PyTorch 线性回归详解:模型定义、保存、加载与网络结构
目录
- 前言
- 一、pytorch框架线性回归
- 1.1 pytorch模型的定义
- 1.2 nn.Sequential()
- 1.2.1 nn.Linear
- 1.2.2 nn.Sequential
- 1.3 nn.ModuleList()
- 1.4 nn.ModuleDict()
- 1.5 nn.Module
- 二、pytorch模型的保存
- 2.1 保存模型的权重和其他参数
- 2.1.1 torch.save()保存字典
- 总结
前言
书接上文
自求导实现线性回归与PyTorch张量详解-CSDN博客文章浏览阅读1.1k次,点赞34次,收藏19次。本文围绕自求导方法实现线性回归算法展开,详细介绍了算法的理论基础、参数初始化、损失函数设计、迭代过程及反向传播求导机制,并通过Python代码实现线性回归模型训练和可视化,直观呈现模型优化轨迹和损失变化。同时,文章深入讲解了PyTorch框架中的tensor概念,解析了tensor的存储结构、数据类型、步长和偏移,重点阐述了tensor连续性与非连续性的区别及其对计算效率的影响,并介绍了contiguous()方法用于解决非连续tensor问题,结合丰富代码示例,帮助读者理解并掌握PyTorch tensohttps://blog.csdn.net/qq_58364361/article/details/147292669?spm=1011.2415.3001.10575&sharefrom=mp_manage_link
一、pytorch框架线性回归
从以下5个方面对深度学习框架Pytorch框架线性回归进行介绍
1.pytorch模型的定义
2.pytorch模型的保存
3.pytorch模型的加载
4.pytorch模型网络结构的查看
5.pytorch框架线性回归的代码实现
上面这5方面的内容,让大家,掌握并理解pytorch框架实现线性回归的过程。
1.1 pytorch模型的定义
torch.nn下的容器
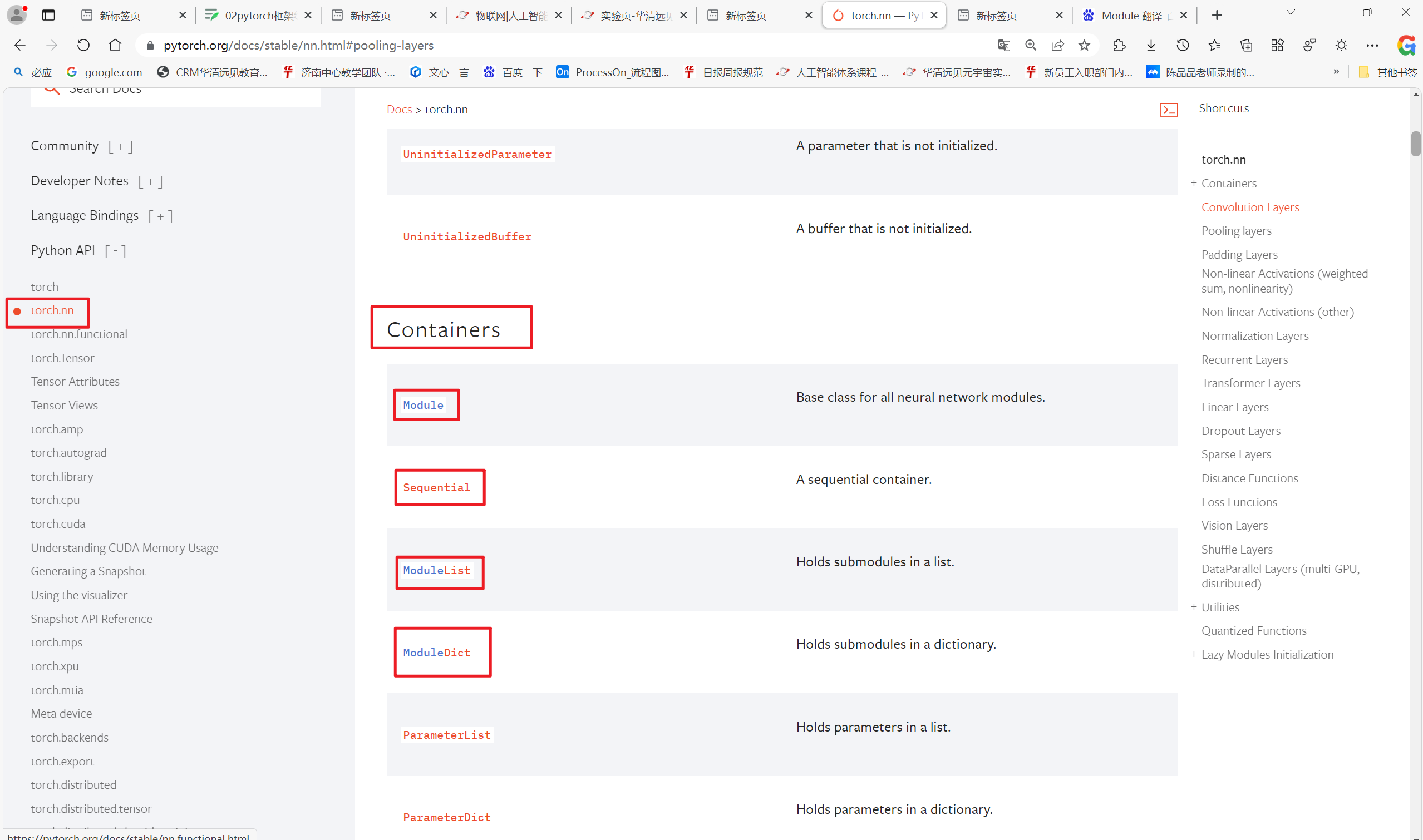
1.2 nn.Sequential()
在nn.Containers下的nn.Sequential()
nn.Sequential()是pytorch的容器,按照顺序组合多个网络层,有forward方法。
注意:forward 方法是输入数据后进行模型调用的(pytorch包含的,如果有forward自动调用,如果没有不调用)

