使用Langfuse和RAGAS,搭建高可靠RAG应用
大家好,在人工智能领域,RAG系统融合了检索方法与生成式AI模型,相比纯大语言模型,提升了准确性、减少幻觉且更具可审计性。不过,在实际应用中,当建好RAG系统投入使用时,如何判断接收信息是否正确、模型回复是否与输入一致,又该怎么衡量和优化系统性能,答案是可观测性。
本文将介绍如何搭建整合Langfuse可观测性与RAGAS评估指标的RAG系统,前者用于监控系统各阶段,后者能衡量回复质量。通过二者结合,打造可不断评估优化的RAG系统。后续会解析各组件、说明其作用并给出整合代码 。
1.RAG
RAG系统主要包含四个组件,各组件依次协同工作,共同实现系统功能。
在“文档处理”阶段,原始文档会被转化为可处理、可索引的格式,为后续流程奠定基础。接着进入“分块和索引”阶段,文档被分割成较小片段,借助向量嵌入技术创建可搜索索引,方便快速定位相关信息。
随后的“检索”阶段,系统依据用户查询,从索引中精准找到最匹配的文档片段。最后在“生成”阶段,系统将检索到的信息与原始查询融合,进而生成全面且准确的答案。
2.Langfuse
Langfuse是一个专为大语言模型应用程序设计的开源可观测性平台,提供了以下详细的可见性:
-
追踪:贯穿整个堆栈的完整请求生命周期
-
指标:性能、成本和质量指标
-
评估:自动评估回复质量
-
实验跟踪:不同配置的A/B测试
对于我们的RAG系统,Langfuse能帮助监控从文档处理到最终回复生成的所有过程,提供持续改进系统所需的见解。
3.RAGAS
RAGAS(检索增强生成评估)是专为评估RAG系统输出而设计的开源框架。
RAGAS评估RAG系统的两个主要方面:检索质量和生成质量。在我们的实现中,会特别使用两个重要指标:
-
忠实度:该指标衡量生成的答案与检索到的文档中的信息的忠实程度。高忠实度分数表明模型是根据我们手头的资源提供答案,而不是凭空捏造。
-
答案相关性:该指标评估生成的答案对用户原始查询的回应程度。高相关性分数表明答案与问题直接相关,满足了用户的信息需求。
通过这些指标,可以定量评估RAG系统的性能,并随着时间的推移进行改进。将RAGAS指标与Langfuse可观测性相结合,我们可以全面了解系统的工作原理和工作效果。
4.实践项目
首先下载使用的库:
pip install langchain langchain_openai faiss-cpu ragas pypdf langfuse
然后进行必要的导入:
import os
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy
from langfuse import Langfuse
from langchain_openai import OpenAIEmbeddings
from langchain_openai import OpenAI as OpenAILLM
from dotenv import load_dotenvload_dotenv()
在编写代码之前,创建Langfuse账户并获取API密钥。为此,需要在https://langfuse.com/上注册,创建一个项目,并获取公钥和私钥。可以在“设置”部分查看API密钥。
然后创建一个.env文件,在其中加载这些信息,并创建Langfuse对象。
# 直接初始化Langfuse
langfuse = Langfuse(public_key=os.environ.get("LANGFUSE_PUBLIC_KEY"),secret_key=os.environ.get("LANGFUSE_SECRET_KEY"),host=os.environ.get("LANGFUSE_HOST", "https://cloud.langfuse.com")
)# 根据需要设置LangChain追踪
os.environ["LANGCHAIN_TRACING_V2"] = "true"
现在开始创建RAG系统来测试监控和评估系统。
# 加载你的PDF文件
print("Loading PDF...")
loader = PyPDFLoader("data/documents/mamba model.pdf")
pages = loader.load()# 为整个过程创建一个追踪
main_trace = langfuse.trace(name="rag_pdf_process",user_id="user-001",metadata={"file": "mamba model.pdf"}
)
首先,加载PDF文档,并创建主Langfuse追踪来跟踪整个过程。
document_splitting = main_trace.span(name="document_splitting",input={"page_count": len(pages)}
)splitter = CharacterTextSplitter(chunk_size=200,chunk_overlap=20
)chunks = splitter.split_documents(pages)document_splitting.update(output={"chunk_count": len(chunks)}
)document_splitting.end()
分块步骤中,在Langfuse中启动一个跨度来监控这个特定操作。首先记录输入,即要处理的页面数量。分块过程完成后,用输出(即创建的块数)更新跨度。最后,显式结束跨度,以捕获和记录整个分块过程的持续时间。
