使用tensorRT10部署低光照补偿模型
1.低光照补偿模型的简单介绍

作者介绍一种Zero-Reference Deep Curve Estimation (Zero-DCE)的方法用于在没有参考图像的情况下增强低光照图像的效果。
具体来说,它将低光照图像增强问题转化为通过深度网络进行图像特定曲线估计的任务。训练了一个轻量级的深度网络 DCE-Net,来估计像素级和高阶曲线,以对给定图像进行动态范围调整。这种曲线估计考虑了像素值范围、单调性和可微性等因素。
Zero-DCE 的优点在于它不需要任何成对或不成对的数据进行训练,它通过一系列精心设计的非参考损失函数来实现这一点,这些函数能隐式地衡量增强质量并驱动网络学习。该方法通过直观且简单的非线性曲线映射实现图像增强,并且在多种照明条件下都具有很好的适用性。
文章还通过大量的实验来证明 Zero-DCE 在亮度、色彩、对比度和自然度等方面的视觉效果优于现有的先进方法,而其他方法在处理极暗背光或生成彩色伪影方面可能会失败。相比之下,Zero-DCE 的训练方式也与其他深度学习方法不同,并且它在黑暗环境下的面部检测方面也具有潜在优势。
这篇论文的方案以及低光照补偿结果如下:
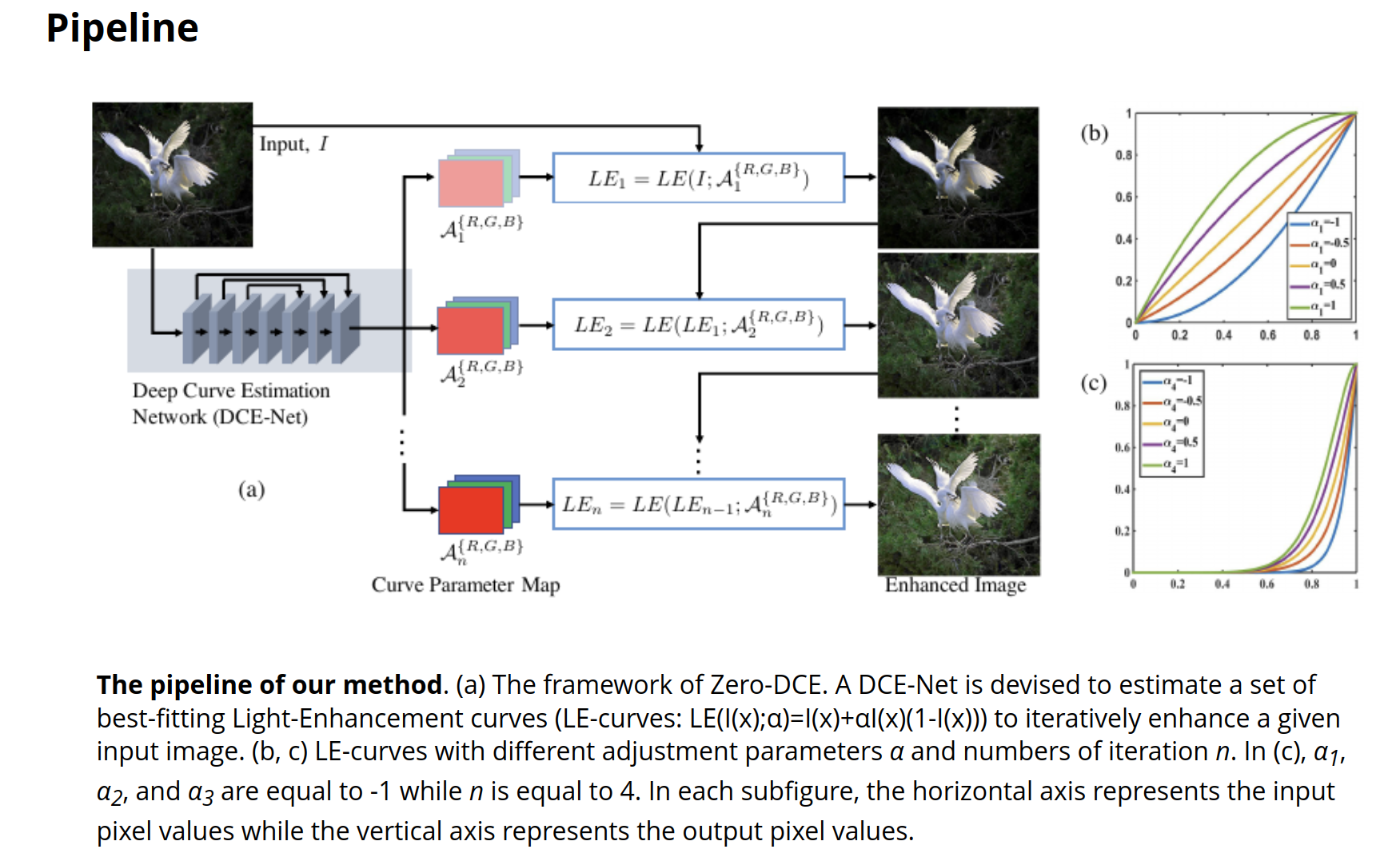


