Python 使用 Requests 模块进行爬虫
目录
- 一、请求数据
- 二、获取并解析数据
- 四、保存数据
- 1. 保存为 CSV 文件
- 2. 保存为 Excel 文件
- 打开网页图片并将其插入到 Excel 文件中
- 五、加密参数逆向分析
- 1. 定位加密位置
- 2. 断点调试分析
- 3. 复制相关 js 加密代码,在本地进行调试(难)
- 4. 获取 sign 加密参数
- 六、其他示例
- 1. 单页数据处理与保存
- 2. 翻页数据采集 — MD5 加密
- 1)分析请求链接 / 参数的变化
- 2)sign 加密参数逆向分析
- 3)Python 代码实现
学习视频;【Python爬虫实战:采集常用软件数据(得物、闲鱼、小红书、微信小程序、验证码识别)】
参考文档:【Requests: 让 HTTP 服务人类】
一、请求数据
Requests 模块通过模拟浏览器对 url 地址发送请求。
- 打开需要采集数据的网站,通过浏览器的开发者工具分析对应的数据位置。
- 右键选择 “检查” → “网络” ,打开开发者工具;
- 刷新网页;
- 通过关键字搜索找到对应的数据位置。

- 请求标头:通过使用请求标头中的参数内容模拟浏览器,该参数需要使用字典
dict={'键':'值',}接收。
PyCharm 批量添加引号和逗号的方法:
- 选中要替换的内容,输入 Ctrl + R 打开替换栏;
- 勾选
.*,使用正则命令匹配数据进行替换;- 第一栏输入
(.*?):(.*),第二栏输入'$1':'$2',,再选中要替换的内容点击 “全部替换” 。

-
请求网址:复制抓包分析找到的链接地址。
-
请求方法:
- POST 请求 → 需要向服务器提交表单数据 / 请求载荷;
- GET 请求 → 向服务器获取数据。

