【RocketMQ Broker 相关源码】- broker 启动源码(2)
文章目录
- 1. 前言
- 2. 创建 DefaultMessageStore
- 3. DefaultMessageStore#load
- 3.1 CommitLog#load
- 3.2 loadConsumeQueue 加载 ConsumeQueue 文件
- 3.3 创建 StoreCheckpoint
- 3.4 indexService.load 加载 IndexFile 文件
- 3.5 recover 文件恢复
- 3.6 延时消息服务加载
- 4. registerProcessor 注册 code 处理器
- 5. ConfigManager.persist
- 6. protectBroker 保护 broker
- 7. fetchNameServerAddr 定时任务定时拉取 NameServer 地址
- 8. 小结
本文章基于 RocketMQ 4.9.3
1. 前言
- 【RocketMQ】- 源码系列目录
- 【RocketMQ Broker 相关源码】- broker 启动源码(1)
在前面【RocketMQ Broker 相关源码】- broker 启动源码(1)这篇文章中,我们对 broker 启动的源码进行了简要梳理,着重介绍了 broker 启动过程中所涉及的各项服务,以及启动流程中具体执行的操作。至于这些服务的具体功能,以及其背后源码的详细实现,还有上一篇文章中遗留下来的一些方法和比较重要的类,我们在这篇文章中去介绍。
2. 创建 DefaultMessageStore
DefaultMessageStore 是 RocketMQ 中默认的消息存储核心类,broker 对消息的操作都需要经过这个类,比如消息查询、消息添加、消息拉取 … 所以在调用 BrokerController#initialize 的时候第二步就是创建 DefaultMessageStore,那么我们就来看下这个类的构造方法。
public DefaultMessageStore(final MessageStoreConfig messageStoreConfig, final BrokerStatsManager brokerStatsManager,final MessageArrivingListener messageArrivingListener, final BrokerConfig brokerConfig) throws IOException {// 消息到达监听器, 消息重放之后会通知 pullRequestHoldService 服务消息到达, 接着就可以处理消费者的消息拉取请求this.messageArrivingListener = messageArrivingListener;// broker 配置this.brokerConfig = brokerConfig;// 消息存储配置this.messageStoreConfig = messageStoreConfig;// broker 数据统计管理类this.brokerStatsManager = brokerStatsManager;// MappedFile 分配服务this.allocateMappedFileService = new AllocateMappedFileService(this);// 实例化 CommitLog, 默认是不支持 Dleger 高可用模式的if (messageStoreConfig.isEnableDLegerCommitLog()) {this.commitLog = new DLedgerCommitLog(this);} else {this.commitLog = new CommitLog(this);}// 创建 ConsumeQueue 集合, 存储了 topic -> (queueId, ConsumeQueue) 的关系this.consumeQueueTable = new ConcurrentHashMap<>(32);// 初始化 ConsumeQueue 刷盘服务this.flushConsumeQueueService = new FlushConsumeQueueService();// 初始化过期 CommitLog 文件清除服务this.cleanCommitLogService = new CleanCommitLogService();// 初始化过期 ConsumeQueue 文件清除服务this.cleanConsumeQueueService = new CleanConsumeQueueService();// 初始化消息存储统计服务this.storeStatsService = new StoreStatsService();// 初始化 Index 索引服务this.indexService = new IndexService(this);// 判断是否初始化 HAService 主从同步服务if (!messageStoreConfig.isEnableDLegerCommitLog()) {this.haService = new HAService(this);} else {this.haService = null;}// 初始化消息重放服务this.reputMessageService = new ReputMessageService();// 初始化延时消息服务this.scheduleMessageService = new ScheduleMessageService(this);// 初始化堆外缓存this.transientStorePool = new TransientStorePool(messageStoreConfig);// 初始化堆外缓存的 ByteBuffer, 默认大小是 5if (messageStoreConfig.isTransientStorePoolEnable()) {this.transientStorePool.init();}// 启动 MappedFile 分配线程this.allocateMappedFileService.start();// 启动 Index 文件服务线程this.indexService.start();// 创建消息重放列表, 用于构建 ConsumeQueue、Index 索引, 默认顺序是 ConsumeQueue -> Indexthis.dispatcherList = new LinkedList<>();this.dispatcherList.addLast(new CommitLogDispatcherBuildConsumeQueue());this.dispatcherList.addLast(new CommitLogDispatcherBuildIndex());// 创建 DefaultMessageStore 的根目录文件File file = new File(StorePathConfigHelper.getLockFile(messageStoreConfig.getStorePathRootDir()));// 确保根文件父目录, 也就是 ${user.home}/store(又或者 broker.conf 里面设置的 storePathRootDir) 被创建MappedFile.ensureDirOK(file.getParent());// 确保 CommitLog 文件父目录, 也就是 ${user.home}/store/commitlog(又或者 broker.conf 里面设置的 storePathCommitLog) 被创建MappedFile.ensureDirOK(getStorePathPhysic());// 确保 ConsumeQueue 文件父目录, 也就是 ${user.home}/store/consumequeue(又或者 broker.conf 里面设置的 storePathConsumeQueue) 被创建MappedFile.ensureDirOK(getStorePathLogic());// 设置文件权限是可读写, 在 DefaultMessageStore 启动的时候会加锁, 确保只有一个 broker 对这个根目录下的文件操作lockFile = new RandomAccessFile(file, "rw");
}
可以看到在这个构造器里面就是初始化了一堆服务,按照顺序一个一个往下说:
messageArrivingListener:消息到达监听器, 消息重放之后会通知 pullRequestHoldService 服务消息到达, 接着就可以处理消费者的消息拉取请求,这个监听器是跟消费者消息拉取有关的,后面讲到消费者拉取消息的时候会重点说下。brokerConfig:broker 配置。messageStoreConfig:消息存储配置,里面记录了消息存储服务的一些参数。brokerStatsManager:broker 数据统计管理类,比如 broker 里面添加了多少次消息,添加的消息的总大小 …allocateMappedFileService:MappedFile 分配服务,用来创建 MappedFile 的,这个服务在文章 【RocketMQ 存储】- RocketMQ 如何高效创建 MappedFile 有详细介绍。CommitLog:就是存储消息的 CommitLog,一个 broker 中有一个 CommitLog,但是 CommitLog 中包含了多个 MappedFile。consumeQueueTable:存储了 topic -> <queueId, ConsumeQueue> 的关系,一个 topic 下面有多个队列,而这些队列可以分配到不同的 broker,所以这个集合保存了当前这个 broker 下面存储的 topic -> (id, queue) 的映射,也就是说通过 topic 可以找到所有的 ConsumeQueue。flushConsumeQueueService:ConsumeQueue 刷盘服务,这个服务在文章 【RocketMQ 存储】ConsumeQueue 刷盘服务 FlushConsumeQueueService 有详细介绍。cleanCommitLogService:CommitLog 文件清除服务,清除 CommitLog 的过期文件,这个服务在文章 【RocketMQ 存储】- CommitLog 过期清除服务 CleanCommitLogService 有详细介绍。cleanConsumeQueueService:ConsumeQueue 文件清除服务,清除 ConsumeQueue 的过期文件,这个服务在文章 【RocketMQ 存储】- ConsumeQueue 过期清除服务 CleanConsumeQueueService 中有详细介绍。storeStatsService:消息存储统计服务。indexService:消息存储统计服务。storeStatsService:Index 索引服务,用于管理 Index 索引,构建、删除 … 逻辑都是在里面进行。haService:主从同步服务,在【RocketMQ 高可用】这几篇文章中有详细介绍这个类。reputMessageService:消息重放服务,用于构建 ConsumeQueue 索引、Index 索引、SQL92 的 bitMap 过滤处理,在 【RocketMQ 存储】消息重放服务-ReputMessageService
中有详细介绍。scheduleMessageService:延时消息服务,处理延时消息的。transientStorePool:堆外缓存,实现读写分离,虽然通过 MappedByteBuffer 的 mmap 进行文件映射到了 page cache,同时通过 mlock 锁定了这篇内存进行 swap 交换。但是当 page cache 脏页数据越来越多的时候,内核的 pdflush 线程就会将 page cache 中的脏页回写到磁盘中,这里是我们不能控制的。所以当脏页写入磁盘之后,我们通过 MappedByteBuffer 写入数据还是会触发缺页中断,这样就会导致写入数据延迟,性能产生毛刺现象。为了解决这个问题,RocketMQ 引入了堆外缓存提供读写分离,当数据要写入的时候,先写入 writeBuffer,这段 writeBuffer 只是普通堆外缓存,不涉及脏页回写,所以写入的时候不会阻塞,而后台线程就会不断将这部分数据 commit 到 page cache 中。lockFile:${user.home}/store/lock(storePathRootDir),当 DefaultMessageStore 启动的时候会往里面写入 lock,这是为了确保只有一个 broker 对这个根目录下的文件操作,根目录默认是 ${user.home}/store,但是也可以在 broker.conf 中设置 storePathRootDir 为根目录。
3. DefaultMessageStore#load
在 BrokerController#initialize 方法中,通过 DefaultMessageStore#load 去加载各个目录下面的文件到内存中,如 CommitLog、ConsumeQueue、StoreCheckPoint 等文件,下面就来看下这个方法的源码。
/*** 加载 MessageStore 下面的消息存储文件* @throws IOException*/
public boolean load() {boolean result = true;try {// 判断下上次 RocketMQ 关闭是不是正常关闭boolean lastExitOK = !this.isTempFileExist();log.info("last shutdown {}", lastExitOK ? "normally" : "abnormally");// 1.加载 CommitLog 文件result = result && this.commitLog.load();// 2.加载 ConsumeQueue 文件result = result && this.loadConsumeQueue();if (result) {// 3.加载 checkpoint 检查点文件,文件位置是 ${home}/store/checkpointthis.storeCheckpoint =new StoreCheckpoint(StorePathConfigHelper.getStoreCheckpoint(this.messageStoreConfig.getStorePathRootDir()));// 4.加载 IndexFile 文件this.indexService.load(lastExitOK);// 5.恢复 ConsumeQueue 和 CommitLog 文件,也就是将这些数据恢复到内存中this.recover(lastExitOK);log.info("load over, and the max phy offset = {}", this.getMaxPhyOffset());if (null != scheduleMessageService) {// 6.加载延时消息服务result = this.scheduleMessageService.load();}}} catch (Exception e) {log.error("load exception", e);result = false;}if (!result) {// 如果上面的操作有异常,这里就停止创建 MappedFile 的服务this.allocateMappedFileService.shutdown();}return result;
}
3.1 CommitLog#load
这个方法就是用于加载 CommitLog 文件,其实就是加载 Commit 存储文件夹下面的文件到内存中,下面是源码。
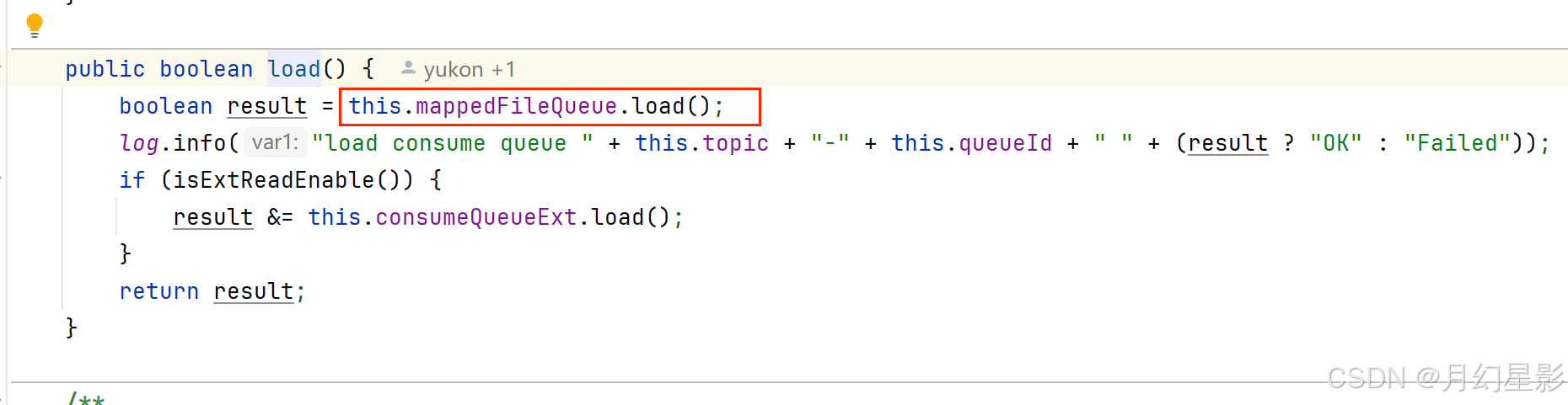
/*** 加载 CommitLog 文件* @return*/
public boolean load() {// 加载 CommitLog 文件boolean result = this.mappedFileQueue.load();log.info("load commit log " + (result ? "OK" : "Failed"));return result;
}/*** 加载文件* @return*/
public boolean load() {// 文件存放目录// ${home}/store/commitlogFile dir = new File(this.storePath);// 获取内部的文件集合File[] ls = dir.listFiles();if (ls != null) {// 如果文件夹下存在文件,那么进行加载return doLoad(Arrays.asList(ls));}return true;
}
因为 CommitLog 一个文件大小是 1GB,所以这个文件夹下面可能有多个文件,需要用到 doLoad 方法,传入一个集合。
/*** 加载文件* @param files* @return*/
public boolean doLoad(List<File> files) {// 将文件按照文件名排序,这里的文件名就是文件的起始偏移量files.sort(Comparator.comparing(File::getName));// 遍历所有文件for (File file : files) {if (file.length() != this.mappedFileSize) {// 到这里就是文件实际大小如果不等于设定的文件大小,就直接返回,不加载其他文件,这里 length 就是创建文件的时候设定的文件大小log.warn(file + "\t" + file.length()+ " length not matched message store config value, please check it manually");return false;}try {// 每一个 CommitLog 或者 ConsumeQueue 文件都需要创建一个MappedFile mappedFile = new MappedFile(file.getPath(), mappedFileSize);// 将下面三个指针位置设置成文件大小// MappedByteBuffer 或者 writeBuffer 中 position 的位置mappedFile.setWrotePosition(this.mappedFileSize);// MappedByteBuffer 或者 writeBuffer 中 flush 刷盘的位置mappedFile.setFlushedPosition(this.mappedFileSize);// writeBuffer 中 commit 提交数据到 page cache 中的位置mappedFile.setCommittedPosition(this.mappedFileSize);// 将 MappedByteBuffer 添加到集合 mappedFiles 中this.mappedFiles.add(mappedFile);log.info("load " + file.getPath() + " OK");} catch (IOException e) {log.error("load file " + file + " error", e);return false;}}return true;
}
可以看到就是在加载文件的时候,会把三个指针 wrotePosition、flushedPosition、committedPosition 设置成 mappedFileSize,这个 mappedFileSize 在 CommitLog 文件下就是 1GB,因为默认从磁盘读取出来的数据肯定就已经是刷盘成功的了,所以这里直接设置为 mappedFileSize,但是有一个问题就是如果你的 RocketMQ 是突然崩溃了,就比如我这里直接 windows 启动,在这之前我只往 CommitLog 里面写入了几条消息,但是这里的设置会导致这三个指针的值都是 1G,就跟实际不符合。

