spark-SOL简介
Spark-SQL简介
一.Spark-SQL是什么
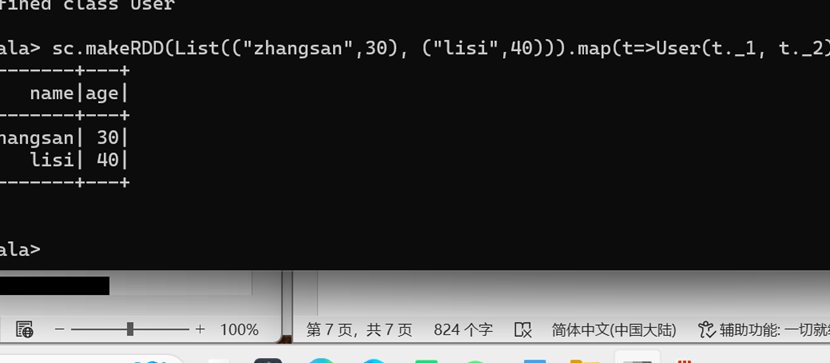
Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块
二.Hive and SparkSQL
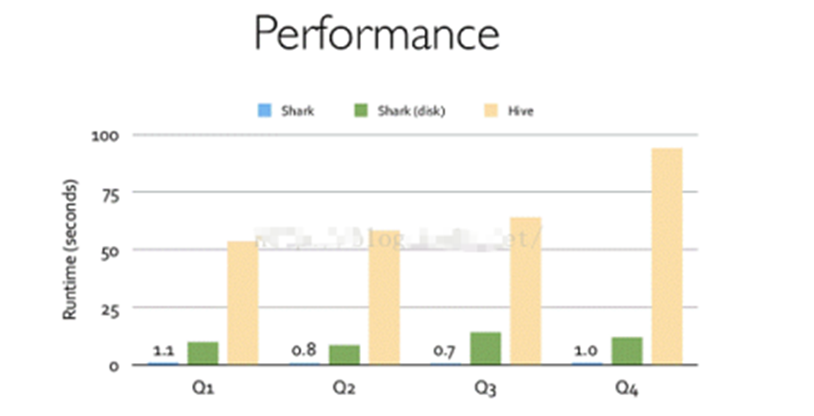
SparkSQL 的前身是 Shark,Shark是给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供的快速上手的工具
Shark 的出现,使得 SQL-on-Hadoop 的性能比 Hive 有了 10-100 倍的提高
三.Spark-SQL 特点
易整合。无缝的整合了 SQL 查询和 Spark 编程
统一的数据访问。使用相同的方式连接不同的数据源
兼容 Hive。在已有的仓库上直接运行 SQL 或者 HQL
标准数据连接。通过 JDBC 或者 ODBC 来连接
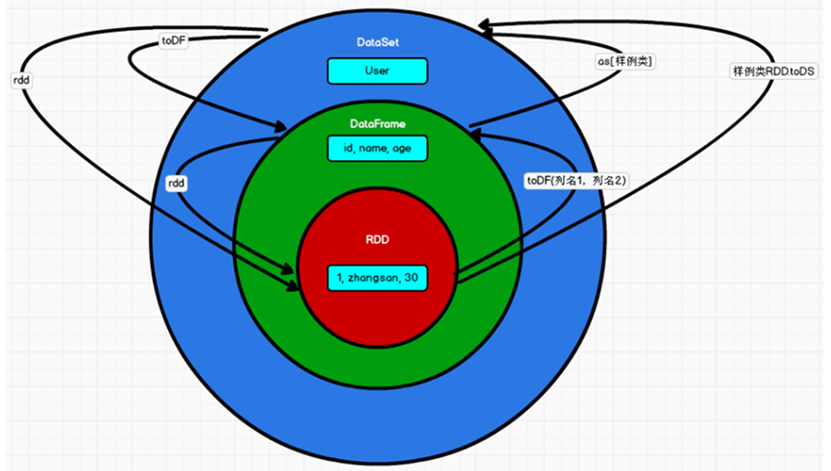
四.DataFrame 是什么
左侧的 RDD[Person]虽然以 Person 为类型参数,但 Spark 框架本身不了解 Person 类的内 部结构。而右侧的 DataFrame 却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道 该数据集中包含哪些列,每列的名称和类型各是什么。 DataFrame 是为数据提供了 Schema 的视图。可以把它当做数据库中的一张表来对待 DataFrame 也是懒执行的,但性能上比 RDD 要高,主要原因:优化的执行计划,即查询计 划通过 Spark catalyst optimiser 进行优化

