【大模型微调】如何解决llamaFactory微调效果与vllm部署效果不一致如何解决
以下个人没整理太全
一、生成式语言模型的对话模板介绍
使用Qwen/Qwen1.5-0.5B-Chat训练

对话模板不一样。回答的内容就会不一样。
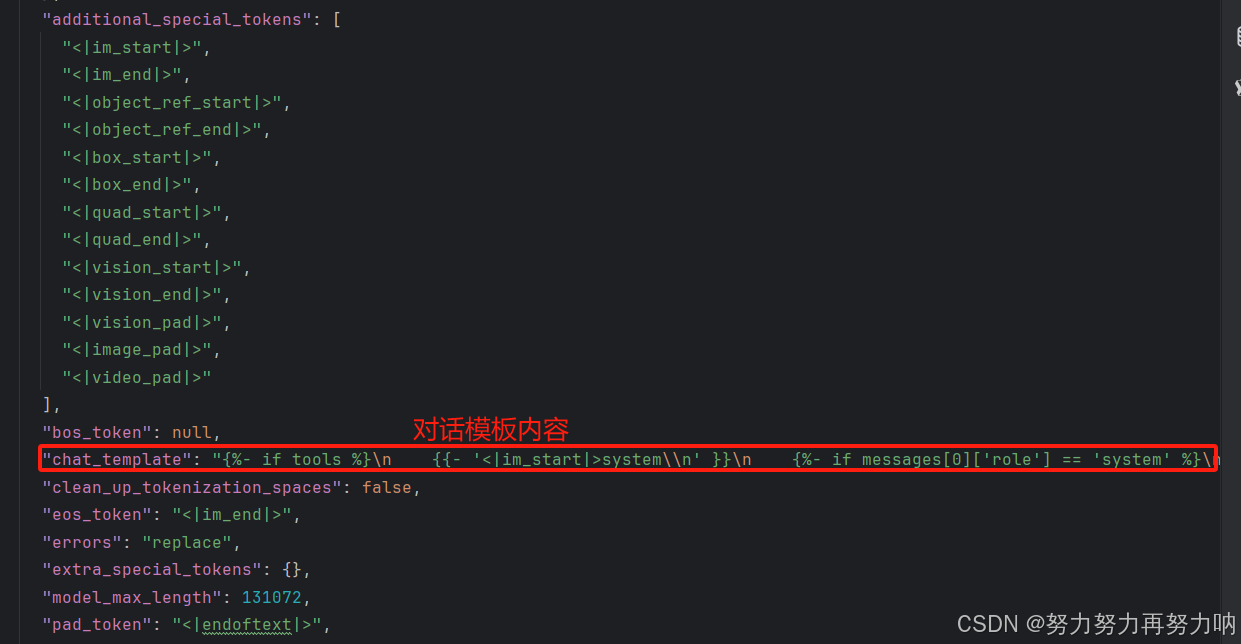
我们可以看到例如qwen模型的tokenizer_config.json文件,就可以看到对话模板,一般同系列的模型,模板基本都一致。可以通过更改chat_template(对话模板)内容,来实现自己想要的对话模板。
如果我们使用open-webui来做前端显示,你会发现open-webui有自己的对话模板,他和我自己训练的qwen系列的大模型对话模板不一样,这就导致了,你用ollama跑qwen时回答的内容,和用open-webui做前端页面渲染回答的内容是不一致的。很奇葩,真的很奇葩。同时你会发现大模型微调框架、推理框架,以及像前端页面转发的open-webui他们的框架对话模板可能也是一样的。这就导致了,你明明在LLamaFactory微调框架的模板回答是自己想要的东西,但是在推理框架,比如vllm上就会不一样。头大吧。

