【2025最新】windows本地部署LightRAG,完成neo4j知识图谱保存
之前在服务器部署neo4j失败,无奈只能在本地部署,导致后期所有使用的知识图谱数据都存在本地,这里为了节省时间,先在本地安装LigthRAG完成整个实验流程,后续在学习各种服务器部署和端口调用。从基础和简单的部分先做起来吧。
1.下载
1.去github下载模型到本地,git clone https://github.com/HKUDS/LightRAG
用idea打开,pycharm新建一个虚拟解释器环境,和其他环境隔开,它的python是基于本地的python来的,左下方红色的报错环境不为空,去删除下就可以了
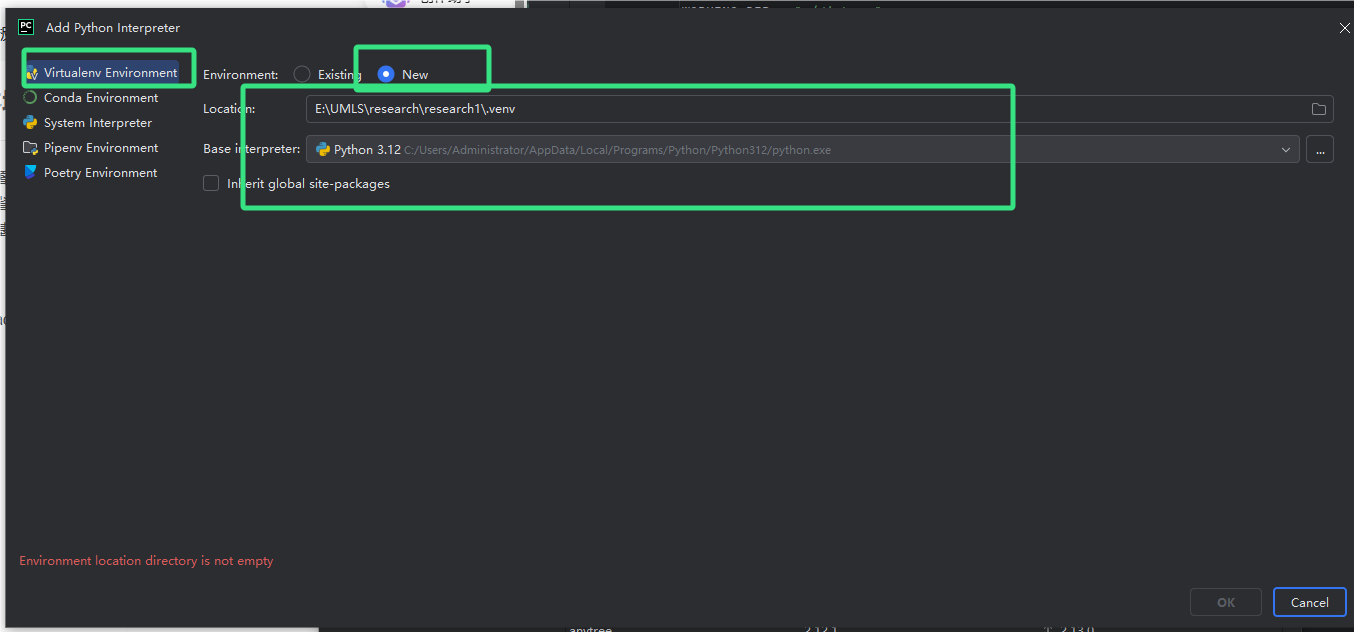
2.选择刚刚创建好的虚拟环境,右下角会变
3.cd 到LightRAG文件夹
cd LightRAG
pip install -e .
接下来开始正式使用,教程如下:
如何快速部署和运行lightRag(轻量版的GraphRag), 并且进行知识图谱的可视化。_哔哩哔哩_bilibili
4.这里我打算基于LLM的现有接口来做,防止部署大模型的麻烦,所以我们打开如下demo
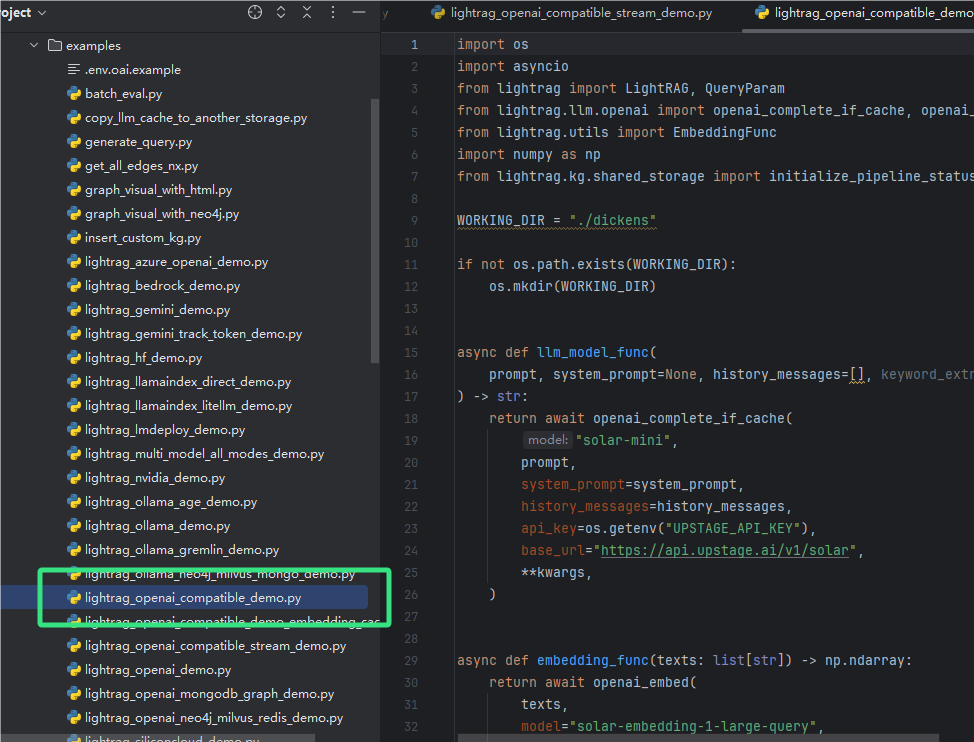
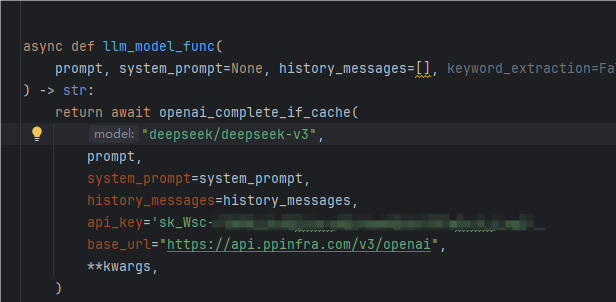
这里我换一下模型接口:
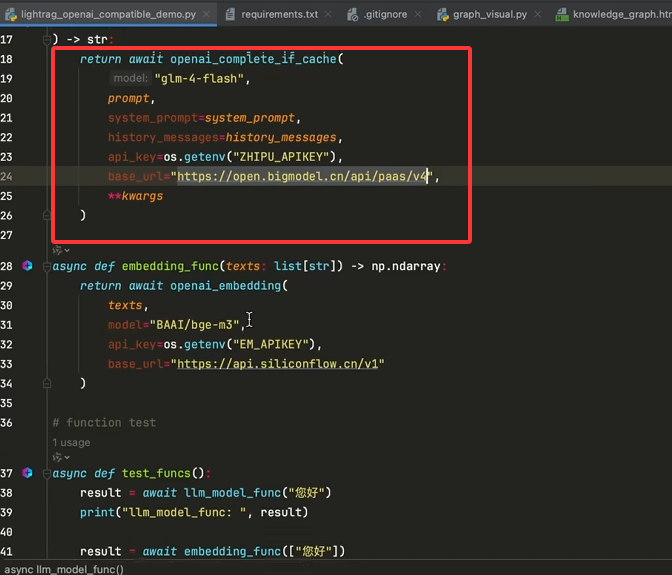
把所示部分换成我的deepseek-v3,我用的是下面这个平台,注册之后就能获取同款deepseek的满血接口和网页版了,花点小钱,但是解决了官网deepseek经常不回复的问题:
Deepseek PPIO算力云https://ppinfra.com/user/register?invited_by=R8Z3RZ注册后访问这里就可以对话式体验(包括可以做一些参数调整)通过上述链接加入记得50元token可通过API开发式 + 网页对话等方式,在体验满血版R1服务(也有其他多种版本),邀请朋友加入,再增 5000 万token!使用教程:用这个版本deepseek/deepseek-r1,别用community,r1和v3必须充钱,送的token可以抵扣一部分,但不能全部抵扣,但是充钱后速度确实又恢复丝滑了,换成下面这样,apikey从我充钱那个网站那里获取
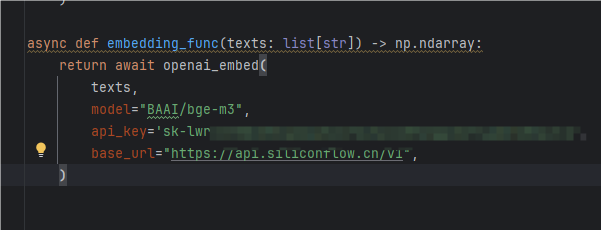
这里的嵌入模型和视频截图用到的一样,因为它免费,申请个api-key就可以用了。注意它使用的embeding是1024维度。获取链接如下:硅基流动用户系统,统一登录 SSO

