机器学习-08-推荐算法-协同过滤
总结
本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则
参考
机器学习(三):Apriori算法(算法精讲)
Apriori 算法 理论 重点
MovieLens:一个常用的电影推荐系统领域的数据集
23张图,带你入门推荐系统
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合
+算法评估+持续调优+工程化接口实现
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用:
对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。

推荐系统
1.推荐系统概述
1.推荐系统概述

2.推荐算法的基本类型
2.推荐算法的基本类型
推荐系统的核心在于根据用户的历史行为和偏好,为其提供个性化的内容或服务。推荐算法是实现这一目标的关键,主要包括以下几种基本类型:
(1)协同过滤(Collaborative Filtering)
协同过滤是一种基于用户行为的推荐方法,它通过分析用户的历史行为数据,找到具有相似行为的用户或物品,并基于这些相似性进行推荐。
常见的协同过滤算法如下:
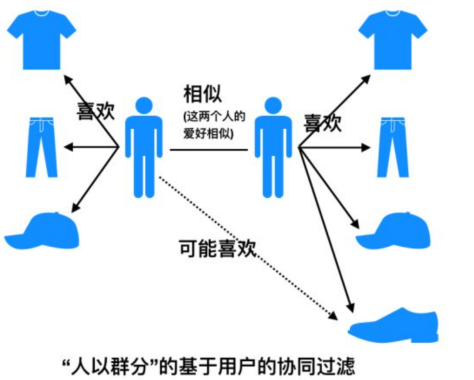
①基于用户的协同过滤(User-based Collaborative Filtering,简称UserCF)。
其中基于用户的协同过滤通过计算用户之间的相似度,推荐与目标用户具有相似行为的其他用户喜欢的物品。比如用户A之前买过T恤,裤子和帽子,并给出了好评。用户B也买过相同的T恤,裤子和帽子,同时用户B也购买了鞋子,也都给出了好评。那么基于用户的协同过滤算法会认为这两位用户相似度较高,从而给用户A推荐用户B买过的鞋子。
基于用户的协同过滤适合做新闻、博客或者微内容的推荐系统,因为其内容更新频率非常高,特别是在社交网络中,基于用户的协同过滤是一个更好的选择,可以增加用户对推荐解释的信服程度。
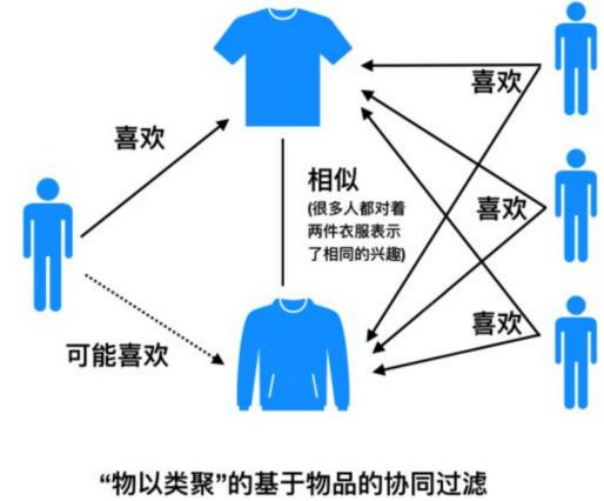
②基于物品的协同过滤(Item-based Collaborative Filtering,简称ItemCF)。
基于物品的协同过滤:通过计算物品之间的相似度,推荐与目标用户历史上喜欢的物品相似的其他物品。需要注意的是,基于物品的协同过滤算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度,即基于物品的协同过滤算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。比如若多个用户都同时喜欢某T恤和卫衣,那么该算法认为,T恤和卫衣具有较大的相似度。这时如果一个用户初次购买T恤了,该算法会给该用户推荐卫衣。
基于物品的协同过滤使用于购物网站,该场景中用户的数量远远超过物品的数量,同时物品的数据相对稳定,因此计算物品的相似度时不但计算量较小,而且不必频繁更新。
③基于用户和物品的混合协同过滤(User-Item CF,简称混合CF)。
混合协同过滤算法:它同时考虑了User(用户)和Item(商品)两个方面,用户和商品的关系,可以抽象为如下的三元组:<User,Item,Rating>。其中,Rating是用户对商品的评分,表征用户对该商品的喜好程度。