但是这里设置了 1G 之后,在 DefaultMessageStore#load 的第 5 步 this.recover(lastExitOK) 会恢复 ConsumeQueue 和 CommitLog 文件,也就是将这些数据恢复到内存中,同时纠正偏移量,所以是没问题的。
3.2 loadConsumeQueue 加载 ConsumeQueue 文件
上面加载完 CommitLog 之后,这里就要加载 ConsumeQueue 文件了。
/*** 加载 ConsumeQueue 文件* @return*/
private boolean loadConsumeQueue() {// 文件路径是 ${user.home}/store/consumequeue, 当然这个 ${user.home}/store 也可以在 broker.conf 里面通过 storePathRootDir 配置根目录File dirLogic = new File(StorePathConfigHelper.getStorePathConsumeQueue(this.messageStoreConfig.getStorePathRootDir()));// 获取这个目录下面的所有文件File[] fileTopicList = dirLogic.listFiles();if (fileTopicList != null) {// 遍历文件for (File fileTopic : fileTopicList) {// 获取文件名, ConsumeQueue 文件和 CommitLog 不一样, CommitLog 是所有 topic 都存到一起, ConsumeQueue 是 topic 分// 开存储, 文件名就是 topicString topic = fileTopic.getName();// 获取 ${storePathRootDir}/consumequeue/${topic} 下面的文件列表File[] fileQueueIdList = fileTopic.listFiles();if (fileQueueIdList != null) {// 遍历, 因为 ConsumeQueue 默认就是 4 个队列, 所以需要遍历这些队列for (File fileQueueId : fileQueueIdList) {int queueId;try {// 队列 IDqueueId = Integer.parseInt(fileQueueId.getName());} catch (NumberFormatException e) {continue;}// 创建 ConsumeQueue, 这里传了 topic 和 queueId 进去构造器, 因为文件路径就是 ${storePathRootDir}/consumequeue/${topic}/${queueId}ConsumeQueue logic = new ConsumeQueue(topic,queueId,StorePathConfigHelper.getStorePathConsumeQueue(this.messageStoreConfig.getStorePathRootDir()),this.getMessageStoreConfig().getMappedFileSizeConsumeQueue(),this);// 将创建出来的 ConsumeQueue 添加到 consumeQueueTable 中this.putConsumeQueue(topic, queueId, logic);// ConsumeQueue#load 方法if (!logic.load()) {return false;}}}}}log.info("load logics queue all over, OK");return true;
}
这里的文件加载和前面 CommitLog 的差不多,只是获取文件名的时候 ConsumeQueue 文件和 CommitLog 不一样,CommitLog 是所有 topic 都存到一起,ConsumeQueue 是 topic 分开存储,所以 ConsumeQueue 的文件路径就是 ${storePathRootDir}/consumequeue/${topic}/${queueId},最后创建出 ConsumeQueue 之后需要添加到 consumeQueueTable 中,添加的逻辑如下。
/*** 添加 ConsumeQueue 映射关系* @param topic* @param queueId* @param consumeQueue*/
private void putConsumeQueue(final String topic, final int queueId, final ConsumeQueue consumeQueue) {// 获取 topic 下面的 ConsumeQueue 集合ConcurrentMap<Integer/* queueId */, ConsumeQueue> map = this.consumeQueueTable.get(topic);if (null == map) {// 初始化map = new ConcurrentHashMap<Integer/* queueId */, ConsumeQueue>();// 添加map.put(queueId, consumeQueue);this.consumeQueueTable.put(topic, map);if (MixAll.isLmq(topic)) {this.lmqConsumeQueueNum.getAndIncrement();}} else {// 直接添加, 会覆盖map.put(queueId, consumeQueue);}
}
添加完之后调用 ConsumeQueue 的 load 方法去加载 ConsumeQueue 文件,但是其实加载的逻辑跟 CommitLog 是一样的,只是加载的文件不同,因为都是走的 mappedFileQueue.load() 的逻辑,这个逻辑上面 3.1 小结也说过了,这里不再赘述。
3.3 创建 StoreCheckpoint
加载 checkpoint 检查点文件,文件位置是 ${storePathRootDir}/checkpoint,这个 checkpoint 就是检查点文件,CommitLog、ConsumeQueue、IndexFile 这三个文件的最新消息的存储时间点会被记录,如果 broker 异常重启了,这时候就会根据这三个时间点来恢复文件。
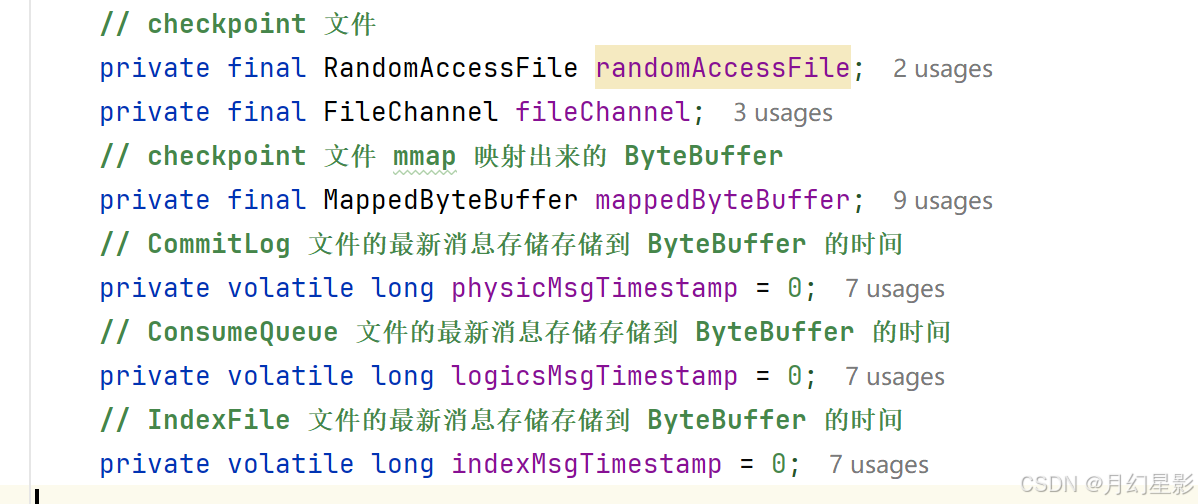
当然这里就是来看一下创建的构造器逻辑,关于这三个值的使用在 recover 方法有用到,之前的文件也讲过,所以如果有需要可以去看下之前的文章,就是正常异常退出恢复那两篇。
public StoreCheckpoint(final String scpPath) throws IOException {// 判断是否存在当前文件// D:\\javaCode\\rocketmq-source\\config\\store\\checkpointFile file = new File(scpPath);MappedFile.ensureDirOK(file.getParent());// 文件是否存在boolean fileExists = file.exists();// mmap 映射this.randomAccessFile = new RandomAccessFile(file, "rw");this.fileChannel = this.randomAccessFile.getChannel();this.mappedByteBuffer = fileChannel.map(MapMode.READ_WRITE, 0, MappedFile.OS_PAGE_SIZE);if (fileExists) {log.info("store checkpoint file exists, " + scpPath);// 记录最新 CommitLog 文件的最新添加到 ByteBuffer 的时间戳this.physicMsgTimestamp = this.mappedByteBuffer.getLong(0);// 最新 ConsumeQueue 文件的最新添加到 ByteBuffer 的时间戳this.logicsMsgTimestamp = this.mappedByteBuffer.getLong(8);// 最新 IndexFile 文件的最新添加到 ByteBuffer 的时间戳this.indexMsgTimestamp = this.mappedByteBuffer.getLong(16);log.info("store checkpoint file physicMsgTimestamp " + this.physicMsgTimestamp + ", "+ UtilAll.timeMillisToHumanString(this.physicMsgTimestamp));log.info("store checkpoint file logicsMsgTimestamp " + this.logicsMsgTimestamp + ", "+ UtilAll.timeMillisToHumanString(this.logicsMsgTimestamp));log.info("store checkpoint file indexMsgTimestamp " + this.indexMsgTimestamp + ", "+ UtilAll.timeMillisToHumanString(this.indexMsgTimestamp));} else {// 文件不存在log.info("store checkpoint file not exists, " + scpPath);}
}
3.4 indexService.load 加载 IndexFile 文件
