论文导读 | 基于GPU的子图匹配算法
摘要
大规模图上的子图匹配在社交网络挖掘,生物信息学,知识图谱等领域具有关键作用。近年来随着以GPU为代表的新硬件的发展,研究人员开始尝试在GPU上实现这一NP难的任务。GPU提供了大量的计算单元和高速的显存带宽,可以显著提升算法效率。然而,由于GPU特殊的线程架构和内存架构,充分利用GPU的硬件资源并非易事,这可能造成一个甚至几个数量级的性能差距。本文将对现有基于GPU的子图匹配算法提出的优化策略进行分类和对比。
引言
给定一个数据图 G = ( V G , E G , L G ) G=(V_G,E_G,L_G) G=(VG,EG,LG)和一个查询图 Q = ( V Q , E Q , L Q ) Q=(V_Q,E_Q,L_Q) Q=(VQ,EQ,LQ),其中:
- $ V $ 为顶点集合,$ E \subseteq V \times V $ 为边集合
- $ L: V \to \Sigma $ 为顶点标签映射函数
子图匹配问题定义为寻找所有满足以下条件的单射函数 f : V Q → V G f:V_Q\to V_G f:VQ→VG,满足:
- ∀ u ∈ V Q , L Q ( u ) = L G ( f ( u ) ) \forall u\in V_Q,L_Q(u)=L_G(f(u)) ∀u∈VQ,LQ(u)=LG(f(u))
- ∀ e ( u 1 , u 2 ) ∈ E Q , e ( f ( u 1 ) , f ( u 2 ) ) ∈ E G \forall e(u_1,u_2)\in E_Q,e(f(u_1),f(u_2))\in E_G ∀e(u1,u2)∈EQ,e(f(u1),f(u2))∈EG.
子图匹配问题是经典的NP难问题,过往已经有诸多基于传统CPU的工作尝试提升其算法效率,然而这些方法都被CPU本身的计算能力所限制。近年来随着GPU的发展,研究人员开始探索在GPU上实现子图匹配任务。
然而,尽管GPU具有远超CPU的计算能力,其特殊的线程架构和内存架构使得简单地将算法移植到GPU上无法充分利用其计算资源。因此,本文先介绍GPU的线程和内存架构,分析在GPU上进行子图匹配的难点与挑战。
GPU的线程架构
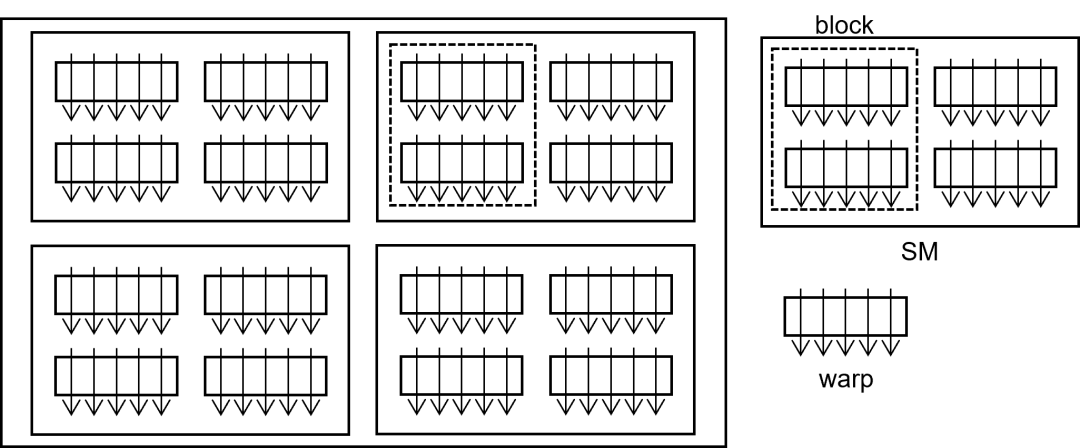
GPU的线程呈现分层的组织架构。如下图所示,GPU包含若干流多处理器(Streaming Multiprocessor, SM),每个SM中包含若干warp以供调度。
Warp是固定数量的线程组成的线程束(通常是32个线程)。SM按照warp为单位调度线程,warp内的线程执行相同的指令,即单指令多线程模型(Single Instruction Multiple Threads, SIMT)。
对于用户而言,线程被组织成若干个线程块(block)构成的线程网格(grid),线程块内的线程可以进行较便捷的数据交互和线程同步。
用户可以在发射GPU执行的核函数时指定一个线程块中的线程数目和总线程块数目。GPU根据每个线程块所需的寄存器和共享内存数目尽可能地将线程块分配给SM,一个线程块只能存在于一个SM中,而一个SM可以同时运行多个线程块。
SM可以调度其中所有线程块内所有的warp,当一个warp因为访存或者同步陷入停滞时,SM通过寻找可以执行的另一个warp继续执行。而当SM内没有可执行的warp时,其计算资源就被浪费。
与CPU的线程调度不同的是,GPU中具有大量的寄存器,寄存器由每个线程独享。因此在切换时,SM无需进行任何上下文切换,从而实现了高效线程调度。
GPU特殊的线程架构对于编程提出如下要求:
- 编程者需要尽可能避免warp内的线程因为条件或循环语句而进入不同分支,因为GPU不会同时执行不同的分支,而是分别顺序执行这些分支,阻滞不在当前分支的线程。
- 编程者需要尽量避免线程块及以上的线程同步,核函数的设计应使得每个warp具有相对独立的计算逻辑。
- 编程者需要合理地安排核函数的各种资源,使得一个SM能同时调度的线程块中能够有充足的warp以供调度来尽可能掩盖因为访存造成的停滞。同时要确保一个线程所需寄存器数量不超过限制,否则溢出的寄存器将使用缓慢的片下内存替代。
GPU的内存架构
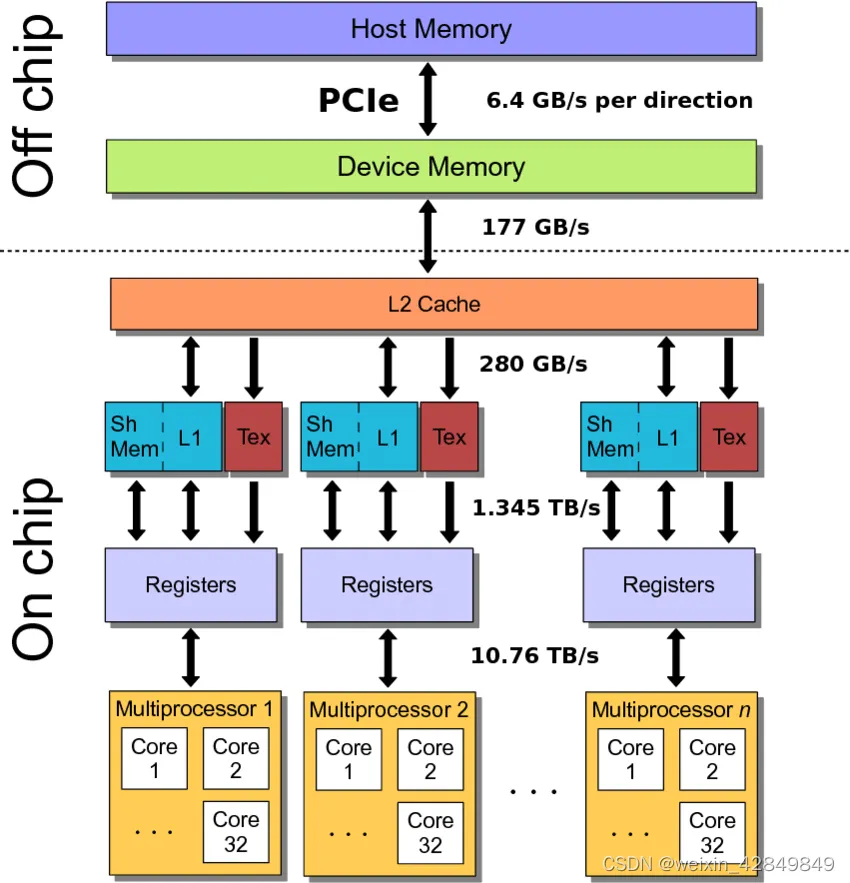
GPU具有丰富多样的内存资源。总体来说可以分为高速的片上内存,和较低速的片下内存。
- 片上内存:类似于CPU中的片上内存结构,GPU中的内存包含寄存器和各级缓存结构。同时,GPU还具有特殊的共享内存(shared memory)可供用户指定存储频繁使用和线程块共享的信息。
- 寄存器:GPU每个SM中具有丰富的寄存器资源,但是这些寄存器被平均分配到每个线程中,用于存储线程内的变量。如果遇到寄存器溢出,编译器会将多余的寄存器用慢速的片下内存替代。
- L1 Cache/shared memory:每一个SM具有一定数量(大约数百KB)的L1 Cache和shared memory,它们共享一片内存,延迟大概在数十个时钟周期。L1 cache由系统决定存储内容,而shared memory由编程者定义,在线程块内存共享。
shared memory中的访存使用多bank存储方式。总共有32个bank,按照4字节为单元顺序存储到每个bank中。当一个warp同时访问shared memory中相同bank的不同地址的内容,即地址差距为128的倍数时,会发生bank conflict,需要通过多次访存才能完成。 - L2 Cache:所有SM共享L2 Cache,访存延迟大约在300个时钟周期左右。
