【数据结构与算法】常见排序算法详解(C++实现)
目录
一、排序的基本概念
二、插入排序
2.1 直接插入排序
2.2 折半插入排序
2.3 希尔排序
三、交换排序
3.1 冒泡排序
3.2 快速排序
四、选择排序
4.1 简单选择排序
4.2 堆排序
五、归并排序
六、基数排序
七、计数排序
结语
一、排序的基本概念
排序
就是重新排列一串记录中的元素,使元素按照其中的某个或某些关键字的大小,递增或递减的排列起来的过程。
排序前:n个记录R1,R2......Rn,对应的关键字为K1,K2......Kn。
排序后:R1',R2'......Rn',对应的关键字顺序K1'<=K2'<=......<=Kn',其中<=可以换成其它比较大小的符号。
稳定性
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,Ri和Rj的关键字Ki=Kj,且Ri在Rj之前,而在排序后的序列中,Ri仍在Rj之前,则称这种排序算法是稳定的,否则称为不稳定的。
内部排序
排序期间数据元素全部放在内存中的排序。
外部排序
排序期间数据元素无法全部同时放在内存中,必须在排序过程中根据要求不断地在内、外存之间移动的排序。
二、插入排序
插入排序的基本思想是每次将一个待排序的记录元素按其关键字大小插入到前面已排好序的子序列中,直到全部记录插入完成。
2.1 直接插入排序
当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移。
void insertSort(vector<int>& arr)
{int n = arr.size();if(n < 2)return;for(int i = 1; i < n; ++i) // 第一个元素作为基准元素,从第二个元素开始把其插到正确的位置{int end = i - 1; // 需要判断第i个元素与前面的多个元素的大小int tmp = arr[i]; // 将第i个元素复制为哨兵while(end >= 0 && arr[end] > tmp) // 找哨兵的正确位置,比哨兵大的元素依次后移{arr[end + 1] = arr[end]; end--;}arr[end + 1] = tmp; //把哨兵插入到正确的位置}
}空间复杂度:O(1),仅使用常数个辅助单元。
时间复杂度:
对于N个元素,将第一个元素看作有序后,需要操作剩下的N-1个元素,也就是需要比较N-1趟,每趟操作都分为比较关键字和移动元素,比较次数与移动元素的次数取决于待排序表的初始状态。
在最好的情况下,表中元素已经有序,N-1个元素只需要插入到已排好序的后面,因此时间复杂度为O(N)。
在最坏的情况下,表中元素为排序结果的逆序,N-1个元素每个比较后都要移动到排好序的最前面,因此时间复杂度为O(N²)。
稳定性:稳定。每次插入元素都是从后往前先比较再移动,所以不会出现相同元素相对位置发生变化的情况。
适用性:适用于顺序存储和链式存储的线性表,采用链式存储时不需要移动元素。
2.2 折半插入排序
插入排序步骤分为比较元素和移动元素,其中对于比较元素这一步骤,由于前面的元素已经排好序,可以使用二分查找提高查找效率。
void insertSort(vector<int>& arr)
{int n = arr.size();if(n < 2)return;for(int i = 1; i < n; ++i) // 第一个元素作为基准元素,从第二个元素开始把其插到正确的位置{int tmp = arr[i]; // 将第i个元素复制为哨兵int left = 0;int right = i - 1; // 二分查找while(left <= right){int mid = left + (right - left) / 2;if(arr[mid] > tmp)right = mid - 1;elseleft = mid + 1;} // 此时 left > right, left 为插入的位置for(int j = i; j > left; j--) // 比哨兵大的元素依次后移{arr[j] = arr[j-1];}arr[left] = tmp; //把哨兵插入到正确的位置}
}空间复杂度:O(1),仅使用常数个辅助单元。
时间复杂度:
虽说改进了查找方法,减少了比较的次数,但元素的移动次数并未改变,因此时间复杂度同直接插入排序一致,最好为O(N),最坏为O(N²)。
稳定性:稳定。和直接插入排序一致。
适用性:采用了随机存取的特点,只适用于顺序存储的线性表。
2.3 希尔排序
直接插入排序在元素接近有序的时候,时间效率较高,一般更适用于基本有序的排序表和数据量不大的排序表。基于这两点,在插入排序的基础上进行改进,得到了希尔排序。
希尔排序又称缩小增量排序。希尔排序法的基本思想是:先选定一个整数,将待排序表分割成若干子表,对各个子表分别进行直接插入排序。重复上述分组和排序的工作。当整数到达1时,所有记录在统一组内排好序。
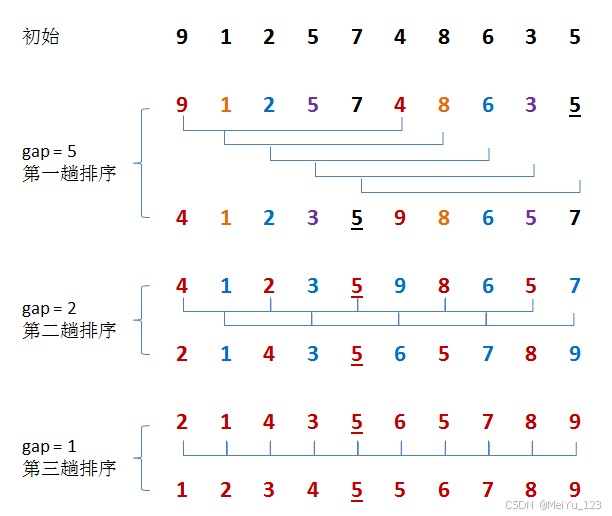
void ShellSort(vector<int>& arr)
{int n = arr.size();if(n < 2) return;int gap = n;while (gap >= 1){gap = gap / 3 + 1; //基于工程经验 三倍比较好for (int i = 0; i < n - gap; i++){int end = i;int tmp = arr[end + gap];while (end >= 0 && tmp < a[end]){arr[end + gap] = arr[end];end -= gap;}arr[end + gap] = tmp;}}
}空间复杂度:O(1),仅使用常数个辅助单元。
时间复杂度:最坏情况下为O(N²),N在某个特定范围时,时间复杂度约为。
稳定性:不稳定。当相同关键字的记录元素被划分到不同的子表时,可能会改变它们之间的相对次序。
适用性:仅适用于顺序存储的线性表。
三、交换排序
交换排序的思想:根据序列中两个元素关键字的比较结果来对换这两个记录在序列中的位置。
3.1 冒泡排序
从前往后(从后往前)两两比较相邻元素的值,若为逆序(A[i-1] > A[i]),则交换它们,直到序列比完。这是一趟冒泡,最后会将最大的元素交换到最后一个位置,这个过程中,关键字最大的元素慢慢的移动到后面,就像冒泡一样。最多n-1趟冒泡就能把所有元素排好序。
void BubbleSort(vector<int>& arr)
{int n = arr.size(); for (int i = 0; i < n - 1; i++){// 标记位,当这一趟冒泡没有交换元素则说明已经有序,可以停止int exchange = 0;for (int j = 0; j < n - 1 - i; j++){if (arr[j] > arr[j + 1]){std::swap(a[j], a[j + 1]);exchange = 1;}}if (exchange == 0)break;}
}空间复杂度: O(1),仅使用常数个辅助单元。
时间复杂度:
当初始序列有序时,只需要第一趟冒泡,比较次数为N-1,移动次数为0,因此最好情况下时间复杂度为O(N)。
当初始序列为逆序时,需要N-1趟冒泡,第i趟排序要进行N-i次关键字的比较,并且要进行N-1次的移动,因此最坏情况下时间复杂度为O(N²)。
稳定性:稳定。当A[i] = A[j] 时,不会发生交换。
适用性:适用于顺序存储和链式存储的线性表。
3.2 快速排序
任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
void QuickSort(vector<int>& arr, int left, int right)