- 请求参数:可以在 “载荷” 中进行查看
- POST 请求 → 隐性;
- GET 请求 → 显性(查询的参数直接在请求网址的链接中就可以看出)。
参考文章:【HTTP 方法:GET 对比 POST | 菜鸟教程】
- 发送请求:使用 requests 模块。
- 如果没有安装该模块,则 Win + R 输入 cmd ,输入
pip install requests命令并运行即可。 - 在 PyCharm 中输入
import requests导入数据请求模块。
- 如果没有安装该模块,则 Win + R 输入 cmd ,输入
Python 代码:
import requests# 请求标头
request_header = {'accept': '*/*','accept-encoding': 'gzip, deflate, br, zstd','accept-language': 'zh-CN,zh;q=0.9','connection': 'keep-alive','content-length': '124','content-type': 'application/json','cookie': '...','host': 'app.dewu.com','ltk': '...','origin': 'https://www.dewu.com','referer': 'https://www.dewu.com/','sec-ch-ua': '"Google Chrome";v="137", "Chromium";v="137", "Not/A)Brand";v="24"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-site','sessionid': '...','shumeiid': '...','sk': '','traceparent': '...','user-agent': '...'
}# 请求网址
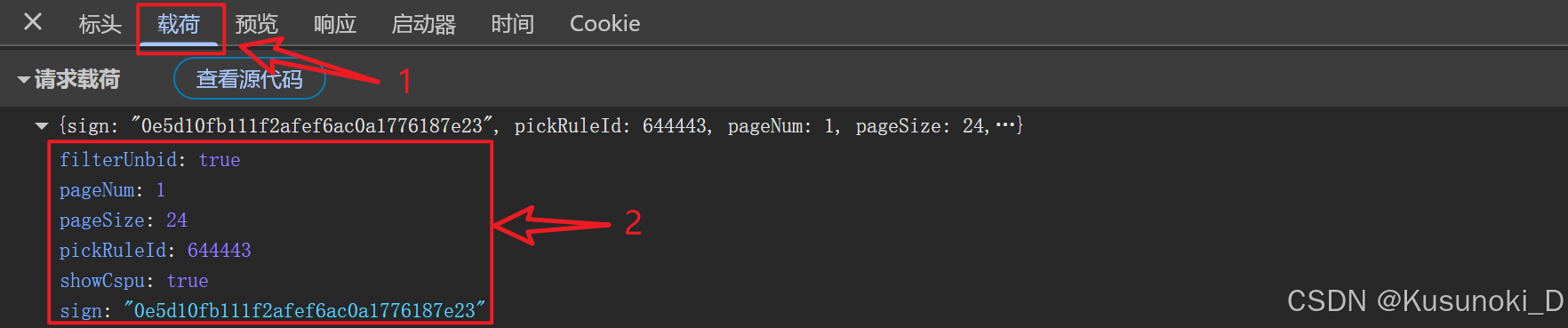
request_url = r'https://app.dewu.com/api/v1/h5/commodity-pick-interfaces/pc/pick-rule-result/feeds/info'# 请求载荷
request_parameters = {'filterUnbid': True,'pageNum': 1, # 页数'pageSize': 24,'pickRuleId': 644443,'showCspu': True,'sign': "0e5d10fb111f2afef6ac0a1776187e23" # 签名(加密参数)
}# 请求数据
response = requests.post(url=request_url, json=request_parameters, headers=request_header)
二、获取并解析数据
-
获取服务器返回的响应数据。
response.text→ 获取响应的文本数据(字符串)response.json()→ 获取响应的 json 数据(字典 / 列表)response.content→ 获取响应的二进制数据(二进制数据)
-
对键值对进行取值,提取出所需信息。
Python 代码:
# from pprint import pprint# 获取数据
data_json = response.json()
# print(data_json)# 解析数据
info_list = data_json['data']['list']
for index in info_list:# pprint(index)# print('-' * 50)info_dict = {'标题': index['title'],'价格': index['price'],'图片网址': index['logoUrl']}for key, value in info_dict.items():print(f'{key} : {value}')print('-' * 50)
注:如果出现 “requests.exceptions.InvalidHeader: xxx” 的报错,说明你的 request_header 字典中的值存在多余的空格,仔细检查后删除即可。
四、保存数据
1. 保存为 CSV 文件
Python 代码:
import requests
import csvrequest_header = {...}
request_url = r'https://app.dewu.com/api/v1/h5/commodity-pick-interfaces/pc/pick-rule-result/feeds/info'
request_parameters = {'filterUnbid': True,'pageNum': 1, # 页数'pageSize': 24,'pickRuleId': 644443,'showCspu': True,'sign': "0e5d10fb111f2afef6ac0a1776187e23" # 签名(加密参数)
}# 创建文件对象
f = open('dewu.csv', mode='w', encoding='utf-8-sig', newline='')
# 字典写入方法
cd = csv.DictWriter(f, fieldnames=['标题', '价格', '图片网址'])
# 写入表头
cd.writeheader()# 请求数据
response = requests.post(url=request_url, json=request_parameters, headers=request_header)
# 获取数据
data_json = response.json()
# 解析数据
info_list = data_json['data']['list']
for index in info_list:info_dict = {'标题': index['title'],'价格': index['price'] / 100,'图片网址': index['logoUrl']}# 写入数据cd.writerow(info_dict)f.close()
2. 保存为 Excel 文件
Python 代码:
import requests
import pandas as pdrequest_header = {...}
request_url = r'https://app.dewu.com/api/v1/h5/commodity-pick-interfaces/pc/pick-rule-result/feeds/info'
request_parameters = {'filterUnbid': True,'pageNum': 1, # 页数'pageSize': 24,'pickRuleId': 644443,'showCspu': True,'sign': "0e5d10fb111f2afef6ac0a1776187e23" # 签名(加密参数)
}# 请求数据
response = requests.post(url=request_url, json=request_parameters, headers=request_header)
# 获取数据
data_json = response.json()
# 创建一个空列表
dewu_info = []# 解析数据
info_list = data_json['data']['list']
for index in info_list:info_dict = {'标题': index['title'],'价格': index['price'] / 100,'图片网址': index['logoUrl']}# 写入数据dewu_info.append(info_dict)# 转换数据
df = pd.DataFrame(dewu_info)
# 导出保存为 Excel 表格
df.to_excel('dewu.xlsx', index=False)
打开网页图片并将其插入到 Excel 文件中
Python 代码:
import openpyxl
from openpyxl.drawing.image import Image as xlImage
from openpyxl.utils import get_column_letter
from PIL import Image
from io import BytesIOdef download_image(url):rg_url = requests.get(url)# 检查响应状态码if rg_url.status_code == 200:# 创建图像对象image = Image.open(BytesIO(rg_url.content))# 统一图像类型if image.mode != 'RGB':image = image.convert('RGB')# 调整图像大小return image.resize((150, 96))else:raise Exception(f"无法下载图片,状态码: {rg_url.status_code}")# 加载 Excel 文件
wb = openpyxl.load_workbook(r'dewu.xlsx')
# 默认为第一个 sheet
sheet = wb.active
# 调整行高和列宽
for row in range(2, sheet.max_row + 1):sheet.row_dimensions[row].height = 75
sheet.column_dimensions['C'].width = 20# 读取链接并下载图片插入到对应位置
for row in range(2, sheet.max_row + 1):# 假设图片链接在第 2 行开始,第 C 列是链接(对应 column = 3),获取链接单元格的值link = sheet.cell(row=row, column=3).value# 清空内容sheet.cell(row=row, column=3).value = None# 如果链接不为空if link:# 发送 HTTP 请求下载图片try:# 尝试下载图像resized_image = download_image(link)except OSError:print(f"下载图片 {link} 失败")continueelse:# 将调整后的图像插入到工作表中img_bytes = BytesIO()resized_image.save(img_bytes, format='PNG') # 将图片保存到内存中img = xlImage(img_bytes)sheet.add_image(img, f'{get_column_letter(3)}{row}') # 插入图片到指定位置wb.save(r'dewu_result.xlsx') # 必要
wb.close() # 必要
参考文章:【Python:openpyxl在excel中读取url并下载、插入图片】
五、加密参数逆向分析
1. 定位加密位置
通过开发者工具定位加密位置。

