Linux深度探索:进程管理与系统架构

1.冯诺依曼体系结构
我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。
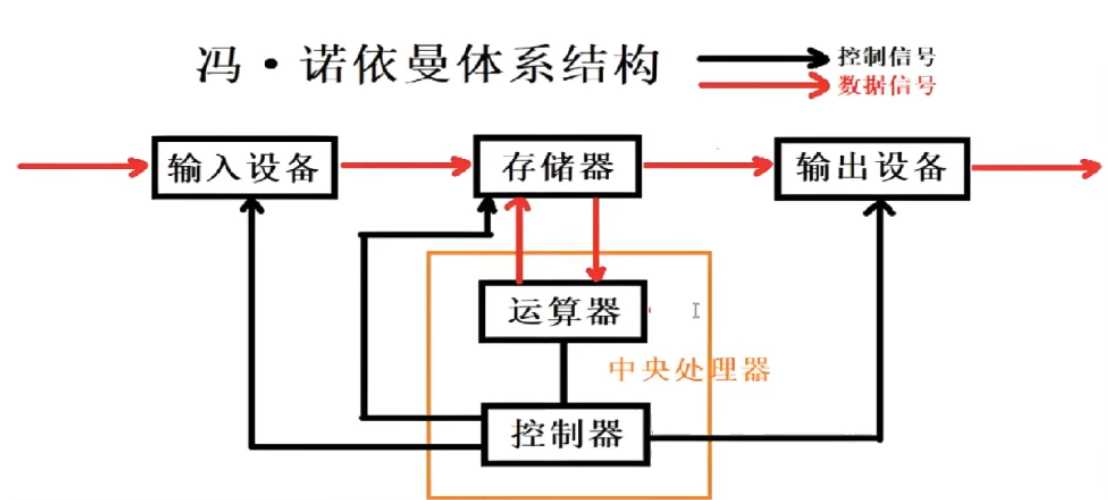
截至目前,我们所认识的计算机,都是由⼀个个的硬件组件组成。
- 输入设备:键盘,鼠标,话筒,摄像头,…,网卡,磁盘
- 输出设备:显示器,磁盘,网卡,打印机,…
- 中央处理器(CPU):含有运算器和控制器等
我们把输入输出设备称为外设。
磁盘(硬盘):外存
关于冯诺依曼,必须强调几点 :
- 这里的存储器指的是内存;
- 不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备);
- 外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。
- 一句话,所有设备都只能直接和内存打交道。
在学习C++进行文件操作时,读文件操作本质是把磁盘中的数据读取到内存中,写文件则是将内存里的数据写入对应的磁盘上,这类数据的读写动作被称为Input/Output(IO)。
从硬件层面来说,站在内存的角度理解IO,当外部设备将数据传输给内存时,这一过程称为Input(输入),而当内存把数据传输给输出设备时,这一过程就叫做Output(输出)。
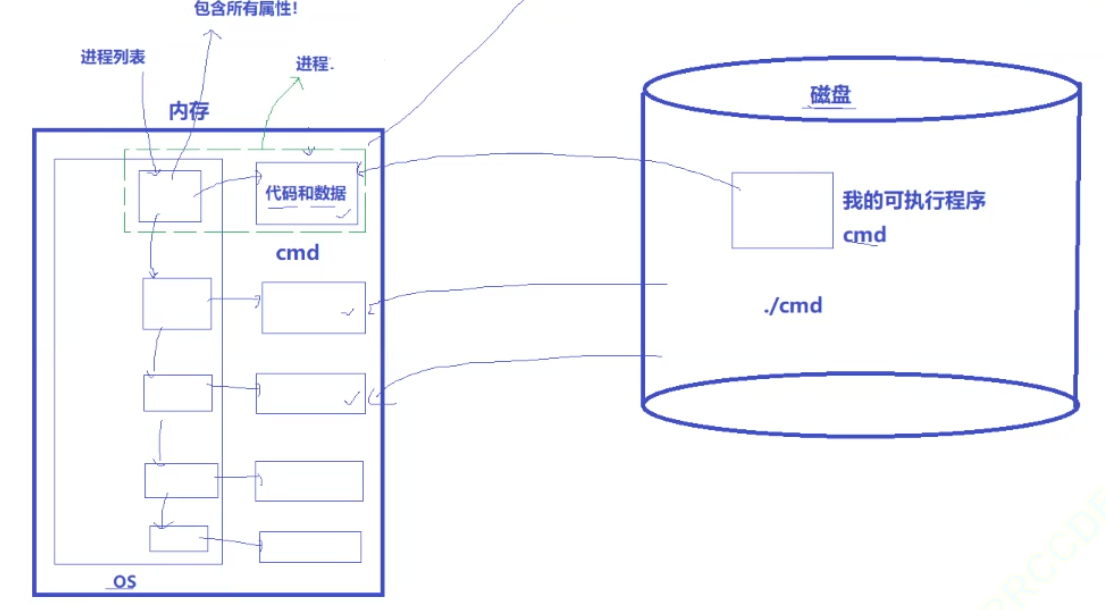
1.我们编译好的软件,它要运行必须先加载到内存?那程序运行之前在哪里?
- 在磁盘,因为我们今天知道,程序就是个文件,它就是我们编译好的,在我们磁盘特定路径下的一个二进制文件。
2.为什么我们对应的程序,运行的时候必须得从我们对应的磁盘加载到我们内存呢?
- 程序运行与内存加载:编译好的软件以二进制文件形式存于磁盘特定路径下,要运行必须先加载到内存。因为在计算机体系结构里,软件运行由CPU执行代码、访问数据,但CPU只能读写内存数据,无法直接读取外设数据,所以程序需从磁盘(外设)加载到内存,该加载过程本质是Input,即把外设数据输入到存储器。
- printf 执行原理:当程序在内存中运行并执行printf代码时,数据不会直接打印到输出设备,而是先存放在缓冲区,待需要时再刷新到外设。这同样是冯·诺依曼体系结构的规定,printf在CPU中执行代码,不能直接输出到外设。
- 数据流动与体系结构效率:数据流动本质是从一个设备“拷贝”到另一个设备。冯·诺依曼体系结构的效率由设备的“拷贝”效率决定。并且在数据层面,CPU只与内存打交道,外设也只与内存打交道。
3.冯诺依曼为什么是这种结构呢?计算机能否不使用内存,仅通过输入设备、CPU和输出设备运行?
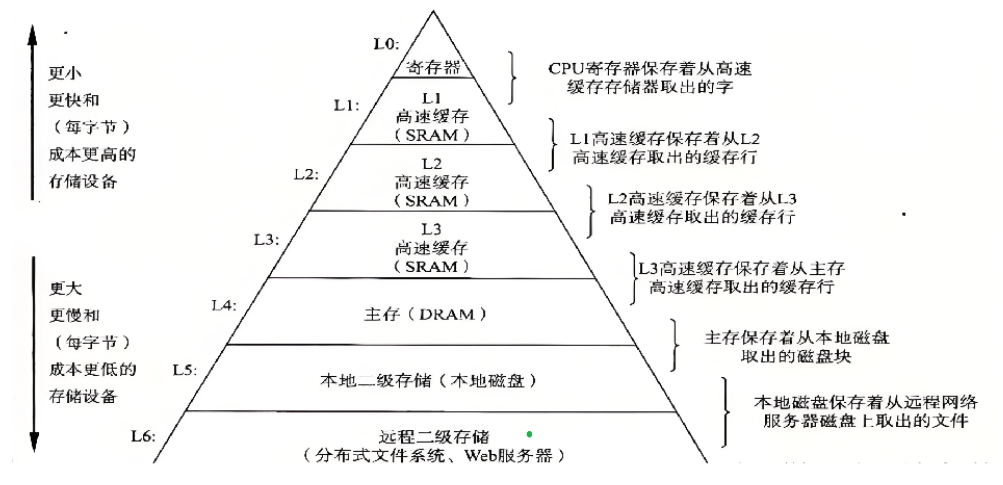
- 存储分级与特点:计算机中有多种存储设备,如离CPU近的寄存器有存储能力,内存离CPU较近,磁盘离CPU较远。离CPU越远存储容量越大、效率越低但价格便宜,如4GB内存几百块,而同等价格可买约800T磁盘。
- 效率差异问题:输入输出设备作为外设运算效率低(如磁盘为毫秒级),CPU运算速度快(纳米级),两者效率相差10⁶倍。若没有内存,外设与CPU、输出设备交互时,会因速度不匹配导致整个体系结构效率由外设决定(木桶原理)。
设想将所有存储设备都换成寄存器可行,但会使计算机造价昂贵。
内存的作用及意义:为平衡效率和价格,计算机体系结构引入内存。内存可适配CPU和外设间的速度不匹配,使计算机既能以较低成本制造,又能有不错的运行效率,当代计算机是性价比的产物。
4.为什么冯诺依曼体系结构从上个世纪五六十年代到现在,基本上是我们当代计算机的主流结构?
- 主流结构原因:冯·诺依曼体系结构的历史意义在于让用户能用较低价格买到效率不错的计算机。随着芯片技术、摩尔定律推动存储技术发展,计算机变得更便宜且效率更高。如今以内存决定计算机效率,使普通人能买得起计算机,进而造就众多网民和互联网,该体系是构建互联网的必要条件。
5.那为什么我们有了内存之后效率就高了呢?木桶定律里里面最短的依然是输入输出设备呀?
- 内存提升效率原理:虽按木桶定律输入输出设备仍是短板,但后来出现的操作系统加载于内存中,它能用算法提前将外设数据搬到内存,配合局部性原理,让CPU可直接读取内存数据,从而使内存发挥最大效果提升效率。
后续内容预告:后续将讨论操作系统在该体系结构中扮演的角色和意义。
6.理解数据流动
举个场景,你在北京,你的朋友在南京,今天你两在QQ进行聊天,当你们两个聊天的时候,请帮我解释一下,今天你通过键盘输入了一个“你好”,那么“你好”这个字符串信息是如何展现在你朋友的显示器上的?如果是在qq上发送⽂件呢?
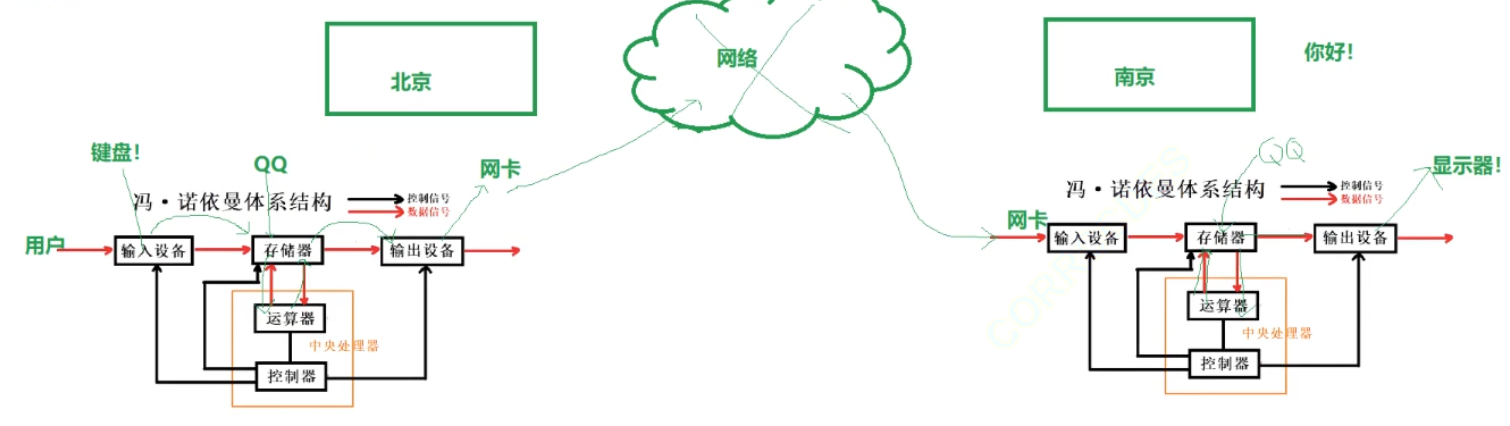
- QQ聊天数据流动:双方用电脑QQ聊天,本质是两台冯·诺依曼体系设备交互。输入方打开并登录QQ,将QQ可执行程序加载到内存,通过键盘输入信息,数据从键盘(输入设备)流入内存(存储器)。QQ对信息加密,经运算器运算、CPU处理后写回内存,再通过网卡(输出设备)发送到网络。接收方网卡(输入设备)获取数据存入内存,启动的QQ读取数据交CPU解密,再写回内存并刷新到显示器(外设)显示。
- QQ发送文件数据流动:文件本质是数据,拖拽文件到QQ程序时,文件从磁盘拷贝到内存,QQ执行代码加密、封包后写回内存,再刷新到网卡发送。对方网卡接收文件数据存入内存,解包、解密后写回内存,甚至打开目标文件,将数据写入磁盘(输出设备)。
总结:聊天是数据从用户键盘经体系结构转发到对方显示器的过程;发送文件是文件从本地磁盘经体系结构拷贝至对方磁盘的过程,软件的作用在于处理存储器和内存之间的关系,数据流动本质是在冯·诺依曼体系中进行。
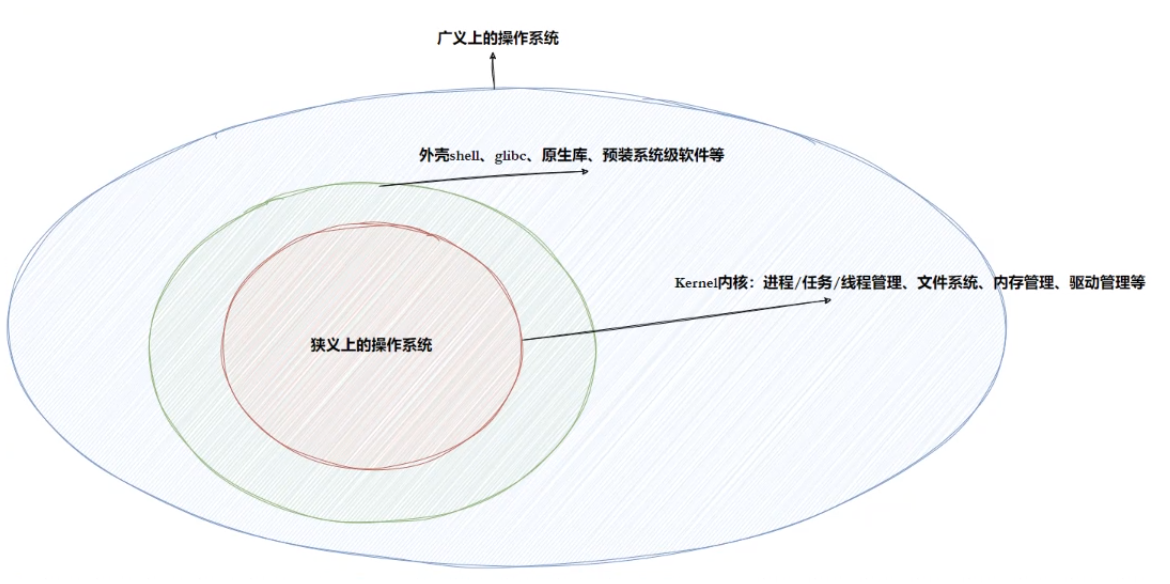
2.操作系统统(Operator System)
2-1概念
任何计算机系统都包含一个基本的程序集合,称为操作系统(OS)。操作系统包括:
- 内核(进程管理,内存管理,文件管理,驱动管理)
- 其他程序(例如函数库,shell程序等等)
安卓系统基于Linux内核构建,负责管理手机硬件资源(CPU、内存、存储等),其本质仍遵循冯·诺依曼架构。与传统PC不同,手机通过触摸屏实现输入输出的高度集成,交互界面需专门设计。为此,安卓在Linux内核之上新增了应用框架层(如图形界面、API库等),开发者可基于此开发移动应用。
对比Windows:
- 安卓采用分层架构,图形界面运行于用户空间,与内核解耦;
- Windows部分图形驱动与内核深度耦合(如DirectX),但因系统闭源,具体细节未知。
2-2设计OS的目的:
- 向下,与硬件交互,管理所有的软硬件资源(不是目的,是手段)
- 对上,为用户程序(应用程序)提供一个良好的执行环境(用户是目的)
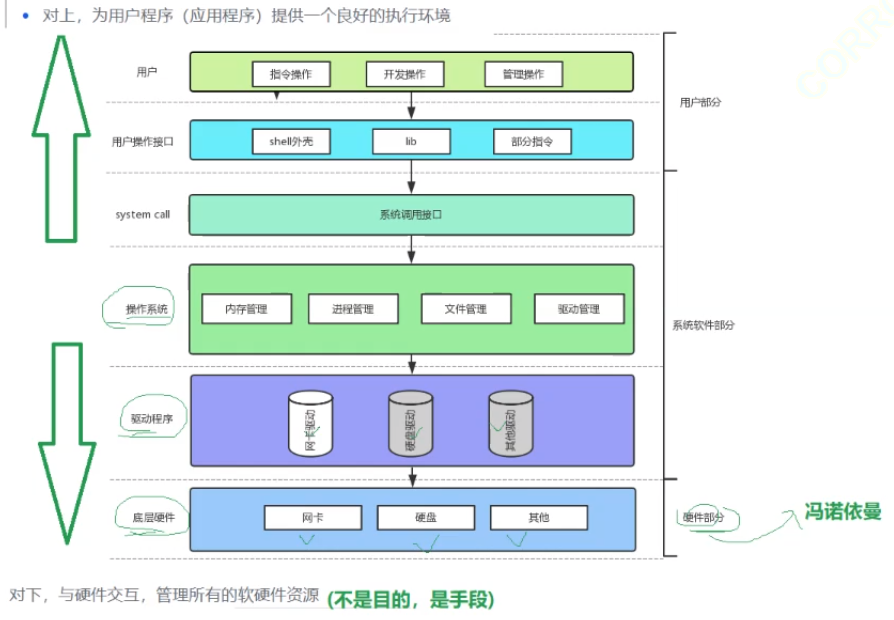
1.软硬件体系结构层状结构;
2.访问操作系统,必须使用系统调用——其实就是函数,只不过是系统提供的;
printf的本质:是你把你的数据写到了硬件(显示器)!
3.我们的程序,只要你判断出它访问了硬件,那么它就必须贯穿整个软硬件体系结构;
4.库可能在底层封装了系统调用。
2-3核心功能
- 在整个计算机软硬件架构中,操作系统的定位是:⼀款纯正的“搞管理”的软件。
2-4理解操作系统的“管理”
如何理解“管理”,我们下面举个例子。
• 管理的例子——学生,辅导员,校长
• 要管理的对象:学生
• 进行管理的对象:校长
做这件事情,管理者校长有决策权,辅导员进行执行,去管理学生。
在这里,操作系统= 校长,底层硬件=学生,驱动程序=辅导员
1.要管理,管理者和被管理者,可以不需要见面
2.管理者和被管理者,怎么管理呢?根据“数据”进行管理!
3.不需要见面,如何得到数据?由中间层获取!