对话的内容也会受一下参数控制,一般后两个参数都是统一的,唯一变化的就是最大生成长度。
这个问题可复现
比如我们在LLamaFactory,跑的是我自己训练过后的qwen模型。
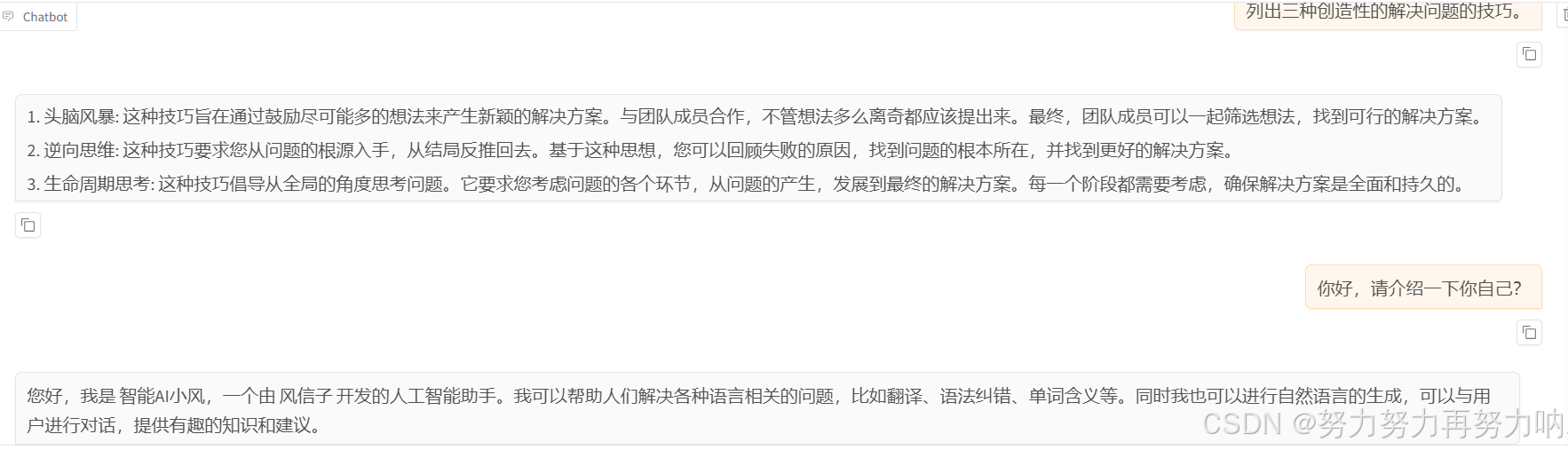
使用vllm跑的自己训练过后的qwen模型
需要安装vllm(必须是Linux环境),不然前后台都会报错。
pip install vllm>=0.4.3,<=0.7.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
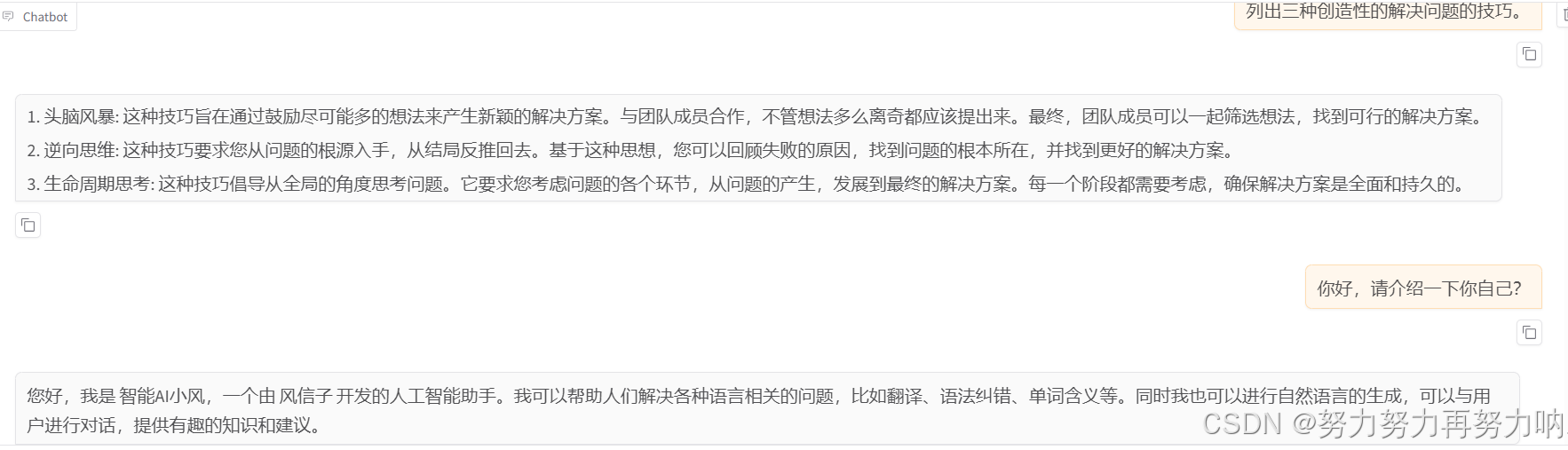
你会发现效果一致了。如果效果不一致,说明你的模型需要继续训练。
2.Lora微调后单独部署大模型输出结果不一致
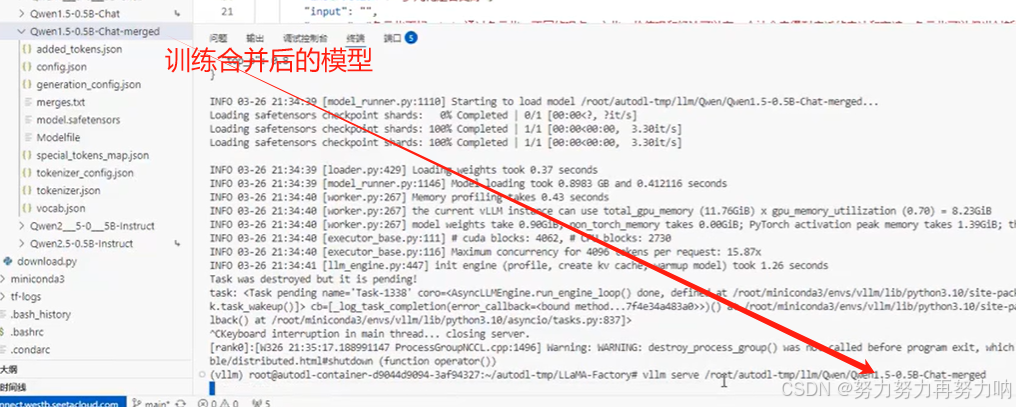
使用vllm serve启动自己训练的模型
vllm serve 你的模型
然后就可以通过后端代码调用对话了。
你会发现其实会有明显的差距,说明模型训练还未收敛,你需要继续训练,让大模型继续学习。

