金融数据分析(Python)个人学习笔记(7):网络数据采集以及FNN分类
一、网络数据采集
证券宝是一个免费、开源的证券数据平台(无需注册),提供大盘准确、完整的证券历史行情数据、上市公司财务数据等,通过python API获取证券数据信息。
1. 安装并导入第三方依赖库 baostock
在命令提示符中运行:pip install baostock
导入依赖库
import baostock as bs
import pandas as ad
如果在安装anaconda之前有安装过Python,那么系统会把依赖库默认下载到之前的Python文件夹中,所以需要把旧路径添加到anaconda中。
import sys
sys.path.append("D:\Study Material\Python 3.13.0(64bit)\Lib\site-packages")
路径只需要添加一次
2. 登录系统
lg = bs.login()
# 显示登录返回信息
print(lg.error_code) # 错误代码,当为0时表示成功,当为非0时表示失败
print(lg.error_msg) # 错误信息,对错误的详细解释
结果:
login success!
0
success
3. 获取上证指数的历史数据
bs.query_history_k_data
分钟线指标:date,time,code,open,high,low,close,volume,amount,adjustflag
周月线指标:date,code,open,high,low,close,volume,amount,adjustflag,turn,pctChg
周月线详细指标参数:日期、代码、开盘价、最高价、最低价、收盘价、成交金额、复权情况、换手率、涨跌幅
rs = bs.query_history_k_data("sh.600000","date,code,open,high,low,close,volume,amount,adjustflag,turn,pctChg",start_date='2021-05-23', end_date='2022-05-23',frequency="d", adjustflag="3")
print(rs.error_code)
print(rs.error_msg)
结果:
0
success
获取具体的信息:从rs中分页查询数据,将每页的数据合并到一个列表中,然后将这些数据转换为Pandas的DataFrame对象,最后将DataFrame保存为 CSV 文件并打印出来
result_list = []
while (rs.error_code == '0') & rs.next(): # 持续执行循环体中的代码,直到循环条件不满足为止# rs.next():如果存在下一行,则返回True,否则返回False# 判断错误码是否为'0'以及是否还有下一行数据。result_list.append(rs.get_row_data())# 调用rs对象的get_row_data方法获取当前行的数据并添加到list中
result = pd.DataFrame(result_list, columns=rs.fields)
# 将result_list列表转换为一个DataFrame对象
# columns=rs.fields:指定DataFrame的列名,rs.fields是一个包含列名的列表。
result.to_csv(".../history_k_data.csv", encoding="gbk", index=False)
# 调用DataFrame对象的to_csv方法将数据保存为CSV文件,index=False:表示不将DataFrame的索引保存到CSV文件中
print(result)
# 登出系统
bs.logout()
结果:
date code open high low close volume \
0 2021-05-24 sh.600000 10.0800 10.1400 10.0500 10.0900 23518901
1 2021-05-25 sh.600000 10.1000 10.3300 10.0600 10.3200 75417564
2 2021-05-26 sh.600000 10.3100 10.4200 10.2800 10.3500 54984815
3 2021-05-27 sh.600000 10.3200 10.4300 10.2600 10.2900 52063330
4 2021-05-28 sh.600000 10.3300 10.3600 10.2500 10.3500 34593293
.. ... ... ... ... ... ... ...
930 2025-03-25 sh.600000 10.6500 10.6900 10.5000 10.6100 37875416
931 2025-03-26 sh.600000 10.6000 10.6100 10.4500 10.4700 36660981
932 2025-03-27 sh.600000 10.5000 10.6600 10.4700 10.5500 42508671
933 2025-03-28 sh.600000 10.5300 10.5700 10.4100 10.4400 36572944
934 2025-03-31 sh.600000 10.4700 10.6300 10.3500 10.4300 49360687 amount adjustflag turn pctChg
0 237130459.3700 3 0.080100 0.000000
1 771994298.4800 3 0.256900 2.279500
2 568991552.4000 3 0.187300 0.290700
3 536862488.3300 3 0.177400 -0.579700
4 356339747.2700 3 0.117900 0.583100
.. ... ... ... ...
930 401332739.2900 3 0.129000 0.000000
931 385049553.5800 3 0.124900 -1.319500
932 449288518.5700 3 0.144800 0.764100
933 382165241.2900 3 0.124600 -1.042700
934 518371937.1300 3 0.168200 -0.095800 [935 rows x 11 columns]
logout success!
<baostock.data.resultset.ResultData at 0x2c815254310>
result
结果:
date code open high low close volume amount adjustflag turn pctChg
0 2021-05-24 sh.600000 10.0800 10.1400 10.0500 10.0900 23518901 237130459.3700 3 0.080100 0.000000
1 2021-05-25 sh.600000 10.1000 10.3300 10.0600 10.3200 75417564 771994298.4800 3 0.256900 2.279500
2 2021-05-26 sh.600000 10.3100 10.4200 10.2800 10.3500 54984815 568991552.4000 3 0.187300 0.290700
3 2021-05-27 sh.600000 10.3200 10.4300 10.2600 10.2900 52063330 536862488.3300 3 0.177400 -0.579700
