26考研 | 王道 | 数据结构 | 第五章 树
第五章 树
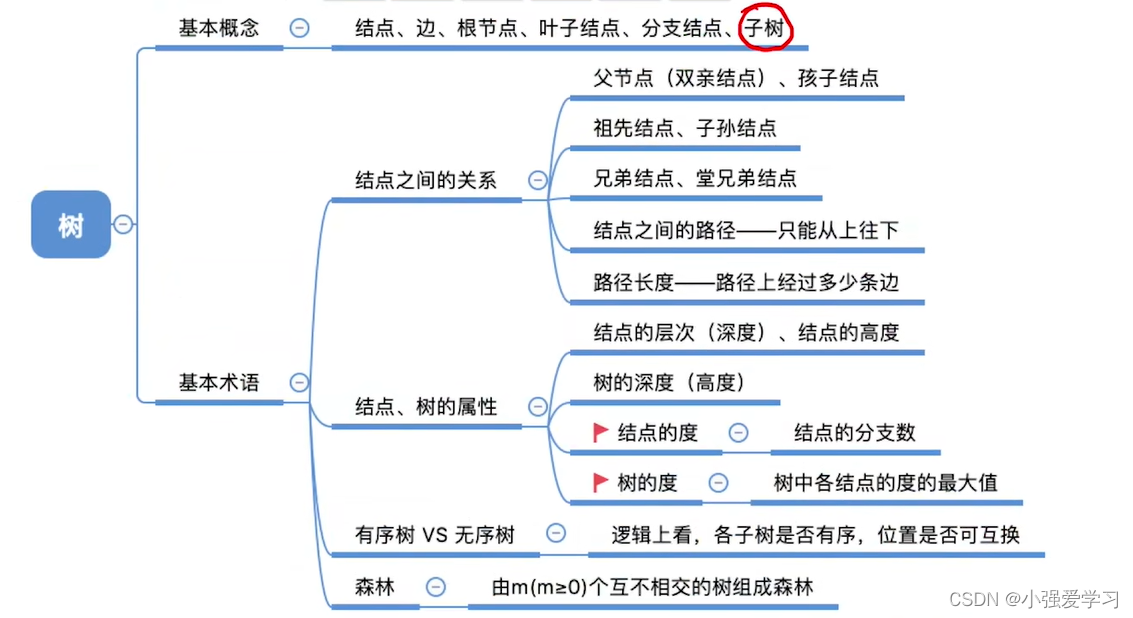
5.1. 树的概念
5.1.1. 树的基本定义
树:n(n>=0)个节点的有限集合,是一种逻辑结构,当n=0时为空树,且非空树满足:
- 有且仅有一个特定的称为根的节点
- 当n>1时,其余结点可分为m (m >0) 个互不相交的有限集合
,其中每个集合本身又是一棵树,并且称为根结点的子树
互不相交就是仅有一个前驱
树是一种递归的数据结构
非空树特点:
- 有且仅有一个根节点
- 没有后继的结点称为“叶子结点”(或终端节点)
- 有后继的结点称为“分支结点” (或非终端结点)
- 除了根节点外,任何一个结点都有且仅有一个前驱
- 每个结点可以有0个或多个后继
基本术语
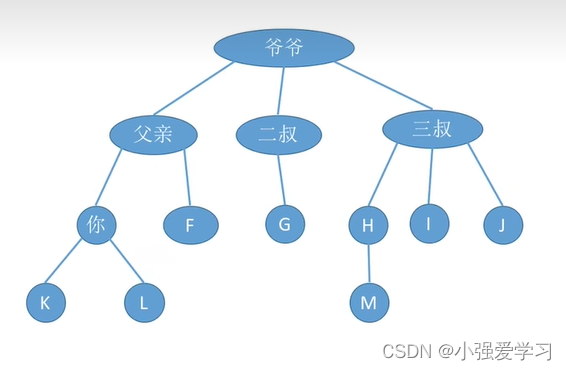
- 祖先结点:从自己出发走到根结点的最短路这条路径上的所有节点都是祖先节点
- 子孙结点:自己的之下都是子孙节点
- 双亲结点 (父节点) :和自己相连的上一个就是父节点
- 孩子结点:和自己相连的下面一个
- 兄弟结点:我自己同一个父节点的
- 堂兄弟结点:同一层的节点
路径:两个结点的间的路径只能从上往下
路径长度:从一个结点到另一个结点所经过了几条边
树的路径长度是指树根到每个节点的路径长的总和
属性:
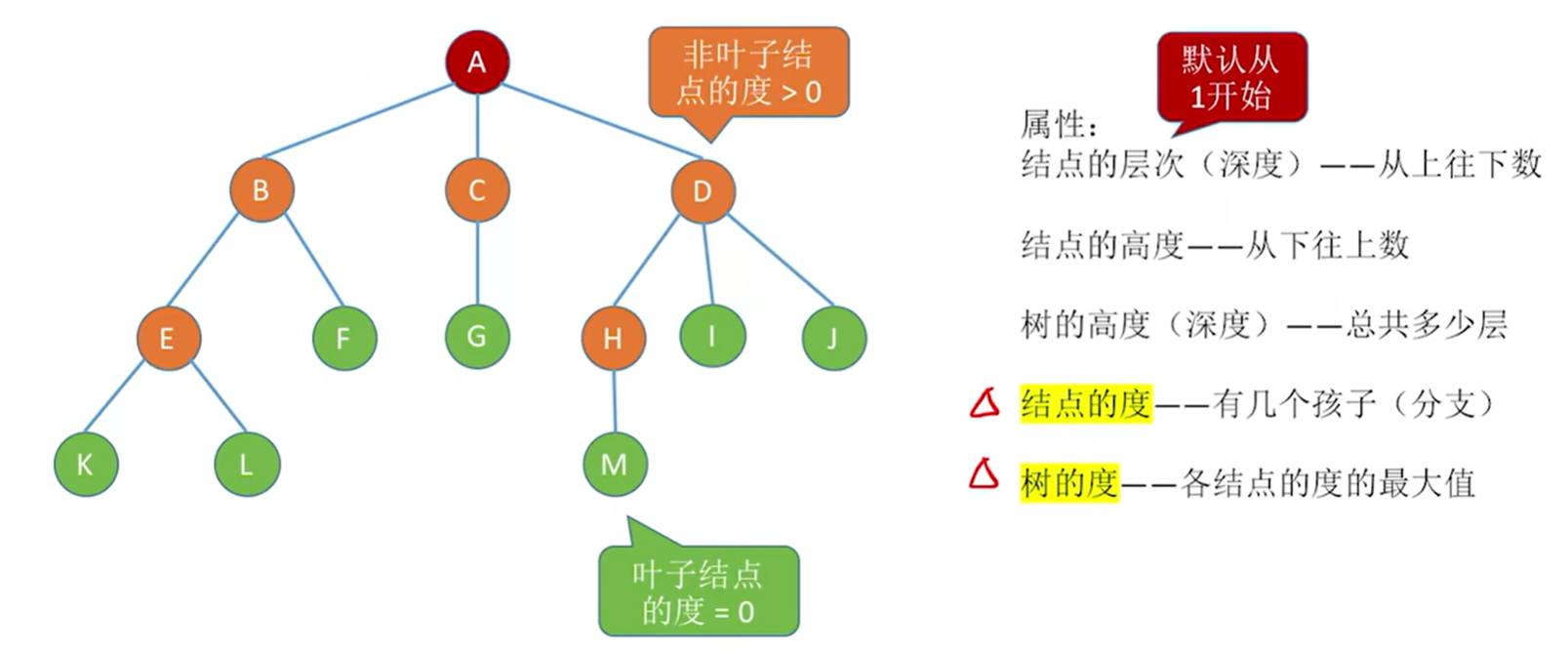
叶子结点的度为0
节点的深度一般是从1开始的,但是有的教材会从0开始,都一样,该怎么算就怎么算就行
有序树和无序树
- 有序树–逻辑上看,树中结点的各子树从左至右是有次序的,不能互换
- 无序树–逻辑上看,树中结点的各子树从左至右是无次序的,可以互换
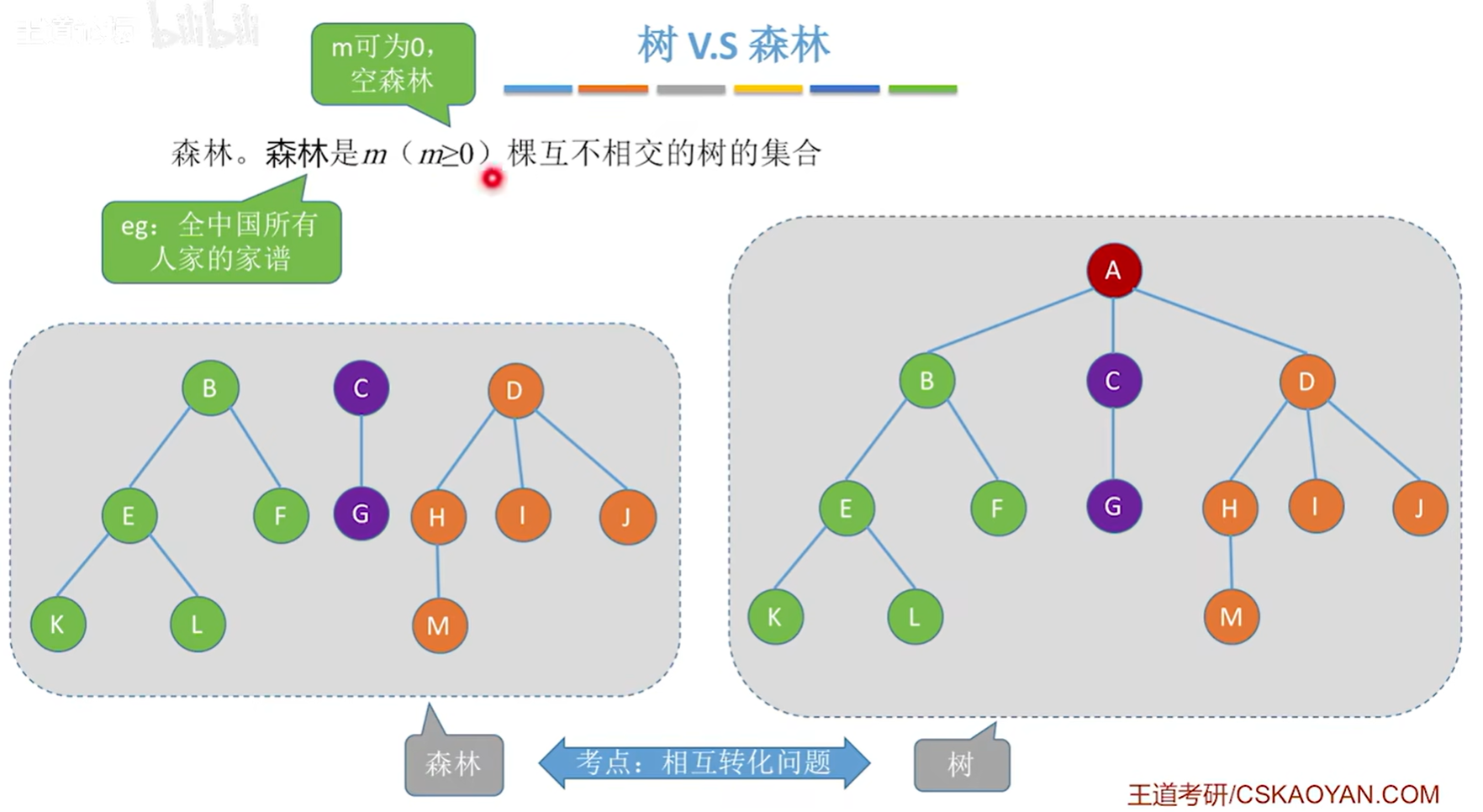
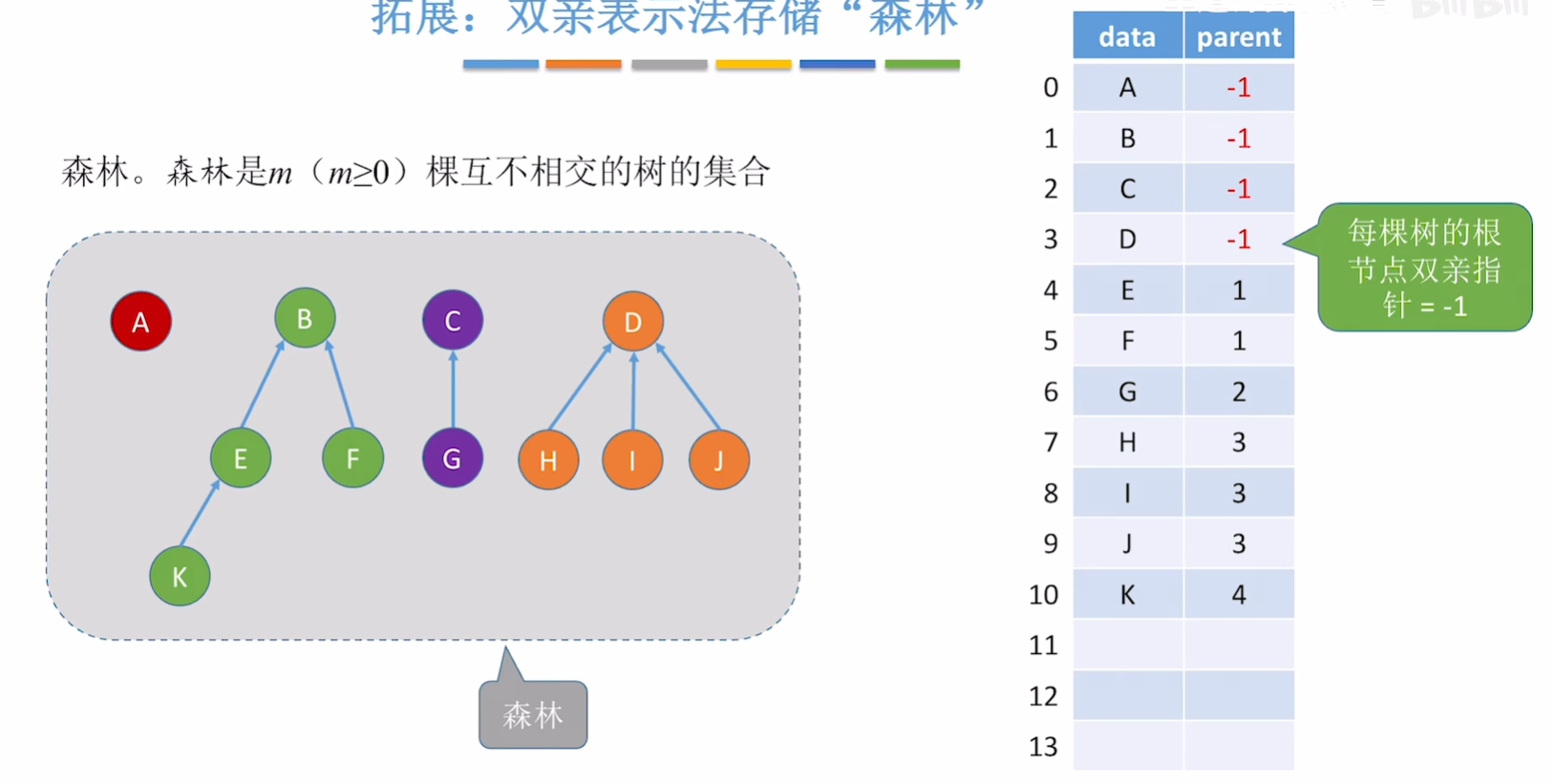
森林是m(>=0)棵互不相交的树的集合。
5.1.2. 树的常考性质
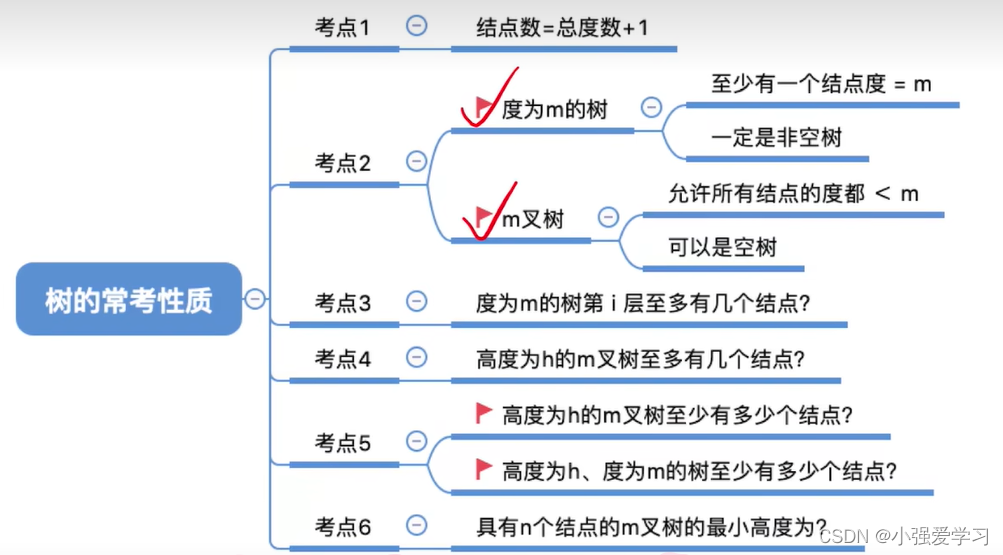
-
常见考点1: 树中的结点数=总度数+1
- 结点的度:节点有几个孩子
-
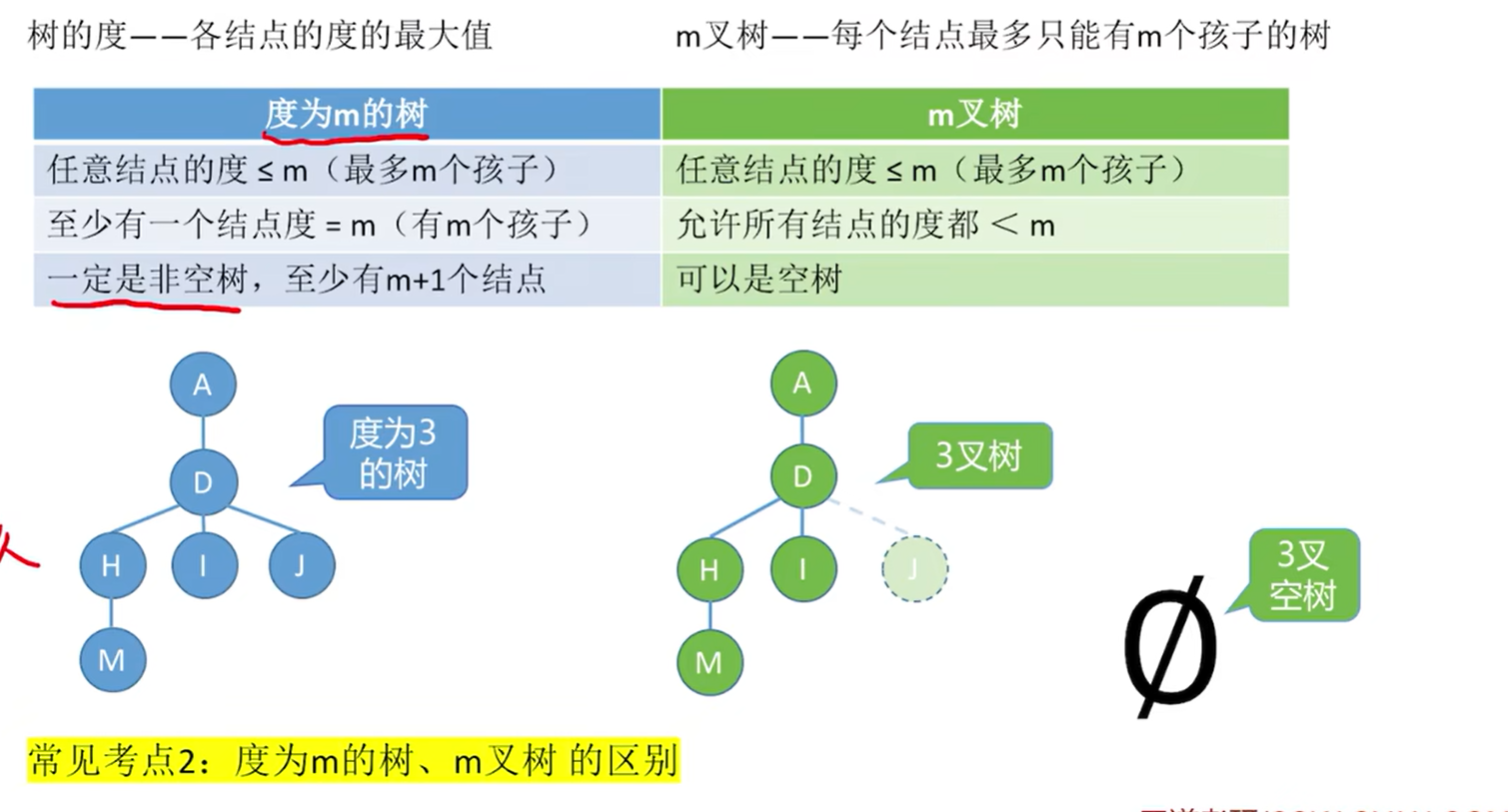
常见考点2:
度为m的树、m叉树的区别:
树的度–各结点的度的最大值;m叉树–每个结点最多只能有m个孩子的树
-
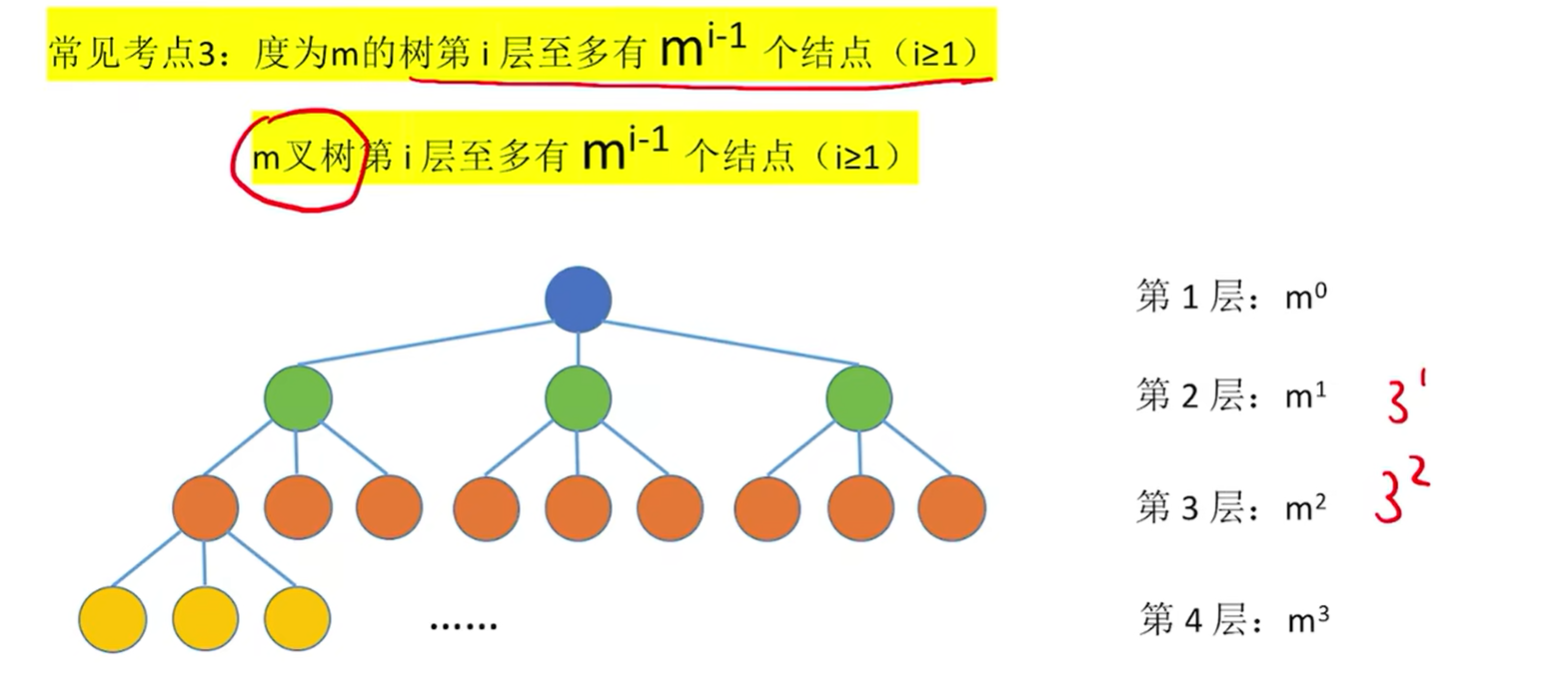
常见考点3: 度为m的树第 i 层至多有
个结点
-
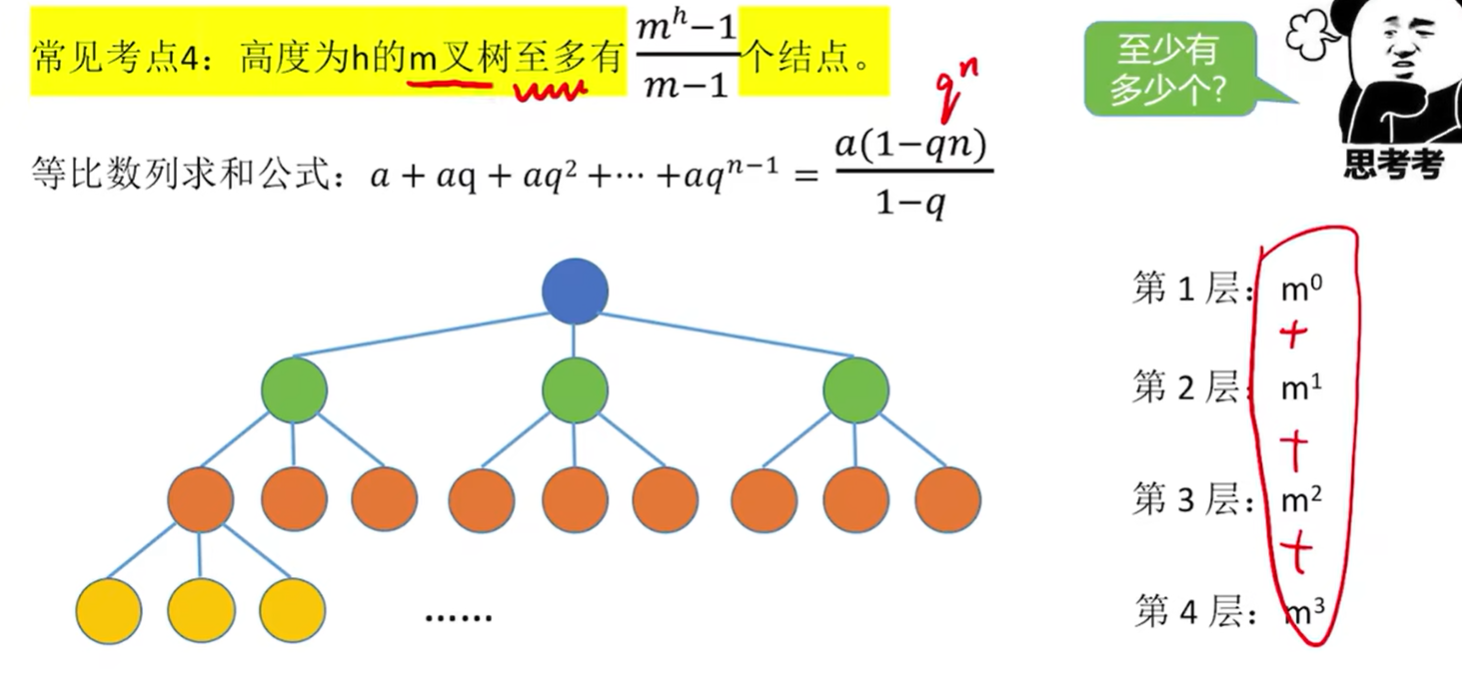
常见考点4: 高度为h的m叉树至多有
个结点。
-
图中是q的n次方并非q*n
-
-
-
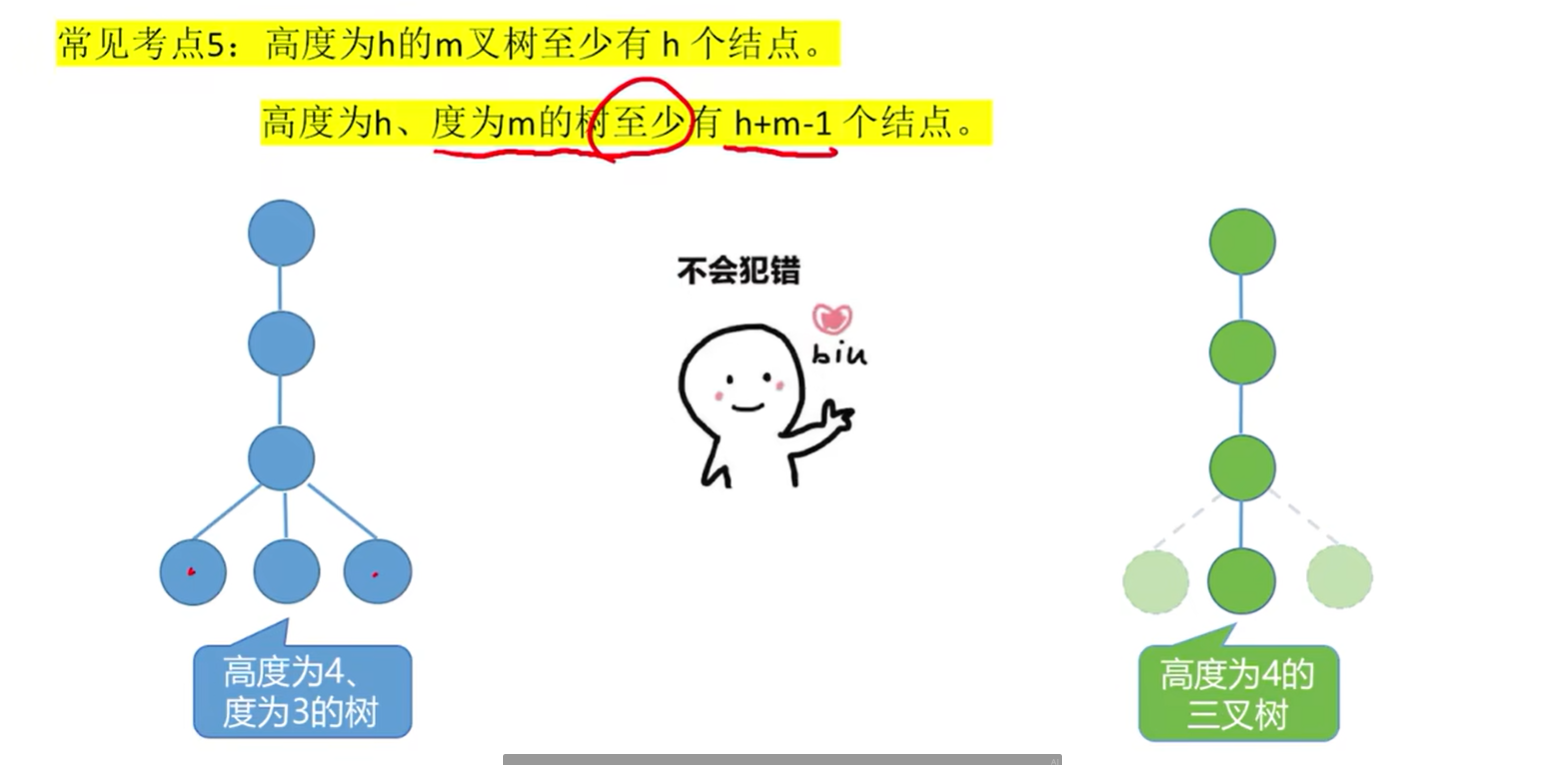
常见考点5:
高度为h的m叉树至少有h个结点;高度为h、度为m的树至少有h+m-1个结点。
-
常见考点6: 具有n个结点的m叉树的最小高度为
-
第二行是m的h次方不是m*h
-

-
5.2. 二叉树
5.2.1. 二叉树的定义
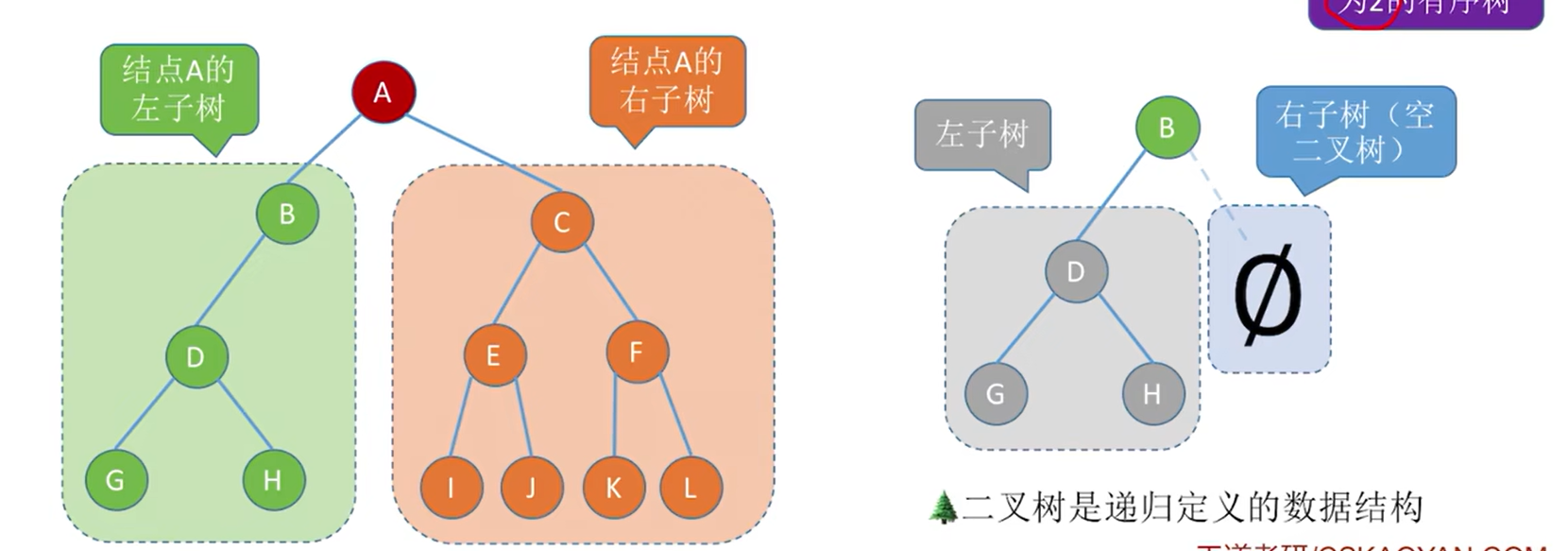
二叉树是n (n>=0)个结点的有限集合:
- 或者为空二叉树,即n =0。
- 或者由一个根结点和两个互不相交的被称为根的左子树和右子树组成。
- 左子树和右子树又分别是一棵二叉树。
特点:
-
每个结点至多只有两棵子树
-
左右子树不能颠倒 (二叉树是有序树)
-
二叉树可以是空集合,根可以有空的左子树和空的右子树
5.2.2. 特殊二叉树
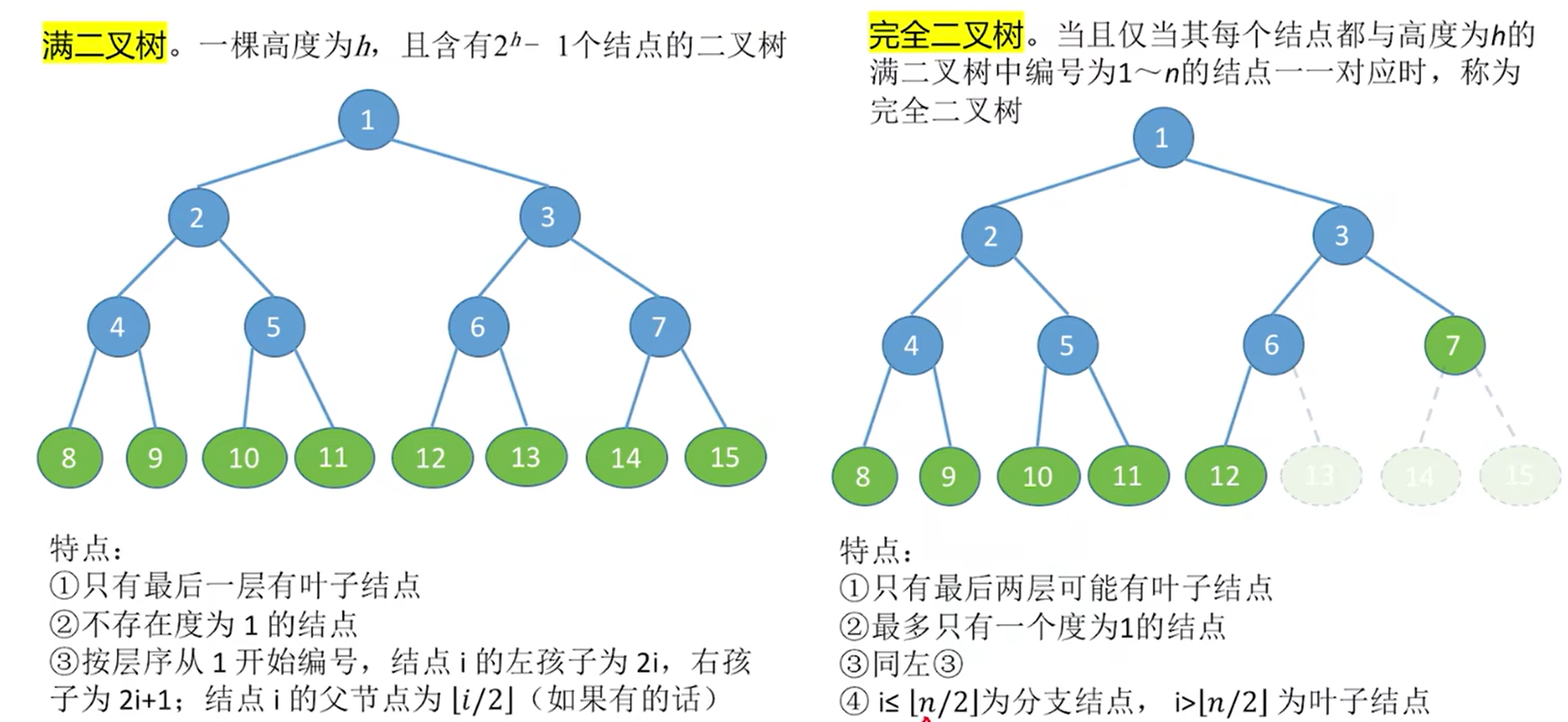
完全二叉树如果有一个节点只有一个孩子,那这个孩子只可能是左孩子不可能是右孩子
二叉排序树:
一棵二叉树或者是空二叉树,或者是具有如下性质的二叉树:
- 左子树上所有结点的关键字均小于根结点的关键字
- 右子树上所有结点的关键字均大于根结点的关键字
- 左子树和右子树又各是一棵二叉排序树

