Python----机器学习(基于PyTorch的垃圾邮件逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。
一、数据集介绍

本例使用了一个垃圾邮件的数据集 Spambase - UCI Machine Learning Repository 实例数量: 4601(垃圾邮件1813封,占39.4%) 属性数量: 58(57个连续属性,1个名义类别标签) 属性信息: 最后一列'spam'(垃圾邮件数据)表示邮件是否被视为垃圾邮件(1)或非垃圾邮件(0),即 不受欢迎的商业电子邮件。多数属性指示特定单词或字符在邮件中是否经常出现。
数据集地址
Spambase - UCI 机器学习存储库
“垃圾邮件”的概念是多种多样的:产品/网站广告、快速赚钱计划、连锁信、色情内容...... 此数据集的分类任务是确定给定电子邮件是否为垃圾邮件。
我们收集的垃圾邮件来自我们的邮政管理员和提交垃圾邮件的个人。我们收集的非垃圾邮件来自归档的工作和个人电子邮件,因此单词“george”和区号“650”是非垃圾邮件的标志。在构建个性化垃圾邮件过滤器时,这些过滤器非常有用。要么必须盲目此类非垃圾邮件指示器,要么获取非常广泛的非垃圾邮件集合以生成通用垃圾邮件过滤器。
有关垃圾邮件的背景信息:Cranor, Lorrie F., LaMacchia, Brian A. Spam!, Communications of the ACM, 41(8):74-83, 1998.
| 变量名称 | 角色 | 类型 | 描述 | 单位 | 缺失值 |
|---|---|---|---|---|---|
| word_freq_make | 特征 | 连续的 | 不 | ||
| word_freq_address | 特征 | 连续的 | 不 | ||
| word_freq_all | 特征 | 连续的 | 不 | ||
| word_freq_3d | 特征 | 连续的 | 不 | ||
| word_freq_our | 特征 | 连续的 | 不 | ||
| word_freq_over | 特征 | 连续的 | 不 | ||
| word_freq_remove | 特征 | 连续的 | 不 | ||
| word_freq_internet | 特征 | 连续的 | 不 | ||
| word_freq_order | 特征 | 连续的 | 不 | ||
| word_freq_mail | 特征 | 连续的 | 不 | ||
| word_freq_receive | 特征 | 连续的 | 不 | ||
| word_freq_will | 特征 | 连续的 | 不 | ||
| word_freq_people | 特征 | 连续的 | 不 | ||
| word_freq_report | 特征 | 连续的 | 不 | ||
| word_freq_addresses | 特征 | 连续的 | 不 | ||
| word_freq_free | 特征 | 连续的 | 不 | ||
| word_freq_business | 特征 | 连续的 | 不 | ||
| word_freq_email | 特征 | 连续的 | 不 | ||
| word_freq_you | 特征 | 连续的 | 不 | ||
| word_freq_credit | 特征 | 连续的 | 不 | ||
| word_freq_your | 特征 | 连续的 | 不 | ||
| word_freq_font | 特征 | 连续的 | 不 | ||
| word_freq_000 | 特征 | 连续的 | 不 | ||
| word_freq_money | 特征 | 连续的 | 不 | ||
| word_freq_hp | 特征 | 连续的 | 不 | ||
| word_freq_hpl | 特征 | 连续的 | 不 | ||
| word_freq_george | 特征 | 连续的 | 不 | ||
| word_freq_650 | 特征 | 连续的 | 不 | ||
| word_freq_lab | 特征 | 连续的 | 不 | ||
| word_freq_labs | 特征 | 连续的 | 不 | ||
| word_freq_telnet | 特征 | 连续的 | 不 | ||
| word_freq_857 | 特征 | 连续的 | 不 | ||
| word_freq_data | 特征 | 连续的 | 不 | ||
| word_freq_415 | 特征 | 连续的 | 不 | ||
| word_freq_85 | 特征 | 连续的 | 不 | ||
| word_freq_technology | 特征 | 连续的 | 不 | ||
| word_freq_1999 | 特征 | 连续的 | 不 | ||
| word_freq_parts | 特征 | 连续的 | 不 | ||
| word_freq_pm | 特征 | 连续的 | 不 | ||
| word_freq_direct | 特征 | 连续的 | 不 | ||
| word_freq_cs | 特征 | 连续的 | 不 | ||
| word_freq_meeting | 特征 | 连续的 | 不 | ||
| word_freq_original | 特征 | 连续的 | 不 | ||
| word_freq_project | 特征 | 连续的 | 不 | ||
| word_freq_re | 特征 | 连续的 | 不 | ||
| word_freq_edu | 特征 | 连续的 | 不 | ||
| word_freq_table | 特征 | 连续的 | 不 | ||
| word_freq_conference | 特征 | 连续的 | 不 | ||
| char_freq_; | 特征 | 连续的 | 不 | ||
| char_freq_( | 特征 | 连续的 | 不 | ||
| char_freq_ | 特征 | 连续的 | 不 | ||
| char_freq_! | 特征 | 连续的 | 不 | ||
| char_freq_ 美元 | 特征 | 连续的 | 不 | ||
| char_freq_# | 特征 | 连续的 | 不 | ||
