机器学习Python实战-第三章-分类问题-3.决策树算法
目录
3.3.1 原理简介
3.3.2 算法步骤
3.3.3 实战
3.3.4 实验
前半部分是理论介绍,后半部分是代码实践,可以选择性阅读。
决策树(decision tree)是功能强大而且相当受欢迎的分类和预估方法,它是一种有监督的学习算法,以树状图为基础,其输出结果是一系列简单实用的规则,故得名决策树。
决策树模型基于特征对实例分类,它是一种树状结构。决策树的优点是可读性强,分类速度快。学习决策树时,通常采用损失函数最小化原则。
3.3.1 原理简介
决策树算法是一个贪心算法,即在特性空间上执行递归的二元分割,决策树由节点和有向边组成。内部节点表示一个特征或者属性;叶子节点表示一个分类。使用决策树进行分类时,将实例分配到叶节点的类中,该叶节点所属的类就是该节点的分类。
决策树可以表示给定特征条件下,类别的条件概率分类。将特征空间划分为互不相交的单元
。设某个单元
内部有
个样本点,则它定义了一个条件概率分布
为第
个分类。
- 每个单元对应于决策树的一条路径。
- 所有单元的条件概率分布构成了决策树所代表的条件概率分布。
- 在单元
。其中,
。即单元
3.3.2 算法步骤
构建决策树通常包括三个步骤:特征选择、决策树生成、决策树剪枝。
构建决策树时,通常将正则化的极大似然函数作为损失函数,其学习目标是损失函数为目标函数的最小化。构建决策树的算法通常是递归地选择最优特征,并根据该特征对训练数据进行分割,步骤如下:
- 构建根节点,使所有的训练样本都位于根节点。
- 选择一个最优特征。通过该特征将训练数据分割成多个子集,确保各个子集都有最好的分类,但要考虑下列两种情况:
- 若子集已能够被较好的分类,则构建叶节点,并将该子集划分到对应的叶节点。
- 若某个子集不能够被较好的分类,则对该子集继续划分。
- 递归执行,直到所有的训练样本都被较好的分类,或者没有合适的特征为止。是否被较好的分类,可通过后面介绍的指标来判断。
通过如上步骤生成的决策树对训练样本有很好的分类能力,但是需要的是对未知样本的分类能力。因此通常需要对已生成的决策树进行剪枝,从而使决策树具有更好的泛化能力。剪枝过程是去掉过于细分的叶节点,从而提高泛化能力。
1.特征选择
特征选择就是选取有较强分类能力的特征。分类能力通过信息增益或者信息增益比来刻画。选择特征的标准是找出局部最优的特征作为判断进行切分,取决于切分后节点数据集中类别的有序程度,划分后的分区数据越纯,切分规则越合适。可衡量节点数据集纯度的有熵、基尼系数和方差。熵和基尼系数是针对分类的,方差是针对回归的。
2.决策树生成
基本的决策树生成算法中,典型的有ID3生成算法和C4.5生成算法,它们生成树的过程大致相似。ID3采用信息增益作为特征选择的度量,而C4.5采用信息增益比。
关于两个算法有几点说明如下:
- C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进。
- 用信息增益比来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足。
- 在树的构造过程中进行剪枝。
- 能够完成对连续属性的离散化处理。
- 能够对不完整数据进行处理。
- C4.5算法的优点:
- 产生的分类规则易于理解;
- 准确率较高。
- C4.5算法的缺点:
- 在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,导致算法低效。
- C4.5算法只适合于能够留驻于内存的数据集,当训练集大到内存无法容纳时,程序无法运行。
- 决策树可能只用到特征集中的部分特征。
- C4.5算法和ID3算法只有树的生成算法,生成的树容易产生过拟合现象。
3.决策树剪枝
需要剪枝的原因是:决策树产生了过拟合现象。
发生过拟合是由于决策树太复杂,解决过拟合的方法是控制模型的复杂度,对于决策树来说就是简化模型,即为剪枝。
决策树剪枝的过程是从已生成的决策树上裁掉一些子树或者叶节点。剪枝的目标是通过极小化决策树的整体损失函数或代价函数来实现的。
决策树剪枝的目的是通过剪枝来提高泛化能力。剪枝的思路就是在决策树对训练数据的预测误差和数据复杂度之间找到一个平衡。
4.CART模型
分类与回归树(classification and regression tree,CART)模型也是一种决策树模型,它既可以用于分类,也可以用于回归。其学习算法分为如下两步:
- 决策树生成:用训练数据生成决策树,生成树尽可能的大。
- 决策树剪枝:基于损失函数最小化的标准,用验证数据对生成的决策树剪枝。
CART模型采用不同的最优化策略。
- CART回归生成树用平方误差最小化策略。
- CART分类生成树用基尼系数最小化策略。
3.3.3 实战
1.数据集
采用鸢尾花数据集。
2.Sklearn实现
DecisionTreeClassifier()函数实现了分类决策树,用于分类问题。
代码如下:
import numpy as np
import matplotlib as plt
from sklearn import datasets
from sklearn import model_selection
from sklearn.tree import DecisionTreeClassifierdef test_DecisionTreeClassifier(* data):X_train, X_test, y_train, y_test = dataclf = DecisionTreeClassifier()clf.fit(X_train, y_train)print("Training score:%f" % (clf.score(X_train, y_train)))print("Testing score:%f" % (clf.score(X_test, y_test)))X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.3, random_state=42)
test_DecisionTreeClassifier(X_train, X_test, y_train, y_test)
运行结果:

实验结果非常好,下面考察评价切分质量的评价准则criterion对分类性能的影响,函数如下
import numpy as np
import matplotlib as plt
from sklearn import datasets
from sklearn import model_selection
from sklearn.tree import DecisionTreeClassifierdef test_DecisionTreeClassifier_criterion(* data):X_train, X_test, y_train, y_test = datacriterions = ['gini', 'entropy']for criterion in criterions:clf = DecisionTreeClassifier(criterion=criterion)clf.fit(X_train, y_train)print("criterion:%s" % criterion)print("Training score:%f" % (clf.score(X_train, y_train)))print("Testing score:%f" % (clf.score(X_test, y_test)))X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.25, random_state=42)
test_DecisionTreeClassifier_criterion(X_train, X_test, y_train, y_test)
实验结果:
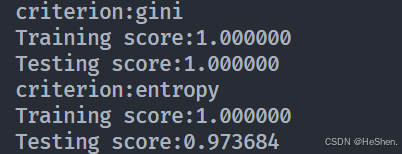
可以看出二者对训练集的拟合效果都很好。接下来检验随即划分与最优划分的影响,函数如下:
import numpy as np
import matplotlib as plt
from sklearn import datasets
from sklearn import model_selection
from sklearn.tree import DecisionTreeClassifierdef test_DecisionTreeClassifier_splitter(* data):X_train, X_test, y_train, y_test = datasplitters = ['best', 'random']for splitter in splitters:clf = DecisionTreeClassifier(splitter=splitter)clf.fit(X_train, y_train)print("splitter:%s" % splitter)print("Training score:%f" % (clf.score(X_train, y_train)))print("Testing score:%f" % (clf.score(X_test, y_test)))X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.25, random_state=42)
test_DecisionTreeClassifier_splitter(X_train, X_test, y_train, y_test)实验结果:
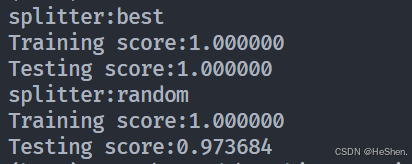
可以看出,二者对训练集的拟合效果都很好。
最后考察决策树深度的影响。决策树的深度对应树的复杂度。决策树越深,则模型越复杂,函数如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import model_selection
from sklearn.tree import DecisionTreeClassifierdef test_DecisionTreeClassifier_deepth(*data, maxdeepth):X_train, X_test, y_train, y_test = datadeepths = np.arange(1, maxdeepth)training_scores = []testing_scores = []for deepth in deepths:clf = DecisionTreeClassifier(max_depth=deepth)clf.fit(X_train, y_train)training_scores.append(clf.score(X_train, y_train))testing_scores.append(clf.score(X_test, y_test))fig = plt.figure()ax = fig.add_subplot(1, 1, 1)ax.plot(deepths, training_scores, label="training score", marker='o')ax.plot(deepths, testing_scores, label="testing score", marker='x')ax.set_xlabel("maxdepth")ax.set_ylabel("score")ax.set_title("Decision Tree Classification")ax.legend(framealpha=0.5, loc='best')plt.show()X, y = datasets.load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.3, random_state=42)
test_DecisionTreeClassifier_deepth(X_train, X_test, y_train, y_test, maxdeepth=100)
实验结果如下:
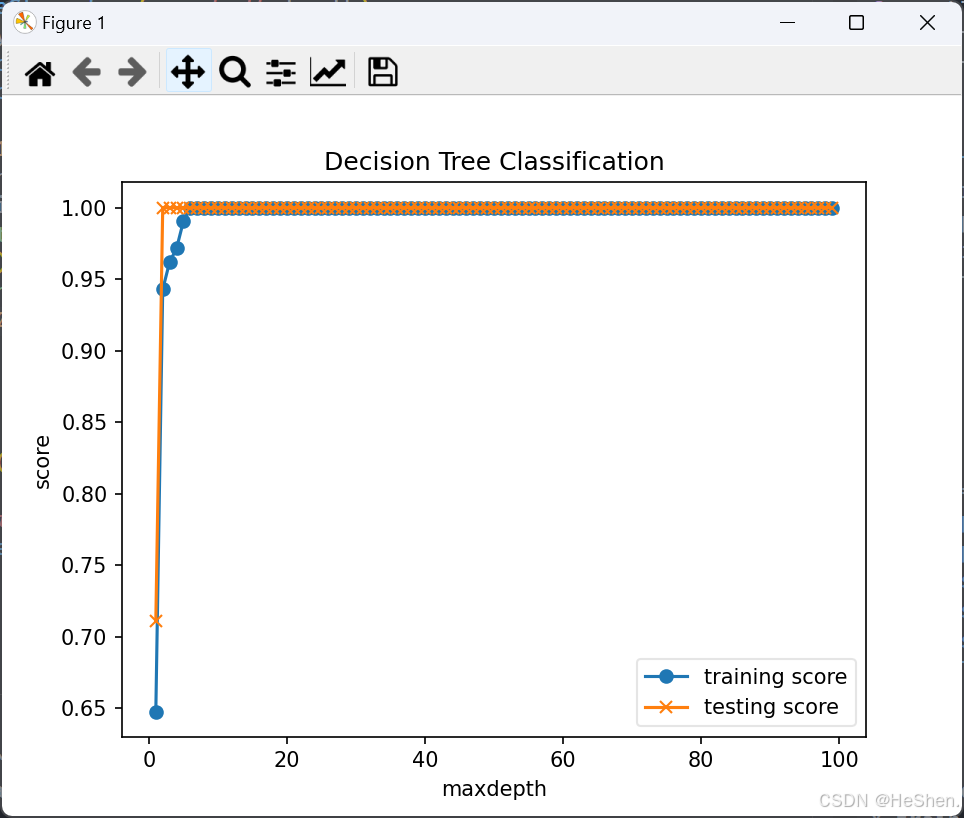
可以看出,随着树深度的增加(对应着模型复杂度的提高),模型对训练集和预测集的拟合度都在提高。这里的训练数据集大小较小(大约150个数据),所以结果看上去非常号,在面对较大的数据集时,效果就会下降。
3.算法实现
下面以一个经典的打球的例子来说明如何构建决策树。是否去打球(play)主要由天气(outlook)、温度(temperature)、湿度(humidity)、是否有风(windy)来决定。样本中共14条数据。
| 序号 | outlook | temperature | humidity | windy | play |
| 1 | sunny | hot | high | FALSE | no |
| 2 | sunny | hot | high | TRUE | no |
| 3 | overcast | hot | high | FALSE | yes |
| 4 | rainy | mild | high | FALSE | yes |
| 5 | rainy | cool | normal | FALSE | yes |
| 6 | rainy | cool | normal | TRUE | no |
| 7 | overcast | cool | normal | TRUE | yes |
| 8 | sunny | mild | high | FALSE | no |
| 9 | sunny | cool | normal | FALSE | yes |
| 10 | rainy | mild | normal | FALSE | yes |
| 11 | sunny | mild | normal | TRUE | yes |
| 12 | overcast | mild | high | TRUE | yes |
| 13 | overcast | hot | normal | FALSE | yes |
| 14 | rainy | mild | high | TRUE | no |
下面将分别介绍使用ID3算法和C4.5算法构建决策树的方法。
1)使用ID3算法构建决策树。
ID3算法是使用信息增益来选择特征的。
步骤如下:
(1)计算play(是否去打球)的经验熵
在本例中,目标变量
就是play(是否去打球),即yes(打球)和no(不打球)。
。
就是目标变量play(是否去打球)的分类数,yes(打球)这个分类下有9个样本,而no(不打球)这个分类下有5个样本,所以信息熵
(2)计算outlook(天气)的经验熵
记outlook特征为特征A,共有3个不同的取值
,即
,根据特征A的取值,将数据集
- sunny的子集:共有5个样本,2个打球,3个不打球
- overcast的子集:共有4个样本,均为打球
- rainy的子集:共有5个样本,3个打球,2个不打球
每个子集可以分别计算熵,公式如下:
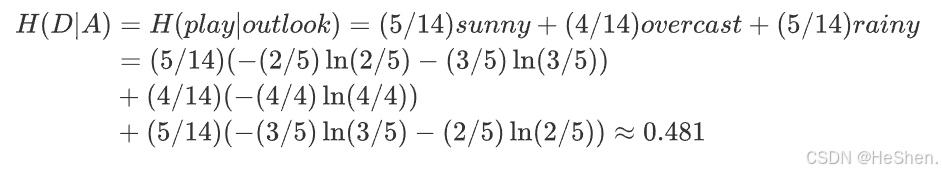
所以outlook特征的信息增益为