1.2.1 nn.Linear

import torch
import torch.nn as nn# 定义一个线性层,输入特征维度为3,输出特征维度为200
m = nn.Linear(3, 200)# 构造输入张量,包含4个样本,每个样本3个特征,数据类型为float32
input = torch.tensor([[1, 2, 3],[3, 4, 5],[6, 7, 8],[9, 10, 11]], dtype=torch.float32)# 将输入数据传入线性层,得到输出张量
output = m(input)# 打印输出张量的形状,结果应为(4, 200),4个样本每个样本200个特征
print(output.shape)D:\python_huanjing\.venv1\Scripts\python.exe C:\Users\98317\PycharmProjects\study_python\机器学习\day4_18.py
torch.Size([4, 200])进程已结束,退出代码为 01.2.2 nn.Sequential

import torch
import numpy as np# 定义包含10组样本的二维数据集,每组包括输入特征和目标值
data = [[-0.5, 7.7],[1.8, 98.5],[0.9, 57.8],[0.4, 39.2],[-1.4, -15.7],[-1.4, -37.3],[-1.8, -49.1],[1.5, 75.6],[0.4, 34.0],[0.8, 62.3]]
# 转换为NumPy数组,方便切片操作
data = np.array(data)# 提取输入特征x和目标值y
x_data = data[:, 0]
y_data = data[:, 1]# 转换为PyTorch张量,数据类型为float32,满足模型输入要求
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)# 导入神经网络模块
import torch.nn as nn# 构建线性回归模型,包含一个输入节点和一个输出节点的线性层
model = nn.Sequential(nn.Linear(1, 1))# 定义均方误差损失函数,用于回归任务衡量误差
criterion = nn.MSELoss()# 采用随机梯度下降优化器,设置学习率为0.01,用于优化模型参数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练模型,循环500次迭代
epoches = 500
for n in range(1, epoches + 1):# 将一维输入张量升维为二维,以适应Linear层输入要求(batch_size, 1)x_train_2d = x_train.unsqueeze(1)# 前向传播计算预测输出,输出形状为(batch_size, 1)y_pre = model(x_train_2d)# 计算预测值与真实值的均方误差,需将预测输出压缩为一维loss = criterion(y_pre.squeeze(1), y_train)# 梯度清零,防止梯度累积影响更新optimizer.zero_grad()# 反向传播计算梯度loss.backward()# 更新模型参数optimizer.step()# 每第1轮及之后每隔10轮输出一次当前迭代次数和损失值if n % 10 == 0 or n == 1:print(f"epoches:{n},loss:{loss}")
1.3 nn.ModuleList()
nn.ModuleList() 和python的基础数据类型list类似,不按照顺序,没有forward方法,不可以定义名字,可以用append加网络。
如果使用需要重写继承nn.Module
import torch
import numpy as np# 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8],[0.4, 39.2], [-1.4, -15.7],[-1.4, -37.3], [-1.8, -49.1],[1.5, 75.6], [0.4, 34.0],[0.8, 62.3]]
# 转换为 NumPy 数组
data = np.array(data)
# 提取 x_data 和 y_data
x_data = data[:, 0]
y_data = data[:, 1]
# 将数据转换为 Tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)# 构建模型
import torch.nn as nn # 导入 PyTorch 的神经网络模块# 使用 ModuleList 的线性模型
class LinearModel(nn.Module):# 初始化方法def __init__(self):super(LinearModel, self).__init__()# 定义一个包含一个线性层的 ModuleListself.layers = nn.ModuleList([nn.Linear(1, 1)])# 前向传播方法def forward(self, x):# 遍历所有层进行计算for layer in self.layers:x = layer(x)return x# 初始化模型
model = LinearModel()# 定义损失函数
criterion = nn.MSELoss()
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 迭代训练
epoches = 500
for n in range(1, epoches + 1):# 增加维度以匹配模型输入x_train_add_dim = x_train.unsqueeze(1)# 前向传播y_pre = model(x_train_add_dim)# 计算损失loss = criterion(y_pre.squeeze(1), y_train)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 更新参数optimizer.step()# 打印损失if n % 10 == 0 or n == 1:print(f"epoches:{n},loss:{loss}")
