# 决策树与PCA降维在电信客户流失预测中的应用
决策树与PCA降维在电信客户流失预测中的应用
在数据分析和机器学习领域,电信客户流失预测是一个经典的案例。本文将通过Python代码实现,探讨决策树模型在电信客户流失预测中的应用,并结合PCA降维技术优化模型性能,同时对比降维前后的模型效果。
数据准备
我们从一个名为“电信客户流失数据.xlsx”的Excel文件中导入数据。这些数据包含了电信客户的各种特征以及他们是否流失的标签。通过pandas库的read_excel函数,我们可以方便地将数据加载到DataFrame中。然后,我们将数据集分为特征变量(data)和目标变量(target),其中特征变量是客户的各种属性,目标变量是客户是否流失。
import pandas as pd# 导入数据
datas = pd.read_excel("电信客户流失数据.xlsx")
# 将变量与结果划分开
data = datas.iloc[:, :-1] # 特征变量
target = datas.iloc[:, -1] # 目标变量
数据预处理
为了使数据适合模型训练,我们首先对特征变量进行标准化处理。使用StandardScaler对数据进行标准化,使每个特征的均值为0,标准差为1。这一步骤对于许多机器学习算法来说都是必要的,因为它可以消除不同特征之间量纲和数值范围的差异,提高模型的性能和稳定性。
from sklearn.preprocessing import StandardScaler# 数据标准化
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
模型训练与评估
我们选择决策树作为分类模型。决策树是一种简单而强大的分类算法,它通过递归地划分特征空间来构建树结构,从而实现对数据的分类。我们设置了决策树的最大深度为4,以防止模型过于复杂而导致过拟合。使用train_test_split函数将数据集划分为训练集和测试集,其中测试集占20%。然后,我们使用训练集对决策树模型进行训练,并在训练集和测试集上分别进行预测,生成混淆矩阵和分类报告。
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt# 划分数据集
data_train, data_test, target_train, target_test = train_test_split(data_scaled, target, test_size=0.2, random_state=42)# 定义决策树
dtr = DecisionTreeClassifier(criterion='gini', max_depth=4, random_state=42)
dtr.fit(data_train, target_train)# 训练集混淆矩阵
train_predicted = dtr.predict(data_train)
print("训练集分类报告:")
print(classification_report(target_train, train_predicted))# 测试集混淆矩阵
test_predicted = dtr.predict(data_test)
print("测试集分类报告:")
print(classification_report(target_test, test_predicted))
为了更直观地展示模型的分类效果,我们绘制了混淆矩阵的可视化图。混淆矩阵是一个表格,用于描述分类模型在测试集上的分类结果。通过混淆矩阵,我们可以清楚地看到模型对每个类别的预测情况,包括真正例、假正例、真负例和假负例的数量。
# 绘制可视化混淆矩阵
def cm_plot(y, yp):cm = confusion_matrix(y, yp)plt.matshow(cm, cmap=plt.cm.Blues)plt.colorbar()for x in range(len(cm)):for y in range(len(cm)):plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center',verticalalignment='center')plt.ylabel('True label')plt.xlabel('Predicted label')# 绘制训练集混淆矩阵
cm_plot(target_train, train_predicted)
plt.title("训练集混淆矩阵")
plt.show()# 绘制测试集混淆矩阵
cm_plot(target_test, test_predicted)
plt.title("测试集混淆矩阵")
plt.show()
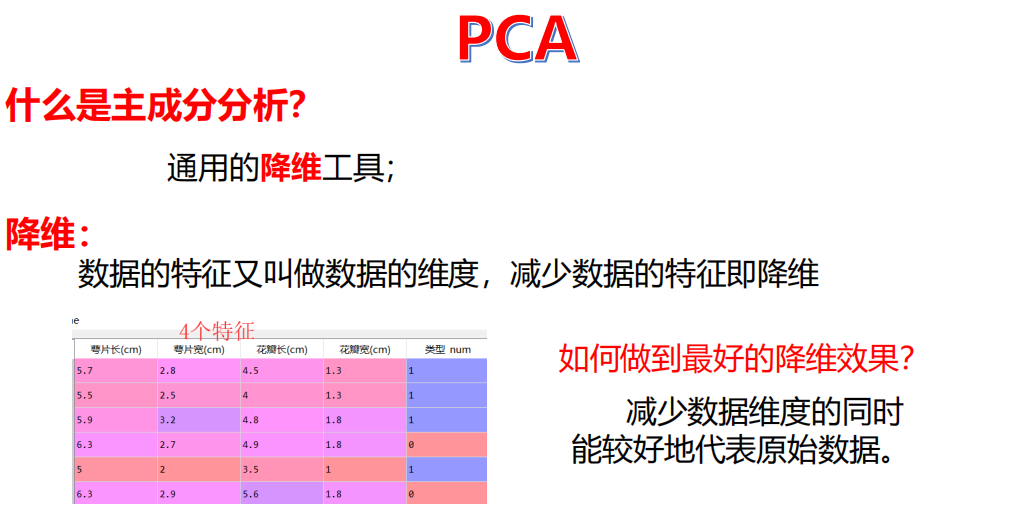
PCA降维
PCA(主成分分析)是一种常用的降维技术,它通过将原始数据投影到新的特征空间,保留数据的主要方差信息,从而减少数据的维度。在本例中,我们设置PCA保留95%的方差,这意味着降维后的数据将保留原始数据95%的信息。我们对训练集和测试集分别进行PCA降维,并使用降维后的数据重新训练决策树模型。

