理
topic分着存储在broker的分区中,分区进一步分为segment。 日志目录中的每一组文件都代表一个段。 段文件名中的后缀表示该段的基本偏移量。 log.segment.bytes表示分段的最大大小。 消息写入分区时,kafka会将这些消息写入段,写满了再创建一个…...
)
Arduino开发物联网ESP32快速入门指南(包含开发语言说明、学习路径和实战教程)
一、Arduino开发语言本质 核心语言:基于C/C的扩展语言,包含Arduino特有的API和库 特点: 去除了C的复杂特性(如STL) 内置硬件操作函数(digitalWrite()、analogRead()等) 支持面向对象编程&…...
》第19章-大数据架构设计理论与实践-01-传统数据处理系统存在的问题)
《系统架构设计师教程(第2版)》第19章-大数据架构设计理论与实践-01-传统数据处理系统存在的问题
文章目录 1. 异步处理队列2. 数据库分区3 读写分离4. 基于Hadoop的 Map/Reduce 管道 1. 异步处理队列 出现的原因:用户访问量增加,数据库无法支撑用户请求的负载,导致数据库服务器无法及时响应用户请求解决:在Web服务器和数据库中…...

Vue接口平台学习五——测试环境页面
一、实现效果图及界面布局简单梳理 这块内容分左侧,中间,右侧三大部分 左侧: 上面一行固定内容,显示icon,名字,一个按钮。下面部分通过v-for循环读取数据库获取的测试环境列表用来展示名称。 中间&#…...

FFMpeg视频编码实战和音频编码实战
视频编码流程 avcodec_find_encoder:首先,通过指定的编码器名称(如H.264、MPEG-4等)找到对应的编码器。avcodec_alloc_context3:为找到的编码器分配一个上下文结构,这个结构包含了编码器所需的各种参数和状…...

vue+uniapp 获取上一页直接传递的参数
在小程序里页面之间跳转有时候需要传递参数给下个页面用 const toDetail item > { uni.navigateTo({ url: /pagesFood/stu/FoodSelection?groupCode1&merchCode2, }); }; 那么下个页面就要获取到这些参数,在实际开发中ÿ…...

各种排序思路及实现
目录 1.排序概念常见的排序算法 2.常见排序算法实现(1)插入排序直接插入排序希尔排序(缩小增量排序) (2)选择排序直接选择排序堆排序 (3)交换排序冒泡排序快速排序(hoare…...

GPT文生图模型新玩法
GPT-4o发布了最新的生图模型GPT-4o-Image,在图像控制力、一致性上实现了显著提升,其表现甚至展现出超越Midjourney的潜力。这款模型不仅能读懂细致的指令,还能赋予照片艺术化的新生命。接下来,我们将介绍几个有趣的实践方向&#…...

uni-app ucharts自定义换行tooltips
实现效果: 第一步:在uni_modules文件夹下找到config-ucharts.js和u-charts.js文件 第二步:在config-ucharts.js文件中配置换行格式 // 换行格式"wrapTooltip":function(item, category, index, opts){return item.name:…...

java 集合进阶
双列集合 map 实例 package mymap;import java.util.HashMap; import java.util.Map;public class MapDemo1 {public static void main(String[] args) {/*V put(K key,v value)添加元素V remove(object key)根据键删除键值对元素void clear()移除所有的键值对元素boolean c…...

RPC 2025/4/8
RPC(Remote Procedure Call),远程过程调用。 应用场景:大型微服务项目,服务部署到不同的服务器上,需要远程调用,可以使用RPC。 两个概念: 远程过程调用本地调用 RPC目的:…...
)
浅层神经网络:全面解析(扩展)
浅层神经网络:全面解析(扩展) 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,可以分享一下给大家。点击跳转到网站。 https://www.captainbed.cn/ccc 一、神经网络架构演进图谱 #mermaid-svg-…...