4 2021-05-28 sh.600000 10.3300 10.3600 10.2500 10.3500 34593293 356339747.2700 3 0.117900 0.583100
... ... ... ... ... ... ... ... ... ... ... ...
930 2025-03-25 sh.600000 10.6500 10.6900 10.5000 10.6100 37875416 401332739.2900 3 0.129000 0.000000
931 2025-03-26 sh.600000 10.6000 10.6100 10.4500 10.4700 36660981 385049553.5800 3 0.124900 -1.319500
932 2025-03-27 sh.600000 10.5000 10.6600 10.4700 10.5500 42508671 449288518.5700 3 0.144800 0.764100
933 2025-03-28 sh.600000 10.5300 10.5700 10.4100 10.4400 36572944 382165241.2900 3 0.124600 -1.042700
934 2025-03-31 sh.600000 10.4700 10.6300 10.3500 10.4300 49360687 518371937.1300 3 0.168200 -0.095800
935 rows × 11 columns
4. 转换数据类型
# 数据类型为 字符串 str
print(type(result.open[0]))
# open[0]:获取可迭代对象中的第一个元素# 去掉 date code adjustflag 列
data = result.drop(['date', 'code', 'adjustflag'], axis =1)
# axis=1:按列操作;axis=0:按行操作# 将数据类型转为 数值 float 类型
for i in data.columns: data.loc[:,i] = pd.to_numeric(data.loc[:,i],errors = 'coerce')
data
'''
data.columns 是一个包含 data 这个 DataFrame 所有列名的索引对象
i 会依次代表 data 中的每一个列名,从而可以对每一列的数据进行操作。
data.loc 是 Pandas 里用于基于标签进行索引的方法。
data.loc[:,i] 表示选择 data 中列名为 i 的整列数据。
pd.to_numeric() 是 Pandas 提供的用于转换为数值类型的一个函数。
errors = 'coerce' 是一个参数设置,它表明在转换过程中,如果遇到无法转换为数值的值,就会将这些值强制转换为 NaN。
'''
print(type(data.open[0]))
结果:
<class 'str'>open high low close volume amount turn pctChg
0 10.08 10.14 10.05 10.09 23518901 2.371305e+08 0.0801 0.0000
1 10.10 10.33 10.06 10.32 75417564 7.719943e+08 0.2569 2.2795
2 10.31 10.42 10.28 10.35 54984815 5.689916e+08 0.1873 0.2907
3 10.32 10.43 10.26 10.29 52063330 5.368625e+08 0.1774 -0.5797
4 10.33 10.36 10.25 10.35 34593293 3.563397e+08 0.1179 0.5831
... ... ... ... ... ... ... ... ...
930 10.65 10.69 10.50 10.61 37875416 4.013327e+08 0.1290 0.0000
931 10.60 10.61 10.45 10.47 36660981 3.850496e+08 0.1249 -1.3195
932 10.50 10.66 10.47 10.55 42508671 4.492885e+08 0.1448 0.7641
933 10.53 10.57 10.41 10.44 36572944 3.821652e+08 0.1246 -1.0427
934 10.47 10.63 10.35 10.43 49360687 5.183719e+08 0.1682 -0.0958
935 rows × 8 columns
<class 'numpy.float64'>
# 最后一列 涨跌幅 pctChg 用 0-1 代替,1:涨,0:未涨
import numpy as np
data.pctChg = (data.pctChg>0)*1
data.to_csv(".../sh600000.csv", encoding="gbk", index=False)
data
'''
data.pctChg 表示访问 data 数据框中的 pctChg 列。
data.pctChg > 0 是一个布尔表达式,会对 pctChg 列中的每个元素进行比较,判断其是否大于 0。比较结果是一个布尔类型的 Series,其中大于 0 的元素对应的位置为 True,小于等于 0 的元素对应的位置为 False。
(data.pctChg > 0) * 1 会将布尔类型的 Series 转换为数值类型的 Series,True 转换为 1,False 转换为 0。
最后,将转换后的 Series 重新赋值给 data.pctChg,实现了对 pctChg 列的二值化处理。
'''
结果:
open high low close volume amount turn pctChg
0 10.08 10.14 10.05 10.09 23518901 2.371305e+08 0.0801 0
1 10.10 10.33 10.06 10.32 75417564 7.719943e+08 0.2569 1
2 10.31 10.42 10.28 10.35 54984815 5.689916e+08 0.1873 1
3 10.32 10.43 10.26 10.29 52063330 5.368625e+08 0.1774 0
4 10.33 10.36 10.25 10.35 34593293 3.563397e+08 0.1179 1
... ... ... ... ... ... ... ... ...
930 10.65 10.69 10.50 10.61 37875416 4.013327e+08 0.1290 0
931 10.60 10.61 10.45 10.47 36660981 3.850496e+08 0.1249 0
932 10.50 10.66 10.47 10.55 42508671 4.492885e+08 0.1448 1
933 10.53 10.57 10.41 10.44 36572944 3.821652e+08 0.1246 0
934 10.47 10.63 10.35 10.43 49360687 5.183719e+08 0.1682 0
935 rows × 8 columns
二、KNN分类和预测
(一)划分训练集和测试集
# 前0.8数据作为训练集,后0.2数据作为测试集
# 前7个属性作为样本,最后一列作为标签
X = data.iloc[:,:-1] # 特征矩阵X
y = data.iloc[:,-1] # 目标向量y
