Python深度学习基础——卷积神经网络(CNN)(PyTorch)
CNN原理
从DNN到CNN
- 卷积层与汇聚
- 深度神经网络DNN中,相邻层的所有神经元之间都有连接,这叫全连接;卷积神经网络 CNN 中,新增了卷积层(Convolution)与汇聚(Pooling)。
- DNN 的全连接层对应 CNN 的卷积层,汇聚是与激活函数类似的附件;单个卷积层的结构是:卷积层-激活函数-(汇聚),其中汇聚可省略。
2.CNN:专攻多维数据
在深度神经网络 DNN 课程的最后一章,使用 DNN 进行了手写数字的识别。但是,图像至少就有二维,向全连接层输入时,需要多维数据拉平为 1 维数据,这样一来,图像的形状就被忽视了,很多特征是隐藏在空间属性里的,如下图所示。
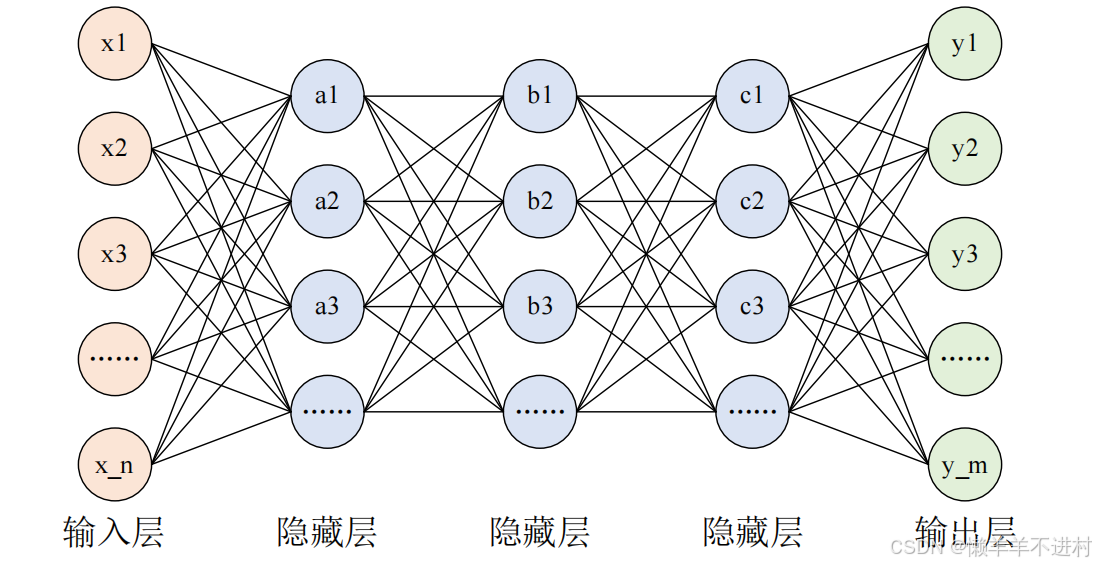
而卷积层可以保持输入数据的维数不变,当输入数据是二维图像时,卷积层会以多维数据的形式接收输入数据,并同样以多维数据的形式输出至下一层,如下图所示。
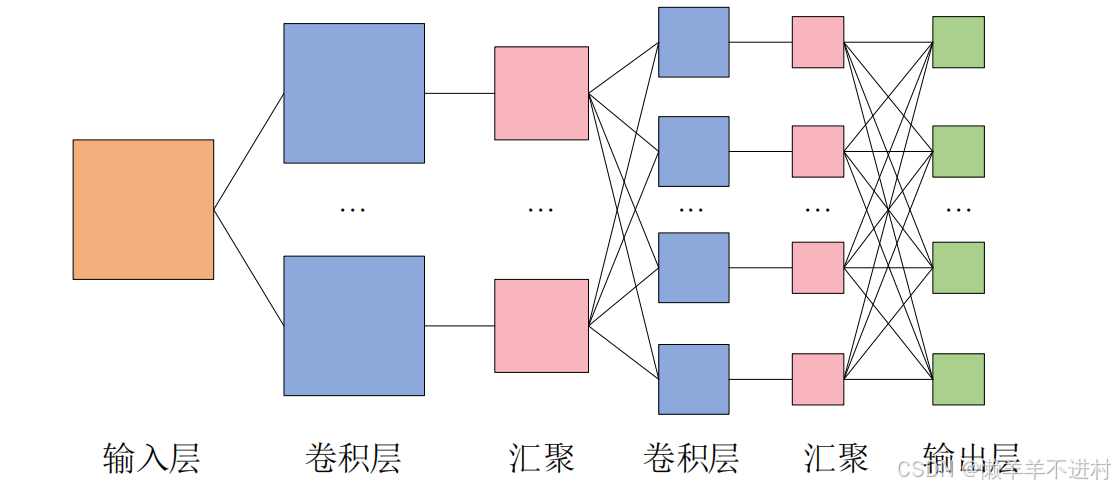
卷积层
CNN 中的卷积层与 DNN 中的全连接层是平级关系,全连接层中的权重与偏置即y = ω1x1 + ω2x2 + ω3x3 + b中的 ω 与 b,卷积层中的权重与偏置变得稍微复杂。
-
内部参数:权重(卷积核)
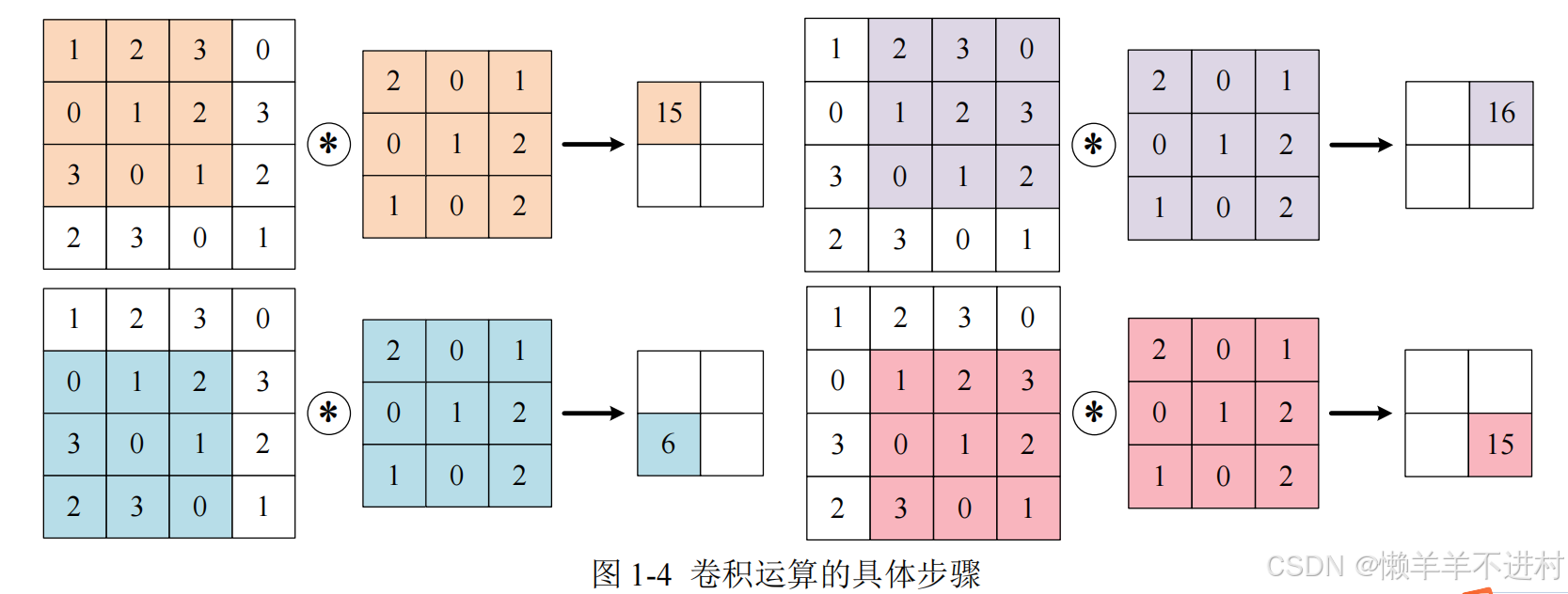
当输入数据进入卷积层后,输入数据会与卷积核进行卷积运算,如下图:

