LangChain + 文档处理:构建智能文档问答系统 RAG 的实战指南

🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、什么是Lang Chain
2、文档问答的典型应用场景
二、文档处理的核心流程全景图
1、文档加载(Document Loading)
2、文本切分(Text Splitting)
3、向量化存储(Embedding + Vector Store)
4、智能问答(RAG: Retrieval-Augmented Generation)
三、构建问答系统:LangChain RAG 实战项目
1、安装依赖
2、读取 Word 文件内容
3、切分文本为 chunks
4、向量化 + 存储到 FAISS 数据库
5、构建问答链(Retrieval + LLM)
6、完整代码
7、测试运行
8、优化建议
一、引言
1、什么是Lang Chain
你有没有想过,让 AI 不仅能回答问题,还能主动思考、查资料、记忆上下文、执行任务?
这就是 LangChain 的魔力所在!✨
🧠 LangChain 是什么?
简单来说,LangChain 是一个帮你构建 “智能 Agent(智能体)” 的工具库。
它就像是给大模型(比如 GPT)加上了“手脚 + 大脑”,让它能真正动起来,不再只是个“回答机”。
🛠️ 它能做什么?
| 功能 | 通俗解释 | 举个例子 |
|---|---|---|
| 🗃️ 记忆(Memory) | 模型可以“记住”你之前说过的话 | 连续聊天时不再重复自我介绍 😅 |
| 🔗 工具调用(Tools) | 模型能调用其他工具,如搜索、计算器 | “帮我查一下北京明天的天气” 🌤️ |
| 📚 知识库(Retrieval) | 模型能查找文档或数据库内容 | “根据公司手册,告诉我请假流程” 📄 |
| 📋 多步骤任务(Chain) | 模型可以分步骤执行复杂任务 | 写报告 → 查资料 → 汇总 → 输出 📊 |
| 🤖 智能 Agent | 像个 AI 助理,能自己决策、自己行动 | “每天早上 9 点给我发个日报提醒” ⏰ |
🏗️ 工作原理(简单比喻)
把 LangChain 想成搭积木:
-
📦 大模型(比如 GPT)是积木核心
-
🔧 工具(如搜索、数据库)是积木配件
-
🧩 LangChain 是连接一切的拼装架构
通过 LangChain,你可以把这些积木灵活组合,搭出属于你自己的 AI 应用!
🧑🍳 举个生活中的例子:做一顿饭
用传统大模型(没 LangChain):
你问:“鸡蛋怎么煮?”它告诉你方法,但没法动手 🤷
用 LangChain 构建的 AI 助理:
它不仅告诉你怎么煮,还能帮你:
-
查询冰箱里有什么 🧊
-
推荐菜谱 🍳
-
自动下单缺的食材 🛒
-
给你发做饭步骤提醒 📱
是不是一下子聪明多了?😎

