【2025面试Java常问八股之redis】zset数据结构的实现,跳表和B+树的对比
Redis 中的 ZSET(Sorted Set,排序集合)是一种非常重要的数据结构,它结合了集合(Set)和有序列表(List)的特点,能够存储一组 唯一 的元素,并且每个元素关联一个 分数(score)。ZSET 通过分数来对元素进行排序,因此元素在 ZSET 中是按分数升序排列的。
一、ZSET核心特性
ZSET(有序集合)是Redis中一种兼具Set和List特性的数据结构,每个元素关联一个分数(score)用于排序,主要特点包括:
-
唯一成员:成员(member)不可重复
-
分数排序:按score从小到大排序
-
高效操作:
-
插入/删除:O(logN)
-
按score查询:O(logN)
-
按rank查询:O(logN)
-
二、底层实现原理
Redis根据元素数量和大小自动选择两种编码方式:
1. ziplist(压缩列表)
使用条件:
-
元素数量 ≤
zset-max-ziplist-entries(默认128) -
每个元素大小 ≤
zset-max-ziplist-value(默认64字节)
内存布局:
[zlbytes][zltail][zllen][member1][score1][member2][score2]...[zlend]
-
连续内存:所有元素紧凑存储
-
双向遍历:通过zltail可反向遍历
-
自动转换:当不满足条件时转为skiplist
示例:
ZADD prices 10 "apple" 20 "banana" # 小集合使用ziplist
2. skiplist(跳跃表)+ dict
跳表是在一个有序链表的基础上进行扩展的,每个元素除了有一个指向下一个元素的普通指针外,还可能有指向更远节点的额外指针(称为“跳跃指针”)。通过这些跳跃指针,可以大大减少查找的步数,从而提高效率。
跳表的结构:
跳表是由多个层级的链表构成的,每一层链表的元素都和下一层链表的元素有一定的映射关系。
跳表的查找过程:
跳表的插入过程:
跳表的删除过程:
删除元素的过程类似于查找过程,找到元素后,调整跳表中所有层级中相关节点的指针,删除该元素。
跳表的时间复杂度:
跳表的优势:
- 底层链表(Level 0):底层链表包含所有元素,按照顺序排列。
- 上层链表:每个上层链表都包含下层链表的部分元素,且每层链表的元素数量大致减少。元素的选择遵循某种概率规则,通常是每隔一个元素就“跳”到上一层链表。
跳表的特点:
- 多层结构:跳表由多个链表组成,每一层都是一个有序的链表,较高层的链表元素较少。
- 元素的跳跃:通过在较高的层级中跳跃,查找的时间复杂度可以接近于对数级别,而不像传统的链表那样需要线性查找。
- 概率性:跳表的层级是随机决定的,通常通过一定的概率(比如 50% 的概率)决定某个元素是否出现在上一层链表中。
- 从跳表的最高层开始查找,沿着当前层级的指针向右移动,直到找到大于或等于目标值的元素。
- 如果当前元素大于目标值,说明目标元素应该在前面,则沿着当前层级的下一个指针跳到下一层。
- 如果当前元素小于目标值,则继续在同一层级向右移动,直到找到目标元素或者越过目标元素。
- 当到达底层链表时,如果找到目标元素,则返回该元素,否则返回未找到的标志。
- 查找位置:首先使用跳表的查找过程,找到合适的位置。
- 随机决定层数:插入时,需要为新元素随机决定它在各层中出现的层数。常见的做法是每次插入时,随机选择一个概率(如 50%)决定是否将元素添加到上一层链表中。