/*** 加载 IndexFile 文件, 路径是 ${storePathRootDir}/index* @param lastExitOK 上一次 RocketMQ 是否正常退出* @return*/
public boolean load(final boolean lastExitOK) {// 首先获取这个文件夹路径下面的所有文件File dir = new File(this.storePath);File[] files = dir.listFiles();if (files != null) {// 文件目录名称排序Arrays.sort(files);for (File file : files) {try {// 构建 IndexFileIndexFile f = new IndexFile(file.getPath(), this.hashSlotNum, this.indexNum, 0, 0);// 加载 IndexFilef.load();// 如果上一次不是正常退出if (!lastExitOK) {// 如果说 IndexFile 最后一条消息的 storeTimeStamp 比 StoreCheckPoint 中记录的要大if (f.getEndTimestamp() > this.defaultMessageStore.getStoreCheckpoint().getIndexMsgTimestamp()) {// 说明这个 IndexFile 有一部分数据是脏数据, 删掉这个文件f.destroy(0);continue;}}log.info("load index file OK, " + f.getFileName());// 加到 indexFileList 里面this.indexFileList.add(f);} catch (IOException e) {log.error("load file {} error", file, e);return false;} catch (NumberFormatException e) {log.error("load file {} error", file, e);}}}return true;
}
这个方法就用到了我们提到的 StoreCheckPoint 文件里面的数据,如果 IndexFile 记录的最新的索引的消息在 CommitLog 的存储时间比 StoreCheckPoint 文件里面记录的 indexMsgTimestamp 要大,说明这个 IndexFile 文件就是一个不合法的文件,至少是数据不合法的,因为 indexMsgTimestamp 这个变量就是在 IndexFile 满了刷盘的时候才会记录,比如将一个写满了的 IndexFile 文件刷盘就记录一下这个 indexMsgTimestamp 变量。
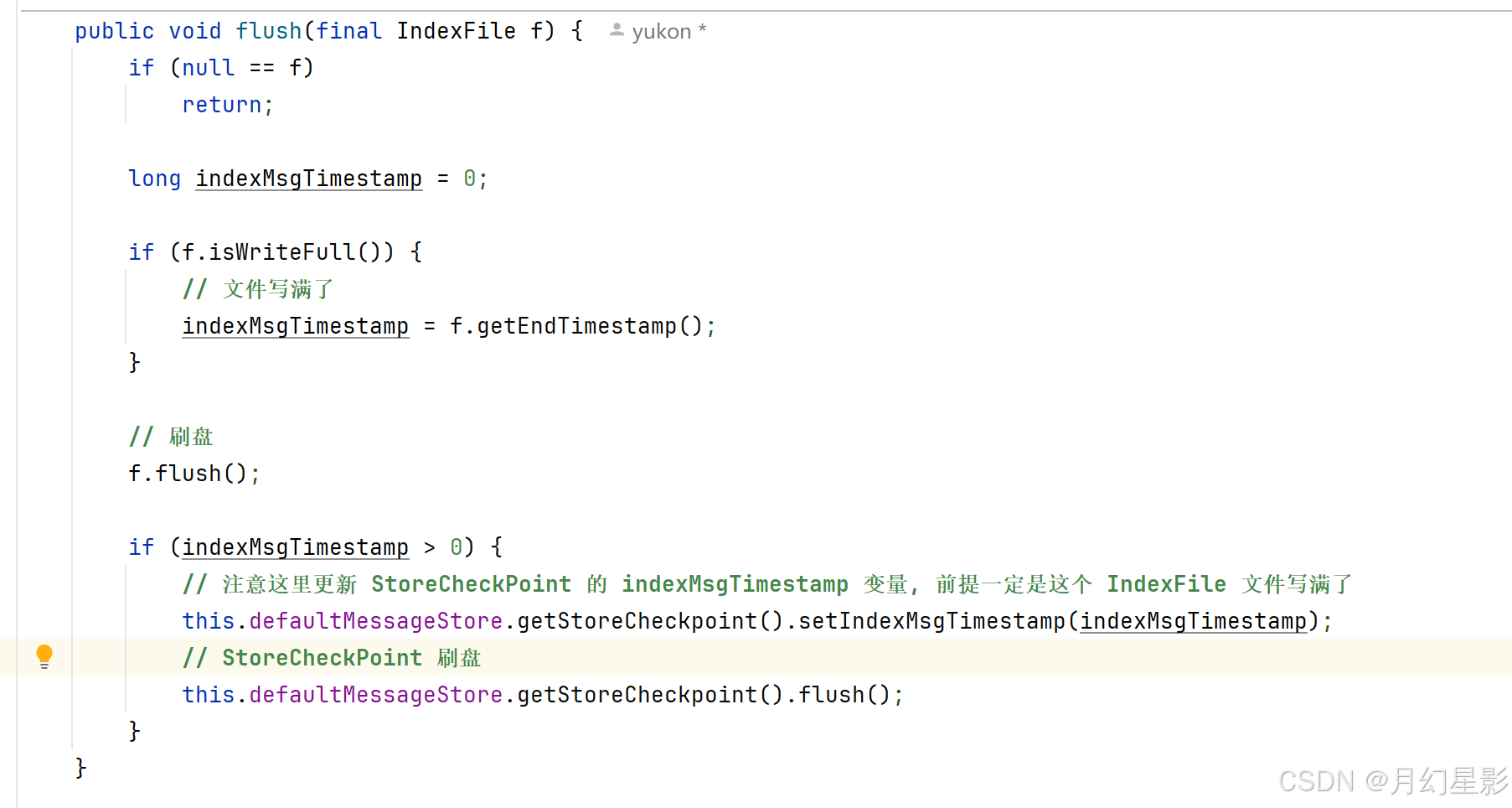
所以看上面图也能看出来,刷盘的时候必须要文件写满了才会去更新 indexMsgTimestamp,这就意味者这个变量就是记录完整的 IndexFile 刷盘的时间,而不是刷盘一次就记录一次,因此如果说 IndexFile 最后一条消息的 storeTimeStamp 比 StoreCheckPoint 中记录的要大,就说明这个 IndexFile 肯定是有问题的。
至于为什么可以这么记录,因为 IndexFile 不像 CommitLog 和 ConsumeQueue 那样,一个 IndexFile 就是一个 MappedFile 来存储所有数据,像 CommitLog 和 ConsumeQueue 都是用 MappedFileQueue 存储 MappedFile 集合的,所以这里还是有点不同的。
3.5 recover 文件恢复
这里的文件恢复代码如下:
/*** 恢复 CommitLog 和 ConsumeQueue 中的数据到内存中* @param lastExitOK*/
private void recover(final boolean lastExitOK) {// 恢复所有 ConsumeQueue 文件,返回的是 ConsumeQueue 中存储的最大有效 CommitLog 偏移量long maxPhyOffsetOfConsumeQueue = this.recoverConsumeQueue();// 上一次 Broker 退出是正常退出还是异常退出if (lastExitOK) {// 这里就是正常退出,所以正常恢复 CommitLogthis.commitLog.recoverNormally(maxPhyOffsetOfConsumeQueue);} else {// 这里就是异常退出,所以异常恢复 CommitLogthis.commitLog.recoverAbnormally(maxPhyOffsetOfConsumeQueue);}// 最后恢复 topicQueueTablethis.recoverTopicQueueTable();
}
正常异常恢复的逻辑在前面讲 RocketMQ 存储部分的时候已经讲过了,所以这里就不再多说。
- 【RocketMQ 存储】- 异常退出恢复逻辑 recoverAbnormally
- 【RocketMQ 存储】- 正常退出恢复逻辑 recoverNormally
3.6 延时消息服务加载
延时消息属于消息消费的一种,这里后面讲到消费者的时候也会详细讲解,这里先不多说。
4. registerProcessor 注册 code 处理器
/*** 注册 Code 处理器*/
public void registerProcessor() {/*** SendMessageProcessor*/SendMessageProcessor sendProcessor = new SendMessageProcessor(this);sendProcessor.registerSendMessageHook(sendMessageHookList);sendProcessor.registerConsumeMessageHook(consumeMessageHookList);// 消息发送的处理器this.remotingServer.registerProcessor(RequestCode.SEND_MESSAGE, sendProcessor, this.sendMessageExecutor);this.remotingServer.registerProcessor(RequestCode.SEND_MESSAGE_V2, sendProcessor, this.sendMessageExecutor);this.remotingServer.registerProcessor(RequestCode.SEND_BATCH_MESSAGE, sendProcessor, this.sendMessageExecutor);this.remotingServer.registerProcessor(RequestCode.CONSUMER_SEND_MSG_BACK, sendProcessor, this.sendMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.SEND_MESSAGE, sendProcessor, this.sendMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.SEND_MESSAGE_V2, sendProcessor, this.sendMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.SEND_BATCH_MESSAGE, sendProcessor, this.sendMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.CONSUMER_SEND_MSG_BACK, sendProcessor, this.sendMessageExecutor);/*** PullMessageProcessor, 专门用于处理 PULL_MESSAGE 这个请求 CODE, 也就是消息拉取请求*/this.remotingServer.registerProcessor(RequestCode.PULL_MESSAGE, this.pullMessageProcessor, this.pullMessageExecutor);this.pullMessageProcessor.registerConsumeMessageHook(consumeMessageHookList);/*** ReplyMessageProcessor*/ReplyMessageProcessor replyMessageProcessor = new ReplyMessageProcessor(this);replyMessageProcessor.registerSendMessageHook(sendMessageHookList);this.remotingServer.registerProcessor(RequestCode.SEND_REPLY_MESSAGE, replyMessageProcessor, replyMessageExecutor);this.remotingServer.registerProcessor(RequestCode.SEND_REPLY_MESSAGE_V2, replyMessageProcessor, replyMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.SEND_REPLY_MESSAGE, replyMessageProcessor, replyMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.SEND_REPLY_MESSAGE_V2, replyMessageProcessor, replyMessageExecutor);/*** QueryMessageProcessor*/NettyRequestProcessor