2、文档问答的典型应用场景
文档问答系统 = 把 AI + 自己的文档整合起来,让 AI 自动“看文档 + 回答问题”
是不是很像一个不会请假的 AI 同事?🤖
💼 企业内部知识问答
🧠 员工问答助手
场景:新员工入职、老员工查询制度
💬 举例:
-
“年假怎么请?”
-
“公司 VPN 怎么配置?”
📝 对应文档:员工手册、制度文件、操作指南
🎯 效果:不用再翻厚厚的文档,直接问 AI!
🏥 医疗领域
📋 医学资料问答系统
场景:医生或患者查询疾病、药品说明
💬 举例:
-
“这个药物有啥副作用?”
-
“手术后的恢复流程是怎样的?”
📝 对应文档:医疗手册、临床指南、药品说明书
🎯 效果:快速查阅,避免误读、节省时间 🩺
⚖️ 法律服务
📘 法规/合同文档问答
场景:律师事务所、法务部门、合同管理
💬 举例:
-
“这份合同的付款条款是怎么规定的?”
-
“劳动法对加班时间有啥要求?”
📝 对应文档:合同文本、法律法规文库
🎯 效果:快速定位法律条款,不用手动 Ctrl+F 疯狂找 😵
🧰 客服和产品说明
🛠️ 产品说明 / 用户手册问答
场景:用户使用产品遇到问题
💬 举例:
-
“这个打印机怎么连接 Wi-Fi?”
-
“为什么启动时出现错误代码 E203?”
📝 对应文档:产品说明书、FAQ、故障手册
🎯 效果:减少人工客服压力,让用户自助解决 🧑🔧
💡 总结一句话:
文档问答 = 把“静态文档”变成“可对话知识库”,让你问一句,它答一句,效率翻倍 🚀
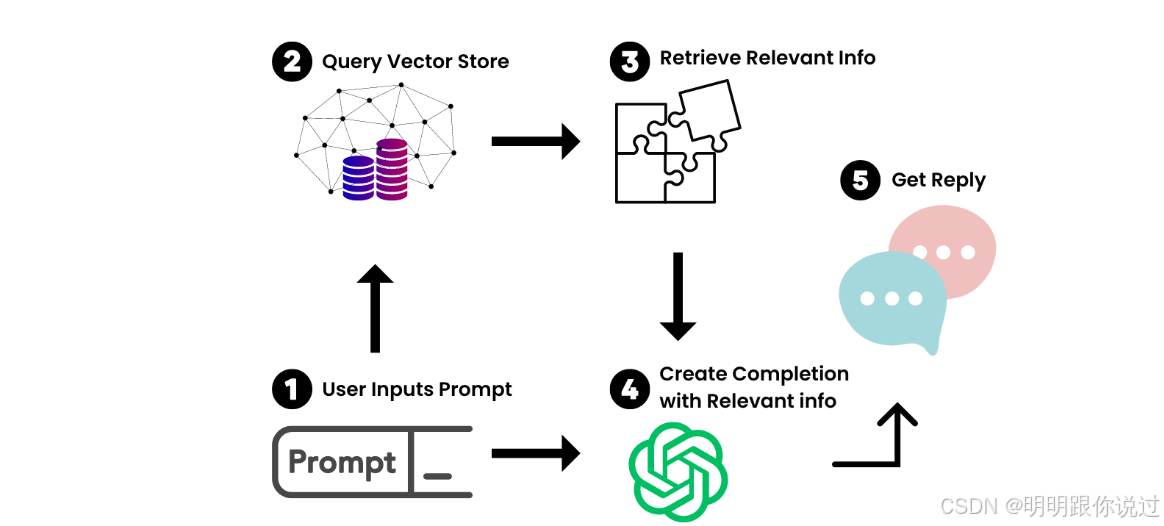
二、文档处理的核心流程全景图
1、文档加载(Document Loading)
把各种格式的文档,读进来变成文本
🧩 用到的 LangChain 模块:DocumentLoader
📂 支持格式广泛:
-
PDF
-
HTML、网页链接
-
TXT、Markdown
-
CSV、Notion、微信公众号……等等
💬 举例:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("report.pdf")
documents = loader.load()✨ 目的:从“文件”变成“字符串文本”,让后续处理成为可能!
2、文本切分(Text Splitting)
把长文档切成小块,模型吃得下才有输出
🧩 用到的模块:TextSplitter(比如 RecursiveCharacterTextSplitter)
📦 原因:
-
大模型有输入长度限制(token 限制)
-
分块后更利于建立向量索引,提升检索效果
💬 举例:
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
docs = splitter.split_documents(documents)✨ 目的:文档变成一堆“小语段”,每段都能独立处理、检索
3、向量化存储(Embedding + Vector Store)
把文本转成向量,用来快速查找“语义相近”的内容
🧩 用到的模块:
-
Embeddings(如 OpenAIEmbeddings) -
VectorStore(如 FAISS、Chroma、Milvus、Pinecone 等)
💬 举例:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISSembeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)📌 每段文本会被转换为一个“语义向量”,然后保存到向量数据库中。
✨ 目的:为后面的智能问答做准备,确保能根据问题找对相关内容!
4、智能问答(RAG: Retrieval-Augmented Generation)
根据问题检索相关片段,然后交给大模型生成答案
🧩 用到的模块:
-
Retriever:检索器,从向量数据库中找相似文本 -
LLM:大语言模型,用于回答问题 -
QA Chain:如RetrievalQA或ConversationalRetrievalChain
💬 举例:
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm=ChatOpenAI(),retriever=vectorstore.as_retriever()
)result = qa_chain.run("Q3 营收是多少?")🧠 底层流程:
用户提问 → 检索相关片段 → 送入大模型 → 生成答案 → 响应用户
✨ 目的:结合“上下文 + 问题”,给出准确、有依据的回答 ✅
流程图示意:
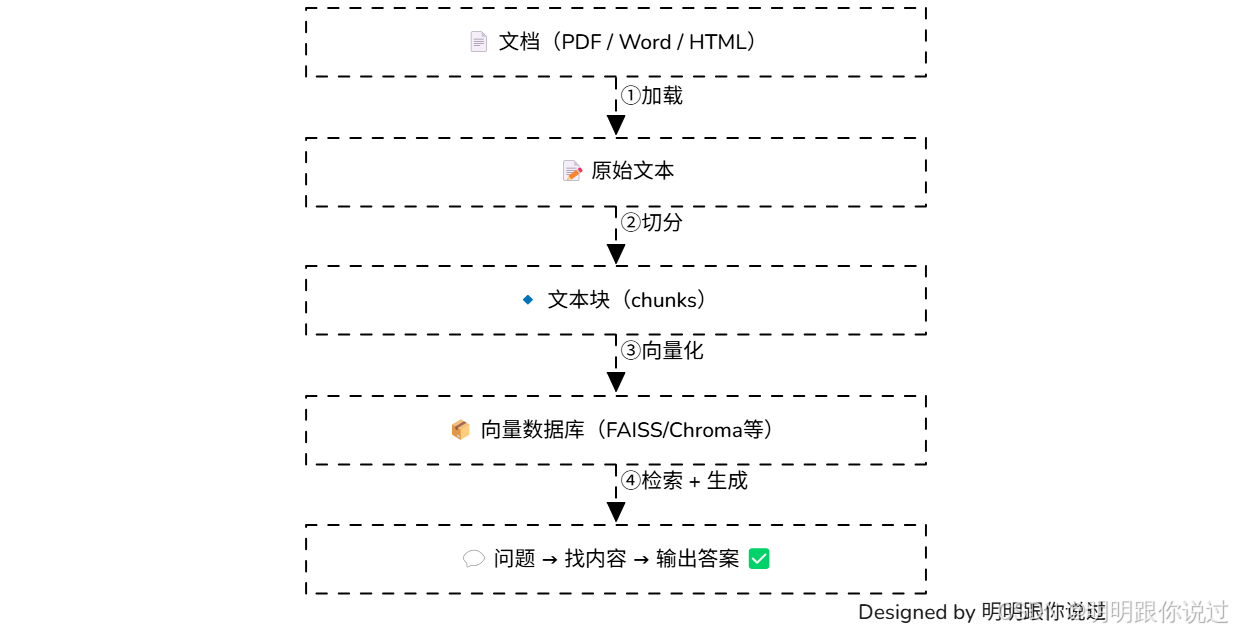
💡 总结一句话:
LangChain 文档问答 = 读文档 + 分片段 + 建索引 + 智能问答,打造属于你的 ChatPDF! 💬📄🤖
三、构建问答系统:LangChain RAG 实战项目
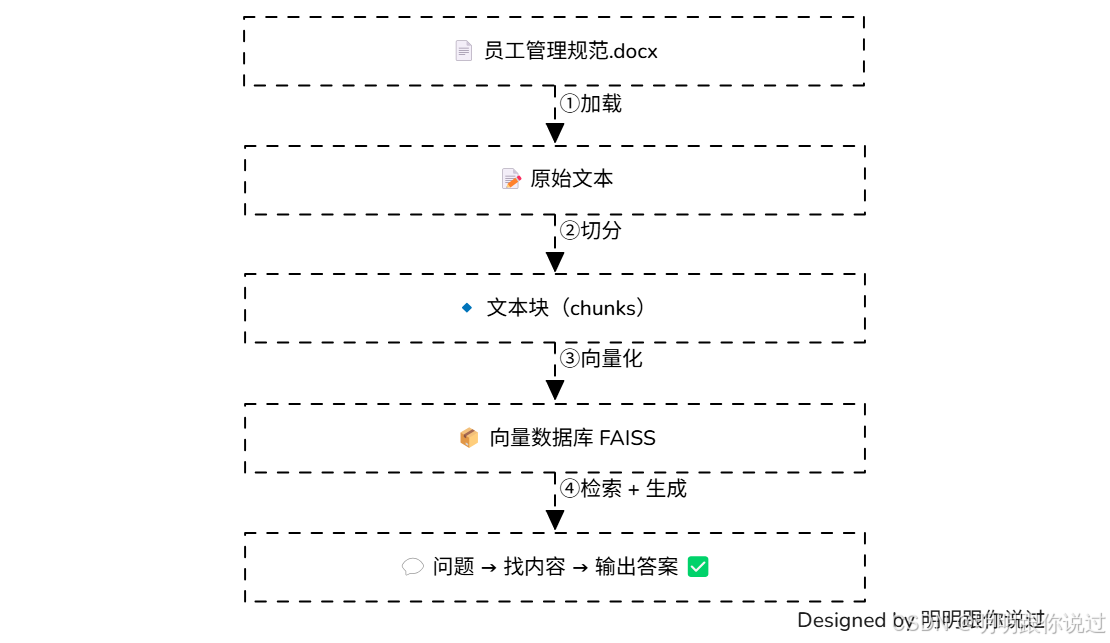
上面的技术相信你已经了解了,接下来我们动手做一个小实验,
我有一个员工管理规范的word,现在,我要将它提取分块后,写入到本地数据库FAISS中
当用户发起聊天时,基于员工管理规范回答用户的问题
流程如下:
1、安装依赖
首先,安装该项目的依赖,在终端执行下面的命令:
pip install docx langchain openai faiss-cpu 2、读取 Word 文件内容
LangChain 没有直接提供 Word 加载器,我们使用 python-docx:
from docx import Documentdef load_word_file(path):doc = Document(path)content = "\n".join([para.text for para in doc.paragraphs if para.text.strip()])return content这段代码的作用是:读取指定路径的 Word 文件,提取出其中所有有效的文本段落,并将它们拼接成一个以换行符分隔的大字符串。我们可以通过调用这个函数,方便地获取文档的全部文本内容,以便后续的处理(如切分、向量化等)。
3、切分文本为 chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document as LCDocument# 加载文本
raw_text = load_word_file("C:/Users/LMT/Desktop/员工管理规范.docx")# 创建 LangChain Document 对象
doc = LCDocument(page_content=raw_text)# 切分
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
docs = splitter.split_documents([doc])这段代码的总体目标是:
-
加载文档:首先,从指定路径加载 Word 文件,并提取文本内容。
-
封装文档:将文本内容封装到 LangChain 的
LCDocument对象中,方便后续操作。 -
切分文本:使用
RecursiveCharacterTextSplitter将长文本按字符数切分为多个较小的片段,每个片段最多 500 个字符,并允许 100 个字符的重叠部分。
最终,docs 变量将包含一个由多个切分后的 LCDocument 对象组成的列表,这些对象分别代表了文档的不同片段,准备好进行向量化、存储或者其他处理。
4、向量化 + 存储到 FAISS 数据库
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS# 创建嵌入模型(你也可以换成 HuggingFaceEmbeddings 或其他)
embeddings = OpenAIEmbeddings()# 向量化 & 构建 FAISS 向量数据库
vectorstore = FAISS.from_documents(docs, embeddings)# 可选:保存到本地
vectorstore.save_local("faiss_index")这段代码的功能是:
-
创建嵌入模型:利用 OpenAI 的 GPT 模型将文档内容转换为嵌入向量(每个文档块都会有一个高维的向量表示,捕捉它的语义)。
-
向量化并构建 FAISS 向量数据库:利用 FAISS 库将这些嵌入向量存储在一个高效的向量数据库中,便于后续进行相似度搜索。
-
保存向量数据库:将构建的 FAISS 向量数据库保存到本地磁盘,方便后续加载和使用。
最终,这样的存储和向量化过程,使得后续的问答系统能够非常高效地从文档中检索出相关信息,以便生成准确的答案。
5、构建问答链(Retrieval + LLM)
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA# 加载本地向量库(如需要)
vectorstore = FAISS.load_local("faiss_index", embeddings, allow_dangerous_deserialization=True)# 构建问答链