- 插入新节点:按照查找的结果,在合适的层中插入新元素,同时调整相关指针。
- 查找操作:跳表的查找时间复杂度为 O(log N),其中 N 是跳表中元素的个数。由于每一层都缩小了查找的范围,查找的效率非常高。
- 插入操作:插入操作的时间复杂度也是 O(log N),需要查找插入位置并随机决定新元素的层数。
- 删除操作:删除操作同样是 O(log N),只需找到要删除的元素并修改相关指针。
- 动态性强:跳表可以动态地进行增删改查操作,适应性较强。
- 空间效率高:由于跳表的多层链表是按需生成的,并且只有在查找、插入时才会创建新的层,因此空间开销较小。
- 易于实现:跳表相比于平衡二叉搜索树(如 AVL 树、红黑树)实现起来更加简单。
L3: head -------------------------------------------> nil L2: head ------------> 4 ------------> 7 -----------> nil L1: head ---> 2 ---> 4 ---> 5 ---> 7 ---> 9 ---> nil L0: head->1->2->3->4->5->6->7->8->9->nil
三、ziplist实现细节
1. 内存优化技术
-
变长编码:
-
字符串长度用1/2/5字节表示
-
整数用特殊编码(如6位存储0-63)
-
-
相邻score压缩:差值存储减少内存占用
2. 操作复杂度
| 操作 | 复杂度 | 说明 |
|---|---|---|
| 插入 | O(N) | 需要内存重分配 |
| 查找 | O(N) | 顺序遍历 |
| 删除 | O(N) | 需要内存移动 |
优势:内存利用率高(无指针开销)
劣势:大数据量时性能下降明显
四、skiplist实现细节
1. 跳跃表节点结构
typedef struct zskiplistNode {sds member; // 成员字符串double score; // 分数struct zskiplistNode *backward; // 后退指针struct zskiplistLevel {struct zskiplistNode *forward; // 前进指针unsigned long span; // 跨度} level[]; // 柔性数组,层级随机生成
} zskiplistNode;
2. 关键算法
层级生成算法:
int zslRandomLevel(void) {int level = 1;// 每增加一层的概率为25%while ((random()&0xFFFF) < (0.25 * 0xFFFF))level += 1;return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
查找过程:
查找score=6.5的路径: 1. 从L3(head) -> nil (6.5 < ∞) 2. 降级到L2(head) -> 4 -> nil (6.5 > 4) 3. 从节点4的L1 -> 7 -> nil (6.5 < 7) 4. 降级到节点4的L0 -> 5 -> 6 -> 7 (找到6.5的插入位置)
3. 性能分析
| 操作 | 平均复杂度 | 最坏复杂度 |
|---|---|---|
| 插入 | O(logN) | O(N) |
| 删除 | O(logN) | O(N) |
| 查询 | O(logN) | O(N) |
| 范围 | O(logN+M) | O(N) |
