【动态规划】 深入动态规划—两个数组的dp问题
文章目录
- 前言
- 例题
- 一、最长公共子序列
- 二、不相交的线
- 三、不同的子序列
- 四、通配符匹配
- 五、交错字符串
- 六、两个字符串的最小ASCII删除和
- 七、最长重复子数组
- 结语

前言
问题本质
它主要围绕着给定的两个数组展开,旨在通过对这两个数组元素间关系的分析,找出满足特定目标的最优解。比如在字符串处理中,两个字符串可看作字符数组,求它们的最长公共子序列等问题;或是在数值数组场景下,计算从两个数组元素组合中得到的最大收益等。
解题关键要素
状态定义:通常构建一个二维数组 dp[i][j] 作为状态表示。这里的 i 对应第一个数组的下标,j 对应第二个数组的下标 。dp[i][j] 代表在考虑第一个数组前 i 个元素和第二个数组前 j 个元素时,问题的最优解值,像上述最长公共子序列问题中,dp[i][j] 就表示对应前缀子串的最长公共子序列长度。
状态转移方程:这是解决问题的核心。需深入剖析问题特性,明确 dp[i][j] 如何由已求解的子问题状态(如 dp[i - 1][j]、dp[i][j - 1]、dp[i - 1][j - 1] 等)推导得出。例如在求两个数组元素匹配的最大得分问题中,若当前两个数组元素匹配,dp[i][j] 可能由 dp[i - 1][j - 1] 加上对应得分转移而来;若不匹配,则需比较 dp[i - 1][j] 和 dp[i][j - 1] 取较大值。
边界条件:初始化 dp 数组的第一行和第一列。如在最长公共子序列问题里,dp[0][j] 和 dp[i][0] 都初始化为 0 ,因为一个空串与另一个串不存在公共子序列。
通过合理定义状态、精准推导状态转移方程并正确处理边界条件,就能借助动态规划高效解决涉及两个数组的各类问题。
下面本篇文章,将通过例题为大家详细动态规划中的两个数组的dp问题!
例题
一、最长公共子序列
- 题目链接:最长公共子序列
- 题目描述:
给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列的长度。如果不存在公共⼦序 列 ,返回 0 。 ⼀个字符串的 ⼦序列 是指这样⼀个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下 删除某些字符(也可以不删除任何字符)后组成的新字符串。 ◦ 例如,“ace” 是 “abcde” 的⼦序列,但 “aec” 不是 “abcde” 的⼦序列。
两个字符串的 公共⼦序列 是这两个字符串所共同拥有的⼦序列。 ⽰例 1: 输⼊:text1 = “abcde”, text2 = “ace”
输出:3 解释:最⻓公共⼦序列是 “ace” ,它的⻓度为 3 。 ⽰例 2: 输⼊:text1 = “abc”, text2 = “abc” 输出:3 解释:最⻓公共⼦序列是 “abc” ,它的⻓度为 3 。 ⽰例 3: 输⼊:text1 = “abc”, text2 = “def” 输出:0 解释:两个字符串没有公共⼦序列,返回 0 。 提⽰:1 <= text1.length, text2.length <= 1000
text1 和 text2 仅由⼩写英⽂字符组成。
-
解法(动态规划):
算法思路:
状态表示: 对于两个数组的动态规划,我们的定义状态表⽰的经验就是:
i. 选取第⼀个数组 [0, i] 区间以及第⼆个数组 [0, j] 区间作为研究对象;
ii. 结合题目要求,定义状态表⽰。 在这道题中,我们根据定义状态表示为:
dp[i][j] 表示: s1 的 [0, i] 区间以及 s2 的 [0, j] 区间内的所有的子序列中,最长公共子序列的长度。
状态转移方程: 分析状态转移方程的经验就是根据「最后⼀个位置」的状况,分情况讨论。 对于 dp[i][j] ,我们可以根据 s1[i] 与 s2[j] 的字符分情况讨论:
i. 两个字符相同, s1[i] = s2[j] :那么最长公共子序列就在 s1 的 [0, i - 1] 以 及 s2 的 [0, j - 1] 区间上找到⼀个最长的,然后再加上 s1[i] 即可。因此dp[i][j] = dp[i - 1][j - 1] + 1 ;
ii. 两个字符不相同, s1[i] != s2[j] :那么最长公共子序列⼀定不会同时以 s1[i]
和 s2[j] 结尾。那么我们找最⻓公共⼦序列时,有下面三种策略:
• 去 s1 的 [0, i - 1] 以及 s2 的 [0, j] 区间内找:此时最⼤⻓度为 dp[i - 1][j] ; • 去 s1 的 [0, i] 以及 s2 的 [0, j - 1] 区间内找:此时最大长度为 dp[i][j - 1] ;
• 去 s1 的 [0, i - 1] 以及 s2 的 [0, j - 1] 区间内找:此时最大长度为dp[i - 1][j - 1] 。 我们要三者的最大值即可。但是我们细细观察会发现,第三种包含在第⼀种和第二种情况里面,但是我们求的是最大值,并不影响最终结果。因此只需求前两种情况下的最大值即可。 综上,状态转移方程为:
if(s1[i] == s2[j]) dp[i][j] = dp[i - 1][j - 1] + 1 ;
if(s1[i] != s2[j]) dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]) 。
初始化:
a. 「空串」是有研究意义的,因此我们将原始 dp 表的规模多加上⼀⾏和⼀列,表⽰空串。
b. 引入空串后,大大的方便我们的初始化。
c. 但也要注意「下标的映射关系」,以及⾥⾯的值要「保证后续填表是正确的」。
当 s1 为空时,没有长度,同理 s2 也是。因此第⼀⾏和第⼀列里面的值初始化为 0 即可保证后续填表是正确的。
填表顺序: 根据「状态转移方程」得:从上往下填写每⼀行,每⼀行从左往右。
返回值: 根据「状态表示」得:返回 dp[m][n] -
代码示例:
public int longestCommonSubsequence(String s1, String s2) {// 1. 创建 dp 表// 2. 初始化// 3. 填表// 4. 返回值int m = s1.length(), n = s2.length();s1 = " " + s1;s2 = " " + s2;int[][] dp = new int[m + 1][n + 1];for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++)if (s1.charAt(i) == s2.charAt(j))dp[i][j] = dp[i - 1][j - 1] + 1;elsedp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);return dp[m][n];}
二、不相交的线
- 题目链接:不相交的线
- 题目描述:
在两条独立的水平线上按给定的顺序写下 nums1 和 nums2 中的整数。 现在,可以绘制⼀些连接两个数字 nums1[i] 和 nums2[j] 的直线,这些直线需要同时满足:
• nums1[i] == nums2[j]
• 且绘制的直线不与任何其他连线(非水平线)相交。
请注意,连线即使在端点也不能相交:每个数字只能属于⼀条连线。 以这种方法绘制线条,并返回可以绘制的最大连线数。
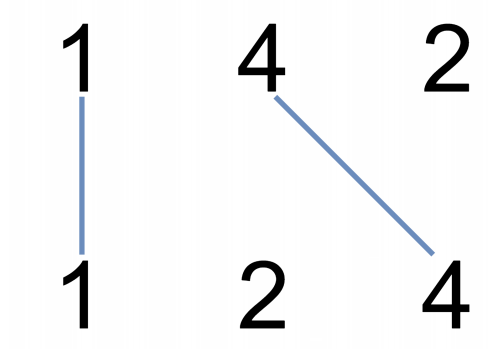
示例 1:
输⼊:nums1 = [1,4,2], nums2 = [1,2,4]
输出:2 解释:可以画出两条不交叉的线,如上图所示。 但无法画出第三条不相交的直线,因为从 nums1[1]=4 到 nums2[2]=4 的直线将与从nums1[2]=2 到 nums2[1]=2 的直线相交。
示例 2: 输入:nums1 = [2,5,1,2,5], nums2 = [10,5,2,1,5,2]
输出:3
示例 3: 输入:nums1 = [1,3,7,1,7,5], nums2 = [1,9,2,5,1]
输出:2
-
解法(动态规划):
算法思路: 如果要保证两条直线不相交,那么我们「下⼀个连线」必须在「上⼀个连线」对应的两个元素的 「后面」寻找相同的元素。这不就转化成「最长公共子序列」的模型了嘛。那就是在这两个数组中 寻找「最长的公共子序列」。
只不过是在整数数组中做⼀次「最长的公共子序列」,代码几乎⼀模⼀样,这里就不再赘述算法原理啦~ -
代码示例:
public int maxUncrossedLines(int[] nums1, int[] nums2) {// 1. 创建 dp 表// 2. 初始化// 3. 填表// 4. 返回值int m = nums1.length, n = nums2.length;int[][] dp = new int[m + 1][n + 1];for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++)if (nums1[i - 1] == nums2[j - 1]) dp[i][j] = dp[i - 1][j - 1] +1;else dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);return dp[m][n];}
三、不同的子序列
- 题目链接:不同的子序列
- 题目描述:
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。 字符串的⼀个子序列是指,通过删除⼀些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,“ACE” 是 “ABCDE” 的⼀个子序列,而 “AEC” 不是) 题目数据保证答案符合 32 位带符号整数范围。
示例 1:输入:s = “rabbbit”, t = “rabbit” 输出:3 解释:如下图所示, 有 3 种可以从 s 中得到 “rabbit” 的⽅案。
rabbbit
rabbbit
rabbbit
示例 2:输⼊:s = “babgbag”, t = “bag” 输出:5
解释:如下图所示, 有 5 种可以从 s 中得到 “bag” 的⽅案。
babgbag
babgbag
babgbag
babgbag
babgbag
-
解法(动态规划): 算法思路:
状态表示: 对于两个字符串之间的 dp 问题,我们⼀般的思考方式如下:
i. 选取第⼀个字符串的 [0, i] 区间以及第⼆个字符串的 [0, j] 区间当成研究对象,结 合题目的要求来定义「状态表示」;
ii. 然后根据两个区间上「最后⼀个位置的字符」,来进行「分类讨论」,从而确定「状态转移方程」。
我们可以根据上面的策略,解决大部分关于两个字符串之间的 dp 问题。
dp[i][j] 表示:在字符串 s 的 [0, j] 区间内的所有子序列中,有多少个 t 字符串 [0,
i] 区间内的子串。
状态转移方程: 老规矩,根据「最后⼀个位置」的元素,结合题目要求,分情况讨论:
i. 当 t[i] == s[j] 的时候,此时的⼦序列有两种选择: • ⼀种选择是:子序列选择 s[j] 作为结尾,此时相当于在状态 dp[i - 1][j - 1]
中的所有符合要求的⼦序列的后⾯,再加上⼀个字符 s[j] (请大家结合状态表示,好好理解这句话),此时 dp[i][j] = dp[i - 1][j - 1] ; • 另⼀种选择是:我就是任性,我就不选择 s[j] 作为结尾。此时相当于选择了状态dp[i][j - 1] 中所有符合要求的⼦序列。我们也可以理解为继承了上个状态⾥⾯的 求得的⼦序列。此时 dp[i][j] = dp[i][j - 1] ; 两种情况加起来,就是 t[i] == s[j] 时的结果。
ii. 当 t[i] != s[j] 的时候,此时的⼦序列只能从 dp[i][j - 1] 中选择所有符合要求的子序列。只能继承上个状态里面求得的子序列, dp[i][j] = dp[i][j - 1] ; 综上所述,状态转移方程为:
▪ 所有情况下都可以继承上⼀次的结果: dp[i][j] = dp[i][j - 1] ; ▪ 当 t[i] == s[j] 时,可以多选择⼀种情况: dp[i][j] += dp[i - 1][j - 1]
初始化:
a. 「空串」是有研究意义的,因此我们将原始 dp 表的规模多加上⼀⾏和⼀列,表⽰空串。
b. 引⼊空串后,⼤⼤的⽅便我们的初始化。
c. 但也要注意「下标的映射关系」,以及⾥⾯的值要「保证后续填表是正确的」。
当 s 为空时, t 的子串中有⼀个空串和它⼀样,因此初始化第⼀⾏全部为 1 。
填表顺序: 「从上往下」填每⼀行,每⼀行「从左往右」。
返回值:根据「状态表⽰」,返回 dp[m][n] 的值。 -
代码示例:
public int numDistinct(String s, String t) {// 1. 创建 dp 表// 2. 初始化// 3. 填表// 4. 返回值int m = t.length(), n = s.length();int[][] dp = new int[m + 1][n + 1];for (int j = 0; j <= n; j++) dp[0][j] = 1;for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++) {dp[i][j] = dp[i][j - 1];if (t.charAt(i - 1) == s.charAt(j - 1))dp[i][j] += dp[i - 1][j - 1];}return dp[m][n];}
四、通配符匹配
- 题目链接:通配符匹配
- 题目描述:
给定⼀个字符串 (s) 和⼀个字符模式 § ,实现⼀个⽀持 ‘?’ 和 ’ * ’ 的通配符匹配。
‘?’ 可以匹配任何单个字符。
’ * ’ 可以匹配任意字符串(包括空字符串)。
两个字符串完全匹配才算匹配成功。 说明: s 可能为空,且只包含从 a-z 的小写字母。 p 可能为空,且只包含从 a-z 的小写字母,以及字符 ? 和 。
示例 1:
输⼊: s = “aa” p = “a” 输出: false
解释: “a” 无法匹配 “aa” 整个字符串。
示例 2:
输入: s = “aa” p = ""
输出: true
解释: ‘’ 可以匹配任意字符串。
示例 3:
输入: s = “cb” p = “?a” 输出: false
解释: ‘?’ 可以匹配 ‘c’, 但第⼆个 ‘a’ ⽆法匹配 ‘b’。 ⽰例 4:
输入: s = “adceb” p = “ab” 输出: true
解释: 第⼀个 '’ 可以匹配空字符串, 第⼆个 '’ 可以匹配字符串 “dce”. ⽰例 5:
输⼊: s = “acdcb” p = "ac?b" 输出: false
-
解法(动态规划):
算法思路:
状态表示: 对于两个字符串之间的 dp 问题,我们⼀般的思考⽅式如下:
i. 选取第⼀个字符串的 [0, i] 区间以及第二个字符串的 [0, j] 区间当成研究对象,结合题目的要求来定义「状态表示」;
ii. 然后根据两个区间上「最后⼀个位置的字符」,来进行「分类讨论」,从而确定「状态转移方程」。
我们可以根据上⾯的策略,解决大部分关于两个字符串之间的 dp 问题。 因此,我们定义状态表示为:
dp[i][j] 表示: p 字符串 [0, j] 区间内的子串能否匹配字符串 s 的 [0, i] 区间内的 ⼦串。
状态转移方程: 老规矩,根据最后⼀个位置的元素,结合题目要求,分情况讨论:
i. 当 s[i] == p[j] 或 p[j] == ‘?’ 的时候,此时两个字符串匹配上了当前的⼀个字 符,只能从 dp[i - 1][j - 1] 中看当前字符前⾯的两个子串是否匹配。只能继承上个状态中的匹配结果, dp[i][j] = dp[i][j - 1] ;
ii. 当 p[j] == ‘’ 的时候,此时匹配策略有两种选择:
• ⼀种选择是: * 匹配空字符串,此时相当于它匹配了⼀个寂寞,直接继承状态 dp[i][j - 1] ,此时 dp[i][j] = dp[i][j - 1] ;
• 另⼀种选择是: * 向前匹配 1 ~ n 个字符,直⾄匹配上整个 s1 串。此时相当于 从 dp[k][j - 1] (0 <= k <= i) 中所有匹配情况中,选择性继承可以成功的 情况。此时 dp[i][j] = dp[k][j - 1] (0 <= k <= i) ;
iii. 当 p[j] 不是特殊字符,且不与 s[i] 相等时,无法匹配。 三种情况加起来,就是所有可能的匹配结果。 综上所述,状态转移⽅程为: ▪ 当 s[i] == p[j] 或 p[j] == ‘?’ 时: dp[i][j] = dp[i][j - 1] ; ▪ 当 p[j] == '’ 时,有多种情况需要讨论: dp[i][j] = dp[k][j - 1] (0 <= k <= i) ; 优化:当我们发现,计算⼀个状态的时候,需要⼀个循环才能搞定的时候,我们要想到去优化。优 化的⽅向就是用⼀个或者两个状态来表示这⼀堆的状态。通常就是把它写下来,然后⽤数学的方式 做⼀下等价替换: 当 p[j] == '’ 时,状态转移方程为:dp[i][j] = dp[i][j - 1] || dp[i - 1][j - 1] || dp[i - 2][j - 1] …
