DrissionPage详细教程
1. 基本概述
DrissionPage 是一个基于 python 的网页自动化工具。它既能控制浏览器,也能像requests一样收发数据包,更重要的是还能把两者合二为一。因此,简单来说DrissionPage可兼顾浏览器自动化的便利性和 requests 的高效率。
DrissionPage功能强大,内置无数人性化设计和便捷功能。并且它的语法简洁而优雅,代码量少,对新手友好。
2. 环境安装
2.1 运行环境
操作系统:Windows、Linux 或 Mac。
python 版本:3.6 及以上
支持浏览器:Chromium 内核(如 Chrome 和 Edge)
2.2 一键安装
请使用 pip 安装 DrissionPage:
#最新版本安装
pip install DrissionPage
pip install DrissionPage --upgrade3. 快速入门
3.1 页面类
在DrissionPage中有一个非常重要的工具叫做“页面类”,用于控制浏览器和收发数据包。DrissionPage 包含三种主要页面类。根据需要在其中选择使用。
ChromiumPage
如果只要控制浏览器,导入ChromiumPage。
from DrissionPage import ChromiumPageSessionPage
如果只要收发数据包,导入SessionPage。
from DrissionPage import SessionPageWebPage
WebPage是功能最全面的页面类,既可控制浏览器,也可收发数据包。
from DrissionPage import WebPage3.2 控制浏览器
如果要控制浏览器,需设置浏览器路径。程序默认设置控制 Chrome,所以下面用 Chrome 演示。
3.2.1 尝试启动浏览器
默认状态下,程序会自动在系统内查找 Chrome 路径。
执行以下代码,浏览器启动并且访问了相关网站,如果访问执行成功说明可直接使用,跳过后面的步骤即可。
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.get('https://www.baidu.com')3.2.2 设置浏览器驱动路径
如果上面的步骤提示出错,说明程序没在系统里找到 Chrome 浏览器。
可用以下其中一种方法设置,设置会持久化记录到默认配置文件,之后程序会使用该设置启动。
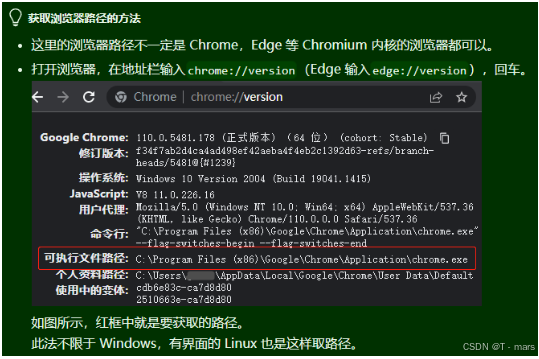
-
方法1:
-
新建一个临时 py 文件,并输入以下代码,填入您电脑里的 Chrome 浏览器可执行文件路径,然后运行。
from DrissionPage import ChromiumOptions path = r'D:\Chrome\Chrome.exe' # 请改为你电脑内Chrome可执行文件路径 ChromiumOptions().set_browser_path(path).save()这段代码会把浏览器路径记录到配置文件,今后启动浏览器皆以新路径为准。
另外,如果是想临时切换浏览器路径以尝试运行和操作是否正常,可以去掉
.save(),以如下方式结合第1️⃣步的代码。from DrissionPage import ChromiumPage, ChromiumOptions path = r'D:\Chrome\Chrome.exe' # 请改为你电脑内Chrome可执行文件路径 co = ChromiumOptions().set_browser_path(path) page = ChromiumPage(co) page.get('http://DrissionPage.cn')
-
-
方法2:
-
在命令行输入以下命令(路径改成自己电脑里的):
dp -p D:\Chrome\chrome.exe
-
现在,请重新执行第1️⃣步的代码,如果正确访问了目标网址,说明已经设置完成。
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.get('https://www.baidu.com')3.2.3 控制浏览器
现在,我们通过一些例子,来直观感受一下 DrissionPage 的工作方式。
本示例演示使用ChromiumPage控制浏览器登录 gitee 网站。
from DrissionPage import ChromiumPage
# 创建页面对象,并启动浏览器
page = ChromiumPage()
# 跳转到登录页面
page.get('https://gitee.com/login')
# 定位到账号文本框,获取文本框元素
ele = page.ele('#user_login')
# 输入对文本框输入账号
ele.input('您的账号')
# 定位到密码文本框并输入密码
page.ele('#user_password').input('您的密码')
# 点击登录按钮:@attrName=value,这是根据属性和属性值进行标签定位的方式
page.ele('@value=登 录').click()注意:ele()方法用于查找元素,它返回一个ChromiumElement对象,用于操作元素。值得一提的是,ele()内置了等待,如果元素未加载,它会执行等待,直到元素出现或到达时限。默认超时时间 10 秒。
3.3 收发数据包
本示例演示用SessionPage已收发数据包的方式采集 gitee 网站数据。这个示例的目标,要获取所有库的名称和链接,为避免对网站造成压力,我们只采集 3 页。网址:热门项目 - Gitee.com
from DrissionPage import SessionPage# 创建页面/请求对象
page = SessionPage()
