李宏毅NLP-2-语音识别part1
语音识别part1

这是一篇名为 “Speech Recognition is Difficult?”(语音识别很难吗? )的文章。作者是 J.R. Pierce,来自贝尔电话实验室(Bell Telephone Laboratories, Inc.) 。文中提到语音识别虽有吸引力,但仅具备某些条件是不够的。还将其吸引力类比为水变汽油、从海水中提取黄金、治愈癌症、登月等极具吸引力的设想 ,暗示语音识别虽诱人但并非易事。
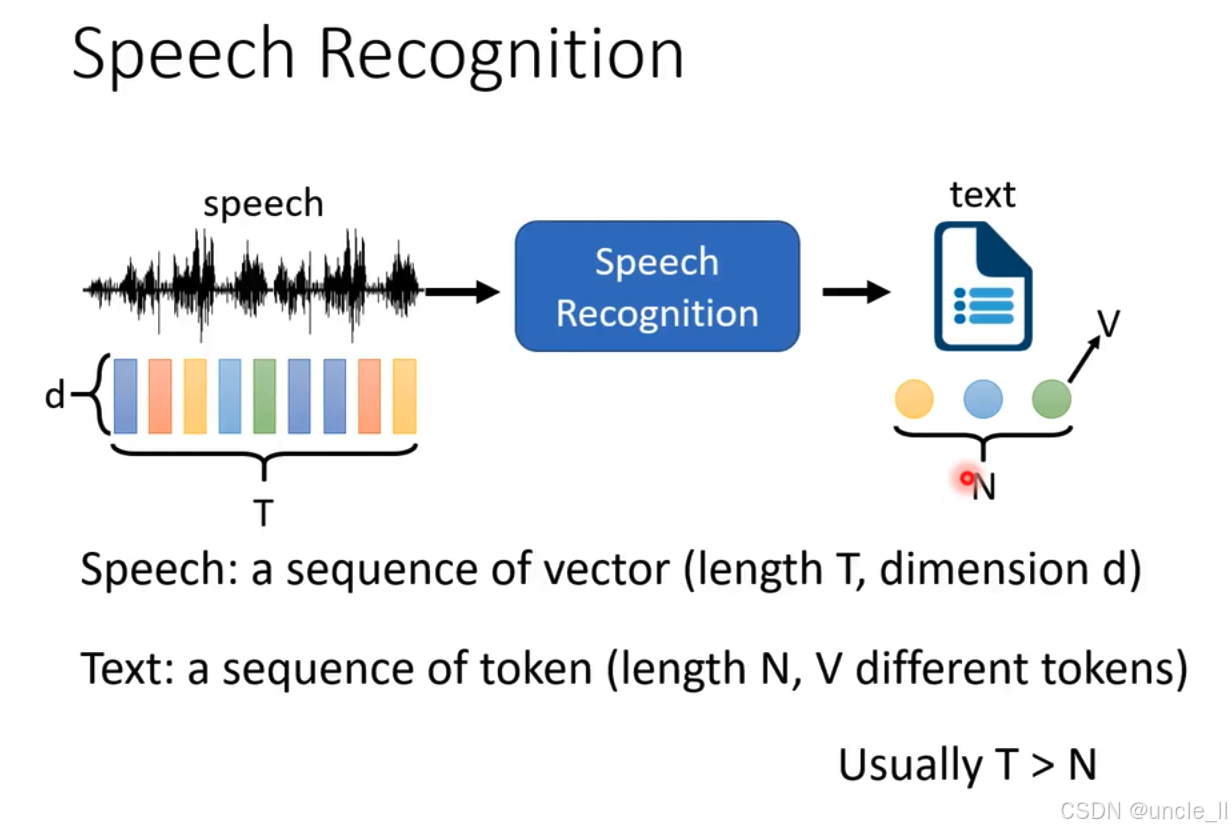
语音识别(Speech Recognition)的基本原理:
- 输入:左侧的波形代表语音(speech) ,语音被表示为一个向量序列,长度为 T,维度为 d 。
- 处理过程:语音信号进入 “Speech Recognition” 模块,该模块对语音进行处理。
- 输出:右侧的文档图标代表文本(text) ,文本是一个标记(token)序列,长度为 N ,有 V 种不同的标记。
- 补充说明:图中还指出通常语音向量序列的长度 T 大于文本标记序列的长度 N 。
介绍与语音识别相关的 “Token”(标记)概念,具体涉及音素(Phoneme)和字素(Grapheme) :
音素(Phoneme)
- 定义:声音的最小单位。
- 示例:图中展示了 “one punch man” 的音素表示分别为 “W AH N” “P AH N CH” “M AE N” 。右上角黄色框是一个词汇表(Lexicon)示例,呈现了单词到音素的映射,如 “cat” 对应 “K AE T” 、“good” 对应 “G UH D” 等 。
字素(Grapheme)
- 定义:书写系统的最小单位。
- 英文示例:以 “one_punch_man” 为例,其长度 N = 13 ,理论上不同字素数量 V 基于 26 个英文字母,再加上空格等可能的字符 。
- 中文示例:给出 “一 拳 超 人” ,长度 N = 4 ,不同字素数量 V 约 4000 ,并指出中文书写系统不需要空格来分隔字词 。
“lexicon free” 表示相关系统或方法不依赖预先设定的词汇表来进行处理,比如某些语音识别技术尝试直接对语音信号进行分析转换,不借助传统词汇表的辅助,以适应更灵活、未知的语言场景 。
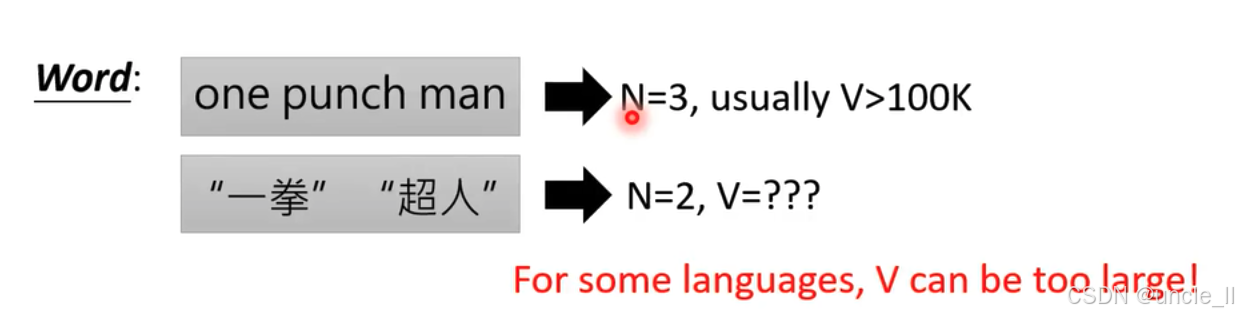
- 英文示例:“one punch man” 被视为一个由 3 个单词组成的序列(N = 3 ) ,一般情况下,英语中不同单词数量 V 通常大于 10 万(V > 100K ) 。
- 中文示例:“一拳超人” 是 2 个词组成的序列(N = 2 ) ,但具体不同字词数量 V 无法明确给出(V = ??? ) 。
- 对于某些语言来说,V(不同字词数量)可能会非常大,这在语音识别、自然语言处理等任务中,会给模型处理带来挑战 。