- 片下内存:一般统称为显存,访存延迟大约在500个时钟周期左右,但是可以根据功能细分成global memory,local memory。constant memory等。
- global memory:所有线程共享,可以从CPU端进行分配和初始化以将数据传递给核函数。global memory的每次访存按照128字节对齐的方式每次返回128字节的内容,称为合并访存(coalesced access)。编程者需要尽可能保证访问对齐的内容,从而避免带宽浪费。
- local memory:用于存放溢出的寄存器和GPU上函数调用时暂存寄存器。
- constant memory:用于存放在GPU端不会修改的内容,其中的内容在读取时会使用独立的只读缓存。
为了充分释放GPU的性能,编程者需要注意以下几点:
- 利用好shared memory,用于线程块内信息共享和手动缓存频繁使用的信息,减少访问显存的次数。
- 合理排布数据结构。尽可能保证访问global memory时以128字节对齐的方式访问相邻的内存。在访问shared memory时,要尽可能避免bank conflict。
GPU上子图匹配的挑战
子图匹配具有复杂的逻辑和不均匀的数据分布。尽管传统CPU上已经发展了诸多优化方案,但是并非所有优化都能很好地贴合GPU的编程架构。例如,GPU上在核函数内不支持灵活的内存动态分配操作,所有内存应当预先在CPU端进行分配和初始化,因此基于运行时的动态剪枝等策略很难实现在GPU上。又例如,GPU中大量的线程使得线程间的同步和信息交互开销相对困难,可能造成线程块甚至整个线程网格的停滞。
传统CPU上的子图匹配大致包含过滤——匹配顺序选择——枚举三个部分。其中前两个部分复杂度为多项式量级,一般在预处理阶段完成,因此在GPU方案中可以较为简单地移植。而在枚举部分,GPU方案则进行比CPU更复杂的线程管理。其中的各种优化策略也因为GPU的内存和线程架构而无法直接使用CPU方案。
算法策略对比
本文将GPU上子图匹配按照搜索策略分为两类:BFS为基础按照层级顺序进行的搜索和DFS为基础按照子树顺序进行的搜索。搜索策略决定了算法需要解决的问题,并限制了优化策略。在总体搜索策略确定后,需要设计计算框架以充分利用GPU的硬件资源,避免内存溢出或者负载不均衡。在计算框架下,尽可能减少冗余计算和利用GPU提供的硬件支持可以有效地提高吞吐量。
搜索策略
子图匹配算法一般可以视作一棵搜索树。其中每个树节点表示一个子匹配。每次选取一个树节点所代表的子匹配,子图匹配算法需要选择一个尚未拓展的查询点,对当前子匹配拓展该查询点的所有可能的匹配作为当前树节点的子节点。具体而言,通过计算待匹配顶点的后向邻居的匹配点的邻域的交集,并进行去重操作即可获得所有可能的匹配方式。其中,后向邻居指的是当前待匹配查询点的已匹配邻居。
拓展搜索树的搜索策略决定了整个算法的计算框架。总体来说,我们可以将子图匹配算法按照搜索策略分成BFS和DFS两类。
- BFS策略:在基于GPU的BFS搜索中,每次发射一个核函数,将现有的子匹配拓展一个顶点[1,2,5,7]。在核函数中,每个warp每次接取一个子匹配,并搜索所有可能的拓展顶点,并生成新的子匹配。BFS搜索策略可以充分利用GPU的并行资源,其每一个线程的工作负载相对均衡。但是当查询图顶点数增多时,每一层子匹配数量指数增加。这就可能导致显存空间不足,匹配失败。此外,频繁地发射核函数,重新分配内存也会导致额外的开销。
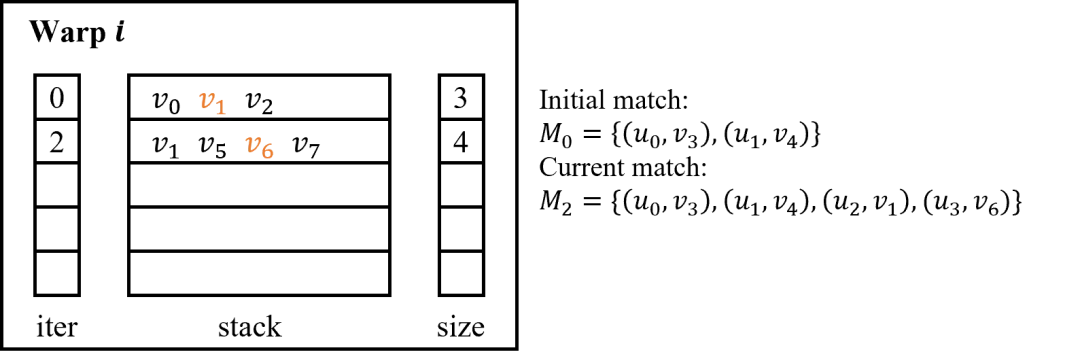
- DFS策略:在基于GPU的DFS搜索中,使用一个核函数完成整个搜索过程[4,6,9,10]。通过在global memory和shared memory中手动维护栈来实现递归搜索。如下图所示,在global memory中维护stack数组,其层数等于待匹配顶点数,其每层用于容纳当前搜索子树下对应层的不同匹配分支,每层的容量为数据图最大顶点度数。在shared memory中维护栈相关的元数据,包括一个iter数组,指向每层当前搜索分支,以及一个size数组,表示stack每层的匹配分支数。DFS算法中每一个warp每次接取一个初始匹配并按照DFS顺序进行搜索。在DFS算法中,内存开销是有限的,随着查询图顶点数和数据图最大顶点度数线性增长。然而,由于数据图密度分布不均匀,搜索子树的大小随着查询图顶点数量指数增加,这会导致严重的负载不均衡。此外,因为搜索栈在global memory中进行维护,访问和维护栈中元素也会导致额外的内存开销。
为了应对两种策略各自的不足,研究者尝试使用DFS-BFS的混合策略。
cuTS[3] 提出了在BFS搜索策略中引入DFS搜索的方案。它将所有初始子匹配按照chunk进行分组,每次选择一个chunk进行BFS搜索。这样可以缓解内存不足的问题。但是当查询图顶点进一步增加时,即便是一个chunk中拓展出的子匹配也会超过显存容量。
EGSM[8] 使用了先BFS,后DFS的搜索策略。它先尽可能地使用BFS策略拓展子匹配。当超过预先开辟的内存容量时,转而用DFS策略完成余下搜索工作。这种方案可以大大减少单个warp的搜索树粒度,从而减少负载不均衡问题,但是同样无法从根源上消除负载不均的问题。
总之,在BFS搜索中无法避免显存不足的问题,而DFS搜索必须面对负载不均的问题。因此,最近的工作采用了具有负载均衡策略的DFS搜索。
负载均衡策略
在基于DFS搜索算法中,可以通过将繁忙warp的任务动态卸载一部分给空闲warp从而实现负载均衡。这种策略可以确保所有warp不会进入长时间空闲,从而基本保证了负载的均衡。
然而,如何有效地在高并发环境中实现高效的负载均衡策略并非易事。
