《Python星球日记》第27天:Seaborn 可视化
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
专栏:《Python星球日记》,限时特价订阅中ing
目录
- 一、Seaborn 简介
- 1. Seaborn 与 Matplotlib 的区别
- 2. 安装与导入
- 二、高级绘图
- 1. 分布图:探索数据分布
- Histplot():组合直方图和密度曲线
- 双变量分布图
- 2. 关系图:探索变量关系
- scatterplot():散点图
- lineplot():折线图
- 带置信区间的线图
- 3. 分类图:比较分组数据
- boxplot():箱线图
- violinplot():小提琴图
- 配对的分类图
- 三、图形组合
- 1. 使用 FacetGrid 绘制多个子图
- 使用FacetGrid绘制不同类型的图
- 2. 成对关系图:pairplot()
- 3. 自定义配色方案
- 使用预设调色板
- 自定义连续调色板
- 在图表中应用自定义调色板
- 四、实战练习:多维度数据分析
- 1. 数据准备与探索
- 2. 多维度可视化分析
- 价格与克拉数的关系
- 不同切工质量的价格分布
- 使用FacetGrid创建多个维度的关系图
- 多变量联合分布
- 成对关系分析
- 3. 价格预测因素分析
- 五、总结与拓展
- 1. 核心要点回顾
- 2. Seaborn优势总结
- 3. 进阶学习方向
- 4. 学习资源推荐
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: Python星球日记 - 第22天:NumPy 基础
欢迎来到Python星球日记第27天🪐!
今天我们将探索Seaborn,一个建立在Matplotlib基础上的高级统计数据可视化库。Seaborn提供了更优雅的界面、更美观的默认样式和更专业的统计图表,让我们能够轻松创建出令人印象深刻的数据可视化作品。
一、Seaborn 简介
1. Seaborn 与 Matplotlib 的区别
Seaborn是一个基于Matplotlib的Python数据可视化库,专注于统计数据的可视化。虽然Matplotlib提供了绘图的基础功能,但Seaborn在此基础上进行了多方面的增强和优化:
- 更美观的默认样式:Seaborn默认就提供了现代、专业的视觉风格,颜色协调且具有可读性
- 更高级的统计图表:内置了多种统计图形,如小提琴图、联合分布图、成对关系图等
- 更简洁的API:通过更少的代码就能创建复杂的可视化效果
- 集成数据结构支持:与Pandas和NumPy深度集成,可直接使用DataFrame作为输入
- 自动处理分类变量:能够自动处理分类变量的映射和标签
- 内置调色板:提供专业的配色方案,适用于各种数据可视化需求
简单来说,Matplotlib是一个全能的底层绘图库,几乎可以绘制任何图形,但需要较多的代码来调整和美化;而Seaborn则是一个专注于统计可视化的高级库,提供了更简洁的API和更美观的默认样式,特别适合于数据分析和探索过程中的可视化需求。
2. 安装与导入
安装Seaborn非常简单:
# 使用pip安装
pip install seaborn# 使用conda安装
conda install seaborn

在代码中导入Seaborn:
# 标准导入方式
import seaborn as sns # 通常使用sns作为别名
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
提示:虽然Seaborn是基于Matplotlib构建的,但通常仍需要导入
matplotlib.pyplot,因为某些操作(如调整图表大小、显示图形等)仍需通过Matplotlib完成。
二、高级绘图
Seaborn 提供了多种高级图表类型,主要分为三类:分布图、关系图和分类图。这些图表类型能够帮助我们深入理解数据的分布特征和变量之间的关系。
1. 分布图:探索数据分布
分布图用于可视化 单变量 或 双变量 的分布情况,帮助我们理解数据的集中趋势、离散程度和形状特征。
Histplot():组合直方图和密度曲线
Histplot()是一个便捷的函数,可以同时绘制直方图和密度曲线:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager# 动态加载字体
font_path = r"C:\Windows\Fonts\simhei.ttf"
font_manager.fontManager.addfont(font_path)
prop = font_manager.FontProperties(fname=font_path)plt.rcParams['font.family'] = prop.get_name()
plt.rcParams['axes.unicode_minus'] = False# 设置风格
sns.set_theme(style="whitegrid")# 生成数据
data = np.random.normal(0, 1, 1000)# 绘制直方图并叠加核密度曲线
plt.figure(figsize=(10, 6))
sns.histplot(data,bins=30,kde=True,color="purple",alpha=0.6,line_kws={"color": "darkblue", "lw": 2})plt.title('标准正态分布的Histplot图', fontsize=15)
plt.xlabel('值', fontsize=12)
plt.ylabel('频率/密度', fontsize=12)
plt.show()
可视化效果:

双变量分布图
Seaborn还可以绘制双变量的联合分布图:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager# 动态加载字体
font_path = r"C:\Windows\Fonts\simhei.ttf"
font_manager.fontManager.addfont(font_path)
prop = font_manager.FontProperties(fname=font_path)# 生成双变量数据
x = np.random.normal(0, 1, 1000)
y = x * 0.5 + np.random.normal(0, 1, 1000) # y与x相关# 绘制双变量分布图
plt.figure(figsize=(10, 6))
sns.jointplot(x=x, y=y, kind="scatter", # 类型:"scatter", "kde", "hex"color="teal", # 颜色height=8, # 图形大小ratio=5, # 散点图与边缘分布图的大小比例marginal_kws=dict(bins=25, fill=False)) # 边缘分布图参数plt.suptitle('双变量联合分布图', y=1.02, fontsize=15)
plt.show()
可视化效果:
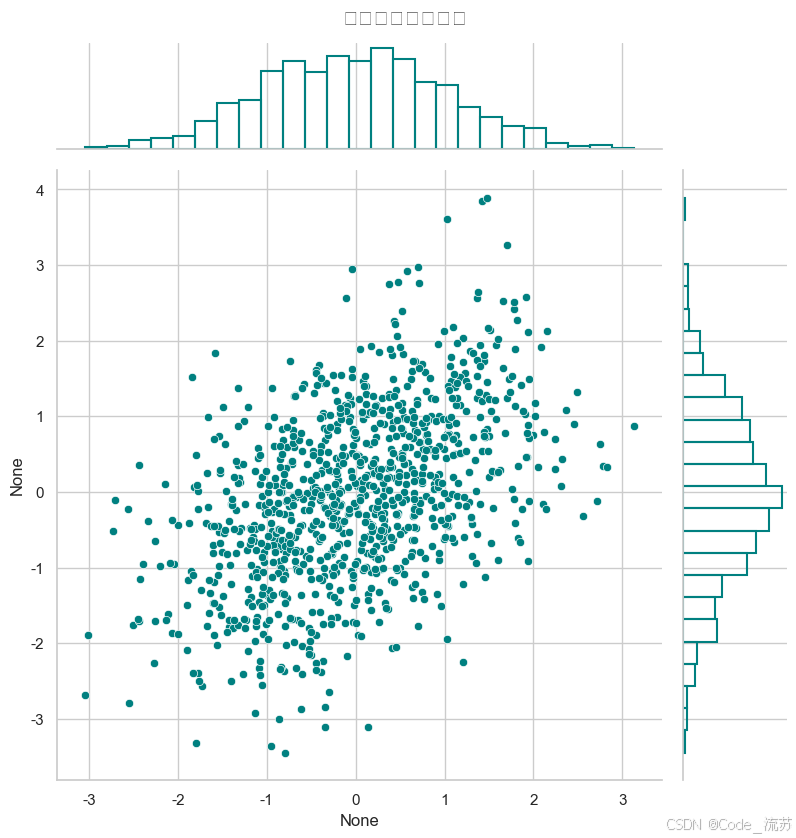
jointplot()可以生成中间的散点图和边缘的分布图,非常适合观察两个变量的联合分布和各自的边缘分布。
2. 关系图:探索变量关系
关系图用于可视化两个或多个变量之间的关系,帮助我们发现数据中的模式、趋势和相关性。
scatterplot():散点图
散点图是观察两个连续变量关系的最基本工具:
import seaborn as sns
import matplotlib.pyplot as plt# 设置中文字体以避免乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 使用内置数据集
tips = sns.load_dataset("tips")# 绘制散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(x="total_bill", y="tip",hue="time", # 按"time"分组着色size="size", # 按"size"调整点大小palette="Set2", # 调色板data=tips) # 数据集# 添加图表标题与轴标签
plt.title('账单金额与小费关系散点图', fontsize=15)
plt.xlabel('账单总额', fontsize=12)
plt.ylabel('小费', fontsize=12)# 显示图表
plt.tight_layout() # 自动调整布局
plt.show()
可视化效果:
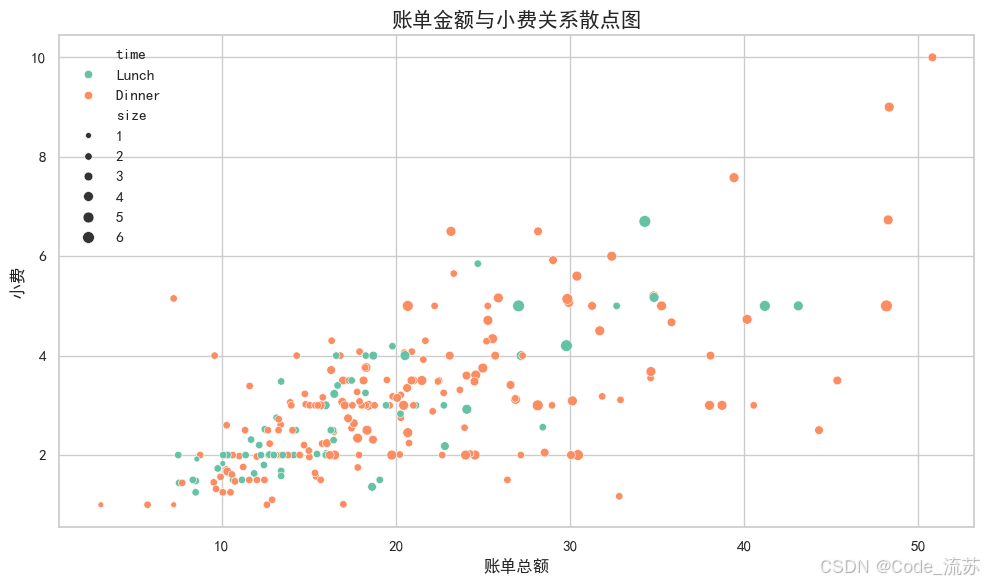
Seaborn的scatterplot()函数比Matplotlib的scatter()更强大,可以直接使用DataFrame,并且能通过hue和size参数轻松添加额外的维度。
lineplot():折线图
折线图适合展示随时间或有序类别变化的趋势:
import seaborn as sns
import matplotlib.pyplot as plt# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 使用内置数据集
flights = sns.load_dataset("flights")# 绘制折线图
plt.figure(figsize=(12, 6))
sns.lineplot(data=flights,x="year", y="passengers", hue="month", # 按月份分组palette="tab10") # 调色板plt.title('1949-1960年各月航班乘客数量趋势', fontsize=15)
plt.xlabel('年份', fontsize=12)
plt.ylabel('乘客数量', fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
可视化效果:
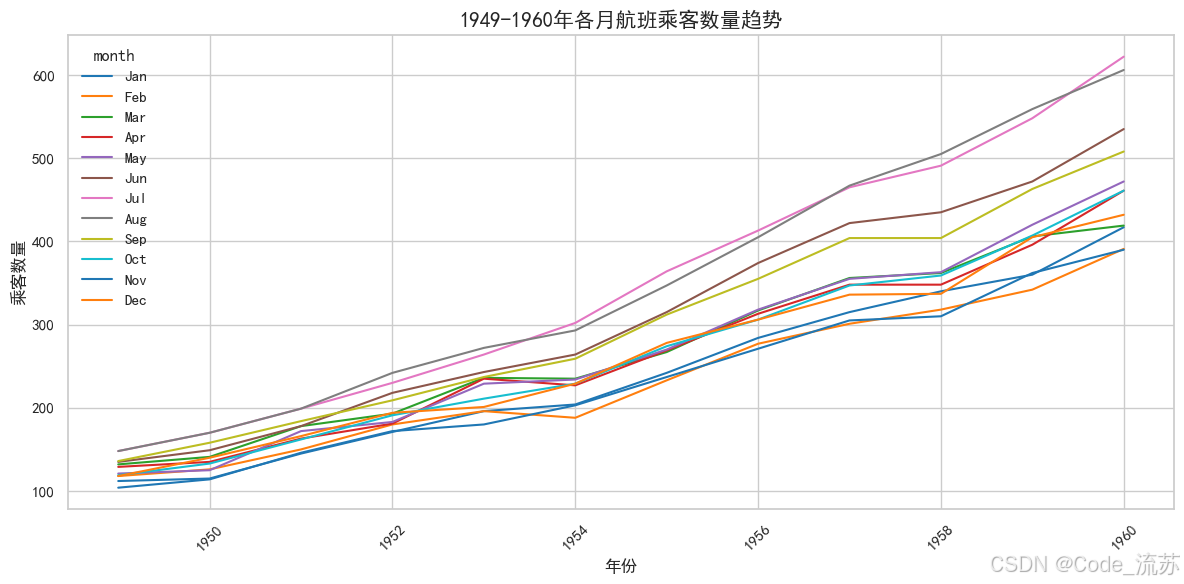
带置信区间的线图
Seaborn的线图默认会显示置信区间:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 生成模拟数据
np.random.seed(0)
x = np.linspace(0, 10, 100)
y = np.sin(x) + np.random.normal(0, 0.2, 100)# 创建DataFrame
df = pd.DataFrame({'x': x, 'y': y})# 绘制带置信区间的线图(使用新版Seaborn参数)
plt.figure(figsize=(10, 6))