查找元素起来很方便,就直接是二分查找
平衡二叉树:树上任一结点的左子树和右子树的深度之差不超过1。
左边是平衡的,右边是不平衡的
这个是希望树往宽的生长而不是往深的生长
平衡二叉搜索树能有更高的搜索效率
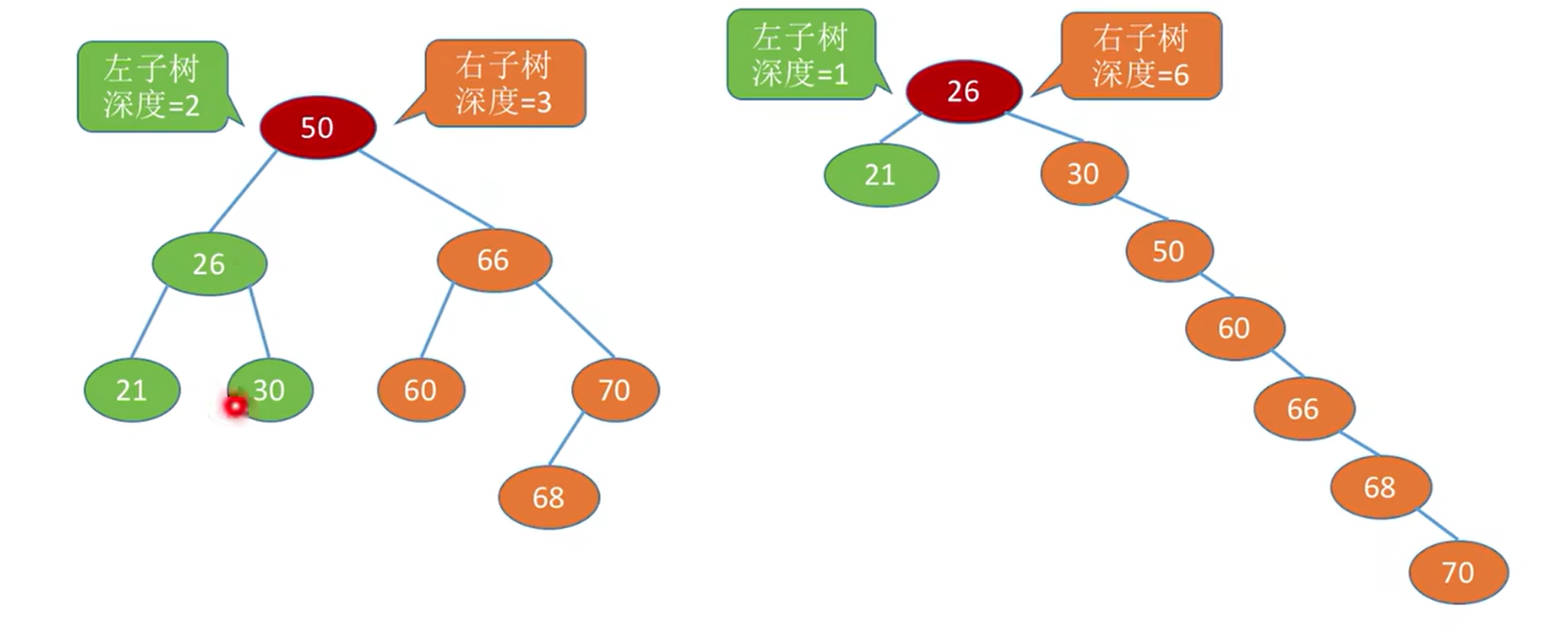
5.2.3. 二叉树的性质
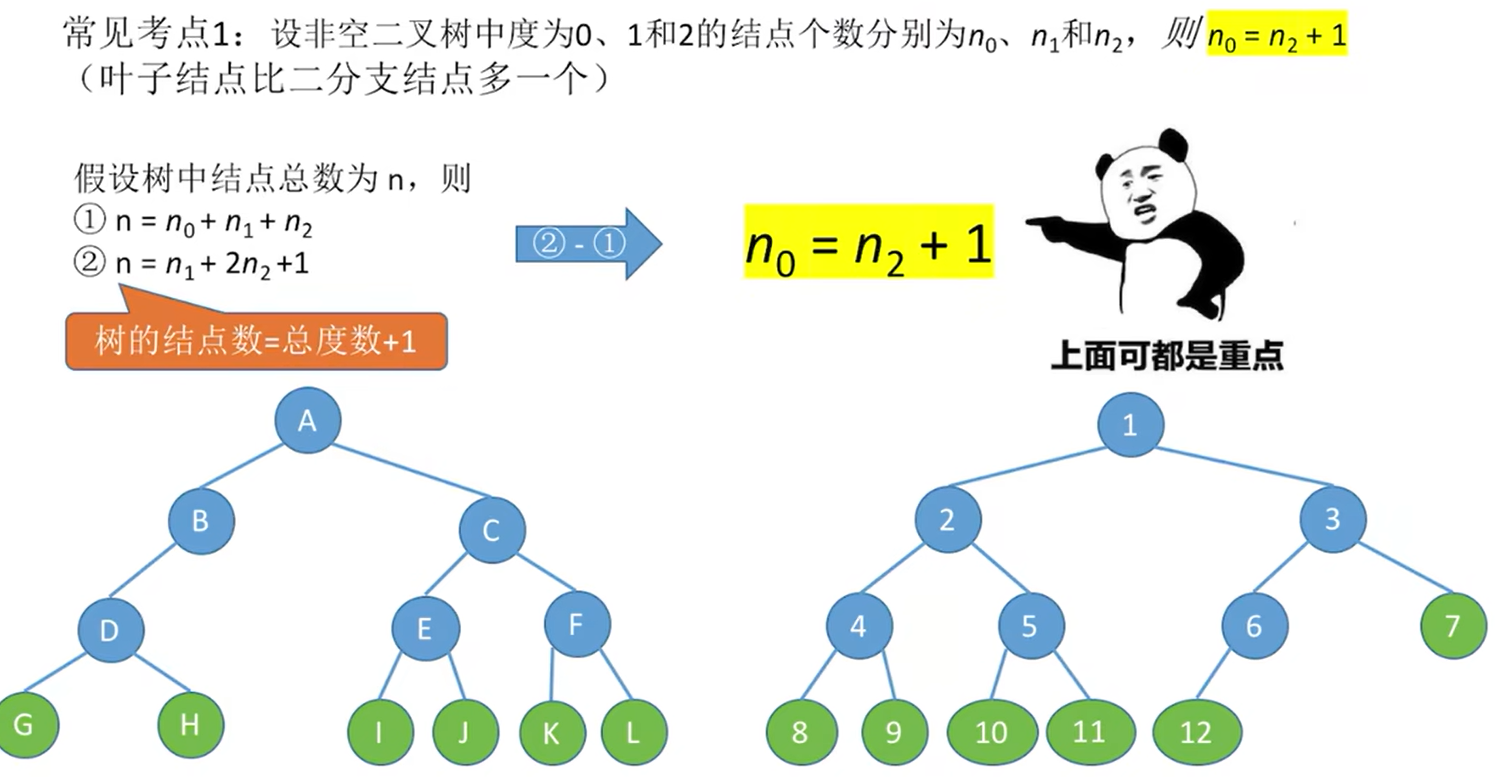
**常见考点1:**设非空二叉树中度为0、1和2的结点个数分别为、
,和
,则
(叶子结点比两个分支结点多一个)
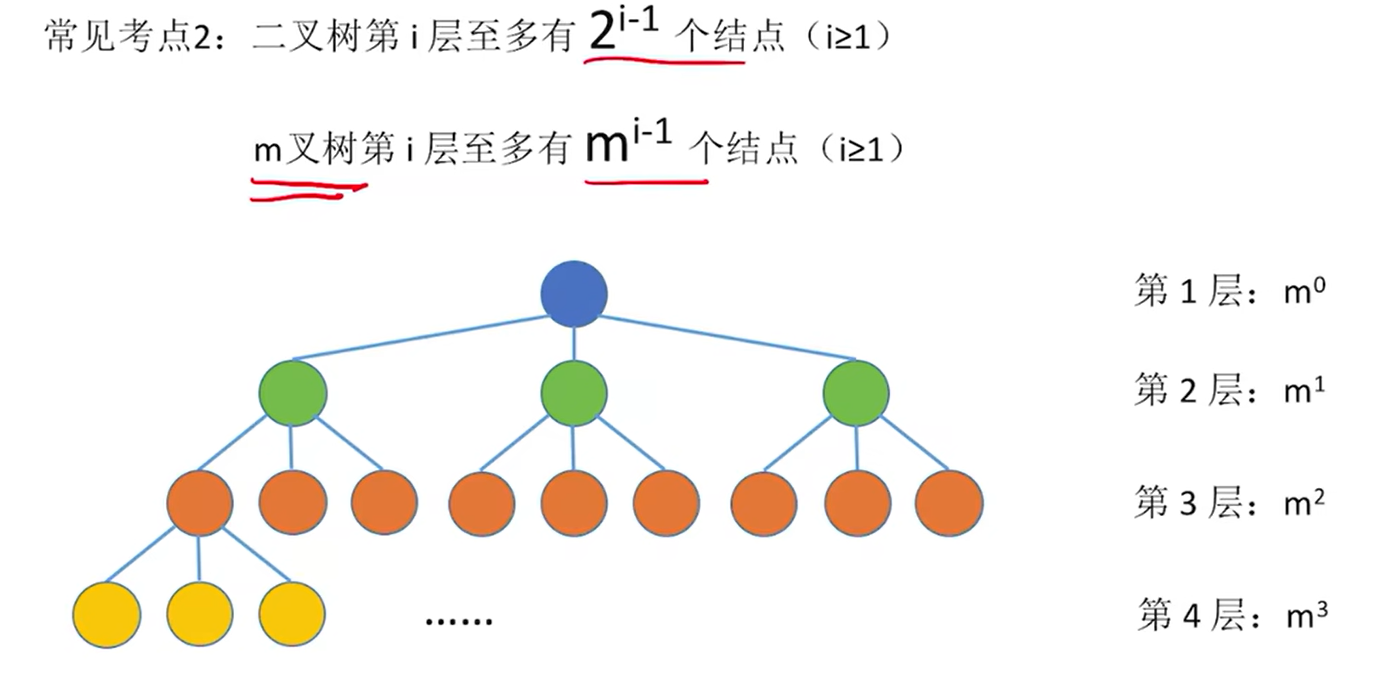
**常见考点2:**二叉树第层至多有
个结点 (
>=1);m叉树第
层至多有
个结点 (
>=1)
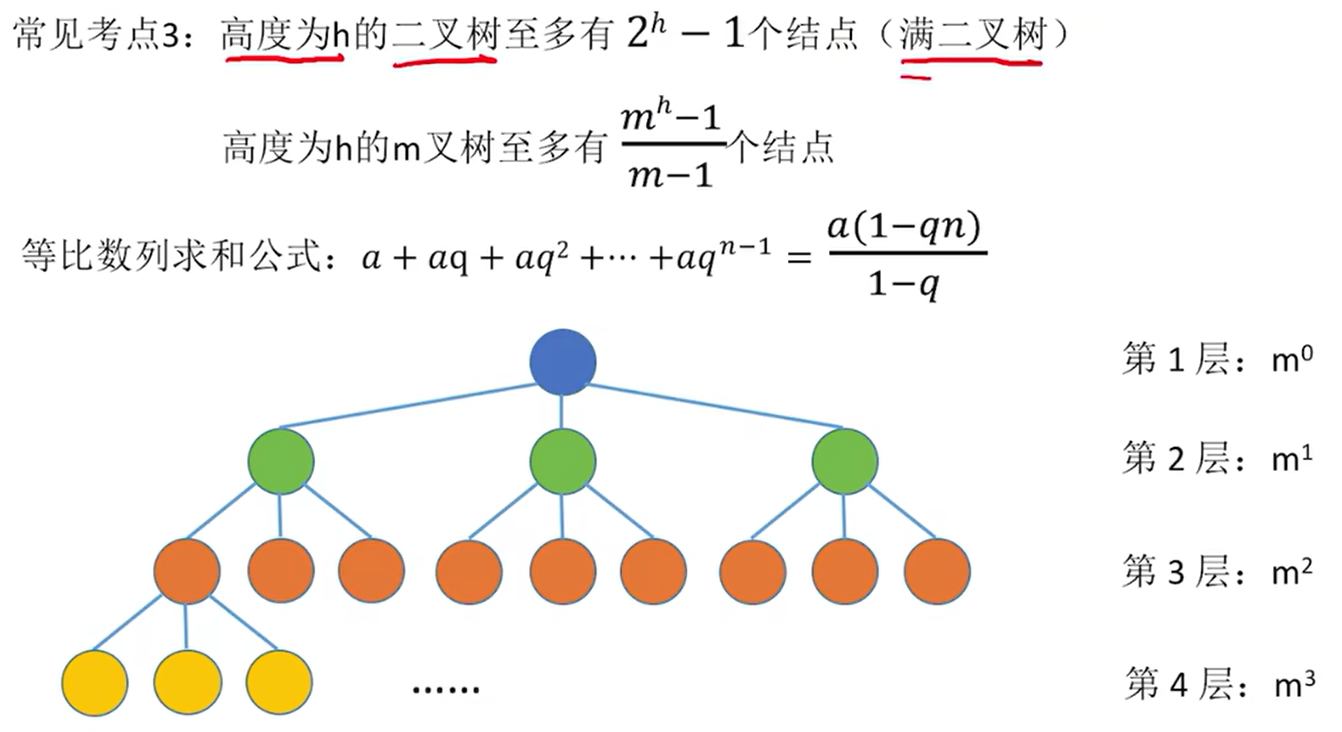
**常见考点3:**高度为h的二叉树至多有个结点(满二叉树);高度为h的m叉树至多
结点,把m=2带入即可
下面是完全二叉树的常考性质
常见考点1:
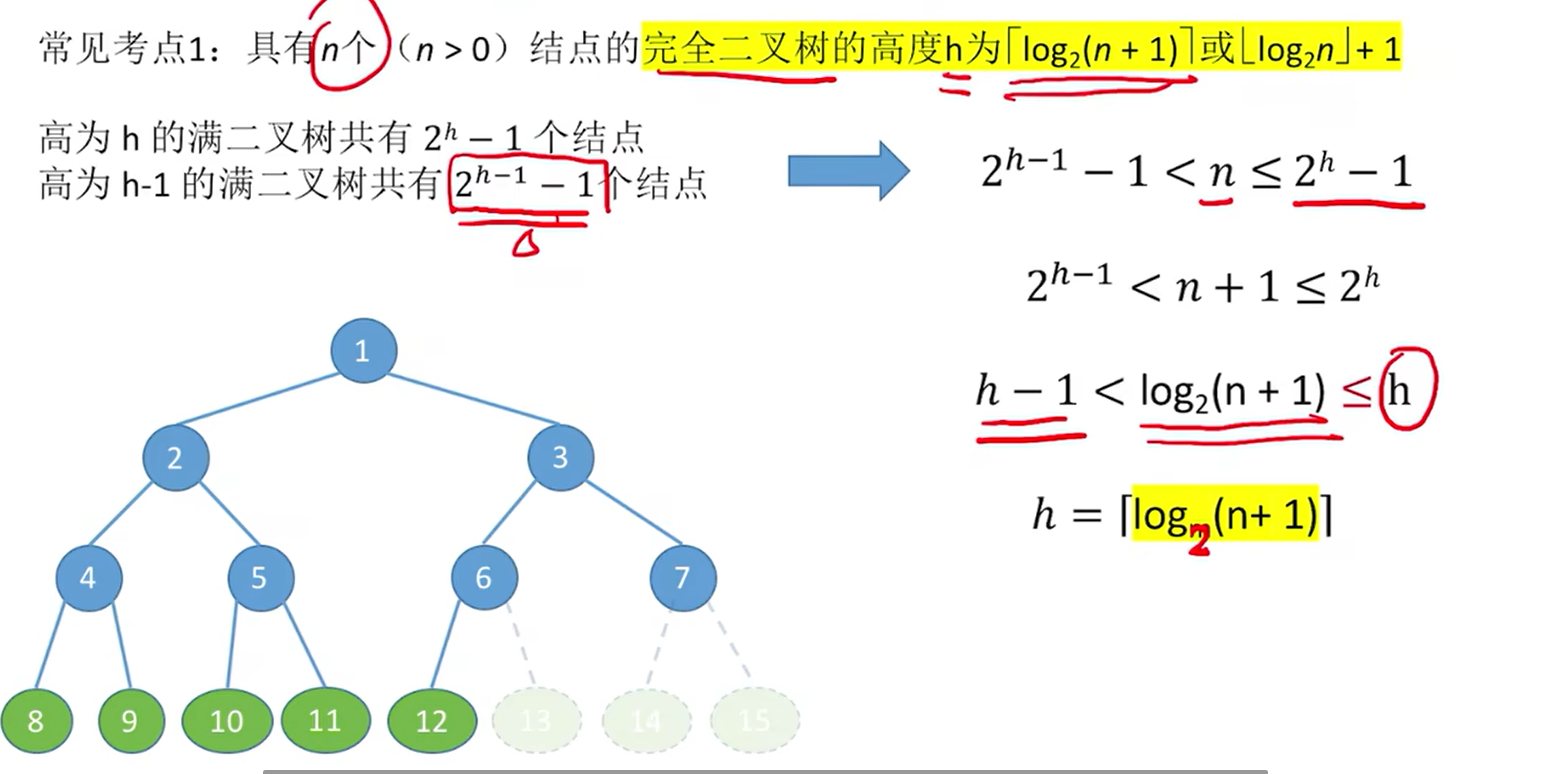
图中是第一个式子的推导过程
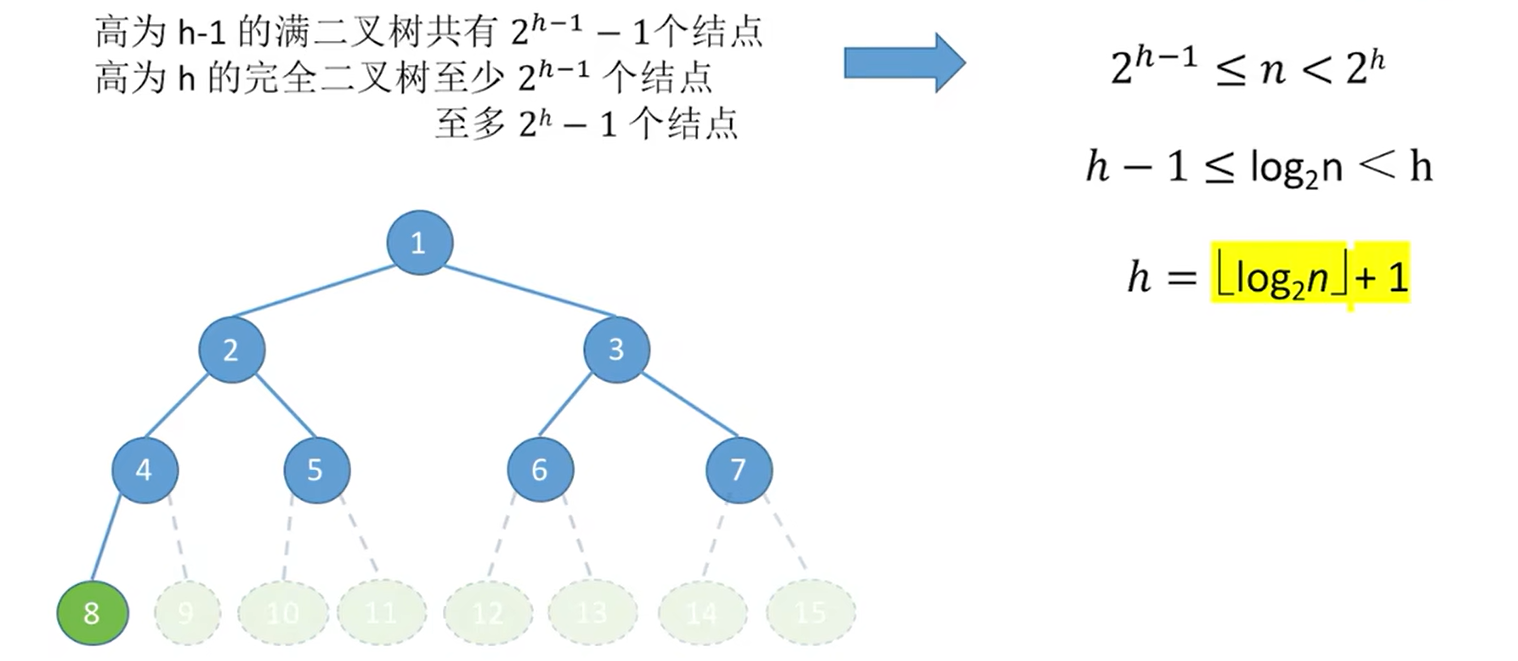
这是第二个式子的推导过程
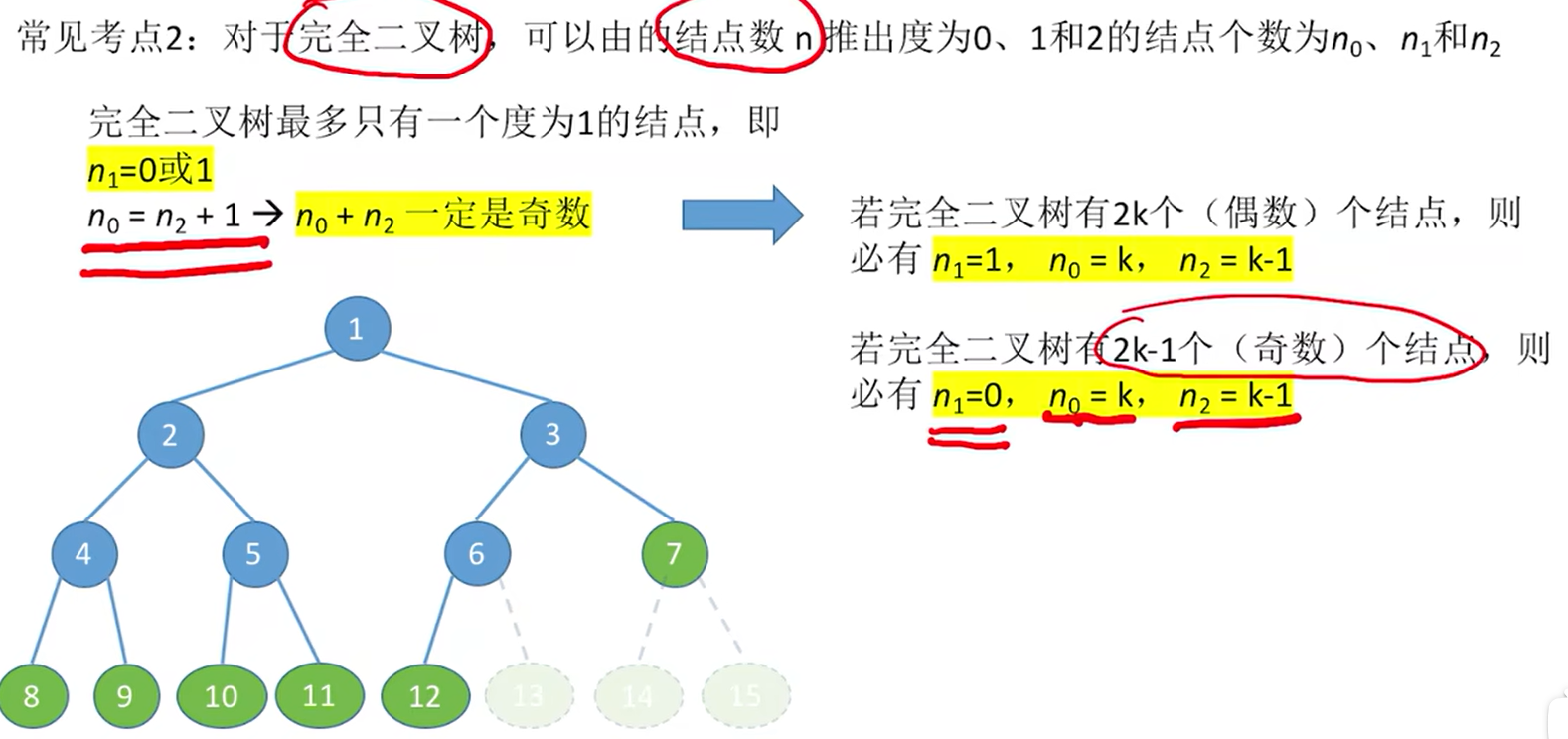
**常见考点2:**对于完全二叉树,可以由总结点数 n 推出度为 0、1 和 2 的结点个数、
、
推导过程:
因为::所以为奇数
又因为:
所以:若完全二叉树有偶数n个节点,则为1;
为
;
为
若完全二叉树有奇数n个节点,则为0;
为
;
为

5.2.4. 二叉树存储实现
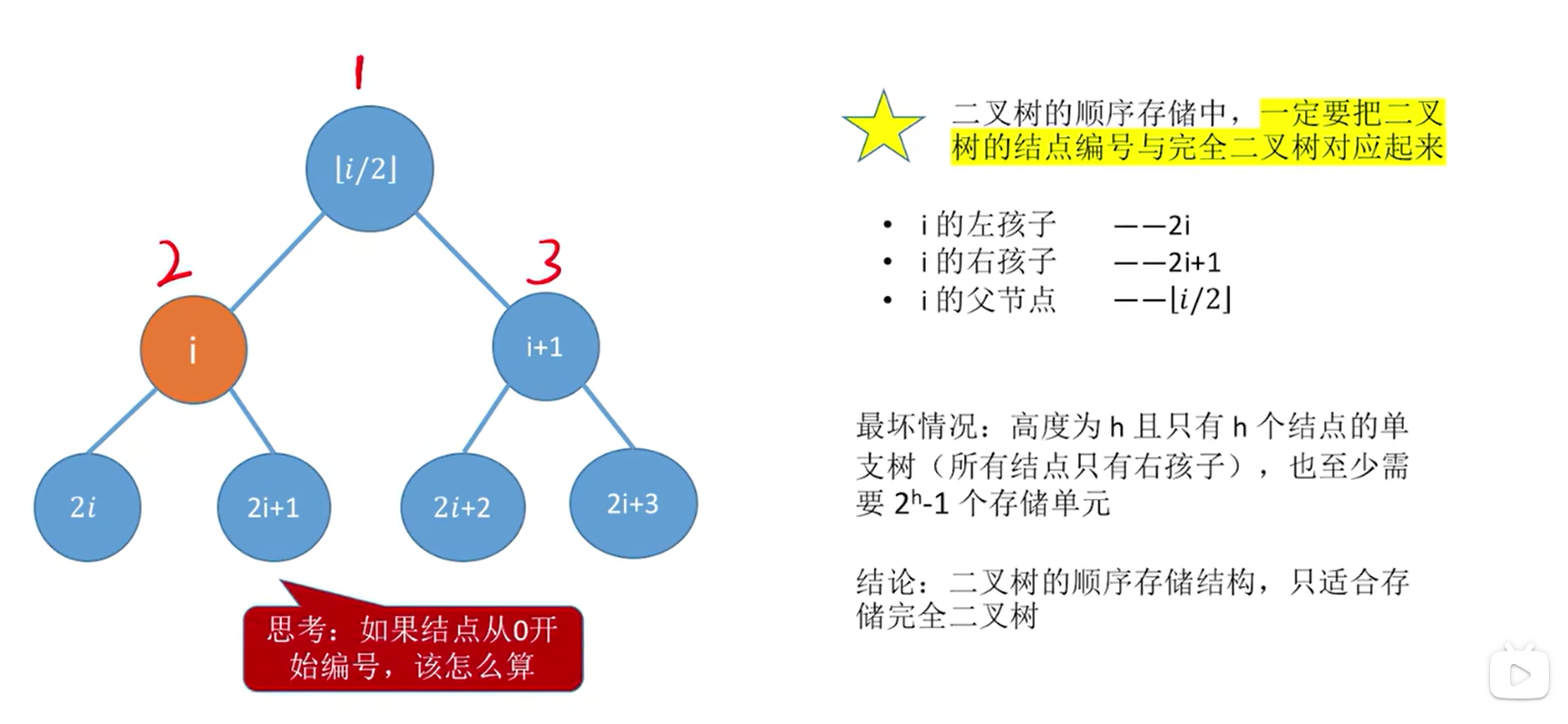
二叉树的顺序存储:
基本只用来存储完全二叉树,对于非完全二叉树来说,存储密度太低了,浪费了很多的空间,所以非完全二叉树不用顺序存储
二叉树的顺序存储中,一定要把二叉树的结点编号与完全二叉树对应起来
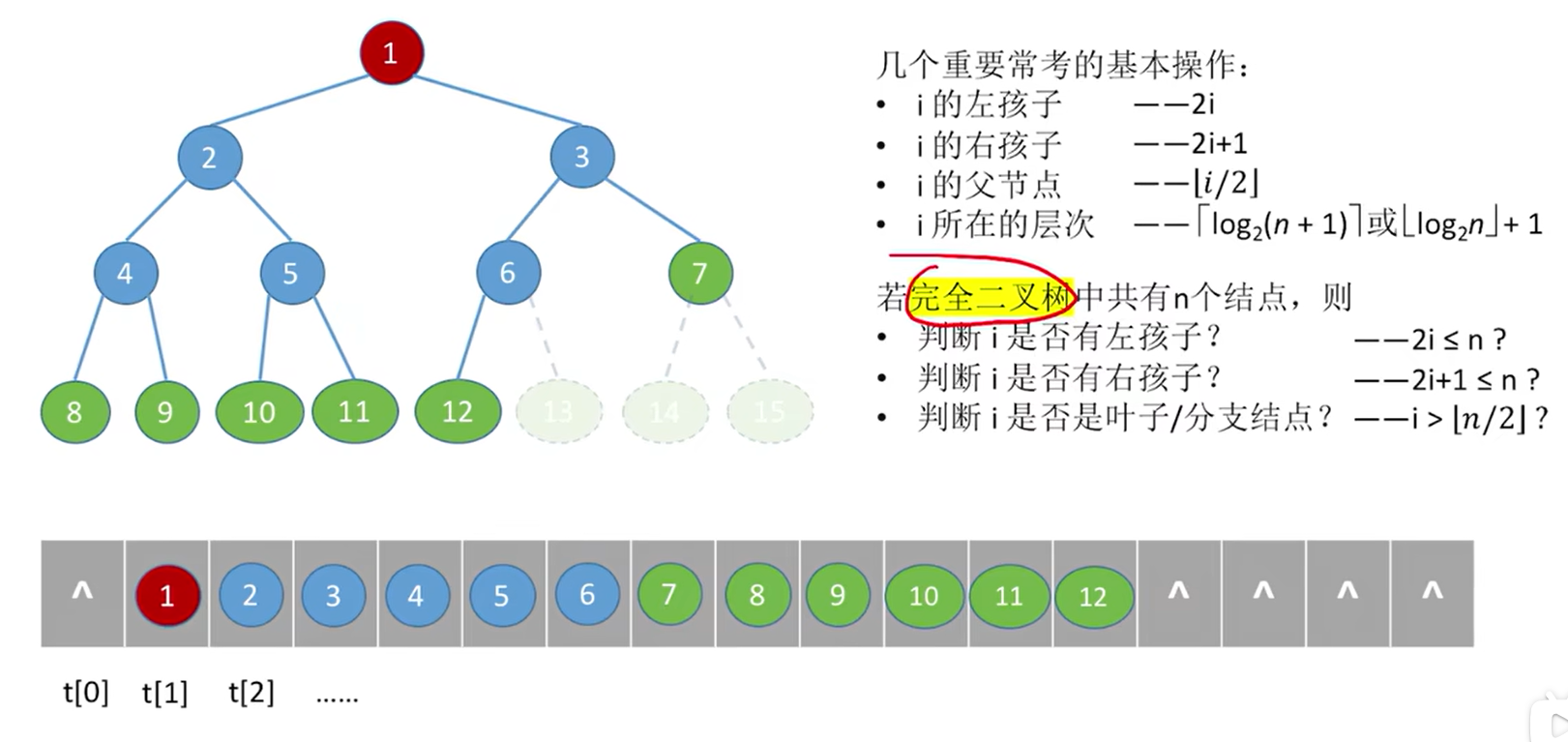
几个重要常考的基本操作:
- i 的左孩子:2i
- i 的右孩子:2i+1
- i 的父节点:i/2
- i 所在的层次:
或者
若完全二叉树中共有n个结点,则
- 判断i是否有左孩子?  ?
- 判断i是否有右孩子?  ?
- 判断i是否是叶子/分支结点?
?
#define MaxSize 100struct TreeNode{ElemType value; //结点中的数据元素bool isEmpty; //结点是否为空
};main(){TreeNode t[MaxSize];for (int i=0; i<MaxSize; i++){t[i].isEmpty = true;}
}
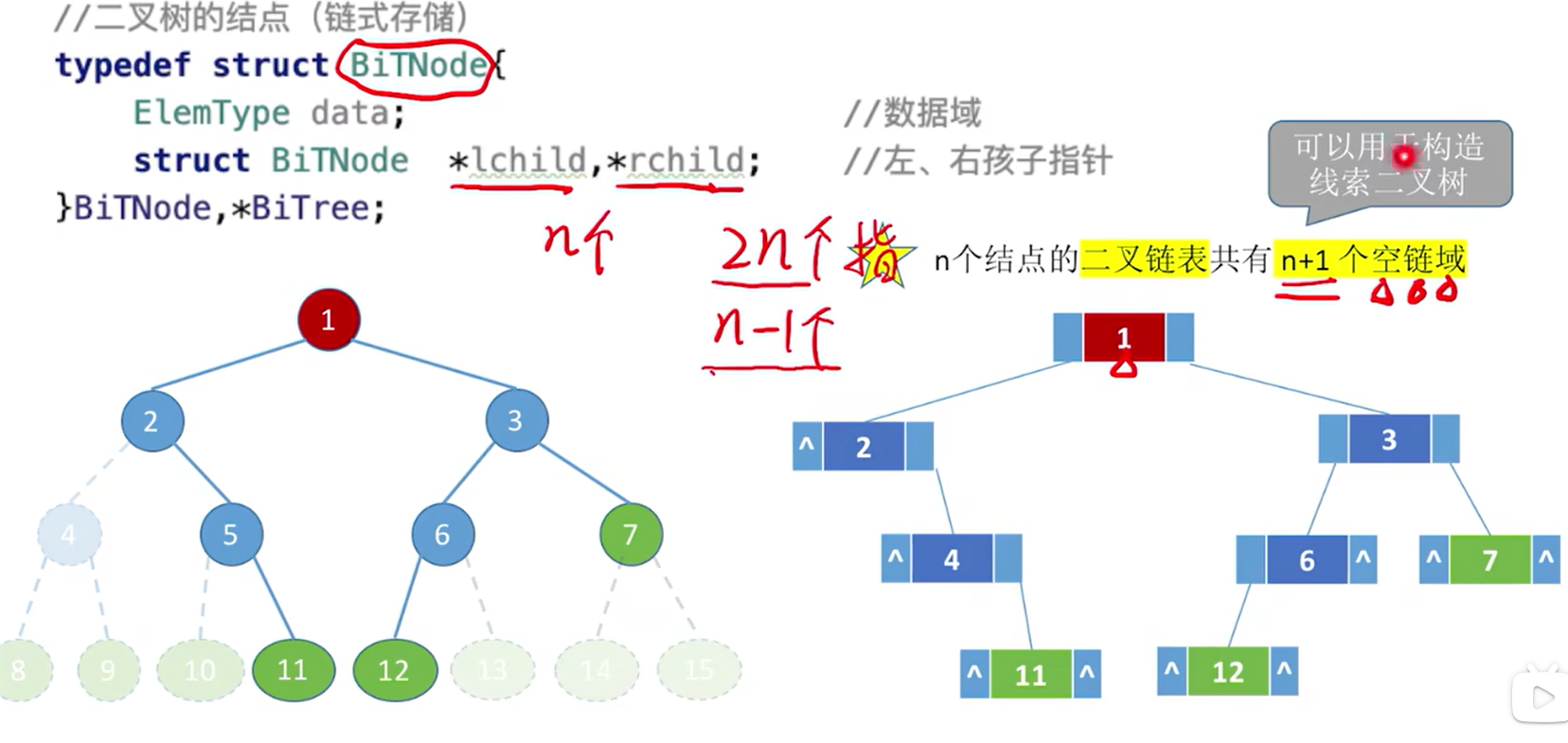
链式存储
重点:n个结点的二叉链表共有n+1个空链域
二叉树从无到有的过程:
(这样构建也太麻烦了,还是看看后面怎么递归建立吧)
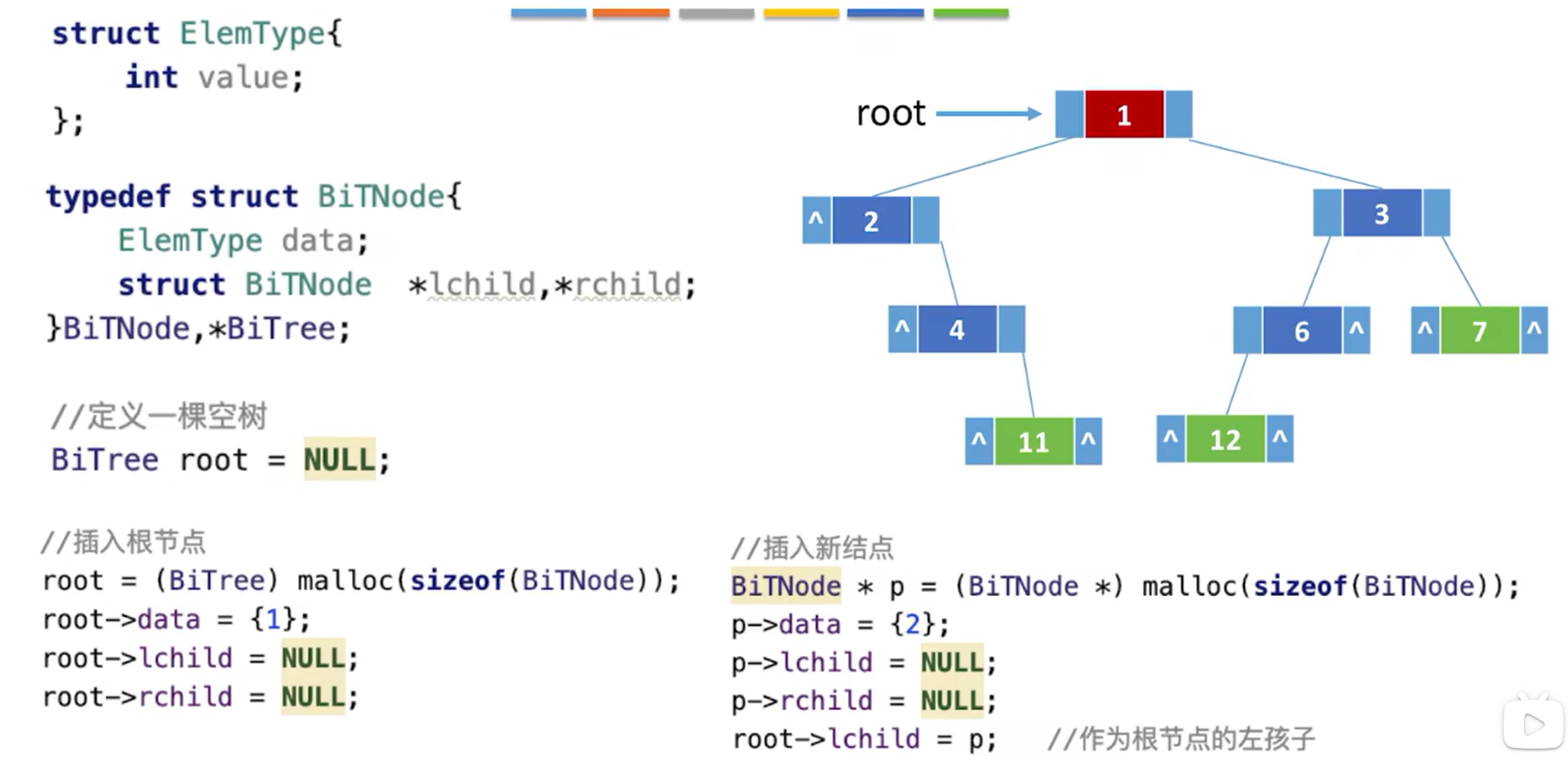
//二叉树的结点struct ElemType{int value;
};typedef struct BiTnode{ElemType data; //数据域struct BiTNode *lchild, *rchild; //左、右孩子指针
}BiTNode, *BiTree;//定义一棵空树
BiTree root = NULL;//插入根节点
root = (BiTree) malloc (sizeof(BiTNode));
root -> data = {1};
root -> lchild = NULL;
root -> rchild = NULL;//插入新结点
BiTNode *p = (BiTree) malloc (sizeof(BiTNode));
p -> data = {2};
p -> lchild = NULL;
p -> rchild = NULL;
root -> lchild = p; //作为根节点的左孩子- 二又树的顺序存储中,一定要把二叉树的结点编号与完全二叉树对应起来
- 最坏情况:高度为 h 且只有 h 个结点的单支树 (所有结点只有右孩子),也至少需要 2^h-1个存储单元
- 结论:二叉树的顺序存储结构,只适合存储完全二叉树
5.3. 二叉树的遍历和线索二叉树
5.3.1. 二叉树的先中后序遍历
- 遍历:按照某种次序把所有结点都访问一遍
- 层次遍历:基于树的层次特性确定的次序规则
二又树的递归特性:
【1】要么是个空二叉树
【2】要么就是由“根节点+左子树+右子树”组成的二叉树
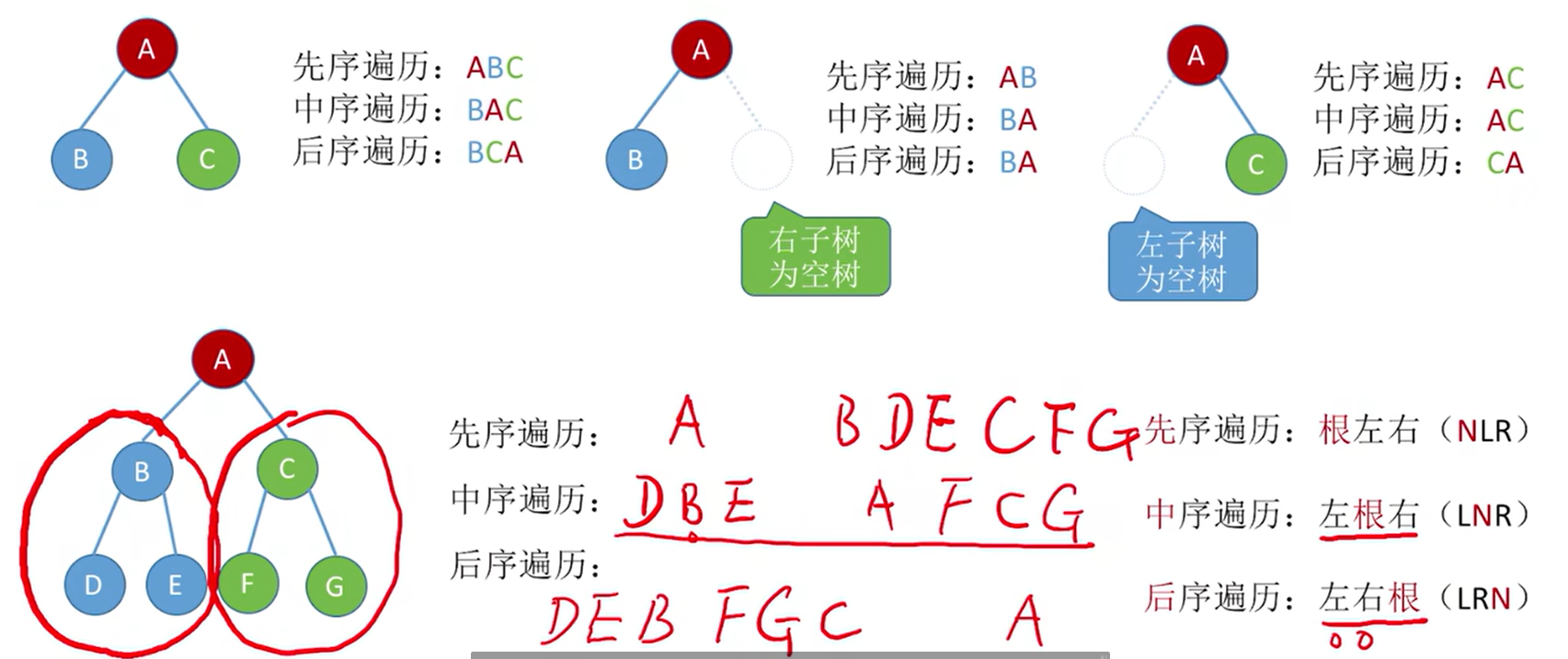

