各种排序思路及实现
目录
- 1.排序
- 概念
- 常见的排序算法
- 2.常见排序算法实现
- (1)插入排序
- 直接插入排序
- 希尔排序(缩小增量排序)
- (2)选择排序
- 直接选择排序
- 堆排序
- (3)交换排序
- 冒泡排序
- 快速排序(hoare版)
- 快速排序优化
- 快速排序(非递归实现)
- (4)归并排序
- 非递归版本的归并排序
- 归并排序的好处
1.排序
概念
排序就是让一串记录按照某个规定,递增或递减的排列起来的操作
稳定性:稳定性就是在排序前后,两个相同元素的下标前后关系保持不变,如 arr[ i ] ==arr [ j ] , i < j ,排序完成之后这两元素的下标还是前面的小于后面的 , 就称为稳定排序,否则就是不稳定排序
如果出现大范围排序,跳跃交换元素,一般就是不稳定排序
内部排序:数据元素全部放在内存中的排序
外部排序:数据元素太多不能放在内存中,根据排序过程的要求不断的在内外存之间移动数据的排序
内存和外存(硬盘)的区别
1.内存的访问速度比硬盘(外存)快
2.内存的存储空间比硬盘(外存)小
3.内存上的数据断电后就消失了
硬盘的数据断电后还在,能持久的存储数据
常见的排序算法
2.常见排序算法实现
(1)插入排序
直接插入排序
类似于往顺序表中间位置插入元素
该排序是稳定排序
排序方式:
给定一个数组,把这个数组分为两个区间
1.有序区间(已排序区间)
2.无序区间(待排序区间)
初始情况下,该数组是未经排序的,此时认为有序区间是空区间,无序区间是整个数组
每次选择无序区间的一个元素,就把这个元素插入到有序区间的合适位置上(如果前一个比待插入元素大,就交换两元素位置,没有则停止),有序区间扩大一位,无序区间缩小一位,直到无序区间大小为0
时间复杂度:O(N2)
空间复杂度:O(1)
实现:
//实现插入排序private static void insertSort(int[] arr){//每次取出循环的第一个元素插入有序区间//整个循环N-1次//bound就是边界,分出有序和无序区间//有序区间[0,bound)//无序区间[bound,arr.length)for (int bound=1;bound<arr.length;bound++){int val=arr[bound];int cur=bound-1;for (;cur>=0;cur--){if(arr[cur]>val){//如果前面元素比后面大,把前面元素搬运到后面arr[cur+1]=arr[cur];}else break;//找到了要插入的位置,此时cur减了1}arr[cur+1]=val;//完成插入}}
测试一下:
public static void main(String[] args) {int[] arr={9,5,2,7};insertSort(arr);System.out.println(Arrays.toString(arr));}

希尔排序(缩小增量排序)
时间复杂度:O(log n)
最坏情况下:O(N2) => 平均复杂度:O (N1.5)
空间复杂度:O(1)
稳定性:不稳定排序
排序原理:分组进行插入排序
1.先把整个数组分成若干组,在针对每一组分别进行插入排序
引入了gap(间隙)的概念
假设gap为3,每隔三个就是一个组的元素(下图相同下标颜色即为一个组)

希尔排序不是值进行一次,而是要进行若干次的
插排完成后,依次把 gap 设置更小,直到变成 1 为止
希尔排序的好处:
普通的插入排序:
1.如果要排序的数组很短,整体效率就高
2.如果排序的数组基本有序了,整体效率也很高
希尔排序就结合了普通插入排序的两个优势, Gap值大时组长度小,Gap值小时数组相对有序,因此效率更高
实现:
//分组进行插入排序//根据gap值把整个数组分成多个组,针对每个组进行插入排序//此处把gap设为 size/2, size/4 ,size/8....1public static void shellSort(int[] arr){int gap=arr.length/2;while (gap>=1){insertShellSort(arr,gap);//分组插排gap/=2;//逐渐把gap值缩小}}public static void insertShellSort(int[] arr,int gap){for (int bound=gap;bound<arr.length;bound++){//针对每个组第1,2,3.。个元素排序int val=arr[bound];int cur=bound-gap;for (;cur>=0;cur-=gap){//分别对组排序if(arr[cur]>val){arr[cur+gap]=arr[cur];//后移元素(为插入元素挪位置)}else break;//找到了}arr[cur+gap]=val;}}
测试:
public static void main(String[] args) {int[] arr={9,5,2,7};//insertSort(arr);shellSort(arr);System.out.println(Arrays.toString(arr));}