sns.lineplot(x="x", y="y", data=df,errorbar=('ci', 95), # 使用新版语法替代cierr_style="band") # 误差显示样式:"band"或"bars"plt.title('带95%置信区间的线图', fontsize=15)
plt.xlabel('X值', fontsize=12)
plt.ylabel('Y值', fontsize=12)
plt.tight_layout()
plt.show()
可视化效果:
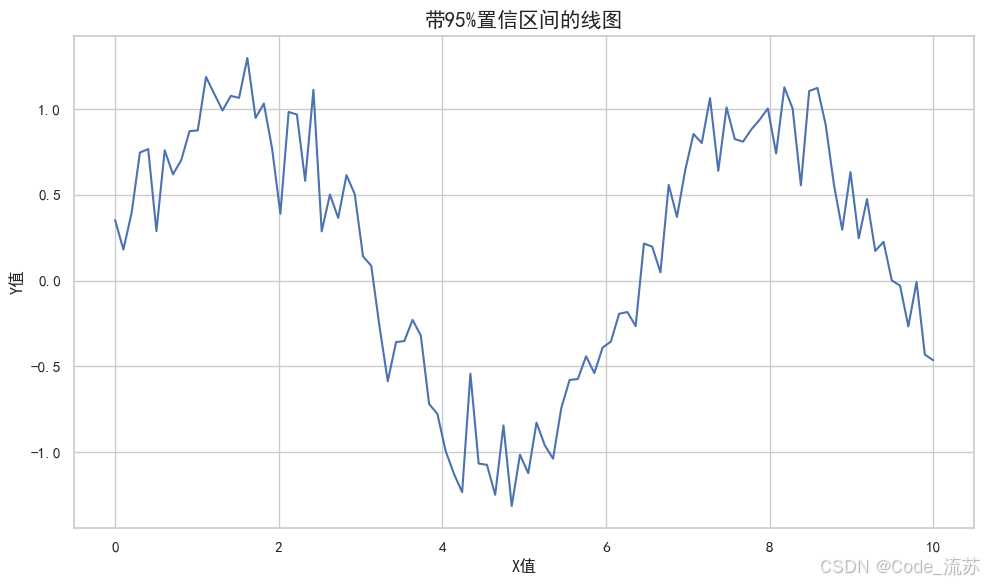
3. 分类图:比较分组数据
分类图用于分析和比较分类变量不同组别中数值变量的分布,是数据分析中非常实用的工具。
boxplot():箱线图
箱线图显示数据的四分位数和异常值,是比较不同类别数据分布的有力工具:
import seaborn as sns
import matplotlib.pyplot as plt# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 使用内置数据集
tips = sns.load_dataset("tips")# 绘制箱线图
plt.figure(figsize=(12, 6))
sns.boxplot(x="day", y="total_bill", hue="smoker", # 按吸烟者/非吸烟者分组palette="Set3", # 调色板data=tips) # 数据集plt.title('不同天的账单金额箱线图', fontsize=15)
plt.xlabel('星期', fontsize=12)
plt.ylabel('账单金额', fontsize=12)
plt.tight_layout()
plt.show()
可视化效果:
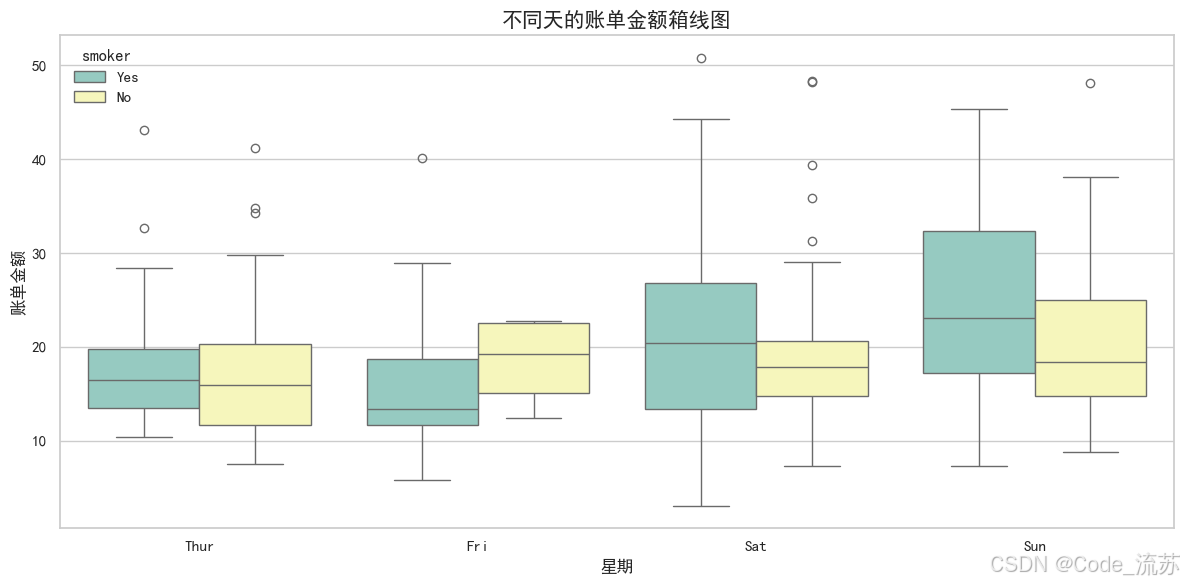
箱线图的元素含义:
- 箱体:从第一四分位数到第三四分位数,表示中间50%的数据
- 中线:表示中位数
- 触须:延伸到最小值和最大值,但不包括异常值
- 点:表示异常值
violinplot():小提琴图
小提琴图结合了箱线图和密度图的特点,展示了数据分布的密度和概率分布:
import seaborn as sns
import matplotlib.pyplot as plt# 中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 加载数据集
tips = sns.load_dataset("tips")# 绘制小提琴图
plt.figure(figsize=(12, 6))
sns.violinplot(x="day", y="total_bill", hue="smoker", # 按吸烟者/非吸烟者分组split=True, # 拆分两组对比inner="quart", # 内部标记:"quart", "box", "stick", "point"palette="Set2", # 调色板data=tips) # 数据集# 图表美化
plt.title('不同天的账单金额小提琴图', fontsize=15)
plt.xlabel('星期', fontsize=12)
plt.ylabel('账单金额', fontsize=12)
plt.tight_layout()plt.show()
可视化效果:
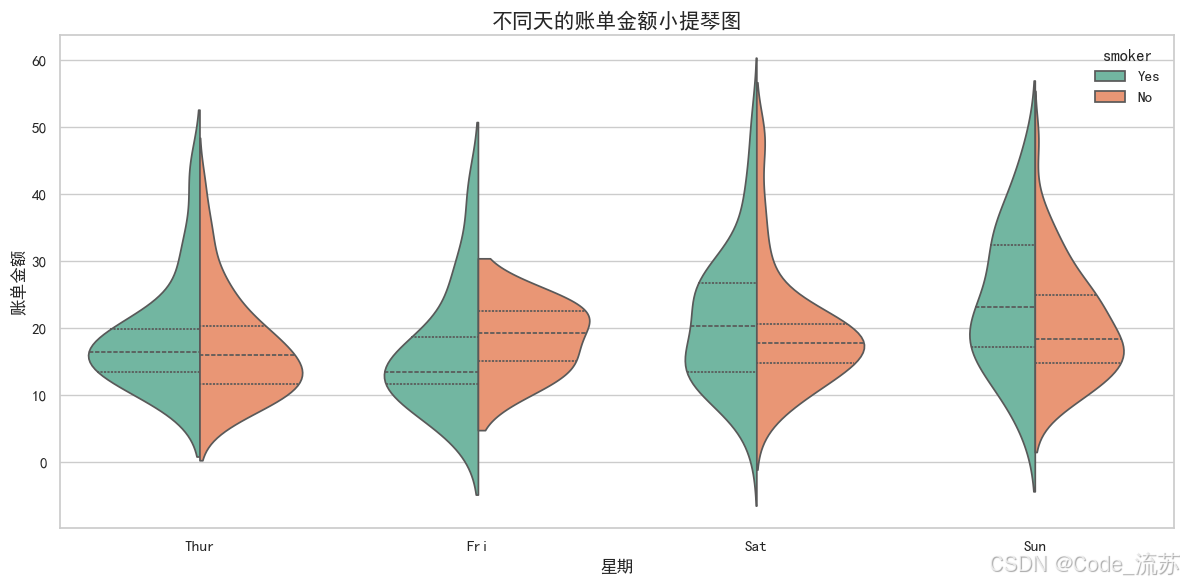
小提琴图比箱线图提供了更多信息,可以看到数据的完整概率密度分布。
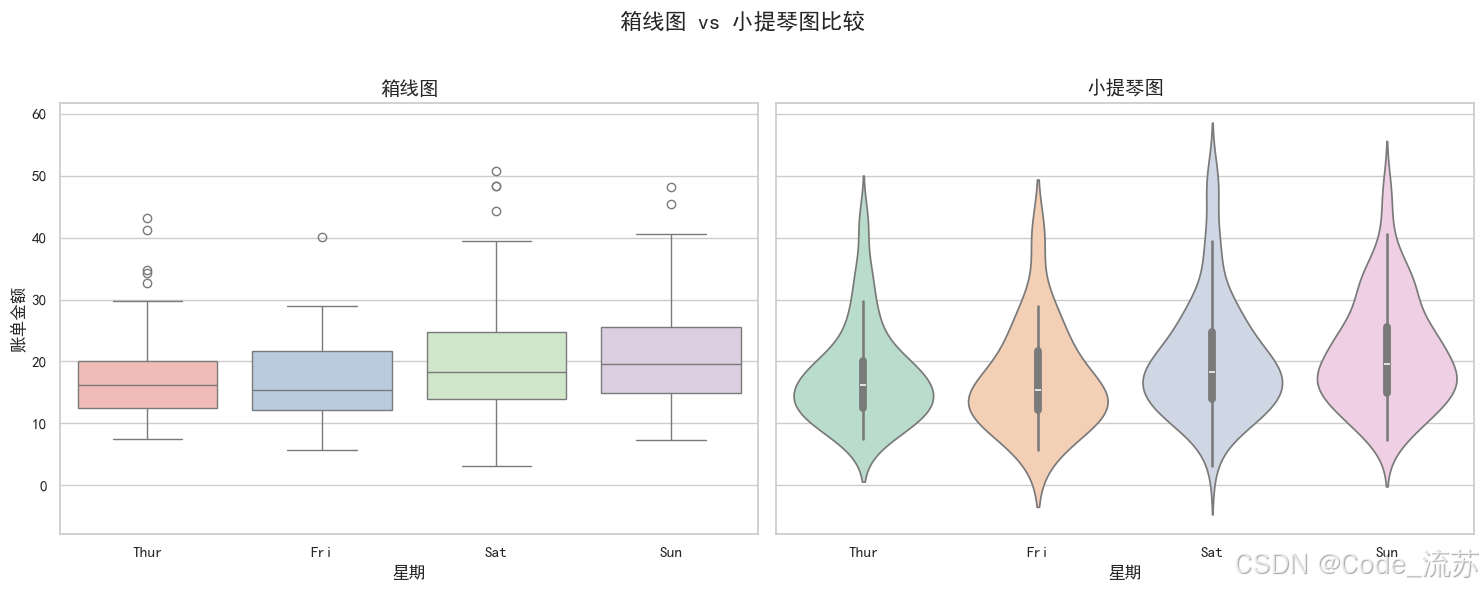
配对的分类图
可以组合多种类型的分类图进行比较:
import seaborn as sns
import matplotlib.pyplot as plt# 中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 加载数据集
tips = sns.load_dataset("tips")# 创建一个包含箱线图和小提琴图的组合
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6), sharey=True)# 箱线图
sns.boxplot(x="day", y="total_bill", data=tips, ax=ax1, palette="Pastel1")
ax1.set_title('箱线图', fontsize=14)
ax1.set_xlabel('星期', fontsize=12)
ax1.set_ylabel('账单金额', fontsize=12)# 小提琴图
sns.violinplot(x="day", y="total_bill", data=tips, ax=ax2, palette="Pastel2")
ax2.set_title('小提琴图', fontsize=14)
ax2.set_xlabel('星期', fontsize=12)
ax2.set_ylabel('') # 共享y轴,不重复显示标签plt.suptitle('箱线图 vs 小提琴图比较', fontsize=16)
plt.tight_layout(rect=[0, 0, 1, 0.96]) # 调整布局
plt.show()
可视化效果:
三、图形组合