我们发现 i 是有规律的减小的,因此我们去看看 dp[i - 1][j] :dp[i - 1][j] = dp[i - 1][j - 1] || dp[i - 2][j - 1] || dp[i - 3][j - 1] …
我们惊奇的发现, dp[i][j] 的状态转移⽅程⾥⾯除了第⼀项以外,其余的都可以用 dp[i - 1][j] 替代。因此,我们优化我们的状态转移⽅程为: dp[i][j] = dp[i - 1][j] || dp[i][j - 1] 。
初始化: 由于 dp 数组的值设置为是否匹配,为了不与答案值混淆,我们需要将整个数组初始化为
false 。 由于需要用到前一行和前一列的状态,我们初始化第一行、第⼀列即可。
◦ dp[0][0] 表⽰两个空串能否匹配,答案是显然的, 初始化为 true 。
◦ 第一行表示 s 是⼀个空串, p 串和空串只有⼀种匹配可能,即 p 串表示为 "*" ,此时 也相当于空串匹配上空串。所以,我们可以遍历 p 串,把所有前导为 "" 的 p ⼦串和空串 的 dp 值设为 true 。 ◦ 第⼀列表示p 是⼀个空串,不可能匹配上 s 串,跟随数组初始化即可。
填表顺序:
从上往下填每一行,每⼀行从左往右。
返回值: 根据状态表示,返回 dp[m][n] 的值。 -
代码示例
public boolean isMatch(String ss, String pp) {// 1. 创建 dp 表// 2. 初始化// 3. 填表// 4. 返回结果int m = ss.length(), n = pp.length();ss = " " + ss;pp = " " + pp;char[] s = ss.toCharArray();char[] p = pp.toCharArray();boolean[][] dp = new boolean[m + 1][n + 1];dp[0][0] = true;for (int j = 1; j <= n; j++)if (p[j] == '*') dp[0][j] = true;else break;for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++)if (p[j] == '*')dp[i][j] = dp[i - 1][j] || dp[i][j - 1];elsedp[i][j] = (p[j] == '?' || p[j] == s[i]) && dp[i - 1][j -1];return dp[m][n];}
五、交错字符串
- 题目链接:
- 题目描述:
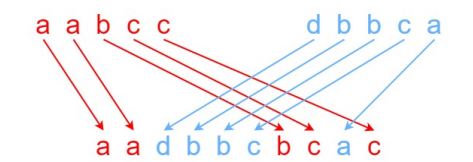
给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错组成的。
两个字符串 s 和 t 交错 的定义与过程如下,其中每个字符串都会被分割成若干非空子字符串: s = s1 + s2 + … + sn
t = t1 + t2 + … + tm |n - m| <= 1 交错 是 s1 + t1 + s2 + t2 + s3 + t3 + … 或者 t1 + s1 + t2 + s2 + t3 + s3 + …
注意:a + b 意味着字符串 a 和 b 连接。
示例 1:
输⼊:s1 = “aabcc”, s2 = “dbbca”, s3 = “aadbbcbcac” 输出:true
示例 2:输入:s1 = “aabcc”, s2 = “dbbca”, s3 = “aadbbbaccc”
输出:false
示例 3:输入:s1 = “”, s2 = “”, s3 = “”
输出:true
-
解法(动态规划): 算法思路: 对于两个字符串之间的 dp 问题,我们⼀般的思考⽅式如下:
i. 选取第⼀个字符串的 [0, i] 区间以及第⼆个字符串的 [0, j] 区间当成研究对象,结 合题⽬的要求来定义「状态表⽰」;
ii. 然后根据两个区间上「最后⼀个位置的字符」,来进⾏「分类讨论」,从⽽确定「状态转移 ⽅程」。
我们可以根据上⾯的策略,解决⼤部分关于两个字符串之间的 dp 问题。
这道题⾥⾯空串是有研究意义的,因此我们先预处理⼀下原始字符串,前⾯统⼀加上⼀个占位符:
s1 = " " + s1, s2 = " " + s2, s3 = " " + s3 。
状态表⽰:
dp[i][j] 表⽰字符串 s1 中 [1, i] 区间内的字符串以及 s2 中 [1, j] 区间内的字符 串,能否拼接成 s3 中 [1, i + j] 区间内的字符串。
状态转移⽅程: 先分析⼀下题目,题目中交错后的字符串为 s1 + t1 + s2 + t2 + s3 + t3… ,看 似⼀个 s ⼀个 t 。实际上 s1 能够拆分成更小的⼀个字符,进而可以细化成 s1 + s2 + s3 + t1 + t2 + s4… 。 也就是说,并不是前⼀个用了 s 的子串,后⼀个必须要用 t 的子串。这⼀点理解,对我们的状态转移很重要。
继续根据两个区间上「最后⼀个位置的字符」,结合题目的要求,来进行「分类讨论」:
i. 当 s3[i + j] = s1[i] 的时候,说明交错后的字符串的最后⼀个字符和 s1 的最后⼀ 个字符匹配了。那么整个字符串能否交错组成,变成:s1 中 [1, i - 1] 区间上的字符串以及 s2 中 [1, j] 区间上的字符串,能够交 错形成 s3 中 [1, i + j - 1] 区间上的字符串,也就是 dp[i - 1][j];此时 dp[i][j] = dp[i - 1][j]
ii. 当 s3[i + j] = s2[j] 的时候,说明交错后的字符串的最后⼀个字符和 s2 的最后 ⼀个字符匹配了。那么整个字符串能否交错组成,变成:s1 中 [1, i] 区间上的字符串以及 s2 中 [1, j - 1] 区间上的字符串,能够交 错形成 s3 中 [1, i + j - 1] 区间上的字符串,也就是 dp[i][j - 1] ;
iii. 当两者的末尾都不等于 s3 最后⼀个位置的字符时,说明不可能是两者的交错字符串。 上述三种情况下,只要有⼀个情况下能够交错组成目标串,就可以返回 true 。因此,我们可以定义状态转移为:
dp[i][j] = (s1[i - 1] == s3[i + j - 1] && dp[i - 1][j]) || (s2[j - 1] == s3[i + j - 1] && dp[i][j - 1])
只要有⼀个成立,结果就是 true 。
初始化: 由于用到 i - 1 , j - 1 位置的值,因此需要初始化「第⼀个位置」以及「第⼀行」和「第⼀ 列」。
◦ 第⼀个位置:
dp[0][0] = true ,因为空串 + 空串能够构成⼀个空串。
◦ 第⼀行: 第⼀行表示 s1 是⼀个空串,我们只用考虑 s2 即可。因此状态转移之和 s2 有关:
dp[0][j] = s2[j - 1] == s3[j - 1] && dp[0][j - 1] , j 从 1 到 n ( n 为 s2 的⻓度) ◦ 第⼀列: 第⼀列表⽰ s2 是⼀个空串,我们只⽤考虑 s1 即可。因此状态转移之和 s1 有关:
dp[i][0] = s1[i - 1] == s3[i - 1] && dp[i - 1][0] , i 从 1 到 m ( m 为 s1 的长度)
填表顺序: 根据「状态转移」,我们需要「从上往下」填每⼀行,每一行「从左往右」。
返回值: 根据「状态表示」,我们需要返回 dp[m][n] 的值。 -
代码示例:
public boolean isInterleave(String s1, String s2, String s3) {// 1. 创建 dp 表// 2. 初始化// 3. 填表// 4. 返回值int m = s1.length(), n = s2.length();if (m + n != s3.length()) return false; // 处理下边界条件s1 = " " + s1;s2 = " " + s2;s3 = " " + s3;boolean[][] dp = new boolean[m + 1][n + 1];dp[0][0] = true; // 初始化for (int j = 1; j <= n; j++) // 初始化第⼀⾏if (s2.charAt(j) == s3.charAt(j)) dp[0][j] = true;else break;for (int i = 1; i <= m; i++) // 初始化第⼀列if (s1.charAt(i) == s3.charAt(i)) dp[i][0] = true;else break;for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++)dp[i][j] = (s1.charAt(i) == s3.charAt(i + j) && dp[i - 1][j])|| (s2.charAt(j) == s3.charAt(i + j) && dp[i][j - 1]);return dp[m][n];}