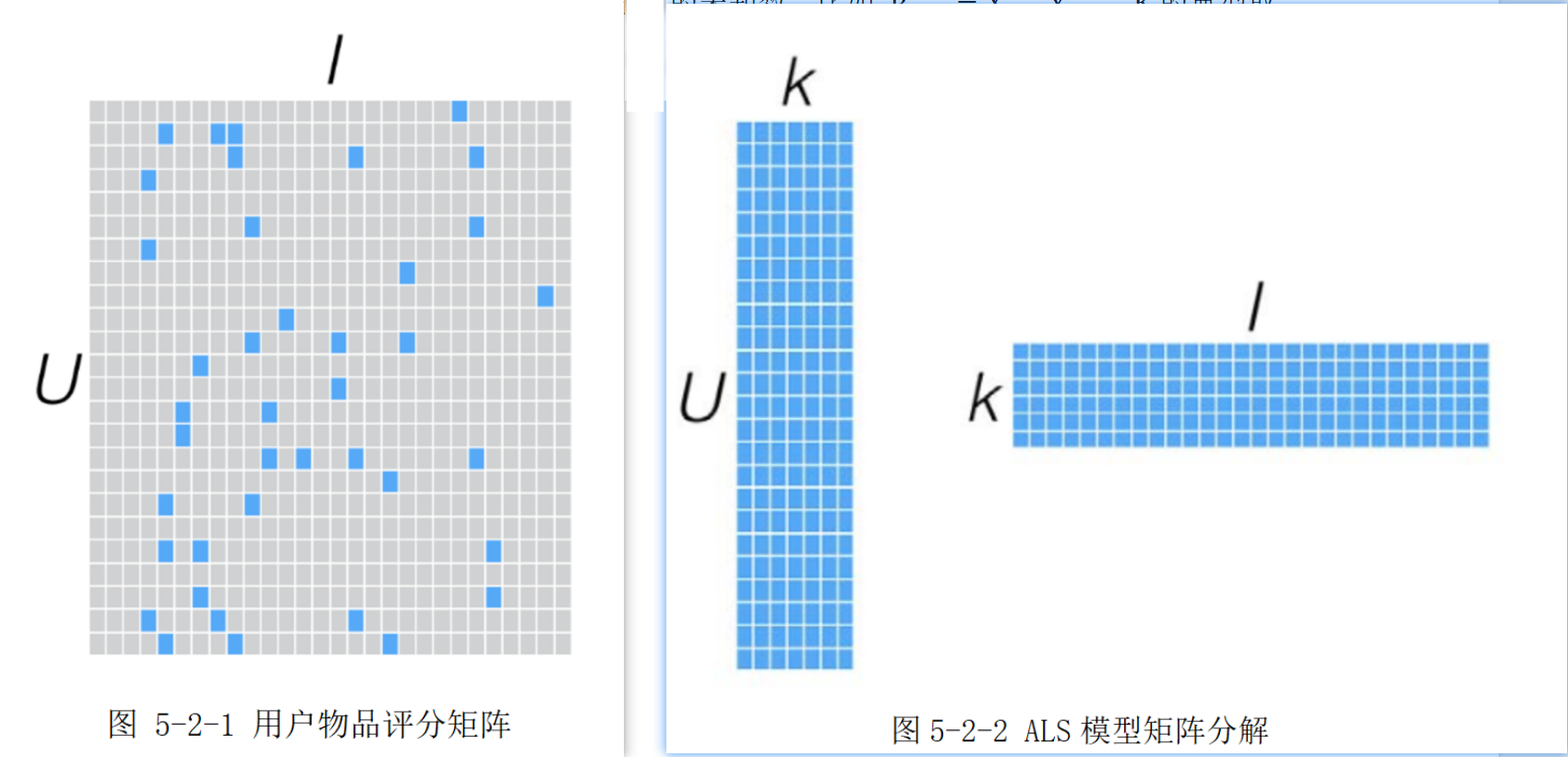
基于用户的协同过滤和基于物品的协同过滤主要缺点在于用户或物品数量极大的情况下,计算复杂度高。这是可以采取ALS(lternating least squares,交替最小二乘法)算法,本任务采用的ALS算法就是混合协同过滤算法,
假设我们有一批用户数据,其中包含m个用户User和n个物品Item,则我们定义用户物品评分矩阵 Rm×n,如图5-2-1所示,该图中每行都是一个用户,每列都是一个物品,每个单元格对应每个用户对物品的评分。
(2)基于内容的推荐(Content-Based Recommendations)
基于内容的推荐算法通过分析物品的内容特征、用户相关信息及用户对物品的操作行为来构建推荐算法模型。
物品的内容特征可以是对物品文字描述的元信息、标签、用户评论、人工标注的信息等。
用户相关信息是指人口统计学信息(如年龄、性别、偏好、地域、收入等等)。
用户对物品的操作行为可以是评论、收藏、点赞、观看、浏览、点击、加购物车、购买等。
在一个非社交网络的网站中,比如给某个用户推荐一本书,采用基于内容的推荐会比较好。因为基于协同过滤的思路是某某和你有相似兴趣的人也看了这本书,这很难让用户信服,因为用户可能根本不认识那个人;但假如给出的理由是因为这本书和你以前看的某本书相似,这样解释相对合理,用户可能就会采纳你的推荐。
基于内容的推荐需要进行特征提取和构建用户画像。特征提取是利用物品的特征(如商品描述、文章内容等)进行分析,并计算物品间的相似度。用户画像是基于用户对物品特征的偏好,构建用户的兴趣画像。再根据用户画像和物品间的相似度,给用户推荐其感兴趣的物品类似的物品
基于内容的推荐优点为能够解决冷启动问题,因为推荐不依赖于其他用户的数据,同时可以推荐用户感兴趣的具体特征的物品。
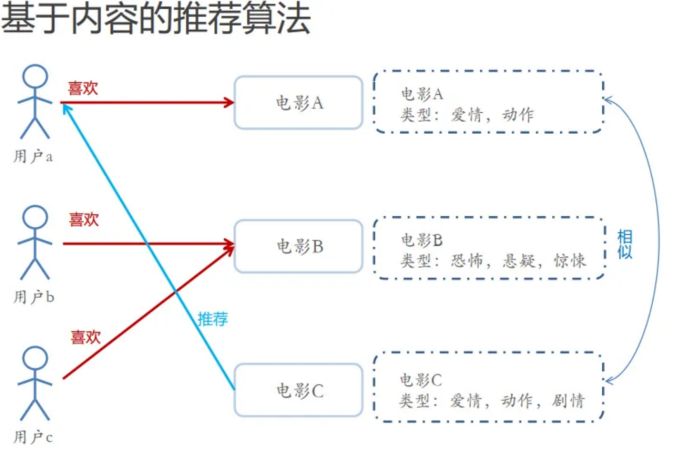
“基于内容的推荐算法思路为根据用户喜欢的内容,为用户推荐相似的内容”
“比如,电影A、电影B、电影C都有类型信息,即电影特征
根据电影特征,计算得出电影A和电影C相似度较高”
“用户a、用户b、用户c有对电影的行为数据,如喜欢某电影”
依据用户行为数据和电影间的相似度,推荐算法向用户a推荐与电影A相似的电影C
3.推荐算法的构建理论
推荐算法其实本质上是一种信息处理逻辑,当获取了用户与内容的信息之后,按照一定的逻辑处理信息后,产生推荐结果。热度排行榜就是最简单的一种推荐方法,它依赖的逻辑就是当一个内容被大多数用户喜欢,那大概率其他用户也会喜欢。但是基于粗放的推荐往往会不够精确,想要挖掘用户个性化的,小众化的兴趣,需要制定复杂的规则运算逻辑,由机器完成。
推荐算法主要分为以下几步:
(1)召回:当用户以及内容量比较大的时候,往往先通过召回策略,将百万量级的内容先缩小到百量级。
(2)过滤:对于内容不可重复消费的领域,例如实时性比较强的新闻等,在用户已经曝光和点击后不会再推送到用户面前。
(3)精排:对于召回并过滤后的内容进行排序,将百量级的内容按照顺序推送。
(4)混排:为避免内容越推越窄,将精排后的推荐结果进行一定修改,例如控制某一类型的频次,EE问题(Exploration and Exploitation,探索与开发)处理等。
(5)强规则:根据业务规则进行修改,例如在活动时将某些文章置顶以及热点内容的强插等。
协同过滤算法
协同过滤的基本流程:
首先,要实现协同过滤,需要以下几个步骤
(1)收集用户偏好
(2)找到相似的用户或物品
(3)计算推荐