文章源码地址:https://github.com/Li-Chongyi/Zero-DCE.git
2. zero_dce源码的简单介绍
2.1模型设计
模型设计比较简单,常规常见的算子
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
#import pytorch_colors as colors
import numpy as npclass enhance_net_nopool(nn.Module):def __init__(self):super(enhance_net_nopool, self).__init__()self.relu = nn.ReLU(inplace=True)number_f = 32self.e_conv1 = nn.Conv2d(3,number_f,3,1,1,bias=True) self.e_conv2 = nn.Conv2d(number_f,number_f,3,1,1,bias=True) self.e_conv3 = nn.Conv2d(number_f,number_f,3,1,1,bias=True) self.e_conv4 = nn.Conv2d(number_f,number_f,3,1,1,bias=True) self.e_conv5 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True) self.e_conv6 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True) self.e_conv7 = nn.Conv2d(number_f*2,24,3,1,1,bias=True) self.maxpool = nn.MaxPool2d(2, stride=2, return_indices=False, ceil_mode=False)self.upsample = nn.UpsamplingBilinear2d(scale_factor=2)def forward(self, x):x1 = self.relu(self.e_conv1(x))# p1 = self.maxpool(x1)x2 = self.relu(self.e_conv2(x1))# p2 = self.maxpool(x2)x3 = self.relu(self.e_conv3(x2))# p3 = self.maxpool(x3)x4 = self.relu(self.e_conv4(x3))x5 = self.relu(self.e_conv5(torch.cat([x3,x4],1)))# x5 = self.upsample(x5)x6 = self.relu(self.e_conv6(torch.cat([x2,x5],1)))x_r = F.tanh(self.e_conv7(torch.cat([x1,x6],1)))r1,r2,r3,r4,r5,r6,r7,r8 = torch.split(x_r, 3, dim=1)x = x + r1*(torch.pow(x,2)-x)x = x + r2*(torch.pow(x,2)-x)x = x + r3*(torch.pow(x,2)-x)enhance_image_1 = x + r4*(torch.pow(x,2)-x) x = enhance_image_1 + r5*(torch.pow(enhance_image_1,2)-enhance_image_1) x = x + r6*(torch.pow(x,2)-x) x = x + r7*(torch.pow(x,2)-x)enhance_image = x + r8*(torch.pow(x,2)-x)r = torch.cat([r1,r2,r3,r4,r5,r6,r7,r8],1)return enhance_image_1,enhance_image,r2.2模型训练和损失函数
模型的损失函数设计部分比较复杂,在训练过程中使用
L_color = Myloss.L_color()L_spa = Myloss.L_spa()L_exp = Myloss.L_exp(16,0.6)L_TV = Myloss.L_TV()而这里的损失函数全都在文件中间的Myloss.py文件中,在训练的过程中:
for epoch in range(config.num_epochs):for iteration, img_lowlight in enumerate(train_loader):img_lowlight = img_lowlight.cuda()enhanced_image_1,enhanced_image,A = DCE_net(img_lowlight)Loss_TV = 200*L_TV(A)loss_spa = torch.mean(L_spa(enhanced_image, img_lowlight))loss_col = 5*torch.mean(L_color(enhanced_image))loss_exp = 10*torch.mean(L_exp(enhanced_image))# best_lossloss = Loss_TV + loss_spa + loss_col + loss_exp2.3 图像的前处理
源码中的图像前处理部分如下:
def __getitem__(self, index):data_lowlight_path = self.data_list[index]data_lowlight = Image.open(data_lowlight_path)data_lowlight = data_lowlight.resize((self.size,self.size), Image.ANTIALIAS)data_lowlight = (np.asarray(data_lowlight)/255.0) data_lowlight = torch.from_numpy(data_lowlight).float()return data_lowlight.permute(2,0,1)在源码的lowlight_test中也可以看到图像的这个模型的前处理的代码:
data_lowlight = Image.open(image_path)data_lowlight = (np.asarray(data_lowlight)/255.0)data_lowlight = torch.from_numpy(data_lowlight).float()data_lowlight = data_lowlight.permute(2,0,1)data_lowlight = data_lowlight.cuda().unsqueeze(0)2.4 源码的后处理代码
源码直接使用torchvisopn.utils.save_image()方法保存了推理的结果
_,enhanced_image,_ = DCE_net(data_lowlight)end_time = (time.time() - start)print(end_time)image_path = image_path.replace('test_data','result')result_path = image_pathif not os.path.exists(image_path.replace('/'+image_path.split("/")[-1],'')):os.makedirs(image_path.replace('/'+image_path.split("/")[-1],''))torchvision.utils.save_image(enhanced_image, result_path)点开save_image()方法
def save_image(tensor: Union[torch.Tensor, List[torch.Tensor]],fp: Union[str, pathlib.Path, BinaryIO],format: Optional[str] = None,**kwargs,
) -> None:"""Save a given Tensor into an image file.Args:tensor (Tensor or list): Image to be saved. If given a mini-batch tensor,saves the tensor as a grid of images by calling ``make_grid``.fp (string or file object): A filename or a file objectformat(Optional): If omitted, the format to use is determined from the filename extension.If a file object was used instead of a filename, this parameter should always be used.**kwargs: Other arguments are documented in ``make_grid``."""if not torch.jit.is_scripting() and not torch.jit.is_tracing():_log_api_usage_once(save_image)grid = make_grid(tensor, **kwargs)# Add 0.5 after unnormalizing to [0, 255] to round to the nearest integerndarr = grid.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to("cpu", torch.uint8).numpy()im = Image.fromarray(ndarr)im.save(fp, format=format)
3. 导出模型
由于这个代码本身没有复杂的算子和其他恶心的操作,我这边直接使用yolov5的环境测试这个lowlight_test.py的文件,发现可以直接运行。这里需要需要注意
DCE_net.load_state_dict(torch.load('/home/zpec/workspace/source-cnn/Zero-DCE-master/Zero-DCE_code/snapshots/Epoch99.pth'))
filePath = '/home/zpec/workspace/source-cnn/Zero-DCE-master/Zero-DCE_code/data/test_data/'
这里使用完整的路径。
在Zero-DCE_code文件夹下面创建export_onnx.py的文件,写如下的导出代码
import torch
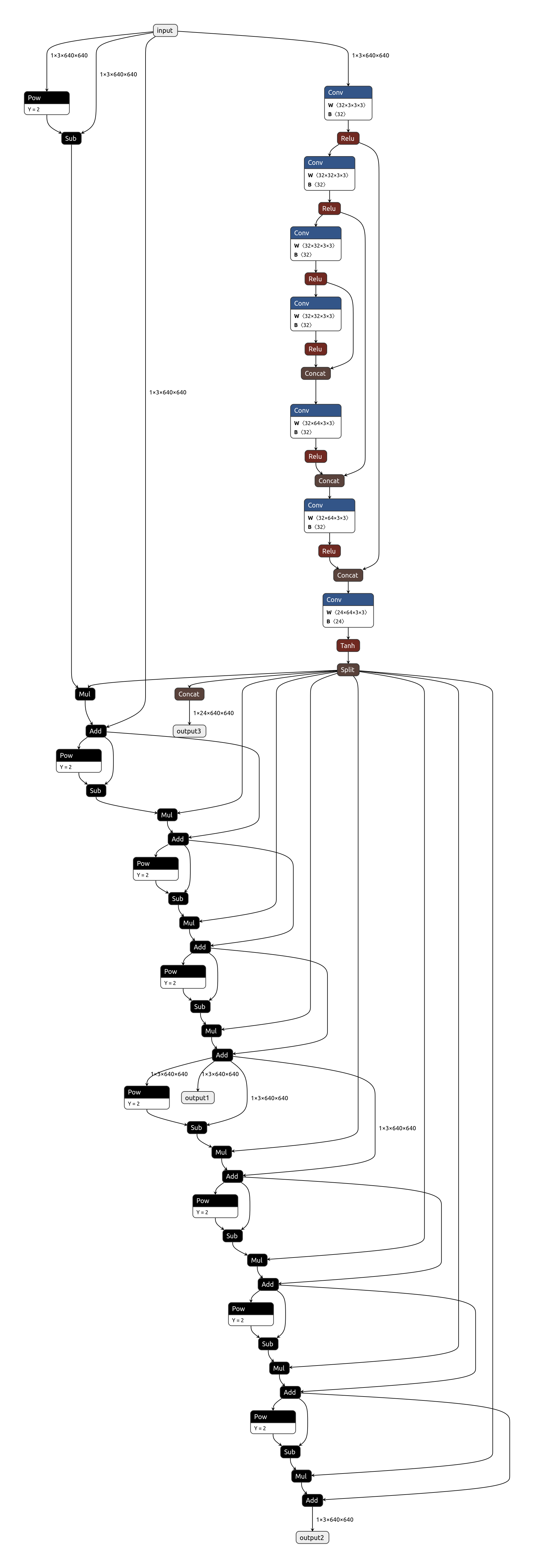
import model def convert_to_static_onnx():# 设备配置device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载预训练模型DCE_net = model.enhance_net_nopool().to(device)DCE_net.load_state_dict(torch.load('/home/zpec/workspace/source-cnn/Zero-DCE-master/Zero-DCE_code/snapshots/Epoch99.pth', map_location=device))DCE_net.eval()static_height = 640 static_width = 640 # 创建固定尺寸的虚拟输入dummy_input = torch.randn(1, 3, static_height, static_width).to(device)# 导出为静态模型torch.onnx.export(DCE_net,dummy_input,"ZeroDCE_static640.onnx",verbose=True,input_names=["input"],output_names=["output1","output2","output3"],opset_version=12, )if __name__ == "__main__":convert_to_static_onnx()运行即可生成对应模型的onnx文件,onnx文件可视化如下:

4. 使用onnx加载推理模型试验
这里加载python版本的onnxruntime来试验推理模型,完整的推理代码如下:
import onnxruntime as ort
import numpy as np
import cv2def preprocess_image_cv2(image_path, input_shape):# 读取图像img = cv2.imread(image_path)# 转换为 RGB 格式img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 调整大小img = cv2.resize(img, (input_shape[2], input_shape[1]))# 归一化img = img / 255.0# 转换为通道优先格式 (C, H, W)img = img.transpose(2, 0, 1)# 添加批次维度 (1, C, H, W)img = np.expand_dims(img, axis=0).astype(np.float32)return imgdef postprocess_image_cv2(output, output_shape):# 去除批次维度output = np.squeeze(output, axis=0)# 转换为 HWC 格式output = output.transpose(1, 2, 0)# 调整大小到原始图像大小output = cv2.resize(output, output_shape)# 转换为 BGR 格式output = cv2.cvtColor(output, cv2.COLOR_RGB2BGR)return output# 示例用法
if __name__ == '__main__':# 示例图像路径image_path = '/home/zpec/workspace/source-cnn/Zero-DCE-master/Zero-DCE_code/data/test_data/DICM/06.jpg'# 模型输入形状 (例如: [3, 640, 640])input_shape = [3, 640, 640]# 预处理图像input_image = preprocess_image_cv2(image_path, input_shape)ort_session = ort.InferenceSession('ZeroDCE_static640.onnx')# 运行推理input_name = ort_session.get_inputs()[0].nameoutput_name = ort_session.get_outputs()[1].name# 检查模型的输入和输出的节点# 获取所有输入节点的信息inputs_info = ort_session.get_inputs()# 获取所有输出节点的信息outputs_info = ort_session.get_outputs()# 打印输入节点的信息print("Input nodes:")for idx, input_info in enumerate(inputs_info):print(f"Input node {idx}:")print(f" Name: {input_info.name}")print(f" Shape: {input_info.shape}")print(f" Type: {input_info.type}")print()# 打印输出节点的信息print("Output nodes:")for idx, output_info in enumerate(outputs_info):print(f"Output node {idx}:")print(f" Name: {output_info.name}")print(f" Shape: {output_info.shape}")print(f" Type: {output_info.type}")print()outputs = ort_session.run([output_name], {input_name: input_image})# 后处理输出# output_image = postprocess_image_cv2(outputs[0], (input_shape[2], input_shape[1]))output_image = postprocess_image_cv2(outputs[0], (640, 480))# 保存结果output_image_path = 'enhanced_image.jpg'cv2.imwrite(output_image_path, (output_image * 255).astype(np.uint8))print(f"Output image saved to {output_image_path}")推理效果展示如下:

说明我们的前处理和后处理没有任何问题。现在开始tensorRT的模型部署和推理吧。
5. 使用tensorRT10部署模型
项目地址:GitHub - YLXA321/ZERO_DCE_model-tensorRT10: 基于tensorRT10部署低光照补偿代码
图像前处理的代码
void preprocess_cpu(cv::Mat &srcImg, float* dstDevData, const int width, const int height) {if (srcImg.data == nullptr) {std::cerr << "ERROR: Image file not found! Program terminated" << std::endl;return;}cv::Mat dstimg;if (srcImg.rows != height || srcImg.cols != width) {cv::resize(srcImg, dstimg, cv::Size(width, height), cv::INTER_AREA);} else {dstimg = srcImg.clone();}// BGR→RGB转换 + HWC→CHW转换int index = 0;int offset_ch0 = width * height * 0; // R通道int offset_ch1 = width * height * 1; // G通道int offset_ch2 = width * height * 2; // B通道for (int i = 0; i < height; i++) {for (int j = 0; j < width; j++) {index = i * width * 3 + j * 3;// 从BGR数据中提取并赋值到目标通道dstDevData[offset_ch0++] = dstimg.data[index + 2] / 255.0f; // RdstDevData[offset_ch1++] = dstimg.data[index + 1] / 255.0f; // GdstDevData[offset_ch2++] = dstimg.data[index + 0] / 255.0f; // B}}
}图像后处理的代码:
cv::Mat decode_cpu(const float* model_output, const int KInputW, const int KInputH, const int src_width, const int src_height) {cv::Mat src_image;if (model_output == nullptr) {std::cerr << "ERROR: Model output is null." << std::endl;return cv::Mat();}// 创建临时浮点图像(HWC格式,RGB顺序)cv::Mat temp_image(KInputH, KInputW, CV_32FC3);float* temp_data = reinterpret_cast<float*>(temp_image.data); // 直接操作内存// 计算各通道的起始指针const int channel_size = KInputH * KInputW;const float* r_channel = model_output + 0; // R通道起始地址const float* g_channel = model_output + channel_size; // G通道起始地址const float* b_channel = model_output + 2 * channel_size; // B通道起始地址// 并行化填充(OpenCV自动优化)for (int i = 0; i < KInputH; ++i) {for (int j = 0; j < KInputW; ++j) {const int pixel_idx = (i * KInputW + j) * 3; // HWC中每个像素的起始位置const int ch_idx = i * KInputW + j; // CHW中当前像素的通道内索引temp_data[pixel_idx] = r_channel[ch_idx]; // Rtemp_data[pixel_idx + 1] = g_channel[ch_idx]; // Gtemp_data[pixel_idx + 2] = b_channel[ch_idx]; // B}}// 反归一化并转为8UC3(与Python一致)temp_image.convertTo(temp_image, CV_8UC3, 255.0);// Resize到目标尺寸(使用INTER_LINEAR)if (KInputW != src_width || KInputH != src_height) {cv::resize(temp_image, src_image, cv::Size(src_width, src_height), cv::INTER_LINEAR);} else {src_image = temp_image.clone();}// RGB转BGR(与Python的cv2.COLOR_RGB2BGR一致)cv::cvtColor(src_image, src_image, cv::COLOR_RGB2BGR);return src_image;}构建模型的推理引擎:
bool genEngine(std::string onnx_file_path, std::string save_engine_path, trtlogger::Logger level, int maxbatch){auto logger = std::make_shared<trtlogger::Logger>(level);// 创建builderauto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(*logger));if(!builder){std::cout<<" (T_T)~~~, Failed to create builder."<<std::endl;return false;}auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(0U));if(!network){std::cout<<" (T_T)~~~, Failed to create network."<<std::endl;return false;}// 创建 configauto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());if(!config){std::cout<<" (T_T)~~~, Failed to create config."<<std::endl;return false;}// 创建parser 从onnx自动构建模型,否则需要自己构建每个算子auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, *logger));if(!parser){std::cout<<" (T_T)~~~, Failed to create parser."<<std::endl;return false;}// 读取onnx模型文件开始构建模型auto parsed = parser->parseFromFile(onnx_file_path.c_str(), 1);if(!parsed){std::cout<<" (T_T)~~~ ,Failed to parse onnx file."<<std::endl;return false;}{auto input = network->getInput(0);auto input_dims = input->getDimensions();auto profile = builder->createOptimizationProfile(); // 配置最小、最优、最大范围input_dims.d[0] = 1; profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, input_dims);profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, input_dims);input_dims.d[0] = maxbatch;profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, input_dims);config->addOptimizationProfile(profile);// 判断是否使用半精度优化模型// if(FP16) config->setFlag(nvinfer1::BuilderFlag::kFP16);config->setFlag(nvinfer1::BuilderFlag::kGPU_FALLBACK);config->setDefaultDeviceType(nvinfer1::DeviceType::kDLA);// 设置默认设备类型为 DLAconfig->setDefaultDeviceType(nvinfer1::DeviceType::kDLA);// 获取 DLA 核心支持情况int numDLACores = builder->getNbDLACores();if (numDLACores > 0) {std::cout << "DLA is available. Number of DLA cores: " << numDLACores << std::endl;// 设置 DLA 核心int coreToUse = 0; // 选择第一个 DLA 核心(可以根据实际需求修改)config->setDLACore(coreToUse);std::cout << "Using DLA core: " << coreToUse << std::endl;} else {std::cerr << "DLA not available on this platform, falling back to GPU." << std::endl;// 如果 DLA 不可用,则设置 GPU 回退config->setFlag(nvinfer1::BuilderFlag::kGPU_FALLBACK);config->setDefaultDeviceType(nvinfer1::DeviceType::kGPU);}};config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 28); /*在新的版本中被使用*/// 创建序列化引擎文件auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));if(!plan){std::cout<<" (T_T)~~~, Failed to SerializedNetwork."<<std::endl;return false;}//! 检查输入部分是否符合要求auto numInput = network->getNbInputs();std::cout<<"模型的输入个数是:"<<numInput<<std::endl;for(auto i = 0; i<numInput; ++i){std::cout<<" 模型的第"<<i<<"个输入:";auto mInputDims = network->getInput(i)->getDimensions();std::cout<<" ✨~ model input dims: "<<mInputDims.nbDims <<std::endl;for(size_t ii=0; ii<mInputDims.nbDims; ++ii){std::cout<<" ✨^_^ model input dim"<<ii<<": "<<mInputDims.d[ii] <<std::endl;}}auto numOutput = network->getNbOutputs();std::cout<<"模型的输出个数是:"<<numOutput<<std::endl;for(auto i=0; i<numOutput; ++i){std::cout<<" 模型的第"<<i<<"个输出:";auto mOutputDims = network->getOutput(i)->getDimensions();std::cout<<" ✨~ model output dims: "<<mOutputDims.nbDims <<std::endl;for(size_t jj=0; jj<mOutputDims.nbDims; ++jj){std::cout<<" ✨^_^ model output dim"<<jj<<": "<<mOutputDims.d[jj] <<std::endl;}}// 序列化保存推理引擎文件文件std::ofstream engine_file(save_engine_path, std::ios::binary);if(!engine_file.good()){std::cout<<" (T_T)~~~, Failed to open engine file"<<std::endl;return false;}engine_file.write((char *)plan->data(), plan->size());engine_file.close();std::cout << " ~~Congratulations! 🎉🎉🎉~ Engine build success!!! ✨✨✨~~ " << std::endl;return true;}创建runtime部分:
bool ZeroDCEModel::Runtime(std::string engine_file_path, trtlogger::Logger level,int maxBatch){auto logger = std::make_shared<trtlogger::Logger>(level);// 初始化trt插件
// initLibNvInferPlugins(&logger, "");std::ifstream engineFile(engine_file_path, std::ios::binary);long int fsize = 0;engineFile.seekg(0, engineFile.end);fsize = engineFile.tellg();engineFile.seekg(0, engineFile.beg);std::vector<char> engineString(fsize);engineFile.read(engineString.data(), fsize);if (engineString.size() == 0) { std::cout << "Failed getting serialized engine!" << std::endl; return false; }// 创建推理引擎m_runtime.reset(nvinfer1::createInferRuntime(*logger));if(!m_runtime){std::cout<<" (T_T)~~~, Failed to create runtime."<<std::endl;return false;}// 反序列化推理引擎m_engine.reset(m_runtime->deserializeCudaEngine(engineString.data(), fsize));if(!m_engine){std::cout<<" (T_T)~~~, Failed to deserialize."<<std::endl;return false;}// 获取优化后的模型的输入维度和输出维度// int nbBindings = m_engine->getNbBindings(); // trt8.5 以前版本int nbBindings = m_engine->getNbIOTensors(); // trt8.5 以后版本// 推理执行上下文m_context.reset(m_engine->createExecutionContext());if(!m_context){std::cout<<" (T_T)~~~, Failed to create ExecutionContext."<<std::endl;return false;}auto input_dims = m_context->getTensorShape("input");input_dims.d[0] = maxBatch;m_context->setInputShape("input", input_dims);std::cout << " ~~Congratulations! 🎉🎉🎉~ create execution context success!!! ✨✨✨~~ " << std::endl;return true;
}申请内存,并且绑定模型输入输出:
bool ZeroDCEModel::trtIOMemory() {m_inputDims = m_context->getTensorShape("input"); // 模型输入m_outputDims[0] = m_context->getTensorShape("output1"); //第一个输出m_outputDims[1] = m_context->getTensorShape("output2"); //第二个输出m_outputDims[2] = m_context->getTensorShape("output3"); //第三个输出this->kInputH = m_inputDims.d[2];this->kInputW = m_inputDims.d[3];m_inputSize = m_inputDims.d[0] * m_inputDims.d[1] * m_inputDims.d[2] * m_inputDims.d[3] * sizeof(float);m_outputSize[0] = m_outputDims[0].d[0] * m_outputDims[0].d[1] * m_outputDims[0].d[2] * m_outputDims[0].d[3] * sizeof(float);m_outputSize[1] = m_outputDims[1].d[0] * m_outputDims[1].d[1] * m_outputDims[1].d[2] * m_outputDims[1].d[3] * sizeof(float);m_outputSize[2] = m_outputDims[2].d[0] * m_outputDims[2].d[1] * m_outputDims[2].d[2] * m_outputDims[2].d[3] * sizeof(float);// 声明cuda的内存大小checkRuntime(cudaMalloc(&buffers[0], m_inputSize));checkRuntime(cudaMalloc(&buffers[1], m_outputSize[0]));checkRuntime(cudaMalloc(&buffers[2], m_outputSize[1]));checkRuntime(cudaMalloc(&buffers[3], m_outputSize[2]));// 声明cpu内存大小checkRuntime(cudaMallocHost(&cpu_buffers[0], m_inputSize));checkRuntime(cudaMallocHost(&cpu_buffers[1], m_outputSize[0]));checkRuntime(cudaMallocHost(&cpu_buffers[2], m_outputSize[1]));checkRuntime(cudaMallocHost(&cpu_buffers[3], m_outputSize[2]));m_context->setTensorAddress("input", buffers[0]);m_context->setTensorAddress("output1", buffers[1]);m_context->setTensorAddress("output2", buffers[2]);m_context->setTensorAddress("output3", buffers[3]);checkRuntime(cudaStreamCreate(&m_stream));return true;
}推理模型:
cv::Mat ZeroDCEModel::doInference(cv::Mat& frame) {if(useGPU){zero_dce_preprocess::preprocess_gpu(frame, (float*)buffers[0], kInputH, kInputW, m_stream);}else{zero_dce_preprocess::preprocess_cpu(frame, cpu_buffers[0], kInputW, kInputH);// Preprocess -- 将host的数据移动到device上checkRuntime(cudaMemcpyAsync(buffers[0], cpu_buffers[0], m_inputSize, cudaMemcpyHostToDevice, m_stream));}bool status = this->m_context->enqueueV3(m_stream);if (!status) std::cerr << "(T_T)~~~, Failed to create ExecutionContext." << std::endl;// 将gpu推理的结果返回到cpu上面处理checkRuntime(cudaMemcpyAsync(cpu_buffers[1], buffers[1], m_outputSize[0], cudaMemcpyDeviceToHost, m_stream));checkRuntime(cudaMemcpyAsync(cpu_buffers[2], buffers[2], m_outputSize[1], cudaMemcpyDeviceToHost, m_stream));checkRuntime(cudaMemcpyAsync(cpu_buffers[3], buffers[3], m_outputSize[2], cudaMemcpyDeviceToHost, m_stream));checkRuntime(cudaStreamSynchronize(m_stream));int height = frame.rows;int width = frame.cols;cv::Mat enhance_image;if(useGPU){enhance_image = zero_dce_postprocess::decode_gpu(buffers[2],kInputW,kInputH,width,height);}else{// cv::Mat enhance_image_1 = zero_dce_postprocess::decode_cpu(cpu_buffers[1],kInputW,kInputH,height,width);enhance_image = zero_dce_postprocess::decode_cpu(cpu_buffers[2],kInputW,kInputH,width,height);// cv::Mat r = zero_dce_postprocess::decode_cpu(cpu_buffers[3],kInputW,kInputH,height,width);}return enhance_image;}部署代码的增强图展示:

至此,完成模型zero_dce_model模型的部署代码。
6. 低光照补偿代码的使用
这是一个低光照补偿的模型部署,一般情况下需要配合其他模型使用。比如在检测模型中,发现实际检测场景比较暗,这个时候可以先配合检查图像的暗亮程度,如果过暗的话,可以使用这个模型先增加图像的亮度,然后再次输入到检测模型中开始检测。
检测图像的暗亮程度,对这个图像灰度化,然后求取图像的平均亮度作为判断条件,然后再使用其他模型。
int main(){cv::VideoCapture cap("media/6.mp4");// 检查视频是否成功打开if (!cap.isOpened()) {std::cerr << "无法打开视频文件或摄像头!" << std::endl;return -1;}// 创建一个窗口用于显示视频cv::namedWindow("Video", cv::WINDOW_NORMAL);cv::Mat frame;while (true) {// 读取一帧if (!cap.read(frame)) {std::cerr << "无法读取视频帧!" << std::endl;break;}//----------------判断的亮度------------------------cv::Mat gray;// 将彩色图转换为灰度图cv::cvtColor(frame, gray, cv::COLOR_BGR2GRAY);cv::Scalar mean_value = cv::mean(gray);std::cout << "[OpenCV] Average: " << mean_value[0] << std::endl;if (mean_value[0]< 30){frame = zero_model.doInference(frame);}//----------------判断的亮度------------------------auto detections = model.doInference(frame);model.draw(frame,detections);// 显示这一帧cv::imshow("Video", frame);// 按下 'q' 键退出循环if (cv::waitKey(30) == 'q') {break;}}// 释放资源并关闭窗口cap.release();cv::destroyAllWindows();return 0;
}相关文章:

使用tensorRT10部署低光照补偿模型
1.低光照补偿模型的简单介绍 作者介绍一种Zero-Reference Deep Curve Estimation (Zero-DCE)的方法用于在没有参考图像的情况下增强低光照图像的效果。 具体来说,它将低光照图像增强问题转化为通过深度网络进行图像特定曲线估计的任务。训练了一个轻量级的深度网络…...

题单:表达式求值1
题目描述 给定一个只包含 “加法” 和 “乘法” 的算术表达式,请你编程计算表达式的值。 输入格式 输入仅有一行,为需要计算的表达式,表达式中只包含数字、加法运算符 和乘法运算符 *,且没有括号。 所有参与运算的数字不超过…...

【ant design】ant-design-vue 4.0实现主题色切换
官网:Ant Design Vue — An enterprise-class UI components based on Ant Design and Vue.js 我图方便,直接在 app.vue 中加入的 <div class"app-content" v-bind:class"appOption.appContentClass"><a-config-provider…...

MinIO深度解析:从入门到实战——对象存储系统全指南
在当今数字化时代,数据存储至关重要。MinIO作为一款高性能的对象存储系统,正逐渐受到广泛关注。它与云原生存储系统相媲美,并且其API与Amazon S3完全兼容。本文将带您快速了解MinIO,并探讨其在实际中的应用场景。 一、关于MinIO …...
python开发经验)
(8)python开发经验
文章目录 1 下载python2 pip安装依赖无法访问3 系统支持4 下载python文档5 设置虚拟环境6 编译安装python 更多精彩内容👉内容导航 👈👉Qt开发 👈👉python开发 👈 1 下载python 下载地址尽量不要下载最新版…...

uniapp自动构建pages.json的vite插件
对于 uniapp 来说,配置 pages.json 无疑是最繁琐的事情,具有以下缺点: 冗长,页面很多时 pages 内容会很长难找,有时候因为内容很长,导致页面配置比较难找,而且看起来比较凌乱json弊端ÿ…...

【MySQL进阶】如何在ubuntu下安装MySQL数据库
前言 🌟🌟本期讲解关于如何在ubuntu环境下安装mysql的详细介绍~~~ 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 🔥 你的点赞就是小编不断更新的最大动力 dz…...

解放双手的全自动抠图工具
软件介绍 本文要介绍的这款软件是Teorex PhotoScissors,是一款全自动抠图软件。 第二段:软件便捷性 这款来自国外的软件堪称神器,目前已解锁可无限使用。使用起来特别方便,无需安装,打开即可直接操作,并…...

Python多进程编程执行任务
我的需求如下:现有一批任务,使用进程池执行,每个任务执行耗时不一样,任务并发执行期间,需要每隔一段时间监控任务执行进度 直接贴代码: import multiprocessing import time import random from multiproc…...

【Linux笔记】——Linux线程封装
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:Linux 🌹往期回顾🌹:【Linux笔记】——Linux线程控制创建、终止与等待|动态库与内核联动 🔖流水不争,争的是…...

ChatGPT + DeepSeek 联合润色的 Prompt 模板指令合集,用来润色SCI论文太香了!
对于非英语母语的作者来说,写SCI论文的时候经常会碰到语法错误、表达不够专业、结构不清晰以及术语使用不准确等问题。传统的润色方式要么成本高、效率低,修改过程又耗时又费力。虽然AI工具可以帮助我们来润色论文,但单独用ChatGPT或DeepSeek都会存在内容泛泛、专业性不足的…...
)
【typenum】 9 与常量泛型桥接(generic_const_mappings.rs)
一、源码 该代码提供了常量结构体与库类型的转换。 // THIS IS GENERATED CODE //! Module with some const-generics-friendly definitions, to help bridge the gap //! between those and typenum types. //! //! - It requires the const-generics crate feature to be…...

并发学习之synchronized,JVM内存图,线程基础知识
文章目录 Java内存图内存图区域介绍执行流程 进程和线程概念解释线程的6种状态简述等待队列和同步队列(阻塞队列)线程之间是独立的 synchronized静态方法非静态方法代码块 知识总结: 方法区存储类信息正在执行的程序叫进程,进程会…...