# 借助iloc方法对data进行切片操作,选取所有行以及除最后一列之外的所有列from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
X_train, y_train, X_test, y_test # 输出四个对象,在实际应用中通常不会这么做
'''
从sklearn.model_selection模块里导入train_test_split函数,该函数可用于把数据集划分成训练集和测试集。
test_size=0.20:表明测试集在整个数据集中所占的比例为20%,那么训练集占比就是80%。
函数返回四个对象:
X_train:训练集的特征矩阵。
X_test:测试集的特征矩阵。
y_train:训练集的目标向量。
y_test:测试集的目标向量。
'''
结果:
( open high low close volume amount turn148 8.56 8.59 8.54 8.57 29833707 2.555905e+08 0.1016502 7.43 7.49 7.39 7.45 20936996 1.557060e+08 0.0713612 6.92 6.92 6.86 6.87 18249280 1.254957e+08 0.0622268 8.05 8.06 8.00 8.01 23369617 1.876911e+08 0.0796513 7.30 7.33 7.23 7.28 17447358 1.268417e+08 0.0594.. ... ... ... ... ... ... ...821 10.31 10.54 10.25 10.40 88307795 9.184083e+08 0.3009474 7.77 8.17 7.76 8.07 143117862 1.148390e+09 0.487674 9.22 9.31 9.20 9.21 35627742 3.295036e+08 0.1214260 7.95 7.98 7.91 7.91 30065154 2.383203e+08 0.102476 9.34 9.39 9.29 9.34 40941784 3.820179e+08 0.1395[748 rows x 7 columns],148 1502 1612 0268 0513 0..821 1474 174 0260 076 0Name: pctChg, Length: 748, dtype: int32,open high low close volume amount turn351 6.70 6.74 6.66 6.71 24034116 1.608915e+08 0.0819458 7.23 7.23 7.18 7.18 20191251 1.453580e+08 0.0688235 7.91 8.05 7.90 8.05 37343358 2.989415e+08 0.127234 9.96 9.99 9.90 9.91 33415612 3.322191e+08 0.1138829 10.12 10.25 10.12 10.14 24017341 2.443456e+08 0.0818.. ... ... ... ... ... ... ...173 8.64 8.71 8.62 8.64 36223235 3.138612e+08 0.1234809 8.37 8.53 8.30 8.52 39163824 3.307787e+08 0.1334550 7.03 7.06 6.98 6.99 24604979 1.724132e+08 0.0838151 8.54 8.57 8.53 8.53 22929621 1.959416e+08 0.0781228 7.98 8.06 7.86 8.03 44512846 3.542461e+08 0.1517[187 rows x 7 columns],351 0458 0235 134 0829 0..173 0809 1550 0151 0228 1Name: pctChg, Length: 187, dtype: int32)
(二)利用KNN算法进行分类并评估
from sklearn.neighbors import KNeighborsClassifier
# 从sklearn.neighbors模块中导入KNeighborsClassifier类,该类用于实现 K 近邻分类算法
knn = KNeighborsClassifier(n_neighbors = 5) # 定义KNN分类器
# 在进行分类时,会考虑最近的 5 个邻居的类别来决定当前样本的类别。
knn.fit(X_train, y_train) # 训练集训练
# 调用knn对象的fit方法,使用训练集的特征矩阵X_train和目标向量y_train对 KNN 模型进行训练。训练过程中,模型会学习训练数据的特征和对应的类别标签之间的关系。
y_pred = knn.predict(X_test) # 测试集预测
# 调用knn对象的predict方法,使用训练好的模型对测试集的特征矩阵X_test进行预测,得到预测的类别标签y_pred。# 比较预测结果和真实结果
from sklearn.metrics import classification_report, confusion_matrix
# 从sklearn.metrics模块中导入classification_report和confusion_matrix函数,这两个函数用于评估分类模型的性能。
print(confusion_matrix(y_test, y_pred)) # 混淆矩阵
print(classification_report(y_test, y_pred)) # 预测结果
print() # 分隔输出
'''
混淆矩阵可以直观地展示模型在每个类别上的预测情况,包括真正例(True Positives)、假正例(False Positives)、真反例(True Negatives)和假反例(False Negatives)。
分类报告包含了每个类别的精确率(Precision)、召回率(Recall)、F1 值(F1-score)和支持度(Support),以及宏平均(Macro Average)和加权平均(Weighted Average)等指标。
macro avg 为列均值
weighted avg 为以类别样本占总样本比例为权重的加权平均
'''x=range(41)
x[0]
'''
range() 函数用于创建一个不可变的整数序列,其语法为 range(start, stop, step),若只传入一个参数,那么 start 默认为 0,step 默认为 1。
x 是一个从 0 到 40 的整数序列。当使用 x[0] 时,是在获取这个序列的第一个元素。因为序列从 0 开始计数,所以第一个元素的值为 0。
'''
结果:
[[49 52][53 33]]precision recall f1-score support0 0.48 0.49 0.48 1011 0.39 0.38 0.39 86accuracy 0.44 187macro avg 0.43 0.43 0.43 187
weighted avg 0.44 0.44 0.44 1870
(三)改变 K 取值,绘制学习曲线
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
'''
从 sklearn.metrics 模块导入 accuracy_score 函数,该函数用于计算分类模型预测结果的准确率。
导入 matplotlib.pyplot 库,matplotlib 是 Python 中常用的绘图库。
'''score = []