上图中的输入大小是(4,4),卷积核大小事(3,3),输出大小是(2,2)卷积运算的原理是逐元素乘积后再相加。
-
内部参数:偏置
在卷积运算的过程中也存在偏置,如下图所示:
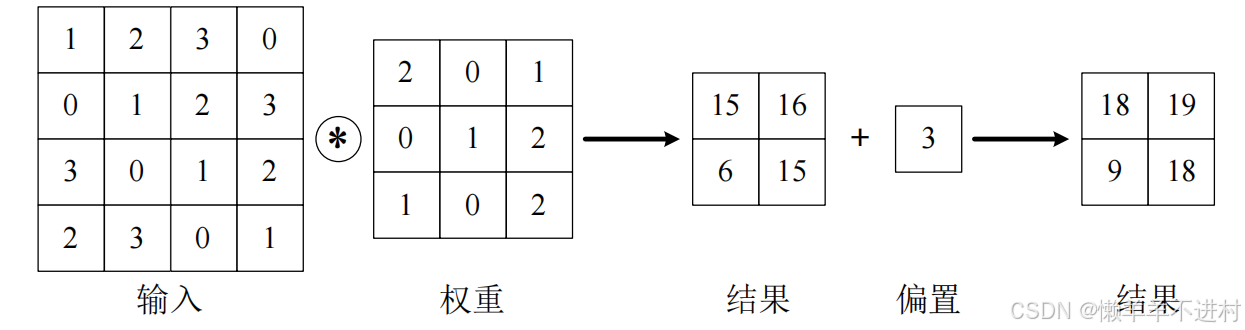
-
外部参数:补充
为了防止经过多个卷积层后图像越卷越小,可以在进行卷积层的处理之前,向输入数据的周围填入固定的数据(比如 0),这称为填充(padding)。
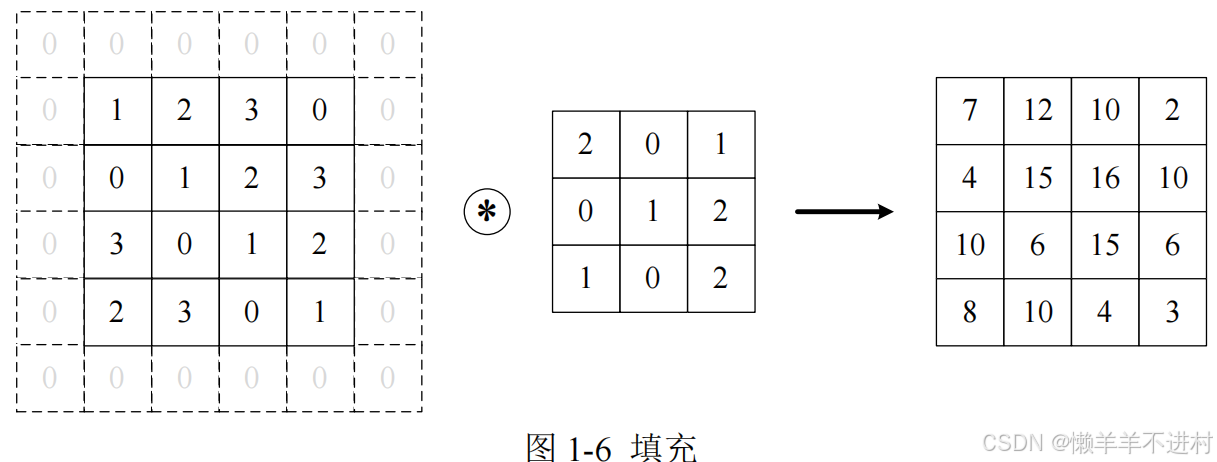
对上图大小为(4, 4)的输入数据应用了幅度为 1 的填充,填充值为 0。 -
外部参数:步幅
使用卷积核的位置间隔被称为步幅(stride),之前的例子中步幅都是 1,如果将步幅设为 2,此时使用卷积核的窗口的间隔变为 2。
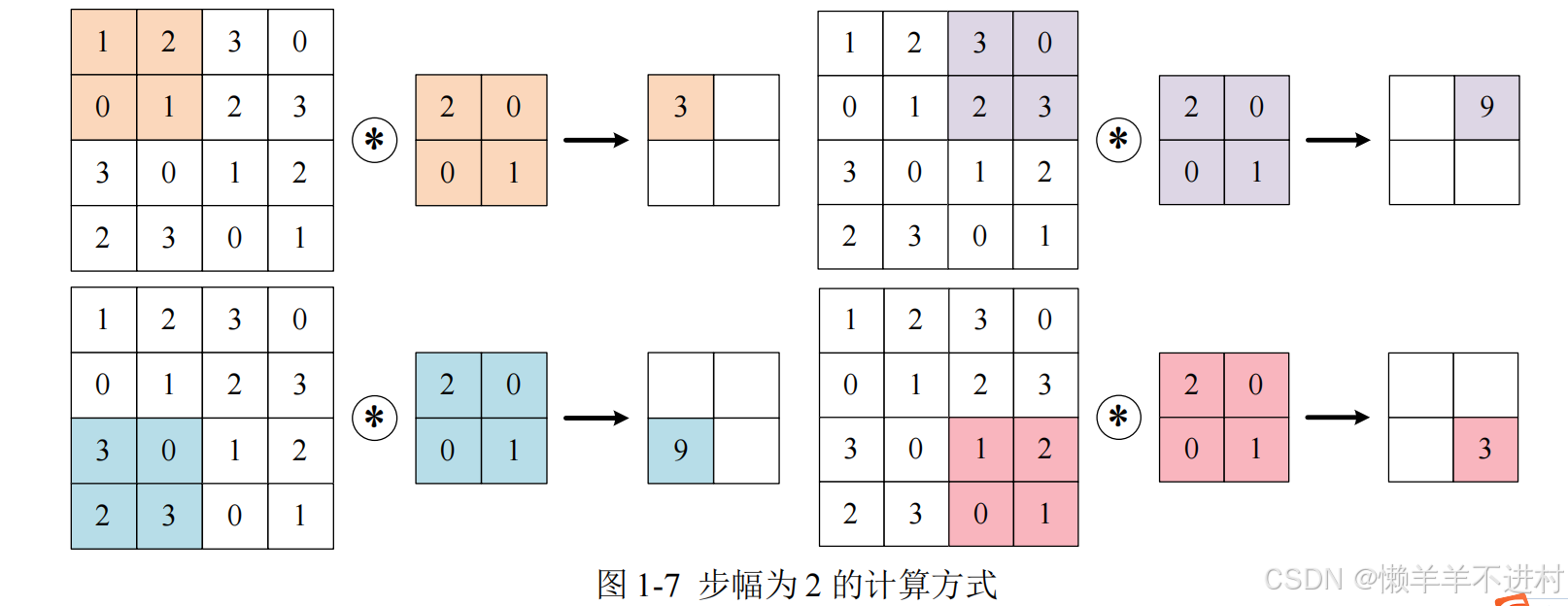
综上,增大填充后,输出尺寸会变大;而增大步幅后,输出尺寸会变小 -
输入与输出尺寸的关系
假设输入尺寸为(H, W),卷积核的尺寸为(FH, FW),填充为 P,步幅为 S。则输出尺寸(OH, OW)的计算公式为
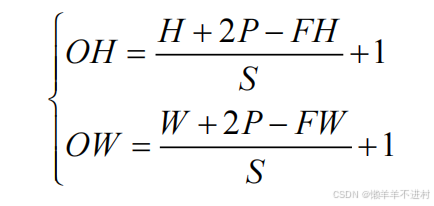
多通道
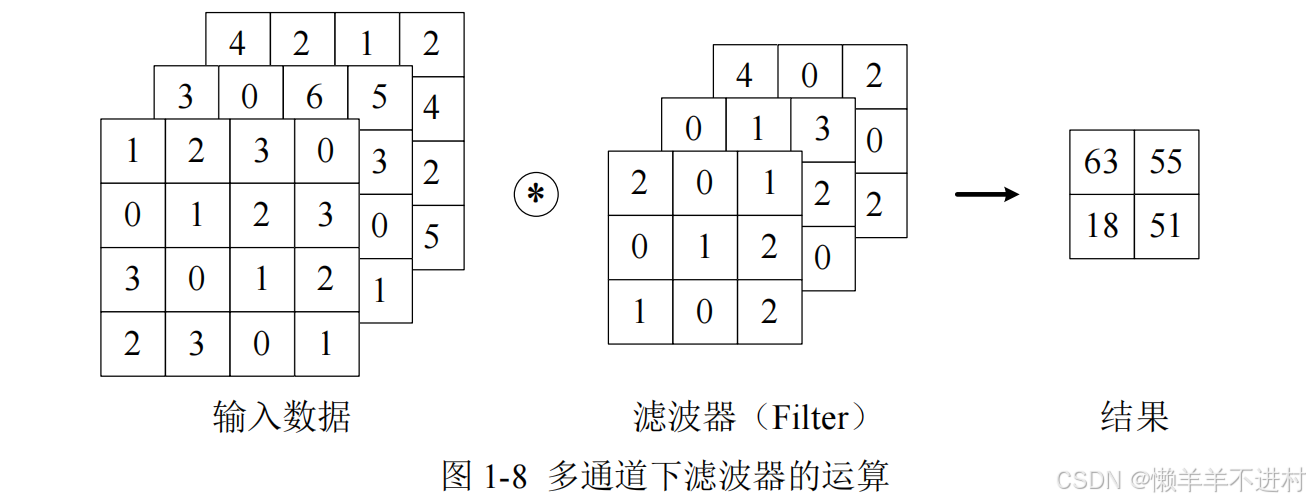
在上一小节讲的卷积层,仅仅针对二维的输入与输出数据(一般是灰度图像),可称之为单通道。
但是,彩色图像除了高、长两个维度之外,还有第三个维度:通道(channel)。例如,以 RGB 三原色为基础的彩色图像,其通道方向就有红、黄、蓝三部分,可视为 3 个单通道二维图像的混合叠加。一般的,当输入数据是二维时,权重被称为卷积核(Kernel);当输入数据是三维或更高时,权重被称为滤波器(Filter)。
1.多通道输入
对三维数据的卷积操作如图 1-8 所示,输入数据与滤波器的通道数必须要设为相同的值,可以发现,这种情况下的输出结果降级为了二维
将数据和滤波器看作长方体,如图 1-9 所示