(3)计算temperature(温度)的经验熵
记temperature特征为特征B,共有3个不同的取值
,即
- hot的子集:共有4个样本,2个打球,2个不打球
- mild的子集:共有6个样本,4个打球,2个不打球
- cool的子集:共有4个样本,3个打球,1个不打球
每个子集可以分别计算熵,公式如下:
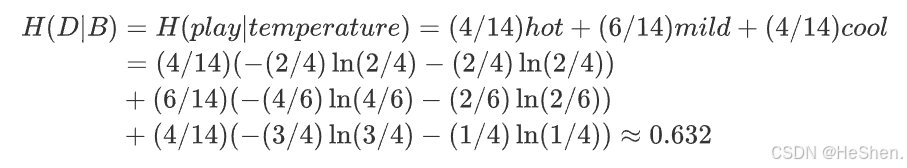
所以temperature特征的信息增益为

(4)计算humidity(湿度)的经验熵
记humidity特征为特征C,共有2个不同的取值
,即
,根据特征C的取值,将数据集
- high的子集:共有7个样本,3个打球,4个不打球
- normal的子集:共有7个样本,6个打球,1个不打球
每个子集可以分别计算熵,公式如下:
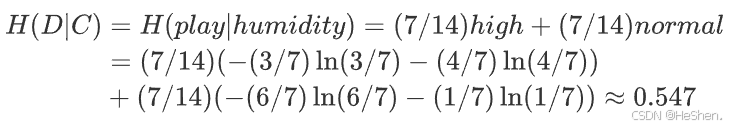
所以humidity特征的信息增益为

(5)计算windy(是否有风)的经验熵
记windy特征为特征E(区别于数据集D),共有2个不同的取值
,即
- TRUE的子集:共有6个样本,2个打球,4个不打球
- FALSE的子集:共有8个样本,6个打球,2个不打球
每个子集可以分别计算熵,公式如下:
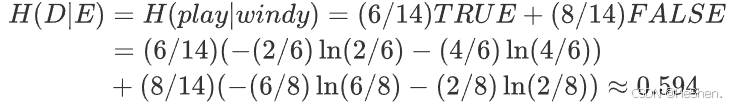
所以humidity特征的信息增益为

(6)确定root节点
对比上面四个特征的信息增益如下:
可以看出outlook特征的信息增益最大,所以选择outlook特征作为决策树的根节点。
特征A(天气)有三个不同的取值
,即
- sunny的子集:共有5个样本,2个打球,3个不打球
- overcast的子集:共有4个样本,均为打球
- rainy的子集:共有5个样本,3个打球,2个不打球
对每个子集分别计算熵如下:
上面的overcast熵=0,如下图所示。也就是也部分已经分好类了,都为打球,所以直接就可以作为叶节点,不需要在进行分类。而sunny熵、rainy熵都大于0,还需要按照上面根节点的选择方式继续选择特征。
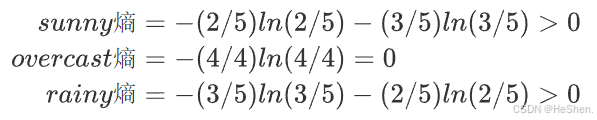
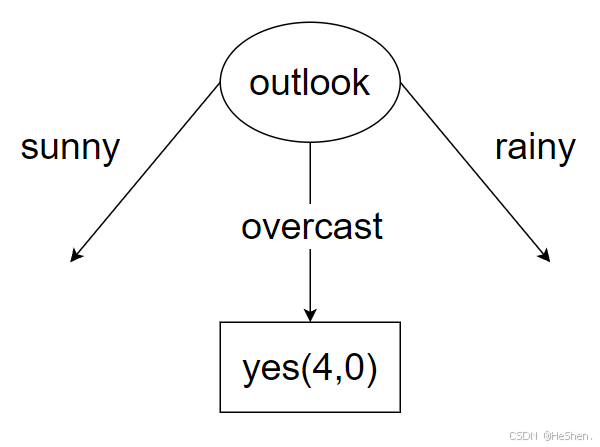
(7)计算outlook特征为sunny的数据集,该数据集如下表所示
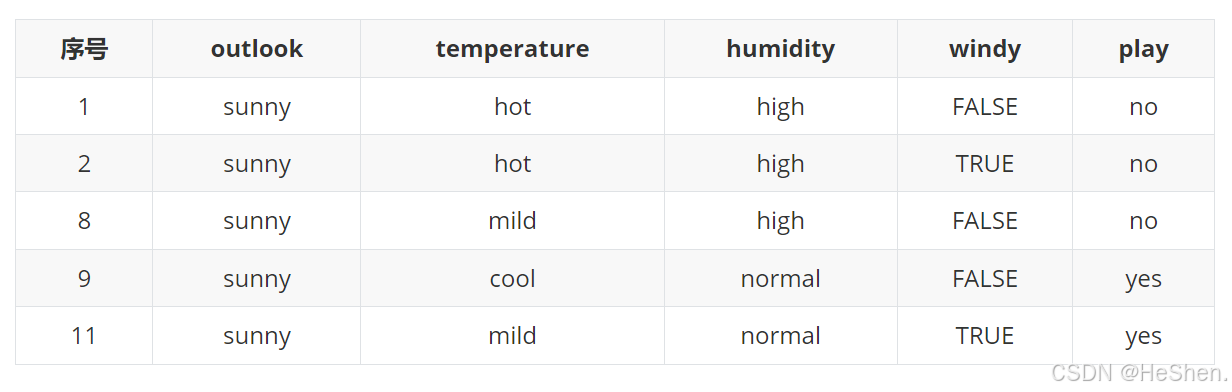
1.计算outlook这个分支样本的信息熵。
yes这个分类下有2个样本,而no这个分类下有3个样本,所以信息熵
2.计算temperature特征的信息增益
记temperature特征为特征A,共有3个不同的取值
- hot的子集:共有2个样本,2个不打球
- mild的子集:共有2个样本,1个打球,1个不打球
- cool的子集:共有1个样本,1个打球
每个子集可以分别计算熵,公式如下:
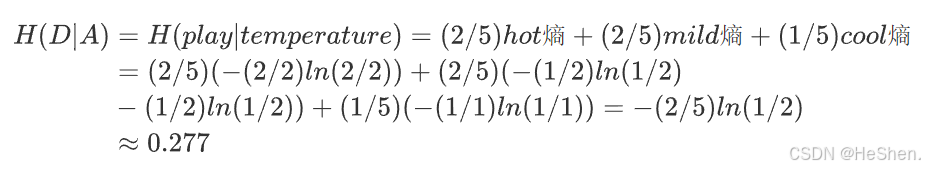
所以temperature特征的信息增益为