| capital_run_length_average | 特征 | 连续的 | 不 | ||
| capital_run_length_longest | 特征 | 连续的 | 不 | ||
| capital_run_length_total | 特征 | 连续的 | 不 | ||
| 类 | 目标 | 二元的 | 垃圾邮件 (1) 或非垃圾邮件 (0) | 不 |
其他变量信息
“spambase.data”的最后一列表示该电子邮件是否被视为垃圾邮件 (1) 或非 (0),即未经请求的商业电子邮件。大多数属性指示电子邮件中是否经常出现某个特定单词或字符。run-length 属性 (55-57) 测量连续大写字母序列的长度。有关每个属性的统计度量,请参阅此文件的末尾。以下是属性的定义:
48 个 word_freq_WORD 类型的连续实数 [0,100] 属性 = 电子邮件中与 WORD 匹配的单词百分比,即 100 * (WORD 在电子邮件中出现的次数)/ 电子邮件中的单词总数。在这种情况下,“word” 是由非字母数字字符或字符串结尾限定的任何字母数字字符字符串。
6 个 char_freq_CHAR] 类型的连续实数 [0,100] 属性 = 电子邮件中与 CHAR 匹配的字符百分比,即 100 *(CHAR 出现次数)/ 电子邮件中的字符总数
1 个 capital_run_length_average 类型的连续实数 [1,...] 属性 = 大写字母不间断序列的平均长度
1 个 capital_run_length_longest 类型的连续整数 [1,...] 属性 = 最长的不间断大写字母序列的长度 1 个 capital_run_length_total 类型的连续整数 [1,...] 属性 = 大写字母的不间断序列的长度之和 = 电子邮件中大写字母的总数
1 个 spam 类型的名义 {0,1} 类属性 = 表示该电子邮件是否被视为垃圾邮件 (1) 或非 (0),即未经请求的商业电子邮件。
二、设计思路
2.1、读取数据
import pandas as pd
df=pd.read_table('spambase.data',header=None,sep=',')
df2.2、划分特征
X=df.iloc[:,:-1]
y=df.iloc[:,-1]2.3、划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.75,random_state=42)2.4、标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X_train_scaler=scaler.fit_transform(X_train)
X_test_scaler=scaler.transform(X_test)2.5、转换为Tensor张量
import torch
X_train_tensor=torch.tensor(X_train_scaler,dtype=torch.float32)
y_train_tensor=torch.tensor(y_train.values,dtype=torch.float32)
X_test_tensor=torch.tensor(X_test_scaler,dtype=torch.float32)
y_test_tensor=torch.tensor(y_test.values,dtype=torch.float32)2.6、创建数据加载器
from torch.utils.data import DataLoader,TensorDataset
dataset=TensorDataset(X_train_tensor,y_train_tensor)
dataloader=DataLoader(dataset,shuffle=True,batch_size=64)2.7、定义逻辑回归模型
import torch.nn as nn
class LogisticRegression(nn.Module):def __init__(self,inputsize):super().__init__()self.liner=nn.Linear(inputsize,1)def forward(self,x):return torch.sigmoid(self.liner(x))
model=LogisticRegression(X_train_tensor.shape[1])2.8、定义损失函数和优化器
from torch.optim import Adam
cri=nn.BCELoss()
optimer=Adam(model.parameters(),lr=0.05)2.9、训练模型
for epoch in range(1,501):total_loss=0model.train()for x,y in dataloader:optimer.zero_grad()y_hat=model(x)loss=cri(y_hat,y.view(-1,1))loss.backward()optimer.step()total_loss+=lossavg_loss=total_loss/len(dataloader)if epoch%100==0 or epoch==1:print(epoch,avg_loss.item())2.10、模型评估
from sklearn.metrics import roc_curve,auc
import torch
with torch.no_grad():model.eval()y_pred=model(X_test_tensor)fpr, tpr, thresholds=roc_curve(y_test.values,y_pred.numpy())roc_auc=auc(fpr, tpr)2.11、可视化
from matplotlib import pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {roc_auc:.2f}')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()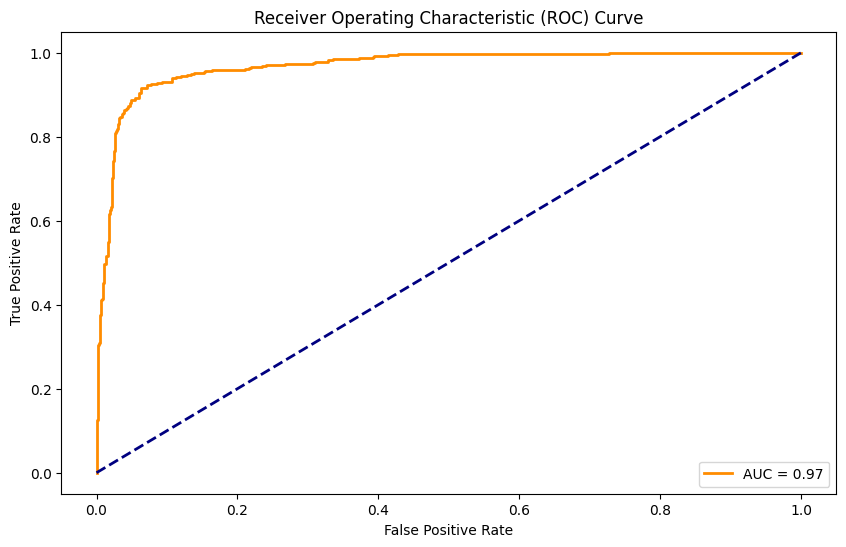 三、完整代码
三、完整代码