2. 断点调试分析
断点调试分析,分析加密规则。
- 搜索后返回了三个文件中的四个匹配行,分析可能的加密位置,然后添加断点。

- 通过对网页进行操作来调试断点,程序停止的位置就是我们要找的断点位置。

- 通过过滤请求网址,找到对应的请求载荷数据,查看 sign: 后的数据是否与刚刚断点处的 sign: c(e) 值一致。


- 移除上面的那个不需要的 sign: c(e) 断点。

注意:
c(e) 返回 sign 值,其中 e 是参数,c 是方法。
- e 是除 sign 以外的 POST 请求载荷。


-
c() 的返回值是 “0e5d10fb111f2afef6ac0a1776187e23”(由 0-9 a-f 组成的 32 位字符)。
-
由 0-9 a-f 组成的 32 位字符可能是 md5 加密。
验证是否为标准的 md5 加密,只需要调用加密函数,并传入字符串参数 ‘123456’ ,如果返回值是以 ‘e10adc’ 开头、‘883e’ 结尾,那么就是标准的 md5 加密。

由参数 e 是字典也可以看出,该方法 c() 不是 md5 加密,因为 md5 加密的参数一般是字符串。
3. 复制相关 js 加密代码,在本地进行调试(难)
较难理解的一部分,详细讲解请见:【Python爬虫实战:采集常用软件数据(得物)】的 0:50:25 处。
- 进入 c() 函数。


- 新建一个 JavaScript 文件(我的命名:js_file.js),并将上图红框中的代码复制进去。
function c(t) {...}t = {filterUnbid: true,pageNum: 1,pageSize: 24,pickRuleId: 644443,showCspu: true
} // 请求载荷console.log(c(t))
- 运行出现错误:
ReferenceError: u is not defined,出现此类报错是正常的,说明存在代码缺失。解决方案就是:缺方法补方法、缺参数补参数、缺环境补环境。

- 找到相应的加载器,并将代码添加至 JavaScript 文件里。


JavaScript 代码如下:
var a_temp; // 添加!function a_method(e) {var n = {}function a(r) {...}a_temp = a // 添加a.e = function (e) {...},a.m = e,a.c = n,a.d = function (e, r, t) {...},a.r = function (e) {...},a.t = function (e, r) {...},a.n = function (e) {...},a.o = function (e, r) {...},a.p = "",a.oe = function (e) {...}
}({});a = (a_temp("cnSC"), a_temp("ODXe"), a_temp("aCH8")) // 将 r 修改为 a_temp
u = a_temp.n(a); // 将 r 修改为 a_tempfunction c(t) {...}t = {filterUnbid: true,pageNum: 1,pageSize: 24,pickRuleId: 644443,showCspu: true
}console.log(c(t))
- 运行上述代码会出现
TypeError: Cannot read properties of undefined (reading 'call')的错误。如下图所示添加代码:

- 将运行后输出的缺失代码添加至 JavaScript 文件里。


JavaScript 代码如下:
var a_temp; // 添加!function a_method(e) {var n = {}function a(r) {...try {console.log(r) // 添加e[r].call(t.exports, t, t.exports, a),o = !1} finally {o && delete n[r]}...}a_temp = a // 添加a.e = function (e) {...},a.m = e,a.c = n,a.d = function (e, r, t) {...},a.r = function (e) {...},a.t = function (e, r) {...},a.n = function (e) {...},a.o = function (e, r) {...},a.p = "",a.oe = function (e) {...}
}({ // 添加cnSC: function (t, e) {...},ODXe: function (e, t, n) {...},BsWD: function (e, t, n) {...},a3WO: function (e, t, n) {...},aCH8: function (t, e, r) {...},ANhw: function (t, e) {...},mmNF: function (t, e) {...},BEtg: function (t, e) {...}
});a = (a_temp("cnSC"), a_temp("ODXe"), a_temp("aCH8")) // 将 r 修改为 a_temp
u = a_temp.n(a); // 将 r 修改为 a_tempfunction c(t) {...}t = {filterUnbid: true,pageNum: 1,pageSize: 24,pickRuleId: 644443,showCspu: true
}console.log(c(t))
详细的 js_file.js 文件代码见:【对得物进行爬虫时使用到的 js 模块】
- 运行结果如下图所示:

4. 获取 sign 加密参数
-
Win + R 输入 cmd 进入命令提示符,输入命令
pip install pyexecjs安装 execjs 库,安装好后在 PyCharm 中输入import execjs就可以使用该模块了。 -
编译 js 代码并获取 sign 加密参数,并将 sign 值添加至请求载荷中。
Python 代码:
import requests
# 导入编译 js 代码模块
import execjs# 请求标头
request_header = {...}
# 请求网址
request_url = r'https://app.dewu.com/api/v1/h5/commodity-pick-interfaces/pc/pick-rule-result/feeds/info'
# 请求载荷
request_parameters = {'filterUnbid': True,'pageNum': 1, # 页码'pageSize': 24,'pickRuleId': 644443, # 类目 ID'showCspu': True
}# 编译 js 代码
js_code = execjs.compile(open('./js_file.js', encoding='utf-8').read())
# 获取 sign 加密参数
sign_data = js_code.call('c', request_parameters)
# 0e5d10fb111f2afef6ac0a1776187e23
# 将 sign 添加至请求载荷中
request_parameters['sign'] = sign_data# 请求数据
response = requests.post(url=request_url, json=request_parameters, headers=request_header)
# 获取数据
data_json = response.json()
# 解析数据
info_list = data_json['data']['list']
for index in info_list:info_dict = {'标题': index['title'],'价格': index['price'] / 100,'图片网址': index['logoUrl']}for key, value in info_dict.items():print(f'{key} : {value}')print('-' * 50)
六、其他示例
1. 单页数据处理与保存
Python 代码:
# 导入数据请求模块
import requests
import csvdef get_data_csv(file_path, head_name):# 模拟浏览器(请求标头)request_header = {'Referer': 'https://www.goofish.com/',# cookie 代表用户信息,常用于检测是否有登陆账户(不论是否登录都有 cookie)'Cookie': '...'# user-agent 代表用户代理,显示浏览器 / 设备的基本身份信息'User-Agent': '...'}# 请求网址request_url = r'https://h5api.m.goofish.com/h5/mtop.taobao.idlemtopsearch.pc.search/1.0/'# 查询参数query_parameters = {'jsv': '2.7.2','appKey': '34839810','t': '1750520204194','sign': '0dba40964b402d00dc448081c8e04127','v': '1.0','type': 'originaljson','accountSite': 'xianyu','dataType': 'json','timeout': '20000','api': 'mtop.taobao.idlemtopsearch.pc.search','sessionOption': 'AutoLoginOnly','spm_cnt': 'a21ybx.search.0.0','spm_pre': 'a21ybx.home.searchSuggest.1.4c053da6IXTxSx','log_id': '4c053da6IXTxSx'}# 表单数据form_data = {"pageNumber": 1,"keyword": "python爬虫书籍","fromFilter": False,"rowsPerPage": 30,"sortValue": "","sortField": "","customDistance": "","gps": "","propValueStr": {},"customGps": "","searchReqFromPage": "pcSearch","extraFilterValue": "{}","userPositionJson": "{}"}print('Data is being requested and processed…')# 发送请求response = requests.post(url=request_url, params=query_parameters, data=form_data, headers=request_header)# 获取响应的 json 数据 → 字典数据类型data_json = response.json()# 键值对取值,提取商品信息所在列表info_list = data_json['data']['resultList']# 创建文件对象f = open(file_path, mode='a', encoding='utf-8-sig', newline='')# 字典写入方法cd = csv.DictWriter(f, fieldnames=head_name)cd.writeheader()# for 循环遍历,提取列表里的元素for index in info_list:# 处理用户名nick_name = '未知'if 'userNickName' in index['data']['item']['main']['exContent']:nick_name = index['data']['item']['main']['exContent']['userNickName']# 处理售价price_list = index['data']['item']['main']['exContent']['price']price = ''for p in price_list:price += p['text']# 处理详情页链接item_id = index['data']['item']['main']['exContent']['itemId']link = f'https://www.goofish.com/item?id={item_id}'temporarily_dict = {'标题': index['data']['item']['main']['exContent']['title'],'地区': index['data']['item']['main']['exContent']['area'],'售价': price,'用户名': nick_name,'详情页链接': link}cd_file.writerow(temporarily_dict)f.close()if __name__ == '__main__':f_path = './fish.csv'h_name = ['标题', '地区', '售价', '用户名', '详情页链接']get_data_csv(f_path, h_name)
2. 翻页数据采集 — MD5 加密
1)分析请求链接 / 参数的变化
如下图所示,其中 t 可以通过 time 模块获取;pageNumber 可以通过 for 循环构建。

2)sign 加密参数逆向分析
- 通过开发者工具定位加密位置。

- 断点调试分析。

k = i(d.token + "&" + j + "&" + h + "&" + c.data) ,其中:
d.token = "b92a905a245d2523e9ca49dd382dad12" // 固定
j = 1750571387066 // 时间戳(变化)
h = "34839810" // 固定
// 表单数据,其中只有页码 pageNumber 会变化
c.data = ('{"pageNumber": 1, ''"keyword": "python爬虫书籍", ''"fromFilter": false, ''"rowsPerPage": 30, ''"sortValue": "", ''"sortField": "", ''"customDistance": "", ''"gps": "", ''"propValueStr": {}, ''"customGps": "", ''"searchReqFromPage": "pcSearch", ''"extraFilterValue": "{}", ''"userPositionJson": "{}"}')k = "1c32f4de228112a3a59df6972d186b41" // 返回值 由 0-9 a-f 构成的 32 位字符
- 判断是否为 md5 加密的方法:调用加密函数
i(),并传入字符串参数 ‘123456’ ,如果返回值是以 ‘e10adc’ 开头、‘883e’ 结尾,那么就是标准的 md5 加密。

