【硬核数学】2. AI如何“学习”?微积分揭秘模型优化的奥秘《从零构建机器学习、深度学习到LLM的数学认知》
在上一篇中,我们探索了线性代数如何帮助AI表示数据(向量、矩阵)和变换数据(矩阵乘法)。但AI的魅力远不止于此,它最核心的能力是“学习”——从数据中自动调整自身,以做出越来越准确的预测或决策。这个“学习”过程的背后功臣,就是我们今天要深入探讨的微积分 (Calculus)。
“微积分?是不是求导、积分,听起来比线性代数还头大!” 很多朋友可能会有这样的印象。确实,微积分有其严谨的数学体系,但其核心思想却非常直观,并且与AI的“学习”机制紧密相连。我们将一起解开:
- 导数 (Derivatives):变化率的奥秘,AI如何感知参数微调的效果?
- 偏导数 (Partial Derivatives):多维世界中的导航,AI如何判断哪个参数更值得调整?
- 梯度 (Gradient):最陡峭的路径,AI如何找到最佳参数组合的方向?
- 链式法则 (Chain Rule):层层递进的智慧,AI如何高效计算复杂模型的“学习信号”?
- Jacobian/Hessian 矩阵:高阶的视角,AI如何更精细地分析和优化模型?
准备好了吗?让我们一起踏上微积分之旅,看看它是如何驱动AI模型不断进化,变得越来越“聪明”的!
导数:洞察变化的瞬时魔法
想象一下你正在开车。你的速度是什么?它告诉你,在某一瞬间,你的位置相对于时间是如何变化的。如果速度是60公里/小时,意味着如果保持这个速度,一小时后你就会前进60公里。这个“速度”,在数学上就是导数 (Derivative) 的一个经典例子。
什么是导数?
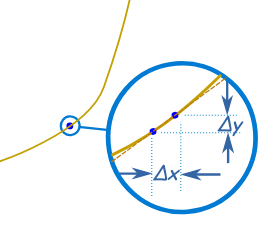
导数衡量的是一个函数 f ( x ) f(x) f(x) 在某一点 x 0 x_0 x0 处,当自变量 x x x 发生极其微小的变化时,函数值 f ( x ) f(x) f(x) 相应变化的速率或趋势。几何上,它代表了函数曲线在该点切线的斜率。
如果函数 f ( x ) f(x) f(x) 在 x 0 x_0 x0 点的导数是正数,说明当 x x x 略微增加时, f ( x ) f(x) f(x) 也倾向于增加(函数在该点“上升”)。
如果导数是负数,说明当 x x x 略微增加时, f ( x ) f(x) f(x) 倾向于减少(函数在该点“下降”)。
如果导数是零,说明函数在该点可能达到了一个平稳状态(可能是局部最高点、最低点或平坦点)。
数学上,导数 f ′ ( x ) f'(x) f′(x) 或 d f d x \frac{df}{dx} dxdf 定义为:
f ′ ( x ) = lim Δ x → 0 f ( x + Δ x ) − f ( x ) Δ x f'(x) = \lim_{\Delta x \to 0} \frac{f(x + \Delta x) - f(x)}{\Delta x} f′(x)=limΔx→0Δxf(x+Δx)−f(x)
这个公式看起来有点吓人,但它的意思就是:当 x x x 的变化量 Δ x \Delta x Δx 趋近于零时,函数值的变化量 f ( x + Δ x ) − f ( x ) f(x + \Delta x) - f(x) f(x+Δx)−f(x) 与 Δ x \Delta x Δx 的比值。
在AI中的意义:损失函数的“敏感度”
在机器学习中,我们通常会定义一个损失函数 (Loss Function) L ( 参数 ) L(\text{参数}) L(参数)。这个函数用来衡量模型的预测结果与真实答案之间的“差距”或“错误程度”。我们的目标是调整模型的参数 (Parameters)(比如线性回归中的权重 w w w 和偏置 b b b,或者神经网络中的大量权重和偏置),使得损失函数的值尽可能小。
假设我们的模型只有一个参数 w w w,损失函数是 L ( w ) L(w) L(w)。那么, L ( w ) L(w) L(w) 关于 w w w 的导数 d L d w \frac{dL}{dw} dwdL 就告诉我们:
当我稍微改变参数 w w w 一点点时,损失函数 L ( w ) L(w) L(w) 会如何变化?
- 如果 d L d w > 0 \frac{dL}{dw} > 0 dwdL>0,意味着增加 w w w 会导致损失增加。所以,为了减小损失,我们应该减小 w w w。
- 如果 d L d w < 0 \frac{dL}{dw} < 0 dwdL<0,意味着增加 w w w 会导致损失减小。所以,为了减小损失,我们应该增加 w w w。
- 如果 d L d w = 0 \frac{dL}{dw} = 0 dwdL=0,意味着我们可能找到了一个损失函数的局部最小值(或者最大值、鞍点)。此时,微调 w w w 对损失的影响很小。
这种“敏感度分析”是AI模型学习和优化的核心。通过计算导数,AI模型知道应该朝哪个方向调整参数才能让损失更小。
一个简单的例子:
假设损失函数是 L ( w ) = w 2 L(w) = w^2 L(w)=w2。这是一个简单的抛物线,在 w = 0 w=0 w=0 处取得最小值0。
它的导数是 d L d w = 2 w \frac{dL}{dw} = 2w dwdL=2w。
- 当 w = 2 w=2 w=2 时, d L d w = 2 × 2 = 4 \frac{dL}{dw} = 2 \times 2 = 4 dwdL=2×2=4 (正数)。这告诉我们,在 w = 2 w=2 w=2 的位置,如果增加 w w w,损失会增加。所以我们应该减小 w w w。
- 当 w = − 3 w=-3 w=−3 时, d L d w = 2 × ( − 3 ) = − 6 \frac{dL}{dw} = 2 \times (-3) = -6 dwdL=2×(−3)=−6 (负数)。这告诉我们,在 w = − 3 w=-3 w=−3 的位置,如果增加 w w w,损失会减小。所以我们应该增加 w w w。
- 当 w = 0 w=0 w=0 时, d L d w = 2 × 0 = 0 \frac{dL}{dw} = 2 \times 0 = 0 dwdL=2×0=0。我们到达了损失函数的最低点。
这就是最基本的优化思想:沿着导数指示的“相反”方向调整参数,就能逐步逼近损失函数的最小值。 这就是著名的梯度下降 (Gradient Descent) 算法的雏形。
小结:导数衡量函数在某一点的变化率或切线斜率。在AI中,损失函数关于模型参数的导数,指明了参数调整的方向,以使损失减小。
偏导数:多维参数空间的导航员
在上一节,我们讨论了只有一个参数 w w w 的简单情况。但现实中的AI模型,比如一个深度神经网络,可能有数百万甚至数十亿个参数!损失函数 L L L 不再是 L ( w ) L(w) L(w),而是 L ( w 1 , w 2 , w 3 , . . . , w n ) L(w_1, w_2, w_3, ..., w_n) L(w1,w2,w3,...,wn),其中 w i w_i wi 是模型的第 i i i 个参数。
这时,我们如何知道应该调整哪个参数,以及如何调整呢?这就需要偏导数 (Partial Derivative)。
什么是偏导数?
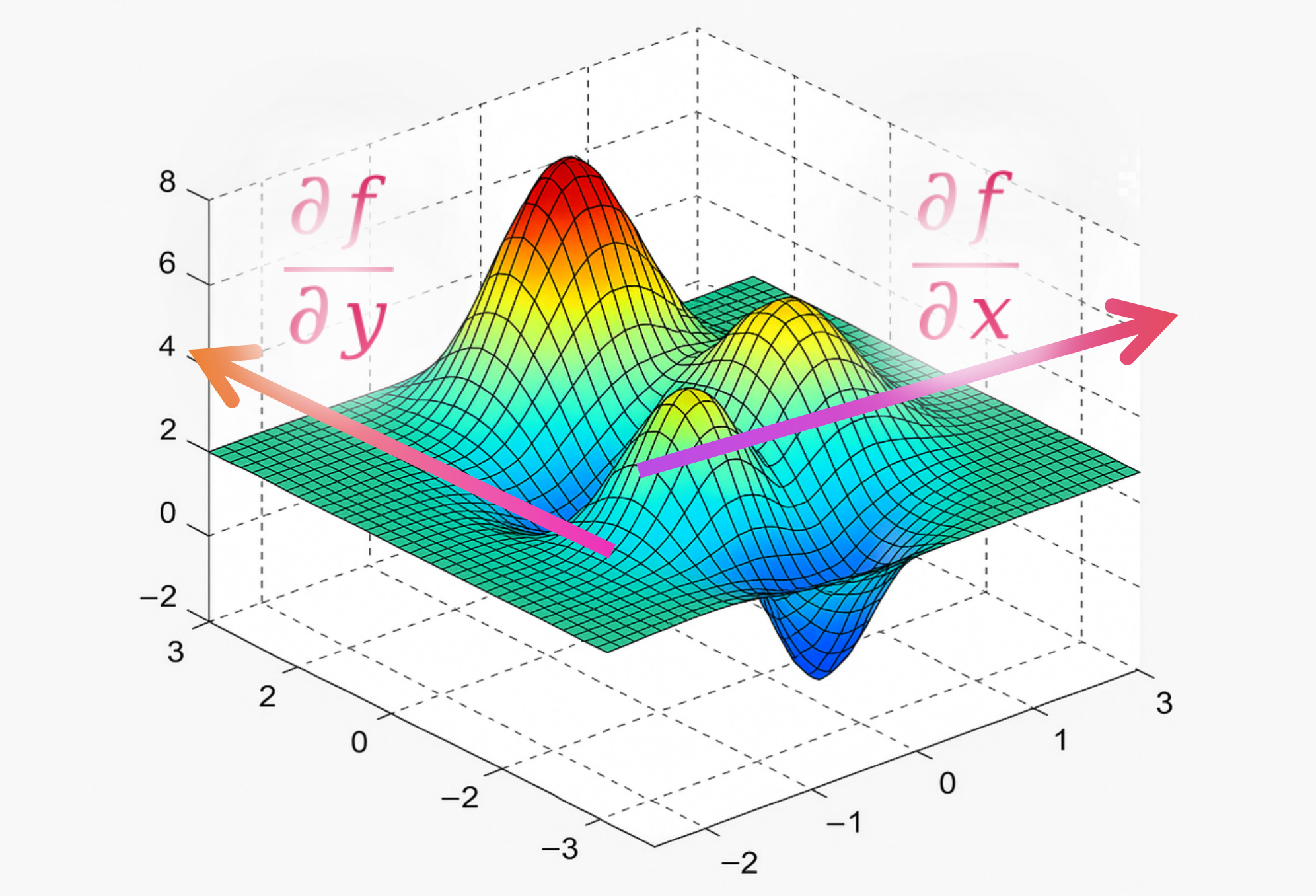
当一个函数依赖于多个自变量时,比如 f ( x , y ) f(x, y) f(x,y),我们想知道当其中一个自变量(比如 x x x)发生微小变化,而保持其他自变量(比如 y y y)不变的情况下,函数值 f ( x , y ) f(x, y) f(x,y) 如何变化。这个变化率就是 f ( x , y ) f(x, y) f(x,y) 关于 x x x 的偏导数,记作 ∂ f ∂ x \frac{\partial f}{\partial x} ∂x∂f 或 f x f_x fx。
同理, f ( x , y ) f(x, y) f(x,y) 关于 y y y 的偏导数 ∂ f ∂ y \frac{\partial f}{\partial y} ∂y∂f 或 f y f_y fy,是保持 x x x 不变, y y y 发生微小变化时,函数值的变化率。
几何直观:想象一个三维空间中的曲面 z = f ( x , y ) z = f(x, y) z=f(x,y)(比如一座山)。
∂ f ∂ x \frac{\partial f}{\partial x} ∂x∂f 表示如果你站在山上的某一点 ( x 0 , y 0 ) (x_0, y_0) (x0,y0),只沿着 x x x 轴方向(东西方向)移动一小步,你的高度会如何变化(坡度)。
∂ f ∂ y \frac{\partial f}{\partial y} ∂y∂f 表示如果你只沿着 y y y 轴方向(南北方向)移动一小步,你的高度会如何变化。
计算偏导数:计算一个变量的偏导数时,只需将其他变量视为常数,然后按照普通单变量函数的求导法则进行即可。
例子:
假设损失函数 L ( w 1 , w 2 ) = w 1 2 + 3 w 1 w 2 + 2 w 2 2 L(w_1, w_2) = w_1^2 + 3w_1w_2 + 2w_2^2 L(w1,w2)=w12+3w1w2+2w22。
计算关于 w 1 w_1 w1 的偏导数 ∂ L ∂ w 1 \frac{\partial L}{\partial w_1} ∂w1∂L:
把 w 2 w_2 w2 看作常数。
∂ L ∂ w 1 = ∂ ∂ w 1 ( w 1 2 ) + ∂ ∂ w 1 ( 3 w 1 w 2 ) + ∂ ∂ w 1 ( 2 w 2 2 ) \frac{\partial L}{\partial w_1} = \frac{\partial}{\partial w_1}(w_1^2) + \frac{\partial}{\partial w_1}(3w_1w_2) + \frac{\partial}{\partial w_1}(2w_2^2) ∂w1∂L=∂w1∂(w12)+∂w1∂(3w1w2)+∂w1∂(2w22)