使用Docker部署Nacos
sudo systemctl start docker sudo systemctl enable docker docker --version 步骤 2: 拉取 Nacos Docker 镜像 拉取 Nacos 镜像: 你可以从 Docker Hub 上拉取官方的 Nacos 镜像,使用以下命令: docker pull nacos/nacos-server 这会从 …...

如何 naive UI n-data-table 改变行移动光标背景色
默认是light 灰,想换个显眼包色,折腾半天,可以了。 无废话上代码: <template><n-data-tablesize"small":columns"columns":data"sortedDataList":bordered"true":row-key"…...

Maven 插件扩展点与自定义生命周期
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

Redis的发布订阅模型是什么,有哪些缺点?
Redis 发布订阅模型概述 Redis 发布订阅(Pub/Sub)是一种消息广播模式,核心角色包括: 发布者(Publisher):向指定频道(Channel)发送消息。频道(Channel&#…...

【EDA软件】【联合Modelsim仿真使用方法】
背景 业界EDA工具仿真功能是必备的,例如Vivado自带仿真工具,且无需联合外部仿真工具,例如MoodelSim。 FUXI工具仿真功能需要联合Modelsim,才能实现仿真功能。 方法一:FUXI联合ModelSim 1 添加testbench文件 新建to…...

C语言_动态内存管理
1. 为什么存在动态内存分配 ? 当前,我们掌握的内存开辟方式有: int val22;// 在栈空间上开辟四个字节 char arr[10]{0};// 在栈空间上开辟10个字节的连续空间而上述的开辟空间的方式有两个特点: 空间开辟大小示固定的数组在申明的时候&am…...

使用Langfuse和RAGAS,搭建高可靠RAG应用
大家好,在人工智能领域,RAG系统融合了检索方法与生成式AI模型,相比纯大语言模型,提升了准确性、减少幻觉且更具可审计性。不过,在实际应用中,当建好RAG系统投入使用时,如何判断接收信息是否正确…...

MySQL 数据库优化:ShardingSphere 原理及实践
在高并发、大数据量的业务场景下,MySQL 作为关系型数据库的核心存储引擎,其性能和扩展性面临严峻挑战。ShardingSphere 作为 Apache 顶级开源项目,提供了分布式数据库解决方案,通过分库分表、读写分离、弹性迁移等能力,帮助开发者实现 MySQL 的水平扩展与性能优化。 本文…...
总结回顾)
【Redis】零碎知识点(易忘 / 易错)总结回顾
一、Redis 是一种基于键值对(key-value)的 NoSQL 数据库 二、Redis 会将所有数据都存放在内存中,所以它的读写性能非常惊人 Redis 还可以将内存的数据利用快照和日志的形式保存到硬盘上,这样在发生类似断电或者机器故障时…...
136.0.7103.93便携增强版|Win中文|安装教程)
谷歌浏览器(Google Chrome)136.0.7103.93便携增强版|Win中文|安装教程
软件下载 【名称】:谷歌浏览器(Google Chrome)136.0.7103.93 【大小】:170M 【语言】:简体中文 【安装环境】:Win10/Win11 【夸克网盘下载链接】(务必手机注册): h…...

【滑动窗口】LeetCode 209题解 | 长度最小的子数组
长度最小的子数组 前言:滑动窗口一、题目链接二、题目三、算法原理解法一:暴力枚举解法二:利用单调性,用滑动窗口解决问题那么怎么用滑动窗口解决问题?分析滑动窗口的时间复杂度 四、编写代码 前言:滑动窗口…...

WebXR教学 07 项目5 贪吃蛇小游戏
WebXR教学 07 项目5 贪吃蛇小游戏 index.html <!DOCTYPE html> <html> <head><title>3D贪吃蛇小游戏</title><style>body { margin: 0; }canvas { display: block; }#score {position: absolute;top: 20px;left: 20px;color: white;font-…...

2.1.3
# Load the data file_path finance数据集.csv data pd.__________(file_path) --- data pd.read_csv(file_path) # 识别数值列用于箱线图 numeric_cols data.select_dtypes(include[float64, int64]).__________ --- numeric_cols data.select_dtypes(include[flo…...

StreamCap v0.0.1 直播录制工具 支持批量录制和直播监控
—————【下 载 地 址】——————— 【本章下载一】:https://drive.uc.cn/s/2fa520a8880d4 【本章下载二】:https://pan.xunlei.com/s/VOQDt_3v0DYPxrql5y2zxgO1A1?pwd2kqi# 【百款黑科技】:https://ucnygalh6wle.feishu.cn/wiki/…...

小蜗牛拨号助手用户使用手册
一、软件简介 小蜗牛拨号助手是一款便捷实用的拨号辅助工具,能自动识别剪贴板中的电话号码,支持快速拨号操作。最小化或关闭窗口后,程序将在系统后台运行,还可设置开机自启,方便随时使用,提升拨号效率。 …...
)
哈夫曼树(Huffman Tree)
1. 基本概念 哈夫曼树(Huffman Tree),又称最优二叉树,是一种带权路径长度(WPL, Weighted Path Length)最短的二叉树。它主要用于数据压缩和编码优化,通过为不同权值的节点分配不同长度的…...

布隆过滤器和布谷鸟过滤器
原文链接:布隆过滤器和布谷鸟过滤器 布隆过滤器 介绍 布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数,检查值是“可能在集合中”还是“绝对不在集合中” 空间效率高&a…...

Vue+Vite学习笔记
Cesium与Vue集成:详解Cesium-Vue项目搭建与运行步骤指南 - 云原生实践 为什么按照这篇↑完成三步会有能打开的网址,不止localhost8080还有用127.0.0.1那个表示的。 用这个构建,出来的是localhost:5173?...

UE 材质基础 第一天
课程:虚幻引擎【UE5】材质宝典【初学者材质基础入门系列】-北冥没有鱼啊_-稍后再看-哔哩哔哩视频 随便记录一些 黑色是0到负无穷,白色是1到无穷 各向异性 有点类似于高光,可以配合切线来使用,R G B 相当于 X Y Z轴,切…...