from sklearn.decomposition import PCA# 应用 PCA 降维
pca = PCA(n_components=0.95) # 保留95%的方差
data_train_pca = pca.fit_transform(data_train)
data_test_pca = pca.transform(data_test)# 定义决策树
dtr_pca = DecisionTreeClassifier(criterion='gini', max_depth=4, random_state=42)
dtr_pca.fit(data_train_pca, target_train)# 测试集混淆矩阵(降维后)
test_predicted_pca = dtr_pca.predict(data_test_pca)
print("降维后测试集分类报告:")
print(classification_report(target_test, test_predicted_pca))
模型性能对比
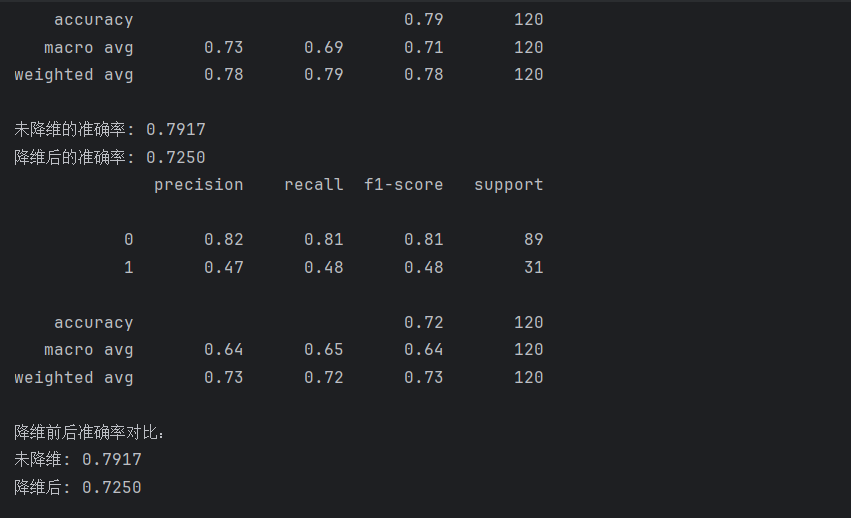
通过对比降维前后的模型性能,我们可以发现一些有趣的现象。在未降维的情况下,模型的准确率达到了一定的水平,但在降维后,模型的准确率可能会有所变化。这可能是因为PCA降维虽然减少了数据的维度,但同时也可能丢失了一些对分类有帮助的信息。然而,如果降维后的模型性能仍然可以接受,那么PCA降维就可以在一定程度上简化模型,提高模型的训练速度和效率。
# 对决策树测试集进行评分
accuracy_no_pca = dtr.score(data_test, target_test)
print(f"未降维的准确率: {accuracy_no_pca:.4f}")# 降维后的准确率
accuracy_with_pca = dtr_pca.score(data_test_pca, target_test)
print(f"降维后的准确率: {accuracy_with_pca:.4f}")# 输出结果
print(f"降维前后准确率对比:")
print(f"未降维: {accuracy_no_pca:.4f}")
print(f"降维后: {accuracy_with_pca:.4f}")
可视化决策树
为了更好地理解决策树模型的结构,我们可以将决策树可视化。通过plot_tree函数,我们可以清晰地看到决策树的每个节点和分支,了解模型是如何进行分类的。
from sklearn.tree import plot_tree# 可视化决策树(未降维)
plt.figure(figsize=(12, 8))
plot_tree(dtr, filled=True, feature_names=data.columns, class_names=["未流失", "流失"])
plt.title("未降维的决策树")
plt.show()# 可视化决策树(降维后)
plt.figure(figsize=(12, 8))
plot_tree(dtr_pca, filled=True, class_names=["未流失", "流失"])
plt.title("降维后的决策树")
plt.show()
运行结果

