Linux网络编程——详解网络层IP协议、网段划分、路由
目录
一、前言
二、IP协议的认识
1、什么是IP协议?
2、IP协议报头
三、网段划分
1、初步认识IP与路由
2、IP地址
I、DHCP动态主机配置协议
3、IP地址的划分
I、CIDR设计
II、子网数目的计算
III、子网掩码的确定
四、特殊的IP地址
五、IP地址的数量限制
六、私有IP地址与公网IP地址
1、私有IP地址
2、公网IP地址
七、路由器
八、路由
1、路由表
八、总结
一、前言
在之前的文章中,出去物理层,我们已经针对TCP/IP五层模型中的应用层、传输层的要点做了介绍。
- 其中应用层的 HTTP/HTTPS 协议主要是针对数据请求的一个超文本传输协议,目的是为了保证服务端和客户端之间的数据传输安全可靠且高效。
- 传输层的 UDP协议就是应用于像我们平时看直播刷视频一样,它并不保证数据的可靠传输,而是能容忍一定的数据丢失的传输层协议。 TCP协议则是通过一系列的机制来保证数据传输的可靠性和完整性。
学习完了应用层和传输层,接下来就是网络层的协议和数据链路层了。
- 网络层主要负责的是路径规划,为数据的传输规划好最优的路径。
- 数据链路层则是负责真正意义上的传输数据,例如以太网、网卡、交换机等都是属于该层。
这篇文章我们主要探讨网络层的IP协议。
二、IP协议的认识
在我们之前学习的时候已经简单了解过了IP,知道了源IP和目的IP,才能将数据包发送到指定的地址。
1、什么是IP协议?
IP(Internet Protocol)是一种网络通信协议,是互联网的核心协议之一,负责在计算机网络中路由数据包,使得数据包能够在不同的设备之间进行有效传输。IP协议的主要作用包括寻址、分组、路由和转发数据包。
从一台主机A向主机B发送消息时,需要经历很多的跳转,所以在路径选择中,IP是非常重要的,它决定了路径如何走。
2、IP协议报头
我们知道在网络协议栈中,各层独立是互相不受影响的,数据包从一个主机发到另一个主机的时候,需要先从自己的网络协议栈自顶向下在每一层进行封装,然后到对方主机时,再自底向上进行解包。我们已经看到过了应用层和传输层的协议格式,同样数据包在走到网络层时,也需要对其封装上IP的协议报头。协议格式如下:

- 4位版本号(Version):标识IP协议版本,4表示IPV4,6表示IPV6.
- 4位首部长度(Header Length): IP报头总长度,与TCP一样,这里4位16个数据的单位并不是1字节,而是4字节,所以说它的最小值为5(20个字节),最大值为15(60个字节)。
- 8位服务类型(Differentiated Services):3位优先权字段(已经弃用),4位TOS字段,,和1位保留字段(必须置为0)。4位TOS分别表示:最小延时、最大吞吐量、最高可靠性、最小成本。这四者相互冲突,只能选择一个。对于 ssh/telnet 这样的应用程序,最小延时比较重要;对于ftp这样的程序,最大吞吐量比较重要。
- 16位总长度(Total Length):表示IP数据报整体占多少个字节,包括首部和数据部分。这个是报文,不是字节流,所以这个能有效保证有效载荷分离。
- 16位标识(Identification):用于唯一地标识一个IP数据段,常用于分片和重组。如果IP报文因为数据链路层被分片了,那么每一片里面的这个id都是相同的。
- 3位标志(Flags):用于指示数据报的处理状态,包括是否可以分片和是否是最后一片。第一位保留(保留的意思是现在不用,但是还没想好说不定以后要用到)。 第二位置为1表示禁止分片,这时候如果报文长度超过MTU,IP模块就会丢弃报文(也就是过滤大的报文)。第三位表示"更多分片",如果分片了的话,最后一个分片置为0,其他是1。类似于一个结束标记。
- 13位片偏移(Fragment Offset):是分片相对于原始IP报文开始处的偏移。其实就是在表示当前分片在原报文中处在哪个位置。实际偏移的字节数是这个值*8得到的,因此,除了最后一个报文之外,其他报文的长度必须是8的整数倍(否则报文就不连续了)。
- 8位生存时间(Time to Live,TTL):表示数据报到达目的地的最大报文跳数,防止数据报在网络中无限循环,一般是64,每经过一个路由器,该值减1,直到为0,数据报将被丢弃。
- 8位协议(Protocol):指示封装在IP数据报中的上层协议,如TCP、UDP等,因为需要向上层传输。
- 16位首部校验和(Header Checksum):使用CRC进行校验,用于检验IP首部中是否发生错误,如果出现问题直接丢掉就行,后面会有重传等一系列措施。
- 32位源地址和32位目标地址:表示发送端和接收端。这两个是IP协议头中最关键的信息。采用点分十进制的形式来表示,分为四组,一组8位。例如1.2.3.4。
- 可选项(Options):可选字段,包括记录路由路径、时间戳、安全和加密等信息。最多40字节。
- 数据:数据部分是IP协议传输的实际数据,可以是TCP、UDP等上层协议封装的数据,包含着来自上层的TCP或者UDP的报头段。
三、网段划分
1、初步认识IP与路由
首先我们需要知道的是网段划分是什么?为什么需要网段划分?网段划分是怎么样划分的?
我们先通过一个例子引入这个话题:
在我们学校中每一个人都有自己的学号,学号总是一长串的数字,它被分为好多段,每一段数字都代表着不同的含义,比如前四个数字表示入学年份,接着两个数字表示所在的院系,接着两个数字表示所在专业,接着后面的数字才表示你是该专业几号。同时,我们每个院系每个专业的负责人都有着自己的小群以便交流。
假设我们现在知道一个人的学号要找这个人,有什么方法呢?第一种就是见人就问学号,看看能否对应上,但是这个方法太粗暴了,效率也低。还有一种方法就是通过该学号找到对应的院系负责人,由院系负责人在自己的小群里一问,找到对应的专业的负责人,再由专业的负责人也在小群里一问,于是就找到了那个人。
可以看到第二种方法的效率很高,这是因为我们可以根据学号一步一步能排除掉大部分不相关的人。所以IP也是同理。
我们都知道通过IP就能找到对应的主机,但是世界上有着那么多的主机,存在着海量的IP地址,我们主机是怎么通过网络找到的呢?
网络地址的划分实际上是按照人口、接入的网络设备等因素划分的,但是为了便于理解,我们就用国家划分。
我们将整个世界类比成一个很大的学校,而学校中的院系就是各个国家,院系中的不同专业就代表了各个国家的不同的地区。而各个负责人的小群就是路由器,通过学号找人的过程也就是通过IP找主机的过程。
所以网段划分就是将IP合理分配的技术,比如所有属于中国的IP的第一位都是1,格式就是1.x.x.x ,属于河北的IP 第二位都是2 ,格式为 1.2.x.x ,所有属于美国的IP的第一位都是2,格式为2.x.x.x 等等,以此类推。当然这些各个国家的IP地址都存在国际路由器中。
通过这样的技术我们就可以很快定位想要寻找的主机。
2、IP地址
我们一般提到的网络地址其实不等于IP地址,网络地址是指IP地址中的网络号的,
IP地址 ::= {<目标网络号>, <目标主机号>}
- 目标网络号:就是用来划分不同的网段,即划分不同的地区,且保证相连的两个网段具有不同的标识。
- 目标主机号:标识同一网段内的不同主机。同一网段内的不同主机具有相同的网络号,所以必须存在不同的主机号来区分它们。
所以IP地址就是给每个连接在Internet上的主机分配的一个32bit地址。按照TCP/IP协议规定,IP地址用二进制来表示,每个IP地址长32bit,比特换算成字节,就是4个字节。包括主机地址和网络地址两部分。如11000000 10101000 00000001 00000110(192.168.1.6)
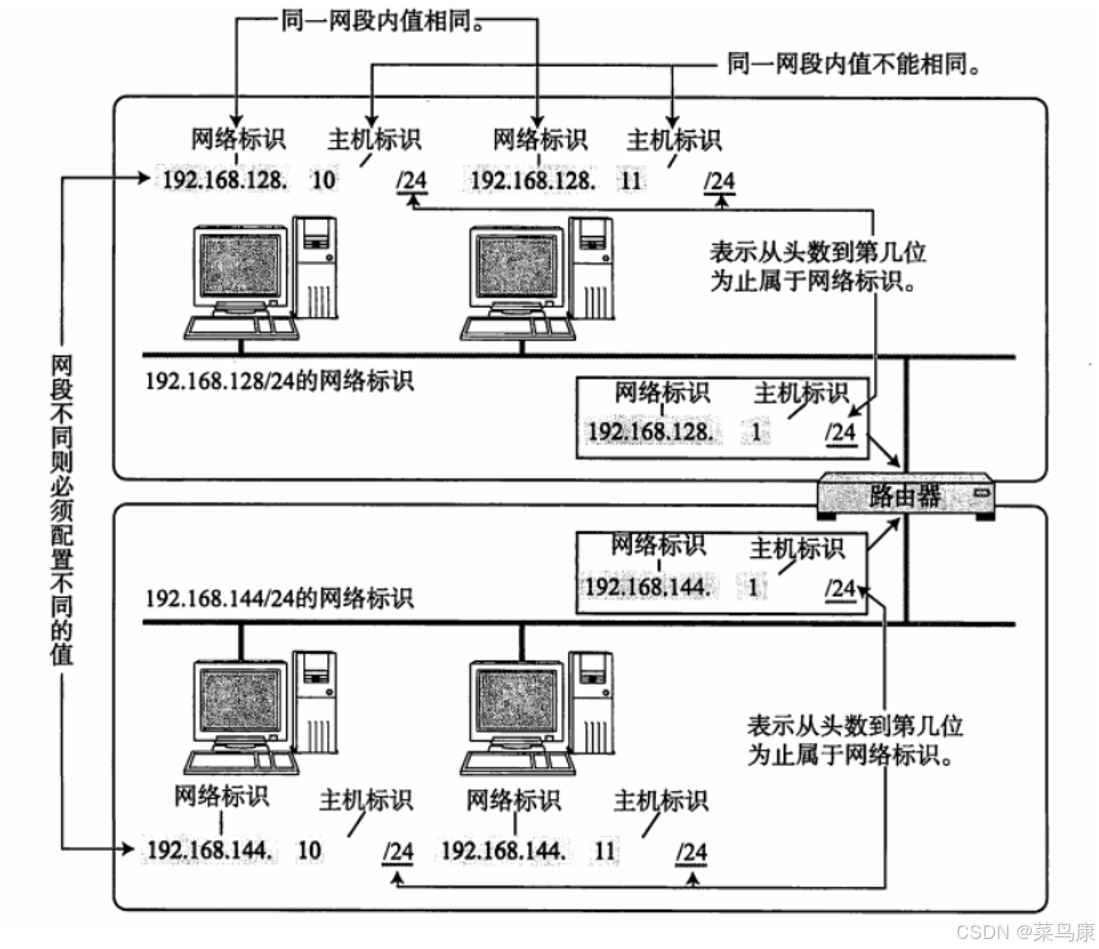
如上图所示,图中上半部分的两个主机处于同一网段内, 他们的网段号都是 192.168.128,后面的 10 和 11 表示的就是主机号, /24 表示的是子网掩码(后面讲)的前24位是网络标识,剩下的8位都是主机标识。
需要注意的是上图中的路由器也是主机,他是连接两个子网的节点主要负责在不同的子网之间转发数据包,同时属于两个子网,所以它也有着两个IP,路由器每个接口都会配置一个IP地址,这个IP地址属于该接口所连接的子网。因此,图中的路由器连接了两个子网,所以它拥两个接口,每个接口配置有一个在这个子网内的唯一IP地址。
通过上面的图示我们不难发现:
- 子网是从一个大的IP网络中划分出来的较小的网络部分。
- 不同的子网其实就是将网络号相同的主机放在一起
- 如果我们想要在该子网中增添一台新的主机,则该主机的网络号必须和子网的网络的号一致,且该主机的主机号必须不同于子网内其他主机。
I、DHCP动态主机配置协议
通过合理地设置主机号和网络号,我们就可以保证在互相连接的网络中,每台主机的IP地址都不相同,但实际上,手动管理子网内IP是一种很麻烦的事情。
DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)是一种网络管理协议,用于自动化地分配IP地址和其他网络配置参数给子网内新增的节点,如计算机、智能手机等,使其能够与网络中的其他设备进行通信,避免了我们的手动管理。我们要知道在手机或者计算机联网之前它是没有IP的,联网的过程其实就是向子网申请IP的过程。
一般的路由器都带有DHCP功能,因此路由器也可以看作是一个DHCP服务器。
3、IP地址的划分
上面我们已经知道了什么是网段划分和为什么需要网段划分,下来我们就要着重探讨IP地址是如何进行划分的。
过去提出的一种IP地址的划分方案是:将IP地址通常分为五个主要类别,即A、B、C、D、E类,如下
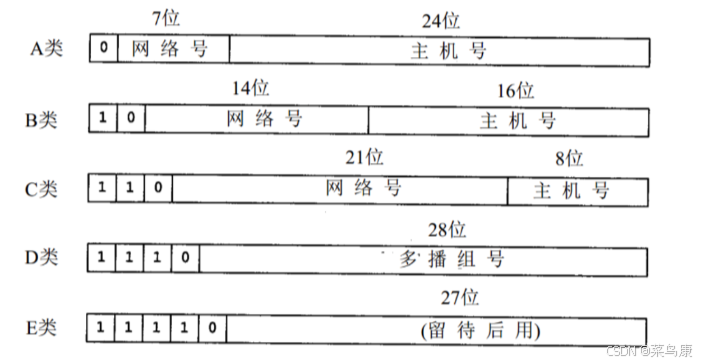
这些类别都是按照IP地址的第一个字节(8位) 来划分的,其中不同类别具有不同的网络号和主机号分配方式。
- A类地址: 1.0.0.0 ~126.255.255.255,最大主机数约 16,777,214(2^24 - 2,减去两个保留地址:全0和全1),该地址通常分配给大型组织或者大型的服务提供商,它们允许大量主机。
- B类地址: 128.0.0.0 ~191.255.255.255, 最大主机数约 65,534(2^16 - 2),该地址通常分配给中等规模的组织或者网络。
- C类地址: 192.0.0.0 ~ 223.255.255.255,最大主机数:约 254(2^8 - 2),该地址通常分配给小型的组织或私人网络。
- D类地址: 224.0.0.0 ~ 239.255.255.255,该地址用于多播,不分配给单独的主机或者网络,用于一次向多个目标发送数据包,例如视频流或音频流。
- E类地址: 240.0.0.0 ~255.255.255.255,该类地址是实验性地址,不常用,保留用于特定用途,用于实验、研究或未来网络发展。
但是上面的地址分配存在着许多的弊端,如
- IP地址浪费:A、B、C类地址的划分方式导致了地址的浪费,特别是在A类地址中,每个网络中都有着大约 16,777,214 个主机地址,而大多数网络远远不需要这么多地址。这导致了 IPv4 地址枯竭的问题。
- 不灵活:由于固定的地址类型,会导致一些网络可能会浪费大量的IP地址,而其他网络的IP地址不够用。
- 无法满足中小型网络需求:B类地址太大,而C类地址又太小,这使得中小型网络在选择合适的地址类别时很难找到平衡点。
- 不适合特定应用:D 类地址是多播地址,而 E 类地址是实验性地址,它们在常规网络中的使用非常有限。这也导致了资源浪费。
随着互联网的快速发展,IPv4 地址越来越不够用了。这并不是直接与地址类别划分相关的弊端。但是 IPv4 地址空间有限,而且已经耗尽了大部分可用地址。这迫使网络行业采用了更高效的地址分配策略,如网络地址转换(NAT)和 IPv6 的广泛采用。
为了解决这些问题,现代网络提出了新的地址分配策略,例如 CIDR(无类别域间路由)和采用 IPv6 地址空间,以更好地满足不同规模和类型的网络需求,减少资源浪费,提供更多的灵活性,并支持现代网络功能。
I、CIDR设计
针对上面的网络划分出现的种种弊端,CIDR(Classless Inter-Domain Routing,无类别域间路由)被提出,它允许将IP地址按需分配给网络,而不受固定类别的限制。
- 他引入了一个额外的子网掩码(subnet mask)来区分网络号和主机号
- 子网掩码也是一个32位的正整数,与IP地址编址格式相同,网络部分和子网络部分对应的位全为“1”,主机部分对应的位全为“0”
- 将IP地址和子网掩码进行 ‘按位与’ 操作,得到的就是网络号(包括子网络号)
- 网络号和主机号的划分与这个IP地址是A类、B类还是什么类无关
- CIDR使用前缀表示法来表示IP地址范围。这个前缀表示法包括IP地址,后面跟着一个斜线和一个数字,表示子网掩码的长度。所以它是由两部分组成 : 网络前缀 + 子网掩码,例如,192.168.1.0/24,其中IP地址表示为192.168.1.0,24就表示子网掩码,表示32位中 高24位是1,其他位是0.它的二进制形式是 11111111.11111111.11111111.00000000,转换为十进制就是255.255.255.0
- CIDR允许多个连续的IP地址范围被聚合成一个更大的范围。这有助于减小路由表的大小,提高路由效率。
子网掩码的格式为前24个比特位全为1,后8个比特位全为0,将来进行子网划分的时候,我们只需要调整子网掩码中从左侧开始的 1 的个数就可以很方便地对IP地址进行比特位级别地子网划分。
下面举个例子:
- 首先给定一个CIDR地址:172.31.128.255 /18
- 表示IP地址是172.31.128.255,二进制为10101100.00011111.10000000.11111111
- 子网掩码地高18位是1,二进制表示为 11111111.11111111.11000000.00000000,所以表示将来得到的网络地址的高18位表示网络部分,剩下的14位表示主机部分。
- 将上面的IP地址和子网掩码的二进制进行‘按位与’运算(全1为1,其余为0)得到网络地址: 10101100.00011111.10000000.00000000,按点分十进制表示为 172.31.128.0
ip: 10101100.00011111.10000000.11111111 子网掩码: 11111111.11111111.11000000.00000000 ---------------------------------------------------- 网络号: 10101100.00011111.10000000.00000000 & 网络号点分法表示: 172.31.128.0 - 所以得到的该网络地址的子网地址范围是网络地址二进制中低14位(主机部分)从全0 到全 1所表示的范围.即10101100.00011111.10000000.00000000~10101100.00011111.10111111.11111111,点分十进制表示为172.31.128.0~172.31.191.255,而我们通常对于全0和全1这两个是不使用的,因为网络号一般用全0表示即172.31.128.0,广播地址用全1表示,即172.31.191.255,所以子网中可用的IP地址的范围就是172.31.128.1-172.31.191.254,这也就是该网络号可以容纳的主机所在的范围。
下面是两个例子可以自行计算