# 导入哈希模块
import hashlibd_token = 'b92a905a245d2523e9ca49dd382dad12'
j = 1750571387066 # <class 'int'>
h = '34839810'
c_data = ('{"pageNumber": 1, ''"keyword": "python爬虫书籍", ''"fromFilter": false, ''"rowsPerPage": 30, ''"sortValue": "", ''"sortField": "", ''"customDistance": "", ''"gps": "", ''"propValueStr": {}, ''"customGps": "", ''"searchReqFromPage": "pcSearch", ''"extraFilterValue": "{}", ''"userPositionJson": "{}"}')
result_str = d_token + "&" + str(j) + "&" + h + "&" + c_data
# 使用 md5 加密
md_str = hashlib.md5()
# 传入加密参数
md_str.update(result_str.encode('utf-8'))
# 进行加密处理
sign = md_str.hexdigest() # <class 'str'>
print(sign) # 1c32f4de228112a3a59df6972d186b41
3)Python 代码实现
# 导入数据请求模块
import requests
import csv
# 导入哈希模块
import hashlib
import timedef get_sign(page):d_token = '...' # token 是有时效性的,请自行填入j = int(time.time() * 1000)h = '...'c_data = ('{"pageNumber": %d, ...}') % pageresult_str = d_token + "&" + str(j) + "&" + h + "&" + c_data# 使用 md5 加密md_str = hashlib.md5()# 传入加密参数md_str.update(result_str.encode('utf-8'))# 进行加密处理sign = md_str.hexdigest()return sign, j, c_datadef get_data_csv(file_path, head_name):# 模拟浏览器(请求标头)request_header = {'Referer': 'https://www.goofish.com/',# cookie 代表用户信息,常用于检测是否有登陆账户(不论是否登录都有 cookie)# cookie 是有时效性的,请自行填入'Cookie': '...',# user-agent 代表用户代理,显示浏览器 / 设备的基本身份信息'User-Agent': '...'}# 请求网址request_url = r'https://h5api.m.goofish.com/h5/mtop.taobao.idlemtopsearch.pc.search/1.0/'# 创建文件对象f = open(file_path, mode='a', encoding='utf-8-sig', newline='')# 字典写入方法cd = csv.DictWriter(f, fieldnames=head_name)cd.writeheader()# for 构建循环翻页num = 10for i in range(1, num + 1):print(f'正在采集第 {i} 页数据…')# 获取 sign 加密参数、时间戳和表单数据sign, j_time, c_data = get_sign(i)# 查询参数query_parameters = {'jsv': '2.7.2','appKey': '34839810','t': str(j_time),'sign': sign,'v': '1.0','type': 'originaljson','accountSite': 'xianyu','dataType': 'json','timeout': '20000','api': 'mtop.taobao.idlemtopsearch.pc.search','sessionOption': 'AutoLoginOnly','spm_cnt': 'a21ybx.search.0.0','spm_pre': 'a21ybx.home.searchSuggest.1.4c053da6IXTxSx','log_id': '4c053da6IXTxSx'}# 表单数据form_data = {"data": c_data}# 发送请求response = requests.post(url=request_url, params=query_parameters, data=form_data, headers=request_header)# 获取响应的 json 数据 → 字典数据类型data_json = response.json()# 键值对取值,提取商品信息所在列表info_list = data_json['data']['resultList']# for 循环遍历,提取列表里的元素for index in info_list:# 处理用户名nick_name = '未知'if 'userNickName' in index['data']['item']['main']['exContent']:nick_name = index['data']['item']['main']['exContent']['userNickName']# 处理售价price_list = index['data']['item']['main']['exContent']['price']price = ''for p in price_list:price += p['text']# 处理详情页链接item_id = index['data']['item']['main']['exContent']['itemId']link = f'https://www.goofish.com/item?id={item_id}'temporarily_dict = {'标题': index['data']['item']['main']['exContent']['title'],'地区': index['data']['item']['main']['exContent']['area'],'售价': price,'用户名': nick_name,'详情页链接': link}cd.writerow(temporarily_dict)f.close()if __name__ == '__main__':f_path = './fish_python.csv'h_name = ['标题', '地区', '售价', '用户名', '详情页链接']get_data_csv(f_path, h_name)
运行结果展示:

注意:运行时可能会出现 {'api': 'mtop.taobao.idlemtopsearch.pc.search', 'data': {}, 'ret': ['FAIL_SYS_TOKEN_EXOIRED::令牌过期'], 'v': '1.0'} 的错误,那是因为 d_token 和 cookie 都是具有时效性的,每过一段时间都会改变,因此自行修改成当下的 d_token 值和 cookie 值即可。
相关文章:

Python 使用 Requests 模块进行爬虫
目录 一、请求数据二、获取并解析数据四、保存数据1. 保存为 CSV 文件2. 保存为 Excel 文件打开网页图片并将其插入到 Excel 文件中 五、加密参数逆向分析1. 定位加密位置2. 断点调试分析3. 复制相关 js 加密代码,在本地进行调试(难)4. 获取 …...

day039-nginx配置补充
文章目录 0. 老男孩思想-如何提升能力?1. nginx登录认证功能1.1 创建密码文件1.2 修改子配置文件1.3 重启服务 2. nginx处理请求流程3. 配置默认站点4. location 命令5. 案例1-搭建大型直播购物网站5.1 配置本地hosts解析5.2 编写子配置文件5.3 创建相关目录/文件并…...

K8s入门指南:架构解析浓缩版与服务间调用实战演示
目录 前言一、k8s概念理解1、k8s整体架构(1) Master 主节点(2) Node 工作节点(3) Etcd 键值存储数据库 2、Pod被视为最小的部署单元3、k8s的五种控制器类型(1)…...

如何用AI开发完整的小程序<10>—总结
通过之前9节的学习。 如何用Ai制作一款简单小程序的内容就已经都介绍完了。 总结起来就以下几点: 1、搭建开发制作环境 2、创建页面(需要手动) 3、在页面上制作UI效果(让Ai搞,自己懂了后可以自己调) 4…...

Javaweb - 3 CSS
CSS 层叠样式表(Cascading Style Sheets),能够对网页中元素位置的排版进行像素级精确控制,支持几乎所有的字体字号样式,拥有对网页对象和模型样式编辑的能力。 简单来说,HTML 搭建一个毛坯房,C…...