import pandas as pd
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader, TensorDataset
import torch.nn as nn
from sklearn.metrics import roc_curve, auc
import torch
from torch.optim import Adam
from sklearn.preprocessing import StandardScaler # 读取数据集,使用制表符作为分隔符
df = pd.read_table('spambase.data', header=None, sep=',') # 分离特征和标签
X = df.iloc[:, :-1] # 特征
y = df.iloc[:, -1] # 标签 # 划分训练集和测试集,训练集占75%
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=42) # 数据标准化
scaler = StandardScaler()
X_train_scaler = scaler.fit_transform(X_train) # 拟合并转换训练数据
X_test_scaler = scaler.transform(X_test) # 仅转换测试数据 # 将数据转换为 PyTorch 张量
X_train_tensor = torch.tensor(X_train_scaler, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test_scaler, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32) # 创建数据集和数据加载器
dataset = TensorDataset(X_train_tensor, y_train_tensor)
dataloader = DataLoader(dataset, shuffle=True, batch_size=64) # 定义逻辑回归模型
class LogisticRegression(nn.Module): def __init__(self, inputsize): super().__init__() self.liner = nn.Linear(inputsize, 1) # 单层线性回归 def forward(self, x): return torch.sigmoid(self.liner(x)) # 使用sigmoid激活函数 # 实例化模型
model = LogisticRegression(X_train_tensor.shape[1]) # 定义损失函数和优化器
cri = nn.BCELoss() # 二元交叉熵损失
optimer = Adam(model.parameters(), lr=0.05) # Adam优化器 # 训练模型
for epoch in range(1, 501): total_loss = 0 # 初始化总损失 model.train() # 切换到训练模式 for x, y in dataloader: optimer.zero_grad() # 清空梯度 y_hat = model(x) # 前向传播 loss = cri(y_hat, y.view(-1, 1)) # 计算损失 loss.backward() # 反向传播 optimer.step() # 更新参数 total_loss += loss # 累加损失 avg_loss = total_loss / len(dataloader) # 计算平均损失 if epoch % 100 == 0 or epoch == 1: print(epoch, avg_loss.item()) # 每100个epoch打印损失 # 评估模型
with torch.no_grad(): model.eval() # 切换到评估模式 y_pred = model(X_test_tensor) # 预测测试数据 fpr, tpr, thresholds = roc_curve(y_test.values, y_pred.numpy()) # 计算ROC曲线 roc_auc = auc(fpr, tpr) # 计算AUC值 # 绘制ROC曲线
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {roc_auc:.2f}') # 绘制ROC曲线
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') # 绘制随机猜测的对角线
plt.xlabel('假阳率 (False Positive Rate)')
plt.ylabel('真阳率 (True Positive Rate)')
plt.title('接收者操作特征 (ROC) 曲线')
plt.legend(loc='lower right')
plt.show() 设计思路
-
数据预处理:
首先读取数据集,并将其分为特征和标签两部分。接着划分训练集和测试集,这里使用了75%的数据用于训练,25%用于测试。使用
StandardScaler对特征进行标准化,使其均值为0,方差为1,有助于提高模型训练的稳定性和收敛速度。 -
数据加载:
将训练数据转换为PyTorch的张量格式,并使用
DataLoader创建可迭代的数据集,以便在训练期间批量加载数据。 -
模型构建:
定义了一个简单的逻辑回归模型,该模型只包含一个线性层,有一层sigmoid激活函数用于二分类任务。
-
训练模型:
使用二元交叉熵损失(
BCELoss)和Adam优化器进行模型训练。训练过程中,使用循环遍历每个epoch,并计算损失,从而逐步优化模型参数。 -
模型评估:
训练完成后,在测试集上进行评价,计算ROC曲线和AUC值,以便直观显示模型的分类性能。
-
可视化结果:
使用Matplotlib绘制ROC曲线,帮助分析模型的表现和分类效果。
相关文章:
)
Python----机器学习(基于PyTorch的垃圾邮件逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 本例使用了…...