BEEP[9]和STMatch[6]在global memory中维护了一个空闲warp的Worker Queue,当繁忙warp发现Worker Queue中存在空闲warp时主动将一部分任务分配给该warp。该方案需要繁忙warp频繁地检查Worker Queue,从而产生了较大开销。
STMatch在线程块内还实现了更快捷的任务窃取策略,空闲warp可以直接从繁忙warp的栈中分割一部分任务。然而在GPU的高并发环境中,必须对栈进行加锁操作,从而增加了维护成本。
T-DFS[10]则提出了基于超时策略任务释放策略。每个warp通过GPU提供的clock64()函数记录当前搜索任务的运行时间。当运行时间超时时,主动分割一部分任务到Task Queue中,并重置运行时间。空闲的warp则等待Task Queue中的任务执行。直到所有warp进入空闲状态。通过使用合适的超时参数,可以有效控制负载均衡的开销和空闲warp的等待时间。
过滤策略
GPU中的过滤策略为每一个查询点生成一个较小的候选集,可以有效地对搜索树进行剪枝。
由于此部分策略一般在预处理阶段执行,GPU中基本沿用了CPU中基于Neighborhood的过滤策略。
为了在GPU上实现更快的过滤方案,部分工作设计了适合GPU访存模式的数据结构。例如,GSI[1]设计了按位存储的signature table,充分利用了合并访存的特性。EGSM[8]设计了cuckoo trie,支持对侯选边的批量插入,检查和删除。
匹配顺序选择策略
匹配顺序会影响搜索树的大小,良好的匹配顺序可以使得大部分无用的搜索分支较早被终止。
GPU上的匹配顺序一般使用启发式的静态匹配顺序。
例如,T-DFS[10]给度数和约束更多的查询点更高的优先级。而GSI[1]则选择候选集大小乘度数最小的点作为先匹配的点。
只有EGSM[8]使用了动态的匹配顺序。在用DFS进行搜索时,每次选择后向邻居最小邻域最小的顶点进行匹配。
重用策略
重用策略用于减少重复的拓展计算。由于子图匹配算法中集合求交运算占据了主要时间,而每一次集合求交运算都是若干数据图顶点的邻域进行求交。在整个搜索过程中,一些顶点的邻域频繁参与求交运算,研究者希望寻找重复的邻域求交运算,进行缓存并重复使用结果,减少计算冗余。
在CPU上的方案已经提出了相当多的重用策略。然而在GPU上不能很容易地移植这些策略。主要是因为(1)GPU上无法在核函数内动态分配内存,因此需要解决缓存结果存储位置的问题,以及(2)GPU上难以实现便捷高效的索引结构,因此需要解决缓存结果查询的问题。
因此,目前GPU上的重用策略要求在预处理阶段可以确定可重用部分,预先划分缓存空间并给出查询缓存结果的方式。这些重用策略基于对查询图进行分析,主要利用查询图顶点的对称性和独立性。
- 基于查询图顶点对称性的重用策略
- Symmetry Breaking:该方案来源于CPU上的重用策略。对于自同构的查询图,该方案避免对自同构的匹配进行重复的计算。
- 基于后向邻居包含关系的重用:该方案来源于CPU上的重用策略。对于一个固定匹配顺序的查询图,如果后匹配的顶点的后向邻居包含先匹配顶点的后向邻居,则可以直接重用数据栈中对应行的内容作为中间结果。
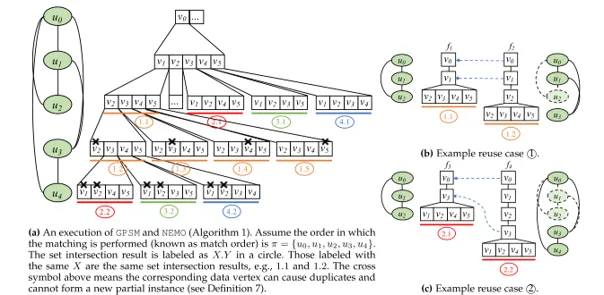
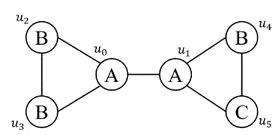
- 基于约束包含关系的重用:RPS[7]提出了约束包含关系。对于前 j j j个查询顶点构成的导出子图,如果它子图同构于前 i i i查询顶点构成的子图,同时该同构在匹配顺序中保序。则对于第 j j j个顶点,其后向邻居可能的集合严格包含于第 i i i个顶点的对应后向邻居的可能集合(约束包含)。例如下图中 ( u 0 , u 1 , u 2 ) (u_0,u_1,u_2) (u0,u1,u2)和 ( u 0 , u 1 , u 3 ) (u_0,u_1, u_3) (u0,u1,u3), ( u 0 , u 3 , u 4 ) (u_0,u_3,u_4) (u0,u3,u4)之间就存在这种约束包含关系。在BFS搜索中,一定可以找到第 i i i层的对应结果进行重用。
- 基于查询图顶点独立性的重用策略
- STMatch[6]利用了在诸如下图所示的查询图中, u 5 u_5 u5的选择独立于 u 2 , u 3 u_2,u_3 u2,u3的匹配选择。因此在DFS搜索时,会对相同的 ( u 1 , u 4 ) (u_1,u_4) (u1,u4)多次进行邻域求交。因此STMatch在预处理阶段检测这种独立性,并在栈中增加行存储 N ( u 1 ) ∩ N ( u 4 ) N(u_1)\cap N(u_4) N(u1)∩N(u4),以进行重用。
多GPU系统上的计算
部分工作探索了在多GPU系统上进行子图匹配。
cuTS[3]采用了简单将不同chunk分配到不同GPU上,而将数据图复制到每个GPU上的策略。
PBE[2]利用Metis算法将数据图划分,使得跨分片的边密度尽量小。在每个GPU上分配一个数据图分片并搜索分片内的匹配,而在CPU上搜索跨分片的匹配。
VSGM[5]根据查询图,对每一个数据图顶点搜索其匹配可达的K-hop邻居作为一个数据图分片,所有的搜索任务可以在分片中完成。VSGM将分片分配到单个或者多个GPU上,并用GPU计算时间掩盖分片准备和数据传输时间。
总结
本文从不同策略角度对现有基于GPU的方案进行了深入的对比和总结。在每一类优化策略上对不同的技术方案进行了分析。本文旨在总结过往工作中的优点与不足,为后续工作提供研究方向的启示。
参考文献