在数据分析中,我们经常需要在同一个图形中展示多个维度的数据,或者按照某个变量的不同值创建多个子图。Seaborn提供了强大的工具来实现这一点。
1. 使用 FacetGrid 绘制多个子图
FacetGrid是Seaborn中最强大的功能之一,它可以按照某个分类变量的值,创建一个网格子图,每个子图显示数据的不同子集。
# 使用FacetGrid创建按time和smoker分组的小提琴图
g = sns.FacetGrid(tips, col="time", # 按列分组变量row="smoker", # 按行分组变量height=4, # 子图高度aspect=1.2) # 宽高比# 在每个子图上映射violinplot函数
g.map_dataframe(sns.violinplot, x="day", y="total_bill", palette="Set2")# 添加标题
g.fig.subplots_adjust(top=0.9) # 为标题腾出空间
g.fig.suptitle('按时间和吸烟状态分组的账单金额分布', fontsize=16)# 设置坐标轴标签
g.set_axis_labels("星期", "账单金额")
g.set_titles(col_template="{col_name}时段", row_template="{row_name}")plt.show()
使用FacetGrid绘制不同类型的图
FacetGrid不仅限于绘制同一类型的图,还可以应用不同的可视化函数:
# 创建分组的散点图,并添加回归线
g = sns.FacetGrid(tips, col="sex", row="smoker", height=4)# 映射regplot函数
g.map_dataframe(sns.regplot, x="total_bill", y="tip", scatter_kws={"s": 50, "alpha": 0.7},line_kws={"color": "red"})g.add_legend()
plt.show()
2. 成对关系图:pairplot()
当我们想要探索数据集中多个变量之间的关系时,pairplot()函数非常有用,它可以创建变量之间两两配对的散点图矩阵:
# 使用鸢尾花数据集
iris = sns.load_dataset("iris")# 绘制成对关系图
sns.pairplot(iris, hue="species", # 按种类着色height=2.5, # 子图大小diag_kind="kde", # 对角线图形类型:"hist"或"kde"markers=["o", "s", "D"], # 不同组的标记类型palette="Set2") # 调色板plt.suptitle('鸢尾花数据集的成对关系图', y=1.02, fontsize=16)
plt.show()
pairplot()会在对角线上绘制每个变量的分布图,在非对角线位置绘制两个变量之间的散点图,非常适合探索性数据分析。
3. 自定义配色方案
Seaborn提供了丰富的调色板选项,可以根据数据类型和可视化目的选择合适的配色方案。
使用预设调色板
# 展示Seaborn预设调色板
plt.figure(figsize=(12, 8))# 创建调色板列表
palettes = ["deep", "muted", "pastel", "bright", "dark", "colorblind"]# 绘制每种调色板
for i, palette in enumerate(palettes):plt.subplot(3, 2, i+1)# 创建5种颜色的调色板current_palette = sns.color_palette(palette, 5)# 显示调色板sns.palplot(current_palette)plt.title(palette)plt.tight_layout()
plt.show()
自定义连续调色板
# 创建不同类型的连续调色板
plt.figure(figsize=(12, 8))# 单色调色板
plt.subplot(3, 1, 1)
sns.palplot(sns.light_palette("seagreen", 10))
plt.title("单色淡色调色板 (light_palette)")# 单色深色调色板
plt.subplot(3, 1, 2)
sns.palplot(sns.dark_palette("purple", 10))
plt.title("单色深色调色板 (dark_palette)")# 双色渐变
plt.subplot(3, 1, 3)
sns.palplot(sns.color_palette("coolwarm", 10))
plt.title("双色渐变调色板 (coolwarm)")plt.tight_layout()
plt.show()
在图表中应用自定义调色板
# 在图表中应用自定义调色板
plt.figure(figsize=(12, 6))# 创建自定义调色板
custom_palette = sns.color_palette("husl", 5)# 应用到条形图
sns.barplot(x="day", y="total_bill", hue="smoker", palette=custom_palette,data=tips)plt.title('使用自定义调色板的条形图', fontsize=15)