{if (left >= right)return;//很大的时候用快速排序if ((right - left + 1) > 10){//int div = PartSort1(arr, left, right);int div = PartSort2(arr, left, right);//int div = PartSort3(arr, left, right);QuickSort(arr, left, div - 1);QuickSort(arr, div + 1, right);}//小了的时候用插入排序else{InsertSort(arr + left, right - left + 1);}
}// 头 中间 尾 三数取中
int GetMidIndex(vector<int>& arr, int begin, int end)
{int mid = (begin + end) / 2;if (arr[begin] < arr[mid]){if (a[mid] < a[end]){return mid;}else if (arr[begin] > arr[end]){return begin;}else{return end;}}else{if (arr[end] > arr[begin]){return begin;}else if (arr[end] < arr[mid]){return mid;}else{return end;}}
}// 左右指针法
int PartSort1(vector<int>& arr, int begin, int end)
{if (begin >= end) return begin;// 三数取中选择基准值索引int midindex = GetMidIndex(arr, begin, end);std::swap(arr[midindex], arr[end]);int keyindex = end;while (begin < end){while (begin < end && arr[begin] <= arr[keyindex])begin++;while (begin < end && arr[end] >= arr[keyindex])end--;std::swap(arr[begin], arr[end]);}// 将基准值放到正确位置std::swap(arr[begin], arr[keyindex]);return begin; // 返回基准值的最终位置
}// 挖坑法:挪动基准值
int PartSort2(vector<int>& arr, int begin, int end)
{int midindex = GetMidIndex(arr, begin, end);std::swap(arr[midindex], arr[end]);int key = arr[end];while (begin < end){while (begin < end && arr[begin] <= key)begin++;arr[end] = arr[begin];while (begin < end && arr[end] >= key)end--;arr[begin] = arr[end];}arr[begin] = key;return begin;
}// 前后指针法
int PartSort3(vector<int>& arr, int begin, int end)
{int midindex = GetMidIndex(arr, begin, end);std::swap(arr[midindex], arr[end]);int key = arr[end];int cur = begin;int prev = cur - 1;while (cur < end){if (arr[cur] < key && ++prev != cur){std::swap(arr[cur], arr[prev]);}cur++;}prev++;std::swap(arr[prev], arr[end]);return prev;
}空间复杂度:快速排序使用了递归,因此空间与递归调用的最大层数一致。最好情况下为O(logN) ,最坏情况下进行N-1次递归调用,空间复杂度为O(N)。
时间复杂度:
最坏情况下每次基准值选的都是最大或者最小的,相当于每次递归的时候一个数组范围为N-1,另一个为0,变成了单个数组排序,时间复杂度为O(N²)。
最好情况下每次基准值都选到了中间的值,那么在递归的时候,每个数组都是N/2的长度,最后的时间复杂度为O(NlogN)。
在这里我们利用了三数取中来避免最坏情况的发生,因此可以将快速排序的时间复杂度看作O(NlogN)。
稳定性:不稳定。划分区间的时候会将两个相同关键字的交换后位置发生变化。
适用性:仅适用于顺序存储的线性表。
四、选择排序
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。
4.1 简单选择排序
void SelectSort(vector<int>& arr)
{int n = arr.size();if(n < 2) return;int begin = 0, end = n - 1;while (begin < end){int mini, maxi;mini = maxi = begin;for (int i = begin + 1; i <= end; i++){if (arr[i] > arr[maxi]){maxi = i;}if (arr[i] < arr[mini]){mini = i;}}std::swap(arr[begin], arr[mini]);if (begin == maxi){maxi = mini;}std::swap(arr[end], arr[maxi]);begin++;end--;}
}空间复杂度: O(1),仅使用常数个辅助单元。
时间复杂度:
一趟选择排序中分为比较和交换两个部分,元素之间比较次数与表的初始状态无关,始终是N(N-1)/2次,而交换与表的初始状态有关,有序或者接近有序则交换的次数少,但是时间复杂度最终都是O(N²)。
稳定性:不稳定。交换的时候会将相同的值的前一个元素交换到后面。
适用性:适用于顺序存储和链式存储的线性表,以及关键字较少的情况。
4.2 堆排序
堆排序是指利用堆这种数据结构所设计的一种排序算法,它是选择排序的一种,通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
这里有需要的可以去我的另一篇文章查看更具体的堆的操作:【重走C++学习之路】11、STL-stack和queue在这篇文章的优先队列讲解中。
void HeapSort(vector<int>& arr)
{int n = arr.size();if(n < 2) return;// 从叶子节点的父节点开始调整for (int i = (n - 1 - 1) / 2; i >= 0;i--){AdjustDown(arr, n, i);}int end = n - 1;while (end > 0){std::swap(arr[0], arr[end]);AdjustDown(arr, end, 0);end--;}
}//大堆向下调整
void AdjustDown(vector<int>& arr, int n, int root)
{int parent = root;int child = parent * 2 + 1;while (child < n){if (child + 1 < n && arr[child] < arr[child + 1]){child++;}if (arr[child] > arr[parent]){std::swap(arr[child], arr[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}空间复杂度: O(1),仅使用常数个辅助单元。