虽然希尔排序效率比普通插入排序高,但还是比不上后面的一些排序算法
(2)选择排序
直接选择排序
时间复杂度:O(N2)
空间复杂度:O(1)
稳定性:不稳定排序
原理:
把整个数组划分成两个部分,前面是有序区间,后面是无序区间
初始情况下,有序区间是空区间
从无序区间中找到最小值(打擂台,以待排序区间的第一个元素位置作为“擂台”,拿后续每个元素都和擂台的元素比较,如果比擂台元素小就交换),把这个值放到无序区间的第一个位置
再把无序区间的第一个元素划分到有序区间,重复上述过程直到无序区间长度为0
实现:
//直接选择排序public static void selectSort(int[] arr){//bound为边界,界定有序和无序区间for(int bound=0;bound<arr.length-1;bound++){for (int cur=bound+1;cur<arr.length;cur++){//cur表示要打擂台的元素位置if(arr[cur]<arr[bound]){//打擂台成功int t=arr[cur];arr[cur]=arr[bound];arr[bound]=t;}}}}
测试运行:
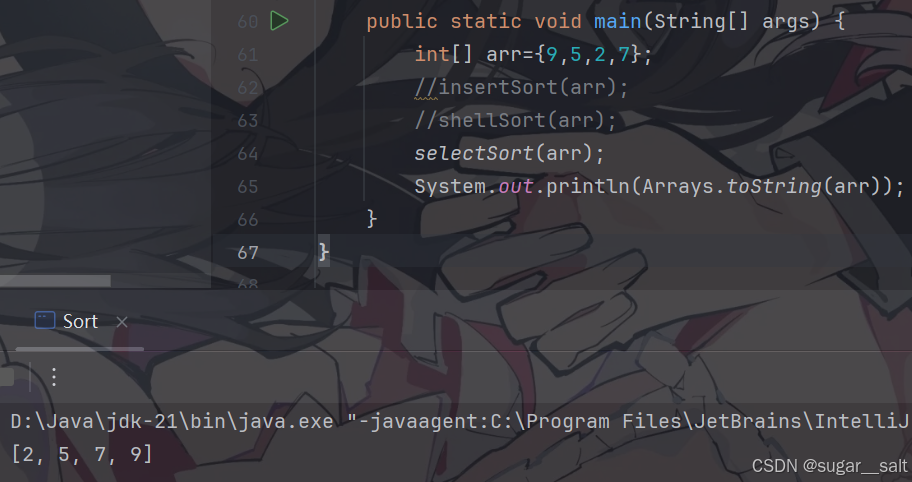
堆排序
时间复杂度:O(NlogN)
空间复杂度:O(1)
稳定性:不稳定排序
堆排序比直接选择排序效率更高,甚至比前面所有排序算法的时间复杂度都低
前面选择排序是已排序在前面,待排序在后面,而堆排序想法,是已排序在后面,待排序在前面
如果要升序排序,就要建立大堆,根据堆顶元素最大的性质,把最大元素放到最后再向下调整,循环往复,直到待排序区间为0
设父节点下标为 i ,左子树下标2i +1,右子树下标2i+2
因为堆的父子下标关系有一个前提,根节点下标是0,所以前半部分不能是已排序区间
堆排序基本思路:
1.针对整个数组建立大堆,初始情况下整个去加都是待排序区间
2.把堆顶(最大元素)和最后一个元素位置交换,无序区间右区间减少一位
3.进行一次向下调整,重回大堆状态
4.重复上述过程,直到无序区间为0
实现:
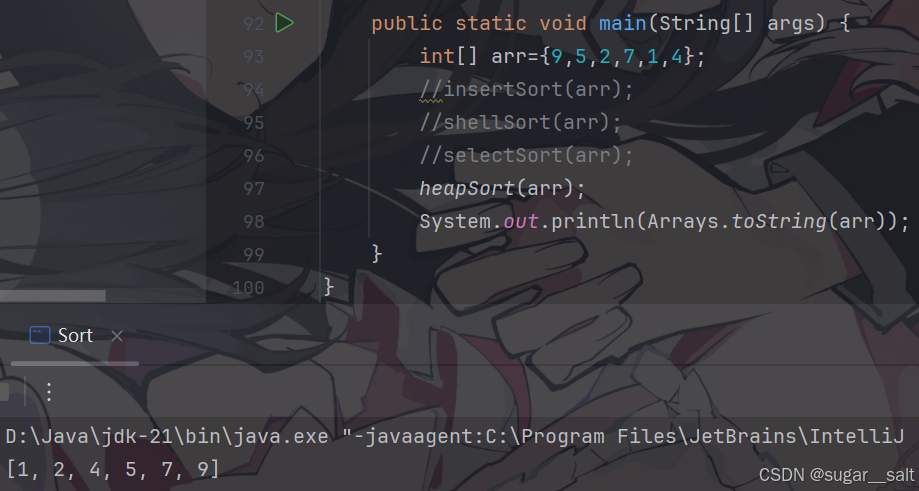
public static void heapSort(int[] arr){createHeap(arr);for (int bound=arr.length-1;bound>=0;bound--){int t=arr[0];arr[0]=arr[bound];arr[bound]=t;shiftDown(arr,bound,0);}}public static void shiftDown(int[] arr,int length,int index){int parent=index;int child=2*parent+1;while (child<length){if(child+1<length && arr[child+1]>arr[child]){child++;}if(arr[child]>arr[parent]){int t=arr[child];arr[child]=arr[parent];arr[parent]=t;}else break;//调整完成parent=child;child=2*parent+1;}}public static void createHeap(int[] arr){for (int i=(arr.length-1-1)/2;i>=0;i--){shiftDown(arr,arr.length,i);}}
测试:
(3)交换排序
冒泡排序
时间复杂度:O(N2)
空间复杂度:O(1)
稳定性:稳定
原理:
比较交换相邻元素
一趟下来就能把最大值放到最后(或从后往前遍历,把最小值放到最前)
实现:
//从后往前遍历实现public static void bubbleSort(int[] arr){for (int i=0;i<arr.length-1;i++){for (int j=arr.length-1;j>i;j--){if(arr[j]<arr[j-1]){int t=arr[j];arr[j]=arr[j-1];arr[j-1]=t;}}}}
快速排序(hoare版)
时间复杂度:最坏情况 [ 待排序序列是反序的 ] 下是O(N2),平均时间复杂度是O(NlogN)
空间复杂度:最坏情况下是O(N),平均是O(logN) ---->因为递归会额外消耗空间
稳定性:不稳定排序
理解分治思想:即把一个大问题拆分成许多个小问题,然后慢慢解决小问题,从而将大问题解决
分治最理想的情况:分出来的左右区间长度差不多
快速排序思想(这里选择最右侧为基准值):
给定一个待排序数组,从数组中选择一个 “ 基准值 ”
拿着数组中的每个元素和基准值比较,把该数组分成三个部分
左侧:比基准值小的元素
中间:基准值
右侧:比基准值大的元素
然后对左右侧递归,重复上述过程(取基准值,分区间),直到区间只有三个或两个元素,排序完成
.
基准值分数组步骤:
1.选定数组最右侧元素为基准值,记录最左侧下标 i 和最右侧下标 j
2.先从左侧找比基准值大的元素(没找到则 i++),再从右侧下标找比基准值小的元素(没找到则 j - - )
第二步会出现两种情况
<1> 左右两侧都找到了元素,就交换两下标位置的元素,然后继续重复第二步
<2> 两下标位置重合,证明找完了(此时因为先从左侧找比基准值大的元素,所以该下标位置元素的值一定比基准值大),把基准值和该下标元素交换
快速排序的基准值也可以选最左侧元素作为基准值,此时要调整思路:
要先从右往左找比基准值小的元素,再从左往右找比基准值大的元素
选取区间最右侧元素作为基准值,代码实现:
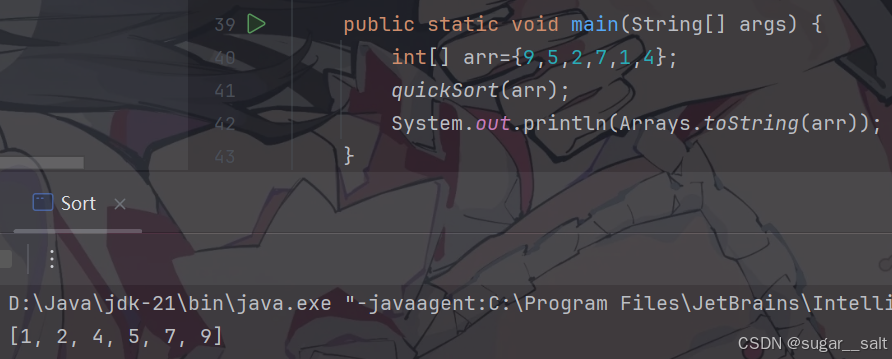
//快速查找,设置基准值为最右侧元素private static void quickSort(int[] arr){quickSort(arr,0,arr.length-1);}//规定区间为[left,right]private static void quickSort(int[] arr,int left,int right){//实现递归if(left>=right) return;int index=partition(arr, left, right);//对区间进行调整,返回调整后基准值下标实现递归quickSort(arr,left,index-1);//对左区间递归调整quickSort(arr,index+1,right);//对右区间递归调整}private static int partition(int[] arr,int left,int right){int l=left;int r=right;while (l<r){while (l<r && arr[right]>arr[l]){//先从左往右找比基准值大的元素l++;}while (l<r && arr[r]>arr[right]){r--;}//两边都找到了,进行交换(就算下标重合交换也没事)swap(arr,l,r);}//最后交换基准值和重合位置元素swap(arr,l,right);return l;//返回基准值下标位置}private static void swap(int[] arr,int left,int right){//交换两元素int t=arr[left];arr[left]=arr[right];arr[right]=t;}
测试:
快速排序优化
1.为了避免反序效率低的极端情况,使用“三数取中” 的策略,即取出数组最左侧,最右侧,中间位置元素,比较三个数的大小,取中间值,再把这个中间值移到 最左侧 / 最右侧,方便后续交换操作
2.当递归到一定程度,每个区间比较小的时候,继续递归依然会消耗很多空间
此时在区间比较小的时候用插入排序速度更快
3.如果是特别大的数组,当地贵到一定深度时,此时区间长度还是比较大,可以使用堆排序对区间进行调整,而非继续递归
快速排序(非递归实现)
思路和上面快速排序一样,只是递归改为用栈模拟实现
static class Range{//保存左右区间int left;int right;public Range(int left, int right) {this.left = left;this.right = right;}}private static void quickSortByStack(int[] arr){Stack<Range> stack=new Stack<>();stack.push(new Range(0,arr.length-1));while (!stack.isEmpty()){Range range=stack.pop();if(range.left>=range.right){continue;}int index=partition(arr,range.left,range.right);stack.push(new Range(range.left,index-1));//向左区间调整stack.push(new Range(index+1,range.right));//向右区间调整}}private static int partition(int[] arr,int left,int right){//就是之前的partitiong方法int l=left;int r=right;while (l<r){while (l<r && arr[right]>arr[l]){//先从左往右找比基准值大的元素l++;}while (l<r && arr[r]>arr[right]){r--;}//两边都找到了,进行交换(就算下标重合交换也没事)swap(arr,l,r);}//最后交换基准值和重合位置元素swap(arr,l,right);return l;//返回基准值下标位置}
(4)归并排序
时间复杂度:O(NlogN)------>和logN相关
空间复杂度:O(N)
递归的空间复杂度:O(logN) ------->分区间是均匀的
由于合并数组要创建临时数组,所以整体复杂度为O(N)