3.计算humidity的信息增益
记humidity特征为特征B,共有2个不同的取值
- high的子集:共有3个样本,3个不打球
- normal的子集:共有3个样本,2个打球
每个子集可以分别计算熵,公式如下:
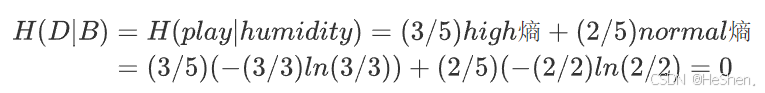
所以humidity特征的信息增益为

humidity特征划分已经将信息熵降到0,所以不用继续计算了,直接把湿度作为分类的特征即可,如下图所示
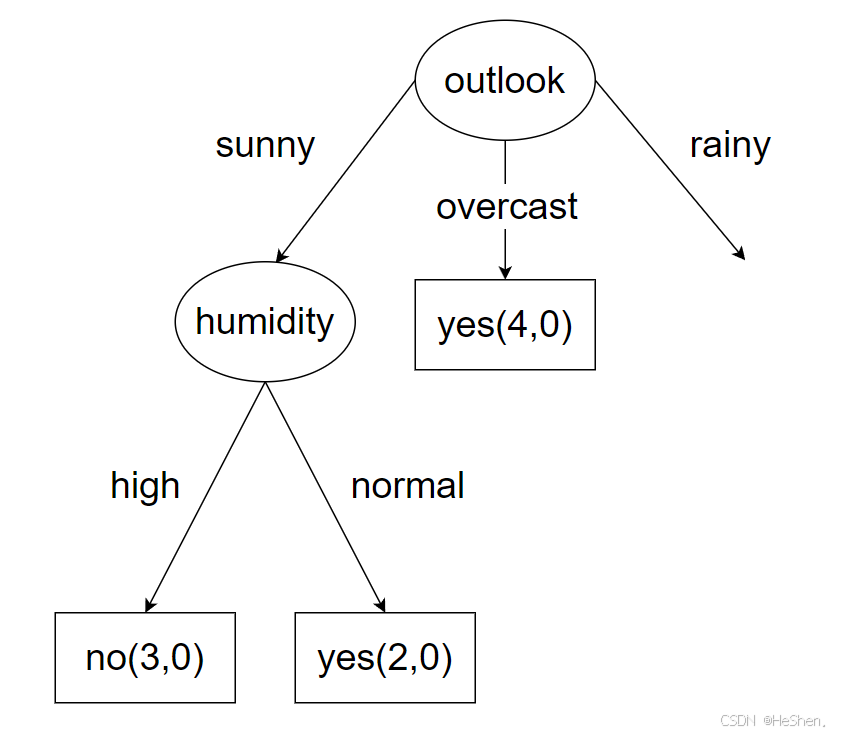
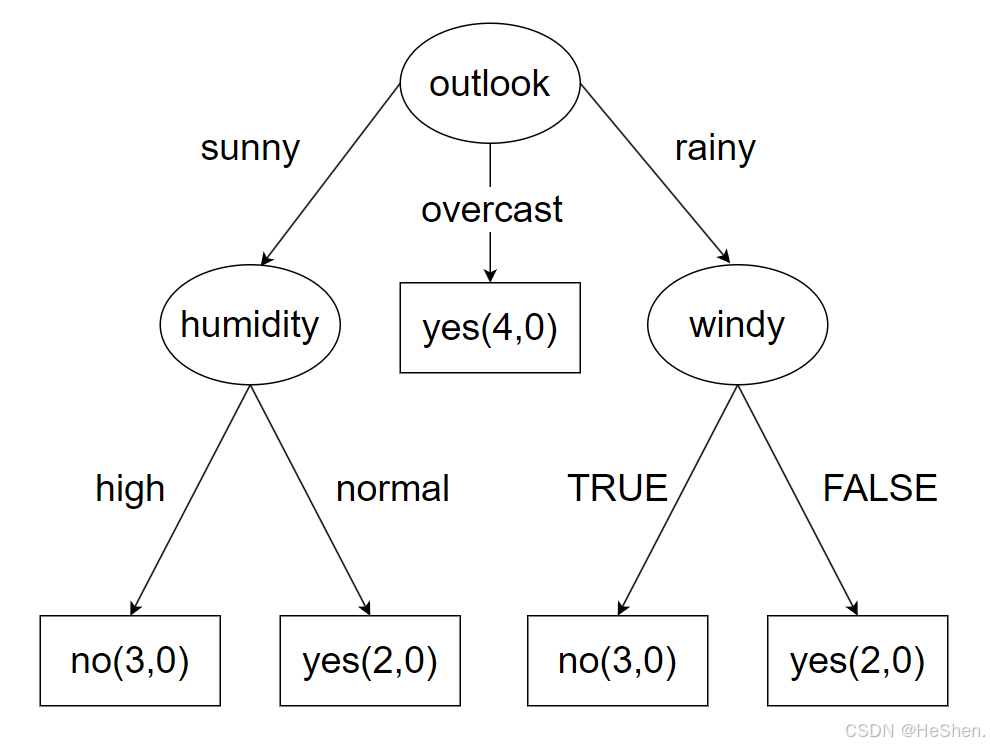
(8)计算outlook特征为rainy的数据集
用相同的方法计算此部分的数据后,最终得出的决策树如下图所示
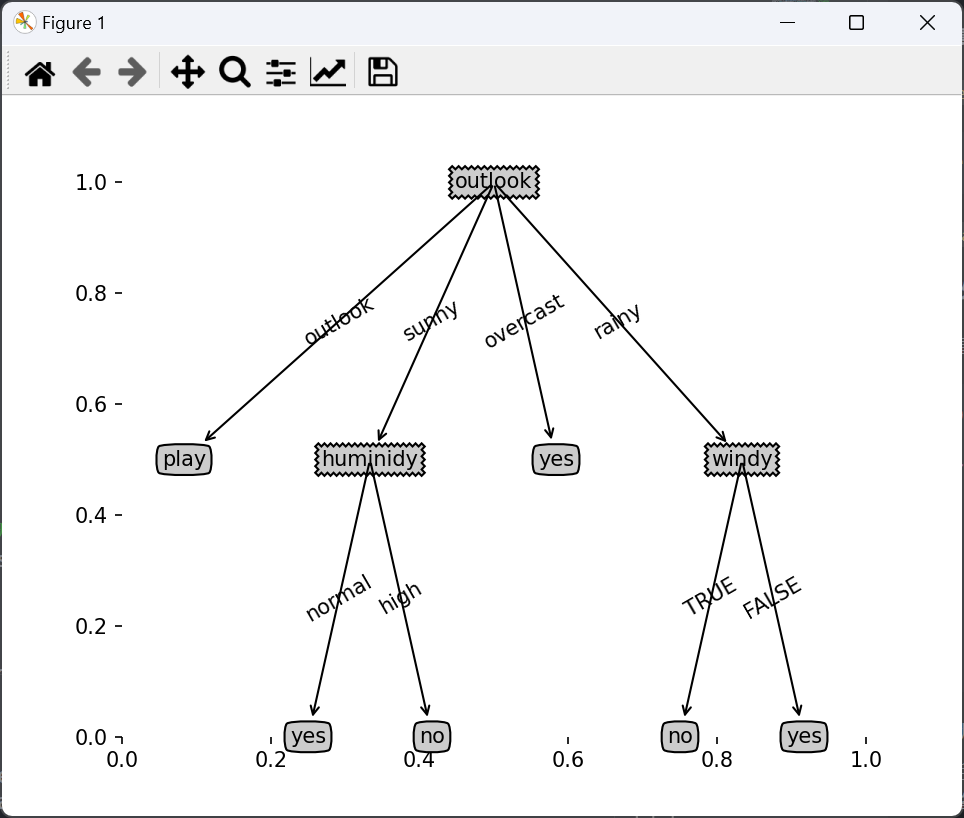
下面的代码是基于ID3算法的信息增益来实现的。
code
代码块过长,这里只展示结果,源码在我的github仓库中。
2)使用C4.5算法构建决策树