基于用户的协同过滤
案例:基于用户的协同过滤。
假设有几个人分别看了如图电影并且给电影有如下评分(5分最高,没看过的不评分),我们目的是要向A用户推荐一部电影:
协同过滤的整体思路只有两步,非常简单:寻找相似用户,推荐电影。

(1)
寻找相似用户:所谓相似,其实是对于电影品味的相似,也就是说需要将A与其他几位用户做比较,判断是不是品味相似。有很多种方法可以用来判断相似性,我们使用“欧几里德距离”来做相似性判定。当把每一部电影看成N维空间中的一个维度,这样每个用户对于电影的评分相当于维度的坐标,那么每一个用户的所有评分,相当于就把用户固定在这个N维空间的一个点上,然后利用欧几里德距离计算N维空间两点的距离。距离越短说明品味越接近。
本例中A只看过两部电影(《老炮儿》和《唐人街探案》),因此只能通过这两部电影来判断品味了,那么计算A和其他几位用户的距离,如下图所示:


(2)推荐电影:
要做电影加权评分推荐。意思是说,品味相近的人对于电影的评价对A选择电影来说更加重要,具体做法可以列一个表,计算加权分,如图所示:
把相似性和对于每个电影的实际评分相乘,就是电影的加权分,如下图所示:



基于物品协同过滤
基于用户的协同过滤,适用于物品较少,用户也不太多的情况。
如果用户太多了,针对每个用户的购买情况来计算哪些用户和他品味类似,效率很低下。
如果商品很多,每个用户购买的商品重合的可能性很小,这样判断品味是否相似也就变得比较困难了。
“基于物品的协同过滤”。消费者每天都在买买买,行为变化很快,但是物品每天虽然也有变化,但是和物品总量相比变化还是少很多。这样,就可以预先计算物品之间的相似程度,然后再利用顾客实际购买的情况找出相似的物品做推荐。这就是“基于物品的协同过滤”。
由于物品整体变化不大,所以这个相似程度不用每天都算,节省计算资源;同时,可以只给某一样商品只备选5个相似商品,推荐时只做这5个相似物品的加权评分,避免对所有商品都进行加权评分,以避免大量计算。这么说有点抽象,还是看一个例子吧。
还是用上一章节的例子,目的是给A推荐一部电影。

首先是计算电影之间的相似度,方法还是有很多,这次用Pearson相关系数来做,公式为:
公式看起来复杂,其实可以分成6个部分分别计算就好了,我们选《寻龙诀》(X)和《小门神》(Y)作为例子,来算一下相似度,则:
X=(3.5,5.0,3.0)
Y=(3.0,3.5,2.0)
数字就是评分,因为只有三个人同时看了这两个电影,所以X,Y两个向量都只有三个元素。按照公式逐步计算:
相关系数取值为(-1,1),1表示完全相似,0表示没关系,-1表示完全相反。
结合到电影偏好上,如果相关系数为负数,比如《老炮儿》和《唐人街探案》,意思是说,喜欢《老炮儿》的人,存在厌恶《唐人街探案》的倾向。
然后就可以为A推荐电影了,思路是:A只看过两个电影,然后看根据其他电影与这两个电影的相似程度,进行加权评分,得出应该推荐给A的电影具体方法如下图:




协同过滤算法案例
构建数据集
# A dictionary of movie critics and their ratings of a small#
critics = {'A': {'老炮儿':3.5,'唐人街探案': 1.0},'B': {'老炮儿':2.5,'唐人街探案': 3.5,'星球大战': 3.0, '寻龙诀': 3.5,'神探夏洛克': 2.5, '小门神': 3.0},'C': {'老炮儿':3.0,'唐人街探案': 3.5,'星球大战': 1.5, '寻龙诀': 5.0,'神探夏洛克': 3.0, '小门神': 3.5},'D': {'老炮儿':2.5,'唐人街探案': 3.5,'寻龙诀': 3.5, '神探夏洛克': 4.0},'E': {'老炮儿':3.5,'唐人街探案': 2.0,'星球大战': 4.5, '神探夏洛克': 3.5,'小门神': 2.0},'F': {'老炮儿':3.0,'唐人街探案': 4.0,'星球大战': 2.0, '寻龙诀': 3.0,'神探夏洛克': 3.0, '小门神': 2.0},'G': {'老炮儿':4.5,'唐人街探案': 1.5,'星球大战': 3.0, '寻龙诀': 5.0,'神探夏洛克': 3.5}}STEP1:编写函数计算欧式距离字典数据中两两用户的欧式距离。
from math import sqrt# Returns a distance-based similarity score for person1 and person2
# 返回 person1 and person2基于距离的相似度
def sim_distance(prefs, person1, person2):# Get the list of shared_itemssi = {}for item in prefs[person1]:if item in prefs[person2]: si[item] = 1# if they have no ratings in common, return 0 如果没有共同评分返回0if len(si) == 0: return 0# Add up the squares of all the differences 所有差异平方相加sum_of_squares = sum([pow(prefs[person1][item] - prefs[person2][item], 2)for item in prefs[person1] if item in prefs[person2]])return 1 / (1 + sqrt(sum_of_squares))# 打印'B'对'星球大战'的评分
print(critics['B']['星球大战'])
# 打印相识分数
print(sim_distance(critics, 'A', 'B'))
输出为:

在STEP1基础上,编写函数依据欧式距离大小以及协同过滤算法(用户)实现电影的推荐。
# Gets recommendations for a person by using a weighted average of every other user's rankings
# 通过加权平均为一个人推荐
def getRecommendations(prefs, person, similarity=sim_distance):# 定义两个空字典totals = {}simSums = {}# 对传入的数据进行循环for other in prefs:# don't compare me to myself# 不与自己比较if other == person: continue# 计算这个人与其它人的评分sim = similarity(prefs, person, other)# ignore scores of zero or lower# 忽略<=0的分数if sim <= 0: continue# 对过滤后的数据再次遍历for item in prefs[other]:# only score movies I haven't seen yet# 只给没看过的电影打分if item not in prefs[person] or prefs[person][item] == 0:# Similarity * Score# 相似度 * 得分totals.setdefault(item, 0)totals[item] += prefs[other][item] * sim# Sum of similarities# 相似度总和simSums.setdefault(item, 0)simSums[item] += sim# Create the normalized list# 创建规范化列表rankings = [(total / simSums[item], item) for item, total in totals.items()]# Return the sorted list# 返回排序后的列表rankings.sort()rankings.reverse()return rankingsprint(getRecommendations(critics, 'A'))
输出为:

基于surprise的协同过滤算法实现
电影数据集介绍
 数据获取:
数据获取:
MovieLens数据集可以从MovieLens网站上免费下载。不同版本的数据集具有不同的规模和数据量,可以根据研究或应用的需求选择适当的版本。
下载地址:https://grouplens.org/datasets/movielens/
按照依赖:
pip install scikit-surprise
STEP1:导入库
导入surprise库中的算法,数据集,网格搜索。
# 导入库
from surprise import SVD
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import GridSearchCV
import os
STEP2:加载数据集
加载movielens-100K数据集,默认在线下载数据集,也可以加载本地数据

# 加载 movielens-100K
# 定义推荐数据集文件路径 绑定你的数据集地址
file_path = '/xxx/u.data'
# 指定分隔符
reader = Reader(line_format='user item rating timestamp', sep='\t')
# 导入文件
data = Dataset.load_from_file(file_path, reader=reader)
STEP3:网格搜索
设置网格搜索参数
# 网格搜索
param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005],'reg_all': [0.4, 0.6]}
gs = GridSearchCV(SVD, param_grid, measures=['rmse', 'mae'], cv=3)
STEP4:训练并获得最佳模型
# 训练模型
gs.fit(data)
# 输出最佳RMSE(均方根误差)得分
print('The best RMSE:',gs.best_score['rmse'])
# 输出最佳RMSE得分的参数组合
print('The best params:',gs.best_params['rmse'])
# 获得最佳算法
algo = gs.best_estimator['rmse']
algo.fit(data.build_full_trainset())
STEP5:模型预测
# 模型预测
uid = str(196) # 原始user id (在评分文件中的)
iid = str(302) # 原始item id (在评分文件中的)
#对某一个具体的user和item给出预测
pred = algo.predict(uid, iid, r_ui=4, verbose=True)
STEP6:输出结果解释
The best RMSE 0.9629441271618542
The best params {'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.4}
user: 196 item: 302 r_ui = 4.00 est = 4.01 {'was_impossible': False}
# 说明:user为用户id,item为项目id,r_ui为真实评分,est为预测评分
推荐系统拓展
推荐系统到底解决的是什么问题
推荐系统从20世纪90年代就被提出来了。随着移动互联网的发展,越来越多的信息开始在互联网上传播,产生了严重的信息过载。因此,如何从众多信息中找到用户感兴趣的信息,这个便是推荐系统的价值。精准推荐解决了用户痛点,提升了用户体验,最终便能留住用户。
推荐系统本质上就是一个
信息过滤系统,通常分为:召回、排序、重排序这3个环节,每个环节逐层过滤,最终从海量的物料库中筛选出几十个用户可能感兴趣的物品推荐给用户。
推荐系统的分阶段过滤流程

推荐系统的应用场景
哪里有海量信息,哪里就有推荐系统,我们每天最常用的APP都涉及到推荐功能:
资讯类:今日头条、腾讯新闻等
电商类:淘宝、京东、拼多多、亚马逊等
娱乐类:抖音、快手、爱奇艺等
生活服务类:美团、大众点评、携程等
社交类:微信、陌陌、脉脉等
头条、京东、网易云音乐中的推荐功能

推荐系统的应用场景通常采用协同过滤算法:
协同过滤推荐算法:这种算法基于用户行为数据的协同过滤技术。它通过分析用户之间的相似性或物品之间的相关性,为用户生成个性化的推荐结果。协同过滤算法主要分为基于用户的协同过滤和基于物品的协同过滤两种方法。基于用户的协同过滤通过比较用户之间的行为数据,找出兴趣相似的用户,并为用户推荐与这些相似用户喜欢的物品。基于物品的协同过滤则是根据物品之间的相似性,为用户推荐与其历史喜欢物品相似的其他物品。
基于协同过滤的推荐算法:
这种算法基于用户行为数据的协同过滤技术。它通过分析用户之间的相似性或物品之间的相关性,为用户生成个性化的推荐结果。协同过滤算法主要分为基于用户的协同过滤和基于物品的协同过滤两种方法。
基于用户维度的推荐:根据用户的历史行为和兴趣进行推荐,比如淘宝首页的猜你喜欢、抖音的首页推荐等。
基于物品维度的推荐:根据用户当前浏览的标的物进行推荐,比如打开京东APP的商品详情页,会推荐和主商品相关的商品给你。
除了关联规则和协同过滤,还有其他一些常见的推荐算法,如基于内容的推荐、基于矩阵分解的推荐、深度学习推荐等。这些算法都有各自的优缺点和适用场景,根据实际需求选择合适的算法进行推荐。
搜索、推荐、广告三者的异同
搜索和推荐是AI算法最常见的两个应用场景,在技术上有相通的地方。这里提到广告,主要考虑很多没做过广告业务的同学不清楚为什么广告和搜索、推荐会有关系,所以做下解释。
搜索:有明确的搜索意图,搜索出来的结果和用户的搜索词相关。
推荐:不具有目的性,依赖用户的历史行为和画像数据进行个性化推荐。
广告:借助搜索和推荐技术实现广告的精准投放,可以将广告理解成搜索推荐的一种应用场景,技术方案更复杂,涉及到智能预算控制、广告竞价等。
推荐系统的整体架构
推荐系统的整体架构