# 爬取3页
for i in range(1, 4):# 访问某一页的网页page.get(f'https://gitee.com/explore/all?page={i}')# 获取所有开源库<a>元素列表(所有库的链接的a标签的class属性值都是一样的)links = page.eles('.title project-namespace-path')# 遍历所有<a>元素for link in links:# 打印链接信息:print(link.text, link.link).text获取元素的文本,.link获取元素的href或src属性。
3.4 模式切换
这个示例演示WebPage如何切换控制浏览器和收发数据包两种模式。
通常,切换模式是用来应付登录检查很严格的网站,可以用控制浏览器的形式处理登录,再转换模式用收发数据包的形式来采集数据。
需求:基于浏览器控制模式进行gitee的登陆,登录成功后切换模式基于收发数据包的性质访问该账户的个人主页,获取该账户主页左下角所有的组织名称。
from DrissionPage import ChromiumOptions
from DrissionPage import WebPage
# 创建页面对象
page = WebPage()
# 访问网址,进行登录
page.get('https://gitee.com/login?redirect_to_url=%2F')
# 定位到账号文本框,获取文本框元素
ele = page.ele('#user_login')
# 输入对文本框输入账号
ele.input('1xxx535')
# 定位到密码文本框并输入密码
page.ele('#user_password').input('bxxx35')
# 点击登录按钮:@attrName=value,这是根据属性和属性值进行标签定位的方式
page.ele('@value=登 录').click()
# 切换到收发数据包模式
page.change_mode() #切换的时候程序会在新模式重新访问当前 url。
#切换模式后,重新访问基于登录状态后新的url(个人主页)
page.get('https://gitee.com/Mr_bobo')
# 根据class属性值获取div标签,然后将该div下面class为item的元素标签批量获取
items = page.ele('.ui middle aligned list').eles('.item')
# 遍历获取到的元素
for item in items:# 打印元素文本print(item('.content').text)4. ChromiumPage详解
顾名思义,ChromiumPage是 Chromium 内核浏览器的页面,使用它,我们可与网页进行交互,如调整窗口大小、滚动页面、操作弹出框等等。还可以跟页面中的元素进行交互,如输入文字、点击按钮、选择下拉菜单、在页面或元素上运行 JavaScript 代码等等。
可以说,操控浏览器的绝大部分操作,都可以由ChromiumPage及其衍生的对象完成,而它们的功能,还在不断增加。除了与页面和元素的交互,ChromiumPage还扮演着浏览器控制器的角色,可以说,一个ChromiumPage对象,就是一个浏览器。
4.1 启动和接管浏览器
用ChromiumPage()创建页面对象。根据不同的配置,可以接管已打开的浏览器,也可以启动新的浏览器。程序结束时,被打开的浏览器不会主动关闭,以便下次运行程序时使用(由 VSCode 启动的会被关闭)。
4.1.1 启动浏览器
这种方式代码最简洁,程序会使用默认配置,自动生成页面对象。创建ChromiumPage对象时会在指定端口启动浏览器。默认情况下,程序使用 9222 端口。
from DrissionPage import ChromiumPage
page = ChromiumPage()指定端口启动浏览器:
# 启动9333端口的浏览器,如该端口空闲,启动一个浏览器
page = ChromiumPage(9333)4.1.2 接管浏览器
当页面对象创建时,只要指定的端口port已有浏览器在运行,就会直接接管。无论浏览器是哪种方式启动的。比如:先通过如下代码启动一个端口为8888的浏览器
from DrissionPage import ChromiumPage
page = ChromiumPage(8888)在启动的端口为8888的浏览器中,手动访问百度页面,然后使用如下程序测试是否可以接管该浏览器:
from DrissionPage import ChromiumPage
page = ChromiumPage(8888)
#打印接管浏览器的page标题和访问的url
print(page.title,page.url)4.1.3 多浏览器共存
如果想要同时操作多个浏览器,或者自己在使用其中一个上网,同时控制另外几个浏览器跑自动化,就需要给这些被程序控制的浏览器设置单独的端口和用户文件夹,否则会造成冲突。
from DrissionPage import ChromiumPage, ChromiumOptions
# 创建多个配置对象,每个指定不同的端口号和用户文件夹路径
do1 = ChromiumOptions().set_paths(local_port=9111, user_data_path=r'D:\data1')
do2 = ChromiumOptions().set_paths(local_port=9222, user_data_path=r'D:\data2')
# 创建多个页面对象
page1 = ChromiumPage(addr_or_opts=do1)
page2 = ChromiumPage(addr_or_opts=do2)
# 每个页面对象控制一个浏览器
page1.get('https://www.baidu.com')
page2.get('http://www.163.com')4.2 页面交互
-