所以下面的维度也要改下参数,改成1024维度

这里注意一下新的url跟之前官网给的不一样
’
准备一个测试文档:我从一个医学网站上爬取的关于阿尔兹海默的专业版介绍,存入txt
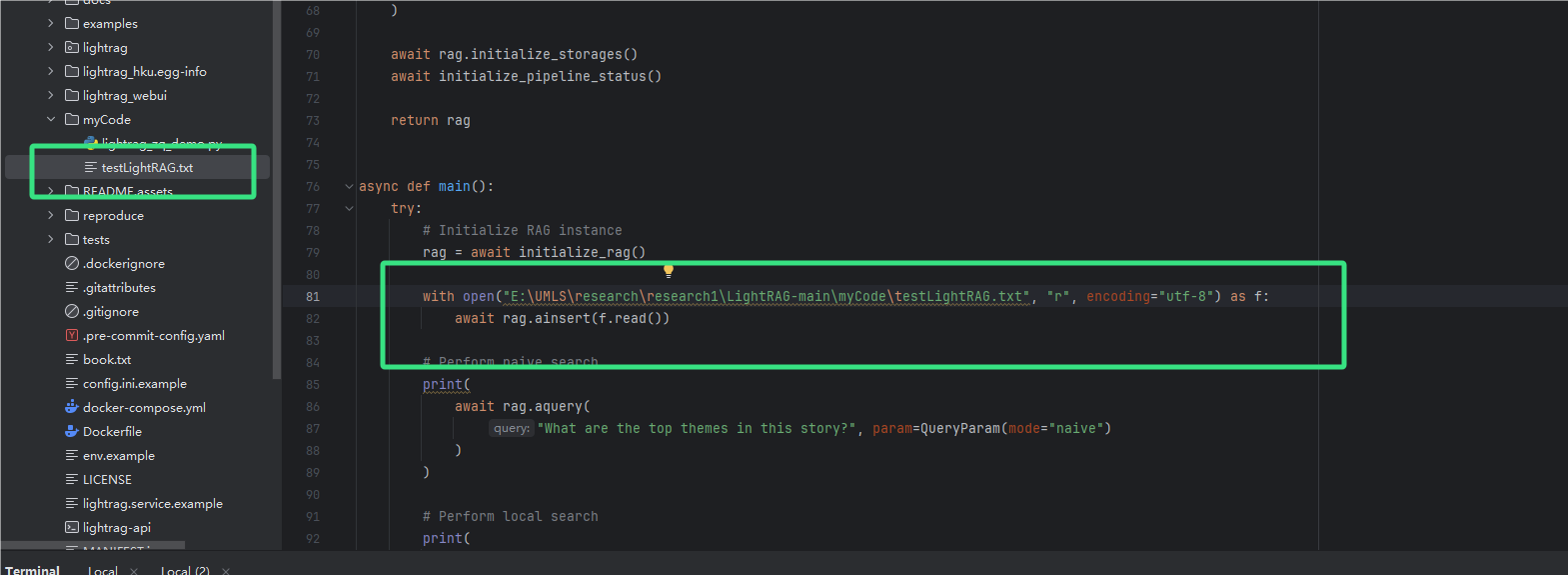
withopen的路径改成我们所需要的测试文档路径
针对文档修改下待会要测试RAG的问题
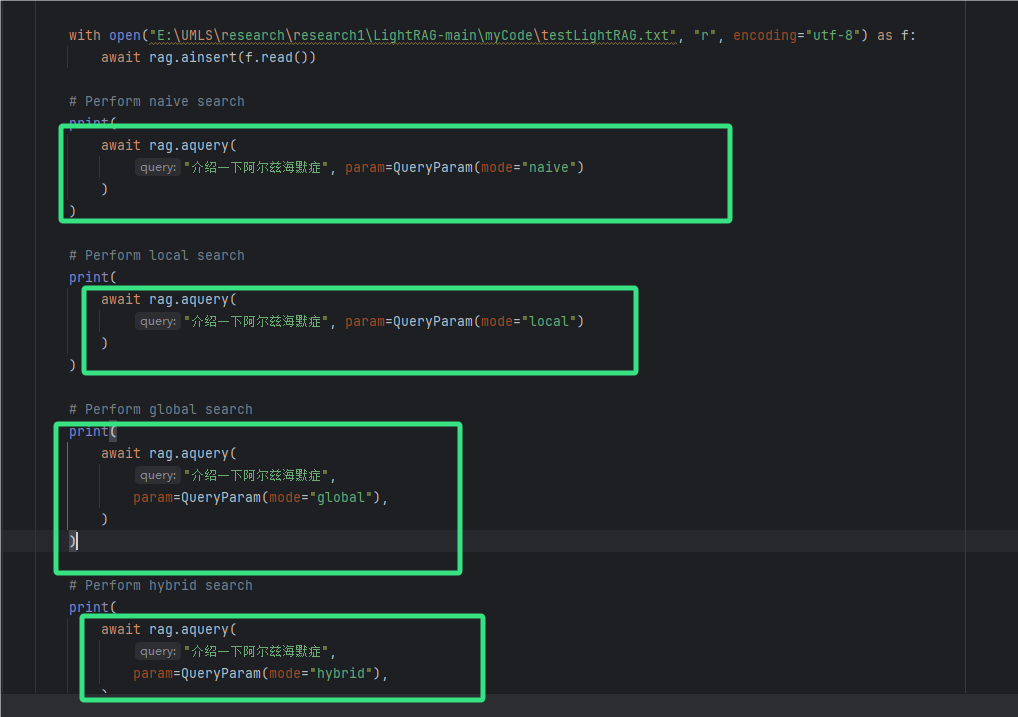
直接运行这个代码应该就行了
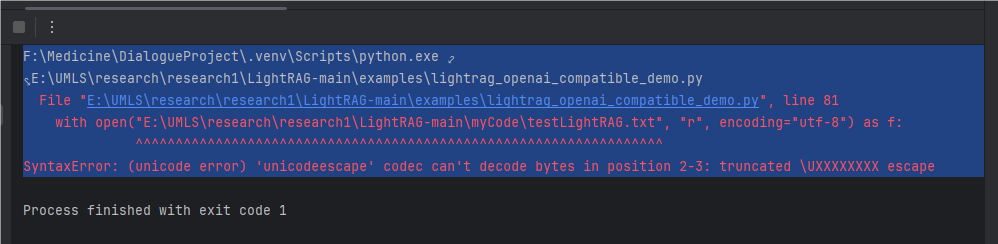
这个错误是因为在 Python 字符串中,反斜杠\在默认情况下被视为转义字符。在你的文件路径字符串中,\U被 Python 解释器识别为一个无效的转义序列,因为它后面没有跟着 8 个十六进制数字(\U用于表示 4 字节的 Unicode 字符),从而导致了SyntaxError错误。
在字符串前面加上r前缀,将其声明为原始字符串,这样 Python 就不会对反斜杠进行转义处理。:
with open(r"E:\UMLS\research\research1\LightRAG-main\myCode\testLightRAG.txt", "r", encoding="utf-8") as f:
运行完以后可以看见RAG的效果已经出来了:
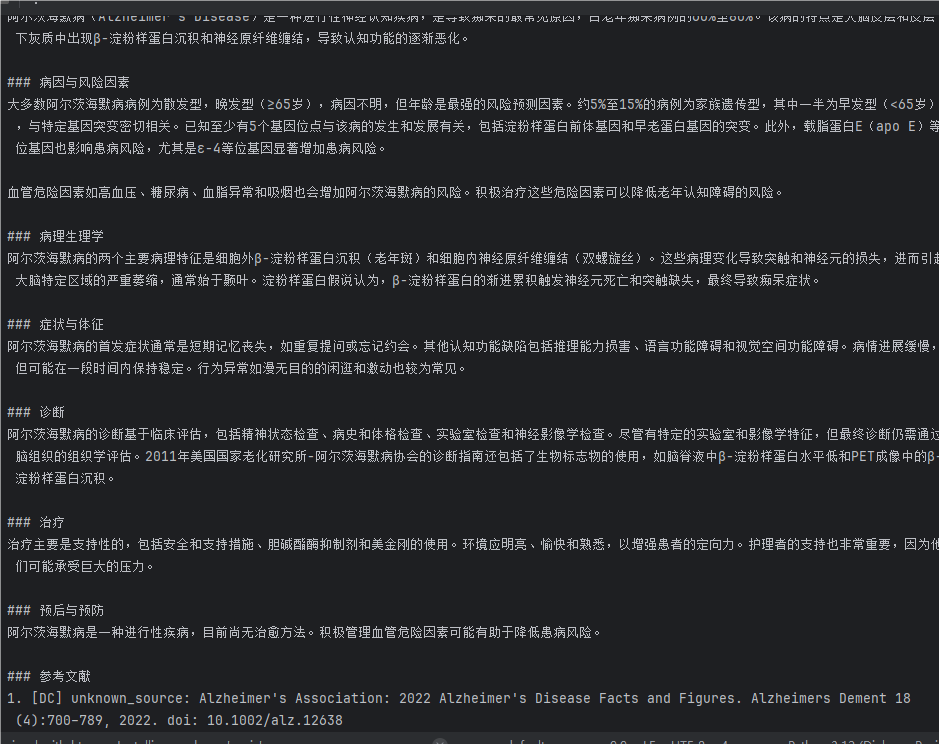
下面分析一下这些检索结果
/n
————————————————————naive模式的输出————————————
/n
阿尔茨海默病(Alzheimer's Disease)是一种进行性神经认知疾病,是导致痴呆的最常见原因,占老年痴呆病例的60%至80%。该病的特点是大脑皮层和皮层下灰质中出现β-淀粉样蛋白沉积和神经原纤维缠结,导致认知功能的逐渐恶化。### 病因与风险因素
大多数阿尔茨海默病病例为散发型,晚发型(≥65岁),病因不明,但年龄是最强的风险预测因素。约5%至15%的病例为家族遗传型,其中一半为早发型(<65岁),与特定基因突变密切相关。已知至少有5个基因位点与该病的发生和发展有关,包括淀粉样蛋白前体基因和早老蛋白基因的突变。此外,载脂蛋白E(apo E)等位基因也影响患病风险,尤其是ε-4等位基因显著增加患病风险。血管危险因素如高血压、糖尿病、血脂异常和吸烟也会增加阿尔茨海默病的风险。积极治疗这些危险因素可以降低老年认知障碍的风险。### 病理生理学
阿尔茨海默病的两个主要病理特征是细胞外β-淀粉样蛋白沉积(老年斑)和细胞内神经原纤维缠结(双螺旋丝)。这些病理变化导致突触和神经元的损失,进而引起大脑特定区域的严重萎缩,通常始于颞叶。淀粉样蛋白假说认为,β-淀粉样蛋白的渐进累积触发神经元死亡和突触缺失,最终导致痴呆症状。### 症状与体征
阿尔茨海默病的首发症状通常是短期记忆丧失,如重复提问或忘记约会。其他认知功能缺陷包括推理能力损害、语言功能障碍和视觉空间功能障碍。病情进展缓慢,但可能在一段时间内保持稳定。行为异常如漫无目的的闲逛和激动也较为常见。### 诊断
阿尔茨海默病的诊断基于临床评估,包括精神状态检查、病史和体格检查、实验室检查和神经影像学检查。尽管有特定的实验室和影像学特征,但最终诊断仍需通过脑组织的组织学评估。2011年美国国家老化研究所-阿尔茨海默病协会的诊断指南还包括了生物标志物的使用,如脑脊液中β-淀粉样蛋白水平低和PET成像中的β-淀粉样蛋白沉积。### 治疗
治疗主要是支持性的,包括安全和支持措施、胆碱酯酶抑制剂和美金刚的使用。环境应明亮、愉快和熟悉,以增强患者的定向力。护理者的支持也非常重要,因为他们可能承受巨大的压力。### 预后与预防
阿尔茨海默病是一种进行性疾病,目前尚无治愈方法。积极管理血管危险因素可能有助于降低患病风险。### 参考文献
