ScholarCopilot:“学术副驾驶“
这里写目录标题
- 引言:学术写作的痛点与 AI 的曙光
- ScholarCopilot 的核心武器库:智能生成与精准引用
- 智能文本生成:不止于“下一句”
- 智能引用管理:让引用恰到好处
- 揭秘背后机制:检索与生成的动态协同
- 快速上手:部署与使用你的 ScholarCopilot
- 部署本地 Demo
- 保持语料库更新
- (可选) 训练专属模型
- 应用前景
- 结论
在学术研究的征途中,论文写作无疑是关键一环,而准确、规范的引用更是衡量学术严谨性的重要标尺。然而,繁琐的文献检索、格式调整以及在写作过程中实时插入恰当引用的需求,常常让研究者们倍感压力。今天,我们将深入探讨一个旨在革新这一流程的开源项目——ScholarCopilot,一个由 TIGER-Lab 倾力打造的智能学术写作助手。它不仅仅是一个简单的文本生成工具,更是一位懂得何时、何地、如何精准引用的“学术副驾驶”。

引言:学术写作的痛点与 AI 的曙光
撰写高质量的学术论文,不仅需要清晰的逻辑、深入的见解,还需要对相关文献的广泛涉猎和精确引用。传统的写作流程中,研究者往往需要在不同的工具和数据库之间切换,手动查找、筛选、整理文献,并按照特定的格式插入文中,这一过程耗时耗力且容易出错。近年来,大型语言模型(LLM)在文本生成方面取得了显著进展,但将其直接应用于需要高度精确性和严谨性的学术写作,尤其是在处理引文方面,仍然面临巨大挑战。通用 LLM 往往难以保证引用的真实性和准确性,甚至可能产生“幻觉”引用。
正是在这样的背景下,ScholarCopilot 应运而生。它并非简单地替换写作者,而是作为一个强大的“Copilot”,在写作过程中提供智能化的辅助,特别是在文本补全和引用管理这两个核心环节上,展现出了令人瞩目的能力。
ScholarCopilot 的核心武器库:智能生成与精准引用
ScholarCopilot 的核心价值在于其两大关键特性:智能化的文本生成和精准的引用管理。这不仅仅是功能的堆砌,而是基于对学术写作流程深刻理解的精心设计。
智能文本生成:不止于“下一句”
许多写作助手都能提供文本建议,但 ScholarCopilot 的目标是提供更贴合学术语境的、结构化的内容生成。
- 上下文感知的句子建议: 它不仅仅是预测下一个词,而是能根据你已经写下的内容,提供接下来三句高度相关的、符合学术表达习惯的句子建议。这有助于打破写作障碍,保持思路流畅。