六、两个字符串的最小ASCII删除和
- 题目链接:两个字符串的最小ASCII删除和
- 题目描述:
给定两个字符串s1 和 s2,返回 使两个字符串相等所需删除字符的 ASCII 值的最小和 。
示例 1:输⼊: s1 = “sea”, s2 = “eat” 输出: 231
解释:在 “sea” 中删除 “s” 并将 “s” 的值(115)加⼊总和。 在 “eat” 中删除 “t” 并将 116 加⼊总和。 结束时,两个字符串相等,115 + 116 = 231 就是符合条件的最⼩和。 ⽰例 2:
输⼊: s1 = “delete”, s2 = “leet” 输出: 403
解释:
在 “delete” 中删除 “dee” 字符串变成 “let”, 将 100[d]+101[e]+101[e] 加⼊总和。在 “leet” 中删除 “e” 将 101[e] 加⼊总和。 结束时,两个字符串都等于 “let”,结果即为 100+101+101+101 = 403 。 如果改为将两个字符串转换为 “lee” 或 “eet”,我们会得到 433 或 417 的结果,比答案更大。
-
解法(动态规划):
算法思路: 正难则反:求两个字符串的最小ASCII 删除和,其实就是找到两个字符串中所有的公共子序列里面, ASCII 最大和。 因此,我们的思路就是按照「最长公共子序列」的分析方式来分析。
状态表示:
dp[i][j] 表示: s1 的 [0, i] 区间以及 s2 的 [0, j] 区间内的所有的子序列中,公 共⼦序列的 ASCII 最⼤和。
状态转移⽅程: 对于 dp[i][j] 根据「最后⼀个位置」的元素,结合题目要求,分情况讨论:
i. 当 s1[i] == s2[j] 时:应该先在 s1 的 [0, i - 1] 区间以及 s2 的 [0, j - 1] 区间内找⼀个公共⼦序列的最⼤和,然后在它们后面加上⼀个 s1[i] 字符即可。 此时 dp[i][j] = dp[i - 1][j - 1] + s1[i] ;
ii. 当 s1[i] != s2[j] 时:公共⼦序列的最大和会有三种可能:
• s1 的 [0, i - 1] 区间以及 s2 的 [0, j] 区间内:此时 dp[i][j] = dp[i - 1][j] ; • s1 的 [0, i] 区间以及 s2 的 [0, j - 1] 区间内:此时 dp[i][j] = dp[i][j - 1] ; • s1 的 [0, i - 1] 区间以及 s2 的 [0, j - 1] 区间内:此时 dp[i][j] = dp[i - 1][j - 1] 。 但是前两种情况⾥⾯包含了第三种情况,因此仅需考虑前两种情况下的最⼤值即可。 综上所述,状态转移方程为:
◦ 当 s1[i - 1] == s2[j - 1] 时, dp[i][j] = dp[i - 1][j - 1] + s1[i] ;
◦ 当 s1[i - 1] != s2[j - 1] 时, dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
初始化:
a. 「空串」是有研究意义的,因此我们将原始 dp 表的规模多加上⼀⾏和⼀列,表⽰空串。
b. 引⼊空串后,大大的「方便我们的初始化」。
c. 但也要注意「下标的映射」关系,以及里面的值要保证「后续填表是正确的」。
当 s1 为空时,没有长度,同理 s2 也是。因此第一行和第⼀列里面的值初始化为 0 即可保证后续填表是正确的。
填表顺序: 「从上往下」填每一行,每⼀行「从左往右」。
返回值: 根据「状态表示」,我们不能直接返回 dp 表里面的某个值:
i. 先找到 dp[m][n] ,也是最大公共 ASCII 和;
ii. 统计两个字符串的 ASCII 码和 s u m;
iii. 返回 sum - 2 * dp[m][n] -
代码示例:
public int minimumDeleteSum(String s1, String s2) {// 1. 创建 dp 表// 2. 初始化// 3. 填表// 4. 返回值int m = s1.length(), n = s2.length();int[][] dp = new int[m + 1][n + 1];for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++) {dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);if (s1.charAt(i - 1) == s2.charAt(j - 1))dp[i][j] = Math.max(dp[i][j], dp[i - 1][j - 1] + s1.charAt(i - 1));}int sum = 0; // 统计元素和for (char ch : s1.toCharArray()) sum += ch;for (char ch : s2.toCharArray()) sum += ch;return sum - dp[m][n] - dp[m][n];}
七、最长重复子数组
- 题目链接:最长重复子数组
- 题目描述:
给两个整数数组 nums1 和 nums2 ,返回两个数组中公共的 、长度最长的子数组的长度 。
示例 1: 输入:nums1 = [1,2,3,2,1], nums2 = [3,2,1,4,7]
输出:3 解释:长度最长的公共子数组是 [3,2,1] 。
示例 2: 输入:nums1 = [0,0,0,0,0], nums2 = [0,0,0,0,0]
输出:5
-
解法(动态规划): 算法思路: ⼦数组是数组中「连续」的⼀段,我们习惯上「以某⼀个位置为结尾」来研究。由于是两个数组, 因此我们可以尝试:以第⼀个数组的 i 位置为结尾以及第⼆个数组的 j 位置为结尾来解决问题。
状态表示:
dp[i][j] 表示「以第⼀个数组的 i 位置为结尾」,以及「第⼆个数组的 j 位置为结尾公共的、长度最长的「子数组」的长度。
状态转移⽅程: 对于 dp[i][j] ,当 nums1[i] == nums2[j] 的时候,才有意义,此时最长重复子数组的长度应该等于 1 加上除去最后⼀个位置时,以 i - 1, j - 1 为结尾的最长重复子数组的长度。因此,状态转移方程为: dp[i][j] = 1 + dp[i - 1][j - 1]
初始化:为了处理「越界」的情况,我们可以添加⼀行和一列, dp 数组的下标从 1 开始,这样就无需初始化。 第⼀行表示第⼀个数组为空,此时没有重复子数组,因此里面的值设置成 0 即可; 第一列也是同理。
填表顺序: 根据「状态转移」,我们需要「从上往下」填每⼀行,每⼀行「从左往右」。
返回值: 根据「状态表示」,我们需要返回 dp 表里面的「最大值」。 -
代码示例:
public int findLength(int[] nums1, int[] nums2) {// 1. 创建 dp 表// 2. 初始化// 3. 填表// 4. 返回值int m = nums1.length, n = nums2.length;int[][] dp = new int[m + 1][n + 1];int ret = 0;for (int i = 1; i <= m; i++)for (int j = 1; j <= n; j++)if (nums1[i - 1] == nums2[j - 1]) {dp[i][j] = dp[i - 1][j - 1] + 1;ret = Math.max(ret, dp[i][j]);}return ret;}
结语
本文到这里就结束了,主要通过几道两个数组dp问题算法题,介绍了这种类型动态规划的做题思路,带大家深入了解了动态规划中两个数组dp问题 算法这一类型。
以上就是本文全部内容,感谢各位能够看到最后,如有问题,欢迎各位大佬在评论区指正,希望大家可以有所收获!创作不易,希望大家多多支持!
最后,大家再见!祝好!我们下期见!
相关文章:

【动态规划】 深入动态规划—两个数组的dp问题
文章目录 前言例题一、最长公共子序列二、不相交的线三、不同的子序列四、通配符匹配五、交错字符串六、两个字符串的最小ASCII删除和七、最长重复子数组 结语 前言 问题本质 它主要围绕着给定的两个数组展开,旨在通过对这两个数组元素间关系的分析,找出…...
个人学习笔记(7):网络数据采集以及FNN分类)
金融数据分析(Python)个人学习笔记(7):网络数据采集以及FNN分类
一、网络数据采集 证券宝是一个免费、开源的证券数据平台(无需注册),提供大盘准确、完整的证券历史行情数据、上市公司财务数据等,通过python API获取证券数据信息。 1. 安装并导入第三方依赖库 baostock 在命令提示符中运行&…...

指定运行级别
linux系统下有7种运行级别,我们需要来了解一下常用的运行级别,方便我们熟悉以后的部署环境,话不多说,来看. 开机流程: 指定数级别 基本介绍 运行级别说明: 0:关机 相当于shutdown -h now ⭐️默认参数不能设置为0,否则系统无法正常启动 1:单用户(用于找回丢…...

7.第二阶段x64游戏实战-string类
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:7.第二阶段x64游戏实战-分析人物属性 string类是字符串类,在计算机中…...