1. [DC] unknown_source: Alzheimer's Association: 2022 Alzheimer's Disease Facts and Figures. Alzheimers Dement 18 (4):700–789, 2022. doi: 10.1002/alz.12638
2. [DC] unknown_source: Kinney JW, Bemiller SM, Murtishaw AS, et al: Inflammation as a central mechanism in Alzheimer's disease. Alzheimers Dement (NY) 4:575–590, 2018. doi: 10.1016/j.trci.2018.06.014
3. [DC] unknown_source: González A, Calfío C, Churruca M, Maccioni RB: Alzheimers Res Ther 14 (1):56, 2022. doi: 10.1186/s13195-022-00996-8
4. [DC] unknown_source: Jack CR Jr, Albert MS, Knopman DS, et al: Introduction to the revised criteria for the diagnosis of Alzheimer’s disease: National Institute on Aging and Alzheimer's Association workgroups. Alzheimers Dement 7 (3):257–262, 2011. doi: 10.1016/j.jalz.2011.03.004
5. [DC] unknown_source: McKhann GM, Knopman DS, Chertkow H, et al: The diagnosis of dementia due to Alzheimer's disease: Recommendations from the National Institute on Aging-Alzheimer's Association workgroups on diagnostic guidelines for Alzheimer's disease. Alzheimers Dement 7 (3):263–269, 2011. doi: 10.1016/j.jalz.2011.03.005/n
————————————————————local模式的输出————————————
/n阿尔茨海默病是一种常见的痴呆症,大多数病例是零散的,年龄是其最大的风险因素。它与其他类型的痴呆症,如血管性痴呆和路易体痴呆,在病因和治疗方法上有所不同,尽管它们的症状可能相似。### 预防措施
以下措施可以帮助降低阿尔茨海默病的发病风险:
- **智力活动**:如学习新技能或做数独。
- **身体锻炼**:有规律的身体锻炼对预防阿尔茨海默病非常重要。
- **控制高血压**和**降低胆固醇水平**:这些健康管理措施有助于降低发病风险。
- **饮食调整**:增加富含ω-3脂肪酸的食物,减少饱和脂肪酸的摄入。
- **适量饮酒**:少量饮酒可能降低风险,但不建议不饮酒者开始饮酒。一旦痴呆发生,建议戒酒。### 治疗
在晚期阿尔茨海默病中,**姑息治疗**可能比激进疗法或住院治疗更为可取。### 诊断与支持
**Alzheimer's Association**提供了关于阿尔茨海默病的诊断工具、研究支持和信息资源,有助于早期诊断和获取相关信息。### 关键点
- 阿尔茨海默病大多数病例是零散的,年龄是最大的风险因素。
- 与其他痴呆症的区分可能困难,但通常可通过临床标准进行区分,诊断准确性可达85%。### References