五.DataSet 是什么
DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象
用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性;
用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字段名称;
DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]。
DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。获取数据时需要指定顺序
Spark-SQL核心编程(一)
一.创建 DataFrame
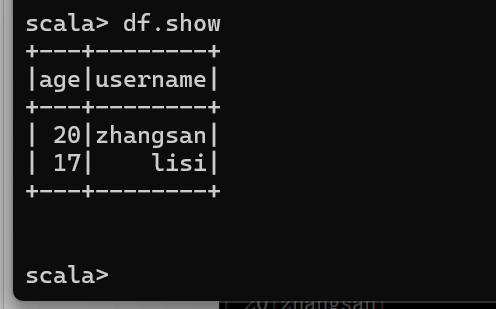
在 spark 的 bin/data 目录中创建 user.json 文件
{"username":"zhangsan","age":20}
{"username":"lisi","age":17}


SQL 语法
SQL 语法风格是指我们查询数据的时候使用 SQL 语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助
读取 JSON 文件创建 DataFrame

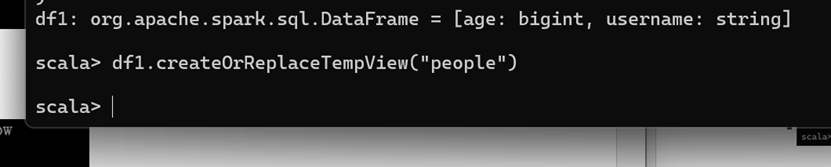
对 DataFrame 创建一个临时表
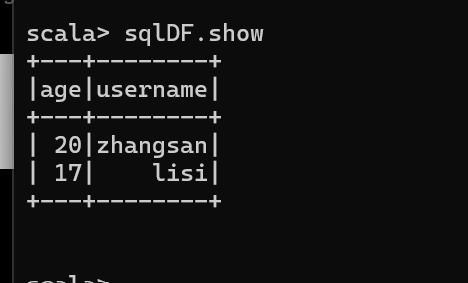
通过 SQL 语句实现查询全表

结果展示
DSL 语法
创建一个 DataFrame

查看 DataFrame 的 Schema 信息
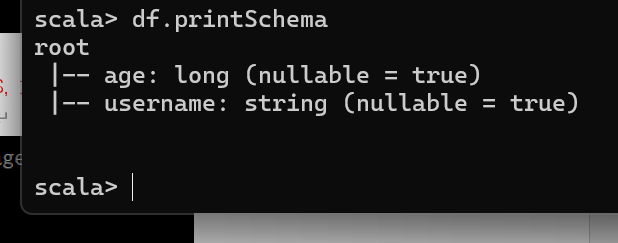
只查看"username"列数据
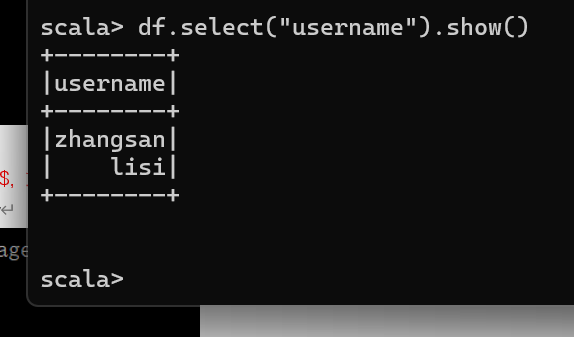
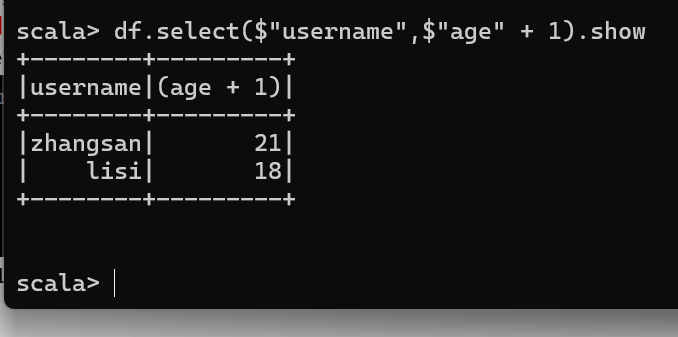
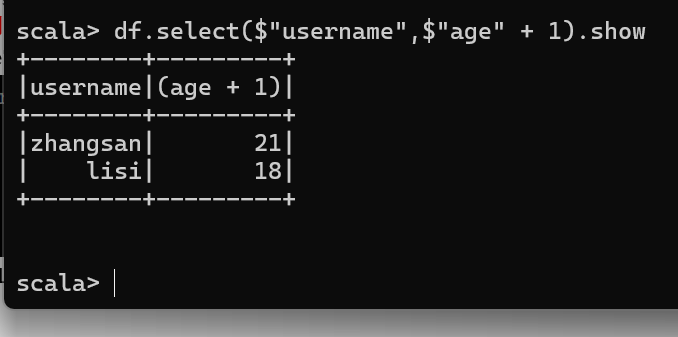
查看"username"列数据以及"age+1"数据