校长管理学生,可以转化为对Excel表格的数据的管理!
要是学生越来越多了,那校长的负担越来越大,而这项工作的本质其实是对数据进行增删查改。
“校长”了解一点编程语言,它只会c语言——因为它是一个操作系统,操作系统是用C语言写的。
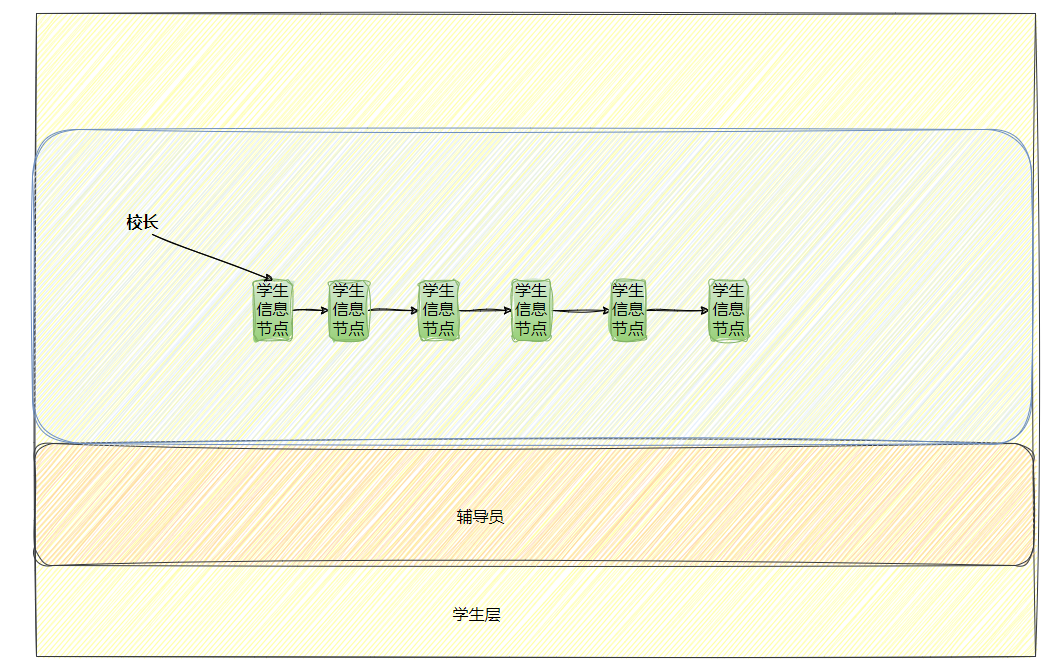
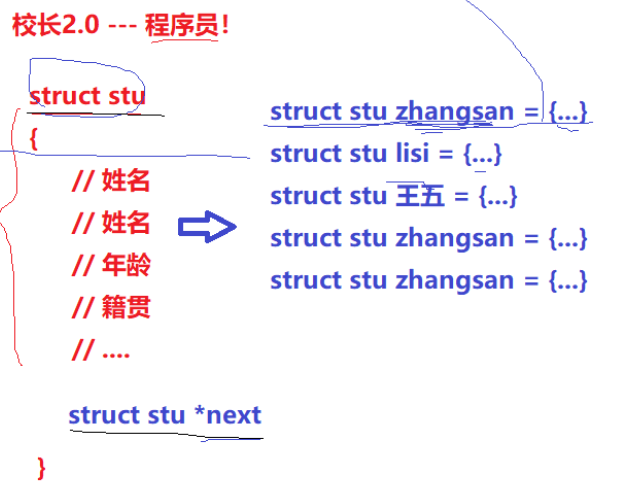
日常的校长管理学生的工作,转化为对链表的增删查改!(其他数据结构也可)
这个建模的过程称为**先描述,再组织!**
对任何“管理”场景进行建模都适用!
- 总结计算机管理硬件:
- 描述起来,用struct结构体
- 组织起来,用链表或其他高效的数据结构
(类:解决先描述的问题;STL:解决的是再组织的问题。)
2-5理解系统调用
-
系统调用与库函数的关系:库函数和系统调用处于上下层关系。从开发层面看,操作系统对外呈现为一个整体,并暴露部分接口,即系统调用。系统调用功能基础,对用户要求较高。开发者可对部分系统调用进行适度封装形成库,方便上层用户或开发者进行二次开发。
-
操作系统的服务:操作系统需向上层提供服务。像printf打印是将字符串写到显示器硬件,scanf读入是从键盘读取硬件数据到软件程序,这些操作都需要操作系统参与,操作系统提供的访问硬件的能力就是服务。同时,操作系统不信任任何用户或人。
-
系统调用的本质:系统调用本质上是操作系统提供的函数调用。用户要访问操作系统获取数据、设置信息等都需通过系统调用完成。由于Linux、Windows、macOS等操作系统基本由C语言编写,所以提供的系统调用一般是C风格的C函数。函数有输入参数(用户提供给操作系统)和返回值(操作系统反馈给用户),系统调用本质是用户与操作系统之间的数据交互。
承上启下: 我们启动的软件都会被加载到内存,因为冯诺依曼规定它必须得加载进来,在内存当中,当我们还没有启动软件的时候,还有一款软件在最开始就加载进来了,叫做操作系统(OS)。
OS必然要对多个被加载到内存中的程序进行管理,采取“先描述,再组织”的办法。
3.进程
3-1基本概念与基本操作