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),retriever=vectorstore.as_retriever(),return_source_documents=True
)# 用户提问
query = "我是一名工龄10年的员工,我每年有多少年假?"
result = qa(query)# 打印结果
print("🤖 答案:", result['result'])
print("📄 来源片段:")
for doc in result['source_documents']:print("-", doc.page_content[:100])这段代码实现了以下功能:
-
加载本地 FAISS 向量数据库:从磁盘加载之前保存的向量数据库。
-
构建问答链:创建一个基于 OpenAI GPT 模型和 FAISS 向量数据库的问答系统。
-
用户提问:用户输入问题,系统会通过 FAISS 检索相关文档,并通过 GPT 生成答案。
-
打印答案和来源片段:显示生成的答案以及相关的文档片段,帮助用户了解模型如何得出答案。
📦 补充说明:
| 模块 | 功能 |
|---|---|
python-docx | 读取 Word 文档内容 |
RecursiveCharacterTextSplitter | 将长文本拆成多个小块 |
OpenAIEmbeddings | 文本嵌入向量生成器 |
FAISS | 本地向量数据库(快 + 离线可用) |
RetrievalQA | 从向量库中取回内容+交给 LLM 回答问题 |
6、完整代码
from docx import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document as LCDocument
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQAdef load_word_file(path):doc = Document(path)content = "\n".join([para.text for para in doc.paragraphs if para.text.strip()])return content# 加载文本
raw_text = load_word_file("C:/Users/LMT/Desktop/员工管理规范.docx")# 创建 LangChain Document 对象
doc = LCDocument(page_content=raw_text)# 切分
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
docs = splitter.split_documents([doc])# 创建嵌入模型(你也可以换成 HuggingFaceEmbeddings 或其他)
embeddings = OpenAIEmbeddings()# 向量化 & 构建 FAISS 向量数据库
vectorstore = FAISS.from_documents(docs, embeddings)# 可选:保存到本地
vectorstore.save_local("faiss_index")embeddings = OpenAIEmbeddings()
# 加载本地向量库(如需要)
vectorstore = FAISS.load_local("C:/Users/LMT/PycharmProjects/AI/LangChain/Document_Q&A/faiss_index", embeddings, allow_dangerous_deserialization=True)# 构建问答链
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),retriever=vectorstore.as_retriever(),return_source_documents=True
)# 用户提问
query = "我是一名工龄10年的员工,我每年有多少年假"
result = qa(query)# 打印结果
print("🤖 答案:", result['result'])
print("📄 来源片段:")
for doc in result['source_documents']:print("-", doc.page_content[:100])7、测试运行
提问 "我是一名工龄10年的员工,我每年有多少年假"
执行结果如下:
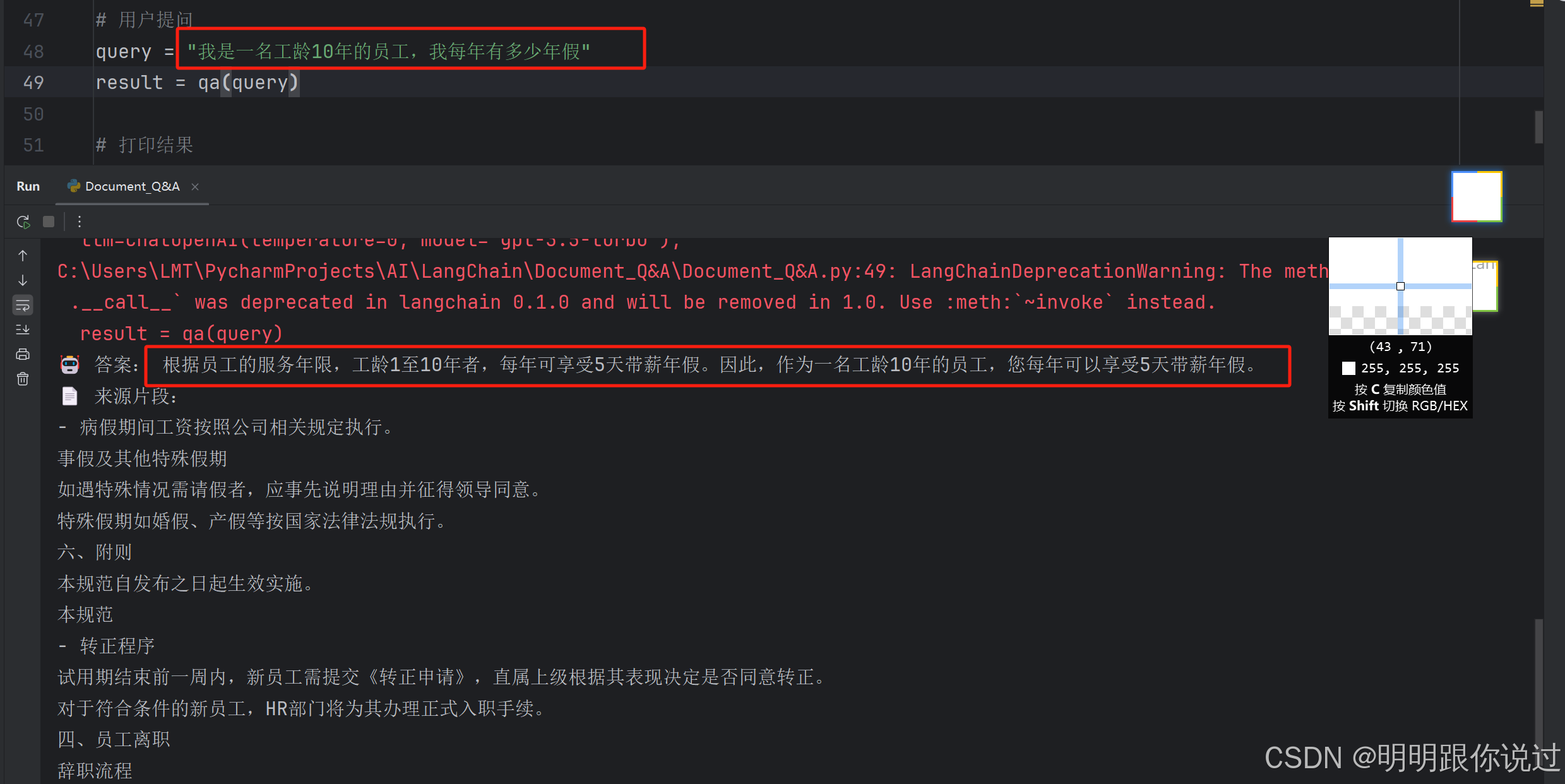
答案来源:
员工管理规范.docx