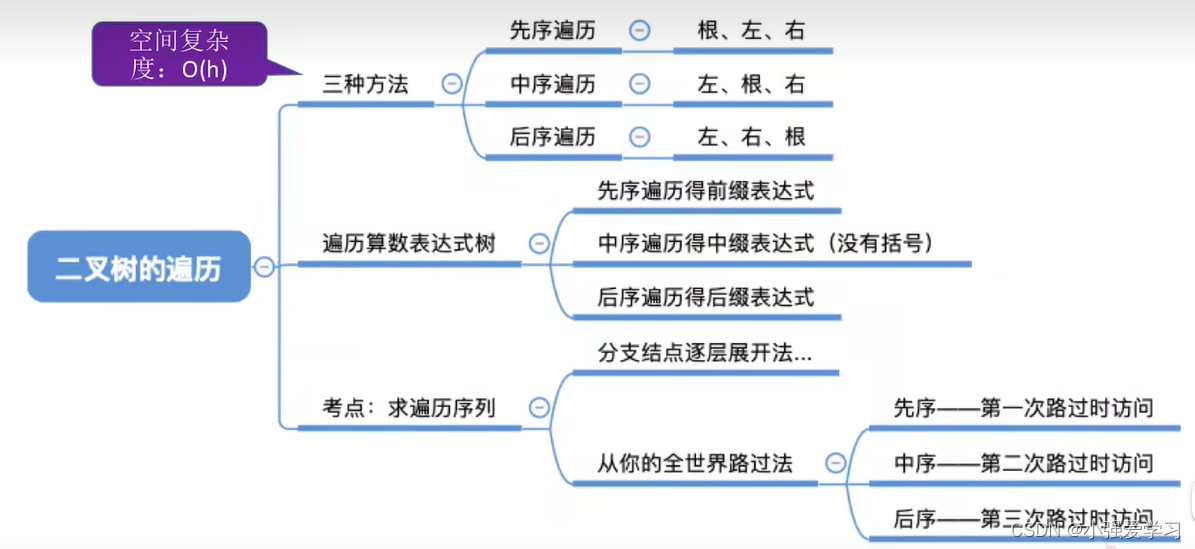
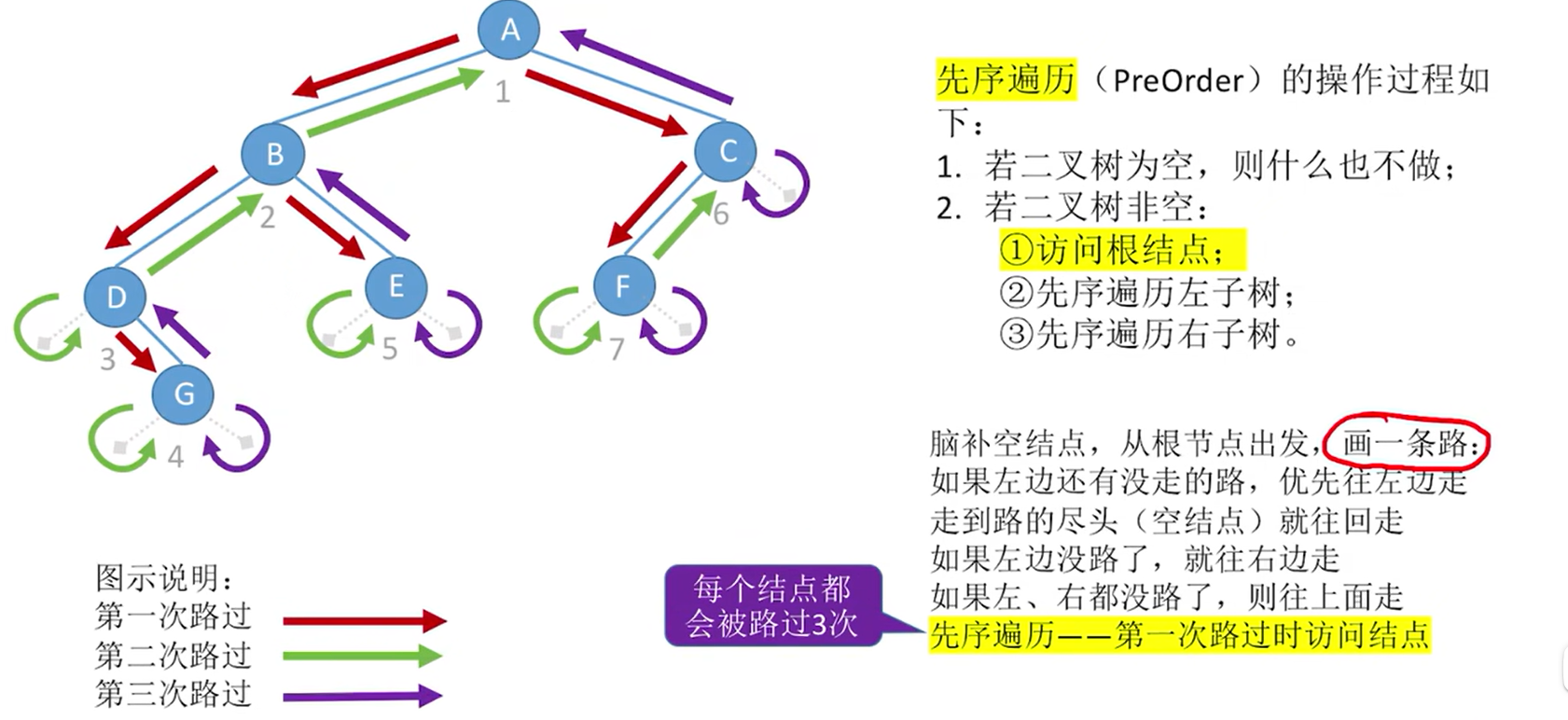
【二叉树的先中后遍历】
- 先序遍历:根左右(NLR)
- 144. 二叉树的前序遍历 - 力扣(LeetCode)
typedef struct BiTnode{ElemType data; struct BiTNode *lchild, *rchild;
}BiTNode, *BiTree;void PreOrder(BiTree T){if(T!=NULL){visit(T); //访问根结点PreOrder(T->lchild); //递归遍历左子树PreOrder(T->rchild); //递归遍历右子树}
}- 中序遍历:左根右 (LNR)
- 94. 二叉树的中序遍历 - 力扣(LeetCode)
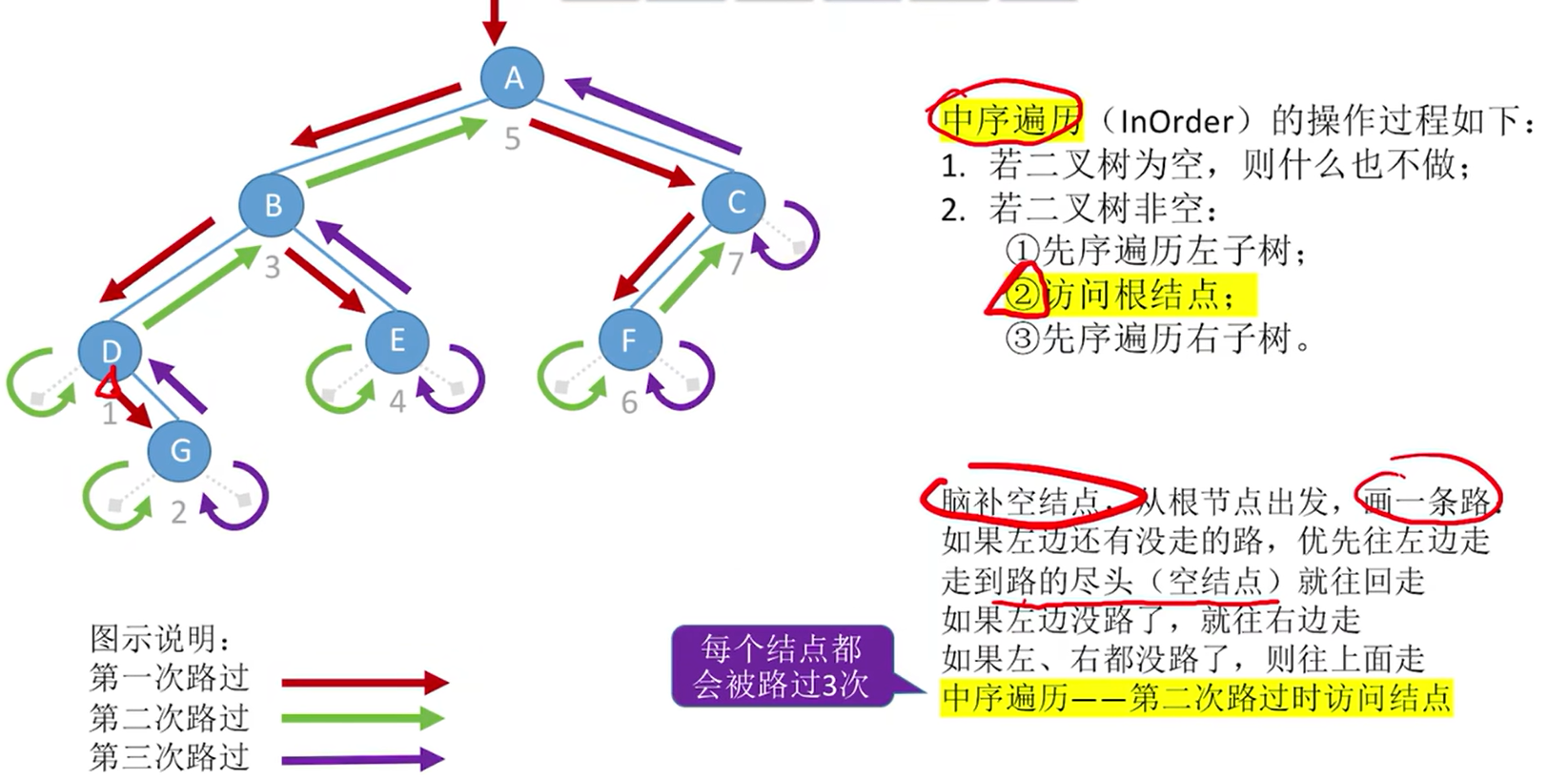
typedef struct BiTnode{ElemType data; struct BiTNode *lchild, *rchild;
}BiTNode, *BiTree;void InOrder(BiTree T){if(T!=NULL){InOrder(T->lchild); //递归遍历左子树visit(T); //访问根结点InOrder(T->rchild); //递归遍历右子树}
}
- 后序遍历:左右根(LRN)
- 145. 二叉树的后序遍历 - 力扣(LeetCode)
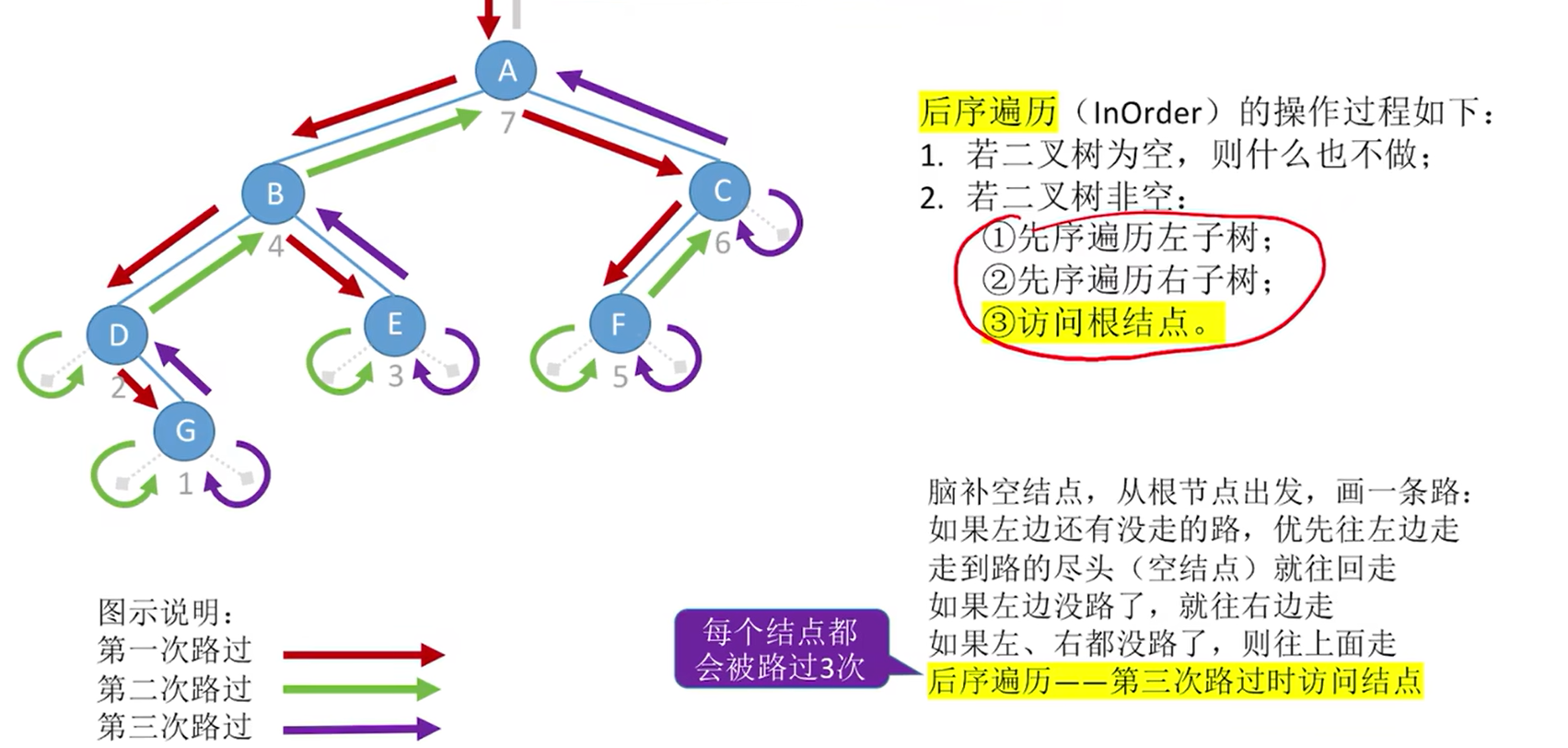
typedef struct BiTnode{ElemType data; struct BiTNode *lchild, *rchild;
}BiTNode, *BiTree;void PostOrder(BiTree T){if(T!=NULL){PostOrder(T->lchild); //递归遍历左子树 PostOrder(T->rchild); //递归遍历右子树visit(T); //访问根结点}
}
5.3.2. 二叉树的层序遍历
102. 二叉树的层序遍历 - 力扣(LeetCode)
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> res;queue<TreeNode*> q;if(root==nullptr)return res;q.push(root);while(!q.empty()){int size=q.size();vector<int> v;for(int i=0;i<size;i++){auto p=q.front();q.pop();v.push_back(p->val);if(p->left)q.push(p->left);if(p->right)q.push(p->right);}res.push_back(v);} return res;}
};算法思想:
- 1.初始化一个辅助队列
- 2.根结点入队
- 3.若队列非空,则队头结点出队,访问该结点,并将孩子插入队尾(如果有的话)
- 4.重复3直至队列为空
//二叉树的结点(链式存储)
typedef struct BiTnode{ElemType data; struct BiTNode *lchild, *rchild;
}BiTNode, *BiTree;//链式队列结点
typedef struct LinkNode{BiTNode * data;typedef LinkNode *next;
}LinkNode;typedef struct{LinkNode *front, *rear;
}LinkQueue;//层序遍历
void LevelOrder(BiTree T){LinkQueue Q;InitQueue (Q); //初始化辅助队列BiTree p;EnQueue(Q,T); //将根节点入队while(!isEmpty(Q)){ //队列不空则循环DeQueue(Q,p); //队头结点出队visit(p); //访问出队结点if(p->lchild != NULL)EnQueue(Q,p->lchild); //左孩子入队if(p->rchild != NULL)EnQueue(Q,p->rchild); //右孩子入队}
}这种写法会让在队列里面的节点并不是同一层的节点,所以笔者更推荐上面的写法,上面的写法做很多题也很方便
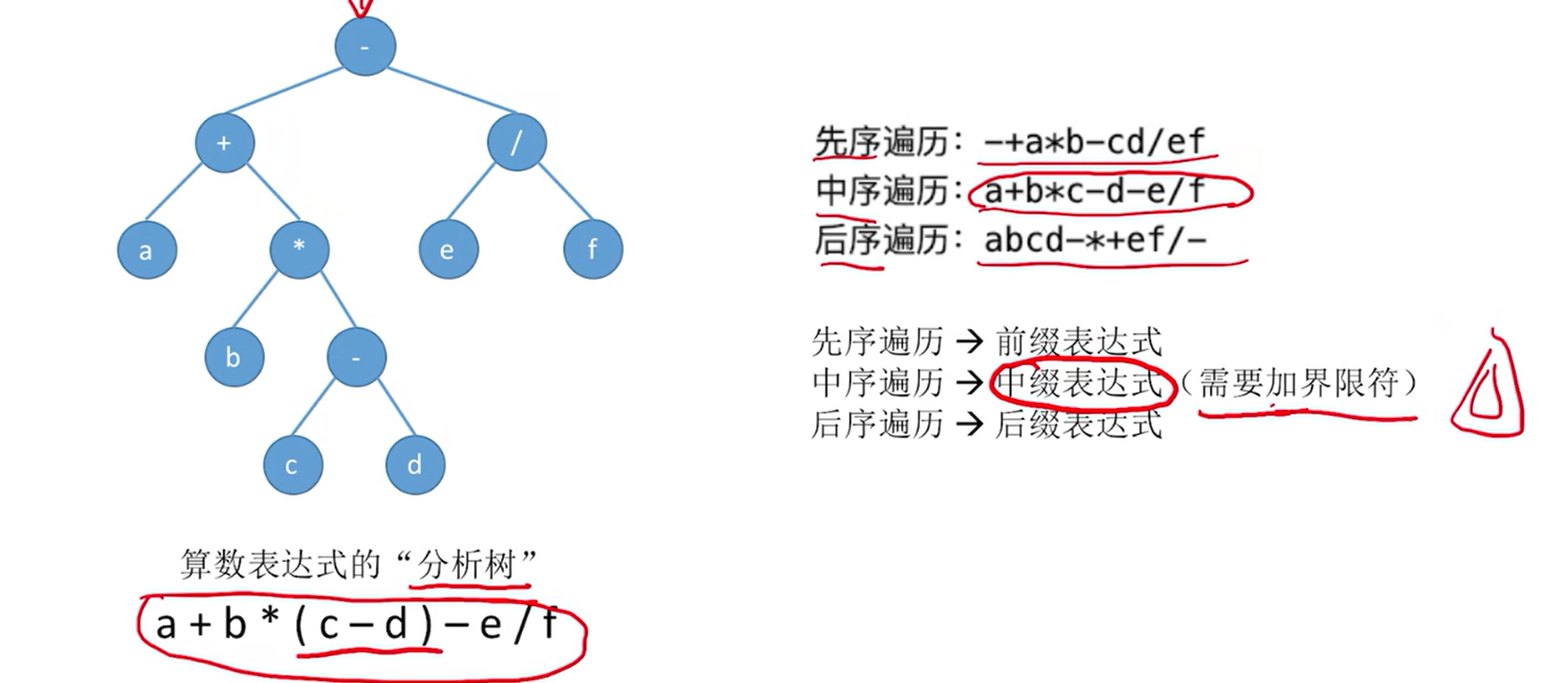
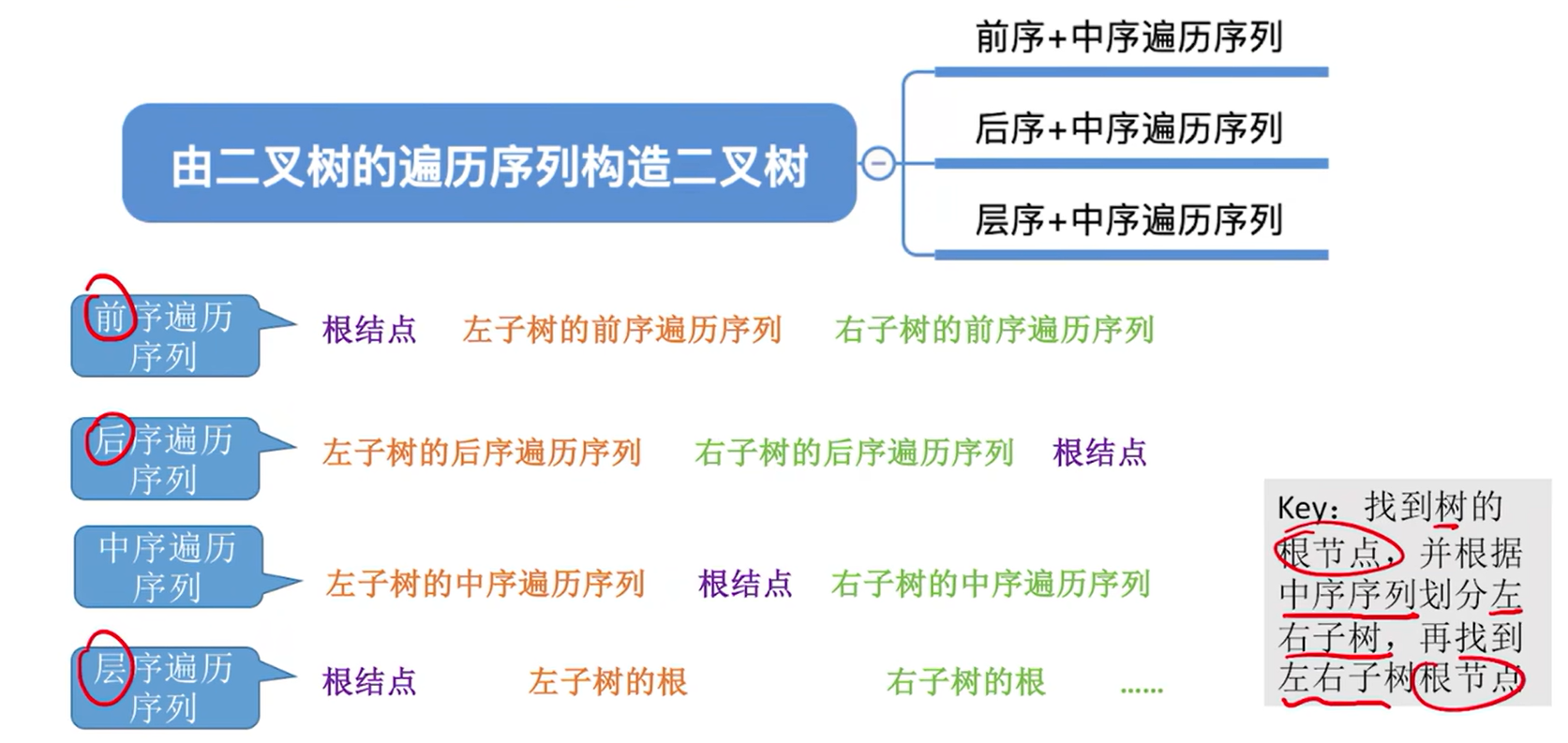
5.3.3. 由遍历序列构造二叉树
-
一个前序遍历序列可能对应多种二叉树形态。同理,一个后序遍历序列、一个中序遍历序列、一个层序遍历序列也可能对应多种二叉树形态。
即:若只给出一棵二叉树的 前/中/后/层序遍历序列 中的一种,不能唯一确定一棵二叉树。
由二叉树的遍历序列构造二叉树:
注:必须得有中序才可以,只有前序和后序不可以唯一确定一颗二叉树
原因:因为前后层序是确定根节点的,只有中序遍历才能够划分左右子树
前序+中序遍历序列
105. 从前序与中序遍历序列构造二叉树 - 力扣(LeetCode)
[Day25 | 二叉树 从中序与后序遍历构造二叉树&&最大二叉树 | Darlingの妙妙屋](https://darling-123456.github.io/2024/10/24/刷题记录/代码随想录 Day25 二叉树:从中序与后序遍历构造二叉树&&最大二叉树/)
代码随想录 | Day25 | 二叉树:从中序与后序遍历构造二叉树&&最大二叉树_根据中序和后序画二叉树-CSDN博客
1.前序第一个肯定是根节点
2.根据根节点在中序中的位置,判断左右子树,在根节点左边的肯定是左子树,在根节点右边的肯定是右子树
3.重复1,2,过程,在结点数不为1的子树中继续寻找根节点和左右子树
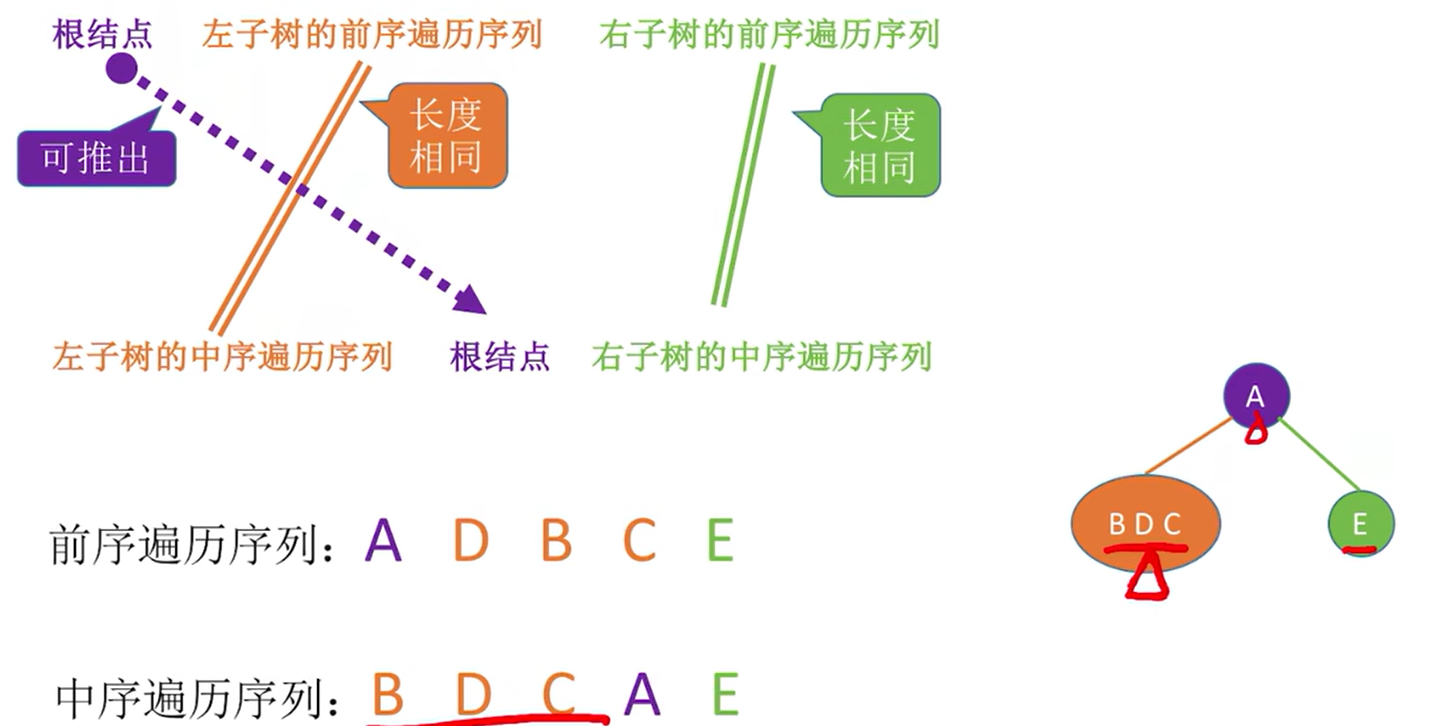
后序+中序遍历序列
106. 从中序与后序遍历序列构造二叉树 - 力扣(LeetCode)
[Day25 | 二叉树 从中序与后序遍历构造二叉树&&最大二叉树 | Darlingの妙妙屋](https://darling-123456.github.io/2024/10/24/刷题记录/代码随想录 Day25 二叉树:从中序与后序遍历构造二叉树&&最大二叉树/)
代码随想录 | Day25 | 二叉树:从中序与后序遍历构造二叉树&&最大二叉树_根据中序和后序画二叉树-CSDN博客
1.后序最后一个肯定是根节点
2.根据根节点在中序中的位置,判断左右子树,在根节点左边的肯定是左子树,在根节点右边的肯定是右子树
3.重复1,2,过程,在结点数不为1的子树中继续寻找根节点和左右子树
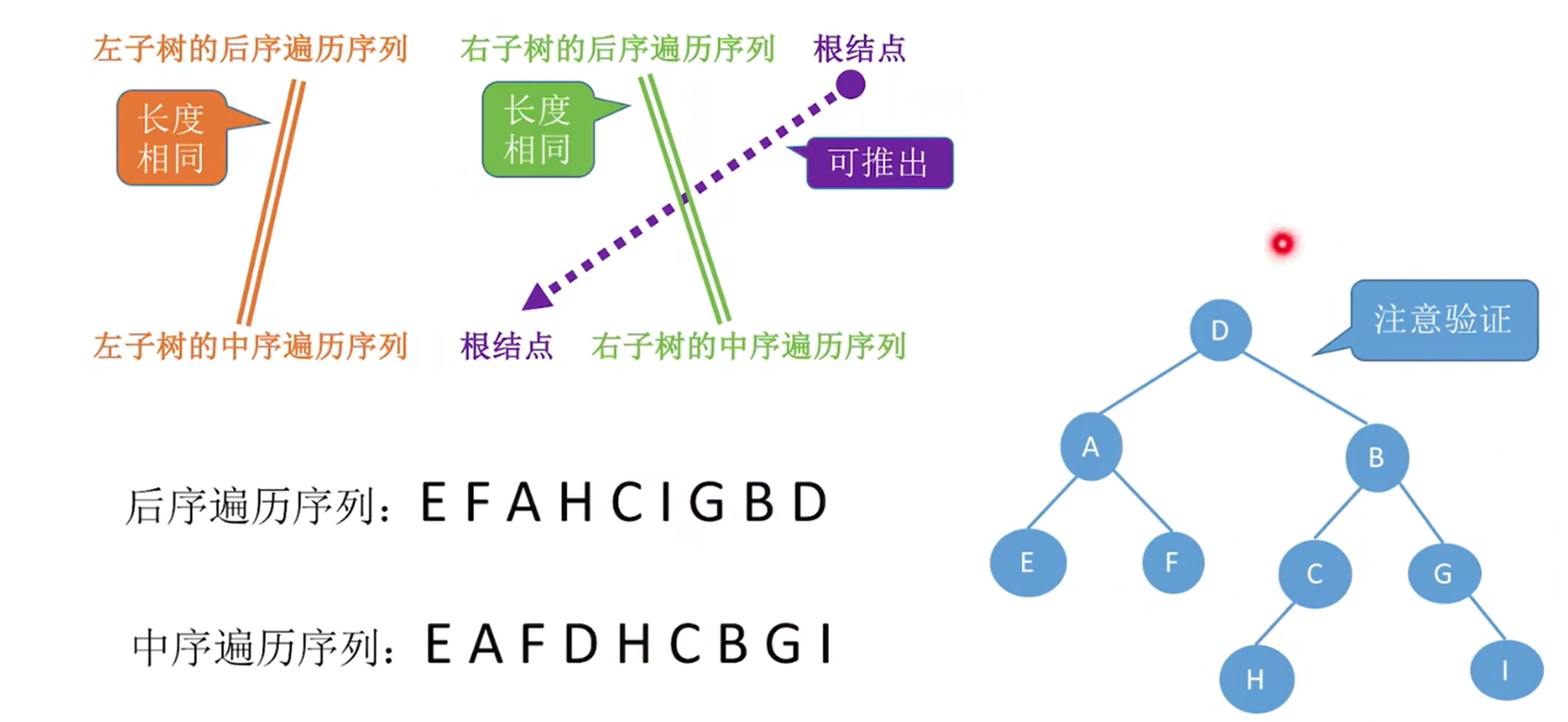
层序+中序遍历序列
1.层序第一个肯定是根节点
2.根据根节点在中序中的位置,判断左右子树,在根节点左边的肯定是左子树,在根节点右边的肯定是右子树
3.重复1,2,过程,在结点数不为1的子树中继续寻找根节点和左右子树
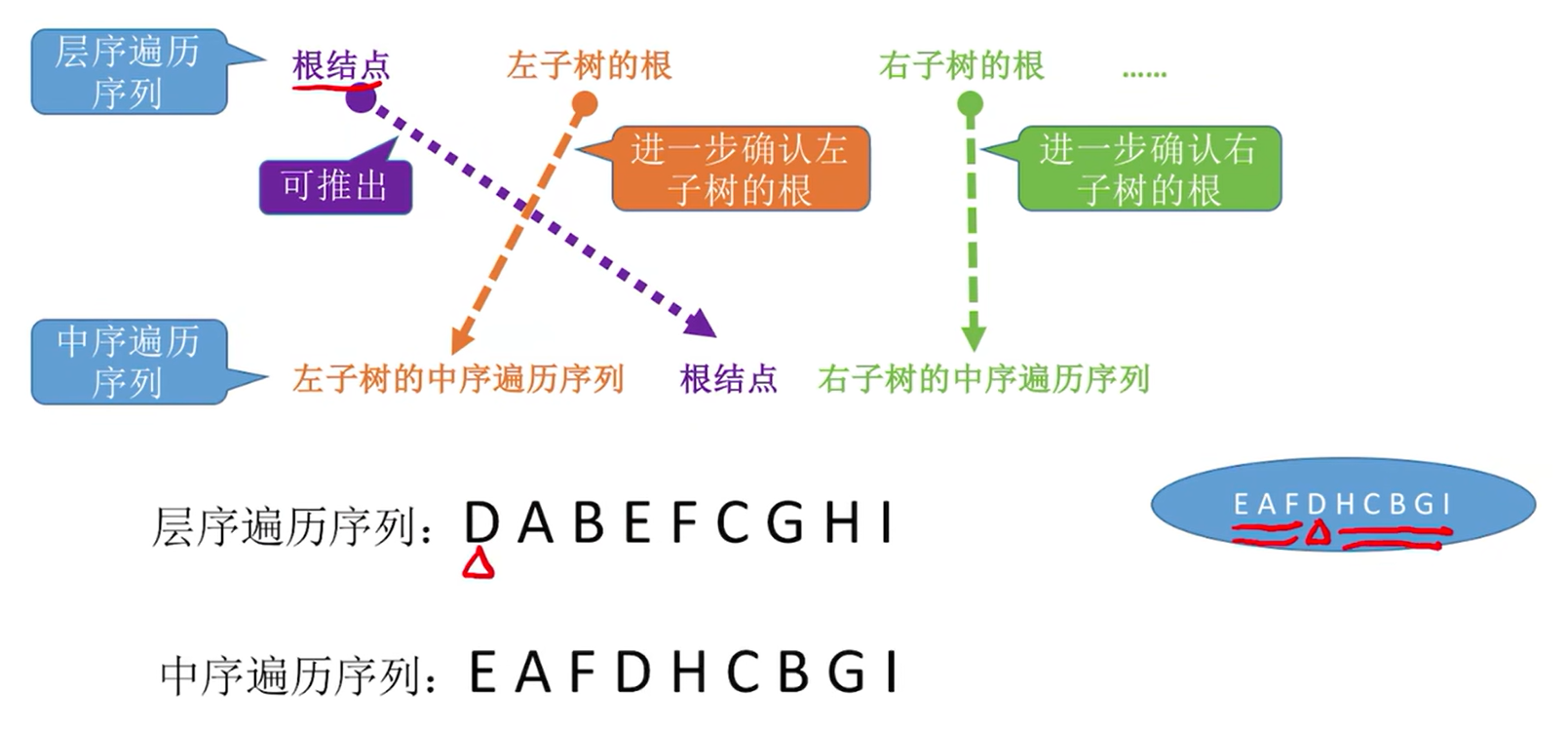
5.3.4. 线索二叉树的概念
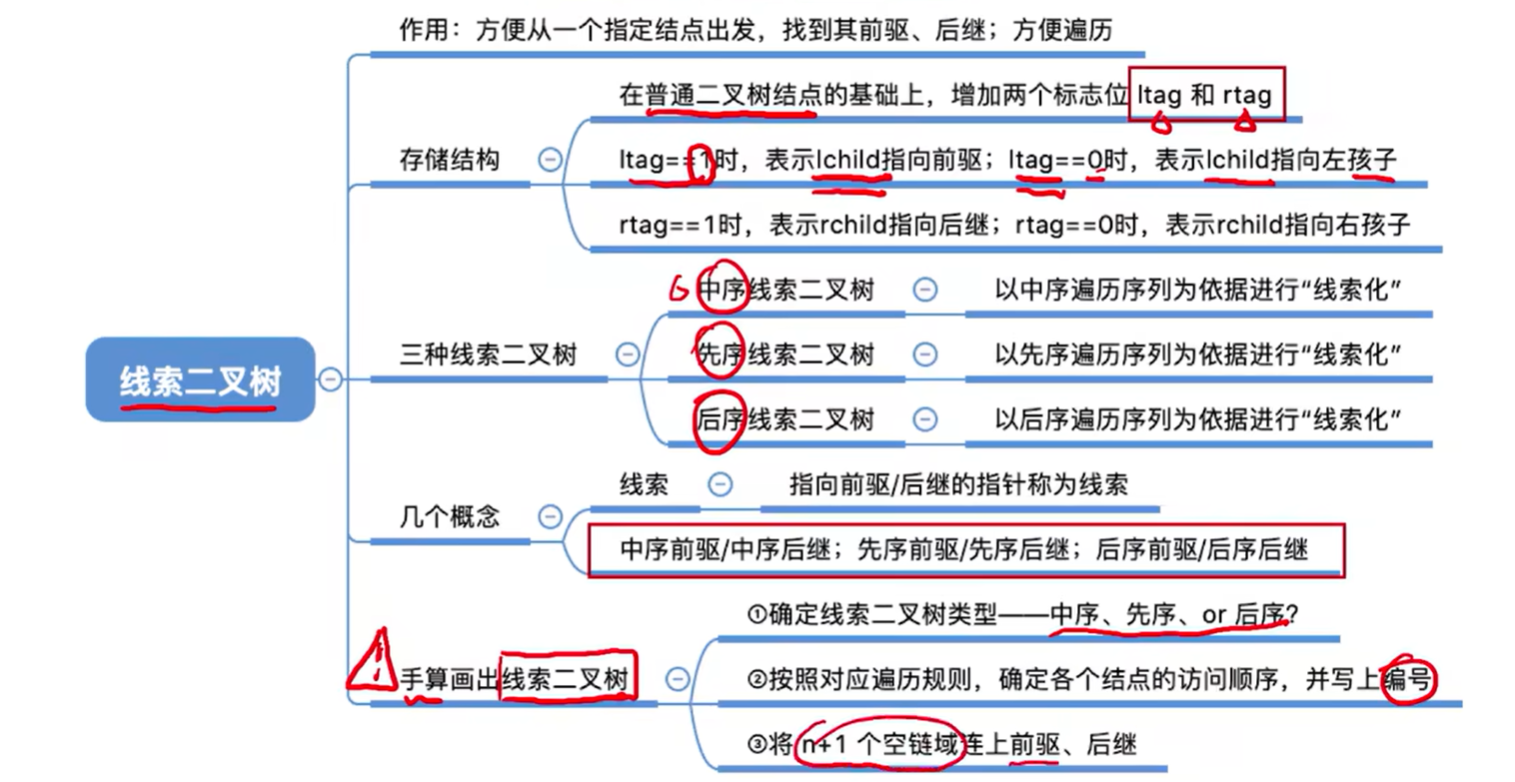
线索二叉树的概念与作用
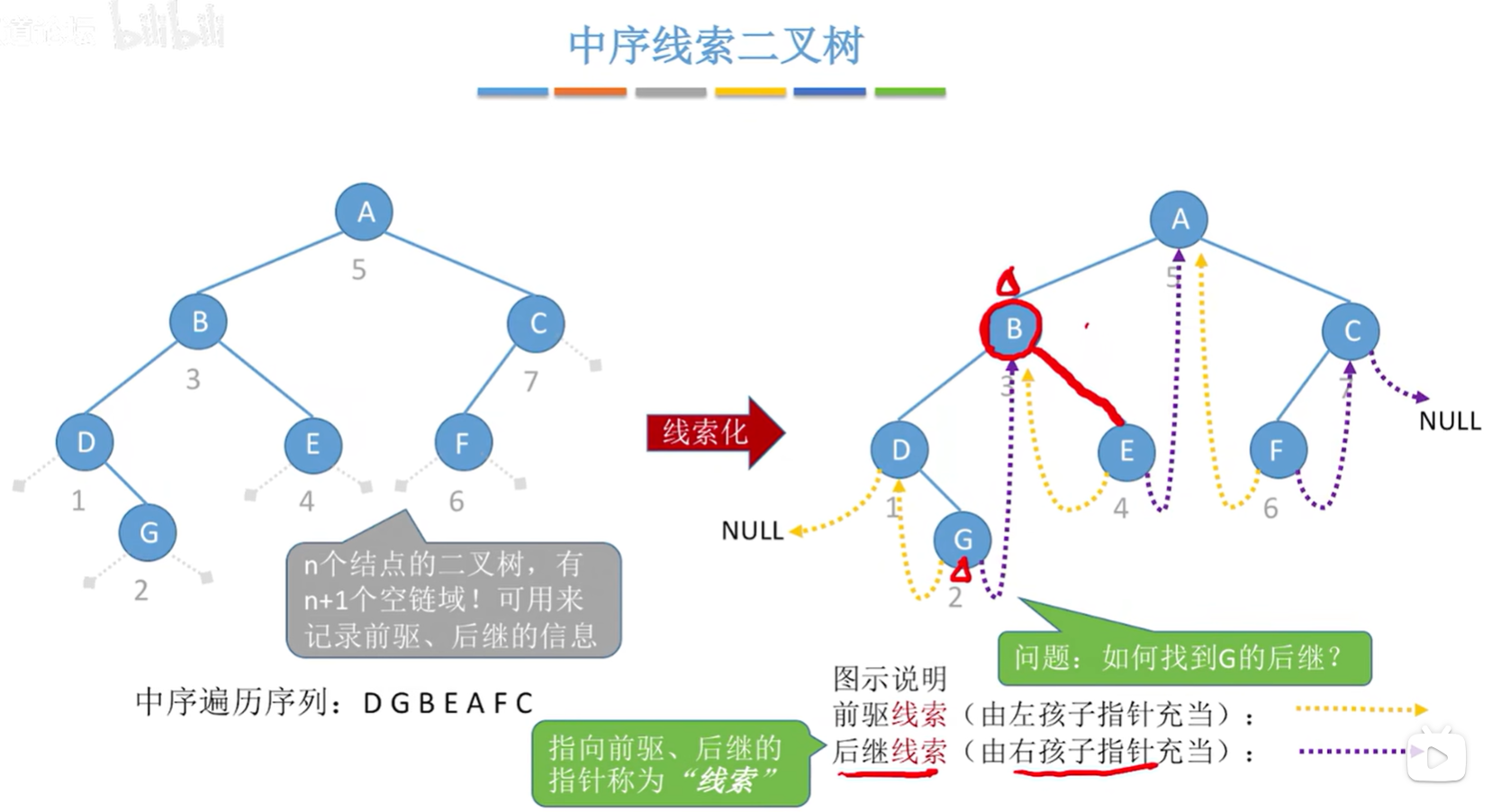
- n 个结点的二叉树,有 n+1 个空链域,可用来记录前驱、后继的信息。
- 指向前驱、后继的指针被称为“线索”,形成的二叉树被称为线索二叉树。
- 在二叉树的结点上加上线索的二叉树称为线索二叉树,对二叉树以某种遍历方式(如先序、中序、后序或层次等)进行遍历,使其变为线索二叉树的过程称为对二叉树进行线索化。
- 线索二叉树的结点在原本二叉树的基础上,新增了左右线索标志 tag。当 tag == 0 时,表示指针指向孩子;当 tag == 1 时,表示指针是“线索”。
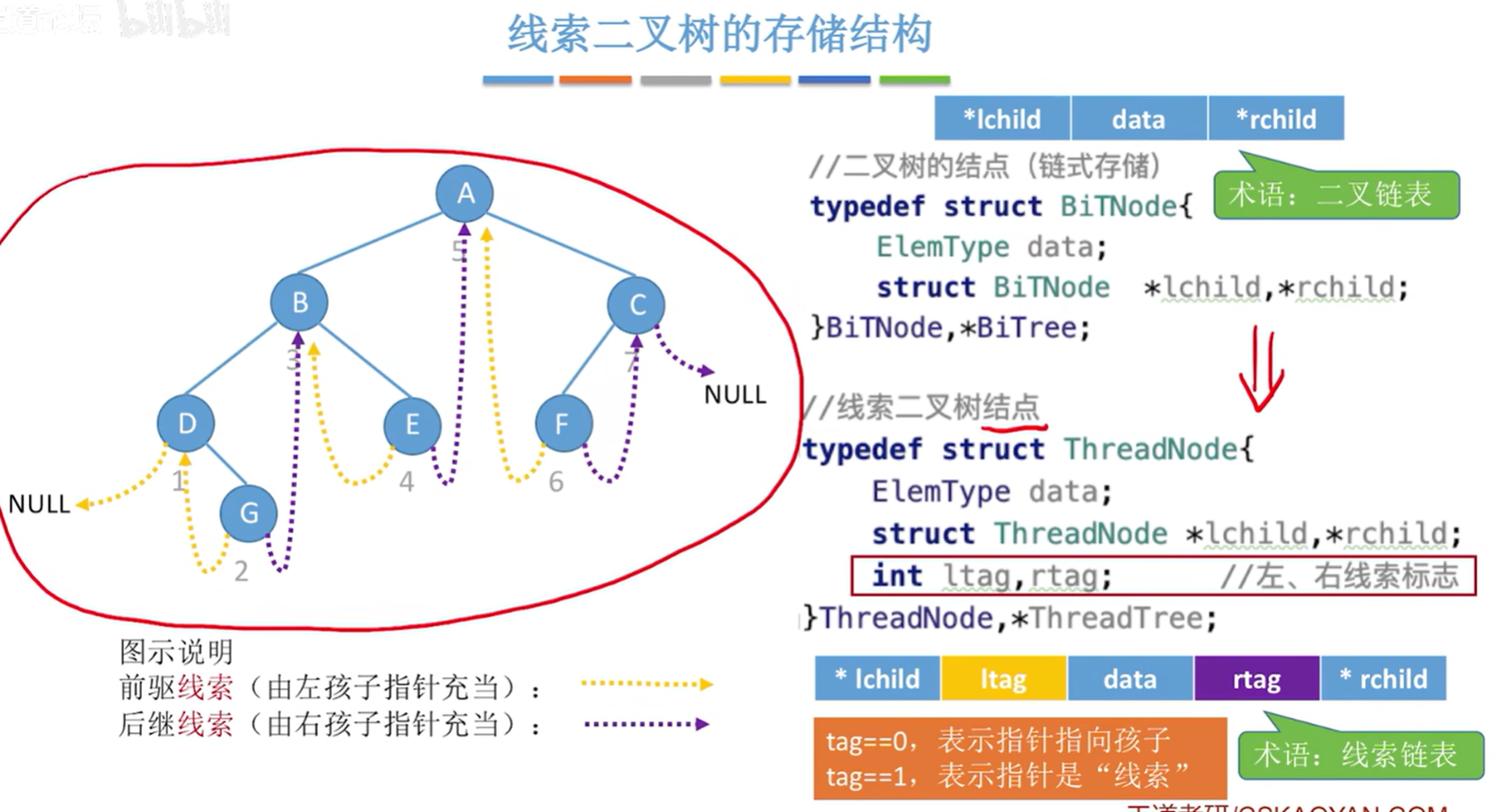
//线索二叉树结点
typedef struct ThreadNode{ElemType data;struct ThreadNode *lchild, *rchild;int ltag, rtag; // 左、右线索标志
}ThreadNode, *ThreadTree;
中序线索化的存储
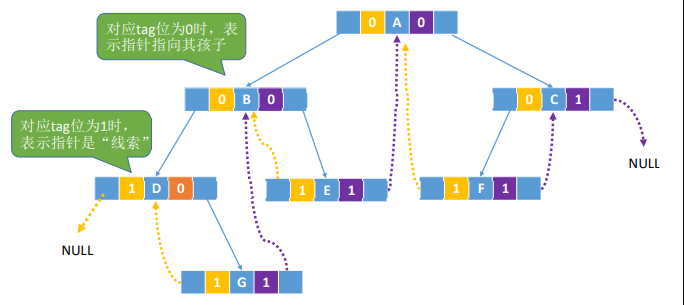
先序线索化的存储
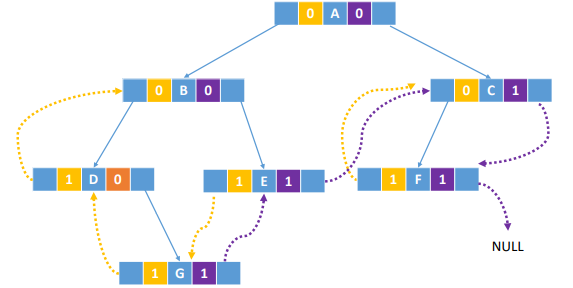
后序线索化的存储
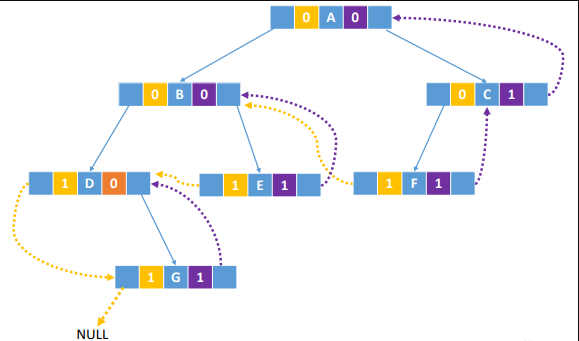
LCR 053. 二叉搜索树中的中序后继 - 力扣(LeetCode)
寻找中序后继的题目,按照咸鱼的思路写就行
class Solution {
public:TreeNode* res=nullptr;TreeNode* pre=nullptr;void tra(TreeNode* t, TreeNode* p){if(t==nullptr)return ;tra(t->left,p);if(pre!=nullptr&&p->val==pre->val)res=t;pre=t;tra(t->right,p);}TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) {tra(root,p);return res;}
};
5.3.5. 二叉树的线索化
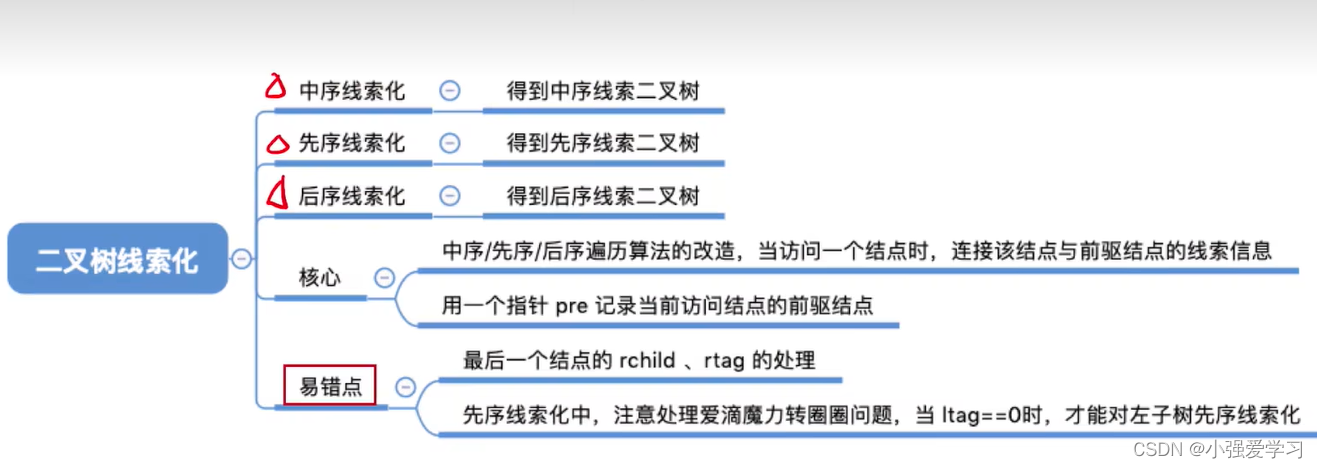