get():该方法用于跳转到一个网址。当连接失败时,程序会进行重试。
page.get('https://www.baidu.com') -
back():此方法用于在浏览历史中后退若干步。
page.back(2) # 后退两个网页 -
forward():此方法用于在浏览历史中前进若干步。
page.forward(2) # 前进两步 -
refresh():此方法用于刷新当前页面。
page.refresh() # 刷新页面 -
run_js():此方法用于执行 js 脚本。
# 用传入参数的方式执行 js 脚本显示弹出框显示 Hello world! #参数1:执行的js脚本。参数2:*args表示给js脚本传递的参数 page.run_js('alert(arguments[0]+arguments[1]);', 'Hello', ' world!') -
run_js_loaded():此方法用于运行 js 脚本,执行前等待页面加载完毕。
page.run_js_loaded('alert(arguments[0]+arguments[1]);', 'Hello', ' world!') -
scroll.to_bottom():此方法用于滚动页面到底部,水平位置不变。
page.scroll.to_bottom()
4.3 查找元素
本节介绍 DrissionPage 自创的查找元素语法。
查找语法能用于指明以哪种方式去查找指定元素,定位语法简洁明了,熟练使用可大幅提高程序可读性。
以下使用这个页面进行讲解test.html(可以在pycharm中使用chrome打开该页面获取页面链接):
<html>
<body>
<div id="one"><p class="p_cls" id="row1" data="a">第一行</p><p class="p_cls" id="row2" data="b">第二行</p><p class="p_cls">第三行</p>
</div>
<div id="two">第二个div
</div>
</body>
</html>基本定位语法:注意下面的ele和eles
page.ele:只能定位满足要求第一次出现的标签
page.eles:定位到满足要求所有的标签
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.get('http://localhost:63342/Code/test.html?_ijt=chuqtur5cikh95asobefg123mf')
#id属性定位
tag1 = page.ele('@id=one') # 获取第一个id为one的元素
#文本定位
tag2 = page.ele('@text()=第一行') # 获取第一个文本为“第一行”的元素
#当需要多个条件同时确定一个元素时,每个属性用'@@'开头。
tag3 = page.ele('@@class=p_cls@@text()=第三行') # 查找class为p_cls且文本为“第三行”的元素
#当需要以或关系条件查找元素时,每个属性用'@|'开头。
tag4 = page.eles('@|id=row1@|id=row2') # 查找所有id为row1或id为row2的元素
#表示模糊匹配,匹配含有指定字符串的文本或属性。
tag5 = page.eles('@id:ow') # 获取id属性包含'ow'的元素
#表示匹配开头,匹配开头为指定字符串的文本或属性。
tag6 = page.eles('@id^row') # 获取id属性以'row'开头的元素
#表示匹配结尾,匹配结尾为指定字符串的文本或属性。
tag7 = page.ele('@id$w1') # 获取id属性以'w1'结尾的元素
print(tag7)选择器定位语法
id选择器定位:
ele1 = page.ele('#one') # 查找id为one的元素
ele2 = page.ele('#=one') # 和上面一行一致
ele3 = page.ele('#:ne') # 查找id属性包含ne的元素
ele4 = page.ele('#^on') # 查找id属性以on开头的元素
ele5 = page.ele('#$ne') # 查找id属性以ne结尾的元素class选择器定位:
e1 = page.ele('.p_cls') # 查找class属性为p_cls的元素
e2 = page.ele('.=p_cls') # 与上一行一致
e3 = page.ele('.:_cls') # 查找class属性包含_cls的元素
e4 = page.ele('.^p_') # 查找class属性以p_开头的元素
e5 = page.ele('.$_cls') # 查找class属性以_cls结尾的元素文本选择器定位:
element1 = page.ele('text=第二行') # 查找文本为“第二行”的元素
element2 = page.ele('text:第二') # 查找文本包含“第二”的元素
element3 = page.ele('第二') # 与上一行一致标签选择器定位:
ele1 = page.ele('tag:div') # 查找第一个div元素
ele2 = page.ele('tag:p@class=p_cls') # 与单属性查找配合使用
ele3 = page.ele('tag:p@@class=p_cls@@text()=第二行') # 与多属性查找配合使用xpath定位:
eles = page.eles('xpath://div/p[@id="row1"]')4.4 获取元素信息
| 属性或方法 | 说明 |
|---|---|
html | 此属性返回元素的 HTML 文本(不包括<iframe>内容) |
inner_html | 此属性返回元素内部的 HTML 文本 |
tag | 此属性返回元素的标签名 |