for K in range(40):K_value = K+1# range(40)生成的是从0到39的整数,加1得到1到40的K值knn = KNeighborsClassifier(n_neighbors = K_value)# 创建一个KNeighborsClassifier对象knn,并指定n_neighbors参数为当前的K_value。knn.fit(X_train, y_train) # 训练模型y_pred = knn.predict(X_test)# 使用训练好的模型对测试集的特征矩阵X_test进行预测,得到预测的类别标签y_pred。score.append(round(accuracy_score(y_test,y_pred)*100,2))# 计算预测结果的准确率,并将其乘以100转换为百分比形式,然后使用round函数保留两位小数,最后将结果添加到score列表中plt.figure(figsize=(12, 6)) # 创建一个新的图形窗口,并设置图形的大小为宽12英寸,高6英寸。
plt.plot(range(1, 41), score, color='red', linestyle='dashed', marker='o', markerfacecolor='blue', markersize=10)
'''
使用 plt.plot 函数绘制学习曲线。
range(1, 41):作为 x 轴的数据,表示 K 的取值范围从 1 到 40。
score:作为 y 轴的数据,表示不同 K 值下模型在测试集上的准确率。
color='red':设置曲线的颜色为红色。
linestyle='dashed':设置曲线的样式为虚线。
marker='o':设置曲线上的数据点为圆形。
markerfacecolor='blue':设置数据点的填充颜色为蓝色。
markersize=10:设置数据点的大小为 10。
'''
plt.title('The Learning curve') # 为图形添加标题
plt.xlabel('K Value') # 为x轴添加标签
plt.ylabel('Score') # 为y轴添加标签
结果:
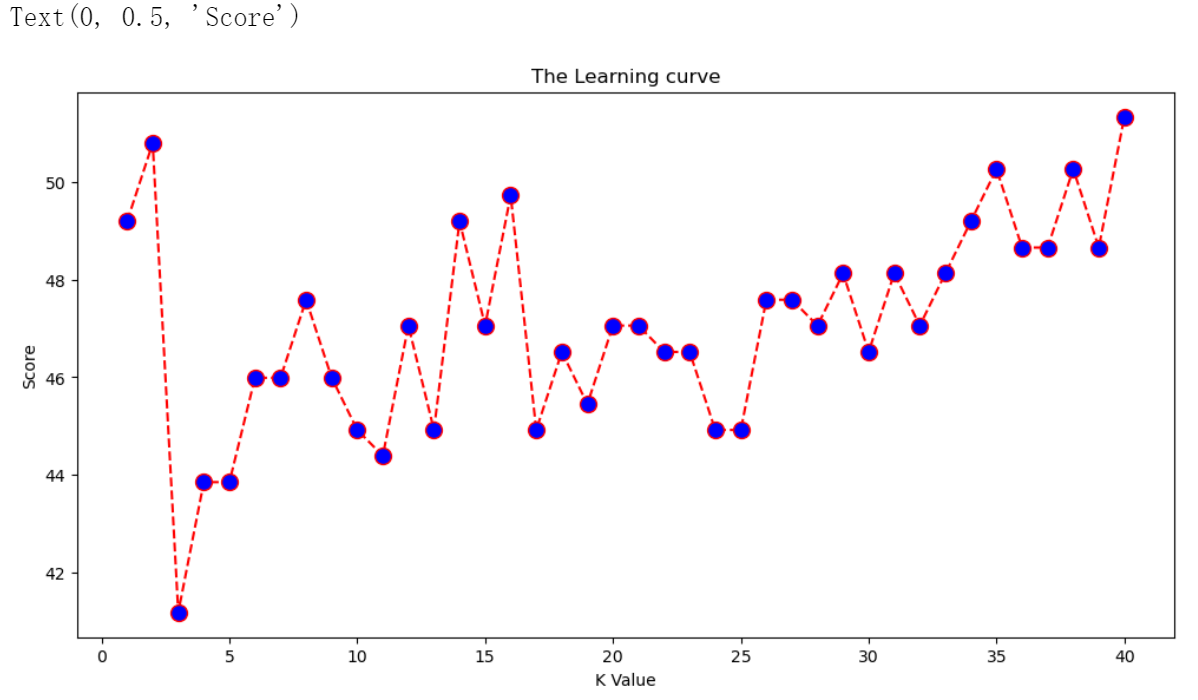
(四)最优K值的选择
error = []
# 计算K值在1-40之间多误差值
for i in range(1, 40): knn = KNeighborsClassifier(n_neighbors=i) # 设置参数knn.fit(X_train, y_train) # 训练模型pred_i = knn.predict(X_test) # 预测error.append(np.mean(pred_i != y_test))# 计算预测结果与真实标签不一致的比例(即误差率),np.mean函数用来计算平均值。plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red', linestyle='dashed', marker='o', markerfacecolor='blue', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
结果:
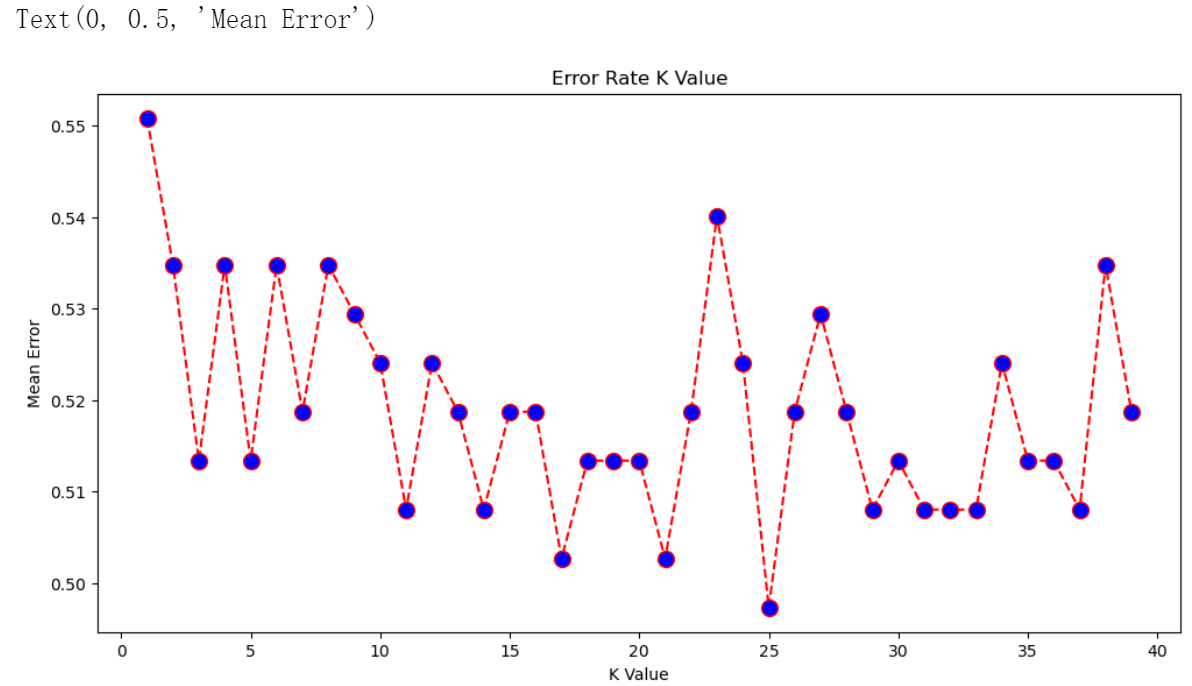
根据 score 和 error 来看,K=2 或 30 时,预测更准确
knn = KNeighborsClassifier(n_neighbors = 2) # 定义KNN分类器
knn.fit(X_train, y_train) # 训练集训练
y_pred = knn.predict(X_test) # 测试集预测
# 比较预测结果和真实结果
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred)) # 混淆矩阵
print(classification_report(y_test, y_pred)) # 预测结果knn = KNeighborsClassifier(n_neighbors = 30) # 定义KNN分类器
knn.fit(X_train, y_train) # 训练集训练
y_pred = knn.predict(X_test) # 测试集预测
# 比较预测结果和真实结果
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred)) # 混淆矩阵
print(classification_report(y_test, y_pred)) # 预测结果
结果:
K=2时
[[67 24][76 20]]precision recall f1-score support0 0.47 0.74 0.57 911 0.45 0.21 0.29 96accuracy 0.47 187macro avg 0.46 0.47 0.43 187
weighted avg 0.46 0.47 0.43 187
K=10时
[[65 26][70 26]]precision recall f1-score support0 0.48 0.71 0.58 911 0.50 0.27 0.35 96accuracy 0.49 187macro avg 0.49 0.49 0.46 187
weighted avg 0.49 0.49 0.46 187
(五)用上面7个特征预测第二天的涨跌
对数据集 data 进行处理,去除最后一行和最后一列,然后根据 close 列的数据计算第二天是否上涨,并将结果添加为新列 up,最后将处理后的数据保存为 CSV 文件。
data
data1=data.iloc[:-1,:-1].copy() # 去掉最后一行和最后一列
data1['up']=((np.array(data.close[1:])-np.array(data.close[:-1]))>0)*1
'''
添加一列 up ,第二天是否上涨
由于iloc切片操作返回的是视图,为了避免后续修改data1时影响原始的data,使用copy()方法创建一个独立的副本。
np.array(data.close[1:]):将 data 数据框中 close 列从第二行开始的数据转换为 NumPy 数组
作差得到相邻两天close价格的差值,然后判断是否大于0,之后把布尔值转换为整数数组(*1)
data1['up']:计算结果作为新列'up',添加到data1中
'''
data1.to_csv(".../sh600000.csv", encoding="gbk", index=False)
# 将data1保存为CSV文件,不将数据框的索引保存到 CSV 文件中。
data1
结果:
open high low close volume amount turn pctChg
0 10.08 10.14 10.05 10.09 23518901 2.371305e+08 0.0801 0
1 10.10 10.33 10.06 10.32 75417564 7.719943e+08 0.2569 1
2 10.31 10.42 10.28 10.35 54984815 5.689916e+08 0.1873 1
3 10.32 10.43 10.26 10.29 52063330 5.368625e+08 0.1774 0
4 10.33 10.36 10.25 10.35 34593293 3.563397e+08 0.1179 1
... ... ... ... ... ... ... ... ...
930 10.65 10.69 10.50 10.61 37875416 4.013327e+08 0.1290 0
931 10.60 10.61 10.45 10.47 36660981 3.850496e+08 0.1249 0
932 10.50 10.66 10.47 10.55 42508671 4.492885e+08 0.1448 1