中序线索化:
typedef struct ThreadNode{int data;struct ThreadNode *lchild, *rchild;int ltag, rtag; // 左、右线索标志
}ThreadNode, *ThreadTree;//全局变量pre, 指向当前访问的结点的前驱
TreadNode *pre=NULL;void InThread(ThreadTree T){if(T!=NULL){InThread(T->lchild); //中序遍历左子树visit(T); //访问根节点InThread(T->rchild); //中序遍历右子树}
}void visit(ThreadNode *q){if(q->lchid = NULL){ //左子树为空,建立前驱线索 q->lchild = pre;q->ltag = 1;}if(pre!=NULL && pre->rchild = NULL){ pre->rchild = q; //建立前驱结点的后继线索pre->rtag = 1;}pre = q;
}//中序线索化二叉树T
void CreateInThread(ThreadTree T){pre = NULL; //pre初始为NULLif(T!=NULL);{ //非空二叉树才能进行线索化InThread(T); //中序线索化二叉树if(pre->rchild == NULL)pre->rtag=1; //处理遍历的最后一个结点}
}先序线索化:

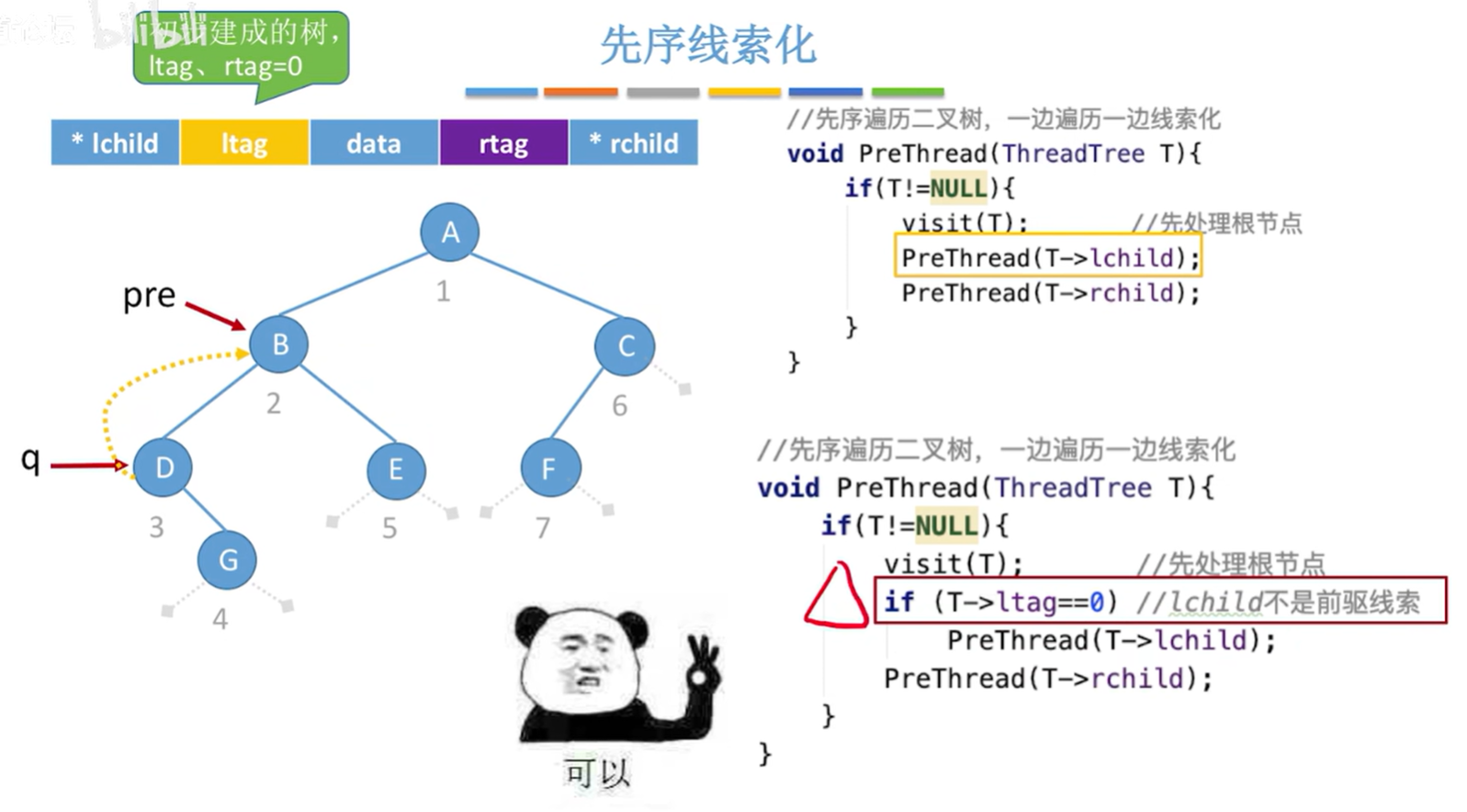
typedef struct ThreadNode{int data;struct ThreadNode *lchild, *rchild;int ltag, rtag; // 左、右线索标志
}ThreadNode, *ThreadTree;//全局变量pre, 指向当前访问的结点的前驱
TreadNode *pre=NULL;//先序遍历二叉树,一边遍历一边线索化
void PreThread(ThreadTree T){if(T!=NULL){visit(T);if(T->ltag == 0) //lchild不是前驱线索PreThread(T->lchild);PreThread(T->rchild);}
}void visit(ThreadNode *q){if(q->lchid = NULL){ //左子树为空,建立前驱线索 q->lchild = pre;q->ltag = 1;}if(pre!=NULL && pre->rchild = NULL){ pre->rchild = q; //建立前驱结点的后继线索pre->rtag = 1;}pre = q;
}//先序线索化二叉树T
void CreateInThread(ThreadTree T){pre = NULL; //pre初始为NULLif(T!=NULL);{ //非空二叉树才能进行线索化PreThread(T); //先序线索化二叉树if(pre->rchild == NULL)pre->rtag=1; //处理遍历的最后一个结点}
}后序线索化:

typedef struct ThreadNode{int data;struct ThreadNode *lchild, *rchild;int ltag, rtag; // 左、右线索标志
}ThreadNode, *ThreadTree;//全局变量pre, 指向当前访问的结点的前驱
TreadNode *pre=NULL;//后序遍历二叉树,一边遍历一边线索化
void PostThread(ThreadTree T){if(T!=NULL){PostThread(T->lchild);PostThread(T->rchild);visit(T); //访问根节点}
}void visit(ThreadNode *q){if(q->lchid = NULL){ //左子树为空,建立前驱线索 q->lchild = pre;q->ltag = 1;}if(pre!=NULL && pre->rchild = NULL){ pre->rchild = q; //建立前驱结点的后继线索pre->rtag = 1;}pre = q;
}//后序线索化二叉树T
void CreateInThread(ThreadTree T){pre = NULL; //pre初始为NULLif(T!=NULL);{ //非空二叉树才能进行线索化PostThread(T); //后序线索化二叉树if(pre->rchild == NULL)pre->rtag=1; //处理遍历的最后一个结点}
}
5.3.6. 在线索二叉树中找前驱/后继
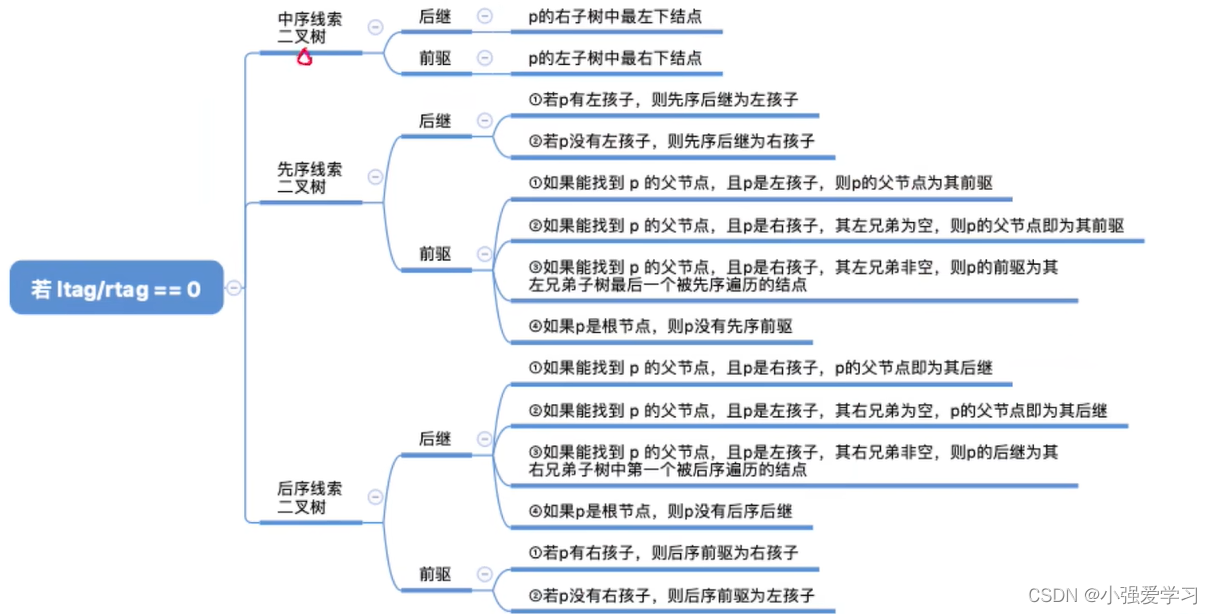

疑惑点:线索二叉树不是左孩子指向前驱,右孩子指向后继吗?那为什么有找不到前序和后继的情况?
如果当前有孩子的话,是不会进行线索化的,只有叶子节点或者结点的孩子中为空的指针才会被线索化
土办法:从根节点重新遍历一次寻找前驱或者后继
如果给了一个线索二叉树中的一个结点p
1.如果是中序线索二叉树的话,我们可以从这个结点开始进行正向的中序遍历,也可以进行逆向的中序遍历,但都不会得到完整序列,只是从p开始而已
2.如果是先序线索二叉树的话,我们可以从这个结点开始进行正向的先序遍历,因为对于没有线索化的节点,我们只能找到后继找不到前驱,除非有父节点
3.如果是后序线索二叉树的话,我们可以从这个结点开始进行逆向的后序遍历,因为对于没有线索化的节点,我们只能找到前驱找不到后继,除非有父节点
最常考的还是手算
中序线索二叉树找到指定结点 * p 的中序后继 next:
-
若
p->rtag==1,则next = p->rchild;说明 p的rchild是一个叶子节点
-
若
p->rtag==0,则 next 为 p 的右子树中最左下结点。说明p是右子树的根节点
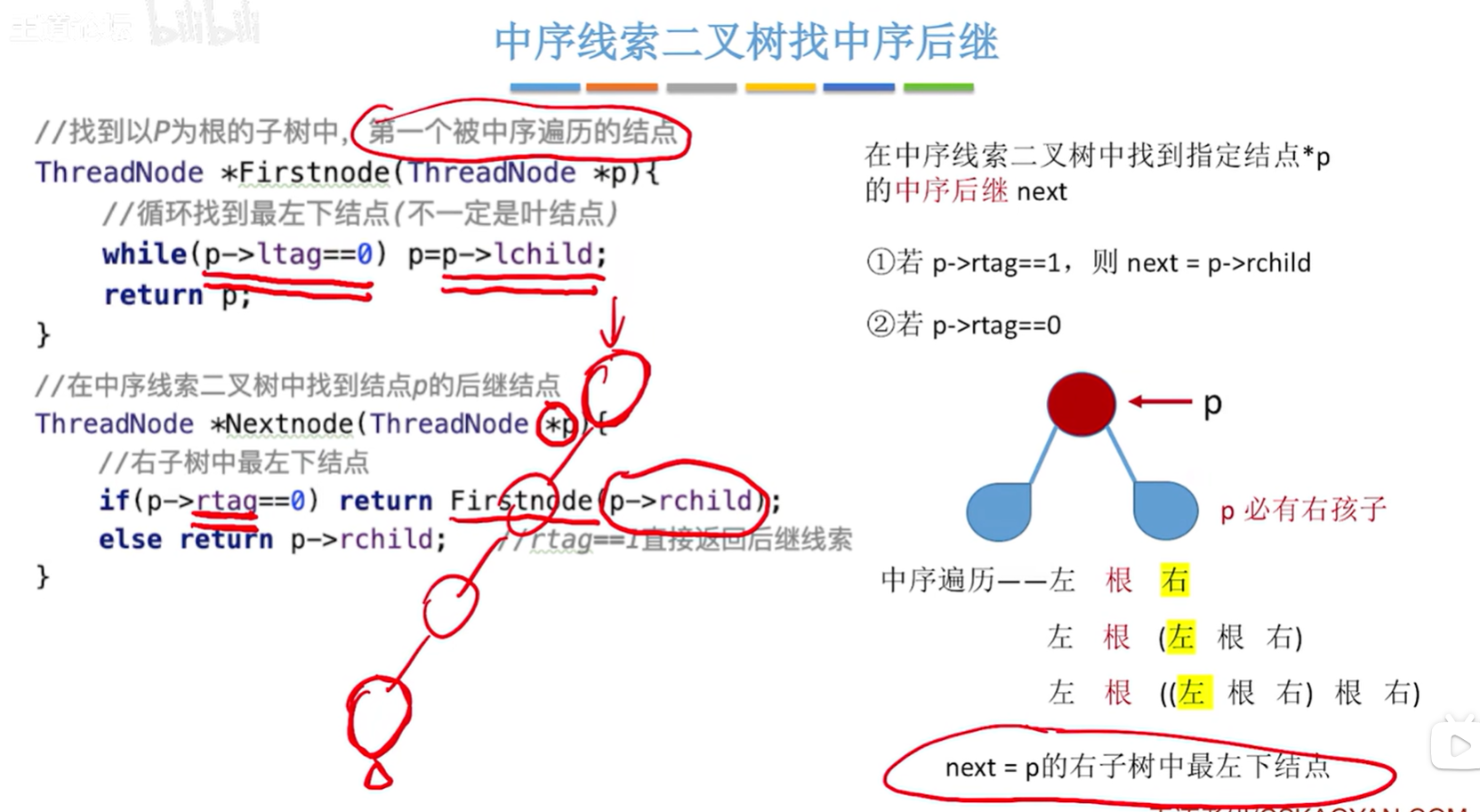