8、优化建议
🚀 BONUS:可选优化方向:
| 优化点 | 说明 |
|---|---|
使用 HuggingFaceEmbeddings | 免费本地化 Embedding 模型 |
使用 Chroma | 替代 FAISS,支持持久化更方便 |
| 构建前端 | 用 Gradio / Streamlit 做个简单问答界面 |
| 上下文记忆 | 增强多轮提问体验 |
| 文档多语种支持 | 支持英文/中英混合文档 |
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
相关文章:

LangChain + 文档处理:构建智能文档问答系统 RAG 的实战指南
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是Lang Chain 2、文档问答的典型应用场景 二、文…...

深入理解 DML 和 DQL:SQL 数据操作与查询全解析
深入理解 DML 和 DQL:SQL 数据操作与查询全解析 在数据库管理中,SQL(结构化查询语言)是操作和查询数据的核心工具。其中,DML(Data Manipulation Language,数据操作语言) 和 DQL&…...

头歌实训之SQL视图的定义与操纵
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习C语言的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...

Excel/WPS表格中图片链接转换成对应的实际图片
Excel 超链图变助手(点击下载可免费试用) 是一款将链接转换成实际图片,批量下载表格中所有图片的转换工具,无需安装,双击打开即可使用。 表格中链接如下图所示: 操作方法: 1、双击以下图标&a…...
)
单例模式的使用场景 以及 饿汉式写法(智能指针)
单例模式的使用场景 以及 饿汉式写法(智能指针) 饿汉式:创建类时就已经创建好了类的实例(用智能指针实现)什么时候用单例模式:1. 全局配置管理2. 日志系统3. 资源管理器4. 硬件设备访问总结 饿汉式…...

示波器探头状态诊断与维护技术指南
一、探头性能劣化特征分析 信号保真度下降 ・时域表现:上升沿时间偏离标称值15%以上(如1ns探头测得≥1.15ns) ・频域特性:-3dB带宽衰减超过探头标称值20%基准稳定性异常 ・直流偏置电压漂移量>5mV(预热30分…...

使用Matlab工具将RAW文件转化为TXT文件,用于FPGA仿真输入
FPGA实现图像处理算法时,通常需要将图像作为TestBench的数据输入。 使用VHDL编写TestBench时,只能读取二进制TXT文件。 现在提供代码,用于实现RAW图像读取,图像显示,图像转化为二进制数据并存入TXT文件中。 clc; cl…...

Missashe考研日记-day23
Missashe考研日记-day23 0 写在前面 博主前几天有事回家去了,断更几天了不好意思,就当回家休息一下调整一下状态了,今天接着开始更新。虽然每天的博客写的内容不算多,但其实还是挺费时间的,比如这篇就花了我40多分钟…...

视频分析设备平台EasyCVR安防视频小知识:安防监控常见故障精准排查方法
随着安防监控技术的飞速发展,监控系统已经成为现代安防体系中不可或缺的核心组成部分,广泛应用于安防监控、交通管理、工业自动化等多个领域。然而,监控系统的稳定运行高度依赖于设备的正确配置、线路的可靠连接以及电源的稳定供电。在实际应…...