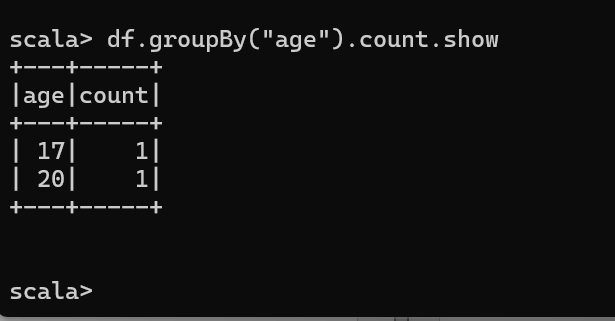
查看"age"大于"18"的数据
按照"age"分组,查看数据条数
RDD 转换为 DataFrame
在 IDEA 中开发程序时,如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入 import spark.implicits._ 这里的 spark 不是 Scala 中的包名,而是创建的 sparkSession 对象的变量名称,所以必 须先创建 SparkSession 对象再导入。这里的 spark 对象不能使用 var 声明,因为 Scala 只支持 val 修饰的对象的引入。
spark-shell 中无需导入,自动完成此操作。

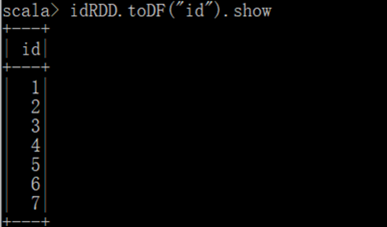
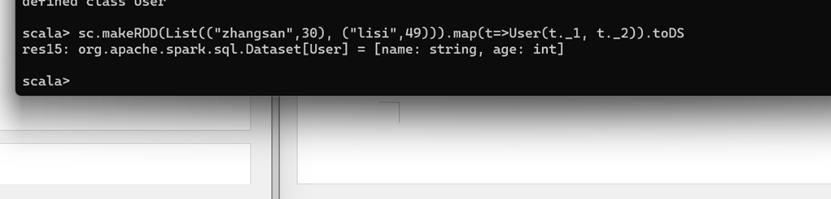
实际开发中,一般通过样例类将 RDD 转换为 DataFrame
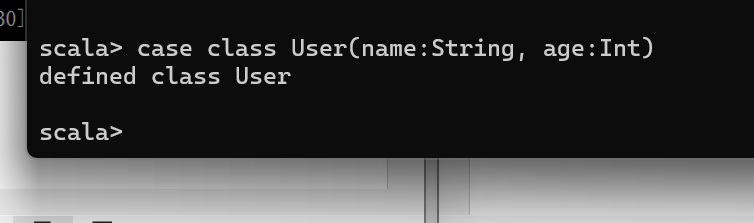
sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1, t._2)).toDF.show
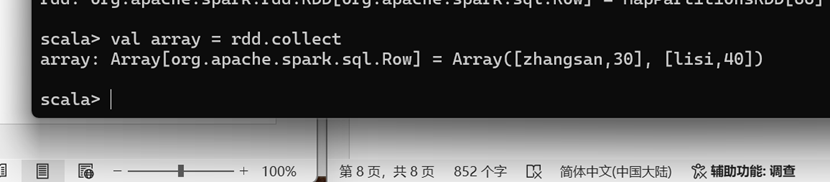
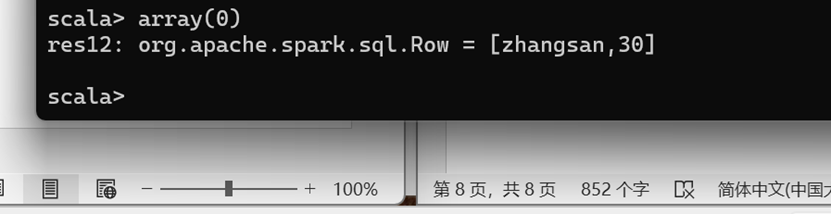
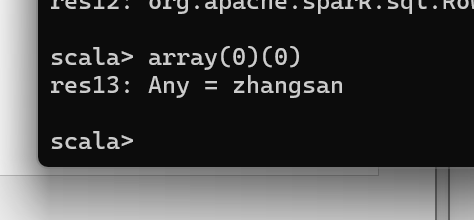
DataFrame 转换为 RDD
DataFrame 其实就是对 RDD 的封装,所以可以直接获取内部的 RDD