= 2 w 1 + 3 w 2 × ∂ ∂ w 1 ( w 1 ) + 0 = 2w_1 + 3w_2 \times \frac{\partial}{\partial w_1}(w_1) + 0 =2w1+3w2×∂w1∂(w1)+0 (因为 2 w 2 2 2w_2^2 2w22 相对于 w 1 w_1 w1 是常数)
= 2 w 1 + 3 w 2 = 2w_1 + 3w_2 =2w1+3w2
计算关于 w 2 w_2 w2 的偏导数 ∂ L ∂ w 2 \frac{\partial L}{\partial w_2} ∂w2∂L:
把 w 1 w_1 w1 看作常数。
∂ L ∂ w 2 = ∂ ∂ w 2 ( w 1 2 ) + ∂ ∂ w 2 ( 3 w 1 w 2 ) + ∂ ∂ w 2 ( 2 w 2 2 ) \frac{\partial L}{\partial w_2} = \frac{\partial}{\partial w_2}(w_1^2) + \frac{\partial}{\partial w_2}(3w_1w_2) + \frac{\partial}{\partial w_2}(2w_2^2) ∂w2∂L=∂w2∂(w12)+∂w2∂(3w1w2)+∂w2∂(2w22)
= 0 + 3 w 1 × ∂ ∂ w 2 ( w 2 ) + 4 w 2 = 0 + 3w_1 \times \frac{\partial}{\partial w_2}(w_2) + 4w_2 =0+3w1×∂w2∂(w2)+4w2 (因为 w 1 2 w_1^2 w12 相对于 w 2 w_2 w2 是常数)
= 3 w 1 + 4 w 2 = 3w_1 + 4w_2 =3w1+4w2
在AI中的意义:分别考察每个参数的影响
对于一个拥有多个参数 w 1 , w 2 , . . . , w n w_1, w_2, ..., w_n w1,w2,...,wn 的AI模型,损失函数 L ( w 1 , . . . , w n ) L(w_1, ..., w_n) L(w1,...,wn) 关于每个参数 w i w_i wi 的偏导数 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L 告诉我们:
如果我只微调参数 w i w_i wi 一点点,同时保持其他所有参数 w j ( j ≠ i ) w_j (j \neq i) wj(j=i) 不变,那么损失函数 L L L 会如何变化?
这个信息至关重要,因为它让我们能够独立地评估每个参数对整体损失的“贡献”或“敏感度”。如果 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L 的绝对值很大,说明参数 w i w_i wi 对损失的影响比较显著,调整它可能会带来较大的损失变化。
小结:偏导数衡量多变量函数在某一点沿着某个坐标轴方向的变化率。在AI中,损失函数关于各个模型参数的偏导数,为我们指明了单独调整每个参数时损失的变化趋势。
梯度:下降最快的方向盘
我们已经知道了如何计算损失函数 L L L 关于每一个参数 w i w_i wi 的偏导数 ∂ L ∂ w i \frac{\partial L}{\partial w_i} ∂wi∂L。这些偏导数各自描述了在一个特定参数维度上的变化趋势。但我们如何把这些信息整合起来,找到一个让损失函数 L L L 整体下降最快的方向呢?答案就是梯度 (Gradient)。
什么是梯度?
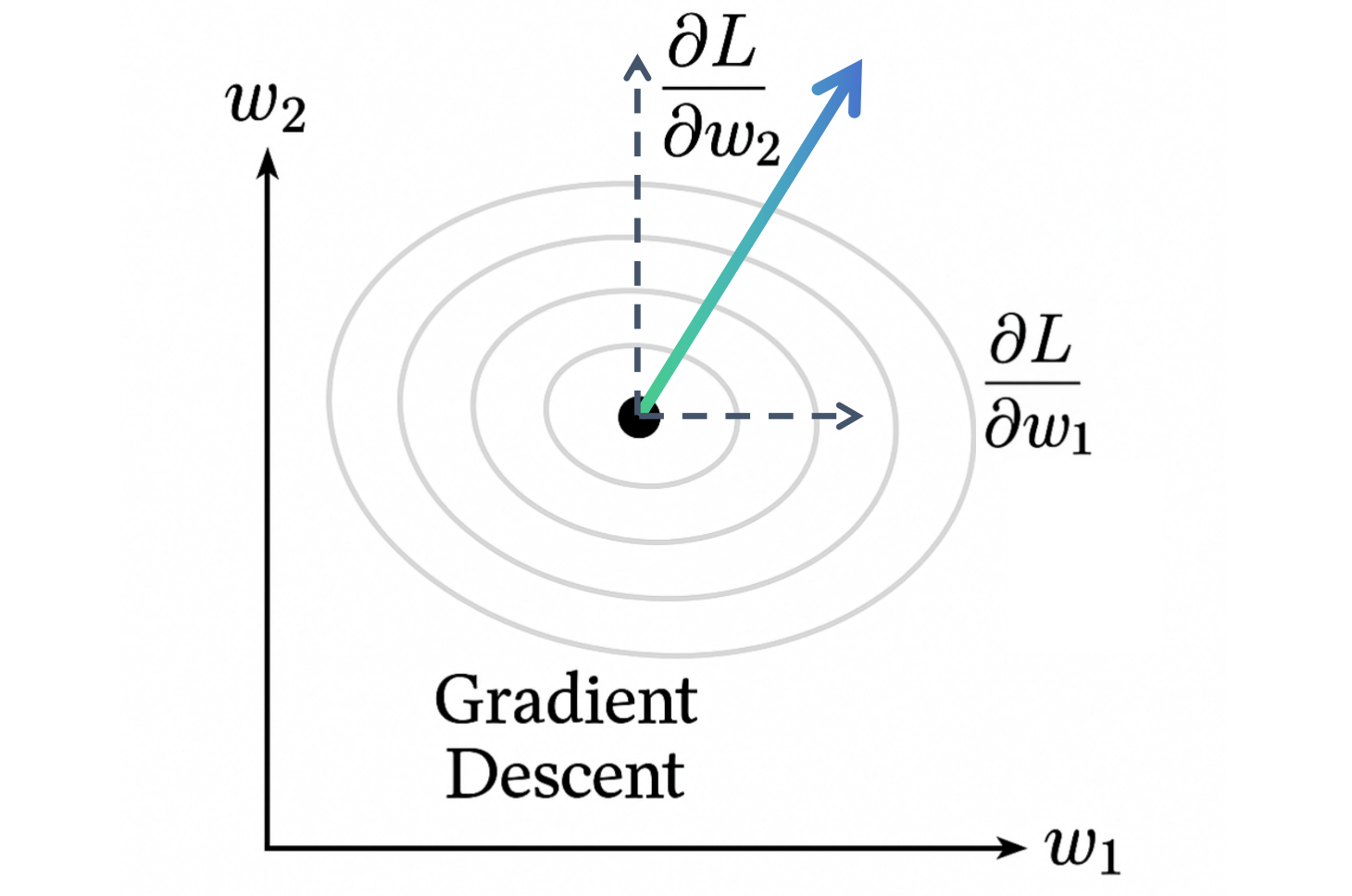
对于一个多变量函数 L ( w 1 , w 2 , . . . , w n ) L(w_1, w_2, ..., w_n) L(w1,w2,...,wn),它的梯度是一个向量,由该函数关于所有自变量的偏导数构成:
∇ L = grad ( L ) = [ ∂ L ∂ w 1 , ∂ L ∂ w 2 , . . . , ∂ L ∂ w n ] \nabla L = \text{grad}(L) = \left[ \frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2}, ..., \frac{\partial L}{\partial w_n} \right] ∇L=grad(L)=[∂w1∂L,∂w2∂L,...,∂wn∂L]
这里的 ∇ \nabla ∇ (nabla) 符号是梯度的标准表示。
梯度的关键特性:
在函数定义域内的任意一点,梯度向量指向该点函数值增长最快的方向。
相应地,负梯度向量 ( − ∇ L -\nabla L −∇L ) 指向该点函数值减小最快的方向。
几何直观:再次想象那座山 z = L ( w 1 , w 2 ) z = L(w_1, w_2) z=L(w1,w2)(这里 w 1 , w 2 w_1, w_2 w1,w2 是平面坐标)。你在山上的某一点,想尽快下到山谷(损失最小的地方)。
- ∂ L ∂ w 1 \frac{\partial L}{\partial w_1} ∂w1∂L 告诉你东西方向的坡度。
- ∂ L ∂ w 2 \frac{\partial L}{\partial w_2} ∂w2∂L 告诉你南北方向的坡度。
- 梯度 ∇ L = [ ∂ L ∂ w 1 , ∂ L ∂ w 2 ] \nabla L = [\frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2}] ∇L=[∂w1∂L,∂w2∂L] 是一个二维向量,它指向山上坡度最陡峭的上坡方向。
- 那么, − ∇ L = [ − ∂ L ∂ w 1 , − ∂ L ∂ w 2 ] -\nabla L = [-\frac{\partial L}{\partial w_1}, -\frac{\partial L}{\partial w_2}] −∇L=[−∂w1∂L,−∂w2∂L] 就指向坡度最陡峭的下坡方向。
梯度下降算法 (Gradient Descent)
梯度下降是AI中最核心、最常用的优化算法之一。它的思想非常朴素和直观:为了最小化损失函数 L L L,我们从一个随机的参数点 W 0 = [ w 1 ( 0 ) , w 2 ( 0 ) , . . . , w n ( 0 ) ] W_0 = [w_1^{(0)}, w_2^{(0)}, ..., w_n^{(0)}] W0=[w1(0),w2(0),...,wn(0)] 开始,然后迭代地沿着负梯度方向更新参数:
W t + 1 = W t − η ∇ L ( W t ) W_{t+1} = W_t - \eta \nabla L(W_t) Wt+1=Wt−η∇L(Wt)
这里的符号解释:
- W t W_t Wt:第 t t t 次迭代时的参数向量。
- ∇ L ( W t ) \nabla L(W_t) ∇L(Wt):在点 W t W_t Wt 处计算的损失函数的梯度。
- η \eta η (eta):称为学习率 (Learning Rate)。它是一个很小的正数(比如0.01, 0.001),控制着每一步沿着负梯度方向前进的“步长”。
- 如果 η \eta η 太小,收敛到最小值的速度会很慢。
- 如果 η \eta η 太大,可能会在最小值附近来回震荡,甚至越过最小值导致发散。选择合适的学习率非常重要。
- W t + 1 W_{t+1} Wt+1:更新后的参数向量。
这个过程就像是一个盲人下山:他不知道山谷在哪,但他可以感知脚下哪个方向坡度最陡峭(负梯度),然后朝那个方向迈一小步(由学习率控制步长)。不断重复这个过程,他就能一步步走到山谷。
梯度下降的步骤:
- 初始化参数 W W W (随机值或预设值)。
- 循环迭代直到满足停止条件(比如达到最大迭代次数,或者损失变化很小):
a. 计算梯度:在当前参数 W t W_t Wt 下,计算损失函数 L L L 关于 W t W_t Wt 的梯度 ∇ L ( W t ) \nabla L(W_t) ∇L(Wt)。
b. 更新参数: W t + 1 = W t − η ∇ L ( W t ) W_{t+1} = W_t - \eta \nabla L(W_t) Wt+1=Wt−η∇L(Wt)。
AI模型的“学习”过程:
当我们说一个AI模型在“学习”时,很多情况下指的就是它在用梯度下降(或其变种,如随机梯度下降SGD、Adam等)来调整内部参数,以最小化在训练数据上的损失函数。
- 模型做出预测。
- 计算预测与真实标签之间的损失。
- 计算损失函数关于模型所有参数的梯度。
- 根据梯度和学习率更新参数。
- 重复以上步骤,直到模型性能不再显著提升。
小结:梯度是由所有偏导数组成的向量,指向函数值增长最快的方向。负梯度则指向下降最快的方向。梯度下降算法利用负梯度来迭代更新模型参数,从而最小化损失函数,这是AI模型学习的核心机制。
链式法则:解开复杂依赖的钥匙
现代AI模型,尤其是深度神经网络,其结构非常复杂。它们通常是由许多层函数嵌套构成的。例如,一个简单的两层神经网络,其输出可能是这样的形式:
Output = f 2 ( W 2 ⋅ f 1 ( W 1 ⋅ Input + b 1 ) + b 2 ) \text{Output} = f_2(W_2 \cdot f_1(W_1 \cdot \text{Input} + b_1) + b_2) Output=f2(W2⋅f1(W1⋅Input+b1)+b2)
这里 f 1 , f 2 f_1, f_2 f1,f2 是激活函数, W 1 , b 1 , W 2 , b 2 W_1, b_1, W_2, b_2 W1,b1,W2,b2 是模型的参数。损失函数 L L L 是基于这个Output和真实标签计算的。
我们想知道损失 L L L 关于 W 1 W_1 W1 或 b 1 b_1 b1 这些深层参数的梯度,以便用梯度下降来更新它们。但是 W 1 W_1 W1 是深深嵌套在里面的,损失 L L L 并不是直接由 W 1 W_1 W1 决定的,而是通过一系列中间变量(比如 f 1 f_1 f1 的输出,以及 f 2 f_2 f2 的输入)间接影响的。这时,链式法则 (Chain Rule) 就派上用场了。
什么是链式法则?