Linux论坛安装
事前准备 1、Discuz_X3.5_SC_UTF8_20230520的压缩包。 2、一台虚拟机,xshell和xftp(用来传输文件) 安装httpd 软件并将压缩包移动到指定目录 mount /dev/sr0 /mnt #### 挂载光盘到 /mnt 目录 dnf install httpd -y ### 安装http…...

瑞吉外卖-分页功能开发中的两个问题
1.分页功能-前端页面展示显示500 原因:项目启动失败 解决:发现是Category实体类中,多定义了一个删除字段,但是我数据库里面没有is_deleted字段,导致查询数据库失败,所以会导致500错误。因为类是从网上其他帖…...

深入理解HotSpot JVM 基本原理
关于JAVA Java编程语言是一种通用的、并发的、面向对象的语言。它的语法类似于C和C++,但它省略了许多使C和C++复杂、混乱和不安全的特性。 Java 是几乎所有类型的网络应用程序的基础,也是开发和提供嵌入式和移动应用程序、游戏、基于 Web 的内容和企业软件的全球标准。. 从…...

[原理分析]安卓15系统大升级:Doze打盹模式提速50%,续航大幅增强,省电提升率5%
技术原理:借鉴中国友商思路缩短进入Doze的时序 开发者米沙尔・拉赫曼(Mishaal Rahman)在其博文中透露,谷歌对安卓15系统进行了显著优化,使得设备进入“打盹模式”(Doze Mode)的速度提升了50%,并且部分机型的待机时间因此得以延长三小时。设备…...

人工智能在慢病管理中的具体应用全集:从技术落地到场景创新
一、AI 赋能慢病管理:技术驱动医疗革新 1.1 核心技术原理解析 在当今数字化时代,人工智能(AI)正以前所未有的态势渗透进医疗领域,尤其是在慢性病管理方面,展现出巨大的潜力和独特优势。其背后依托的机器学习、深度学习、自然语言处理(NLP)以及物联网(IoT)与可穿戴设…...

视频生成上下文并行方案
在多张rtx4090上的并行生成方案,主要就是xdit和paraattention中的并行上下文注意力机制。希望找到一个和skyreel一致的para attn的并行方案。 1.ParaAttention https://github.com/chengzeyi/ParaAttentionhttps://github.com/chengzeyi/ParaAttention目前只支持了文生视频的…...
厘清Gradle的版本)
Unity接入安卓SDK(3)厘清Gradle的版本
接入过程中,很多人遇到gradle的各种错误,由于对各种gradle版本的概念不甚了了,模模糊糊一顿操作猛如虎,糊弄的能编译通过就万事大吉,下次再遇到又是一脸懵逼。所以我们还是一起先厘清gradle的版本概念。 1 明晰概念 …...
)
牛行为-目标检测数据集(包括VOC格式、YOLO格式)
牛行为-目标检测数据集(包括VOC格式、YOLO格式) 数据集: 链接: https://pan.baidu.com/s/1hTLiiNOJYjzcejNwZpVsqA?pwdzhhb 提取码: zhhb 数据集信息介绍: 共有 8869张图像和一一对应的标注文件 标注文件格式提供了两种&#x…...

ubuntu 22.04 安装和配置 mysql 8.0,设置开机启动
# 更新软件包列表 sudo apt update && sudo apt upgrade -y # 安装MySQL 8.0 sudo apt install mysql-server-8.0 -y # 启动MySQL服务并设置开机启动 sudo systemctl start mysql sudo systemctl enable mysql # 安全安装MySQL,一路回车 sudo mysql…...

掌握Go空接口强大用途与隐藏陷阱
掌握Go空接口:强大用途与隐藏陷阱 Go语言中的空接口interface{}初看像是一种超能力工具。它能容纳任何东西——数字、字符串、结构体,应有尽有。但能力越大责任越大……如果不小心使用,它也会带来一堆麻烦。本文将深入探讨interface{}的工作原理,挖掘其合理的使用场景,并…...

CSS预处理工具有哪些?分享主流产品
目前主流的CSS预处理工具包括:Sass、Less、Stylus、PostCSS等。其中,Sass是全球使用最广泛的CSS预处理工具之一,以强大的功能、灵活的扩展性以及完善的社区生态闻名。Sass通过增加变量、嵌套、混合宏(mixin)等功能&…...

【2025面试Java常问八股之redis】zset数据结构的实现,跳表和B+树的对比
Redis 中的 ZSET(Sorted Set,排序集合)是一种非常重要的数据结构,它结合了集合(Set)和有序列表(List)的特点,能够存储一组 唯一 的元素,并且每个元素关联一个…...

VR制作攻略:如何制作VR
VR制作基础步骤 制作VR内容,特别是VR全景图,是一个涉及多个关键步骤的过程,包括设备准备、拍摄、拼接、后期处理及优化等。 以下将详细介绍这些步骤,并结合众趣科技的支持进行阐述。 1. 设备准备 相机: 选择配备广…...

Linux深度探索:进程管理与系统架构
1.冯诺依曼体系结构 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。 截至目前,我们所认识的计算机,都是由⼀个个的硬件组件组成。 输入设备:键盘,鼠标…...