总结
通过本文的实验,我们可以看到决策树模型在电信客户流失预测中的应用效果,以及PCA降维对模型性能的影响。在实际应用中,我们可以根据具体的数据和需求,选择合适的模型和降维方法,以达到最佳的预测效果。同时,可视化工具如混淆矩阵的可视化图和决策树的可视化图,也可以帮助我们更好地理解和评估模型的性能。
相关文章:

# 决策树与PCA降维在电信客户流失预测中的应用
决策树与PCA降维在电信客户流失预测中的应用 在数据分析和机器学习领域,电信客户流失预测是一个经典的案例。本文将通过Python代码实现,探讨决策树模型在电信客户流失预测中的应用,并结合PCA降维技术优化模型性能,同时对比降维前…...

go语言的语法糖以及和Java的区别
1. Go 语言的语法糖及简化语法 Go 语言本身设计理念是简洁、清晰,虽然不像某些动态语言那样“花哨”,但它提供了几种便捷语法,使代码更简洁: 1.1 短变量声明(Short Variable Declaration) 语法࿱…...

WebRtc 视频流卡顿黑屏解决方案
// node webrtc视频转码服务 const url "http://10.169.xx.xx:8000" <video :ref"videoRefs${index}" :id"videoRefs4_${index}" :src"item" controls:key"item" autoplay muted click"preventDefaultClick"…...

信息安全测评中心-国产化!
项目上使用产品,必须通过国家信息安全测评/ 信息技术产品安全测评,有这个需求的话,可以到CN信息安全测评中心官网中的--测评公告一栏中,找符合要求的产品。 测评公告展示的包括硬件产品、系统、服务资质等。 网址及路径…...

MySQL学习笔记九
第十一章使用数据处理函数 11.1函数 SQL支持函数来处理数据但是函数的可移植性没有SQL强。 11.2使用函数 11.2.1文本处理函数 输入: SELECT vend_name,UPPER(vend_name) AS vend_name_upcase FROM vendors ORDER BY vend_name; 输出: 说明&#…...

DFS 蓝桥杯
最大数字 问题描述 给定一个正整数 NN 。你可以对 NN 的任意一位数字执行任意次以下 2 种操 作: 将该位数字加 1 。如果该位数字已经是 9 , 加 1 之后变成 0 。 将该位数字减 1 。如果该位数字已经是 0 , 减 1 之后变成 9 。 你现在总共可以执行 1 号操作不超过 A…...
)
动态规划dp专题-(上)
目录 dp理论知识🔥🔥 🎯一、线性DP (1)🚀斐波那契数 -入门级 (2)🚀898. 数字三角形-acwing ---入门级 (3)往期题目 ①选数异或:在…...
)
正则表达式(一)
一、模式(Patterns)和修饰符(flags) 通过正则表达式,我们可以在文本中进行搜索和替换操作,也可以和字符串方法结合使用。 正则表达式 正则表达式(可叫作 “regexp”,或 “reg”&…...

需求变更导致成本超支,如何止损
需求变更导致成本超支时,可以通过加强需求管理、严格的变更控制流程、优化资源配置、实施敏捷开发、提高风险管理意识等方法有效止损。其中,加强需求管理是止损的核心措施之一。需求管理涉及需求明确化、需求跟踪和变更的管理,有效的需求管理…...
ch5-实训代码)
《数据分析与可视化》(清华)ch5-实训代码
小费数据集预处理——求思考题_有问必答-CSDN问答 以上代码在Jupyter Notebook中可以运行,但是在python中就会出如下问题: 这个错误表明在尝试计算均值填充缺失值时,数据中包含非数值类型的列(如文本列),…...