C4.5算法使用信息增益率来进行特征选择。由于前面ID3算法使用信息增益选择分裂属性的方式会倾向于选择具有大量值的特征,如对于no,每条数据都对应一个play值,即按此特征划分,每个划分都是纯的(即完全的划分,只有属于一个类别),no的信息增益为最大值1,但这种按该特征的每个值进行分类的方式是没有任何意义的。为了解决这一弊端,有人提出了采用信息增益率(GainRate)来选择分裂特征。计算方式如下:
其中,
就是ID3算法中的新增增益。
计算各特征的信息增益率如下:
1.outlook特征的信息增益率。
上述内容已经计算了
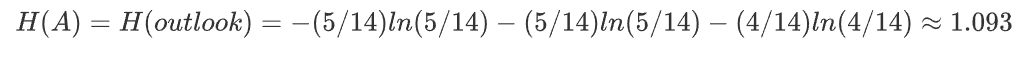
2.temperature特征的信息增益率
上述内容已经计算了
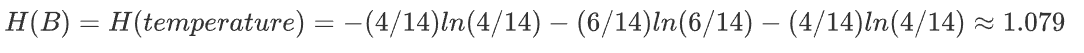
3.humidity特征的信息增益率
上述内容已经计算了
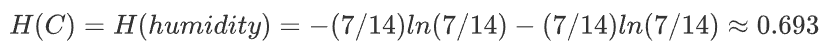
4.windy特征的信息增益率
上述内容已经计算了
对比上面四个特征的信息增益率,outlook特征的信息增益率最大,所以outlook作为root节点。其他计算方法类似。
code
代码块过长,这里只展示结果,源码在我的github仓库中。