3.如何导出LLama Factory的对话模板
同时我们可以看一下LLamaFactory源码下的qwen对话模板
源码搜索就可以找到了
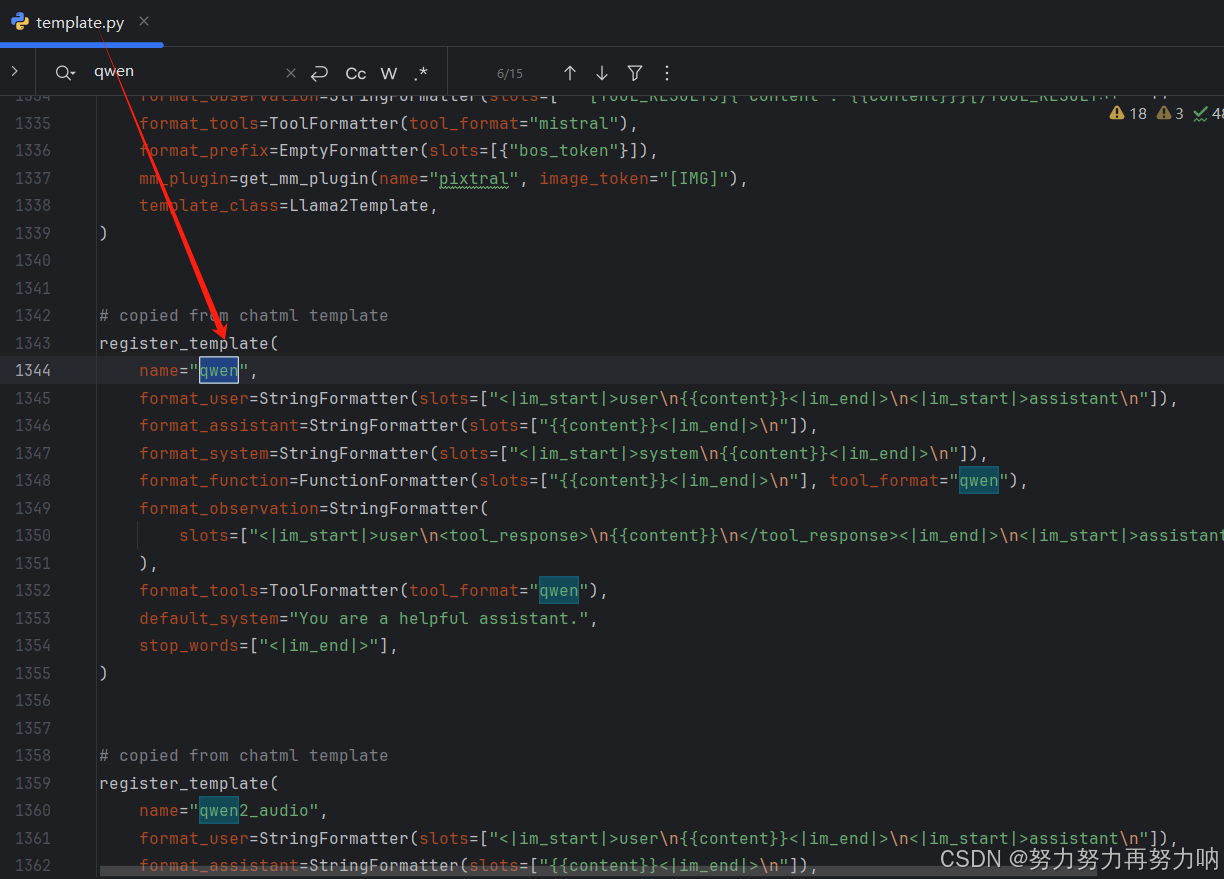
你会发现LLamaFactory整合了同一系列的对话模板。
LLamaFactory找到这个jinja模板
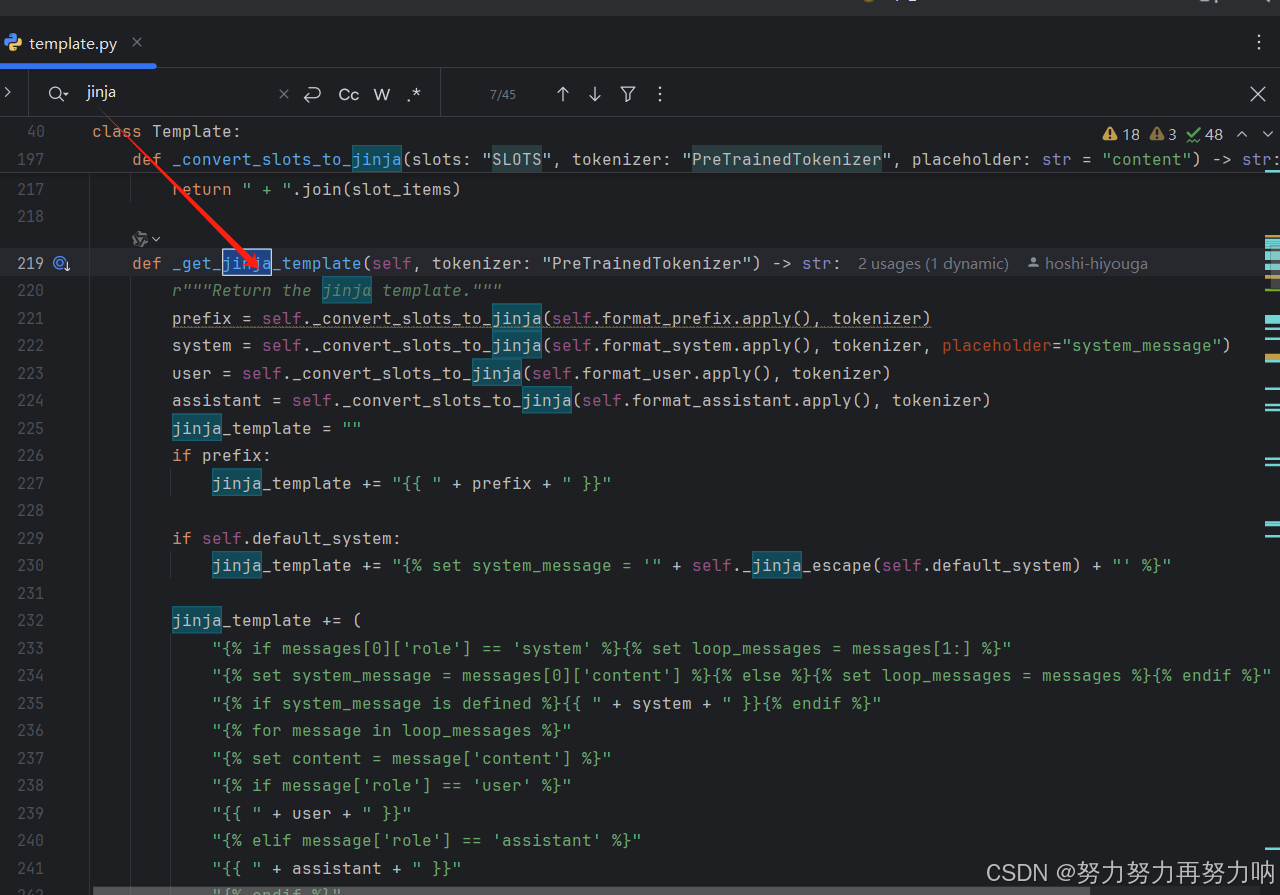
我们可以看到他是一个私有化的方法,外部没法调用,但是可以调用
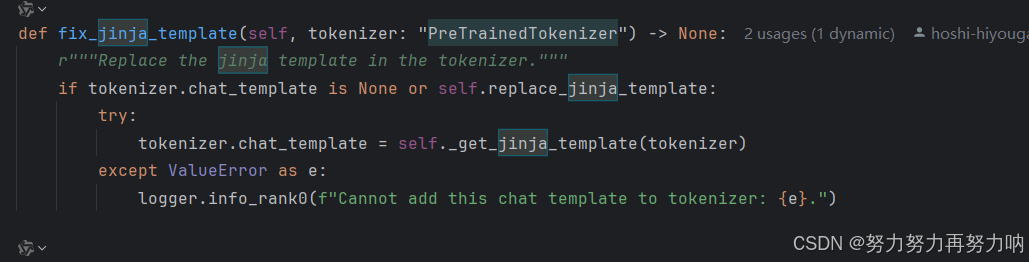
fix_jinja_template生成jinja模板。那么就需要我们自己写代码了。可以用ai工具生成。
# mytest.py
import sys
import os# 将项目根目录添加到 Python 路径
# root_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
# sys.path.append(root_dir)from llamafactory.data.template import TEMPLATES
from transformers import AutoTokenizer# 1. 初始化分词器(任意支持的分词器均可)
tokenizer = AutoTokenizer.from_pretrained(r"D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\models\Qwen\Qwen2___5-1___5B-Instruct-merge")# 2. 获取模板对象
template_name = "qwen" # 替换为你需要查看的模板名称
template = TEMPLATES[template_name]# 3. 修复分词器的 Jinja 模板
template.fix_jinja_template(tokenizer)# 4. 直接输出模板的 Jinja 格式
print("=" * 40)
print(f"Template [{template_name}] 的 Jinja 格式:")
print("=" * 40)
print(tokenizer.chat_template)
就可以得到jinja得到qwen的path-to-chat-template.jinja模板,就可以给vllm用了。
{%- if tools %}{{- '<|im_start|>system\n' }}{%- if messages[0]['role'] == 'system' %}{{- messages[0]['content'] }}{%- else %}{{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}{%- endif %}{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}{%- for tool in tools %}{{- "\n" }}{{- tool | tojson }}{%- endfor %}{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}{%- if messages[0]['role'] == 'system' %}{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}{%- else %}{{- '<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n' }}{%- endif %}
{%- endif %}
{%- for message in messages %}{%- if (message.role == "user") or (message.role == "system" and not loop.first) or (message.role == "assistant" and not message.tool_calls) %}{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}{%- elif message.role == "assistant" %}{{- '<|im_start|>' + message.role }}{%- if message.content %}{{- '\n' + message.content }}{%- endif %}{%- for tool_call in message.tool_calls %}{%- if tool_call.function is defined %}{%- set tool_call = tool_call.function %}{%- endif %}{{- '\n<tool_call>\n{"name": "' }}{{- tool_call.name }}{{- '", "arguments": ' }}{{- tool_call.arguments | tojson }}{{- '}\n</tool_call>' }}{%- endfor %}{{- '<|im_end|>\n' }}{%- elif message.role == "tool" %}{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}{{- '<|im_start|>user' }}{%- endif %}{{- '\n<tool_response>\n' }}{{- message.content }}{{- '\n</tool_response>' }}{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}{{- '<|im_end|>\n' }}{%- endif %}{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}{{- '<|im_start|>assistant\n' }}