text | 此属性返回元素内所有文本组合成的字符串 |
texts() | 此方法返回元素内所有直接子节点的文本(列表) |
attrs | 此属性以字典形式返回元素所有属性及值 |
attr('attrName') | 此方法返回元素某个 attribute 属性值 |
link | 此方法返回元素的 href 属性或 src 属性 |
xpath | 此属性返回当前元素在页面中 xpath 的绝对路径 |
元素列表中批量获取信息
eles()等返回的元素列表,自带get属性,可用于获取指定信息。
from DrissionPage import SessionPage
page = SessionPage()
page.get('https://www.baidu.com')
eles = page.ele('#s-top-left').eles('t:a')
print(eles.get.texts()) # 获取所有元素的文本
print(eles.get.links()) # 获取所有元素的链接
print(eles.get.attrs("class")) # 获取所有元素的指定属性值5. SessionPage详解
顾名思义,SessionPage是一个使用Session(requests 库)对象的页面,且它还封装了网络连接和 html 解析功能,使收发数据包也可以像操作页面一样便利。
并且,由于加入了本库独创的查找元素方法,使数据的采集便利性远超 requests + beautifulsoup 等组合。
获取 gitee 推荐项目第一页所有项目。
# 导入
from DrissionPage import SessionPage
# 创建页面对象
page = SessionPage()
# 访问网页
page.get('https://gitee.com/explore/all')
# 在页面中查找元素
items = page.eles('tag:h3')
# 遍历元素
for item in items[:-1]:# 获取当前<h3>元素下的<a>元素lnk = item('tag:a')# 打印<a>元素文本和href属性print(lnk.text, lnk.link)5.1 get请求
get()方法语法与 requests 的get()方法一致,在此基础上增加了连接失败重试功能。与 requests 不一样的是,它不返回Response对象,而是返回一个bool值,表示请求是否成功。
示例:请求51游戏指定关键字对应的搜索结果页面
from DrissionPage import SessionPage
page = SessionPage()
url = 'https://game.51.com/search/action/game/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
cookies = {'name': 'value'}
# proxies = {'http': '127.0.0.1:1080', 'https': '127.0.0.1:1080'}
param = {"q":'传奇'}
page.get(url, headers=headers, cookies=cookies,params=param,proxies=None)
print(page.html,page.title)其他参数:
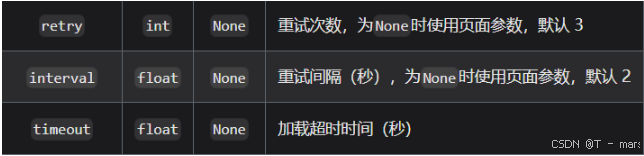
5.2 post请求
请求:中国人事考试网---站内搜索:中国人事考试网
from DrissionPage import SessionPage
page = SessionPage()
url = 'http://www.cpta.com.cn/category/search'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'}
cookies = {'name': 'value'}
# proxies = {'http': '127.0.0.1:1080', 'https': '127.0.0.1:1080'}
data = {"keywords":'财务','搜索':'搜索'}
page.post(url, headers=headers, cookies=cookies,data=data,proxies=None)
print(page.html,page.title)注意:在get和post请求中,headers中的User-Agent可以不写,因为SessionPage和WebPage在创建页面对象时会自动加载一个ini的配置文件,该配置文件中已经存在了User-Agent。
ini 文件初始内容如下:
......
[session_options]
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'connection': 'keep-alive', 'accept-charset': 'GB2312,utf-8;q=0.7,*;q=0.7'}
[timeouts]
base = 10
page_load = 30
script = 30
[proxies]
http =
https =
[others]
retry_times = 3
retry_interval = 25.3 page对象常用属性
url:此属性返回当前访问的 url。
title:此属性返回当前页面title文本。
raw_data:此属性返回访问到的二进制数据,即Response对象的content属性。
html:此属性返回当前页面 html 文本。
json:此属性把返回内容解析成 json。比如请求接口时,若返回内容是 json 格式,用html属性获取的话会得到一个字符串,用此属性获取可将其解析成dict。相关文章:

DrissionPage详细教程
1. 基本概述 DrissionPage 是一个基于 python 的网页自动化工具。它既能控制浏览器,也能像requests一样收发数据包,更重要的是还能把两者合二为一。因此,简单来说DrissionPage可兼顾浏览器自动化的便利性和 requests 的高效率。 DrissionPa…...

6.1 GitHub亿级数据采集实战:双通道架构+三级容灾设计,破解API限制与反爬难题
GitHub 项目数据获取功能设计与实现 关键词:GitHub API 集成、网页爬虫开发、数据存储设计、定时任务调度、异常处理机制 1. 数据获取架构设计 采用双通道数据采集策略,同时使用 GitHub 官方 API 和网页爬虫技术确保数据完整性: #mermaid-svg-XUg7xhHrzFAozG4J {font-fami…...

LabVIEW 控制电机需注意的关键问题
在自动化控制系统中,LabVIEW 作为图形化编程平台,因其高度可视化、易于集成硬件等优势,被广泛应用于电机控制场景。然而,要实现稳定、精确、高效的电机控制,仅有软件并不足够,还需结合硬件选型、控制逻辑设…...

Linux系统远程操作和程序编译
目录 一、Linux远程终端登录、图形桌面访问、 X图形窗口访问和FTP文件传输操作 1.1 桥接模式 1.2 putty远程登录Ubuntu 1.3 win10远程登录并上传下载文件 1.4 X server仿真软件安装 1.5 树莓派在putty上的远程登录 1.6 使用ftp远程登录并实现文件上传下载 1.7 Linux下的…...

Mac配置开发环境
博主是一名Python后端开发,有时候环境太多 需要配置太多,故做此文章 环境Macbook ,请注意自己的是ARM 还是x86 结构 Vscode/Cursor配置Python debug 配置Debug launch.json {"version": "0.2.0","configuratio…...

LabVIEW配电器自动测试系统
随着航天技术的迅猛发展,航天器供配电系统的结构越来越复杂,对配电器的功能完整性、稳定性和可靠性提出了更高要求。传统人工测试方式难以满足高效率、高精度、可重复的测试需求。本项目开发了一套基于LabVIEW平台的宇航配电器自动测试系统,融…...

生成与强化学习:赋予VLA系统物理行动能力
引言:从“理解世界”到“改变世界” 当机器能够“看懂”图像、“听懂”指令时,一个更根本的挑战浮现:如何让它们像人类一样,将认知转化为精准的物理动作?无论是机械臂抓取杯子,还是自动驾驶汽车紧急避障&a…...
)
基于Springboot+Mysql的闲一品(含LW+PPT+源码+系统演示视频+安装说明)
系统功能 管理员功能:首页、个人中心、用户管理、零食分类管理、零食信息管理、订单评价管理、系统管理、订单管理。用户功能:首页、个人中心、订单评价管理、我的收藏管理、订单管理。前台首页功能:首页、零食信息、零食资讯、个人中心、后…...

jupyter4.4安装使用
一、chrome谷歌浏览器 1. 安装 1.1 下载地址: 下载地址: https://www.google.cn/intl/zh-CN_ALL/chrome/fallback/ 2 插件markdown-viewer 2.1 下载地址: 下载地址:https://github.com/simov/markdown-viewer/releases 2.2…...

Linux虚拟内存详解
引言 虚拟内存是现代操作系统中的核心概念之一,它为进程提供了一个连续的、独立的地址空间,有效解决了物理内存限制问题,并大大简化了程序开发和执行。本文将深入探讨Linux系统中虚拟内存的工作原理、实现机制以及相关的内存管理技术&#x…...
(保姆级教程))
数据库安装(基于Linux下centos7)(保姆级教程)
前言:笔者有段时间没写博客了,今天笔者要分享新的知识了,那就是数据库,笔者会通过博客系统的且通俗易懂的分享数据库知识,对于想要学习数据库和学习过数据库的老铁复习都是非常有用的,绝对干货满满,那么今天…...

【自动驾驶 机器人】速度规划 |梯形/S型速度曲线
参考文章: (1)【自动驾驶】运动规划丨速度规划丨T型/S型速度曲线 (2)一文教你快速搞懂速度曲线规划之S形曲线(超详细图文推导附件代码) 1 梯形速度曲线 如下图所示梯形速度/加速度/加加速度曲…...