933 10.53 10.57 10.41 10.44 36572944 3.821652e+08 0.1246 0
934 10.47 10.63 10.35 10.43 49360687 5.183719e+08 0.1682 0
935 rows × 8 columnsopen high low close volume amount turn up
0 10.08 10.14 10.05 10.09 23518901 2.371305e+08 0.0801 1
1 10.10 10.33 10.06 10.32 75417564 7.719943e+08 0.2569 1
2 10.31 10.42 10.28 10.35 54984815 5.689916e+08 0.1873 0
3 10.32 10.43 10.26 10.29 52063330 5.368625e+08 0.1774 1
4 10.33 10.36 10.25 10.35 34593293 3.563397e+08 0.1179 0
... ... ... ... ... ... ... ... ...
929 10.42 10.63 10.42 10.61 46449659 4.895272e+08 0.1582 0
930 10.65 10.69 10.50 10.61 37875416 4.013327e+08 0.1290 0
931 10.60 10.61 10.45 10.47 36660981 3.850496e+08 0.1249 1
932 10.50 10.66 10.47 10.55 42508671 4.492885e+08 0.1448 0
933 10.53 10.57 10.41 10.44 36572944 3.821652e+08 0.1246 0
934 rows × 8 columns
# 前7个属性作为样本,最后一列作为标签
X = data1.iloc[:,:-1]
y = data1.iloc[:,-1]# 前0.8数据作为训练集,后0.2数据作为测试集
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # 标准化
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test) # 改变 K 取值,比较错误率
error = []# 计算K值在1-40之间多误差值
for i in range(1, 40): knn = KNeighborsClassifier(n_neighbors=i)knn.fit(X_train, y_train)pred_i = knn.predict(X_test)error.append(np.mean(pred_i != y_test))
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red', linestyle='dashed', marker='o', markerfacecolor='blue', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
结果:
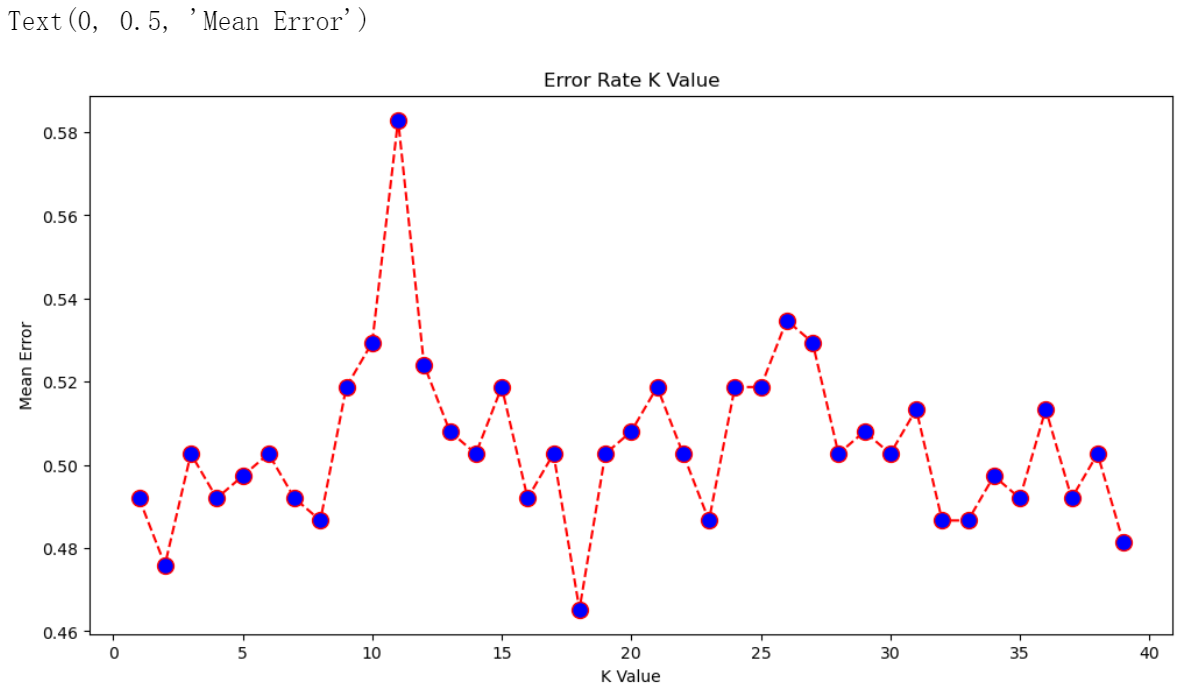
# 取 K = 29
knn = KNeighborsClassifier(n_neighbors = 29) # 定义KNN分类器
knn.fit(X_train, y_train) # 训练集训练
y_pred = knn.predict(X_test) # 测试集预测# 比较预测结果和真实结果
print(confusion_matrix(y_test, y_pred)) # 混淆矩阵
print(classification_report(y_test, y_pred)) # 预测结果
结果:
[[60 45][50 32]]precision recall f1-score support0 0.55 0.57 0.56 1051 0.42 0.39 0.40 82accuracy 0.49 187macro avg 0.48 0.48 0.48 187
weighted avg 0.49 0.49 0.49 187
预测精确率为 57%
(六)鸢尾花数据
from sklearn import datasets # 提供示例数据集
import pandas as pd # 用于数据处理和分析的强大库
import numpy as np # 于科学计算的基础库,提供了高效的数组操作功能
import matplotlib # 常用的绘图库
import matplotlib.pyplot as plt # 提供了类似 MATLAB 的绘图接口iris = datasets.load_iris() # 鸢尾花数据
# 调用datasets模块中的load_iris函数来加载鸢尾花数据集,返回一个包含数据集信息的字典对象,将其赋值给变量 iris# 前0.8数据作为训练集,后0.2数据作为测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.20) # 标准化
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test) # 改变 K 取值,比较错误率
error = []# 计算K值在1-40之间多误差值
for i in range(1, 40): knn = KNeighborsClassifier(n_neighbors=i)knn.fit(X_train, y_train)pred_i = knn.predict(X_test)error.append(np.mean(pred_i != y_test))
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red', linestyle='dashed', marker='o', markerfacecolor='blue', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
结果:
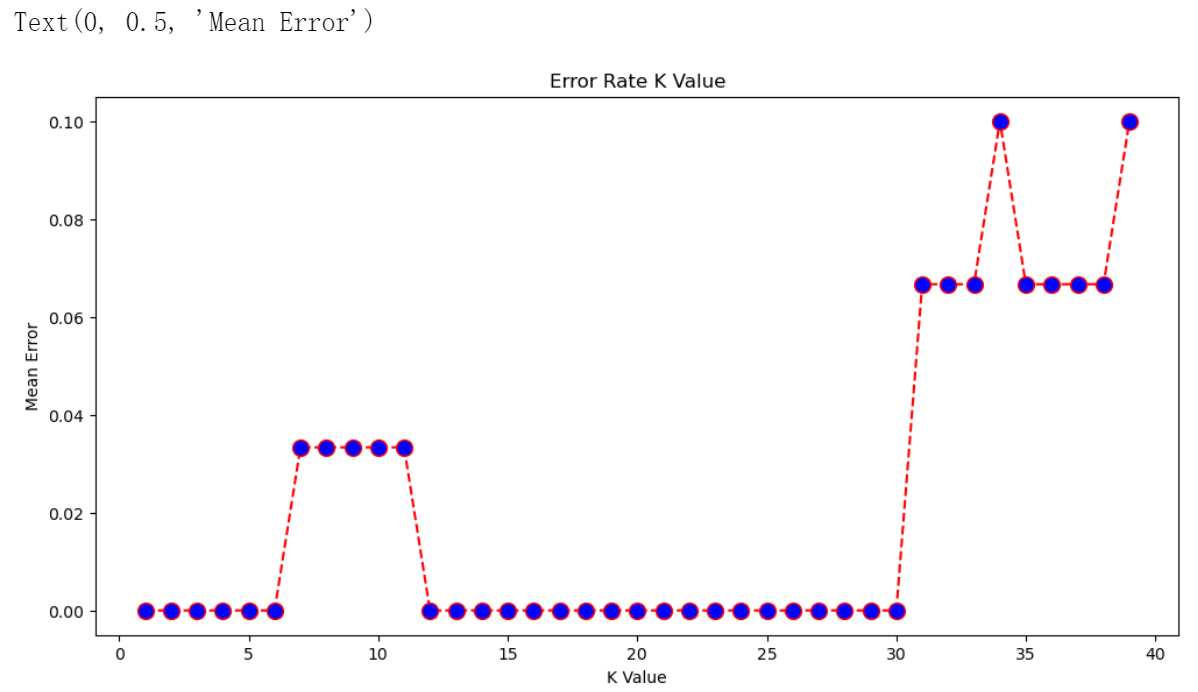
# 取 K = 5
knn = KNeighborsClassifier(n_neighbors = 5) # 定义KNN分类器
knn.fit(X_train, y_train) # 训练集训练
y_pred = knn.predict(X_test) # 测试集预测# 比较预测结果和真实结果
print(confusion_matrix(y_test, y_pred)) # 混淆矩阵
print(classification_report(y_test, y_pred)) # 预测结果
结果:
[[10 0 0][ 0 13 0][ 0 0 7]]precision recall f1-score support0 1.00 1.00 1.00 101 1.00 1.00 1.00 132 1.00 1.00 1.00 7accuracy 1.00 30macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
预测精度为 100%
相关文章:
个人学习笔记(7):网络数据采集以及FNN分类)
金融数据分析(Python)个人学习笔记(7):网络数据采集以及FNN分类
一、网络数据采集 证券宝是一个免费、开源的证券数据平台(无需注册),提供大盘准确、完整的证券历史行情数据、上市公司财务数据等,通过python API获取证券数据信息。 1. 安装并导入第三方依赖库 baostock 在命令提示符中运行&…...