稳定性:稳定排序
它也体现了分治思想
思路:
先把一个无序的数组拆分,如:
假设数组长度为N,先把这些数组对半拆,一直拆到每个区间长度为1,即只有一个元素
再两两合并数组,此时就是有序的数组了,一直合并直到整个区间长度为N
模拟实现:
private static void mergeSort(int[] arr){mergeSort(arr,0,arr.length-1);//递归分区间}private static void mergeSort(int[] arr,int left,int right){//递归取得区间if(left>=right) return;int mid=(left+right)/2;//取得要分开的下标mergeSort(arr,left,mid);//左半区间递归mergeSort(arr,mid+1,right);//右半区间递归//递归完了,对两个区间进行调整merge(arr,left,mid,right);//合并区间}private static void merge(int[] arr,int left,int mid,int right){int[] newArr=new int[right-left+1];int resultSize=0;//记录位置int cur1=left;int cur2=mid+1;while (cur1<=mid && cur2<=right){//模拟顺序表合并if(arr[cur1]<=arr[cur2]){//稳定性取决于这个,两者相等取左边newArr[resultSize++]=arr[cur1];cur1++;}else{newArr[resultSize++]=arr[cur2];cur2++;}}while (cur1<=mid)newArr[resultSize++]=arr[cur1++];while (cur2<=right)newArr[resultSize++]=arr[cur2++];for(int i=0;i<resultSize;i++){//把临时数组的元素放到原数组中arr[left+i]=newArr[i];}}
归并排序与快速排序比较
1.快速排序:平均效率高,但是可能会出现极端情况,使得效率变低(发挥不稳定,忽高忽低)
2.归并排序:平均效率高,而且不存在极端最坏情况(发挥很稳定)
两者相较,归并排序更优
非递归版本的归并排序
时间复杂度和空间复杂度与前面的一致
思路:
数组从小区间开始合并,然后区间长度逐渐增大
实现:
//非递归版本归并排序private static void mergeSortByLoop(int[] arr){for(int size=1;size<arr.length;size*=2){//数组区间长度for(int i=0;i<arr.length;i+=size*2){//对每个小区间合并//左区间[i,i+size] 右区间[i+size+1,i+size*2-1]int left=i;int mid=i+size;if(mid>arr.length-1){//避免超出范围mid=arr.length-1;}int right=i+size*2-1;if(right>arr.length-1){//避免超出范围right=arr.length-1;}merge(arr,left,mid,right);}}}private static void merge(int[] arr,int left,int mid,int right){//和上面的的方法是一样的int[] newArr=new int[right-left+1];int resultSize=0;//记录位置int cur1=left;int cur2=mid+1;while (cur1<=mid && cur2<=right){//模拟顺序表合并if(arr[cur1]<=arr[cur2]){newArr[resultSize++]=arr[cur1];cur1++;}else{newArr[resultSize++]=arr[cur2];cur2++;}}while (cur1<=mid)newArr[resultSize++]=arr[cur1++];while (cur2<=right)newArr[resultSize++]=arr[cur2++];for(int i=0;i<resultSize;i++){//把临时数组的元素放到原数组中arr[left+i]=newArr[i];}}
归并排序的好处
1.归并排序是可以针对链表进行排序的
堆排序/快速排序 (依赖下标)虽然效率都很高,但是只能针对数组,不能针对链表
归并排序是链表的高效排序的做法
2.归并排序,对于海量数据(数据太多,内存无法同时保存下),也是能够处理的
其他排序都要求所有数据必须同时在内存中才可以进行
例如有1000G的数据要排序,归并排序会先把1000GB拆分成1000个1GB,分别对1GB排序,再把这些数据合并
上述排序算法中,实用的排序
堆排序,快速排序,归并排序
相关文章:

各种排序思路及实现
目录 1.排序概念常见的排序算法 2.常见排序算法实现(1)插入排序直接插入排序希尔排序(缩小增量排序) (2)选择排序直接选择排序堆排序 (3)交换排序冒泡排序快速排序(hoare…...

GPT文生图模型新玩法
GPT-4o发布了最新的生图模型GPT-4o-Image,在图像控制力、一致性上实现了显著提升,其表现甚至展现出超越Midjourney的潜力。这款模型不仅能读懂细致的指令,还能赋予照片艺术化的新生命。接下来,我们将介绍几个有趣的实践方向&#…...

uni-app ucharts自定义换行tooltips
实现效果: 第一步:在uni_modules文件夹下找到config-ucharts.js和u-charts.js文件 第二步:在config-ucharts.js文件中配置换行格式 // 换行格式"wrapTooltip":function(item, category, index, opts){return item.name:…...

java 集合进阶
双列集合 map 实例 package mymap;import java.util.HashMap; import java.util.Map;public class MapDemo1 {public static void main(String[] args) {/*V put(K key,v value)添加元素V remove(object key)根据键删除键值对元素void clear()移除所有的键值对元素boolean c…...

RPC 2025/4/8
RPC(Remote Procedure Call),远程过程调用。 应用场景:大型微服务项目,服务部署到不同的服务器上,需要远程调用,可以使用RPC。 两个概念: 远程过程调用本地调用 RPC目的:…...
)
浅层神经网络:全面解析(扩展)
浅层神经网络:全面解析(扩展) 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,可以分享一下给大家。点击跳转到网站。 https://www.captainbed.cn/ccc 一、神经网络架构演进图谱 #mermaid-svg-…...

【Hadoop入门】Hadoop生态之ZooKeeper简介
1 什么是ZooKeeper? 在分布式系统的世界里,协调各节点之间的工作是一项复杂而关键的任务。ZooKeeper正是为解决这一问题而生的开源分布式协调服务,它像一个高效的"和事佬",帮助分布式系统中的各个组件达成一致、同步状态…...
)
树和图论(详细整理,简单易懂!)
树和图论 树的遍历模版 #include <iostream> #include <cstring> #include <vector> #include <queue> // 添加queue头文件 using namespace std;const int MAXN 100; // 假设一个足够大的数组大小 int ls[MAXN], rs[MAXN]; // 定义左右子树数…...
)
CWGAN-GP 原理及实现(pytorch版)
CWGAN-GP 一、CWGAN-GP 原理1.1 CWGAN-GP 的核心改进1.2 CWGAN-GP 的损失函数1.3 CWGAN-GP 的优势1.4 关键参数选择1.5 应用场景 二、CWGAN-GP 实现2.1 导包2.2 数据加载和处理2.3 构建生成器2.4 构建判别器2.5 训练和保存模型2.6 查看训练损失2.7 图片转GIF2.8 模型加载和推理…...

zookeeper平滑扩缩容
在进行ZooKeeper的扩容和缩容操作时,需要注意以下几点: 数据一致性 重要性:ZooKeeper的核心特性之一是保证数据的一致性。在操作过程中,必须确保数据的一致性,以避免数据丢失或损坏。 实现方式:ZooKeeper通…...