时间复杂度:
建堆的时间复杂度为O(N),建堆完后需要将最顶上的值挪动到最后来,又需要进行调整,这里的时间复杂度为O(H),最后总的时间复杂度为O(NlogN)。
稳定性:不稳定。建堆的时候有可能把后面相同关键字的元素调整到前面,
适用性:仅适用于顺序存储的线性表。
五、归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列:即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
void MergeSort(vector<int>& arr)
{int n = arr.size();if(n < 2) return;_MergeSort(arr, 0, n-1);
}void _MergeSort(vector<int>& arr, int left, int right)
{if (left >= right)return;int mid = (left + right) / 2;_MergeSort(arr, left, mid);_MergeSort(arr, mid + 1, right);int n1 = mid - left + 1;int n2 = right - mid;vector<int> L(n1), R(n2);// 拷贝数据到临时数组for (int i = 0; i < n1; i++) L[i] = arr[left + i];for (int j = 0; j < n2; j++) R[j] = arr[mid + 1 + j];// 合并临时数组到原数组int i = 0, j = 0, k = left;while (i < n1 && j < n2) {if (L[i] <= R[j]) arr[k++] = L[i++];else arr[k++] = R[j++];}// 剩余没拷贝完的while (i < n1) arr[k++] = L[i++];while (j < n2) arr[k++] = R[j++];
}
空间复杂度: O(N),在合并数组的时候借助了辅助空间,开辟了大小为N的数组。
时间复杂度:
每趟归并的时间复杂度为O(N),共需要进行[logN]趟归并,因此算法的时间复杂度为O(NlogN)。
稳定性:稳定。合并的时候不会改变相同关键字记录的相对顺序。
适用性:适用于顺序存储和链式存储的线性表。
六、基数排序
基数排序不基于比较和移动进行排序,而基于关键字各位的大小进行排序。基数排序的思想:不管多大多小的数,都是由0~9这十个基本数字组成的,不同的数只是位数不同或同一位(权值)上的基数不同。借此,我们先从每个数的最低位(如个位)开始比较,将它们分类(借助队列),然后依次取出再比较上一位(如十位),还是同样的方法,直到最后所有数最高位均为0时排序结束。
// 获取最大位数
int getMaxDigits(const vector<int>& arr)
{if (arr.empty()) return 0;int maxVal = *max_element(arr.begin(), arr.end());int digits = 0;while (maxVal > 0) {digits++;maxVal /= 10;}return digits;
}// LSD(低位优先)基数排序
void radixSortLSD(vector<int>& arr)
{if (arr.size() < 2) return;int maxDigits = getMaxDigits(arr);vector<int> temp(arr.size());vector<int> count(10, 0); // 十进制每一位的计数器for (int exp = 1; exp <= maxDigits; exp++) {int power = 1;for (int i = 1; i < exp; i++) power *= 10;// 重置计数器fill(count.begin(), count.end(), 0);// 统计每个位的出现次数for (int num : arr) {int digit = (num / power) % 10;count[digit]++;}// 转换为前缀和数组,确定元素在temp中的位置for (int i = 1; i < 10; i++) {count[i] += count[i - 1];}// 从后向前填充temp数组,保证稳定性for (int i = arr.size() - 1; i >= 0; i--) {int digit = (arr[i] / power) % 10;temp[--count[digit]] = arr[i];}// 复制回原数组arr = temp;}
}空间复杂度: O(N),借助了一个N个元素大小的数组存放临时结果。
时间复杂度:
每趟需要进行分配和收集操作,分配需要遍历所有关键字,时间复杂度为O(N),收集需要合并r个队列,时间复杂度为O(r),总共需要d趟,其中d为最大的位数,因此基数排序的时间复杂度为O(d(N+r))。
稳定性:稳定。每一趟分配和收集都是从后往前进行的,不会交换相同关键字的相对位置。
适用性:适用于顺序存储和链式存储的线性表。
七、计数排序
计数排序不基于比较,主要思想是:对于每个待排序元素x,统计小于x的元素个数,利用该信息就可以确定x的最终位置。
void stableCountingSort(vector<int>& arr)
{if (arr.empty()) return;// 计算最小值和最大值,确定计数数组的大小int minVal = *min_element(arr.begin(), arr.end());int maxVal = *max_element(arr.begin(), arr.end());int range = maxVal - minVal + 1;// 创建计数数组并统计每个元素的出现次数vector<int> count(range, 0);for (int num : arr) {count[num - minVal]++;}// 将计数数组转换为前缀和数组,记录每个元素的最终位置for (int i = 1; i < range; i++) {count[i] += count[i - 1];}// 创建临时数组,从后向前填充元素以保证稳定性vector<int> temp(arr.size());for (int i = arr.size() - 1; i >= 0; i--) {int value = arr[i];int index = count[value - minVal] - 1;temp[index] = value;count[value - minVal]--; // 更新位置指针}// 将临时数组复制回原数组arr = temp;
}空间复杂度: O(范围),其中范围为排序中最大的元素到0之间的个数。
时间复杂度:
O(MAX(N,范围)),这里有三个for循环,两个个是排序数组的N次,另一个是数中范围的次数,看这两个谁更大。
稳定性:稳定。最后参考排序表中元素的位置,从后往前遍历数组,相同元素在输出数组中的相对位置不会改变。
适用性:适用于顺序存储的线性表,并且序列中元素是整数且元素的范围不大。
结语
到这里基本上就解释完了常见的排序算法,排序在面试中非常常见,在学习的时候需要了解各个排序的思想,思想掌握了再写出来就不麻烦了。
相关文章:
)
【数据结构与算法】常见排序算法详解(C++实现)
目录 一、排序的基本概念 二、插入排序 2.1 直接插入排序 2.2 折半插入排序 2.3 希尔排序 三、交换排序 3.1 冒泡排序 3.2 快速排序 四、选择排序 4.1 简单选择排序 4.2 堆排序 五、归并排序 六、基数排序 七、计数排序 结语 一、排序的基本概念 排序 就是重新…...