{%- endif %}
那么接下来启动
vllm serve 模型名称 --chat-template ./path-to-chat-template.jinja
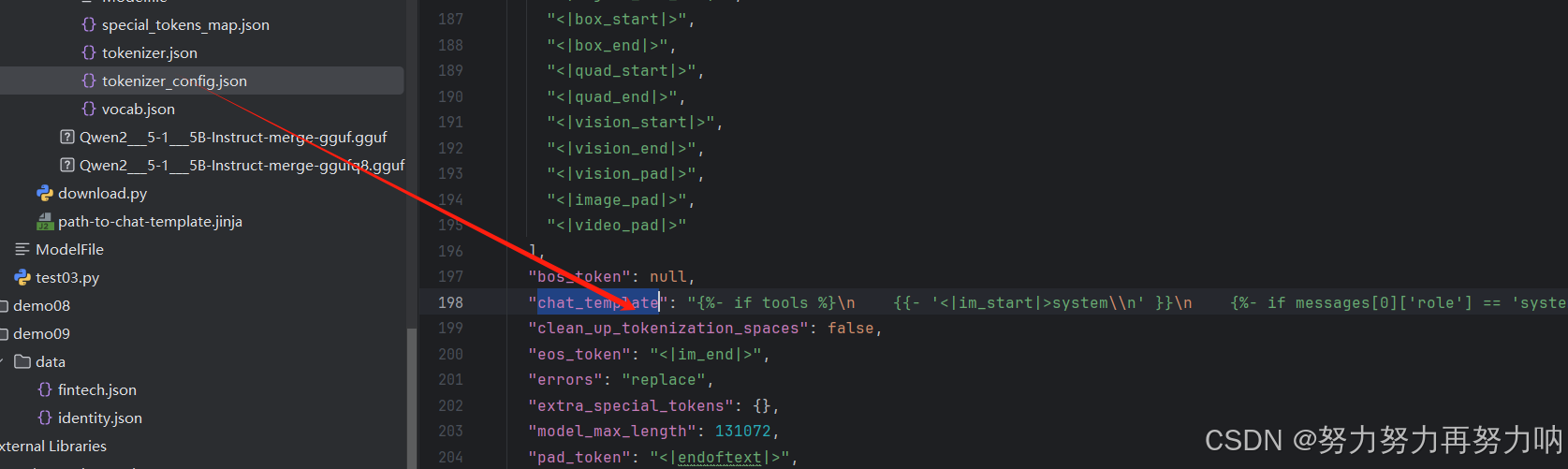
最方便的方法是可以直接替换LLamaFactory里的tokenizer_config.json里的chat_template模板里的内容
四、vllm推理模型时自定义对话模板
一、vLLM聊天模板
-
作用:为了使语言模型支持聊天协议,vLLM要求模型在其tokenizer配置中包含聊天模板。
-
聊天模板定义:聊天模板是一个Jinja2模板,用于指定角色、消息和其他特定于聊天的token如何在输入中编码。
可以在 NousResearch/Meta-Llama-3-8B-Instruct 的示例聊天模板可以在这里找到。 -
使用场景:
- 有些模型即使经过指令/聊天微调,也不提供聊天模板。对于这些模型,可以在
--chat-template参数中使用聊天模板的文件路径或字符串形式的模板手动指定其聊天模板。 - 如果没有聊天模板,服务器将无法处理聊天,并且所有聊天请求都会出错。
- 有些模型即使经过指令/聊天微调,也不提供聊天模板。对于这些模型,可以在
-
使用方法:
vllm serve <model> --chat-template ./path-to-chat-template.jinja -
模板来源:vLLM社区为流行的模型提供了一组聊天模板,可以在
examples目录下找到它们。
二、LMDeploy自定义对话模板
-
添加对话模板形式:
- 利用现有对话模板:直接配置一个json文件使用。
- 自定义Python对话模板类:注册成功后直接使用,优点是自定义程度高,可控性强。
-
json文件配置示例:
{"model_name": "your awesome chat template name","system": "<|im_start|>system\n","meta_instruction": "You are a robot developed by LMDeploy.","eosys": "<|im_end|>\n","user": "<|im_start|>user\n","eoh": "<|im_end|>\n","assistant": "<|im_start|>assistant\n","eoa": "<|im_end|>","separator": "\n","capability": "chat","stop_words": ["<|im_end|>"]
}
model_name为必填项,可以是LMDeploy内置对话模板名,也可以是新名字。- 其他字段可选填。当
model_name是内置对话模板名时,json文件中各非null字段会覆盖原有对话模板的对应属性。 - 当
model_name是新名字时,它会把BaseChatTemplate直接注册成新的对话模板。
- 模板拼接形式:
{system}{meta_instruction}{eosys}{user}{user_content}{eoh}{assistant}{assistant_content}{eoa}{separator}{user}...
-
使用方法:
- 使用CLI工具时,可以通过
--chat-template传入自定义对话模板。lmdeploy serve api_server internlm/internlm2_5-7b-chat --chat-template ${JSON_FILE} - 通过接口函数传入。
from lmdeploy import ChatTemplateConfig, serve serve('internlm/internlm2_5-7b-chat', chat_template_config=ChatTemplateConfig.from_json('${JSON_FILE}'))
- 使用CLI工具时,可以通过
-
自定义Python对话模板类示例:
from lmdeploy.model import MODELS, BaseChatTemplate@MODELS.register_module(name='customized_model')
class CustomizedModel(BaseChatTemplate):"""A customized chat template."""def __init__(self,system='<|im_start|>system\n',meta_instruction='You are a robot developed by LMDeploy.', user='<|im_start|>user\n',assistant='<|im_start|>assistant\n',eosys='<|im_end|>\n',eoh='<|im_end|>\n',eoa='<|im_end|>',separator='\n',stop_words=['<|im_end|>', '<|action_end|>']):super().__init__(system=system,meta_instruction=meta_instruction,eosys=eosys,user=user,eoh=eoh,assistant=assistant,eoa=eoa,separator=separator,stop_words=stop_words)from lmdeploy import ChatTemplateConfig, pipelinemessages = [{'role': 'user', 'content': 'who are you?'}]
pipe = pipeline('internlm/internlm2_5-7b-chat', chat_template_config=ChatTemplateConfig('customized_model'))
for response in pipe.stream_infer(messages):print(response.text, end='')