- 完整章节的自动补全: 对于论文中的标准章节(如引言、相关工作、方法等),ScholarCopilot 能够根据上下文和用户的初步输入,生成结构完整、逻辑连贯的章节草稿。这极大地提高了初稿的撰写效率。
- 保持连贯性: 所有的文本生成都基于对现有文本的理解,确保新生成的内容与前文在风格、术语和逻辑上保持一致,避免了通用模型可能产生的突兀感。
智能引用管理:让引用恰到好处
这是 ScholarCopilot 最具特色的功能,也是其区别于许多通用写作工具的关键所在。
- 实时上下文引用建议: 在你写作时,ScholarCopilot 会实时分析文本内容,并在它认为需要引用支撑的地方,主动推荐相关的参考文献。这就像有一位经验丰富的导师在旁边提醒你:“这里需要一个引用来支持你的观点。”
- 一键式引用插入: 对于推荐的文献,用户只需简单点击,即可将其按照规范的学术格式(如 [1], (Author, Year) 等,具体格式可能需配置)插入到当前光标位置。
- BibTeX 条目自动生成与导出: 更为便捷的是,所有插入的引用,ScholarCopilot 都能自动生成对应的 BibTeX 条目,方便用户在论文末尾整理参考文献列表,并导出使用。
揭秘背后机制:检索与生成的动态协同
如此智能的功能是如何实现的?ScholarCopilot 的 README 文件揭示了其核心的推理流程:一个巧妙融合了检索(Retrieval)与生成(Generation)的统一模型架构。
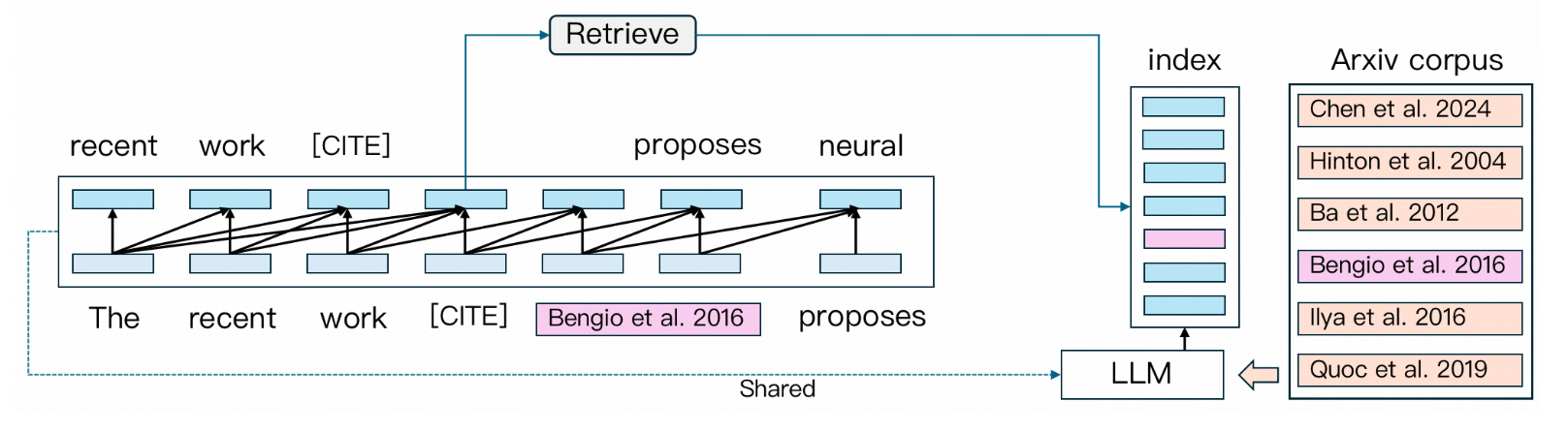
(图片来源: ScholarCopilot GitHub Repository)
这个流程的关键在于一种动态切换机制。模型在生成文本的过程中,并非一味地向前输出,而是会利用其学习到的“引用模式”(learned citation patterns)来判断当前位置是否适合插入引用。
当模型判定需要引用时,它会暂停文本生成任务,并利用生成到“引用标记”(citation token)时的隐藏状态(hidden states)。这些隐藏状态编码了当前上下文的语义信息,可以被视为一个高效的查询向量。模型使用这个向量在其内部或外部的论文语料库(Corpus)中进行检索,找到最相关的几篇论文。
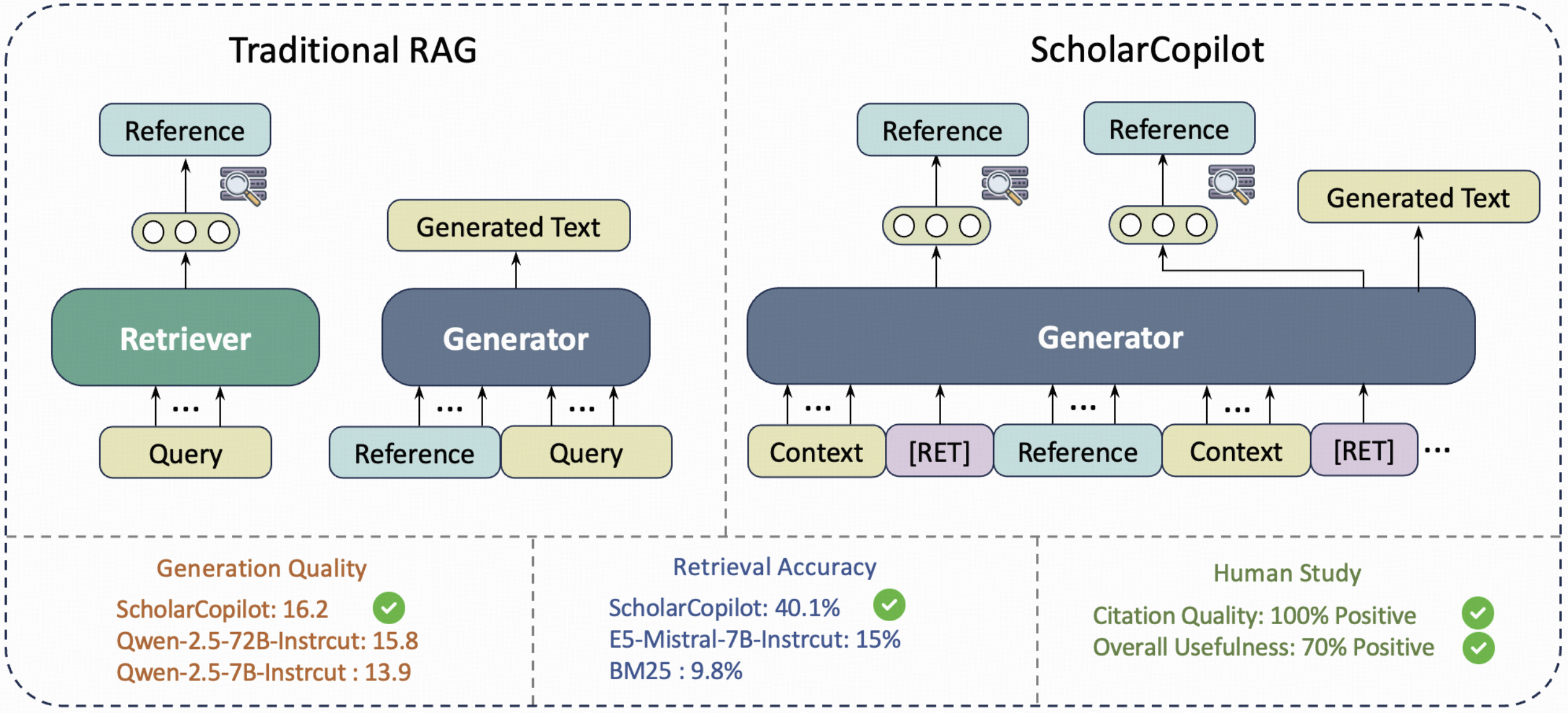