【Hadoop入门】Hadoop生态之ZooKeeper简介
1 什么是ZooKeeper? 在分布式系统的世界里,协调各节点之间的工作是一项复杂而关键的任务。ZooKeeper正是为解决这一问题而生的开源分布式协调服务,它像一个高效的"和事佬",帮助分布式系统中的各个组件达成一致、同步状态…...
)
树和图论(详细整理,简单易懂!)
树和图论 树的遍历模版 #include <iostream> #include <cstring> #include <vector> #include <queue> // 添加queue头文件 using namespace std;const int MAXN 100; // 假设一个足够大的数组大小 int ls[MAXN], rs[MAXN]; // 定义左右子树数…...
)
CWGAN-GP 原理及实现(pytorch版)
CWGAN-GP 一、CWGAN-GP 原理1.1 CWGAN-GP 的核心改进1.2 CWGAN-GP 的损失函数1.3 CWGAN-GP 的优势1.4 关键参数选择1.5 应用场景 二、CWGAN-GP 实现2.1 导包2.2 数据加载和处理2.3 构建生成器2.4 构建判别器2.5 训练和保存模型2.6 查看训练损失2.7 图片转GIF2.8 模型加载和推理…...

zookeeper平滑扩缩容
在进行ZooKeeper的扩容和缩容操作时,需要注意以下几点: 数据一致性 重要性:ZooKeeper的核心特性之一是保证数据的一致性。在操作过程中,必须确保数据的一致性,以避免数据丢失或损坏。 实现方式:ZooKeeper通…...

Github 热点项目 ChartDB AI自动导表结构+迁移脚本,3分钟生成专业数据库关系图
ChartDB堪称数据库设计神器!亮点①:动动手指输入SQL,秒出结构图,表关系一目了然,团队评审时再也不用画图两小时。亮点②:AI智能转换超贴心,MySQL转PostgreSQL只需点个按钮,跨平台迁移…...

RVOS-1.环境搭建与系统引导
0.环境搭建 riscv-operating-system-mooc: 开放课程《循序渐进,学习开发一个 RISC-V 上的操作系统》配套教材代码仓库。 mirror to https://github.com/plctlab/riscv-operating-system-mooc 在 Ubuntu 20.04 以上环境下我们可以直接使用官方提供的 GNU工具链和 QEM…...

Java List<JSONObject> 转换为 List<实体类>
可以使用 Fastjson 的 toJavaObject 方法直接转换,无需中间序列化步骤。以下是具体实现和注意事项: import com.alibaba.fastjson.JSONObject; import java.util.List; import java.util.stream.Collectors;public class Converter {public static List…...

CesiumEarth v1.12 更新,支持安卓平板离线浏览3DTiles格式的三维倾斜模型
CesiumEarth v1.12 更新 2025年4月8日 阅读需 1 分钟 发布时间:2025年04月08日 新增用户登录: 从1.12版本开始需要通过登录方可使用CesiumEarth 账号可以通过邮箱免费注册 后续将陆续发布云服务相关的功能 发布Desktop版本: Deskt…...

OpenEuler运维实战-系统资源监控与性能优化-CPU·内存·IO
CPU 基本概念定界定位思路常用CPU性能分析工具 基本概念 中央处理器(Central Processing Unit,简称CPU)是计算机的主要设备之一,其功能是解释计算机指令以及处理计算机软件中的数据。 物理核:可以真实看到的CPU核&…...

react实现SVG地图区域中心点呈现圆柱体,不同区域数据不同,圆柱体高度不同
效果图: 代码: import React, { useState, useEffect } from react;const InnerMongoliaMap () > {// 每个区域的数据(名称、中心坐标、圆柱体高度值)const [regionData, setRegionData] useState([{ id: "呼和浩特市…...

Qwen - 14B 怎么实现本地部署,权重参数大小:21GB
Qwen - 14B 权重参数大小:21GB 参数量与模型占用存储空间(GB)是不同概念。Qwen - 14B参数量约140亿 。其模型大小在不同精度下占用存储空间不同,如在一些资料中提到,Qwen - 14B在特定情况下占用空间约21GB 。实际存储…...