LLamaFactory找到这个jinja模板,然后使用代码导出模板,然后给vllm做模板。
我们可以看到他是一个私有化的方法,外部没法调用,但是可以调用
fix_jinja_template生成jinja模板。那么就需要我们自己写代码了。可以用ai工具生成。
# mytest.py
import sys
import os# 将项目根目录添加到 Python 路径
# root_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
# sys.path.append(root_dir)from llamafactory.data.template import TEMPLATES
from transformers import AutoTokenizer# 1. 初始化分词器(任意支持的分词器均可)
tokenizer = AutoTokenizer.from_pretrained(r"D:\Program Files\python\PycharmProjects\AiStudyProject\demo07\models\Qwen\Qwen2___5-1___5B-Instruct-merge")# 2. 获取模板对象
template_name = "qwen" # 替换为你需要查看的模板名称
template = TEMPLATES[template_name]# 3. 修复分词器的 Jinja 模板
template.fix_jinja_template(tokenizer)# 4. 直接输出模板的 Jinja 格式
print("=" * 40)
print(f"Template [{template_name}] 的 Jinja 格式:")
print("=" * 40)
print(tokenizer.chat_template)
就可以得到jinja得到qwen的path-to-chat-template.jinja模板,就可以给vllm用了。
{%- if tools %}{{- '<|im_start|>system\n' }}{%- if messages[0]['role'] == 'system' %}{{- messages[0]['content'] }}{%- else %}{{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}{%- endif %}{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}{%- for tool in tools %}{{- "\n" }}{{- tool | tojson }}{%- endfor %}{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}{%- if messages[0]['role'] == 'system' %}{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}{%- else %}{{- '<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n' }}{%- endif %}
{%- endif %}
{%- for message in messages %}{%- if (message.role == "user") or (message.role == "system" and not loop.first) or (message.role == "assistant" and not message.tool_calls) %}{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}{%- elif message.role == "assistant" %}{{- '<|im_start|>' + message.role }}{%- if message.content %}{{- '\n' + message.content }}{%- endif %}{%- for tool_call in message.tool_calls %}{%- if tool_call.function is defined %}{%- set tool_call = tool_call.function %}{%- endif %}{{- '\n<tool_call>\n{"name": "' }}{{- tool_call.name }}{{- '", "arguments": ' }}{{- tool_call.arguments | tojson }}{{- '}\n</tool_call>' }}{%- endfor %}{{- '<|im_end|>\n' }}{%- elif message.role == "tool" %}{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}{{- '<|im_start|>user' }}{%- endif %}{{- '\n<tool_response>\n' }}{{- message.content }}{{- '\n</tool_response>' }}{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}{{- '<|im_end|>\n' }}{%- endif %}{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}{{- '<|im_start|>assistant\n' }}
{%- endif %}
那么接下来启动,把模板丢给vllm
vllm serve 模型名称 --chat-template ./path-to-chat-template.jinja
注意:如果你使用修改后的模板启动,然后用open-webui做前端页面转发,修改后的模板不生效。这是因为open-webui每次都会覆盖原模型的模板,使用自己的模板,适合自己用。
启动open-webui