链式法则用于计算复合函数 (Composite Function) 的导数。
如果一个变量 y y y 是变量 u u u 的函数,即 y = f ( u ) y = f(u) y=f(u),而 u u u 又是变量 x x x 的函数,即 u = g ( x ) u = g(x) u=g(x),那么 y y y 最终也是 x x x 的函数 y = f ( g ( x ) ) y = f(g(x)) y=f(g(x))。
链式法则告诉我们如何计算 y y y 关于 x x x 的导数 d y d x \frac{dy}{dx} dxdy:
d y d x = d y d u ⋅ d u d x \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} dxdy=dudy⋅dxdu
直观理解:想象一串多米诺骨牌。
- d u d x \frac{du}{dx} dxdu:第一块骨牌 x x x 倒下时,推动第二块骨牌 u u u 倒下的“效率”( x x x 的小变化导致 u u u 的变化率)。
- d y d u \frac{dy}{du} dudy:第二块骨牌 u u u 倒下时,推动第三块骨牌 y y y 倒下的“效率”( u u u 的小变化导致 y y y 的变化率)。
- d y d x \frac{dy}{dx} dxdy:第一块骨牌 x x x 倒下时,最终导致第三块骨牌 y y y 倒下的“总效率”。这个总效率就是各环节效率的乘积。
推广到多变量和多层嵌套:
链式法则可以推广到多个中间变量和更深的函数嵌套。对于多变量函数,它涉及到偏导数和雅可比矩阵(后面会提到)。
例如,如果 L L L 是 a a a 的函数, a a a 是 z z z 的函数, z z z 是 w w w 的函数 ( L → a → z → w L \rightarrow a \rightarrow z \rightarrow w L→a→z→w),那么:
∂ L ∂ w = ∂ L ∂ a ⋅ ∂ a ∂ z ⋅ ∂ z ∂ w \frac{\partial L}{\partial w} = \frac{\partial L}{\partial a} \cdot \frac{\partial a}{\partial z} \cdot \frac{\partial z}{\partial w} ∂w∂L=∂a∂L⋅∂z∂a⋅∂w∂z
AI中的核心:反向传播算法 (Backpropagation)
在深度学习中,反向传播 (Backpropagation) 算法就是链式法则在神经网络中的系统性应用。它是计算损失函数关于网络中所有参数(权重和偏置)梯度的标准方法。
反向传播的核心思想:
- 前向传播 (Forward Pass):输入数据通过网络,逐层计算,直到得到最终的输出,然后计算损失 L L L。
- 反向传播 (Backward Pass):
- 从损失 L L L 开始,首先计算 L L L 关于网络最后一层输出的梯度。
- 然后,利用链式法则,将这个梯度“反向传播”到前一层,计算 L L L 关于前一层输出(或激活值)的梯度。
- 同时,计算 L L L 关于当前层参数(权重和偏置)的梯度。
- 重复这个过程,一层一层向后,直到计算出 L L L 关于网络第一层参数的梯度。
例如,对于上面那个简单的两层网络,我们要计算 ∂ L ∂ W 1 \frac{\partial L}{\partial W_1} ∂W1∂L:
假设中间变量是:
z 1 = W 1 ⋅ Input + b 1 z_1 = W_1 \cdot \text{Input} + b_1 z1=W1⋅Input+b1 (第一层线性输出)
a 1 = f 1 ( z 1 ) a_1 = f_1(z_1) a1=f1(z1) (第一层激活输出)
z 2 = W 2 ⋅ a 1 + b 2 z_2 = W_2 \cdot a_1 + b_2 z2=W2⋅a1+b2 (第二层线性输出)
Output = a 2 = f 2 ( z 2 ) \text{Output} = a_2 = f_2(z_2) Output=a2=f2(z2) (第二层激活输出,即模型最终输出)
L = LossFunction ( a 2 , TrueLabel ) L = \text{LossFunction}(a_2, \text{TrueLabel}) L=LossFunction(a2,TrueLabel)
那么, ∂ L ∂ W 1 \frac{\partial L}{\partial W_1} ∂W1∂L 可以通过链式法则分解为:
∂ L ∂ W 1 = ∂ L ∂ a 2 ⋅ ∂ a 2 ∂ z 2 ⋅ ∂ z 2 ∂ a 1 ⋅ ∂ a 1 ∂ z 1 ⋅ ∂ z 1 ∂ W 1 \frac{\partial L}{\partial W_1} = \frac{\partial L}{\partial a_2} \cdot \frac{\partial a_2}{\partial z_2} \cdot \frac{\partial z_2}{\partial a_1} \cdot \frac{\partial a_1}{\partial z_1} \cdot \frac{\partial z_1}{\partial W_1} ∂W1∂L=∂a2∂L⋅∂z2∂a2⋅∂a1∂z2⋅∂z1∂a1⋅∂W1∂z1
这里每一项的偏导数通常都比较容易计算:
- ∂ L ∂ a 2 \frac{\partial L}{\partial a_2} ∂a2∂L: 损失函数对网络输出的导数。
- ∂ a 2 ∂ z 2 \frac{\partial a_2}{\partial z_2} ∂z2∂a2: 第二层激活函数 f 2 f_2 f2 对其输入的导数。
- ∂ z 2 ∂ a 1 \frac{\partial z_2}{\partial a_1} ∂a1∂z2: 等于 W 2 T W_2^T W2T (需要矩阵求导知识,但直观上是 a 1 a_1 a1 对 z 2 z_2 z2 的贡献,由 W 2 W_2 W2 决定)。
- ∂ a 1 ∂ z 1 \frac{\partial a_1}{\partial z_1} ∂z1∂a1: 第一层激活函数 f 1 f_1 f1 对其输入的导数。
- ∂ z 1 ∂ W 1 \frac{\partial z_1}{\partial W_1} ∂W1∂z1: 等于 Input T \text{Input}^T InputT (直观上是 W 1 W_1 W1 对 z 1 z_1 z1 的贡献,由 Input \text{Input} Input 决定)。
反向传播算法的美妙之处在于,它提供了一种高效计算这些链式乘积的方法,避免了对每个参数都从头推导整个链条。它从后往前,逐层计算和存储中间梯度,使得整个计算过程非常模块化和高效。现代深度学习框架(TensorFlow, PyTorch)都内置了自动微分(Autograd)功能,它们会自动构建计算图并应用链式法则(即反向传播)来计算所有参数的梯度。
小结:链式法则用于计算复合函数的导数,即一个变量通过一系列中间变量间接影响另一个变量时的变化率。在AI中,反向传播算法是链式法则在神经网络上的巧妙应用,它能够高效地计算损失函数关于网络中所有参数的梯度,是深度学习模型训练的基石。
Jacobian 和 Hessian 矩阵:高阶的洞察力 (进阶预览)
到目前为止,我们主要关注的是损失函数(一个标量输出)关于参数(向量输入)的一阶导数(梯度)。但在更高级的优化算法或模型分析中,我们可能需要更高阶的导数信息。这里简单介绍两个重要的概念:Jacobian矩阵和Hessian矩阵。对于初学者,了解它们的存在和大致用途即可。
Jacobian 矩阵 (雅可比矩阵)
当我们的函数是一个向量值函数时,即函数的输入是向量,输出也是向量,比如 F : R n → R m F: \mathbb{R}^n \to \mathbb{R}^m F:Rn→Rm,其中 F ( x ) = [ f 1 ( x ) , f 2 ( x ) , . . . , f m ( x ) ] F(x) = [f_1(x), f_2(x), ..., f_m(x)] F(x)=[f1(x),f2(x),...,fm(x)],而 x = [ x 1 , x 2 , . . . , x n ] x = [x_1, x_2, ..., x_n] x=[x1,x2,...,xn]。
Jacobian 矩阵 J F J_F JF 是一个 m × n m \times n m×n 的矩阵,包含了 F F F 的所有一阶偏导数:
J F = ( ∂ f 1 ∂ x 1 ∂ f 1 ∂ x 2 … ∂ f 1 ∂ x n ∂ f 2 ∂ x 1 ∂ f 2 ∂ x 2 … ∂ f 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ f m ∂ x 1 ∂ f m ∂ x 2 … ∂ f m ∂ x n ) J_F = \begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \frac{\partial f_1}{\partial x_2} & \dots & \frac{\partial f_1}{\partial x_n} \\ \frac{\partial f_2}{\partial x_1} & \frac{\partial f_2}{\partial x_2} & \dots & \frac{\partial f_2}{\partial x_n} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial f_m}{\partial x_1} & \frac{\partial f_m}{\partial x_2} & \dots & \frac{\partial f_m}{\partial x_n} \end{pmatrix} JF= ∂x1∂f1∂x1∂f2⋮∂x1∂fm∂x2∂f1∂x2∂f2⋮∂x2∂fm……⋱…∂xn∂f1∂xn∂f2⋮∂xn∂fm