II、子网数目的计算
首先将/18换成为我们习惯的表示法:
11111111.11111111.11000000.000000转为十进制就是255.255.192.0,可以看到这个掩码的左边两节和B类默认掩码是一致的,所以这个掩码是在B类默认掩码的范围内,意味着我们将对B类大网进行子网划分。B类掩码默类是用16位(16个0)来表示可分配的IP 地址,这里的掩码在B类默认掩码的基础上多出了两个表示网络号的1,也就是向主机位借了两个1这就是说是将B类大网划分为2的2次方个子网(2^n,n表示所借1的个数),所以最终的子网数目是4
III、子网划分的计算
已知IP 192.168.1.133 ,子网掩码为255.255.255.192;求划分的子网的个数和范围
首先将子网掩码写为二进制的形式方便观察将其转换成二进制后和255.255.255.0对比可发现,前掩码的前24位没有变化,只是在原来表示主机号的部分头两位变成了1。
192.168.1.113: 11000000.10101000.00000001.10000101 (1)255.255.255.192: 11111111.11111111.11111111.11000000 (2)
----------------------------------------------------
255.255.255.0: 11111111.11111111.11111111.00000000 (3)我们把IP地址中的前24位(192.168.1)先不关注,因为前24位对应掩码没有变化它们始终表示网络号。
原本255.255.255.192在192为0,及255.255.255.0的情况下属于C类地址的默认子网掩码
按照子网掩码的定义,子网掩码1所对应的位为网络号位,而0所对应的位为主机号位
主机号中被借走了两位用来表示网络号了,这就是子网号。二进制一位用0或1表示,那么占用了两位就有2*2=4种表示,这里占用了2位,也就是说我们将原有的192.168.1.0这个网络分成了四份,即4个子网)这四段的网络号分别是00000000、01000000、10000000、11000000,现在我们将它们转换成10进制就分别是0、64、128、192,现在把前24位加进来。
192.168.1.0 192.168.1.64 192.168.1.128 192.168.1.192
至于后面的网络号和广播地址和之前的计算方法是一样的。可用IP为
192.168.1.1 ------> 192.168.1.62192.168.1.65-------> 192.168.1.126 192.168.1.129------> 192.168.1.190192.168.1.193------> 192.168.1.254
IV、子网掩码的确定
学校新建5个机房,每个房间有30台机器,如果给定一C类网络地址:192.168.1.0,问如何将其划分为5个子网,子网掩码该如何设置?
子网划分建议按以下步骤和实例计算子网掩码:
- 将要划分的子网数目转换为2的m次方。如要分8个子网,8=23。
- 取上述要划分子网数的2m的幂m。如2^3,即m=3。
- 将上一步确定的幂m按高序占用主机地址m位后转换为十进制。
- 如m为3 则是11100000,转换为十进制为224,即为最终确定的子网掩码。
- 如果是C类网,则子网掩码为255.255.255.224;如果是B类网,则子网掩码为255.255.224.0;如果是A类网,则子网掩码为255.224.0.0。
2^3 =8(大于5的最小的2的整幂次数),向主机号中借走三位作为网络号,而剩下的5位主机号,每个网段内可容纳的主机数是25即32,可用主机需要再减2即为30,满足每个房间30台机器的题目要求。取23的幂,即3,即占用了主机号中的高3位即为11100000,转换为十进制为224,所以该地址为C类地址的子网掩码应该设置为255.255.255.224。各机房IP和子网掩码配置如下(已经去掉广播地址和主机地址):
机房号 子网掩码 IP地址范围
机房1 255.255.255.224 192.168.1.1~192.168.1.30机房2 255.255.255.224 192.168.1.33~192.168.1.62机房3 255.255.255.224 192.168.1.65~192.168.1.94机房4 255.255.255.224 192.168.1.97~192.168.1.126机房5 255.255.255.224 192.168.1.129~192.168.1.158
一般在一个子网中,管理子网中IP的设备通常是路由器,目标网络和子网掩码及子网中的主机都会被路由器管理,目标网络和子网掩码都是在路由器中配置的。
四、特殊的IP地址
现实中存在着一些特殊的IP地址,这些IP地址通常不用于一般的主机通信,而是用于特定的网络任务和服务。以下是一些常见的特殊IP地址类型及其详细解释:
- 私有IP地址(下文会讲解):私有IP地址是在内部网络中使用的IP地址,不可从公共Internet访问。它们用于在局域网(LAN)内部进行通信。私有IP地址范围通常包括以下三个区段: 1. 10.0.0.0 到 10.255.255.255
2. 172.16.0.0 到 172.31.255.255
3. 192.168.0.0 到 192.168.255.255 - 回环IP地址:回环IP地址是127.0.0.1,通常表示本地主机或设备上的回环测试。当一个计算机发送数据到回环地址,数据会被发送到自己,用于测试和诊断网络连接和服务。
- 广播地址:将IP地址中的主机地址全部设为1,就成为了广播地址。广播地址用于向同一网络中的所有设备发送数据包。在IPv4中,广播地址通常是特定网络的最大地址
- 将IP地址中的主机地址全部设为0,就成为了网络号,代表这个局域网。
五、IP地址的数量限制
我们知道,IP地址(IPv4)是一个4字节32位的正整。那么一共只有 2的32次方 个IP地址,大概是43亿左右。而TCP/IP协议规定,每个主机都需要有一个IP地址。现这意味着,一共只有43亿台主机能接入网络么?
实际上,由于一些特殊的IP地址的存在,数量远不足43亿;另外IP地址并非是按照主机台数来配置的,而是每一个网卡都需要配置一个或多个IP地址。那么一个家庭就会用掉很多IP地址。CIDR在一定程度上缓解了IP地址不够用的问题(提高了利用率,减少了浪费,但是IP地址的绝对上限并没有增加),仍然不是很够用。这时候有三种方式来解决:
- 动态分配IP地址:只给接入网络的设备分配IP地址。因此同一个MAC地址的设备,每次接入互联网中,得到的IP地址不一定是相同的。在入网时分配地址,退网时回收地址。
- NAT技术:通常用于将私有网络内部的多个设备共享单个公共IP地址的情况(下篇文章会讲解)。
- IPv6: IPv6并不是IPv4的简单升级版。这是互不相干的两个协议,彼此并不兼容。IPv6用16字节128位来表 示一个IP地址,但是目前IPv6还没有普及。
六、私有IP地址与公网IP地址
1、私有IP地址
如果在一个组织内部组件局域网,IP地址只能用于局域网通信,而不是直接连接到Internet上,理论上使用任意的IP地址都是可以的,但是RFC 1918规定了用于组建局域网的私有IP地址如下:
- 92.168.0.0 到 192.168.255.255
- 172.16.0.0 到 172.31.255.255
- 10.0.0.0 到 10.255.255.255
它们可以在内部网络中自由使用,但不能直接在互联网上路由。这些地址主要用于家庭、企业或其他组织内部的局域网(LAN)或广域网(WAN)。私有IP地址的主要优点是可以重复使用,从而缓解了IPv4地址空间有限的问题。
2、公网IP地址