- [KG] unknown_source
- [KG] unknown_source
- [KG] unknown_source
- [KG] unknown_source
- [KG] unknown_source/n
————————————————————global模式的输出————————————
/n
阿尔茨海默病(Alzheimer's disease)是一种常见的痴呆症,大多数病例是零散的,年龄是其最大的风险因素。这种疾病的预防措施包括智力活动、身体锻炼、控制血压和胆固醇水平等。以下是一些关键点:### 预防措施
1. **智力活动**:如学习新技能或做数独,可以降低阿尔茨海默病的发病风险。
2. **身体锻炼**:有规律的身体锻炼是预防阿尔茨海默病的重要措施之一。
3. **饮食调整**:减少饱和脂肪酸的摄入,增加富含ω-3脂肪酸的食物,有助于降低风险。
4. **健康管理**:控制高血压和降低胆固醇水平也是预防阿尔茨海默病的关键因素。
5. **饮酒**:少量饮酒可能降低阿尔茨海默病的风险,但不建议不饮酒者开始饮酒。一旦痴呆发生,建议戒酒。### 诊断与治疗
阿尔茨海默病的诊断可能与其他类型的痴呆症(如血管性痴呆和路易体痴呆)有所混淆,但通常可以通过临床标准进行区分,诊断准确性可达85%。在晚期阿尔茨海默病中,姑息治疗可能比激进疗法或住院治疗更为可取。### 资源支持
Alzheimer's Association 是一个提供阿尔茨海默病诊断工具、研究支持和信息的网站,可以帮助患者和家属获取更多资源和信息。### References
1. [KG] unknown_source
2. [KG] unknown_source
3. [KG] unknown_source/n
————————————————————hybrid模式的输出————————————
/n
阿尔茨海默病(阿尔兹海默症)是一种常见的痴呆症,大多数病例是零散的,年龄是其最大的风险因素。以下是关于阿尔茨海默病的一些关键信息:### 预防措施
1. **智力活动**:如学习新技能或做数独,可以降低发病风险。
2. **身体锻炼**:有规律的身体锻炼是预防阿尔茨海默病的重要措施之一。
3. **控制高血压**:降低高血压有助于减少发病风险。
4. **降低胆固醇水平**:保持健康的胆固醇水平有助于预防阿尔茨海默病。
5. **饮食调整**:富含ω-3脂肪酸、少含饱和脂肪酸的食物有助于降低风险。
6. **饮酒**:少量饮酒可能降低风险,但不建议不饮酒者开始饮酒。一旦痴呆发生,建议戒酒。### 与其他痴呆症的区别
阿尔茨海默病与血管性痴呆和路易体痴呆是不同类型的痴呆症,尽管症状相似,但病因和治疗方法有所不同。### 晚期治疗
在晚期阿尔茨海默病中,姑息治疗可能比激进疗法或住院治疗更为可取。### 资源支持
Alzheimer's Association 提供关于阿尔茨海默病的诊断工具、研究支持和信息资源。### 关键点
- 大多数阿尔茨海默病病例是零散的,年龄是最大的风险因素。
- 区分阿尔茨海默病和其他原因引起的痴呆(如血管性痴呆、路易体痴呆)可能困难,但通常可使用临床标准区分,诊断准确性达85%。### References
1. [KG] unknown_source
2. [KG] unknown_source
3. [KG] unknown_source
4. [KG] unknown_source
5. [KG] unknown_source
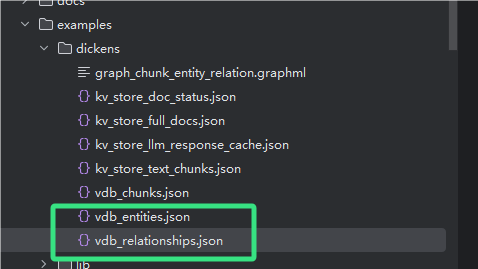
运行之后会在example里生成/dickens文件夹,生成这个运行过程中生成的一些过程文件,如果运行正确,会生成如下文件(包含知识图谱的边,节点等内容),根据所至py文件运行一下,生成可视化:

运行可视化相关的py文件之后,
按照之前代码的逻辑,运行后会在当前工作目录生成knowledge_graph.html文件,你可以通过以下方式查看可视化效果:
- 文件资源管理器:打开文件资源管理器,导航到运行代码时所在的目录(根据代码中
net.show("knowledge_graph.html"),推测是E:\UMLS\research\research1\LightRAG-main\examples目录)。找到knowledge_graph.html文件,双击打开它,浏览器会加载并展示可视化的图形。 
这个目录可以看生成的实体和关系,我第一次运行没抽取出来,应该是文档模型抽风了,再运行一次就好啦
知识图谱的效果如下:

接下来研究下怎么把LightRAG生成的图谱存入neo4j,方便后续使用

neo4j中我已经提前存过其它知识图谱了,我想在不干扰原图谱的情况下,把新图谱存入已有的database,方法就是在节点和关系上都打上特殊的标签,查询和使用的时候带上标签就行,因此,我要对demo里的example进行以下修改,代码如下:
import os
import json
from lightrag.utils import xml_to_json
from neo4j import GraphDatabaseWORKING_DIR = "./dickens"
BATCH_SIZE_NODES = 500
BATCH_SIZE_EDGES = 100NEO4J_URI = "bolt://localhost:7687"
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = ""def convert_xml_to_json(xml_path, output_path):if not os.path.exists(xml_path):print(f"Error: File not found - {xml_path}")return Nonejson_data = xml_to_json(xml_path)if json_data:with open(output_path, "w", encoding="utf-8") as f:json.dump(json_data, f, ensure_ascii=False, indent=2)print(f"JSON file created: {output_path}")return json_dataelse:print("Failed to create JSON data")return Nonedef process_in_batches(tx, query, data, batch_size):for i in range(0, len(data), batch_size):batch = data[i: i + batch_size]print(f"[INFO] Inserting batch {i // batch_size + 1} with {len(batch)} items...")tx.run(query, {"items": batch})def main():xml_file = os.path.join(WORKING_DIR, "graph_chunk_entity_relation.graphml")json_file = os.path.join(WORKING_DIR, "graph_data.json")json_data = convert_xml_to_json(xml_file, json_file)if json_data is None:returnnodes = json_data.get("nodes", [])edges = json_data.get("edges", [])print(f"[INFO] Total nodes found: {len(nodes)}")print(f"[INFO] Total edges found: {len(edges)}")if len(nodes) == 0 and len(edges) == 0:print("[ERROR] No nodes or edges found!")return# 自动创建所有节点属性create_nodes_query = """UNWIND $items AS nodeMERGE (e:Entity {id: node.id})SET e += nodeWITH e, nodeCALL apoc.create.addLabels(e, ['med_network', node.entity_type]) YIELD node AS labeledNodeRETURN count(*)"""# 自动创建所有边属性create_edges_query = """UNWIND $items AS edgeMERGE (source:Entity {id: edge.source})MERGE (target:Entity {id: edge.target})WITH source, target, edge,'med_network_' + REPLACE(SPLIT(edge.keywords, ',')[0], '\"', '') AS relTypeCALL apoc.create.relationship(source, relType, edge, target) YIELD relRETURN count(*)"""driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))try:with driver.session(database="umls") as session:print("[INFO] Inserting nodes...")session.execute_write(process_in_batches, create_nodes_query, nodes, BATCH_SIZE_NODES)print("[INFO] Inserting edges...")session.execute_write(process_in_batches, create_edges_query, edges, BATCH_SIZE_EDGES)print("[SUCCESS] med_network knowledge graph inserted with full attributes!")except Exception as e:print(f"[ERROR] Neo4j execution error: {e}")finally:driver.close()if __name__ == "__main__":main()
效果如下,不知道为啥插入还有中英文的版本,但我的原文档没有英文:

下面是大模型对于存在英文抽取的解释:
这个现象其实是 LightRAG 知识图谱构建逻辑的必然结果,核心原因是 ——
LightRAG 的知识抽取模型(特别是 Entity 和 Relation 的抽取)默认是使用英文基础模型或者英文优先的多语言模型,它并不完全区分输入文本的语言。
具体机制
LightRAG 的流程大致是:
-
输入文档(不管是中文/英文)
-
切分句子 -> 分词 -> 实体识别(NER)-> 关系抽取(RE)
-
将识别到的 Entity / Relation 存入 Neo4j 等图数据库
-
Entity 和 Relation 的命名依赖:
-
文本中出现的原文
-
模型内置的英文知识库(Embedding / LLM 检索补全)
-
Tokenizer(很多是英文分词器)
-
-
最终生成的三元组:
mathematica
复制编辑
(中文Entity, 英文Relation, 中文Entity) (英文Entity, 英文Relation, 英文Entity) (中文Entity, 中文Relation, 英文Entity)
这种混合非常常见。
为什么中文文档中会混入英文 Entity/Relation?
| 原因 | 说明 |
|---|---|
| 1. Entity Linking / Entity Normalization | 抽取到的实体如果在英文知识库有对应 entry,可能会被自动转为英文版 |
| 2. Relation Schema 设计是英文 | LightRAG 内置的 relation schema 直接是英文,比如:cause_of、located_in、treats |
| 3. 使用的 NER 和 RE 模型是英文优先 | 中文的实体如果模型觉得是医学术语、专业词汇,容易强行补全英文对应 |
| 4. tokenizer 或 embeddings 不支持纯中文 | 很多 pretrain 的模型使用英文词表为主,导致中英文混用是常态 |
举个例子
输入中文:
阿尔茨海默病 是一种 神经系统疾病
LightRAG 知识图谱输出:
css
复制编辑
(:Entity {id: '阿尔茨海默病'}) -[:type_of]-> (:Entity {id: 'neuro disease'})
原因是:
-
type_of来自内置 relation schema -
neuro disease是模型自动 linking 到医学知识库的英文 entry
如何避免这种情况?
方法一:定制 relation schema
-
全部中文定义 relation
-
代码中指定:
python
复制编辑
relation_schema = { '属于': 'type_of', '位于': 'located_in', '导致': 'cause_of', ... }
抽取后强制替换 relation 名称。
方法二:禁用 entity linking
-
不让模型自动 link 英文知识
-
保留原文 entity
-
只做中文实体 + 中文关系
缺点:丧失一部分跨语言知识补全能力
方法三:自定义抽取模型
-
用中文NER + 中文RE
-
推荐:
-
中文版 Bert-NER
-
中文版 CasRel / TPLinker
-
-
Huggingface 已有很多中文版本
方法四:抽取后做一遍 entity normalize
-
自定义 entity normalization 映射表
-
将所有英文 entity 替换回中文
最推荐的方案
| 场景 | 推荐做法 |
|---|---|
| 医疗知识图谱、科研知识图谱 | 保留中英文双语(专业英文保留,有利于跨文献对齐) |
| 面向C端业务、用户知识问答 | 强制全中文化,优化体验 |
结论
你现在看到的中英文混杂,是 LightRAG 知识抽取模型为了增强知识丰富度,主动做的 linking 行为 —— 但可以通过定制 relation schema、entity normalize 或自定义模型来控制。
其它:
词嵌入模型,如果要用LightRAG处理的原文档是中文的,可以去魔塔下载bge-large-zh-v1.5
了解一下LightRAG
知识图谱抽取过程)(是用提前写好的大模型提示词封装好之后完成的)
学习资料来自下方博主:基于知识图谱做rag Lightrag中实体关系的提取及图谱的生成_哔哩哔哩_bilibili

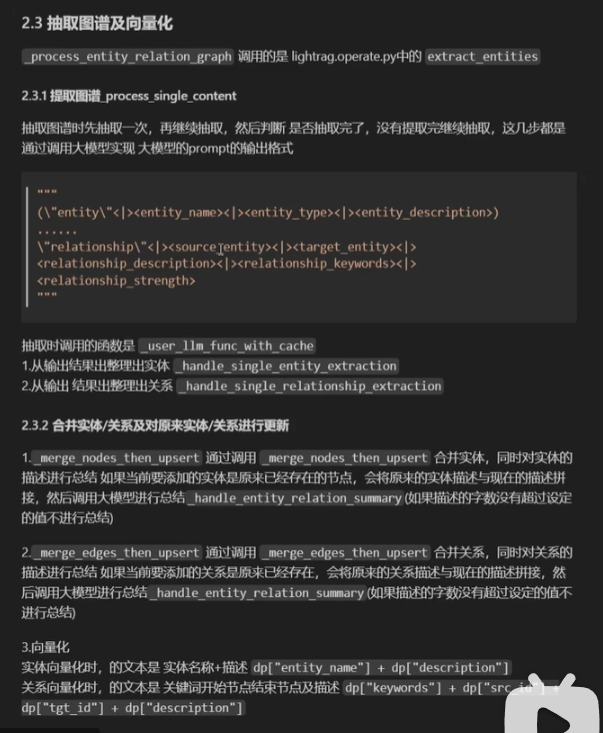
抽取的内容不仅有实体、关系、还有关系强度。其中节点和关系都有一个描述,当再次抽取到类似实体和关系时,知识图谱的节点和边不会更新,但是他们的描述会更新