其中,第 i i i 行是第 i i i 个输出函数 f i f_i fi 的梯度 ∇ f i T \nabla f_i^T ∇fiT。
特殊情况:
- 如果 m = 1 m=1 m=1 (函数输出是标量,比如损失函数 L ( W ) L(W) L(W)),那么Jacobian矩阵就退化为一个 1 × n 1 \times n 1×n 的行向量,即梯度向量的转置 ∇ L T \nabla L^T ∇LT。
- 如果 n = 1 n=1 n=1 (函数输入是标量),Jacobian矩阵就退化为一个 m × 1 m \times 1 m×1 的列向量,包含了各个输出函数 f i f_i fi 关于输入 x x x 的普通导数。
AI中的应用:
- 链式法则的推广:当复合函数中的某个环节是向量到向量的映射时,链式法则需要用到Jacobian矩阵。例如,如果 y = F ( u ) y=F(u) y=F(u) 且 u = G ( x ) u=G(x) u=G(x),那么 d y d x \frac{dy}{dx} dxdy (这里表示的是Jacobian) 等于 J F ( G ( x ) ) ⋅ J G ( x ) J_F(G(x)) \cdot J_G(x) JF(G(x))⋅JG(x) (矩阵乘法)。反向传播在计算梯度时,隐式地处理了这些Jacobian向量积。
- 某些高级优化算法。
- 敏感性分析:分析输出的各个分量对输入的各个分量的敏感程度。
Hessian 矩阵 (海森矩阵)
Hessian矩阵描述了标量值函数 L ( W ) L(W) L(W) 的二阶偏导数信息,即梯度的梯度。对于一个有 n n n 个参数 W = [ w 1 , . . . , w n ] W=[w_1, ..., w_n] W=[w1,...,wn] 的损失函数 L ( W ) L(W) L(W),其Hessian矩阵 H L H_L HL 是一个 n × n n \times n n×n 的对称矩阵:
H L = ( ∂ 2 L ∂ w 1 2 ∂ 2 L ∂ w 1 ∂ w 2 … ∂ 2 L ∂ w 1 ∂ w n ∂ 2 L ∂ w 2 ∂ w 1 ∂ 2 L ∂ w 2 2 … ∂ 2 L ∂ w 2 ∂ w n ⋮ ⋮ ⋱ ⋮ ∂ 2 L ∂ w n ∂ w 1 ∂ 2 L ∂ w n ∂ w 2 … ∂ 2 L ∂ w n 2 ) H_L = \begin{pmatrix} \frac{\partial^2 L}{\partial w_1^2} & \frac{\partial^2 L}{\partial w_1 \partial w_2} & \dots & \frac{\partial^2 L}{\partial w_1 \partial w_n} \\ \frac{\partial^2 L}{\partial w_2 \partial w_1} & \frac{\partial^2 L}{\partial w_2^2} & \dots & \frac{\partial^2 L}{\partial w_2 \partial w_n} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^2 L}{\partial w_n \partial w_1} & \frac{\partial^2 L}{\partial w_n \partial w_2} & \dots & \frac{\partial^2 L}{\partial w_n^2} \end{pmatrix} HL= ∂w12∂2L∂w2∂w1∂2L⋮∂wn∂w1∂2L∂w1∂w2∂2L∂w22∂2L⋮∂wn∂w2∂2L……⋱…∂w1∂wn∂2L∂w2∂wn∂2L⋮∂wn2∂2L
其中 ( H L ) i j = ∂ 2 L ∂ w i ∂ w j (H_L)_{ij} = \frac{\partial^2 L}{\partial w_i \partial w_j} (HL)ij=∂wi∂wj∂2L。如果函数 L L L 的二阶偏导数连续,则 H L H_L HL 是对称的,即 ∂ 2 L ∂ w i ∂ w j = ∂ 2 L ∂ w j ∂ w i \frac{\partial^2 L}{\partial w_i \partial w_j} = \frac{\partial^2 L}{\partial w_j \partial w_i} ∂wi∂wj∂2L=∂wj∂wi∂2L。
Hessian矩阵的意义:
Hessian矩阵描述了损失函数在某一点附近的曲率 (curvature)。
- 如果在一个临界点(梯度为零的点),Hessian矩阵是正定的(所有特征值都为正),那么该点是一个局部最小值。
- 如果Hessian矩阵是负定的(所有特征值都为负),该点是一个局部最大值。
- 如果Hessian矩阵的特征值有正有负,该点是一个鞍点 (Saddle Point)。在深度学习中,高维损失函数的鞍点远比局部最小值更常见,这是优化的一大挑战。
AI中的应用:
- 二阶优化算法:像牛顿法 (Newton’s Method) 及其变种就利用Hessian矩阵来进行参数更新,它们通常能比一阶方法(如梯度下降)更快地收敛,尤其是在接近最优点时。更新规则类似于 W t + 1 = W t − η [ H L ( W t ) ] − 1 ∇ L ( W t ) W_{t+1} = W_t - \eta [H_L(W_t)]^{-1} \nabla L(W_t) Wt+1=Wt−η[HL(Wt)]−1∇L(Wt)。然而,计算和存储Hessian矩阵(及其逆)对于参数量巨大的现代神经网络来说代价高昂( O ( n 2 ) O(n^2) O(n2) 存储, O ( n 3 ) O(n^3) O(n3) 求逆),所以实际应用中更多采用近似Hessian的方法(如L-BFGS)。
- 分析损失函数的几何形状:帮助理解优化过程中的难点,如鞍点、平坦区域等。
- 确定学习率:Hessian的特征值可以用来指导学习率的选择。
小结:Jacobian矩阵是一阶偏导数对向量值函数的推广,是链式法则在多维情况下表达的关键。Hessian矩阵是标量值函数的二阶偏导数矩阵,描述了函数的局部曲率,可用于二阶优化算法和分析临界点性质。它们为AI提供了更深层次的优化和分析工具。
总结:微积分,驱动AI学习的引擎
我们今天一起探索了微积分的核心概念——导数、偏导数、梯度、链式法则,以及简要了解了Jacobian和Hessian矩阵。希望你现在能理解,微积分并非只是抽象的数学公式,而是AI模型能够“学习”和“优化”自身的关键所在:
- 导数和偏导数让模型感知到单个参数微调对整体性能(损失)的影响。
- 梯度整合了所有参数的影响,为模型指明了“变得更好”(损失减小)的最快方向。
- 梯度下降算法则是模型沿着梯度方向小步快跑,不断迭代调整参数,以达到最佳性能的过程。
- **链式法则(反向传播)**是高效计算复杂模型(如深度神经网络)中所有参数梯度的“总调度师”,使得大规模模型的训练成为可能。
- Jacobian和Hessian则为更精细的分析和更高级的优化算法提供了数学工具。
如果说线性代数为AI提供了表示和操作数据的“骨架”,那么微积分就为AI注入了学习和进化的“引擎”和“导航系统”。正是因为有了微积分,AI模型才能从数据中总结规律,自动调整参数,最终实现各种令人惊叹的功能。
理解这些数学原理,不仅能帮助你更深入地理解AI的工作方式,也能让你在未来学习更高级的AI技术时更有底气。数学是AI的基石,也是创新的源泉。让我们继续这座奇妙的数学之旅吧!
习题
来几道练习题,检验一下今天的学习成果!
1. 理解导数
假设一个AI模型的损失函数关于某个权重参数 w w w 的关系是 L ( w ) = ( w − 3 ) 2 + 5 L(w) = (w-3)^2 + 5 L(w)=(w−3)2+5。
(a) 当 w = 1 w=1 w=1 时,损失 L ( w ) L(w) L(w) 关于 w w w 的导数 d L d w \frac{dL}{dw} dwdL 是多少?
(b) 根据这个导数值,为了减小损失,我们应该增加 w w w 还是减小 w w w?
2. 计算偏导数
一个简单的损失函数依赖于两个参数 w 1 w_1 w1 和 w 2 w_2 w2: L ( w 1 , w 2 ) = 2 w 1 2 − 3 w 1 w 2 + w 2 3 L(w_1, w_2) = 2w_1^2 - 3w_1w_2 + w_2^3 L(w1,w2)=2w12−3w1w2+w23。
请计算:
(a) ∂ L ∂ w 1 \frac{\partial L}{\partial w_1} ∂w1∂L (损失函数关于 w 1 w_1 w1 的偏导数)
(b) ∂ L ∂ w 2 \frac{\partial L}{\partial w_2} ∂w2∂L (损失函数关于 w 2 w_2 w2 的偏导数)
3. 梯度与梯度下降
对于上一题的损失函数 L ( w 1 , w 2 ) = 2 w 1 2 − 3 w 1 w 2 + w 2 3 L(w_1, w_2) = 2w_1^2 - 3w_1w_2 + w_2^3 L(w1,w2)=2w12−3w1w2+w23。
(a) 写出其梯度向量 ∇ L ( w 1 , w 2 ) \nabla L(w_1, w_2) ∇L(w1,w2)。
(b) 假设当前参数为 ( w 1 , w 2 ) = ( 1 , 1 ) (w_1, w_2) = (1, 1) (w1,w2)=(1,1),学习率为 η = 0.1 \eta = 0.1 η=0.1。应用一步梯度下降,新的参数 ( w 1 ′ , w 2 ′ ) (w_1', w_2') (w1′,w2′) 是多少?
4. 理解链式法则
假设一个简单的模型: y = u 2 y = u^2 y=u2,其中 u = 2 x + 1 u = 2x + 1 u=2x+1。损失函数 L = ( y − 10 ) 2 L = (y-10)^2 L=(y−10)2。我们想求损失 L L L 关于参数 x x x 的导数 d L d x \frac{dL}{dx} dxdL。