- 进程的组成:进程由内核数据结构对象和自身的代码与数据构成。
3-2描述进程——PCB
基本概念
- 进程信息被放在⼀个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
- 课本上称之为PCB(process control block),Linux操作系统下的PCB是: task_struct
task_struct-PCB的⼀种
- 在Linux中描述进程的结构体叫做task_struct。
- task_struct是Linux内核的⼀种数据结构,它会被装载到RAM(内存)⾥并且包含着进程的信息。
对进程理解的误区:
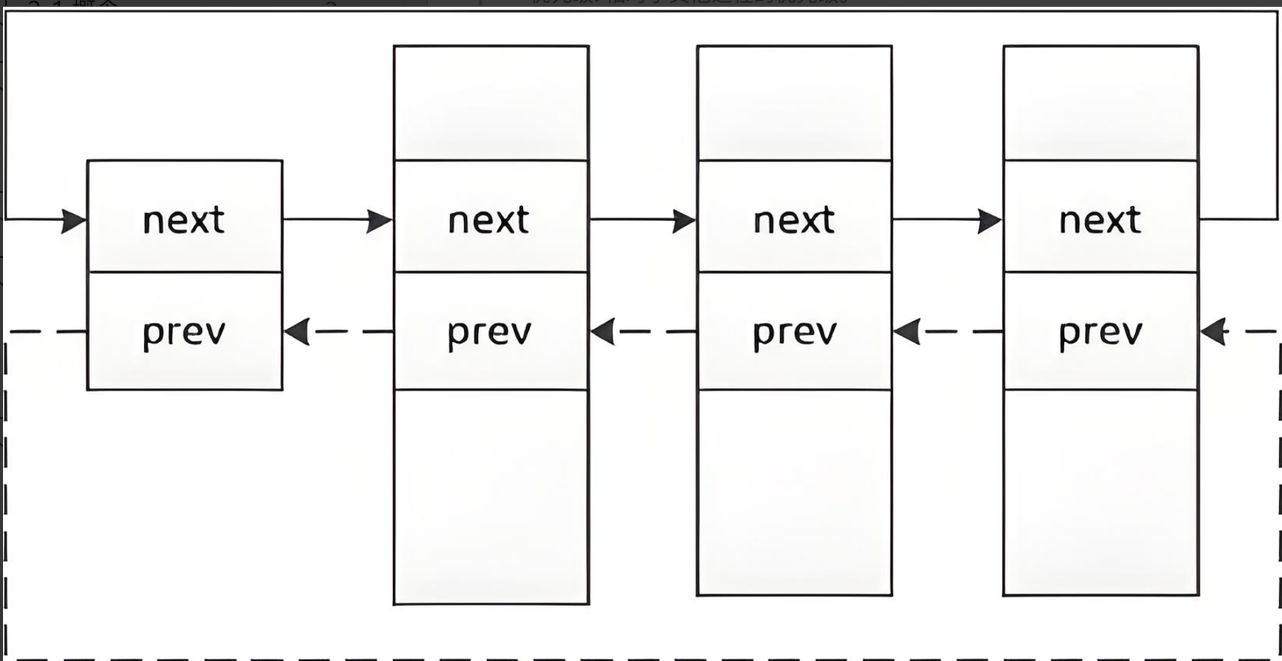
- 很多人错误地认为将程序和代码加载到内存中就是进程。实际上,进程加载时,除了将代码和数据加载到内存,操作系统还会在内部为其创建对应的task_struct结构体,该结构体可找到对应的代码和数据。并且所有的task_struct在操作系统内常以链表形式被管理起来,因此操作系统对进程的管理最终转化为对进程链表的增删查改。
创建PCB的原因:
- 操作系统为加载的进程创建对应的PCB(task_struct)结构体对象,是因为要管理进程。而管理进程必须先进行描述再组织,所以需要有描述进程的task_struct,之后通过特定数据结构(如链表)进行组织管理,这样操作系统对进程的管理就转变为对数据结构的增删查改操作。
3-3task_struct
内容分类:

组织进程
可以在内核源代码里找到它。所有运行在系统里的进程都以task_struct链表的形式存在内核里。
3-4查看进程
我们历史上执行的所有的指令、工具、自己的程序,运行起来,全部都是进程。
- 进程一旦启动,我们可以使用
ps来查所有进程axj,a表示所有。
top也可以查所有进程。
如果我们只想看到我们自己刚启动的进程,可以用下面的命令:

在Linux中我们想同时执行两条命令可以用分号相隔。分号可以用&&代替,效果相同。

当我们去查进程的时候,对应的这个grep选项它总是会被显示出来,为什么呢?
8993 11868 11867 8993 pts/1 11867 S+ 0 0:00 grep --color=auto myprocess
因为整条命令从左向右查的时候,grep也是个命令,当它最终要把你对应的查显示出来的结果做过滤的时候,grep命令一旦跑起来自己也是个进程,而它自己的过滤关键字里面本来就包括myprocess,所有它也会自己把自己查出来。
要是我们不想要查到grep可以使用下面命令:

这样就只会查到只是包含./myprocess对应进程ID8807了.
- 我们也可以通过一个Linux当中的目录结构叫做proc目录,也就是可以通过文件的形式去查看进程:
ls /proc
在操作系统中,不仅能用 ls 等命令通过目录结构查看磁盘上的文件,还能以文件形式呈现内存相关数据,让用户动态查看。比如 /proc 是内存级文件系统,其数据都来自内存,与磁盘无关。由于 Linux 遵循“一切皆文件”的设计理念,在 Linux 的设计中,甚至每个进程都能转化为若干个文件。
3-5通过系统调用获取进程标示符
我们来学习第一个系统调用:getpid
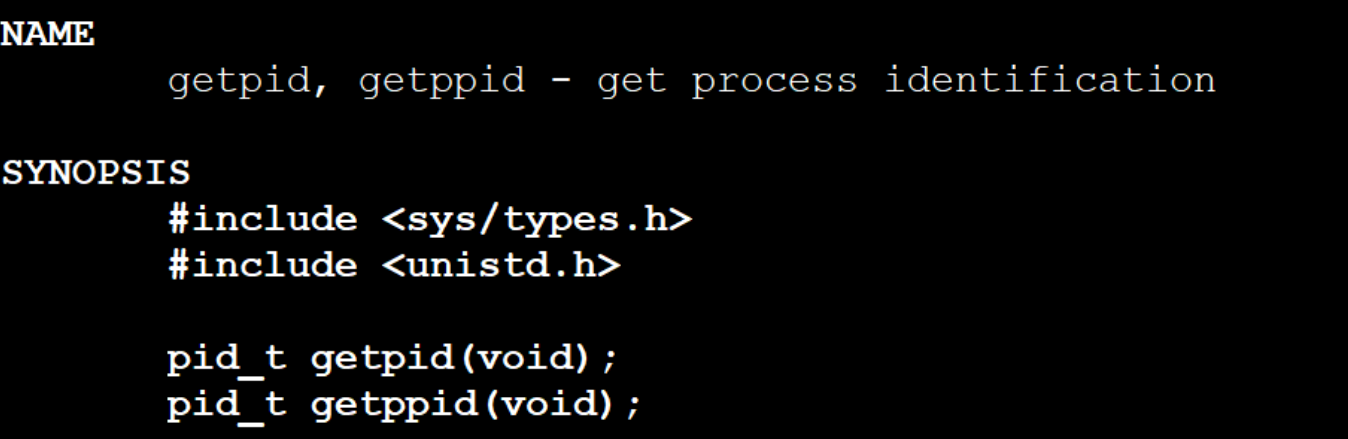
pid_t getpid(void); //获取进程ID
pid在哪里?在你当前task_struct的标识符中。
所以我们调用getpid,本质是让操作系统把当前进程的,从PCB把我的pid给拷贝出来,让用户看到自己的ID是什么。
- 只要是一个进程,就必然有自己的ID信息,所有只要有ID,我们就能证明这是一个进程。
pid_t是系统提供的,不是C语言的double这些,但Linux也是由C语言写的,这pid_t虽然是个系统级的类型,但它其实就是个int。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{printf("pid: %d\n", getpid());printf("ppid: %d\n", getppid());return 0;
}
3-6终止进程的方法
1.ctrl+c是杀掉进程的!
2.输入命令:kill -9 +PID值(-9是一个信号编号)