vectorization = main_trace.span(name="vectorization",input={"chunk_count": len(chunks)}
)embedding = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embedding)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3}
)vectorization.end()
同样,在向量化步骤中,创建一个跨度来跟踪这个操作。首先记录过程中涉及的相关输入。接下来,生成嵌入并构建向量存储。最后,结束跨度,以捕获整个向量化步骤的时间信息。
在准备好文档块并创建向量存储后,下一个关键步骤是设置将处理用户查询的问答链。这段代码设置了语言模型,并配置了与检索系统的交互方式:
# 构建RAG链
chain_setup = main_trace.span(name="chain_setup")llm = OpenAILLM(model_name="gpt-4o",max_tokens=256,temperature=0
)qa = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=retriever,return_source_documents=True
)chain_setup.end()
创建名为“chain_setup”的跨度,以便在Langfuse中进行追踪。然后指定要使用的模型。最后,使用langchain结构创建一个RAG链。提出一个问题:
query = "What are the main topics covered in the PDF?"
RAG系统最重要的组件是以下处理用户查询并生成回复的函数。
def ask_with_langfuse(query, trace):query_generation = trace.generation(name="query_execution",model="gpt-4o",model_parameters={"max_tokens": 256},input={"query": query})try:# 执行查询result = qa({"query": query})# 提取源文档,以便以可序列化的格式进行日志记录source_docs = []for doc in result["source_documents"][:2]:# 确保元数据是可序列化的metadata = {}for key, value in doc.metadata.items():if isinstance(value, (str, int, float, bool, list, dict)) or value isNone:metadata[key] = valuesource_docs.append({"content": doc.page_content,"metadata": metadata})# 用结果更新生成的内容query_generation.end(output={"answer": result["result"]},metadata={"source_count": len(result["source_documents"])})return resultexcept Exception as e:# 记录任何错误query_generation.end(error={"message": str(e), "type": type(e).__name__})trace.update(status="error")raise e
这个函数与Langfuse集成工作,并记录每个步骤发生的事情。当函数开始工作时,它首先在Langfuse中创建一个监控点。这个监控点记录技术细节,如使用的模型、最大令牌数和用户的原始查询。
然后,它使用我们之前设置的问答链处理用户的查询。在此过程中,从向量数据库中提取相关的文档片段,并将这些信息传输到语言模型以生成回复。系统接收生成的回复和用于创建此回复的源文档。
源文档可能无法直接保存到Langfuse中,因为包含复杂的数据结构。因此,该函数将文档转换为Langfuse可以处理的简单格式。当成功生成回复时,回复本身以及使用的源文档数量等信息都会保存在Langfuse中。
如果在过程中发生任何错误,该函数也会在Langfuse中记录此错误。这有助于稍后检测和解决问题。通过这种方式,可以确切地看到系统每次运行时的状况,评估其性能,并进行必要的改进。
在设置好系统并定义了查询函数后,进入运行系统并评估其性能的阶段。在下面的代码块中,可以看到使用RAGAS进行查询处理和评估的过程:
# 运行查询
print("Running query...")
response = ask_with_langfuse(query, main_trace)
print("Answer:", response["result"])# 🧪 使用RAGAS进行评估
print("Evaluating with RAGAS...")
eval_span = main_trace.span(name="ragas_evaluation")contexts = [doc.page_content for doc in response["source_documents"][:2]]
