数据结构第七章(四)-B树和B+树
数据结构第七章(四)
- B树和B+树
- 一、B树
- 1.B树
- 2.B树的高度
- 二、B树的插入删除
- 1.插入
- 2.删除
- 三、B+树
- 1.B+树
- 2.B+树的查找
- 3.B树和B+树的区别
- 总结
B树和B+树
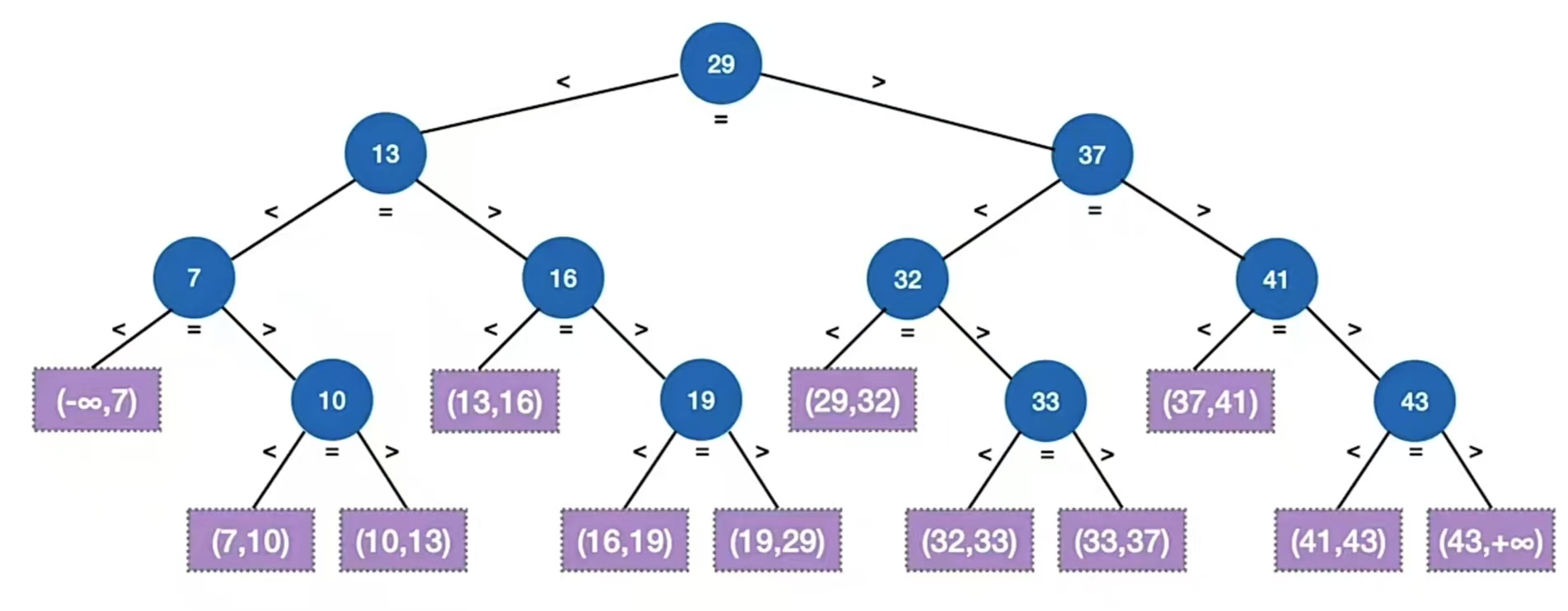
还记得我们的二叉排序树BST吗?比如就是下面这个:
结构体也就关键字和左右指针:
//二叉排序树的结点
typedef struct BSTNode{int key;struct BSTNode *lchild,*rchild;
}BSTNode, *BSTree;
那我们再看这个树,其实是不是可以发现,它每一个结点都把无穷集(-∞,+∞)分割了一下,什么意思呢?就是比如根节点“29”,它就是把(-∞,+∞)分割成了(-∞,29),(29,+∞),(-∞,29)是根结点“29”左子树的区间,(29,+∞)是根结点“29”右子树的区间。
那如果不是“二叉”排序树,是多叉排序树呢?