Spark-SQL
概念 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。 Spark-SQL 特点: 1,易整合,无缝的整合了 SQL 查询和 Spark 编程。 2,统一的数据访问,使用相同的方式连接不同的数据源。 3…...

spark-sql核心
在大数据处理领域,Apache Spark已成为极为重要的分布式计算框架,而Spark SQL作为其重要组件,极大地拓展了Spark的能力边界,为结构化数据处理提供了高效、便捷的解决方案。 一、Spark SQL架构剖析 Spark SQL的架构设计精妙&#…...

TypeScript 进阶指南 - 使用泛型与keyof约束参数
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Micro麦可乐的博客 🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战 🌺《RabbitMQ》…...

labview的VI密码破解程序
上图即为密码破解原理,若需源代码可联系我...

AI技术前沿:蓝耘元生代智算云快速入门教程详解,与其他云人工智能大模型深度对比
文章目录 一、前言二、蓝耘元生代智算云基础概念2.1 什么是智算云2.2 蓝耘元生代智算云的特点 三、蓝耘元生代智算云使用前准备3.1 注册与登录3.2 了解计费方式3.3 熟悉控制台界面 四、在蓝耘元生代智算云上运行第一个任务4.1 创建计算资源4.2 上传代码和数据4.3 安装依赖库4.4…...

Spring MVC 请求处理流程详解
步骤1:用户发起请求 所有请求首先被 DispatcherServlet(前端控制器)拦截,它是整个流程的入口。 DispatcherServlet 继承自 HttpServlet,通过 web.xml 或 WebApplicationInitializer 配置映射路径(如 /&…...