5.怎么运行
需要三个主要部分:调用处理大模型、调用嵌入模型,运行lightRAG的主代码(标志是会执行rag.insert(f.aread这一句)
第一部分 配置大模型和嵌入模型的代码长下面这样,这里的模型是调接口获得的,应该是阿里云的智谱平台
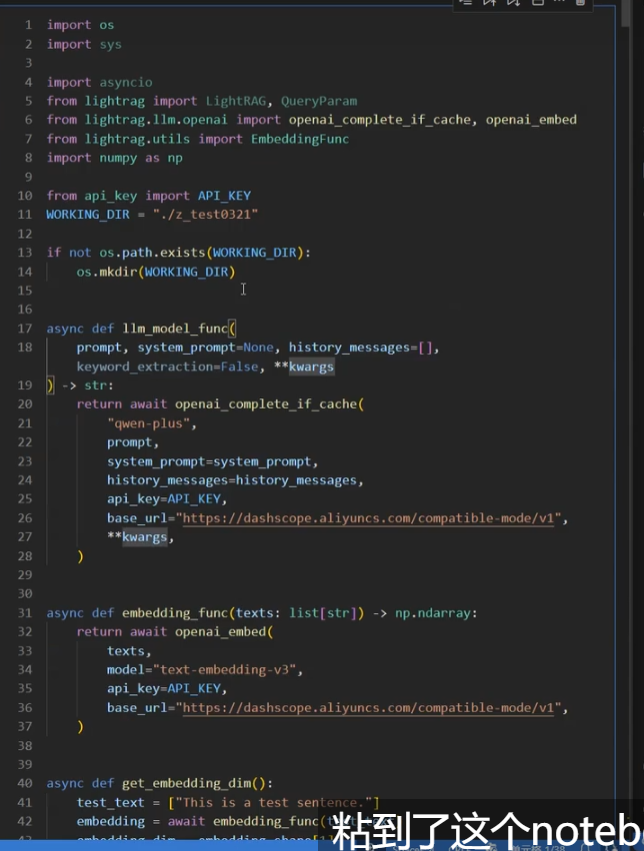
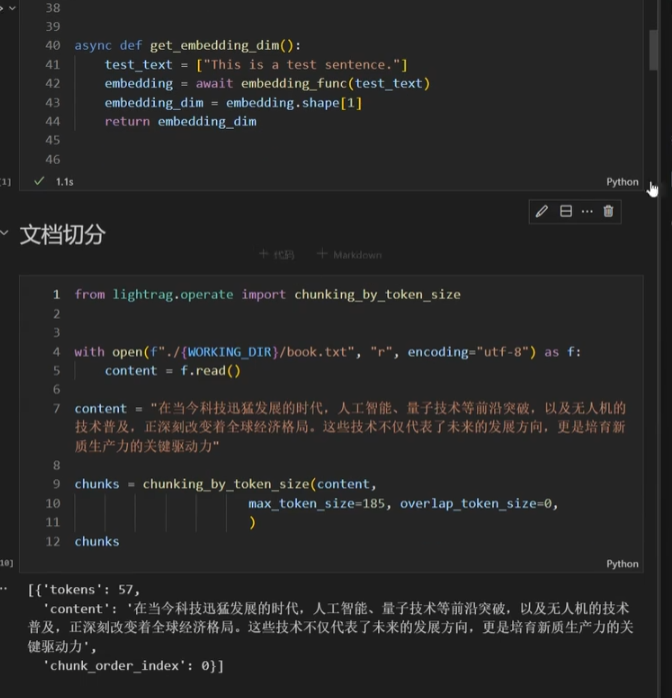
主代码如下:
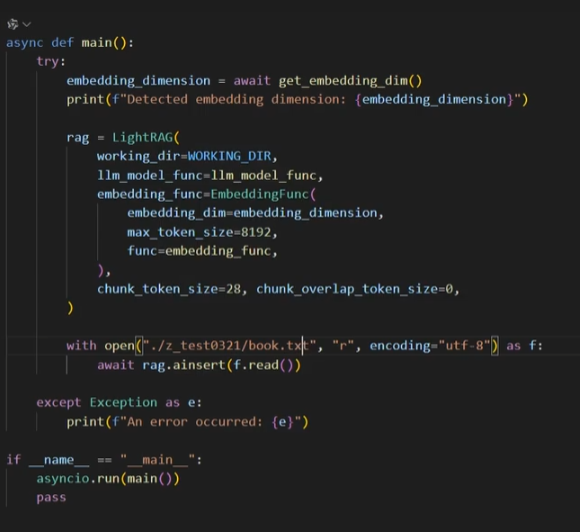
运行主函数后,就会从ainsert进行文档处理,分块,分布抽取等过程,关系和实体都处理完之后会做向量化保存
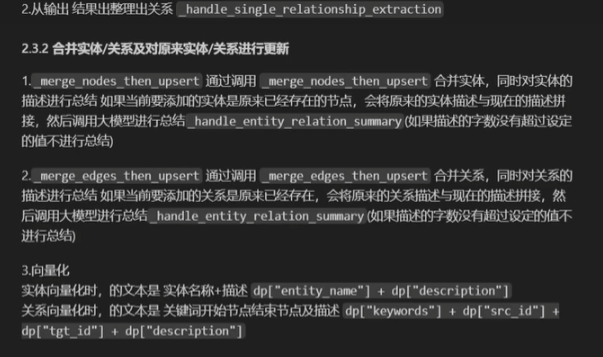
接着用大模型进行去重,判断实体等是否相同dakda'k,
相关文章:

【2025最新】windows本地部署LightRAG,完成neo4j知识图谱保存
之前在服务器部署neo4j失败,无奈只能在本地部署,导致后期所有使用的知识图谱数据都存在本地,这里为了节省时间,先在本地安装LigthRAG完成整个实验流程,后续在学习各种服务器部署和端口调用。从基础和简单的部分先做起来…...

思考力提升的黄金标准:广度、深度与速度的深度剖析
文章目录 引言一、广度的拓展:构建多元知识网络1.1 定义与重要性1.2 IT技术实例与提升策略小结:构建多元知识网络,提升IT领域思考力广度 二、深度的挖掘:追求知识的精髓2.1 定义与重要性2.2 IT技术实例与提升策略小结:…...

7个向量数据库对比:Milvus、Pinecone、Vespa、Weaviate、Vald、GSI 和 Qdrant
7个向量数据库对比:Milvus、Pinecone、Vespa、Weaviate、Vald、GSI 和 Qdrant 本文简要总结了当今市场上正在积极开发的7个向量数据库,Milvus、Pinecone、Vespa、Weaviate、Vald、GSI 和 Qdrant 的详细比较。 我们已经接近在搜索引擎体验的基础层面上涉…...
——3.5指令系统的发展)
计算机组成原理笔记(十五)——3.5指令系统的发展
不同类型的计算机有各具特色的指令系统,由于计算机的性能、机器结构和使用环境不同,指令系统的差异也是很大的。 3.5.1 x86架构的扩展指令集 x86架构的扩展指令集是为了增强处理器在多媒体、三维图形、并行计算等领域的性能而设计的。这些扩展指令集通…...

Rust 中的Relaxed 内存指令重排演示:X=0 Y=0 是怎么出现的?
🔥 Rust 中的内存重排演示:X0 && Y0 是怎么出现的? 在并发编程中,我们经常会听说“内存重排(Memory Reordering)”这个术语,但它似乎总是只出现在理论或者别人口中的幻觉里。本文将通过…...

vp 2023 icpc 合肥 解题补题记录 [F E J G]
gym 链接: https://codeforces.com/gym/104857 F. Colorful Balloons 血签, 用 map 存一下每个颜色气球出现的次数, 找出出现次数大于一半的颜色. #include<bits/stdc.h> using namespace std;#define int long long #define endl \nsigned main() {int n;cin >> …...