上面是推荐系统的整体架构图,自下而上分成了多层,各层的主要作用如下:
数据源:推荐算法所依赖的各种数据源,包括物品数据、用户数据、行为日志、其他可利用的业务数据、甚至公司外部的数据;
计算平台:负责对底层的各种异构数据进行清洗、加工,离线计算和实时计算;
数据存储层:存储计算平台处理后的数据,根据需要可落地到不同的存储系统中,比如Redis中可以存储用户特征和用户画像数据,ES中可以用来索引物品数据,Faiss中可以存储用户或者物品的embedding向量等;
召回层:包括各种推荐策略或者算法,比如经典的协同过滤,基于内容的召回,基于向量的召回,用于托底的热门推荐等。为了应对线上高并发的流量,召回结果通常会预计算好,建立好倒排索引后存入缓存中;
融合过滤层:触发多路召回,由于召回层的每个召回源都会返回一个候选集,因此这一层需要进行融合和过滤;
排序层:利用机器学习或者深度学习模型,以及更丰富的特征进行重排序,筛选出更小、更精准的推荐集合返回给上层业务。
从数据存储层到召回层、再到融合过滤层和排序层,候选集逐层减少,但是精准性要求越来越高,因此也带来了计算复杂度的逐层增加,这个便是推荐系统的最大挑战。
其实对于推荐引擎来说,最核心的部分主要是两块:特征和算法。
推荐引擎的核心功能和技术方案

特征计算由于数据量大,通常采用大数据的离线和实时处理技术,像Spark、Flink等。然后将计算结果保存在Redis或者其他存储系统中(比如HBase、MongoDB或者ES),供召回和排序模块使用。
召回算法的作用是:从海量数据中快速获取一批候选数据,要求是快和尽可能的准。这一层通常有丰富的策略和算法,用来确保多样性,为了更好的推荐效果,某些算法也会做成近实时的。
排序算法的作用是:对多路召回的候选集进行精细化排序。它会利用物品、用户以及它们之间的交叉特征,然后通过复杂的机器学习或者深度学习模型进行打分排序,这一层的特点是计算复杂但是结果更精准。
图解经典的协同过滤算法
协同过滤(Collaborative Filtering,CF)是一个简单同时效果很好的算法,只要你有初中数学的基础就能看懂。协同过滤算法的核心就是「找相似」,它基于用户的历史行为(浏览、收藏、评论等),去发现用户对物品的喜好,并对喜好进行度量和打分,最终筛选出推荐集合,它又包括两个分支:
1)基于用户的协同过滤
User-CF,核心是找相似的人。
比如下图中,用户 A 和用户 C 都购买过物品 a 和物品 b,那么可以认为 A 和 C 是相似的,因为他们共同喜欢的物品多。这样,就可以将用户 A 购买过的物品 d 推荐给用户 C。
基于用户的协同过滤示例

2)基于物品的协同过滤
Item-CF,核心是找相似的物品。比如下图中,物品 a 和物品 b 同时被用户 A,B,C 购买了,那么物品 a 和 物品 b 被认为是相似的,因为它们的共现次数很高。
这样,如果用户 D 购买了物品 a,则可以将和物品 a 最相似的物品 b 推荐给用户 D。
基于物品的协同过滤示例

如何找相似?
前面讲到,协同过滤的核心就是找相似,User-CF是找用户之间的相似,Item-CF是找物品之间的相似,那到底如何衡量两个用户或者物品之间的相似性呢?
我们都知道,对于坐标中的两个点,如果它们之间的夹角越小,这两个点越相似,这就是初中学过的余弦距离,它的计算公式如下:
举个例子,A坐标是(0,3,1),B坐标是(4,3,0),那么这两个点的余弦距离是0.569,余弦距离越接近1,表示它们越相似。
除了余弦距离,衡量相似性的方法还有很多种,比如:欧式距离、皮尔逊相关系数、Jaccard 相似系数等等,这里不做展开,只是计算公式上的差异而已。


Item-CF的算法流程
清楚了相似性的定义后,下面以Item-CF为例,详细说下这个算法到底是如何选出推荐物品的?
第一步:整理物品的共现矩阵
假设有 A、B、C、D、E 5个用户,其中用户 A 喜欢物品 a、b、c,用户 B 喜欢物品 a、b等等。
所谓共现,即:两个物品被同一个用户喜欢了。比如物品 a 和 b,由于他们同时被用户 A、B、C 喜欢,所以 a 和 b 的共现次数是3,采用这种统计方法就可以快速构建出共现矩阵。

第二步:计算物品的相似度矩阵
对于 Item-CF 算法来说,一般不采用前面提到的余弦距离来衡量物品的相似度,而是采用下面的公式:
其中,
N(u) 表示喜欢物品 u 的用户数,N(v) 表示喜欢物品 v 的用户数,
两者的交集表示同时喜欢物品 u 和物品 v 的用户数。
很显然,如果两个物品同时被很多人喜欢,那么这两个物品越相似。
基于第1步计算出来的共现矩阵以及每个物品的喜欢人数,便可以构造出物品的相似度矩阵:


第三步:推荐物品
最后一步,便可以基于相似度矩阵推荐物品了,公式如下:
其中,Puj 表示用户 u 对物品 j 的感兴趣程度,值越大,越值得被推荐。N(u) 表示用户 u 感兴趣的物品集合,S(j,N) 表示和物品 j 最相似的前 N 个物品,Wij 表示物品 i 和物品 j 的相似度,Rui表示用户 u 对物品 i 的兴趣度。

上面的公式有点抽象,直接看例子更容易理解,假设我要给用户 E 推荐物品,前面我们已经知道用户 E 喜欢物品 b 和物品 c,喜欢程度假设分别为 0.6 和 0.4。那么,利用上面的公式计算出来的推荐结果如下:
因为物品 b 和物品 c 已经被用户 E 喜欢过了,所以不再重复推荐。最终对比用户 E 对物品 a 和物品 d 的感兴趣程度,因为 0.682 > 0.3,因此选择推荐物品 a。

从0到1搭建一个推荐系统
有了上面的理论基础后,我们就可以用 Python 快速实现出一个推荐系统。
- 选择数据集
这里采用的是推荐领域非常经典的 MovieLens 数据集,它是一个关于电影评分的数据集,官网上提供了多个不同大小的版本,下面以 ml-1m 数据集(大约100万条用户评分记录)为例。
下载解压后,文件夹中包含:ratings.dat、movies.dat、users.dat 3个文件,共6040个用户,3900部电影,1000209条评分记录。各个文件的格式都是一样的,每行表示一条记录,字段之间采用 :: 进行分割。
以ratings.dat为例,每一行包括4个属性:UserID, MovieID, Rating, Timestamp。通过脚本可以统计出不同评分的人数分布:

- 读取原始数据
程序主要使用数据集中的 ratings.dat 这个文件,通过解析该文件,抽取出 user_id、movie_id、rating 3个字段,最终构造出算法依赖的数据,并保存在变量 dataset 中,它的格式为:dict[user_id][movie_id] = rate