金融行业 AI 报告自动化:Word+PPT 双引擎生成方案
—从数据到决策,10倍效率提升的智能金融解决方案 一、金融行业报告制作的四大核心痛点 1. 人工制作成本高 传统流程耗时: 分析师撰写Word报告:8-12小时/份设计师制作PPT:4-6小时/份团队协作修改:反复沟通,…...

01_JDBC
文章目录 一、概述1.1、什么是JDBC1.2、JDBC原理 二、JDBC入门2.1、准备工作2.1.1、建库建表2.1.2、新建项目 2.2、建立连接2.2.1、准备四大参数2.2.2、加载驱动2.2.3、准备SQL语句2.2.4、建立连接2.2.5、常见问题 2.3、获取发送SQL的对象2.4、执行SQL语句2.5、处理结果2.6、释…...

三层架构与分层解耦:深入理解IOC与DI设计模式
目录 一、软件架构演进与三层架构概述 1.1 从单体架构到分层架构 1.2 经典三层架构详解 1.3 三层架构的优势 二、分层解耦的核心思想 2.1 耦合与解耦的基本概念 2.2 分层解耦的实现手段 2.3 分层解耦的实践原则 三、控制反转(IOC)深度解析 3.1…...

[react]Next.js之自适应布局和高清屏幕适配解决方案
序言 阅读前首先了解即将要用到的两个包的作用 1.postcss-pxtorem 自动将 CSS 中的 px 单位转换为 rem 单位按照设计稿尺寸直接写 px 值,由插件自动计算 rem 值 2.amfe-flexible 动态设置根元素的 font-size(即 1rem 的值)根据设备屏幕宽度和…...

TensorFlow深度学习实战——基于语言模型的动态词嵌入技术
TensorFlow深度学习实战——基于语言模型的动态词嵌入技术 0. 前言1. 基于语言模型的词嵌入1.1 ELMo 与 ULMFiT1.2 GPT1.3 BERT 2. 使用 BERT 作为特征提取器相关链接 0. 前言 基于语言模型的词嵌入技术,通过利用上下文信息来生成动态的词向量,大大提升…...
)
欧拉服务器操作系统部署deekseep(Ollama+DeekSeep+open WebUI)
一、解压并安装 Ollama # 1. 解压文件(默认会得到一个二进制文件) tar -xzvf ollama-linux-amd64.tgz# 2. 将二进制文件安装到系统路径 sudo mv ollama /usr/local/bin/ sudo chmod x /usr/local/bin/ollama# 3. 验证安装 ollama --version链接…...
)
cocosCreator安卓隐私弹窗(链接版)
每次新上游戏都要重新弄这个隐私弹窗,记录一下下次直接抄。 一、创建Activity 1 用androidStudio 打开项目并切换到Android视角。 2 右键项目new一个空的Activity 3 修改Activity的名字并完成如下图 二、增加依赖文件 1 增加全局颜色定义文件:项目根目录 / res/values/ …...

统计销量前十的订单
传入参数: 传入begin和end两个时间 返回参数 返回nameList和numberList两个String类型的列表 controller层 GetMapping("/top10")public Result<SalesTop10ReportVO> top10(DateTimeFormat(pattern "yyyy-MM-dd") LocalDate begin,Dat…...

【Python爬虫】简单案例介绍2
本文继续接着我的上一篇博客【Python爬虫】简单案例介绍1-CSDN博客 目录 跨页 3.2 环境准备 跨页 当对单个页面的结构有了清晰的认识并成功提取数据后,接下来就需要考虑页面之间的跨页问题。此时我们便迎来了下一个关键任务:如何实现跨页爬取…...

适合单片机裸机环境的运行的软件定时器框架
如下这篇文档介绍了一个适用于裸机环境的软件定时器模块,其核心功能和实现如下: 模块功能:该模块通过硬件定时器中断实现时基累加,适合用于裸机程序的调度处理。它使用硬件定时中断(如1ms一次)来增加hw_ti…...