每一次启动同一个进程,pid的值不同是很正常的;
我们运行的所有的命令,在系统里都是进程。只不过ls运行特别快,一启动就退出;只不过top命令一启动不退出,需要手动q来退出。
在Linux系统里,我们用户是以进程的方式,来反问操作系统。把用户看做一名老师,操作系统是一名学生,老师给学生布置任务,让学生去完成,可以布置很多任务,所以我们一般把进程也叫任务。所以PCB在Linux里,它叫做task.
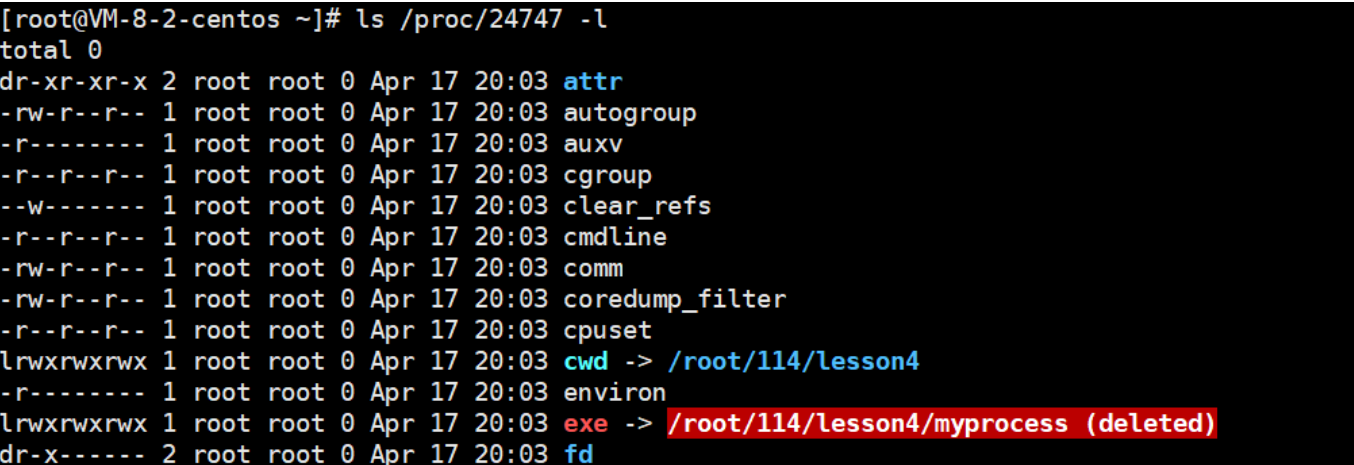
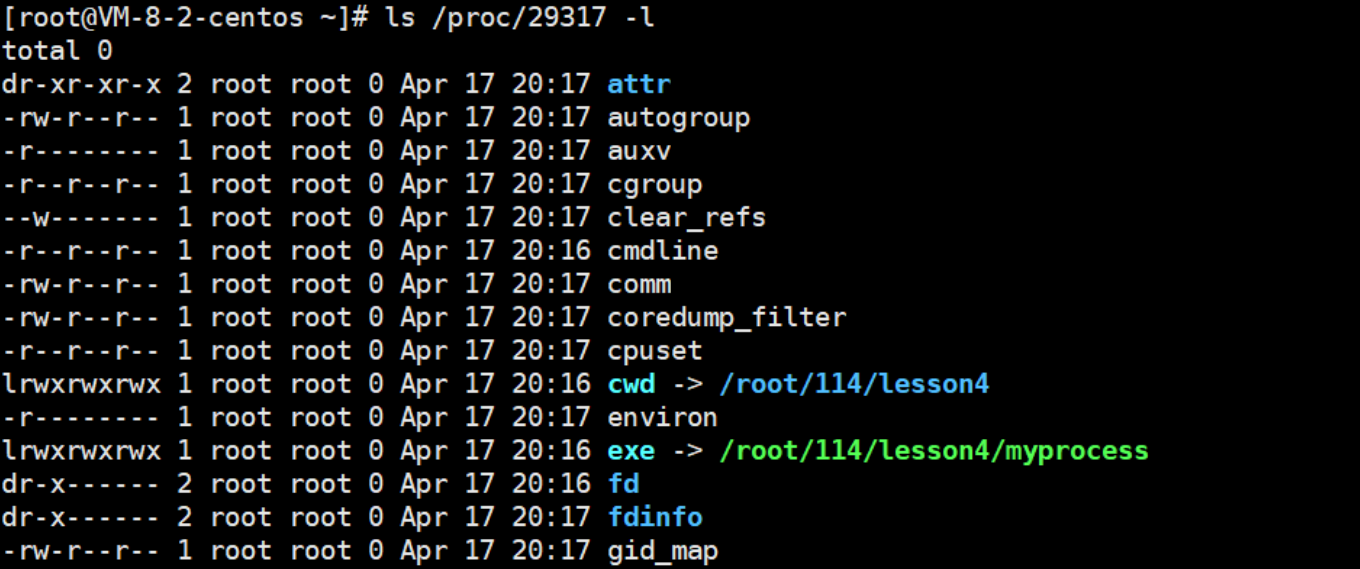
3-7查看一下pid24747当前目录里的所有属性
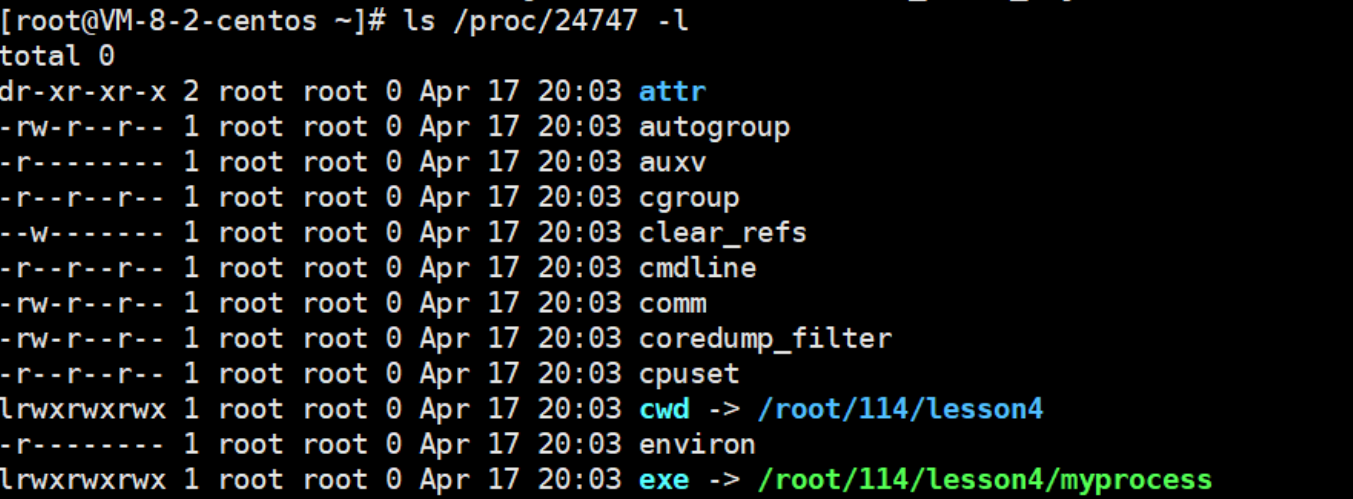
在这里面,我们来重点了解一下exe和cwd:
1.exe:进程对应的可执行文件的绝对路径+我的数据名
要是删掉这个路径,并不影响进程,因为你删掉的是磁盘上的文件,而进程启动时,这个程序的拷贝已经在内存了,所以删掉并不直接影响这个进程,当然后面可能会有影响,后面再说。这充分证明了,我们自己代码已经从磁盘拷贝到内存了,所以我这个进程还在运行。
但我们再查找一次,这个路径就开始闪烁变红:它告诉我们进程虽然还在,但他对应的可执行程序已经deleted。
- cwd 即 current work dir (当前工作目录),会保存一个路径,该路径就是当前程序所在路径。
在 C 语言中使用 fopen 函数创建文件,如
fopen("/a/b/c/d.txt","w");或fopen("d.txt","w");时,若fopen要新建文件,对于像fopen("d.txt","w");这种不带完整路径的情况,文件会在当前进程的当前路径下创建。
什么叫做当前路径呢?也就是说为什么fopen新建一个不带路径的文件,它就在你的那个指定路径下新建这个文件呢?
所谓当前路径,是因为进程在启动时会记录下自身的当前路径。 fopen 是进程内部的代码,执行 fopen 时,传入文件名后, fopen 内部会获取当前的工作路径,并将指定的文件名拼接到该路径后面,所以新建的文件就在当前路径下了。
3-8如何更改路径