3.3.4 实验
1.实验目的
学会决策树的基本原理和基本的构建方法。了解分类问题以及训练集、测试集的构造以及决策树的基本定义,决策树的用法,构建决策树的方法流程。并拓展到在属性选择时用什么指标来衡量,了解ID3信息熵以及CART使用基尼系数进行度量的两种重要方法。
2.实验数据
打球数据集
打球数据集示例
| 序号 | outlook | temperature | humidity | windy | play |
| 1 | sunny | hot | high | FALSE | no |
| 2 | sunny | hot | high | TRUE | no |
| 3 | overcast | hot | high | FALSE | yes |
| 4 | rainy | mild | high | FALSE | yes |
| 5 | rainy | cool | normal | FALSE | yes |
| 6 | rainy | cool | normal | TRUE | no |
| 7 | overcast | cool | normal | TRUE | yes |
| 8 | sunny | mild | high | FALSE | no |
| 9 | sunny | cool | normal | FALSE | yes |
| 10 | rainy | mild | normal | FALSE | yes |
| 11 | sunny | mild | normal | TRUE | yes |
| 12 | overcast | mild | high | TRUE | yes |
| 13 | overcast | hot | normal | FALSE | yes |
| 14 | rainy | mild | high | TRUE | no |
3.实验要求
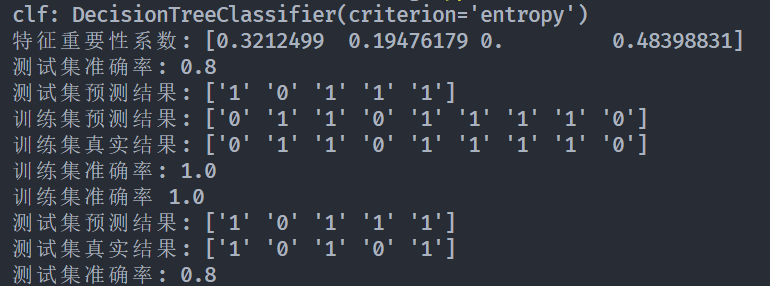
分别使用scikit-learn的相关包、Python语言编程来构建ID3、ID4.5决策树,最后将训练出的决策树以图表形式显示。
即为算法实现中的结果。
相关文章:

机器学习Python实战-第三章-分类问题-3.决策树算法
目录 3.3.1 原理简介 3.3.2 算法步骤 3.3.3 实战 3.3.4 实验 前半部分是理论介绍,后半部分是代码实践,可以选择性阅读。 决策树(decision tree)是功能强大而且相当受欢迎的分类和预估方法&…...

Spring三级缓存学习
Spring的三级缓存机制主要用于解决单例Bean的循环依赖问题。其核心在于提前暴露Bean的引用,允许未完全初始化的对象被其他Bean引用。以下是三级缓存的详细说明及其解决循环依赖的原理: 三级缓存结构 一级缓存(singletonObjects) 存…...

欧拉函数φ
函数作用 计算 1 1 1 ~ n n n中有多少个与 n n n互质的数。 函数公式 φ ( n ) n p 1 − 1 p 1 p 2 − 1 p 2 … … p m − 1 p m φ(n)n\times\frac{p_1-1}{p_1}\times\frac{p_2-1}{p_2}\times……\times\frac{p_m-1}{p_m} φ(n)np1p1−1p2p2−1……pmp…...

蓝桥杯刷题指南
蓝桥杯是中国普及性最好的计算机程序设计竞赛之一,参加者包括大学生、高中生和草根程序员等各个群体。通过刷题来提升自己的编程能力是参加蓝桥杯比赛的常见做法。下面是一些蓝桥杯常见的题型和刷题技巧,希望对大家有所帮助。 基础入门题目:…...

ctfshow WEB web12
发现只有这样一句话,应该是要看页面源代码的,右键查看页面源代码 发现可能存在代码执行漏洞,拼接一个?cmdphpinfo(); 成功显示出php信息, 说明存在代码执行漏洞 接下来遍历目录,我们要用到一个函数 glob() glob() 函数可以查找…...

ChromeOS 135 版本更新
ChromeOS 135 版本更新 一、ChromeOS 135 更新内容 1. ChromeOS 电池寿命优化策略 为了延长 Chromebook 的使用寿命,ChromeOS 135 引入了一项全新的电池充电限制策略 —— DevicePowerBatteryChargingOptimization,可提供更多充电优化选项,…...

redis的缓存
redis的缓存 一.缓存简介1.缓存2.redis作为数据库(MySQL)缓存的原因 二.缓存更新策略1.定期生成2.实时生成3.内存淘汰策略1)FIFO(First In First Out) 先进先出2)LRU(Least Recently Used)淘汰最久未使用的3)LFU(Least…...
)
字符串与相应函数(上)
字符串处理函数分类 求字符串长度:strlen长度不受限制的字符串函数:strcpy,strcat,strcmp长度受限制的字符串函数:strncpy,strncat,strncmp字符串查找:strstr,strtok错误信息报告:strerror字符操作,内存操作函数&…...
)
【微知】Mellanox网卡网线插入后驱动的几个日志?(Cable plugged;IPv6 ... link becomes ready)
概要 本文是一个简单的信息记录。记录的是当服务器网卡的光模块插入后内核的日志打印。通过这种日志打印,可以在定位分析问题的时候,知道进行过一次模块插拔。 日志 截图版: 文字版: [32704.121294] mlx5_core 0000:01:00.0…...

spring security oauth2.0的四种模式
OAuth 2.0 定义了 4 种授权模式(Grant Type),用于不同场景下的令牌获取。以下是每种模式的详细说明、适用场景和对比: 一、授权码模式(Authorization Code Grant) 适用场景 • Web 应用(有后端…...

MyBatis-Plus 核心功能
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、条件构造器1、核心 Wrapper 类型基础查询示例SQL 查询使用 QueryWrapper 实现查询 更新操作示例场景一:基础更新SQL 查询使用 QueryWrapper 实现更新…...

阿里云实时计算Flink版产品体验测评
阿里云实时计算Flink版产品体验测评 什么是阿里云实时计算Flink应用场景实时计算Flink&自建Flink集群性价比开发效率运维管理企业安全 场景落地 什么是阿里云实时计算Flink 实时计算Flink大家可能并不陌生,在实时数据处理上,可能会有所接触…...
)
少儿编程 scratch四级真题 2025年3月电子学会图形化编程等级考试Scratch四级真题解析(判断题)
2025年3月scratch编程等级考试四级真题 判断题(共10题,每题2分,共20分) 11、小圆点角色的程序如下左图所示,程序运行后的效果如下右图所示,自制积木中又调用了自己,这种算法叫做递归。 答案&a…...

【连载3】基础智能体的进展与挑战综述
基础智能体的进展与挑战综述 从类脑智能到具备可进化性、协作性和安全性的系统 【翻译团队】刘军(liujunbupt.edu.cn) 钱雨欣玥 冯梓哲 李正博 李冠谕 朱宇晗 张霄天 孙大壮 黄若溪 2. 认知 人类认知是一种复杂的信息处理系统,它通过多个专门的神经回路协调运行…...