Github 热点项目 ChartDB AI自动导表结构+迁移脚本,3分钟生成专业数据库关系图
ChartDB堪称数据库设计神器!亮点①:动动手指输入SQL,秒出结构图,表关系一目了然,团队评审时再也不用画图两小时。亮点②:AI智能转换超贴心,MySQL转PostgreSQL只需点个按钮,跨平台迁移…...

RVOS-1.环境搭建与系统引导
0.环境搭建 riscv-operating-system-mooc: 开放课程《循序渐进,学习开发一个 RISC-V 上的操作系统》配套教材代码仓库。 mirror to https://github.com/plctlab/riscv-operating-system-mooc 在 Ubuntu 20.04 以上环境下我们可以直接使用官方提供的 GNU工具链和 QEM…...

Java List<JSONObject> 转换为 List<实体类>
可以使用 Fastjson 的 toJavaObject 方法直接转换,无需中间序列化步骤。以下是具体实现和注意事项: import com.alibaba.fastjson.JSONObject; import java.util.List; import java.util.stream.Collectors;public class Converter {public static List…...

CesiumEarth v1.12 更新,支持安卓平板离线浏览3DTiles格式的三维倾斜模型
CesiumEarth v1.12 更新 2025年4月8日 阅读需 1 分钟 发布时间:2025年04月08日 新增用户登录: 从1.12版本开始需要通过登录方可使用CesiumEarth 账号可以通过邮箱免费注册 后续将陆续发布云服务相关的功能 发布Desktop版本: Deskt…...

OpenEuler运维实战-系统资源监控与性能优化-CPU·内存·IO
CPU 基本概念定界定位思路常用CPU性能分析工具 基本概念 中央处理器(Central Processing Unit,简称CPU)是计算机的主要设备之一,其功能是解释计算机指令以及处理计算机软件中的数据。 物理核:可以真实看到的CPU核&…...

react实现SVG地图区域中心点呈现圆柱体,不同区域数据不同,圆柱体高度不同
效果图: 代码: import React, { useState, useEffect } from react;const InnerMongoliaMap () > {// 每个区域的数据(名称、中心坐标、圆柱体高度值)const [regionData, setRegionData] useState([{ id: "呼和浩特市…...

Qwen - 14B 怎么实现本地部署,权重参数大小:21GB
Qwen - 14B 权重参数大小:21GB 参数量与模型占用存储空间(GB)是不同概念。Qwen - 14B参数量约140亿 。其模型大小在不同精度下占用存储空间不同,如在一些资料中提到,Qwen - 14B在特定情况下占用空间约21GB 。实际存储…...

线程实现参考资料
参考 并发编程系列 - Java线程池监控及CompletableFuture详解_taskexecutor.execute没有执行如何监控到-CSDN博客 JAVA异步实现的四种方式_java异步编程的四种方法-CSDN博客 Java线程池深度解析与自定义实战-CSDN博客 Java8 CompletableFuture 异步多线程的实现_java_脚本之…...

python-63-前后端分离之图书管理系统的Flask后端
文章目录 1 flask后端1.1 数据库实例extension.py1.2 数据模型models.py1.3 .flaskenv1.4 app.py1.5 运行1.6 测试链接2 关键函数和文件2.1 请求视图类MethodView2.2 .flaskenv文件3 参考附录基于flask形成了图书管理系统的后端,同时对其中使用到的关键文件.flaskenv和函数类M…...

Qt网络编程之服务端
Qt网络编程之服务端 TCP(传输控制协议)是一种可靠的、面向流的、面向连接的传输协议。它特别适合连续的数据传输。 1. 主要类和函数 1.1 QTcpServer 监听函数: bool QTcpServer::listen(const QHostAddress &address QHostAddress::…...

案例-流量统计
1.建一个data目录,在data下建log.txt文件 输入手机号码 上行流量 下行流量 2.在com.example.flow下建四个Java类3.flowBean flowMapper flowReducer flowDriver...
管理员引导和恢复)
开源身份和访问管理方案之keycloak(二)管理员引导和恢复
文章目录 开源身份和访问管理方案之keycloak(二)管理员引导和恢复管理员引导和恢复在 Keycloak 启动时引导临时管理员帐户对于恢复丢失的管理员访问权限使用专用命令引导管理员用户或服务帐户创建一个管理员用户创建一个服务账号重新获得对具有更高安全性…...

TCP,UDP协议和域名地址
1.TCP(传输控制协议)是面向连接,UDP(用户数据报协议)是无连接的 2.应用层:FTP,HTTP,SMTP,TELNET,DNS,TFTP 传输层;TCP,UDP 网际层:IP,ICMP,ARP,RARP 3.TCP21:20端口数据传输;21端…...

