ubuntu 18.04安装tomcat,zookeeper,kafka,hadoop,MySQL,maxwell
事情是这样的,因为昨天发现我用的ubuntu16.04官方不维护了,以及之前就觉得不是很好用,于是升级到了18.04。如图:
但是!由于为备份升级前忘记关闭服务,上面装好的东西所剩无几。
于是我重装了。。。
如何启动
1. Java 环境(JDK)
你的系统已安装 jdk1.8.0_371,确保环境变量已配置:
export JAVA_HOME=/home/zhangxuanyu/jdk1.8.0_371
export PATH=$JAVA_HOME/bin:$PATH
验证:
java -version
结果:
zhangxuanyu@ubuntu:~$ java -version
java version "1.8.0_371"
2. Apache Tomcat
(1)解压并启动
cd ~
tar -xzf apache-tomcat-8.5.100-linux.tar.gz # 如果未解压
cd apache-tomcat-8.5.100/bin
./startup.sh # 启动
(2)验证
curl http://localhost:8080 # 或浏览器访问
(3)停止
./shutdown.sh
3. ZooKeeper
(1)解压并配置
cd ~
tar -xzf zookeeper-3.4.14.tar.gz
cd zookeeper-3.4.14/conf
cp zoo_sample.cfg zoo.cfg # 创建默认配置
(2)启动
cd ../bin
./zkServer.sh start # 启动
结果:
ZooKeeper JMX enabled by default
Using config: /home/zhangxuanyu/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
(3)验证
./zkCli.sh # 连接本地 ZooKeeper
(4)停止
./zkServer.sh stop
结果:
ZooKeeper JMX enabled by default
Using config: /home/zhangxuanyu/zookeeper-3.4.14/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
4. Kafka
(1)解压并启动
cd ~
tar -xzf kafka_2.12-3.3.2.tgz
#先启动zookeeper
cd kafka_2.12-3.3.2
bin/kafka-server-start.sh config/server.properties
(2)验证
ps aux | grep kafka #检查进程
(3)停止
bin/kafka-server-stop.sh
bin/zookeeper-server-stop.sh
5. Hadoop
以下是 Ubuntu 18.04 上安装 Hadoop 3.3.5 的详细步骤(基于已有的 hadoop-3.3.5.tar.gz 安装包):
1. 环境准备
安装 Java
Hadoop 依赖 Java 8/11(推荐 OpenJDK 8):
sudo apt update
sudo apt install openjdk-8-jdk -y# 验证安装
java -version # 应显示 "openjdk version 1.8.0_xxx"
配置 SSH 免密登录
Hadoop 本地模式需要 SSH 无密码访问:
sudo apt install openssh-server -y
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa # 生成密钥
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys# 测试免密登录
ssh localhost # 首次需输入yes,之后应直接进入
exit # 退出SSH会话终极测试是否ok:
zhangxuanyu@ubuntu:~$ ssh localhost "echo ‘SSH免密登录成功!’"结果:
ssh localhost "echo 'SSH免密登录成功'"
SSH免密登录成功
2. 安装 Hadoop
解压安装包
cd ~
tar -xzvf hadoop-3.3.5.tar.gz # 解压到当前目录
mv hadoop-3.3.5 hadoop # 重命名(可选)
配置环境变量
编辑 ~/.bashrc:
nano ~/.bashrc
在文件末尾添加:
# Java Environment
export JAVA_HOME=/usr/lib/jnm/jdk1.8.0_371
export PATH=$JAVA_HOME/bin:$PATH# Hadoop Environment
export HADOOP_HOME=/home/zhangxuanyu/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
激活配置:
source ~/.bashrc
检查是否生效:
zhangxuanyu@ubuntu:~$ echo $HADOOP_HOME
结果:
/home/zhangxuanyu/hadoop
zhangxuanyu@ubuntu:~$ hadoop version
结果:
Hadoop 3.3.5
3. 配置 Hadoop
修改核心配置文件
进入配置目录:
cd ~/hadoop/etc/hadoop
1. hadoop-env.sh
设置 Java 路径:
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> hadoop-env.sh
2. core-site.xml
配置 HDFS 地址和临时目录:
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><property><name>hadoop.tmp.dir</name><value>/tmp/hadoop-tmp</value></property>
</configuration>
检查:
zhangxuanyu@ubuntu:~/hadoop/etc/hadoop$ cat ~/hadoop/etc/hadoop/core-site.xml | grep -A 1 "hadoop.tmp.dir"
结果:<name>hadoop.tmp.dir</name><value>/tmp/hadoop-tmp</value>
3. hdfs-site.xml
配置副本数(单机模式设为1):
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>/tmp/hadoop/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>/tmp/hadoop/datanode</value></property>
</configuration>
检查:
zhangxuanyu@ubuntu:~/hadoop/etc/hadoop$ hdfs getconf -confKey dfs.replication
1
zhangxuanyu@ubuntu:~/hadoop/etc/hadoop$ hdfs getconf -confKey dfs.namenode.name.dir
/tmp/hadoop/namenode
zhangxuanyu@ubuntu:~/hadoop/etc/hadoop$ hdfs getconf -confKey dfs.datanode.data.dir
/tmp/hadoop/datanode
4. mapred-site.xml
配置使用 YARN:
<configuration><!-- 核心配置:声明使用YARN框架 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 临时目录设置(避免使用默认/tmp) --><property><name>mapreduce.cluster.temp.dir</name><value>/opt/hadoop/tmp/mapred</value></property><!-- 内存资源限制(根据机器配置调整) --><property><name>mapreduce.map.memory.mb</name><value>1024</value> <!-- 每个Map任务的内存 --></property><property><name>mapreduce.reduce.memory.mb</name><value>2048</value> <!-- 每个Reduce任务的内存 --></property><!-- JVM堆内存限制(需小于上述memory.mb) --><property><name>mapreduce.map.java.opts</name><value>-Xmx768m</value> <!-- Map任务的JVM堆内存 --></property><property><name>mapreduce.reduce.java.opts</name><value>-Xmx1536m</value> <!-- Reduce任务的JVM堆内存 --></property><!-- 任务重试策略 --><property><name>mapreduce.map.maxattempts</name><value>4</value> <!-- Map任务最大重试次数 --></property><property><name>mapreduce.reduce.maxattempts</name><value>4</value> <!-- Reduce任务最大重试次数 --></property><!-- 数据本地化优化 --><property><name>mapreduce.tasktracker.prefetch.local</name><value>true</value> <!-- 优先在数据所在节点执行任务 --></property>
</configuration>
5. yarn-site.xml
<configuration><!-- 你已存在的配置 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 新增关键配置 ▼▼▼ --><!-- 1. 指定Shuffle处理类 --><property><name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><!-- 2. 定义ResourceManager主机 --><property><name>yarn.resourcemanager.hostname</name><value>ubuntu</value> <!-- 替换为你的主节点主机名 --></property><!-- 3. 内存资源池配置 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>8192</value> <!-- 建议=物理内存*0.8 --></property><!-- 4. 关闭虚拟内存检查(避免任务被误杀) --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><!-- 5. 启用日志聚合 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property>
</configuration>
4. 初始化并启动 Hadoop
格式化 HDFS
hdfs namenode -format # 仅首次运行需要
成功的标准:
2025-04-13 13:40:23,513 INFO common.Storage: Storage directory /tmp/hadoop/namenode has been successfully formatted.
启动 HDFS 和 YARN
start-dfs.sh # 启动HDFS
start-yarn.sh # 启动YARN
验证服务
-
检查进程:
jps
hadoop 启动成功的标志:
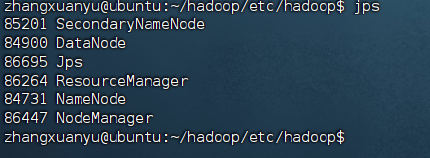
85201 SecondaryNameNode
84900 DataNode
86695 Jps
86264 ResourceManager
84731 NameNode
86447 NodeManager
-
访问 Web UI:
- HDFS: http://localhost:9870
- YARN: http://localhost:8088
5. 运行测试任务
创建 HDFS 目录
hdfs dfs -mkdir /input
hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml /input # 上传测试文件
运行 MapReduce 示例
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep /input /output 'dfs[a-z.]+'
查看结果
hdfs dfs -cat /output/*
6. 停止 Hadoop
stop-yarn.sh
stop-dfs.sh
常见问题解决
-
端口冲突:
-
检查
9000、9870、8088端口是否被占用:sudo netstat -tulnp | grep -E '9000|9870|8088'
-
-
权限问题:
-
如果遇到权限错误,尝试:
sudo chown -R $USER:$USER /tmp/hadoop*
-
-
日志排查:
-
查看日志文件:
tail -n 100 ~/hadoop/logs/*.log
-
6.安装MySQL
在 Ubuntu 18.04 上安装 MySQL 的完整步骤如下(适用于 MySQL 5.7,Ubuntu 18.04 默认版本):
方法 1:使用 APT 安装(推荐)
1. 更新软件包列表
sudo apt update
2. 安装 MySQL Server
sudo apt install mysql-server -y
- 这会安装 MySQL 5.7(Ubuntu 18.04 默认版本)。
3. 运行安全配置向导
sudo mysql_secure_installation
- 按提示操作
- 设置 root 密码(我设置的My@Secure123)
- 移除匿名用户
- 禁止远程 root 登录
- 删除测试数据库
- 立即刷新权限
4. 检查 MySQL 状态
sudo systemctl status mysql
- 如果显示
active (running),说明安装成功。
进入:
sudo mysql -u root -p
输入密码后:
为了后面的Maxwell,需要修改mysql配置
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
在[mysqld]区块末尾下面加:
server_id = 12345
log_bin = /var/log/mysql/mysql-bin.log
binlog_format = ROW
binlog_row_image = FULL
expire_logs_days = 10
max_binlog_size = 100M
再重启Mysql服务:
sudo systemctl restart mysql
7. Maxwell(MySQL Binlog 监听)
(1)解压并配置
cd ~
tar -xzf maxwell-1.29.2.tar.gz
cd maxwell-1.29.2
需修改 config.properties:
nano config.properties
修改为:
producer=kafka
kafka.bootstrap.servers=localhost:9092
# mysql login info
host=localhost
user=root #mysql用户
password=My@Secure123 #mysql密码
(2)启动
bin/maxwell --config config.properties &
(3)验证
tail -f logs/maxwell.log # 查看日志
总结
| 软件 | 启动命令 | 停止命令 |
|---|---|---|
| Tomcat | ./startup.sh | ./shutdown.sh |
| Nginx | ~/nginx/sbin/nginx | ~/nginx/sbin/nginx -s stop |
| ZooKeeper | ./zkServer.sh start | ./zkServer.sh stop |
| Kafka | ./kafka-server-start.sh ... | ./kafka-server-stop.sh |
| Hadoop | sbin/start-dfs.sh + start-yarn.sh | sbin/stop-dfs.sh + stop-yarn.sh |
| Maxwell | bin/maxwell --config ... | kill 对应进程 |
相关文章:

ubuntu 18.04安装tomcat,zookeeper,kafka,hadoop,MySQL,maxwell
事情是这样的,因为昨天发现我用的ubuntu16.04官方不维护了,以及之前就觉得不是很好用,于是升级到了18.04。如图: 但是!由于为备份升级前忘记关闭服务,上面装好的东西所剩无几。 于是我重装了。。。 如何启…...
-享元模式)
设计模式(结构型)-享元模式
摘要 在软件开发的广阔领域中,随着系统规模的不断膨胀,资源的有效利用逐渐成为了一个至关重要的议题。当一个系统中存在大量相似的对象时,如何优化这些对象的管理,减少内存的占用,提升系统的整体性能,成为了…...

1.1显存
显存是显卡(GPU)专用的高性能内存,负责存储渲染所需的纹理、帧缓冲、几何数据等。其设计直接影响图形性能、分辨率和复杂场景处理能力 苹果统一内存(Unified Memory)、集成显卡共享内存(Integrated Graphi…...

C# 选择文件的路径、导出文件储存路径
1、选择导入文件,获取其路径 C#通过这段代码将弹出一个文件选择对话框,允许用户选择一个文件,并返回所选文件的完整路径。如果用户取消了选择,则直接返回结束函数。 string OpenFilePath;//存储选择到的文件的完整路径OpenFileDia…...