创建 DataSet
使用样例类序列创建 DataSet
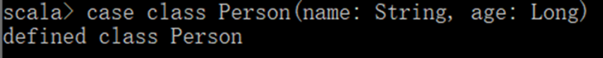

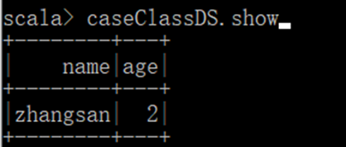
使用基本类型的序列创建 DataSet


。
RDD 转换为 DataSet
SparkSQL 能够自动将包含有 case 类的 RDD 转换成 DataSet,case 类定义了 table 的结 构,case 类属性通过反射变成了表的列名。Case 类可以包含诸如 Seq 或者 Array 等复杂的结构。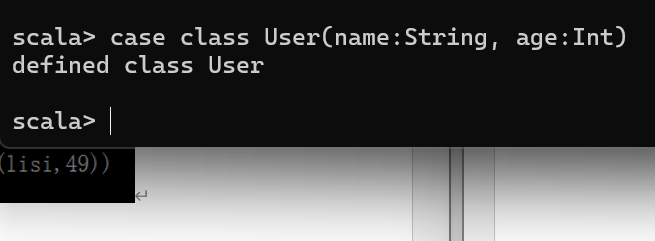



DataFrame 和 DataSet 转换



DataSet 转换为 DataFrame


RDD、DataFrame、DataSet 三者的关系
Spark1.0 => RDD
Spark1.3 => DataFrame
Spark1.6 => Dataset
三者的共性
RDD、DataFrame、DataSet 全都是 spark 平台下的分布式弹性数据集,为处理超大型数
据提供便利;
三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行,只有在遇到
Action 如 foreach 时,三者才会开始遍历运算;
三者有许多共同的函数,如 filter,排序等;
在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包:
import spark.implicits._(在创建好 SparkSession 对象后尽量直接导入)
三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会
内存溢出
三者都有分区(partition)的概念
DataFrame 和 DataSet 均可使用模式匹配获取各个字段的值和类型
三者的区别
RDD
RDD 一般和 spark mllib 同时使用
RDD 不支持 sparksql 操作
2) DataFrame
与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为Row,每一列的值没法直
访问,只有通过解析才能获取各个字段的值
DataFrame 与 DataSet 一般不与 spark mllib 同时使用
DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能
注册临时表/视窗,进行 sql 语句操作
DataFrame 与 DataSet 支持一些特别方便的保存方式,比如保存成 csv,可以带上表
头,这样每一列的字段名一目了然
3) DataSet
Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。
DataFrame 其实就是 DataSet 的一个特例 type DataFrame = Dataset[Row]
DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row
相关文章:

spark-SOL简介
Spark-SQL简介 一.Spark-SQL是什么 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块 二.Hive and SparkSQL SparkSQL 的前身是 Shark,Shark是给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供的快速上手的工具 …...
 / 连续子数组最大和(动态规划) / 非对称之美(贪心))
【今日三题】经此一役小红所向无敌(模拟) / 连续子数组最大和(动态规划) / 非对称之美(贪心)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 经此一役小红所向无敌(模拟)连续子数组最大和(动态规划)非对称之美(贪心) 经此一役小红所向无敌(模拟) 经此一役小红所向无…...