# 创建与RAGAS兼容的数据集
eval_dataset = Dataset.from_dict({"question": [query],"answer": [response["result"]],"contexts": [contexts],"ground_truth": ["Summary of main PDF topics"]
})
在本节中,首先通过调用之前定义的ask_with_langfuse函数来处理查询。这个函数从向量数据库中检索相关文档,生成回复,并在Langfuse中记录整个过程。生成回复后,将其显示在控制台中。
然后,为RAGAS评估做准备。在Langfuse中启动名为“ragas_evaluation”的新监控间隔。为了进行评估,我们取出生成回复时使用的前两个文档片段,并创建一个RAGAS数据集。这个数据集包含四个基本元素:查询、生成的回复、使用的上下文(文档片段)和参考回复(真实答案)。
# 运行评估
try:result = evaluate(eval_dataset,metrics=[faithfulness, answer_relevancy])# 将评估结果转换为简单格式metrics = {}# 根据结果对象的字符串表示处理结果对象result_str = str(result)print("RAGAS result:", result_str)# 如果可能,尝试直接提取值try:# 首先尝试像字典一样访问metrics["faithfulness"] = float(result["faithfulness"])metrics["answer_relevancy"] = float(result["answer_relevancy"])except (TypeError, KeyError):# 如果失败,尝试解析字符串表示import refaithfulness_match = re.search(r"faithfulness[^\d]+([\d\.]+)", result_str)relevancy_match = re.search(r"answer_relevancy[^\d]+([\d\.]+)", result_str)if faithfulness_match:metrics["faithfulness"] = float(faithfulness_match.group(1))if relevancy_match:metrics["answer_relevancy"] = float(relevancy_match.group(1))# 用指标更新评估跨度eval_span.update(output={"metrics": metrics})print("Evaluation metrics:", metrics)
except Exception as e:print(f"RAGAS evaluation error: {e}")eval_span.update(error={"message": str(e), "type": type(e).__name__})
在评估代码中,使用RAGAS的evaluate函数评估数据集中的回复。使用两个重要指标:忠实度和答案相关性。这些指标衡量回复的准确性和相关性。
由于RAGAS结果对象在不同版本中可能有不同的结构,尝试几种不同的方法来获取指标。首先,尝试将结果对象当作字典使用。如果失败,尝试使用正则表达式从结果的文本表示中提取值。这种方法使我们能够在不同版本的RAGAS中工作。
在Langfuse的评估追踪中更新结果指标。如果发生任何错误,也会在Langfuse中记录错误。
eval_span.end()
# 结束主追踪
main_trace.update(status="success")
print("RAG process completed and logged to Langfuse")
最后,关闭评估追踪,并将主Langfuse追踪标记为成功。这表明整个RAG流程已成功完成并记录在Langfuse中。
试用一下这个系统,提出以下问题:
query = "What are the main topics covered in the PDF?"
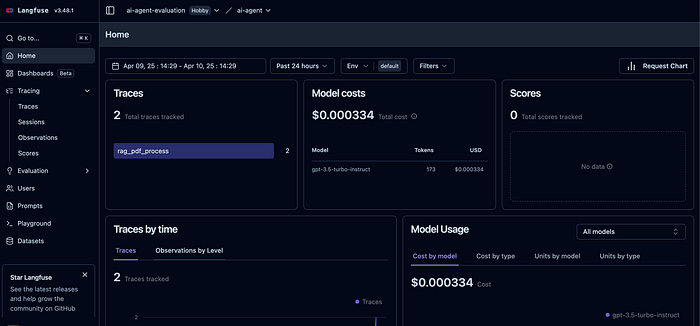
Langfuse主页看起来会像这样。因为问了两个问题,所以出现了2条追踪记录。
然后从左侧导航栏中选择“Traces”(追踪)。
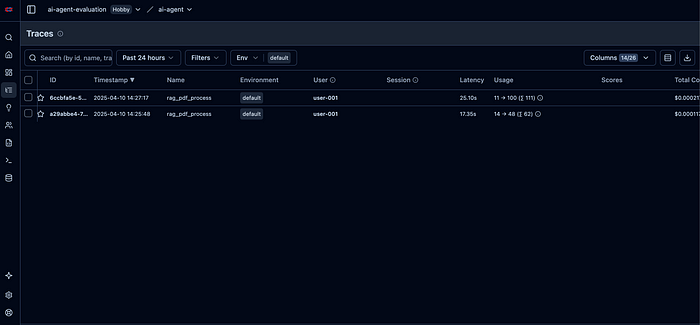
这个页面包含进行的所有事务的追踪记录。当点击其中任何一个时,会打开详细信息页面。
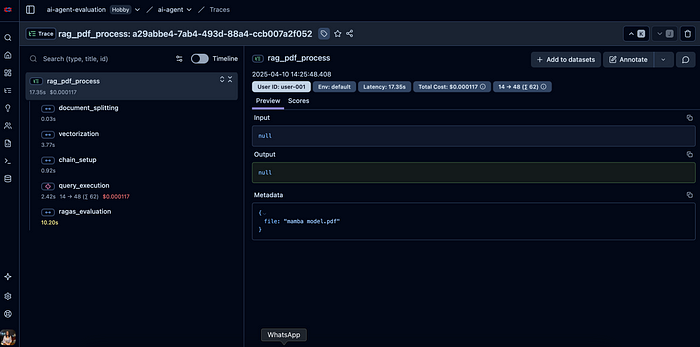
在这个页面上,左侧“rag_pdf_process”下有我们确定并创建了跨度的步骤。你还可以在右侧观察到“Total cost”(总成本)和“Latency”(延迟)等指标。当在左侧选择“query_execution”时,可以看到模型给出的答案。
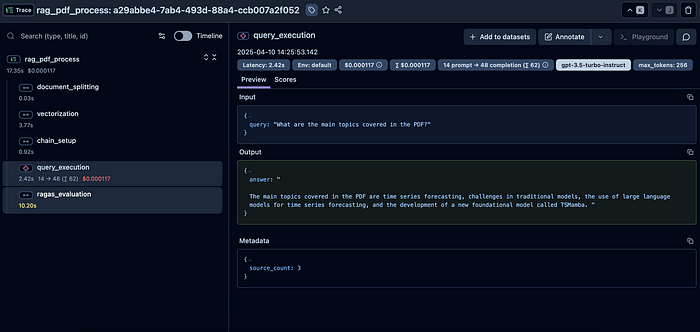
如果想查看RAGAS指标,也可以从“ragas_evaluation”部分进行查看。
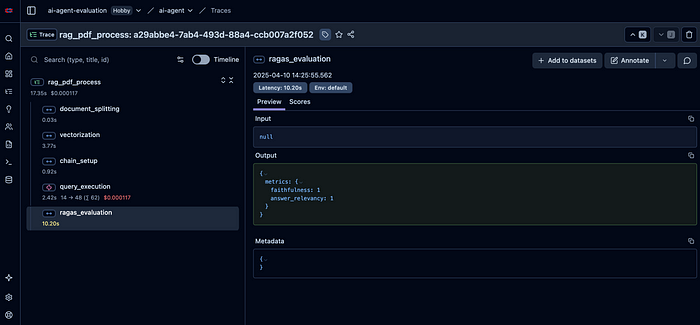
可以尝试使用不同的示例和问题来开发这个系统。
相关文章:

使用Langfuse和RAGAS,搭建高可靠RAG应用
大家好,在人工智能领域,RAG系统融合了检索方法与生成式AI模型,相比纯大语言模型,提升了准确性、减少幻觉且更具可审计性。不过,在实际应用中,当建好RAG系统投入使用时,如何判断接收信息是否正确…...

MySQL 数据库优化:ShardingSphere 原理及实践
在高并发、大数据量的业务场景下,MySQL 作为关系型数据库的核心存储引擎,其性能和扩展性面临严峻挑战。ShardingSphere 作为 Apache 顶级开源项目,提供了分布式数据库解决方案,通过分库分表、读写分离、弹性迁移等能力,帮助开发者实现 MySQL 的水平扩展与性能优化。 本文…...
总结回顾)
【Redis】零碎知识点(易忘 / 易错)总结回顾
一、Redis 是一种基于键值对(key-value)的 NoSQL 数据库 二、Redis 会将所有数据都存放在内存中,所以它的读写性能非常惊人 Redis 还可以将内存的数据利用快照和日志的形式保存到硬盘上,这样在发生类似断电或者机器故障时…...
136.0.7103.93便携增强版|Win中文|安装教程)
谷歌浏览器(Google Chrome)136.0.7103.93便携增强版|Win中文|安装教程
软件下载 【名称】:谷歌浏览器(Google Chrome)136.0.7103.93 【大小】:170M 【语言】:简体中文 【安装环境】:Win10/Win11 【夸克网盘下载链接】(务必手机注册): h…...