【ComfyUI】蓝耘元生代 | ComfyUI深度解析:高性能AI绘画工作流实践
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈人工智能与大模型应用 ⌋ ⌋ ⌋ 人工智能(AI)通过算法模拟人类智能,利用机器学习、深度学习等技术驱动医疗、金融等领域的智能化。大模型是千亿参数的深度神经网络(如ChatGPT&…...

js的es6模块中 暴露的使用方法简介
在 JavaScript 的 ES6 模块系统中,一个模块文件只能有一个 export default。export default 用于导出一个默认值,这个默认值在导入时可以使用任意名称。 示例: 导出默认值: // myModule.jsexport default function greet() {con…...
,源码可白嫖!)
基于Android的旅游自助APP(源码+lw+部署文档+讲解),源码可白嫖!
摘要 旅游自助APP设计的目的是为用户提供对景点信息和路线攻略、周边美食等方面的平台。 与PC端应用程序相比,旅游自助的设计主要面向于旅行者,旨在为用户提供一个旅游自助。用户可以通过APP及时景点信息,并对景点进行购票或收藏等。相反&am…...
:合并字段,使用UNION,首先应使用SELECT进行检索,再使用UMION进行拼接)
SQL(7):合并字段,使用UNION,首先应使用SELECT进行检索,再使用UMION进行拼接
核心功能:合并查询结果 想象一下,你有两个不同的名单,你想把它们合并成一个大名单。UNION 和 UNION ALL 都是 SQL 里用来干这个“合并名单”的活儿的。它们可以把两个(或更多)SELECT 查询语句的结果合并到一起&#x…...

Spring MVC 全栈指南:RESTful 架构、核心注解与 JSON 实战解析
目录 RESTful API 设计规范Spring MVC 核心注解解析静态资源处理策略JSON 数据交互全解高频问题与最佳实践 一、RESTful API 设计规范 1.1 核心原则 原则说明示例 URI资源为中心URI 使用名词(复数形式)/users ✔️ /getUser ❌HTTP 方法语义化GET&…...

【第43节】实验分析windows异常分发原理
目录 前言 一、异常处理大致流程图 二、实验一:分析 KiTrap03 三、实验二:分析CommonDispatchException 四、代码探究:分析 KiDispatchException 函数 五、代码探究:伪代码分析用户层KiUserExceptionDispatcher 前言 在Wind…...

自动化测试概念篇
文章目录 目录1. 自动化1.1 自动化概念1.1.1 回归测试 1.2 自动化分类1.3 自动化测试金字塔 2. web自动化测试2.1 驱动2.1.1 安装驱动管理2.1.2 selenium库 3. Selenium3.1 一个简单的web自动化示例3.2 selenium驱动浏览器的工作原理 目录 自动化web自动化测试Selenium 1. 自…...

「数据可视化 D3系列」之开篇:开启数据可视化之旅
一、系列介绍 欢迎来到《快速学习D3.js》系列!在这个系列中,我们将一起从零开始掌握D3.js(Data-Driven Documents),一个强大的JavaScript库,用于创建动态、交互式的数据可视化。 无论你是前端开发者、数据…...

编译构建 WSO2 产品时的一些注意事项
编译构建 WSO2 产品时的一些注意事项 1、JDK 版本2、maven 版本3、npm 和 node 版本4、编译命令示例 1、JDK 版本 对于 WSO2 ESB、WSO2 EI 老产品,可以直接使用 JDK 1.8对于 WSO2 APIM、WSO2 IS、WSO2 MI 等产品的新版本,需要 JDK 11 以上 特别注意&…...
)
字符串与相应函数(下)
字符串处理函数分类 求字符串长度:strlen长度不受限制的字符串函数:strcpy,strcat,strcmp长度受限制的字符串函数:strncpy,strncat,strncmp字符串查找:strstr字符串切割:strtok错误信息报告:strerror字符操作…...