queryProcessor = new QueryMessageProcessor(this);this.remotingServer.registerProcessor(RequestCode.QUERY_MESSAGE, queryProcessor, this.queryMessageExecutor);this.remotingServer.registerProcessor(RequestCode.VIEW_MESSAGE_BY_ID, queryProcessor, this.queryMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.QUERY_MESSAGE, queryProcessor, this.queryMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.VIEW_MESSAGE_BY_ID, queryProcessor, this.queryMessageExecutor);/*** ClientManageProcessor*/ClientManageProcessor clientProcessor = new ClientManageProcessor(this);this.remotingServer.registerProcessor(RequestCode.HEART_BEAT, clientProcessor, this.heartbeatExecutor);this.remotingServer.registerProcessor(RequestCode.UNREGISTER_CLIENT, clientProcessor, this.clientManageExecutor);this.remotingServer.registerProcessor(RequestCode.CHECK_CLIENT_CONFIG, clientProcessor, this.clientManageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.HEART_BEAT, clientProcessor, this.heartbeatExecutor);this.fastRemotingServer.registerProcessor(RequestCode.UNREGISTER_CLIENT, clientProcessor, this.clientManageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.CHECK_CLIENT_CONFIG, clientProcessor, this.clientManageExecutor);/*** ConsumerManageProcessor*/ConsumerManageProcessor consumerManageProcessor = new ConsumerManageProcessor(this);this.remotingServer.registerProcessor(RequestCode.GET_CONSUMER_LIST_BY_GROUP, consumerManageProcessor, this.consumerManageExecutor);this.remotingServer.registerProcessor(RequestCode.UPDATE_CONSUMER_OFFSET, consumerManageProcessor, this.consumerManageExecutor);this.remotingServer.registerProcessor(RequestCode.QUERY_CONSUMER_OFFSET, consumerManageProcessor, this.consumerManageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.GET_CONSUMER_LIST_BY_GROUP, consumerManageProcessor, this.consumerManageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.UPDATE_CONSUMER_OFFSET, consumerManageProcessor, this.consumerManageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.QUERY_CONSUMER_OFFSET, consumerManageProcessor, this.consumerManageExecutor);/*** EndTransactionProcessor*/this.remotingServer.registerProcessor(RequestCode.END_TRANSACTION, new EndTransactionProcessor(this), this.endTransactionExecutor);this.fastRemotingServer.registerProcessor(RequestCode.END_TRANSACTION, new EndTransactionProcessor(this), this.endTransactionExecutor);/*** Default*/AdminBrokerProcessor adminProcessor = new AdminBrokerProcessor(this);this.remotingServer.registerDefaultProcessor(adminProcessor, this.adminBrokerExecutor);this.fastRemotingServer.registerDefaultProcessor(adminProcessor, this.adminBrokerExecutor);
}
这里就是注册处理器的逻辑,上一篇文章我们说过,RocketMQ 发送请求的时候会在请求头设置 code 表示这个请求是什么类型的请求,这个请求需要使用什么处理器来处理就是在这里注册的,同时 broker 处理请求的时候不可能是单线程处理的,肯定是封装成一个 runnable 线程任务去处理,所以需要传入一个线程池来并发执行。
5. ConfigManager.persist
在 BrokerController#initialize 中启动了多个定时任务来定时持久化,下面来看下这个持久化的源码。
/*** 持久化到文件中, 持久化 json 和 json.bak 文件*/
public synchronized void persist() {// 需要持久化的数据String jsonString = this.encode(true);if (jsonString != null) {// 需要持久化的文件路径String fileName = this.configFilePath();try {// 持久化逻辑MixAll.string2File(jsonString, fileName);} catch (IOException e) {log.error("persist file " + fileName + " exception", e);}}
}
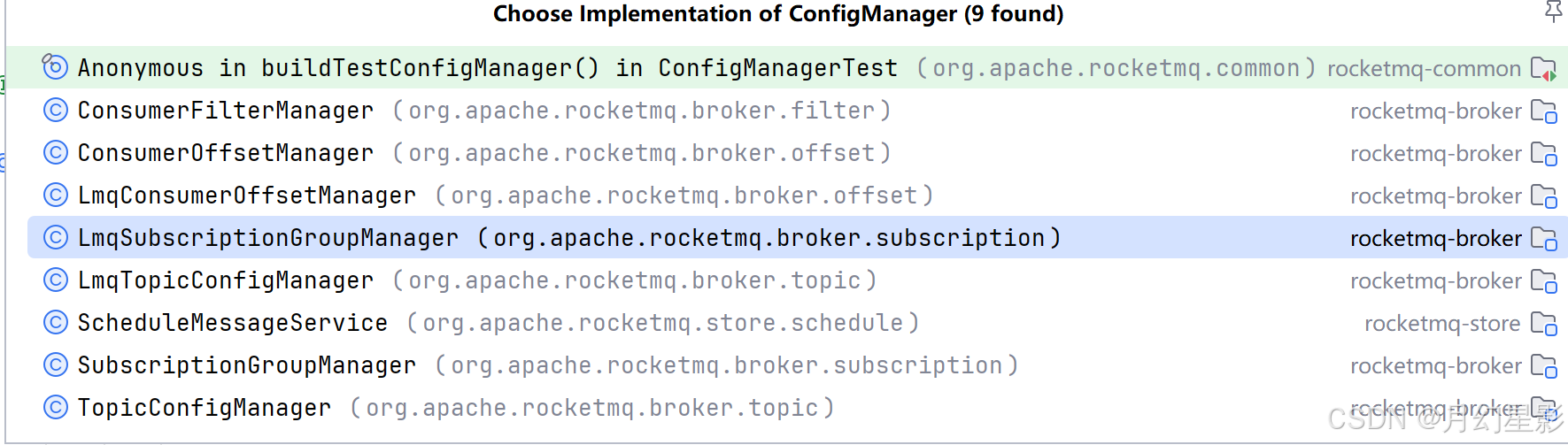
这里面就是用了模板方法的设计模式,ConfigManager 是一个抽象类,需要持久化的数据 encode、需要持久化的文件路径 configFilePath 都是子类实现的,下面是 ConfigManager 的子类。
6. protectBroker 保护 broker
RocketMQ 作为消息队列,肯定会存在消息堆积的情况,如果是堆积量比较少那还行,可以新启动多几个消费者来加速消费,但是如果堆积量比较大,这就不得不怀疑是不是消费者出什么问题了,比如代码出 bug 导致消费进度一致不变。
我们知道消费者消费之前都会先去 broker 拉取消息到本地,然后再在本地消费,所以如果消费者拉取消息的进度一直不变,而生产者又在不断新增消息,就会导致消息堆积量越来越多。
这个 protectBroker 方法就是去检测如果这个消费者组的消息拉取进度落后最新消息超过 16G, 说明有可能这个消费者组里面的消费者出问题了, 不能正常消费消息, 所以这时候就会将消费者组的订阅配置设置为禁止消费, 需要人为介入去修复。
public void protectBroker() {// 如果禁止消费者缓慢读取if (this.brokerConfig.isDisableConsumeIfConsumerReadSlowly()) {final Iterator<Map.Entry<String, MomentStatsItem>> it = this.brokerStatsManager.getMomentStatsItemSetFallSize().getStatsItemTable().entrySet().iterator();while (it.hasNext()) {final Map.Entry<String, MomentStatsItem> next = it.next();// fallBehindBytes 记录的是消费者组剩余可以拉取的消息大小final long fallBehindBytes = next.getValue().getValue().get();// 如果超过了 16Gif (fallBehindBytes > this.brokerConfig.getConsumerFallbehindThreshold()) {final String[] split = next.getValue().getStatsKey().split("@");final String group = split[2];LOG_PROTECTION.info("[PROTECT_BROKER] the consumer[{}] consume slowly, {} bytes, disable it", group, fallBehindBytes);// 设置这个消费者组的 consumeEnable 为 false, 禁止这个消费者组里面的消费者对这个 topic 消费this.subscriptionGroupManager.disableConsume(group);}}}}