学习SqlSugar的跨库查询基本用法
使用SqlSugar操作数据库通常都是单库操作,跨库查询的情况要么是单个系统数据不完整,需要其它系统的关联业务数据支撑,要么就是需要整合汇总多个系统的数据进行数据数据分析、处理、展示。遇到上述情况,可以要求另外的系统提供查询…...

智慧工厂可视化系统,赋能工业生产智能化升级
借助图扑软件 HT 搭建智慧工厂可视化系统。利用先进 3D 建模,对工厂布局、设备运行、生产流程进行逼真复刻。实时展示设备状态、生产进度、质量检测数据等,助力管理者精准洞察生产,高效决策,推动工厂智能化转型。...

案例驱动的 IT 团队管理:创新与突破之路: 第四章 危机应对:从风险预见到创新破局-4.1.2债务评估模型与优先级排序
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 4.1.2 技术债务评估模型与优先级排序:构建智能决策体系一、技术债务的"冰山效应"与量化困境二、三维评估模型:穿透债务迷雾的探照灯2.1 评…...

nfs共享目录主配置文件权限参数
/etc/exports 文件默认为空文件,需要输入nfs共享命令 格式:共享目录的路径 允许访问的NFS客户端(共享权限参数) #编辑共享目录配置文件(即/etc/exports) [rootserver ~]# mkdir /nfs_share (创建共享的目录…...

C++ 编程指南35 - 为保持ABI稳定,应避免模板接口
一:概述 模板在 C 中是编译期展开的,不同模板参数会生成不同的代码,这使得模板类/函数天然不具备 ABI 稳定性。为了保持ABI稳定,接口不要直接用模板,先用普通类打个底,模板只是“外壳”,这样 AB…...

探索 MCP 和 A2A 协议: 本质上新协议都基于 HTTP的
以下是以 CSDN 博客的形式记录你对 MCP 协议和 A2A 协议数据传递的理解,重点探讨了它们为何基于 HTTP 协议、HTTP 的优势,以及数据传输的本质。文章面向技术社区,结构清晰,适合分享。 探索 MCP 和 A2A 协议:为何新协议…...

Linux网络http与https
应用层协议HTTP 提示 因为现在大多数都是https,所以就用https来介绍http,https比http多了一个加密功能,不影响介绍http。 什么是http 虽然我们说, 应用层协议是我们程序猿自己定的. 但实际上, 已经有大佬们定义了一些现成的, 又非常好用的…...
:STL list 完全解析,从入门到高效使用)
C++ 算法(2):STL list 完全解析,从入门到高效使用
1. list概述 std::list是C标准模板库(STL)中的一个双向链表容器。与vector和deque不同,list不支持随机访问,但它在任何位置插入和删除元素都非常高效,时间复杂度为O(1)。 2. list的基本特性 双向链表结构:每个元素都包含指向前驱…...

【Linux实践系列】:匿名管道收尾+完善shell外壳程序
🔥 本文专栏:Linux Linux实践项目 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: 人生总会有自己能力所不及的范围,但是如果你在你能力所及的范围尽了全部的努力,那你还有什么遗…...

Linux基本指令2
1.head 查看文件的前面内容 head 路径 :查看路径开头部分内容,如下图:head /var/log/messages查看/var/log/messages这个日志中前面内容 head -数字 路径 :查看路径开头指定数字行部分内容,如下图:he…...

Tkinter使用Canvas绘制图形
在Tkinter中,Canvas是一个非常强大的控件,用于绘制图形、显示图片和实现自定义图形界面。通过Canvas,您可以绘制各种形状、线条、文本等,并且能够进行灵活的动画和交互。掌握Canvas的使用将使您能够创建丰富的图形界面。 8.1 创建Canvas控件 Canvas控件是一个区域,用于绘…...

CF985G Team Players
我敢赌,就算你知道怎么做,也必然得调试半天才能 AC。 [Problem Discription] \color{blue}{\texttt{[Problem Discription]}} [Problem Discription] 图片来自洛谷。 [Analysis] \color{blue}{\texttt{[Analysis]}} [Analysis] 显然不可能正面计算。所以…...

ngx_conf_read_token - events
file_size ngx_file_size(&cf->conf_file->file.info); 获取 配置文件的大小 此时 file_size364 for ( ;; ) {if (b->pos > b->last) { 此时 b->pos 0x5cd4701487e4 b->last 0x5cd47014893c b->start0x5cd4701487d0 条件不成立 ch *b->pos;…...

L2范数与权重衰退
权重衰退 定义损失函数 $ \ell(\mathbf{w}, b) $ 来衡量模型的预测值与真实值的差距 使用L2范数作为硬性限制 通过限制参数值的选择范围来控制模型容量 min ℓ ( w , b ) s u b j e c t t o ∥ w ∥ 2 ≤ θ \min \ell(\mathbf{w}, b) \quad \\ subject \ to \|\mathbf{w…...
——3.4指令类型)
计算机组成原理笔记(十四)——3.4指令类型
一台计算机的指令系统可以有上百条指令,这些指令按其功能可以分成几种类型,下面分别介绍。 3.4.1数据传送类指令 一、核心概念与功能定位 数据传送类指令是计算机指令系统中最基础的指令类型,负责在 寄存器、主存、I/O设备 之间高效复制数…...
)
GM DC Monitor v2.0 数据中心监控预警平台-CMDB使用教程(第九篇)
SNMP配置管理功能使用手册 本模块主要用于导入设备厂家的mib库文件,也可以手工创建对应的oid信息,用以实现设备的被动监控功能。 另:系统部署完毕后,已经集成了个别厂家的MIB库数据。 设计思路及使用教程 设计思路:通…...

try-with-resources 详解
try-with-resources 详解 一、基本概念 try-with-resources 是 Java 7 引入的语法结构,用于自动管理资源(如文件流、数据库连接等需要关闭的对象)。 核心特点 自动资源释放:无需手动调用 close() 简洁代码:减少 tr…...

第二十四:查看当前 端口号是否被占用
查看当前 端口号是否被占用: mac 情况下: lsof -i :端口号 netstat -an | grep 端口号 系统将显示监听该端口的进程信息,包括进程名称、进程ID、用户和协议等。如果需要更多信息,可以添加-P和-n参数,例如…...
)
【数据结构与算法】——堆(补充)
前言 上一篇文章讲解了堆的概念和堆排序,本文是对堆的内容补充 主要包括:堆排序的时间复杂度、TOP 这里写目录标题 前言正文堆排序的时间复杂度TOP-K 正文 堆排序的时间复杂度 前文提到,利用堆的思想完成的堆排序的代码如下(包…...

【Web功能测试】Web商城搜索模块测试用例设计深度解析
Web商城的搜索模块功能测试用例设计 1.搜索功能设计 1.1 搜索框设计 位置显眼:通常置于页面顶部中央,符合用户习惯。 智能提示(Autocomplete):输入时实时推荐关键词、商品或分类(如“手机 苹果”&#x…...

ubuntu 18.04安装tomcat,zookeeper,kafka,hadoop,MySQL,maxwell
事情是这样的,因为昨天发现我用的ubuntu16.04官方不维护了,以及之前就觉得不是很好用,于是升级到了18.04。如图: 但是!由于为备份升级前忘记关闭服务,上面装好的东西所剩无几。 于是我重装了。。。 如何启…...
-享元模式)
设计模式(结构型)-享元模式
摘要 在软件开发的广阔领域中,随着系统规模的不断膨胀,资源的有效利用逐渐成为了一个至关重要的议题。当一个系统中存在大量相似的对象时,如何优化这些对象的管理,减少内存的占用,提升系统的整体性能,成为了…...