Qt C++内存泄漏排查方法
在Qt C++中排查内存泄漏可以按照以下步骤进行,结合工具使用和代码审查: 1. 使用内存检测工具 Valgrind (Linux/macOS) 安装Valgrind:sudo apt-get install valgrind运行程序并检测内存泄漏:valgrind --leak-check=full ./your_qt_app分析输出结果,定位未释放的内存块。Dr…...
AOF篇章)
[redis进阶一]redis的持久化(2)AOF篇章
目录 一 为什么有了RDB持久化机制还要有AOF呢 板书介绍具体原因: 编辑二 详细讲解AOF机制 (1)AOF的基本使用 1)板书如下 2)开启AOF机制: 3) AOF工作流程 (2)AOF是否会影响到redis性能 编辑 (3)AOF缓冲区刷新策略 (4)AOF的重写机制 板书如下: 为什么要有这个重写机…...
)
聊天室项目day4(redis实现验证码期限,实现redis连接池)
1.redis连接池操作和之前所学过的io_context连接池原理一样这里不多赘述,也是创建多个连接,使用时按顺序取出来。 2.知识补充redisConnect()函数建立与 Redis 服务器的非阻塞网络连接,成功返回 redisContext*(连接上下文指针&…...

Redis之分布式锁
面试切入点 锁的分类 单机版同一个JVM虚拟机内,synchronized或者Lock接口分布式多个不同JVM虚拟机,单机的线程锁不再起作用,资源类在不同的服务器之间共享了 一个靠谱分布式锁需要具备的条件与刚需 独占性:onlyOneÿ…...

AF3 ProteinDataset类的__getitem__方法解读
AlphaFold3 protein_dataset 模块 ProteinDataset 类 __getitem__ 方法用于从数据集中获取一个条目,并根据配置对数据进行处理。 源代码: def __getitem__(self, idx):"""Return an entry from the dataset.If a clusters file is provided, then the idx i…...

NLP 梳理02 — 标点符号和大小写
文章目录 一、说明二、为什么文本预处理中需要小写2.1 为什么小写在文本预处理中至关重要?2.2 区分大小写对 NLP 任务的影响 三、删除标点符号及其对 NLP 任务的影响3.1 什么是标点符号?3.2 为什么在文本预处理中删除标点符号?3.3 删除标点符…...

HarmonyOS中的多线程并发机制
目录 多线程并发1. 多线程并发概述2 多线程并发模型3 TaskPool简介4 Worker简介4.1 Woker注意事项4.2 Woker基本用法示例 5. TaskPool和Worker的对比5.1 实现特点对比5.2 适用场景对比 多线程并发 1. 多线程并发概述 并发模型是用来实现不同应用场景中并发任务的编程模型&…...
)
游戏引擎学习第221天:(实现多层次过场动画)
资产: intro_art.hha 已发布 在下载页面,你会看到一个新的艺术包。你将需要这个艺术包来进行接下来的开发工作。这个艺术包是由一位艺术家精心制作并打包成我们设计的格式,旨在将这些艺术资源直接应用到游戏中。它包含了许多我们会在接下来的直播中使用…...

Python | 在Pandas中按照中值对箱形图排序
箱形图是可视化数据分布的强大工具,因为它们提供了对数据集内的散布、四分位数和离群值的洞察。然而,当处理多个组或类别时,通过特定的测量(如中位数)对箱形图进行排序可以提高清晰度并有助于揭示模式。在本文中&#…...

openapi + knife4j的使用
一、依赖作用与关系 1. springdoc-openapi-starter-webmvc-api • 核心功能: 基于 OpenAPI 3 规范,自动生成 API 文档元数据(JSON 格式),并集成 Spring MVC。 提供Tag Operation、Schema 等注解,支持通过…...

数据结构*包装类泛型
包装类 什么是包装类 在讲基本数据类型的时候,有提到过包装类。 基本数据类型包装类byteByteshortShortintIntegerlongLongfloatFloatdoubleDoublecharCharacterbooleanBoolean 我们知道:基本数据类型并不是对象,没有对象所具有的方法和属…...

Azure Synapse Dedicated SQL pool里大型表对大型表分批合并数据的策略
Azure Synapse Dedicated SQL pool中大型表的数据通过MERGE INTO语句合并到另一张大型表的时间很长,容易造成运行超时,而有的时候超时的时间是管理设置,由客户控制,无法修改。这种时候为了确保操作可以运行成功,需要将…...