source activate openwebui
export HF_ENDPOINT=https://hf-mirror.com
export ENABLE_OLLAMA_API=False #关闭调用ollama的api,使用vllm的
export OPENAI_API_BASE_URL=http://localhost:8000/v1 #vllm端口
open-webui sever
端口映射

相关文章:

【大模型微调】如何解决llamaFactory微调效果与vllm部署效果不一致如何解决
以下个人没整理太全 一、生成式语言模型的对话模板介绍 使用Qwen/Qwen1.5-0.5B-Chat训练 对话模板不一样。回答的内容就会不一样。 我们可以看到例如qwen模型的tokenizer_config.json文件,就可以看到对话模板,一般同系列的模型,模板基本都…...

基于视觉语言模型的机器人实时探索系统!ClipRover:移动机器人零样本视觉语言探索和目标发现
作者:Yuxuan Zhang 1 ^{1} 1, Adnan Abdullah 2 ^{2} 2, Sanjeev J. Koppal 3 ^{3} 3, and Md Jahidul Islam 4 ^{4} 4单位: 2 , 4 ^{2,4} 2,4佛罗里达大学电气与计算机工程系RoboPI实验室, 1 , 3 ^{1,3} 1,3佛罗里达大学电气与计算机工程系F…...

Java常用工具算法-6--秘钥托管云服务AWS KMS
前言: 之前我们介绍了一些常用的加密算法(如:对称加密AES,非对称加密RSA,ECC等),不论是哪一种都需要涉及到秘钥的管理。通常的做法都是把秘钥放到配置文件中进行配置,但是对于一些高…...

Shell脚本的学习
编写脚本文件 定义以开头:#!/bin/bash #!用来声明脚本由什么shell解释,否则使用默认shel 第一步:编写脚本文件 #!/bin/bash #注释 echo "这是输出" 第二步:加上执行权限:chmod x 脚本文件名.sh 第三步&…...

Java——pdf增加水印
文章目录 前言方式一 itextpdf项目依赖引入编写PDF添加水印工具类测试效果展示 方式二 pdfbox依赖引入编写实现类效果展示 扩展1、将inputstream流信息添加水印并导出zip2、部署出现找不到指定字体文件 资料参考 前言 近期为了知识库文件导出,文件数据安全处理&…...

Redis过期key处理、内存淘汰策略与缓存一致性策略实践方案
在现代的高性能应用开发中,Redis作为一款极为热门的内存数据库,其快速的读写性能和丰富的数据结构使其在缓存、消息队列等诸多领域得到了广泛应用。然而,在实际使用过程中,处理好Redis过期key、选择合适的内存淘汰策略以及确保缓存…...

深入 C++ 线程库:从创建到同步的探索之旅
C在<thread>中定义了C线程库. 创建多线程 #include <iostream> #include <thread> using namespace std; void show(int id, int count) { //线程函数for (int i 0; i < count; i) {cout << "id:" << id << ",值:&qu…...

LangChain使用大语言模型构建强大的应用程序
LangChain简介 LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互ÿ…...
:Tag Manager系统代码操作与行业发展剖析)
程序化广告行业(72/89):Tag Manager系统代码操作与行业发展剖析
程序化广告行业(72/89):Tag Manager系统代码操作与行业发展剖析 大家好!在技术领域不断探索的过程中,我深刻体会到知识共享的重要性。写这篇博客,就是希望能和大家一起深入了解程序化广告行业,…...

数据结构实验3.3:求解迷宫路径问题
文章目录 一,问题描述二,基本要求三,算法分析(一)整体思路(二)详细步骤1. 输入迷宫大小并生成迷宫2. 定义走步规则3. 深度优先搜索(DFS)4. 输出结果 (三&…...

基于SpringBoot的线上历史馆藏系统【附源码】
基于SpringBoot的线上历史馆藏系统(源码L文说明文档) 4 系统设计 系统在设计的过程中,必然要遵循一定的原则才可以,胡乱设计是不可取的。首先用户在使用过程中,能够直观感受到功能操作的便利性,符合…...

Mybatis的springboot项目使用
删除数据 & 占位符 一般常用占位符进行数据库操作,也就是预编译sql。 在UserMapper中定义删除接口 /** 根据id删除用户*/ Delete("delete from user where id #{id}") void deleteById(Integer id);若想要获取返回值,声明为Integer (s…...

网站集群批量管理-Ansible剧本与变量
复盘内容:链接指北 查看ansible命令文档 ansible-doc -s systemd一、剧本 何为剧本: playbook 文件,用于长久保存并且实现批量管理,维护,部署的文件. 类似于脚本存放命令和变量 剧本yaml格式,yaml格式的文件:空格,冒号. 剧本未来我们批量管理,运维必会的内容. …...

HOW - React Developer Tools 调试器
目录 React Developer Tools使用Components 功能特性1. 查看和编辑 props/state/hooks2. 查找组件3. 检查组件树4. 打印组件信息5. 检查子组件 Profiler 功能特性Commit ChartFlame Chart 火焰图Ranked Chart 排名图 why-did-you-render 参考文档: React调试利器&a…...