公网IP地址是全球唯一的IP地址,可以直接在互联网上路由。每个连接到互联网的设备或服务都需要一个唯一的公网IP地址来进行数据传输。
公网IP地址由互联网名称与数字地址分配机构(ICANN)或地区性的互联网注册机构(RIR)管理和分配给各个ISP(互联网服务提供商),再由ISP分配给其用户。
- 公网IP地址可以确保任何两个设备之间能够在互联网上直接相互寻址。
- 它们对于服务器来说特别重要,因为服务器需要拥有一个固定的公网IP地址以便客户端能够随时访问。
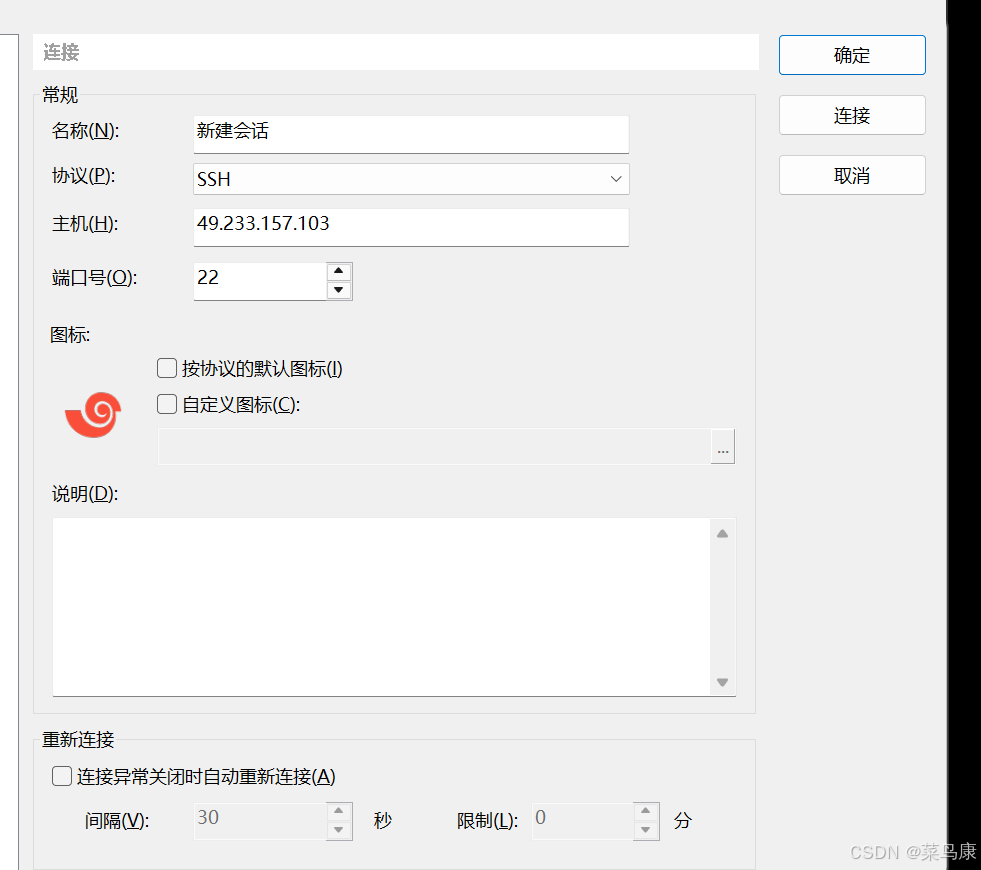
当我们需要使用Xshell连接到远端服务器时,如下图所示这个IP就是公网IP,这个IP标示了全网的、具有唯一性质的一台服务器
当我们登录我们自己的用户账号时,使用ifconfig命令查看,也会有一个IP地址,它就是一个私有IP,如下图
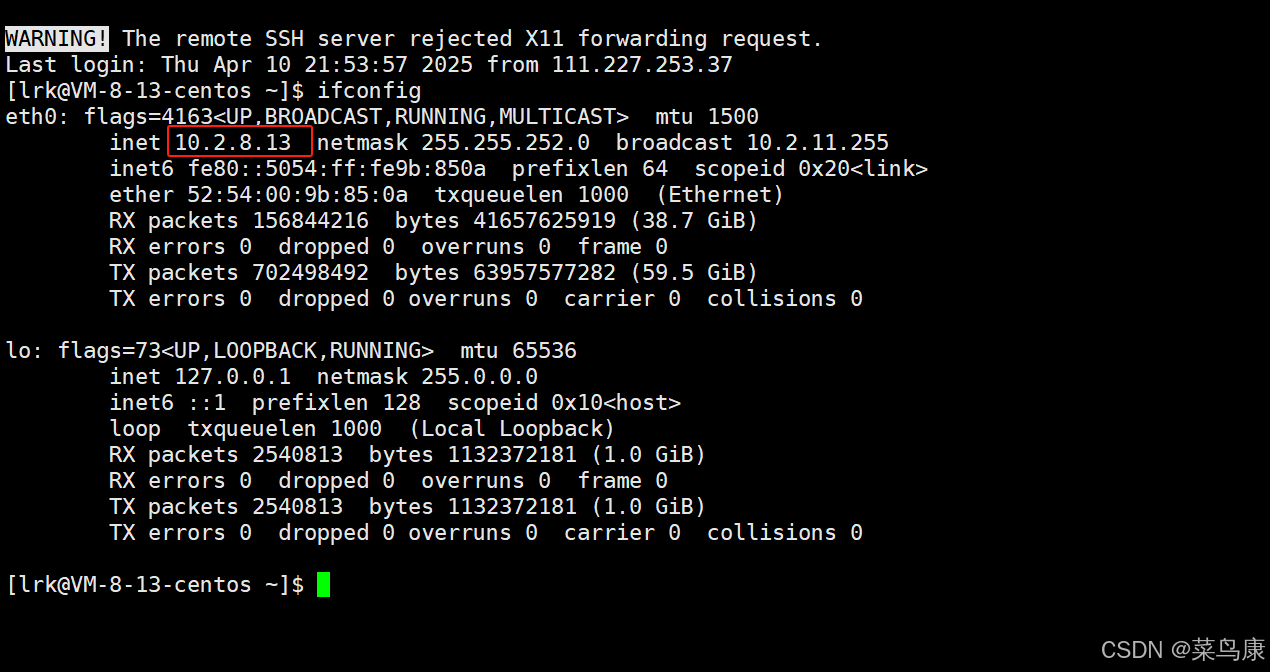 当有多个用户时,就会多个不同的私有IP。该私有IP地址只在该局域网内部有效,不能在互联网上直接访问。那私有IP怎么访问公网呢?通常在局域网中使用网络地址转换(NAT)技术,将多个内部设备共享一个公网IP地址,以便它们可以访问互联网。
当有多个用户时,就会多个不同的私有IP。该私有IP地址只在该局域网内部有效,不能在互联网上直接访问。那私有IP怎么访问公网呢?通常在局域网中使用网络地址转换(NAT)技术,将多个内部设备共享一个公网IP地址,以便它们可以访问互联网。
七、路由器
路由器是一种用于连接多个网络或网段的网络设备,它能够将数据从一个网络转发到另一个网络。路由器在互联网和许多私有网络中扮演着至关重要的角色,主要负责寻址、最佳路径选择以及数据包的转发。这是通过查找路由表来实现的,路由表中包含了不同网络之间的关系,以确定最佳路径。而且路由器本身天然的就会构建局域网(子网)。路由器的主要功能有:
- 转发数据
- DHCP分配
- 组建局域网(配置无线网络)
- NAT等
通过上面我们也知道了路由器也是一个主机,所以它也要有自己的IP地址,由于它承担着数据包转发的工作,所以它必然存在着多个接口,而路由器在其物理结构上是有着两种主要类型的网络接口: LAN口(局域网口)、WAN口(广域网口), 它们在网络连接和数据传输中扮演着不同的角色:
- LAN口(局域网口):
- 局域网接口:LAN口通常用于连接本地网络内的设备,如计算机、手机、智能家居设备等。这些设备通常位于同一个物理位置,例如您的家庭或办公室内,这是路由器对内的表现,即面对的是自己构建的子网。
- 本地数据交换:LAN口用于在局域网内传输数据包,使本地设备能够相互通信,共享文件、打印机、互联网连接等。
- WAN口(广域网口):
- 广域网接口:WAN口通常用于连接到广域网,如互联网服务提供商(ISP)的网络。这是您的局域网与外部互联网之间的关键接口,这是对外的表现,即自己本身也是被人构建的一个子网内的一个主机。
- 外部数据传输:WAN口负责将数据包从局域网传输到外部网络(互联网),并将来自外部网络的数据包传送回局域网。这是实现互联网连接的关键。
WAN口,也可理解为自己所在的上级子网所分配的IP。说是广域网口也不是很准确
所以说:
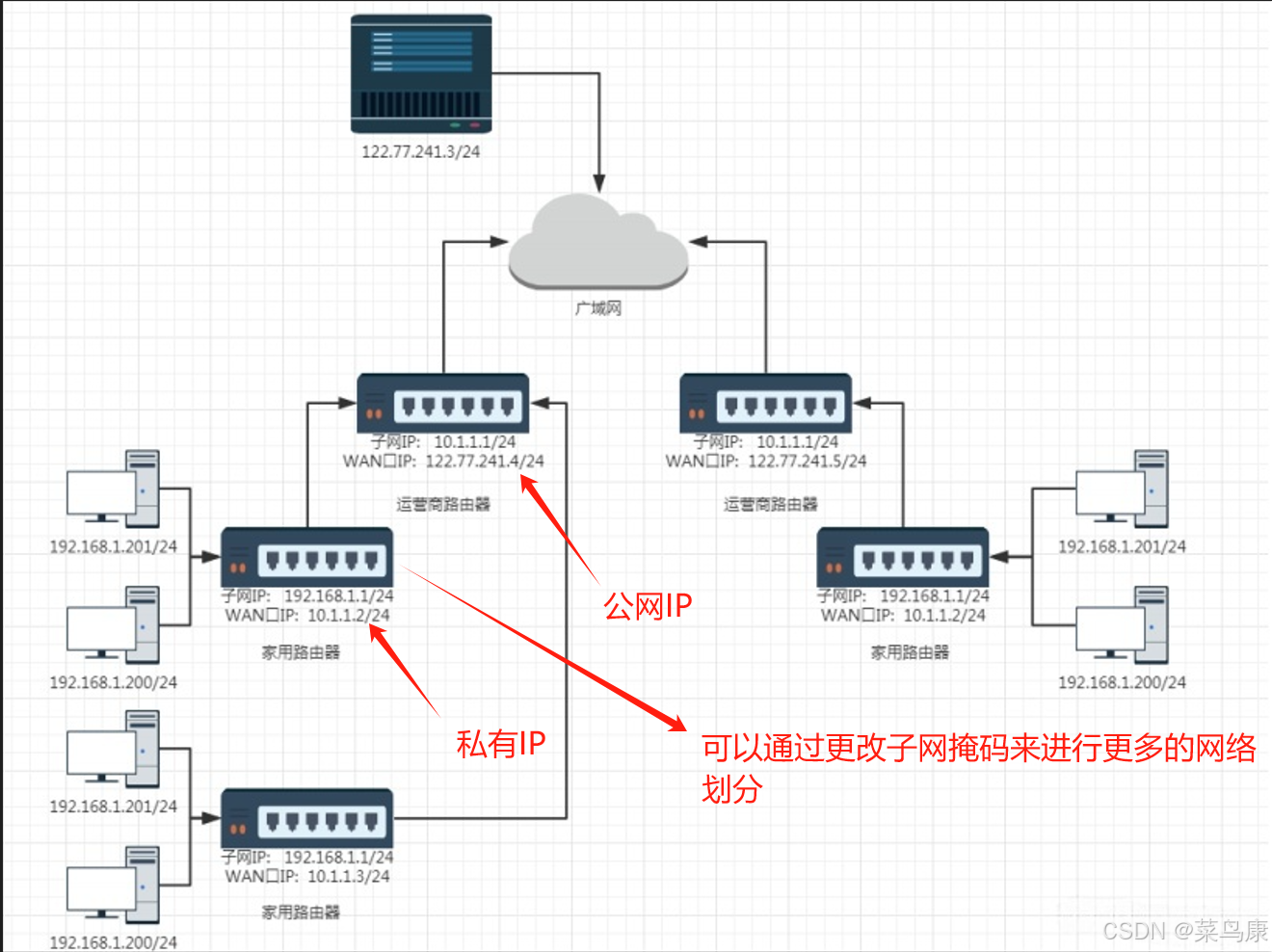
- 一个路由器可以配置两个IP地址,一个是WAN口IP,一个是LAN口IP(子网IP)
- 路由器LAN口连接的主机都从属于当前这个路由器的子网中
- 不同的路由器,子网IP其实都是一样的(通常都是192.168.1.1)。子网内的主机IP(私有IP)地址不能重复,但是子网之间的IP地址就可以重复了。
- 每一个家用路由器,其实又作为运营商路由器的子网中的一个节点。这样的运营商路由器可能会有很多级,最外层的运营商路由器,WAN口IP就是一个公网IP了。
- 子网内的主机需要和外网进行通信时,路由器将IP首部中的IP地址进行替换(替换成WAN口IP),这样逐级替换,最终数据包中的IP地址成为一个公网IP。这种技术称为NAT(Network Address Translation,网络地址转换)。
- 如果希望我们自己实现的服务器程序,能够在公网上被访问到,就需要把程序部署在一台具有外网IP的服务器上。这样的服务器可以在阿里云/腾讯云上进行购买。
因为有了私有IP,每个局域网内的私有IP是可以重复的,这样就大大缓解了IP地址不足窘迫。通常在局域网中使用网络地址转换(NAT)技术(本质上就是不断的将私有IP向上替换成公网IP进行通信),将多个内部设备共享一个公网IP地址,以便它们可以访问互联网。
八、路由
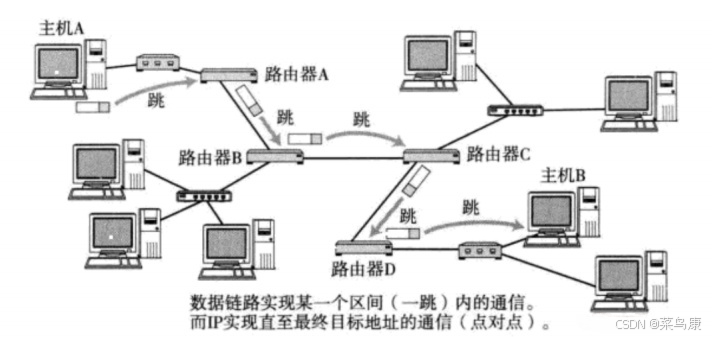
在网络中将数据从一台主机发往另一台主机的过程,本质上就是数据在网络中不断路由(找路)的过程。数据路由是指将数据从源地址传输到目标地址的过程。在路由的过程成,我们最主要的就是解决下一跳(从这个路由器跳到下一个路由器)问题。
数据包的路由过程其实就是在问路的过程,就像唐僧西天取经一样,有了源IP(长安城)和目的IP(西天大雷音寺),唐僧(数据包)每到一处找妖怪问路,就如同数据包每到一个路由器,如五指山妖怪、流沙河妖怪、火焰山妖怪等,这些路由器都有着自己的路由表,这些路由表中记录了去往目的IP所要经过的下一站的地址
- 例如:
- 五指山妖怪说:"去西天?往西走火焰山,或者绕道车迟国。"
- 火焰山妖怪说:"去西天?过牛魔王的地盘,或者借铁扇公主的扇子。"
如果这个路由表中没有记录对应的目的IP(即该路由器也不知道路要怎么走),它会将数据包转发给自己的默认网关,也就是默认的下一站地址,然后从这个默认的路由器再开始上述的查找,就像唐僧在火焰山问牛魔王去西天的路,牛魔王说不知道,但是牛魔王说你去哪哪哪找一个老头,每次有人问我不知道的路的时候,我都会让它们去找老头。这个老头就是牛魔王路由器的默认路由器。
有了上面的形象的例子,我们现在详细解释一下路由的过程:
假设我们有一个简单的局域网(LAN)网络,其中包含3台计算机A、B和C,它们分别连接到一个路由器R。现在,计算机A想要向计算机C发送一些数据。
在网络中路由(找路)。数据路由是指将数据从源地址传输到目标地址的过程。在路由的过程成,我们最主要的就是解决下一跳(从这个路由器跳到下一个路由器)问题。在计算机网络中,数据通常以数据包的形式进行传输。下面我将举例详细解释数据的路由过程。
假设我们有一个简单的局域网(LAN)网络,其中包含3台计算机A、B和C,它们分别连接到一个路由器R。现在,计算机A想要向计算机C发送一些数据。
- 数据封装:发送端的计算机A首先将要发送的数据封装成一个数据包。数据包通常包含源IP地址(计算机A的IP地址)、目标IP地址(计算机C的IP地址)以及实际的数据内容。
- 路由表查找:计算机A将数据包发送到路由器R。在路由器R上有一个路由表,它包含了关于如何将数据包从一个网络发送到另一个网络的信息。路由器R使用目标IP地址来查找路由表,确定下一跳的地址。
- 下一跳选择:路由器R根据路由表查找结果选择下一跳的地址。如果目标IP地址与路由表中的某个目标网络匹配,路由器R将选择将数据包发送到该目标网络所连接的下一个路由器或目标主机。如果没有匹配,则进行默认的下一跳,即默认路由。
- 数据转发:路由器R将数据包转发到下一个目标。这个过程涉及到查找最佳路径,根据网络拓扑、链路状态和其他因素来选择下一跳。
- 路由器之间的传递:数据包通过一系列的路由器从源地址传输到目标地址。每个路由器都会重复执行上述步骤,查找最佳路径并将数据包转发到下一个目标。
- 数据到达:最终,数据包到达目标计算机C。目标计算机C接收数据包,并解析其中的数据内容。
可以看着下图理解
1、路由表
上述的路由过程重点是路由表的查询。 每个路由器都有维护的自己一张路由表。在Linux下使用 route 命令可以查询系统的路由表信息。