【算法】【优选算法】优先级队列
目录 一、1046.最后一块石头的重量二、703. 数据流中的第 K 大元素三、692. 前 K 个⾼频单词四、295. 数据流的中位数 一、1046.最后一块石头的重量 题目链接:1046.最后一块石头的重量 题目描述: 题目解析: 题意就是让我们拿出提供的数组…...

PaddleOCR + Flask 构建 Web OCR 服务实战
1、前言 随着图像识别技术的发展,OCR(光学字符识别)已经成为很多应用场景中的基础能力。PaddleOCR 是百度开源的一个高性能 OCR 工具库,支持中英文、多语言、轻量级部署等特性。 而 Flask 是一个轻量级的 Python Web 框架,非常适合快速构建 RESTful API 或小型 Web 应用…...

openapi-generator-maven-plugin自动生成HTTP远程调用客户端
Java开发中调用http接口的时候,有很多可选的技术方案,比如:HttpURLConnection、RestTemplate、WebClient、Feign、Retrofit、Okhttp等,今天我们来看一个更优的技术方案OpenAPI Generator(http://openapi-generator.tech/) OpenAP…...

ms-swift 部分命令行参数说明
参考链接 命令行参数 — swift 3.6.0.dev0 文档 Qwen Chat num_train_epochs 训练的epoch数,默认为3 假设你有 1000 条训练样本,并且设置了: num_train_epochs 3 这意味着: 模型会完整地遍历这 1000 条数据 3 次。每一次…...

【学习笔记】深入理解Java虚拟机学习笔记——第10章 前端编译与优化
第10章 前端编译与优化 10.1 概述 1>前端编译器:Javac命令。 【.java文件->.class文件】 2>即时编译器:Hotspot.C1.C2 【.class文件->机器码】 3>提前编译器:JDK的Jaotc等【.java->机器码】 10.2 Javac 编译器 10.2.1 …...

删除node并且重装然后重装vue
参考第一篇文章 node.js卸载与安装超详细教程_node卸载重装-CSDN博客 第二篇文章安装vue Vue安装与配置教程(非常详细)_安装vue-CSDN博客...

Flink源码阅读环境准备全攻略:搭建高效探索的基石
想要深入探索Flink的底层原理,搭建一套完整且适配的源码阅读环境是必经之路。这不仅能让我们更清晰地剖析代码逻辑,还能在调试过程中精准定位关键环节。接下来,结合有道云笔记内容,从开发工具安装、源码获取导入到调试配置&#x…...

【破局痛点,赋能未来】领码 SPARK:铸就企业业务永续进化的智慧引擎—— 深度剖析持续演进之道,引领数字化新范式
摘要 在瞬息万变的数字时代,企业对业务连续性、敏捷创新及高效运营的需求日益迫切。领码 SPARK 融合平台,秉持“持续演进”这一核心理念,以 iPaaS 与 aPaaS 为双擎驱动,深度融合元数据驱动、智能端口调度、自动化灰度切换、AI 智…...

Flink SQL Connector Kafka 核心参数全解析与实战指南
Flink SQL Connector Kafka 是连接Flink SQL与Kafka的核心组件,通过将Kafka主题抽象为表结构,允许用户使用标准SQL语句完成数据读写操作。本文基于Apache Flink官方文档(2.0版本),系统梳理从表定义、参数配置到实战调优…...

Linux 服务器运维:磁盘管理与网络配置
🤵♂️ 个人主页:布说在见 ✍🏻作者简介: 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏…...

PyTorch 入门学习笔记
目录 1 张量 1)张量的初始化和属性 2)张量操作 3)使用 NumPy 进行桥接 2 torch.autograd 1)背景 2)在 PyTorch 中的使用 3)Autograd 的微分机制 4)计算图原理 3 神经网络 1ÿ…...

9大策略深度解析MySQL多表JOIN性能优化
一、多表JOIN的现实挑战 在实际开发中,MySQL多表JOIN场景主要源于两类场景: • 历史遗留系统:老代码中未严格遵循范式设计的SQL语句• 数据库迁移:从Oracle迁移至MySQL时保留的复杂关联查询 这类操作潜藏多重风险: …...

CSS 逐帧动画
CSS 逐帧动画实现指南 逐帧动画(frame-by-frame animation)是一种通过快速连续显示一系列静态图像来创造运动效果的技术。以下是使用CSS实现逐帧动画的几种方法。 1. 使用 steps() 计时函数 这是实现逐帧动画最常用的方法,通过animation-timing-function的steps(…...

UE5 游戏模板 —— ThirdPersonGame
UE5 游戏模板 —— ThirdPersonGame 前言一、初始化旋转控制参数1.参数一2.参数二3.参数三4.参数四 二、输入系统总结 前言 有了前面的铺垫,第三人称模板简直是手到擒来了,我们只需要注意一些初始化的变量是做什么的即可,因为UE的Character …...

java中关于异步转同步的一些解决方案的对比与思考。【spring mvc堵塞式】
文章目录 1、Spring MVC堵塞式编程中的技术方案a) 最简单的方案,使用 DeferredResult 代码如下,代码解读:最终控制台输出如下。用户收到的结果 b) 上点难度,使用redis监听事件,根据事件的不同返回不同的数据…...