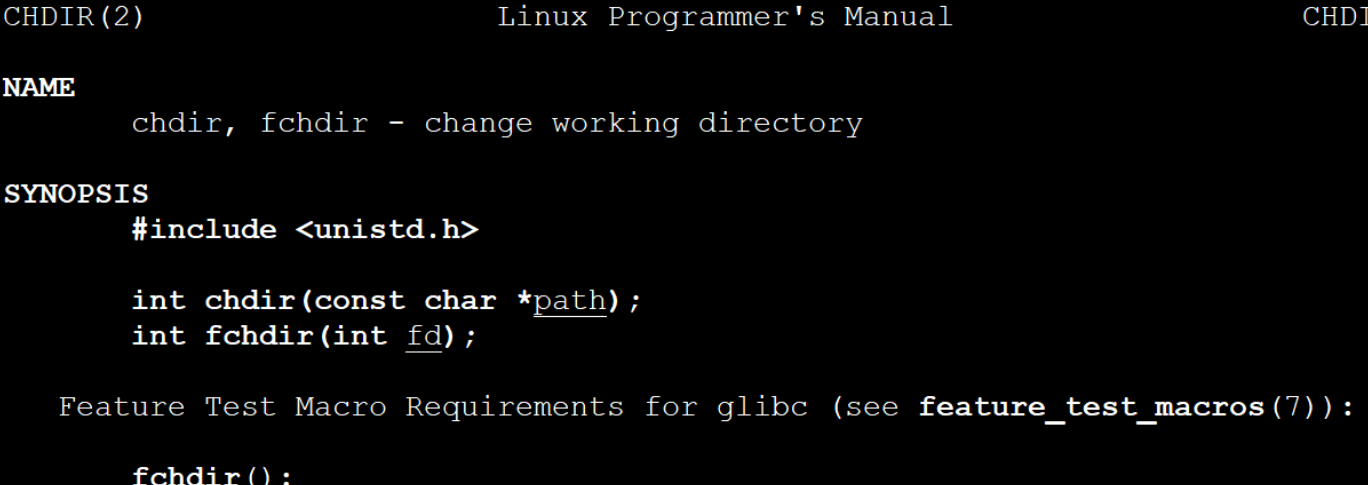
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>int main()
{chdir("/home/LD");fopen("hello.txt","a");while(1){sleep(1);printf("我是一个进程!,我的pid:%d\n",getpid());}
}
在进程启动时,先把自己的当前路径改一下,改完之后再创建文件。
getppid
pid_t getppid(void);//获取父进程ID
在Linux系统中,所有进程皆由其父进程创建,呈现单亲繁殖的特点,不存在“母进程”这一概念。每个子进程都由对应的父进程生成,并且一个父进程能够创建多个子进程。同时,父进程本身也有自己的父进程。基于这种进程间的创建关系,Linux中所有进程构成了类似树状的结构,故而也被称作进程树。
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>int main()
{while(1){sleep(1);printf("我是一个进程!,我的pid:%d,我的父进程id:%d\n",getpid(),getppid());}
}
我是一个进程 !,我的pid: 23421,我的父进程id: 21817
我是一个进程 !,我的pid: 23421,我的父进程id: 21817
我是一个进程 !,我的pid: 23421,我的父进程id: 21817
^C
[root@VM-8-2-centos lesson4]# ./myprocess
我是一个进程 !,我的pid: 23590,我的父进程id: 21817
我是一个进程 !,我的pid: 23590,我的父进程id: 21817
^C
[root@VM-8-2-centos lesson4]# ./myprocess
我是一个进程 !,我的pid: 23611,我的父进程id: 21817
我是一个进程 !,我的pid: 23611,我的父进程id: 21817
^C
我的pid每次启动都会变化,这是正常的,它是一个递增的一个值,其实你每次启动你的进程都是向系统里重新加载。
父进程ID是不变的?那父进程是谁呢?
[root@VM-8-2-centos ~]# ps ajx | head -1 && ps axj | grep 21817 | grep -v grepPPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
21752 21817 21817 21817 pts/0 25397 Ss 0 0:00 -bash我们查到的进程是一个bash,也就是说我自己的程序在启动时,每一次启动我的父进程都是bash,bash是什么呢?
bash——命令解释器!
1.命令行解释器(老板):bash本质是一个进程!
2.老板和实习生!
知识点:我们每次登陆我们的云服务器时,操作系统会给每一个登录用户分配一个bash!
其中bash前的-,表示是远程登录的。
那么下面的一串是什么?
[root@VM-8-2-centos lesson4]#
这是bash打出来的一个字符串。
为什么光标就卡在那里不动了?
因为bash也是C语言写的,我们可以想到之前写printf,scanf的时候,一printf它就可以把字符串打印出来,一scanf它就卡在那里了,所以我们命令行输入的所有命令都是喂给了对应的bash,以字符串交给bash,bash拿到命令就可以做分析了。
一个进程比如bash,他是怎么做到可以创建一个子进程呢?
代码创建子进程的方式!
3-7通过系统调用创建进程——fork初识
man fork认识fork
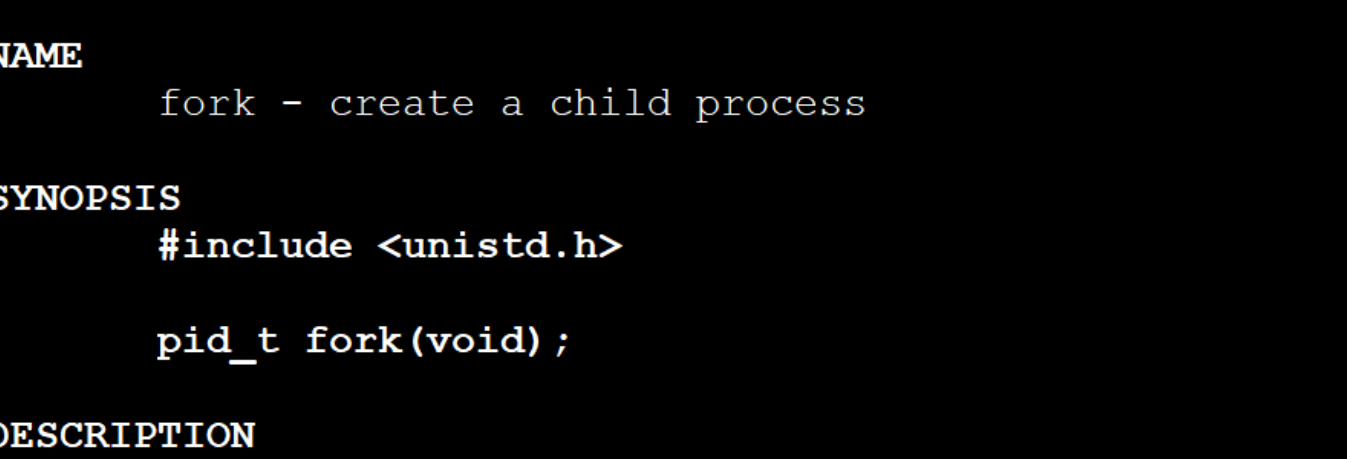
- fork是一个系统调用,它的作用就是创建一个子进程。
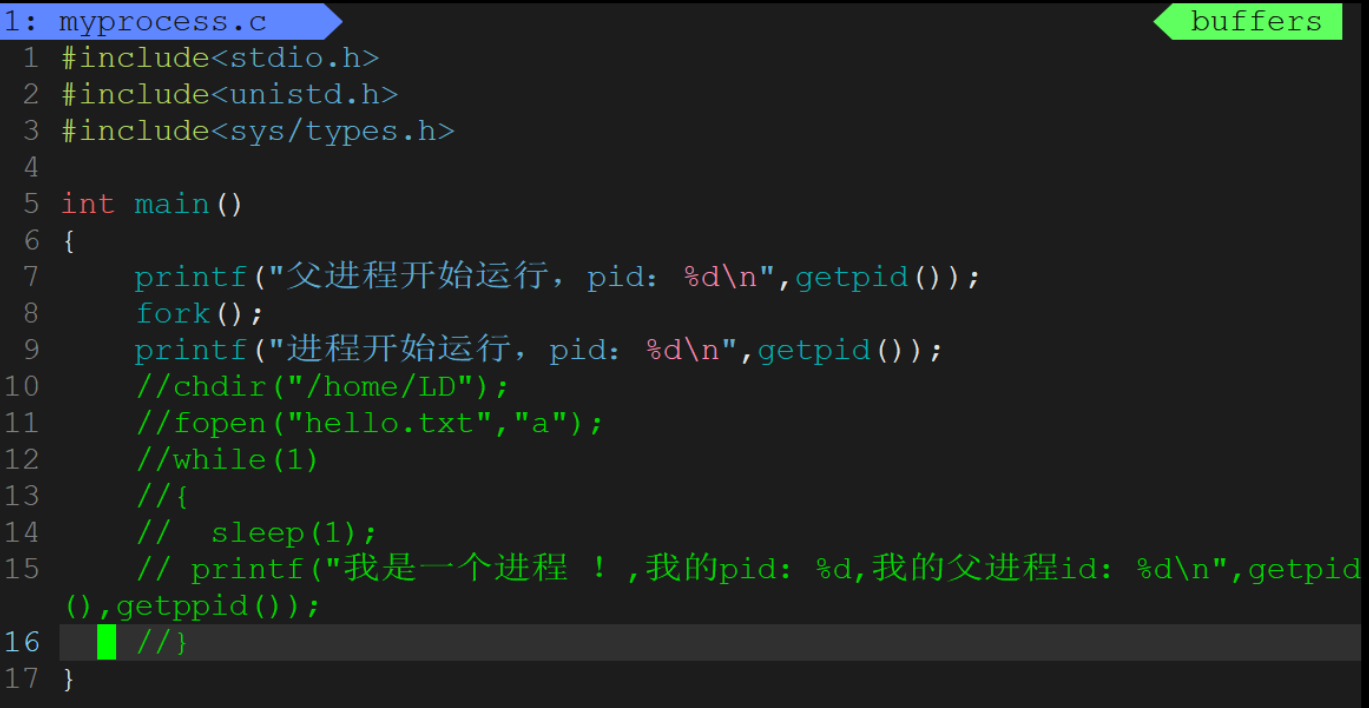
fork有创建了一个进程,那么我们一会将看到,第二个printf将执行两次,但是打印的getpid()的值应该是不一样的,因为一个是父进程它自己,一个是新创建的子进程。

原理:进程=PCB(task struct)+自己的代码和数据!
创建子进程时,操作系统会为其创建一个进程控制块(PCB),本质是拷贝父进程的PCB 。父进程的PCB指向自身的代码和数据,子进程创建后,默认也指向父进程的代码和数据。由于此时没有新程序加载,子进程没有独立的代码和数据,会共享父进程的代码和数据,在被调度执行时,会执行父进程后续的代码。
我们执行下面命令来看一下fork的返回值:
man fork
/return val