二叉排序树有两个叉,几叉排序树就有几个叉。比如下面这个5叉排序树:
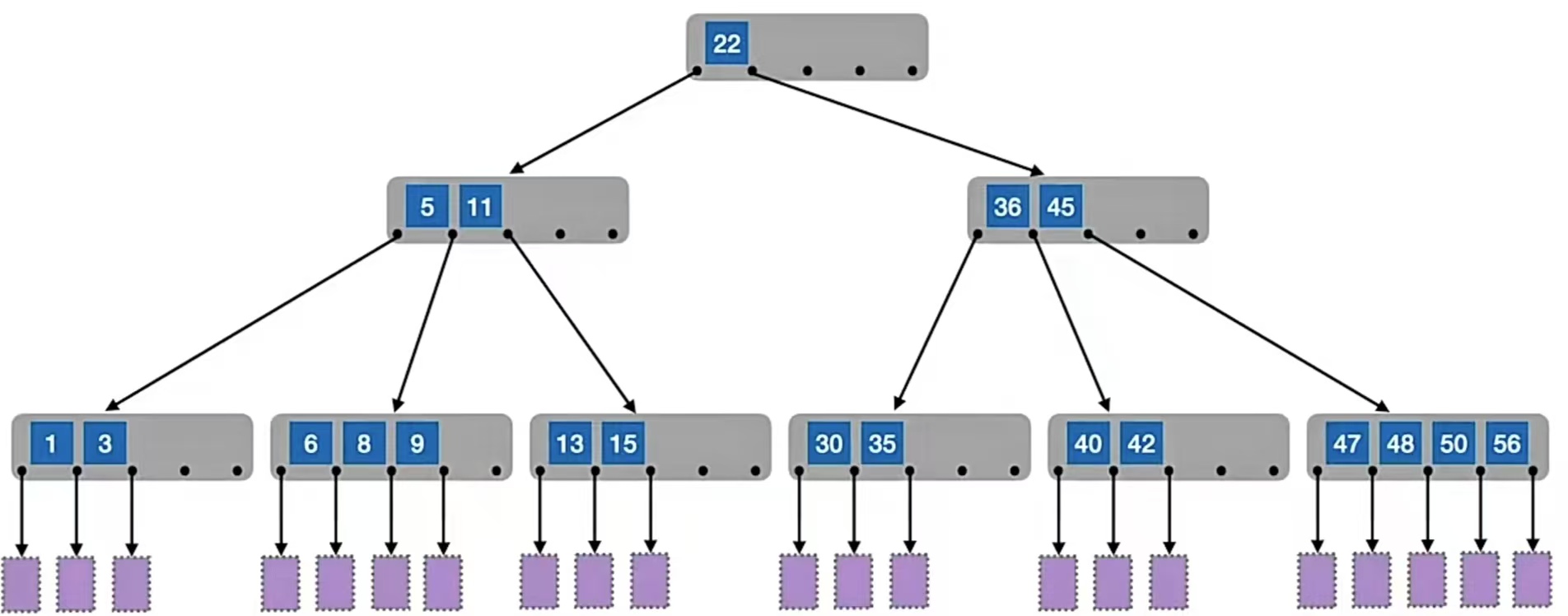
这个的本质也是分割区间。比如根结点“22”,把(-∞,+∞)分割成了(-∞,22),(22,+∞),(-∞,22)是根结点“22”左子树的区间,(22,+∞)是根结点“22”右子树的区间;再看右子树,右孩子结点里面有“36”,“45”,所以把(22,+∞)分割成了(22,36),(36,45),(45,+∞)……这样分割,查找到的就落在查找到的结点上,未查找到的就落在图中的最下层方形结点(失败结点)上。
比如结点“15”右边指针指向的那个失败结点,指向的区间就是(15, 22),比15大的比22小的没查找到就落在这个失败结点内这样。
//5叉排序树的结点
typedef struct BSTNode{int keys[4]; //最多4个关键字struct Node *child[5]; //最多5个孩子int num; //结点中有几个关键字
};
为啥最多4个关键字?因为1个关键字两个叉(刚刚不是说了吗,分割为2个区间),所以4个关键字就是5个叉,而它是个5叉查找树,所以叉不能再多了,故最多4个关键字。
注:
结点内关键字有序,所以我们在结点内查找的时候,既可以使用顺序查找,也可以使用折半查找。
比如我们在结点内用顺序查找,要查找“9”,则先和根节点“22”作对比,发现 9<22,所以去根节点的左子树找;在根节点的左孩子内进行顺序查找,发现 5<9<11,所以在“5”右边指向的那个结点内进行顺序查找,发现6<9,8<9,9=9,查找成功。同理,当落到右边指针指向为NULL时,查找失败。
当然,由上面那个5叉树的图可以看出,如果每个结点内关键字太少,导致树变高,要查更多层结点,效率就会很低。那么我们如何保证查找效率?其实就是不要让它那么“高”,不要让它每个结点内关键字太少。
so我们规定,m叉查找树中,除了
根结点外,任何结点至少有 ⌈m/2⌉ 个分叉,即至少含有⌈m/2⌉ - 1 个关键字,这样就可以使得它并不会太“高”了。注意这里是“除了根结点”,因为如果我们整棵树只有1个元素,就没法满足这个“至少有 ⌈m/2⌉ 个分叉”,所以根结点可以只有1个元素2个分叉。
比如,对于5叉排序树,规定除了根结点外,任何结点都至少有3个分叉,2个关键字(⌈5/2⌉ = 3)。
但是我们规定了这个,还有一种可能就是全部都是左子树,这样就会很“高”,不如左右子树都有的情况“矮”,也就是说,不够“平衡”,树就会很高,要查很多层结点。
so我们又规定,m叉查找树中,对于任何一个结点,其所有子树的高度都要相同。