【数据结构与算法】数据结构核心概念系统梳理
第一章 绪论:基础概念体系 🚩算法:问题求解步骤的描述。 🚩非递归的算法效率更高。 1.1 逻辑结构 vs 存储结构 维度逻辑结构存储结构(物理结构)定义数据元素之间的逻辑关系数据结构在计算机中的实现方式分类线性/树形/图/集合顺序/链式/索引/散列独立性独立于存储结构…...

《HTTP权威指南》 第7章 缓存
带着问题学习: 缓存如何提高性能如何衡量缓存的有效性缓存置于何处作用最大HTTP如何保持缓存副本的新鲜度缓存如何与其他缓存及服务器通信 web缓存是可以自动保存常见文档副本的HTTP设备。 缓存优点 减少冗余的数据传输,节省网络费用缓解网络瓶颈问题&…...

【Zephyr 系列 28】MCU 闪存文件系统详解:LittleFS + NVS + 块设备设计实战
🧠关键词:Zephyr 文件系统、LittleFS、NVS、Flash 分区、嵌入式存储、断电保护、wear leveling 📌 1. 为什么 MCU 上需要文件系统? 在嵌入式开发中,很多开发者起初直接操作 Flash 保存参数,但随着需求增长…...
论文总结)
ICML 2025 | 时间序列(Time Series)论文总结
ICML 2025将在2025年7月13日至7月19日(周六)在温哥华会议中心举行,本文总结了ICML 2025有关时间序列(Time Series)相关文章,共计63篇。 时间序列Topic:预测,分类,异常检测,生成&…...
)
理解后端开发中的中间件(以gin框架为例)
中间件(Middleware)是后端开发中的一个核心概念,它在请求(Request)和响应(Response)之间扮演着桥梁角色。以下是关于中间件的详细解释: 基本概念 中间件是在请求到达最终处理程序之前或响应返回客户端之前执行的一系列函数或组件。它可以: 访…...

【分布式技术】Bearer Token以及MAC Token深入理解
Bearer Token以及MAC Token深入理解 **Bearer Token 详解****1. 什么是 Bearer Token?****2. Bearer Token 的构建详情****(1)生成流程****(2)Token 示例(JWT)****(3)Tok…...
:媒体能力协商)
WebRTC(七):媒体能力协商
目的 在 WebRTC 中,每个浏览器或终端支持的音视频编解码器、分辨率、码率、帧率等可能不同。媒体能力协商的目的就是: 确保双方能“听得懂”对方发的媒体流;明确谁发送、谁接收、怎么发送;保障连接的互操作性和兼容性。 P2P的基…...
Normal Equation(正规方程))
(线性代数最小二乘问题)Normal Equation(正规方程)
Normal Equation(正规方程) 是线性代数中的一个重要概念,主要用于解决最小二乘问题(Least Squares Problem)。它通过直接求解一个线性方程组,找到线性回归模型的最优参数(如权重或系数ÿ…...

【机器学习】数学基础——标量
目录 一、标量的定义 二、标量的核心特征:无方向的纯粹量级 2.1 标量 vs 矢量 直观对比 三、 标量的数学本质:零阶张量 3.1 张量阶数金字塔 3.2 标量的数学特性 四、 现实世界的标量图谱 4.1 常见标量家族 4.2 经典案例解析 五、 标量的运算奥秘…...
)
基于python代码的通过爬虫方式实现TK下载视频(2025年6月)
Tk的视频页面通常需要登录才能获取完整数据,但通过构造匿名游客的请求,我们可以绕过登录限制,提取视频的元信息(如标题、ID和播放地址)。核心思路如下: 构造匿名Cookie:通过模拟浏览器的请求,获取Tk服务器分配的游客Cookie。解析网页:利用BeautifulSoup解析HTML,定位…...

Go 语言的堆糖图片爬虫
基于 Go 语言的堆糖图片爬取探索之旅 在互联网的浩瀚海洋中,堆糖网以其丰富多样的高清图片、美图壁纸等内容吸引了众多用户。对于图片爱好者来说,能高效获取心仪的图片资源无疑是一件极具吸引力的事情。今天,就带大家走进一段基于 Go 语言的…...

python+uni-app基于微信小程序的儿童安全教育系统
文章目录 具体实现截图本项目支持的技术路线源码获取详细视频演示:文章底部获取博主联系方式!!!!本系统开发思路进度安排及各阶段主要任务java类核心代码部分展示主要参考文献:源码获取/详细视频演示 ##项目…...

DAY 39 图像数据与显存
图像数据的格式:灰度和彩色数据模型的定义显存占用的4种地方 模型参数梯度参数优化器参数数据批量所占显存神经元输出中间状态 batchisize和训练的关系 import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader ,…...

ELK搭建
1、elasticsearch和kibana搭建配置见 https://blog.csdn.net/yh_zeng2/article/details/148812447?spm1001.2014.3001.5501 2、logstash 下载 下载和elasticsearch版本一致的logstash,下载地址: Past Releases of Elastic Stack Software | Elastic …...
 从零搭建实战记录:日志采集与可视化】)
【ELK(Elasticsearch+Logstash+Kibana) 从零搭建实战记录:日志采集与可视化】
ELK(ElasticsearchLogstashKibana) 从零搭建实战记录:日志采集与可视化 本文记录了我在搭建ELK(Elasticsearch, Logstash, Kibana)技术栈时的完整实战过程。使用Docker Compose快速搭建了ELK服务端(监控主机),并通过Filebeat实现…...