7. fetchNameServerAddr 定时任务定时拉取 NameServer 地址
broker 启动的时候在 start 方法会启动一个定时任务去定期拉取 NameServer 地址,当然这里的定期拉取 NameServer 地址的前提是用户没有在 broker.conf 文件中设置 namesrvAddr 配置。
public String fetchNameServerAddr() {try {// 从地址服务器拉取 nameserver 的地址String addrs = this.topAddressing.fetchNSAddr();if (addrs != null) {if (!addrs.equals(this.nameSrvAddr)) {log.info("name server address changed, old: {} new: {}", this.nameSrvAddr, addrs);this.updateNameServerAddressList(addrs);// 更新 nameSrvAddr 属性this.nameSrvAddr = addrs;return nameSrvAddr;}}} catch (Exception e) {log.error("fetchNameServerAddr Exception", e);}return nameSrvAddr;
}
核心源码是下面的 fetchNSAddr,来看下代码。
/*** 拉取 nameserver 的地址* @return*/
public final String fetchNSAddr() {return fetchNSAddr(true, 3000);
}/*** 拉取 nameserver 的地址* @param verbose* @param timeoutMills* @return*/
public final String fetchNSAddr(boolean verbose, long timeoutMills) {String url = this.wsAddr;try {// 向 wsAddr 地址发送查询 NameServer 的请求if (!UtilAll.isBlank(this.unitName)) {url = url + "-" + this.unitName + "?nofix=1";}HttpTinyClient.HttpResult result = HttpTinyClient.httpGet(url, null, null, "UTF-8", timeoutMills);if (200 == result.code) {String responseStr = result.content;if (responseStr != null) {// 处理返回结果return clearNewLine(responseStr);} else {log.error("fetch nameserver address is null");}} else {log.error("fetch nameserver address failed. statusCode=" + result.code);}} catch (IOException e) {if (verbose) {log.error("fetch name server address exception", e);}}if (verbose) {String errorMsg ="connect to " + url + " failed, maybe the domain name " + MixAll.getWSAddr() + " not bind in /etc/hosts";errorMsg += FAQUrl.suggestTodo(FAQUrl.NAME_SERVER_ADDR_NOT_EXIST_URL);log.warn(errorMsg);}return null;
}private static String clearNewLine(final String str) {// 去除前后的空格String newString = str.trim();int index = newString.indexOf("\r");if (index != -1) {// 截取 \r 前面的字符串return newString.substring(0, index);}index = newString.indexOf("\n");if (index != -1) {// 截取 \n 前面的字符串return newString.substring(0, index);}// 没有 \r 和 \n 字符, 直接返回原来的字符串return newString;
}
拉取的逻辑就是往 url 发送 get 请求来获取地址,所以这里的核心就是如何找到这个 url,也就是代码中的 wsAddr。由于这个属性是 TopAddressing 的,我们就看下这个属性是怎么设置的。
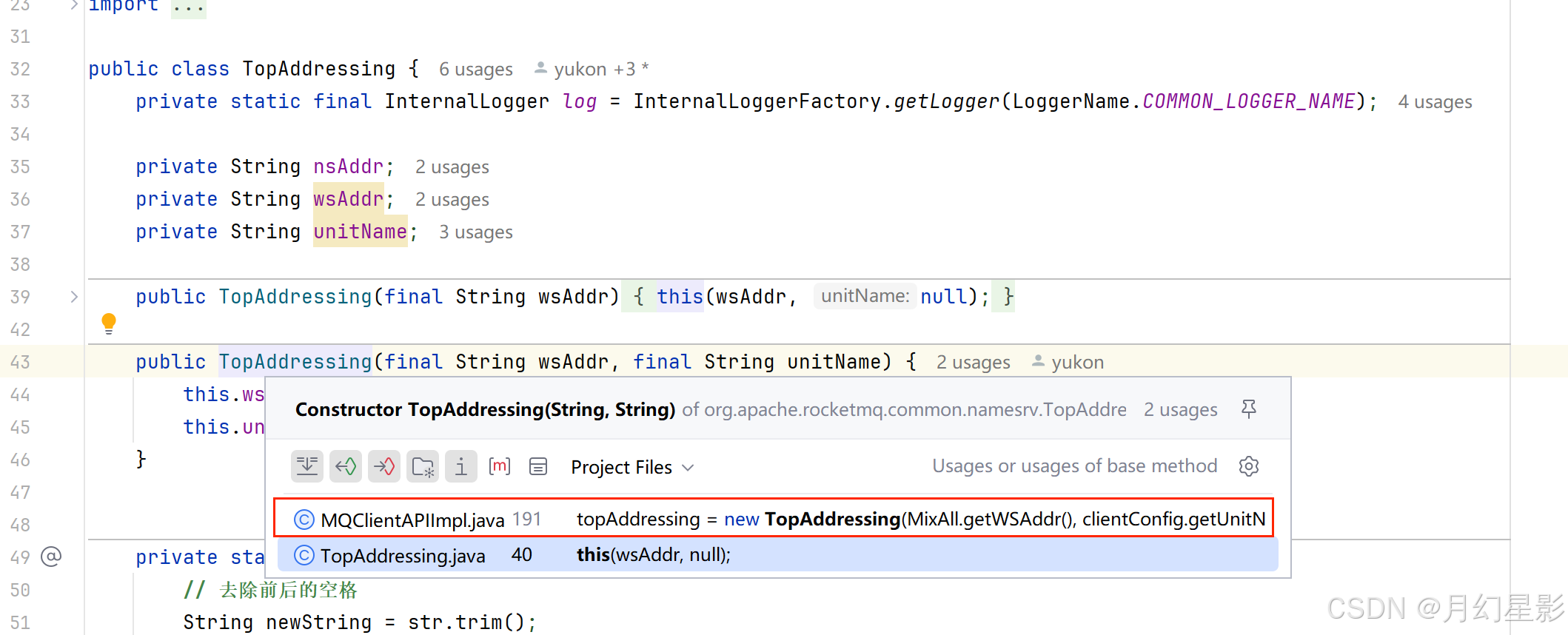
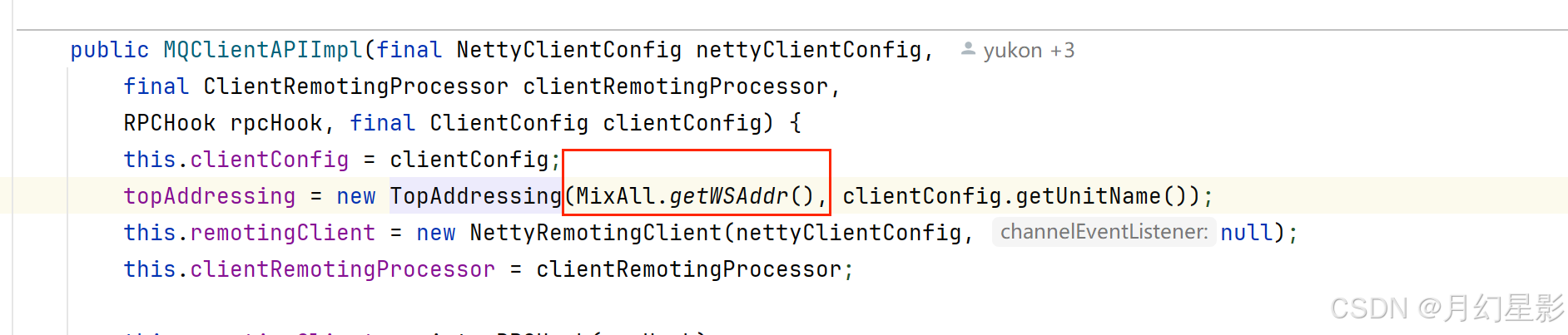
可以看到这个属性就是从 MixAll.getWSAddr 这个方法获取到的,这个方法就是用于获取地址服务器的请求地址。
/*** 获取 WS 地址* @return*/
public static String getWSAddr() {// 属性 rocketmq.namesrv.domain,默认值 jmenv.tbsite.netString wsDomainName = System.getProperty("rocketmq.namesrv.domain", DEFAULT_NAMESRV_ADDR_LOOKUP);// 属性 rocketmq.namesrv.domain.subgroup,默认值 nsaddrString wsDomainSubgroup = System.getProperty("rocketmq.namesrv.domain.subgroup", "nsaddr");// wsAddr 的默认值是 http://jmenv.tbsite.net:8080/rocketmq/nsaddrString wsAddr = "http://" + wsDomainName + ":8080/rocketmq/" + wsDomainSubgroup;// 如果存在 ':', 比如说 127.0.0.1:9876if (wsDomainName.indexOf(":") > 0) {// wsAddr 的会被设置成 http://127.0.0.1:9876/rocketmq/nsaddrwsAddr = "http://" + wsDomainName + "/rocketmq/" + wsDomainSubgroup;}// 返回 ws 地址return wsAddr;
}
如果在没有配置系统变量的情况下,默认就是 http://jmenv.tbsite.net:8080/rocketmq/nsaddr,这个一般也用不到吧,除非是用一个服务来统一管理 NameServer 地址,这里就看下注释即可。
8. 小结
承接上一篇文章,本篇对其中一些关键方法进行了补充说明。将这两篇文章结合起来,我们就梳理出了 broker 启动的大致逻辑。
在 broker 启动过程中,涉及众多方法,本文已着重对部分重要方法进行了补充介绍。不过,还有一些同样关键的操作尚未展开,比如将 broker 信息注册到 NameServer 这一操作。考虑到其重要性和复杂性,我会专门撰写一篇文章深入剖析。
至此,关于 broker 启动的大致逻辑就讲解到这里了。后续文章,我们再一同深入探讨其他关键环节。
如有错误,欢迎指出!!!!
相关文章:
)
【RocketMQ Broker 相关源码】- broker 启动源码(2)
文章目录 1. 前言2. 创建 DefaultMessageStore3. DefaultMessageStore#load3.1 CommitLog#load3.2 loadConsumeQueue 加载 ConsumeQueue 文件3.3 创建 StoreCheckpoint3.4 indexService.load 加载 IndexFile 文件3.5 recover 文件恢复3.6 延时消息服务加载 4. registerProcesso…...
 和 int(10) 有什么区别?)
mysql中int(1) 和 int(10) 有什么区别?
困惑 最近遇到个问题,有个表的要加个user_id字段,user_id字段可能很大,于是我提mysql工单alter table xxx ADD user_id int(1)。领导看到我的sql工单,于是说:这int(1)怕是不够用吧,接下来是一通解…...
tensorrt C++ api介绍)
jetson orin nano super AI模型部署之路(八)tensorrt C++ api介绍
我们基于tensorrt-cpp-api这个仓库介绍。这个仓库的代码是一个非常不错的tensorrt的cpp api实现,可基于此开发自己的项目。 我们从src/main.cpp开始按顺序说明。 一、首先是声明我们创建tensorrt model的参数。 // Specify our GPU inference configuration optio…...