C、H、W 是固定的顺序,通道数要写在高与宽的前面
图 1-9 可看出,仅通过一个卷积层,三维就被降成二维了。大多数时候我们想让三维的特征多经过几个卷积层,因此就需要多通道输出,如图 1-10 所示。
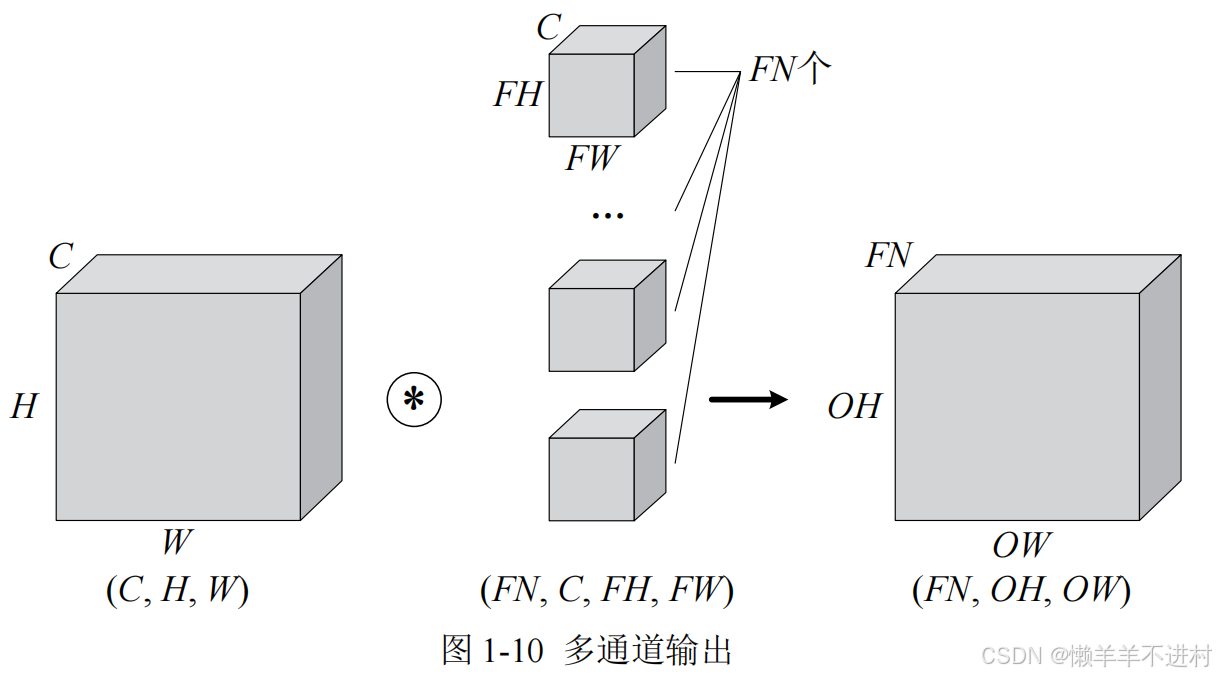
别忘了,卷积运算中存在偏置,如果进一步追加偏置的加法运算处理,则结果如图 1-11 所示,每个通道都有一个单独的偏置。

汇聚(很多教材也叫做池化)
汇聚(Pooling)仅仅是从一定范围内提取一个特征值,所以不存在要学习的内部参数。一般有平均汇聚与最大值汇聚。
-
平均汇聚
一个以步幅为2进行的2*2窗口的平均汇聚,如图1-12所示