算法进阶指南 分形
问题描述 分形,具有以非整数维形式充填空间的形态特征。通常被定义为: “一个粗糙或零碎的几何形状,可以分成数个部分,且每一部分都(至少近似地)是整体缩小后的形状”,即具有自相似的性质。 现…...

2025年 npm淘宝镜像最新地址
查看当前镜像 npm config get registry 切换陶宝镜像源 npm config set registry https://registry.npmmirror.com/ 验证npm镜像源是否切换成功 npm config get registry 如果返回的地址是https://registry.npmmirror.com/,那么说明你已经成功切换到淘宝的npm…...

0基础 | 硬件 | LM386芯片
LM386芯片:音频功率放大器芯片 内部集成三极管功能将微弱信号放大20-200倍,并且驱动内阻为8Ω的扬声器注意CD系列芯片,内部集成MOS管 LM386特性 LM386主要由以下三个部分组成 内部电路 差分输入 差分输入 多个三极管左右对称,形…...

Spring Boot集成APK Parser库实现APK文件解析
目录 1. 添加依赖 2. 创建APK解析服务 3. 创建控制器 4. 测试 注意事项 在Spring Boot项目中集成APK Parser库并解析APK文件,可以按照以下步骤进行操作: 1. 添加依赖 在项目的pom.xml文件中添加apk-parser库的依赖: <dependency&…...

java基础 迭代Iterable接口以及迭代器Iterator
Itera迭代 Iterable < T>迭代接口(1) Iterator iterator()(2) forEach(Consumer<? super T> action)forEach结合Consumer常见场景forEach使用注意细节 (3)Spliterator spliterator() Iterator< T>迭代器接口如何“接收” Iterator<T>核心方法迭代器的…...

Linux: network: tcpdump: packets dropped by kernel
文章目录 最近遇到一个问题原因libpcap/tcpdump 接口linux/libpcap 接口内核的处理原因可能有以下几种:解决方法:man pcap_stats最近遇到一个问题 tcpdump命令显示有dropped的包,而且是被内核drop的。 [root@-one-01 ~]# tcpdump -i any udp and port 8080 -v -w /root/udp…...

TCP三次握手和TCP四次挥手
一 TCP三次握手 TCP建立连接的过程叫做握手,握手需要客户端和服务器之间交换三个TCP报文段。如图所示,假设主机A为TCP客户端,主机B为TCP服务端。在最初时间,两端的TCP进程都是处于CLOSED状态 (1)主机A主动…...

博途 TIA Portal之1200做主站与调试助手的TCP通讯
博途支持的通讯非常多,常见的有S7、TCP/IP,UDP等等,本文将演示TCP的通讯,通讯的双方是1200PLC和调试助手之间,编程采用ST语言。 1、硬件准备 1200PLC一台,带调试助手的PC机一台,调试助手是我经…...

第十天 - socket编程基础 - TCP/UDP服务开发 - 练习:简易端口扫描器
Python网络编程入门:从Socket到端口扫描器实战 一、前言:为什么要学网络编程? 在这个万物互联的时代,掌握网络编程技术就像拥有了一把打开互联网世界的钥匙。无论是开发聊天软件、网络游戏,还是构建分布式系统&#…...

欧税通香港分公司办公室正式乔迁至海港城!
3月20日,欧税通香港分公司办公室正式乔迁至香港油尖旺区的核心商业区海港城!左手挽着内地市场,右手牵起国际航道——这波乔迁选址操作堪称“地理课代表”! 乔迁仪式秒变行业大联欢!感谢亚马逊合规团队、亚马逊云、阿里国际站、Wayfair、coupang、美客多…...

Maven的安装配置-项目管理工具
各位看官,大家早安午安晚安呀~~~ 如果您觉得这篇文章对您有帮助的话 欢迎您一键三连,小编尽全力做到更好 欢迎您分享给更多人哦 今天我们来学习:Maven的安装配置-项目管理工具 目录 1.什么是Maven?Maven用来干什么的?…...

【Linux篇】缓冲区的工作原理:如何影响你程序的输入输出速度
从内存到磁盘:缓冲区如何提升文件I/O效率 一. 缓冲区1.1 什么是缓冲区1.2 为什么要引入缓冲区1.3 缓冲区类型1.4 FILE1.4.1 基本概念1.4.2 FILE 结构体的作用1.4.3 FILE 的工作机制 二. 最后 在程序开发中,缓冲区是一个经常被提及却不容易深入理解的概念…...

编写junit测试类 import org.junit.Test;
1. 添加依赖 <!-- Spring Boot Starter Test --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> 2. …...