-
构造物品的相似度矩阵
基于第 2 步的 dataset,可以进一步统计出每部电影的评分次数以及电影的共生矩阵,然后再生成相似度矩阵。

-
基于相似度矩阵推荐物品
最后,可以基于相似度矩阵进行推荐了,输入一个用户id,先针对该用户评分过的电影,依次选出 top 10 最相似的电影,然后加权求和后计算出每个候选电影的最终评分,最后再选择得分前 5 的电影进行推荐。

-
调用推荐系统
下面选择UserId=1 这个用户,看下程序的执行结果。由于推荐程序输出的是 movieId 列表,为了更直观的了解推荐结果,这里转换成电影的标题进行输出。

最终推荐的前5个电影为:

线上推荐系统的挑战

相关文章:

机器学习-08-推荐算法-协同过滤
总结 本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则 参考 机器学习(三):Apriori算法(算法精讲) Apriori 算法 理论 重点 MovieLens:一个常用的电影推荐系统领域的数据集 23张图&#x…...

03-HTML常见元素
一、HTML常见元素 常见元素及功能: 元素用途<h1>~<h6>标题从大到小<p>段落,不同段落会有间距<img>显示图片,属性src为图片路径,alt为图片无法显示时的提示文本<a>超链接,属性href为链…...

LangChain + 文档处理:构建智能文档问答系统 RAG 的实战指南
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是Lang Chain 2、文档问答的典型应用场景 二、文…...

深入理解 DML 和 DQL:SQL 数据操作与查询全解析
深入理解 DML 和 DQL:SQL 数据操作与查询全解析 在数据库管理中,SQL(结构化查询语言)是操作和查询数据的核心工具。其中,DML(Data Manipulation Language,数据操作语言) 和 DQL&…...

头歌实训之SQL视图的定义与操纵
🌟 各位看官好,我是maomi_9526! 🌍 种一棵树最好是十年前,其次是现在! 🚀 今天来学习C语言的相关知识。 👍 如果觉得这篇文章有帮助,欢迎您一键三连,分享给更…...

Excel/WPS表格中图片链接转换成对应的实际图片
Excel 超链图变助手(点击下载可免费试用) 是一款将链接转换成实际图片,批量下载表格中所有图片的转换工具,无需安装,双击打开即可使用。 表格中链接如下图所示: 操作方法: 1、双击以下图标&a…...
)
单例模式的使用场景 以及 饿汉式写法(智能指针)
单例模式的使用场景 以及 饿汉式写法(智能指针) 饿汉式:创建类时就已经创建好了类的实例(用智能指针实现)什么时候用单例模式:1. 全局配置管理2. 日志系统3. 资源管理器4. 硬件设备访问总结 饿汉式…...

示波器探头状态诊断与维护技术指南
一、探头性能劣化特征分析 信号保真度下降 ・时域表现:上升沿时间偏离标称值15%以上(如1ns探头测得≥1.15ns) ・频域特性:-3dB带宽衰减超过探头标称值20%基准稳定性异常 ・直流偏置电压漂移量>5mV(预热30分…...

使用Matlab工具将RAW文件转化为TXT文件,用于FPGA仿真输入
FPGA实现图像处理算法时,通常需要将图像作为TestBench的数据输入。 使用VHDL编写TestBench时,只能读取二进制TXT文件。 现在提供代码,用于实现RAW图像读取,图像显示,图像转化为二进制数据并存入TXT文件中。 clc; cl…...

Missashe考研日记-day23
Missashe考研日记-day23 0 写在前面 博主前几天有事回家去了,断更几天了不好意思,就当回家休息一下调整一下状态了,今天接着开始更新。虽然每天的博客写的内容不算多,但其实还是挺费时间的,比如这篇就花了我40多分钟…...

视频分析设备平台EasyCVR安防视频小知识:安防监控常见故障精准排查方法
随着安防监控技术的飞速发展,监控系统已经成为现代安防体系中不可或缺的核心组成部分,广泛应用于安防监控、交通管理、工业自动化等多个领域。然而,监控系统的稳定运行高度依赖于设备的正确配置、线路的可靠连接以及电源的稳定供电。在实际应…...

Linux论坛安装
事前准备 1、Discuz_X3.5_SC_UTF8_20230520的压缩包。 2、一台虚拟机,xshell和xftp(用来传输文件) 安装httpd 软件并将压缩包移动到指定目录 mount /dev/sr0 /mnt #### 挂载光盘到 /mnt 目录 dnf install httpd -y ### 安装http…...

瑞吉外卖-分页功能开发中的两个问题
1.分页功能-前端页面展示显示500 原因:项目启动失败 解决:发现是Category实体类中,多定义了一个删除字段,但是我数据库里面没有is_deleted字段,导致查询数据库失败,所以会导致500错误。因为类是从网上其他帖…...

深入理解HotSpot JVM 基本原理
关于JAVA Java编程语言是一种通用的、并发的、面向对象的语言。它的语法类似于C和C++,但它省略了许多使C和C++复杂、混乱和不安全的特性。 Java 是几乎所有类型的网络应用程序的基础,也是开发和提供嵌入式和移动应用程序、游戏、基于 Web 的内容和企业软件的全球标准。. 从…...

[原理分析]安卓15系统大升级:Doze打盹模式提速50%,续航大幅增强,省电提升率5%
技术原理:借鉴中国友商思路缩短进入Doze的时序 开发者米沙尔・拉赫曼(Mishaal Rahman)在其博文中透露,谷歌对安卓15系统进行了显著优化,使得设备进入“打盹模式”(Doze Mode)的速度提升了50%,并且部分机型的待机时间因此得以延长三小时。设备…...

人工智能在慢病管理中的具体应用全集:从技术落地到场景创新
一、AI 赋能慢病管理:技术驱动医疗革新 1.1 核心技术原理解析 在当今数字化时代,人工智能(AI)正以前所未有的态势渗透进医疗领域,尤其是在慢性病管理方面,展现出巨大的潜力和独特优势。其背后依托的机器学习、深度学习、自然语言处理(NLP)以及物联网(IoT)与可穿戴设…...