【最后203篇系列】027 基于消息队列的处理架构
起因 之所以写这篇文章,主要是梳理一下进展。因为同时研究好几块内容,切换起来要点时间。这次也是因为协作的同事们把各自的分工都搞定了,瓶颈反而在我自己这里,哈哈。 除了帮自己思路恢复过来,我觉得这方法可能也有…...

多线程与Tkinter界面交互
在现代图形用户界面(GUI)应用程序中,可能会遇到需要长时间运行的任务,例如网络请求、数据处理或文件读取等。如果这些任务直接在主线程中运行,会导致GUI界面“卡顿”或“不响应”。为了保持界面流畅和响应用户操作,我们可以通过使用多线程来将这些任务移到后台运行。然而…...
)
【工程开发】LLMC准确高效的LLM压缩工具(一)
【文献阅读】LLMC: Benchmarking Large Language Model Quantization with a Versatile Compression Toolkit 北航 2024年10月 摘要 大语言模型(LLMs)的最新进展凭借其卓越的涌现能力和推理能力,正推动我们迈向通用人工智能。然而&#…...

回顾CSA,CSA复习
RHCSA redhat certificate system Administrator RHCE redhat certificate engineer 回顾CSA 文件管理 创建文件:touch 、重定向、vim 阅读文件:cat看短小的文件、vim、head看文件前面部分、tail看文件的尾部内容、more、less看文档使用more和less…...

基于电子等排体的3D分子生成模型 ShEPhERD - 评测
一、背景介绍 ShEPhERD 是一个由 MIT 开发的一个 3D 相互作用感知的 ligand-based的分子生成模型,以 arXiv 预印本的形式发表于 2024 年,被ICLR2025 会议接收。文章链接:https://openreview.net/pdf?idKSLkFYHlYg ShEPhERD 是一种基于去噪扩…...

平凡日子里的挣扎
2025年4月13日,9~23℃,好 待办: 融智云考平台《物理》《物理2》~~《地理》《地理1》~~重修试卷 卫健委统考监考(2025年4月12日早上7点半) 冶金《物理》课程标准 冶金《物理》教案 期中教学检查——自查表材料ÿ…...

智能制造方案精读:117页MES制造执行系统解决方案【附全文阅读】
本方案围绕制造执行系统(MES)展开,阐述了智能制造相关概念及发展趋势,指出 MES 是连接 ERP 与生产现场的关键系统。介绍其在加工、装配及其他场景的应用,通过实例展示各场景下的功能、特点和实施效果,如实现生产信息可视化、产品追溯、设备监控等。还提及实施 MES 面临的…...
)
[推荐]AI驱动的知识图谱生成器(AI Powered Knowledge Graph Generator)
网址:https://github.com/robert-mcdermott/ai-knowledge-graph# 一、介绍 简介:以非结构化文本文档为输入,使用您选择的LLM以主语-谓语-宾语 (SPO) 三元组的形式提取知识,并将这些关系可视化为交互式知识图谱 特点:…...
从算法仿真到工程源码实现-第七节-关于波束10个基本概念)
波束形成(BF)从算法仿真到工程源码实现-第七节-关于波束10个基本概念
一、波束10个基本概念 1.作用: 对多路麦克风信号进行合并处理,抑制非目标方向的干扰信号,增强目标方向的声音信号。 2.原理: 调整相位阵列的基本单元参数,使得某些角度的信号获得相长干涉,而另一些角度的…...
)
深度学习(第一集)
123 import torch# 创建一个需要计算梯度的张量 x1 torch.tensor([2.0], requires_gradTrue)# 定义一个简单的函数 y x^2 y x1 ** 4# 计算梯度 y.backward()print("x1.grad 的值:", ) # 打印 x1.grad print("x1.grad 的值:", x1…...

Spring 事务传播行为
在Spring框架中,事务传播行为(Transaction Propagation)定义了事务在多个方法调用之间的行为方式。理解这些传播行为对于设计可靠的事务管理策略至关重要。以下是Spring支持的七种事务传播行为及其应用场景的详细说明: 1. REQUIRED(默认) 行为:如果当前存在事务,则加入…...