一旦用户确认或模型选择了合适的参考文献,系统会将其格式化并插入文本。随后,模型会无缝地切换回生成模式,基于更新后的上下文继续撰写连贯的文本。这种“生成-判断-检索-插入-继续生成”的闭环,使得 ScholarCopilot 能够将精准的引用有机地融入流畅的写作过程中,这相较于传统的“先写后补”或依赖外部插件的引用方式,无疑是巨大的进步。
快速上手:部署与使用你的 ScholarCopilot
TIGER-Lab 不仅发布了研究成果,还提供了代码和 Demo,让开发者和研究者能够快速体验和部署。
部署本地 Demo
1、克隆仓库:
git clone git@github.com:TIGER-AI-Lab/ScholarCopilot.git
cd ScholarCopilot/run_demo
2、设置环境:
pip install -r requirements.txt
3、下载模型与数据: 项目提供了便捷的脚本来下载所需资源。
bash download.sh
4、启动 Demo:
bash run_demo.sh
执行完毕后,根据提示即可在本地访问 ScholarCopilot 的演示界面。
保持语料库更新
学术研究日新月异,保持引用语料库的更新至关重要。ScholarCopilot 也考虑到了这一点,提供了更新 arXiv 语料库的流程:
1、从 Kaggle 等渠道下载最新的 arXiv 元数据。
2、使用提供的 Python 脚本处理元数据:
cd utils/
python process_arxiv_meta_data.py ARXIV_META_DATA_PATH ../data/corpus_data_arxiv_1215.jsonl
3、为新的语料库生成嵌入(Embedding),这是后续高效检索的基础:
bash encode_corpus.sh
4、构建 HNSW(Hierarchical Navigable Small World)索引,以实现快速相似性搜索:
python build_hnsw_index.py --input_dir <embedding dir> --output_dir <hnsw index dir>
通过这些步骤,你可以将最新的研究成果纳入 ScholarCopilot 的“视野”。
(可选) 训练专属模型
对于有更高定制化需求或希望在特定领域语料上进行优化的用户,项目还提供了训练指南:
1、下载训练数据:cd train/ && bash download.sh