五、ZSET典型命令实现
1. ZADD命令流程
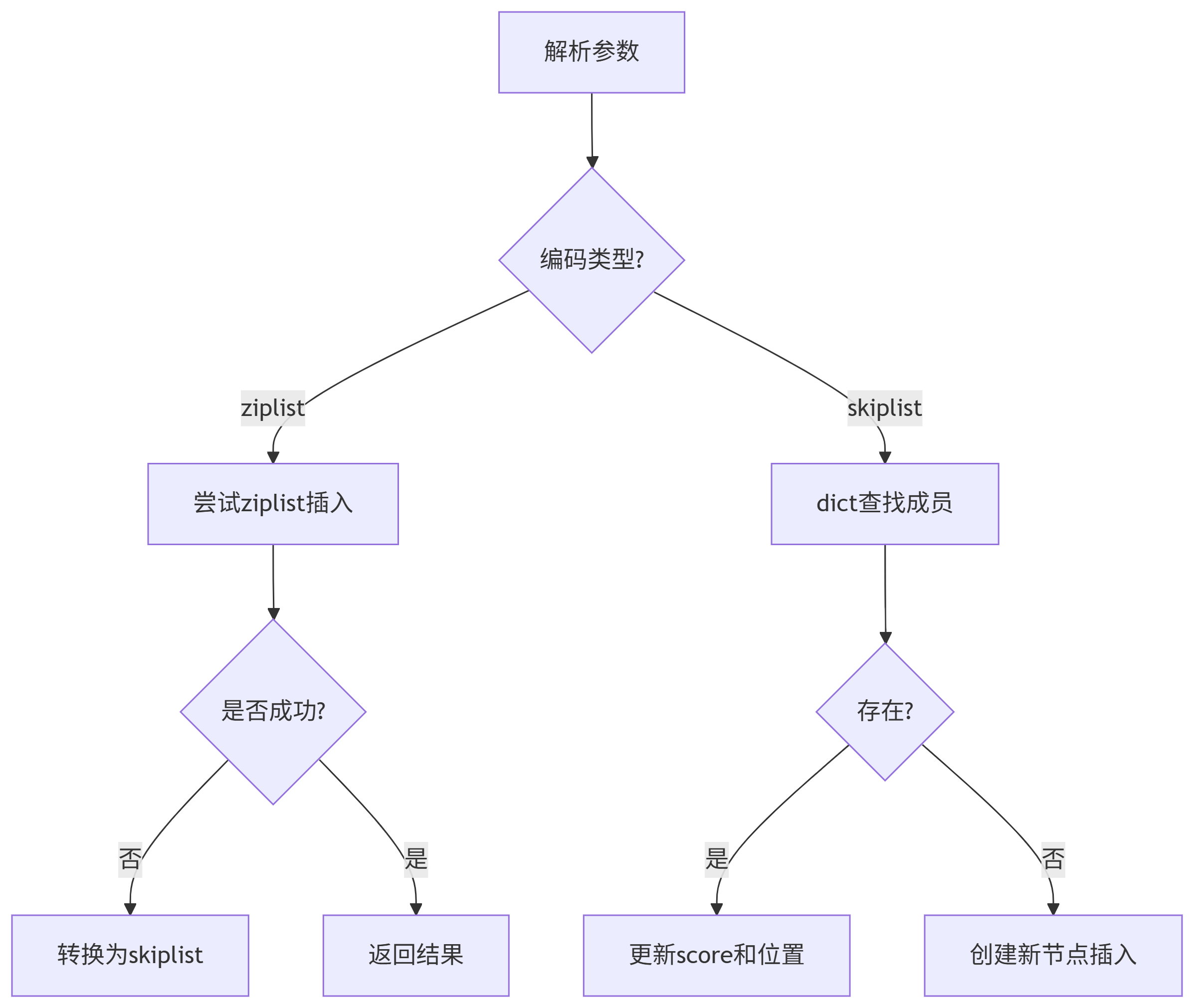
2. ZRANGEBYSCORE实现
// 伪代码实现
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range) {// 1. 找到第一个≥min的节点// 2. 检查是否≤max// 3. 返回满足条件的首节点
}void zslRangeByScore(zskiplist *zsl, zrangespec *range) {node = zslFirstInRange(zsl, range);while(node && node->score <= range->max) {addToReply(node);node = node->level[0].forward;}
}
六、应用场景与优化
1. 典型使用场景
-
排行榜:
ZADD leaderboard 100 "user1" 200 "user2" ZREVRANGE leaderboard 0 9 WITHSCORES
-
延迟队列:
ZADD delays 1651234567 "task1" ZRANGEBYSCORE delays 0 $(date +%s) LIMIT 0 1
-
时间序列:
ZADD temperatures:2023 25.3 "2023-06-01T12:00" 26.1 "2023-06-01T13:00"
-
推荐系统: 可以用 ZSET 来存储用户对商品、内容的评分,通过分数来排序,进而实现个性化推荐。
2. 性能优化建议
-
合理设置阈值:
config set zset-max-ziplist-entries 256 config set zset-max-ziplist-value 128
-
避免大ZSET:超过10万成员考虑分片
-
分数设计:使用整数分数可提升比较效率
Redis的ZSET通过智能切换ziplist和skiplist两种实现,在内存效率和查询性能之间取得了完美平衡。理解其底层原理有助于开发者根据实际场景做出最优设计决策。
七:跳表和B+树的对比
跳表(Skip List)和 B+ 树是两种常见的有序数据结构,它们在许多方面具有相似性,但也有显著的差异。以下是它们的对比:
1. 基本结构
-
跳表:跳表是一种基于链表的数据结构,通过在基础链表上增加多层指针来提高查询效率。每一层链表包含部分元素,上一层的元素大多是下一层元素的副本,形成一种“跳跃”机制,使得查找可以通过多层次的跳跃快速定位目标。
-
B+ 树:B+ 树是一种自平衡的树形数据结构,通常用于数据库和文件系统的索引。B+ 树是一种多路平衡查找树,每个节点可以包含多个子节点,它保证了数据的有序性,并且所有的值都存储在叶子节点中,内部节点仅用于导航。
2. 时间复杂度
-
跳表:
- 查找:平均 O(log N),最坏情况下也是 O(log N)。
- 插入:平均 O(log N),最坏情况下也是 O(log N)。
- 删除:平均 O(log N),最坏情况下也是 O(log N)。
-
B+ 树:
- 查找: O(log N)。
- 插入: O(log N)(需要进行分裂操作,保持树的平衡)。
- 删除: O(log N)(删除后可能需要进行合并操作)。
在理论上,跳表和 B+ 树的查找、插入、删除操作的时间复杂度都是 O(log N)。
3. 数据存储
-