搬运机器人的基本工作场景及原理
搬运机器人广泛应用于工业生产中,主要用于搬运、堆放、装配等工作。它通过机械手臂的运动,结合机器视觉技术完成各种自动化作业。 一、搬运机器人的设计原理 搬运机器人通常采用可移动门架式结构,手臂承载机构安装在导轨上,可以沿…...

Ubuntu终端中常用的快捷键整理
1. 导航与编辑 光标移动: Ctrl A:跳转到行首。 Ctrl E:跳转到行尾。 Alt B:向左移动一个单词(或 Ctrl ←)。 Alt F:向右移动一个单词(或 Ctrl →)。 删除操作…...
+ ProxySQL 架构)
mysql安装-MySQL MGR(Group Replication)+ ProxySQL 架构
文章目录 前言一、环境规划二、安装 MySQL 8.0.36(主库,CentOS 9)2.1 添加 Yum 源2.2 安装 MySQL 8.0.362.3 初始化 三、配置主库 my.cnf(192.168.1.101)四、(可选)创建远程可访问的用户&#x…...

Opencv使用cuda实现图像处理
main.py import os import cv2 print(fOpenCV: {cv2.__version__} for python installed and working) image cv2.imread(bus.jpg) if image is None:print("无法加载图像1") print(cv2.cuda.getCudaEnabledDeviceCount()) cv2.cuda.setDevice(0) cv2.cuda.printCu…...

ubuntu 安装samba
ubuntu 版本:Ubuntu 24.04.2 LTS 1. 保证连网 2. 安装samba sudo apt install samba 在安装结束以后,我们可以使用下面的命令来查看安装: apt list | grep samba freeipa-client-samba/noble 4.11.1-2 amd64 ldb-tools/noble 2:2.8.0samba…...
之将对话记录保存到数据库中)
山东大学软件学院创新项目实训开发日志(12)之将对话记录保存到数据库中
在之前的功能开发中,已经成功将deepseekAPI接口接入到springbootvue项目中,所以下一步的操作是将对话和消息记录保存到数据库中 在之前的开发日志中提到数据库建表,所以在此刻需要用到两个表,conversation表和message表ÿ…...

欢乐力扣:反转链表二
文章目录 1、题目描述2、思路 1、题目描述 反转链表二。 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 2、思路 参考官方题解,基本思路…...

【CS*N是狗】亲测可用!!WIN11上禁用Chrome自动更新IDM插件
现象:每次打开chrome后IDM会弹出提示插件版本不一致。经过排查后发现是chrome把IDM插件给更新了,导致IDM提示版本不匹配。经过摸索后,得到了可行的方案。 第一步,打开Chrome,把IDM插件卸载掉,然后重新安装I…...
)
Linux:DNS服务配置(课堂实验总结)
遇到的问题,都有解决方案,希望我的博客能为你提供一点帮助。 操作系统:rocky Linux 9.5 一、配置DNS服务器的核心步骤 步骤 1:安装 BIND 软件 检查是否安装: rpm -qa | grep "^bind"…...

啥是Spring,有什么用,既然收费,如何免费创建SpringBoot项目,依赖下载不下来的解决方法,解决99%问题!
一、啥是Spring,为啥选择它 我们平常说的Spring指的是Spring全家桶,我们为什么要选择Spring,看看官方的话: 意思就是:用这个东西,又快又好又安全,反正就是好处全占了,所以我们选择它…...

【LeetCode】算法详解#4 ---合并区间
1.题目介绍 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 1 < intervals.length < 104interval…...

安装树莓派3B+环境
目录 一、安装树莓派3B环境 1.1 格式化SD卡 1.2 环境安装与配置 1.2.1 安装Raspberry Pi 1.2.2 SSH访问树莓派 1.3 创建用户账号 二、在树莓派上用C和Python编程运行一个简单的程序 2.1 C语言程序 2.2 Python程序 三、总结 树莓派是一款功能强大的微型计算机…...
通过串口直接向 ATmega328P(5V 系统)发送数据,居然能正常通信)
STM32(3.3V 系统)通过串口直接向 ATmega328P(5V 系统)发送数据,居然能正常通信
核心结论 如果 STM32(3.3V 系统)通过串口直接向 ATmega328P(5V 系统)发送数据,3.3V 的 TX 高电平可能无法被 ATmega328P 可靠识别为逻辑“1”!以下是详细分析: 1.…...
)
Java 8中的Lambda 和 Stream (from Effective Java 第三版)
42.Lambda 优先于匿名类 在之前的做法中(Historically),使用单个抽象方法的接口(或很少的抽象类【只有一个抽象方法的抽象类数量比较少】)被用作函数类型。它们的实例称为函数对象,代表一个函数或一种行为。…...