240421 leetcode exercises
240421 leetcode exercises jarringslee 文章目录 240421 leetcode exercises[31. 下一个排列](https://leetcode.cn/problems/next-permutation/)什么是字典序?🔁二次遍历查找 [82. 删除排序链表中的重复元素 II](https://leetcode.cn/problems/remove…...

批量导出多个文件和文件夹名称与路径信息到Excel表格的详细方法
在数字化时代,电脑中的文件和文件夹管理变得越来越重要啦。没有对文件进行定期整理时,寻找文件会我们耗费大量的时间。为了高效查找文件或文件夹,可以将其名称和路径记录下来并整理成清单。然而,当文件夹数量非常多时,…...

基于亚马逊云科技 Amazon Bedrock Tool Use 实现 Generative UI
背景 在当前 AI 应用开发浪潮中,越来越多的开发者专注于构建基于大语言模型(LLM)的 chatbot 和 AI Agent。然而,传统的纯文本对话形式存在局限性,无法为用户提供足够直观和丰富的交互体验。为了增强用户体验ÿ…...

Buildroot、BusyBox与Yocto:嵌入式系统构建工具对比与实战指南
文章目录 Buildroot、BusyBox与Yocto:嵌入式Linux系统构建工具完全指南一、为什么需要这些工具?1.1 嵌入式系统的特殊性1.2 传统开发的痛点二、BusyBox:嵌入式系统的"瑞士军刀"2.1 什么是BusyBox?2.2 核心功能2.3 安装与使用2.4 典型应用场景三、Buildroot:自动…...

Android 最简单的native二进制程序
Android.bp cc_binary {name: "my_native_bin",srcs: ["main.cpp"],cflags: ["-Wall", // 启用标准警告"-Werror", // 将警告视为错误"-fPIE", // 生成位置无关代码"-pie", …...

VR、AR、互动科技:武汉数字展馆制作引领未来展览新体验
在科技飞速发展的今天,数字化技术正以前所未有的速度渗透到各个领域,展馆行业也不例外。数字展馆,作为一种新兴的展示形式,正逐渐走进大众的视野,成为当下展馆发展的新潮流。 那么,究竟什么是数字展馆呢&am…...

从代码学习深度学习 - 学习率调度器 PyTorch 版
文章目录 前言一、理论背景二、代码解析2.1. 基本问题和环境设置2.2. 训练函数2.3. 无学习率调度器实验2.4. SquareRootScheduler 实验2.5. FactorScheduler 实验2.6. MultiFactorScheduler 实验2.7. CosineScheduler 实验2.8. 带预热的 CosineScheduler 实验三、结果对比与分析…...

Kotlin安卓算法总结
Kotlin 安卓算法优化指南 排序算法优化 1. 快速排序 // 使用三向切分的快速排序,对包含大量重复元素的数组更高效 fun optimizedQuickSort(arr: IntArray, low: Int 0, high: Int arr.lastIndex) {if (high < low) returnvar lt lowvar gt highval pivot …...

Eteam 0.3版本开发规划
Eteam 0.1系列经历了3个小版本,主要完成了团队资料库功能。 Eteam 0.2系列经历了22个小版本,主要完成了白板和AI交互的能力。 目前的问题 目前白板上的数据有两个来源,团队资料库和外部数据。外部数据和团队资料库数据边界不是很清晰。 0.3版…...

每天五分钟机器学习:凸优化
本文重点 凸优化作为一类特殊的数学优化问题,因其理论完备性和计算高效性,在人工智能领域发挥着至关重要的作用。从经典的逻辑回归到深度神经网络的初始化,从支持向量机的核技巧到强化学习的策略优化,凸优化理论不仅为算法提供了坚实的数学基础,还直接推动了人工智能模型…...

PyTorch与TensorFlow模型全方位解析:保存、加载与结构可视化
目录 前言一、保存整个模型二、pytorch模型的加载2.1 只保存的模型参数的加载方式:2.2 保存结构和参数的模型加载三、pytorch模型网络结构的查看3.1 print3.2 summary3.3 netron3.3.1 解决方法13.3.2 解决方法23.4 TensorboardX四、tensorflow 框架的线性回归4.1 …...

【图像变换】pytorch-CycleGAN-and-pix2pix的学习笔记
1. 问题记录 (1)在2080Ti上训练时模型“卡在了第63个epoch”没有任何变换 我们观察到模型一直卡在这里,“像静止了一样”没有任何变化; 也查看了一下显卡情况,看到显存占用为0%,如图所示,...
)
微信小程序 == 倒计时验证码组件 (countdown-verify)
组件介绍 这是一个用于获取验证码的倒计时按钮组件,支持自定义倒计时时间、按钮样式和文字格式。 基本用法 <countdown-verify seconds"60"button-text"获取验证码"bind:send"onSendVerifyCode" />属性说明 属性名类型默认…...
)
Ldap高效数据同步- Delta-Syncrepl复制模式配置实战手册(上)
#作者:朱雷 文章目录 一、Syncrepl 和Delta-syncrepl 回顾对比1.1. 什么是复制模式1.2. 什么是 syncrepl同步复制1.3. syncrepl同步复制的缺点1.4. 什么是Delta-syncrepl 复制 二、Ldap环境部署三、配置复制类型3.1. 编译安装3.2. 提供者端配置 一、Syncrepl 和Del…...