指定运行级别
linux系统下有7种运行级别,我们需要来了解一下常用的运行级别,方便我们熟悉以后的部署环境,话不多说,来看. 开机流程: 指定数级别 基本介绍 运行级别说明: 0:关机 相当于shutdown -h now ⭐️默认参数不能设置为0,否则系统无法正常启动 1:单用户(用于找回丢…...

7.第二阶段x64游戏实战-string类
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:7.第二阶段x64游戏实战-分析人物属性 string类是字符串类,在计算机中…...

【MySQL基础】左右连接实战:掌握数据关联的完整视图
1 左右连接基础概念 左连接(left join)和右连接(right join)是MySQL中两种重要的表连接方式,它们与内连接不同,能够保留不匹配的记录,为我们提供更完整的数据视图。 核心区别: left join:保留左表所有记录,…...

建筑工程行业如何选OA系统?4大主流产品分析
工程行业项目的复杂性与业务流程的繁琐性对办公效率提出了极高要求。而OA 系统(办公自动化系统)的出现,为工程企业提供了一种全新的、高效的管理模式。 工程行业OA系统选型关键指标 功能深度:项目管理模块完整度、文档版本控制能…...

动态科技感html导航网站源码
源码介绍 动态科技感html导航网站源码,这个设计完美呈现了科幻电影中的未来科技界面效果,适合展示技术类项目或作为个人作品集的入口页面,自适应手机。 修改卡片中的链接指向你实际的HTML文件可以根据需要调整卡片内容、图标和颜色要添加更…...

CLIPGaze: Zero-Shot Goal-Directed ScanpathPrediction Using CLIP
摘要 目标导向的扫描路径预测旨在预测人们在搜索视觉场景中的目标时的视线移动路径。大多数现有的目标导向扫描路径预测方法在面对训练过程中未出现的目标类别时,泛化能力较差。此外,它们通常采用不同的预训练模型分别提取目标提示和图像的特征,导致两者之间存在较大的特征…...

wsl-docker环境下启动ES报错vm.max_map_count [65530] is too low
问题描述 在windows环境下用Docker Desktop(wsl docker)启动 elasticsearch时报错 max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]解决方案 方案一 默认的vm.max_map_count值是65530,而es需要至少262…...

js chrome 插件,下载微博视频
起因, 目的: 最初是想下载微博上的NBA视频,因为在看网页上看视频很不方便,快进一次是10秒,而本地 VLC 播放器,快进一次是5秒。另外我还想做点视频剪辑。 对比 原来手动下载的话,右键检查,复制…...

游戏引擎学习第212天
"我们将同步…"α 之前我们有一些内容是暂时搁置的,因为在调整代码的过程中,我们做了一些变动以使代码更加简洁,这样可以把数据放入调试缓冲区并显示出来,这一切现在看起来已经好多了。尽管现在看起来更好,…...

PXE远程安装服务器
目录 搭建PXE远程安装服务器 1、准备Linux安装源: 2、安装并启用TFTP服务: 3、准备Linux内核、初始化镜像文件 4、准备PXE引导程序 5、安装并启用DHCP服务 6、(1)配置启动菜单文件(有人应答) 6、(2)…...