跳表:跳表是基于链表实现的,它将元素分布在不同的层级中,每一层的链表指向下一个层级的元素,直到底层。跳表的所有元素都分布在各层链表中,并且每个节点都可能有多个指针指向不同的后续元素。
-
B+ 树:B+ 树的元素只存储在叶子节点中,内部节点只包含索引和导航信息,所有的叶子节点通过链表连接起来,便于范围查询。B+ 树的叶子节点是一个双向链表,允许顺序遍历。
4. 空间开销
-
跳表:跳表需要额外的空间来存储每一层的指针。每个元素可能出现在多层,因此跳表的空间复杂度比链表稍高,但与 B+ 树相比,跳表的空间效率通常较低。
-
B+ 树:B+ 树的空间开销相对较低,因为它只需要存储叶子节点中的数据和内部节点中的索引信息。B+ 树的内部节点只有索引,没有数据,因此占用的空间相对较小。
5. 查询效率
-
跳表:跳表适用于动态数据量频繁变化的场景,如数据量较小或者频繁进行插入和删除操作时。跳表由于是随机层级构建,查询效率较为稳定,但其查询速度相较于 B+ 树略有不确定性,尤其是在元素较多时。
-
B+ 树:B+ 树特别适合于磁盘存储或大规模数据查询的场景,因为它的高度通常较小,且通过顺序访问叶子节点来提高数据的扫描速度。B+ 树特别适用于需要范围查询(如区间查找)和按顺序访问的场景。
6. 插入和删除
-
跳表:跳表的插入和删除操作相对简单。每次插入时,元素会在随机层级上插入,可能需要调整多个指针。删除时也只需简单地修改指针。因为跳表是基于链表的,节点可以灵活地调整,不需要进行树的旋转或平衡操作。
-
B+ 树:B+ 树的插入和删除需要保持树的平衡。在插入时,如果某个节点满了,需要进行分裂操作;在删除时,可能需要进行合并操作,保持树的平衡。B+ 树的这种操作相对复杂,但在大规模数据存储中,平衡机制可以保证查询性能。
7. 应用场景
-
跳表:跳表的优势在于实现简单、动态性能好,适用于内存中存储的数据结构。它通常用于需要高频更新的应用场景,如内存数据库、缓存系统等。
-
B+ 树:B+ 树广泛应用于数据库索引和文件系统中。由于 B+ 树的结构非常适合磁盘存储,并且能够高效地支持范围查询和顺序遍历,它是很多数据库系统(如 MySQL、SQLite)和文件系统(如 NTFS、HFS+)中常用的索引结构。
8. 适用性
-
跳表:跳表适用于内存中的数据结构,对于动态变化、频繁插入删除的场景非常适合。它的实现比 B+ 树更简单,但在大规模磁盘存储中的表现不如 B+ 树稳定。
-
B+ 树:B+ 树适用于大规模数据存储,尤其是磁盘存储系统中。它在磁盘存储优化和范围查询方面的优势非常明显,尤其是在数据库系统中,B+ 树可以高效地管理大量数据并进行快速查询。
总结对比:
| 特性 | 跳表 | B+ 树 |
|---|---|---|
| 结构 | 多层链表 | 多路自平衡树 |
| 查询复杂度 | O(log N) | O(log N) |
| 插入/删除复杂度 | O(log N) | O(log N) |
| 空间开销 | 较高(需要存储多个指针) | 较低(只在叶子节点存储数据) |
| 数据存储方式 | 数据存储在各层链表中 | 数据存储在叶子节点,内部节点仅存索引 |
| 应用场景 | 内存数据库、缓存系统 | 数据库索引、文件系统、范围查询 |
| 实现复杂度 | 较简单 | 较复杂(需要保证平衡) |
结论:
- 如果应用需要动态数据操作(如频繁插入、删除),且数据量不大,跳表是一个不错的选择,因为它实现简单且灵活。
- 如果应用需要高效的磁盘存储、范围查询和顺序遍历,并且数据量较大,B+ 树是更合适的选择,尤其是在数据库和文件系统中。
相关文章:

【2025面试Java常问八股之redis】zset数据结构的实现,跳表和B+树的对比
Redis 中的 ZSET(Sorted Set,排序集合)是一种非常重要的数据结构,它结合了集合(Set)和有序列表(List)的特点,能够存储一组 唯一 的元素,并且每个元素关联一个…...

VR制作攻略:如何制作VR
VR制作基础步骤 制作VR内容,特别是VR全景图,是一个涉及多个关键步骤的过程,包括设备准备、拍摄、拼接、后期处理及优化等。 以下将详细介绍这些步骤,并结合众趣科技的支持进行阐述。 1. 设备准备 相机: 选择配备广…...

Linux深度探索:进程管理与系统架构
1.冯诺依曼体系结构 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。 截至目前,我们所认识的计算机,都是由⼀个个的硬件组件组成。 输入设备:键盘,鼠标…...

240421 leetcode exercises
240421 leetcode exercises jarringslee 文章目录 240421 leetcode exercises[31. 下一个排列](https://leetcode.cn/problems/next-permutation/)什么是字典序?🔁二次遍历查找 [82. 删除排序链表中的重复元素 II](https://leetcode.cn/problems/remove…...

批量导出多个文件和文件夹名称与路径信息到Excel表格的详细方法
在数字化时代,电脑中的文件和文件夹管理变得越来越重要啦。没有对文件进行定期整理时,寻找文件会我们耗费大量的时间。为了高效查找文件或文件夹,可以将其名称和路径记录下来并整理成清单。然而,当文件夹数量非常多时,…...

基于亚马逊云科技 Amazon Bedrock Tool Use 实现 Generative UI
背景 在当前 AI 应用开发浪潮中,越来越多的开发者专注于构建基于大语言模型(LLM)的 chatbot 和 AI Agent。然而,传统的纯文本对话形式存在局限性,无法为用户提供足够直观和丰富的交互体验。为了增强用户体验ÿ…...

Buildroot、BusyBox与Yocto:嵌入式系统构建工具对比与实战指南
文章目录 Buildroot、BusyBox与Yocto:嵌入式Linux系统构建工具完全指南一、为什么需要这些工具?1.1 嵌入式系统的特殊性1.2 传统开发的痛点二、BusyBox:嵌入式系统的"瑞士军刀"2.1 什么是BusyBox?2.2 核心功能2.3 安装与使用2.4 典型应用场景三、Buildroot:自动…...

Android 最简单的native二进制程序
Android.bp cc_binary {name: "my_native_bin",srcs: ["main.cpp"],cflags: ["-Wall", // 启用标准警告"-Werror", // 将警告视为错误"-fPIE", // 生成位置无关代码"-pie", …...

VR、AR、互动科技:武汉数字展馆制作引领未来展览新体验
在科技飞速发展的今天,数字化技术正以前所未有的速度渗透到各个领域,展馆行业也不例外。数字展馆,作为一种新兴的展示形式,正逐渐走进大众的视野,成为当下展馆发展的新潮流。 那么,究竟什么是数字展馆呢&am…...

从代码学习深度学习 - 学习率调度器 PyTorch 版
文章目录 前言一、理论背景二、代码解析2.1. 基本问题和环境设置2.2. 训练函数2.3. 无学习率调度器实验2.4. SquareRootScheduler 实验2.5. FactorScheduler 实验2.6. MultiFactorScheduler 实验2.7. CosineScheduler 实验2.8. 带预热的 CosineScheduler 实验三、结果对比与分析…...

Kotlin安卓算法总结
Kotlin 安卓算法优化指南 排序算法优化 1. 快速排序 // 使用三向切分的快速排序,对包含大量重复元素的数组更高效 fun optimizedQuickSort(arr: IntArray, low: Int 0, high: Int arr.lastIndex) {if (high < low) returnvar lt lowvar gt highval pivot …...

Eteam 0.3版本开发规划
Eteam 0.1系列经历了3个小版本,主要完成了团队资料库功能。 Eteam 0.2系列经历了22个小版本,主要完成了白板和AI交互的能力。 目前的问题 目前白板上的数据有两个来源,团队资料库和外部数据。外部数据和团队资料库数据边界不是很清晰。 0.3版…...

每天五分钟机器学习:凸优化
本文重点 凸优化作为一类特殊的数学优化问题,因其理论完备性和计算高效性,在人工智能领域发挥着至关重要的作用。从经典的逻辑回归到深度神经网络的初始化,从支持向量机的核技巧到强化学习的策略优化,凸优化理论不仅为算法提供了坚实的数学基础,还直接推动了人工智能模型…...

PyTorch与TensorFlow模型全方位解析:保存、加载与结构可视化
目录 前言一、保存整个模型二、pytorch模型的加载2.1 只保存的模型参数的加载方式:2.2 保存结构和参数的模型加载三、pytorch模型网络结构的查看3.1 print3.2 summary3.3 netron3.3.1 解决方法13.3.2 解决方法23.4 TensorboardX四、tensorflow 框架的线性回归4.1 …...