Spring Cloud Alibaba微服务治理实战:Nacos+Sentinel深度解析
一、引言 在微服务架构中,服务发现、配置管理、流量控制是保障系统稳定性的核心问题。Spring Cloud Netflix 生态曾主导微服务解决方案,但其部分组件(如 Eureka、Hystrix)已进入维护模式。 Spring Cloud Alibaba 凭借 高性能、轻…...

《AI换脸时代的攻防暗战:从技术滥用走向可信未来》
技术迭代图谱 过去五年里,Deepfake技术经历了飞速迭代,从最初的萌芽到如今的广泛应用和对抗措施形成。2017年前后,利用深度学习进行人脸换装的技术首次在社区中出现。一位Reddit网友昵称“deepfakes”,将名人面孔替换到色情影片上…...

25/4/9 算法笔记 DBGAN+强化学习+迁移学习实现青光眼图像去模糊1
整体实验介绍 实验主要是结合DBGAN对抗网络强化学习增强迁移学习增强实现青光眼图像去模糊。今天则是先完成了DBGAN板块模型的训练。 实验背景介绍 青光眼的主要特征有: 视盘形态与杯盘比CDR:青光眼患者主要表现为视杯扩大,盘沿变窄。 视…...

【Claude AI大语言模型连接Blender生成资产】Windows安装Blender MCP教程
前言 最近在学习资产制作,了解到了个好玩的东西,利用AI一步一步搭建资产: 上面这副图就是利用Claude AI调用Blender的Python接口一步一步实现的,挺丑但好玩。 安装教程 进入Github: Blender-MCP 网站,下载该项目&a…...

JSP运行环境安装及常用HTML标记使用
制作一个静态网站的基本页面index.html 实验代码:<form> <label for"username">用户名:</label> <input type"text" id"username" name"username"><br> <label for"password&…...

Git 的进阶功能和技巧
1、分支的概念和使用 1.1、什么是分支? 分支(Branch)是在版本控制中非常重要的概念。几乎所有版本控制系统都支持某种形式的分支。在 Git 中,分支是 Git 强大功能之一,它允许我们从主开发线分离出来,在不…...

WSL1升级到WSL2注意事项
今天要在WSL上安装docker,因为机器上安装了wsl1,docker安装后启动不了,通过询问deepseek发现docker只能在wsl2上安装,因此就想着将本机的wsl1升级到wsl2。 确保你的 Windows 系统是 Windows 10(版本 1903 及以上&…...

392. 判断子序列
https://leetcode.cn/problems/is-subsequence/?envTypestudy-plan-v2&envIdtop-interview-150因为是子序列我们只要关心后一个字符在前一个字符后面出现过就行,至于在哪出现出现几次我们不关心,所以我们可以用HashMap<Character, ArrayList<…...

在 VMware 中为 Ubuntu 24.04 虚拟机设置共享文件夹后,在虚拟机中未能看到共享的内容
在 VMware 中为 Ubuntu 24.04 虚拟机设置共享文件夹后,如果在虚拟机中未能看到共享的内容,可能是由于以下原因: VMware Tools 未正确安装:共享文件夹功能依赖于 VMware Tools 或 Open VM Tools。如果未安装或安装不完整࿰…...

台式电脑插入耳机没有声音或麦克风不管用
目录 一、如何确定插孔对应功能1.常见音频插孔颜色及功能2.如何确认电脑插孔?3.常见问题二、 解决方案1. 检查耳机连接和设备选择2. 检查音量设置和静音状态3. 更新或重新安装声卡驱动4. 检查默认音频格式5. 禁用音频增强功能6. 排查硬件问题7. 检查系统服务8. BIOS设置(可选…...

Windchill开发-WTContainer相关API整理
Windchill开发-WTContainer相关API整理 概述各容器对象相关方法站点容器组织容器产品容器/存储库容器上下文团队角色组 文件夹 方法汇总 概述 Windchill 的环境由一组容器组成,容器分为三级:第一级为站点容器,第二级为组织容器,第…...

理解JSON-RPC 2.0 协议
JSON-RPC 2.0是指一种基于 JSON 的远程过程调用协议,用于在网络上进行跨平台和跨语言的通信。它提供了一种简单、轻量级的方式来实现客户端和服务器之间的方法调用和数据交换。在原文中,JSON-RPC 2.0被用来描述 STDIO 传输机制中消息的格式,即…...

【 C# 使用 MiniExcel 库的典型场景】
以下是 C# 使用 MiniExcel 库的典型场景及代码示例: 一、基础读取操作 强类型读取(需定义数据模型类) 定义与 Excel 列名匹配的类后直接映射为对象集合: csharp Copy Code public class UserAccount { public int Id { get; …...

创建 Pod 失败,运行时报错 no space left on device?
遇到创建Pod失败并报错“no space left on device”时,请按照以下步骤排查和解决问题: 1. 定位问题来源 查看Pod事件: kubectl describe pod <pod-name> -n <namespace> 在输出中查找 Events 部分,确认错误是否与…...

[leetcode]查询区间内的所有素数
一.暴力求解 #include<iostream> #include<vector> using namespace std; vector<int> result; bool isPrime(int i) { if (i < 2) return false; for (int j 2;j * j < i;j) { if (i % j 0) { …...

【Web安全】如何在 CDN 干扰下精准检测 SSRF?Nuclei + Interactsh 实战
❤️博客主页: iknow181 🔥系列专栏: 网络安全、 Python、JavaSE、JavaWeb、CCNP 🎉欢迎大家点赞👍收藏⭐评论✍ 背景 在日常漏洞复核中,我们常用 DNSLog 平台判断目标是否存在 SSRF 漏洞:只要请…...

输入框只能输入非中文字符
在 Qt 中,可以通过设置输入法过滤器(QInputContext)或使用正则表达式来限制输入框(QLineEdit 或 QTextEdit)只能输入非中文字符。以下是两种实现方法: ### 方法 1:使用正则表达式 可以通过 QLi…...

LeeCode 136. 只出现一次的数字
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。 示例 1 : 输入࿱…...