1.4 nn.ModuleDict()
nn.ModuleDict(),和dict类似,不按照顺序,没有forward方法,可以定义每层的名字
import torch
import numpy as np# 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8],[0.4, 39.2], [-1.4, -15.7],[-1.4, -37.3], [-1.8, -49.1],[1.5, 75.6], [0.4, 34.0],[0.8, 62.3]]
# 转换为 NumPy 数组
data = np.array(data)
# 提取 x_data 和 y_data
x_data = data[:, 0]
y_data = data[:, 1]
# 将数据转换为 Tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)import torch.nn as nn# 使用 ModuleList 的线性模型
class LinearModelDict(nn.Module):def __init__(self):super(LinearModelDict, self).__init__()self.layers_dict = nn.ModuleDict({'linear1': nn.Linear(1, 1)}) # 定义一个包含线性层的 ModuleDictdef forward(self, x):for key in self.layers_dict:x = self.layers_dict[key](x) # 遍历 ModuleDict 中的每一层并应用到输入数据 xreturn x# 初始化模型
model = LinearModelDict()# 定义损失函数
criterion = nn.MSELoss()
# 选择优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 使用随机梯度下降(SGD)优化器# 迭代训练
epoches = 500
for n in range(1, epoches + 1):x_train_add_dim = x_train.unsqueeze(1) # 增加维度以适应模型输入y_pre = model(x_train_add_dim) # 前向传播,获取预测值# 计算损失loss = criterion(y_pre.squeeze(1), y_train) # 计算预测值和真实值之间的均方误差# 梯度更新optimizer.zero_grad() # 清空之前的梯度# 计算损失函数对模型参数的梯度loss.backward() # 反向传播,计算梯度# 根据优化算法更新参数optimizer.step() # 更新模型参数if n % 10 == 0 or n == 1:print(f"epoches:{n},loss:{loss}")
1.5 nn.Module
直接重写继承nn.Module
import torch
import numpy as np# 定义输入数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8],[0.4, 39.2], [-1.4, -15.7],[-1.4, -37.3], [-1.8, -49.1],[1.5, 75.6], [0.4, 34.0],[0.8, 62.3]]
# 转换为 NumPy 数组
data = np.array(data)
# 提取 x_data 和 y_data
x_data = data[:, 0]
y_data = data[:, 1]
# 将数据转换为 Tensor
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)import torch.nn as nn# 定义线性模型
class LinearModel(nn.Module):def __init__(self):super(LinearModel, self).__init__()self.layers = nn.Linear(1, 1) # 定义一个线性层,输入和输出维度都是1def forward(self, x):x = self.layers(x) # 将输入 x 通过线性层return x# 初始化模型
model = LinearModel()# 定义损失函数
criterion = nn.MSELoss() # 均方误差损失函数
# 选取优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器,学习率为0.01# 迭代训练
epoches = 500
for n in range(1, epoches + 1):x_train_add_dim = x_train.unsqueeze(1) # 增加维度以适应模型输入y_pre = model(x_train_add_dim) # 前向传播,获取预测值# 计算损失loss = criterion(y_pre.squeeze(1), y_train) # 计算预测值和真实值之间的均方误差# 梯度更新optimizer.zero_grad() # 清空之前的梯度# 计算损失函数对模型参数的梯度loss.backward() # 反向传播,计算梯度# 根据优化算法更新参数optimizer.step() # 更新模型参数if n % 10 == 0 or n == 1:print(f"epoches:{n},loss:{loss}")
二、pytorch模型的保存
有两种保存方式
2.1 保存模型的权重和其他参数
保存:使用torch.save()保存,该函数将模型的状态字典保存到文件中,其中包括模型的权重和其他参数。