【MySQL基础】左右连接实战:掌握数据关联的完整视图
1 左右连接基础概念 左连接(left join)和右连接(right join)是MySQL中两种重要的表连接方式,它们与内连接不同,能够保留不匹配的记录,为我们提供更完整的数据视图。 核心区别: left join:保留左表所有记录,…...

建筑工程行业如何选OA系统?4大主流产品分析
工程行业项目的复杂性与业务流程的繁琐性对办公效率提出了极高要求。而OA 系统(办公自动化系统)的出现,为工程企业提供了一种全新的、高效的管理模式。 工程行业OA系统选型关键指标 功能深度:项目管理模块完整度、文档版本控制能…...

动态科技感html导航网站源码
源码介绍 动态科技感html导航网站源码,这个设计完美呈现了科幻电影中的未来科技界面效果,适合展示技术类项目或作为个人作品集的入口页面,自适应手机。 修改卡片中的链接指向你实际的HTML文件可以根据需要调整卡片内容、图标和颜色要添加更…...

CLIPGaze: Zero-Shot Goal-Directed ScanpathPrediction Using CLIP
摘要 目标导向的扫描路径预测旨在预测人们在搜索视觉场景中的目标时的视线移动路径。大多数现有的目标导向扫描路径预测方法在面对训练过程中未出现的目标类别时,泛化能力较差。此外,它们通常采用不同的预训练模型分别提取目标提示和图像的特征,导致两者之间存在较大的特征…...

wsl-docker环境下启动ES报错vm.max_map_count [65530] is too low
问题描述 在windows环境下用Docker Desktop(wsl docker)启动 elasticsearch时报错 max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]解决方案 方案一 默认的vm.max_map_count值是65530,而es需要至少262…...

js chrome 插件,下载微博视频
起因, 目的: 最初是想下载微博上的NBA视频,因为在看网页上看视频很不方便,快进一次是10秒,而本地 VLC 播放器,快进一次是5秒。另外我还想做点视频剪辑。 对比 原来手动下载的话,右键检查,复制…...

游戏引擎学习第212天
"我们将同步…"α 之前我们有一些内容是暂时搁置的,因为在调整代码的过程中,我们做了一些变动以使代码更加简洁,这样可以把数据放入调试缓冲区并显示出来,这一切现在看起来已经好多了。尽管现在看起来更好,…...

PXE远程安装服务器
目录 搭建PXE远程安装服务器 1、准备Linux安装源: 2、安装并启用TFTP服务: 3、准备Linux内核、初始化镜像文件 4、准备PXE引导程序 5、安装并启用DHCP服务 6、(1)配置启动菜单文件(有人应答) 6、(2)…...

软件测试之功能测试详解
一、测试项目启动与研读需求文档 (一) 组建测试团队 1、测试团队中的角色 2、测试团队的基本责任 尽早地发现软件程序、系统或产品中所有的问题。 督促和协助开发人员尽快地解决程序中的缺陷。 帮助项目管理人员制定合理的开发和测试计划。 对缺陷进行…...
(PyTorch))
Python深度学习基础——卷积神经网络(CNN)(PyTorch)
CNN原理 从DNN到CNN 卷积层与汇聚 深度神经网络DNN中,相邻层的所有神经元之间都有连接,这叫全连接;卷积神经网络 CNN 中,新增了卷积层(Convolution)与汇聚(Pooling)。DNN 的全连接…...

pytorch 反向传播
文章目录 概念计算图自动求导的两种模式 自动求导-代码标量的反向传播非标量变量的反向传播将某些计算移动到计算图之外 概念 核心:链式法则 深度学习框架通过自动计算导数(自动微分)来加快求导。 实践中,根据涉及号的模型,系统会构建一个计…...