耳其语作为黏着语(Agglutinative language)的特点: - 信息来源:标明信息来自 “http://tkturkey.com/(土女時代)” 。
- 单词演变示例:以 “Müvaffak”(成功的 )为例,展示通过添加词缀进行词性和词义变化。如 “Müvaffakiyet” 转为名词;“Müvaffakiyetsiz” (添加 “siz” )变为 “不成功” ;“Müvaffakiyetsizleş”(添加 “leş” )是 “變得不成功” ;“Müvaffakiyetsizleştir” (添加 “ştir” )是 “使變得不成功” 。
- 超长单词展示:给出一个长达 70 个字符的单词 “Müvaffakiyetsizleştiricileştiriveremeyebileceklerimizdenmişsinizcesine” ,并附有中文翻译 “如果你是我們當中不容易變成不成功者的其中一個” ,体现黏着语通过不断添加词缀构成复杂长词的特性。

词素(Morpheme):
- 定义: 指出词素是最小的有意义的语言单位,其规模小于单词(word) ,大于字素(grapheme )。
- 示例: 以 “unbreakable” 为例,可拆分为 “un”(表示否定 )、“break”(打破 )、“able”(能够…… 的 ) 三个词素。以 “rekillable” 为例,可拆分为 “re”(表示重复 )、“kill”(杀死 )、“able”(能够…… 的 )三个词素 。
- 确定词素的角度可以是语言学(linguistic )层面或统计学(statistic )层面
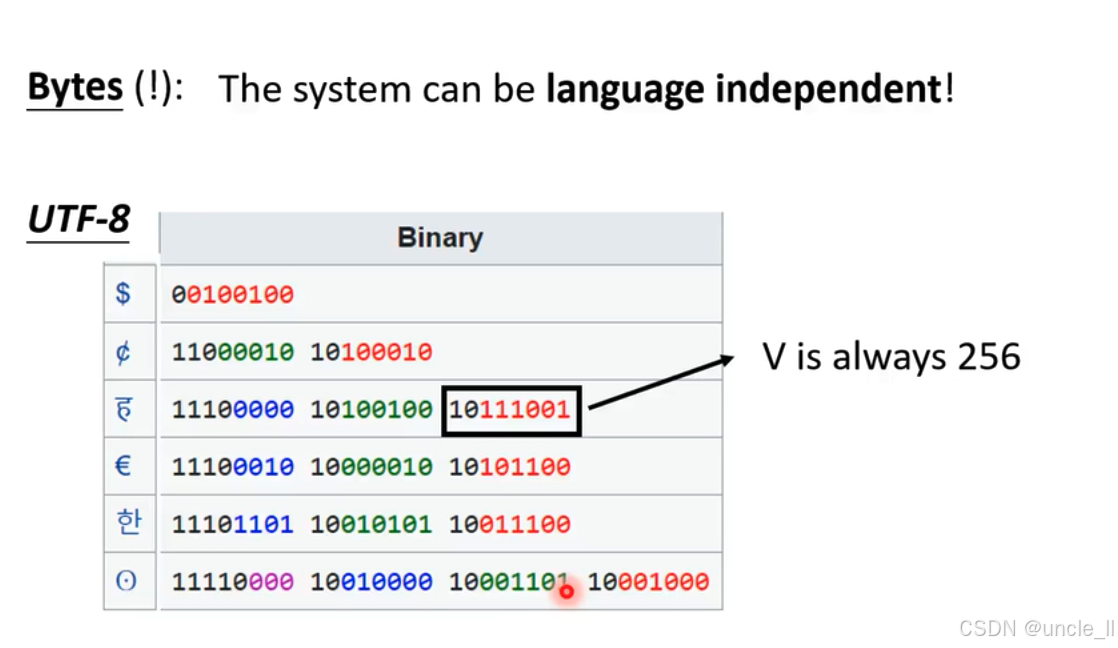
字节(Bytes)在实现语言无关性系统方面的作用,采用 UTF - 8 编码方式: - 标题 “Bytes (!): The system can be language independent!” 表明通过字节处理,系统能够实现语言无关性 。