-
最大值汇聚
一个以步幅为 2 进行 2*2 窗口的最大值汇聚,如图 1-13 所示
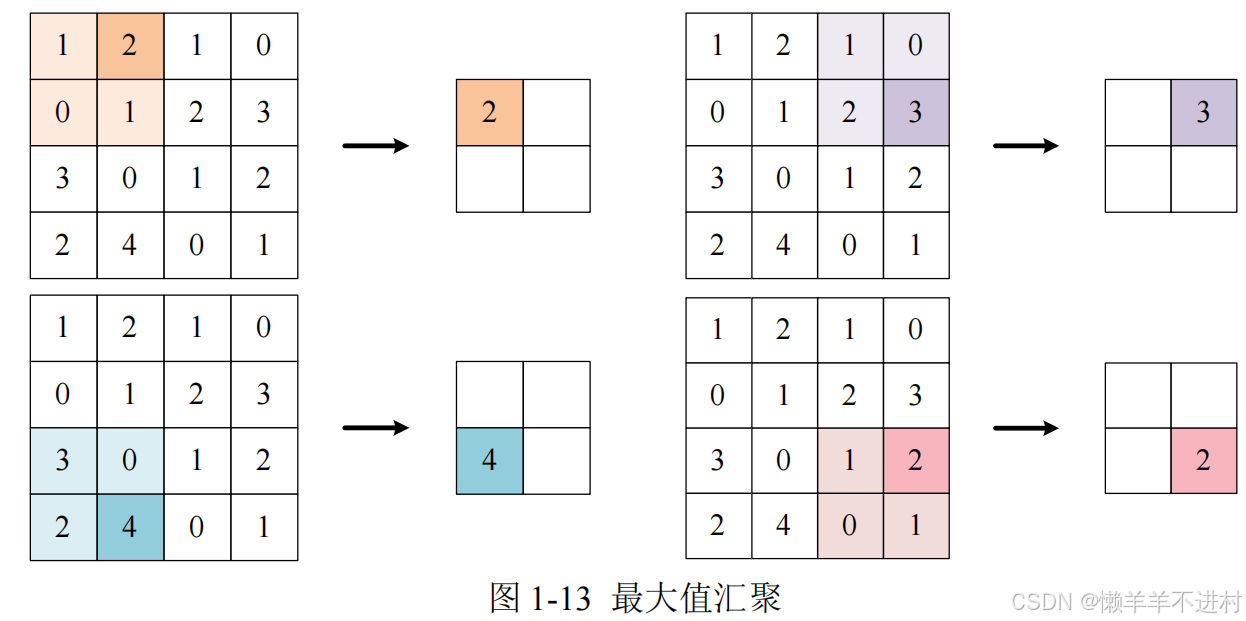
汇聚对图像的高 H 和宽 W 进行特征提取,不改变通道数 C。
尺寸变换总结
- 卷积层
现假设卷积层的填充为P,步幅为S,由
- 输入数据的尺寸是:( C,H,W) 。
- 滤波器的尺寸是:(FN,C,FH,FW)。
- 输出数据的尺寸是:(FN,OH,OW) 。
可得
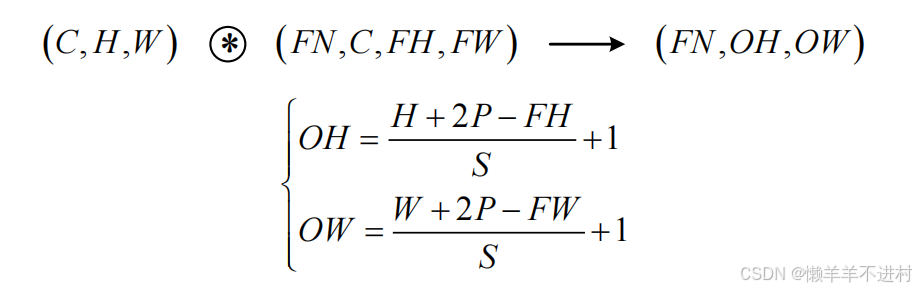
2. 汇聚
现假设汇聚的步幅为 S,由
- 输入数据的尺寸是:( C,H,W) 。
- 输出数据的尺寸是:(C,OH,OW) 。
可得
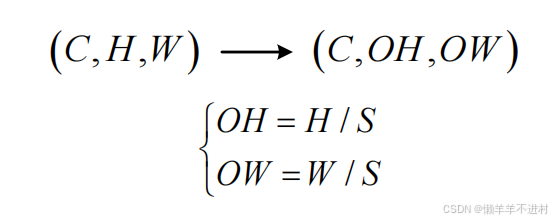
LeNet-5
网络结构
LeNet-5 虽诞生于 1998 年,但基于它的手写数字识别系统则非常成功。
该网络共 7 层,输入图像尺寸为 28×28,输出则是 10 个神经元,分别表示某手写数字是 0 至 9 的概率。
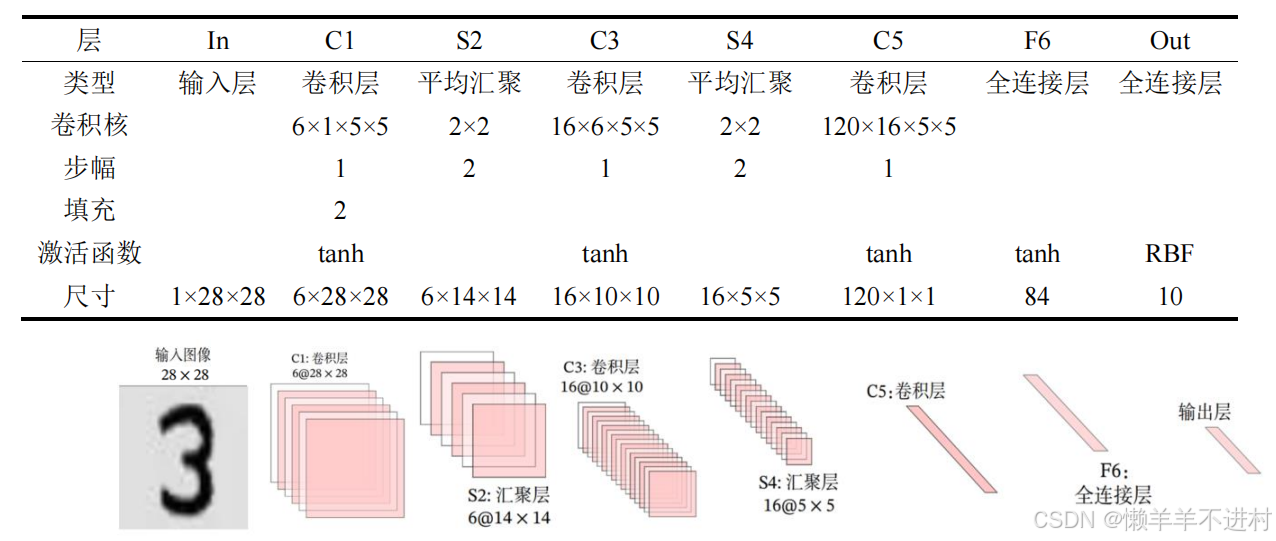
PS:输出层由 10 个径向基函数 RBF 组成,用于归一化最终的结果,目前RBF 已被 Softmax 取代。
根据网络结构,在 PyTorch 的 nn.Sequential 中编写为
self.net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(), # C1:卷积层nn.AvgPool2d(kernel_size=2, stride=2), # S2:平均汇聚nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(), # C3:卷积层nn.AvgPool2d(kernel_size=2, stride=2), # S4:平均汇聚nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(), # C5:卷积层nn.Flatten(), # 把图像铺平成一维nn.Linear(120, 84), nn.Tanh(), # F5:全连接层nn.Linear(84, 10) # F6:全连接层
)
其中,nn.Conv2d( )需要四个参数,分别为
- in_channel:此层输入图像的通道数;
- out_channel:此层输出图像的通道数;
- kernel_size:卷积核尺寸;
- padding:填充;
- stride:步幅。
制作数据集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作数据集
# 数据集转换参数
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.MNIST(root = 'D:/Jupyter/dataset/mnist/', # 下载路径train = True, # 是 train 集download = True, # 如果该路径没有该数据集,就下载transform = transform # 数据集转换参数
)
test_Data = datasets.MNIST(root = 'D:/Jupyter/dataset/mnist/', # 下载路径train = False, # 是 test 集download = True, # 如果该路径没有该数据集,就下载transform = transform # 数据集转换参数
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=256)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=256)
搭建神经网络
class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(16, 120, kernel_size=5), nn.Tanh(),nn.Flatten(),nn.Linear(120, 84), nn.Tanh(),nn.Linear(84, 10))def forward(self, x):y = self.net(x)return y
# 查看网络结构
X = torch.rand(size= (1, 1, 28, 28))
for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )

# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数
# 优化算法的选择
learning_rate = 0.9 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 训练网络
epochs = 5
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
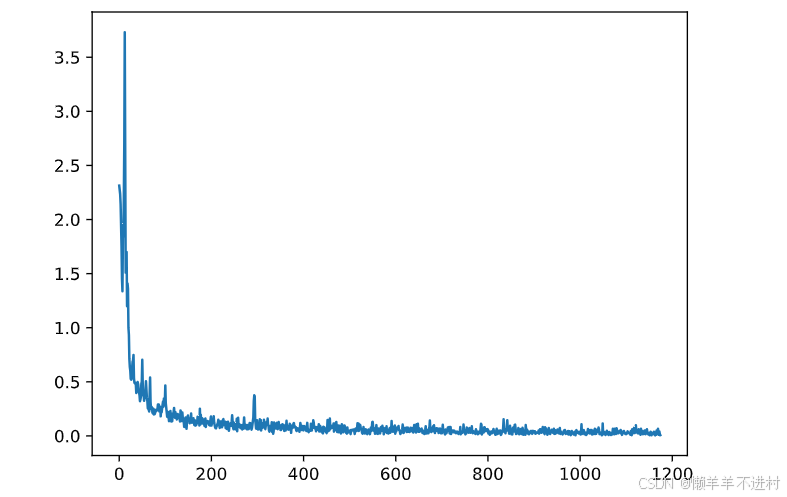
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能for (x, y) in test_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0) print(f'测试集精准度: {100*correct/total} %') #OUT:测试集精准度: 9.569999694824219 %
AlexNet
网络结构
AlexNet 是第一个现代深度卷积网络模型,其首次使用了很多现代网络的技术方法,作为 2012 年 ImageNet 图像分类竞赛冠军,输入为 3×224×224 的图像,输出为 1000 个类别的条件概率。
考虑到如果使用 ImageNet 训练集会导致训练时间过长,这里使用稍低亿档的 1×28×28 的 MNIST 数据集,并手动将其分辨率从 1×28×28 提到 1×224×224,同时输出从 1000 个类别降到 10 个,修改后的网络结构见下表。
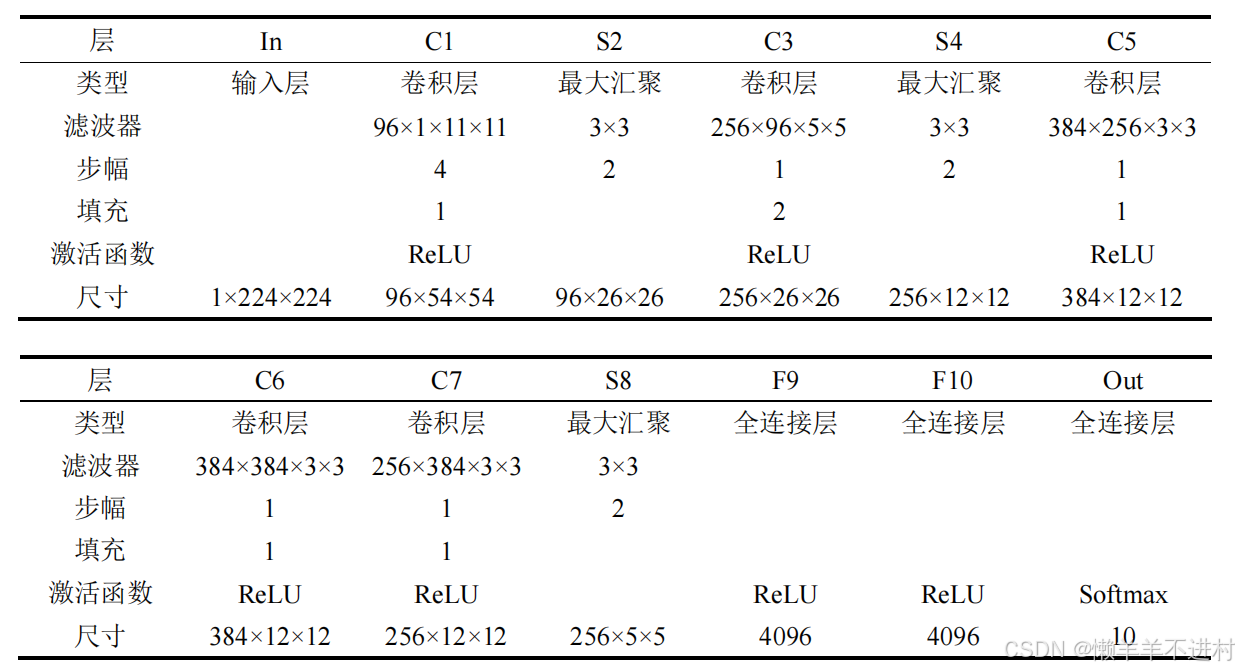
根据网络结构,在 PyTorch 的 nn.Sequential 中编写为
self.net = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5), # Dropout——随机丢弃权重nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5), # 按概率 p 随机丢弃突触nn.Linear(4096, 10)
)
制作数据集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作数据集
# 数据集转换参数
transform = transforms.Compose([transforms.ToTensor(),transforms.Resize(224),transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = True,download = True,transform = transform
)
test_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = False,download = True,transform = transform
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=128)
搭建神经网络
class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(96, 256, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(256, 384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),nn.Linear(6400, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 10))def forward(self, x):y = self.net(x)return y
# 查看网络结构
X = torch.rand(size= (1, 1, 224, 224))
for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )
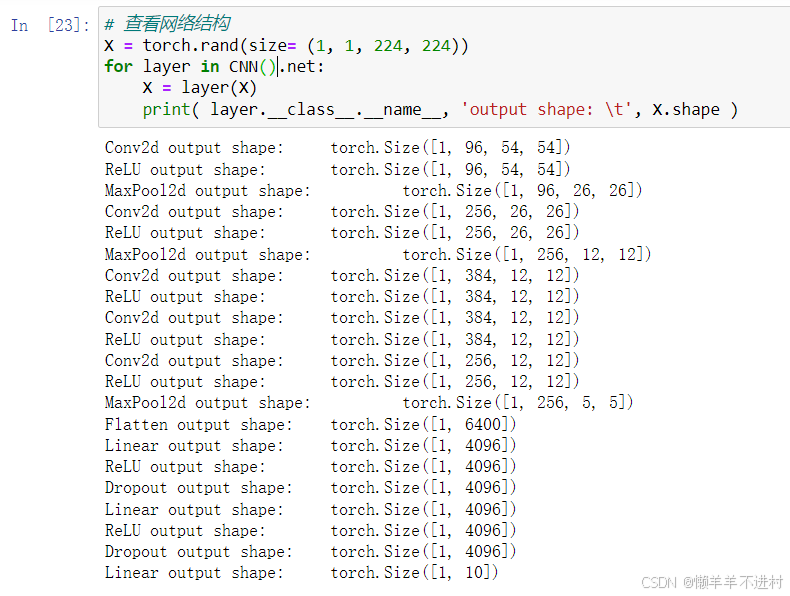
# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss() # 自带 softmax 激活函数
# 优化算法的选择
learning_rate = 0.1 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 训练网络
epochs = 10
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能for (x, y) in test_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)
print(f'测试集精准度: {100*correct/total} %')
GoogLeNet
网络结构
2014 年,获得 ImageNet 图像分类竞赛的冠军是 GoogLeNet,其解决了一个重要问题:滤波器超参数选择困难,如何能够自动找到最佳的情况。
其在网络中引入了一个小网络——Inception 块,由 4 条并行路径组成,4 条路径互不干扰。这样一来,超参数最好的分支的那条分支,其权重会在训练过程中不断增加,这就类似于帮我们挑选最佳的超参数,如示例所示。
# 一个 Inception 块
class Inception(nn.Module):def __init__(self, in_channels):super(Inception, self).__init__()self.branch1 = nn.Conv2d(in_channels, 16, kernel_size=1)self.branch2 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=3, padding=1),nn.Conv2d(24, 24, kernel_size=3, padding=1))self.branch3 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=5, padding=2))self.branch4 = nn.Conv2d(in_channels, 24, kernel_size=1)def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
此外,分支 2 和分支 3 上增加了额外 1×1 的滤波器,这是为了减少通道数,降低模型复杂度。
GoogLeNet 之所以叫 GoogLeNet,是为了向 LeNet 致敬,其网络结构为
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 10, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=10),nn.Conv2d(88, 20, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=20),nn.Flatten(),nn.Linear(1408, 10) )def forward(self, x):y = self.net(x)return y
制作数据集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作数据集
# 数据集转换参数
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = True,download = True,transform = transform
)
test_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = False,download = True,transform = transform
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=128)
搭建神经网络