驾驭 Linux 云: JavaWeb 项目安全部署
目录 1. 引言 2. Linux 基础指令 2.1 ls 展示目录/文件 2.2 pwd 查看所在路径 2.3 mkdir 创建文件夹 2.4 cd 切换路径 2.5 touch 创建文件 2.6 rm 删除文件 2.6 rm -r/rf 删除文件夹 2.7 rz/sz 上传/下载文件 2.7.1 rz 上传文件 2.7.2 sz 下载文件 2.8 mv 移动文件…...

【MySQL数据库】InnoDB存储引擎:逻辑存储结构、内存架构、磁盘架构
逻辑存储结构 一个数据库是由一张张表组成的,而表中是由一个个段构成的,一个段是由区构成的,区空间是由页构成的,页是行构成的。 ①表空间:.ibd文件,一个mysql实例可以对应多个表空间,用于存储…...

HJ16 购物单
https://www.nowcoder.com/exam/oj/ta?tpId37 HJ16 购物单 描述 王强决定把年终奖用于购物,他把想买的物品分为两类:主件与附件。 主件可以没有附件,至多有 2个附件。附件不再有从属于自己的附件。如果要买归类为附件的物品,必…...

SLAM文献之DM-VIO: Delayed Marginalization Visual-Inertial Odometry
1. 算法概述 DM-VIO (Delayed Marginalization Visual-Inertial Odometry) 是一种基于延迟边缘化的视觉-惯性里程计算法,它结合了视觉和惯性测量单元(IMU)的数据进行位姿估计。该算法是VINS-Mono的改进版本,主要创新点在于采用了一种延迟边缘化策略&…...

【信息安全】黑芝麻A1000芯片安全启动方案
基于黑芝麻A1000芯片的安全启动方案实现指南: 一、安全启动流程架构设计 // 启动阶段状态机定义(基于A1000芯片手册) typedef enum {ROM_BOOT = 0x01, // BootROM验证 SPL_VERIFY = 0x02, // 二级加载器验证 ATF_SIGN_CHECK = 0x03, // ARM Trusted Firmware验证 OS_LOADE…...

初识Redis · list和hash类型
目录 前言: 哈希类型 基本命令 编码方式 应用场景 列表 基本命令 编码方式 应用场景 前言: 前文我们已经介绍了string的基本使用,以及对应的基本命令,最后也是简单的理解了一下string的应用场景,比如计数统计…...

golang-非orm数据库的操作与对比 database/sql、sqlx 和 sqlc
简单介绍 database/sql database/sql 是一个标准库软件包,负责与数据库(主要是 SQL 关系数据库)的连接和交互。 它为类 SQL 交互提供泛型接口、类型和方法。database/sql 在创建时将简单易用纳入考量,配置为支持与类 SQL 数据库…...

DeepSeek模型在非图形智能体的应用中是否需要GPU
答:不一定 概念 1、是否需要GPU与应用是否图形处理应用无关 2、文本内容智能体大多也需要GPU来提供更好的性能 3、DeepSeek模型在非图形智能体的应用中是否需要GPU取决于具体的模型版本和部署环境 不需要GPU的模型版本 DeepSeek-R1-1.5B: 这…...

RadioMaster POCKET遥控器进入ExpressLRS界面一直显示Loading的问题解决方法
RadioMaster POCKET遥控器进入ExpressLRS界面一直显示Loading的问题解决方法 问题描述解决方法 问题描述 有一天我发现我的 RadioMaster POCKET 遥控器进入 ExpressLRS 设置界面时,界面却一直停留在 “Loading” 状态,完全无法进入设置界面。 我并没有…...

idea的快捷键使用以及相关设置
文章目录 快捷键常用设置 快捷键 快捷键作用ctrlshift/注释选中内容Ctrl /注释一行/** Enter文档注释ALT SHIFT ↑, ALT SHIFT ↓上下移动当前代码Ctrl ALT L格式化代码Ctrl X删除所在行并复制该行Ctrl D复制当前行数据到下一行main/psvm快速生成入口程序soutSystem.o…...

【DDR 内存学习专栏 1.4 -- DDR 的 Bank Group】
文章目录 BankgroupBankgroup 与 Bank 的关系 DDR4 中的 BankgroupDDR4-3200 8Gb芯片为例组织结构访问场景 实际应用示例 Bankgroup Bankgroup是DDR4及后续标准(DDR5)中引入的一个更高层次的组织结构。它将多个Bank组合在一起形成一个Bankgroup,目的是为了进一步提…...