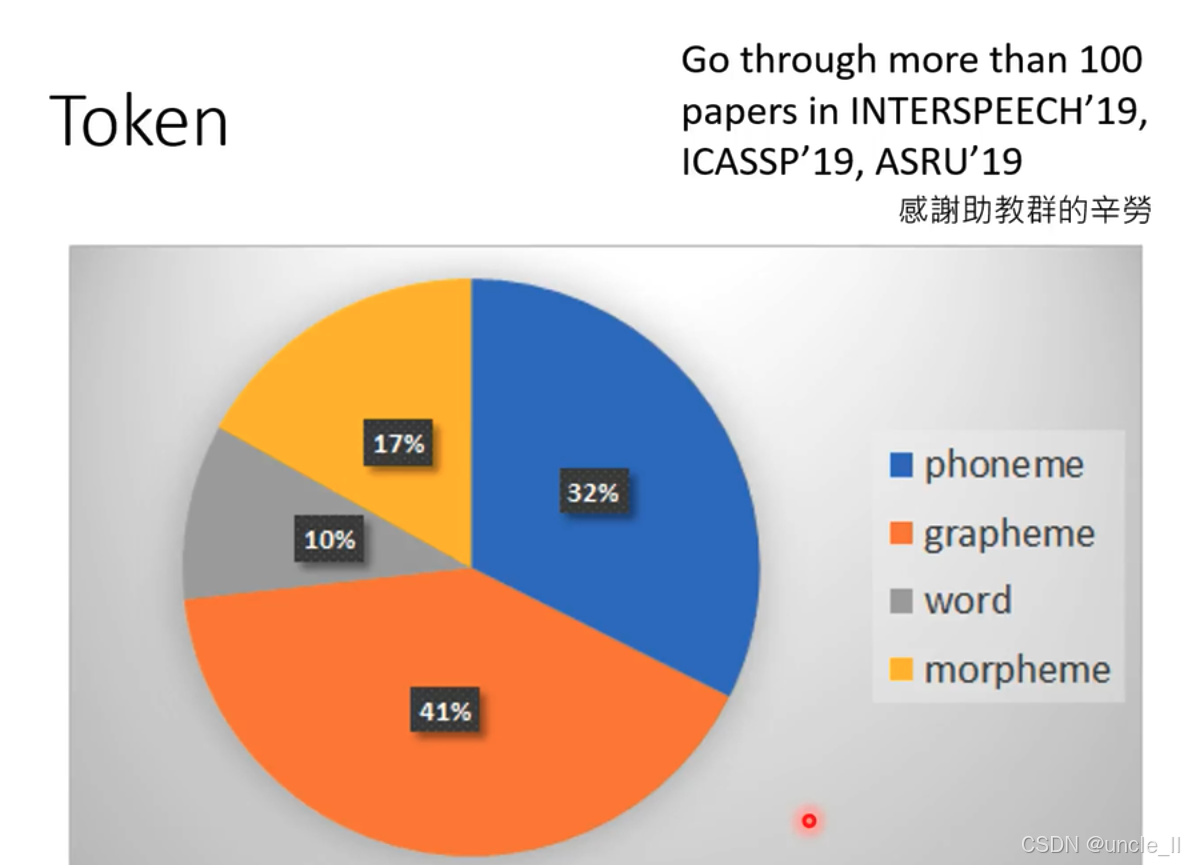
数据来源于对 INTERSPEECH’19、ICASSP’19、ASRU’19 这三个会议超 100 篇论文的调研 ,并感谢助教群的辛苦工作。 图中不同颜色代表不同类型的 Token:
- 蓝色(phoneme,音素):占比 32% ,音素是声音的最小单位。
- 橙色(grapheme,字素):占比 41% ,字素是书写系统的最小单位。
- 灰色(word,单词):占比 10% 。
- 黄色(morpheme,词素):占比 17% ,词素是最小的有意义的语言单位。 该图直观呈现了不同类型 Token 在相关论文研究中的占比情况 。
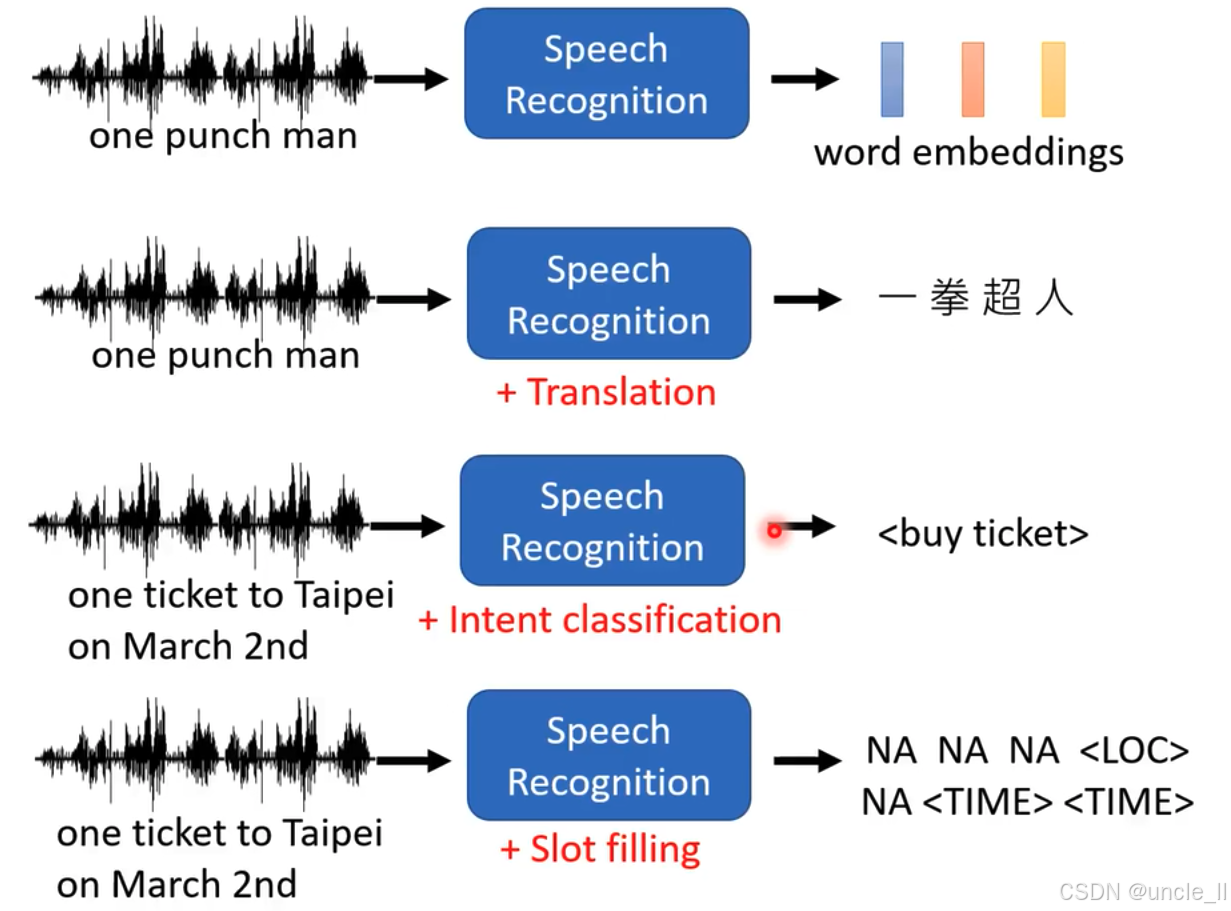
语音识别(Speech Recognition)在不同应用场景下的处理流程:
生成词嵌入(word embeddings)
- 输入语音“one punch man” ,经过语音识别模块,输出为“word embeddings” ,即把语音转换为词的向量表示,用于进一步的自然语言处理任务 。
语音识别加翻译(Translation)
- 同样输入“one punch man” ,经过语音识别后,再进行翻译操作,最终输出为中文“一拳超人” ,体现语音识别与翻译结合的应用 。
语音识别加意图分类(Intent classification)
- 输入语音“one ticket to Taipei on March 2nd” ,经语音识别后,通过意图分类判断用户意图,输出为“” ,表明识别出用户有购票意图 。
语音识别加槽位填充(Slot filling)
- 输入“one ticket to Taipei on March 2nd” ,经语音识别后进行槽位填充操作,输出为“NA NA NA NA