MYSQL MVCC详解
这里写自定义目录标题 **一、MVCC 解决的核心问题****二、MVCC 的核心实现机制****1. 隐藏字段与版本链****2. Undo Log****3. ReadView(一致性视图)** **三、MVCC 的可见性判断过程****四、不同隔离级别下的 MVCC 行为****五、MVCC 的优缺点****六、示例…...

Trinity三位一体开源程序是可解释的 AI 分析工具和 3D 可视化
一、软件介绍 文末提供源码和程序下载学习 Trinity三位一体开源程序是可解释的 AI 分析工具和 3D 可视化。Trinity 提供性能分析和 XAI 工具,非常适合深度学习系统或其他执行复杂分类或解码的模型。 二、软件作用和特征 Trinity 通过结合具有超维感知能力的不同交…...

用 Deepseek 写的uniapp血型遗传查询工具
引言 在现代社会中,了解血型遗传规律对于优生优育、医疗健康等方面都有重要意义。本文将介绍如何使用Uniapp开发一个跨平台的血型遗传查询工具,帮助用户预测孩子可能的血型。 一、血型遗传基础知识 人类的ABO血型系统由三个等位基因决定:I…...

展示数据可视化的魅力,如何通过图表、动画等形式让数据说话
在当今信息爆炸的时代,数据的量级和复杂性不断增加。如何从海量数据中提取有价值的信息,并将其有效地传达给用户,成为了一个重要的课题。数据可视化作为一种将复杂数据转化为直观图形、图表和动画的技术,能够帮助用户快速理解数据…...

解决安卓开发“No Android devices detected.”问题
解决安卓开发“No Android devices detected.”问题 当我们插入移动设备的USB时,却发现这并未显示已连接到的设备 点击右侧的Assistant,根据提示打开移动设备开发者模式并启用USB调试模式,然后发现我们未连接到移动设备的原因是ABD服务的原因 问题确定了&…...
)
Android13 WIFI调试(rtl8821cs)
一、WiFi框架概述 1、Wi‑Fi 是一种无线通信技术,在 Linux 系统上一般可处于三种工作模式,分别是: STATION、AP、MONITOR。 station :工作sta模式,类比手机主动连网。 ap:工作ap模式,类比手机开热点。 mon…...

Android常见界面控件、程序活动单元Activity练习
第3章 Android常见界面控件、第4章程序活动单元Activity 一. 填空题 1. (填空题)Activity的启动模式包括standard、singleTop、singleTask和_________。 正确答案: (1) singleInstance 2. (填空题)启动一个新的Activity并且获取这个Activity的返回数据ÿ…...

过拟合、归一化、正则化、鞍点
过拟合 过拟合的本质原因往往是因为模型具备方差很大的权重参数。 定义一个有4个特征的输入,特征向量为,定义一个模型,其只有4个参数,表示为。当模型过拟合时,这四个权重参数的方差会很大,可以假设为。当经过这个模型后…...

关于多agent多consumer架构设想
多个agent接入设备 每个agent对接同一个消费队列,非竞争设置,通过判断consumer中的参数如果是发给自己的,则下发,如果不是,则快速跳过。每个消费者接收消息时通过Header中值判断是来着哪个agent服务器的,发…...

国内互联网大厂推出的分布式数据库 的详细对比,涵盖架构、性能、适用场景、核心技术等维度
以下是 国内互联网大厂推出的分布式数据库 的详细对比,涵盖架构、性能、适用场景、核心技术等维度: 一、主流分布式数据库列表 大厂数据库名称类型适用场景发布时间腾讯云TDSQL分布式HTAP金融、电商、游戏、政企2010年阿里云OceanBase分布式HTAP银行核…...