VSCode解决中文乱码方法
目录 一、底层原因 二、解决方法原理 三、解决方式: 1.预设更改cmd临时编码法 2.安装插件法: 一、底层原因 当在VSCode中遇到中文显示乱码的问题时,这通常是由于文件编码与VSCode的默认或设置编码不匹配,或…...

pandas.DataFrame.dtypes--查看和验证 DataFrame 列的数据类型!
查看每列的数据类型,方便分析是否需要数据类型转换 property DataFrame.dtypes[source] Return the dtypes in the DataFrame. This returns a Series with the data type of each column. The result’s index is the original DataFrame’s columns. Columns with…...

高性能服务开发利器:redis+lua
Redis 与 Lua 脚本的结合,其核心价值在于 原子性操作 和 减少网络开销。 一、Redis 执行 Lua 脚本的优势 原子性 Lua 脚本在 Redis 中原子执行,避免多命令竞态条件。 减少网络开销 将多个 Redis 命令合并为一个脚本,减少客…...

开源智能体MetaGPT记忆模块解读
MetaGPT 智能体框架 1. 框架概述 MetaGPT 是一个多智能体协作框架,通过模拟软件公司组织架构与工作流程,将大语言模型(LLM)转化为具备专业分工的智能体,协同完成复杂任务。其最大特点是能够将自然语言需…...

Docker部署MySQL大小写不敏感配置与数据迁移实战20250409
Docker部署MySQL大小写不敏感配置与数据迁移实战 🧭 引言 在企业实际应用中,尤其是使用Java、Hibernate等框架开发的系统,MySQL默认的大小写敏感特性容易引发各种兼容性问题。特别是在Linux系统中部署Docker版MySQL时,默认行为可…...

【RabbitMQ】延迟队列
1.概述 延迟队列其实就是队列里的消息是希望在指定时间到了以后或之前取出和处理,简单来说,延时队列就是用来存放需要在指定时间被处理的元素的队列。 延时队列的使用场景: 1.订单在十分钟之内未支付则自动取消 2.新创建的店铺,…...

深兰科技携多款AI医疗创新成果亮相第七届世界大健康博览会
4月8日,以“AI赋能 健康生活”为主题的2025年(第七届)世界大健康博览会(以下简称健博会)在武汉隆重开幕。应参展企业武汉市三甲医院——武汉中心医院的邀请,深兰科技最新研发的新一代智慧医疗解决方案和产品在其展位上公开亮相。 本届展会吸引了来自18个…...

20周年系列|美创科技再度入围「年度高成长企业」系列榜单
近日,资深产业信息服务平台【第一新声】发布「2024年度科技行业最佳CEO及高成长企业榜」,美创科技凭借在数据安全领域的持续创新和广泛行业实践, 再度入围“年度网络安全高成长企业”、“年度高科技高成长未来独角兽企业TOP30”。 美创科技作…...

saltstack分布式部署
一、saltstack分布式 在minion数量过多时,通过部署salt代理,减轻master负载 1、在master上删除说有minion证书 2、在minion上删除旧master信息 3、安装部署salt-syndic 4、修改minion 5、在master上签署代理的证书 6、在代理上签署minion证书 7、测试...

CCRC 与 EMVCo 双认证:中国智能卡企业的全球化突围
在全球经济一体化的浪潮中,智能卡行业正经历着前所未有的变革与发展。中国智能卡企业凭借技术优势与成本竞争力,在国内市场成绩斐然。然而,要想在国际市场站稳脚跟,获取权威认证成为关键一步。CCRC 与 EMVCo 双认证,宛…...

逆向工程的多层次解析:从实现到领域的全面视角
目录 前言1. 什么是逆向工程?2. 实现级逆向:揭示代码背后的结构2.1 抽象语法树的构建2.2 符号表的恢复2.3 过程设计表示的推导 3. 结构级逆向:重建模块之间的协作关系3.1 调用图与依赖分析3.2 程序与数据结构的映射 4. 功能级逆向:…...

【Docker项目实战】使用Docker部署ToDoList任务管理工具
【Docker项目实战】使用Docker部署ToDoList任务管理工具 一、ToDoList介绍1.1 ToDoList简介1.2 ToDoList主要特点二、本次实践规划2.1 本地环境规划2.2 本次实践介绍三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本四、下载ToDoList镜像…...

基于SpinrgBoot+Vue的医院管理系统-026
一、项目技术栈 Java开发工具:JDK1.8 后端框架:SpringBoot 前端:Vue开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 二、功能介绍 (1)…...

如何进行数据安全风险评估总结
一、基于场景进行安全风险评估 一、概述 数据安全风险评估总结(一)描述了数据安全风险评估的相关理论,数据安全应该关注业务流程,以基础安全为基础,以数据生命周期及数据应用场景两个维度为入口进行数据安全风险评估。最后以《信息安全技术 信息安全风险评估规范》为参考,…...

用 npm list -g --depth=0 探索全局包的秘密 ✨
用 npm list -g --depth0 探索全局包的秘密 🚀✨ 嗨,各位开发者朋友们!👋 今天我们要聊一个超实用的小命令——npm list -g --depth0!它就像一个“全局包侦探”🕵️♂️,能帮你快速查出系统中…...

依靠视频设备轨迹回放平台EasyCVR构建视频监控,为幼教连锁园区安全护航
一、项目背景 幼教行业连锁化发展态势越发明显。在此趋势下,幼儿园管理者对于深入了解园内日常教学与生活情况的需求愈发紧迫,将这些数据作为提升管理水平、优化教育服务的重要依据。同时,安装监控系统不仅有效缓解家长对孩子在校安全与生活…...

新闻发稿软文发布投稿选择媒体时几大注意
企业在选择新闻稿发布媒体时,需要综合考虑以下几个关键因素: 1. 匹配媒体定位 企业应根据自身品牌定位和传播目标,选择与之契合的媒体平台。确保新闻稿的内容和风格与媒体的定位高度一致,从而提高稿件被采纳的可能性。 2. 衡量…...