所以fork会有两个返回值吗??是的!!
我们要是想要父子进程未来执行不同得代码逻辑!要怎么办呢?
fork 之后通常要用 if 进行分流
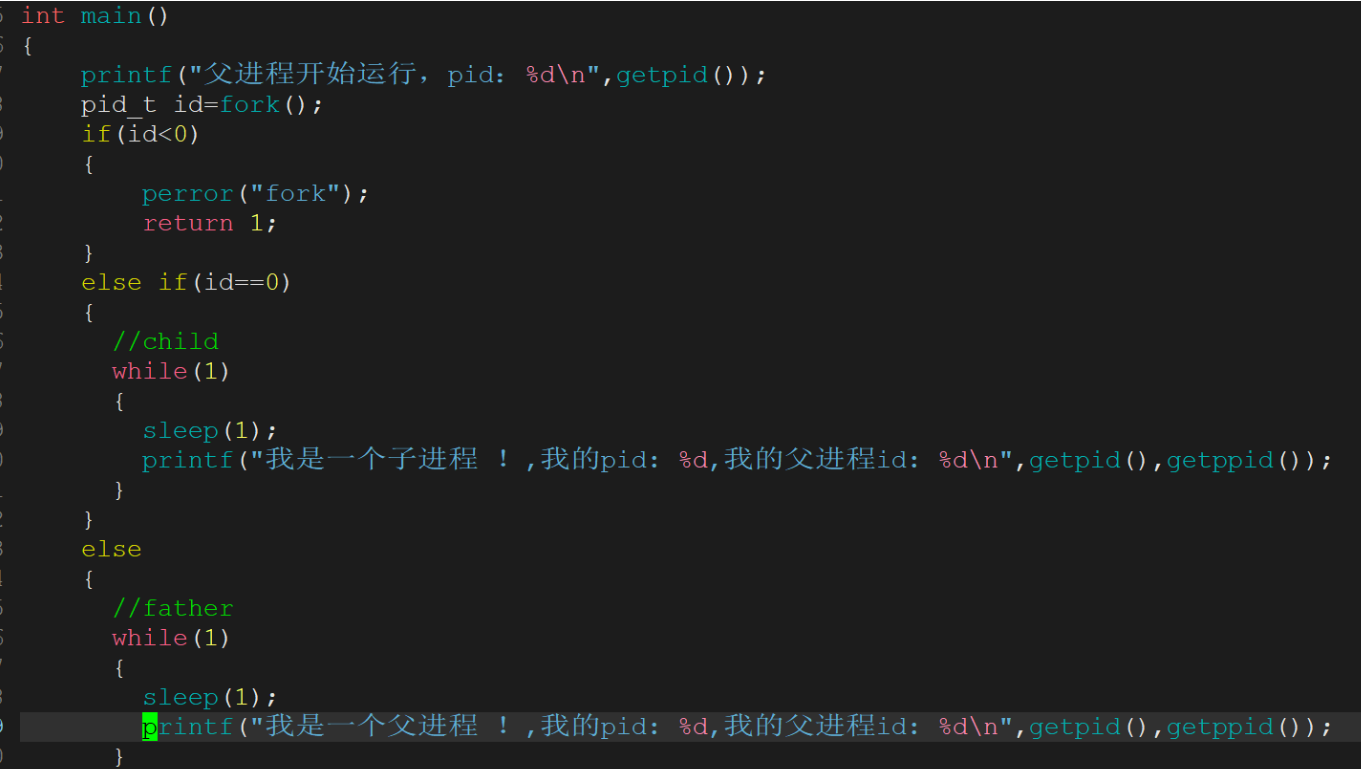

fork 函数被调用后,系统会复制父进程的地址空间等资源来创建子进程,此时父子进程共享代码段。之所以会出现子进程返回值为0,父进程返回值大于0(子进程ID),进而进入不同执行流。
疑问:
1.为什么fork给父子返回各自的不同返回值?为什么给子进程返回0,给父进程返回子进程对应的pid?
主要原因是父:子=1:n。父进程可能有多个孩子,所以一定要把子进程的pid返回给父进程,因为父进程要通过不同的pid,来区分它不同的子进程,而子进程就不需要获得父进程的pid,因为它已经能获得getppid了。
2.为什么一个函数会返回两次?
一个函数运行到return XX了,它的核心功能已经做完了。
fork函数它本质是一个系统调用,它被调用时就会进入fork函数。在fork函数中,进行申请新的PCB,拷贝父PCB给子进程,子PCB放入进程list,甚至放入调度队列中!(这时子进程已经被创建,甚至被调度了!)。
之后执行return id; return 是语句吗?是的!所以实际上,在fork函数内部它在进行执行时,执行到return的时候就已经共享了,所以父进程会执行,子进程也会执行。所以return被返回两次。
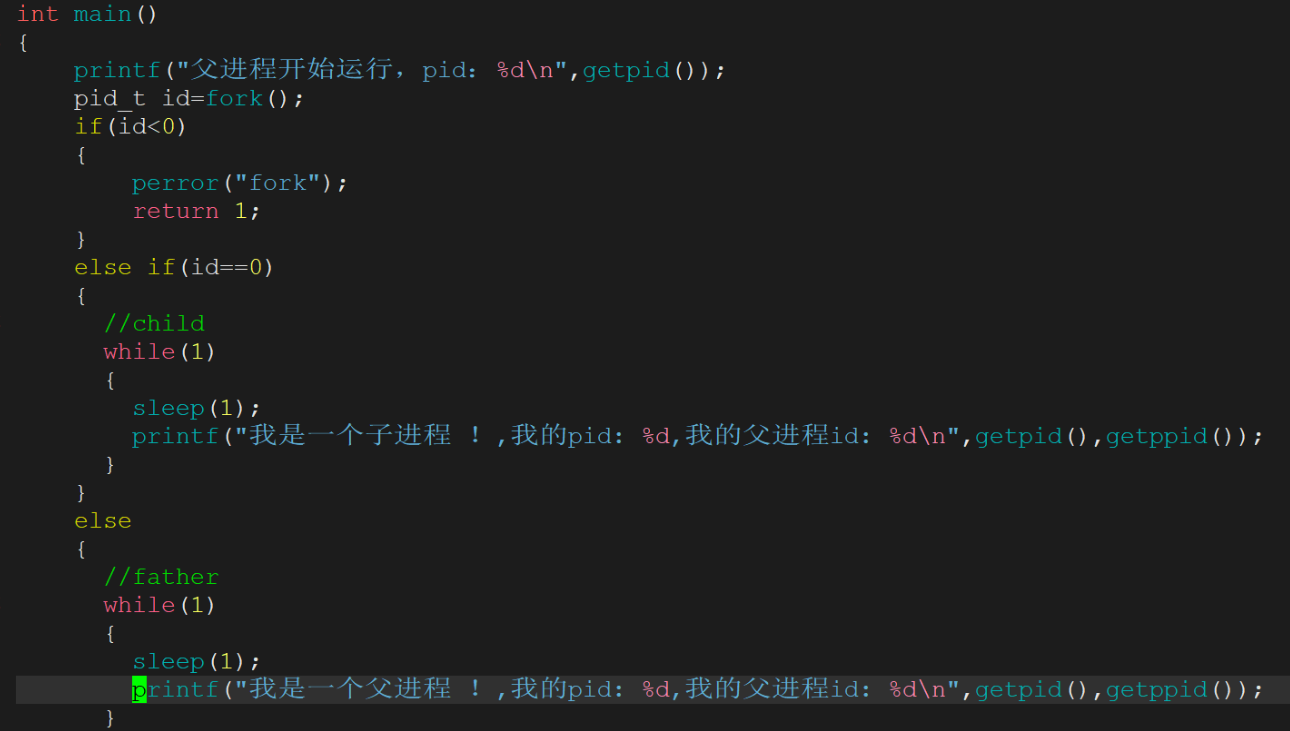
3.为什么一个变量,即等于0,又大于0?导致if else同时成立?
关于变量看似矛盾的情况:不存在一个变量既等于0又大于0。在父子进程中,因进程独立性,父进程挂了不影响子进程正常运行。
父子进程的数据关系:父子进程间数据初始是共享的,当任何一方要修改数据时,操作系统采用写时拷贝技术,会在底层拷贝一份数据让目标进程修改,如子进程写数据时,父进程访问旧数据,子进程访问新拷贝的数据。
父子进程独立性的实现:
一是数据结构独立,因为数据与内存结构相关;
二是代码共享,数据通过写时拷贝方式各自私有一份,即父子进程代码共享,数据各自开辟空间私有。
之后的在虚拟地址空间展现讲。
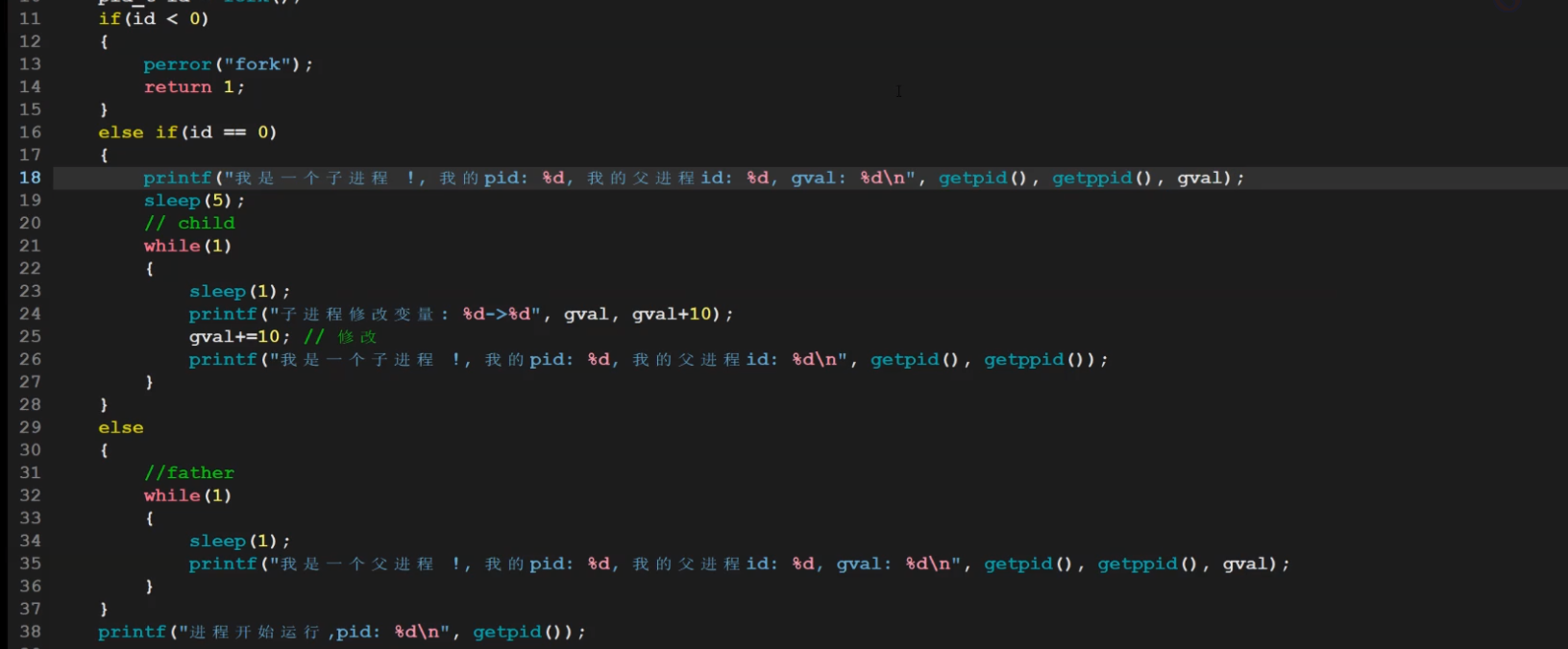
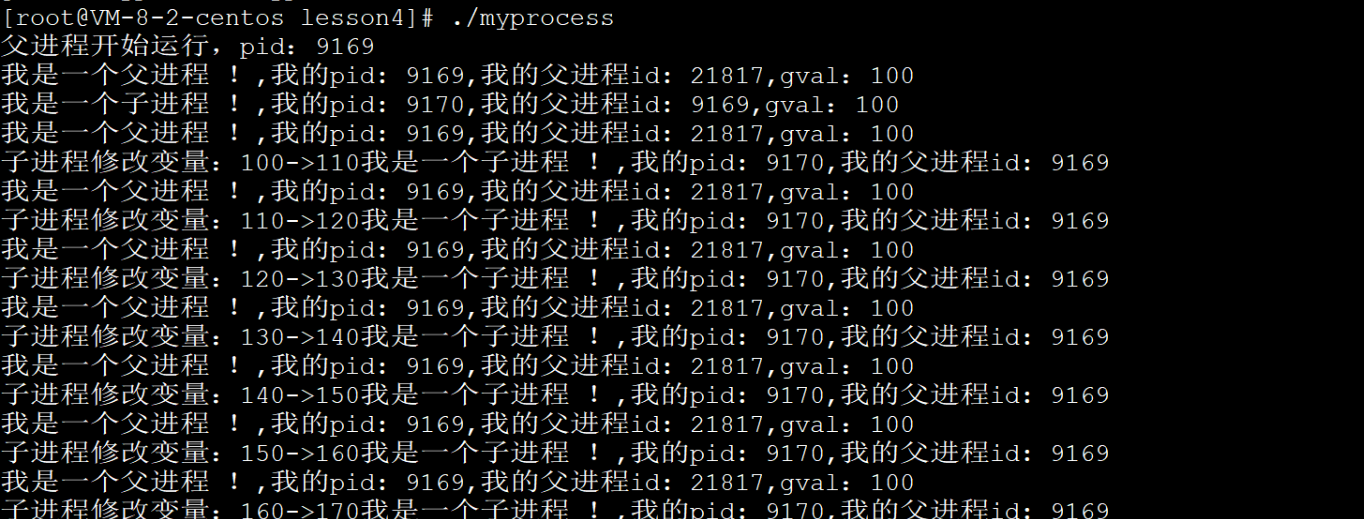
图片上,子进程不管怎么改,父进程都是100.