语音信号的声学特征(Acoustic Feature)
语音波形与帧
- 图中展示了一段语音的波形。语音处理常将其分割成帧,图中红色框出时长25ms的片段,在16KHz采样率下对应400个采样点 。
- 标注出帧移为10ms ,意味着每10ms移动一次窗口截取语音帧。由此可知,1秒的语音会被划分为100帧(1s = 1000ms,1000ms÷10ms = 100 ) 。
声学特征
- 帧(frame):代表语音信号被划分后的基本单元。
- 特征维度:介绍了两种常用的声学特征,39维的梅尔频率倒谱系数(MFCC) ,以及80维的滤波器组输出(filter bank output) 。右上角彩色方块表示声学特征序列,长度为T,维度为d ,是语音信号处理后的特征表示形式 。 这张图主要阐述语音信号如何从时域波形转换为便于后续语音识别等任务处理的声学特征 。
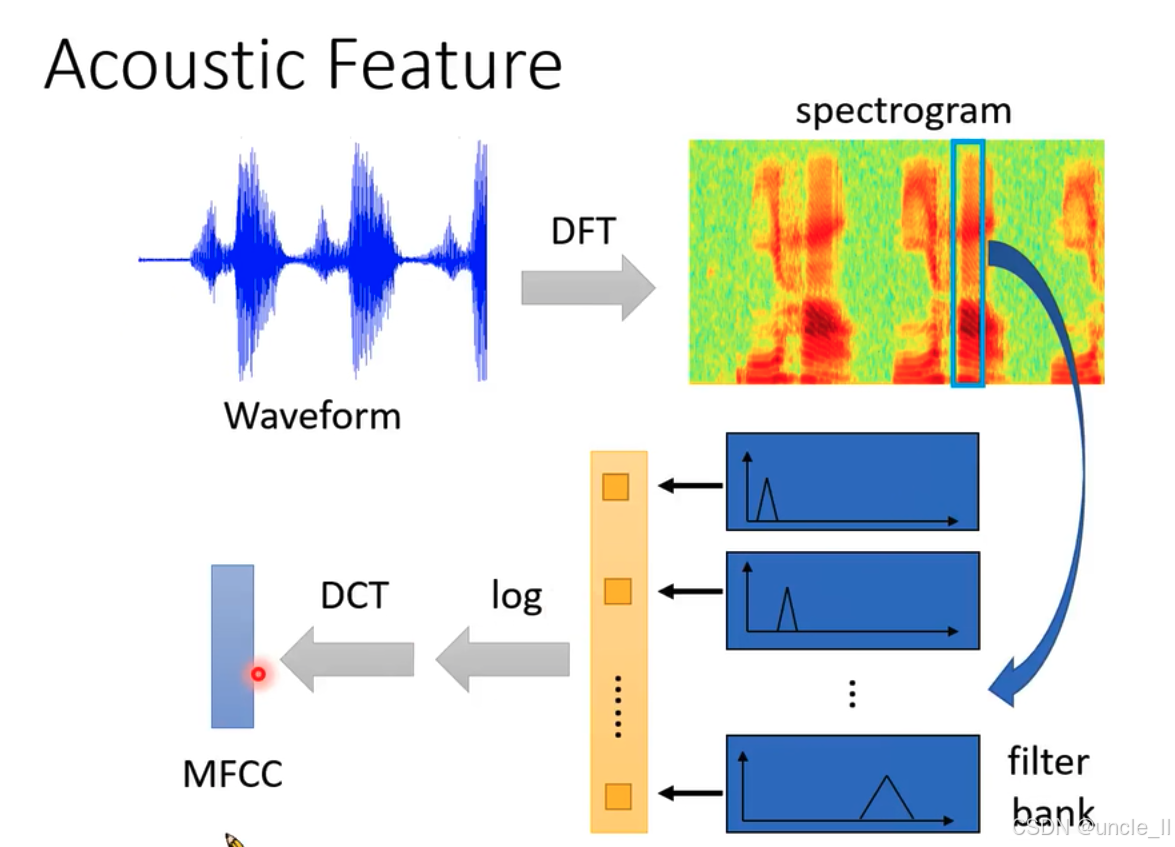
这张图展示了从语音波形(Waveform)到梅尔频率倒谱系数(MFCC)这一声学特征提取的过程:
从波形到时频谱图
- 左侧的蓝色波形代表语音信号的原始时域波形。通过离散傅里叶变换(DFT) ,将时域的语音信号转换到频域,得到右侧的时频谱图(spectrogram) ,呈现语音信号在不同时间和频率上的能量分布 。
梅尔频率倒谱系数提取
- 时频谱图经过滤波器组(filter bank)处理,滤波器组由多个三角形滤波器组成,对频域信号进行滤波 。
- 滤波后的信号取对数(log)操作,再通过离散余弦变换(DCT) ,最终得到梅尔频率倒谱系数(MFCC) 。MFCC是语音识别中常用的声学特征,能够有效表征语音信号的特性 。 图中清晰呈现了语音信号从原始波形到MFCC特征提取的关键步骤 。

关于声学特征(Acoustic Feature)使用占比的饼状图 。数据源于对 INTERSPEECH’19、ICASSP’19、ASRU’19 三个会议超 100 篇论文的调研。 图中不同颜色代表不同类型的声学特征及其占比:
- 深蓝色(filter bank output,滤波器组输出):占比 75% ,是使用最广泛的声学特征。
- 橙色(MFCC,梅尔频率倒谱系数):占比 18% 。
- 灰色(spectrogram,频谱图):占比 4% 。
- 黄色(waveform,波形):占比 2% 。
- 浅蓝色(other,其他):占比 1% 。
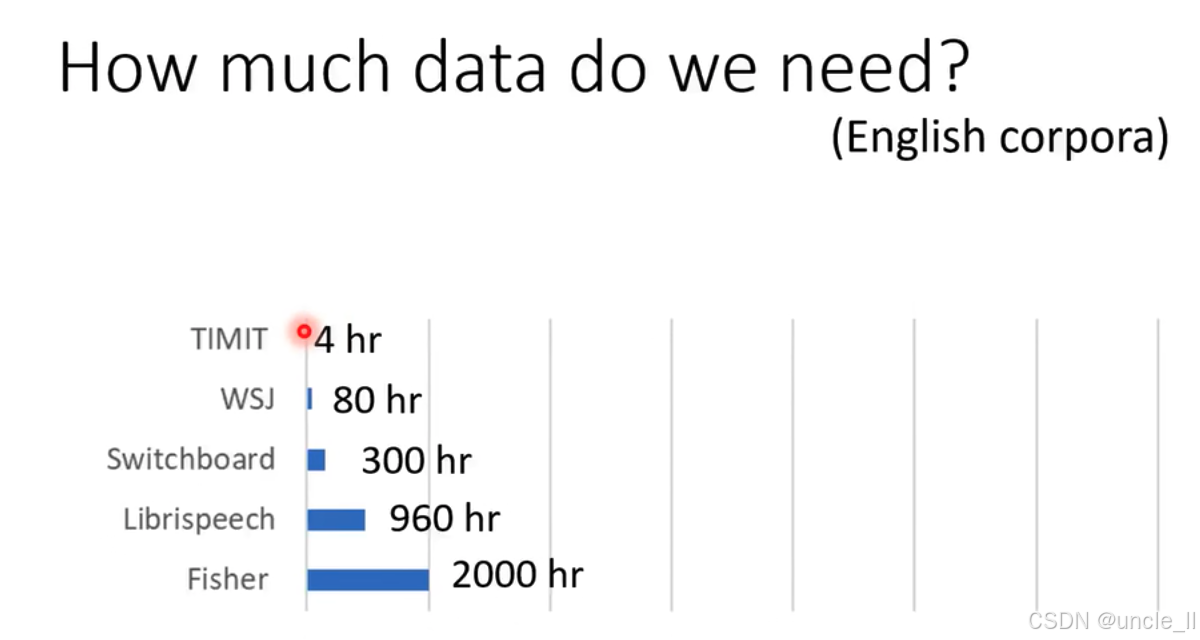
图中展示了几种常见英语语音数据集及其数据量:
- TIMIT:数据量为4小时,是相对较小的数据集 。
- WSJ(Wall Street Journal):数据量为80小时 。
- Switchboard:数据量为300小时 。
- Librispeech:数据量为960小时 。
- Fisher:数据量最大,为2000小时 。
将cv的数据集转换成nlp数据集的情况下,是多大:

对于大公司的训练资料而言,都超过了1万小时。

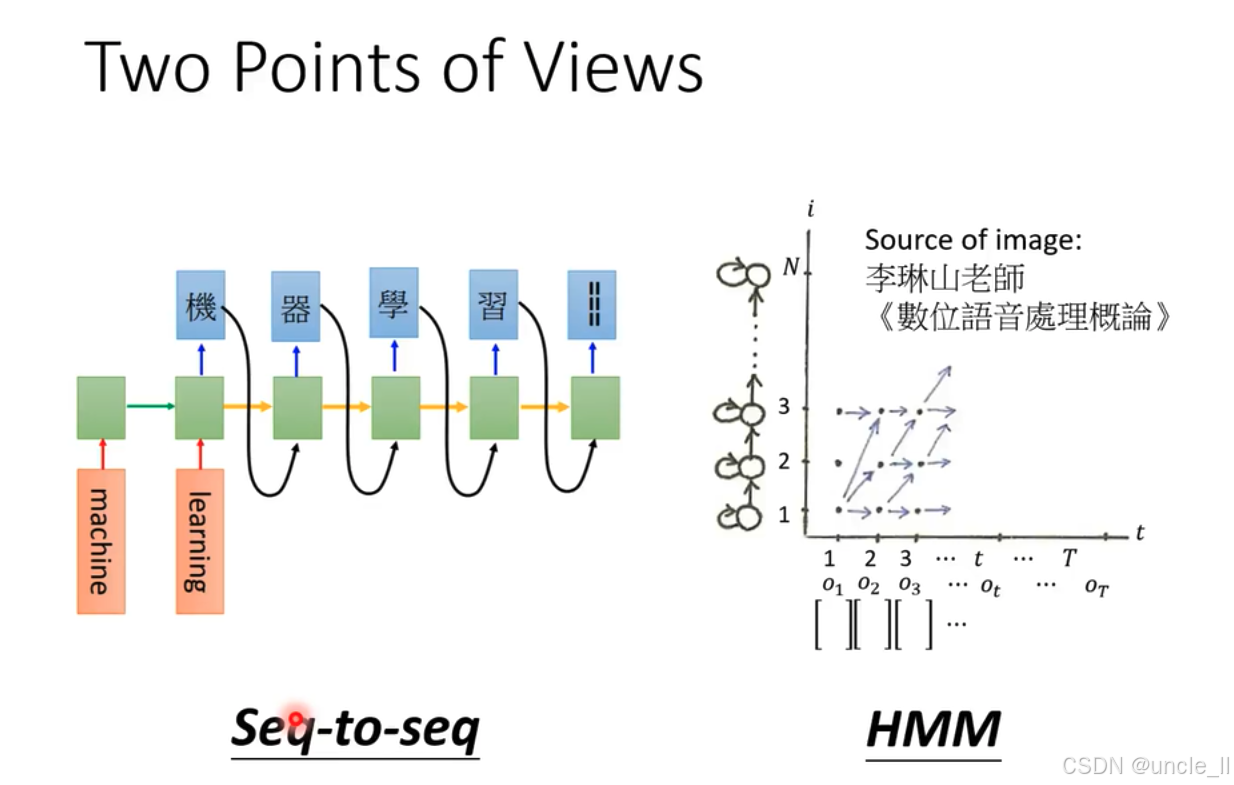
语音处理中的两种观点,分别是序列到序列(Seq - to - seq)模型和隐马尔可夫模型(HMM) :
序列到序列(Seq - to - seq)模型
- 左侧部分展示了Seq - to - seq模型结构。底部橙色的“machine”和“learning”通过箭头指向绿色模块,代表机器学习相关操作。绿色模块之间通过橙色箭头依次连接,体现数据的序列处理过程,每个绿色模块又通过黑色箭头与上方蓝色模块相连,蓝色模块内有汉字“機器學習” ,表示模型对输入序列进行处理并输出相应序列 。
隐马尔可夫模型(HMM)
- 右侧部分展示了HMM。横轴t代表时间,从1到T ,纵轴i从1到N ,表示状态。图中有多个状态节点,用圆圈表示,节点间有箭头连接,表示状态转移。下方的 o 1 o_1 o1到 o T o_T oT表示在不同时间点的观测值。图像来源标注为李琳山老师的《數位語音處理概論》 。