model是模型名称可以换成其他名称。
model.state_dict()返回模型的状态字典,其中包含模型的所有参数,然后,torch.save()函数将这个状态字典保存到名为model.pth的文件中 pth是pytorch的标准的一个模型文件,不加路径就是当前路径,加了路径就是指定的路径。
2.1.1 torch.save()保存字典
import torch
import numpy as np# 准备数据
data = [[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8],[0.4, 39.2], [-1.4, -15.7],[-1.4, -37.3], [-1.8, -49.1],[1.5, 75.6], [0.4, 34.0],[0.8, 62.3]]
data = np.array(data)
x_data = data[:, 0] # 获取 x 数据
y_data = data[:, 1] # 获取 y 数据
x_train = torch.tensor(x_data, dtype=torch.float32) # 将 x 数据转换为 PyTorch 张量
y_train = torch.tensor(y_data, dtype=torch.float32) # 将 y 数据转换为 PyTorch 张量from torch.utils.data import DataLoader, TensorDataset# 创建 TensorDataset,用于将 x_train 和 y_train 打包成数据集
dataset = TensorDataset(x_train, y_train)
# 创建 DataLoader,用于批量加载数据
dataloader = DataLoader(dataset, batch_size=2, shuffle=False)import torch.nn as nn# 定义线性模型
class LinearModel(nn.Module):def __init__(self):super(LinearModel,self,).__init__()# 定义一个线性层self.layers = nn.Linear(1, 1)def forward(self,x):# 前向传播函数x = self.layers(x) # 通过线性层return x# 实例化线性模型
model = LinearModel()# 定义损失函数
criterion = nn.MSELoss()
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
# 定义训练轮数
epoches = 500
# 训练模型
for n in range(1, epoches + 1):epoch_loss = 0# 迭代 DataLoaderfor batch_x, batch_y in dataloader:# 增加维度x_batch_add_dim = batch_x.unsqueeze(1)# 预测y_pre = model(x_batch_add_dim)# 计算损失batch_loss = criterion(y_pre.squeeze(1), batch_y)# 梯度清零optimizer.zero_grad()# 反向传播batch_loss.backward()# 更新参数optimizer.step()epoch_loss = epoch_loss + batch_loss# 计算平均损失avg_loss = epoch_loss / (len(dataloader))# 每 100 轮保存一次模型if n % 100 == 0 or n == 1:torch.save(model.state_dict(), f'model.pth_{n}')print(f"epoches:{n},loss:{avg_loss}")
总结
本文详细介绍了使用PyTorch框架实现线性回归的五个关键方面:模型定义(包括nn.Sequential, nn.Linear, nn.ModuleList, nn.ModuleDict, nn.Module等容器的使用)、模型保存(通过torch.save()保存模型权重和其他参数)、模型加载、模型网络结构的查看以及线性回归的具体代码实现。通过对这些内容的学习,读者可以掌握并理解PyTorch框架下线性回归的完整流程,并能够灵活运用各种模型定义方法和保存策略。
相关文章:

PyTorch 线性回归详解:模型定义、保存、加载与网络结构
目录 前言一、pytorch框架线性回归1.1 pytorch模型的定义1.2 nn.Sequential()1.2.1 nn.Linear1.2.2 nn.Sequential 1.3 nn.ModuleList()1.4 nn.ModuleDict()1.5 nn.Module二、pytorch模型的保存2.1 保存模型的权重和其他参数2.1.1 torch.save()保存字典总结 前言 书接上文 自…...