软件测试之功能测试详解
一、测试项目启动与研读需求文档 (一) 组建测试团队 1、测试团队中的角色 2、测试团队的基本责任 尽早地发现软件程序、系统或产品中所有的问题。 督促和协助开发人员尽快地解决程序中的缺陷。 帮助项目管理人员制定合理的开发和测试计划。 对缺陷进行…...
(PyTorch))
Python深度学习基础——卷积神经网络(CNN)(PyTorch)
CNN原理 从DNN到CNN 卷积层与汇聚 深度神经网络DNN中,相邻层的所有神经元之间都有连接,这叫全连接;卷积神经网络 CNN 中,新增了卷积层(Convolution)与汇聚(Pooling)。DNN 的全连接…...

pytorch 反向传播
文章目录 概念计算图自动求导的两种模式 自动求导-代码标量的反向传播非标量变量的反向传播将某些计算移动到计算图之外 概念 核心:链式法则 深度学习框架通过自动计算导数(自动微分)来加快求导。 实践中,根据涉及号的模型,系统会构建一个计…...

VSCode解决中文乱码方法
目录 一、底层原因 二、解决方法原理 三、解决方式: 1.预设更改cmd临时编码法 2.安装插件法: 一、底层原因 当在VSCode中遇到中文显示乱码的问题时,这通常是由于文件编码与VSCode的默认或设置编码不匹配,或…...

pandas.DataFrame.dtypes--查看和验证 DataFrame 列的数据类型!
查看每列的数据类型,方便分析是否需要数据类型转换 property DataFrame.dtypes[source] Return the dtypes in the DataFrame. This returns a Series with the data type of each column. The result’s index is the original DataFrame’s columns. Columns with…...

高性能服务开发利器:redis+lua
Redis 与 Lua 脚本的结合,其核心价值在于 原子性操作 和 减少网络开销。 一、Redis 执行 Lua 脚本的优势 原子性 Lua 脚本在 Redis 中原子执行,避免多命令竞态条件。 减少网络开销 将多个 Redis 命令合并为一个脚本,减少客…...

开源智能体MetaGPT记忆模块解读
MetaGPT 智能体框架 1. 框架概述 MetaGPT 是一个多智能体协作框架,通过模拟软件公司组织架构与工作流程,将大语言模型(LLM)转化为具备专业分工的智能体,协同完成复杂任务。其最大特点是能够将自然语言需…...

Docker部署MySQL大小写不敏感配置与数据迁移实战20250409
Docker部署MySQL大小写不敏感配置与数据迁移实战 🧭 引言 在企业实际应用中,尤其是使用Java、Hibernate等框架开发的系统,MySQL默认的大小写敏感特性容易引发各种兼容性问题。特别是在Linux系统中部署Docker版MySQL时,默认行为可…...

【RabbitMQ】延迟队列
1.概述 延迟队列其实就是队列里的消息是希望在指定时间到了以后或之前取出和处理,简单来说,延时队列就是用来存放需要在指定时间被处理的元素的队列。 延时队列的使用场景: 1.订单在十分钟之内未支付则自动取消 2.新创建的店铺,…...

深兰科技携多款AI医疗创新成果亮相第七届世界大健康博览会
4月8日,以“AI赋能 健康生活”为主题的2025年(第七届)世界大健康博览会(以下简称健博会)在武汉隆重开幕。应参展企业武汉市三甲医院——武汉中心医院的邀请,深兰科技最新研发的新一代智慧医疗解决方案和产品在其展位上公开亮相。 本届展会吸引了来自18个…...

20周年系列|美创科技再度入围「年度高成长企业」系列榜单
近日,资深产业信息服务平台【第一新声】发布「2024年度科技行业最佳CEO及高成长企业榜」,美创科技凭借在数据安全领域的持续创新和广泛行业实践, 再度入围“年度网络安全高成长企业”、“年度高科技高成长未来独角兽企业TOP30”。 美创科技作…...

saltstack分布式部署
一、saltstack分布式 在minion数量过多时,通过部署salt代理,减轻master负载 1、在master上删除说有minion证书 2、在minion上删除旧master信息 3、安装部署salt-syndic 4、修改minion 5、在master上签署代理的证书 6、在代理上签署minion证书 7、测试...

CCRC 与 EMVCo 双认证:中国智能卡企业的全球化突围
在全球经济一体化的浪潮中,智能卡行业正经历着前所未有的变革与发展。中国智能卡企业凭借技术优势与成本竞争力,在国内市场成绩斐然。然而,要想在国际市场站稳脚跟,获取权威认证成为关键一步。CCRC 与 EMVCo 双认证,宛…...

逆向工程的多层次解析:从实现到领域的全面视角
目录 前言1. 什么是逆向工程?2. 实现级逆向:揭示代码背后的结构2.1 抽象语法树的构建2.2 符号表的恢复2.3 过程设计表示的推导 3. 结构级逆向:重建模块之间的协作关系3.1 调用图与依赖分析3.2 程序与数据结构的映射 4. 功能级逆向:…...

【Docker项目实战】使用Docker部署ToDoList任务管理工具
【Docker项目实战】使用Docker部署ToDoList任务管理工具 一、ToDoList介绍1.1 ToDoList简介1.2 ToDoList主要特点二、本次实践规划2.1 本地环境规划2.2 本次实践介绍三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本四、下载ToDoList镜像…...

基于SpinrgBoot+Vue的医院管理系统-026
一、项目技术栈 Java开发工具:JDK1.8 后端框架:SpringBoot 前端:Vue开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 二、功能介绍 (1)…...

如何进行数据安全风险评估总结
一、基于场景进行安全风险评估 一、概述 数据安全风险评估总结(一)描述了数据安全风险评估的相关理论,数据安全应该关注业务流程,以基础安全为基础,以数据生命周期及数据应用场景两个维度为入口进行数据安全风险评估。最后以《信息安全技术 信息安全风险评估规范》为参考,…...

用 npm list -g --depth=0 探索全局包的秘密 ✨
用 npm list -g --depth0 探索全局包的秘密 🚀✨ 嗨,各位开发者朋友们!👋 今天我们要聊一个超实用的小命令——npm list -g --depth0!它就像一个“全局包侦探”🕵️♂️,能帮你快速查出系统中…...

依靠视频设备轨迹回放平台EasyCVR构建视频监控,为幼教连锁园区安全护航
一、项目背景 幼教行业连锁化发展态势越发明显。在此趋势下,幼儿园管理者对于深入了解园内日常教学与生活情况的需求愈发紧迫,将这些数据作为提升管理水平、优化教育服务的重要依据。同时,安装监控系统不仅有效缓解家长对孩子在校安全与生活…...

新闻发稿软文发布投稿选择媒体时几大注意
企业在选择新闻稿发布媒体时,需要综合考虑以下几个关键因素: 1. 匹配媒体定位 企业应根据自身品牌定位和传播目标,选择与之契合的媒体平台。确保新闻稿的内容和风格与媒体的定位高度一致,从而提高稿件被采纳的可能性。 2. 衡量…...