- Destination(目标地址):表示目标网络/主机的IP地址。
- Gateway(网关):表示下一跳的网关地址,即将数据包发送到目标网络的下一跳路由器的IP地址。
- Genmask(网络掩码):表示与目标地址相对应的网络掩码,用于确定网络范围。
-
标志(Flags):表示该路由的状态和特殊标志。
U(Up):表示路由处于活动状态,正在使用。此条目有效,可以用来禁用某些条目
H(Host):表示目标为主机而非网络。
G(Gateway):表示此条目的下一跳地址是某个路由器的地址,没有该标志的条目表示目的网络地址是与本机接口直接相连的网络,不必经过路由器转发。
D(Dynamic):表示路由是由动态路由协议学习得到的。
M(Modified):表示路由已被手动修改。 - Metric(优先级):表示路由的优先级,用于确定数据包选择哪条路由发送。
- RefCnt(参考数):表示对该路由的引用计数,记录有多少个路由条目引用该项。
- Use(使用数):表示该路由的使用计数,记录自系统启动以来有多少数据包通过该路由发送。
- Iface(接口):表示将数据包发送到目标网络所使用的网络接口,如eth0、wlan0等,即数据包从该路由器哪一个接口发送出去。
- 图中default表示默认路由
八、总结
网络层的IP协议主要负责从一台主机到另一台主机的数据传输提供决策。在网络山转发的是IP报文,但是实际上在网线上跑的是MAC帧,这就是属于数据链路层的内容了。下篇文章就会对该部分进行详解了。
感谢阅读!
相关文章:

Linux网络编程——详解网络层IP协议、网段划分、路由
目录 一、前言 二、IP协议的认识 1、什么是IP协议? 2、IP协议报头 三、网段划分 1、初步认识IP与路由 2、IP地址 I、DHCP动态主机配置协议 3、IP地址的划分 I、CIDR设计 II、子网数目的计算 III、子网掩码的确定 四、特殊的IP地址 五、IP地址的数量限…...

解析医疗器械三大文档:DHF、DMR与DHR
医疗器械的 DHF、DMR 和 DHR 是质量管理体系(QMS)中的核心文件,贯穿产品全生命周期, 确保医疗器械的安全性、有效性和合规性。 一、三大文件的定义与法规依据 缩写全称法规依据(以 FDA 为例)核心目的DHF…...

SQL 全文检索原理
全文检索(Full-Text Search)是SQL中用于高效搜索文本数据的技术,与传统的LIKE操作或简单字符串比较相比,它能提供更强大、更灵活的文本搜索能力。 基本概念 全文检索的核心思想是将文本内容分解为可索引的单元(通常是词或词组),然后建立倒排…...

基于Rosen梯度投影法的约束优化问题求解及MATLAB实现
摘要 在工程优化、经济建模等领域,约束优化问题普遍存在,其核心是在满足线性或非线性约束条件下求解目标函数的极值。本文聚焦Rosen梯度投影法,系统阐述其算法原理、实现步骤及MATLAB编程方法。 关键词:Rosen梯度投影法…...
 - 尝试创建和测试一下MCP Server)
Model Context Protocol (MCP) - 尝试创建和测试一下MCP Server
1.简单介绍 MCP是Model Context Protocol的缩写,是Anthropic开源的一个标准协议。MCP使得大语言模型可以和外部的数据源,工具进行集成。当前MCP在社区逐渐地流行起来了。同时official C# SDK(仓库是csharp-sdk) 也在不断更新中,目前最新版本…...
)
Linux上位机开发实践(关于Qt的移植)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 linux平台上面,很多界面应用,都是基于qt开发的。不管是x86平台,还是arm平台,qt使用的地方都比较多。…...