2、配置并运行训练脚本:cd src/ && bash start_train.sh
- 注意:根据文档,复现论文结果需要相当大的计算资源(例如 4 台机器,每台 8 个 GPU,共 32 个 GPU)。
应用前景
ScholarCopilot 的出现,为广大学生、教师和科研工作者带来了福音。
- 效率提升: 大幅缩短文献检索、引用格式调整和文本撰写的时间,让研究者能更专注于思考和创新。
- 质量保障: 智能推荐和一键插入有助于减少引用错误和遗漏,提高论文的规范性和严谨性。
- 降低门槛: 对于初涉科研的学生,它能作为一个很好的辅助工具,帮助他们更快地掌握学术写作规范。
相较于市面上其他写作工具或通用大模型,ScholarCopilot 的核心优势在于其深度整合的、上下文感知的、以精准引用为目标的设计理念。它不是简单地做文本生成或文献管理,而是将两者无缝结合,真正服务于学术写作的特殊需求。
当然,作为一项新兴技术,它也可能存在一些局限性,例如对特定领域、非英语文献的覆盖程度,对复杂引用格式的适应性,以及对计算资源的需求等。但其展现出的潜力已足够令人兴奋。
结论
ScholarCopilot 以其创新的思路和实用的功能,为我们描绘了 AI 赋能学术写作的美好图景。它通过智能化的文本生成和精准的引用管理,有望将研究者从繁琐的事务性工作中解放出来,显著提升科研产出的效率和质量。虽然项目仍在发展中,但其开源的模式、清晰的架构和详尽的指南,无疑为社区的进一步贡献和完善奠定了良好基础。
如果你也为学术写作中的引用问题所困扰,不妨关注并尝试一下 ScholarCopilot。它或许就是你一直在寻找的那个“学术副驾驶”。
资源链接:
- 项目主页: https://tiger-ai-lab.github.io/ScholarCopilot/
- 论文: https://arxiv.org/abs/2504.00824
- 数据: https://huggingface.co/datasets/TIGER-Lab/ScholarCopilot-Data-v1/
- 模型: https://huggingface.co/TIGER-Lab/ScholarCopilot-v1
- Demo: https://huggingface.co/spaces/TIGER-Lab/ScholarCopilot
- GitHub: https://github.com/TIGER-AI-Lab/ScholarCopilot
相关文章:

ScholarCopilot:“学术副驾驶“
这里写目录标题 引言:学术写作的痛点与 AI 的曙光ScholarCopilot 的核心武器库:智能生成与精准引用智能文本生成:不止于“下一句”智能引用管理:让引用恰到好处 揭秘背后机制:检索与生成的动态协同快速上手:…...

Node.js项目开启多进程的2种方案
当node项目只部署一个单进程单实例时,遇到异常发生后程序会崩溃,此时杀掉进程在重启单这段时间会导致服务不能正常使用,这显然会影响用户体验。 所以需要以多进程的模式去部署应用,这样当某一个进程发生异常重启时,此时有其他请求被接受后,其他进程依旧可以对外提供服务…...

论文导读 | 基于GPU的子图匹配算法
摘要 大规模图上的子图匹配在社交网络挖掘,生物信息学,知识图谱等领域具有关键作用。近年来随着以GPU为代表的新硬件的发展,研究人员开始尝试在GPU上实现这一NP难的任务。GPU提供了大量的计算单元和高速的显存带宽,可以显著提升算…...

中天科技旗下的中天智能装备有限公司,在立库方面有哪些优势?
中天科技旗下的中天智能装备有限公司在立库方面优势显著,主要体现在产品与方案、技术研发、项目经验和服务质量管控等多个维度,能够为客户提供全方位、高品质的立库相关服务。 产品与解决方案优势 多种立库解决方案:提供托盘式立库、料箱式立…...

HTML5+CSS前端开发【保姆级教学】+超链接标签
一、引入: Hello!,各位编程猿们!一个页面可以跳转到其他页面,去访问其他资源,使得我们的文档更加的灵动,那我们如何实现不同页面的跳转呢?本期主要介绍超链接标签 那么什么是超链接…...

【游戏安全】文本校验类风险
文本风险定义: 在游戏中除了动画,声音参与和玩家的交互之外,游戏中的文本也属于和玩家交互中一项重要的元素。由玩家操作触发任何不同于游戏自身逻辑设定,进而破坏游戏平衡的文本内容都可以称之为文本类风险漏洞。(这个定义自己瞎写的…) 文本风险危害(漏洞举例): …...

快速排序及其应用
快速排序及其应用 标准写法改成稳定版本求第k小值O(n)做法快排的另一种写法 标准写法 #include <bits/stdc.h>using namespace std;using ll long long;int a[] {8, 5, 18, 11, 7, 2, 21, 15, 3, 8};void quickSort(int l, int r) {if (l > r) return ; // 元素个数…...

南柯电子|新能源汽车EMC电磁兼容性测试整改:突破行业规范之路
随着新能源汽车产业的蓬勃发展,车辆电子化、智能化程度不断提高,电磁兼容性(EMC)问题日益凸显。作为衡量汽车电子系统稳定性的关键指标,EMC性能不仅影响车辆功能安全,更关乎道路交通的整体安全性。 一、EM…...

LabVIEW 程序持续优化
LabVIEW 以其独特的图形化编程方式,在工业自动化、测试测量、数据分析等众多领域发挥着关键作用。为了让 LabVIEW 程序始终保持高效、稳定,并契合不断变化的实际需求,持续改进必不可少。下面将从多个关键维度,为大家细致地介绍通用…...

裂缝检测数据集,支持yolo,coco json,pasical voc xml,darknet格式的标注,1673张原始训练集图片,正确识别率99.4%
数据集详情: 裂缝检测数据集,支持yolo,coco json,pasical voc xml,darknet格式的标注,1673张原始训练集图片,正确识别率99.4% 2394总图像 数据集分割 训练集占比 70% 1673图片 有效集20% 477图片 测试集...

Webrtc让浏览器实现无服务器中转的安全私密聊天
私密聊天平台的应用介绍 在当今数字时代,隐私和安全成为人们日益关注的焦点。许多人发现,他们的聊天记录、个人信息甚至行为习惯都可能被第三方平台记录、分析甚至滥用。无论是出于保护个人隐私的需要,还是希望实现真正的点对点直接通信&…...

数据结构-限定性线性表 - 栈与队列
栈和队列是数据结构中非常重要的两种限定性线性表,它们在实际应用中有着广泛的用途。这篇文章将深入讲解栈和队列的概念、抽象数据类型、实现方式、应用场景以及性能分析,并通过代码示例帮助大家更好地理解和实践。 一、栈的概念与抽象数据类型 1.1 栈…...

接口的集成测试步骤
一、集成测试是什么 接口的集成测试是指在软件开发过程中,将各个模块或组件按照设计要求组合在一起,并测试它们之间的接口是否能够正确交互和协同工作的过程。集成测试是软件开发中的一个重要阶段,通常在单元测试之后进行,目的…...
)
Python 实现的运筹优化系统数学建模详解(多目标规划模型)
一、引言 在数学建模的广阔领域中,多目标规划模型占据着极为重要的地位。它致力于在复杂的实际场景里,同时优化多个相互冲突的目标,寻求一组决策变量,让多个目标函数在满足特定约束条件下达到某种平衡。这种模型广泛应用于生产调度…...