E: The package APP needs to be reinstalled, but I can‘t find an archive for it.
要解决错误 “E: The package mytest needs to be reinstalled, but I can’t find an archive for it”,通常是因为系统中存在损坏的软件包记录或安装过程中断导致 /var/lib/dpkg/status 文件异常。以下是综合多篇搜索结果的解决方案: 解决步骤 备份关…...
详解)
若依startPage()详解
背景 startPage基于PageHelper来进行强化,在用户传入pagesize,pageNum等标准参数的时候不需要进行解析 步骤 1.通过ServletUtils工具类getRequestAttributes来获取当前线程的上下文信息 public static ServletRequestAttributes getRequestAttributes() {try {R…...

Oracle AQ
Oracle AQ(Advanced Queuing) 是 Oracle 数据库内置的一种消息队列(Message Queue)技术,用于在应用或系统之间实现异步通信、可靠的消息传递和事件驱动架构。它是 Oracle 数据库的核心功能之一,无需依赖外部…...

npm报错CERT_HAS_EXPIRED解决方案
npm报错解决方案 npm ERR! code CERT_HAS_EXPIRED npm ERR! errno CERT_HAS_EXPIRED方案1:尝试切换镜像 # 使用腾讯云镜像 npm config set registry https://mirrors.cloud.tencent.com/npm/# 或使用官方npm源(科学上网) npm config set registry http…...

pnpm 中 Next.js 模块无法找到问题解决
问题概述 项目在使用 pnpm 管理依赖时,出现了 “Cannot find module ‘next/link’ or its corresponding type declarations” 的错误。这是因为 pnpm 的软链接机制在某些情况下可能导致模块路径解析问题。 问题诊断 通过命令 pnpm list next 确认项目已安装 Next.js 15.2.…...

急速实现Anaconda/Miniforge虚拟环境的克隆和迁移
目录 参考资料 点击Anaconda Prompt (anaconda_base) 查看现有环境 开始克隆,以克隆pandas_env为例,新的环境名字为image (base) C:\Users\hello>conda create -n image --clone pandas_env查看克隆结果,image环境赫然在列。 然后粘贴…...
——图像的掩膜)
OpenCv高阶(二)——图像的掩膜
目录 掩膜 bitwise_and原理 掩膜的实现 1、基于像素操作 2、使用形态学操作 3、基于阈值处理 案例 1、读取原图并绘制掩膜 2、掩膜的实现 3、绘制掩膜的直方图 应用 掩膜 OpenCV 中图像掩膜(Mask)实现的原理是通过一个与原始图像大小相同的二…...
--最小生成树)
数据结构和算法(十二)--最小生成树
一、最小生成树 定义:图的生成树是它的一颗含有其所有顶点的无环连通子图,一副加权无向图的最小生成树它的一颗权值(树中所有边的权重之和)最小的生成树。 约定:只考虑连通图。最小生成树的定义说明它只能存在于连通图…...

开源酷炫的Linux监控工具:sampler
sampler是一个开源的监控工具,来自GitHub用户sqshq(Alexander Lukyanchikov)的匠心之作。 简单来说,sampler能干这些事儿: 实时监控:CPU、内存、磁盘、网络,甚至应用程序的状态,它…...

InternVideo2.5:Empowering Video MLLMs with Long and Rich Context Modeling
一、TL;DR InternVideo2.5通过LRC建模来提升MLLM的性能。层次化token压缩和任务偏好优化(mask时空 head)整合到一个框架中,并通过自适应层次化token压缩来开发紧凑的时空表征MVBench/Perception Test/EgoSchema/MLVU数据benchmar…...

OSPF基础与特性
一.OSPF 的技术背景 OSPF出现是因为RIP协议无法满足大型网络的配置 RIP协议中存在的问题 RIP中存在最大跳数为15的限制,不能适应大规模组网 RIP周期性发送全部路由信息,占用大量的带宽资源 路由收敛速度慢 以跳数作为度量衡,选路可能会不优 存在路由环路的可能性 每隔30秒更新…...

[Linux]从零开始的ARM Linux交叉编译与.so文件链接教程
一、前言 最近在项目需要将C版本的opencv集成到原本的代码中从而进行一些简单的图像处理。但是在这其中遇到了一些问题,首先就是原本的opencv我们需要在x86的架构上进行编译然后将其集成到我们的项目中,这里我们到底应该将opencv编译为x86架构的还是编译…...

golang 中 make 和 new 的区别?
在Go语言中,make 和 new 都是用于内存分配的关键字,但它们在使用场景、返回值和初始化方式等方面存在一些区别,以下是具体分析: 使用场景 make 只能用于创建 map、slice 和 channel 这三种引用类型,用于初始化这些类型…...