基础服务系列-Jupyter Notebook 支持JavaScript
IJavascript is a Javascript kernel for the Jupyter notebook. npm install npm i -g ijavascript 报以上错误,执行以下命令。 npm i -g ijavascript --unsafe-perm 说明:npm会有生命周期,某个包会有生命周期来执行一些东西,…...

LabVIEW数据采集与传感系统
开发了一个基于LabVIEW的智能数据采集系统,该系统主要通过单片机与LabVIEW软件协同工作,实现对多通道低频传感器信号的有效采集、处理与显示。系统的设计旨在提高数据采集的准确性和效率,适用于各种需要高精度和低成本解决方案的工业场合。 项…...

如何编写单元测试
一.如何编写单元测试 下面我们以 fetchEnv 方法作为案例,编写一套完整的单元测试用例供读者参考 编写 fetchEnv 方法 ./src/utils/fetchEnv.ts 文件 /*** 环境参数枚举*/enum IEnvEnum {DEV dev, // 开发TEST test, // 测试PRE pre, // 预发PROD prod, // 生…...
)
【网络编程】从零开始彻底了解网络编程(三)
本篇博客给大家带来的是网络编程的知识点. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 要开心要快乐顺便进步 TCP流…...
Java/python/JavaScript/C++/C语言/GO六种最佳实现)
华为OD机试真题——数据分类(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C、C语言、GO六种语言的最佳实现方式! 本文收录于专栏:《2025华为OD真题目录全流程解析/备考攻略/经验…...

3步拆解Linux内核源码的思维模型
3步拆解Linux内核源码的思维模型 ——从“不敢碰”到“庖丁解牛” 一、第一步:资料收集与框架搭建——像拼图一样找到“地图” 初看Linux内核源码的人,往往会被其千万行代码淹没。但正如登山前需要地形图,阅读内核前必须构建认知框架。 1…...

图像预处理-图像轮廓特征查找
其实就是外接轮廓,有了轮廓点就可以找到最上、最下、最左、最右的四个坐标(因为有xmin,xmax,ymin,ymax)。就可以绘制出矩形。 一.外接矩形 cv.boundingRect(轮廓点) - 返回x,y,w,h,传入一个轮廓的轮廓点,若有多个轮廓需…...

布尔差分法解析:从逻辑导数到电路优化
#布尔差分法解析:从逻辑导数到电路优化 一、背景数学知识:布尔代数基础 布尔变量与函数 在布尔代数中,变量的取值只有 0(表示假)和 1(表示真)。例如,一个布尔变量 x 可以取 0 或 1。…...

【NVIDIA】Isaac Sim 4.5.0 加载 Franka 机械臂
目录 一、NVIDIA Isaac Sim 4.5.0二、Isaac Sim 4.5.0 核心特性解析1. 基于 Omniverse 的跨平台仿真框架2. 模块化机器人开发架构3. 面向AI的强化学习支持 三、Isaac Sim 4.5.0 仿真环境搭建四、加载 Franka 机械臂1. Python源码2. 代码解析(按执行流程)…...
)
边缘计算场景下的GPU虚拟化实践(基于vGPU的QoS保障与算力隔离方案)
在智慧交通、工业质检等边缘计算场景中,GPU虚拟化技术面临严苛的实时性与资源隔离挑战。本文基于NVIDIA vGPU与国产算力池化方案,深入探讨多租户环境下算力隔离的工程实践,并给出可复用的优化策略。 一、边缘GPU虚拟化的核心痛点 动态负载…...

使用go-git同步文件到gitee
go-git是golang上纯go实现的git客户端,可用来同步文件到git仓库。 为什么不用gitee官方openapi,因为我需要强制推送覆盖,官方api不支持。 下面是一个通过xml.gz文件到gitee的代码示例 package clientimport ("fmt""gin-epg…...