Day81 | 灵神 | 快慢指针 链表的中间结点 环形链表
Day81 | 灵神 | 快慢指针 链表的中间结点 环形链表 876.链表的中间结点 876. 链表的中间结点 - 力扣(LeetCode) 思路: 设置两个指针,一个快指针r一个慢指针l 初始都是头结点 我们要求的是中间节点 所以快指针走两步&#x…...

【DDR 内存学习专栏 1.2 -- DDR Channel 介绍】
文章目录 1. DDR中的通道(Channel)概念1.1 DDR Channel 与 DDRC1.2 DIMM 内存插槽1.3 物理通道的定义1.3.1 多通道的作用 1.4 通道的硬件实现1.5 多核系统的DDR通道分配策略 1. DDR中的通道(Channel)概念 关于 DDR 通道ÿ…...

深入解析xDeepFM:结合压缩交互网络与深度神经网络的推荐系统新突破
今天是周日,我来解读一篇有趣的文章——xDeepFM。这篇文章由 Mao et al. 发表在SIGIR 2019会议。文章提出了一个新的网络模型——压缩交互网络(CIN),用于显式地学习高阶特征交互。通过结合 CIN 和传统的深度神经网络(D…...

Mybatis 中 <mappers> 标签四种配置方式
在MyBatis中,我们可以通过四种不同的方式来配置Mappers标签 : 1. 使用 <package name=""> 批量扫描包 这种方式通过指定一个包名,MyBatis 会自动扫描该包下的所有接口并注册为映射器。 <mappers><package name="com.example.mapper"/&…...

科技赋能记忆共生-郑州
故事背景 故事发生在中国河南郑州的现代城市环境中,这里描绘了人与科技的交融与共生。多样的场景展示了人与自然、历史与未来的互动,通过各种科技手段与古老文化相结合,展现出未来城市的独特魅力。 故事内容 在中国河南郑州,一座科…...

根据开始日期和结束日志统计共有多少天和每天的营业额
controller 重点:根据时间格式接受时间类型参数 DateTimeFormat(pattern "yyyy-MM-dd") LocalDateTime begin, DateTimeFormat(pattern "yyyy-MM-dd") LocalDateTime end) RestController RequestMapping("/admin/report") Slf4…...

LLMs之Agent之A2A:A2A的简介、安装和使用方法、案例应用之详细攻略
LLMs之Agent之A2A:A2A的简介、安装和使用方法、案例应用之详细攻略 目录 相关文章 LLMs之Agent之A2A:《Announcing the Agent2Agent Protocol (A2A)》翻译与解读 LLMs之Agent之A2A:A2A的简介、安装和使用方法、案例应用之详细攻略 A2A协议…...

深入学习OpenCV:第一章简介
本专栏为零基础开发者打造,聚焦OpenCV在Python中的高效应用,用100%代码实践带你玩转图像处理! 从 环境配置到实战项目,内容涵盖: 1️⃣ 基础篇:图像读写、阈值处理、色彩空间转换 2️⃣ 进阶篇ÿ…...

汉诺塔问题——用贪心算法解决
目录 一:起源 二:问题描述 三:规律 三:解决方案 递归算法 四:代码实现 复杂度分析 一:起源 汉诺塔(Tower of Hanoi)问题起源于一个印度的古老传说。在世界中心贝拿勒斯&#…...

【双指针】专题:LeetCode 283题解——移动零
移动零 一、题目链接二、题目三、题目解析四、算法原理两个指针的作用以及三个区间总结 五、与快速排序的联系六、编写代码七、时间复杂度、空间复杂度 一、题目链接 移动零 二、题目 三、题目解析 “保持非零元素的相对顺序”,比如,示例1中非零元素1…...

2025-4-12-C++ 学习 XOR 三元组 异或 急转弯问题
C的学习必须更加精进一些,对于好多的函数和库的了解必须深入一些。 文章目录 3513. 不同 XOR 三元组的数目 I题解代码 3514. 不同 XOR 三元组的数目 II题解代码 晚上,10点半,参加了LC的竞赛,ok了一道,哈哈~ 第二道…...

[MySQL] 索引
索引 1.为什么有索引?2.MySQL的存储(MySQL与磁盘交互的基本单位)3.小总结4.索引的进一步理解4.1测试案例4.2 理解单个page4.3 理解多个page页目录单页情况多页情况 4.4 B树 VS B树4.5 聚簇索引 VS 非聚簇索引1.非聚簇索引2.聚簇索引 5.索引操…...

软考高级--案例分析
架构风格 重点 交互方式数据结构控制结构扩展方法 分类 管道-过滤器风格 数据流 数据仓储风格 星型结构以数据为中心,其他构件围绕数据进行交互 企业服务总线esb 定义 以一个服务总线充当中间件的角色,把各方服务对接起来,所有服务…...