列出了几种语音识别领域的模型:
Listen, Attend, and Spell (LAS)
- 由Chorowski等人在NIPS’15(神经信息处理系统大会,2015年 )上提出。该模型结合注意力机制,使模型在处理语音时能聚焦关键部分,提升识别效果 。
Connectionist Temporal Classification (CTC)
- 由Graves等人在ICML’06(国际机器学习会议,2006年 )上提出。用于解决语音序列和文本序列难以精准对齐的问题,允许模型直接处理未对齐的语音数据 。
RNN Transducer (RNN-T)
- 由Graves在ICML workshop’12(国际机器学习会议研讨会,2012年 )上提出。结合循环神经网络(RNN) ,可有效处理语音的时序信息,在语音识别任务中广泛应用 。
Neural Transducer
- 由Jaitly等人在NIPS’16(神经信息处理系统大会,2016年 )上提出。属于端到端的语音识别模型,旨在更高效地将语音转换为文本 。
Monotonic Chunkwise Attention (MoChA)
- 由Chiu等人在ICLR’18(国际学习表征会议,2018年 )上提出。基于注意力机制,以分块方式处理语音数据,提高模型处理效率和识别准确性 。 幻灯片为后续对这些模型的详细讲解做铺垫 。
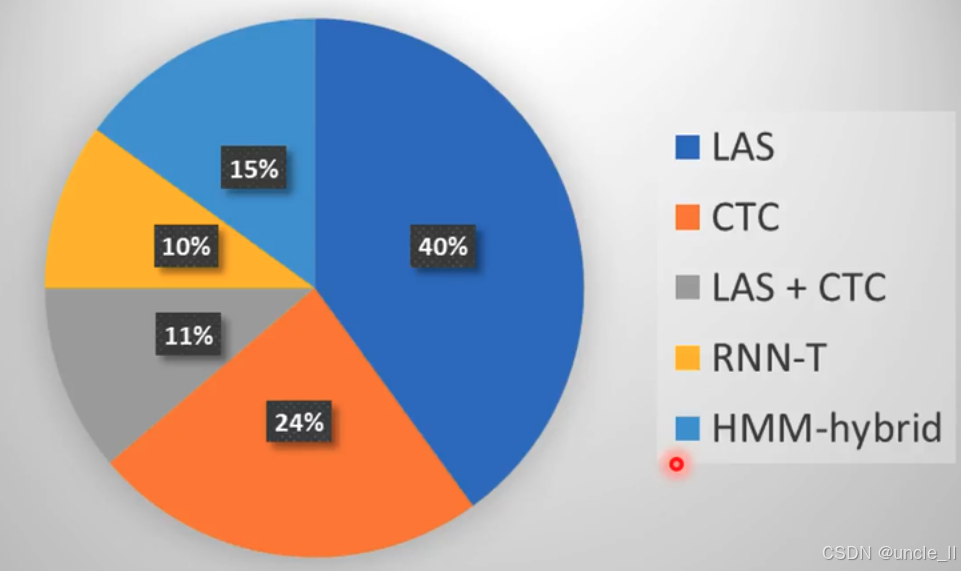
这是一张关于语音识别模型使用占比的饼状图 。数据来源于对INTERSPEECH’19、ICASSP’19、ASRU’19三个会议超100篇论文的调研。图中不同颜色代表不同的语音识别模型及其占比:
- 深蓝色(LAS):占比40% ,是使用最广泛的模型之一。
- 橙色(CTC):占比24% 。
- 灰色(LAS + CTC ):占比11% ,表示结合了LAS和CTC的模型。
- 黄色(RNN-T):占比10% 。
- 浅蓝色(HMM-hybrid):占比15% 。
相关文章:

李宏毅NLP-2-语音识别part1
语音识别part1 这是一篇名为 “Speech Recognition is Difficult?”(语音识别很难吗? )的文章。作者是 J.R. Pierce,来自贝尔电话实验室(Bell Telephone Laboratories, Inc.) 。文中提到语音识别虽有吸引力…...

AUTOSAR图解==>AUTOSAR_SWS_MemoryMapping
AUTOSAR 内存映射机制详解 深入解析AUTOSAR标准中的内存映射技术 目录 AUTOSAR 内存映射机制详解 目录1. 概述2. 内存映射架构 2.1 架构组成2.2 映射类型2.3 关键组件3. 配置数据模型 3.1 主要配置容器3.2 内存段类型3.3 初始化策略4. 映射使用流程 4.1 配置阶段4.2 开发阶段...

探索 HTML5 新特性:提升网页开发的现代体验
在 Web 开发的演进历程中,HTML5 无疑是一座重要的里程碑。它不仅为网页带来了更丰富的功能,还提升了开发效率与用户体验。本文将深入探讨 HTML5 那些令人瞩目的新特性,助你紧跟现代 Web 开发潮流。 一、语义化标签:让结构更清晰 …...

系统设计思维的讨论
我们经常说自己熟悉了spring,能够搭建起一个项目基本框架,并且在此之上进行开发,用户or客户提出需求碰到不会的百度找找就可以实现。干个四五年下一份工作就去面试架构师了,运气好一些可能在中小公司真的找到一份架构师、技术负责…...

【音视频】SDL播放PCM音频
相关API 打开音频设备 int SDLCALL SDL_OpenAudio(SDL_AudioSpec * desired, SDL_AudioSpec * obtained); desired:期望的参数。obtained:实际音频设备的参数,一般情况下设置为NULL即可。 SDL_AudioSpec typedef struct SDL_AudioSpec { i…...

FATFS文件系统配置
1、FatFs模块功能配置选项参考ffconf.h函数配置链接:FatFs模块功能配置选项 2、FATFS配置 FATFS 支持长文件名链接: FATFS:配置 FATFS 支持长文件名 3、 FATFS移植链接1 4、 FATFS移植链接2 5、FAT32 和 FATFS 是两个不同层次的概念,分别属于…...

JVM 字节码是如何存储信息的?
JVM 字节码是 Java 虚拟机 (JVM) 执行的指令集,它是一种与平台无关的二进制格式,在任何支持 JVM 的平台上都可运行的Java 程序。 字节码存储信息的方式,主要通过以下几个关键组成部分和机制来实现: 1. 指令 (Opcodes) 和 操作数 …...
——select)
Linux:多路转接(上)——select
目录 一、select接口 1.认识select系统调用 2.对各个参数的认识 二、编写select服务器 一、select接口 1.认识select系统调用 int select(int nfds, fd_set readfds, fd_set writefds, fd_set exceptfds, struct timeval* timeout); 头文件:sys/time.h、sys/ty…...

如何解决DDoS攻击问题 ?—专业解决方案深度分析
本文深入解析DDoS攻击面临的挑战与解决策略,提供了一系列防御技术和实践建议,帮助企业加强其网络安全架构,有效防御DDoS攻击。从攻击的识别、防范措施到应急响应,为网络安全工作者提供了详细的操作指引。 DDoS攻击概览:…...

机器学习Python实战-第三章-分类问题-3.决策树算法
目录 3.3.1 原理简介 3.3.2 算法步骤 3.3.3 实战 3.3.4 实验 前半部分是理论介绍,后半部分是代码实践,可以选择性阅读。 决策树(decision tree)是功能强大而且相当受欢迎的分类和预估方法&…...

Spring三级缓存学习
Spring的三级缓存机制主要用于解决单例Bean的循环依赖问题。其核心在于提前暴露Bean的引用,允许未完全初始化的对象被其他Bean引用。以下是三级缓存的详细说明及其解决循环依赖的原理: 三级缓存结构 一级缓存(singletonObjects) 存…...