# 一个 Inception 块
class Inception(nn.Module):def __init__(self, in_channels):super(Inception, self).__init__()self.branch1 = nn.Conv2d(in_channels, 16, kernel_size=1)self.branch2 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=3, padding=1),nn.Conv2d(24, 24, kernel_size=3, padding=1))self.branch3 = nn.Sequential(nn.Conv2d(in_channels, 16, kernel_size=1),nn.Conv2d(16, 24, kernel_size=5, padding=2))self.branch4 = nn.Conv2d(in_channels, 24, kernel_size=1)def forward(self, x):branch1 = self.branch1(x)branch2 = self.branch2(x)branch3 = self.branch3(x)branch4 = self.branch4(x)outputs = [branch1, branch2, branch3, branch4]return torch.cat(outputs, 1)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 10, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=10),nn.Conv2d(88, 20, kernel_size=5), nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),Inception(in_channels=20),nn.Flatten(),nn.Linear(1408, 10))def forward(self, x):y = self.net(x) return y
# 查看网络结构
X = torch.rand(size= (1, 1, 28, 28))
for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )
# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss()
# 优化算法的选择
learning_rate = 0.1 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 训练网络
epochs = 10
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能for (x, y) in test_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)print(f'测试集精准度: {100*correct/total} %')
ResNet
网络结构
残差网络(Residual Network,ResNet)荣获 2015 年的 ImageNet 图像分类竞赛冠军,其可以缓解深度神经网络中增加深度带来的“梯度消失”问题。
在反向传播计算梯度时,梯度是不断相乘的,假如训练到后期,各层的梯度均小于 1,则其相乘起来就会不断趋于 0。因此,深度学习的隐藏层并非越多越好,隐藏层越深,梯度越趋于 0,此之谓“梯度消失”。
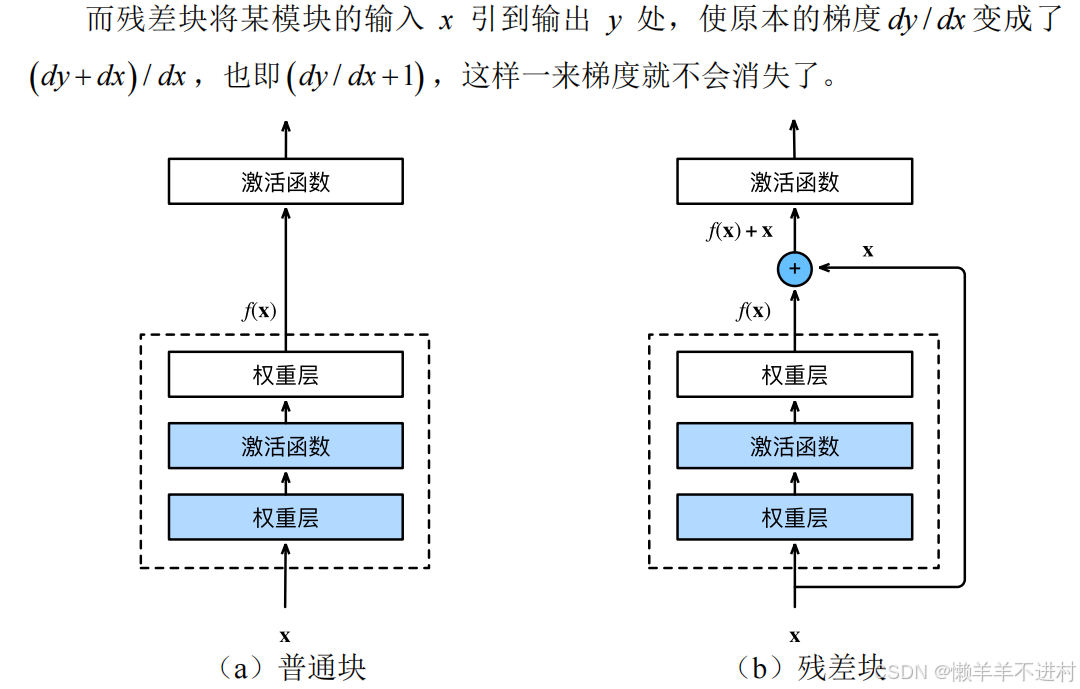
制作数据集
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
%matplotlib inline
# 展示高清图
from matplotlib_inline import backend_inline
backend_inline.set_matplotlib_formats('svg')
# 制作数据集
# 数据集转换参数
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.1307, 0.3081)
])
# 下载训练集与测试集
train_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = True,download = True,transform = transform
)
test_Data = datasets.FashionMNIST(root = 'D:/Jupyter/dataset/mnist/',train = False,download = True,transform = transform
)
# 批次加载器
train_loader = DataLoader(train_Data, shuffle=True, batch_size=128)
test_loader = DataLoader(test_Data, shuffle=False, batch_size=128)
搭建神经网络
# 残差块
class ResidualBlock(nn.Module):def __init__(self, channels):super(ResidualBlock, self).__init__()self.net = nn.Sequential(nn.Conv2d(channels, channels, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(channels, channels, kernel_size=3, padding=1),)def forward(self, x):y = self.net(x)return nn.functional.relu(x+y)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(nn.Conv2d(1, 16, kernel_size=5), nn.ReLU(),nn.MaxPool2d(2), ResidualBlock(16),nn.Conv2d(16, 32, kernel_size=5), nn.ReLU(),nn.MaxPool2d(2), ResidualBlock(32),nn.Flatten(),nn.Linear(512, 10))def forward(self, x):y = self.net(x) return y
# 查看网络结构
X = torch.rand(size= (1, 1, 28, 28))for layer in CNN().net:X = layer(X)print( layer.__class__.__name__, 'output shape: \t', X.shape )
# 创建子类的实例,并搬到 GPU 上
model = CNN().to('cuda:0')
训练网络
# 损失函数的选择
loss_fn = nn.CrossEntropyLoss()
# 优化算法的选择
learning_rate = 0.1 # 设置学习率
optimizer = torch.optim.SGD(model.parameters(),lr = learning_rate,
)
# 训练网络
epochs = 10
losses = [] # 记录损失函数变化的列表
for epoch in range(epochs):for (x, y) in train_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)loss = loss_fn(Pred, y) # 计算损失函数losses.append(loss.item()) # 记录损失函数的变化optimizer.zero_grad() # 清理上一轮滞留的梯度loss.backward() # 一次反向传播optimizer.step() # 优化内部参数
Fig = plt.figure()
plt.plot(range(len(losses)), losses)
plt.show()
测试网络
# 测试网络
correct = 0
total = 0
with torch.no_grad(): # 该局部关闭梯度计算功能for (x, y) in test_loader: # 获取小批次的 x 与 yx, y = x.to('cuda:0'), y.to('cuda:0')Pred = model(x) # 一次前向传播(小批量)_, predicted = torch.max(Pred.data, dim=1)correct += torch.sum( (predicted == y) )total += y.size(0)
print(f'测试集精准度: {100*correct/total} %')
相关文章:
(PyTorch))
Python深度学习基础——卷积神经网络(CNN)(PyTorch)
CNN原理 从DNN到CNN 卷积层与汇聚 深度神经网络DNN中,相邻层的所有神经元之间都有连接,这叫全连接;卷积神经网络 CNN 中,新增了卷积层(Convolution)与汇聚(Pooling)。DNN 的全连接…...