【滑动窗口】LeetCode 209题解 | 长度最小的子数组
长度最小的子数组 前言:滑动窗口一、题目链接二、题目三、算法原理解法一:暴力枚举解法二:利用单调性,用滑动窗口解决问题那么怎么用滑动窗口解决问题?分析滑动窗口的时间复杂度 四、编写代码 前言:滑动窗口…...

WebXR教学 07 项目5 贪吃蛇小游戏
WebXR教学 07 项目5 贪吃蛇小游戏 index.html <!DOCTYPE html> <html> <head><title>3D贪吃蛇小游戏</title><style>body { margin: 0; }canvas { display: block; }#score {position: absolute;top: 20px;left: 20px;color: white;font-…...

2.1.3
# Load the data file_path finance数据集.csv data pd.__________(file_path) --- data pd.read_csv(file_path) # 识别数值列用于箱线图 numeric_cols data.select_dtypes(include[float64, int64]).__________ --- numeric_cols data.select_dtypes(include[flo…...

StreamCap v0.0.1 直播录制工具 支持批量录制和直播监控
—————【下 载 地 址】——————— 【本章下载一】:https://drive.uc.cn/s/2fa520a8880d4 【本章下载二】:https://pan.xunlei.com/s/VOQDt_3v0DYPxrql5y2zxgO1A1?pwd2kqi# 【百款黑科技】:https://ucnygalh6wle.feishu.cn/wiki/…...

小蜗牛拨号助手用户使用手册
一、软件简介 小蜗牛拨号助手是一款便捷实用的拨号辅助工具,能自动识别剪贴板中的电话号码,支持快速拨号操作。最小化或关闭窗口后,程序将在系统后台运行,还可设置开机自启,方便随时使用,提升拨号效率。 …...
)
哈夫曼树(Huffman Tree)
1. 基本概念 哈夫曼树(Huffman Tree),又称最优二叉树,是一种带权路径长度(WPL, Weighted Path Length)最短的二叉树。它主要用于数据压缩和编码优化,通过为不同权值的节点分配不同长度的…...

布隆过滤器和布谷鸟过滤器
原文链接:布隆过滤器和布谷鸟过滤器 布隆过滤器 介绍 布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数,检查值是“可能在集合中”还是“绝对不在集合中” 空间效率高&a…...

Vue+Vite学习笔记
Cesium与Vue集成:详解Cesium-Vue项目搭建与运行步骤指南 - 云原生实践 为什么按照这篇↑完成三步会有能打开的网址,不止localhost8080还有用127.0.0.1那个表示的。 用这个构建,出来的是localhost:5173?...

UE 材质基础 第一天
课程:虚幻引擎【UE5】材质宝典【初学者材质基础入门系列】-北冥没有鱼啊_-稍后再看-哔哩哔哩视频 随便记录一些 黑色是0到负无穷,白色是1到无穷 各向异性 有点类似于高光,可以配合切线来使用,R G B 相当于 X Y Z轴,切…...

网络编程中的直接内存与零拷贝
本篇文章会介绍 JDK 与 Linux 网络编程中的直接内存与零拷贝的相关知识,最后还会介绍一下 Linux 系统与 JDK 对网络通信的实现。 1、直接内存 所有的网络通信和应用程序中(任何语言),每个 TCP Socket 的内核中都有一个发送缓冲区…...