STM32GPIO输入实战-按键key模板及移植
STM32GPIO输入实战-按键key模板及移植 一,按键模板展示二,按键模板逻辑1,准备工作:头文件与全局变量2,读取硬件状态:key_read_raw()3,核心处理:key_process_simple() 的四行代码 三,…...

LeetCode 1128.等价多米诺骨牌对的数量:计数
【LetMeFly】1128.等价多米诺骨牌对的数量:计数 力扣题目链接:https://leetcode.cn/problems/number-of-equivalent-domino-pairs/ 给你一组多米诺骨牌 dominoes 。 形式上,dominoes[i] [a, b] 与 dominoes[j] [c, d] 等价 当且仅当 (a …...

Spring MVC设计与实现
DispatcherServlet的初始化与请求处理流程 初始化阶段 Servlet 生命周期触发:当 Web 容器(如 Tomcat)启动时,根据注解/配置,DispatcherServlet 的 init() 方法被调用。 初始化 WebApplicationContext 根 WebApplicat…...
:语法单词)
日语学习-日语知识点小记-进阶-JLPT-N1阶段(1):语法单词
日语学习-日语知识点小记-进阶-JLPT-N1阶段(1):语法单词 1、前言(1)情况说明(2)工程师的信仰(3)高级语法N1语法和难点一、N1语法学习内容(高级语法ÿ…...