Schaefer 400图谱
图谱下载: https://github.com/ThomasYeoLab/CBIG/tree/master/stable_projects/brain_parcellation/Schaefer2018_LocalGlobal/Parcellations/MNI 图 (第一行)显示了 Yeo et al. (2011) 的 7 网络和 17 网络分包。图…...

通过uri获取文件路径手机适配
青铜版本 return contentResolver.query(this, arrayOf(MediaStore.MediaColumns.DATA), null, null).let {if (it?.moveToFirst() true) {val columnIndex it.getColumnIndex(MediaStore.MediaColumns.DATA)val path it.getString(columnIndex)it.close()return path}&quo…...

Ubuntu 22.04 完美安装 ABAQUS 教程:从零到上手,解决兼容问题
教程概述与安装准备 本教程详细介绍了在 Ubuntu 22.04 系统上安装 ABAQUS 2023 及 ifort 2021 的步骤,并实现用户子程序的链接。教程同样适用于 ABAQUS 2021(需相应调整文件名和路径)以及 Ubuntu 18.04 至 22.04 系统,尽管未在所有版本上测试。需要注意的是,Intel 的 One…...

雷池WAF防火墙如何构筑DDoS防护矩阵?——解读智能语义解析对抗新型流量攻击
本文深度解析雷池WAF防火墙在DDoS攻防中的技术突破,通过智能语义解析、动态基线建模、协同防护体系三大核心技术,实现从流量特征识别到攻击意图预判的进化。结合2023年金融行业混合攻击防御案例,揭示新一代WAF如何通过协议级漏洞预判与AI行为…...

Linux权限理解
1.shell命令以及运行原理 下面来介绍一个话题,关于指令的运行原理,这里先简单理解就可以。当我们登上Linux后: yxx这里称之为用户名,VM-8-2-centos是主机名,~是当前目录,$是命令行提示符。 其中我们把上面的…...

使用labelme进行实例分割标注
前言 最近在学习实例分割算法,参考b站视频课教程,使用labelme标注数据集,在csdn找到相关教程进行数据集格式转换,按照相关目标检测网络对数据集格式的训练要求划分数据集。 1.使用labelme标注图片 在网上随便找了几张蘑菇图片&am…...

策略模式实现 Bean 注入时怎么知道具体注入的是哪个 Bean?
Autowire Resource 的区别 1.来源不同:其中 Autowire 是 Spring2.5 定义的注解,而 Resource 是 Java 定义的注解 2.依赖查找的顺序不同: 依赖注入的功能,是通过先在 Spring IoC 容器中查找对象,再将对象注入引入到当…...

PromptUp 网站介绍:AI助力,轻松创作
1. 网站定位与核心功能 promptup.net 可能是一个面向 创作者、设计师、营销人员及艺术爱好者 的AI辅助创作平台,主打 零门槛、智能化的内容生成与优化。其核心功能可能包括: AI艺术创作:通过输入关键词、选择主题或拖放模板,快速生成风格多样的数字艺术作品(如插画、海报…...

软件架构评估利器:质量效用树全解析
质量效用树是软件架构评估中的一种重要工具,它有助于系统地分析和评估软件架构在满足各种质量属性方面的表现。以下是关于质量效用树的详细介绍: 一、定义与作用 质量效用树是一种以树形结构来表示软件质量属性及其相关效用的模型。它将软件的质量目标…...
IP核时钟框架介绍)
XILINX DDR3专题---(1)IP核时钟框架介绍
1.什么是Reference Clock,这个时钟一定是200MHz吗? 2.为什么APP_DATA是128bit,怎么算出来的? 3.APP :MEM的比值一定是1:4吗? 4.NO BUFFER是什么意思? 5.什么情况下Reference Clock的时钟源可…...

ubuntu 2204 安装 vcs 2018
安装评估 系统 : Ubuntu 22.04.1 LTS 磁盘 : ubuntu 自身占用了 9.9G , 按照如下步骤 安装后 , 安装后的软件 占用 13.1G 仓库 : 由于安装 libpng12-0 , 添加了一个仓库 安装包 : 安装了多个包(lsb及其依赖包 libpng12-0)安装步骤 参考 ubuntu2018 安装 vcs2018 安装该…...

Python与去中心化存储:从理论到实战的全景指南【无标题】
Python与去中心化存储:从理论到实战的全景指南 随着区块链技术和Web3理念的兴起,去中心化存储逐渐成为构建新型互联网的核心模块之一。传统中心化存储的模式存在易被攻击、单点故障和高昂成本等问题,而去中心化存储通过分布式架构实现了更高的安全性、可靠性和数据透明度。…...

C++语言程序设计——01 C++程序基本结构
目录 编程语言一、C程序执行过程二、C基础框架三、输出语句cout换行 四、注释方法 编程语言 我们知道c是一门编程语言,它是在c语言的基础上发展而来,添加了类、对象、继承、多态等概念,我们可以称为它是一种面向对象编程的语言。 不过在学习…...
Unity UI中的Pixels Per Unit
Pixels Per Unit在图片导入到Unity的时候,将图片格式设置为Sprite的情况下会出现,其意思是精灵中的多少像素对应世界中的一个单位,默认是100 1. 对于在世界坐标中 在世界坐标中,一般对于Sprite的应用是Sprite Renderer组件 使…...
安卓开发中的后端接口调用详讲解)
(十八)安卓开发中的后端接口调用详讲解
在安卓开发中,后端接口调用是连接移动应用与服务器的重要环节,用于实现数据的获取、提交和处理。本文将详细讲解安卓开发中后端接口调用的步骤,结合代码示例和具体的使用场景,帮助你全面理解这一过程。 什么是后端接口?…...

使用freebsd-update 升级FreeBSD从FreeBSD 14.1-RELEASE-p5到FreeBSD 14.2-RELEASE
使用freebsd-update 升级FreeBSD从FreeBSD 14.1-RELEASE-p5到FreeBSD 14.2-RELEASE 先升级小版本 准备升级前,先把当前的小版本升级到顶,比如现在是FreeBSD 14.1-RELEASE-p5,先升级到最新的14.1版本,使用命令: # fr…...
)
基础排序算法(三傻排序)
1. 选择排序 原理:每次从未排序部分选出最小(或最大)元素,放到已排序部分的末尾。时间复杂度:O(n),效率低但实现简单,适合小规模数据。 //选择排序public static void selectSort(int[] arr){i…...