语音转文字
语音转文字工具大全 1. 网易 网易见外(网页) 地址:网易见外 - AI智能语音转写听翻平台 特点:完全免费,支持音频转文字,每日上限2小时 有道云笔记(安卓/iOS) 地址&a…...

软件设计师考试《综合知识》创建型设计模式考点分析
软件设计师考试《综合知识》创建型设计模式考点分析 1. 分值占比与考察趋势(75分制) 模式名称近5年题量分值占比高频考察点最新趋势抽象工厂模式45.33%产品族创建/跨平台应用结合微服务配置考查(2023)工厂方法模式56.67%单一产品扩展/日志系统与IoC容器…...

【八股战神篇】Java集合高频面试题
专栏简介 八股战神篇专栏是基于各平台共上千篇面经,上万道面试题,进行综合排序提炼出排序前百的高频面试题,并对这些高频八股进行关联分析,将每个高频面试题可能进行延伸的题目再次进行排序选出高频延伸八股题。面试官都是以点破…...

STM32F103定时器1每毫秒中断一次
定时器溢出中断,在程序设计中经常用到。在使用TIM1和TIM8溢出中断时,需要注意“TIM_TimeBaseStructure.TIM_RepetitionCounter0;”,它表示溢出一次,并可以设置中断标志位。 TIM1_Interrupt_Initializtion(1000,72); //当arr1…...

BC 范式与 4NF
接下来我们详细解释 BC 范式(Boyce-Codd范式,简称 BCNF),并通过具体例子说明其定义和应用。 一、BC范式的定义 BC范式(Boyce-Codd范式,BCNF)是数据库规范化理论中的一种范式,它比第…...

Data whale LLM universe
使用LLM API开发应用 基本概念 Prompt Prompt 最初指的是自然语言处理研究人员为下游任务设计的一种任务专属的输入模板。 Temperature 使用Temperature参数控制LLM生成结果的随机性和创造性,一般取值设置在0~1之间,当取值接近1的时候预测的随机性较…...
-B树和B+树)
数据结构第七章(四)-B树和B+树
数据结构第七章(四) B树和B树一、B树1.B树2.B树的高度 二、B树的插入删除1.插入2.删除 三、B树1.B树2.B树的查找3.B树和B树的区别 总结 B树和B树 还记得我们的二叉排序树BST吗?比如就是下面这个: 结构体也就关键字和左右指针&…...

如何利用 Python 获取京东商品 SKU 信息接口详细说明
在电商领域,SKU(Stock Keeping Unit,库存进出计量的基本单元)信息是商品管理的核心数据之一。它不仅包含了商品的规格、价格、库存等关键信息,还直接影响到库存管理、价格策略和市场分析等多个方面。京东作为国内知名的…...

【机器学习】第二章模型的评估与选择
A.关键概念 2.1 经验误差和过拟合 经验误差与泛化误差:学习器在训练集上的误差为经验误差,在新样本上的误差为泛化误差 过拟合:学习器训练过度后,把训练样本自身的一些特点当作所有潜在样本具有一般性质,使得泛化性能…...

[PMIC]PMIC重要知识点总结
PMIC重要知识点总结 摘要:PMIC (Power Management Integrated Circuit) 是现代电子设备中至关重要的组件,负责电源管理,包括电压调节、电源转换、电池管理和功耗优化等。PMIC 中的数字部分主要涉及控制逻辑、状态机、寄存器配置、通信接口&am…...

LVGL- Calendar 日历控件
1 日历控件 1.1 日历背景 lv_calendar 是 LVGL(Light and Versatile Graphics Library)提供的标准 GUI 控件之一,用于显示日历视图。它支持用户查看某年某月的完整日历,还可以实现点击日期、标记日期、导航月份等操作。这个控件…...

ubuntu安装google chrome
更新系统 sudo apt update安装依赖 sudo apt install curl software-properties-common apt-transport-https ca-certificates -y导入 GPG key curl -fSsL https://dl.google.com/linux/linux_signing_key.pub | gpg --dearmor | sudo tee /usr/share/keyrings/google-chrom…...