Node.js 项目 用 `Docker Compose` 发布的完整流程
Node.js 项目 用 Docker Compose 发布的完整流程 ✅ 一、基本项目结构示例 以一个简单 Express 项目为例: my-node-app/ ├── app.js # 启动文件 ├── package.json ├── package-lock.json ├── Dockerfile # 构建 Node 容器 ├…...

Java基础:浅析Java中的XML文件处理
概述 XML(全称Extensible Markup Language,可扩展标记语言) .本质是一种数据的格式,可以用来存储复杂的数据结构,和数据关系 XML特点 1.XML中的“<标签名>”成为一个标签或者一个元素,一般成对出现的 2.XML…...
文件格式详解及Python代码)
MCU刷写——S19(S-Record)文件格式详解及Python代码
工作之余来写写关于MCU的Bootloader刷写的相关知识,以免忘记。今天就来聊聊S19这种文件的格式,我是分享人M哥,目前从事车载控制器的软件开发及测试工作。 学习过程中如有任何疑问,可底下评论! 如果觉得文章内容在工作学习中有帮助到你,麻烦点赞收藏评论+关注走一波!感谢…...

HTML — 过渡与动画
HTML过渡与动画是提升网页交互体验的核心技术,主要通过CSS实现动态效果。 过渡 CSS过渡(Transition)介绍 适用于元素属性变化时的平滑渐变效果,如悬停变色、尺寸调整。通过定义transition-property(过渡属性…...

python【标准库】multiprocessing
文章目录 介绍多进程Process 创建子进程共享内存数据多进程通信Pool创建子进程多进程案例多进程注意事项介绍 python3.10.17版本multiprocessing 是一个多进程标准模块,使用类似于threading模块的API创建子进程,充分利用多核CPU来并行处理任务。提供本地、远程的并发,高效避…...
网点)
BANK OF CHINA(HONG KONG)网点
BANK OF CHINA(HONG KONG)网点开户 ZoneBankAddressDates东区杏花邨分行香港柴湾杏花邨东翼商场205-208号20240415: 11:15, 13:00, 11:15, 13:00, 11:15, 13:0020240412: 11:15, 13:00东区鲗鱼涌分行香港鰂鱼涌英皇道1060号柏惠苑20240412: 09:45 注意事项 到达指定分行时&am…...
)
基于springboot的“嗨玩旅游网站”的设计与实现(源码+数据库+文档+PPT)
基于springboot的“嗨玩旅游网站”的设计与实现(源码数据库文档PPT) 开发语言:Java 数据库:MySQL 技术:springboot 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统功能结构图 局部E-R图 系统首页界面 系统注册…...
——决策树)
机器学习(3)——决策树
文章目录 1. 决策树基本原理1.1. 什么是决策树?1.2. 决策树的基本构成:1.3. 核心思想 2. 决策树的构建过程2.1. 特征选择2.1.1. 信息增益(ID3)2.1.2. 基尼不纯度(CART)2.1.3. 均方误差(MSE&…...

【人脸识别中的“类内差异”和“类间差异】
核心问题:人脸识别中的“类内差异”和“类间差异” 想象你在教一个小朋友认人: 类间差异(不同人之间的区别): 目标:让小朋友能分清“爸爸”和“妈妈”。方法:指着爸爸说“这是爸爸”࿰…...

第十六届蓝桥杯 省赛C/C++ 大学B组
编程题目现在在洛谷上都可以提交了。 未完待续,写不动了。 C11 编译命令 g A.cpp -o A -Wall -lm -stdc11A. 移动距离 本题总分:5 分 问题描述 小明初始在二维平面的原点,他想前往坐标 ( 233 , 666 ) (233, 666) (233,666)。在移动过程…...

SpringBoot3.0 +GraalVM21 + Docker 打包成可执行文件
SpringBoot3.0 GraalVM21 Docker 打包成可执行文件 前言 随着时代的飞速发展,JDK 17 及以上版本开始支持通过 GraalVM 将运行在 JVM 上的 jar 包直接打包成可在操作系统上运行的原生可执行文件。这一特性能使开发者在某些场景下更加灵活地部署 Java 程序。 在云原…...

从编程范式看 “万物皆智能,万事皆自动” 愿景
从编程范式看“万物皆智能,万事皆自动”愿景 引言 在信息技术飞速发展的今天,“万物皆智能,万事皆自动”成为了众多 IT 从业者和科技爱好者心中的终极愿景。这一愿景描绘了一个所有事物都具备智能、所有事情都能自动完成的美好未来。而在实现这一愿景的征程中,面向对象编…...

Vue 项目中 package.json 文件的深度解析
Vue 项目中 package.json 文件的深度解析 在 Vue 项目中,package.json 文件是项目配置的核心,它管理着项目的依赖关系、脚本命令、版本信息等重要内容。正确理解和配置 package.json 文件,对于项目的开发、构建、测试和部署都至关重要。本文…...

解决2080Ti使用节点ComfyUI-PuLID-Flux-Enhanced中遇到的问题
使用蓝大的工作流《一键同时换头、换脸、发型、发色之双pulid技巧》 刚开始遇到的是不支持bf16的错误 根据《bf16 is only supported on A100 GPUs #33》中提到,修改pulidflux.py中的dtype 为 dtype torch.float16 后,出现新的错误,这个…...

1 程序的本质,计算机语言简史,TIOBE 指数,C 语言的独特魅力、发展历程、发行版本和应用场景
👋 嘿,各位编程探险家们!是不是一提到 C 语言,脑海中就浮现出指针乱舞、内存泄漏的恐怖画面?别怕,你并不孤单!😅 今天,你踏入了这个专为 “C 语言恐惧症” 患者打造的避…...

python格式化字符串漏洞
什么是python格式化字符串漏洞 python中,存在几种格式化字符串的方式,然而当我们使用的方式不正确的时候,即格式化的字符串能够被我们控制时,就会导致一些严重的问题,比如获取敏感信息 python常见的格式化字符串 百…...

撰写学位论文Word图表目录的自动生成
第一步:为图片和表格添加题注 选中图片或表格 右键点击需要编号的图片或表格,选择 【插入题注】(或通过菜单栏 引用 → 插入题注)。 设置题注标签 在弹窗中选择 标签(如默认有“图”“表”,若无需自定义标…...
)
SDC命令详解:使用相对路径访问设计对象(current_instance命令)
相关阅读 SDC命令详解https://blog.csdn.net/weixin_45791458/category_12931432.html?spm1001.2014.3001.5482 在使用get_cells等命令访问设计对象时,需要指定设计对象的名字,这个名字是一个相对路径,本文就将对此进行讨论。 相对路径 使…...

vector的应用
在平常使用c是,只使用普通数组肯定不够便捷,这时,我们就可以使用vector来使代码更加简洁 目录 1.vector的定义 2.在vector末尾增加一个元素 3.输出元素 (1)输出单个元素 (2)循环输出元素 4…...

pytorch查询字典、列表维度
输出tensor变量维度 print(a.shape)输出字典维度 for key, value in output_dict.items():if isinstance(value, torch.Tensor):print(f"{key} shape:", value.shape)输出列表维度 def get_list_dimensions(lst):# 基线条件:如果lst不是列表࿰…...

征程 6 VIO Frame 时间戳介绍
1. 时间类型 征程 6 内部的时间类型如下 Linux 系统时间是基于 arm system counter 抽象的,Linux 的基于 arm system counter 抽象了很多种时间,图中画了两种。CLOCK_MONOTONIC_RAW 是不会被时间同步调整的。 2. Frame 时间戳 从 VIO 侧获取的图像数…...

DotnetCore开源库SampleAdmin源码编译
1.报错: System.Net.Sockets.SocketException HResult0x80004005 Message由于目标计算机积极拒绝,无法连接。 SourceSystem.Net.Sockets StackTrace: 在 System.Net.Sockets.Socket.AwaitableSocketAsyncEventArgs.ThrowException(SocketError error, C…...
)
QML之ScrollView(滚动视图)
ScrollView 是 Qt Quick Controls 2 中提供的可滚动视图容器,用于创建可滚动区域。以下是详细使用方法: 基本用法 qml import QtQuick 2.15 import QtQuick.Controls 2.15ScrollView {id: scrollViewwidth: 300height: 200clip: true// 背景设置&…...