【深度学习】自定义实现DataSet和DataLoader
dataset数据集 作用: 存储数据集的信息获取数据集长度 __len__获取数据集某特定条目的内容 __getitem__ dataloader 数据加载器 作用: 从数据集中随机加载数据, 并拼接为一个 batch实现迭代器, 可以使用时, 迭代获取数据内容 代码实现:…...

spark简介和核心编程
简介 1. Spark-SQL概述:Spark SQL是Spark处理结构化数据的模块,前身是Shark。Shark基于Hive开发,提升了SQL-on-Hadoop的性能,但对Hive的过度依赖制约了Spark发展。SparkSQL抛弃Shark代码,汲取其优点后重新开发&#x…...
)
47、Spring Boot 详细讲义(四)
六. Spring Boot 与数据库 目录 JDBC 集成 Spring Data JPA MyBatis 集成 事务管理 1、JDBC 集成 1.1 JDBC简介 1.1.1 定义和作用 JDBC(Java Database Connectivity)是Java中用于与关系型数据库进行交互的API。它为Java程序提供了一个标准的、统一的接口…...
)
Dify - 整合Ollama + Xinference私有化部署Dify平台(01)
文章目录 总体方案服务器在Ubuntu 20.04上安装Docker更新软件包索引安装一些必要的软件包,以便apt能够通过HTTPS使用仓库:添加Docker的官方GPG密钥设置稳定的仓库再次更新软件包索引从新添加的仓库中安装Docker CE验证Docker是否安装成功(可选…...

【RocketMQ】关于RocketMQ配置好了jdk环境变量却一直报需要配置环境变量的问题
正如上图所示,我明明已经配置好了环境变量,也显示配置好了,jdk与我的rocketmq的版本也是适配的,可每次启动namesrv和broker却一直显示要去配置环境变量,其实很简单,配置环境变量时特殊符号会影响路径查找&a…...
)
【信息系统项目管理师】高分论文:论信息系统项目的范围管理(投资信息化全流程管理项目)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 1、规划范围管理2、收集需求3、定义范围4、创建wbs5、确认范围6、控制范围2018年2月,我有幸参加了 XX省自贸区财政投资信息化全流程管理项目的假设,作为项目发起单位,省自贸办经过审时度势,及时响应国家自贸…...

Jmeter创建使用变量——能够递增递减的计数器
Jmeter创建使用变量——能够递增递减的计数器 如下图所示,创建一个 取值需限定为0 2 4这三个值内的变量。 Increment:每次迭代后 递增的值,给计数器增加的值 Maximum value:计数器的最大值,如果超过最大值࿰…...

数据分析不只是跑个SQL!
数据分析不只是跑个SQL! 数据分析五大闭环,你做到哪一步了?闭环一:认识现状闭环二:原因分析闭环三:优化表现闭环四:预测走势闭环五:主动解读数据 数据思维:WHY-WHAT-HOW模…...

批量将文件夹名称、文件夹路径提取到 Excel 清单
在日常工作中,管理大量文件夹和文件路径可能变得十分繁琐。无论是在进行文件整理、备份还是数据分析时,提取文件夹的名称与路径信息,能够帮助你更高效地管理文件。本文将为您提供如何快速提取文件夹名称与路径,并将这些信息整理到…...

Git 基本使用
一、Git简介 简单的内容追踪系统;是一个快速、可扩展的分布式版本控制系统,拥有异常丰富的命令集提供高级操作和对内部的完全访问。 二、Git安装 详情看本人此文章。 三、Git 命令(基础版) 把 Git 分为上层封装命令(…...

LLM - Dify 平台介绍
文章目录 引言官网核心功能架构图典型应用场景在线平台 引言 Dify 是一款开源的 LLM(大语言模型)应用开发平台,旨在帮助开发者快速构建、部署和管理基于大语言模型的智能化应用。 官网 https://dify.ai/zh https://github.com/langgenius/…...

linux编译adbd工具使用
在使用linux时,通常是没有现成的adbd文件使用的,这就需要我们进行文件的编译了,编译可以分为三步进行,在编译前我们需要下载对应的源码使用,我们可以从 https://launchpad.net/android-tools地址处下载需要的android-tools源码使用…...