[Scade One] Swan与Scade 6的区别 - signal 特性的移除
signal 特性移除 在 Scade One 引入的Swan中,移除了Scade 6中存在的signal 特性。比如 Scade 6 中的signal声明 sig sig_o;或者signal使用,比如 o sig_o; 在Swan中已经被移除。 不过Swan仍旧保留了对布尔流的emit操作,比如 emit a if c …...

亚马逊推出“站外代购革命“:跨境购物进入全平台整合时代
一、创新功能解析:平台边界消融的购物新范式 亚马逊最新推出的External Product Fulfillment(EPF)服务,正以技术创新重构全球电商格局。这项被称作"代购终结者"的功能具备三大核心突破: 全链路智能化 • 智能…...

Java 常用安全框架的 授权模型 对比分析,涵盖 RBAC、ABAC、ACL、基于权限/角色 等模型,结合框架实现方式、适用场景和优缺点进行详细说明
以下是 Java 常用安全框架的 授权模型 对比分析,涵盖 RBAC、ABAC、ACL、基于权限/角色 等模型,结合框架实现方式、适用场景和优缺点进行详细说明: 1. 授权模型类型与定义 模型名称定义特点RBAC(基于角色的访问控制)通…...

达梦数据库迁移问题总结
问题一、DTS工具运行乱码 开启图形化 [rootlocalhost ~]# xhost #如果命令不存在执行sudo yum install xorg-x11-server-utils xhost: unable to open display "" [rootlocalhost ~]# su - dmdba 上一次登录: 三 4月 9 19:50:44 CST 2025 pts/0 上…...

JS | 函数柯里化
函数柯里化(Currying):将一个接收多个参数函数,转换为一系列只接受一个参数的函数的过程。即 逐个接收参数。 例子: 普通函数: function add(a, b, c) {return a b c; } add(1, 2, 3); // 输出 6柯里化…...

Elasticsearch中的基本全文搜索和过滤
Elasticsearch中的基本全文搜索和过滤 知识点参考: https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-filter-tutorial.html#full-text-filter-tutorial-range-query 1. 索引设计与映射 多字段类型(Multi-Fields) ÿ…...

蓝桥杯嵌入式第十五届
一、底层 根据它的硬件配置可以看出来这套题目使用到了按键、LED、LCD、输入捕获这几个功能 (1)输入捕获功能 首先在CubeMx里面的配置 题目中说到了我们使用的是PA15和PB4(实际在板子上对应的的是R39和R40),所以我们…...

基于ueditor编辑器的功能开发之给编辑器图片增加水印功能
用户需求,双击编辑器中的图片的时候,出现弹框,用户可以选择水印缩放倍数、距离以及水印所放置的方位(当然有很多水印插件,位置大小透明度用户都能够自定义,但是用户需求如此,就自己写了…...

DDR中的DLL
在DDR4内存系统中,DLL(Delay Locked Loop,延迟锁相环)是一个非常重要的组件,用于确保数据信号(DQS)和时钟信号(CK)之间的同步。以下是DLL的作用以及DLL on和DLL off的影响…...

Python学习之jieba
Python学习之jieba jieba是优秀的中文分词第三方库,由于中文文本之间每个汉字都是连续书写的,我们需要通过特定的手段来获得其中的每个词组,这种手段叫做分词,我们可以通过jieba库来完成这个过程。jieba库的分词原理:利用一个中文词库,确定汉字之间的关联频率,汉字向概率大的组…...

快速幂fast_pow
快速幂算法讲解 快速幂算法是一种高效计算幂运算的算法,其核心思想是利用指数的二进制分解,把幂运算的时间复杂度从 O(p) 降低到 O(logp)。 原理 假设要计算 an,将 n 表示成二进制形式:n2k12k2⋯2km,那么 ana…...
)
Go并发背后的双引擎:CSP通信模型与GMP调度|Go语言进阶(4)
为什么需要理解CSP与GMP? 当我们启动一个Go程序时,可能会创建成千上万个goroutine,它们是如何被调度到有限的CPU核心上的?为什么Go能够如此轻松地处理高并发场景?为什么有时候我们的并发程序会出现奇怪的性能瓶颈&…...

42、JavaEE高级主题:WebSocket详解
WebSocket 一、WebSocket协议与实现 WebSocket是一种基于TCP协议的全双工通信协议,能够在客户端和服务器之间建立实时、双向的通信通道。通过WebSocket,客户端和服务器可以在任何时候发送数据,并立即接收到对方的响应。 1.1 WebSocket协议…...

UGUI源代码之Text—实现自定义的字间距属性
以下内容是根据Unity 2020.1.01f版本进行编写的 UGUI源代码之Text—实现自定义的字间距属性 1、目的2、参考3、代码阅读4、准备修改UGUI源代码5、实现自定义Text组件,增加字间距属性6、最终效果 1、目的 很多时候,美术在设计的时候是想要使用文本的字间…...

【AI】MCP概念
一文讲透 MCP(附 Apifox MCP Server 内测邀请) 7分钟讲清楚MCP是什么?统一Function calling规范,工作量锐减至1/6,人人手搓Manus!? | 一键链接千台服务器,几行代码接入海量外部工具…...
获取位置信息)
HarmonyOS:使用geoLocationManager (位置服务)获取位置信息
一、简介 位置服务提供GNSS定位、网络定位(蜂窝基站、WLAN、蓝牙定位技术)、地理编码、逆地理编码、国家码和地理围栏等基本功能。 使用位置服务时请打开设备“位置”开关。如果“位置”开关关闭并且代码未设置捕获异常,可能导致应用异常。 …...

深入解析原生鸿蒙中的 RN 日志系统:从入门到精通!
全文目录: 开篇语📖 目录🎯 前言:鸿蒙日志系统究竟有多重要?🛠️ 鸿蒙 RN 日志系统的基础结构📜 1. 日志的作用⚙️ 2. 日志分类 🔧 如何在鸿蒙 RN 中使用日志系统🖋️ 1…...

【前端】【Nuxt3】Nuxt3中usefetch,useAsyncData,$fetch使用与区别
一、Nuxt3 中不同数据获取方式的请求行为对比 (一)总结:请求行为一览 useFetch 和 useAsyncData 是 Nuxt 推荐的数据获取 API,自动集成 SSR 与客户端导航流程。$fetch 是更底层的请求方法,不具备自动触发、缓存等集成…...

【Linux系统】Linux基础指令
l i n u x linux linux 命令是对 L i n u x Linux Linux 系统进行管理的命令。对于 L i n u x Linux Linux 系统来说,无论是中央处理器、内存、磁盘驱动器、键盘、鼠标,还是用户等都是文件, L i n u x Linux Linux 系统管理的命令是它正常运…...