即,左右两边得一样高,不可以左边比右边高一层或者右边比左边高一层这样,也就是我们上面那个5叉查找树那种情况。
一、B树
1.B树
说了那么多,那么什么是B树呢?其实刚刚那个5叉查找树就是一棵满足B树要求的B树,再看一下:
在B树中,我们把失败结点(最底下那个方形的)称为叶子结点,把最底下一层有关键字的称为终端结点。
准备好了吗?那么我们B树的定义要来喽~
B树,又称多路平衡查找树,B树中所被允许的孩子个数的最大值称为B树的阶,通常用 m 表示。一棵 m 阶B树或为空树,或为满足如下特性的m叉树:
-
树中每个结点至多有 m 棵子树,即至多含有 m-1 个关键字;
-
若根结点不是终端结点,则至少有两棵子树;
-
除根结点外的所有非叶结点至少有 ⌈m/2⌉ 棵子树,即至少含有⌈m/2⌉ -1 个关键字; -
所有非叶结点的结构如下:
n P0 K1 P1 K2 P2 … Kn Pn 其中,Ki(i=1,2,……,n)为结点的关键字,且满足 K1<K2<…<Kn;Pi(i=0,1,……,n)为指向子树根结点的指针,且指针 Pi-1所指子树中所有结点的关键字均小于 Ki,Pi所指子树中所有结点的关键字均大于Ki,n(⌈m/2⌉-1 ≤ n ≤ m-1)为结点中关键字的个数;
-
所有的叶结点都出现在同一层次上,并且不带信息(可以视为外部结点或类似于折半查找判定树的查找失败结点,实际上这些结点不存在,指向这些结点的指针为空)。
什么意思呢?别介,一条一条看。
先看第1条,m阶B树显然最多有m个叉,所以每个结点至多有 m 棵子树,那么就最多有 m-1 个关键字;
第2条,根节点不是终端结点是指这个B树不止有一层(只有一层的话那么根结点不就是终端结点嘛),所以这个就是规定根结点是至少有1个关键字的,不然不就是个空的了,所以至少有2棵子树;
第3条,也就是我们刚刚为了保证查找效率让它不要那么“高”做的规定,除根结点的所有非叶结点(有关键字的结点,也就是不是失败结点的结点)至少有 ⌈m/2⌉ 棵子树,即至少含有 ⌈m/2⌉ -1 个关键字,这样就可以使得它并不会太“高”了;
第4条,其实就是满足二叉排序树的定义,要满足左≤根≤右,结点内也是有序的,因为B树也是一棵水灵灵的二叉排序树;
第5条,所谓的叶结点就是失败结点,因为我要保持B树的平衡,所以左右子树都是一样高的,所以失败结点一定是会出现在同一层的,不然的话就不满足我们规定的“平衡”了。
看起来很多,但其实我们归纳总结一下也就是下面三个特性:
m 阶B树的核心特性:
- 根结点的子树数 ∈ [2,m],关键字数 ∈ [1,m-1];