plt.show()
四、实战练习:多维度数据分析
在这个练习中,我们将使用Seaborn对一个真实数据集进行多维度分析和可视化。我们将使用Seaborn内置的钻石数据集,它包含了近54,000颗钻石的价格和属性数据。
1. 数据准备与探索
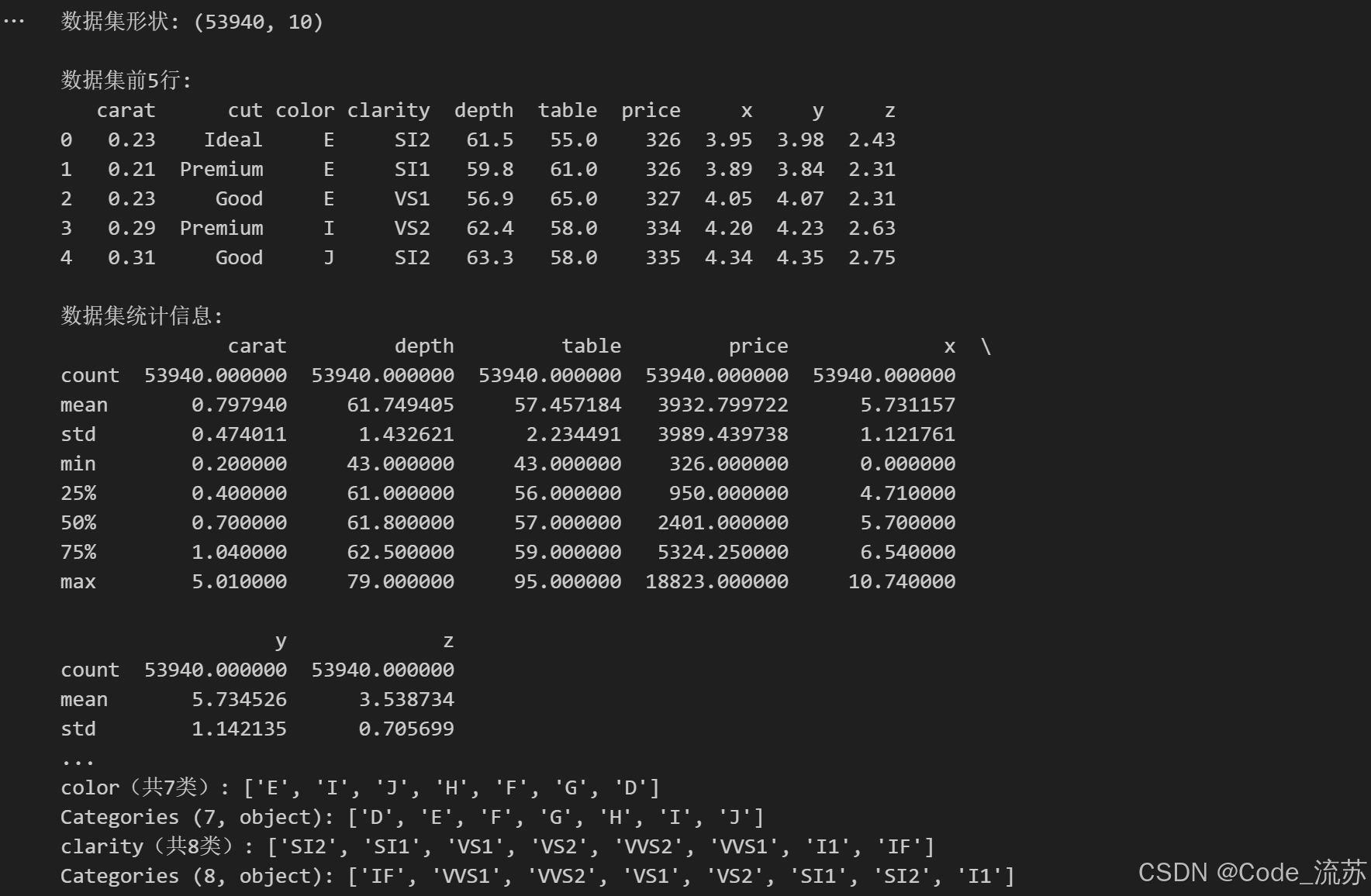
import seaborn as sns# 加载钻石数据集
diamonds = sns.load_dataset("diamonds")# 查看数据集形状
print("数据集形状:", diamonds.shape)# 查看前5行数据
print("\n数据集前5行:")
print(diamonds.head())# 查看数值型字段的统计信息
print("\n数据集统计信息:")
print(diamonds.describe())# 查看分类变量的唯一值
print("\n分类变量的唯一值:")
for col in ['cut', 'color', 'clarity']:unique_vals = diamonds[col].unique()print(f"{col}(共{len(unique_vals)}类): {unique_vals}")
输出结果:
2. 多维度可视化分析
价格与克拉数的关系
# 设置Seaborn风格
sns.set_theme(style="whitegrid")# 绘制价格与克拉数的散点图
plt.figure(figsize=(12, 8))
sns.scatterplot(x="carat", y="price", hue="cut", # 按切工质量着色size="depth", # 按深度调整点大小palette="viridis", # 使用viridis调色板sizes=(20, 200), # 点大小范围alpha=0.7, # 透明度data=diamonds.sample(1000)) # 为了性能,随机抽样1000颗钻石plt.title('钻石价格与克拉数的关系', fontsize=16)
plt.xlabel('克拉数', fontsize=12)
plt.ylabel('价格 (美元)', fontsize=12)
plt.show()
输出结果:
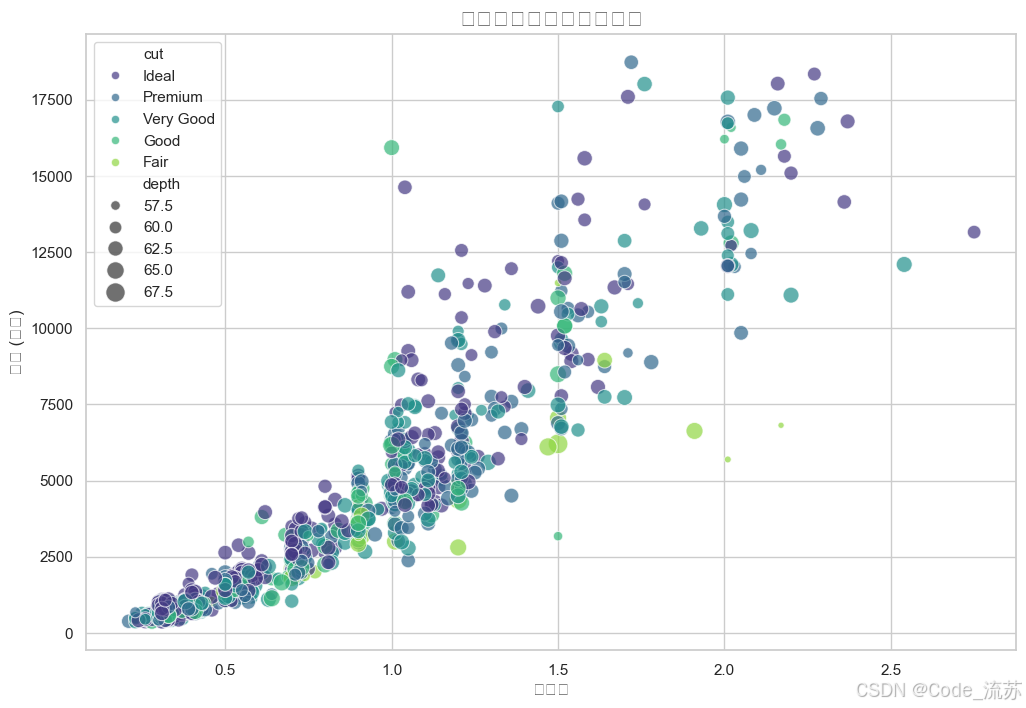
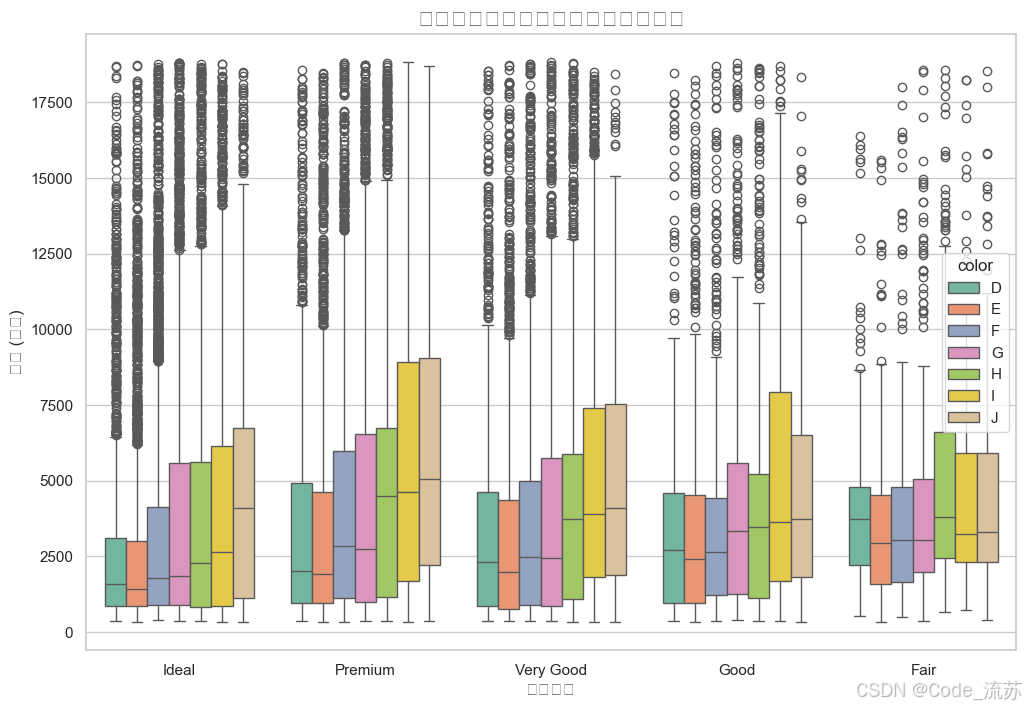
不同切工质量的价格分布
# 绘制不同切工质量的价格分布
plt.figure(figsize=(12, 8))
sns.boxplot(x="cut", y="price", hue="color", # 按颜色分组palette="Set2", # 使用Set2调色板data=diamonds) # 使用全部数据plt.title('不同切工质量和颜色的钻石价格分布', fontsize=16)
plt.xlabel('切工质量', fontsize=12)
plt.ylabel('价格 (美元)', fontsize=12)
plt.xticks(rotation=0)
plt.show()
输出结果:
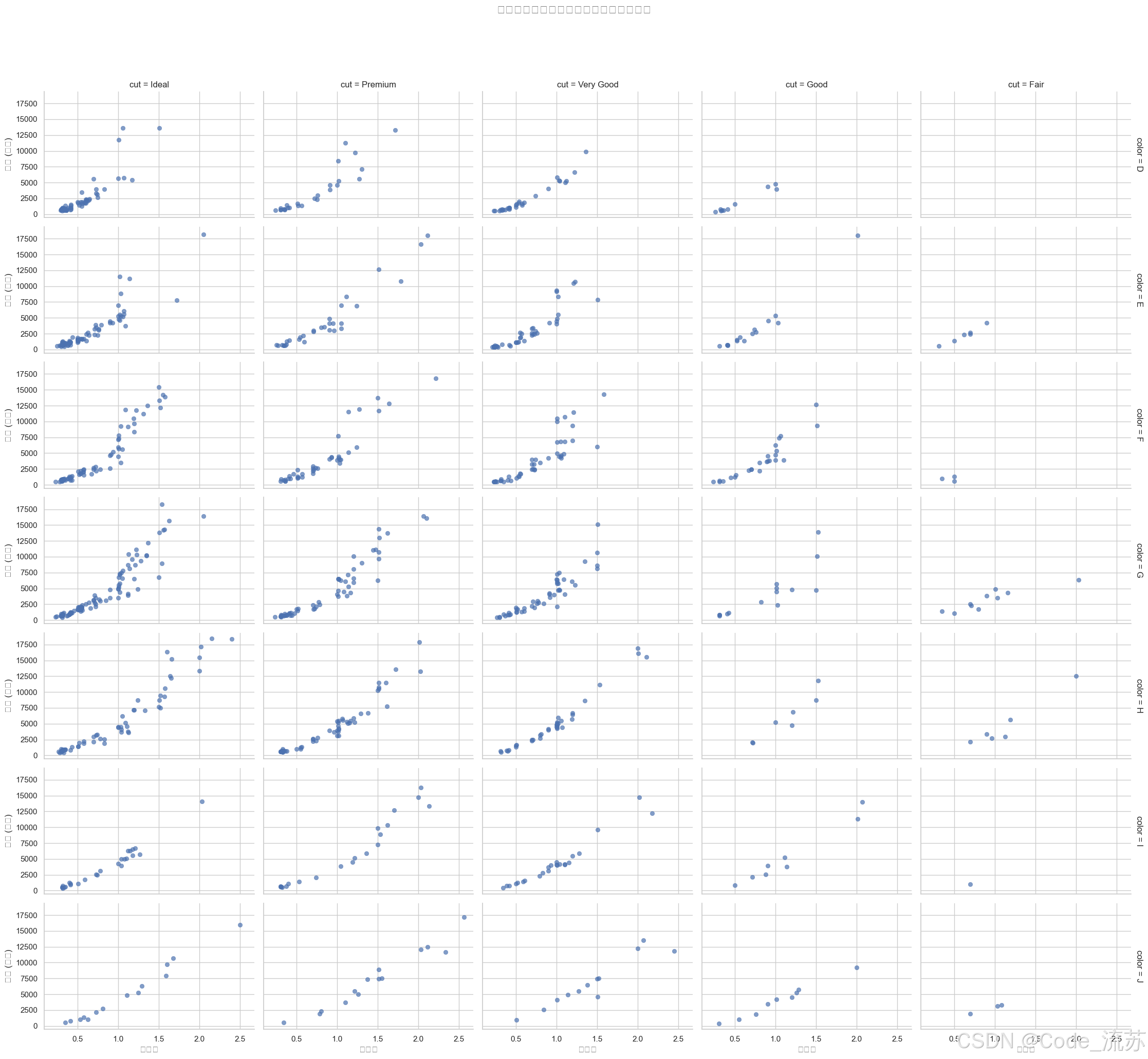
使用FacetGrid创建多个维度的关系图
# 创建按切工质量和颜色分组的散点图
g = sns.FacetGrid(diamonds.sample(1000), col="cut", # 按列分组变量row="color", # 按行分组变量height=3, # 子图高度aspect=1.5, # 宽高比margin_titles=True)# 在每个子图上映射散点图
g.map_dataframe(sns.scatterplot, x="carat", y="price", alpha=0.7,edgecolor=None)# 添加标题
g.fig.subplots_adjust(top=0.9)
g.fig.suptitle('不同切工和颜色的钻石价格与克拉数关系', fontsize=16)# 设置坐标轴标签
g.set_axis_labels("克拉数", "价格 (美元)")plt.show()
输出结果:
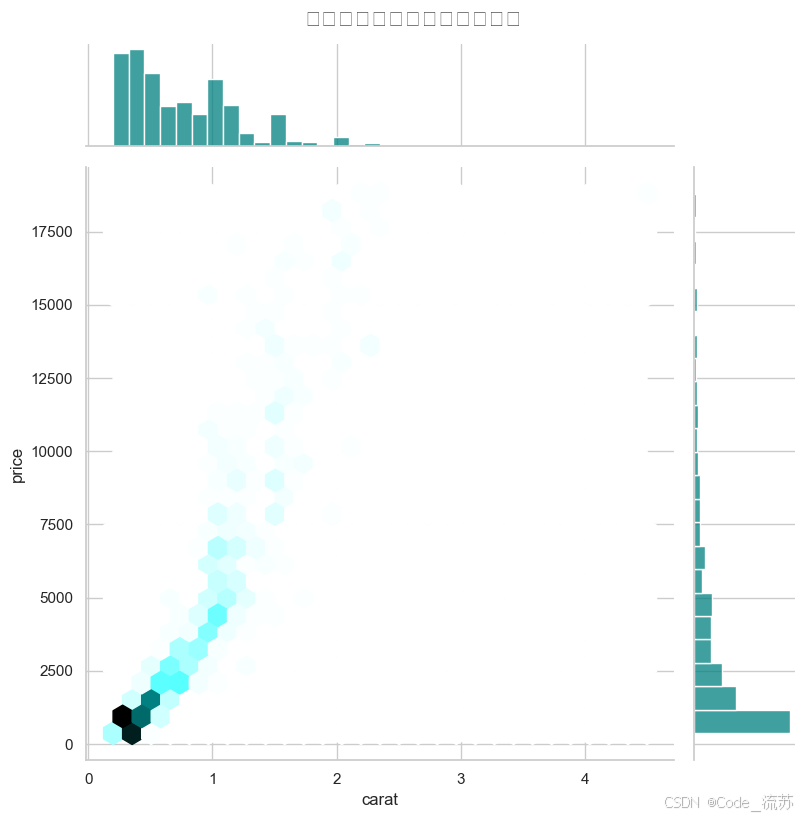
多变量联合分布
# 探索price, carat和depth的联合分布
plt.figure(figsize=(10, 8))
sns.jointplot(x="carat", y="price", data=diamonds.sample(1000),kind="hex", # 使用六边形箱height=8, # 图形大小ratio=5, # 散点图与边缘分布图的大小比例color="teal") # 颜色plt.suptitle('钻石价格与克拉数的联合分布', y=1.02, fontsize=16)
plt.show()
输出结果:
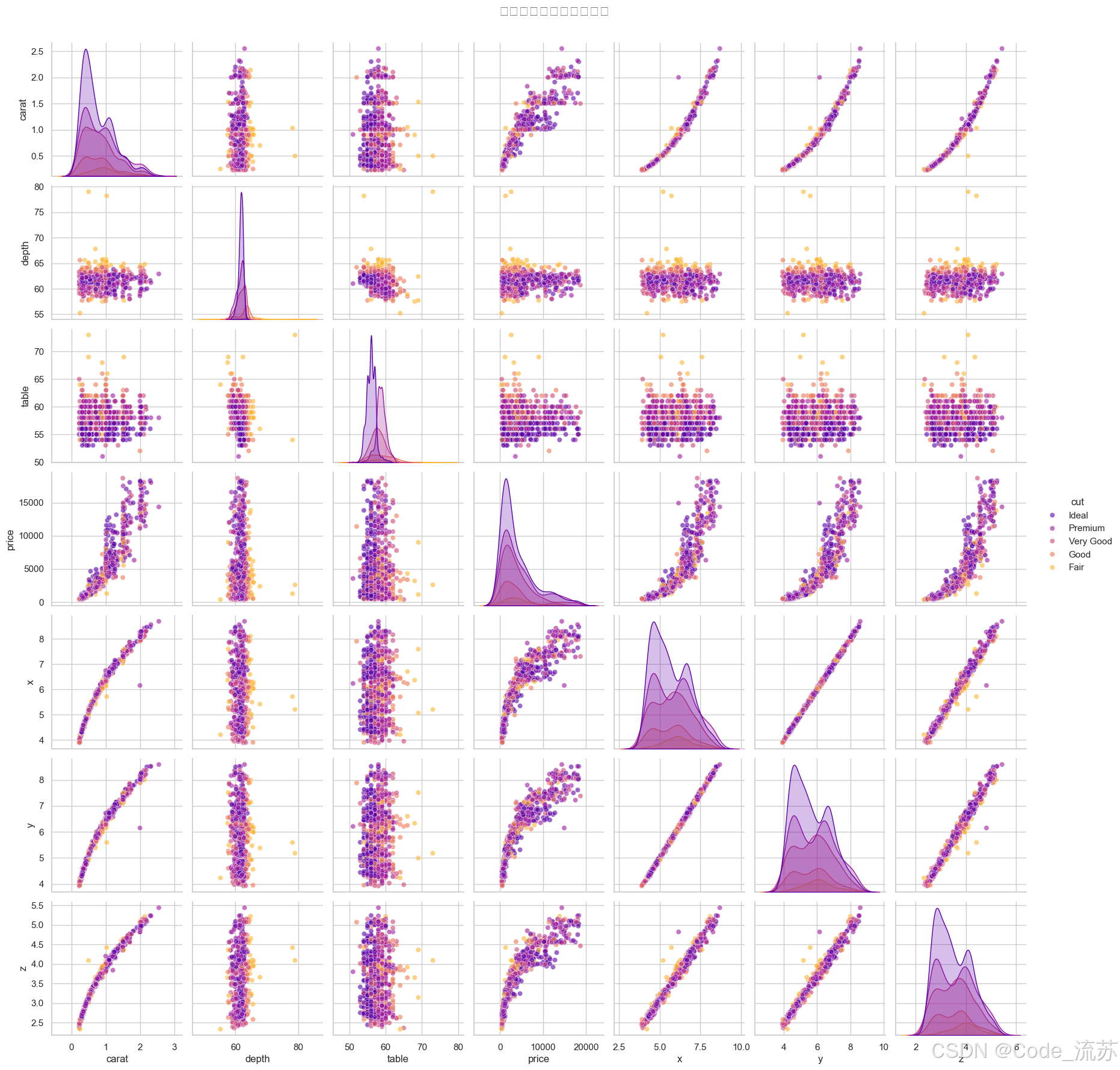
成对关系分析
# 选择数值变量进行成对关系分析
diamonds_sample = diamonds.sample(1000) # 抽样以提高性能