pytorch 反向传播
文章目录 概念计算图自动求导的两种模式 自动求导-代码标量的反向传播非标量变量的反向传播将某些计算移动到计算图之外 概念 核心:链式法则 深度学习框架通过自动计算导数(自动微分)来加快求导。 实践中,根据涉及号的模型,系统会构建一个计…...

VSCode解决中文乱码方法
目录 一、底层原因 二、解决方法原理 三、解决方式: 1.预设更改cmd临时编码法 2.安装插件法: 一、底层原因 当在VSCode中遇到中文显示乱码的问题时,这通常是由于文件编码与VSCode的默认或设置编码不匹配,或…...

pandas.DataFrame.dtypes--查看和验证 DataFrame 列的数据类型!
查看每列的数据类型,方便分析是否需要数据类型转换 property DataFrame.dtypes[source] Return the dtypes in the DataFrame. This returns a Series with the data type of each column. The result’s index is the original DataFrame’s columns. Columns with…...

高性能服务开发利器:redis+lua
Redis 与 Lua 脚本的结合,其核心价值在于 原子性操作 和 减少网络开销。 一、Redis 执行 Lua 脚本的优势 原子性 Lua 脚本在 Redis 中原子执行,避免多命令竞态条件。 减少网络开销 将多个 Redis 命令合并为一个脚本,减少客…...

开源智能体MetaGPT记忆模块解读
MetaGPT 智能体框架 1. 框架概述 MetaGPT 是一个多智能体协作框架,通过模拟软件公司组织架构与工作流程,将大语言模型(LLM)转化为具备专业分工的智能体,协同完成复杂任务。其最大特点是能够将自然语言需…...

Docker部署MySQL大小写不敏感配置与数据迁移实战20250409
Docker部署MySQL大小写不敏感配置与数据迁移实战 🧭 引言 在企业实际应用中,尤其是使用Java、Hibernate等框架开发的系统,MySQL默认的大小写敏感特性容易引发各种兼容性问题。特别是在Linux系统中部署Docker版MySQL时,默认行为可…...

【RabbitMQ】延迟队列
1.概述 延迟队列其实就是队列里的消息是希望在指定时间到了以后或之前取出和处理,简单来说,延时队列就是用来存放需要在指定时间被处理的元素的队列。 延时队列的使用场景: 1.订单在十分钟之内未支付则自动取消 2.新创建的店铺,…...

深兰科技携多款AI医疗创新成果亮相第七届世界大健康博览会
4月8日,以“AI赋能 健康生活”为主题的2025年(第七届)世界大健康博览会(以下简称健博会)在武汉隆重开幕。应参展企业武汉市三甲医院——武汉中心医院的邀请,深兰科技最新研发的新一代智慧医疗解决方案和产品在其展位上公开亮相。 本届展会吸引了来自18个…...

20周年系列|美创科技再度入围「年度高成长企业」系列榜单
近日,资深产业信息服务平台【第一新声】发布「2024年度科技行业最佳CEO及高成长企业榜」,美创科技凭借在数据安全领域的持续创新和广泛行业实践, 再度入围“年度网络安全高成长企业”、“年度高科技高成长未来独角兽企业TOP30”。 美创科技作…...

saltstack分布式部署
一、saltstack分布式 在minion数量过多时,通过部署salt代理,减轻master负载 1、在master上删除说有minion证书 2、在minion上删除旧master信息 3、安装部署salt-syndic 4、修改minion 5、在master上签署代理的证书 6、在代理上签署minion证书 7、测试...

CCRC 与 EMVCo 双认证:中国智能卡企业的全球化突围
在全球经济一体化的浪潮中,智能卡行业正经历着前所未有的变革与发展。中国智能卡企业凭借技术优势与成本竞争力,在国内市场成绩斐然。然而,要想在国际市场站稳脚跟,获取权威认证成为关键一步。CCRC 与 EMVCo 双认证,宛…...

逆向工程的多层次解析:从实现到领域的全面视角
目录 前言1. 什么是逆向工程?2. 实现级逆向:揭示代码背后的结构2.1 抽象语法树的构建2.2 符号表的恢复2.3 过程设计表示的推导 3. 结构级逆向:重建模块之间的协作关系3.1 调用图与依赖分析3.2 程序与数据结构的映射 4. 功能级逆向:…...

【Docker项目实战】使用Docker部署ToDoList任务管理工具
【Docker项目实战】使用Docker部署ToDoList任务管理工具 一、ToDoList介绍1.1 ToDoList简介1.2 ToDoList主要特点二、本次实践规划2.1 本地环境规划2.2 本次实践介绍三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本四、下载ToDoList镜像…...

基于SpinrgBoot+Vue的医院管理系统-026
一、项目技术栈 Java开发工具:JDK1.8 后端框架:SpringBoot 前端:Vue开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 二、功能介绍 (1)…...

如何进行数据安全风险评估总结
一、基于场景进行安全风险评估 一、概述 数据安全风险评估总结(一)描述了数据安全风险评估的相关理论,数据安全应该关注业务流程,以基础安全为基础,以数据生命周期及数据应用场景两个维度为入口进行数据安全风险评估。最后以《信息安全技术 信息安全风险评估规范》为参考,…...

用 npm list -g --depth=0 探索全局包的秘密 ✨
用 npm list -g --depth0 探索全局包的秘密 🚀✨ 嗨,各位开发者朋友们!👋 今天我们要聊一个超实用的小命令——npm list -g --depth0!它就像一个“全局包侦探”🕵️♂️,能帮你快速查出系统中…...

依靠视频设备轨迹回放平台EasyCVR构建视频监控,为幼教连锁园区安全护航
一、项目背景 幼教行业连锁化发展态势越发明显。在此趋势下,幼儿园管理者对于深入了解园内日常教学与生活情况的需求愈发紧迫,将这些数据作为提升管理水平、优化教育服务的重要依据。同时,安装监控系统不仅有效缓解家长对孩子在校安全与生活…...

新闻发稿软文发布投稿选择媒体时几大注意
企业在选择新闻稿发布媒体时,需要综合考虑以下几个关键因素: 1. 匹配媒体定位 企业应根据自身品牌定位和传播目标,选择与之契合的媒体平台。确保新闻稿的内容和风格与媒体的定位高度一致,从而提高稿件被采纳的可能性。 2. 衡量…...

[Scade One] Swan与Scade 6的区别 - signal 特性的移除
signal 特性移除 在 Scade One 引入的Swan中,移除了Scade 6中存在的signal 特性。比如 Scade 6 中的signal声明 sig sig_o;或者signal使用,比如 o sig_o; 在Swan中已经被移除。 不过Swan仍旧保留了对布尔流的emit操作,比如 emit a if c …...

亚马逊推出“站外代购革命“:跨境购物进入全平台整合时代
一、创新功能解析:平台边界消融的购物新范式 亚马逊最新推出的External Product Fulfillment(EPF)服务,正以技术创新重构全球电商格局。这项被称作"代购终结者"的功能具备三大核心突破: 全链路智能化 • 智能…...

Java 常用安全框架的 授权模型 对比分析,涵盖 RBAC、ABAC、ACL、基于权限/角色 等模型,结合框架实现方式、适用场景和优缺点进行详细说明
以下是 Java 常用安全框架的 授权模型 对比分析,涵盖 RBAC、ABAC、ACL、基于权限/角色 等模型,结合框架实现方式、适用场景和优缺点进行详细说明: 1. 授权模型类型与定义 模型名称定义特点RBAC(基于角色的访问控制)通…...

达梦数据库迁移问题总结
问题一、DTS工具运行乱码 开启图形化 [rootlocalhost ~]# xhost #如果命令不存在执行sudo yum install xorg-x11-server-utils xhost: unable to open display "" [rootlocalhost ~]# su - dmdba 上一次登录: 三 4月 9 19:50:44 CST 2025 pts/0 上…...

JS | 函数柯里化
函数柯里化(Currying):将一个接收多个参数函数,转换为一系列只接受一个参数的函数的过程。即 逐个接收参数。 例子: 普通函数: function add(a, b, c) {return a b c; } add(1, 2, 3); // 输出 6柯里化…...

Elasticsearch中的基本全文搜索和过滤
Elasticsearch中的基本全文搜索和过滤 知识点参考: https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-filter-tutorial.html#full-text-filter-tutorial-range-query 1. 索引设计与映射 多字段类型(Multi-Fields) ÿ…...

蓝桥杯嵌入式第十五届
一、底层 根据它的硬件配置可以看出来这套题目使用到了按键、LED、LCD、输入捕获这几个功能 (1)输入捕获功能 首先在CubeMx里面的配置 题目中说到了我们使用的是PA15和PB4(实际在板子上对应的的是R39和R40),所以我们…...

基于ueditor编辑器的功能开发之给编辑器图片增加水印功能
用户需求,双击编辑器中的图片的时候,出现弹框,用户可以选择水印缩放倍数、距离以及水印所放置的方位(当然有很多水印插件,位置大小透明度用户都能够自定义,但是用户需求如此,就自己写了…...