MIPI协议介绍
MIPI协议介绍 mipi 协议分为 CSI 和DSI,两者的区别在于 CSI用于接收sensor数据流 DSI用于连接显示屏 csi分类 csi 分为 csi2 和 csi3 csi2根据物理层分为 c-phy 和 d-phy, csi-3采用的是m-phy 一般采用csi2 c-phy 和 d-phy的区别 d-phy的时钟线和数据线是分开的,2根线一对…...

深入解析 HTML 中 `<script>` 标签的 async 和 defer 属性
一、背景与问题 在网页性能优化中,脚本的加载和执行方式直接影响页面渲染速度和用户体验。传统 <script> 标签的阻塞行为可能导致页面“白屏”,而 async 和 defer 属性提供了非阻塞的解决方案。本周重点研究二者的差异、适用场景及实际应用。 二、…...
)
【从0到1学Elasticsearch】Elasticsearch从入门到精通(上)
黑马商城作为一个电商项目,商品的搜索肯定是访问频率最高的页面之一。目前搜索功能是基于数据库的模糊搜索来实现的,存在很多问题。 首先,查询效率较低。 由于数据库模糊查询不走索引,在数据量较大的时候,查询性能很差…...

2.0 全栈运维管理:Linux网络基础核心概念解析、Proxmox网络组件详解、虚拟化网络模型分类
本文是Proxmox VE 全栈管理体系的系列文章之一,如果对 Proxmox VE 全栈管理感兴趣,可以关注“Proxmox VE 全栈管理”专栏,后续文章将围绕该体系,从多个维度深入展开。 摘要:Linux 网络基础借助桥接、VLAN 和 Bonding 实…...

案例驱动的 IT 团队管理:创新与突破之路: 第四章 危机应对:从风险预见到创新破局-4.1.3重构过程中的团队士气管理
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 案例驱动的 IT 团队管理:创新与突破之路 - 第四章 危机应对:从风险预见到创新破局4.1.3 重构过程中的团队士气管理1. 技术债务重构与团队士气的矛盾2…...

洛谷刷题小结
#include <iostream> using namespace std; int n, m,ans0; char s[105][105]; //深搜 void dfs(int x, int y) {//将搜索到的水坑看为干地s[x][y] .;//确定八个方向int next[8][2] {{0,1},{0,-1},{1,0},{-1,0},{1,1},{1,-1},{-1,1},{-1,-1},};//朝八个方向搜索for (in…...

Android Compose 权限申请完整指南
Android Compose 权限申请完整指南 在 Jetpack Compose 中处理运行时权限申请需要结合传统的权限 API 和 Compose 的状态管理。以下是完整的实现方案: 1. 基本权限申请流程 添加依赖 implementation "com.google.accompanist:accompanist-permissions:0.34…...

VirtualBox虚拟机转换到VMware
VirtualBox虚拟机转换到VMware **参考文章:**https://blog.csdn.net/qq_30054403/article/details/123451969 一.找到对应文件位置 Windows11系统,VirtualBox版本为6.1.50,VMware版本为17.5.2 1.首先找到自己需要转换的vdi文件位置 D:\v…...
:RedisTemplate的List类型操作)
Spring Boot(二十二):RedisTemplate的List类型操作
RedisTemplate和StringRedisTemplate的系列文章详见: Spring Boot(十七):集成和使用Redis Spring Boot(十八):RedisTemplate和StringRedisTemplate Spring Boot(十九)…...