反无人机系统:技术利刃如何守护低空安全?
反无人机系统:技术利刃如何守护低空安全? ——从军事防御到城市安防的全景解析 一、技术体系:从“电磁软杀伤”到“激光硬摧毁”的立体防御网 反无人机技术本质是一场“降维打击”:用百万级防御系统对抗千元级消费无人机。当前…...
)
第十章——8天Python从入门到精通【itheima】-102-Python基础综合案例-数据可视化(pyecharts的入门使用+数据处理)
目录 102节——pyecharts的入门使用 1.学习目标 2.pyecharts入门——基础折线图 3.pyecharts的配置对象有哪些? 4.全局配置——set_global_opts 5.小节总结 103节——数据处理 1.学习目标 2.无法继续关于第一阶段的pyecharts的相关学习 因为关于JSON数据获…...

Neo4j 中存储和查询数组数据的完整指南
Neo4j 中存储和查询数组数据的完整指南 图形数据库 Neo4j 不仅擅长处理节点和关系,还提供了强大的数组(Array)存储和操作能力。本文将全面介绍如何在 Neo4j 中高效地使用数组,包括存储、查询、优化以及实际应用场景。 数组在 Neo4j 中的基本使用 数组…...

云原生/容器相关概念记录
文章目录 网络与虚拟化技术云平台与架构容器与编排容器网络方案性能优化与工具硬件与协议 网络与虚拟化技术 P4可编程网关 P4: Programming Protocol-independent Packet Processors一种基于P4语言的可编程网络设备,支持自定义数据包处理逻辑。P4可编程技术详解&am…...

uni-app项目实战笔记21--uniapp缓存的写入和读取
一、缓存的写入 uni.setStorageSync("storageClassList",classifyList.value) 二、缓存的读取,如果缓存不存在,则返回空数组 const storageClassList uni.getStorageSync("storageClassList") || []; 三、对读取到的数据进行转…...

操作系统概述
覆盖了操作系统概述、运行机制、中断、异常、操作系统的五大结构、虚拟机。 借鉴:王道、我的好朋友杨某、我的笔记。 一、操作系统概念 概念 1.操作系统体现了封装思想 由于底层硬件只接受二进制的指令不方便用户操作,所以操作系统把这些封装成简易的…...

探索数据的力量:Elasticsearch中指定链表字段的统计查询记录
目录 一、基本的数据结构说明 二、基本的统计记录 (一)统计当前索引中sellingProducts的所有类型 (二)检索指定文档中sellingProducts的数据总量 (三)检索指定文档中sellingProducts指定类型的数量统计…...

【Datawhale组队学习202506】YOLO-Master task03 IOU总结
系列文章目录 task01 导学课程 task02 YOLO系列发展线 文章目录 系列文章目录前言1 功能分块1.1 骨干网络 Backbone1.2 颈部网络 Neck1.3 头部网络 Head1.3.1 边界框回归头1.3.2 分类头 2 关键概念3 典型算法3.1 NMS3.2 IoU 总结 前言 Datawhale是一个专注于AI与数据科学的开…...

C/C++数据结构之静态数组
概述 静态数组是C/C中一种基础的数据结构,它允许用户在编译时便确定数组的大小,并分配固定数量的连续存储空间来存放相同类型的元素。静态数组的主要特点是:其大小在声明时就必须指定,且在其生命周期内保持不变。这也意味着&#…...

pyqt f-string
文章目录 一、f-string的基本语法二、代码中的具体应用拼接效果 三、f-string的核心优势四、与其他字符串格式化方式的对比五、在Qt程序中的实际作用六、扩展用法:在f-string中添加格式说明 Python的 f-string(格式化字符串字面值) 特性&…...

夏普 AR-2348SV 打印机信息
基本信息:这是一款黑白 A3 激光多功能数码复合机,可实现打印、复印、扫描功能。性能参数 打印 / 复印速度:23 张 / 分钟。分辨率:600x600dpi,能确保文字和图像清晰。最大打印 / 复印尺寸:A3。纸张支持&…...
跨个体预训练与轻量化Transformer在手势识别中的应用:Bioformer
目录 一、从深度学习到边缘部署,手势识别的新突破 (一)可穿戴设备 边缘计算 个性化医疗新可能 (二)肌电信号(sEMG):手势识别的关键媒介 (三)挑战&#…...

探索常识性概念图谱:构建智能生活的知识桥梁
目录 一、知识图谱背景介绍 (一)基本背景 (二)与NLP的关系 (三)常识性概念图谱的引入对比 二、常识性概念图谱介绍 (一)常识性概念图谱关系图示例 (二)…...

人人都是音乐家?腾讯开源音乐生成大模型SongGeneration
目录 前言 一、SongGeneration 带来了什么? 1.1 文本控制与风格跟随:你的想法,AI 精准实现 1.2 多轨生成:从“成品”到“半成品”的巨大飞跃 1.3 开源:推倒“高墙”,共建生态 二、3B 参数如何媲美商业…...

一,python语法教程.内置API
一,字符串相关API string.strip([chars])方法:移除字符串开头和结尾的空白字符(如空格、制表符、换行符等),它不会修改原始字符串,而是返回一个新的处理后的字符串 chars(可选)&…...