Go - 内存逃逸
概念 每个函数都有自己的内存区域来存放自己的局部变量、返回地址等,这个内存区域在栈中进行分配。当函数结束时,这段内存区域会进行释放。 但有些变量,我们想在函数结束后仍然使用它,那么就要把这个变量在堆上分配,这…...

【数字电路】第四章 组合逻辑电路
一、组合逻辑电路的概述 1.逻辑电路的分类 2.逻辑功能的描述 二、组合逻辑电路的分析方法 根据输出可以粗略判断输入的数值的大小。 三、组合逻辑电路的基本设计方法 1.进行逻辑抽象 2.写出逻辑函数式 3.逻辑函数的化简或变换 4.画出逻辑电路图 5.设计验证与工艺设计 转换为…...

提权实战!
就是提升权限,当我们拿到一个shell权限较低,当满足MySQL提权的要求时,就可以进行这个提权。 MySQL数据库提权(Privilege Escalation)是指攻击者通过技术手段,从低权限的数据库用户提升到更高权限ÿ…...

单双线程的理解 和 lua基础语法
1.什么是单进程 ,什么是多进程 当一个程序开始运行时,它就是一个进程,进程包括运行中的程序和程序所使用到的内存和系统资源。而一个进程又是由单个或多个线程所组成的。 1.1 像apache nginx 这类 服务器中间件就是多进程的软件 ࿰…...
)
深度学习(对抗)
数据预处理:像素标记与归一化 在 GAN 里,图像的确会被分解成一个个像素点来处理。在你的代码里,transform transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]) 这部分对图像进行了预处理: tra…...

【NLP】 18. Tokenlisation 分词 BPE, WordPiece, Unigram/SentencePiece
1. 翻译系统性能评价方法 在机器翻译系统性能评估中,通常既有人工评价也有自动评价方法: 1.1 人工评价 人工评价主要关注以下几点: 流利度(Fluency): 判断翻译结果是否符合目标语言的语法和习惯。充分性…...

详解MYSQL表空间
目录 表空间文件 表空间文件结构 行格式 Compact 行格式 变长字段列表 NULL值列表 记录头信息 列数据 溢出页 数据页 当我们使用MYSQL存储数据时,数据是如何被组织起来的?索引又是如何组织的?在本文我们将会解答这些问题。 表空间文…...
)
lwip移植基于freertos(w5500以太网芯片)
目录 一、背景二、lwip移植基于w5500(MACPHY,数据链路层和物理层)1.移植需要的相关文件2、协议栈层级调用3、w5500关键初始化说明 三、附录 一、背景 1.OSI七层模型 图片来自网络 lwip协议栈工作在应用层、传输层、网络层; 网卡…...

【TI MSPM0】IQMath库学习
一、与DSP库的区别 二、IQMath库详解 RTS是靠纯软件实现的,而MathACL是靠硬件加速,速度更快 三、工程详解 1.导入工程 2.样例详解 使用一系列的运算来展示IQMath库,使用的是MathACL实现版本的IQMath库 编译加载运行,结果变量叫…...

51单片机 光敏电阻5506与ADC0832驱动程序
电路图 5506光敏电阻光强增加电阻值减小 以上电路实测无光时电压1.5v 有光且较亮时电压2.7v。 转换程序和ADC0832程序如下 // ADC0832引脚定义 sbit ADC_CS P1^2; // 片选信号 sbit ADC_CLK P1^0; // 时钟信号 sbit ADC_DIO P1^1; // 数据线// 获取电压值 - 返回c…...

【Linux】进程创建、进程终止、进程等待
Linux 1.进程创建1.fork 函数2.写时拷贝3.为什么要有写时拷贝? 2.进程终止1.进程退出场景2.退出码3.进程常见退出方法1.main函数return2.exit库函数3._exit系统调用 3.进程等待1.概念2.必要性3.方法1.wait2.waitpid3.参数status4.参数option5.非阻塞轮询 1.进程创建…...

ReliefF 的原理
🌟 ReliefF 是什么? ReliefF 是一种“基于邻居差异”的特征选择方法,用来评估每个特征对分类任务的贡献大小。 它的核心问题是: “我怎么知道某个特征是不是重要?是不是有能力把不同类别的数据区分开?” 而…...

C++ 数据结构之图:从理论到实践
一、图的基本概念 1.1 图的定义与组成 图(Graph)由顶点(Vertex)和边(Edge)组成,形式化定义为: G (V, E) 顶点集合 V:表示实体(如城市、用户) …...