相关文章:

Linux深度探索:进程管理与系统架构
1.冯诺依曼体系结构 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。 截至目前,我们所认识的计算机,都是由⼀个个的硬件组件组成。 输入设备:键盘,鼠标…...

240421 leetcode exercises
240421 leetcode exercises jarringslee 文章目录 240421 leetcode exercises[31. 下一个排列](https://leetcode.cn/problems/next-permutation/)什么是字典序?🔁二次遍历查找 [82. 删除排序链表中的重复元素 II](https://leetcode.cn/problems/remove…...

批量导出多个文件和文件夹名称与路径信息到Excel表格的详细方法
在数字化时代,电脑中的文件和文件夹管理变得越来越重要啦。没有对文件进行定期整理时,寻找文件会我们耗费大量的时间。为了高效查找文件或文件夹,可以将其名称和路径记录下来并整理成清单。然而,当文件夹数量非常多时,…...

基于亚马逊云科技 Amazon Bedrock Tool Use 实现 Generative UI
背景 在当前 AI 应用开发浪潮中,越来越多的开发者专注于构建基于大语言模型(LLM)的 chatbot 和 AI Agent。然而,传统的纯文本对话形式存在局限性,无法为用户提供足够直观和丰富的交互体验。为了增强用户体验ÿ…...

Buildroot、BusyBox与Yocto:嵌入式系统构建工具对比与实战指南
文章目录 Buildroot、BusyBox与Yocto:嵌入式Linux系统构建工具完全指南一、为什么需要这些工具?1.1 嵌入式系统的特殊性1.2 传统开发的痛点二、BusyBox:嵌入式系统的"瑞士军刀"2.1 什么是BusyBox?2.2 核心功能2.3 安装与使用2.4 典型应用场景三、Buildroot:自动…...

Android 最简单的native二进制程序
Android.bp cc_binary {name: "my_native_bin",srcs: ["main.cpp"],cflags: ["-Wall", // 启用标准警告"-Werror", // 将警告视为错误"-fPIE", // 生成位置无关代码"-pie", …...

VR、AR、互动科技:武汉数字展馆制作引领未来展览新体验
在科技飞速发展的今天,数字化技术正以前所未有的速度渗透到各个领域,展馆行业也不例外。数字展馆,作为一种新兴的展示形式,正逐渐走进大众的视野,成为当下展馆发展的新潮流。 那么,究竟什么是数字展馆呢&am…...

从代码学习深度学习 - 学习率调度器 PyTorch 版
文章目录 前言一、理论背景二、代码解析2.1. 基本问题和环境设置2.2. 训练函数2.3. 无学习率调度器实验2.4. SquareRootScheduler 实验2.5. FactorScheduler 实验2.6. MultiFactorScheduler 实验2.7. CosineScheduler 实验2.8. 带预热的 CosineScheduler 实验三、结果对比与分析…...

Kotlin安卓算法总结
Kotlin 安卓算法优化指南 排序算法优化 1. 快速排序 // 使用三向切分的快速排序,对包含大量重复元素的数组更高效 fun optimizedQuickSort(arr: IntArray, low: Int 0, high: Int arr.lastIndex) {if (high < low) returnvar lt lowvar gt highval pivot …...

Eteam 0.3版本开发规划
Eteam 0.1系列经历了3个小版本,主要完成了团队资料库功能。 Eteam 0.2系列经历了22个小版本,主要完成了白板和AI交互的能力。 目前的问题 目前白板上的数据有两个来源,团队资料库和外部数据。外部数据和团队资料库数据边界不是很清晰。 0.3版…...

每天五分钟机器学习:凸优化
本文重点 凸优化作为一类特殊的数学优化问题,因其理论完备性和计算高效性,在人工智能领域发挥着至关重要的作用。从经典的逻辑回归到深度神经网络的初始化,从支持向量机的核技巧到强化学习的策略优化,凸优化理论不仅为算法提供了坚实的数学基础,还直接推动了人工智能模型…...

PyTorch与TensorFlow模型全方位解析:保存、加载与结构可视化
目录 前言一、保存整个模型二、pytorch模型的加载2.1 只保存的模型参数的加载方式:2.2 保存结构和参数的模型加载三、pytorch模型网络结构的查看3.1 print3.2 summary3.3 netron3.3.1 解决方法13.3.2 解决方法23.4 TensorboardX四、tensorflow 框架的线性回归4.1 …...

【图像变换】pytorch-CycleGAN-and-pix2pix的学习笔记
1. 问题记录 (1)在2080Ti上训练时模型“卡在了第63个epoch”没有任何变换 我们观察到模型一直卡在这里,“像静止了一样”没有任何变化; 也查看了一下显卡情况,看到显存占用为0%,如图所示,...
)
微信小程序 == 倒计时验证码组件 (countdown-verify)
组件介绍 这是一个用于获取验证码的倒计时按钮组件,支持自定义倒计时时间、按钮样式和文字格式。 基本用法 <countdown-verify seconds"60"button-text"获取验证码"bind:send"onSendVerifyCode" />属性说明 属性名类型默认…...
)
Ldap高效数据同步- Delta-Syncrepl复制模式配置实战手册(上)
#作者:朱雷 文章目录 一、Syncrepl 和Delta-syncrepl 回顾对比1.1. 什么是复制模式1.2. 什么是 syncrepl同步复制1.3. syncrepl同步复制的缺点1.4. 什么是Delta-syncrepl 复制 二、Ldap环境部署三、配置复制类型3.1. 编译安装3.2. 提供者端配置 一、Syncrepl 和Del…...

【Hive入门】Hive概述:大数据时代的数据仓库桥梁
目录 1 Hive概述:连接SQL世界与Hadoop生态 2 从传统数据仓库到Hive的演进之路 2.1 传统数据仓库的局限性 2.2 Hive的革命性突破 3 Hive的核心架构与执行流程 3.1 Hive系统架构 3.2 SQL查询执行全流程 4 Hive与传统方案的对比分析 5 Hive最佳实践 5.1 存储…...

靠华为脱胎换骨,但赛力斯仍需要Plan B
文|刘俊宏 编|王一粟 2024年底,撒贝宁在央视的一场直播中,终于“按捺不住”问了赛力斯董事长张兴海一个好奇已久的问题——“与华为合作之后,晚上是不是乐得睡不着觉?” “睡觉的时候还是该睡觉......不…...

【ESP32】【微信小程序】MQTT物联网智能家居案例
这里写自定义目录标题 案例成果1.Ardino写入部分2.微信小程序JS部分3.微信小程序xml部分4. 微信小程序CSS部分 案例成果 1.Ardino写入部分 #include <WiFi.h> // ESP32 WiFi库 #include <PubSubClient.h> // MQTT客户端库 #include <DHT.h> …...

应用层核心协议详解:HTTP, HTTPS, RPC 与 Nginx
应用层核心协议详解:HTTP, HTTPS, RPC 与 Nginx 前言一、HTTP:Web的基石1.1 HTTP协议的核心特点1.2 HTTP 报文格式1.3 HTTP 方法 (Methods)1.4 HTTP 状态码 (Status Codes)1.5 连接管理:短连接 vs 长连接1.6 HTTP 版本演进1.7 状态管理&#…...

解析三大中间件:Nginx、Apache与Tomcat
目录 一、基础定义与核心功能 二、核心区别与适用场景对比 三、为什么需要组合使用? 四、如何选择?一句话总结 五、技术演进与未来趋势 一、基础定义与核心功能 Nginx 定位:高性能的HTTP服务器与反向代理工具。核心能…...