stm32week14
stm32学习 十.GPIO 2.基本结构 基本结构: F1与其它的的最大区别是上下拉电阻的位置 施密特触发器是一种整形电路,可以将非标准方波,整形成方波 图中MOS管的输出规则: 3.8中工作模式 ①输入浮空: 上下拉电阻均不工…...

WPF中Binding
绑定ViewModel中的数据 添加数据上下文 方法一:在XAML中添加 <Window.DataContext><local:MainWindowViewModel /> </Window.DataContext>方法二:在界面层的cs文件中添加 this.DataContext new MainWindowViewModel();绑定 publ…...
 协议和挑战!)
Google Agent space时代,浅谈Agent2Agent (A2A) 协议和挑战!
如果说去年Google Cloud大会大家还在数“AI”这个词被提了多少次,那么今年,绝对是“Agent”的主场!开发者主题演讲几乎被它“刷屏”,展区的许多 Demo 也都号称是 Agent 应用。 但我得诚实地说,大会现场关于 Agents 的 …...

爬虫的应用
在自然语言处理(NLP)领域,文本数据的预处理是至关重要的基础环节。它如同工匠雕琢璞玉前的打磨工作,直接影响后续模型分析与挖掘的效果。本文将基于 Python,以电商平台的差评和优质评价文本数据为例,详细展…...

力扣面试150题--相同的树
Day 41 题目描述 做法 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val val; }* TreeNode(int val, TreeNode left, TreeNode right…...

Java后端开发day40--异常File
(以下内容全部来自上述课程) 异常 异常:异常就是代表程序出现的问题 1. 异常的分类 1.1 Error 代表的是系统级别的错误(属于严重问题) 系统一旦出现问题,sun公司会把这些错误封装成Error对象。 Error…...

集成算法学习
集成算法通过组合多个弱学习器提升模型性能,以下是核心内容详解: 一、核心思想 - 组合优势:结合多个简单模型(如决策树),通过“少数服从多数”或“加权平均”等策略,降低方差、偏差或过拟合风险…...

工业认知智能:从数据分析到知识创造
工业认知智能:从数据分析到知识创造 引言 当前制造业面临的知识管理困境令人震惊:68%的工艺知识存储于老员工头脑中,30%的企业因知识传承断层导致质量事故。麦肯锡研究显示,应用认知智能技术的企业,其工艺创新速度提升3-5倍。本文将系统阐述工业认知智能的"感知-理…...