请用链式法则逐步写出计算过程(即 d L d x = d L d y ⋅ d y d u ⋅ d u d x \frac{dL}{dx} = \frac{dL}{dy} \cdot \frac{dy}{du} \cdot \frac{du}{dx} dxdL=dydL⋅dudy⋅dxdu 的每一项)。
5. Jacobian 与 Hessian (概念)
(a) 如果一个神经网络的某个层将一个10维的输入向量映射到一个5维的输出向量,描述这个层变换的Jacobian矩阵的维度是多少?
(b) Hessian矩阵的对角线元素 ∂ 2 L ∂ w i 2 \frac{\partial^2 L}{\partial w_i^2} ∂wi2∂2L 在直观上告诉我们关于损失函数在 w i w_i wi 方向上的什么信息?(提示:考虑单变量函数的二阶导数)
答案
1. 理解导数
L ( w ) = ( w − 3 ) 2 + 5 = w 2 − 6 w + 9 + 5 = w 2 − 6 w + 14 L(w) = (w-3)^2 + 5 = w^2 - 6w + 9 + 5 = w^2 - 6w + 14 L(w)=(w−3)2+5=w2−6w+9+5=w2−6w+14
(a) d L d w = 2 w − 6 \frac{dL}{dw} = 2w - 6 dwdL=2w−6。
当 w = 1 w=1 w=1 时, d L d w = 2 ( 1 ) − 6 = 2 − 6 = − 4 \frac{dL}{dw} = 2(1) - 6 = 2 - 6 = -4 dwdL=2(1)−6=2−6=−4。
(b) 导数值为-4(负数),这意味着如果增加 w w w,损失会减小。所以,为了减小损失,我们应该增加 w w w。
2. 计算偏导数
L ( w 1 , w 2 ) = 2 w 1 2 − 3 w 1 w 2 + w 2 3 L(w_1, w_2) = 2w_1^2 - 3w_1w_2 + w_2^3 L(w1,w2)=2w12−3w1w2+w23
(a) ∂ L ∂ w 1 = ∂ ∂ w 1 ( 2 w 1 2 ) − ∂ ∂ w 1 ( 3 w 1 w 2 ) + ∂ ∂ w 1 ( w 2 3 ) = 4 w 1 − 3 w 2 + 0 = 4 w 1 − 3 w 2 \frac{\partial L}{\partial w_1} = \frac{\partial}{\partial w_1}(2w_1^2) - \frac{\partial}{\partial w_1}(3w_1w_2) + \frac{\partial}{\partial w_1}(w_2^3) = 4w_1 - 3w_2 + 0 = 4w_1 - 3w_2 ∂w1∂L=∂w1∂(2w12)−∂w1∂(3w1w2)+∂w1∂(w23)=4w1−3w2+0=4w1−3w2
(b) ∂ L ∂ w 2 = ∂ ∂ w 2 ( 2 w 1 2 ) − ∂ ∂ w 2 ( 3 w 1 w 2 ) + ∂ ∂ w 2 ( w 2 3 ) = 0 − 3 w 1 + 3 w 2 2 = − 3 w 1 + 3 w 2 2 \frac{\partial L}{\partial w_2} = \frac{\partial}{\partial w_2}(2w_1^2) - \frac{\partial}{\partial w_2}(3w_1w_2) + \frac{\partial}{\partial w_2}(w_2^3) = 0 - 3w_1 + 3w_2^2 = -3w_1 + 3w_2^2 ∂w2∂L=∂w2∂(2w12)−∂w2∂(3w1w2)+∂w2∂(w23)=0−3w1+3w22=−3w1+3w22
3. 梯度与梯度下降
(a) 梯度向量 ∇ L ( w 1 , w 2 ) = [ ∂ L ∂ w 1 , ∂ L ∂ w 2 ] = [ 4 w 1 − 3 w 2 , − 3 w 1 + 3 w 2 2 ] \nabla L(w_1, w_2) = \left[ \frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial w_2} \right] = [4w_1 - 3w_2, -3w_1 + 3w_2^2] ∇L(w1,w2)=[∂w1∂L,∂w2∂L]=[4w1−3w2,−3w1+3w22]
(b) 当前参数 ( w 1 , w 2 ) = ( 1 , 1 ) (w_1, w_2) = (1, 1) (w1,w2)=(1,1)。
梯度 ∇ L ( 1 , 1 ) = [ 4 ( 1 ) − 3 ( 1 ) , − 3 ( 1 ) + 3 ( 1 ) 2 ] = [ 4 − 3 , − 3 + 3 ] = [ 1 , 0 ] \nabla L(1, 1) = [4(1) - 3(1), -3(1) + 3(1)^2] = [4 - 3, -3 + 3] = [1, 0] ∇L(1,1)=[4(1)−3(1),−3(1)+3(1)2]=[4−3,−3+3]=[1,0]。
学习率 η = 0.1 \eta = 0.1 η=0.1。
新的参数 ( w 1 ′ , w 2 ′ ) (w_1', w_2') (w1′,w2′):
w 1 ′ = w 1 − η ⋅ ∂ L ∂ w 1 ( 1 , 1 ) = 1 − 0.1 ⋅ 1 = 1 − 0.1 = 0.9 w_1' = w_1 - \eta \cdot \frac{\partial L}{\partial w_1}(1,1) = 1 - 0.1 \cdot 1 = 1 - 0.1 = 0.9 w1′=w1−η⋅∂w1∂L(1,1)=1−0.1⋅1=1−0.1=0.9
w 2 ′ = w 2 − η ⋅ ∂ L ∂ w 2 ( 1 , 1 ) = 1 − 0.1 ⋅ 0 = 1 − 0 = 1 w_2' = w_2 - \eta \cdot \frac{\partial L}{\partial w_2}(1,1) = 1 - 0.1 \cdot 0 = 1 - 0 = 1 w2′=w2−η⋅∂w2∂L(1,1)=1−0.1⋅0=1−0=1
所以,新的参数为 ( w 1 ′ , w 2 ′ ) = ( 0.9 , 1 ) (w_1', w_2') = (0.9, 1) (w1′,w2′)=(0.9,1)。
4. 理解链式法则
L = ( y − 10 ) 2 L = (y-10)^2 L=(y−10)2, y = u 2 y = u^2 y=u2, u = 2 x + 1 u = 2x + 1 u=2x+1.
d L d x = d L d y ⋅ d y d u ⋅ d u d x \frac{dL}{dx} = \frac{dL}{dy} \cdot \frac{dy}{du} \cdot \frac{du}{dx} dxdL=dydL⋅dudy⋅dxdu
- d L d y = 2 ( y − 10 ) ⋅ d d y ( y − 10 ) = 2 ( y − 10 ) ⋅ 1 = 2 ( y − 10 ) \frac{dL}{dy} = 2(y-10) \cdot \frac{d}{dy}(y-10) = 2(y-10) \cdot 1 = 2(y-10) dydL=2(y−10)⋅dyd(y−10)=2(y−10)⋅1=2(y−10)
- d y d u = d d u ( u 2 ) = 2 u \frac{dy}{du} = \frac{d}{du}(u^2) = 2u dudy=dud(u2)=2u
- d u d x = d d x ( 2 x + 1 ) = 2 \frac{du}{dx} = \frac{d}{dx}(2x+1) = 2 dxdu=dxd(2x+1)=2
所以, d L d x = 2 ( y − 10 ) ⋅ 2 u ⋅ 2 = 8 u ( y − 10 ) \frac{dL}{dx} = 2(y-10) \cdot 2u \cdot 2 = 8u(y-10) dxdL=2(y−10)⋅2u⋅2=8u(y−10)。
如果需要完全用 x x x 表示,可以将 u = 2 x + 1 u=2x+1 u=2x+1 和 y = u 2 = ( 2 x + 1 ) 2 y=u^2=(2x+1)^2 y=u2=(2x+1)2 代入:
d L d x = 8 ( 2 x + 1 ) ( ( 2 x + 1 ) 2 − 10 ) \frac{dL}{dx} = 8(2x+1)((2x+1)^2 - 10) dxdL=8(2x+1)((2x+1)2−10)
5. Jacobian 与 Hessian (概念)
(a) Jacobian矩阵的维度是 (输出维度) × \times × (输入维度)。所以,这个Jacobian矩阵的维度是 5 × 10 5 \times 10 5×10。
(b) Hessian矩阵的对角线元素 ∂ 2 L ∂ w i 2 \frac{\partial^2 L}{\partial w_i^2} ∂wi2∂2L 是损失函数 L L L 关于参数 w i w_i wi 的二阶偏导数(保持其他参数不变)。类似于单变量函数的二阶导数,它描述了损失函数在 w i w_i wi 方向上的曲率或“弯曲程度”。
* 如果 ∂ 2 L ∂ w i 2 > 0 \frac{\partial^2 L}{\partial w_i^2} > 0 ∂wi2∂2L>0,表示在 w i w_i wi 方向上,损失函数的图像是向上凹的(像碗一样)。
* 如果 ∂ 2 L ∂ w i 2 < 0 \frac{\partial^2 L}{\partial w_i^2} < 0 ∂wi2∂2L<0,表示在 w i w_i wi 方向上,损失函数的图像是向下凹的(像帽子一样)。
* 如果 ∂ 2 L ∂ w i 2 = 0 \frac{\partial^2 L}{\partial w_i^2} = 0 ∂wi2∂2L=0,表示在 w i w_i wi 方向上,曲率可能是平坦的(需要更高阶导数判断)。
这对于判断一个临界点是局部最小值、最大值还是鞍点的一部分信息很有用。
相关文章:

【硬核数学】2. AI如何“学习”?微积分揭秘模型优化的奥秘《从零构建机器学习、深度学习到LLM的数学认知》
在上一篇中,我们探索了线性代数如何帮助AI表示数据(向量、矩阵)和变换数据(矩阵乘法)。但AI的魅力远不止于此,它最核心的能力是“学习”——从数据中自动调整自身,以做出越来越准确的预测或决策…...

[Java][Leetcode middle] 151. 反转字符串中的单词
思路挺简单的 自己想的,步骤挺复杂的 先统计处开头和结尾的空格数跳过开头这些空格,将单词放到数组中统计最后一个可能漏过的单词(例如:“hello word”,没有空格退出)倒序输出 public String reverseWor…...

力扣每日一题5-18
class Solution { public int colorTheGrid(int m, int n) { // 每一列可能的状态总数 每个单元有3可能 int totalState 1; for (int i 0; i < m; i) totalState * 3; // pre[k] 代表前一轮dp 状态为k 的方案总数 int [] pre new int [totalState]; // 初始化合法填色 的…...

leetcode 74. Search a 2D Matrix
题目描述 要求时间复杂度必须是log(m*n)。那么对每一行分别执行二分查找就不符合要求,这种做法的时间复杂度是m*log(n)。 方法一,对每一行分别执行二分查找: class Solution { public:bool searchMatrix(vector<vector<int>>&a…...