FreeRTOS使任务处于就绪状态的API
在FreeRTOS中,任务的**就绪状态(Ready State)**意味着任务已准备好运行,但尚未被调度器分配CPU时间。以下是通过API使任务进入就绪状态的常见方法及其分类: 1. 恢复被挂起的任务 vTaskResume(TaskHandle_t xTaskToResume) 将被挂起(Suspended)的任务恢复为就绪状态。 示…...

第四篇:Python文件操作与异常处理
第一章:文件操作基础与核心原理 1.1 文件系统基础 文件系统是操作系统用于管理存储设备中数据的核心机制。Python通过内置的open()函数实现文件操作,支持文本文件(.txt、.csv)和二进制文件(.jpg、.dat)的…...

蓝桥杯 嵌入式 小结
一、BSP模版 1. Key 按键扫描模版,需要注意的是 key_val 。 uint8_t Key_Scan(void) {uint8_t key_val0;if(HAL_GPIO_ReadPin(GPIOB,GPIO_PIN_0)GPIO_PIN_RESET){key_val1;}if(HAL_GPIO_ReadPin(GPIOB,GPIO_PIN_1)GPIO_PIN_RESET){key_val2;}if(HAL_GPIO_ReadPin(…...

【音视频】SDL渲染YUV格式像素
SDL视频显示的流程 实现流程 准备视频文件 准备一个格式为yuv420p,分辨率为320x240的yuv数据,并且将视频文件放入项目构建的目录下: 初始化SDL 初始化SDL的视频模块 //初始化 SDL if(SDL_Init(SDL_INIT_VIDEO)) {fprintf( stderr, "…...
)
ThingsBoard3.9.1 MQTT Topic(1)
1.网关转发子设备的遥测信息, Topic:v1/gateway/telemetry { "m1": [{ "mode": "CW", "temperature": 23 }], "m2": [{ "mode": "CW", "temperature": 23 }] } 说明:json格式&a…...

如何查看自己抖音的IP属地?详细教程+常见问题解答
在当今互联网时代,IP属地信息已成为各大社交平台(如抖音、微博、快手等)展示用户真实网络位置的重要功能。无论是出于隐私保护、账号安全,还是单纯好奇自己的IP归属地,了解如何查看抖音IP属地都很有必要。 本文将详细介…...

李宏毅NLP-2-语音识别part1
语音识别part1 这是一篇名为 “Speech Recognition is Difficult?”(语音识别很难吗? )的文章。作者是 J.R. Pierce,来自贝尔电话实验室(Bell Telephone Laboratories, Inc.) 。文中提到语音识别虽有吸引力…...

AUTOSAR图解==>AUTOSAR_SWS_MemoryMapping
AUTOSAR 内存映射机制详解 深入解析AUTOSAR标准中的内存映射技术 目录 AUTOSAR 内存映射机制详解 目录1. 概述2. 内存映射架构 2.1 架构组成2.2 映射类型2.3 关键组件3. 配置数据模型 3.1 主要配置容器3.2 内存段类型3.3 初始化策略4. 映射使用流程 4.1 配置阶段4.2 开发阶段...

探索 HTML5 新特性:提升网页开发的现代体验
在 Web 开发的演进历程中,HTML5 无疑是一座重要的里程碑。它不仅为网页带来了更丰富的功能,还提升了开发效率与用户体验。本文将深入探讨 HTML5 那些令人瞩目的新特性,助你紧跟现代 Web 开发潮流。 一、语义化标签:让结构更清晰 …...

系统设计思维的讨论
我们经常说自己熟悉了spring,能够搭建起一个项目基本框架,并且在此之上进行开发,用户or客户提出需求碰到不会的百度找找就可以实现。干个四五年下一份工作就去面试架构师了,运气好一些可能在中小公司真的找到一份架构师、技术负责…...

【音视频】SDL播放PCM音频
相关API 打开音频设备 int SDLCALL SDL_OpenAudio(SDL_AudioSpec * desired, SDL_AudioSpec * obtained); desired:期望的参数。obtained:实际音频设备的参数,一般情况下设置为NULL即可。 SDL_AudioSpec typedef struct SDL_AudioSpec { i…...

FATFS文件系统配置
1、FatFs模块功能配置选项参考ffconf.h函数配置链接:FatFs模块功能配置选项 2、FATFS配置 FATFS 支持长文件名链接: FATFS:配置 FATFS 支持长文件名 3、 FATFS移植链接1 4、 FATFS移植链接2 5、FAT32 和 FATFS 是两个不同层次的概念,分别属于…...

JVM 字节码是如何存储信息的?
JVM 字节码是 Java 虚拟机 (JVM) 执行的指令集,它是一种与平台无关的二进制格式,在任何支持 JVM 的平台上都可运行的Java 程序。 字节码存储信息的方式,主要通过以下几个关键组成部分和机制来实现: 1. 指令 (Opcodes) 和 操作数 …...
——select)
Linux:多路转接(上)——select
目录 一、select接口 1.认识select系统调用 2.对各个参数的认识 二、编写select服务器 一、select接口 1.认识select系统调用 int select(int nfds, fd_set readfds, fd_set writefds, fd_set exceptfds, struct timeval* timeout); 头文件:sys/time.h、sys/ty…...

如何解决DDoS攻击问题 ?—专业解决方案深度分析
本文深入解析DDoS攻击面临的挑战与解决策略,提供了一系列防御技术和实践建议,帮助企业加强其网络安全架构,有效防御DDoS攻击。从攻击的识别、防范措施到应急响应,为网络安全工作者提供了详细的操作指引。 DDoS攻击概览:…...

机器学习Python实战-第三章-分类问题-3.决策树算法
目录 3.3.1 原理简介 3.3.2 算法步骤 3.3.3 实战 3.3.4 实验 前半部分是理论介绍,后半部分是代码实践,可以选择性阅读。 决策树(decision tree)是功能强大而且相当受欢迎的分类和预估方法&…...

Spring三级缓存学习
Spring的三级缓存机制主要用于解决单例Bean的循环依赖问题。其核心在于提前暴露Bean的引用,允许未完全初始化的对象被其他Bean引用。以下是三级缓存的详细说明及其解决循环依赖的原理: 三级缓存结构 一级缓存(singletonObjects) 存…...

欧拉函数φ
函数作用 计算 1 1 1 ~ n n n中有多少个与 n n n互质的数。 函数公式 φ ( n ) n p 1 − 1 p 1 p 2 − 1 p 2 … … p m − 1 p m φ(n)n\times\frac{p_1-1}{p_1}\times\frac{p_2-1}{p_2}\times……\times\frac{p_m-1}{p_m} φ(n)np1p1−1p2p2−1……pmp…...

蓝桥杯刷题指南
蓝桥杯是中国普及性最好的计算机程序设计竞赛之一,参加者包括大学生、高中生和草根程序员等各个群体。通过刷题来提升自己的编程能力是参加蓝桥杯比赛的常见做法。下面是一些蓝桥杯常见的题型和刷题技巧,希望对大家有所帮助。 基础入门题目:…...

ctfshow WEB web12
发现只有这样一句话,应该是要看页面源代码的,右键查看页面源代码 发现可能存在代码执行漏洞,拼接一个?cmdphpinfo(); 成功显示出php信息, 说明存在代码执行漏洞 接下来遍历目录,我们要用到一个函数 glob() glob() 函数可以查找…...

ChromeOS 135 版本更新
ChromeOS 135 版本更新 一、ChromeOS 135 更新内容 1. ChromeOS 电池寿命优化策略 为了延长 Chromebook 的使用寿命,ChromeOS 135 引入了一项全新的电池充电限制策略 —— DevicePowerBatteryChargingOptimization,可提供更多充电优化选项,…...