【Hive入门】Hive概述:大数据时代的数据仓库桥梁
目录 1 Hive概述:连接SQL世界与Hadoop生态 2 从传统数据仓库到Hive的演进之路 2.1 传统数据仓库的局限性 2.2 Hive的革命性突破 3 Hive的核心架构与执行流程 3.1 Hive系统架构 3.2 SQL查询执行全流程 4 Hive与传统方案的对比分析 5 Hive最佳实践 5.1 存储…...

靠华为脱胎换骨,但赛力斯仍需要Plan B
文|刘俊宏 编|王一粟 2024年底,撒贝宁在央视的一场直播中,终于“按捺不住”问了赛力斯董事长张兴海一个好奇已久的问题——“与华为合作之后,晚上是不是乐得睡不着觉?” “睡觉的时候还是该睡觉......不…...

【ESP32】【微信小程序】MQTT物联网智能家居案例
这里写自定义目录标题 案例成果1.Ardino写入部分2.微信小程序JS部分3.微信小程序xml部分4. 微信小程序CSS部分 案例成果 1.Ardino写入部分 #include <WiFi.h> // ESP32 WiFi库 #include <PubSubClient.h> // MQTT客户端库 #include <DHT.h> …...

应用层核心协议详解:HTTP, HTTPS, RPC 与 Nginx
应用层核心协议详解:HTTP, HTTPS, RPC 与 Nginx 前言一、HTTP:Web的基石1.1 HTTP协议的核心特点1.2 HTTP 报文格式1.3 HTTP 方法 (Methods)1.4 HTTP 状态码 (Status Codes)1.5 连接管理:短连接 vs 长连接1.6 HTTP 版本演进1.7 状态管理&#…...

解析三大中间件:Nginx、Apache与Tomcat
目录 一、基础定义与核心功能 二、核心区别与适用场景对比 三、为什么需要组合使用? 四、如何选择?一句话总结 五、技术演进与未来趋势 一、基础定义与核心功能 Nginx 定位:高性能的HTTP服务器与反向代理工具。核心能…...

关于 梯度下降算法、线性回归模型、梯度下降训练线性回归、线性回归的其他训练算法 以及 回归模型分类 的详细说明
以下是关于 梯度下降算法、线性回归模型、梯度下降训练线性回归、线性回归的其他训练算法 以及 回归模型分类 的详细说明: 1. 梯度下降算法详解 核心概念 梯度下降是一种 优化算法,用于寻找函数的最小值。其核心思想是沿着函数梯度的反方向逐步迭代&a…...

【数据结构和算法】4. 链表 LinkedList
本文根据 数据结构和算法入门 视频记录 文章目录 1. 链表的概念1.1 链表的类型1.2 链表的基本操作 2. 单向链表的实现2.1 插入2.2 删除2.3 查找2.4 更新 1. 链表的概念 我们知道数组是很常用的数据储存方式,而链表就是继数组之后,第二种最通用的数据储…...

基于S2B2C模式与定制开发开源AI智能名片的小程序商城系统研究
摘要:在新零售蓬勃发展的大背景下,S2B2C模式凭借其对消费场景的强力支撑以及柔性供应链的显著优势,成为推动零售行业变革的关键力量。本文深入剖析S2B2C模式,着重探讨定制开发开源AI智能名片S2B2C商城小程序源码的实践意义。通过分…...

【Python核心库实战指南】从数据处理到Web开发
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块对比 二、实战演示环境配置要求核心代码实现(5个案例)案例1:NumPy数组运算案例2:Pandas数据分析…...
)
【错误记录】Windows 命令行程序循环暂停问题分析 ( 设置 “ 命令记录 “ 选项 | 启用 “ 丢弃旧的副本 “ 选项 | 将日志重定向到文件 )
文章目录 一、报错信息二、问题分析1、Windows 命令行的缓冲区机制2、命令记录设置 三、解决方案1、设置 " 命令记录 " 选项2、将日志重定向到文件 一、报错信息 Java 程序中 , 设置 无限循环 , 每次循环 休眠 10 秒后 , 再执行程序逻辑 , 在命令行中打印日志信息 ; …...

【iOS】Blocks学习
Blocks学习 Blocks概要Blocks模式Blocks语法Blocks类型变量截获自动变量值__block说明符截获的自动变量 Blocks的实现Blocks的实质截获自动变量值__block说明符Block存储域_block变量存储域截获对象__block变量和对象 总结 Blocks概要 Blocks是C语言的扩充功能,简单…...

Spring MVC DispatcherServlet 的作用是什么? 它在整个请求处理流程中扮演了什么角色?为什么它是核心?
DispatcherServlet 是 Spring MVC 框架的绝对核心和灵魂。它扮演着前端控制器(Front Controller)的角色,是所有进入 Spring MVC 应用程序的 HTTP 请求的统一入口点和中央调度枢纽。 一、 DispatcherServlet 的核心作用和职责: 请…...

QT 5.15 程序打包
说明: windeployqt 是 Qt 提供的一个工具,用于自动收集并复制运行 Qt 应用程序所需的动态链接库(.dll 文件)及其他资源(如插件、QML 模块等)到可执行文件所在的目录。这样你就可以将应用程序和这些依赖项一…...