1.1显存
显存是显卡(GPU)专用的高性能内存,负责存储渲染所需的纹理、帧缓冲、几何数据等。其设计直接影响图形性能、分辨率和复杂场景处理能力 苹果统一内存(Unified Memory)、集成显卡共享内存(Integrated Graphi…...

C# 选择文件的路径、导出文件储存路径
1、选择导入文件,获取其路径 C#通过这段代码将弹出一个文件选择对话框,允许用户选择一个文件,并返回所选文件的完整路径。如果用户取消了选择,则直接返回结束函数。 string OpenFilePath;//存储选择到的文件的完整路径OpenFileDia…...

【最后203篇系列】027 基于消息队列的处理架构
起因 之所以写这篇文章,主要是梳理一下进展。因为同时研究好几块内容,切换起来要点时间。这次也是因为协作的同事们把各自的分工都搞定了,瓶颈反而在我自己这里,哈哈。 除了帮自己思路恢复过来,我觉得这方法可能也有…...

多线程与Tkinter界面交互
在现代图形用户界面(GUI)应用程序中,可能会遇到需要长时间运行的任务,例如网络请求、数据处理或文件读取等。如果这些任务直接在主线程中运行,会导致GUI界面“卡顿”或“不响应”。为了保持界面流畅和响应用户操作,我们可以通过使用多线程来将这些任务移到后台运行。然而…...
)
【工程开发】LLMC准确高效的LLM压缩工具(一)
【文献阅读】LLMC: Benchmarking Large Language Model Quantization with a Versatile Compression Toolkit 北航 2024年10月 摘要 大语言模型(LLMs)的最新进展凭借其卓越的涌现能力和推理能力,正推动我们迈向通用人工智能。然而&#…...

回顾CSA,CSA复习
RHCSA redhat certificate system Administrator RHCE redhat certificate engineer 回顾CSA 文件管理 创建文件:touch 、重定向、vim 阅读文件:cat看短小的文件、vim、head看文件前面部分、tail看文件的尾部内容、more、less看文档使用more和less…...

基于电子等排体的3D分子生成模型 ShEPhERD - 评测
一、背景介绍 ShEPhERD 是一个由 MIT 开发的一个 3D 相互作用感知的 ligand-based的分子生成模型,以 arXiv 预印本的形式发表于 2024 年,被ICLR2025 会议接收。文章链接:https://openreview.net/pdf?idKSLkFYHlYg ShEPhERD 是一种基于去噪扩…...

平凡日子里的挣扎
2025年4月13日,9~23℃,好 待办: 融智云考平台《物理》《物理2》~~《地理》《地理1》~~重修试卷 卫健委统考监考(2025年4月12日早上7点半) 冶金《物理》课程标准 冶金《物理》教案 期中教学检查——自查表材料ÿ…...

智能制造方案精读:117页MES制造执行系统解决方案【附全文阅读】
本方案围绕制造执行系统(MES)展开,阐述了智能制造相关概念及发展趋势,指出 MES 是连接 ERP 与生产现场的关键系统。介绍其在加工、装配及其他场景的应用,通过实例展示各场景下的功能、特点和实施效果,如实现生产信息可视化、产品追溯、设备监控等。还提及实施 MES 面临的…...
)
[推荐]AI驱动的知识图谱生成器(AI Powered Knowledge Graph Generator)
网址:https://github.com/robert-mcdermott/ai-knowledge-graph# 一、介绍 简介:以非结构化文本文档为输入,使用您选择的LLM以主语-谓语-宾语 (SPO) 三元组的形式提取知识,并将这些关系可视化为交互式知识图谱 特点:…...
从算法仿真到工程源码实现-第七节-关于波束10个基本概念)
波束形成(BF)从算法仿真到工程源码实现-第七节-关于波束10个基本概念
一、波束10个基本概念 1.作用: 对多路麦克风信号进行合并处理,抑制非目标方向的干扰信号,增强目标方向的声音信号。 2.原理: 调整相位阵列的基本单元参数,使得某些角度的信号获得相长干涉,而另一些角度的…...
)
深度学习(第一集)
123 import torch# 创建一个需要计算梯度的张量 x1 torch.tensor([2.0], requires_gradTrue)# 定义一个简单的函数 y x^2 y x1 ** 4# 计算梯度 y.backward()print("x1.grad 的值:", ) # 打印 x1.grad print("x1.grad 的值:", x1…...

Spring 事务传播行为
在Spring框架中,事务传播行为(Transaction Propagation)定义了事务在多个方法调用之间的行为方式。理解这些传播行为对于设计可靠的事务管理策略至关重要。以下是Spring支持的七种事务传播行为及其应用场景的详细说明: 1. REQUIRED(默认) 行为:如果当前存在事务,则加入…...

搬运机器人的基本工作场景及原理
搬运机器人广泛应用于工业生产中,主要用于搬运、堆放、装配等工作。它通过机械手臂的运动,结合机器视觉技术完成各种自动化作业。 一、搬运机器人的设计原理 搬运机器人通常采用可移动门架式结构,手臂承载机构安装在导轨上,可以沿…...

Ubuntu终端中常用的快捷键整理
1. 导航与编辑 光标移动: Ctrl A:跳转到行首。 Ctrl E:跳转到行尾。 Alt B:向左移动一个单词(或 Ctrl ←)。 Alt F:向右移动一个单词(或 Ctrl →)。 删除操作…...
+ ProxySQL 架构)
mysql安装-MySQL MGR(Group Replication)+ ProxySQL 架构
文章目录 前言一、环境规划二、安装 MySQL 8.0.36(主库,CentOS 9)2.1 添加 Yum 源2.2 安装 MySQL 8.0.362.3 初始化 三、配置主库 my.cnf(192.168.1.101)四、(可选)创建远程可访问的用户&#x…...

Opencv使用cuda实现图像处理
main.py import os import cv2 print(fOpenCV: {cv2.__version__} for python installed and working) image cv2.imread(bus.jpg) if image is None:print("无法加载图像1") print(cv2.cuda.getCudaEnabledDeviceCount()) cv2.cuda.setDevice(0) cv2.cuda.printCu…...

ubuntu 安装samba
ubuntu 版本:Ubuntu 24.04.2 LTS 1. 保证连网 2. 安装samba sudo apt install samba 在安装结束以后,我们可以使用下面的命令来查看安装: apt list | grep samba freeipa-client-samba/noble 4.11.1-2 amd64 ldb-tools/noble 2:2.8.0samba…...
之将对话记录保存到数据库中)
山东大学软件学院创新项目实训开发日志(12)之将对话记录保存到数据库中
在之前的功能开发中,已经成功将deepseekAPI接口接入到springbootvue项目中,所以下一步的操作是将对话和消息记录保存到数据库中 在之前的开发日志中提到数据库建表,所以在此刻需要用到两个表,conversation表和message表ÿ…...

欢乐力扣:反转链表二
文章目录 1、题目描述2、思路 1、题目描述 反转链表二。 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 2、思路 参考官方题解,基本思路…...

【CS*N是狗】亲测可用!!WIN11上禁用Chrome自动更新IDM插件
现象:每次打开chrome后IDM会弹出提示插件版本不一致。经过排查后发现是chrome把IDM插件给更新了,导致IDM提示版本不匹配。经过摸索后,得到了可行的方案。 第一步,打开Chrome,把IDM插件卸载掉,然后重新安装I…...
)
Linux:DNS服务配置(课堂实验总结)
遇到的问题,都有解决方案,希望我的博客能为你提供一点帮助。 操作系统:rocky Linux 9.5 一、配置DNS服务器的核心步骤 步骤 1:安装 BIND 软件 检查是否安装: rpm -qa | grep "^bind"…...