[1] Li Zeng, Lei Zou, M. Tamer ¨Ozsu, Lin Hu, and FanZhang. Gsi: Gpu-friendly subgraph isomorphism. In2020 IEEE 36th International Conference on DataEngineering (ICDE), pages 1249–1260, 2020.
[2] Wentian Guo, Yuchen Li, Mo Sha, Bingsheng He, Xi-aokui Xiao, and Kian-Lee Tan. Gpu-accelerated sub-graph enumeration on partitioned graphs. In Proceed-ings of the 2020 ACM SIGMOD International Con-ference on Management of Data, SIGMOD ’20, page1067–1082, New York, NY, USA, 2020. Associationfor Computing Machinery.
[3] Lizhi Xiang, Arif Khan, Edoardo Serra, MahanteshHalappanavar, and Aravind Sukumaran-Rajam. cuts:scaling subgraph isomorphism on distributed multi-gpu systems using trie based data structure. In Pro-ceedings of the International Conference for High Per-formance Computing, Networking, Storage and Anal-ysis, SC ’21, New York, NY, USA, 2021. Associationfor Computing Machinery.
[4] Vibhor Dodeja, Mohammad Almasri, Rakesh Nagi,Jinjun Xiong, and Wen-mei Hwu. Parsec: Parallel subgraph enumeration in cuda. In 2022 IEEE Inter-national Parallel and Distributed Processing Sympo-sium (IPDPS), pages 168–178, 2022.
[5] Guanxian Jiang, Qihui Zhou, Tatiana Jin, Boyang Li,Yunjian Zhao, Yichao Li, and James Cheng. Vsgm:View-based gpu-accelerated subgraph matching on large graphs. In SC22: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–15, 2022.
[6] Yihua Wei and Peng Jiang. Stmatch: accelerating graph pattern matching on gpu with stack-based loop optimizations. In Proceedings of the International Conference on High Performance Computing, Net-working, Storage and Analysis, SC ’22. IEEE Press,2022.
[7] Wentian Guo, Yuchen Li, and Kian-Lee Tan. Exploiting reuse for gpu subgraph enumeration. IEEETransactions on Knowledge and Data Engineering,34(9):4231–4244, 2022.
[8] Xibo Sun and Qiong Luo. Efficient gpu-acceleratedsubgraph matching. Proc. ACM Manag. Data, 1(2),June 2023.
[9] Samiran Kawtikwar, Mohammad Almasri, Wen-MeiHwu, Rakesh Nagi, and Jinjun Xiong. Beep: Balanced efficient subgraph enumeration in parallel. In Proceedings of the 52nd International Conference onParallel Processing, ICPP ’23, page 142–152, New York, NY, USA, 2023. Association for Computing Machinery.
[10] T-DFS Lyuheng Yuan, Da Yan, Jiao Han, Akhlaque Ahmad,Yang Zhou, and Zhe Jiang. Faster depth-first sub-graph matching on gpus. In 2024 IEEE 40th International Conference on Data Engineering (ICDE),pages 3151–3163, 2024.
相关文章:

论文导读 | 基于GPU的子图匹配算法
摘要 大规模图上的子图匹配在社交网络挖掘,生物信息学,知识图谱等领域具有关键作用。近年来随着以GPU为代表的新硬件的发展,研究人员开始尝试在GPU上实现这一NP难的任务。GPU提供了大量的计算单元和高速的显存带宽,可以显著提升算…...

中天科技旗下的中天智能装备有限公司,在立库方面有哪些优势?
中天科技旗下的中天智能装备有限公司在立库方面优势显著,主要体现在产品与方案、技术研发、项目经验和服务质量管控等多个维度,能够为客户提供全方位、高品质的立库相关服务。 产品与解决方案优势 多种立库解决方案:提供托盘式立库、料箱式立…...

HTML5+CSS前端开发【保姆级教学】+超链接标签
一、引入: Hello!,各位编程猿们!一个页面可以跳转到其他页面,去访问其他资源,使得我们的文档更加的灵动,那我们如何实现不同页面的跳转呢?本期主要介绍超链接标签 那么什么是超链接…...

【游戏安全】文本校验类风险
文本风险定义: 在游戏中除了动画,声音参与和玩家的交互之外,游戏中的文本也属于和玩家交互中一项重要的元素。由玩家操作触发任何不同于游戏自身逻辑设定,进而破坏游戏平衡的文本内容都可以称之为文本类风险漏洞。(这个定义自己瞎写的…) 文本风险危害(漏洞举例): …...