欧拉函数φ
函数作用 计算 1 1 1 ~ n n n中有多少个与 n n n互质的数。 函数公式 φ ( n ) n p 1 − 1 p 1 p 2 − 1 p 2 … … p m − 1 p m φ(n)n\times\frac{p_1-1}{p_1}\times\frac{p_2-1}{p_2}\times……\times\frac{p_m-1}{p_m} φ(n)np1p1−1p2p2−1……pmp…...

蓝桥杯刷题指南
蓝桥杯是中国普及性最好的计算机程序设计竞赛之一,参加者包括大学生、高中生和草根程序员等各个群体。通过刷题来提升自己的编程能力是参加蓝桥杯比赛的常见做法。下面是一些蓝桥杯常见的题型和刷题技巧,希望对大家有所帮助。 基础入门题目:…...

ctfshow WEB web12
发现只有这样一句话,应该是要看页面源代码的,右键查看页面源代码 发现可能存在代码执行漏洞,拼接一个?cmdphpinfo(); 成功显示出php信息, 说明存在代码执行漏洞 接下来遍历目录,我们要用到一个函数 glob() glob() 函数可以查找…...

ChromeOS 135 版本更新
ChromeOS 135 版本更新 一、ChromeOS 135 更新内容 1. ChromeOS 电池寿命优化策略 为了延长 Chromebook 的使用寿命,ChromeOS 135 引入了一项全新的电池充电限制策略 —— DevicePowerBatteryChargingOptimization,可提供更多充电优化选项,…...

redis的缓存
redis的缓存 一.缓存简介1.缓存2.redis作为数据库(MySQL)缓存的原因 二.缓存更新策略1.定期生成2.实时生成3.内存淘汰策略1)FIFO(First In First Out) 先进先出2)LRU(Least Recently Used)淘汰最久未使用的3)LFU(Least…...
)
字符串与相应函数(上)
字符串处理函数分类 求字符串长度:strlen长度不受限制的字符串函数:strcpy,strcat,strcmp长度受限制的字符串函数:strncpy,strncat,strncmp字符串查找:strstr,strtok错误信息报告:strerror字符操作,内存操作函数&…...
)
【微知】Mellanox网卡网线插入后驱动的几个日志?(Cable plugged;IPv6 ... link becomes ready)
概要 本文是一个简单的信息记录。记录的是当服务器网卡的光模块插入后内核的日志打印。通过这种日志打印,可以在定位分析问题的时候,知道进行过一次模块插拔。 日志 截图版: 文字版: [32704.121294] mlx5_core 0000:01:00.0…...

spring security oauth2.0的四种模式
OAuth 2.0 定义了 4 种授权模式(Grant Type),用于不同场景下的令牌获取。以下是每种模式的详细说明、适用场景和对比: 一、授权码模式(Authorization Code Grant) 适用场景 • Web 应用(有后端…...

MyBatis-Plus 核心功能
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、条件构造器1、核心 Wrapper 类型基础查询示例SQL 查询使用 QueryWrapper 实现查询 更新操作示例场景一:基础更新SQL 查询使用 QueryWrapper 实现更新…...

阿里云实时计算Flink版产品体验测评
阿里云实时计算Flink版产品体验测评 什么是阿里云实时计算Flink应用场景实时计算Flink&自建Flink集群性价比开发效率运维管理企业安全 场景落地 什么是阿里云实时计算Flink 实时计算Flink大家可能并不陌生,在实时数据处理上,可能会有所接触…...
)
少儿编程 scratch四级真题 2025年3月电子学会图形化编程等级考试Scratch四级真题解析(判断题)
2025年3月scratch编程等级考试四级真题 判断题(共10题,每题2分,共20分) 11、小圆点角色的程序如下左图所示,程序运行后的效果如下右图所示,自制积木中又调用了自己,这种算法叫做递归。 答案&a…...

【连载3】基础智能体的进展与挑战综述
基础智能体的进展与挑战综述 从类脑智能到具备可进化性、协作性和安全性的系统 【翻译团队】刘军(liujunbupt.edu.cn) 钱雨欣玥 冯梓哲 李正博 李冠谕 朱宇晗 张霄天 孙大壮 黄若溪 2. 认知 人类认知是一种复杂的信息处理系统,它通过多个专门的神经回路协调运行…...

Schaefer 400图谱
图谱下载: https://github.com/ThomasYeoLab/CBIG/tree/master/stable_projects/brain_parcellation/Schaefer2018_LocalGlobal/Parcellations/MNI 图 (第一行)显示了 Yeo et al. (2011) 的 7 网络和 17 网络分包。图…...

通过uri获取文件路径手机适配
青铜版本 return contentResolver.query(this, arrayOf(MediaStore.MediaColumns.DATA), null, null).let {if (it?.moveToFirst() true) {val columnIndex it.getColumnIndex(MediaStore.MediaColumns.DATA)val path it.getString(columnIndex)it.close()return path}&quo…...

Ubuntu 22.04 完美安装 ABAQUS 教程:从零到上手,解决兼容问题
教程概述与安装准备 本教程详细介绍了在 Ubuntu 22.04 系统上安装 ABAQUS 2023 及 ifort 2021 的步骤,并实现用户子程序的链接。教程同样适用于 ABAQUS 2021(需相应调整文件名和路径)以及 Ubuntu 18.04 至 22.04 系统,尽管未在所有版本上测试。需要注意的是,Intel 的 One…...

雷池WAF防火墙如何构筑DDoS防护矩阵?——解读智能语义解析对抗新型流量攻击
本文深度解析雷池WAF防火墙在DDoS攻防中的技术突破,通过智能语义解析、动态基线建模、协同防护体系三大核心技术,实现从流量特征识别到攻击意图预判的进化。结合2023年金融行业混合攻击防御案例,揭示新一代WAF如何通过协议级漏洞预判与AI行为…...

Linux权限理解
1.shell命令以及运行原理 下面来介绍一个话题,关于指令的运行原理,这里先简单理解就可以。当我们登上Linux后: yxx这里称之为用户名,VM-8-2-centos是主机名,~是当前目录,$是命令行提示符。 其中我们把上面的…...

使用labelme进行实例分割标注
前言 最近在学习实例分割算法,参考b站视频课教程,使用labelme标注数据集,在csdn找到相关教程进行数据集格式转换,按照相关目标检测网络对数据集格式的训练要求划分数据集。 1.使用labelme标注图片 在网上随便找了几张蘑菇图片&am…...

策略模式实现 Bean 注入时怎么知道具体注入的是哪个 Bean?
Autowire Resource 的区别 1.来源不同:其中 Autowire 是 Spring2.5 定义的注解,而 Resource 是 Java 定义的注解 2.依赖查找的顺序不同: 依赖注入的功能,是通过先在 Spring IoC 容器中查找对象,再将对象注入引入到当…...