HTTP 和 HTTPS 有什么区别?
文章目录 安全性端口号连接方式证书性能搜索引擎优化(SEO) HTTP(Hypertext Transfer Protocol,超文本传输协议)和 HTTPS(Hypertext Transfer Protocol Secure,超文本传输安全协议)都…...

【C++软件实战问题排查经验分享】UI界面卡顿 | CPU占用高 | GDI对象泄漏 | 线程堵塞 系列问题排查总结
目录 1、UI界面卡顿问题排查 2、软件CPU占用高问题排查 3、UI界面显示异常(GDI对象泄漏导致窗口绘制异常)问题排查 4、软件线程堵塞(包含线程死锁)问题排查 5、最后 C软件异常排查从入门到精通系列教程(核心精品专…...

ADB->查看某个应用的版本信息
查看某个应用版本的版本 在Android开发和测试过程中,我们经常需要获取应用的版本信息。本文将详细介绍如何使用ADB命令来查询特定应用(以com.example.myapplication为例)的版本号。 基本命令 要获取com.example.myapplication应用的版本名…...

Selenium的ActionChains:自动化Web交互的强大工具
目录 ActionChains简介环境准备基础操作鼠标操作键盘操作拖放操作高级用法常见问题与解决方案最佳实践总结 ActionChains简介 ActionChains是Selenium WebDriver提供的一个用于执行复杂用户交互的工具类。它允许我们模拟鼠标移动、点击、拖放以及键盘输入等操作,…...

管道位移自动化监测方案
一、背景 管道系统在区域性地质沉降作用下易形成非均匀应力场集中现象,诱发管体屈曲变形及环焊缝界面剥离等连续损伤累积效应,进而导致管道力学性能退化与临界承载能力衰减。传统人工巡检受限于空间覆盖度不足及数据采集周期长(≥72h…...

CompletableFuture并行处理任务
CompletableFuture并行处理任务 CompletableFuture基本概念与特性创建CompletableFuture实例 任务编排方法线程池选择默认线程池自定义线程池线程池配置建议 代码示例同步代码 CompletableFuture 基本概念与特性 异步执行: CompletableFuture允许任务在后台线程中…...

【系统架构设计师】信息安全的概念
目录 1. 5个基本要素2. 范围2.1 设备安全2.2 数据安全2.3 内容安全2.4 行为安全 3. 例题3.1 例题1 1. 5个基本要素 1.信息安全包括5个基本要素:机密性、完整性、可用性、可控性与可审查性。2.机密性:确保信息不暴露给未授权的实体或进程。3.完整性:只有得到允许的人才能修改数…...

华为云获取IAM用户Token的方式及适用分析
🧠 一、为什么要获取 IAM 用户 Token? 我们用一个生活中的比喻来解释👇: 🏢 比喻场景: 你要去一个 高级写字楼(华为云物联网平台) 办事(调用接口管理设备)&…...

齐次坐标系下的变换矩阵
理解齐次坐标系下的变换矩阵 文章目录 理解齐次坐标系下的变换矩阵1 引言2 齐次坐标系的简要介绍2.1 齐次坐标系的定义2.2 为什么需要齐次坐标系?2.3 齐次坐标系的特殊性质2.3.1 点和向量的区分2.3.2 投影变换 3 齐次坐标系下的变换矩阵3.1 二维变换矩阵平移变换缩放…...

web原生API AbortController网络请求取消方法使用介绍:防止按钮重复点击提交得最佳方案
在前端开发中,取消网络请求是一个常见的需求,尤其是在用户频繁操作或需要中断长时间请求的场景下。 AbortController 主要用于 优雅地管理和取消异步操作: 浏览器原生 API 一、代码解析 1. 创建 AbortController 实例 const controlle…...

74.搜索二维矩阵
题目: 给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非严格递增顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则&#x…...

基于Spring Boot+微信小程序的智慧农蔬微团购平台-项目分享
基于Spring Boot微信小程序的智慧农蔬微团购平台-项目分享 项目介绍项目摘要目录系统功能图管理员E-R图用户E-R图项目预览登录页面商品管理统计分析用户地址添加 最后 项目介绍 使用者:管理员、用户 开发技术:MySQLSpringBoot微信小程序 项目摘要 随着…...

机器学习-08-推荐算法-协同过滤
总结 本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则 参考 机器学习(三):Apriori算法(算法精讲) Apriori 算法 理论 重点 MovieLens:一个常用的电影推荐系统领域的数据集 23张图&#x…...