渗透测试中扫描成熟CMS目录的意义与技术实践
在渗透测试领域,面对一个成熟且“看似安全”的CMS(如WordPress、Drupal),许多初级测试者常陷入误区:认为核心代码经过严格审计的CMS无需深入排查。然而,目录扫描(Directory Bruteforcing&#x…...

数字信号处理学习笔记--Chapter 1 离散时间信号与系统
1 离散时间信号与系统 包含以下内容: (1)离散时间信号--序列 (2)离散时间系统 (3)常系数线性差分方程 (4)连续时间信号的抽样 2 离散时间信号--序列 为了便于计算机对信号…...

LeetCode 热题 100 994. 腐烂的橘子
LeetCode 热题 100 | 994. 腐烂的橘子 大家好,今天我们来解决一道经典的算法题——腐烂的橘子。这道题在LeetCode上被标记为中等难度,要求我们计算网格中所有新鲜橘子腐烂所需的最小分钟数,或者返回不可能的情况。下面我将详细讲解解题思路&…...

软考-软件设计师中级备考 11、计算机网络
1、计算机网络的分类 按分布范围分类 局域网(LAN):覆盖范围通常在几百米到几千米以内,一般用于连接一个建筑物内或一个园区内的计算机设备,如学校的校园网、企业的办公楼网络等。其特点是传输速率高、延迟低、误码率低…...