PromptUp 网站介绍:AI助力,轻松创作
1. 网站定位与核心功能 promptup.net 可能是一个面向 创作者、设计师、营销人员及艺术爱好者 的AI辅助创作平台,主打 零门槛、智能化的内容生成与优化。其核心功能可能包括: AI艺术创作:通过输入关键词、选择主题或拖放模板,快速生成风格多样的数字艺术作品(如插画、海报…...

软件架构评估利器:质量效用树全解析
质量效用树是软件架构评估中的一种重要工具,它有助于系统地分析和评估软件架构在满足各种质量属性方面的表现。以下是关于质量效用树的详细介绍: 一、定义与作用 质量效用树是一种以树形结构来表示软件质量属性及其相关效用的模型。它将软件的质量目标…...
IP核时钟框架介绍)
XILINX DDR3专题---(1)IP核时钟框架介绍
1.什么是Reference Clock,这个时钟一定是200MHz吗? 2.为什么APP_DATA是128bit,怎么算出来的? 3.APP :MEM的比值一定是1:4吗? 4.NO BUFFER是什么意思? 5.什么情况下Reference Clock的时钟源可…...

ubuntu 2204 安装 vcs 2018
安装评估 系统 : Ubuntu 22.04.1 LTS 磁盘 : ubuntu 自身占用了 9.9G , 按照如下步骤 安装后 , 安装后的软件 占用 13.1G 仓库 : 由于安装 libpng12-0 , 添加了一个仓库 安装包 : 安装了多个包(lsb及其依赖包 libpng12-0)安装步骤 参考 ubuntu2018 安装 vcs2018 安装该…...

Python与去中心化存储:从理论到实战的全景指南【无标题】
Python与去中心化存储:从理论到实战的全景指南 随着区块链技术和Web3理念的兴起,去中心化存储逐渐成为构建新型互联网的核心模块之一。传统中心化存储的模式存在易被攻击、单点故障和高昂成本等问题,而去中心化存储通过分布式架构实现了更高的安全性、可靠性和数据透明度。…...

C++语言程序设计——01 C++程序基本结构
目录 编程语言一、C程序执行过程二、C基础框架三、输出语句cout换行 四、注释方法 编程语言 我们知道c是一门编程语言,它是在c语言的基础上发展而来,添加了类、对象、继承、多态等概念,我们可以称为它是一种面向对象编程的语言。 不过在学习…...
Unity UI中的Pixels Per Unit
Pixels Per Unit在图片导入到Unity的时候,将图片格式设置为Sprite的情况下会出现,其意思是精灵中的多少像素对应世界中的一个单位,默认是100 1. 对于在世界坐标中 在世界坐标中,一般对于Sprite的应用是Sprite Renderer组件 使…...
安卓开发中的后端接口调用详讲解)
(十八)安卓开发中的后端接口调用详讲解
在安卓开发中,后端接口调用是连接移动应用与服务器的重要环节,用于实现数据的获取、提交和处理。本文将详细讲解安卓开发中后端接口调用的步骤,结合代码示例和具体的使用场景,帮助你全面理解这一过程。 什么是后端接口?…...

使用freebsd-update 升级FreeBSD从FreeBSD 14.1-RELEASE-p5到FreeBSD 14.2-RELEASE
使用freebsd-update 升级FreeBSD从FreeBSD 14.1-RELEASE-p5到FreeBSD 14.2-RELEASE 先升级小版本 准备升级前,先把当前的小版本升级到顶,比如现在是FreeBSD 14.1-RELEASE-p5,先升级到最新的14.1版本,使用命令: # fr…...
)
基础排序算法(三傻排序)
1. 选择排序 原理:每次从未排序部分选出最小(或最大)元素,放到已排序部分的末尾。时间复杂度:O(n),效率低但实现简单,适合小规模数据。 //选择排序public static void selectSort(int[] arr){i…...

五分钟了解智能体
在2025年人工智能技术全面渗透社会的背景下,“智能体”(Agent)已成为推动第四次工业革命的核心概念之一。从自动驾驶汽车到医疗诊断系统,从智能家居中枢到金融量化交易平台,智能体正在重构人类与技术交互的方式。本文将…...

【机器学习】笔记| 通俗易懂讲解:生成模型和判别模型|01
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾:【科研小白系列】这些基础linux命令,你都掌握了嘛?每日一言🌼: “脑袋想不明白的,就用脚想”—…...
)
Jieba分词的原理及应用(三)
前言 “结巴”中文分词:做最好的 Python 中文分词组件 上一篇文章讲了使用TF-IDF分类器范式进行企业级文本分类的案例。其中提到了中文场景不比英文场景,在喂给模型之前需要进行分词操作。 分词的手段有很多,其中最常用的手段还是Jieba库进行…...

神经网络背后的数学原理
神经网络背后的数学原理 数学建模神经网络数学原理 数学建模 标题民科味道满满。其实这篇小短文就是自我娱乐。 物理世界是物种多样,千姿百态。可以从不同的看待眼中的世界,包括音乐、绘画、舞蹈、雕塑等各种艺术形式。但这些主观的呈现虽然在各人眼中…...
)
常用图像滤波及色彩调节操作(Opencv)
1. 常用滤波/模糊操作 import cv2 import numpy as np import matplotlib.pyplot as plotimg cv2.imread("tmp.jpg") img cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img_g cv2.GaussianBlur(img, (7,7), 0) img_mb cv2.medianBlur(img, ksize7) #中指滤波 img_bm …...

FFMPEG和opencv的编译
首先 sudo apt-get update -qq && sudo apt-get -y install autoconf automake build-essential cmake git-core libass-dev libfreetype6-dev libgnutls28-dev libmp3lame-dev libsdl2-dev libtool libva-dev libvdpau-dev libvorbis-de…...

用户登录不上linux服务器
一般出现这种问题,重新用root用户修改lsy用户的密码即可登录,但是当修改了还是登录不了的时候,去修改一个文件用root才能修改, 然后在最后添加上改用户的名字,例如 原本是只有user的,现在我加上了lsy了&a…...

【项目管理】第11章 项目成本管理-- 知识点整理
相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应:第6章-第19章 (二)知识笔记 第11章 项目成本管理 1.管理基础…...
)
Python中的strip()
文章目录 基本语法:示例:1. 默认移除空白字符:2. 移除指定字符:3. 不修改原字符串: 相关方法:示例: 注意事项: 在 Python 中, strip() 是一个字符串方法,用于…...
完整讲解与实战应用)
设计模式 Day 9:命令模式(Command Pattern)完整讲解与实战应用
🔄 回顾 Day 8:策略模式 在 Day 8 中我们讲解了策略模式: 用于封装多个可切换的算法逻辑,让调用者在运行时选择合适的策略。它强调的是“行为选择”,是针对“算法或行为差异”而设计。通过 PaymentStrategy、路径规划…...