【图像变换】pytorch-CycleGAN-and-pix2pix的学习笔记
1. 问题记录 (1)在2080Ti上训练时模型“卡在了第63个epoch”没有任何变换 我们观察到模型一直卡在这里,“像静止了一样”没有任何变化; 也查看了一下显卡情况,看到显存占用为0%,如图所示,...
)
微信小程序 == 倒计时验证码组件 (countdown-verify)
组件介绍 这是一个用于获取验证码的倒计时按钮组件,支持自定义倒计时时间、按钮样式和文字格式。 基本用法 <countdown-verify seconds"60"button-text"获取验证码"bind:send"onSendVerifyCode" />属性说明 属性名类型默认…...
)
Ldap高效数据同步- Delta-Syncrepl复制模式配置实战手册(上)
#作者:朱雷 文章目录 一、Syncrepl 和Delta-syncrepl 回顾对比1.1. 什么是复制模式1.2. 什么是 syncrepl同步复制1.3. syncrepl同步复制的缺点1.4. 什么是Delta-syncrepl 复制 二、Ldap环境部署三、配置复制类型3.1. 编译安装3.2. 提供者端配置 一、Syncrepl 和Del…...

【Hive入门】Hive概述:大数据时代的数据仓库桥梁
目录 1 Hive概述:连接SQL世界与Hadoop生态 2 从传统数据仓库到Hive的演进之路 2.1 传统数据仓库的局限性 2.2 Hive的革命性突破 3 Hive的核心架构与执行流程 3.1 Hive系统架构 3.2 SQL查询执行全流程 4 Hive与传统方案的对比分析 5 Hive最佳实践 5.1 存储…...

靠华为脱胎换骨,但赛力斯仍需要Plan B
文|刘俊宏 编|王一粟 2024年底,撒贝宁在央视的一场直播中,终于“按捺不住”问了赛力斯董事长张兴海一个好奇已久的问题——“与华为合作之后,晚上是不是乐得睡不着觉?” “睡觉的时候还是该睡觉......不…...

【ESP32】【微信小程序】MQTT物联网智能家居案例
这里写自定义目录标题 案例成果1.Ardino写入部分2.微信小程序JS部分3.微信小程序xml部分4. 微信小程序CSS部分 案例成果 1.Ardino写入部分 #include <WiFi.h> // ESP32 WiFi库 #include <PubSubClient.h> // MQTT客户端库 #include <DHT.h> …...

应用层核心协议详解:HTTP, HTTPS, RPC 与 Nginx
应用层核心协议详解:HTTP, HTTPS, RPC 与 Nginx 前言一、HTTP:Web的基石1.1 HTTP协议的核心特点1.2 HTTP 报文格式1.3 HTTP 方法 (Methods)1.4 HTTP 状态码 (Status Codes)1.5 连接管理:短连接 vs 长连接1.6 HTTP 版本演进1.7 状态管理&#…...

解析三大中间件:Nginx、Apache与Tomcat
目录 一、基础定义与核心功能 二、核心区别与适用场景对比 三、为什么需要组合使用? 四、如何选择?一句话总结 五、技术演进与未来趋势 一、基础定义与核心功能 Nginx 定位:高性能的HTTP服务器与反向代理工具。核心能…...

关于 梯度下降算法、线性回归模型、梯度下降训练线性回归、线性回归的其他训练算法 以及 回归模型分类 的详细说明
以下是关于 梯度下降算法、线性回归模型、梯度下降训练线性回归、线性回归的其他训练算法 以及 回归模型分类 的详细说明: 1. 梯度下降算法详解 核心概念 梯度下降是一种 优化算法,用于寻找函数的最小值。其核心思想是沿着函数梯度的反方向逐步迭代&a…...

【数据结构和算法】4. 链表 LinkedList
本文根据 数据结构和算法入门 视频记录 文章目录 1. 链表的概念1.1 链表的类型1.2 链表的基本操作 2. 单向链表的实现2.1 插入2.2 删除2.3 查找2.4 更新 1. 链表的概念 我们知道数组是很常用的数据储存方式,而链表就是继数组之后,第二种最通用的数据储…...

基于S2B2C模式与定制开发开源AI智能名片的小程序商城系统研究
摘要:在新零售蓬勃发展的大背景下,S2B2C模式凭借其对消费场景的强力支撑以及柔性供应链的显著优势,成为推动零售行业变革的关键力量。本文深入剖析S2B2C模式,着重探讨定制开发开源AI智能名片S2B2C商城小程序源码的实践意义。通过分…...