快速排序及其应用
快速排序及其应用 标准写法改成稳定版本求第k小值O(n)做法快排的另一种写法 标准写法 #include <bits/stdc.h>using namespace std;using ll long long;int a[] {8, 5, 18, 11, 7, 2, 21, 15, 3, 8};void quickSort(int l, int r) {if (l > r) return ; // 元素个数…...

南柯电子|新能源汽车EMC电磁兼容性测试整改:突破行业规范之路
随着新能源汽车产业的蓬勃发展,车辆电子化、智能化程度不断提高,电磁兼容性(EMC)问题日益凸显。作为衡量汽车电子系统稳定性的关键指标,EMC性能不仅影响车辆功能安全,更关乎道路交通的整体安全性。 一、EM…...

LabVIEW 程序持续优化
LabVIEW 以其独特的图形化编程方式,在工业自动化、测试测量、数据分析等众多领域发挥着关键作用。为了让 LabVIEW 程序始终保持高效、稳定,并契合不断变化的实际需求,持续改进必不可少。下面将从多个关键维度,为大家细致地介绍通用…...

裂缝检测数据集,支持yolo,coco json,pasical voc xml,darknet格式的标注,1673张原始训练集图片,正确识别率99.4%
数据集详情: 裂缝检测数据集,支持yolo,coco json,pasical voc xml,darknet格式的标注,1673张原始训练集图片,正确识别率99.4% 2394总图像 数据集分割 训练集占比 70% 1673图片 有效集20% 477图片 测试集...

Webrtc让浏览器实现无服务器中转的安全私密聊天
私密聊天平台的应用介绍 在当今数字时代,隐私和安全成为人们日益关注的焦点。许多人发现,他们的聊天记录、个人信息甚至行为习惯都可能被第三方平台记录、分析甚至滥用。无论是出于保护个人隐私的需要,还是希望实现真正的点对点直接通信&…...

数据结构-限定性线性表 - 栈与队列
栈和队列是数据结构中非常重要的两种限定性线性表,它们在实际应用中有着广泛的用途。这篇文章将深入讲解栈和队列的概念、抽象数据类型、实现方式、应用场景以及性能分析,并通过代码示例帮助大家更好地理解和实践。 一、栈的概念与抽象数据类型 1.1 栈…...

接口的集成测试步骤
一、集成测试是什么 接口的集成测试是指在软件开发过程中,将各个模块或组件按照设计要求组合在一起,并测试它们之间的接口是否能够正确交互和协同工作的过程。集成测试是软件开发中的一个重要阶段,通常在单元测试之后进行,目的…...
)
Python 实现的运筹优化系统数学建模详解(多目标规划模型)
一、引言 在数学建模的广阔领域中,多目标规划模型占据着极为重要的地位。它致力于在复杂的实际场景里,同时优化多个相互冲突的目标,寻求一组决策变量,让多个目标函数在满足特定约束条件下达到某种平衡。这种模型广泛应用于生产调度…...

AJAX原理与XMLHttpRequest
目录 一、XMLHttpRequest使用步骤 基本语法 步骤 1:创建 XHR 对象 步骤 2:调用 open() 方法 步骤 3:监听 loadend 事件 步骤 4:调用 send() 方法 二、完整示例 1. GET 请求(带查询参数) 2. POST 请…...
css中的3d使用:深入理解 CSS Perspective 与 Transform-Style
在前端开发的奇妙世界中,CSS 不仅负责页面的布局和样式,还能赋予元素生动的动态效果。要实现引人入胜的 3D 变换,perspective 和 transform-style 这两个属性扮演着至关重要的角色。本文将带您深入了解这两个属性,揭开它们如何协同…...
)
在 JMeter 中,Active Threads Over Time 是一个非常有用的监听器(Listener)
在 JMeter 中,Active Threads Over Time 是一个非常有用的监听器(Listener),它可以帮助你实时观察测试过程中活跃线程数(并发用户数)的变化趋势,从而分析系统的并发处理能力和负载情况。 1. Active Threads Over Time 的作用 实时监控并发用户数:显示测试过程中活跃线程…...

未来七轴机器人会占据主流?深度解析具身智能方向当前六轴机器人和七轴机器人的区别,七轴力控机器人发展会加快吗?
六轴机器人和七轴机器人在设计、功能和应用场景上存在明显区别。六轴机器人是工业机器人的传统架构,而七轴机器人则在多自由度和灵活性方面进行了增强。 本文将在理解这两者的区别以及为何六轴机器人仍然是市场主流,从多个方面进行深入解读六轴和七轴区…...

spark-SOL简介
Spark-SQL简介 一.Spark-SQL是什么 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块 二.Hive and SparkSQL SparkSQL 的前身是 Shark,Shark是给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供的快速上手的工具 …...
 / 连续子数组最大和(动态规划) / 非对称之美(贪心))
【今日三题】经此一役小红所向无敌(模拟) / 连续子数组最大和(动态规划) / 非对称之美(贪心)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 经此一役小红所向无敌(模拟)连续子数组最大和(动态规划)非对称之美(贪心) 经此一役小红所向无敌(模拟) 经此一役小红所向无…...