AJAX原理与XMLHttpRequest
目录 一、XMLHttpRequest使用步骤 基本语法 步骤 1:创建 XHR 对象 步骤 2:调用 open() 方法 步骤 3:监听 loadend 事件 步骤 4:调用 send() 方法 二、完整示例 1. GET 请求(带查询参数) 2. POST 请…...
css中的3d使用:深入理解 CSS Perspective 与 Transform-Style
在前端开发的奇妙世界中,CSS 不仅负责页面的布局和样式,还能赋予元素生动的动态效果。要实现引人入胜的 3D 变换,perspective 和 transform-style 这两个属性扮演着至关重要的角色。本文将带您深入了解这两个属性,揭开它们如何协同…...
)
在 JMeter 中,Active Threads Over Time 是一个非常有用的监听器(Listener)
在 JMeter 中,Active Threads Over Time 是一个非常有用的监听器(Listener),它可以帮助你实时观察测试过程中活跃线程数(并发用户数)的变化趋势,从而分析系统的并发处理能力和负载情况。 1. Active Threads Over Time 的作用 实时监控并发用户数:显示测试过程中活跃线程…...

未来七轴机器人会占据主流?深度解析具身智能方向当前六轴机器人和七轴机器人的区别,七轴力控机器人发展会加快吗?
六轴机器人和七轴机器人在设计、功能和应用场景上存在明显区别。六轴机器人是工业机器人的传统架构,而七轴机器人则在多自由度和灵活性方面进行了增强。 本文将在理解这两者的区别以及为何六轴机器人仍然是市场主流,从多个方面进行深入解读六轴和七轴区…...

spark-SOL简介
Spark-SQL简介 一.Spark-SQL是什么 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块 二.Hive and SparkSQL SparkSQL 的前身是 Shark,Shark是给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供的快速上手的工具 …...
 / 连续子数组最大和(动态规划) / 非对称之美(贪心))
【今日三题】经此一役小红所向无敌(模拟) / 连续子数组最大和(动态规划) / 非对称之美(贪心)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 经此一役小红所向无敌(模拟)连续子数组最大和(动态规划)非对称之美(贪心) 经此一役小红所向无敌(模拟) 经此一役小红所向无…...

MYSQL MVCC详解
这里写自定义目录标题 **一、MVCC 解决的核心问题****二、MVCC 的核心实现机制****1. 隐藏字段与版本链****2. Undo Log****3. ReadView(一致性视图)** **三、MVCC 的可见性判断过程****四、不同隔离级别下的 MVCC 行为****五、MVCC 的优缺点****六、示例…...

Trinity三位一体开源程序是可解释的 AI 分析工具和 3D 可视化
一、软件介绍 文末提供源码和程序下载学习 Trinity三位一体开源程序是可解释的 AI 分析工具和 3D 可视化。Trinity 提供性能分析和 XAI 工具,非常适合深度学习系统或其他执行复杂分类或解码的模型。 二、软件作用和特征 Trinity 通过结合具有超维感知能力的不同交…...

用 Deepseek 写的uniapp血型遗传查询工具
引言 在现代社会中,了解血型遗传规律对于优生优育、医疗健康等方面都有重要意义。本文将介绍如何使用Uniapp开发一个跨平台的血型遗传查询工具,帮助用户预测孩子可能的血型。 一、血型遗传基础知识 人类的ABO血型系统由三个等位基因决定:I…...

展示数据可视化的魅力,如何通过图表、动画等形式让数据说话
在当今信息爆炸的时代,数据的量级和复杂性不断增加。如何从海量数据中提取有价值的信息,并将其有效地传达给用户,成为了一个重要的课题。数据可视化作为一种将复杂数据转化为直观图形、图表和动画的技术,能够帮助用户快速理解数据…...

解决安卓开发“No Android devices detected.”问题
解决安卓开发“No Android devices detected.”问题 当我们插入移动设备的USB时,却发现这并未显示已连接到的设备 点击右侧的Assistant,根据提示打开移动设备开发者模式并启用USB调试模式,然后发现我们未连接到移动设备的原因是ABD服务的原因 问题确定了&…...
)
Android13 WIFI调试(rtl8821cs)
一、WiFi框架概述 1、Wi‑Fi 是一种无线通信技术,在 Linux 系统上一般可处于三种工作模式,分别是: STATION、AP、MONITOR。 station :工作sta模式,类比手机主动连网。 ap:工作ap模式,类比手机开热点。 mon…...