// 找到以p为根的子树中,第一个被中序遍历的结点
ThreadNode *FirstNode(ThreadNode *p){// 循环找到最左下结点(不一定是叶结点)while(p->ltag==0)p=p->lchild;return p;
}// 在中序线索二叉树中找到结点p的后继结点
ThreadNode *NextNode(ThreadNode *p){// 右子树中最左下的结点if(p->rtag==0)return FirstNode(p->rchild);elsereturn p->rchild;
}// 对中序线索二叉树进行中序循环(非递归方法实现)
void InOrder(ThreadNode *T){for(ThreadNode *p=FirstNode(T); p!=NULL; p=NextNode(p)){visit(p);}
}
中序线索二叉树找到指定结点 * p 的中序前驱 pre:
- 若
p->ltag==1,则pre = p->lchild; - 若
p->ltag==0,则 next 为 p 的左子树中最右下结点。
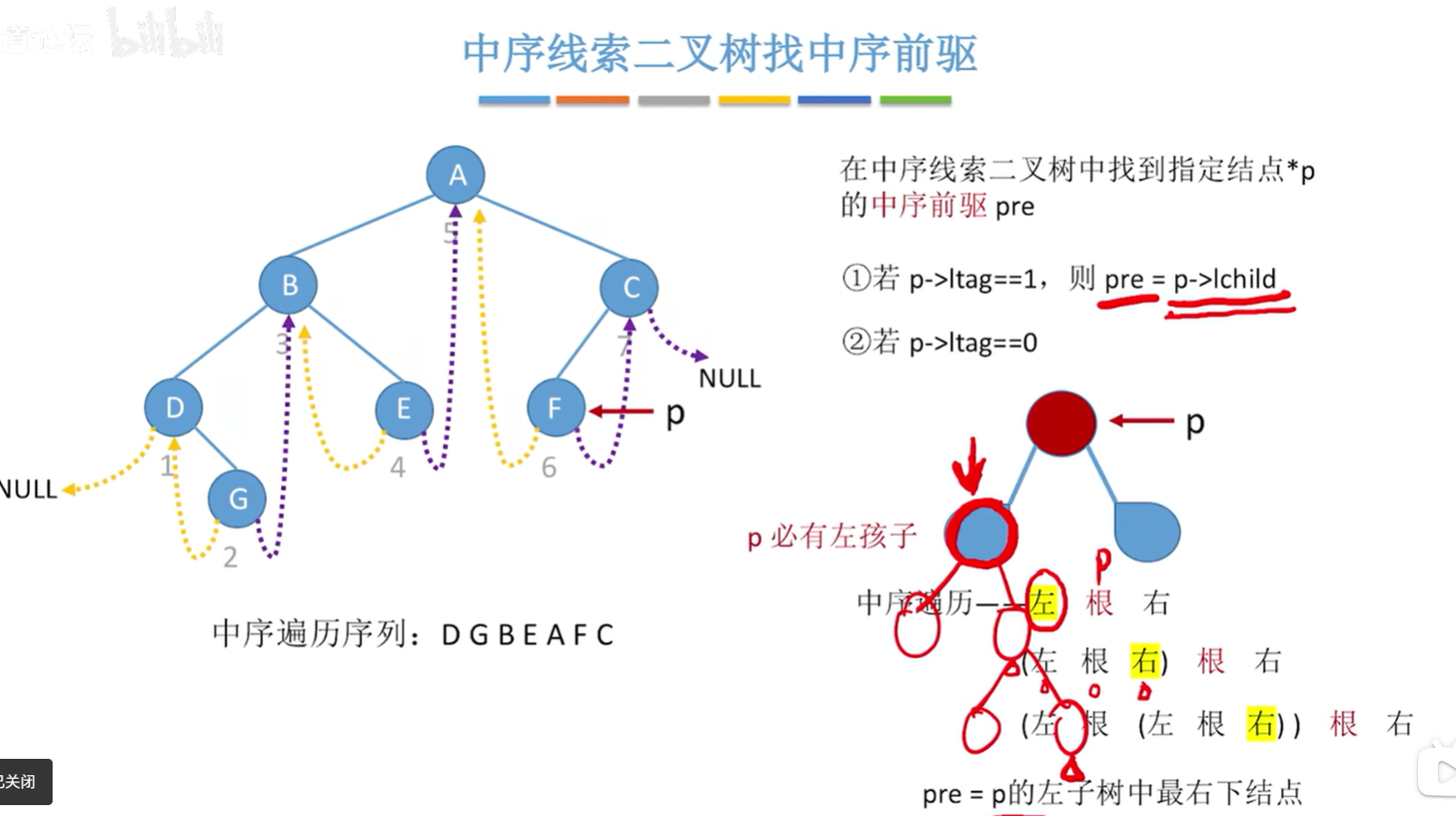
// 找到以p为根的子树中,最后一个被中序遍历的结点
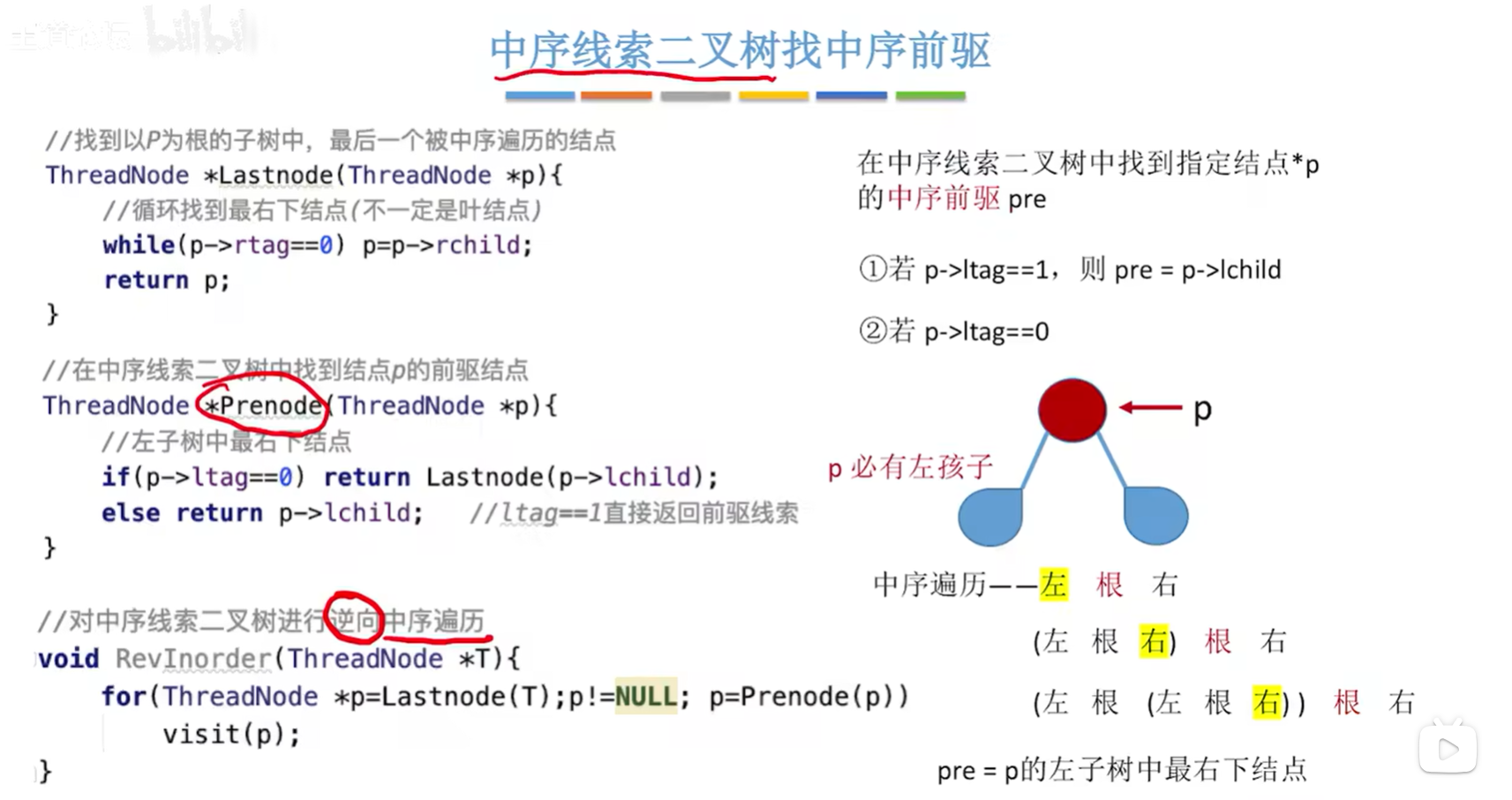
ThreadNode *LastNode(ThreadNode *p){// 循环找到最右下结点(不一定是叶结点)while(p->rtag==0)p=p->rchild;return p;
}// 在中序线索二叉树中找到结点p的前驱结点
ThreadNode *PreNode(ThreadNode *p){// 左子树中最右下的结点if(p->ltag==0)return LastNode(p->lchild);elsereturn p->lchild;
}// 对中序线索二叉树进行中序循环(非递归方法实现)
void RevOrder(ThreadNode *T){for(ThreadNode *p=LastNode(T); p!=NULL; p=PreNode(p))visit(p);
}
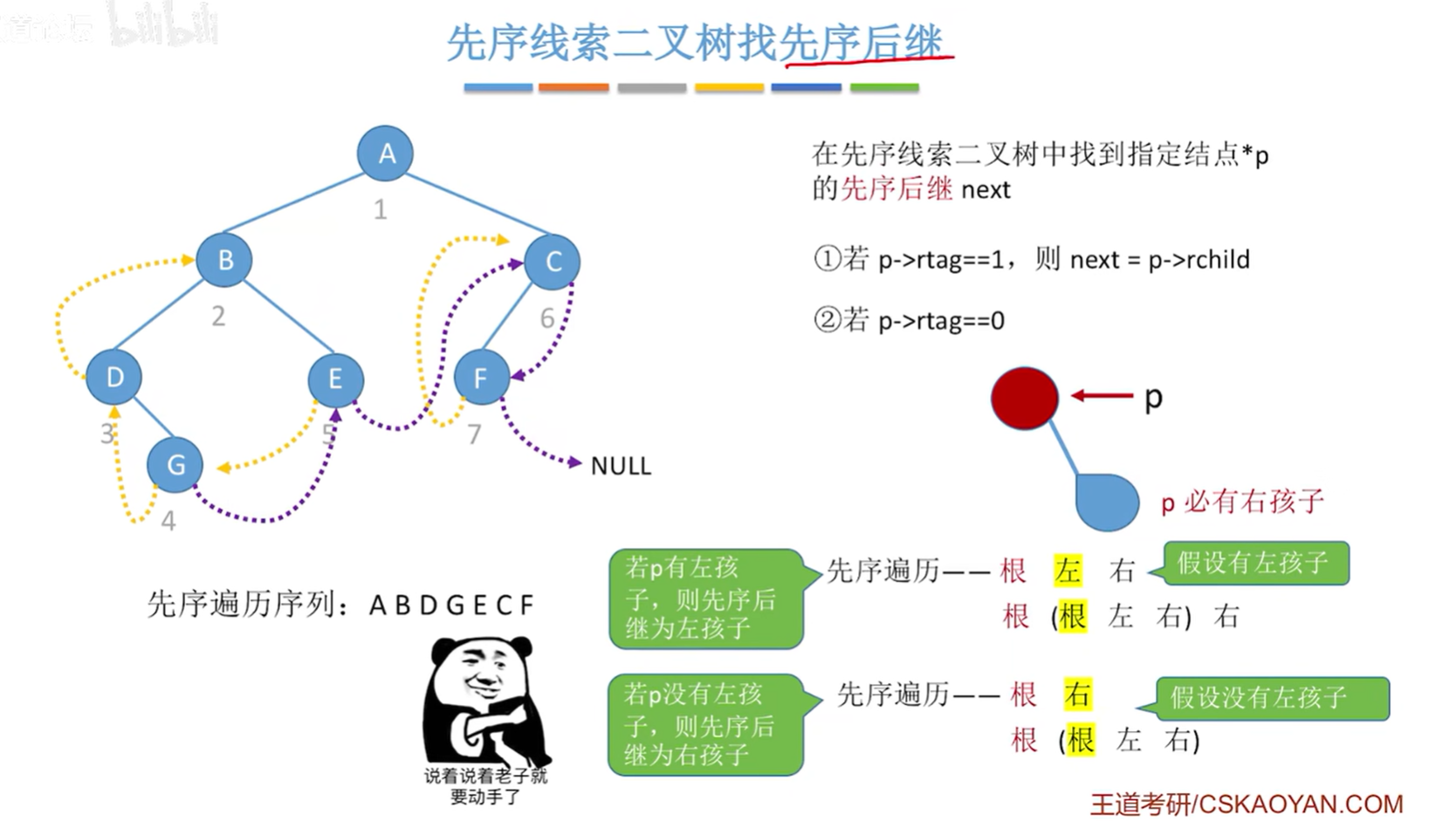
先序线索二叉树找到指定结点 * p 的先序后继 next:
-
若
p->rtag==1,则next = p->rchild; -
若p->rtag==0:
- 若 p 有左孩子,则先序后继为左孩子;
- 若 p 没有左孩子,则先序后继为右孩子。
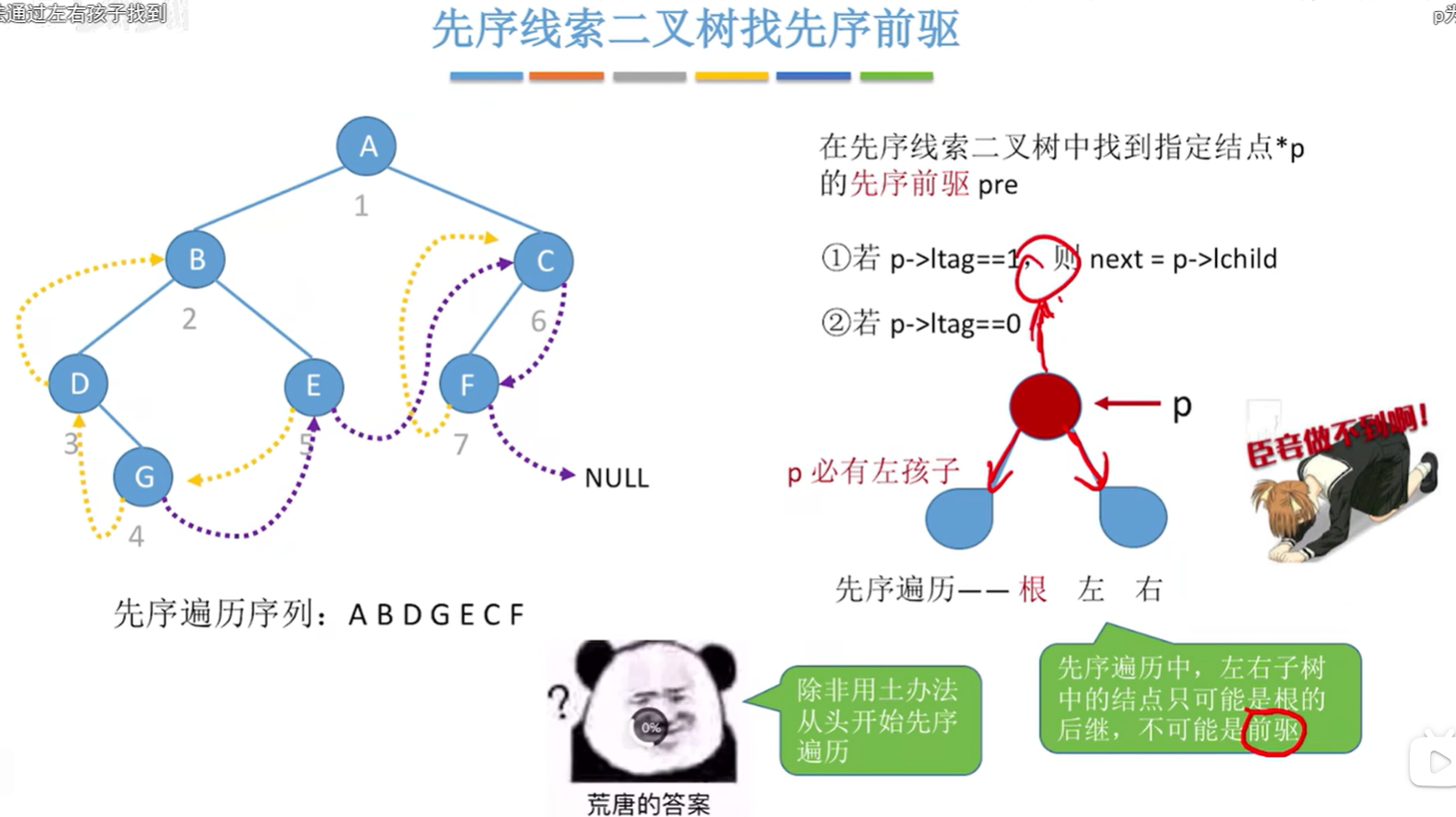
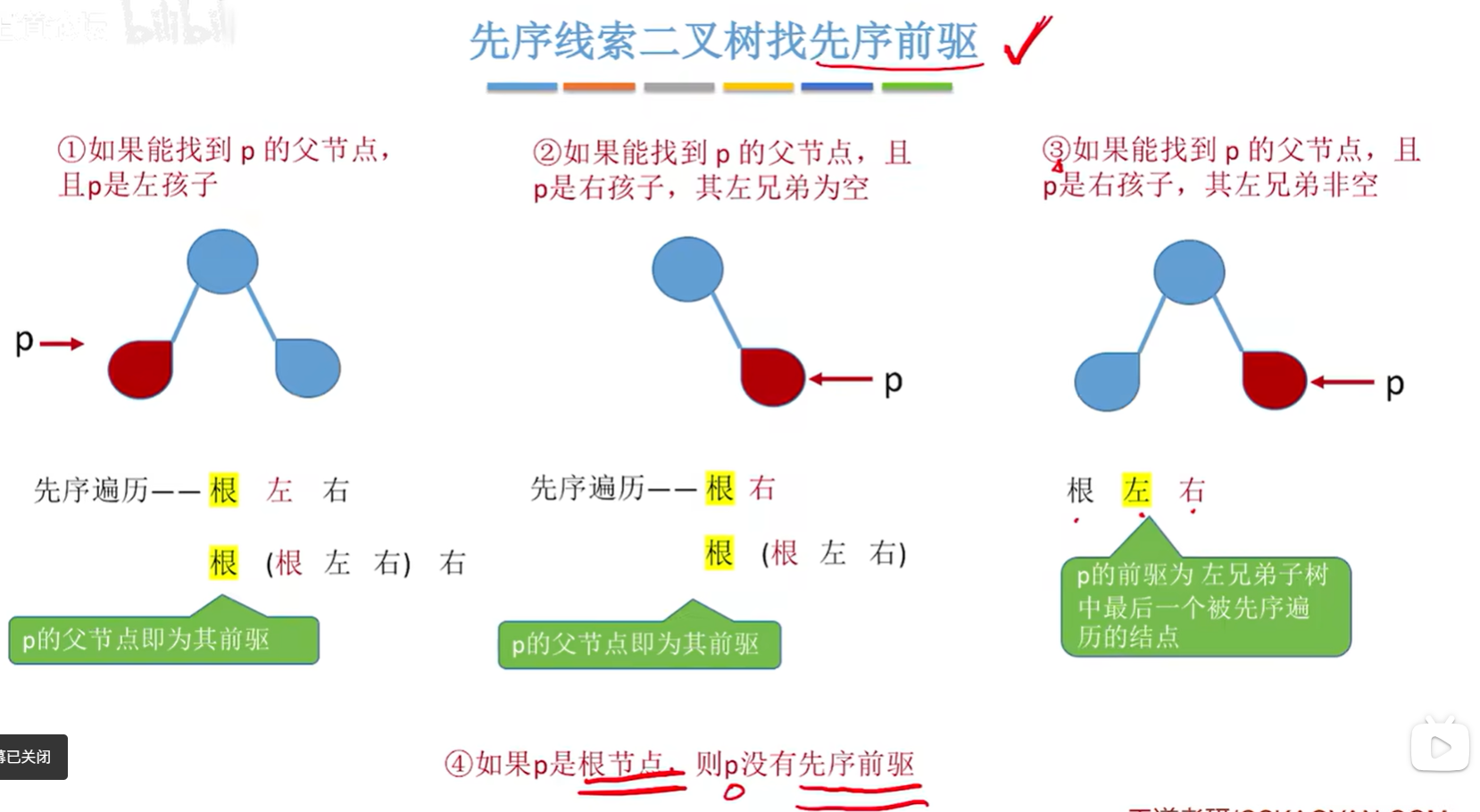
先序线索二叉树找到指定结点 * p 的先序前驱 pre:
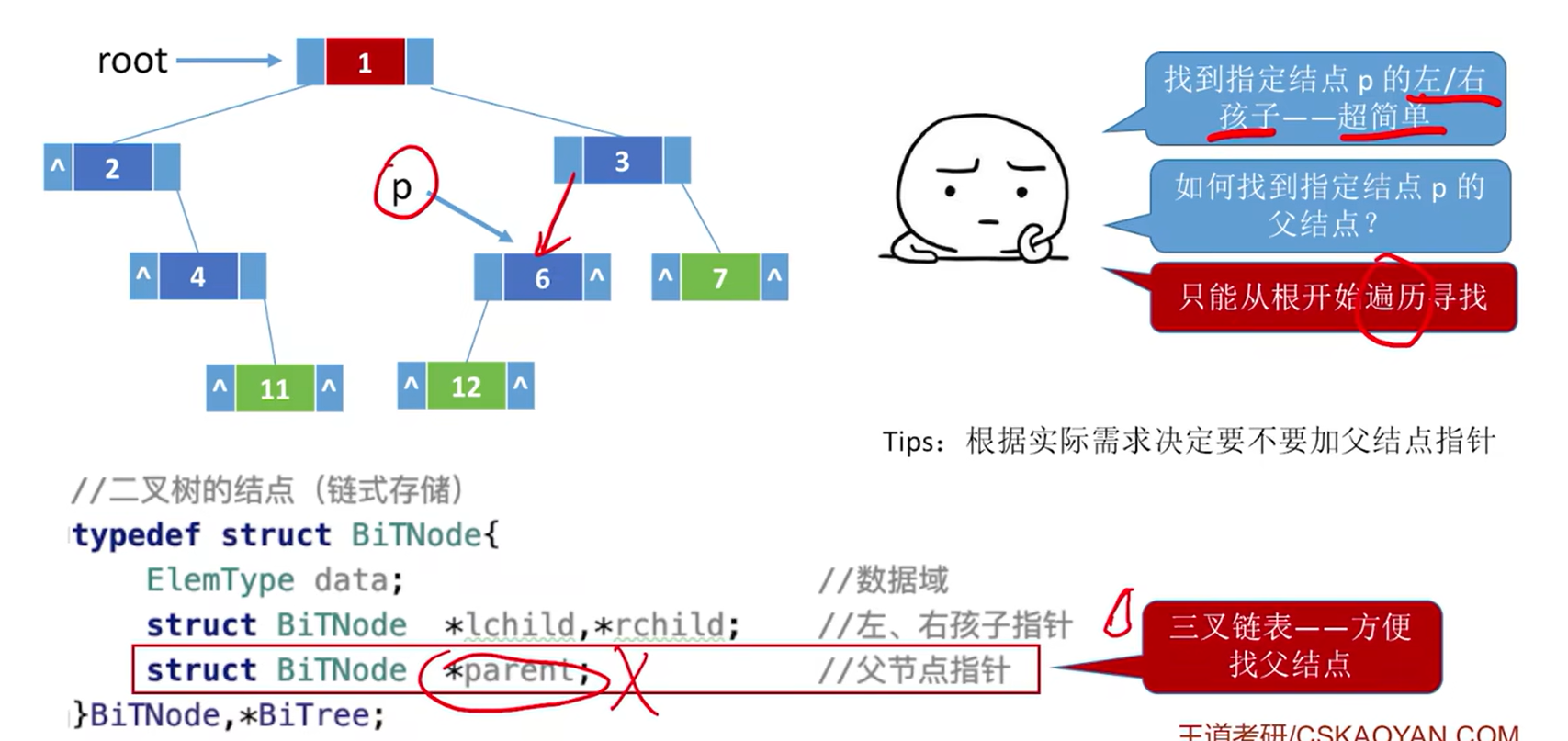
- 前提:改用三叉链表,可以找到结点 * p 的父节点。如果找不到父节点,p结点本身也不是左孩子是一颗子树而不是叶子的话,就找不到先序前驱
- 如果能找到 p 的父节点,且 p 是左孩子:p 的父节点即为其前驱;
- 如果能找到 p 的父节点,且 p 是右孩子,其左兄弟为空:p 的父节点即为其前驱;
- 如果能找到 p 的父节点,且 p 是右孩子,其左兄弟非空:p 的前驱为左兄弟子树中最后一个被先序遍历的结点;
- 如果 p 是根节点,则 p 没有先序前驱。
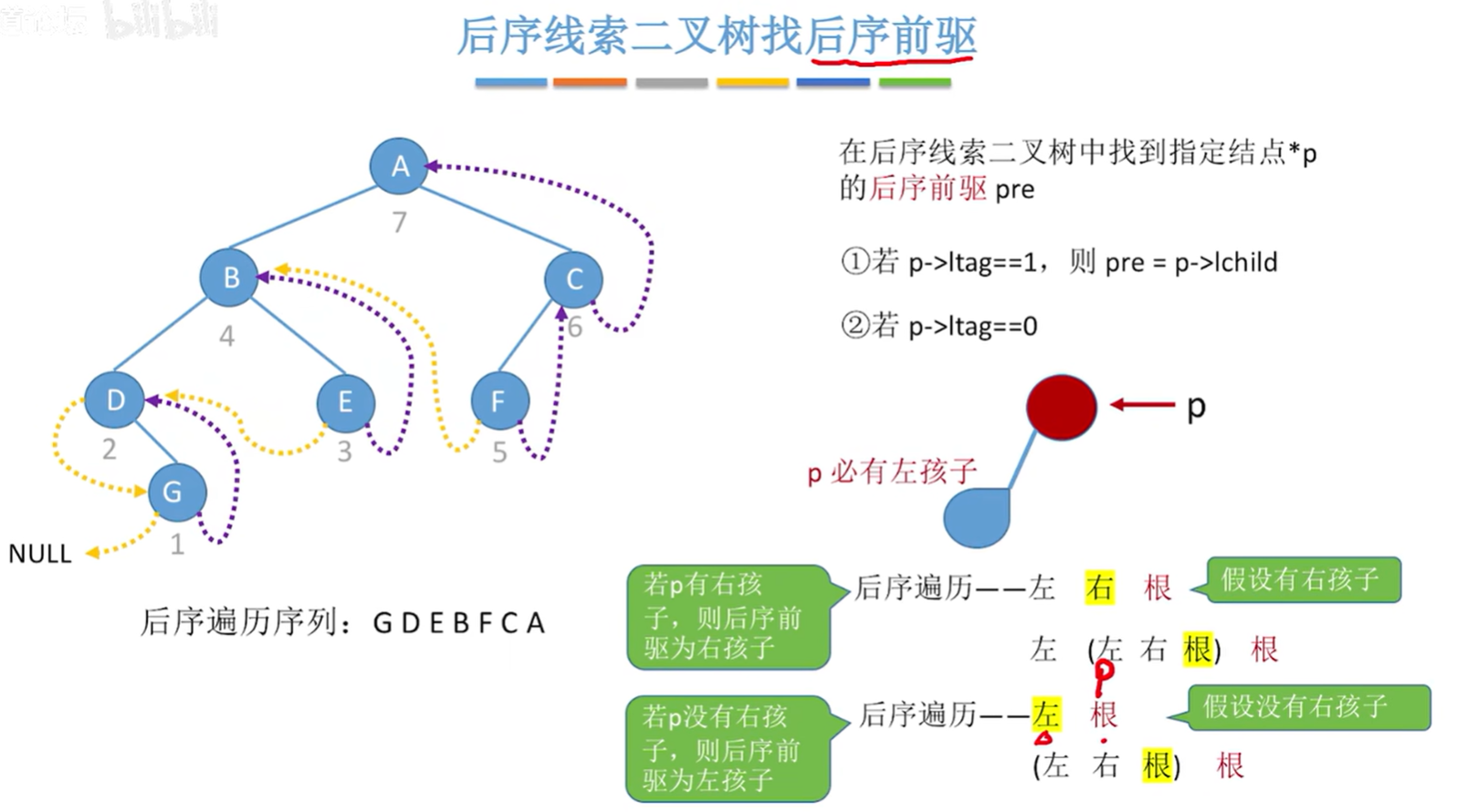
后序线索二叉树找到指定结点 * p 的后序前驱 pre:
- 若p->ltag==1,则pre = p->lchild;
- 若p->ltag==0:
- 若 p 有右孩子,则后序前驱为右孩子;
- 若 p 没有右孩子,则后续前驱为右孩子。
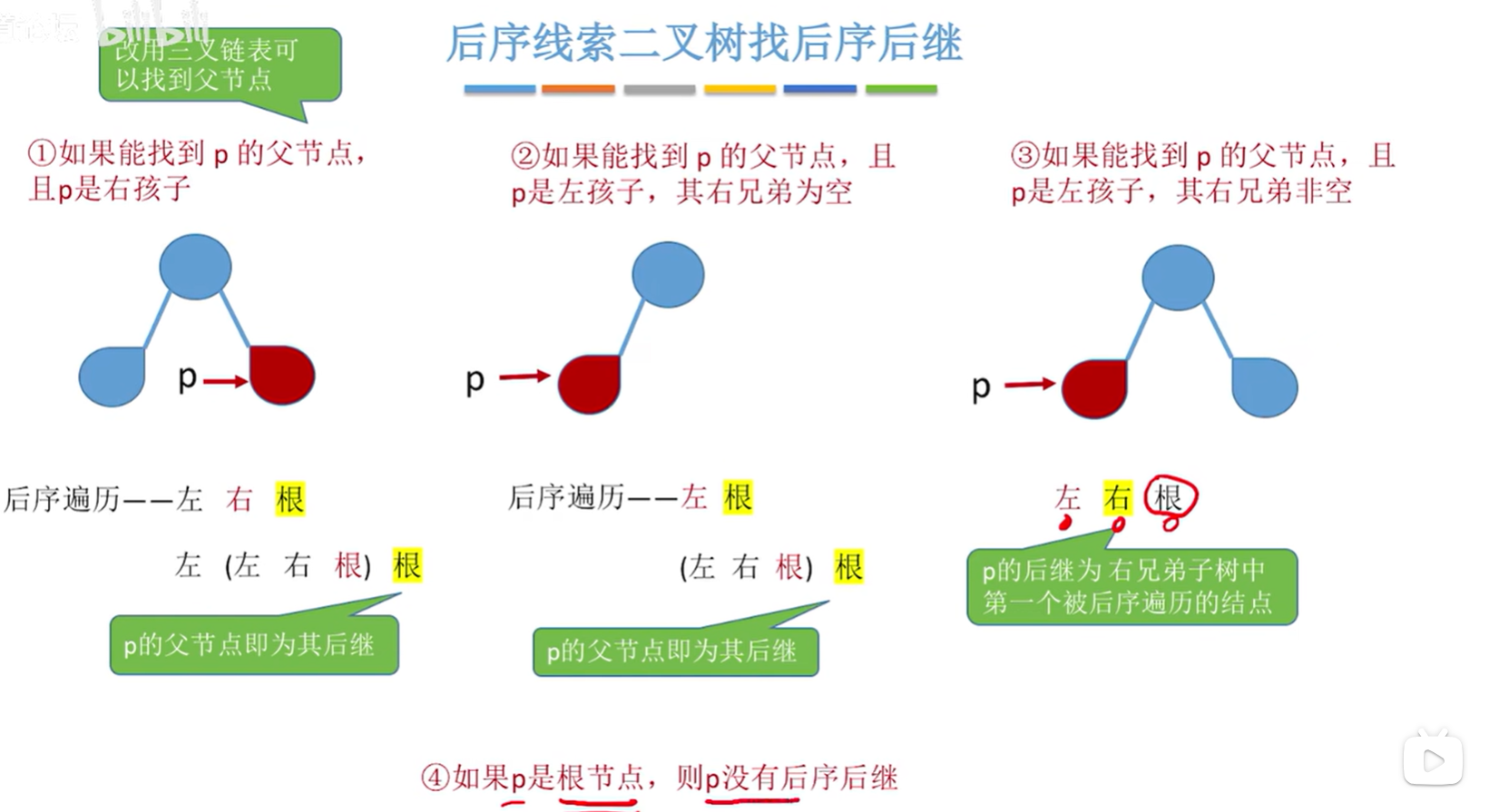
后序线索二叉树找到指定结点 * p 的后序后继 next:
- 前提:改用三叉链表,可以找到结点 * p 的父节点。
- 如果能找到 p 的父节点,且 p 是右孩子:p 的父节点即为其后继;
- 如果能找到 p 的父节点,且 p 是左孩子,其右兄弟为空:p 的父节点即为其后继;
- 如果能找到 p 的父节点,且 p 是左孩子,其右兄弟非空:p 的后继为右兄弟子树中第一个被后序遍历的结点;
- 如果 p 是根节点,则 p 没有后序后继。
5.4. 树和森林
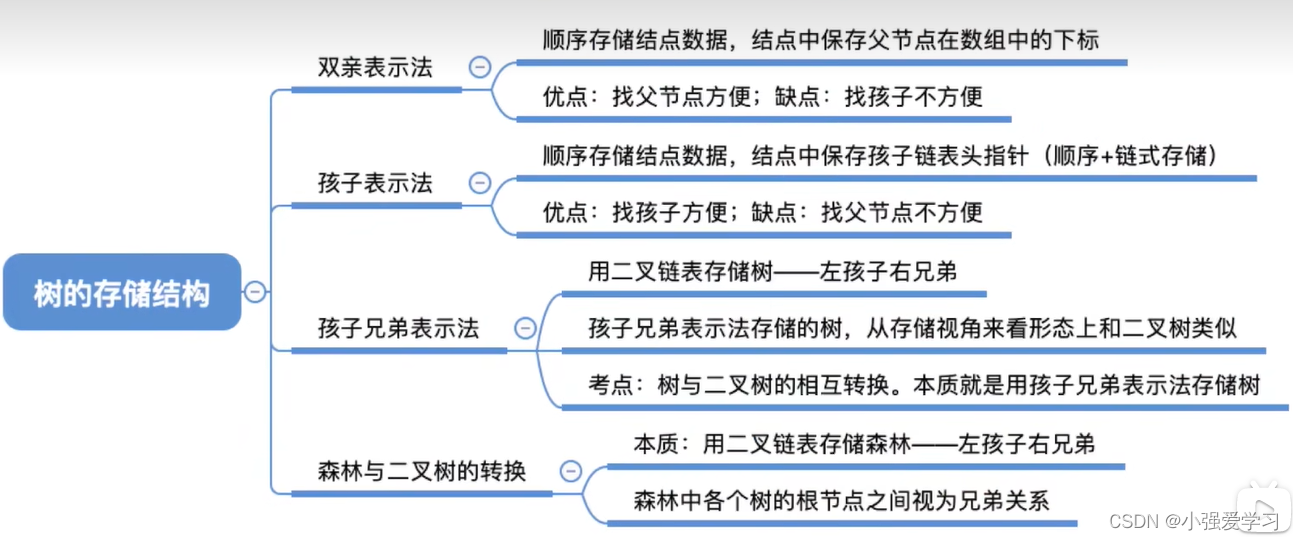
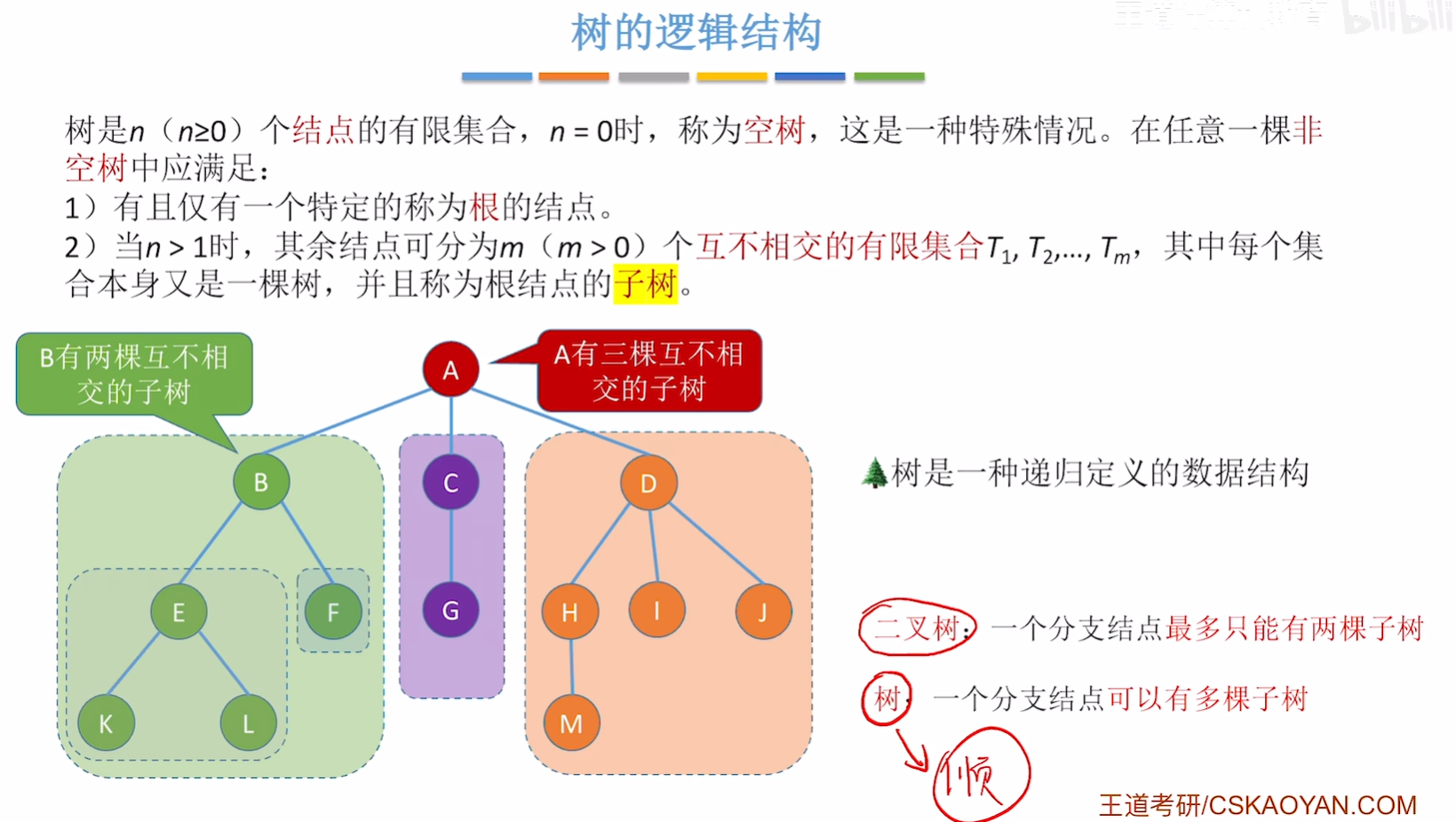
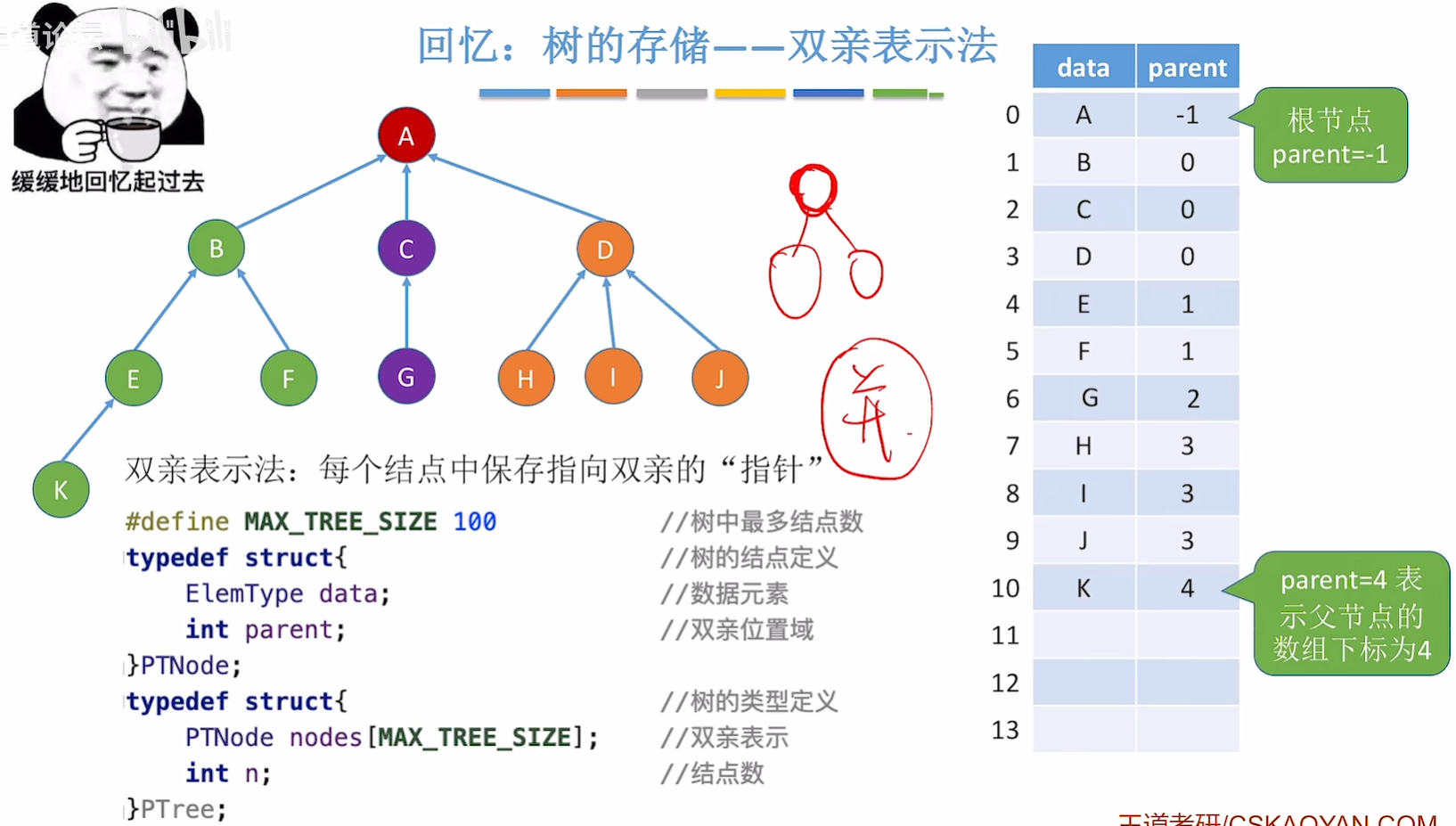
5.4.1. 树的存储结构
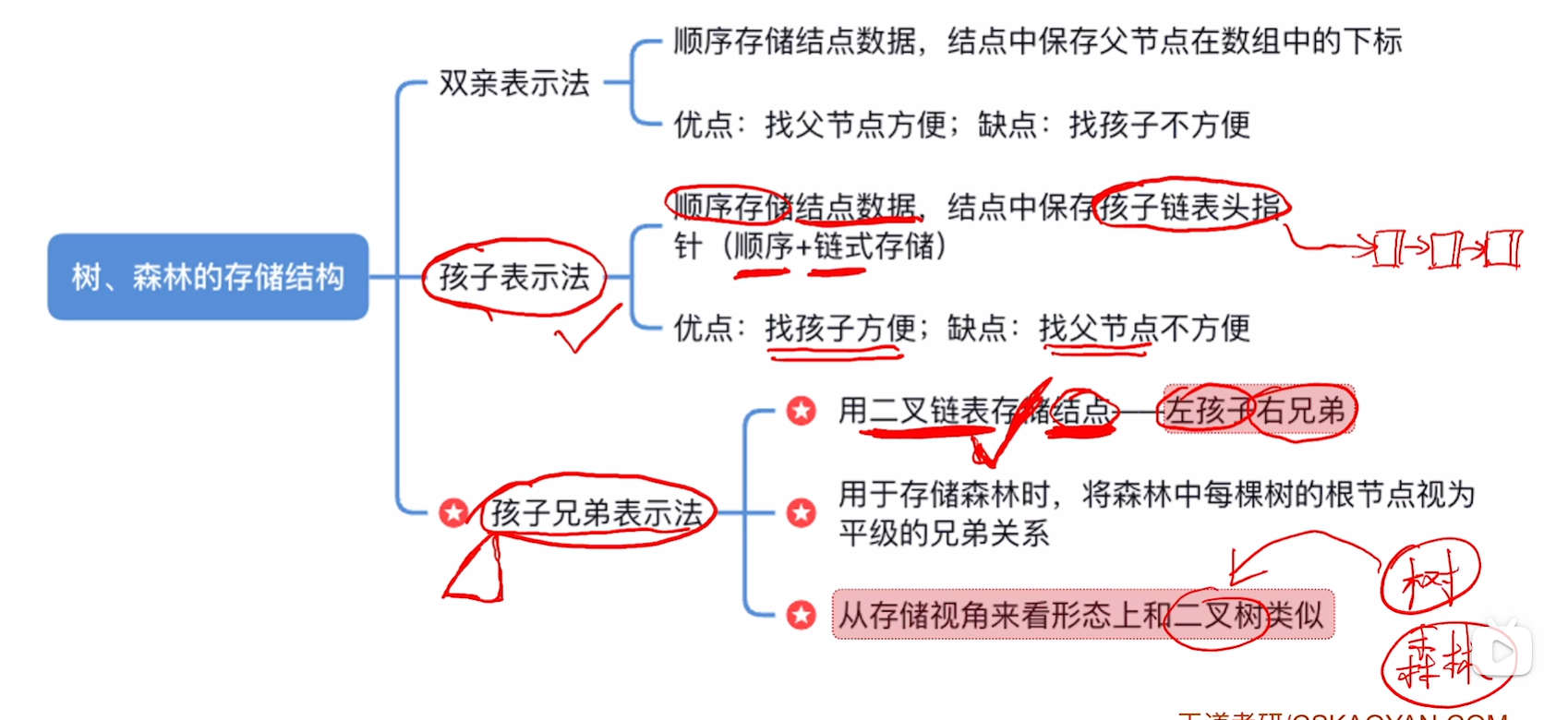
双亲表示法(顺序存储):每个结点中保存指向双亲的“指针”。
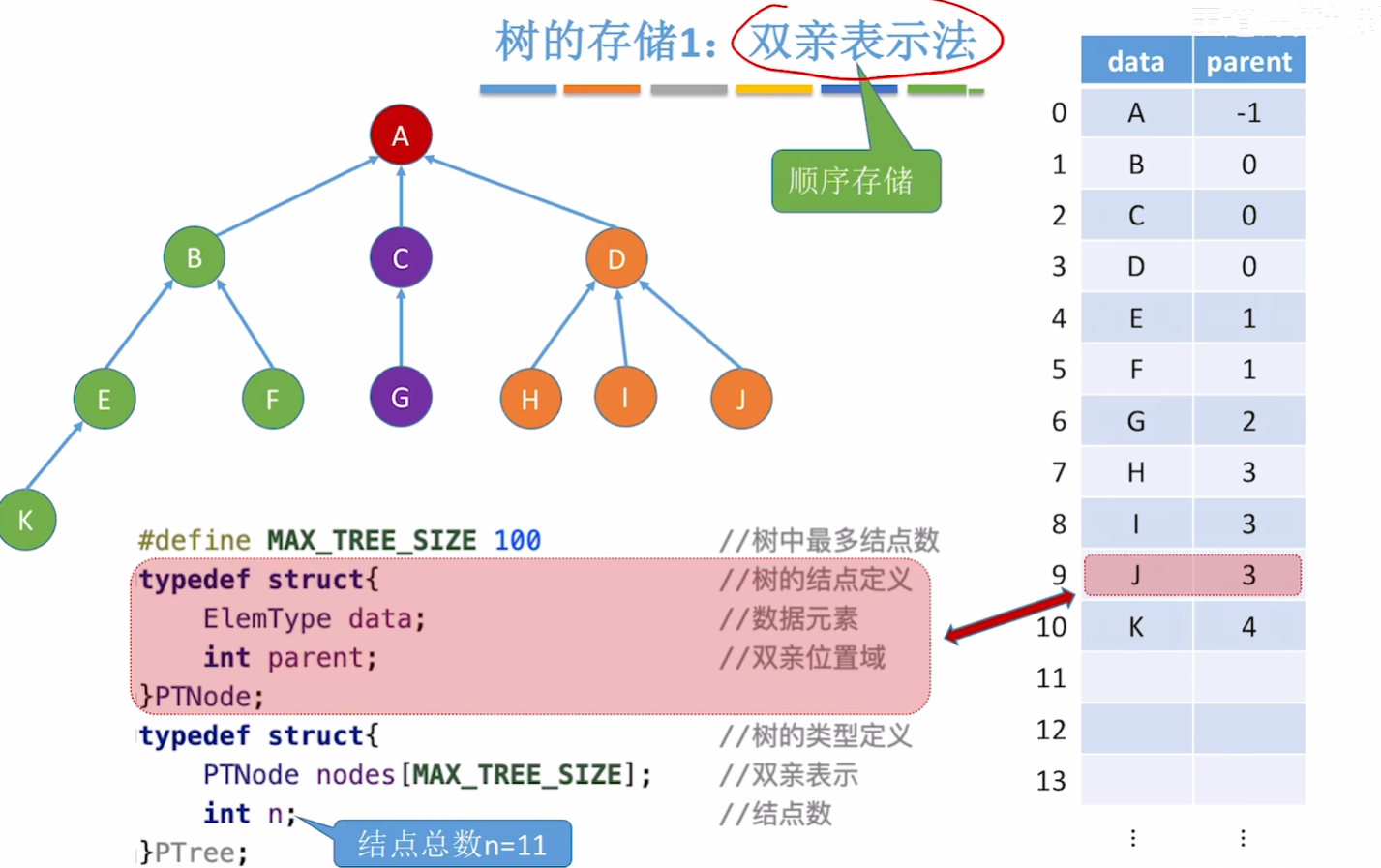
//数据域:存放结点本身信息。
//双亲域:指示本结点的双亲结点在数组中的位置。
#define MAX_TREE_SIZE 100 //树中最多结点数typedef struct{ //树的结点定义ElemType data; int parent; //双亲位置域
}PTNode;typedef struct{ //树的类型定义PTNode nodes[MAX_TREE_SIZE]; //双亲表示int n; //结点数
}PTree;
**增:**新增数据元素,无需按逻辑上的次序存储;(需要更改结点数n)
删:(叶子结点):
① 将伪指针域设置为-1;
②用后面的数据填补;(需要更改结点数n)
查询:
①优点-查指定结点的双亲很方便;
②缺点-查指定结点的孩子只能从头遍历,空数据导致遍历更慢;
优点: 查指定结点的双亲很方便
缺点:查指定结点的孩子只能从头遍历
孩子表示法(顺序+链式存储)
孩子表示法:顺序存储各个节点,每个结点中保存孩子链表头指针。
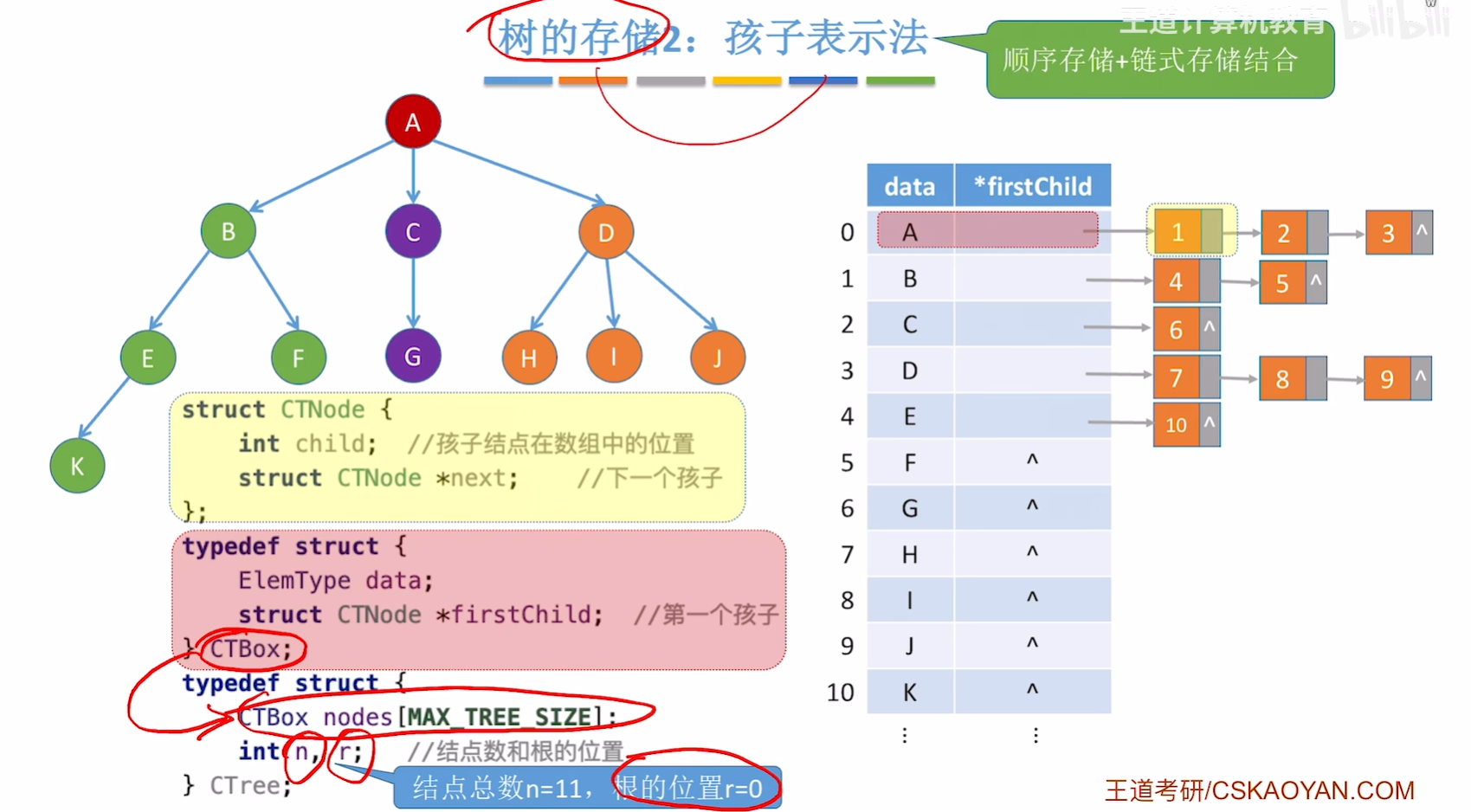
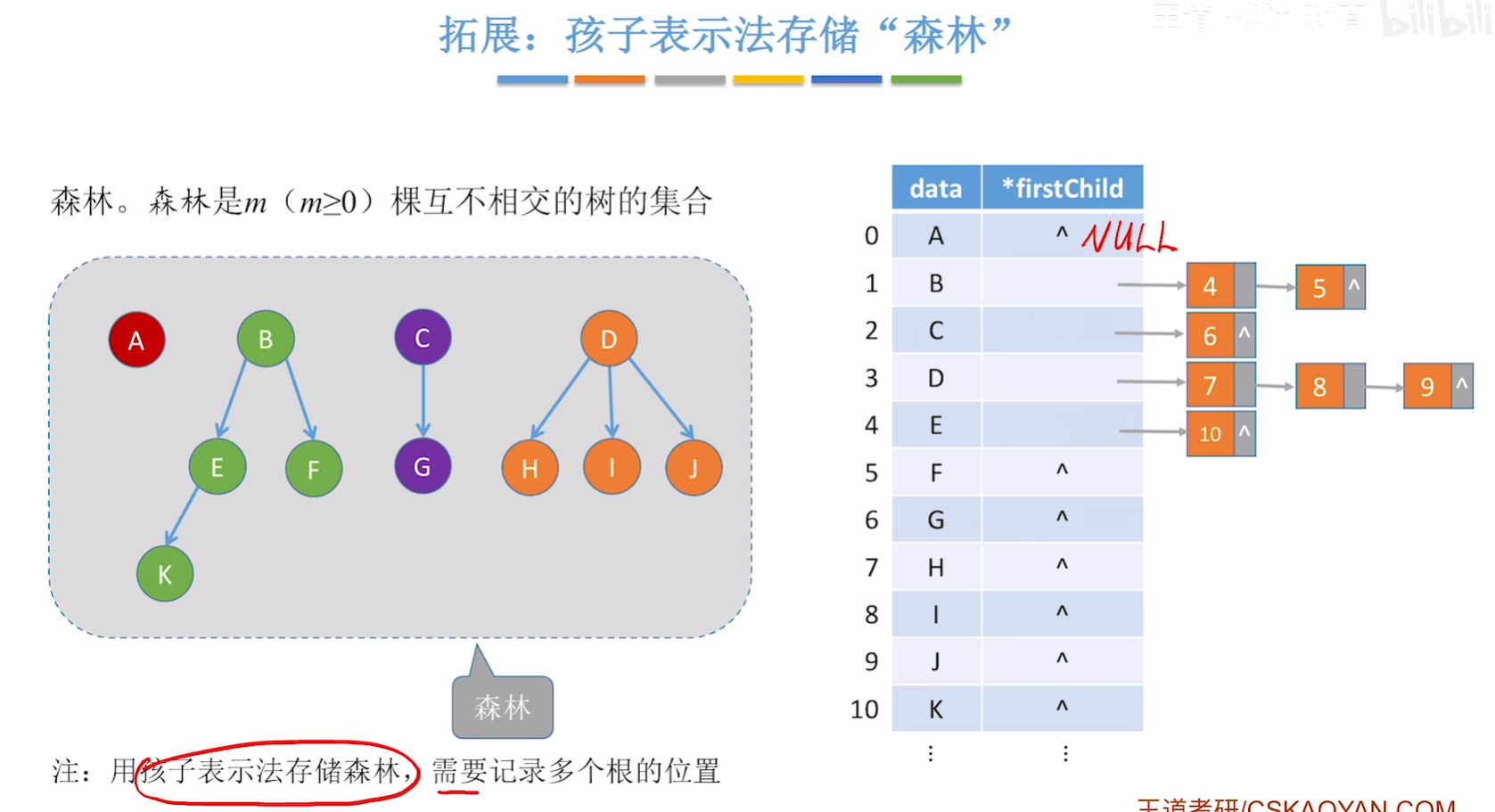
struct CTNode{int child; //孩子结点在数组中的位置struct CTNode *next; // 下一个孩子
};typedef struct{ElemType data;struct CTNode *firstChild; // 第一个孩子
}CTBox;typedef struct{CTBox nodes[MAX_TREE_SIZE];int n, r; // 结点数和根的位置
}CTree;
孩子兄弟表示法(链式存储)
用孩子兄弟表示法可以将树转换为二叉树的形式。
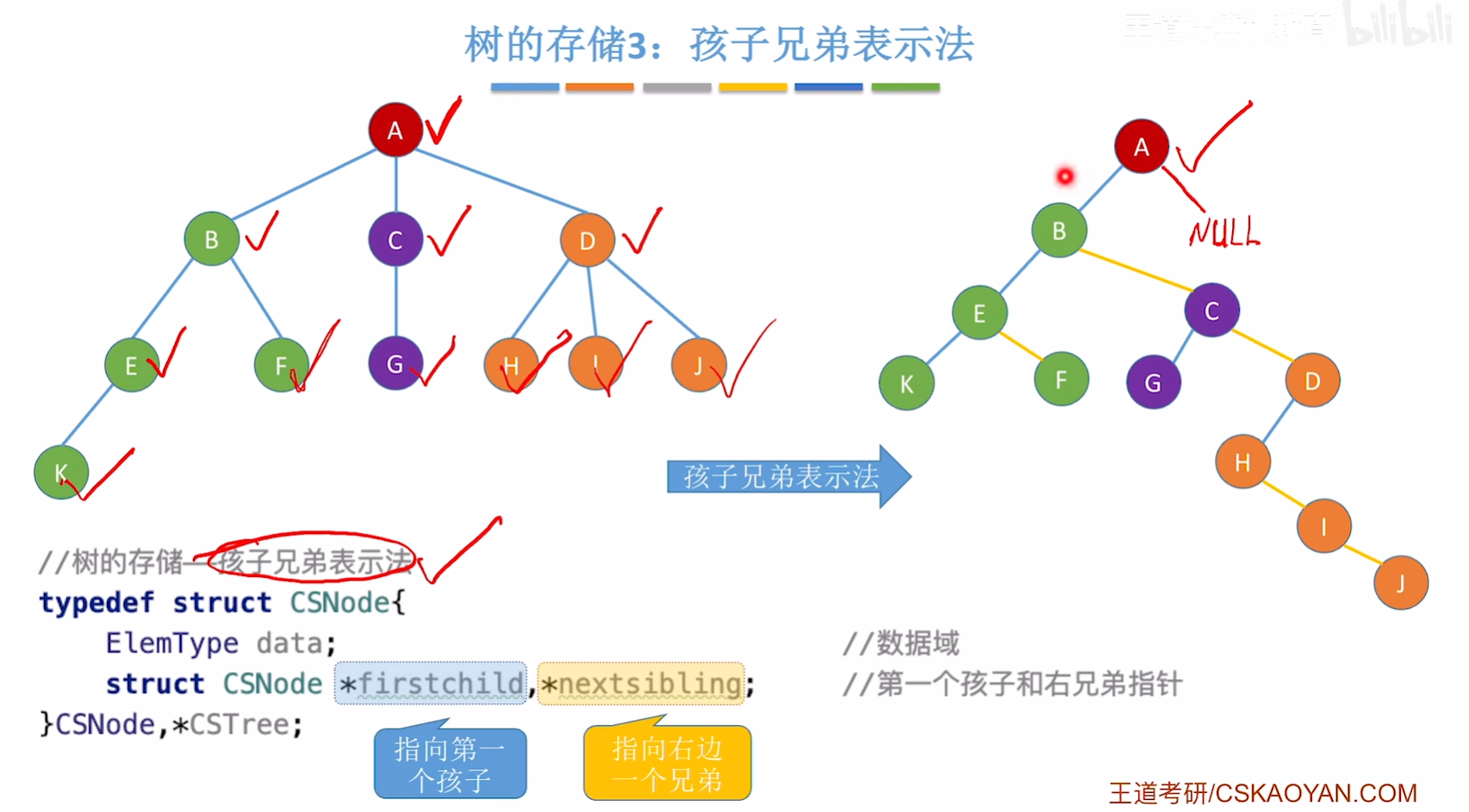
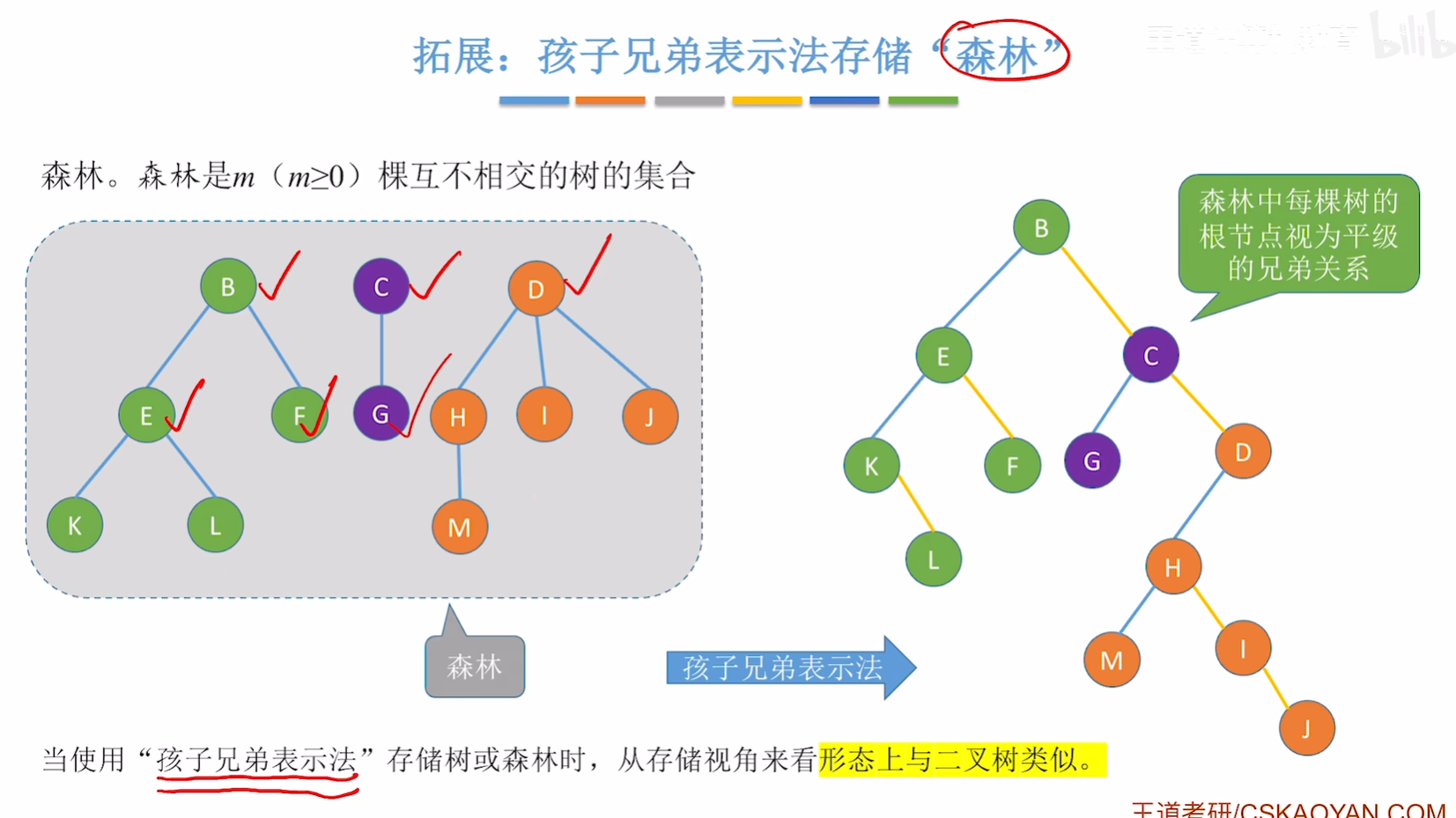
//孩子兄弟表示法结点
typedef struct CSNode{ElemType data;struct CSNode *firstchild, *nextsibling; //第一个孩子和右兄弟结点
}CSNode, *CSTree;
5.4.2. 树和森林 与二叉树之间的转换
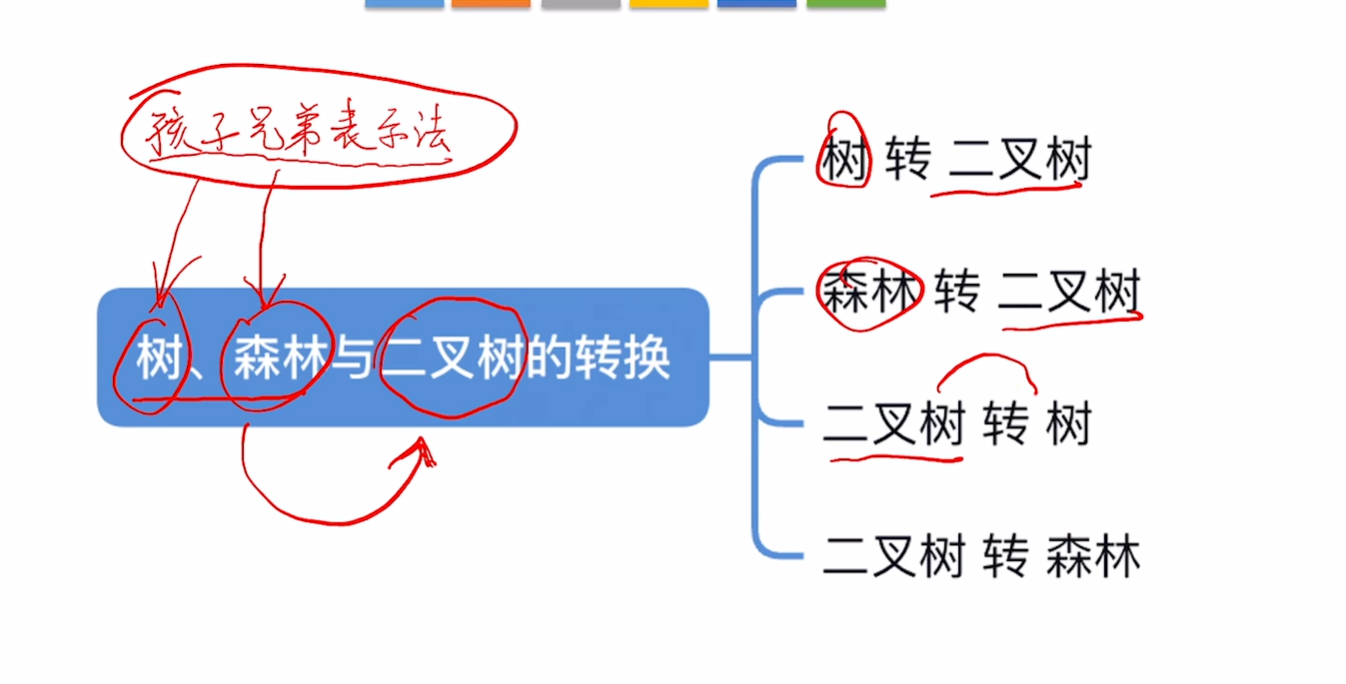
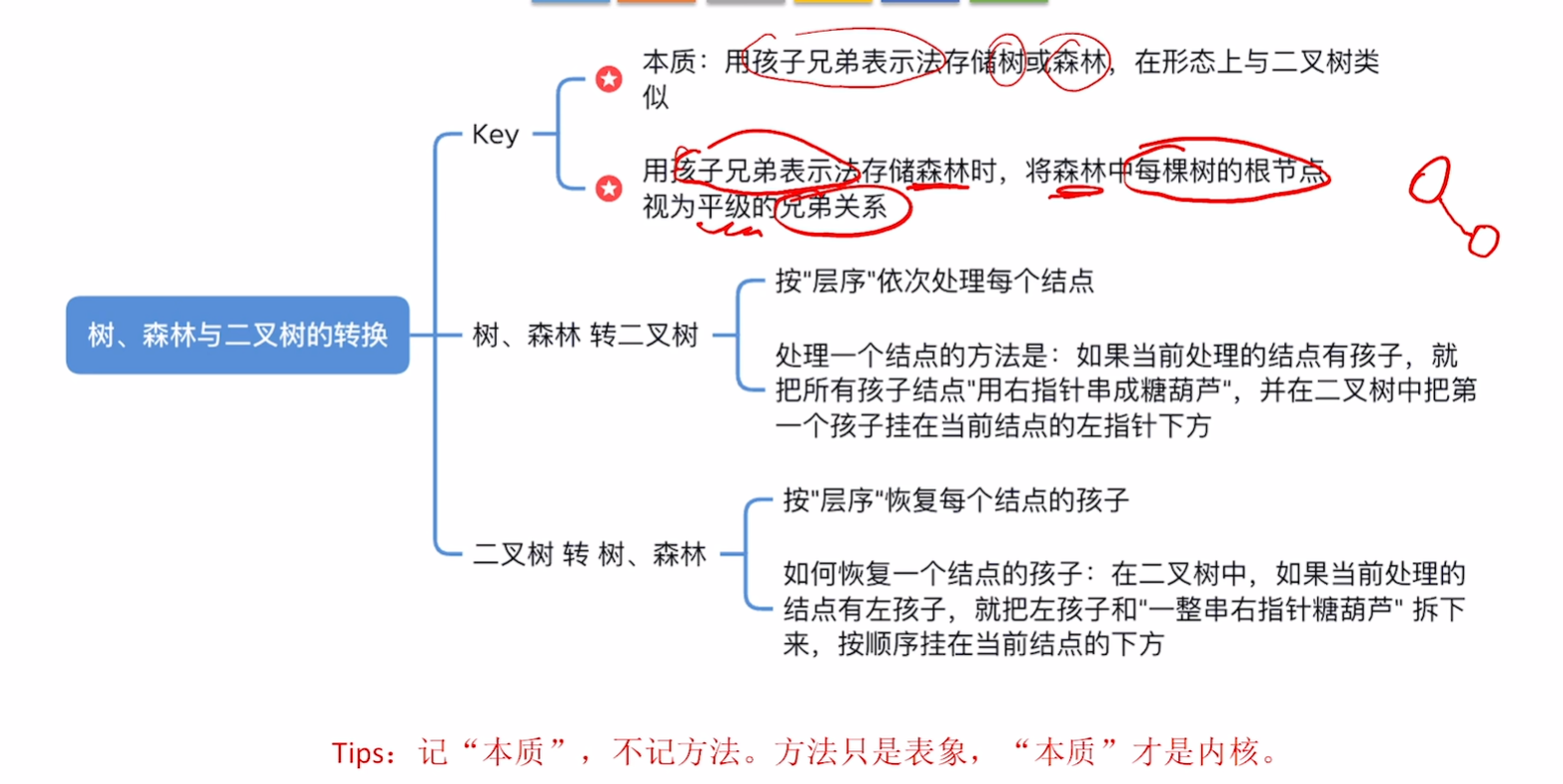
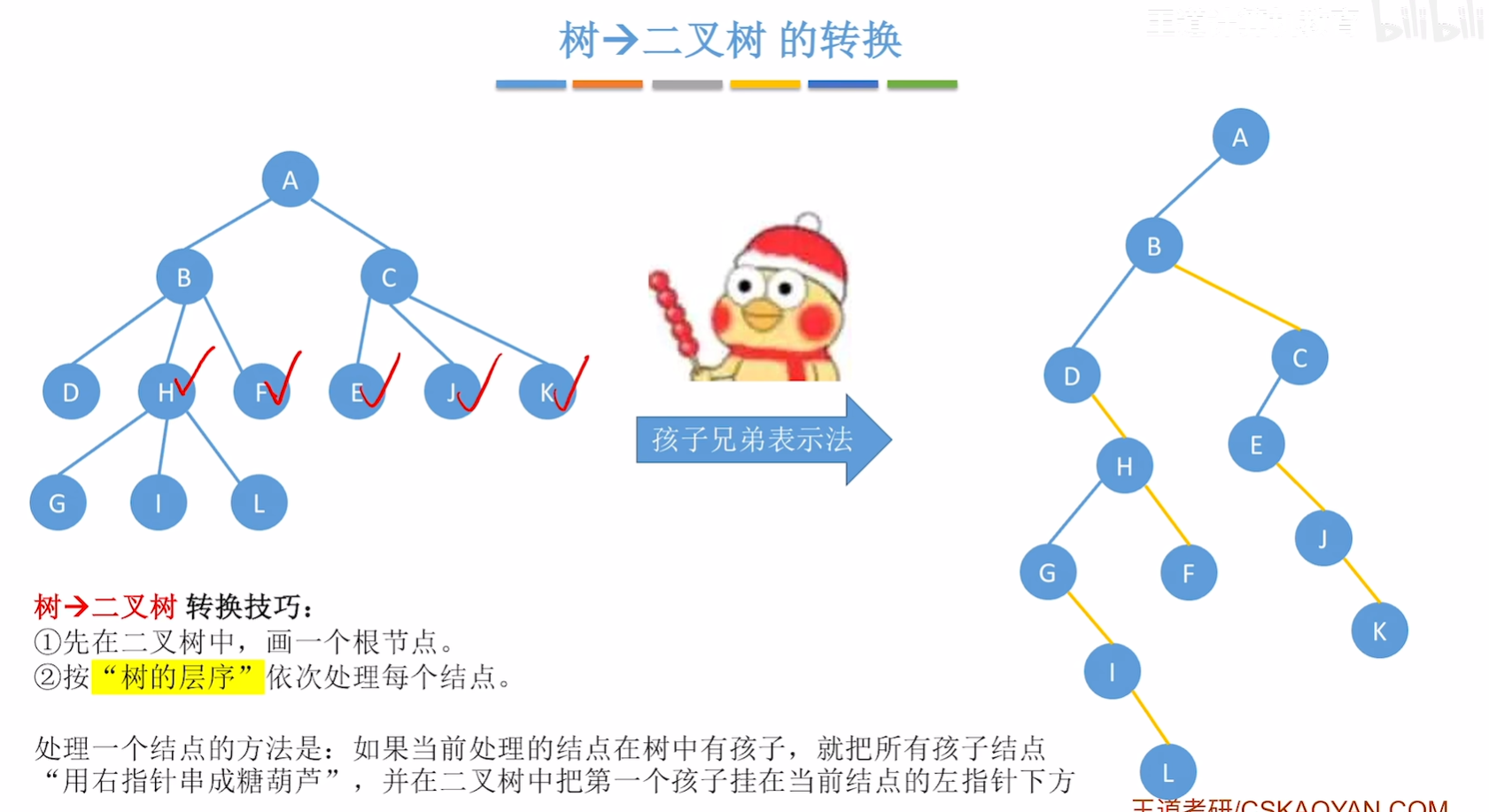
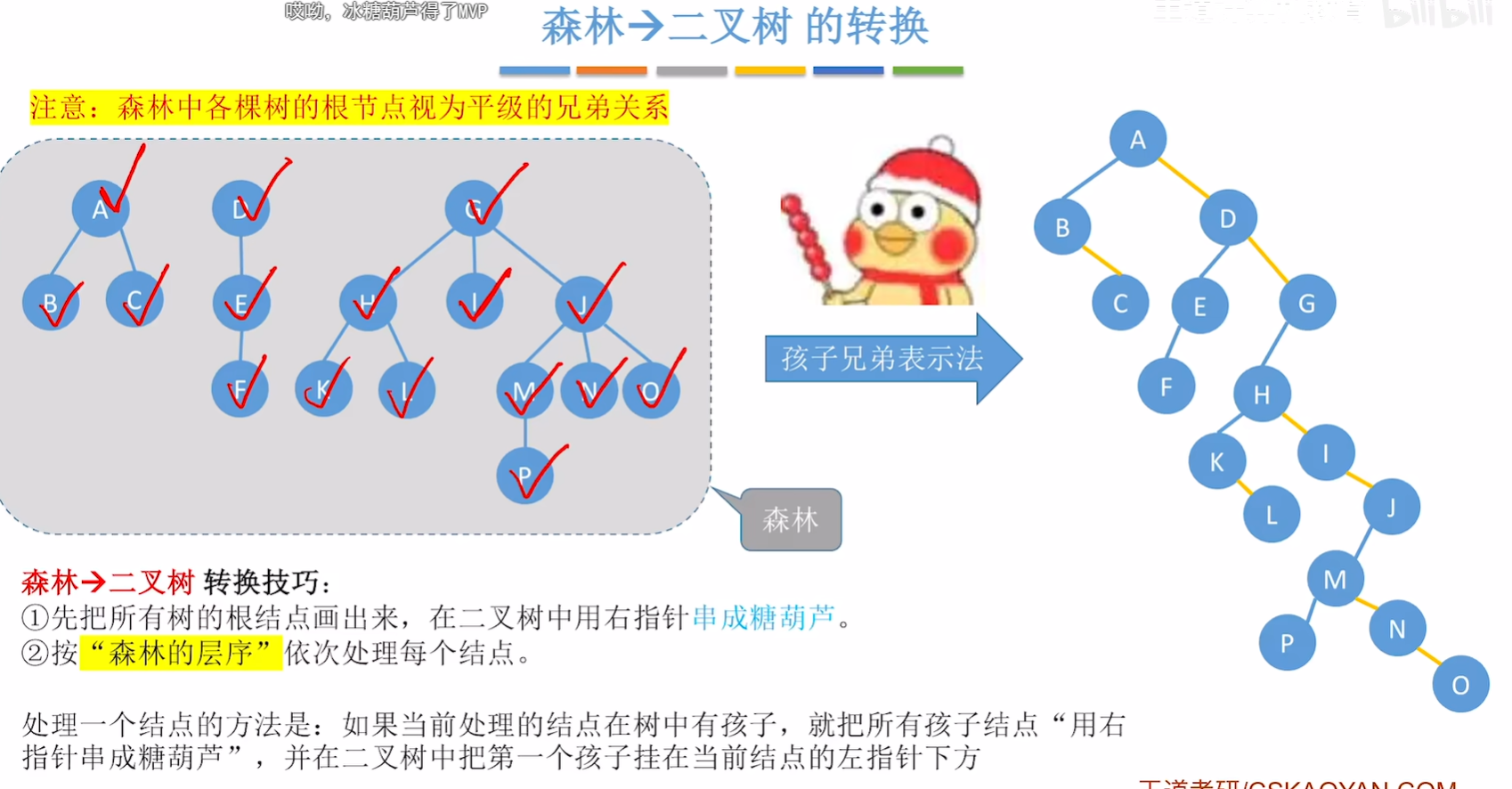
树和森林 -> 二叉树
其实就是写出来孩子兄弟表示法表示的树和森林
二叉树->树
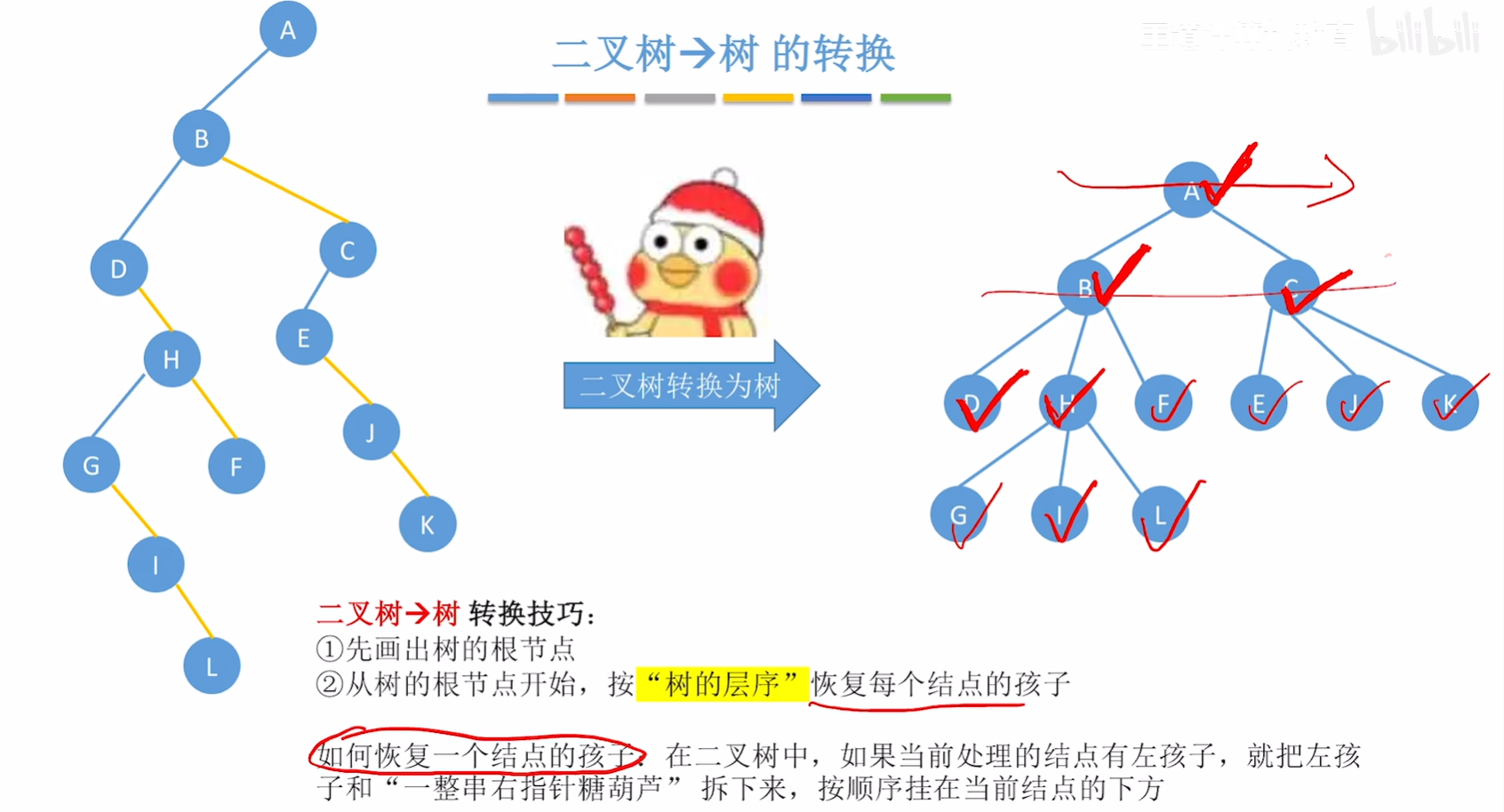
二叉树->森林
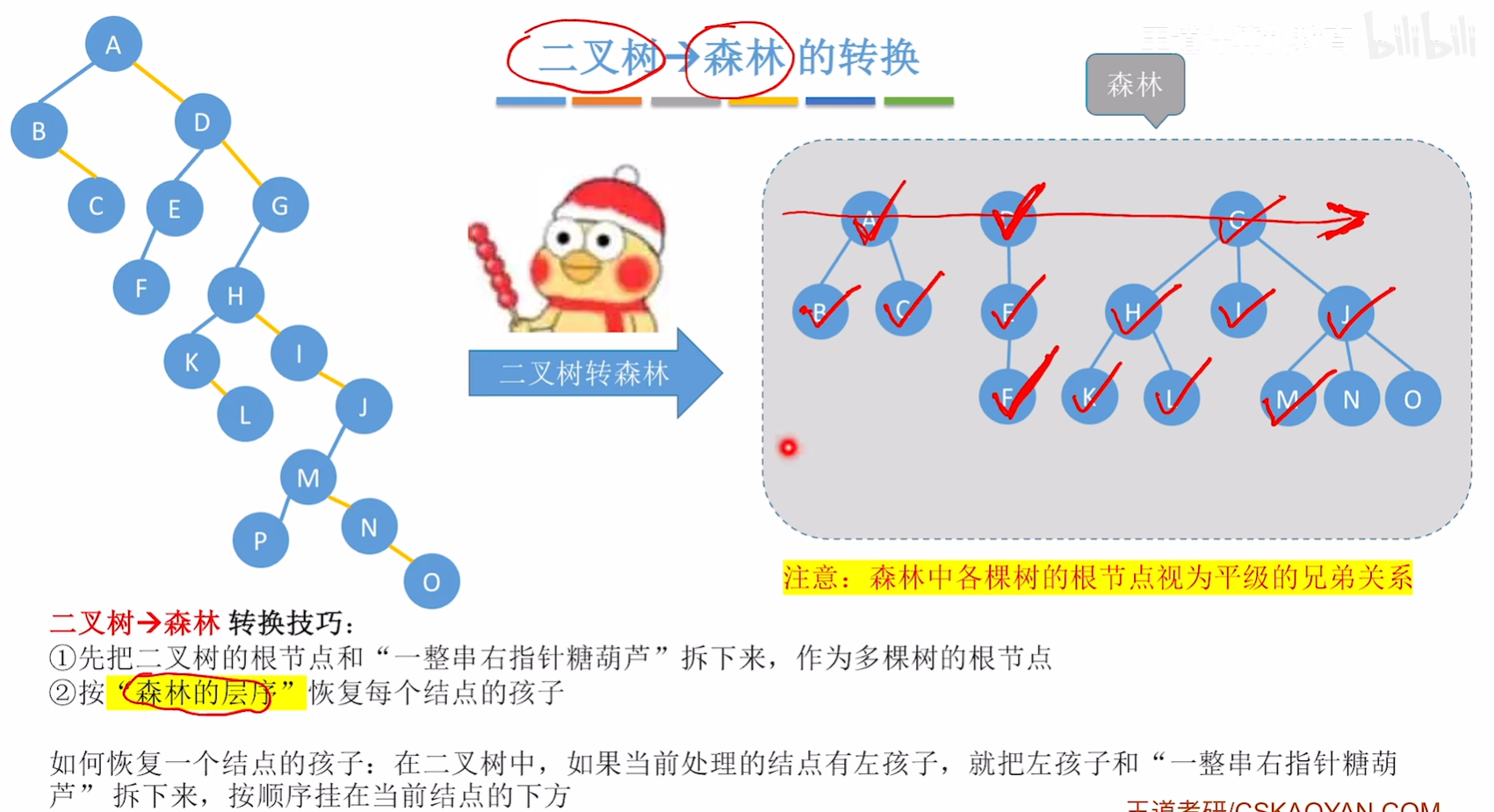
5.4.3. 树和森林的遍历
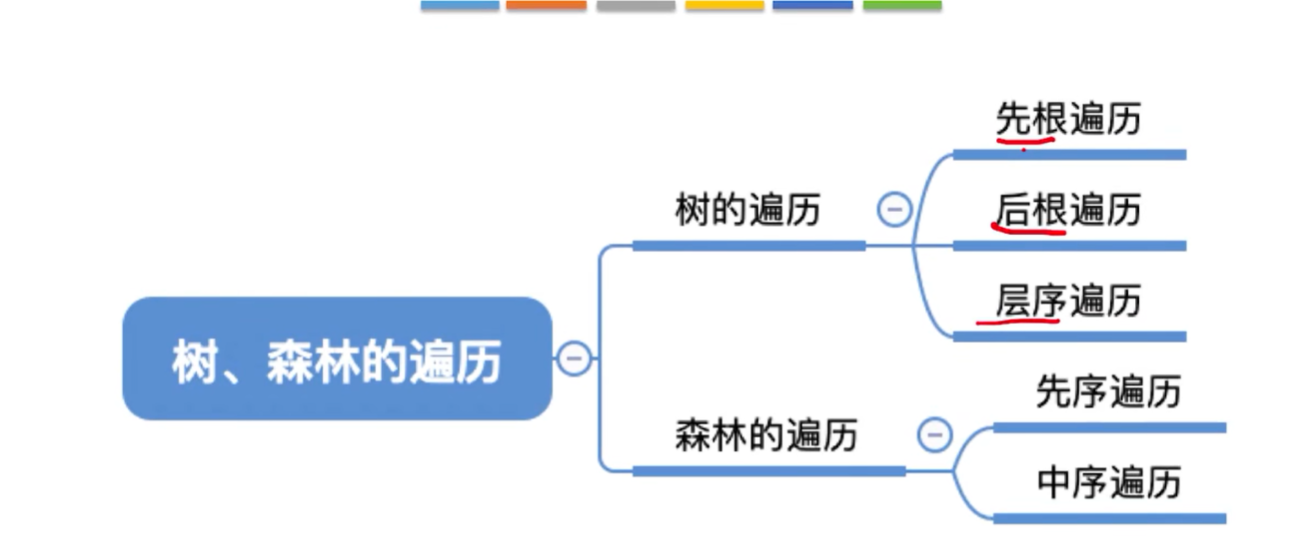
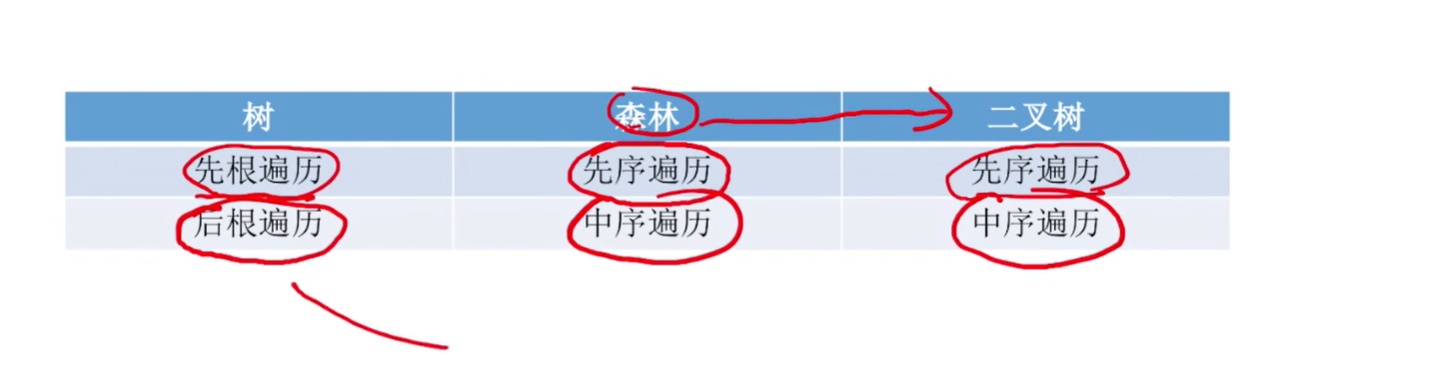
树的先根遍历
若树非空,先访问根结点,再依次对每棵子树进行先根遍历;(与对应二叉树的先序遍历序列相同)
树的先根遍历序列与这棵树相应二叉树的先序序列相同
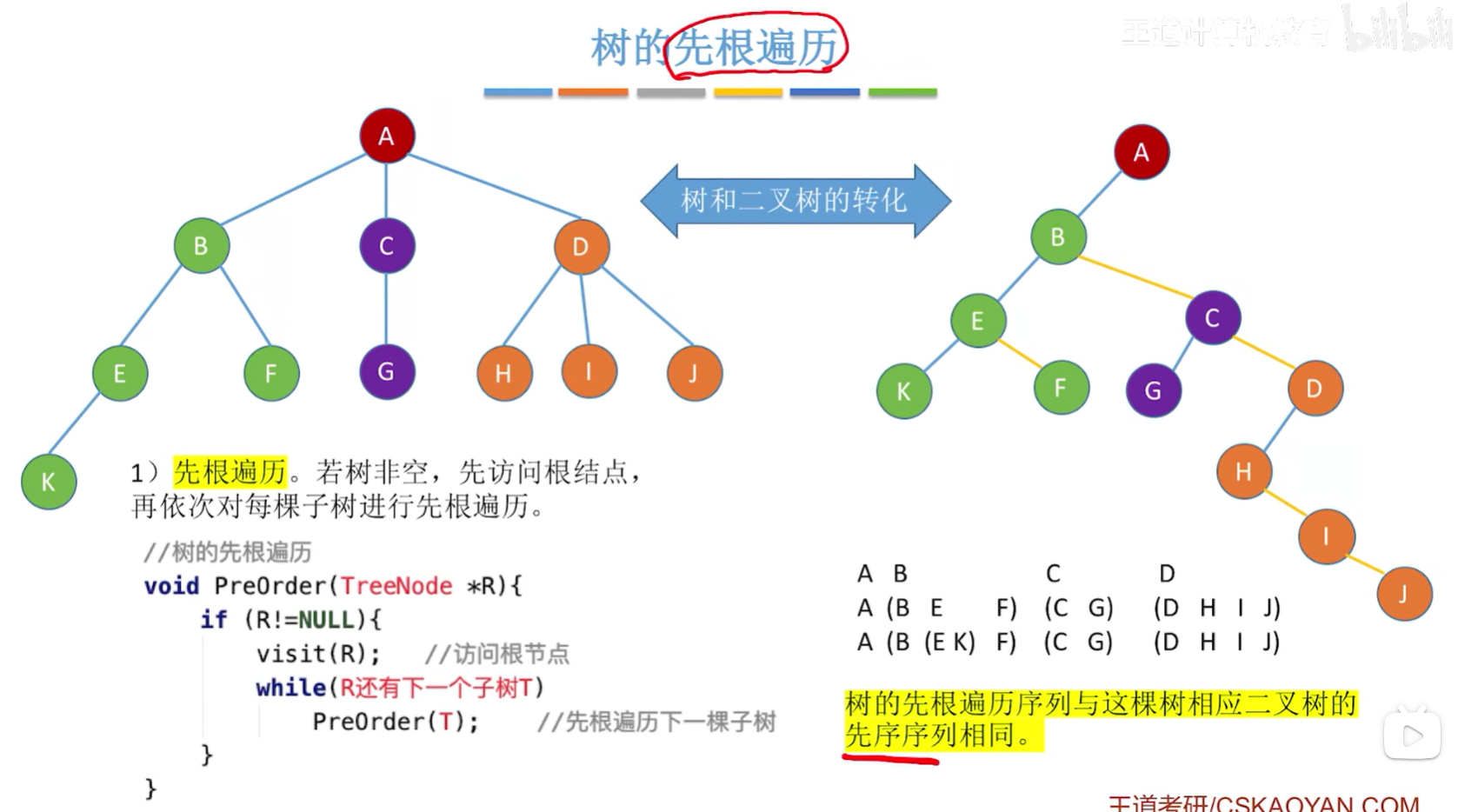
void PreOrder(TreeNode *R){if(R!=NULL){visit(R); //访问根节点while(R还有下一个子树T)PreOrder(T); //先跟遍历下一个子树}
}
树的后根遍历
若树非空,先依次对每棵子树进行后根遍历,最后再访问根结点。(深度优先遍历)
树的后根遍历序列与这棵树相应二叉树的中序序列相同
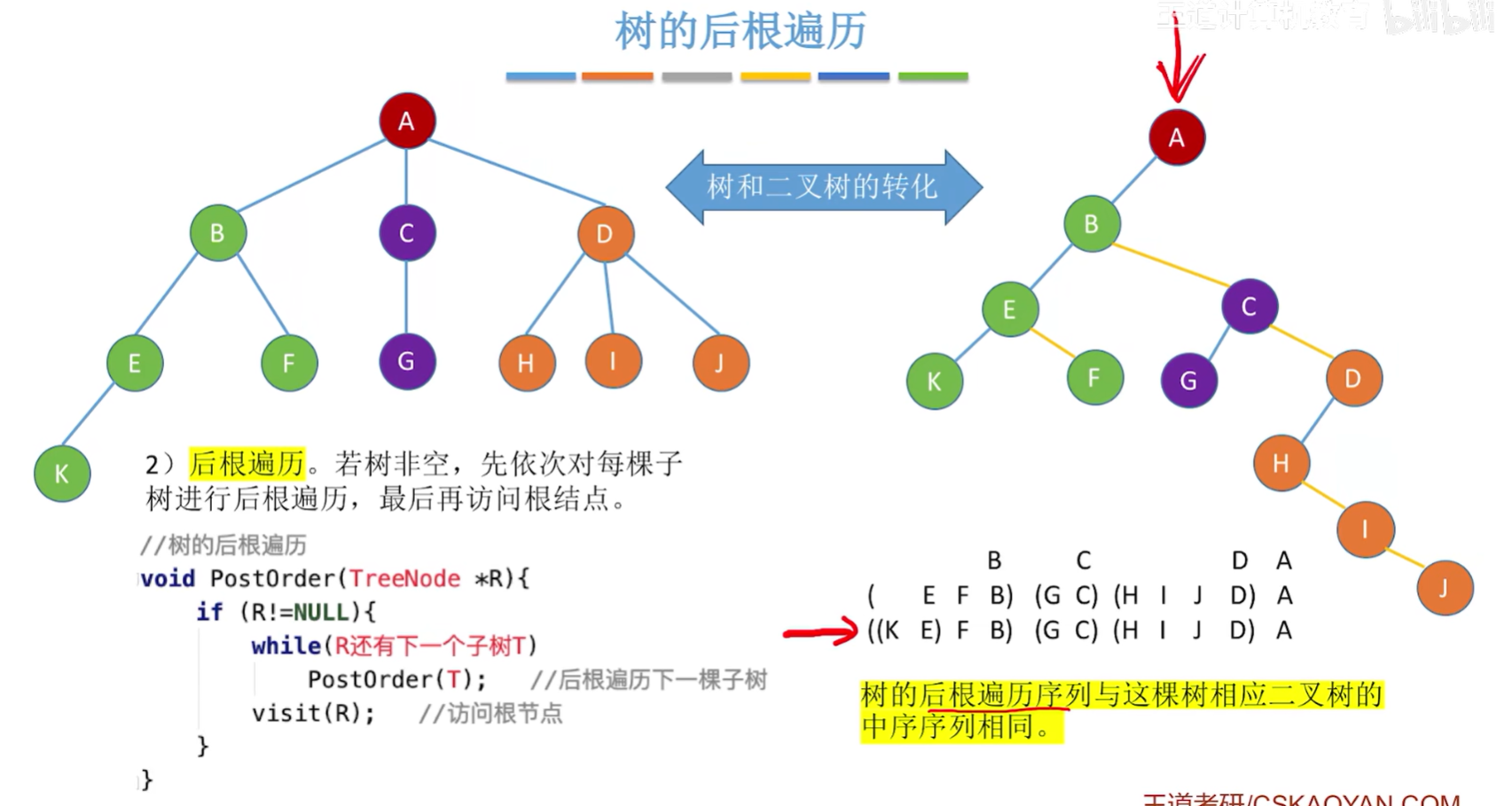
void PostOrder(TreeNode *R){if(R!=NULL){while(R还有下一个子树T)PostOrder(T); //后跟遍历下一个子树visit(R); //访问根节点}
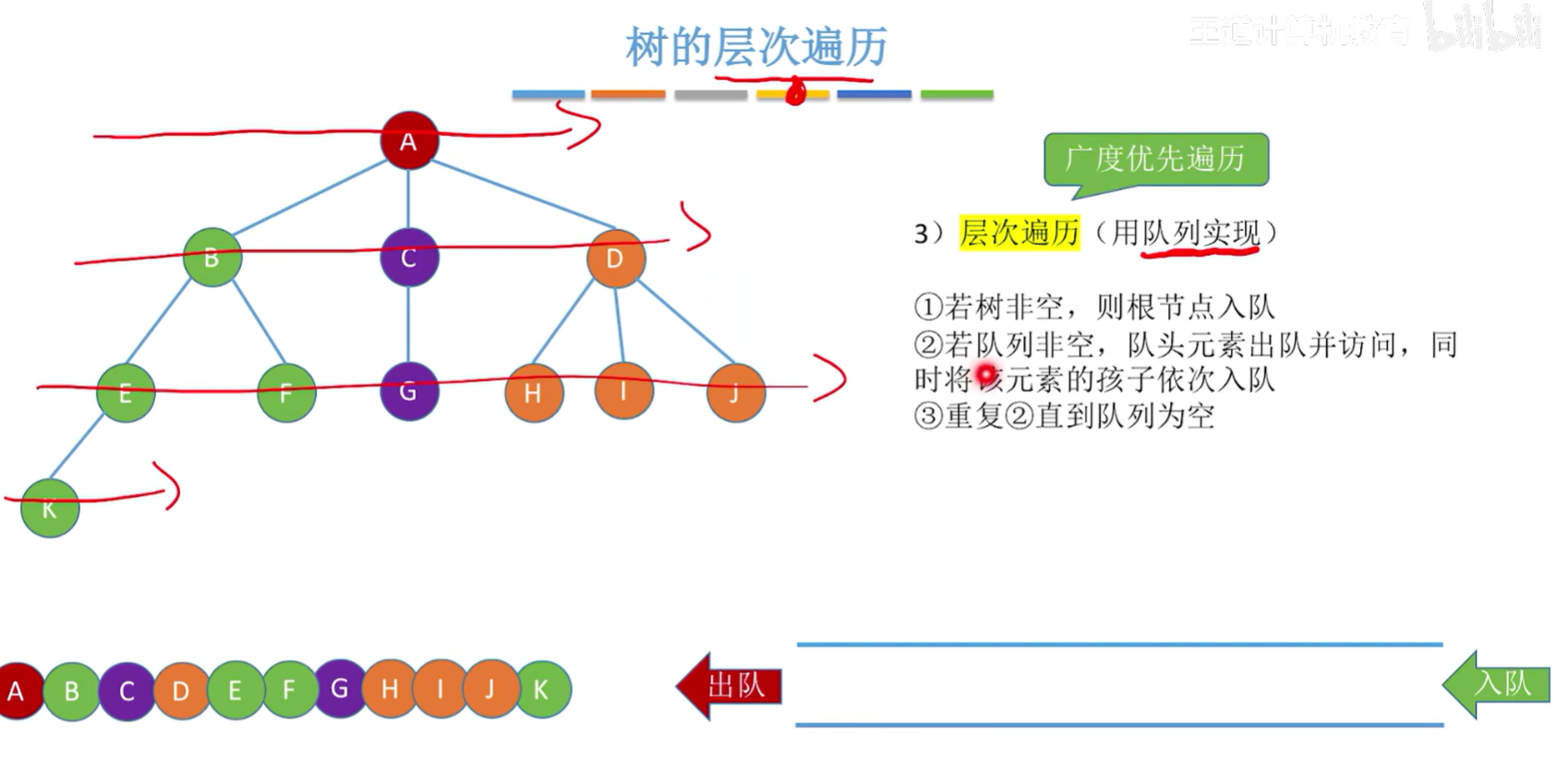
}层序遍历(队列实现)
和二叉树一样的思路
- 若树非空,则根结点入队;
- 若队列非空,队头元素出队并访问,同时将该元素的孩子依次入队;
- 重复以上操作直至队尾为空;
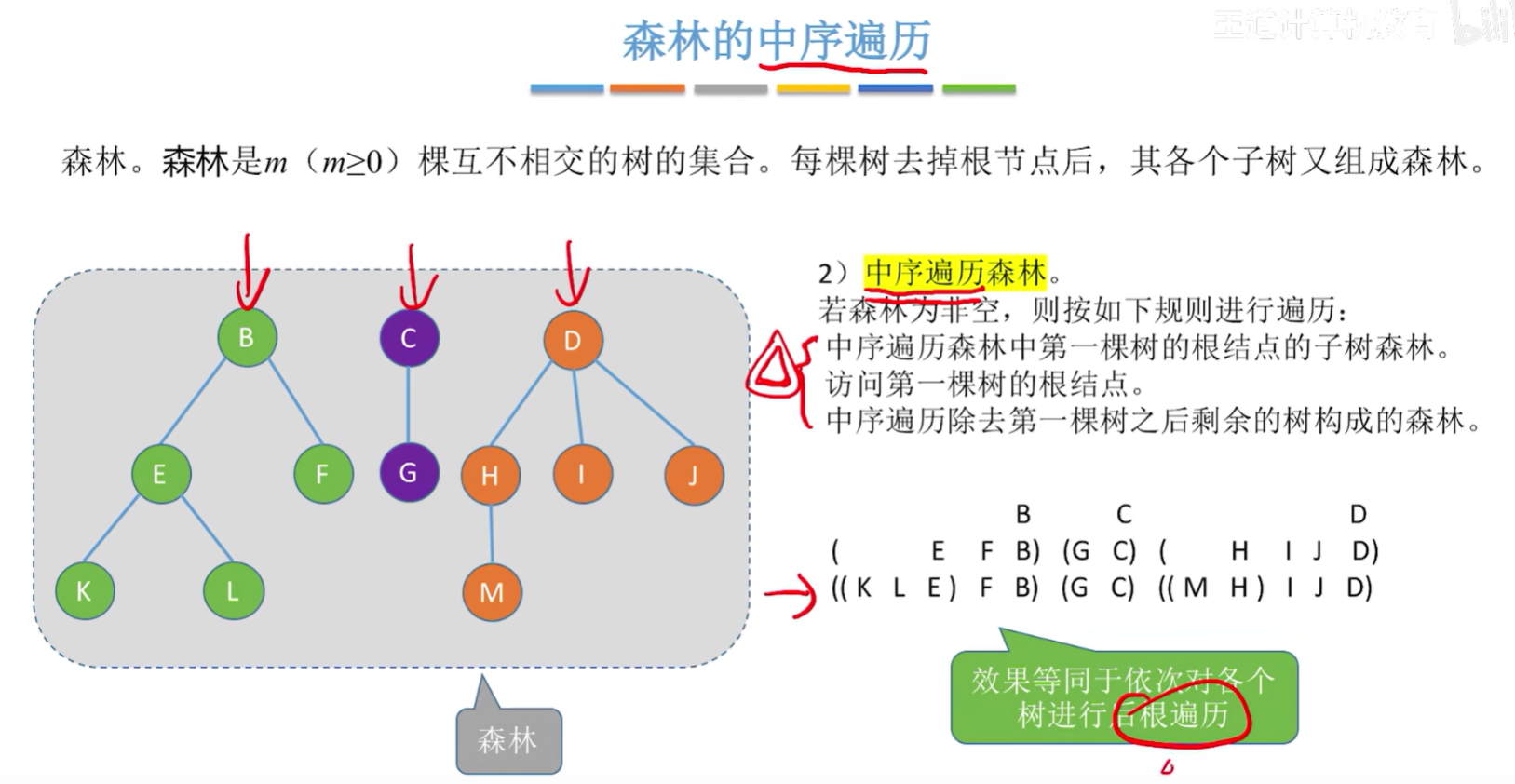
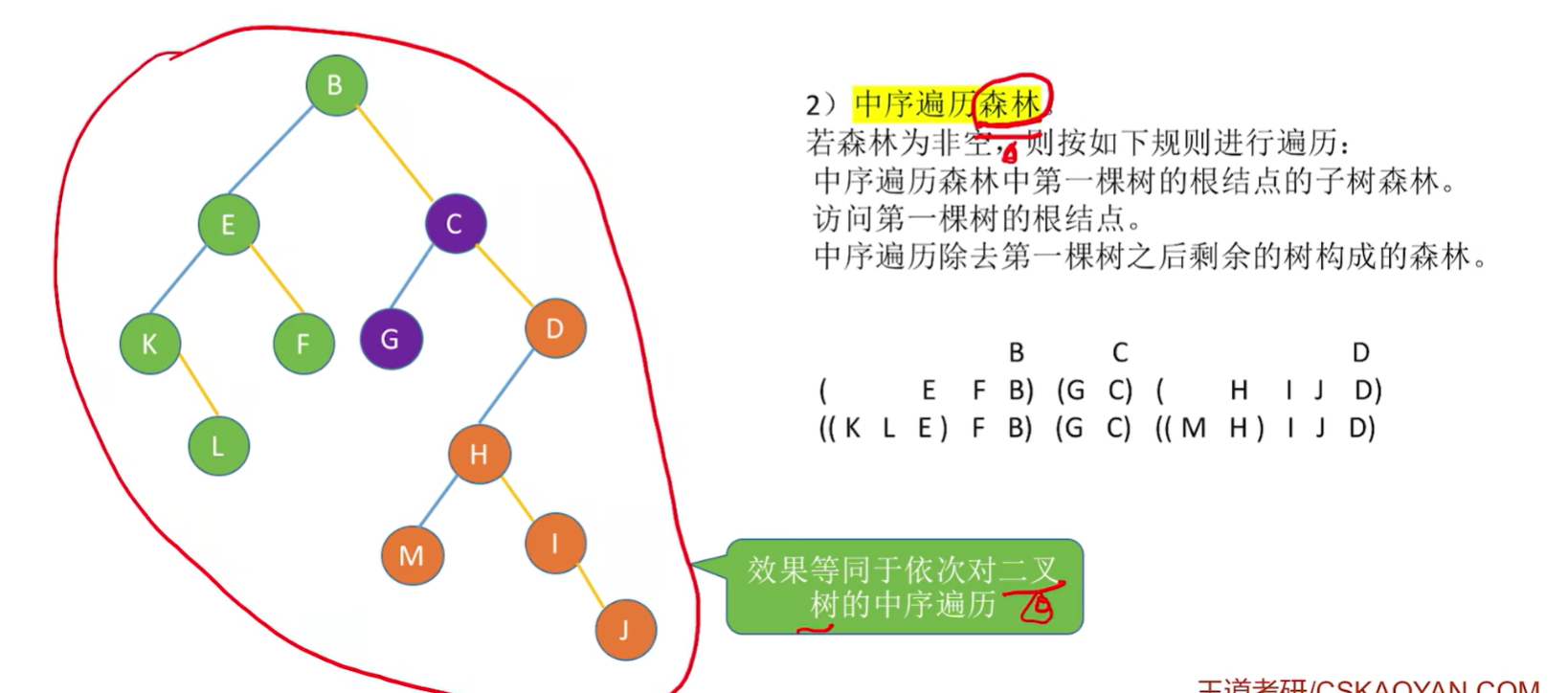
森林的遍历
- 先序遍历:等同于依次对各个树进行先根遍历;也可以先转换成与之对应的二叉树,对二叉树进行先序遍历;
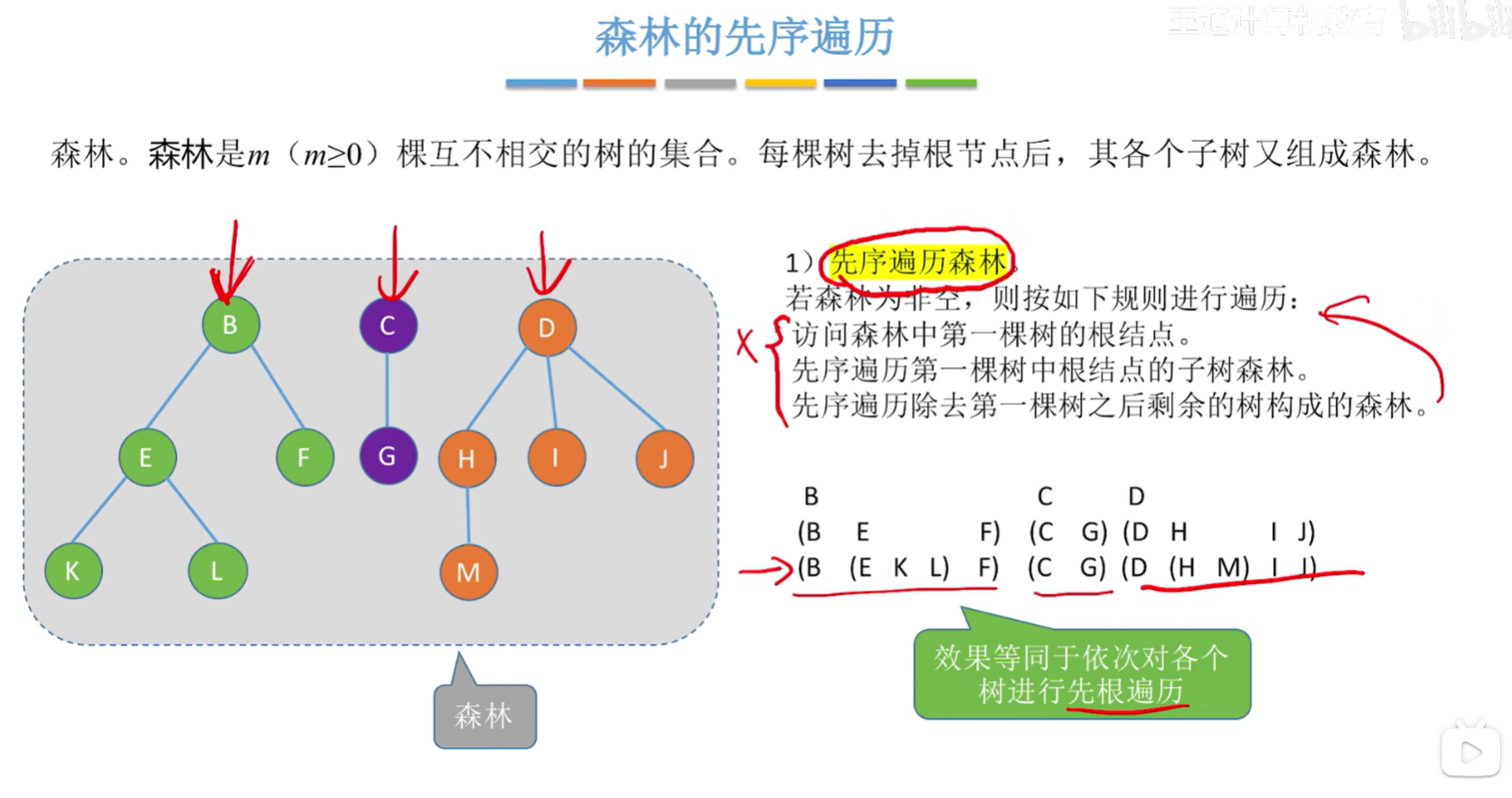
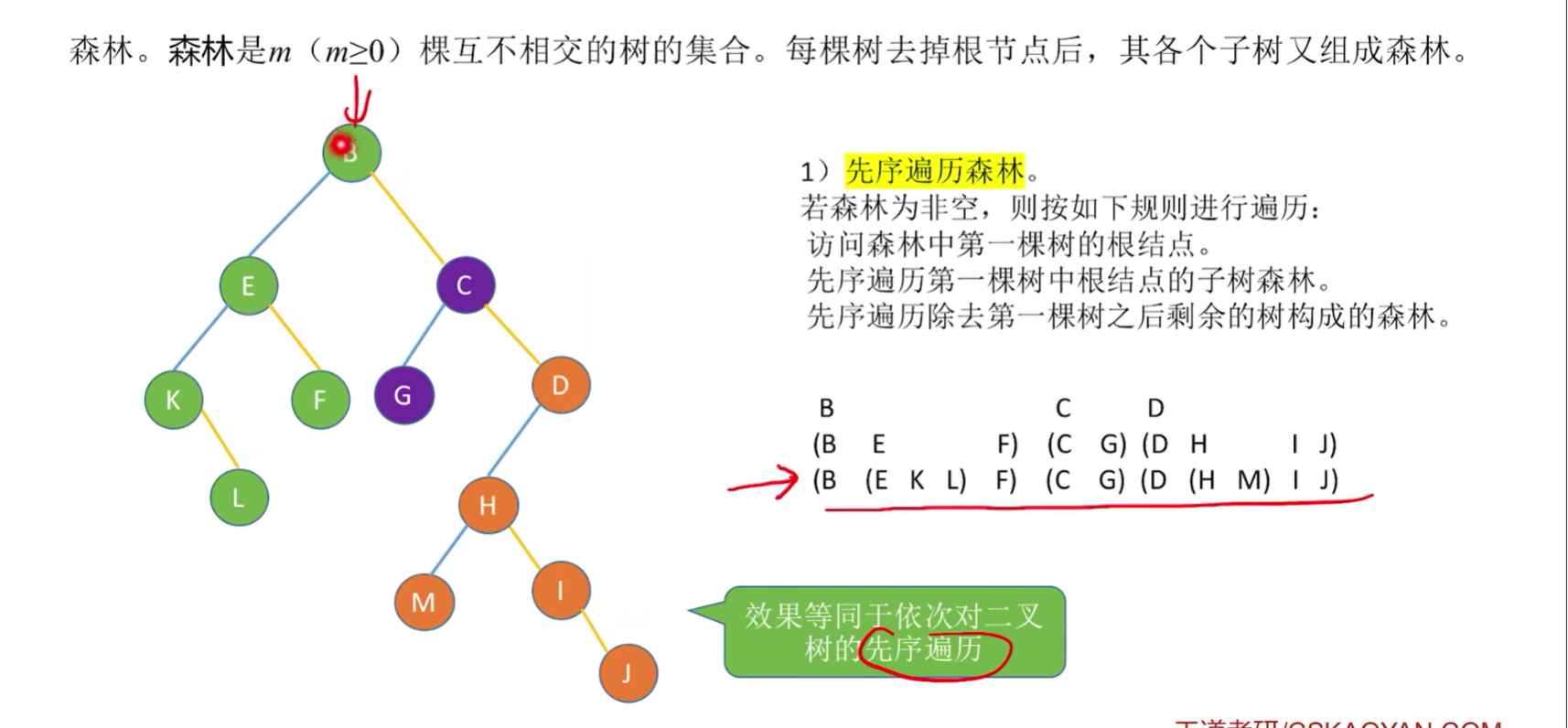
- 中序遍历:等同于依次对各个树进行后根遍历;也可以先转换成与之对应的二叉树,对二叉树进行中序遍历;
5.5. 应用
5.5.1. 哈夫曼树
1、哈夫曼树定义
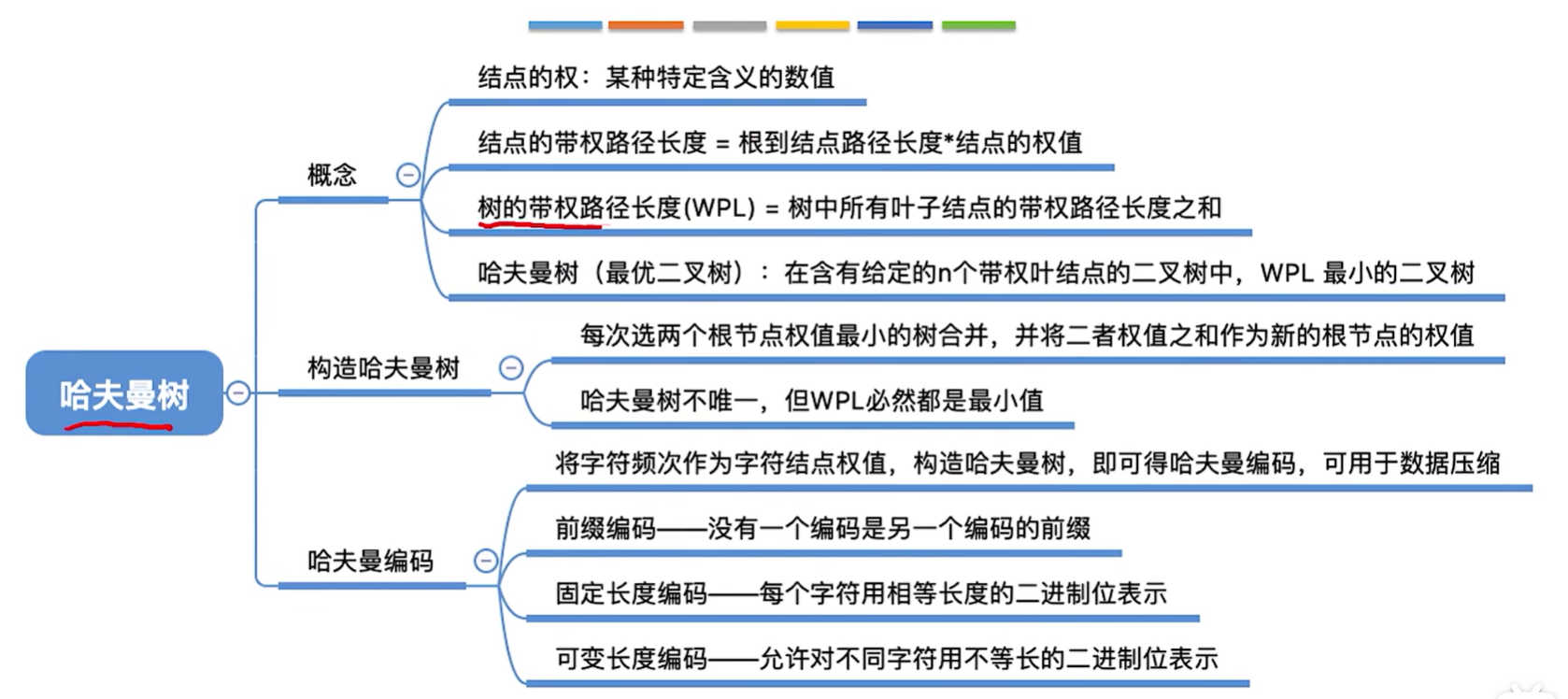
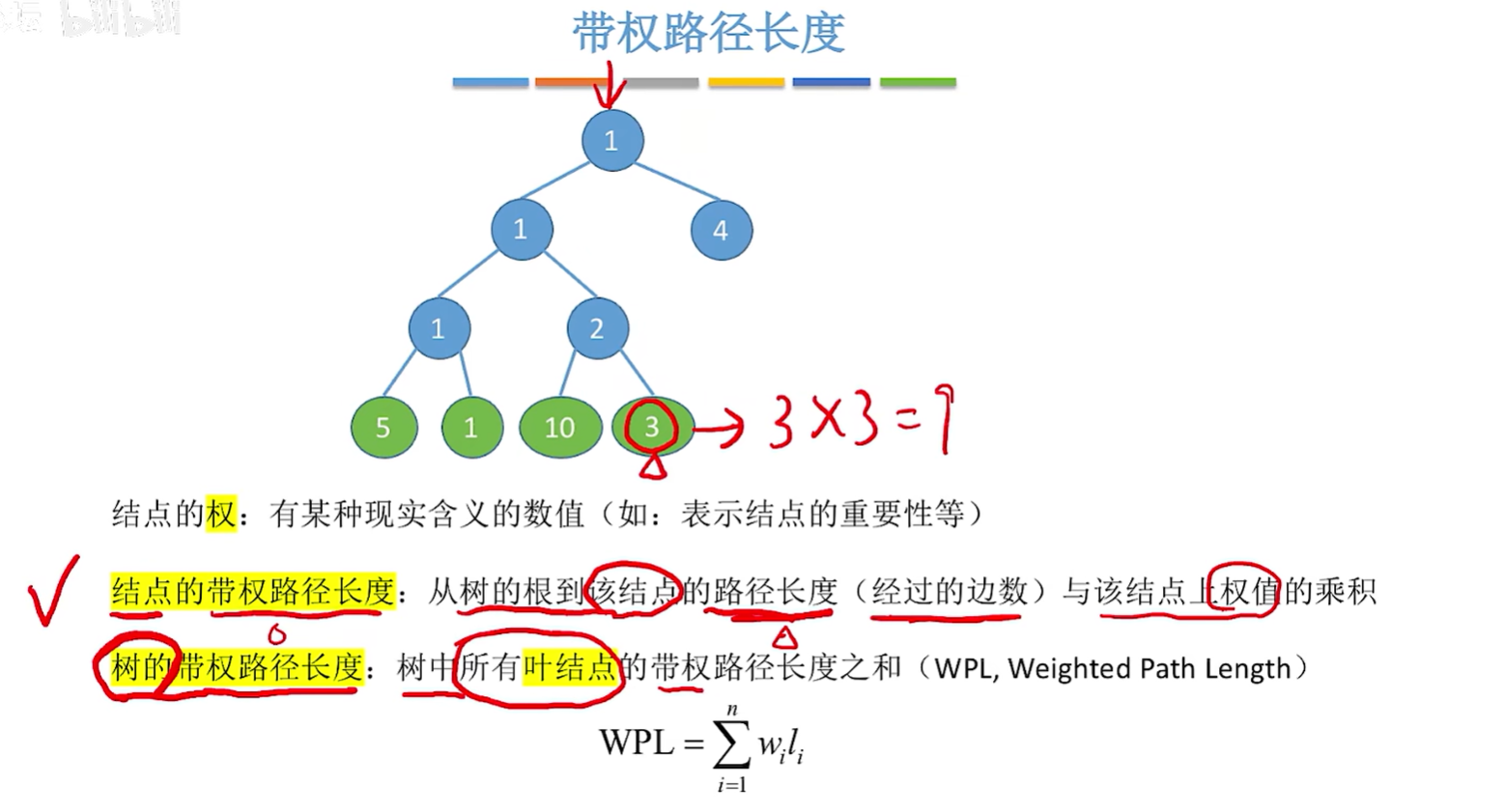
- 结点的权:有某种现实含义的数值(如:表示结点的重要性等)
- 结点的带权路径长度:从树的根到该结点的路径长度(经过的边数)与该结点上权值的乘积。
- 树的带权路径长度:树中所有叶结点的带权路径长度之和 (WPL,Weighted Path Length)。
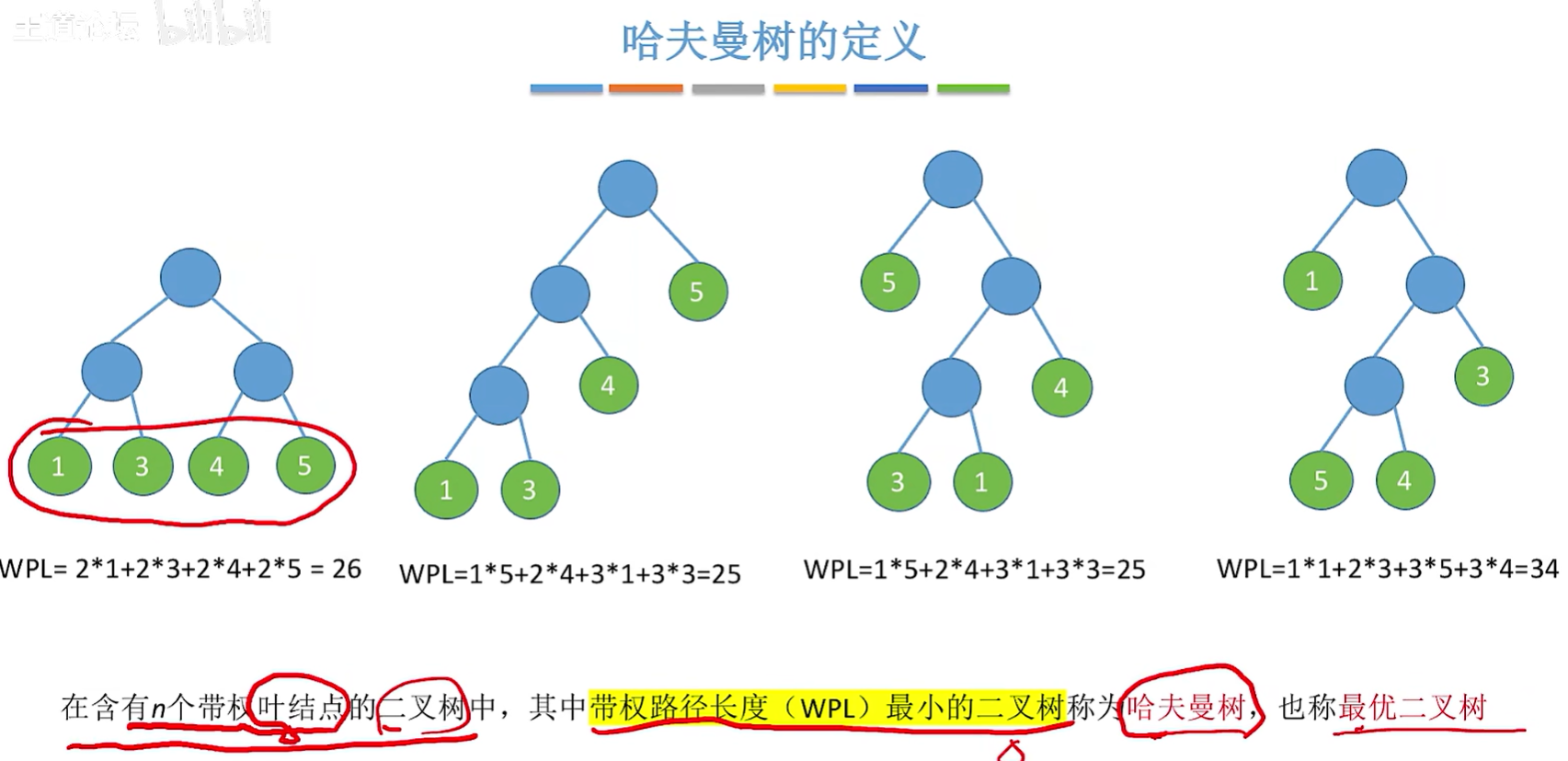
- 哈夫曼树的定义:在含有n个带权叶结点的二叉树中,其中带权路径长度(WPL) 最小的二叉树,也称最优二叉树。
2、哈夫曼树的构造(重点)
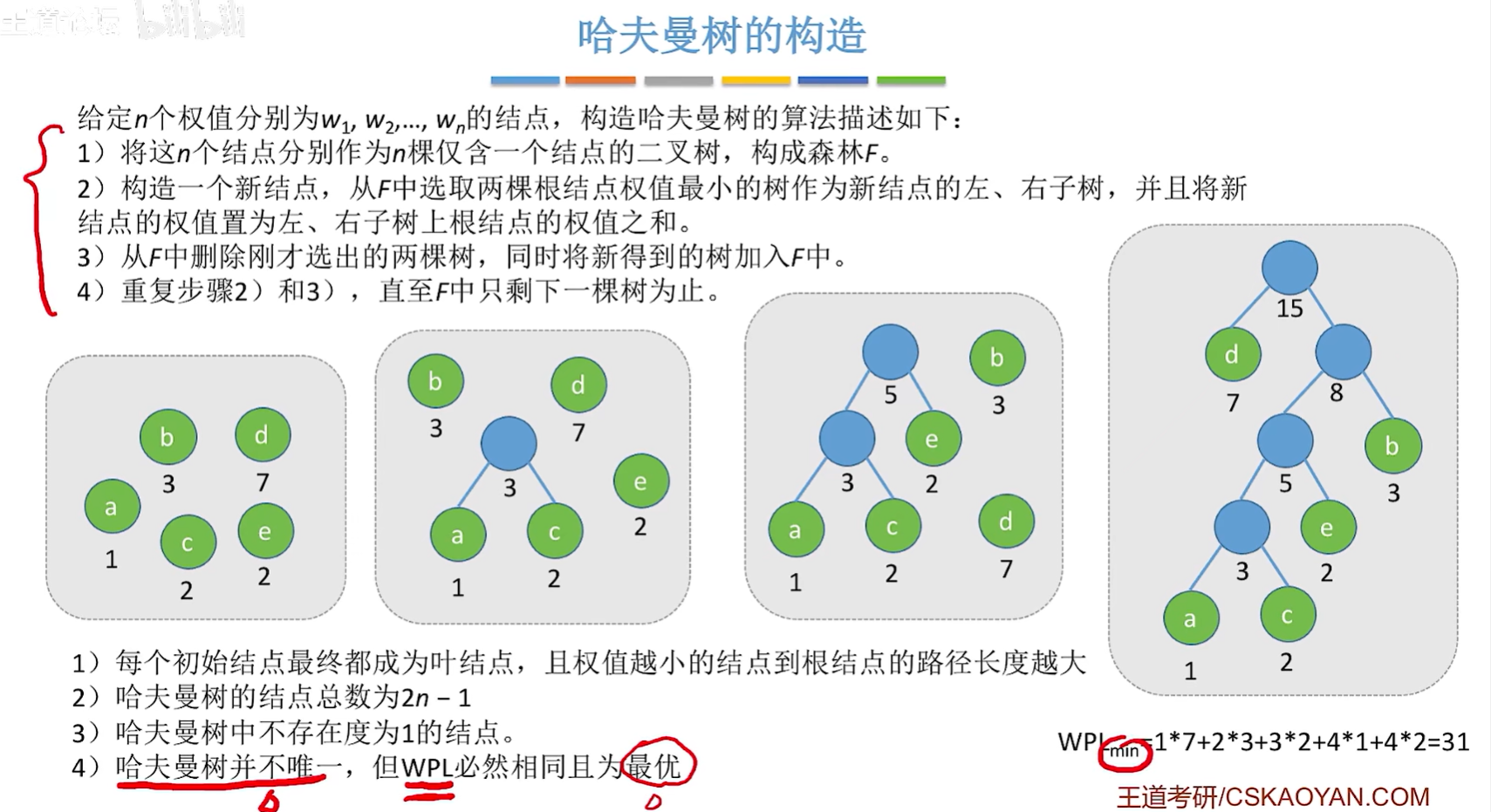
一共合并n-1次
构造哈夫曼树的注意事项:
- 每个初始结点最终都成为叶结点,且权值越小的结点到根结点的路径长度越大
- 哈夫曼树的结点总数为2n - 1
- 叶子结点为n,非叶子节点为n-1个,叶子结点比非叶子节点多一个
- 哈夫曼树中不存在度为1的结点
- 哈夫曼树并不唯一,但WPL必然相同且为最优
3、哈杜曼编码(重点)
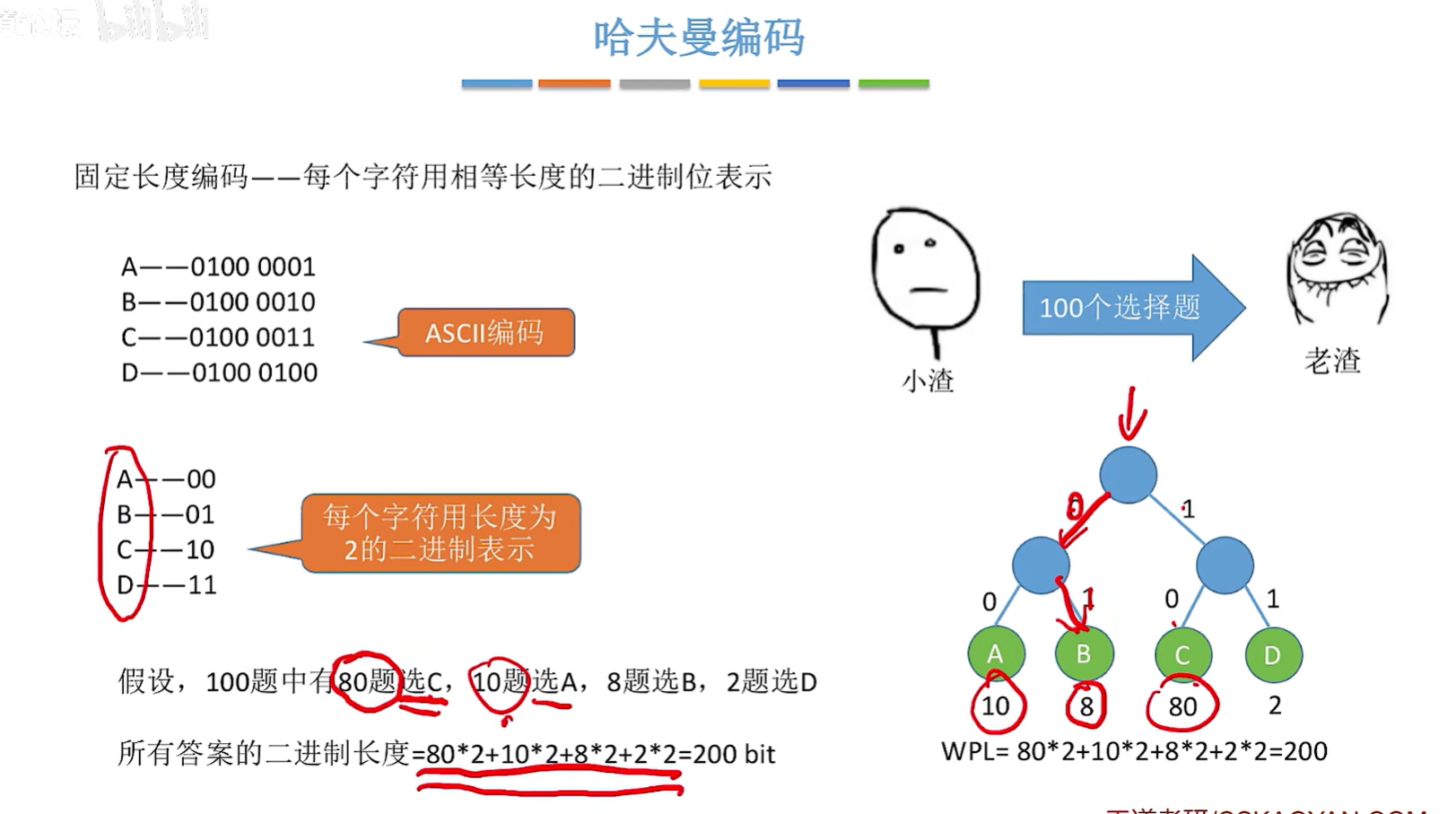
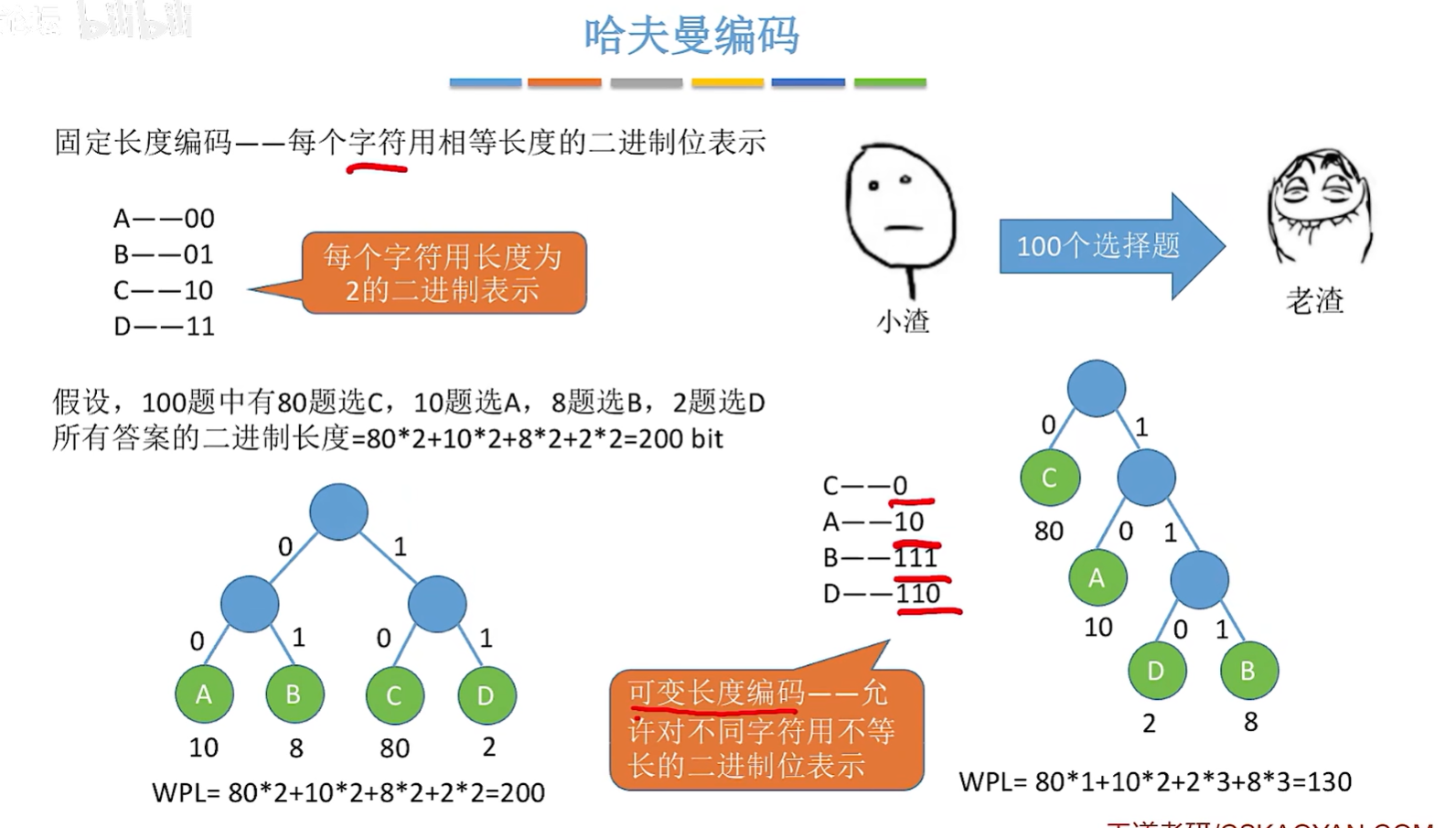
- 固定长度编码:每个字符用相等长度的二进制位表示
- 可变长度编码:允许对不同字符用不等长的二进制位表示
- 若没有一个编码是另一个编码的前缀,则称这样的编码为前缀编码、
- 前缀编码解码无歧义
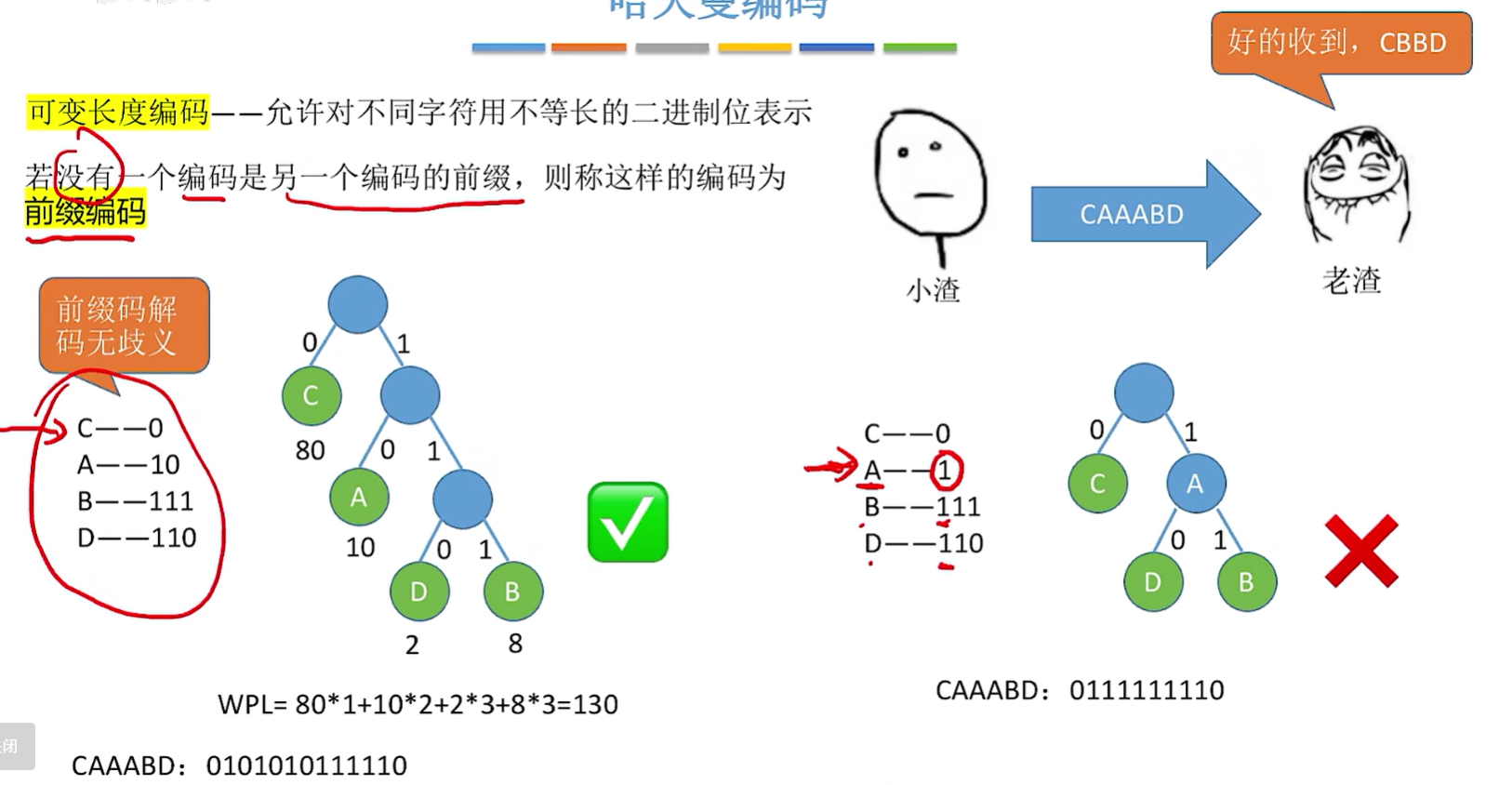
曼树得到哈夫曼编码–字符集中的每个字符作为一个叶子结点,各个字符出现的频度作为结点的权值,根据之前介绍的方法构造哈夫曼树 。
因为哈夫曼树不唯一,所以哈夫曼编码也不唯一
哈夫曼编码还可以用于数据的压缩
重点:
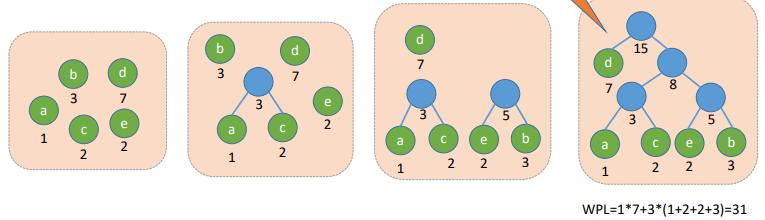
哈夫曼树并非只有下图这个形状,要严格构造出来一颗子树后要严格按照取集合中的最小值来构造
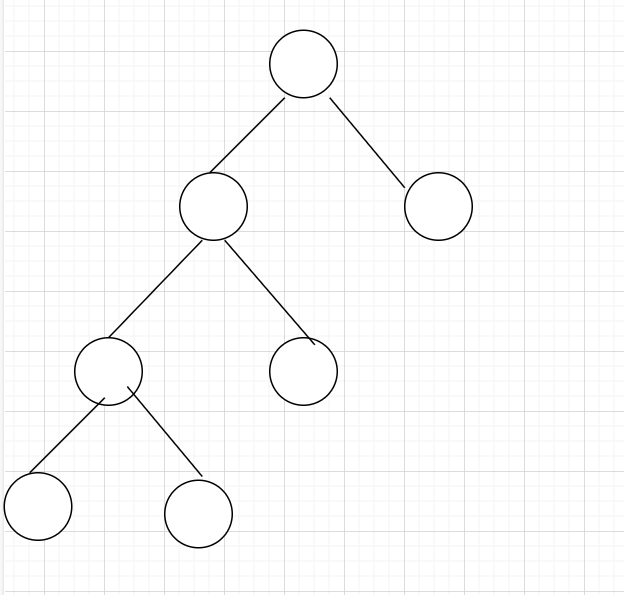
还可以是下面这种的,还可以是别的各种形状的,不要刻板印象了
5.5.2 并查集
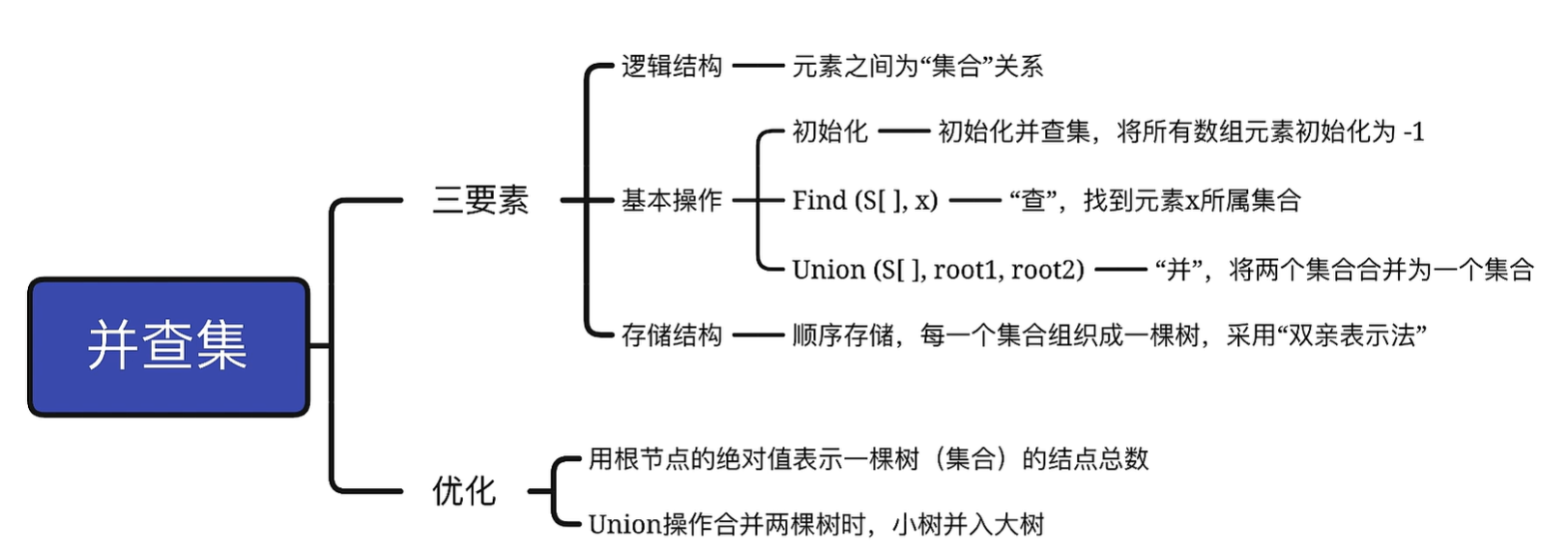
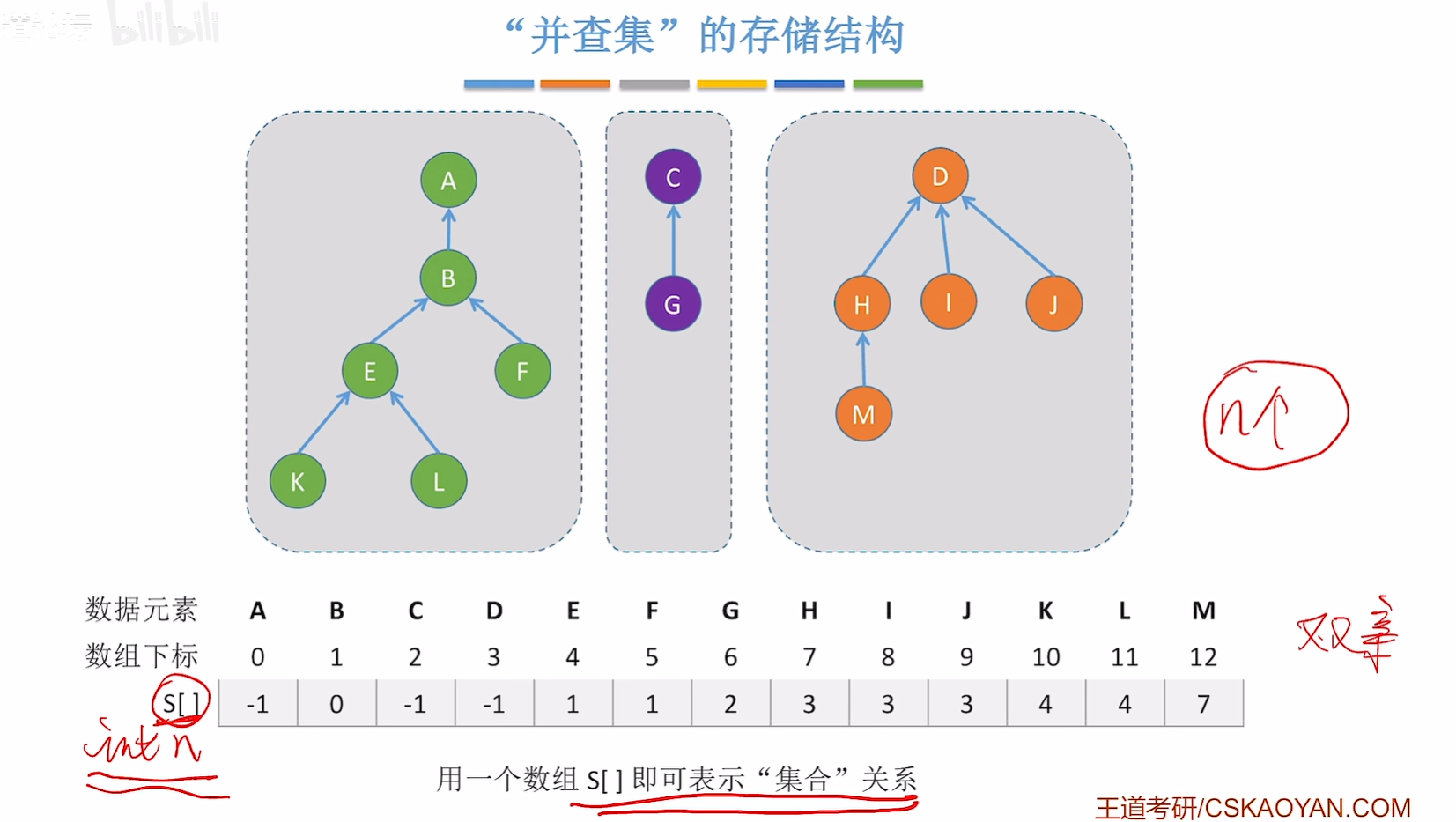
并查集:一种简单的集合表示,它支持以下三种操作
1.IniTial(S):将集合s中的每个元素都初始化为只有一个单元素的子集合
2.Union(S,Root1,Root2):把s中的子集合Root2并入子集合Root1。要求Root1和Root2不相交,否则不执行
3.Find(S,x):查找集合S中单元素X所在的子集合,并返回该子集合的根节点
S表示一个森林,每个集合都是这森林中的一颗树
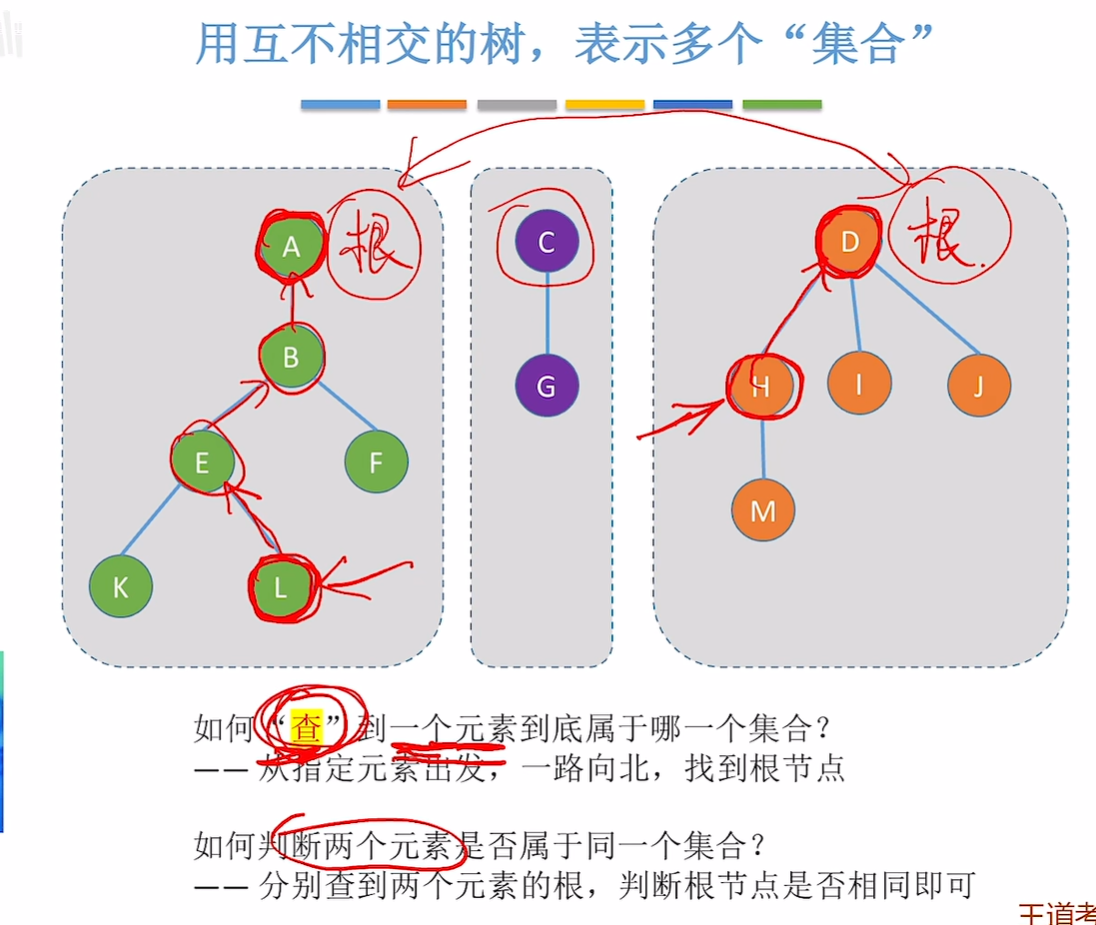
查的操作:
1.查一个元素属于哪个集合,从指定元素出发找到根节点
2.查两个元素是不是一个集合的,分别找这两个元素的根节点,相同就是同一个集合,否则不是
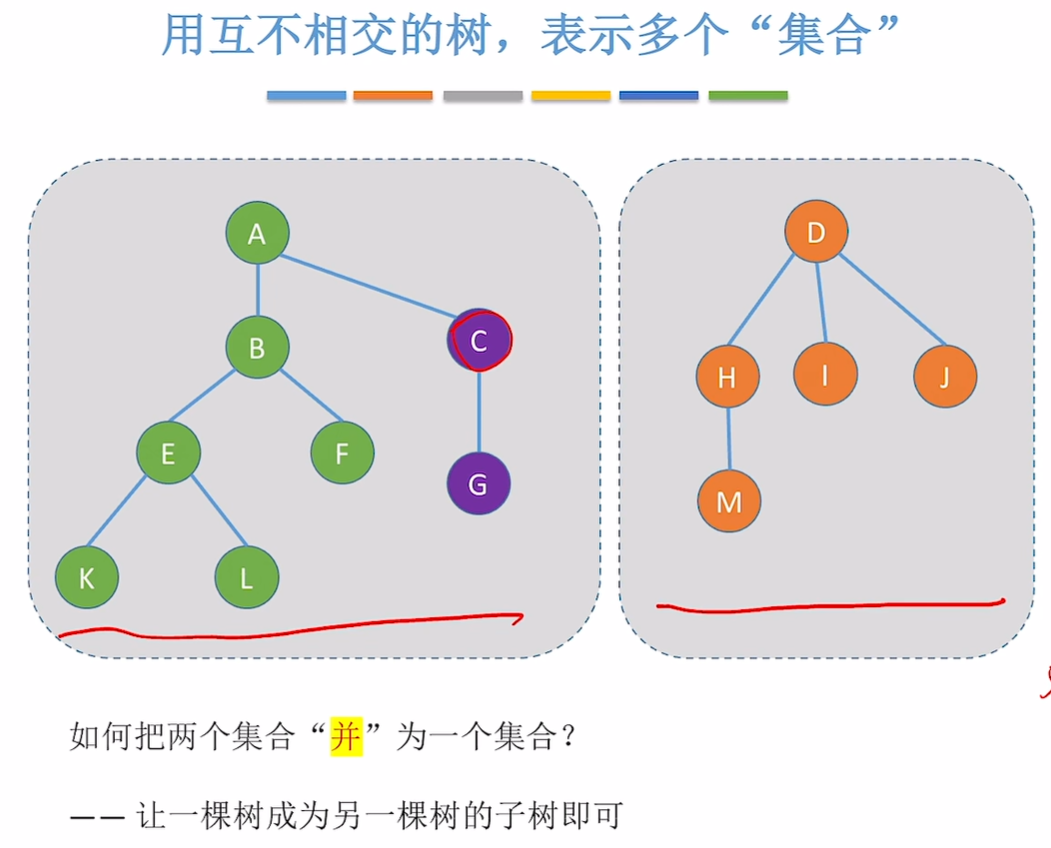
并的操作:
两个集合并为一个集合,让一棵树成为另一棵树的子树
使用双亲表示法更好实现并查集,会让查和并更好的实现
因为我们要实现查的操作要找根节点,那就是一级一级的去找父节点,找父节点自然是双亲表示法比较好了
而并的操作只需要让另外一个子树的根节点指向当前子树的根节点就好了
并查集的存储结构
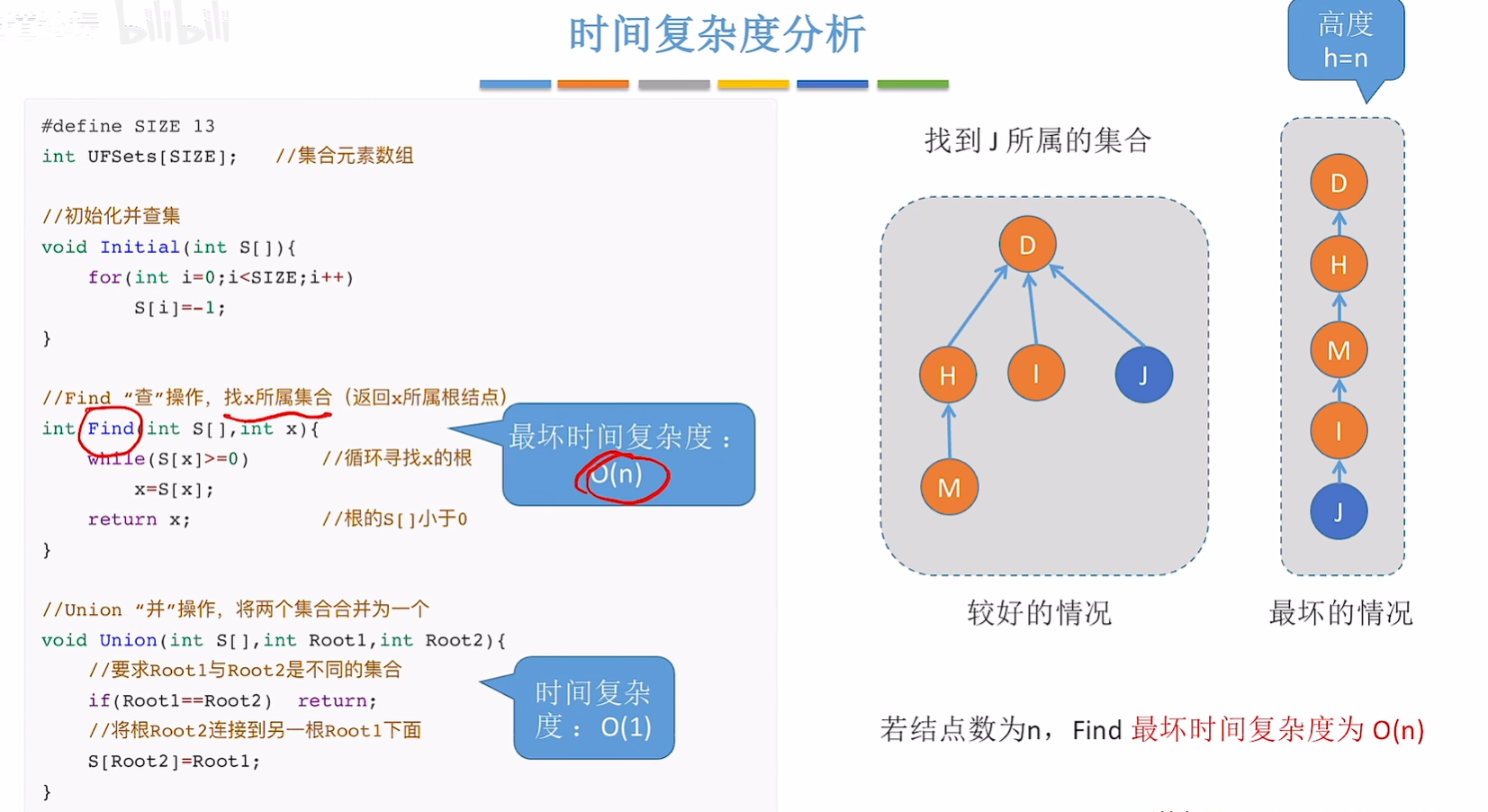
并查集的代码实现
#define SIZE 13
int UFSets[SIZE];//集合元素数组 表示的是森林//初始化并查集
void Inittial(int S[])
{for (int i = 0; i < SIZE; i++)s[i] = -1;
}//Find 查操作,找x所属集合 返回x所属集合的根节点
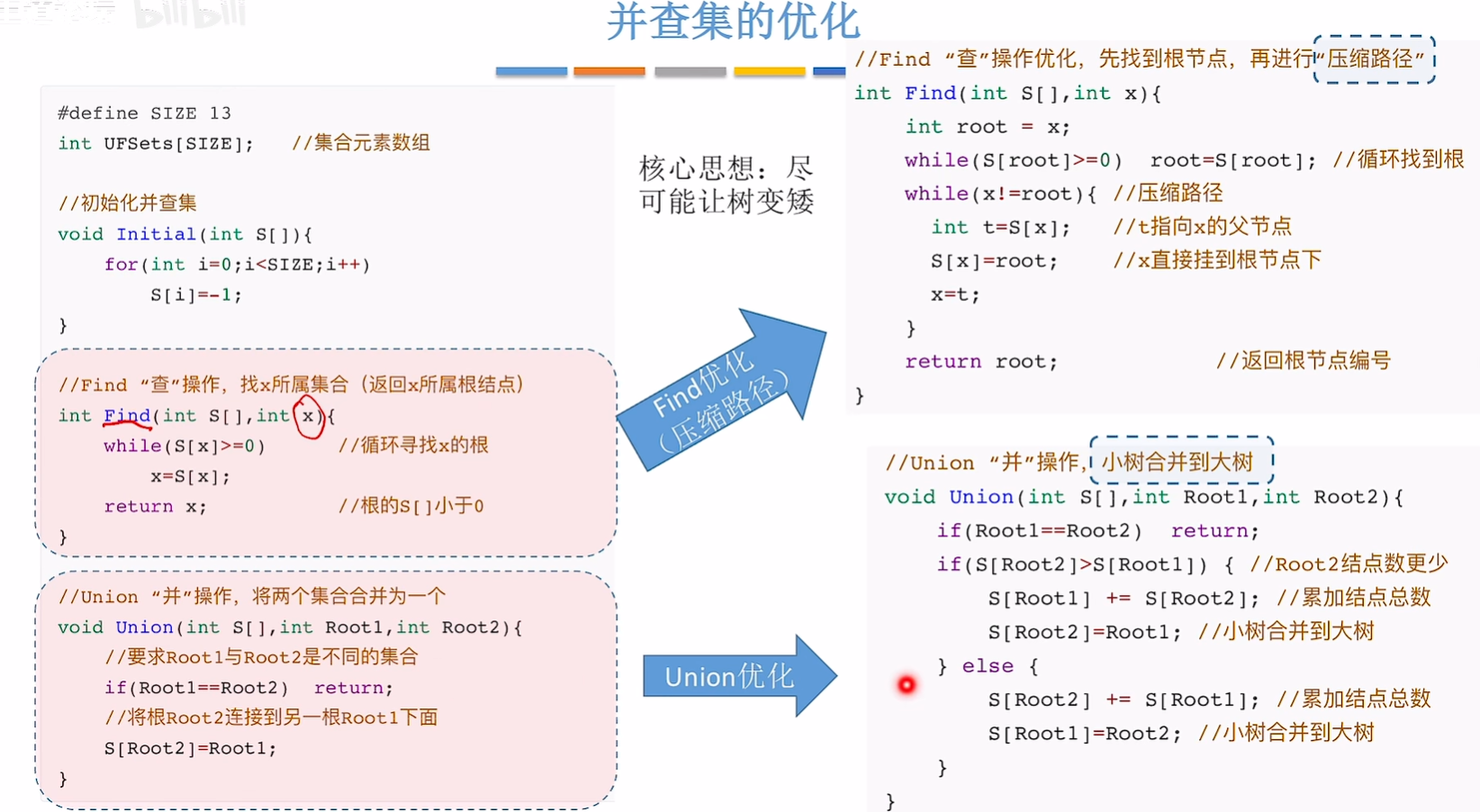
int Find(int S[], int x)
{//循环寻找x的跟while (S[x] >= 0)x = S[X];//根的值是-1,小于0return x;
}//Union 并操作,将两个集合并成一个
void Union(int S[], int Root1, int Root2)
{//要求Root1和Root2不是同一个子树if (Root1 == Root2)return;//把Root2接到Root1上面S[Root2] = Root1;
}
Union优化
这个优化感觉很糟糕,因为一个子树的节点数量大并不能说明这个子树的高度就高
如果一个子树节点很多但所有结点全是根结点的孩子,那这棵树只有两层而已,另外一个节点少但是高度高的接过来反而高度比原来两个子树都更高,查找的就更慢了