安全人员如何对漏洞进行定级?
CVSS 标准 CVSS 介绍 CVSS,即通用漏洞评分系统(Common Vulnerability Scoring System),是一个用于评估计算机系统漏洞严重程度的行业标准。 CVSS为安全专业人员、漏洞管理团队和系统管理员提供了一种标准化的方法来评估和比较不…...
:组合使用子树)
【ROS2】行为树 BehaviorTree(四):组合使用子树
1、大树调用子树 如下图,左边为大树主干: 1)如果门没有关,直接通过; 2)如果门关闭了,执行开门动作,然后通过 右边为子树,主要任务是开门 1)尝试直接开门; 2)尝试开锁开门,最多尝试5次; 3)最后尝试砸门! XML如何描述大树主干调佣子树:使用关键字 SubTree 来…...
)
第十六届蓝桥杯Java b组(试题C:电池分组)
问题描述: 输入格式: 输出格式: 样例输入: 2 3 1 2 3 4 1 2 3 4 样例输出: YES NO 说明/提示 评测用例规模与约定 对于 30% 的评测用例,1≤T≤10,2≤N≤100,1≤Ai≤10^3。对于 100…...

HarmonyOS:使用Refresh组件实现页面下拉刷新
一、前言 可以进行页面下拉操作并显示刷新动效的容器组件。 说明 该组件从API Version 8开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。该组件从API Version 12开始支持与垂直滚动的Swiper和Web的联动。当Swiper设置loop属性为true时&…...
)
Python----机器学习(基于PyTorch的垃圾邮件逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 本例使用了…...

Spark-SQL
概念 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。 Spark-SQL 特点: 1,易整合,无缝的整合了 SQL 查询和 Spark 编程。 2,统一的数据访问,使用相同的方式连接不同的数据源。 3…...

spark-sql核心
在大数据处理领域,Apache Spark已成为极为重要的分布式计算框架,而Spark SQL作为其重要组件,极大地拓展了Spark的能力边界,为结构化数据处理提供了高效、便捷的解决方案。 一、Spark SQL架构剖析 Spark SQL的架构设计精妙&#…...

TypeScript 进阶指南 - 使用泛型与keyof约束参数
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Micro麦可乐的博客 🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战 🌺《RabbitMQ》…...

labview的VI密码破解程序
上图即为密码破解原理,若需源代码可联系我...

AI技术前沿:蓝耘元生代智算云快速入门教程详解,与其他云人工智能大模型深度对比
文章目录 一、前言二、蓝耘元生代智算云基础概念2.1 什么是智算云2.2 蓝耘元生代智算云的特点 三、蓝耘元生代智算云使用前准备3.1 注册与登录3.2 了解计费方式3.3 熟悉控制台界面 四、在蓝耘元生代智算云上运行第一个任务4.1 创建计算资源4.2 上传代码和数据4.3 安装依赖库4.4…...

Spring MVC 请求处理流程详解
步骤1:用户发起请求 所有请求首先被 DispatcherServlet(前端控制器)拦截,它是整个流程的入口。 DispatcherServlet 继承自 HttpServlet,通过 web.xml 或 WebApplicationInitializer 配置映射路径(如 /&…...

金融行业 AI 报告自动化:Word+PPT 双引擎生成方案
—从数据到决策,10倍效率提升的智能金融解决方案 一、金融行业报告制作的四大核心痛点 1. 人工制作成本高 传统流程耗时: 分析师撰写Word报告:8-12小时/份设计师制作PPT:4-6小时/份团队协作修改:反复沟通,…...

01_JDBC
文章目录 一、概述1.1、什么是JDBC1.2、JDBC原理 二、JDBC入门2.1、准备工作2.1.1、建库建表2.1.2、新建项目 2.2、建立连接2.2.1、准备四大参数2.2.2、加载驱动2.2.3、准备SQL语句2.2.4、建立连接2.2.5、常见问题 2.3、获取发送SQL的对象2.4、执行SQL语句2.5、处理结果2.6、释…...

三层架构与分层解耦:深入理解IOC与DI设计模式
目录 一、软件架构演进与三层架构概述 1.1 从单体架构到分层架构 1.2 经典三层架构详解 1.3 三层架构的优势 二、分层解耦的核心思想 2.1 耦合与解耦的基本概念 2.2 分层解耦的实现手段 2.3 分层解耦的实践原则 三、控制反转(IOC)深度解析 3.1…...

[react]Next.js之自适应布局和高清屏幕适配解决方案
序言 阅读前首先了解即将要用到的两个包的作用 1.postcss-pxtorem 自动将 CSS 中的 px 单位转换为 rem 单位按照设计稿尺寸直接写 px 值,由插件自动计算 rem 值 2.amfe-flexible 动态设置根元素的 font-size(即 1rem 的值)根据设备屏幕宽度和…...