Android常见界面控件、程序活动单元Activity练习
第3章 Android常见界面控件、第4章程序活动单元Activity 一. 填空题 1. (填空题)Activity的启动模式包括standard、singleTop、singleTask和_________。 正确答案: (1) singleInstance 2. (填空题)启动一个新的Activity并且获取这个Activity的返回数据ÿ…...

过拟合、归一化、正则化、鞍点
过拟合 过拟合的本质原因往往是因为模型具备方差很大的权重参数。 定义一个有4个特征的输入,特征向量为,定义一个模型,其只有4个参数,表示为。当模型过拟合时,这四个权重参数的方差会很大,可以假设为。当经过这个模型后…...

关于多agent多consumer架构设想
多个agent接入设备 每个agent对接同一个消费队列,非竞争设置,通过判断consumer中的参数如果是发给自己的,则下发,如果不是,则快速跳过。每个消费者接收消息时通过Header中值判断是来着哪个agent服务器的,发…...

国内互联网大厂推出的分布式数据库 的详细对比,涵盖架构、性能、适用场景、核心技术等维度
以下是 国内互联网大厂推出的分布式数据库 的详细对比,涵盖架构、性能、适用场景、核心技术等维度: 一、主流分布式数据库列表 大厂数据库名称类型适用场景发布时间腾讯云TDSQL分布式HTAP金融、电商、游戏、政企2010年阿里云OceanBase分布式HTAP银行核…...

【深度学习】自定义实现DataSet和DataLoader
dataset数据集 作用: 存储数据集的信息获取数据集长度 __len__获取数据集某特定条目的内容 __getitem__ dataloader 数据加载器 作用: 从数据集中随机加载数据, 并拼接为一个 batch实现迭代器, 可以使用时, 迭代获取数据内容 代码实现:…...

spark简介和核心编程
简介 1. Spark-SQL概述:Spark SQL是Spark处理结构化数据的模块,前身是Shark。Shark基于Hive开发,提升了SQL-on-Hadoop的性能,但对Hive的过度依赖制约了Spark发展。SparkSQL抛弃Shark代码,汲取其优点后重新开发&#x…...
)
47、Spring Boot 详细讲义(四)
六. Spring Boot 与数据库 目录 JDBC 集成 Spring Data JPA MyBatis 集成 事务管理 1、JDBC 集成 1.1 JDBC简介 1.1.1 定义和作用 JDBC(Java Database Connectivity)是Java中用于与关系型数据库进行交互的API。它为Java程序提供了一个标准的、统一的接口…...
)
Dify - 整合Ollama + Xinference私有化部署Dify平台(01)
文章目录 总体方案服务器在Ubuntu 20.04上安装Docker更新软件包索引安装一些必要的软件包,以便apt能够通过HTTPS使用仓库:添加Docker的官方GPG密钥设置稳定的仓库再次更新软件包索引从新添加的仓库中安装Docker CE验证Docker是否安装成功(可选…...

【RocketMQ】关于RocketMQ配置好了jdk环境变量却一直报需要配置环境变量的问题
正如上图所示,我明明已经配置好了环境变量,也显示配置好了,jdk与我的rocketmq的版本也是适配的,可每次启动namesrv和broker却一直显示要去配置环境变量,其实很简单,配置环境变量时特殊符号会影响路径查找&a…...
)
【信息系统项目管理师】高分论文:论信息系统项目的范围管理(投资信息化全流程管理项目)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 1、规划范围管理2、收集需求3、定义范围4、创建wbs5、确认范围6、控制范围2018年2月,我有幸参加了 XX省自贸区财政投资信息化全流程管理项目的假设,作为项目发起单位,省自贸办经过审时度势,及时响应国家自贸…...