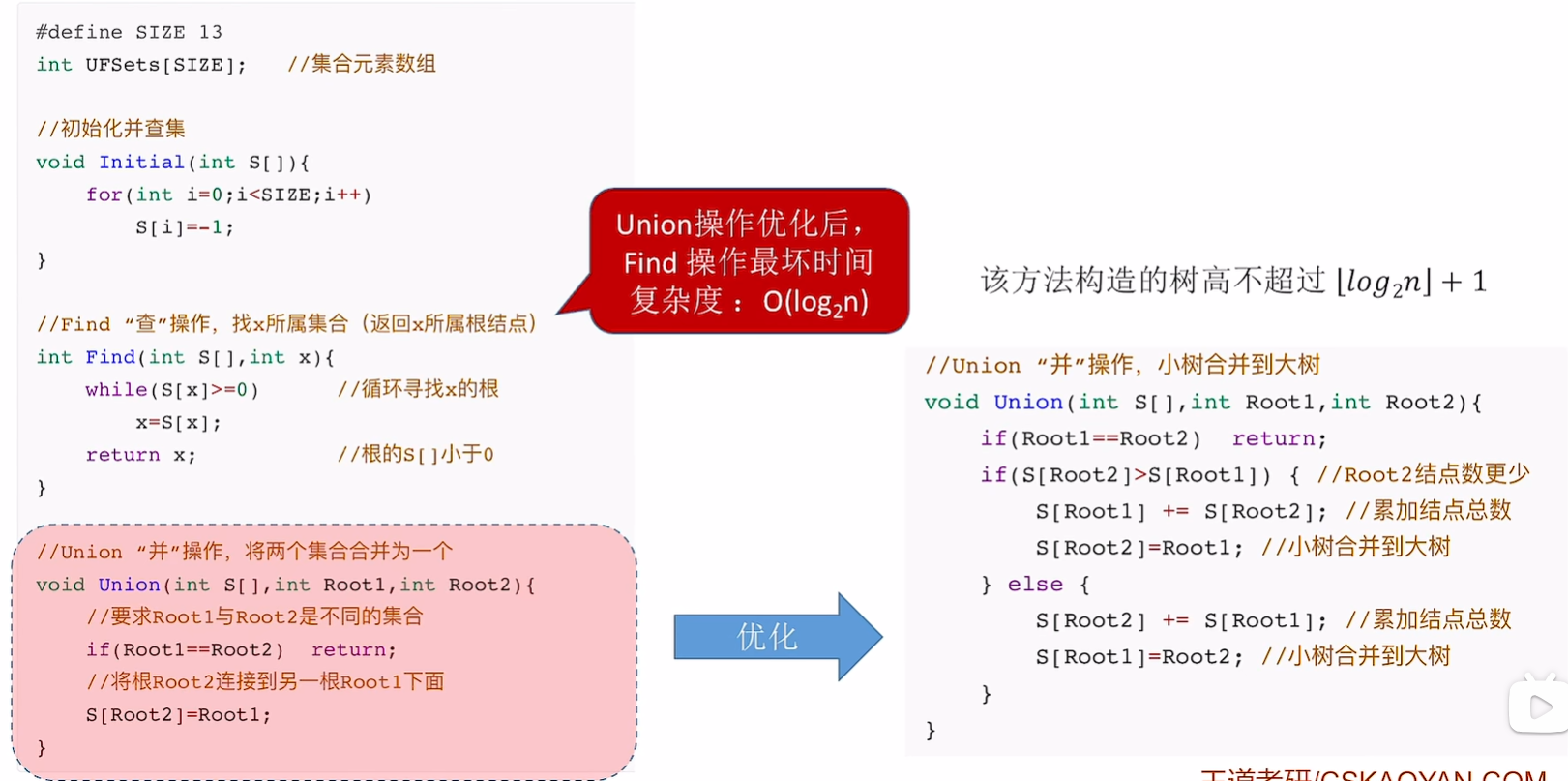
//Union优化
void Union(int S[], int Root1, int Root2)
{//要求Root1和Root2不是同一个子树if (Root1 == Root2)return;//把Root2接到Root1上面if (S[Root2] > S[Root1]) {//Root2结点数更少S[Root1] += S[Root2];//累加结点总数S[Root2] = Root1;//小树合并到大树}else {S[Root2] += S[Root1];//累加结点总数S[Root1] = Root2;//小树合并到大树}
}
find优化:压缩路径
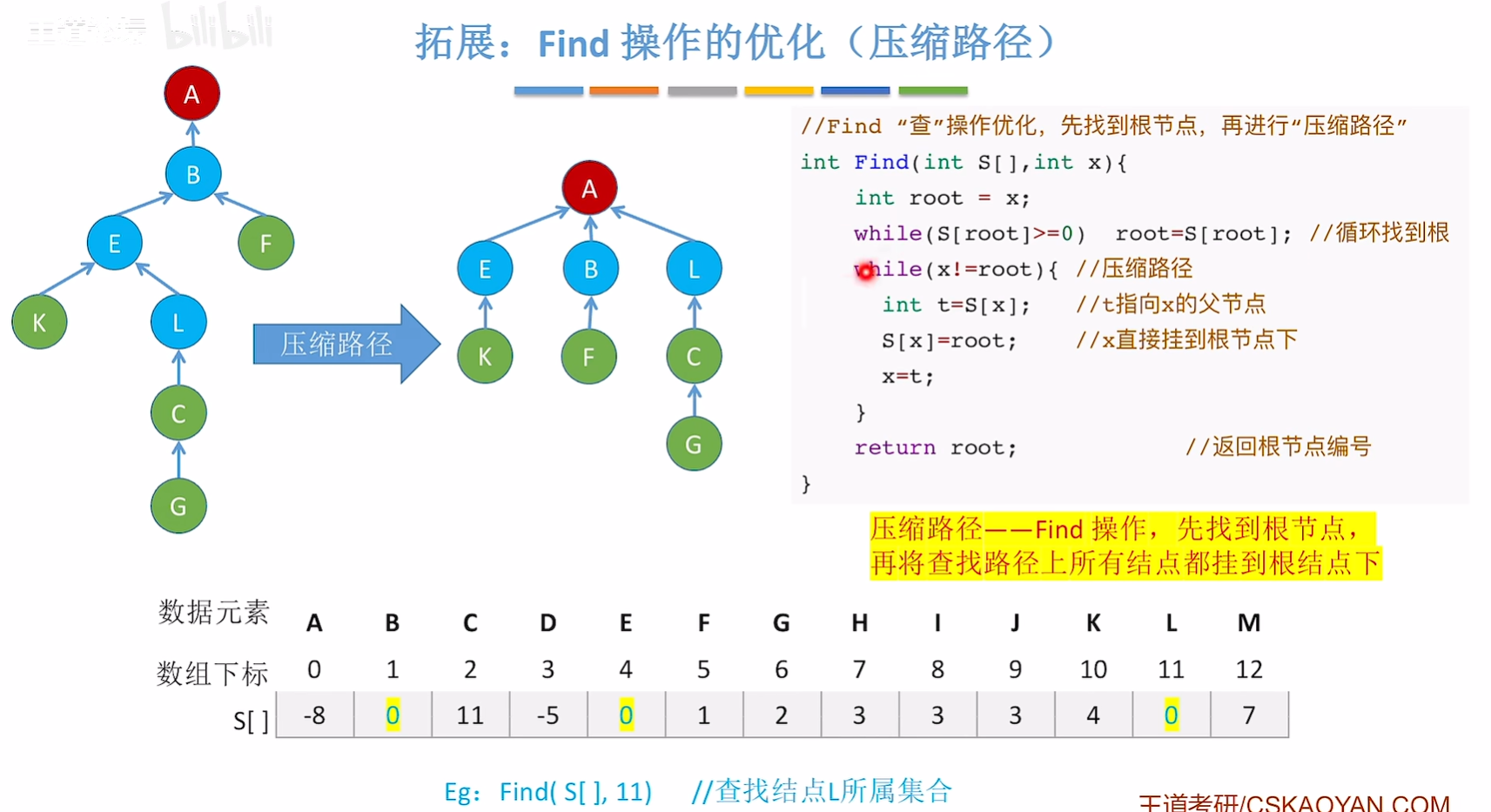
//Find“查”操作优化,先找到根节点,再进行“压缩路径”
int Find(int S[], int x)
{int root = x;while (S[root] >= 0)root = S[root];//循环找到根//压缩路径while (x != root) {//t指向x的父节点int t = S[x];//x直接挂到根节点下S[x] = root;x = t;}//返回根节点编号return root;
}