碧螺春是绿茶还是红茶
碧螺春是绿茶,不是红茶。 碧螺春的特点: 类别: 碧螺春属于中国六大茶类中的绿茶类。产地: 它产自中国江苏省苏州市太湖的东山和西山(现称金庭镇),是中国十大名茶之一。外形: 碧螺春茶叶外形卷曲如螺,色泽…...

Linux平台搭建MQTT测试环境
Paho MQTT Paho MQTT 是 Eclipse 基金会下的一个开源项目,旨在为多种编程语言提供 MQTT 协议的客户端实现。MQTT(Message Queuing Telemetry Transport)是一种轻量级的发布/订阅(Pub/Sub)消息传输协议ÿ…...
)
【AI学习】AI Agent(人工智能体)
1,AI agent 1)定义 是一种能够感知环境、基于所感知到的信息进行推理和决策,并通过执行相应动作来影响环境、进而实现特定目标的智能实体。 它整合了多种人工智能技术,具备自主学习、自主行动以及与外界交互的能力,旨…...
安装与注册完整教程 - Windows/macOS双平台指南)
克魔助手(Kemob)安装与注册完整教程 - Windows/macOS双平台指南
iOS设备管理工具克魔助手便携版使用全指南 前言:为什么需要专业的iOS管理工具 在iOS开发和设备管理过程中,开发者经常需要突破系统限制,实现更深层次的控制和调试。本文将详细介绍一款实用的便携式工具的使用方法,帮助开发者快速…...

了解GPIO对应的主要功能
GPIO GPIO是通用输入输出端口的简称,芯片上的GPIO引脚与外部设备连接实现通讯、控制以及数据采集等功能,最基本的输出功能是通过控制引脚输出高低电平继而实现开关控制,比如引脚接入LED灯可控制LED灯的亮灭,接入继电器或三极管可…...

Dubbo 注册中心与服务发现
注册中心与服务发现 注册中心概述 注册中心是dubbo服务治理的核心组件,Dubbo依赖注册中心的协调实现服务发现,自动化的服务发现是微服务实现动态扩容、负载均衡、流量治理的基础。 Dubbo的服务发现机制经历了Dubbo2时代的接口级服务发现、Dubbo3时代的…...

一文详解LibTorch环境搭建:Ubuntu20.4配置LibTorch CUDA与cuDNN开发环境
随着深度学习技术的迅猛发展,越来越多的应用程序开始集成深度学习模型以提供智能化服务。为了满足这一需求,开发者们不仅依赖于Python等高级编程语言提供的便捷框架,也开始探索如何将这些模型与C应用程序相结合,以便在性能关键型应…...

micro ubuntu 安装教程
micro ubuntu 安装教程 官网地址 : https://micro-editor.github.io 以下是在 Ubuntu 系统中安装 micro 编辑器 的详细教程: 方法 1:通过 apt 直接安装(推荐) 适用于 Ubuntu 20.04 及以上版本(官方仓库已收录…...

观成科技:利用DoH加密信道的C2流量分析
概述 DoH(DNS over HTTPS)是一种通过HTTPS协议加密传输DNS查询的信道,将DNS请求封装在HTTP/2或HTTP/3中,DoH没有标准端口,部分服务沿用TLS的443端口。传统DNS明文传输易被拦截或篡改,而DoH通过加密提升了隐…...

行星际空间的磁流体动力激波:理论综述
Magnetohydrodynamic Shocks in the Interplanetary Space: a Theoretical Review ( Part 2 ) Magnetohydrodynamic Shocks in the Interplanetary Space: a Theoretical Review | Brazilian Journal of Physics Magnetohydrodynamic Shocks 1. The Rankine-Hu…...

Java垃圾回收的隐性杀手:过早晋升的识别与优化实战
目录 一、现象与症状 二、过早晋升的成因 (一)Young区(Eden区)配置过小 (二)分配速率过高 (三)晋升年龄阈值(MaxTenuringThreshold)配置不当 三、动态晋…...