如何开发专业小模型
在专业领域场景下,通过针对性优化大模型的词汇表、分词器和模型结构,确实可以实现参数规模的显著缩减而不损失专业能力。这种优化思路与嵌入式设备的字库剪裁有相似性,但需要结合大模型的特性进行系统性设计。以下从技术可行性、实现方法和潜…...

EXO 可以将 Mac M4 和 Mac Air 连接起来,并通过 Ollama 运行 DeepSeek 模型
EXO 可以将 Mac M4 和 Mac Air 连接起来,并通过 Ollama 运行 DeepSeek 模型。以下是具体实现方法: 1. EXO 的分布式计算能力 EXO 是一个支持 分布式 AI 计算 的开源框架,能够将多台 Mac 设备(如 M4 和 Mac Air)组合成…...

Git Worktree 使用
新入职了一家公司,发现不同项目用的使用一个 git 仓库管理。不久之后我看到这篇文章。 Git 的设计部分是为了支持实验。一旦你确定你的工作被安全地跟踪,并且存在安全的状态,以便在出现严重错误时可以恢复,你就不会害怕尝试新…...

【Linux网络】内网穿透
内网穿透 基本概念 内网穿透(Port Forwarding/NAT穿透) 是一种网络技术,主要用于解决处于 内网(局域网)中的设备无法直接被公网访问 的问题。 1. 核心原理 内网与公网的隔离:家庭、企业等局域网内的设备…...

反射机制动态解析
代码解释与注释 package com.xie.javase.reflect;import java.lang.reflect.Field; import java.lang.reflect.Modifier;public class ReflectTest01 {public static void main(String[] args) throws ClassNotFoundException {// 1. 获取java.util.HashMap类的Class对象Class…...

10 分钟打造一款超级马里奥小游戏,重拾20 年前的乐趣
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 你好,我是悟空。 前言 小时候看到村里的大朋友家里都有一款 FC 游戏机,然后旁边还放…...

鸿蒙ArkUI体验:Hexo博客客户端开发心得
最近部门也在跟进鸿蒙平台的业务开发,自己主要是做 Android 开发,主要使用 Kotlin/Java 语言。,需要对新的开发平台和开发模式进行学习,在业余时间开了个项目练手,做了个基于 Hexo 博客内容开发的App。鸿蒙主要使用Ark…...
?)
人工智能100问☞第25问:什么是循环神经网络(RNN)?
目录 一、通俗解释 二、专业解析 三、权威参考 循环神经网络(RNN)是一种通过“记忆”序列中历史信息来处理时序数据的神经网络,可捕捉前后数据的关联性,擅长处理语言、语音等序列化任务。 一、通俗解释 想象你在和朋友聊天,每说一句话都会根据之前的对话内容调整语气…...
】Zuul路由访问映射规则配置及使用(含源代码)(十二))
【springcloud学习(dalston.sr1)】Zuul路由访问映射规则配置及使用(含源代码)(十二)
该系列项目整体介绍及源代码请参照前面写的一篇文章【springcloud学习(dalston.sr1)】项目整体介绍(含源代码)(一) springcloud学习(dalston.sr1)系统文章汇总如下: 【springcloud学习(dalston…...

STM32IIC协议基础及Cube配置
STM32IIC协议基础及Cube配置 一,IC协议简介1,核心特点2,应用场景 二,IC协议基础概念1,总线结构2,主从架构3,设备寻址4,起始和停止条件5,数据传输6,应答机制 三…...

Python异常模块和包
异常 当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”, 也就是我们常说的BUG 例如:以r方式打开一个不存在的文件。 f open(‘python1.txt’,‘r’,encoding‘utf-8’) 当我们…...