MYSQL MVCC详解
这里写自定义目录标题 **一、MVCC 解决的核心问题****二、MVCC 的核心实现机制****1. 隐藏字段与版本链****2. Undo Log****3. ReadView(一致性视图)** **三、MVCC 的可见性判断过程****四、不同隔离级别下的 MVCC 行为****五、MVCC 的优缺点****六、示例…...

Trinity三位一体开源程序是可解释的 AI 分析工具和 3D 可视化
一、软件介绍 文末提供源码和程序下载学习 Trinity三位一体开源程序是可解释的 AI 分析工具和 3D 可视化。Trinity 提供性能分析和 XAI 工具,非常适合深度学习系统或其他执行复杂分类或解码的模型。 二、软件作用和特征 Trinity 通过结合具有超维感知能力的不同交…...

用 Deepseek 写的uniapp血型遗传查询工具
引言 在现代社会中,了解血型遗传规律对于优生优育、医疗健康等方面都有重要意义。本文将介绍如何使用Uniapp开发一个跨平台的血型遗传查询工具,帮助用户预测孩子可能的血型。 一、血型遗传基础知识 人类的ABO血型系统由三个等位基因决定:I…...

展示数据可视化的魅力,如何通过图表、动画等形式让数据说话
在当今信息爆炸的时代,数据的量级和复杂性不断增加。如何从海量数据中提取有价值的信息,并将其有效地传达给用户,成为了一个重要的课题。数据可视化作为一种将复杂数据转化为直观图形、图表和动画的技术,能够帮助用户快速理解数据…...

解决安卓开发“No Android devices detected.”问题
解决安卓开发“No Android devices detected.”问题 当我们插入移动设备的USB时,却发现这并未显示已连接到的设备 点击右侧的Assistant,根据提示打开移动设备开发者模式并启用USB调试模式,然后发现我们未连接到移动设备的原因是ABD服务的原因 问题确定了&…...
)
Android13 WIFI调试(rtl8821cs)
一、WiFi框架概述 1、Wi‑Fi 是一种无线通信技术,在 Linux 系统上一般可处于三种工作模式,分别是: STATION、AP、MONITOR。 station :工作sta模式,类比手机主动连网。 ap:工作ap模式,类比手机开热点。 mon…...

Android常见界面控件、程序活动单元Activity练习
第3章 Android常见界面控件、第4章程序活动单元Activity 一. 填空题 1. (填空题)Activity的启动模式包括standard、singleTop、singleTask和_________。 正确答案: (1) singleInstance 2. (填空题)启动一个新的Activity并且获取这个Activity的返回数据ÿ…...

过拟合、归一化、正则化、鞍点
过拟合 过拟合的本质原因往往是因为模型具备方差很大的权重参数。 定义一个有4个特征的输入,特征向量为,定义一个模型,其只有4个参数,表示为。当模型过拟合时,这四个权重参数的方差会很大,可以假设为。当经过这个模型后…...

关于多agent多consumer架构设想
多个agent接入设备 每个agent对接同一个消费队列,非竞争设置,通过判断consumer中的参数如果是发给自己的,则下发,如果不是,则快速跳过。每个消费者接收消息时通过Header中值判断是来着哪个agent服务器的,发…...

国内互联网大厂推出的分布式数据库 的详细对比,涵盖架构、性能、适用场景、核心技术等维度
以下是 国内互联网大厂推出的分布式数据库 的详细对比,涵盖架构、性能、适用场景、核心技术等维度: 一、主流分布式数据库列表 大厂数据库名称类型适用场景发布时间腾讯云TDSQL分布式HTAP金融、电商、游戏、政企2010年阿里云OceanBase分布式HTAP银行核…...

【深度学习】自定义实现DataSet和DataLoader
dataset数据集 作用: 存储数据集的信息获取数据集长度 __len__获取数据集某特定条目的内容 __getitem__ dataloader 数据加载器 作用: 从数据集中随机加载数据, 并拼接为一个 batch实现迭代器, 可以使用时, 迭代获取数据内容 代码实现:…...

spark简介和核心编程
简介 1. Spark-SQL概述:Spark SQL是Spark处理结构化数据的模块,前身是Shark。Shark基于Hive开发,提升了SQL-on-Hadoop的性能,但对Hive的过度依赖制约了Spark发展。SparkSQL抛弃Shark代码,汲取其优点后重新开发&#x…...
)
47、Spring Boot 详细讲义(四)
六. Spring Boot 与数据库 目录 JDBC 集成 Spring Data JPA MyBatis 集成 事务管理 1、JDBC 集成 1.1 JDBC简介 1.1.1 定义和作用 JDBC(Java Database Connectivity)是Java中用于与关系型数据库进行交互的API。它为Java程序提供了一个标准的、统一的接口…...
)
Dify - 整合Ollama + Xinference私有化部署Dify平台(01)
文章目录 总体方案服务器在Ubuntu 20.04上安装Docker更新软件包索引安装一些必要的软件包,以便apt能够通过HTTPS使用仓库:添加Docker的官方GPG密钥设置稳定的仓库再次更新软件包索引从新添加的仓库中安装Docker CE验证Docker是否安装成功(可选…...