2noise团队开源ChatTTS,支持多语言、流式合成、语音的情感、停顿和语调控制
简介 ChatTTS 是一个开源的文本转语音(Text-to-Speech, TTS)项目,由 2noise 团队开发,专门为对话场景设计。它在 GitHub 上广受欢迎,因其自然流畅的语音合成能力和多功能性而备受关注。 项目背景 目标:设计…...

企业级防火墙与NAT网关配置
实训背景 某公司需部署一台Linux网关服务器,要求实现以下功能: 基础防火墙:仅允许SSH(22)、HTTP(80)、HTTPS(443)入站,拒绝其他所有流量。共享上网…...

AI数据分析的正道是AI+BI,而不是ChatBI
一、AI大模型在数据分析中的应用现状与局限 当前用户直接上传PDF、Excel等原始数据至AI大模型进行自动分析的趋势显著,但其技术成熟度与落地效果仍需审慎评估。 1.主流AI大模型的数据分析能力对比 GPT-4/Claude 3系列:在通用数据分析任务中表现突出&a…...

C++设计模式优化实战:提升项目性能与效率
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle…...

G1学习打卡
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 import argparse import os import numpy as np import torchvision.transforms as transforms from torchvision.utils import save_image from torch.utils.…...

8.2 对话框2
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 8.2.3 FolderBrowserDialog(文件夹对话框) 组件 FolderBrowserDialog组件,用于选择文件夹 Folder…...
:操作与实现详解)
Java中的列表(List):操作与实现详解
引言 列表(List)是Java集合框架中最基础且使用最频繁的线性数据结构。它允许有序存储元素,支持重复值和快速访问。本文将深入探讨Java列表的核心操作方法,并剖析两种经典实现类(ArrayList和LinkedList)的底…...

在kotlin的安卓项目中使用dagger
在 Kotlin 的 Android 项目中使用 Dagger(特别是 Dagger Hilt,官方推荐的简化版)进行依赖注入(DI)可以大幅提升代码的可测试性和模块化程度。 1. 配置 Dagger Hilt 1.1 添加依赖 在 bu…...
)
MongoDB常见面试题总结(上)
MongoDB 基础 MongoDB 是什么? MongoDB 是一个基于 分布式文件存储 的开源 NoSQL 数据库系统,由 C 编写的。MongoDB 提供了 面向文档 的存储方式,操作起来比较简单和容易,支持“无模式”的数据建模,可以存储比较复杂…...

leetcode6.Z字形变换
题目说是z字形变化,但其实模拟更像n字形变化,找到字符下标规律就逐个拼接就能得到答案 class Solution {public String convert(String s, int numRows) {if(numRows1)return s;StringBuilder stringBuilder new StringBuilder();for (int i 0; i <…...

VSCode中选择Anaconda的Python环境
1、安装Anaconda 2、安装VSCode 一、创建创建新的 Conda 环境 conda create --name myenv python3.8 conda activate myenv 二、在 VSCode 中配置 Conda 环境 1、打开 VSCode,安装 Python 插件。 2、按 CtrlShiftP 打开命令面板,输入并选择 Pytho…...

【基于规则】基于距离的相似性度量
基于点:设时两条序曲线分别为X,Y,在曲线上选取点Xx和Yy,计算点之间的距离,用来度量两条曲线的相似性。这类算法的精确度取决于选点的规则,以及距离的计算方式 欧几里得距离:不允许时间偏移,直接计算两个时序数据点之间的距离,适用于长度相同的序列 dtw:优化了选点的方…...
)
Python 序列构成的数组(当列表不是首选时)
当列表不是首选时 虽然列表既灵活又简单,但面对各类需求时,我们可能会有更好的选 择。比如,要存放 1000 万个浮点数的话,数组(array)的效率要高 得多,因为数组在背后存的并不是 float 对象&…...
)
LeetCode零钱兑换(动态规划)
题目描述 给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认为每种硬币的数量是无…...

vscode+wsl 运行编译 c++
linux 的 windows 子系统(wsl)是 windows 的一项功能,可以安装 Linux 的发行版,例如(Ubuntu,Kali,Arch Linux)等,从而可以直接在 windows 下使用 Linux 应用程序…...

C++学习之libevent ②
目录 1.连接服务器函数bufferevent_socket_connect() 2.bufferevent缓冲区的读写函数bufferevent_write() bufferevent_read() 3.给bufferevent设置回调函数bufferevent_setcb() 4.bufferevent回调函数的函数原型 5.基于bufferevent的套接字客户端处…...