[Scade One] Swan与Scade 6的区别 - signal 特性的移除
signal 特性移除 在 Scade One 引入的Swan中,移除了Scade 6中存在的signal 特性。比如 Scade 6 中的signal声明 sig sig_o;或者signal使用,比如 o sig_o; 在Swan中已经被移除。 不过Swan仍旧保留了对布尔流的emit操作,比如 emit a if c …...

亚马逊推出“站外代购革命“:跨境购物进入全平台整合时代
一、创新功能解析:平台边界消融的购物新范式 亚马逊最新推出的External Product Fulfillment(EPF)服务,正以技术创新重构全球电商格局。这项被称作"代购终结者"的功能具备三大核心突破: 全链路智能化 • 智能…...

Java 常用安全框架的 授权模型 对比分析,涵盖 RBAC、ABAC、ACL、基于权限/角色 等模型,结合框架实现方式、适用场景和优缺点进行详细说明
以下是 Java 常用安全框架的 授权模型 对比分析,涵盖 RBAC、ABAC、ACL、基于权限/角色 等模型,结合框架实现方式、适用场景和优缺点进行详细说明: 1. 授权模型类型与定义 模型名称定义特点RBAC(基于角色的访问控制)通…...

达梦数据库迁移问题总结
问题一、DTS工具运行乱码 开启图形化 [rootlocalhost ~]# xhost #如果命令不存在执行sudo yum install xorg-x11-server-utils xhost: unable to open display "" [rootlocalhost ~]# su - dmdba 上一次登录: 三 4月 9 19:50:44 CST 2025 pts/0 上…...

JS | 函数柯里化
函数柯里化(Currying):将一个接收多个参数函数,转换为一系列只接受一个参数的函数的过程。即 逐个接收参数。 例子: 普通函数: function add(a, b, c) {return a b c; } add(1, 2, 3); // 输出 6柯里化…...

Elasticsearch中的基本全文搜索和过滤
Elasticsearch中的基本全文搜索和过滤 知识点参考: https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-filter-tutorial.html#full-text-filter-tutorial-range-query 1. 索引设计与映射 多字段类型(Multi-Fields) ÿ…...

蓝桥杯嵌入式第十五届
一、底层 根据它的硬件配置可以看出来这套题目使用到了按键、LED、LCD、输入捕获这几个功能 (1)输入捕获功能 首先在CubeMx里面的配置 题目中说到了我们使用的是PA15和PB4(实际在板子上对应的的是R39和R40),所以我们…...

基于ueditor编辑器的功能开发之给编辑器图片增加水印功能
用户需求,双击编辑器中的图片的时候,出现弹框,用户可以选择水印缩放倍数、距离以及水印所放置的方位(当然有很多水印插件,位置大小透明度用户都能够自定义,但是用户需求如此,就自己写了…...

DDR中的DLL
在DDR4内存系统中,DLL(Delay Locked Loop,延迟锁相环)是一个非常重要的组件,用于确保数据信号(DQS)和时钟信号(CK)之间的同步。以下是DLL的作用以及DLL on和DLL off的影响…...

Python学习之jieba
Python学习之jieba jieba是优秀的中文分词第三方库,由于中文文本之间每个汉字都是连续书写的,我们需要通过特定的手段来获得其中的每个词组,这种手段叫做分词,我们可以通过jieba库来完成这个过程。jieba库的分词原理:利用一个中文词库,确定汉字之间的关联频率,汉字向概率大的组…...

快速幂fast_pow
快速幂算法讲解 快速幂算法是一种高效计算幂运算的算法,其核心思想是利用指数的二进制分解,把幂运算的时间复杂度从 O(p) 降低到 O(logp)。 原理 假设要计算 an,将 n 表示成二进制形式:n2k12k2⋯2km,那么 ana…...
)
Go并发背后的双引擎:CSP通信模型与GMP调度|Go语言进阶(4)
为什么需要理解CSP与GMP? 当我们启动一个Go程序时,可能会创建成千上万个goroutine,它们是如何被调度到有限的CPU核心上的?为什么Go能够如此轻松地处理高并发场景?为什么有时候我们的并发程序会出现奇怪的性能瓶颈&…...

42、JavaEE高级主题:WebSocket详解
WebSocket 一、WebSocket协议与实现 WebSocket是一种基于TCP协议的全双工通信协议,能够在客户端和服务器之间建立实时、双向的通信通道。通过WebSocket,客户端和服务器可以在任何时候发送数据,并立即接收到对方的响应。 1.1 WebSocket协议…...

UGUI源代码之Text—实现自定义的字间距属性
以下内容是根据Unity 2020.1.01f版本进行编写的 UGUI源代码之Text—实现自定义的字间距属性 1、目的2、参考3、代码阅读4、准备修改UGUI源代码5、实现自定义Text组件,增加字间距属性6、最终效果 1、目的 很多时候,美术在设计的时候是想要使用文本的字间…...

【AI】MCP概念
一文讲透 MCP(附 Apifox MCP Server 内测邀请) 7分钟讲清楚MCP是什么?统一Function calling规范,工作量锐减至1/6,人人手搓Manus!? | 一键链接千台服务器,几行代码接入海量外部工具…...
获取位置信息)
HarmonyOS:使用geoLocationManager (位置服务)获取位置信息
一、简介 位置服务提供GNSS定位、网络定位(蜂窝基站、WLAN、蓝牙定位技术)、地理编码、逆地理编码、国家码和地理围栏等基本功能。 使用位置服务时请打开设备“位置”开关。如果“位置”开关关闭并且代码未设置捕获异常,可能导致应用异常。 …...

深入解析原生鸿蒙中的 RN 日志系统:从入门到精通!
全文目录: 开篇语📖 目录🎯 前言:鸿蒙日志系统究竟有多重要?🛠️ 鸿蒙 RN 日志系统的基础结构📜 1. 日志的作用⚙️ 2. 日志分类 🔧 如何在鸿蒙 RN 中使用日志系统🖋️ 1…...

【前端】【Nuxt3】Nuxt3中usefetch,useAsyncData,$fetch使用与区别
一、Nuxt3 中不同数据获取方式的请求行为对比 (一)总结:请求行为一览 useFetch 和 useAsyncData 是 Nuxt 推荐的数据获取 API,自动集成 SSR 与客户端导航流程。$fetch 是更底层的请求方法,不具备自动触发、缓存等集成…...