【RocketMQ】关于RocketMQ配置好了jdk环境变量却一直报需要配置环境变量的问题
正如上图所示,我明明已经配置好了环境变量,也显示配置好了,jdk与我的rocketmq的版本也是适配的,可每次启动namesrv和broker却一直显示要去配置环境变量,其实很简单,配置环境变量时特殊符号会影响路径查找&a…...
)
【信息系统项目管理师】高分论文:论信息系统项目的范围管理(投资信息化全流程管理项目)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 1、规划范围管理2、收集需求3、定义范围4、创建wbs5、确认范围6、控制范围2018年2月,我有幸参加了 XX省自贸区财政投资信息化全流程管理项目的假设,作为项目发起单位,省自贸办经过审时度势,及时响应国家自贸…...

Jmeter创建使用变量——能够递增递减的计数器
Jmeter创建使用变量——能够递增递减的计数器 如下图所示,创建一个 取值需限定为0 2 4这三个值内的变量。 Increment:每次迭代后 递增的值,给计数器增加的值 Maximum value:计数器的最大值,如果超过最大值࿰…...

数据分析不只是跑个SQL!
数据分析不只是跑个SQL! 数据分析五大闭环,你做到哪一步了?闭环一:认识现状闭环二:原因分析闭环三:优化表现闭环四:预测走势闭环五:主动解读数据 数据思维:WHY-WHAT-HOW模…...

批量将文件夹名称、文件夹路径提取到 Excel 清单
在日常工作中,管理大量文件夹和文件路径可能变得十分繁琐。无论是在进行文件整理、备份还是数据分析时,提取文件夹的名称与路径信息,能够帮助你更高效地管理文件。本文将为您提供如何快速提取文件夹名称与路径,并将这些信息整理到…...

Git 基本使用
一、Git简介 简单的内容追踪系统;是一个快速、可扩展的分布式版本控制系统,拥有异常丰富的命令集提供高级操作和对内部的完全访问。 二、Git安装 详情看本人此文章。 三、Git 命令(基础版) 把 Git 分为上层封装命令(…...

LLM - Dify 平台介绍
文章目录 引言官网核心功能架构图典型应用场景在线平台 引言 Dify 是一款开源的 LLM(大语言模型)应用开发平台,旨在帮助开发者快速构建、部署和管理基于大语言模型的智能化应用。 官网 https://dify.ai/zh https://github.com/langgenius/…...

linux编译adbd工具使用
在使用linux时,通常是没有现成的adbd文件使用的,这就需要我们进行文件的编译了,编译可以分为三步进行,在编译前我们需要下载对应的源码使用,我们可以从 https://launchpad.net/android-tools地址处下载需要的android-tools源码使用…...

安全人员如何对漏洞进行定级?
CVSS 标准 CVSS 介绍 CVSS,即通用漏洞评分系统(Common Vulnerability Scoring System),是一个用于评估计算机系统漏洞严重程度的行业标准。 CVSS为安全专业人员、漏洞管理团队和系统管理员提供了一种标准化的方法来评估和比较不…...
:组合使用子树)
【ROS2】行为树 BehaviorTree(四):组合使用子树
1、大树调用子树 如下图,左边为大树主干: 1)如果门没有关,直接通过; 2)如果门关闭了,执行开门动作,然后通过 右边为子树,主要任务是开门 1)尝试直接开门; 2)尝试开锁开门,最多尝试5次; 3)最后尝试砸门! XML如何描述大树主干调佣子树:使用关键字 SubTree 来…...
)
第十六届蓝桥杯Java b组(试题C:电池分组)
问题描述: 输入格式: 输出格式: 样例输入: 2 3 1 2 3 4 1 2 3 4 样例输出: YES NO 说明/提示 评测用例规模与约定 对于 30% 的评测用例,1≤T≤10,2≤N≤100,1≤Ai≤10^3。对于 100…...

HarmonyOS:使用Refresh组件实现页面下拉刷新
一、前言 可以进行页面下拉操作并显示刷新动效的容器组件。 说明 该组件从API Version 8开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。该组件从API Version 12开始支持与垂直滚动的Swiper和Web的联动。当Swiper设置loop属性为true时&…...
)
Python----机器学习(基于PyTorch的垃圾邮件逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 本例使用了…...

Spark-SQL
概念 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。 Spark-SQL 特点: 1,易整合,无缝的整合了 SQL 查询和 Spark 编程。 2,统一的数据访问,使用相同的方式连接不同的数据源。 3…...

spark-sql核心
在大数据处理领域,Apache Spark已成为极为重要的分布式计算框架,而Spark SQL作为其重要组件,极大地拓展了Spark的能力边界,为结构化数据处理提供了高效、便捷的解决方案。 一、Spark SQL架构剖析 Spark SQL的架构设计精妙&#…...

TypeScript 进阶指南 - 使用泛型与keyof约束参数
🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Micro麦可乐的博客 🐥《Docker实操教程》专栏以最新的Centos版本为基础进行Docker实操教程,入门到实战 🌺《RabbitMQ》…...

labview的VI密码破解程序
上图即为密码破解原理,若需源代码可联系我...

AI技术前沿:蓝耘元生代智算云快速入门教程详解,与其他云人工智能大模型深度对比
文章目录 一、前言二、蓝耘元生代智算云基础概念2.1 什么是智算云2.2 蓝耘元生代智算云的特点 三、蓝耘元生代智算云使用前准备3.1 注册与登录3.2 了解计费方式3.3 熟悉控制台界面 四、在蓝耘元生代智算云上运行第一个任务4.1 创建计算资源4.2 上传代码和数据4.3 安装依赖库4.4…...