网络编程中的直接内存与零拷贝
本篇文章会介绍 JDK 与 Linux 网络编程中的直接内存与零拷贝的相关知识,最后还会介绍一下 Linux 系统与 JDK 对网络通信的实现。 1、直接内存 所有的网络通信和应用程序中(任何语言),每个 TCP Socket 的内核中都有一个发送缓冲区…...

语音转文字
语音转文字工具大全 1. 网易 网易见外(网页) 地址:网易见外 - AI智能语音转写听翻平台 特点:完全免费,支持音频转文字,每日上限2小时 有道云笔记(安卓/iOS) 地址&a…...

软件设计师考试《综合知识》创建型设计模式考点分析
软件设计师考试《综合知识》创建型设计模式考点分析 1. 分值占比与考察趋势(75分制) 模式名称近5年题量分值占比高频考察点最新趋势抽象工厂模式45.33%产品族创建/跨平台应用结合微服务配置考查(2023)工厂方法模式56.67%单一产品扩展/日志系统与IoC容器…...

【八股战神篇】Java集合高频面试题
专栏简介 八股战神篇专栏是基于各平台共上千篇面经,上万道面试题,进行综合排序提炼出排序前百的高频面试题,并对这些高频八股进行关联分析,将每个高频面试题可能进行延伸的题目再次进行排序选出高频延伸八股题。面试官都是以点破…...

STM32F103定时器1每毫秒中断一次
定时器溢出中断,在程序设计中经常用到。在使用TIM1和TIM8溢出中断时,需要注意“TIM_TimeBaseStructure.TIM_RepetitionCounter0;”,它表示溢出一次,并可以设置中断标志位。 TIM1_Interrupt_Initializtion(1000,72); //当arr1…...

BC 范式与 4NF
接下来我们详细解释 BC 范式(Boyce-Codd范式,简称 BCNF),并通过具体例子说明其定义和应用。 一、BC范式的定义 BC范式(Boyce-Codd范式,BCNF)是数据库规范化理论中的一种范式,它比第…...

Data whale LLM universe
使用LLM API开发应用 基本概念 Prompt Prompt 最初指的是自然语言处理研究人员为下游任务设计的一种任务专属的输入模板。 Temperature 使用Temperature参数控制LLM生成结果的随机性和创造性,一般取值设置在0~1之间,当取值接近1的时候预测的随机性较…...
-B树和B+树)
数据结构第七章(四)-B树和B+树
数据结构第七章(四) B树和B树一、B树1.B树2.B树的高度 二、B树的插入删除1.插入2.删除 三、B树1.B树2.B树的查找3.B树和B树的区别 总结 B树和B树 还记得我们的二叉排序树BST吗?比如就是下面这个: 结构体也就关键字和左右指针&…...

如何利用 Python 获取京东商品 SKU 信息接口详细说明
在电商领域,SKU(Stock Keeping Unit,库存进出计量的基本单元)信息是商品管理的核心数据之一。它不仅包含了商品的规格、价格、库存等关键信息,还直接影响到库存管理、价格策略和市场分析等多个方面。京东作为国内知名的…...

【机器学习】第二章模型的评估与选择
A.关键概念 2.1 经验误差和过拟合 经验误差与泛化误差:学习器在训练集上的误差为经验误差,在新样本上的误差为泛化误差 过拟合:学习器训练过度后,把训练样本自身的一些特点当作所有潜在样本具有一般性质,使得泛化性能…...

[PMIC]PMIC重要知识点总结
PMIC重要知识点总结 摘要:PMIC (Power Management Integrated Circuit) 是现代电子设备中至关重要的组件,负责电源管理,包括电压调节、电源转换、电池管理和功耗优化等。PMIC 中的数字部分主要涉及控制逻辑、状态机、寄存器配置、通信接口&am…...

LVGL- Calendar 日历控件
1 日历控件 1.1 日历背景 lv_calendar 是 LVGL(Light and Versatile Graphics Library)提供的标准 GUI 控件之一,用于显示日历视图。它支持用户查看某年某月的完整日历,还可以实现点击日期、标记日期、导航月份等操作。这个控件…...

ubuntu安装google chrome
更新系统 sudo apt update安装依赖 sudo apt install curl software-properties-common apt-transport-https ca-certificates -y导入 GPG key curl -fSsL https://dl.google.com/linux/linux_signing_key.pub | gpg --dearmor | sudo tee /usr/share/keyrings/google-chrom…...

如何开发专业小模型
在专业领域场景下,通过针对性优化大模型的词汇表、分词器和模型结构,确实可以实现参数规模的显著缩减而不损失专业能力。这种优化思路与嵌入式设备的字库剪裁有相似性,但需要结合大模型的特性进行系统性设计。以下从技术可行性、实现方法和潜…...

EXO 可以将 Mac M4 和 Mac Air 连接起来,并通过 Ollama 运行 DeepSeek 模型
EXO 可以将 Mac M4 和 Mac Air 连接起来,并通过 Ollama 运行 DeepSeek 模型。以下是具体实现方法: 1. EXO 的分布式计算能力 EXO 是一个支持 分布式 AI 计算 的开源框架,能够将多台 Mac 设备(如 M4 和 Mac Air)组合成…...

Git Worktree 使用
新入职了一家公司,发现不同项目用的使用一个 git 仓库管理。不久之后我看到这篇文章。 Git 的设计部分是为了支持实验。一旦你确定你的工作被安全地跟踪,并且存在安全的状态,以便在出现严重错误时可以恢复,你就不会害怕尝试新…...

【Linux网络】内网穿透
内网穿透 基本概念 内网穿透(Port Forwarding/NAT穿透) 是一种网络技术,主要用于解决处于 内网(局域网)中的设备无法直接被公网访问 的问题。 1. 核心原理 内网与公网的隔离:家庭、企业等局域网内的设备…...

反射机制动态解析
代码解释与注释 package com.xie.javase.reflect;import java.lang.reflect.Field; import java.lang.reflect.Modifier;public class ReflectTest01 {public static void main(String[] args) throws ClassNotFoundException {// 1. 获取java.util.HashMap类的Class对象Class…...