每日算法刷题Day9 5.17:leetcode定长滑动窗口3道题,用时1h
9. 1652.拆炸弹(简单,学习) 1652. 拆炸弹 - 力扣(LeetCode) 思想 为了获得正确的密码,你需要替换掉每一个数字。所有数字会 同时 被替换。 如果 k > 0 ,将第 i 个数字用 接下来 k 个数字之和替换。如果 k < 0…...

题单:递归求和
宣布一个重要的事情,我的洛谷有个号叫 题目描述 给一个数组 a:a[0],a[1],...,a[n−1]a:a[0],a[1],...,a[n−1] 请用递归的方式出数组的所有数之和。 提示:递推方程 f(x)f(x−1)a[x]f(x)f(x−1)a[x]; 输入格式 第一行一个正整数 n (n≤100)n (n≤100)…...
手动实现 Transformer 模型
本文使用 Pytorch 库手动实现了传统 Transformer 模型中的多头自注意力机制、残差连接和层归一化、前馈层、编码器、解码器等子模块,进而实现了对 Transformer 模型的构建。 """ Title: 解析 Transformer Time: 2025/5/10 Author: Michael Jie &quo…...

【鸿蒙开发避坑】使用全局状态变量控制动画时,动画异常甚至动画方向与预期相反的原因分析以及解决方案
【鸿蒙开发避坑】使用全局状态变量控制动画,动画异常甚至动画方向相反的原因分析以及解决方案 一、问题复现1、问题描述2、问题示意图 二、原因深度解析1、查看文档2、调试3、原因总结:(1)第一次进入播放页面功能一切正常的原因&a…...

天拓四方锂电池卷绕机 PLC 物联网解决方案
近年来,锂电制造行业作为新能源领域的核心支柱产业,呈现出迅猛发展的态势,市场需求持续高涨。在此背景下,行业内对产品质量、生产效率以及成本控制等方面提出了更为严苛的要求。锂电制造流程涵盖混料、涂布、辊压、分切、制片、卷…...

RFID系统:技术解析与应用全景
一、技术架构与运行逻辑 RFID(Radio Frequency Identification)系统通过无线电波实现非接触式数据交互,其核心由三部分组成: 电子标签(Tag): 无源标签:依赖读写器电磁场供电&…...

hbuilderX 安装Prettier格式化代码
一、打开插件安装 搜索输入:Prettier 安装后,重启hbuilderX ,再按AltShiftF 没安装Prettier格式化: import {saveFlow,getTemplate } from "../../api/flowTemplate.js"; 安装Prettier格式化后: import …...

Python-92:最大乘积区间问题
问题描述 小R手上有一个长度为 n 的数组 (n > 0),数组中的元素分别来自集合 [0, 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024]。小R想从这个数组中选取一段连续的区间,得到可能的最大乘积。 你需要帮助小R找到最大乘积的区间,并输出这…...
--多点触控)
Compose笔记(二十三)--多点触控
这一节主要了解一下Compose中多点触控,在Jetpack Compose 中,多点触控处理需要结合Modifier和手势API来实现,一般通过组合 pointerInput、TransformableState 和 TransformModifier 来创建支持缩放、旋转和平移的组件。 一、 API 1. Pointer…...

2025.05.17淘天机考笔试真题第一题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 01. 魔法棋盘构造 问题描述 LYA 正在设计一款魔法棋盘游戏。游戏棋盘由 2 n 2 \times n...

python的漫画网站管理系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核…...
:结构化编程)
系统架构设计(十):结构化编程
定义 结构化编程是一种遵循清晰逻辑结构、避免使用 goto 的编程方法。它强调使用有限的三种基本控制结构来组织程序,提高程序的可读性、可维护性和可测试性。 它是现代程序设计的基础,被广泛应用于命令式语言(如 C、Pascal、Java࿰…...
:数据流图)
系统架构设计(七):数据流图
定义 数据流图(Data Flow Diagram, DFD)是一种用于表示信息系统数据流转及处理过程的图形工具。 它反映系统功能及数据之间的关系,是结构化分析与设计的重要工具。 主要符号 符号说明描述举例方框外部实体(源或终点)…...