【MySQL】关于何时使用start slave和start slave user=‘’ password=‘’
这个问题是我在配置三个服务器的复制拓扑时,一开始没有给复制用户 repl 创建密码,搭建好循环拓扑后,给server1的复制用户通过 ALTER USER USER() IDENTIFIED BY oracle 设置了密码,然后同步给了server2和server3。 这时server2突…...
第十六届蓝桥杯大赛软件赛省赛C/C++ 研究生组)
(个人题解)第十六届蓝桥杯大赛软件赛省赛C/C++ 研究生组
宇宙超级无敌声明:个人题解(好久不训练,赛中就是一个憨憨) 先放代码吧,回头写思路。 文章目录 A. 数位倍数B. IPv6C. 变换数组D. 最大数字E. 冷热数据队列F. 01串G. 甘蔗H. 原料采购 A. 数位倍数 问: 在1至…...

GitLab + Jenkins + .Net8 实现CICD部署
前提条件:需要安装好 Jenkins 和 GitLab 。 1. Jenkins配置 登录 Jenkins 找到自己的一个任务,点击配置(没有任务就新建)。 按图操作 点击高级展开后截图,点击生成Token 配置好自己的作业(我的是一个 .Ne…...

AI工具导航 快速找到喜欢的AI工具 功能使用介绍
此篇文章内容来源CTO Plus技术服务栈官网:http://www.mdrsec.com/ 在人工智能技术迅猛发展的2025年,AI工具的数量和种类呈爆炸式增长,涵盖文本生成、图像创作、视频编辑、编程辅助等多个领域。面对琳琅满目的AI工具,如何高效筛选和…...
 E - level up)
[题解] Educational Codeforces Round 168 (Rated for Div. 2) E - level up
链接 思路 1 注意到在 k ∈ [ 1 , n ] k \in [1,n] k∈[1,n] 可以得到的最高等级分别为: n , n 2 , n 3 . . . . . n n n,\frac{n}{2},\frac{n}{3}.....\frac{n}{n} n,2n,3n.....nn, 总的个数是一个调和级数, s u m n ∗ ln n sumn*\ln n sumn∗lnn, 完全可以处…...

达梦数据库-学习-19-兼容ORACLE相关参数介绍
目录 一、环境信息 二、介绍 三、参数 一、环境信息 名称值CPU12th Gen Intel(R) Core(TM) i7-12700H操作系统CentOS Linux release 7.9.2009 (Core)内存4G逻辑核数2DM版本1 DM Database Server 64 V8 2 DB Version: 0x7000c 3 03134284194-202…...

如何通过 Spring 层面进行事务回滚?
Spring 中事务可以分为声明式事务和编程式事务,那么解下来就从这两方面说一说在 Spring 层面个怎么进行回滚 声明式事务回滚: 1. 基础注解配置 通过Transactional注解实现自动回滚,默认对RuntimeException和Error生效 Transactional publ…...

学Qt笔记
使用的是Qt SDK5.14.0 根据比特汤众老师的课程学习 先叠个甲:本人正在学qt,视角还不完备,如有错误请多多包含 选了widget开始学习 1.qt creator设计提供了拖拽式的编辑ui的控件,和代码直接编辑构建的方式 2.浅浅的认识了qt的对…...

【HarmonyOS 5】鸿蒙实现手写板
【HarmonyOS 5】鸿蒙实现手写板 一、前言 实现一个手写板功能,基本思路如下: 创建一个可交互的组件,用户在屏幕上触摸并移动手指时,会根据触摸的位置动态生成路径,并使用黑色描边绘制在屏幕上。当用户按下屏幕时…...

JavaWeb 课堂笔记 —— 09 MySQL 概述 + DDL
本系列为笔者学习JavaWeb的课堂笔记,视频资源为B站黑马程序员出品的《黑马程序员JavaWeb开发教程,实现javaweb企业开发全流程(涵盖SpringMyBatisSpringMVCSpringBoot等)》,章节分布参考视频教程,为同样学习…...

设计模式 --- 访问者模式
访问者模式是一种行为设计模式,它允许在不改变对象结构的前提下,定义作用于这些对象元素的新操作。 优点: 1.符合开闭原则:新增操作只需添加新的访问者类,无需修改现有对象结构。 2.操作逻辑集中管理&am…...

【Linux C】简单bash设计
主要功能 循环提示用户输入命令(minibash$)。创建子进程(fork())执行命令(execlp)。父进程等待子进程结束(waitpid)。关键问题 参数处理缺失:scanf("%s", buf)…...