视频生成上下文并行方案
在多张rtx4090上的并行生成方案,主要就是xdit和paraattention中的并行上下文注意力机制。希望找到一个和skyreel一致的para attn的并行方案。 1.ParaAttention https://github.com/chengzeyi/ParaAttentionhttps://github.com/chengzeyi/ParaAttention目前只支持了文生视频的…...
厘清Gradle的版本)
Unity接入安卓SDK(3)厘清Gradle的版本
接入过程中,很多人遇到gradle的各种错误,由于对各种gradle版本的概念不甚了了,模模糊糊一顿操作猛如虎,糊弄的能编译通过就万事大吉,下次再遇到又是一脸懵逼。所以我们还是一起先厘清gradle的版本概念。 1 明晰概念 …...
)
牛行为-目标检测数据集(包括VOC格式、YOLO格式)
牛行为-目标检测数据集(包括VOC格式、YOLO格式) 数据集: 链接: https://pan.baidu.com/s/1hTLiiNOJYjzcejNwZpVsqA?pwdzhhb 提取码: zhhb 数据集信息介绍: 共有 8869张图像和一一对应的标注文件 标注文件格式提供了两种&#x…...

ubuntu 22.04 安装和配置 mysql 8.0,设置开机启动
# 更新软件包列表 sudo apt update && sudo apt upgrade -y # 安装MySQL 8.0 sudo apt install mysql-server-8.0 -y # 启动MySQL服务并设置开机启动 sudo systemctl start mysql sudo systemctl enable mysql # 安全安装MySQL,一路回车 sudo mysql…...

掌握Go空接口强大用途与隐藏陷阱
掌握Go空接口:强大用途与隐藏陷阱 Go语言中的空接口interface{}初看像是一种超能力工具。它能容纳任何东西——数字、字符串、结构体,应有尽有。但能力越大责任越大……如果不小心使用,它也会带来一堆麻烦。本文将深入探讨interface{}的工作原理,挖掘其合理的使用场景,并…...

CSS预处理工具有哪些?分享主流产品
目前主流的CSS预处理工具包括:Sass、Less、Stylus、PostCSS等。其中,Sass是全球使用最广泛的CSS预处理工具之一,以强大的功能、灵活的扩展性以及完善的社区生态闻名。Sass通过增加变量、嵌套、混合宏(mixin)等功能&…...

【2025面试Java常问八股之redis】zset数据结构的实现,跳表和B+树的对比
Redis 中的 ZSET(Sorted Set,排序集合)是一种非常重要的数据结构,它结合了集合(Set)和有序列表(List)的特点,能够存储一组 唯一 的元素,并且每个元素关联一个…...

VR制作攻略:如何制作VR
VR制作基础步骤 制作VR内容,特别是VR全景图,是一个涉及多个关键步骤的过程,包括设备准备、拍摄、拼接、后期处理及优化等。 以下将详细介绍这些步骤,并结合众趣科技的支持进行阐述。 1. 设备准备 相机: 选择配备广…...

Linux深度探索:进程管理与系统架构
1.冯诺依曼体系结构 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。 截至目前,我们所认识的计算机,都是由⼀个个的硬件组件组成。 输入设备:键盘,鼠标…...

240421 leetcode exercises
240421 leetcode exercises jarringslee 文章目录 240421 leetcode exercises[31. 下一个排列](https://leetcode.cn/problems/next-permutation/)什么是字典序?🔁二次遍历查找 [82. 删除排序链表中的重复元素 II](https://leetcode.cn/problems/remove…...

批量导出多个文件和文件夹名称与路径信息到Excel表格的详细方法
在数字化时代,电脑中的文件和文件夹管理变得越来越重要啦。没有对文件进行定期整理时,寻找文件会我们耗费大量的时间。为了高效查找文件或文件夹,可以将其名称和路径记录下来并整理成清单。然而,当文件夹数量非常多时,…...

基于亚马逊云科技 Amazon Bedrock Tool Use 实现 Generative UI
背景 在当前 AI 应用开发浪潮中,越来越多的开发者专注于构建基于大语言模型(LLM)的 chatbot 和 AI Agent。然而,传统的纯文本对话形式存在局限性,无法为用户提供足够直观和丰富的交互体验。为了增强用户体验ÿ…...

Buildroot、BusyBox与Yocto:嵌入式系统构建工具对比与实战指南
文章目录 Buildroot、BusyBox与Yocto:嵌入式Linux系统构建工具完全指南一、为什么需要这些工具?1.1 嵌入式系统的特殊性1.2 传统开发的痛点二、BusyBox:嵌入式系统的"瑞士军刀"2.1 什么是BusyBox?2.2 核心功能2.3 安装与使用2.4 典型应用场景三、Buildroot:自动…...

Android 最简单的native二进制程序
Android.bp cc_binary {name: "my_native_bin",srcs: ["main.cpp"],cflags: ["-Wall", // 启用标准警告"-Werror", // 将警告视为错误"-fPIE", // 生成位置无关代码"-pie", …...

VR、AR、互动科技:武汉数字展馆制作引领未来展览新体验
在科技飞速发展的今天,数字化技术正以前所未有的速度渗透到各个领域,展馆行业也不例外。数字展馆,作为一种新兴的展示形式,正逐渐走进大众的视野,成为当下展馆发展的新潮流。 那么,究竟什么是数字展馆呢&am…...

从代码学习深度学习 - 学习率调度器 PyTorch 版
文章目录 前言一、理论背景二、代码解析2.1. 基本问题和环境设置2.2. 训练函数2.3. 无学习率调度器实验2.4. SquareRootScheduler 实验2.5. FactorScheduler 实验2.6. MultiFactorScheduler 实验2.7. CosineScheduler 实验2.8. 带预热的 CosineScheduler 实验三、结果对比与分析…...

Kotlin安卓算法总结
Kotlin 安卓算法优化指南 排序算法优化 1. 快速排序 // 使用三向切分的快速排序,对包含大量重复元素的数组更高效 fun optimizedQuickSort(arr: IntArray, low: Int 0, high: Int arr.lastIndex) {if (high < low) returnvar lt lowvar gt highval pivot …...

Eteam 0.3版本开发规划
Eteam 0.1系列经历了3个小版本,主要完成了团队资料库功能。 Eteam 0.2系列经历了22个小版本,主要完成了白板和AI交互的能力。 目前的问题 目前白板上的数据有两个来源,团队资料库和外部数据。外部数据和团队资料库数据边界不是很清晰。 0.3版…...