TensorFlow深度学习实战——基于语言模型的动态词嵌入技术
TensorFlow深度学习实战——基于语言模型的动态词嵌入技术 0. 前言1. 基于语言模型的词嵌入1.1 ELMo 与 ULMFiT1.2 GPT1.3 BERT 2. 使用 BERT 作为特征提取器相关链接 0. 前言 基于语言模型的词嵌入技术,通过利用上下文信息来生成动态的词向量,大大提升…...
)
欧拉服务器操作系统部署deekseep(Ollama+DeekSeep+open WebUI)
一、解压并安装 Ollama # 1. 解压文件(默认会得到一个二进制文件) tar -xzvf ollama-linux-amd64.tgz# 2. 将二进制文件安装到系统路径 sudo mv ollama /usr/local/bin/ sudo chmod x /usr/local/bin/ollama# 3. 验证安装 ollama --version链接…...
)
cocosCreator安卓隐私弹窗(链接版)
每次新上游戏都要重新弄这个隐私弹窗,记录一下下次直接抄。 一、创建Activity 1 用androidStudio 打开项目并切换到Android视角。 2 右键项目new一个空的Activity 3 修改Activity的名字并完成如下图 二、增加依赖文件 1 增加全局颜色定义文件:项目根目录 / res/values/ …...

统计销量前十的订单
传入参数: 传入begin和end两个时间 返回参数 返回nameList和numberList两个String类型的列表 controller层 GetMapping("/top10")public Result<SalesTop10ReportVO> top10(DateTimeFormat(pattern "yyyy-MM-dd") LocalDate begin,Dat…...

【Python爬虫】简单案例介绍2
本文继续接着我的上一篇博客【Python爬虫】简单案例介绍1-CSDN博客 目录 跨页 3.2 环境准备 跨页 当对单个页面的结构有了清晰的认识并成功提取数据后,接下来就需要考虑页面之间的跨页问题。此时我们便迎来了下一个关键任务:如何实现跨页爬取…...

适合单片机裸机环境的运行的软件定时器框架
如下这篇文档介绍了一个适用于裸机环境的软件定时器模块,其核心功能和实现如下: 模块功能:该模块通过硬件定时器中断实现时基累加,适合用于裸机程序的调度处理。它使用硬件定时中断(如1ms一次)来增加hw_ti…...

【ComfyUI】蓝耘元生代 | ComfyUI深度解析:高性能AI绘画工作流实践
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈人工智能与大模型应用 ⌋ ⌋ ⌋ 人工智能(AI)通过算法模拟人类智能,利用机器学习、深度学习等技术驱动医疗、金融等领域的智能化。大模型是千亿参数的深度神经网络(如ChatGPT&…...

js的es6模块中 暴露的使用方法简介
在 JavaScript 的 ES6 模块系统中,一个模块文件只能有一个 export default。export default 用于导出一个默认值,这个默认值在导入时可以使用任意名称。 示例: 导出默认值: // myModule.jsexport default function greet() {con…...
,源码可白嫖!)
基于Android的旅游自助APP(源码+lw+部署文档+讲解),源码可白嫖!
摘要 旅游自助APP设计的目的是为用户提供对景点信息和路线攻略、周边美食等方面的平台。 与PC端应用程序相比,旅游自助的设计主要面向于旅行者,旨在为用户提供一个旅游自助。用户可以通过APP及时景点信息,并对景点进行购票或收藏等。相反&am…...
:合并字段,使用UNION,首先应使用SELECT进行检索,再使用UMION进行拼接)
SQL(7):合并字段,使用UNION,首先应使用SELECT进行检索,再使用UMION进行拼接
核心功能:合并查询结果 想象一下,你有两个不同的名单,你想把它们合并成一个大名单。UNION 和 UNION ALL 都是 SQL 里用来干这个“合并名单”的活儿的。它们可以把两个(或更多)SELECT 查询语句的结果合并到一起&#x…...

Spring MVC 全栈指南:RESTful 架构、核心注解与 JSON 实战解析
目录 RESTful API 设计规范Spring MVC 核心注解解析静态资源处理策略JSON 数据交互全解高频问题与最佳实践 一、RESTful API 设计规范 1.1 核心原则 原则说明示例 URI资源为中心URI 使用名词(复数形式)/users ✔️ /getUser ❌HTTP 方法语义化GET&…...