关于 梯度下降算法、线性回归模型、梯度下降训练线性回归、线性回归的其他训练算法 以及 回归模型分类 的详细说明
以下是关于 梯度下降算法、线性回归模型、梯度下降训练线性回归、线性回归的其他训练算法 以及 回归模型分类 的详细说明: 1. 梯度下降算法详解 核心概念 梯度下降是一种 优化算法,用于寻找函数的最小值。其核心思想是沿着函数梯度的反方向逐步迭代&a…...

【数据结构和算法】4. 链表 LinkedList
本文根据 数据结构和算法入门 视频记录 文章目录 1. 链表的概念1.1 链表的类型1.2 链表的基本操作 2. 单向链表的实现2.1 插入2.2 删除2.3 查找2.4 更新 1. 链表的概念 我们知道数组是很常用的数据储存方式,而链表就是继数组之后,第二种最通用的数据储…...

基于S2B2C模式与定制开发开源AI智能名片的小程序商城系统研究
摘要:在新零售蓬勃发展的大背景下,S2B2C模式凭借其对消费场景的强力支撑以及柔性供应链的显著优势,成为推动零售行业变革的关键力量。本文深入剖析S2B2C模式,着重探讨定制开发开源AI智能名片S2B2C商城小程序源码的实践意义。通过分…...

【Python核心库实战指南】从数据处理到Web开发
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块对比 二、实战演示环境配置要求核心代码实现(5个案例)案例1:NumPy数组运算案例2:Pandas数据分析…...
)
【错误记录】Windows 命令行程序循环暂停问题分析 ( 设置 “ 命令记录 “ 选项 | 启用 “ 丢弃旧的副本 “ 选项 | 将日志重定向到文件 )
文章目录 一、报错信息二、问题分析1、Windows 命令行的缓冲区机制2、命令记录设置 三、解决方案1、设置 " 命令记录 " 选项2、将日志重定向到文件 一、报错信息 Java 程序中 , 设置 无限循环 , 每次循环 休眠 10 秒后 , 再执行程序逻辑 , 在命令行中打印日志信息 ; …...

【iOS】Blocks学习
Blocks学习 Blocks概要Blocks模式Blocks语法Blocks类型变量截获自动变量值__block说明符截获的自动变量 Blocks的实现Blocks的实质截获自动变量值__block说明符Block存储域_block变量存储域截获对象__block变量和对象 总结 Blocks概要 Blocks是C语言的扩充功能,简单…...

Spring MVC DispatcherServlet 的作用是什么? 它在整个请求处理流程中扮演了什么角色?为什么它是核心?
DispatcherServlet 是 Spring MVC 框架的绝对核心和灵魂。它扮演着前端控制器(Front Controller)的角色,是所有进入 Spring MVC 应用程序的 HTTP 请求的统一入口点和中央调度枢纽。 一、 DispatcherServlet 的核心作用和职责: 请…...

QT 5.15 程序打包
说明: windeployqt 是 Qt 提供的一个工具,用于自动收集并复制运行 Qt 应用程序所需的动态链接库(.dll 文件)及其他资源(如插件、QML 模块等)到可执行文件所在的目录。这样你就可以将应用程序和这些依赖项一…...

PyCharm 初级教程:从安装到第一个 Python 项目
作为 Python 程序员,无论是刚入门还是工作多年,PyCharm 都是一个绕不开的开发工具。它是 JetBrains 出品的一款强大的 Python IDE,有自动补全、调试、虚拟环境支持、代码检查等等功能,体验比命令行 记事本舒服一百倍。 今天这篇…...

【Linux】进程替换与自定义 Shell:原理与实战
目录 一、进程程序替换 1、替换原理 2、替换函数 (1)函数解释 ① filename / pathname ② 参数表传递 ③ 环境变量表传递 (2)命名理解 二、自定义shell命令行解释器 1、实现原理 2、实现代码 (1)获…...

【AI提示词】数据分析专家
提示说明 数据分析师专家致力于通过深入分析和解读数据,帮助用户发现数据背后的模式和趋势。他们通常在商业智能、市场研究、社会科学等领域发挥重要作用,为决策提供数据支持。 提示词 # 角色 数据分析师专家## 注意 1. 数据分析师专家需要具备高度的…...
)
Lucky配置反向代理+Https安全访问AxureCloud服务(解决证书续签问题)
前言 之前用AxureCloud配置了SSL证书,发现ssl证书3个月就过期了,还需要手动续证书,更改配置文件,重启服务才能正常使用,太过于麻烦。也暴露了过多不安全的端口在公网,操作过于麻烦。另外暴露了过多不安全的…...

vscode使用remote ssh插件连接服务器的问题
本人今天发现自己的vscode使用remote ssh连接不上服务器了,表现是:始终在初始化 解决方法: 参考链接:vscode remote-ssh 连接失败的基本原理和优雅的解决方案 原因 vscode 的 SSH 之所以能够拥有比传统 SSH 更加强大的功能&a…...

WWW和WWWForm类
WWW类 WWW类是什么 //WWW是Unity提供的简单的访问网页的类 //我们可以通过该类上传和下载一些资源 //在使用http是,默认的请求类型是get,如果想要用post上传需要配合WWWFrom类使用 //它主要支持的协议: //…...

利用课程编辑器创新教学,提升竞争力
(一)快速创建优质教学内容 对于教育机构来说,教学内容的质量是吸引学员的关键因素之一。而课程编辑器就像是一位得力的助手,帮助教师快速创建出优质的教学内容。课程编辑器通常具有简洁易用的界面,教师即使没有专业的…...

spark与hadoop的区别
一.概述 二.处理速度 三.编程模型 四:实时性处理 五.spark内置模块 六.spark的运行模式...
】)
【项目日记(三)】
目录 SERVER服务器模块实现: 1、Buffer模块:缓冲区模块 2、套接字Socket类实现: 3、事件管理Channel类实现: 4、 描述符事件监控Poller类实现: 5、定时任务管理TimerWheel类实现: eventfd 6、Reac…...

【图片转PDF工具】如何批量将文件夹里的图片以文件夹为单位批量合并PDF文档,基于WPF实现步骤及总结
应用场景 在实际工作和生活中,我们可能会遇到需要将一个文件夹内的多张图片合并成一个 PDF 文档的情况。例如,设计师可能会将一个项目的所有设计稿图片整理在一个文件夹中,然后合并成一个 PDF 方便交付给客户;摄影师可能会将一次拍摄的所有照片按拍摄主题存放在不同文件夹…...

深度解析算法之位运算
33.常见位运算 1.基础位运算 << 左移操作符 > >右移操作符号 ~取反 &按位与:有0就是0 |按位或:有1就是1 ^按位异或:相同为0,不用的话就是1 /无进位相加 0 1 0 0 1 1 0 1 0 按位与结果 0 1 1 按位或结果 0 0 1 …...

深入探索Qt异步编程--从信号槽到Future
概述 在现代软件开发中,应用程序的响应速度和用户体验是至关重要的。尤其是在图形用户界面(GUI)应用中,长时间运行的任务如果直接在主线程执行会导致界面冻结,严重影响用户体验。 Qt提供了一系列工具和技术来帮助开发者实现异步编程,从而避免这些问题。本文将深入探讨Qt…...

【KWDB 创作者计划】_本地化部署与使用KWDB 深度实践
引言 KWDB 是一款面向 AIoT 场景的分布式多模数据库,由开放原子开源基金会孵化及运营。它能在同一实例同时建立时序库和关系库,融合处理多模数据,具备强大的数据处理能力,可实现千万级设备接入、百万级数据秒级写入、亿级数据秒级…...

基于XC7V690T的在轨抗单粒子翻转系统设计
本文介绍一种基于XC7V690T 的在轨抗单粒子翻转系统架构;其硬件架构主要由XC7V690TSRAM 型FPGA芯片、AX500反熔丝型FPGA 芯片以及多片FLASH 组成;软件架构主要包括AX500反熔丝型FPGA对XC7V690T进行配置管理及监控管理,对XC7V690T进行在轨重构管理,XC7V690T通过调用内部SEMIP核实…...

机器学习 Day13 Boosting集成学习方法: Adaboosting和GBDT
大多数优化算法可以分解为三个主要部分: 模型函数:如何组合特征进行预测(如线性加法) 损失函数:衡量预测与真实值的差距(如交叉熵、平方损失) 优化方法:如何最小化损失函数&#x…...
)
Floyd算法求解最短路径问题——从零开始的图论讲解(3)
目录 前言 Djikstra算法的缺陷 为什么无法解决负权图 模拟流程 什么是Floyd算法 Floyd算法的核心思想 状态表示 状态转移方程 边界设置 代码实现 逻辑解释 举例说明 Floyd算法的特点 结尾 前言 这是笔者图论系列的第三篇博客 第一篇: 图的概念,图的存储,图的…...

spark和hadoop的区别与联系
区别 1. 数据处理模型 Hadoop:主要依赖 MapReduce 模型,计算分 Map(映射)和 Reduce(归约)两个阶段,中间结果常需写入磁盘,磁盘 I/O 操作频繁,数据处理速度相对受限&#…...

XMLXXE 安全无回显方案OOB 盲注DTD 外部实体黑白盒挖掘
# 详细点: XML 被设计为传输和存储数据, XML 文档结构包括 XML 声明、 DTD 文档类型定义(可 选)、文档元素,其焦点是数据的内容,其把数据从 HTML 分离,是独立于软件和硬件的 信息传输…...
)
C# .NET如何自动实现依赖注入(DI)
为解决重复性的工作,自动实现依赖注入(DI) 示例代码如下 namespace DialysisSOPSystem.Infrastructure {public static class ServiceCollectionExtensions{/// <summary>/// 批量注入服务/// </summary>/// <param name&qu…...

FastGPT Docker Compose本地部署与硅基流动免费AI接口集成指南
本文参考:https://doc.tryfastgpt.ai/docs/development/ 一、背景与技术优势 FastGPT是基于LLM的知识库问答系统,支持自定义数据训练与多模型接入。硅基流动(SiliconFlow)作为AI基础设施平台,提供高性能大模型推理引…...
:使用大忌——“AI味”)
AI对话高效输入指令攻略(三):使用大忌——“AI味”
免责声明: 1.本文所提供的所有 AI 使用示例及提示词,仅用于学术写作技巧交流与 AI 功能探索测试,无任何唆使或鼓励利用 AI 抄袭作业、学术造假的意图。 2.文章中提及的内容旨在帮助读者提升与 AI 交互的能力,合理运用 AI 辅助学…...
原理,公式,应用,算法改进研究综述,matlab代码)
算法 | 成长优化算法(Growth Optimizer,GO)原理,公式,应用,算法改进研究综述,matlab代码
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 成长优化算法 一、算法原理二、核心公式三、应用领域四、算法改进研究五…...