03-HTML常见元素
一、HTML常见元素 常见元素及功能: 元素用途<h1>~<h6>标题从大到小<p>段落,不同段落会有间距<img>显示图片,属性src为图片路径,alt为图片无法显示时的提示文本<a>超链接,属性href为链…...

LangChain + 文档处理:构建智能文档问答系统 RAG 的实战指南
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是Lang Chain 2、文档问答的典型应用场景 二、文…...

深入理解 DML 和 DQL:SQL 数据操作与查询全解析
深入理解 DML 和 DQL:SQL 数据操作与查询全解析 在数据库管理中,SQL(结构化查询语言)是操作和查询数据的核心工具。其中,DML(Data Manipulation Language,数据操作语言) 和 DQL&…...

头歌实训之SQL视图的定义与操纵
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习C语言的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...

Excel/WPS表格中图片链接转换成对应的实际图片
Excel 超链图变助手(点击下载可免费试用) 是一款将链接转换成实际图片,批量下载表格中所有图片的转换工具,无需安装,双击打开即可使用。 表格中链接如下图所示: 操作方法: 1、双击以下图标&a…...
)
单例模式的使用场景 以及 饿汉式写法(智能指针)
单例模式的使用场景 以及 饿汉式写法(智能指针) 饿汉式:创建类时就已经创建好了类的实例(用智能指针实现)什么时候用单例模式:1. 全局配置管理2. 日志系统3. 资源管理器4. 硬件设备访问总结 饿汉式…...

示波器探头状态诊断与维护技术指南
一、探头性能劣化特征分析 信号保真度下降 ・时域表现:上升沿时间偏离标称值15%以上(如1ns探头测得≥1.15ns) ・频域特性:-3dB带宽衰减超过探头标称值20%基准稳定性异常 ・直流偏置电压漂移量>5mV(预热30分…...

使用Matlab工具将RAW文件转化为TXT文件,用于FPGA仿真输入
FPGA实现图像处理算法时,通常需要将图像作为TestBench的数据输入。 使用VHDL编写TestBench时,只能读取二进制TXT文件。 现在提供代码,用于实现RAW图像读取,图像显示,图像转化为二进制数据并存入TXT文件中。 clc; cl…...

Missashe考研日记-day23
Missashe考研日记-day23 0 写在前面 博主前几天有事回家去了,断更几天了不好意思,就当回家休息一下调整一下状态了,今天接着开始更新。虽然每天的博客写的内容不算多,但其实还是挺费时间的,比如这篇就花了我40多分钟…...

视频分析设备平台EasyCVR安防视频小知识:安防监控常见故障精准排查方法
随着安防监控技术的飞速发展,监控系统已经成为现代安防体系中不可或缺的核心组成部分,广泛应用于安防监控、交通管理、工业自动化等多个领域。然而,监控系统的稳定运行高度依赖于设备的正确配置、线路的可靠连接以及电源的稳定供电。在实际应…...

Linux论坛安装
事前准备 1、Discuz_X3.5_SC_UTF8_20230520的压缩包。 2、一台虚拟机,xshell和xftp(用来传输文件) 安装httpd 软件并将压缩包移动到指定目录 mount /dev/sr0 /mnt #### 挂载光盘到 /mnt 目录 dnf install httpd -y ### 安装http…...

瑞吉外卖-分页功能开发中的两个问题
1.分页功能-前端页面展示显示500 原因:项目启动失败 解决:发现是Category实体类中,多定义了一个删除字段,但是我数据库里面没有is_deleted字段,导致查询数据库失败,所以会导致500错误。因为类是从网上其他帖…...

深入理解HotSpot JVM 基本原理
关于JAVA Java编程语言是一种通用的、并发的、面向对象的语言。它的语法类似于C和C++,但它省略了许多使C和C++复杂、混乱和不安全的特性。 Java 是几乎所有类型的网络应用程序的基础,也是开发和提供嵌入式和移动应用程序、游戏、基于 Web 的内容和企业软件的全球标准。. 从…...