养生指南:重塑健康生活的实用方案
一、饮食:均衡膳食,滋养身心 三餐以 “轻盐、轻油、轻糖” 为准则。早餐搭配全麦三明治、无糖酸奶和一小把蓝莓,补充优质碳水与抗氧化物质;午餐选用糙米饭、白灼虾及蒜蓉西蓝花,保证蛋白质与膳食纤维摄入;…...

IPTABLES四表五链祥解
在Linux中,iptables 是一个强大的防火墙工具,用于管理和过滤网络流量。iptables 使用四个不同的表,每个表都包含多个链,来控制流量的处理。 一、iptables四个表 表名功能说明filter默认表,负责对进出数据包的过滤操作…...

嵌入式学习--江协51单片机day8
这个本来应该周末写的,可是一直想偷懒,只能是拖到周一了,今天把51结个尾,明天开始学32了。 学习内容LCD1602,直流电机,AD/DA,红外遥控 LCD1602 内部的框架结构 屏幕小于数据显示区ÿ…...

内网穿透与内网映射是什么?
在互联网技术快速迭代的当下,网络通信架构日益复杂,内网穿透与内网映射作为实现公网访问内网资源的核心技术,在企业办公、个人开发、智能家居等领域发挥着关键作用。尽管两者都致力于打通公网与内网的连接通道,但它们在底层原理、…...

51单片机点亮一个LED介绍
LED介绍 LED就是发光二极管,一般来说如果是直插式的,那就是长正短负,如果是贴片式的,那就带彩色标记是阴极,如果是三角形的,水平箭头指的就是阴极,通常一般的工作电压在3mA~20mA,当…...

WebRTC技术EasyRTC嵌入式音视频通信SDK助力智能电视搭建沉浸式实时音视频交互
一、方案概述 EasyRTC是一款基于WebRTC技术的开源实时音视频通信解决方案,具备低延迟、高画质、跨平台等优势。将EasyRTC功能应用于智能电视,能够为用户带来全新的交互体验,满足智能电视在家庭娱乐、远程教育、远程办公、远程医疗等多种场…...

uniapp 小程序 CSS 实现多行文本展开收起 组件
效果 组件 <template><!-- 最外层弹性盒子 --><div class"box" :style"boxStyle"><!-- 文本区域,动态类名控制展开/收起状态 --><div ref"textRef" :class"[text-cont, btnFlag ? text-unfold : t…...

嵌入式51单片机:C51
sbit TISCON^1的意思是定义TI为SCON的次低位(最低位标记为0,其次为1,再次为2)...

【回眸】香橙派zero2 嵌入式数据库SQLite
前言 SQLite介绍 安装SQLite3 SQLite 使用 创建数据库 创建一张表格 插入数据 查看数据库的记录 删除一条记录 更改一条记录 删除一张表 增加一列(性别) SQLite编程操作 前言 还有2个项目没更新完...披星戴月更新中... SQLite介绍 基于嵌入…...

vue3个生命周期解析,及setup
合理使用各生命周期,切勿乱用,不是所有东西都需要,合理使用可以提高效率和性能。 Vue 3 生命周期钩子详解 Vue 3的生命周期钩子分为以下几个阶段: onBeforeMount 调用时机:在组件挂载到DOM之前调用。使用场景…...

MySQL死锁:面试通关“三部曲”心法
想象一下,你的MySQL数据库里有两张桌子(数据表),比如一张“产品库存表”,一张“订单表”。现在来了两个顾客(并发事务),都想同时操作这两张桌子上的东西: 顾客A 先锁住了…...
)
Spring Boot 与 RabbitMQ 的深度集成实践(四)
实战案例 业务场景描述 在电商系统中,用户下单是一个核心业务操作。当用户成功下单后,系统需要执行一系列后续任务,如发送邮件通知用户订单已成功提交,更新库存信息以确保商品库存的准确性,以及记录订单相关的日志信…...

ES6详解
一、变量声明 let 与 const 块级作用域:替代 var 的函数作用域 const 声明常量(不可重新赋值,但对象属性可修改) if (true) {let x 10const PI 3.14 } console.log(x) // 报错 二、箭头函数 简写语法与 this 绑定 // 传统函数…...

C语言—字符函数和字符串函数
1.字符分类函数 字符控制函数:int iscntrl ( int c ); 控制字符通常不是可打印字符,该函数是用来判断参数是否为控制字符,需要的头文件为<ctype.h>标准ASCII码中,不可打印字符主要包括以下两类: 控制字符&…...
--优雅数组)
【LeetCode】大厂面试算法真题回忆(93)--优雅数组
题目描述 如果一个数组中出现次数最多的元素出现大于等于k次,被称为k-优雅数组,k也可以被称为优雅阈值。 例如,数组[1, 2, 3, 1, 2, 3, 1],它是一个3-优雅数组,因为元素1出现次数大于等于3次。数组[1, 2, 3, 1, 2]就不是一个3-优雅数组,因为其中出现次数最多的元素是1和…...

【MySQL成神之路】MySQL常用语法总结
目录 MySQL 语法总结 数据库操作 表操作 数据操作 查询语句 索引操作 约束 事务控制 视图操作 存储过程和函数 触发器 用户和权限管理 数据库操作 创建数据库: CREATE DATABASE database_name; 选择数据库: USE database_name; 删除数…...

机器学习第十六讲:K-means → 自动把超市顾客分成不同消费群体
机器学习第十六讲:K-means → 自动把超市顾客分成不同消费群体 资料取自《零基础学机器学习》。 查看总目录:学习大纲 关于DeepSeek本地部署指南可以看下我之前写的文章:DeepSeek R1本地与线上满血版部署:超详细手把手指南 K-me…...

多商户1.8.1版本前端问题优化集合指南
1、逛逛社区上传一张图时,进入详情页面显示不出来 修改路径:pages ---> discover ---> components ---> discoverDetails.vue 解读:这里是因为图片高度没有定义,图片没显示出来。修改如下: <!--逛逛类型为…...
——网络ping通)
基于正点原子阿波罗F429开发板的LWIP应用(1)——网络ping通
说在开头 正点原子F429开发板主芯片采用的是STM32F429IGT6,网络PHY芯片采用的是LAN8720A(V1)和YT8512C(V2),采用的是RMII连接,PHY_ADDR为0;在代码中将会对不同的芯片做出适配。 CubeMX版本:6.6.1; F4芯片组…...
)
第 1 章:数字 I/O 与串口通信(GPIO UART)
本章目标: 掌握 GPIO 的硬件原理、寄存器配置与典型驱动框架 深入理解 UART/USART 的帧格式、波特率配置、中断与 DMA 驱动 通过实战案例,将 GPIO 与 UART 结合,实现 AT 命令式外设控制 章节结构 GPIO 概述与硬件原理 GPIO 驱动实现:寄存器、中断与去抖 UART/USART 原理与帧…...
)
MCU 温度采样理论(-ADC Temperature sensor)
温度传感器可以使用ADC来测量芯片温度。 为了准确测量运行时的芯片温度,请使用在生产过程中运行的参考测量值,此参考值与其他校准数据一起存放在SFlash中。 一、温度测量流程 1、ADC校准:关于偏移和增益调整的实例,见9.3。 2、检查CREFH和VREL:参见8.2。 3、设置参考…...

stm32week16
stm32学习 十一.中断 4.使用中断 EXTI的配置步骤: 使能GPIO时钟设置GPIO输入模式使能AFIO/SYSCFG时钟设置EXTI和IO对应关系设置EXTI屏蔽,上/下沿设置NVIC设计中断服务函数 HAL库的使用: 使能GPIO时钟:__HAL_RCC_GPIOx_CLK_EN…...