新晋前端框架技术:小程序容器与SuperApp构建
2025年,前端开发领域持续迭代,主流框架如Vue、React等纷纷推出新版本,在性能、开发效率及适用场景上实现突破,进一步巩固其技术地位。 1. Vue 3的全面普及与创新 Vue 3通过多项核心特性优化了开发体验: Teleport组件…...

强化学习:基于价值的方法做的是回归,基于策略的方法做的是分类,可以这么理解吗?
在强化学习领域,基于价值的方法(Value-based Methods)和基于策略的方法(Policy-based Methods)是两种核心范式。本文将从目标函数、优化机制以及与机器学习任务的类比角度,探讨这两种方法是否可以被分别理解为回归和分类任务,并深入分析其内在逻辑。 一、基于价值的方法…...

蓝耘元生代AIDC OS:一站式MaaS平台,助力AI应用快速落地
文章目录 引言1. 什么是MaaS平台?MaaS平台的典型特点 2. 蓝耘元生代AIDC OS 热门模型3. 快速入门:如何调用API?步骤1:注册并获取API Key步骤2:调用API(Python示例) 4. 与Chatbox搭配使用&#x…...

3.2.2.3 Spring Boot配置拦截器
在Spring Boot应用中配置拦截器(Interceptor)可以对请求进行预处理和后处理,实现如权限检查、日志记录等功能。通过实现HandlerInterceptor接口并注册到Spring容器,拦截器可以自动应用到匹配的请求路径。案例中,创建了…...
)
Python----机器学习(基于PyTorch的蘑菇逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 本例使用了…...
)
Python----机器学习(基于PyTorch的乳腺癌逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 在本例中&…...

如何配置AWS EKS自动扩展组:实现高效弹性伸缩
本文详细讲解如何在AWS EKS中配置节点组(Node Group)和Pod的自动扩展,优化资源利用率并保障应用高可用。 一、准备工作 工具安装 安装并配置AWS CLI 安装eksctl(EKS管理工具) 安装kubectl(Kubernetes命令…...
)
【C++ Qt】认识Qt、Qt 项目搭建流程(图文并茂、通俗易懂)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本章将开启Qt的学习,Qt是一个较为古老但仍然在GUI图形化界面设计中有着举足轻重的地位,因为它适合嵌入式和多种平台而被广泛使用…...

用Python打造去中心化知识产权保护系统:科技驱动创作者权益新方案
用Python打造去中心化知识产权保护系统:科技驱动创作者权益新方案 近年来,区块链技术和去中心化系统的兴起为知识产权保护提供了新的可能性。在传统模式下,知识产权保护通常依赖于集中化管理机构,这种方式不仅成本高,还可能因不透明导致权益争议。于是,我们萌生了一个设…...

CVE重要漏洞复现-Fastjson1.2.24-RCE漏洞
本文仅供网络学习,不得用于非法目的,否则后果自负 1、漏洞简介 fastjson是阿里巴巴的开源JSON解析库,它可以解析JSON格式的字符串,也可以从JSON字符串反序列化到JavaBean。即fastjson的主要功能就是将Java Bean序列化成JSON字符…...

Windows 图形显示驱动开发-WDDM 1.2功能—显示设备硬件软件认证要求
一、容器技术id技术的硬件级实现要求 1.1 EDID规范深度适配 1.物理层要求: 必须使用EDID 2.0及以上版本数据结构 容器ID需写入VSDB区块的0x50-0x6F区域,采用Little-Endian格式存储 允许的最大传输延迟:I2C总线时钟频率≤100KHz时…...

Coze流搭建--写入飞书多维表格
目标 使用coze搭建一个业务流,将业务流生产出的数据写入飞书保存 测试业务流 使用图片生成插件,配置prompt生产图片,将生产的结果写入飞书文档 coze流 运行后最终效果 搭建流程 第一步:飞书创建多维表格 注册飞书创建多维表…...