numeric_cols = ['carat', 'depth', 'table', 'price', 'x', 'y', 'z']# 绘制成对关系图
sns.pairplot(diamonds_sample[numeric_cols + ['cut']], hue="cut", # 按切工质量着色height=2.5, # 子图大小diag_kind="kde", # 对角线图形类型plot_kws={"alpha": 0.6}, # 散点图参数palette="plasma") # 调色板plt.suptitle('钻石数据集的成对关系图', y=1.02, fontsize=16)
plt.show()
输出结果:
3. 价格预测因素分析
# 分析哪些因素对钻石价格影响最大
plt.figure(figsize=(12, 10))# 创建一个包含4个子图的面板
plt.subplot(2, 2, 1)
sns.scatterplot(x="carat", y="price", hue="cut", palette="viridis", data=diamonds.sample(1000))
plt.title('克拉数与价格')plt.subplot(2, 2, 2)
sns.boxplot(x="color", y="price", palette="plasma", data=diamonds.sample(5000))
plt.title('颜色与价格')plt.subplot(2, 2, 3)
sns.boxplot(x="clarity", y="price", palette="magma", data=diamonds.sample(5000))
plt.title('净度与价格')
plt.xticks(rotation=45)plt.subplot(2, 2, 4)
sns.violinplot(x="cut", y="price", palette="cividis", data=diamonds.sample(5000))
plt.title('切工与价格')plt.tight_layout()
plt.suptitle('钻石价格影响因素分析', y=1.02, fontsize=16)
plt.show()
可视化结果:
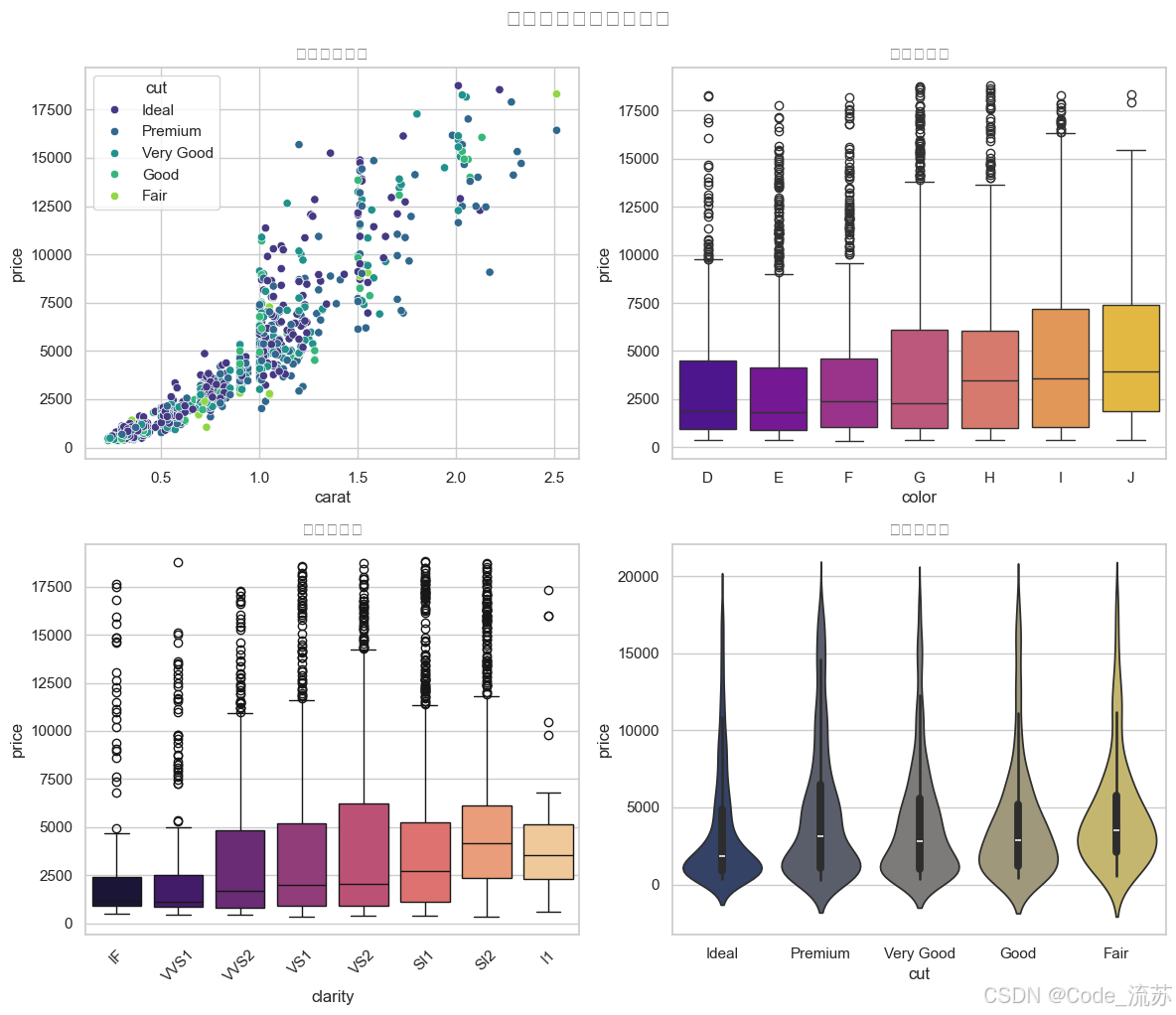
五、总结与拓展
1. 核心要点回顾
在本文中,我们学习了:
- Seaborn的基本概念:它是建立在Matplotlib基础上的高级统计数据可视化库
- Seaborn与Matplotlib的区别:Seaborn提供了更美观的默认样式和更高级的统计图表
- 分布图:通过
distplot()、kdeplot()等函数可视化数据分布 - 关系图:使用
scatterplot()、lineplot()等探索变量之间的关系 - 分类图:通过
boxplot()、violinplot()等比较不同类别的数据分布 - 图形组合:使用
FacetGrid创建多维度的可视化,实现数据的深入探索 - 自定义配色:利用Seaborn丰富的调色板选项美化可视化效果
2. Seaborn优势总结
- 高级接口:简化了创建常见统计图表的过程
- 美观的默认样式:减少了样式调整的工作量
- 与Pandas无缝集成:直接支持DataFrame作为输入
- 统计功能内置:自动计算并显示置信区间、回归线等统计信息
- 分组可视化能力:轻松实现按类别分组的多维度可视化
3. 进阶学习方向
如果你想进一步提升Seaborn可视化技能,可以探索以下内容:
- 高级统计图表:如回归图(
regplot)、残差图(residplot)、二元核密度图(kdeplot) - 矩阵可视化:使用
heatmap()和clustermap()可视化大型数据矩阵 - 复杂图形定制:深入学习Seaborn与Matplotlib的结合使用,实现高度定制化的可视化
- 交互式扩展:结合Plotly或Bokeh,为Seaborn图表添加交互功能
- 深色模式:使用
set_theme(style="darkgrid")实现暗色背景的可视化效果
4. 学习资源推荐
- 官方文档:Seaborn官方文档
- 图例集:Seaborn示例图库
- 在线教程:Datacamp、Coursera上的Python数据可视化课程
- 书籍:《Python for Data Analysis》和《Python Data Science Handbook》中的可视化章节
在下一篇文章中,我们将探索如何将我们学到的数据分析和可视化技能应用于实际项目,从数据获取、清洗到分析和可视化的完整工作流程。
练习题:
- 尝试使用Seaborn的
lmplot()函数,创建一个包含回归线的散点图,并按照某个分类变量分组。 - 使用任意开放数据集,创建一个FacetGrid,展示至少3个变量之间的关系。
- 探索Seaborn的
catplot()函数,尝试使用不同的kind参数创建不同类型的分类图,比较它们的优缺点。
希望这篇文章能帮助你掌握Seaborn的强大功能,创建更加专业和美观的数据可视化作品!如有问题,欢迎在评论区留言交流!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:

《Python星球日记》第27天:Seaborn 可视化
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、Seabor…...

获取1688商品评论接口的实践指南
在电商领域,商品评论是消费者了解产品真实情况的重要依据,对于商家来说,分析商品评论可以帮助他们改进产品、优化服务。1688作为国内知名的B2B电商平台,提供了丰富的商品评论接口,方便开发者获取商品的评论数据。本文将…...

c++中继承方面的知识点
继承的概念及定义 继承的概念 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保 持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象 程序设计的层次结…...

青少年编程考试 CCF GESP图形化编程 一级认证真题 2025年3月
图形化编程 一级 2025 年 03 月 一、单选题(共 10 题,每题 3 分,共 30 分) 1、2025 年春节有两件轰动全球的事件,一个是 DeepSeek 横空出世,另一个是贺岁片《哪吒 2》票房惊人,入了全球票房榜。…...

Openlayers:flat样式介绍
在前段时间我在使用WebGL矢量图层时接触到了flat样式,我对其十分的感兴趣,于是我花了几天的时间对其进行了了解,在这篇文章中我将简单的介绍一下flat样式的使用方式以及我对其的一些理解。 一、了解flat样式 1.什么是flat样式? …...

[特殊字符] 第十三讲 | 地统计模拟与空间不确定性评估
📘 专栏:科研统计方法实战分享 | 地学/农学人的数据分析工具箱 ✍️ 作者:平常心0715 🎯 关键词:地统计模拟、随机函数、空间不确定性、条件模拟、SGS、R语言 🧠 核心导语 在现实数据有限、空间异质性强的…...

Vue接口平台学习六——接口列表及部分调试页面
一、实现效果图及界面布局简单梳理 整体布局分左右,左边调试,右边显示接口列表 左侧: 一个输入框按钮;下面展示信息,大部分使用代码编辑器就好了,除了请求体传文件类型需要额外处理。然后再下方显示响应信…...

Spring 中的 @Cacheable 缓存注解
1 什么是缓存 第一个问题,首先要搞明白什么是缓存,缓存的意义是什么。 对于普通业务,如果要查询一个数据,一般直接select数据库进行查找。但是在高流量的情况下,直接查找数据库就会成为性能的瓶颈。因为数据库查找的…...

Context的全面解析:在不同技术应用中的通用作用与差异
Context的全面解析:在不同技术应用中的通用作用与差异 引言: 在软件开发中,“Context”这个概念被广泛使用。它不仅限于某个特定的技术或编程语言,实际上,Context 作为一种抽象的设计模式,贯穿在许多开发领…...
——逻辑回归)
机器学习(2)——逻辑回归
文章目录 1. 什么是逻辑回归?2. 核心思想3. 逻辑回归模型的训练:4. 参数估计(损失函数与优化)4.1. **损失函数:**4.2. 极大似然估计(MLE)4.3. 优化方法 5. 决策边界6. 模型评估指标7 . 假设与适用条件8. 逻…...

Sentinel核心算法解析の滑动窗口算法
文章目录 前言一、回顾:快速失败二、固定窗口算法三、滑动窗口算法三、源码体现3.1、ArrayMetric的初始化3.2、addPass3.2.1、currentWindow3.2.2、wrap.value().addPass 总结 前言 在Sentinel中,流控效果有快速失败、预热和排队等待。其中快速失败的统计…...

ida 使用记录
文章目录 伪代码-汇编hexstring快捷键 伪代码-汇编 流程图界面——F5——伪代码界面——再点Tab——流程图界面——再按空格——汇编界面流程图界面——空格——汇编界面 hex view - open subviews - hex dump string view - open subviews - string快捷键: sh…...

数字统计:
1.题意: 在1~N之间寻找d出现的个数,然后输出即可;例如:d2,N23,那么满足条件的有2,12,21,23,所以是4个 2.思路: 1.暴力枚举(不可能):可以先写出来去找规律 …...

【架构师从入门到进阶】第五章:DNSCDN网关优化思路——第八节:网关-注入攻击与预防
【架构师从入门到进阶】第五章:DNS&CDN&网关优化思路——第八节:网关-注入攻击与预防 SQL注入攻击的原理攻击者获取数据库表结构预防SQL注入的方法 这篇文章我们来看SQL注入。 SQL注入攻击的原理 SQL注入攻击的原理呢?我们来简单说…...
从算法仿真到工程源码实现-第五节-线性约束最小方差波束形成算法(LCMV))
波束形成(BF)从算法仿真到工程源码实现-第五节-线性约束最小方差波束形成算法(LCMV)
一、概述 本节我们讨论线性约束最小方差波束形成算法(Linearly constrained minimum variance,LCMV)波束形成算法,包括原理分析及代码实现。 更多资料和代码可以进入https://t.zsxq.com/qgmoN ,同时欢迎大家提出宝贵的建议,以共同探讨学习。 …...

Java类加载机制原理与应用
前言 Java 中的类加载机制(Class Loading Mechanism)是 JVM 架构中的核心组成部分,它控制着类从编译后的 .class 文件被加载到内存、并最终变成可以被程序使用的对象的全过程。涉及类加载器、双亲委派模型及加载过程。下面我们从原理到实际应…...
surfcaeflinger的DEQUEUED、QUEUED)
android display 笔记(十三)surfcaeflinger的DEQUEUED、QUEUED
BufferQueue 的核心作用 BufferQueue 是 生产者-消费者模型 的核心组件,协调应用(生产者)和 SurfaceFlinger(消费者)之间的图形缓冲区(GraphicBuffer)传递。 生产者:应用࿰…...

数据库预热
介绍 Database Warm-up 🧠 一句话理解 数据库是在应用启动阶段,提前建立数据库连接 或 执行轻量 SQL 操作,从而 加快首个请求的响应速度 的一种优化手段 🎯 为什么需要数据库预热? 当 FastAPI 或其他 Web 服务刚启…...

C语言—程序的编译和链接
1. 翻译环境和运行环境 在ANSI S的任何一种实现中,存在两个不同的环境 第一种是翻译环境,在这个环境中源代码被转换为可执行的机器指令(二进制指令) 第二种是执行环境,它用于实际执行代码 2. 翻译环境 翻译环境是由…...

Neo4j GDS-10-neo4j GDS 库中相似度算法介绍
neo4j apoc 系列 Neo4j APOC-01-图数据库 apoc 插件介绍 Neo4j GDS-01-graph-data-science 图数据科学插件库概览 Neo4j GDS-02-graph-data-science 插件库安装实战笔记 Neo4j GDS-03-graph-data-science 简单聊一聊图数据科学插件库 Neo4j GDS-04-图的中心性分析介绍 Ne…...

Unity 动画
Apply Root Motion 勾选的话就会使用动画片段自带的位移 Update Mode (动画重新计算骨骼位置转向缩放的数值): Normal : 随Update走,每次Update都计算Animate Physics :与 fixed Update() 同步࿰…...