8.1 Python+Docker+企业微信集成实战:自动化报告生成与CI/CD部署全攻略
Python+Docker+企业微信集成实战:自动化报告生成与CI/CD部署全攻略 关键词:PDF报告生成, Word文档自动化, 企业微信集成, Docker容器化, CI/CD流水线 1. 多格式报告生成实战 通过扩展报告输出格式,满足不同用户的文档需求。我们使用Python生态的成熟库实现PDF/Word生成,并…...

25.5.4数据结构|哈夫曼树 学习笔记
知识点前言 一、搞清楚概念 ●权:___________ ●带权路径长度:__________ WPL所有的叶子结点的权值*路径长度之和 ●前缀编码:____________ 二、构造哈夫曼树 n个带权值的结点,构造哈夫曼树算法: 1、转化成n棵树组成的…...

统计学中的p值是什么?怎么使用?
李升伟 整理 在统计学中,p值(p-value)是帮助研究者判断假设检验结果是否具有统计显著性的重要指标。以下是关于p值的详细解释和使用方法: 1. p值的定义 p值表示在原假设(H0)为真的情况下,观察…...

22:一维码与二维码区别
一维码(条形码) 一维条码即指条码条和空的排列规则,常用的一维码的码制包括:EAN码、39码、交叉25码、UPC码、128码、93码,ISBN码,及Codabar(库德巴码)等。 条码是由一组规则排列的条…...

Java学习手册:SQL 优化技巧
一、SQL 查询优化 选择合适的索引列 :索引可以显著提高查询速度,但需要选择合适的列来创建索引。通常,对于频繁作为查询条件的列、连接操作的列以及排序或分组操作的列,应该考虑创建索引。例如,在一个订单表中…...

《Vue3学习手记8》
vue3中的一些API shallowRef ( ) 和shallowReactive ( ) shallowRef (浅层响应式) 1.作用:创建一个响应式数据,但只对顶层属性进行响应式处理。 2.用法: const originalref(...) const original2shallowRef(original) 3.特点:只跟踪引用值的变化,不关心…...
)
平衡二叉搜索树模拟实现1-------AVL树(插入,删除,查找)
本章目标 1.AVL树的概念 2.AVL树的模拟实现 1.AVL树的概念 1.AVL树是最先被发明的平衡二叉搜索树,AVL树是一颗空树或者具有以下的性质 它的左右子树都是AVL树,并且左右高度差不超过1,AVL树是一颗高度平衡二叉搜索树,通过高度差去控制平衡 2.为什么高度差是1? 当结点个数为8…...

运算放大器的主要技术指标
运放(运算放大器)是一种基础电子器件,具有输入阻抗高、开环放大倍数大、输入端电流小、同相端与反相端电压几乎相等等特点。在选型时,需要考虑技术指标如输入失调电压、输入失调电压漂移、输入失调电流、共模抑制比、压摆率、建立…...

51单片机入门教程——每个音符对应的重装载值
前言 本教程基于B站江协科技课程进行个人学习整理,专为拥有C语言基础的零基础入门51单片机新手设计。既帮助解决因时间差导致的设备迭代调试难题,也助力新手快速掌握51单片机核心知识,实现从C语言理论到单片机实践应用的高效过渡 。...

新一代智能座舱娱乐系统软件架构设计文档
一 文档概述 本文档描述了基于Android系统与多模态大模型融合的新一代智能座舱娱乐系统的软件架构设计。该系统将通过深度学习的个性化适配、多模态感知融合和持续自进化能力,重新定义人车交互体验。 二 整体架构设计 2.1 分层架构视图 系统采用五层垂直架构与三…...
与广度优先搜索(BFS):图与树遍历的两大利器)
深度优先搜索(DFS)与广度优先搜索(BFS):图与树遍历的两大利器
深度优先搜索(DFS)与广度优先搜索(BFS):图与树遍历的两大利器 在数据结构与算法的世界中,深度优先搜索(DFS)和广度优先搜索(BFS)是两种非常经典的遍历算法。…...

比较 TensorFlow 和 PyTorch
TensorFlow和PyTorch是深度学习领域中两个非常流行的开源机器学习框架,下面为你详细介绍。 1. 历史与背景 TensorFlow:由Google开发和维护,于2015年开源。因其强大的生产能力和广泛的工具支持,在工业界得到了广泛应用。PyTorch&…...

jeecg查询指定时间
jeecg查询指定时间 ApiOperation(value"请假表-分页列表查询", notes"请假表-分页列表查询")GetMapping(value "/list")public Result<IPage<MlLeaveRequest>> queryPageList(MlLeaveRequest mlLeaveRequest,RequestParam(name&qu…...