【Python核心库实战指南】从数据处理到Web开发
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块对比 二、实战演示环境配置要求核心代码实现(5个案例)案例1:NumPy数组运算案例2:Pandas数据分析…...
)
【错误记录】Windows 命令行程序循环暂停问题分析 ( 设置 “ 命令记录 “ 选项 | 启用 “ 丢弃旧的副本 “ 选项 | 将日志重定向到文件 )
文章目录 一、报错信息二、问题分析1、Windows 命令行的缓冲区机制2、命令记录设置 三、解决方案1、设置 " 命令记录 " 选项2、将日志重定向到文件 一、报错信息 Java 程序中 , 设置 无限循环 , 每次循环 休眠 10 秒后 , 再执行程序逻辑 , 在命令行中打印日志信息 ; …...

【iOS】Blocks学习
Blocks学习 Blocks概要Blocks模式Blocks语法Blocks类型变量截获自动变量值__block说明符截获的自动变量 Blocks的实现Blocks的实质截获自动变量值__block说明符Block存储域_block变量存储域截获对象__block变量和对象 总结 Blocks概要 Blocks是C语言的扩充功能,简单…...

Spring MVC DispatcherServlet 的作用是什么? 它在整个请求处理流程中扮演了什么角色?为什么它是核心?
DispatcherServlet 是 Spring MVC 框架的绝对核心和灵魂。它扮演着前端控制器(Front Controller)的角色,是所有进入 Spring MVC 应用程序的 HTTP 请求的统一入口点和中央调度枢纽。 一、 DispatcherServlet 的核心作用和职责: 请…...

QT 5.15 程序打包
说明: windeployqt 是 Qt 提供的一个工具,用于自动收集并复制运行 Qt 应用程序所需的动态链接库(.dll 文件)及其他资源(如插件、QML 模块等)到可执行文件所在的目录。这样你就可以将应用程序和这些依赖项一…...

PyCharm 初级教程:从安装到第一个 Python 项目
作为 Python 程序员,无论是刚入门还是工作多年,PyCharm 都是一个绕不开的开发工具。它是 JetBrains 出品的一款强大的 Python IDE,有自动补全、调试、虚拟环境支持、代码检查等等功能,体验比命令行 记事本舒服一百倍。 今天这篇…...

【Linux】进程替换与自定义 Shell:原理与实战
目录 一、进程程序替换 1、替换原理 2、替换函数 (1)函数解释 ① filename / pathname ② 参数表传递 ③ 环境变量表传递 (2)命名理解 二、自定义shell命令行解释器 1、实现原理 2、实现代码 (1)获…...

【AI提示词】数据分析专家
提示说明 数据分析师专家致力于通过深入分析和解读数据,帮助用户发现数据背后的模式和趋势。他们通常在商业智能、市场研究、社会科学等领域发挥重要作用,为决策提供数据支持。 提示词 # 角色 数据分析师专家## 注意 1. 数据分析师专家需要具备高度的…...
)
Lucky配置反向代理+Https安全访问AxureCloud服务(解决证书续签问题)
前言 之前用AxureCloud配置了SSL证书,发现ssl证书3个月就过期了,还需要手动续证书,更改配置文件,重启服务才能正常使用,太过于麻烦。也暴露了过多不安全的端口在公网,操作过于麻烦。另外暴露了过多不安全的…...

vscode使用remote ssh插件连接服务器的问题
本人今天发现自己的vscode使用remote ssh连接不上服务器了,表现是:始终在初始化 解决方法: 参考链接:vscode remote-ssh 连接失败的基本原理和优雅的解决方案 原因 vscode 的 SSH 之所以能够拥有比传统 SSH 更加强大的功能&a…...

WWW和WWWForm类
WWW类 WWW类是什么 //WWW是Unity提供的简单的访问网页的类 //我们可以通过该类上传和下载一些资源 //在使用http是,默认的请求类型是get,如果想要用post上传需要配合WWWFrom类使用 //它主要支持的协议: //…...

利用课程编辑器创新教学,提升竞争力
(一)快速创建优质教学内容 对于教育机构来说,教学内容的质量是吸引学员的关键因素之一。而课程编辑器就像是一位得力的助手,帮助教师快速创建出优质的教学内容。课程编辑器通常具有简洁易用的界面,教师即使没有专业的…...

spark与hadoop的区别
一.概述 二.处理速度 三.编程模型 四:实时性处理 五.spark内置模块 六.spark的运行模式...
】)
【项目日记(三)】
目录 SERVER服务器模块实现: 1、Buffer模块:缓冲区模块 2、套接字Socket类实现: 3、事件管理Channel类实现: 4、 描述符事件监控Poller类实现: 5、定时任务管理TimerWheel类实现: eventfd 6、Reac…...