初识数据结构——深入理解LinkedList与链表:吃透LinkedList与链表的终极指南
📌 深入理解LinkedList与链表:从原理到实战应用 🌟 引言 在Java集合框架中,LinkedList和ArrayList是最常用的两种列表结构。它们各有优劣,适用于不同的场景。本文将带你深入探索LinkedList的底层实现——链表&#x…...

C++版Qt之登录界面设计
在C开发中,使用Qt框架可以快速构建美观且功能强大的GUI应用程序。本文将介绍如何设计一个漂亮的登录界面,包括账号和密码输入框,并确保只有验证成功后才能进入主窗口。 项目结构 文件列表 LoginDialog.h:登录对话框的头文件Logi…...
)
Java logback框架日志输出中文乱码的解决方案(windows)
在Java开发中,日志记录是一个重要的部分,它可以帮我们定位问题、运行时监控、错误排查与故障恢复。但是,在有些情况下,使用Logback记录的中文日志会出现乱码,这会影响日志的可读性,给维护带来麻烦。本文将探…...

【c++】c/c++内存管理
小编个人主页详情<—请点击 小编个人gitee代码仓库<—请点击 c系列专栏<—请点击 倘若命中无此运,孤身亦可登昆仑,送给屏幕面前的读者朋友们和小编自己! 目录 前言一、c语言内存管理二、一图搞懂c/c中的程序内存区域划分三、c内存管理1. new和d…...

【C++】Stack Queue 仿函数
📝前言: 这篇文章我们来讲讲STL中的stack和queue。因为前面我们已经有了string、vector和list的学习基础,所以这篇文章主要关注一些stack和queue的细节问题,以及了解一下deque(缝合怪)和priority_queue &am…...

Python:基于Flask框架的数据可视化系统
以下是一个基于Flask框架的数据可视化系统代码示例,包含核心功能实现: python 复制 # app.py 后端核心代码 from flask import Flask, render_template, jsonify import sqlite3 from collections import defaultdict import jieba import reapp Fla…...
)
JVM即时编译(JIT)
JVM基础回顾 Java 作为一门高级程序语言,由于它自身的语言特性,它并非直接在硬件上运行,而是通过编译器(前端编译器)将 Java 程序转换成该虚拟机所能识别的指令序列,也就是字节码,然后运行在虚拟机之上的;…...

JVM高阶架构:并发模型×黑科技×未来趋势解析
🚀前言 “你是否还在为synchronized锁竞争头疼?是否好奇ZGC如何实现亚毫秒停顿?Java的未来将走向何方? 本文将带你深入JVM最硬核的三大领域: 并发模型:揭秘happens-before如何保证多线程安全(…...

Java的JDK、JRE、JVM关系与作用
Java的JDK、JRE、JVM关系与作用 java中的JDK、JRE和JVM是三个核心组件,各自承担不同角色,且存在层级依赖关系 1. JVM(Java Virtual Machine,Java虚拟机) 是什么: JVM是虚拟的计算机,能够执行…...

XMLHttpRequest vs Fetch API:一场跨越时代的“浏览器宫斗剧“
## 序幕:两个API的"身世之谜" 在Web开发的江湖里,XMLHttpRequest(简称XHR)就像一位身经百战的老将,而Fetch API则是手持光剑的绝地武士。让我们先来段"DNA检测": - **XHR(…...

Windows Anaconda使用Sentence-BERT获取句子向量
1、安装Anaconda: Anaconda是一个流行的Python数据科学平台,它包含了许多科学计算和数据分析的库,包括transformers和sentence_transformers。虽然不是必需的,但使用Anaconda可以简化环境管理和依赖安装的过程。 可以从Anaconda官…...

【Java设计模式】第5章 工厂方法模式讲解
5. 工厂方法模式 5.1 工厂方法讲解 定义:定义一个创建对象的接口,由子类决定实例化的类,将对象创建延迟到子类。适用场景: 创建对象需要大量重复代码。客户端不依赖具体产品的创建细节。优点: 符合开闭原则,新增产品只需扩展子类。客户端仅依赖抽象接口,不依赖具体实现…...

结合 Less + CSS 变量实现切换主题
一开始的思路是通过 Less 变量作用范围 来切换 light 和 dark 主题,但 Less 本身不会动态监听类名变化,所以直接这样写是 不可行的,因为 Less 是 预处理语言,它在编译阶段就确定了 color 的值,而不是在运行时动态切换。…...

数据分析之python处理常用复杂转置数据
前段时间根据需求配合ai写了个转置excel代码,挺好用的,而且可以选择excel,不局限于excel存在哪个地方,都可以转置,但是转置后的excel记得要先创建放在转置文件的目录下。 原本的数据长这样 转置后则可以变为这样&…...