NHANES指标推荐:LC9
文章题目:Association between lifes crucial 9 and kidney stones: a population-based study DOI:10.3389/fmed.2025.1558628 中文标题:生命的关键 9 与肾结石之间的关联:一项基于人群的研究 发表杂志:Front Med 影响…...

使用 Azure DevSecOps 和 AIOps 构建可扩展且安全的多区域金融科技 SaaS 平台
引言 金融科技行业有一个显著特点:客户期望能够随时随地即时访问其财务数据,并且对宕机零容忍。即使是短暂的中断也会损害用户的信心和忠诚度。与此同时,对数据泄露的担忧已将安全提升到整个行业的首要地位。 在本文中,我们将探…...

原子单位制换算表
速度 0.12.1880.24.3760.36.5640.48.7520.510.940.613.1280.715.3160.817.5040.919.692121.881.532.82243.762.554.7...

【C++重载操作符与转换】下标操作符
目录 一、下标操作符重载基础 1.1 什么是下标操作符重载 1.2 默认行为与需求 1.3 基本语法 二、下标操作符的核心实现策略 2.1 基础实现:一维数组模拟 2.2 多维数组实现:矩阵类示例 三、下标操作符的高级用法 3.1 自定义索引类型:字…...
)
文章记单词 | 第62篇(六级)
一,单词释义 noon [nuːn] n. 中午,正午clothes [kləʊz] n. 衣服,衣物reward [rɪˈwɔːd] n. 报酬,奖赏;vt. 奖励,奖赏newly [ˈnjuːli] adv. 最近,新近;以新的方式premier [ˈ…...

《CUDA:解构GPU计算的暴力美学与工程哲学》
《CUDA:解构GPU计算的暴力美学与工程哲学》 CUDA 的诞生,宛如在 GPU 发展史上划下了一道分水岭。它不仅赋予了 GPU 走出图形处理的 “舒适区”,投身通用计算的 “新战场” 的能力,更是一场对计算资源分配与利用逻辑的彻底重构。在这场技术革命中,CUDA 以它犀利的架构设…...
)
Linux ACPI - ACPI系统描述表架构(2)
ACPI系统描述表架构 1.概要 ACPI defines a hardware register interface that an ACPI-compatible OS uses to control core power management features of a machine, as described in ACPI Hardware Specification ACPI also provides an abstract interface for controlli…...

实时在线状态
以下是一个完整的 OnlineUsers 类实现,包含线程安全的在线用户管理功能: import java.util.*; import java.util.concurrent.ConcurrentHashMap; import java.util.stream.Collectors;/*** 在线用户管理器(线程安全)* 功能&#…...
》阅读笔记:p6-p6)
《算法导论(第4版)》阅读笔记:p6-p6
《算法导论(第4版)》学习第 4 天,p6-p6 总结,总计 1 页。 一、技术总结 无。 二、英语总结(生词:1) 1. disposal (1)dispose: dis-(“aprt”) ponere(“to put, place”) vt. dispose literally means “to put apart(to separate sth…...

录播课制作技术指南
1.技术版本选择策略 优先采用长期支持版本作为课程开发基础,此类版本在企业级应用中普及度高且稳定性强。技术选型直接影响课程生命周期,稳定的底层框架可降低后续维护成本,避免因技术迭代导致教学内容快速过时。建议定期查看技术社区官方公告…...

【2025软考高级架构师】——知识脑图总结
摘要 本文是一份关于 2025 年软考高级架构师的知识脑图总结。整体涵盖系统工程与信息系统基础、软件工程、项目管理等众多板块,每个板块又细分诸多知识点,如系统工程部分提及系统工程方法、信息系统生命周期等内容,旨在为备考人员提供系统全…...

Allegro23.1新功能之如何设置高压爬电间距规则操作指导
Allegro23.1新功能之如何设置高压爬电间距规则操作指导 Allegro23.1升级到了23.1之后,新增了一个设置高压爬电间距的规则 如下图,不满足爬电间距要求,以DRC的形式报出来了...

**电商推荐系统设计思路**
互联网大厂Java面试实录:马小帅的生死时速 第一轮提问 面试官(严肃地):马小帅,请你先简单介绍一下你过往的项目经验,特别是你在项目中使用的技术栈。 马小帅(紧张地搓手)ÿ…...

BC19 反向输出一个四位数
题目:BC19 反向输出一个四位数 描述 将一个四位数,反向输出。(有前导零的时候保留前导零) 输入描述: 一行,输入一个整数n(1000 < n < 9999)。 输出描述: 针对每组…...

【前端】【面试】在 Vue-React 的迁移重构工作中,从状态管理角度来看,Vuex 迁移到 Redux 最大的挑战是什么,你是怎么应对的?
在从 Vue(Vuex)迁移到 React(Redux)时,状态管理无疑是重构中最具挑战性的部分之一。两者虽本质上都实现了全局状态集中式管理,但在思想、结构与实现方式上存在显著差异。 Vuex 到 Redux 状态管理迁移的挑战…...
)
ActiveMQ 与其他 MQ 的对比分析:Kafka/RocketMQ 的选型参考(一)
消息队列简介 在当今的分布式系统架构中,消息队列(Message Queue,MQ)扮演着举足轻重的角色,已然成为构建高可用、高性能系统不可或缺的组件。消息队列本质上是一种异步通信的中间件,它允许不同的应用程序或…...

OPENGLPG第九版学习 -视口变换、裁减、剪切与反馈
文章目录 5.1 观察视图5.1.1 视图模型—相机模型OpenGL的整个处理过程中所用到的坐标系统:视锥体视锥体的剪切 5.1.2 视图模型--正交视图模型 5.2 用户变换5.2.1 矩阵乘法的回顾5.2.2 齐次坐标5.2.3 线性变换与矩阵SRT透视投影正交投影 5.2.4 法线变换逐像素计算法向…...

大连理工大学选修课——图形学:第一章 图形学概述
第一章 图形学概述 计算机图形学及其研究内容 计算机图形学:用数学算法将二维或三维图形转化为计算机显示器的格栅形式的科学。 图形 计算机图形学的研究对象为图形广义来说,能在人的视觉系统形成视觉印象的客观对象都可称为图形。 既包括了各种几何…...