DDR中的DLL
在DDR4内存系统中,DLL(Delay Locked Loop,延迟锁相环)是一个非常重要的组件,用于确保数据信号(DQS)和时钟信号(CK)之间的同步。以下是DLL的作用以及DLL on和DLL off的影响…...

Python学习之jieba
Python学习之jieba jieba是优秀的中文分词第三方库,由于中文文本之间每个汉字都是连续书写的,我们需要通过特定的手段来获得其中的每个词组,这种手段叫做分词,我们可以通过jieba库来完成这个过程。jieba库的分词原理:利用一个中文词库,确定汉字之间的关联频率,汉字向概率大的组…...

快速幂fast_pow
快速幂算法讲解 快速幂算法是一种高效计算幂运算的算法,其核心思想是利用指数的二进制分解,把幂运算的时间复杂度从 O(p) 降低到 O(logp)。 原理 假设要计算 an,将 n 表示成二进制形式:n2k12k2⋯2km,那么 ana…...
)
Go并发背后的双引擎:CSP通信模型与GMP调度|Go语言进阶(4)
为什么需要理解CSP与GMP? 当我们启动一个Go程序时,可能会创建成千上万个goroutine,它们是如何被调度到有限的CPU核心上的?为什么Go能够如此轻松地处理高并发场景?为什么有时候我们的并发程序会出现奇怪的性能瓶颈&…...

42、JavaEE高级主题:WebSocket详解
WebSocket 一、WebSocket协议与实现 WebSocket是一种基于TCP协议的全双工通信协议,能够在客户端和服务器之间建立实时、双向的通信通道。通过WebSocket,客户端和服务器可以在任何时候发送数据,并立即接收到对方的响应。 1.1 WebSocket协议…...

UGUI源代码之Text—实现自定义的字间距属性
以下内容是根据Unity 2020.1.01f版本进行编写的 UGUI源代码之Text—实现自定义的字间距属性 1、目的2、参考3、代码阅读4、准备修改UGUI源代码5、实现自定义Text组件,增加字间距属性6、最终效果 1、目的 很多时候,美术在设计的时候是想要使用文本的字间…...

【AI】MCP概念
一文讲透 MCP(附 Apifox MCP Server 内测邀请) 7分钟讲清楚MCP是什么?统一Function calling规范,工作量锐减至1/6,人人手搓Manus!? | 一键链接千台服务器,几行代码接入海量外部工具…...
获取位置信息)
HarmonyOS:使用geoLocationManager (位置服务)获取位置信息
一、简介 位置服务提供GNSS定位、网络定位(蜂窝基站、WLAN、蓝牙定位技术)、地理编码、逆地理编码、国家码和地理围栏等基本功能。 使用位置服务时请打开设备“位置”开关。如果“位置”开关关闭并且代码未设置捕获异常,可能导致应用异常。 …...

深入解析原生鸿蒙中的 RN 日志系统:从入门到精通!
全文目录: 开篇语📖 目录🎯 前言:鸿蒙日志系统究竟有多重要?🛠️ 鸿蒙 RN 日志系统的基础结构📜 1. 日志的作用⚙️ 2. 日志分类 🔧 如何在鸿蒙 RN 中使用日志系统🖋️ 1…...

【前端】【Nuxt3】Nuxt3中usefetch,useAsyncData,$fetch使用与区别
一、Nuxt3 中不同数据获取方式的请求行为对比 (一)总结:请求行为一览 useFetch 和 useAsyncData 是 Nuxt 推荐的数据获取 API,自动集成 SSR 与客户端导航流程。$fetch 是更底层的请求方法,不具备自动触发、缓存等集成…...

【Linux系统】Linux基础指令
l i n u x linux linux 命令是对 L i n u x Linux Linux 系统进行管理的命令。对于 L i n u x Linux Linux 系统来说,无论是中央处理器、内存、磁盘驱动器、键盘、鼠标,还是用户等都是文件, L i n u x Linux Linux 系统管理的命令是它正常运…...

Android中Jetpack设计理念、核心组件 和 实际价值
一、Jetpack 的定义与定位(基础必答) Jetpack 是 Google 推出的 Android 开发组件集合,旨在: 加速开发:提供标准化、开箱即用的组件 消除样板代码:解决传统开发中的重复劳动问题 兼容性保障:…...
)
flutter开发音乐APP(前提准备)
1、项目的一些环境: 2、接口文档: 酷狗音乐 NodeJS 版 API 3、接口数据结构化 Instantly parse JSON in any language | quicktype UI样式借鉴参考: Coffee-Expert/Apple-Music-New-UI: Apple Music Clone on Flutter, with redesigned UI…...

网络协议学习
最近在适配ESP32的网络驱动,借此机会先学习一下网络通信协议。 以太网帧、IP包及TCP与UDP的报文格式 提问腾讯元宝提示词: TCP窗口是干什么的拥塞窗口是什么的...

示波器直流耦合与交流耦合:何时使用哪种?
直流耦合和交流耦合的基本区别应该在于它们如何处理信号的直流分量和交流分量。直流分量是指信号中的固定电压部分,而交流分量则是信号中变化的电压部分。 例如,一个5V的直流电压叠加了一个1V的正弦波交流信号,整个信号会在4V到6V之间波动。如…...

js解除禁止复制、禁止鼠标右键效果
有的网页会禁止复制,甚至禁止鼠标右键,如何解决 按F12进入检查模式,在控制台输入下面的js代码 1.解除禁止复制 document.addEventListener(copy,function(event){event.stopImmediatePropagation();},true); 2.解除禁止鼠标右键 document…...

如何把未量化的 70B 大模型加载到笔记本电脑上运行?
并行运行 70B 大模型 我们已经看到,量化已经成为在低端 GPU(比如 Colab、Kaggle 等)上加载大型语言模型(LLMs)的最常见方法了,但这会降低准确性并增加幻觉现象。 那如果你和你的朋友们把一个大型语言模型分…...

xwiki的权限-页面特殊设置>用户权限>组权限
官方文档https://www.xwiki.org/xwiki/bin/view/Documentation/AdminGuide/Access%20Rights/ 他有组权限、用户权限、页面及子页面特别设置。 页面特殊设置 > 用户权限 > 组权限 XWiki提供了设置wiki范围内权限、细粒度页面级权限的能力,以及在需要更多控制的…...

Go语言比较递归和循环执行效率
一、概念 1.递归 递归是指一个函数在其定义中直接或间接调用自身的编程方法 。简单来说,就是函数自己调用自己。递归主要用于将复杂的问题分解为较小的、相同类型的子问题,通过不断缩小问题的规模,直到遇到一个最简单、最基础的情况&#x…...

Windows 图形显示驱动开发-WDDM 2.0功能_供应和回收更改
供应和回收更改 对于 Windows 显示驱动程序模型 (WDDM) v2,有关 套餐 和 回收 的要求正在放宽。 用户模式驱动程序不再需要在内部分配上使用套餐和回收。 空闲/挂起的应用程序将使用 Microsoft DirectX 11.1 中引入的 TrimAPI 删除驱动程序内部资源。 API 级别将继…...

MongoDB 新手笔记
MongoDB 新手笔记 1. MongoDB 1.1 概述 MongoDB 是一种 文档型数据库(NoSQL),数据以类似 JSON 的 BSON 格式存储,适合处理非结构化或半结构化数据。 对比 MySQL: MySQL 是关系型数据库,数据以表格形式存…...

Pytorch查看神经网络结构和参数量
基本方法 print(model) print(type(model))# 模型参数 numEl_list [p.numel() for p in model.parameters()] total_params_mb sum(numEl_list) / 1e6print(fTotal parameters: {total_params_mb:.2f} MB) # sum(numEl_list), numEl_list print(sum(numEl_list)) print(numE…...

Pytorch Dataset问题解决:数据集读取报错DatasetGenerationError或OSError
问题描述 在huggingface上下载很大的数据集,用多个parquet文件的格式下载到本地。使用load_dataset加载的时候,进度条加载到一半会报错DatasetGenerationError: An error occurred while generating the dataset;如果加载为IterableDataset&…...