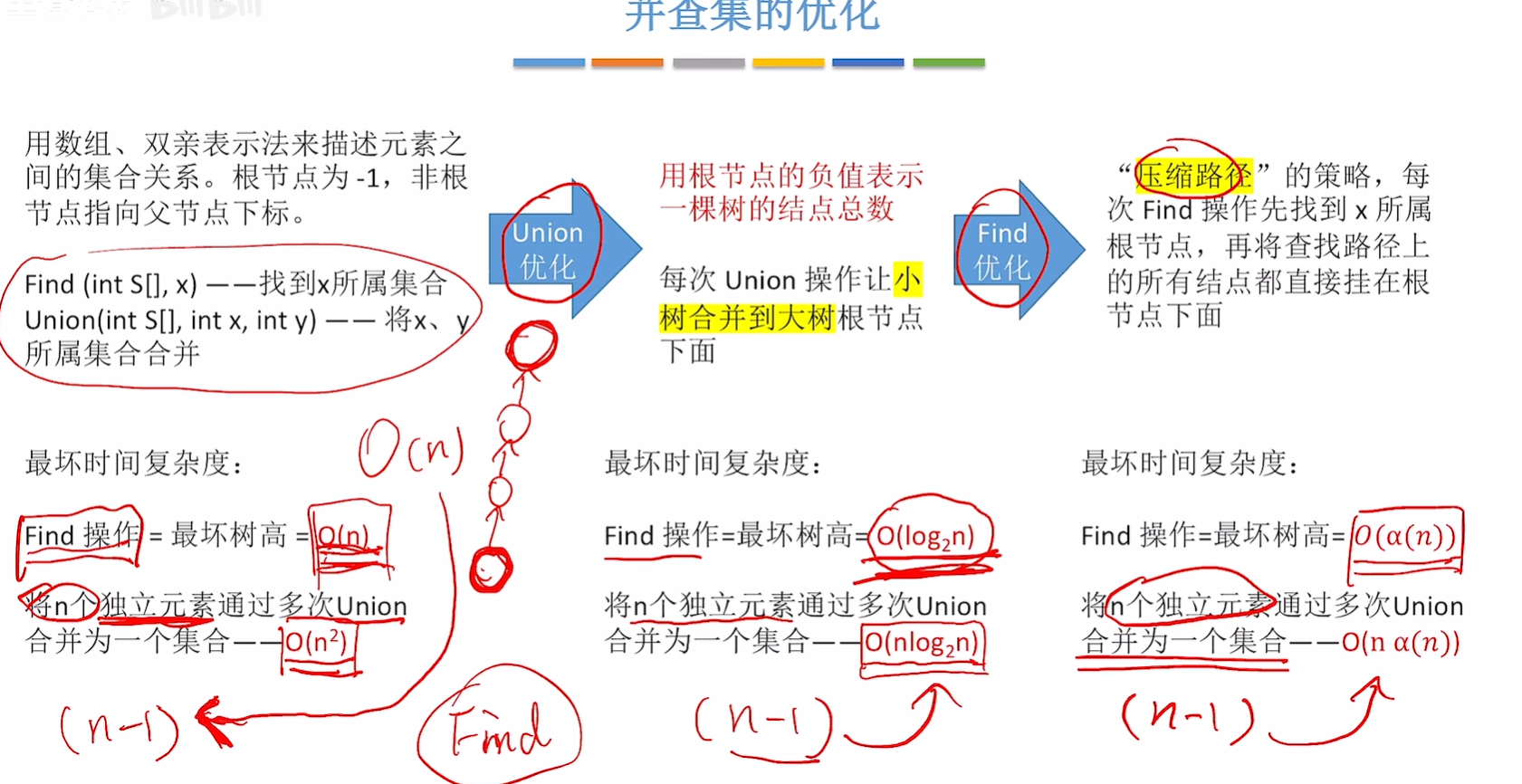
每次将两个独立元素通过union的是时候都要找两个独立元素的根节点,然后才能进行合并,所以最终的构造一个并查集的复杂度和find的复杂度有关
然后n个元素要union进行n-1次,所以就是find的复杂度*n就是最后的复杂度