无人机视觉:连接像素与现实世界 —— 像素与GPS坐标双向转换指南
在无人机航拍应用中,一个核心的需求是将图像上的某个点与现实世界中的地理位置精确对应起来。无论是目标跟踪、地图测绘还是农情监测,理解图像像素与其对应的经纬度(GPS坐标)之间的关系至关重要。本文将详细介绍如何实现单个像素坐…...

php study 网站出现404 - Page Not Found 未找到
最近在用php study搭建本地网站时,出现了404 - Page Not Found 未找到的情况,解决方式如下: 第一种:在wp 后台固定链接设置中修改链接形式 第二种:没有安装伪静态! 小皮面板中 设置--配置文件--编辑你所搭建的网站 在红色框框处…...

互联网大厂Java求职面试:核心技术点深度解析
互联网大厂Java求职面试:核心技术点深度解析 在互联网大厂的Java岗位面试中,技术总监级别的面试官通常会从实际业务场景出发,层层深入地考察候选人的技术能力。本文通过一个严肃专业的技术总监与搞笑但有技术潜力的程序员郑薪苦之间的互动对…...

【Java idea配置】
IntelliJ IDEA创建类时自动生成注释 /** * program: ${PROJECT_NAME} * * since: jdk1.8 * * description: ${description} * * author: ${USER} * * create: ${YEAR}-${MONTH}-${DAY} ${HOUR}:${MINUTE} **/自动导入和自动移除无用导入 idea彩色日志不生效 调试日志输出 在…...

[GESP202503 四级] 二阶矩阵c++
题目描述 小 A 有一个 n 行 m 列的矩阵 A。 小 A 认为一个 22 的矩阵 D 是好的,当且仅当 。其中 表示矩阵 D 的第 i 行第 j 列的元素。 小 A 想知道 A 中有多少个好的子矩阵。 输入 第一行,两个正整数 n,m。 接下来 n 行,每行 m 个整数…...

PyQt5基本介绍
PyQt5是基于Digia公司强大图形框架Qt5的python接口,由一组python模块构成。是一个用于创建桌面应用程序的Python库,它是Qt图形用户界面工具包的Python绑定。 Qt是一个跨平台的C库,提供了一套丰富的工具和功能,用于开发图形用户界…...

Spring AI 实战:第十章、Spring AI RAG之博学多才
引言:从“博闻强记”到“博学多才” 在人工智能的发展历程中,大语言模型(LLM)已经展现了惊人的“博闻强记”能力——它们能写诗、编码、解答常识问题,甚至模拟人类对话。然而,当面对专业领域知识或实时更新的信息时,这些模型往往会暴露其局限性:要么“一本正经地胡说八…...

Runnable 组件生命周期监听器与使用场景
Runnable 生命周期监听器 1.1 监听机制演进 在 LangChain 框架中,Runnable 组件提供两种监控方案: 传统模式:通过 config callbacks 参数传递回调配置增强模式:使用 with_listeners() 方法实现生命周期订阅 …...

五、shell脚本--函数与脚本结构:搭积木,让脚本更有条理
随着我们的脚本越来越长、越来越复杂,直接把所有命令堆在一起会变得难以阅读和维护。这时候,函数 (Function) 就派上大用场了! 函数就像一个可以重复使用的代码块,你可以给它起个名字,然后在脚本的任何地方通过名字来…...
、可视化Qt?)
单调栈与单调队列(c艹)、可视化Qt?
单调栈和单调队列的区别在于 ChatGLM 单调栈和单调队列都是数据结构中用于处理序列问题的工具,它们在处理问题时具有不同的特性和应用场景。以下是单调栈和单调队列的主要区别: 定义: 单调栈:是一种特殊的栈,其中的元…...

哈夫曼树和哈夫曼编码
哈夫曼编码一般用来对字符串进行编码格式的表示。其中要克服的最大问题,莫过于就是一串由0或者1组成的编码,你无法区分哪些01组成的编码部分是属于哪些字符的,因此哈夫曼编码的出现解决了这个问题。 在介绍哈夫曼编码之前,先介绍…...