[原理分析]安卓15系统大升级:Doze打盹模式提速50%,续航大幅增强,省电提升率5%
技术原理:借鉴中国友商思路缩短进入Doze的时序 开发者米沙尔・拉赫曼(Mishaal Rahman)在其博文中透露,谷歌对安卓15系统进行了显著优化,使得设备进入“打盹模式”(Doze Mode)的速度提升了50%,并且部分机型的待机时间因此得以延长三小时。设备…...

人工智能在慢病管理中的具体应用全集:从技术落地到场景创新
一、AI 赋能慢病管理:技术驱动医疗革新 1.1 核心技术原理解析 在当今数字化时代,人工智能(AI)正以前所未有的态势渗透进医疗领域,尤其是在慢性病管理方面,展现出巨大的潜力和独特优势。其背后依托的机器学习、深度学习、自然语言处理(NLP)以及物联网(IoT)与可穿戴设…...

视频生成上下文并行方案
在多张rtx4090上的并行生成方案,主要就是xdit和paraattention中的并行上下文注意力机制。希望找到一个和skyreel一致的para attn的并行方案。 1.ParaAttention https://github.com/chengzeyi/ParaAttentionhttps://github.com/chengzeyi/ParaAttention目前只支持了文生视频的…...
厘清Gradle的版本)
Unity接入安卓SDK(3)厘清Gradle的版本
接入过程中,很多人遇到gradle的各种错误,由于对各种gradle版本的概念不甚了了,模模糊糊一顿操作猛如虎,糊弄的能编译通过就万事大吉,下次再遇到又是一脸懵逼。所以我们还是一起先厘清gradle的版本概念。 1 明晰概念 …...
)
牛行为-目标检测数据集(包括VOC格式、YOLO格式)
牛行为-目标检测数据集(包括VOC格式、YOLO格式) 数据集: 链接: https://pan.baidu.com/s/1hTLiiNOJYjzcejNwZpVsqA?pwdzhhb 提取码: zhhb 数据集信息介绍: 共有 8869张图像和一一对应的标注文件 标注文件格式提供了两种&#x…...

ubuntu 22.04 安装和配置 mysql 8.0,设置开机启动
# 更新软件包列表 sudo apt update && sudo apt upgrade -y # 安装MySQL 8.0 sudo apt install mysql-server-8.0 -y # 启动MySQL服务并设置开机启动 sudo systemctl start mysql sudo systemctl enable mysql # 安全安装MySQL,一路回车 sudo mysql…...

掌握Go空接口强大用途与隐藏陷阱
掌握Go空接口:强大用途与隐藏陷阱 Go语言中的空接口interface{}初看像是一种超能力工具。它能容纳任何东西——数字、字符串、结构体,应有尽有。但能力越大责任越大……如果不小心使用,它也会带来一堆麻烦。本文将深入探讨interface{}的工作原理,挖掘其合理的使用场景,并…...

CSS预处理工具有哪些?分享主流产品
目前主流的CSS预处理工具包括:Sass、Less、Stylus、PostCSS等。其中,Sass是全球使用最广泛的CSS预处理工具之一,以强大的功能、灵活的扩展性以及完善的社区生态闻名。Sass通过增加变量、嵌套、混合宏(mixin)等功能&…...

【2025面试Java常问八股之redis】zset数据结构的实现,跳表和B+树的对比
Redis 中的 ZSET(Sorted Set,排序集合)是一种非常重要的数据结构,它结合了集合(Set)和有序列表(List)的特点,能够存储一组 唯一 的元素,并且每个元素关联一个…...

VR制作攻略:如何制作VR
VR制作基础步骤 制作VR内容,特别是VR全景图,是一个涉及多个关键步骤的过程,包括设备准备、拍摄、拼接、后期处理及优化等。 以下将详细介绍这些步骤,并结合众趣科技的支持进行阐述。 1. 设备准备 相机: 选择配备广…...

Linux深度探索:进程管理与系统架构
1.冯诺依曼体系结构 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。 截至目前,我们所认识的计算机,都是由⼀个个的硬件组件组成。 输入设备:键盘,鼠标…...

240421 leetcode exercises
240421 leetcode exercises jarringslee 文章目录 240421 leetcode exercises[31. 下一个排列](https://leetcode.cn/problems/next-permutation/)什么是字典序?🔁二次遍历查找 [82. 删除排序链表中的重复元素 II](https://leetcode.cn/problems/remove…...