隨筆 20250519 基于MAUI Blazor整合SQLite数据库与Star打印机的详细步骤
以下是基于MAUI Blazor整合SQLite数据库与Star打印机的详细步骤,包含必要的NuGet包引入及核心代码实现: 零、目錄結構 一、整合SQLite数据库 1. 安装NuGet包 # SQLite核心库 Install-Package sqlite-net-pcl # SQLite平台适配库&am…...
)
电子电路原理第十六章(负反馈)
1927年8月,年轻的工程师哈罗德布莱克(Harold Black)从纽约斯塔顿岛坐渡轮去上班。为了打发时间,他粗略写下了关于一个新想法的几个方程式。后来又经过反复修改, 布莱克提交了这个创意的专利申请。起初这个全新的创意被认为像“永动机”一样愚蠢可笑,专利申请也遭到拒绝。但…...

推客小程序系统开发:全栈式技术解决方案与行业赋能实践
在数字化营销深度渗透各行业的当下,传统推广模式已难以满足企业精细化运营与高效获客的需求。专业的推客小程序系统凭借其强大的裂变传播能力与灵活的推广机制,成为企业构建私域流量池、提升推广效能的核心工具。我们基于多年技术沉淀与行业洞察&…...

【prometheus+Grafana篇】基于Prometheus+Grafana实现Oracle数据库的监控与可视化
💫《博主主页》: 🔎 CSDN主页 🔎 IF Club社区主页 🔥《擅长领域》:擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了…...

【Android构建系统】Soong构建系统,通过.bp + .go定制编译
背景介绍 本篇是一篇实操内容,是对【Android构建系统】如何在Camera Hal的Android.bp中选择性引用某个模块的优化与改进。本篇内容主要想通过一个具体例子介绍Soong构建系统较复杂的定制化方法和步骤,以便在今后的工作学习中更好的使用Soong构建系统。 …...

Qt开发:QUdpSocket的详解
文章目录 一、QUdpSocket 简介二、常用函数的介绍和使用三、接收端完整示例四、发送端完整示例 一、QUdpSocket 简介 在 Qt 中,UDP(User Datagram Protocol,用户数据报协议)是通过 QUdpSocket 类实现的。UDP 是一种无连接的、轻量…...

【android bluetooth 协议分析 01】【HCI 层介绍 9】【ReadLocalSupportedCommands命令介绍】
1. HCI_Read_Local_Supported_Commands 命令介绍 1. 命令介绍(Description) HCI_Read_Local_Supported_Commands 是 HCI 层中非常重要的查询命令。它允许 Host(如 Android 系统中的 Bluetooth stack)获取 Controller(…...
nanoGPT)
Model 速通系列(一)nanoGPT
这个是新开的一个系列用来手把手复现一些模型工程,之所以开这个系列是因为有人留言说看到一个工程不知道从哪里读起,出于对自身能力的提升与兴趣,故新开了这个系列。由于主要动机是顺一遍代码并提供注释。 该系列第一篇博客是 nanoGPT &…...

星际争霸小程序:用Java实现策略模式的星际大战
在游戏开发的世界里,策略模式是一种非常实用的设计模式,它允许我们在运行时动态地选择算法或行为。今天,我将带你走进一场星际争霸的奇幻之旅,用Java实现一个简单的星际争霸小程序,通过策略模式来模拟不同种族单位的战…...

网络Tips20-007
网络威胁会导致非授权访问、信息泄露、数据被破坏等网络安全事件发生, 其常见的网络威胁包括窃听、拒绝服务、病毒、木马、( 数据完整性破坏 )等, 常见的网络安全防范措施包括访问控制、审计、身份认证、数字签名、( 数据加密 )、 包过滤和检测等。 AE…...

2.微服务-配置
引入springcloud的pom配置 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.12</version><relativePath/></parent> <dependencyManagemen…...
)
python实现pdf转图片(针对每一页)
from pdf2image import convert_from_path import ospdf_file rC:\Users\\Desktop\拆分\产权证.pdf poppler_path rC:\poppler-24.08.0\Library\bin # 这里改成你自己的路径output_dir rC:\Users\\Desktop\拆分\output_images os.makedirs(output_dir, exist_okTrue)image…...

Python编程从入门到实践 PDF 高清版
各位程序员朋友们,还在为找不到合适的Python学习资料而烦恼吗?还在为晦涩难懂的编程书籍而头疼吗?今天,就给大家带来一份重磅福利——237完整版PDF, 我用网盘分享了「Python编程:从入门到实践__超清版.pdf…...

CVE-2015-3934 Fiyo CMS SQL注入
CVE-2015-3934 Fiyo CMS SQL注入 页面抓登录数据包 构造延时注入语句在user处’%2B(select(0)from(select(sleep(5)))v)%2B’ 存在延时注入,使用脚本即可...

【Pandas】pandas DataFrame mode
Pandas2.2 DataFrame Computations descriptive stats 方法描述DataFrame.abs()用于返回 DataFrame 中每个元素的绝对值DataFrame.all([axis, bool_only, skipna])用于判断 DataFrame 中是否所有元素在指定轴上都为 TrueDataFrame.any(*[, axis, bool_only, skipna])用于判断…...
洛谷 P11232 CSPS2024 超速检测 题解)
(思维题、贪心)洛谷 P11232 CSPS2024 超速检测 题解
这一题在 2024 将我击败,但我怎么现在才补题解 …… 题意 原题 思路 对于每一辆车,我们可以算出,其在距离左端点哪段位置会超速 [ l , r ] [l,r] [l,r],那么这辆车会被 l l l 右侧最近的测速仪到 r r r 左侧最近的测速仪检…...

C#:多线程
一.线程常用概念 线程(Thread):操作系统执行程序的最小单位 进程(Process):程序在内存中的运行实例 并发(Concurrency):多个任务交替执行(单核CPU࿰…...

虚拟币制度钱包开发:功能设计与成本全解析
虚拟币制度钱包开发:功能设计与成本全解析 ——从基础架构到合规风控的完整解决方案 一、开发成本:分层定价与关键影响因素 根据2024-2025年行业数据显示,虚拟币钱包App开发成本跨度较大,主要受功能复杂度、技术架构与合规要求三…...
TransmittableThreadLocal实现上下文传递-笔记
1.TransmittableThreadLocal简介 com.alibaba.ttl.TransmittableThreadLocal(简称 TTL)是阿里巴巴开源的一个工具类,旨在解决 ThreadLocal 在线程池中无法传递上下文变量 的问题。它是对 InheritableThreadLocal 的增强,尤其适用…...

应对WEEE 2025:猎板PCB的区块链追溯与高温基材创新
在全球电子产业加速向循环经济转型的背景下,欧盟《绿色新政》与《WEEE指令》对PCB行业提出更高要求。作为行业先行者,猎板PCB(Hunter PCB)以生物降解基材为核心,结合全球合规体系与产业链协同创新,构建从材…...

大陆资产在香港发行RWA的合规路径与核心限制
大陆资产在香港发行RWA的合规路径与核心限制 ——从“双重合规原则”到资产准入边界的全景解读 一、法律框架:双重合规原则的刚性约束 根据香港金管局Ensemble沙盒项目要求,大陆资产在香港发行RWA需遵循“双重合规原则”,即底层资产需同时符…...

爬虫攻防战:从入门到放弃的完整对抗史与实战解决方案
爬虫攻防战:从入门到放弃的完整对抗史与实战解决方案 这张有趣的图片生动描绘了爬虫开发者与反爬工程师之间的"军备竞赛"。作为技术博主,我将基于这张图的各个阶段,深入分析爬虫技术的演进与对应的反制措施,提供一套完整的反爬解决方案,包括技术原理、实施方法…...
)
Fabric初体验(踩坑笔记)
搭建fabric部署合约学习笔记 环境准备CURl安装docker 参照官网文档实现(2025.05.19)根据前言交代的文章去尝试(失败版)安装fabric-samples安装指定2.2.0版本Fabric二进制文件和配置文件直接手动下载(不建议)…...

区块链blog2_中心化与效率
🌿中心化出现原因 信息/服务分散在各处会浪费时间且不方便使用,由此,把信息/服务集中在一起,便于管理,避免了不必要的效率损失。 即集中资源,使得对信息处理的全过程效率升高。中心化不是网络中产生的&…...