基于 AI 的人像修复与编辑技术:CompleteMe 系统的研究与应用
概述 加利福尼亚大学默塞德分校与 Adobe 的新合作在人像补全领域取得了突破性进展——人像补全是一项备受关注的任务,旨在“揭示”人像中被遮挡或隐藏的部分,可用于虚拟试穿、动画制作和照片编辑等场景。 除了修复损坏的图像或根据用户意愿更改图像外&a…...

spring 使用FactoryBean注入bean
spring 使用FactoryBean注入bean 1、介绍 通常是ApplicationContext,就是IOC容器,ApplicationContext是BeanFactory的实现类,是spring最核心的接口。用getBean来加载bean。BeanFactory相当于是IOC的基础类。而FactoryBean是另一个东西&a…...

AI 编程日报 · 2025 年 5 月 04 日|GitHub Copilot Agent 模式发布,Ultralytics 优化训练效率
1、OpenAI 确认 GPT-4o“谄媚”个性更新已完全回滚 OpenAI 官方已确认,先前推送的一项旨在改进 GPT-4o 模型个性的更新已被完全撤销。该更新最初目标是提升模型的智能与个性,使其交互更直观有效,但实际效果却导致模型表现出过度“谄媚”和“…...

C++ STL简介:构建高效程序的基石
0. 引言 在现代软件开发领域,C语言凭借其强大的性能和灵活性占据着重要地位。而C标准模板库(Standard Template Library,简称STL)作为C标准库的核心组件,更是开发者手中不可或缺的利器。它犹如一座知识宝库࿰…...
RAG 版面分析——文本分块面)
大模型(LLMs)RAG 版面分析——文本分块面
大模型(LLMs)RAG 版面分析——文本分块面 一、为什么需要对文本分块? 二、能不能介绍一下常见的文本分块方法? 2.1 一般的文本分块方法 2.2 正则拆分的文本分块方法 2.3 Spacy Text Splitter 方法 2.4 基于 langchain 的 Cha…...

系统思考:核心价值与竞争力
最近,设计师的小伙伴跟我提到,行业内竞争越来越激烈,大家都开始拼命降价。但从系统思考的角度来看,我想说一句话:“人多的地方,不要去。” 为什么这么说?在竞争愈发激烈的环境中,我…...
)
【RocketMQ Broker 相关源码】- broker 启动源码(2)
文章目录 1. 前言2. 创建 DefaultMessageStore3. DefaultMessageStore#load3.1 CommitLog#load3.2 loadConsumeQueue 加载 ConsumeQueue 文件3.3 创建 StoreCheckpoint3.4 indexService.load 加载 IndexFile 文件3.5 recover 文件恢复3.6 延时消息服务加载 4. registerProcesso…...
 和 int(10) 有什么区别?)
mysql中int(1) 和 int(10) 有什么区别?
困惑 最近遇到个问题,有个表的要加个user_id字段,user_id字段可能很大,于是我提mysql工单alter table xxx ADD user_id int(1)。领导看到我的sql工单,于是说:这int(1)怕是不够用吧,接下来是一通解…...
tensorrt C++ api介绍)
jetson orin nano super AI模型部署之路(八)tensorrt C++ api介绍
我们基于tensorrt-cpp-api这个仓库介绍。这个仓库的代码是一个非常不错的tensorrt的cpp api实现,可基于此开发自己的项目。 我们从src/main.cpp开始按顺序说明。 一、首先是声明我们创建tensorrt model的参数。 // Specify our GPU inference configuration optio…...

渗透测试中扫描成熟CMS目录的意义与技术实践
在渗透测试领域,面对一个成熟且“看似安全”的CMS(如WordPress、Drupal),许多初级测试者常陷入误区:认为核心代码经过严格审计的CMS无需深入排查。然而,目录扫描(Directory Bruteforcing&#x…...

数字信号处理学习笔记--Chapter 1 离散时间信号与系统
1 离散时间信号与系统 包含以下内容: (1)离散时间信号--序列 (2)离散时间系统 (3)常系数线性差分方程 (4)连续时间信号的抽样 2 离散时间信号--序列 为了便于计算机对信号…...

LeetCode 热题 100 994. 腐烂的橘子
LeetCode 热题 100 | 994. 腐烂的橘子 大家好,今天我们来解决一道经典的算法题——腐烂的橘子。这道题在LeetCode上被标记为中等难度,要求我们计算网格中所有新鲜橘子腐烂所需的最小分钟数,或者返回不可能的情况。下面我将详细讲解解题思路&…...

软考-软件设计师中级备考 11、计算机网络
1、计算机网络的分类 按分布范围分类 局域网(LAN):覆盖范围通常在几百米到几千米以内,一般用于连接一个建筑物内或一个园区内的计算机设备,如学校的校园网、企业的办公楼网络等。其特点是传输速率高、延迟低、误码率低…...