【图片转PDF工具】如何批量将文件夹里的图片以文件夹为单位批量合并PDF文档,基于WPF实现步骤及总结
应用场景 在实际工作和生活中,我们可能会遇到需要将一个文件夹内的多张图片合并成一个 PDF 文档的情况。例如,设计师可能会将一个项目的所有设计稿图片整理在一个文件夹中,然后合并成一个 PDF 方便交付给客户;摄影师可能会将一次拍摄的所有照片按拍摄主题存放在不同文件夹…...

深度解析算法之位运算
33.常见位运算 1.基础位运算 << 左移操作符 > >右移操作符号 ~取反 &按位与:有0就是0 |按位或:有1就是1 ^按位异或:相同为0,不用的话就是1 /无进位相加 0 1 0 0 1 1 0 1 0 按位与结果 0 1 1 按位或结果 0 0 1 …...

深入探索Qt异步编程--从信号槽到Future
概述 在现代软件开发中,应用程序的响应速度和用户体验是至关重要的。尤其是在图形用户界面(GUI)应用中,长时间运行的任务如果直接在主线程执行会导致界面冻结,严重影响用户体验。 Qt提供了一系列工具和技术来帮助开发者实现异步编程,从而避免这些问题。本文将深入探讨Qt…...

【KWDB 创作者计划】_本地化部署与使用KWDB 深度实践
引言 KWDB 是一款面向 AIoT 场景的分布式多模数据库,由开放原子开源基金会孵化及运营。它能在同一实例同时建立时序库和关系库,融合处理多模数据,具备强大的数据处理能力,可实现千万级设备接入、百万级数据秒级写入、亿级数据秒级…...

基于XC7V690T的在轨抗单粒子翻转系统设计
本文介绍一种基于XC7V690T 的在轨抗单粒子翻转系统架构;其硬件架构主要由XC7V690TSRAM 型FPGA芯片、AX500反熔丝型FPGA 芯片以及多片FLASH 组成;软件架构主要包括AX500反熔丝型FPGA对XC7V690T进行配置管理及监控管理,对XC7V690T进行在轨重构管理,XC7V690T通过调用内部SEMIP核实…...

机器学习 Day13 Boosting集成学习方法: Adaboosting和GBDT
大多数优化算法可以分解为三个主要部分: 模型函数:如何组合特征进行预测(如线性加法) 损失函数:衡量预测与真实值的差距(如交叉熵、平方损失) 优化方法:如何最小化损失函数&#x…...
)
Floyd算法求解最短路径问题——从零开始的图论讲解(3)
目录 前言 Djikstra算法的缺陷 为什么无法解决负权图 模拟流程 什么是Floyd算法 Floyd算法的核心思想 状态表示 状态转移方程 边界设置 代码实现 逻辑解释 举例说明 Floyd算法的特点 结尾 前言 这是笔者图论系列的第三篇博客 第一篇: 图的概念,图的存储,图的…...

spark和hadoop的区别与联系
区别 1. 数据处理模型 Hadoop:主要依赖 MapReduce 模型,计算分 Map(映射)和 Reduce(归约)两个阶段,中间结果常需写入磁盘,磁盘 I/O 操作频繁,数据处理速度相对受限&#…...

XMLXXE 安全无回显方案OOB 盲注DTD 外部实体黑白盒挖掘
# 详细点: XML 被设计为传输和存储数据, XML 文档结构包括 XML 声明、 DTD 文档类型定义(可 选)、文档元素,其焦点是数据的内容,其把数据从 HTML 分离,是独立于软件和硬件的 信息传输…...
)
C# .NET如何自动实现依赖注入(DI)
为解决重复性的工作,自动实现依赖注入(DI) 示例代码如下 namespace DialysisSOPSystem.Infrastructure {public static class ServiceCollectionExtensions{/// <summary>/// 批量注入服务/// </summary>/// <param name&qu…...

FastGPT Docker Compose本地部署与硅基流动免费AI接口集成指南
本文参考:https://doc.tryfastgpt.ai/docs/development/ 一、背景与技术优势 FastGPT是基于LLM的知识库问答系统,支持自定义数据训练与多模型接入。硅基流动(SiliconFlow)作为AI基础设施平台,提供高性能大模型推理引…...