Traefik应用:配置容器多个网络时无法访问问题
Traefik应用:配置容器多个网络时无法访问问题 介绍解决方法问题原因: **容器多网络归属导致 Traefik 无法正确发现路由规则**。解决方案方法 1:将应用容器 **仅连接** 到 traefik-public 网络方法 2:显式指定 Traefik 监听的网络 …...

超便捷超实用的文档处理工具,PDF排序,功能强大,应用广泛,无需下载,在线使用,简单易用快捷!
小白工具https://www.xiaobaitool.net/files/pdf-sort/ 中的 PDF 排序功能是一项便捷实用的文档处理服务,以下是其具体介绍: 操作便捷直观:用户上传 PDF 文件后,可通过直接拖动页面缩略图来调整顺序,就像在纸质文档中…...

zsh: command not found - 鸿蒙 HarmonyOS Next
终端中执行 hdc 命令抛出如下错误; zsh: command not found 解决办法 首先,查找到 DevEco-Studio 的 toolchains 目录路径; 其次,按照类似如下的文件夹层级结果推理到 toolchains 子级路径下,其中 sdk 后一级的路径可能会存在差异,以实际本地路径结构为主,直至找到 openharm…...

【动态规划】 深入动态规划—两个数组的dp问题
文章目录 前言例题一、最长公共子序列二、不相交的线三、不同的子序列四、通配符匹配五、交错字符串六、两个字符串的最小ASCII删除和七、最长重复子数组 结语 前言 问题本质 它主要围绕着给定的两个数组展开,旨在通过对这两个数组元素间关系的分析,找出…...
个人学习笔记(7):网络数据采集以及FNN分类)
金融数据分析(Python)个人学习笔记(7):网络数据采集以及FNN分类
一、网络数据采集 证券宝是一个免费、开源的证券数据平台(无需注册),提供大盘准确、完整的证券历史行情数据、上市公司财务数据等,通过python API获取证券数据信息。 1. 安装并导入第三方依赖库 baostock 在命令提示符中运行&…...

指定运行级别
linux系统下有7种运行级别,我们需要来了解一下常用的运行级别,方便我们熟悉以后的部署环境,话不多说,来看. 开机流程: 指定数级别 基本介绍 运行级别说明: 0:关机 相当于shutdown -h now ⭐️默认参数不能设置为0,否则系统无法正常启动 1:单用户(用于找回丢…...

7.第二阶段x64游戏实战-string类
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:7.第二阶段x64游戏实战-分析人物属性 string类是字符串类,在计算机中…...

【MySQL基础】左右连接实战:掌握数据关联的完整视图
1 左右连接基础概念 左连接(left join)和右连接(right join)是MySQL中两种重要的表连接方式,它们与内连接不同,能够保留不匹配的记录,为我们提供更完整的数据视图。 核心区别: left join:保留左表所有记录,…...

建筑工程行业如何选OA系统?4大主流产品分析
工程行业项目的复杂性与业务流程的繁琐性对办公效率提出了极高要求。而OA 系统(办公自动化系统)的出现,为工程企业提供了一种全新的、高效的管理模式。 工程行业OA系统选型关键指标 功能深度:项目管理模块完整度、文档版本控制能…...

动态科技感html导航网站源码
源码介绍 动态科技感html导航网站源码,这个设计完美呈现了科幻电影中的未来科技界面效果,适合展示技术类项目或作为个人作品集的入口页面,自适应手机。 修改卡片中的链接指向你实际的HTML文件可以根据需要调整卡片内容、图标和颜色要添加更…...

CLIPGaze: Zero-Shot Goal-Directed ScanpathPrediction Using CLIP
摘要 目标导向的扫描路径预测旨在预测人们在搜索视觉场景中的目标时的视线移动路径。大多数现有的目标导向扫描路径预测方法在面对训练过程中未出现的目标类别时,泛化能力较差。此外,它们通常采用不同的预训练模型分别提取目标提示和图像的特征,导致两者之间存在较大的特征…...

wsl-docker环境下启动ES报错vm.max_map_count [65530] is too low
问题描述 在windows环境下用Docker Desktop(wsl docker)启动 elasticsearch时报错 max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]解决方案 方案一 默认的vm.max_map_count值是65530,而es需要至少262…...

js chrome 插件,下载微博视频
起因, 目的: 最初是想下载微博上的NBA视频,因为在看网页上看视频很不方便,快进一次是10秒,而本地 VLC 播放器,快进一次是5秒。另外我还想做点视频剪辑。 对比 原来手动下载的话,右键检查,复制…...

游戏引擎学习第212天
"我们将同步…"α 之前我们有一些内容是暂时搁置的,因为在调整代码的过程中,我们做了一些变动以使代码更加简洁,这样可以把数据放入调试缓冲区并显示出来,这一切现在看起来已经好多了。尽管现在看起来更好,…...

PXE远程安装服务器
目录 搭建PXE远程安装服务器 1、准备Linux安装源: 2、安装并启用TFTP服务: 3、准备Linux内核、初始化镜像文件 4、准备PXE引导程序 5、安装并启用DHCP服务 6、(1)配置启动菜单文件(有人应答) 6、(2)…...

软件测试之功能测试详解
一、测试项目启动与研读需求文档 (一) 组建测试团队 1、测试团队中的角色 2、测试团队的基本责任 尽早地发现软件程序、系统或产品中所有的问题。 督促和协助开发人员尽快地解决程序中的缺陷。 帮助项目管理人员制定合理的开发和测试计划。 对缺陷进行…...
(PyTorch))
Python深度学习基础——卷积神经网络(CNN)(PyTorch)
CNN原理 从DNN到CNN 卷积层与汇聚 深度神经网络DNN中,相邻层的所有神经元之间都有连接,这叫全连接;卷积神经网络 CNN 中,新增了卷积层(Convolution)与汇聚(Pooling)。DNN 的全连接…...

pytorch 反向传播
文章目录 概念计算图自动求导的两种模式 自动求导-代码标量的反向传播非标量变量的反向传播将某些计算移动到计算图之外 概念 核心:链式法则 深度学习框架通过自动计算导数(自动微分)来加快求导。 实践中,根据涉及号的模型,系统会构建一个计…...