五分钟了解智能体
在2025年人工智能技术全面渗透社会的背景下,“智能体”(Agent)已成为推动第四次工业革命的核心概念之一。从自动驾驶汽车到医疗诊断系统,从智能家居中枢到金融量化交易平台,智能体正在重构人类与技术交互的方式。本文将…...

【机器学习】笔记| 通俗易懂讲解:生成模型和判别模型|01
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾:【科研小白系列】这些基础linux命令,你都掌握了嘛?每日一言🌼: “脑袋想不明白的,就用脚想”—…...
)
Jieba分词的原理及应用(三)
前言 “结巴”中文分词:做最好的 Python 中文分词组件 上一篇文章讲了使用TF-IDF分类器范式进行企业级文本分类的案例。其中提到了中文场景不比英文场景,在喂给模型之前需要进行分词操作。 分词的手段有很多,其中最常用的手段还是Jieba库进行…...

神经网络背后的数学原理
神经网络背后的数学原理 数学建模神经网络数学原理 数学建模 标题民科味道满满。其实这篇小短文就是自我娱乐。 物理世界是物种多样,千姿百态。可以从不同的看待眼中的世界,包括音乐、绘画、舞蹈、雕塑等各种艺术形式。但这些主观的呈现虽然在各人眼中…...
)
常用图像滤波及色彩调节操作(Opencv)
1. 常用滤波/模糊操作 import cv2 import numpy as np import matplotlib.pyplot as plotimg cv2.imread("tmp.jpg") img cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img_g cv2.GaussianBlur(img, (7,7), 0) img_mb cv2.medianBlur(img, ksize7) #中指滤波 img_bm …...

FFMPEG和opencv的编译
首先 sudo apt-get update -qq && sudo apt-get -y install autoconf automake build-essential cmake git-core libass-dev libfreetype6-dev libgnutls28-dev libmp3lame-dev libsdl2-dev libtool libva-dev libvdpau-dev libvorbis-de…...

用户登录不上linux服务器
一般出现这种问题,重新用root用户修改lsy用户的密码即可登录,但是当修改了还是登录不了的时候,去修改一个文件用root才能修改, 然后在最后添加上改用户的名字,例如 原本是只有user的,现在我加上了lsy了&a…...

【项目管理】第11章 项目成本管理-- 知识点整理
相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应:第6章-第19章 (二)知识笔记 第11章 项目成本管理 1.管理基础…...
)
Python中的strip()
文章目录 基本语法:示例:1. 默认移除空白字符:2. 移除指定字符:3. 不修改原字符串: 相关方法:示例: 注意事项: 在 Python 中, strip() 是一个字符串方法,用于…...
完整讲解与实战应用)
设计模式 Day 9:命令模式(Command Pattern)完整讲解与实战应用
🔄 回顾 Day 8:策略模式 在 Day 8 中我们讲解了策略模式: 用于封装多个可切换的算法逻辑,让调用者在运行时选择合适的策略。它强调的是“行为选择”,是针对“算法或行为差异”而设计。通过 PaymentStrategy、路径规划…...

【正点原子】STM32MP257 同构多核架构下的 ADC 电压采集与处理应用开发实战
在嵌入式系统中,ADC模拟电压的读取是常见的需求。如何高效、并发、且可控地完成数据采集与处理?本篇文章通过双线程分别绑定在 Linux 系统的不同 CPU 核心上,采集 /sys/bus/iio 接口的 ADC 原始值与缩放系数 scale,并在另一个核上…...

区块链从专家到小白
文章目录 含义应用场景典型特征 含义 以非对称加密算法为基础。 每个**区块(Block)**包含: 交易数据(如转账记录、合约内容)。 时间戳(记录生成时间)。 哈希值(当前区…...
)
记录centos8安装宝塔过程(两个脚本)
1、切换系统源(方便使用宝塔安装脚本下载) bash <(curl -sSL https://linuxmirrors.cn/main.sh) 2、宝塔安装脚本在宝塔的官网 宝塔面板下载,免费全能的服务器运维软件 根据自己的系统选择相应的脚本 urlhttps://download.bt.cn/insta…...

DAY 42 leetcode 151--哈希表.反转字符串中的单词
题号151 给你一个字符串 s ,请你反转字符串中 单词 的顺序。 单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。 返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。 我的解法 暴力解法,先将String转为字…...

[VTK] 四元素实现旋转平移
VTK 实现旋转,有四元数的方案,也有 vtkTransform 的方案;主要示例代码如下: //构造旋转四元数vtkQuaterniond rotation;rotation.SetRotationAngleAndAxis(vtkMath::RadiansFromDegrees(90.0),0.0, 1.0, 0.0);//构造旋转点四元数v…...
2.2 分词器Tokenizer)
AI大模型:(二)2.2 分词器Tokenizer
目录 1.分词技术的发展 2.分词器原理 2.1.基于词分词 2.2.基于字符分词 2.3.基于子词分词 3.手搓Byte-Pair Encoding (BPE)分词及训练 3.1.Byte-Pair Encoding (BPE)分词原理 3.2.手搓Byte-Pair Encoding (BPE)分词器 4.如何选择已有的分词器 1. 常见子词分词器及特点…...

codeforces A. Simple Palindrome
目录 题面 代码 题面 A. 简单回文串 每个测试用例时间限制:1 秒 每个测试用例内存限制:256 兆字节 纳雷克要在幼儿园陪一些两岁的孩子度过两个小时。他想教孩子们竞技编程,他们的第一堂课是关于回文串的。 纳雷克发现孩子们只认识英文字母…...
:冯诺依曼结构)
Linux 进程基础(一):冯诺依曼结构
文章目录 一、冯诺依曼体系结构是什么?🧠二、冯诺依曼体系为何成为计算机组成的最终选择?(一)三大核心优势奠定主流地位(二)对比其他架构的不可替代性 三、存储分级:速度与容量的平衡…...
详解)
向量存储(VectorStore)详解
一、向量存储的核心概念 向量存储(VectorStore)是一种用于存储和检索高维向量数据的数据库或存储解决方案,特别适用于处理经过嵌入模型转化后的数据。与传统关系数据库不同,VectorStore 执行的是相似性搜索,而非精确匹…...