Jmeter创建使用变量——能够递增递减的计数器
Jmeter创建使用变量——能够递增递减的计数器 如下图所示,创建一个 取值需限定为0 2 4这三个值内的变量。 Increment:每次迭代后 递增的值,给计数器增加的值 Maximum value:计数器的最大值,如果超过最大值࿰…...

数据分析不只是跑个SQL!
数据分析不只是跑个SQL! 数据分析五大闭环,你做到哪一步了?闭环一:认识现状闭环二:原因分析闭环三:优化表现闭环四:预测走势闭环五:主动解读数据 数据思维:WHY-WHAT-HOW模…...

批量将文件夹名称、文件夹路径提取到 Excel 清单
在日常工作中,管理大量文件夹和文件路径可能变得十分繁琐。无论是在进行文件整理、备份还是数据分析时,提取文件夹的名称与路径信息,能够帮助你更高效地管理文件。本文将为您提供如何快速提取文件夹名称与路径,并将这些信息整理到…...

Git 基本使用
一、Git简介 简单的内容追踪系统;是一个快速、可扩展的分布式版本控制系统,拥有异常丰富的命令集提供高级操作和对内部的完全访问。 二、Git安装 详情看本人此文章。 三、Git 命令(基础版) 把 Git 分为上层封装命令(…...

LLM - Dify 平台介绍
文章目录 引言官网核心功能架构图典型应用场景在线平台 引言 Dify 是一款开源的 LLM(大语言模型)应用开发平台,旨在帮助开发者快速构建、部署和管理基于大语言模型的智能化应用。 官网 https://dify.ai/zh https://github.com/langgenius/…...

linux编译adbd工具使用
在使用linux时,通常是没有现成的adbd文件使用的,这就需要我们进行文件的编译了,编译可以分为三步进行,在编译前我们需要下载对应的源码使用,我们可以从 https://launchpad.net/android-tools地址处下载需要的android-tools源码使用…...

安全人员如何对漏洞进行定级?
CVSS 标准 CVSS 介绍 CVSS,即通用漏洞评分系统(Common Vulnerability Scoring System),是一个用于评估计算机系统漏洞严重程度的行业标准。 CVSS为安全专业人员、漏洞管理团队和系统管理员提供了一种标准化的方法来评估和比较不…...
:组合使用子树)
【ROS2】行为树 BehaviorTree(四):组合使用子树
1、大树调用子树 如下图,左边为大树主干: 1)如果门没有关,直接通过; 2)如果门关闭了,执行开门动作,然后通过 右边为子树,主要任务是开门 1)尝试直接开门; 2)尝试开锁开门,最多尝试5次; 3)最后尝试砸门! XML如何描述大树主干调佣子树:使用关键字 SubTree 来…...
)
第十六届蓝桥杯Java b组(试题C:电池分组)
问题描述: 输入格式: 输出格式: 样例输入: 2 3 1 2 3 4 1 2 3 4 样例输出: YES NO 说明/提示 评测用例规模与约定 对于 30% 的评测用例,1≤T≤10,2≤N≤100,1≤Ai≤10^3。对于 100…...

HarmonyOS:使用Refresh组件实现页面下拉刷新
一、前言 可以进行页面下拉操作并显示刷新动效的容器组件。 说明 该组件从API Version 8开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。该组件从API Version 12开始支持与垂直滚动的Swiper和Web的联动。当Swiper设置loop属性为true时&…...
)
Python----机器学习(基于PyTorch的垃圾邮件逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 本例使用了…...

Spark-SQL
概念 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。 Spark-SQL 特点: 1,易整合,无缝的整合了 SQL 查询和 Spark 编程。 2,统一的数据访问,使用相同的方式连接不同的数据源。 3…...

spark-sql核心
在大数据处理领域,Apache Spark已成为极为重要的分布式计算框架,而Spark SQL作为其重要组件,极大地拓展了Spark的能力边界,为结构化数据处理提供了高效、便捷的解决方案。 一、Spark SQL架构剖析 Spark SQL的架构设计精妙&#…...

TypeScript 进阶指南 - 使用泛型与keyof约束参数
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Micro麦可乐的博客 🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战 🌺《RabbitMQ》…...