雅思听力--75个重点单词/词组
文章目录 1. in + 一段时间2. struggle with + doing sth.3. due to + n. / doing sth.4. all kinds of + n.5. supply6. get sb. down7. sth. be a hit8. ups and downs1. in + 一段时间 “in ten minutes”表示“10分钟内”,“in + 一段时间”表示“在一段时间之内”。 You…...

dubbo 参数校验-ValidationFilter
org.apache.dubbo.rpc.Filter 核心功能 拦截RPC调用流程 Filter是Dubbo框架中实现拦截逻辑的核心接口,作用于服务消费者和提供者的作业链路,支持在方法调用前后插入自定义逻辑。如参数校验、异常处理、日志记录等。扩展性机制 Dubbo通过SPI扩展机制动态…...
论文笔记和启发)
Fine Structure-Aware Sampling(AAAI 2024)论文笔记和启发
文章目录 本文解决的问题本文提出的方法以及启发 本文解决的问题 传统的基于Pifu的人体三维重建一般通过采样来进行学习。一般选择的采样方法是空间采样,具体是在surface的表面随机位移进行样本的生成。这里的采样是同时要在XYZ三个方向上进行。所以这导致了一个问…...

股票单因子的检验方法有哪些?
股票单因子的检验方法主要包括以下四类方法及相关指标: 一、统计指标检验 IC值分析法 定义:IC值(信息系数)衡量因子值与股票未来收益的相关性,包括两种计算方式: Normal IC:基于Pearson相关系数…...
)
Android第三次面试总结之activity和线程池篇(补充)
一、线程池高频面试题 1. 为什么 Android 中推荐使用线程池而非手动创建线程?(字节跳动 / 腾讯真题) 核心考点:线程池的优势、资源管理、性能优化答案要点: 复用线程:避免重复创建 / 销毁线程的开销&…...

【Trae+LucidCoder】三分钟编写专业Dashboard页面
AI辅助编码作为一项革命性技术,正在改变开发者的工作方式。本文将深入探讨如何利用Trae的AI Coding功能构建专业的Dashboard页面,同时向您推荐一个极具价值的工具——Lucids.top,它能够将页面截图转换为AI IDE的prompt,从而生成精…...

CUDA Toolkit 12.9 与 cuDNN 9.9.0 发布,带来全新特性与优化
NVIDIA 近日发布了 CUDA Toolkit 12.9,为开发者提供了一系列新功能和改进,旨在进一步提升 GPU 加速应用的性能和开发效率。CUDA Toolkit 是创建高性能 GPU 加速应用的关键开发环境,广泛应用于从嵌入式系统到超级计算机的各种计算平台。 新特…...

chrome 浏览器怎么不自动提示是否翻译网站
每次访问外国语网页都会弹出这个对话框,很是麻烦,每次都得手动关闭一下。 不让他弹出来方法: 设置》语言》首选语言》添加语言,搜索英语添加上 如果需要使用翻译,就点击三个点,然后选择翻译...

编程速递-RAD Studio 12.3 Athens四月补丁:关注软件性能的开发者,安装此补丁十分必要
2025年4月22日,Embarcadero发布了针对RAD Studio 12.3、Delphi 12.3以及CBuilder 12.3的四月补丁。此更新旨在提升这些产品的质量,特别关注于Delphi编译器、C 64位现代工具链、RAD Studio 64位IDE及其调试器、VCL库和其他RAD Studio特性。强烈建议所有使…...

Linux54 源码包的安装、修改环境变量解决 axel命令找不到;getfacl;测试
始终报错 . 补充链接 tinfo 库时报错软件包 ncurses-devel-5.9-14.20130511.el7_4.x86_64 已安装并且是最新版本 没有可用软件包 tinfo-devel。 无须任何处理 make LDLIBS“-lncurses"报错编译时报错make LDLIBS”-lncurses" ? /opt/rh/devtoolset-11/roo…...
:Linux 内核子系统的特性全解析)
驱动开发硬核特训 · Day 27(上篇):Linux 内核子系统的特性全解析
在过去数日的练习中,我们已经深入了解了字符设备驱动、设备模型与总线驱动模型、regulator 电源子系统、I2C 驱动模型、of_platform_populate 自动注册机制等关键模块。今天进入 Day 27,我们将正式梳理 Linux 内核子系统的核心特性与通用结构,…...

【学习笔记】深度学习:典型应用
作者选择了由 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 三位大佬撰写的《Deep Learning》(人工智能领域的经典教程,深度学习领域研究生必读教材),开始深度学习领域学习,深入全面的理解深度学习的理论知识。 之前的文章参考下面的链接…...

万字详解ADC药物Payload
抗体药物偶联物(ADC)是一种有前景的癌症治疗方式,能够选择性地将有效载荷(Payload)细胞毒性分子递送至肿瘤,降低副作用的严重程度。通常ADC由3个关键成分组成:抗体,连接子和有效载荷…...

算法笔记.求约数
代码实现: #include<iostream> using namespace std; #include<vector> void check(int x) {vector<int> v;for(int i 1;i< x/i;i){if(x%i 0) {cout << i<<" ";v.push_back(i);}}for(int i v.size()-1;i>0;i--){…...

Assetto Corsa 神力科莎 [DLC 解锁] [Steam] [Windows]
Assetto Corsa 神力科莎 [DLC 解锁] [Steam] [Windows] 需要有游戏正版基础本体,安装路径不能带有中文,或其它非常规拉丁字符; DLC 版本 至最新全部 DLC 后续可能无法及时更新文章,具体最新版本见下载文件说明 DLC 解锁列表&…...

启发式算法-遗传算法
遗传算法是一种受达尔文生物进化论和孟德尔遗传学说启发的启发式优化算法,通过模拟生物进化过程,在复杂搜索空间中寻找最优解或近似最优解。遗传算法的核心是将问题的解编码为染色体,每个染色体代表一个候选解,通过模拟生物进化中…...

生成式AI将重塑的未来工作
在人类文明的长河中,技术革命始终是推动社会进步的核心动力。从蒸汽机的轰鸣到互联网的浪潮,每一次技术跃迁都在重塑着人类的工作方式与生存形态。而今,生成式人工智能(Generative AI)的崛起,正以超越以往任何时代的速度与深度,叩响未来工作范式变革的大门。这场变革并非…...

【操作系统】吸烟者问题
问题描述 吸烟者问题是一个经典的同步问题,涉及三个抽烟者进程和一个供应者进程。每个抽烟者需要三种材料(烟草、纸和胶水)来卷烟,但每个抽烟者只有一种材料。供应者每次提供两种材料,拥有剩下那种材料的抽烟者可以卷烟…...

mysql-内置函数,复合查询和内外连接
一 日期函数 函数名称描述示例current_date()返回当前日期(格式:yyyy-mm-dd)select current_date(); → 2017-11-19current_time()返回当前时间(格式:hh:mm:ss)select current_time(); → 13:51:21current…...
:浅析ATAM 在软件技术架构评估中的应用)
软件架构之旅(6):浅析ATAM 在软件技术架构评估中的应用
文章目录 一、引言1.1 研究背景1.2 研究目的与意义 二、ATAM 的理论基础2.1 ATAM 的定义与核心思想2.2 ATAM 涉及的质量属性2.3 ATAM 与其他架构评估方法的关系 三、ATAM 的评估流程3.1 准备阶段3.2 场景和需求收集阶段3.3 架构描述阶段3.4 评估阶段3.5 结果报告阶段 四、ATAM …...

【SQL触发器、事务、锁的概念和应用】
【SQL触发器、事务、锁的概念和应用】 1.触发器 (一)触发器概述 1.触发器的定义 触发器(Trigger)是一种特殊的存储过程,它与表紧密相连,可以是表定义的一部分。当预定义的事件(如用户修改指定表或者视图中的数据)发生时,触发器会自动执行。 触发器基于一个表创建,…...

5.4学习记录
今天的目标是复习刷过往的提高课的DP题目:重点是数位DP,状态压缩DP,然后去做一些新的DP题目 然后明天的任务就是把DP的题目汇总,复习一些疑难的问题 方格取数: 题目背景 NOIP 2000 提高组 T4 题目描述 设有 NN 的方…...

Hadoop 1.x设计理念解析
一、背景 有人可能会好奇,为什么要学一个二十年前的东西呢? Hadoop 1.x虽然是二十年前的,但hadoop生态系统中的一些组件如今还在广泛使用,如hdfs和yarn,当今流行spark和flink都依赖这些组件 通过学习它们的历史设计…...

缓存与数据库的高效读写流程解析
目录 前言1 读取数据的流程1.1 检查缓存是否命中1.2 从数据库读取数据1.3 更新缓存1.4 返回数据 2 写入数据的流程2.1 更新数据库2.2 更新或删除缓存2.3 缓存失效 3 缓存与数据库的一致性问题3.1 写穿(Write-through)策略3.2 写回(Write-back…...

Linux中的粘滞位和开发工具和文本编辑器vim
1.粘滞位的使用的背景: 当几个普通用户需要文件共享操作时,他们就需要在同一个目录下进行操作,那么就诞生一个问题,由谁来创建这个公共的目录文件?假设是由其中的一个普通用户来创建一个默认的目录文件,这就…...