每天五分钟机器学习:凸优化
本文重点 凸优化作为一类特殊的数学优化问题,因其理论完备性和计算高效性,在人工智能领域发挥着至关重要的作用。从经典的逻辑回归到深度神经网络的初始化,从支持向量机的核技巧到强化学习的策略优化,凸优化理论不仅为算法提供了坚实的数学基础,还直接推动了人工智能模型…...

PyTorch与TensorFlow模型全方位解析:保存、加载与结构可视化
目录 前言一、保存整个模型二、pytorch模型的加载2.1 只保存的模型参数的加载方式:2.2 保存结构和参数的模型加载三、pytorch模型网络结构的查看3.1 print3.2 summary3.3 netron3.3.1 解决方法13.3.2 解决方法23.4 TensorboardX四、tensorflow 框架的线性回归4.1 …...

【图像变换】pytorch-CycleGAN-and-pix2pix的学习笔记
1. 问题记录 (1)在2080Ti上训练时模型“卡在了第63个epoch”没有任何变换 我们观察到模型一直卡在这里,“像静止了一样”没有任何变化; 也查看了一下显卡情况,看到显存占用为0%,如图所示,...
)
微信小程序 == 倒计时验证码组件 (countdown-verify)
组件介绍 这是一个用于获取验证码的倒计时按钮组件,支持自定义倒计时时间、按钮样式和文字格式。 基本用法 <countdown-verify seconds"60"button-text"获取验证码"bind:send"onSendVerifyCode" />属性说明 属性名类型默认…...
)
Ldap高效数据同步- Delta-Syncrepl复制模式配置实战手册(上)
#作者:朱雷 文章目录 一、Syncrepl 和Delta-syncrepl 回顾对比1.1. 什么是复制模式1.2. 什么是 syncrepl同步复制1.3. syncrepl同步复制的缺点1.4. 什么是Delta-syncrepl 复制 二、Ldap环境部署三、配置复制类型3.1. 编译安装3.2. 提供者端配置 一、Syncrepl 和Del…...

【Hive入门】Hive概述:大数据时代的数据仓库桥梁
目录 1 Hive概述:连接SQL世界与Hadoop生态 2 从传统数据仓库到Hive的演进之路 2.1 传统数据仓库的局限性 2.2 Hive的革命性突破 3 Hive的核心架构与执行流程 3.1 Hive系统架构 3.2 SQL查询执行全流程 4 Hive与传统方案的对比分析 5 Hive最佳实践 5.1 存储…...

靠华为脱胎换骨,但赛力斯仍需要Plan B
文|刘俊宏 编|王一粟 2024年底,撒贝宁在央视的一场直播中,终于“按捺不住”问了赛力斯董事长张兴海一个好奇已久的问题——“与华为合作之后,晚上是不是乐得睡不着觉?” “睡觉的时候还是该睡觉......不…...

【ESP32】【微信小程序】MQTT物联网智能家居案例
这里写自定义目录标题 案例成果1.Ardino写入部分2.微信小程序JS部分3.微信小程序xml部分4. 微信小程序CSS部分 案例成果 1.Ardino写入部分 #include <WiFi.h> // ESP32 WiFi库 #include <PubSubClient.h> // MQTT客户端库 #include <DHT.h> …...

应用层核心协议详解:HTTP, HTTPS, RPC 与 Nginx
应用层核心协议详解:HTTP, HTTPS, RPC 与 Nginx 前言一、HTTP:Web的基石1.1 HTTP协议的核心特点1.2 HTTP 报文格式1.3 HTTP 方法 (Methods)1.4 HTTP 状态码 (Status Codes)1.5 连接管理:短连接 vs 长连接1.6 HTTP 版本演进1.7 状态管理&#…...

解析三大中间件:Nginx、Apache与Tomcat
目录 一、基础定义与核心功能 二、核心区别与适用场景对比 三、为什么需要组合使用? 四、如何选择?一句话总结 五、技术演进与未来趋势 一、基础定义与核心功能 Nginx 定位:高性能的HTTP服务器与反向代理工具。核心能…...

关于 梯度下降算法、线性回归模型、梯度下降训练线性回归、线性回归的其他训练算法 以及 回归模型分类 的详细说明
以下是关于 梯度下降算法、线性回归模型、梯度下降训练线性回归、线性回归的其他训练算法 以及 回归模型分类 的详细说明: 1. 梯度下降算法详解 核心概念 梯度下降是一种 优化算法,用于寻找函数的最小值。其核心思想是沿着函数梯度的反方向逐步迭代&a…...

【数据结构和算法】4. 链表 LinkedList
本文根据 数据结构和算法入门 视频记录 文章目录 1. 链表的概念1.1 链表的类型1.2 链表的基本操作 2. 单向链表的实现2.1 插入2.2 删除2.3 查找2.4 更新 1. 链表的概念 我们知道数组是很常用的数据储存方式,而链表就是继数组之后,第二种最通用的数据储…...

基于S2B2C模式与定制开发开源AI智能名片的小程序商城系统研究
摘要:在新零售蓬勃发展的大背景下,S2B2C模式凭借其对消费场景的强力支撑以及柔性供应链的显著优势,成为推动零售行业变革的关键力量。本文深入剖析S2B2C模式,着重探讨定制开发开源AI智能名片S2B2C商城小程序源码的实践意义。通过分…...

【Python核心库实战指南】从数据处理到Web开发
目录 前言:技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块对比 二、实战演示环境配置要求核心代码实现(5个案例)案例1:NumPy数组运算案例2:Pandas数据分析…...
)
【错误记录】Windows 命令行程序循环暂停问题分析 ( 设置 “ 命令记录 “ 选项 | 启用 “ 丢弃旧的副本 “ 选项 | 将日志重定向到文件 )
文章目录 一、报错信息二、问题分析1、Windows 命令行的缓冲区机制2、命令记录设置 三、解决方案1、设置 " 命令记录 " 选项2、将日志重定向到文件 一、报错信息 Java 程序中 , 设置 无限循环 , 每次循环 休眠 10 秒后 , 再执行程序逻辑 , 在命令行中打印日志信息 ; …...

【iOS】Blocks学习
Blocks学习 Blocks概要Blocks模式Blocks语法Blocks类型变量截获自动变量值__block说明符截获的自动变量 Blocks的实现Blocks的实质截获自动变量值__block说明符Block存储域_block变量存储域截获对象__block变量和对象 总结 Blocks概要 Blocks是C语言的扩充功能,简单…...