【位运算】只出现一次的数字 II
文章目录 137. 只出现一次的数字 II解题思路一:借用数组的位运算解法二:不使用数组的位运算 137. 只出现一次的数字 II 137. 只出现一次的数字 II 给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 **…...

模型开发中的微调是干什么
在模型开发中,微调(Fine-tuning) 是指利用预训练模型(Pre-trained Model)的参数作为初始值,在特定任务或数据集上进一步调整模型参数的过程。它是迁移学习(Transfer Learning)的核心…...

leetcode 204. Count Primes
题目描述 这是道纯数学类问题。 先回忆一下,素数的定义。 质数(英文名:Prime number)又称素数,是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。 质数又称素数。一个大于1的自然数&…...

fastadmin后端添加页面,自主控制弹出框关闭,关闭父页面弹框
Form.api.bindevent($(“form[roleform]”), (data, ret) > { 重写绑定事件,返回false即可 注意:只有返回code1才能拦截,其他值不进行拦截 add: function () {//获取当前search里面的type值var type location.search.split(type)[1];Form.api.bindevent($("form[role…...

LeetCode 255 超通俗讲解:Swift 验证前序是否 BST
文章目录 摘要描述题解答案题解代码分析核心点解释: 示例测试及结果时间复杂度空间复杂度总结未来展望 摘要 在做算法题的时候,树相关的题总是“神神叨叨”的,但其实抓住核心规则,它们也挺有逻辑的。今天这题——LeetCode 255&am…...

Win32++ 使用初探
文章目录 1. 环境要求2. Win32安装3. 项目创建3.1 项目创建(1)直接使用Win32里的示例Sample(2)自行创建项目 最近想用 VC写些 UI,但又不太想用 MFC,正好对界面要求不太高,就使用了一下 Win3…...

求解时间复杂度
1.设 t 法 当求解出现while循环时,设t求解 void fun(int n) {int i 1;while(i < n)i i * 2; } 解法: 1.设循环次数为t; 2.将while循环中的语句展开到循环t次 1 2 3 …… t 2 2^2 2^3 …… 2^t 3.跳出循环 2^t > n …...

深度解析:如何高效识别并定位问题关键词
什么是问题关键词? 问题关键词是人们在搜索引擎中输入以查找信息、答案或解决方案的问题。这些查询以问题指示符开头,例如: who、what、where、when、why、how、which、will、would、should、can、could、is、are、was、were、do、does 或 d…...

c++小做——完全数
今天,我们来写一个完全数的代码 首先是 long long n; cin>>n; (you~输入的数) 然后是 long long b0;//因数的和 long long cnt0;//计数器 接着是 for(long long i2;i<n-1;i) {} 在里面插入 bb-i;再写一个for for(int a1;a&…...
)
GGML源码逐行调试(下)
目录 前言1. 简述2. 预分配计算图内存2.1 创建图内存分配器2.2 构建最坏情况的计算图2.3 预留计算图内存 3. 分词4. 模型推理与生成4.1 模型推理4.2 采样 结语下载链接参考 前言 学习 UP 主 比飞鸟贵重的多_HKL 的 GGML源码逐行调试 视频,记录下个人学习笔记&#x…...
)
JavaScript学习教程,从入门到精通, JavaScript 函数全面解析与案例实践(11)
JavaScript 函数全面解析与案例实践 项目导读 JavaScript 函数是编程中的核心概念,是执行特定任务的代码块。本教程将全面讲解函数的定义、参数、返回值及调用方式,并通过实际案例加深理解。 学习目标 掌握 JavaScript 函数的定义与调用方法理解函数…...

音视频之H.265/HEVC编码框架及编码视频格式
一、编码框架: H.265/HEVC采用混合编码框架,包括变换、量化、熵编码、帧内预测、帧预测以及环路滤波等模块。但是,H.265/HEVC几乎在每个模块都引入了新的编码技术。 1、帧内预测: 该模块主要用于去除图像的空间相关性。通过编码后…...

栈与队列:两种经典线性数据结构的深度解析
一、栈:LIFO 特性的完美诠释 (一)核心概念与抽象模型 定义与特性 栈是一种严格遵循后进先出(LIFO)原则的线性数据结构,其操作被限制在栈顶(Top)进行。形象化理解:如同堆…...

0x01、Redis 主从复制的实现原理是什么?
Redis 主从复制概述 Redis 的主从复制是一种机制,允许一个主节点(主实例)将数据复制到一个或多个从节点(从实例)。通过这一机制,从节点可以获取主节点的数据并与之保持同步。 复制流程 开始同步…...

Python实现贪吃蛇一
贪吃蛇是一款经典的小游戏,最近尝试用Python实现它。先做一个基础版本实现以下目标: 1、做一个按钮,控制游戏开始 2、按Q键退出游戏 3、右上角显示一个记分牌 4、随机生成一个食物,蛇吃到食物后长度加一,得10分 5、蛇碰…...

01-libVLC的视频播放器:环境搭建以及介绍
项目展示项目播放器 VLC简介VLC媒体播放器(VideoLAN Client)是一款开源、跨平台的自由多媒体播放器,由VideoLAN项目开发。它支持众多音频与视频格式(如MPEG-2、MPEG-4、H.264、MKV、WebM、WMV、MP3等),以及DVD、VCD和各种流媒体协议。 VLC的特点跨平台支持:Windows、mac…...

linux内核升级
这里介绍一下linux内核升级 因为需要搭建k8s集群内核内核版本过低会导致集群出现问题,为了避免问题发生我们对集群内核进行升级处理 这个是我目前本身的内核版本 用了很多的镜像站去进行更新发现更新不了(阿里云不能用了,貌似是删除了&…...

电感详解:定义、作用、分类与使用要点
一、电感的基本定义 电感(Inductor) 是由导线绕制而成的储能元件,其核心特性是阻碍电流变化,将电能转化为磁能存储。 基本公式: 自感电动势: E -L * (di/dt) (L:电感值,…...

扩散模型简介
扩散模型简介 基本原理 扩散模型是一种基于概率扩散过程的生成模型,其核心思想是通过正向扩散过程和反向去噪过程生成数据: 正向扩散过程:从真实数据(如图像)开始,逐步添加高斯噪声,最终将数据…...

MySQL安装实战分享
一、在 Windows 上安装 MySQL 1. 下载 MySQL 安装包 访问 MySQL 官方下载页面。选择适合你操作系统的版本。一般推荐下载 MySQL Installer。 2. 运行安装程序 双击下载的安装文件(例如 mysql-installer-community-<version>.msi)。如果出现安全…...

掌握 Git 的十大基础命令
李升伟 编译 在 IT 领域,很少有技术能像 Git 一样占据绝对主导地位,几乎无人能及。Git 在软件开发中扮演着核心角色,其影响力之大甚至让其他版本控制系统(如 SVN 和 Mercurial)几乎被淘汰。如今,我们已难以…...

58-使用wordpress快速创建个人网站
直接找台可以联网的linux(我的环境是rocky8.9)一顿运行,思路就是安装docker,然后启动一个数据库,然后启动一个wordpress,然后就是把端口暴露出来。 227 yum remove podman 228 yum install -y yum-utils…...

若依前后端分离版运行教程、打包教程、部署教程
后端打包教程 注意:需要先运行redis 2、前端运行教程 2.1安装依赖 2.2运行 打开浏览器查看,地址:http://localhost:80 3、前端打包教程 3.1打包 3.2运行打包好的文件,先找到打包好的文件 这是nginx的文件结构 将打包好的文件放到html目录下…...

【Python3教程】Python3基础篇之数据结构
博主介绍:✌全网粉丝22W+,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物联网、机器学习等设计与开发。 感兴趣的可…...
transformers的 pipeline是什么:将模型加载、数据预处理、推理等步骤进行了封装
transformers的 pipeline是什么:将模型加载、数据预处理、推理等步骤进行了封装 pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=50 )pipeline :这是 transformers 库中一个非常实用的工具函数。它可以基于预训练模型快速构…...

十七、TCP编程
TCP 编程是网络通信的核心,其 API 围绕面向连接的特性设计,涵盖服务端和客户端的交互流程。以下是基于 C 语言的 TCP 编程核心 API 及使用流程的详细解析: 核心 API 概览 函数角色描述socket()通用创建套接字,指定协议族…...

Obsidian 技巧篇
Obsidian 技巧篇 本篇文章主要汇总分享几个 Ob 中好用的小技巧,包括嵌入视频播放、文本颜色设置、插入大纲、Mermaid 绘制图形。原文见于:Obsidian技巧篇。 嵌入视频播放 <iframe width"860" height"700" src"https://ww…...

使用Fortran读取HDF5数据
使用Fortran读取HDF5数据 下面我将介绍如何在Fortran中读取HDF5文件中的各种类型数组数据,包括一维数组、二维数组、元数组和变长数组。 准备工作 首先需要确保系统安装了HDF5库,并且在编译时链接了HDF5库。例如使用gfortran编译时: gfor…...
 (双指针思想,内含详细的优化过程))
L36.【LeetCode题解】查找总价格为目标值的两个商品(剑指offer:和为s的两个数字) (双指针思想,内含详细的优化过程)
目录 1.LeetCode题目 2.分析 方法1:暴力枚举(未优化的双指针) 方法2:双指针优化:利用有序数组的单调性 版本1代码 提问:版本1代码有可以优化的空间吗? 版本2代码 提问:版本2代码有可以优化的空间吗? 版本3代码(★推荐★) 3.牛客网题目:和为s的数字 1.LeetCode题目 …...