对union小树接大树优化的困惑解答
在并查集的 union 操作优化中,按秩合并(Union by Rank) 的核心目标是通过合理的合并策略减少树的高度增长,从而提升后续 find 操作的效率。关于你提到的疑问(小树接大树 vs 高度低的接高度高的),以下是详细分析:
1.两种常见的“秩”定义
并查集的优化策略中,“秩”可以有两种定义方式:
- 树的高度(Height):表示以当前节点为根的树的最大深度。
- 树的节点数量(Size):表示以当前节点为根的树包含的节点总数。
两种定义各有优劣,但最终目标都是通过控制合并方向来减少树的高度。
2.为何“小树接大树”可以优化?
当选择 节点数量作为秩 时,合并策略是让节点数量少的树(小树)的根节点连接到节点数量多的树(大树)的根节点。这种优化策略的有效性体现在:
- 合并后的树高度不会显著增加:如果小树的高度较大,但节点数量少,即使合并到大树上,大树原有的高度仍可能保持不变(除非两棵树高度相同)。例如:
- 大树高度为 3,小树高度为 4,合并后大树高度仍为 4。
- 但若大树高度为 4,小树高度为 3,合并后大树高度仍为 4。
- 路径压缩的辅助优化:后续的find操作会通过路径压缩将树的高度压平,减少实际访问路径长度
3.“高度低的接高度高的”是否更优?
若选择 高度作为秩(即高度低的树合并到高度高的树),理论上可以避免合并后高度增加的问题。例如:
- 大树高度为 3,小树高度为 2,合并后大树高度仍为 3。
- 若两棵树高度相同,合并后新树高度加 1
但这种策略需要维护树高度的准确信息,而 路径压缩会破坏高度的实时性。
例如:路径压缩后,树的实际高度可能小于记录的秩(高度),导致合并时误判
4.两种策略的对比与选择
| 策略 | 优点 | 缺点 |
|---|---|---|
| 按节点数量(小树接大树) | 合并后树的总高度增长较慢 | 可能出现小树高度 > 大树高度 |
| 按树高度(低接高) | 严格避免合并后高度增加 | 需要维护精确高度,路径压缩后可能失效 |
实际应用中,优先选择按节点数量合并,原因如下:
- 实现简单:只需维护节点数量,无需频繁更新高度。
- 与路径压缩兼容:路径压缩会动态压平树结构,弥补合并导致的潜在高度增长
- 时间复杂度稳定:结合路径压缩和按秩合并,操作均摊时间接近常数
5.示例分析
假设两棵树:
- 树A:节点数 100,高度 2。
- 树B:节点数 5,高度 4。
- 按节点数量合并(树B接树A):
- 合并后树A的高度仍为 4(因为树B的高度更高)。
- 后续
find操作通过路径压缩,将树B中原有长路径压平,最终实际高度可能降为 2。
- 按高度合并(树A接树B):
- 合并后树B高度为 4,但需维护高度的准确性(路径压缩可能破坏这一信息)。
6.总结
按节点数量合并(小树接大树)是一种更稳健的优化策略,尤其在结合路径压缩后,能有效控制树的实际高度。虽然理论上可能出现小树高度大于大树的情况,但路径压缩的动态调整会抵消这种负面影响。而按高度合并的优化需要更复杂的高度维护,实际应用较少。
相关文章:

26考研 | 王道 | 数据结构 | 第五章 树
第五章 树 5.1. 树的概念 5.1.1. 树的基本定义 树:n(n>0)个节点的有限集合,是一种逻辑结构,当n0时为空树,且非空树满足: 有且仅有一个特定的称为根的节点当n>1时,其余结点可分为m (m >0) 个互不相交的有限集合&#x…...

Spring 怎么解决循环依赖问题?
Spring 循环依赖(circular dependency) 指的是多个 Bean 之间的相互依赖,比如: A 依赖 B,B 又依赖 A;或者 A → B → C → A 这种嵌套循环依赖。 这是一个常见又棘手的问题,但 Spring 是可以解…...

微软推出首款量子计算芯片Majorana 1
全球首款拓扑架构量子芯片问世,2025年2月20日,经过近20年研究,微软推出了首款量子计算芯片Majorana 1,其宣传视频如本文末尾所示。 微软表示,开发Majorana 1需要创造一种全新的物质状态,即所谓的“拓扑体”…...
)
OSI模型中协议数据单元(PDU)
OSI模型中协议数据单元(PDU) 协议数据单元(Protocol Data Unit, PDU)是网络通信中每一层协议处理的数据单位,其内容和格式由特定层的协议定义。PDU在不同OSI层次中有不同的名称和结构,体现了分层模型的核心…...

代码训练营day24 回溯算法
回溯算法part03 93.复原IP地址 题目链接/文章讲解:代码随想录 视频讲解:回溯算法如何分割字符串并判断是合法IP?| LeetCode:93.复原IP地址_哔哩哔哩_bilibili 本题关键在于终止条件 插入3个’.’时判断 ip地址最后一段是否…...

DP Alt Mode 与 DP协议的关系
1. 什么是 “Alt Mode”(替代模式)? Alt Mode(Alternative Mode) 是 USB Type-C 接口 的扩展协议机制,允许通过 物理接口复用(Pin Reuse) 将USB-C接口动态切换为其他协议࿰…...

【欧拉筛】哥德巴赫猜想题解
哥德巴赫猜想题解 题目传送门 1292. 哥德巴赫猜想 一、题目描述 哥德巴赫猜想指出:任意一个大于4的偶数都可以拆成两个奇素数之和。给定多个偶数(6 ≤ n < 10^6),验证它们是否符合这个猜想。对于每个偶数,输出其素数分解中两数差最大的…...

A*算法详解及Python实现
一、什么是A*算法? A*(读作"A-star")算法是一种广泛使用的路径查找和图形遍历算法,它结合了Dijkstra算法的完备性和贪婪最佳优先搜索的高效性。A*算法通过使用启发式函数来估算从当前节点到目标节点的成本,…...
——详解+代码示例)
【C++】第九节—string类(中)——详解+代码示例
hello! 云边有个稻草人-CSDN博客 C_云边有个稻草人的博客-CSDN博客 菜鸡进化中。。。 目录 【补充】 二、string类里面的常用接口 1.resize 2.insert 3.assign 4.erase 5.replacefind 6.c_str 7.rfindsubstr 8.find_first_of、find_last_of、find_first…...

vite.config.js常用配置
vite 是一个基于 Vue3 单文件组件的非打包开发服务器,它做到了本地快速开发启动: 快速的冷启动,不需要等待打包操作; 即时的热模块更新,替换性能和模块数量的解耦让更新飞起; 真正的按需编译,不…...
】—— 我与C++的不解之缘(三十二))
【C++11(下)】—— 我与C++的不解之缘(三十二)
前言 随着 C11 的引入,现代 C 语言在语法层面上变得更加灵活、简洁。其中最受欢迎的新特性之一就是 lambda 表达式(Lambda Expression),它让我们可以在函数内部直接定义匿名函数。配合 std::function 包装器 使用,可以…...

李臻20242817_安全文件传输系统项目报告_第6周
安全文件传输系统项目报告(第 1 周) 1. 代码链接 Gitee 仓库地址:https://gitee.com/li-zhen1215/homework/tree/master/Secure-file 代码结构说明: project-root/├── src/ # 源代码目录│ ├── main.c # 主程序入口│ ├…...

使用SymPy求解矩阵微分方程
引言 在数学、物理、工程等领域,微分方程常常被用来描述系统的变化和动态过程。对于多变量系统或者多方程系统,矩阵微分方程是非常常见的,它可以用来描述如电路、控制系统、振动系统等复杂的动态行为。今天,我们将通过Python 中的 SymPy 库来求解矩阵微分方程,帮助大家轻…...

Flutter之用户输入网络数据缓存
目录: 1、处理用户输入1.1、按钮1.2、文本1.3、富文本1.4、TextField1.5、Form 2、复选框、Switch 和 Radio2.1、复选框2.2、Switch2.3、Radio 3、选择日期或时间4、滑动5、网络和数据6、本地缓存6.1、在本地内存中缓存数据 7、web端和Flutter样式控制对比7.1、文本…...
)
华为IP(4)
VRRP(虚拟路由冗余协议) 前言: 局域网中的用户终端通常采用配置一个默认网关的形式访问外部网络,如果默认网关设备发生故障,那么所有用户终端访问外部网络的流量将会中断。可以通过部署多个网关的方式来解决单点故障…...
)
蓝桥杯刷题周计划(第四周)
目录 前言题目一题目代码题解分析 题目二题目代码题解分析 题目三题目代码题解分析 题目四题目代码题解分析 题目五题目代码题解分析 题目六题目代码题解分析 题目七题目代码题解分析 题目八题目代码题解分析 题目九题目代码题解分析 题目十题目代码题解分析题目代码题解分析 题…...

华为网路设备学习-17
目录 一、加密算法 二、验证算法 三、IPsec协议 1.IKE协议(密钥交换协议) ①ISAKMP(Internet Security Association and Key Management Protocol)互联网安全关联和密钥管理协议 ②安全关联(SA) ③…...

【动态规划】深入动态规划 非连续子序列问题
文章目录 前言例题一、最长递增子序列二、摆动序列三、最长递增子序列的个数四、最长数对链五、最长定差子序列六、最长的斐波那契子序列的长度七、最长等差数列八、等差数列划分II - 子序列 结语 前言 什么是动态规划中的非连续子序列问题? 动态规划中的非连续子序…...

灵魂拷问,指针为什么是C语言的灵魂?
目录 | 引 言 | 内存操作 | 构造复杂的数据结构 | 底层硬件交互 | 指针的陷阱 | 文 末 | 引 言 指针是C语言的灵魂! 这句话是不是很耳熟?但为什么这么说,你知道吗? 本篇小文就从内存、数据结构、底层硬件交互这三个维度来…...

Node.js自定义中间件
目录 Node.js 自定义中间件详细介绍 1. 目录结构 2. 什么是自定义中间件? 3. 代码实现 1. 自定义日志中间件(记录请求信息) 2. 自定义身份验证中间件(校验用户权限) 3. 自定义请求时间中间件(记录请…...

Qt 音乐播放器项目
具体代码见:https://gitee.com/Suinnnnnn/MusicPlayer 文章目录 0. 预备1. 界面1.1 各部位长度1.2 ui文件1.3 窗口前置设置1.4 设置QSS 2. 自定义控件2.1 按钮2.2 推荐页面2.3 CommonPage2.4 滑杆 3. 音乐管理4. 歌词界面4.1 ui文件4.2 LrcPage.h文件 5. 音乐播放控…...

初识数据结构——Java集合框架解析:List与ArrayList的完美结合
📚 Java集合框架解析:List与ArrayList的完美结合 🌟 前言:为什么我们需要List和ArrayList? 在日常开发中,我们经常需要处理一组数据。想象一下,如果你要管理一个班级的学生名单,或…...

LightRAG实战:轻松构建知识图谱,破解传统RAG多跳推理难题
作者:后端小肥肠 🍊 有疑问可私信或评论区联系我。 🥑 创作不易未经允许严禁转载。 姊妹篇: 2025防失业预警:不会用DeepSeek-RAG建知识库的人正在被淘汰_deepseek-embedding-CSDN博客 从PDF到精准答案:Coze…...

Hyperlane框架全面详解与应用指南 [特殊字符][特殊字符][特殊字符]
Hyperlane框架全面详解与应用指南 🚀🚀🚀 📚 前言 欢迎来到Hyperlane框架的全面详解与应用指南!🎉🎉🎉 本文档旨在为开发者提供一个全面、详尽的Hyperlane框架使用指南,…...

使用LVS的 NAT 模式实现 3 台RS的轮询访问
题目 使用LVS的 NAT 模式实现 3 台RS的轮询访问。IP地址和主机自己规划。 -i— turn,-g——DR模式,-m——NAT模式 节点规划 仅主机网段:192.168.216.0/24 NAT网段:192.168.88.0/24 主机角色系统网络ipclientclientredhat9.5仅…...

BGP路由协议之属性4
MED 多出口鉴别器 可选非过渡属性 EBGP 的邻居 Cost 开销值,控制如何进入 AS。越小越优。继承 IGP 的开销值,默认 0 MED(Multi-Exit Discriminator,多出口鉴别器)是可选非过属性,是一种度量值用于向外部对等体指出进入本 AS 的首…...

数据库的操作
1.创建数据库 CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,create_specification] ...]create_specification: [DEFAULT] CHARACTER SET charset_name [DEFAULT] COLLATE collation_name 大写的表示关键字。[]是可选项。CHARACTER SET:指定…...

【愚公系列】《高效使用DeepSeek》055-可靠性评估与提升
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! 👉 江湖人称"愚公搬代码",用七年如一日的精神深耕技术领域,以"…...

记录clickhouse记录一次性能优化,从60s到1s
文章目录 问题表结构类似如下分析第一步调整第一步观察多磁盘读继续观察sql 问题 一个查询接口,涉及多个clickhouse 查询,查询用时一下变成要60s 表结构类似如下 CREATE TABLE demo.test_local (id UUID,date DateTime,type String ) ENGINE Replic…...

二叉树的层序遍历
102. Binary Tree Level Order Traversal 广度优先搜索 将每个结点的层号记录下。 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* …...

嵌入式硬件篇---TOF陀螺仪SPI液晶屏
文章目录 前言1. TOF传感器(Time of Flight)原理STM32使用方法硬件连接SDASCLVCC\GND 软件配置初始化I2C外设库函数驱动:读取数据 2. 陀螺仪(如MPU6050)原理STM32使用方法硬件连接SDA/SCLINTVCC/GND 软件配置初始化I2C…...

OpenCV 在树莓派上进行实时人脸检测
这段 Python 代码借助 OpenCV 库实现了在树莓派上进行实时人脸检测的功能。它会开启摄像头捕获视频帧,在每一帧里检测人脸并以矩形框标记出来,同时在画面上显示帧率(FPS)。 依赖库 cv2:OpenCV 库,用于计算…...

55.跳跃游戏
题目来源: leetcode题目,网址:55. 跳跃游戏 - 力扣(LeetCode) 解题思路: 遍历数组,若当前节点可达,更新可到达的最远距离,否则返回false。若可遍历整个数组…...

awk 实现listagg ,count 功能
awk命令实现分组统计 测试数据 ABC a1 ABC a2 ABC a3 ABD c1 ABD c2 分组统计 abc a1,a2,a3 3 abd c1,c2 awk 命令 awk {arr[$1]arr[$1] ? arr[$1] "," $2 : $2; count[$1]} END{for (i in arr) print tolower(i), arr[i], count[i]} group_…...

瑞萨RA4M2使用心得-GPIO输出
目录 一、新建项目 二、图形化开发 1.初始化IO 2.界面介绍 3.代码编写 4.所有内部函数的封装位置 5.LED闪烁函数编写 三.debug运行 总结 环境: 开发板:RA-Eco-RA4M2-100PIN-V1.0 IDE:e2 studio 一、新建项目 正常操作,下…...

uniapp微信小程序引入vant组件库
1、首先要有uniapp项目,根据vant官方文档使用yarn或npm安装依赖: 1、 yarn init 或 npm init2、 # 通过 npm 安装npm i vant/weapp -S --production# 通过 yarn 安装yarn add vant/weapp --production# 安装 0.x 版本npm i vant-weapp -S --production …...

COZE通关指南:工作流与插件开发
前言 本文隶属于专栏《AI Agent 通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见《AI Agent 通关指南》 正文 1. 平台基础介绍 🌟 1.1 COZE平台概述 COZE平台(coze.cn)是一个强大的AI应用开发平台…...

在Unity中,如果物体上的脚本丢失,可以通过编写一个自定义编辑器脚本来查找并删除这些丢失的组件
在Unity中,如果物体上的脚本丢失,可以通过编写一个自定义编辑器脚本来查找并删除这些丢失的组件。以下是一个示例脚本,它可以帮助你一键检索场景中所有丢失脚本的物体,并删除这些丢失的组件。 步骤: 创建编辑器脚本&a…...

青少年编程与数学 02-016 Python数据结构与算法 04课题、栈与队列
青少年编程与数学 02-016 Python数据结构与算法 04课题、栈与队列 一、栈1. 栈的定义2. 栈的特点3. 栈的基本操作示例 4. 栈的实现(1)数组实现(2)链表实现 5. 栈的应用(1)函数调用(2)…...

Lucene.Net全文搜索引擎:架构解析与全流程实战指南
文章目录 引言:为什么选择Lucene.Net?一、Lucene.Net核心架构剖析1.1 模块化设计 二、Lucene.Net索引原理揭秘2.1 倒排索引:搜索的基石2.2 段(Segment)机制 三、全流程实战:从0到1构建搜索引擎3.1 环境准备…...

OpenSceneGraph 中的 LOD详解
LOD (Level of Detail,细节层次) 是3D图形中一种重要的优化技术,OpenSceneGraph 通过 osg::LOD 类提供了完整的LOD支持。 一、LOD 基本概念 1. 什么是LOD 核心思想:根据物体与相机的距离显示不同细节程度的模型 目的:减少远处物…...
:AdX/SSP系统广告位设置全解析)
程序化广告行业(64/89):AdX/SSP系统广告位设置全解析
程序化广告行业(64/89):AdX/SSP系统广告位设置全解析 大家好!我一直觉得在技术和营销不断融合的当下,程序化广告领域充满了机遇与挑战。之前和大家分享了程序化广告PDB模式的相关知识,今天想接着和大家一起…...
是什么)
Pytorch中的计算图(Computational Graph)是什么
🧩 一、什么是计算图? 计算图是一种“有向无环图(DAG)”,表示变量(张量)之间的运算关系。 节点:张量或操作(如加法、乘法)边:数据流(即…...
)
Java 大视界 -- Java 大数据在航天遥测数据分析中的技术突破与应用(177)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...

【Linux操作系统——学习笔记三】Linux环境下多级目录构建与管理的命令行实践报告
1.在用户主目录下,使用以下方法新建目录,并显示详细执行过程: (1)使用绝对路径在当前目录下创建 new_dir目录 (2)使用相对路径、在当前目录创建dir1、dir2、dir3目录 (3)…...

java.util.Collections中常用api
在Java中,java.util.Collections 是一个工具类,提供了大量静态方法用于操作或返回集合(如List、Set、Map等)。以下是常用的API分类整理: 1. 排序与顺序操作 sort(List<T> list) 对List进行自然顺序排序ÿ…...

批量将图片统一色调
from PIL import Image, ImageEnhance # 确保导入 ImageEnhance 模块 import osdef adjust_image_tone(image_path, output_path, r_weight1.0, g_weight1.0, b_weight1.0, brightness1.0):"""调整图片的色调、明暗,并进行去图处理。参数:image_pat…...

OCC Shape 操作
#pragma once #include <iostream> #include <string> #include <filesystem> #include <TopoDS_Shape.hxx> #include <string>class GeometryIO { public:// 加载几何模型:支持 .brep, .step/.stp, .iges/.igsstatic TopoDS_Shape L…...

docker的run命令 笔记250406
docker的run命令 笔记250406 Docker 的 run 命令用于创建并启动一个新的容器。它是 Docker 中最常用的命令之一,基本语法为: docker run [OPTIONS] IMAGE [COMMAND] [ARG...]常用选项(OPTIONS) 参数说明-d 或 --detach后台运行…...

批量将 HTML 转换为 Word/Txt/PDF 等其它格式
HTML是一种超文本标记语言,在进行网页编辑的时候非常常见,我们浏览的网站内容,都可以保存为 html 格式,如果想要将 html 格式的文档转为其它格式,比如 Word、PDF 或者 Txt,我们应该怎么做呢?今天…...