其他结点的子树数 ∈ [ ⌈m/2⌉ ,m];关键字数 ∈ [ ⌈m/2⌉-1 ,m-1 ] - 对任一结点,其所有子树高度都相同
- 关键字的值:子树0<关键字1<子树1<关键字2<子树2……(类比二叉查找树,左<中<右)
这就是总结了一下,其实就是根结点和其他结点的关键字数有最小和最大限制、平衡、满足二叉排序树特性,就这些。
2.B树的高度
那么我们B树的高度是多高呢?即,含 n 个关键字的 m 阶B树,最小高度、最大高度是多少?
最小高度——让每个结点尽可能地满
假设我们B树的高度为h
每个结点有 m-1 个关键字,m个分叉,则装满的情况下,关键字总数为(m-1)*结点个数,结点个数第一层1个,第二层m个(m个分叉),第三层m2个(第二层每个有m个分叉,第二层共m个)……以此类推,h层一共有(1+m+m2+……+mh-1)个结点,所以h层装满的情况下关键字个数为(m-1)(1+m+m2+……+mh-1),那么我们的关键字肯定是小于等于这个树的,所以
n ≤ (m-1)(1+m+m2+……+mh-1)
所以 h ≥ logm(n+1),含 n 个关键字的 m 阶B树,最小高度为 logm(n+1)
最大高度——让每个结点包含的关键字、分叉尽可能的少。
各层结点至少有:第一层 1、第二层 2、第三层 2⌈m/2⌉……第h层 2⌈m/2⌉h-2 (因为根结点至少一个,除了根节点的其他结点至少有⌈m/2⌉个),第h+1层共有叶子结点(失败结点) 2⌈m/2⌉h-1个
又因为 n个关键字的B树必有n+1个叶子结点(我说一下哈,这可以通过两种方式得到这个结论,一个是我们刚刚说到的“分区间”,每个关键字都把(-∞,+∞)分割开,所以我们分割后就有 n+1 个区间,失败结点(叶子结点)就分别代表这些区间,所以n个关键字的B树必有n+1个叶子结点)。
我们第h+1层最少有的叶子结点数为2⌈m/2⌉h-1个, 所以我们的B树的叶子节点数一定大于这个树,即 n+1 ≥ 2⌈m/2⌉h-1
所以 h ≤ log⌈m/2⌉(n+1)/2 +1,含 n 个关键字的 m 阶B树,最大高度为 log⌈m/2⌉(n+1)/2 +1
更直观的话,我们记 k=⌈m/2⌉,则:
| 最少结点数 | 最少关键字数 | |
|---|---|---|
| 第一层 | 1 | 1 |
| 第二层 | 2 | 2(k-1) |
| 第三层 | 2k | 2k(k-1) |
| 第四层 | 2k2 | 2k2(k-1) |
| … | … | … |
| 第 h 层 | 2kh-2 | 2kh-2(k-1) |
h层的m阶B树至少包含关键字总数 1+2(k-1)(k0+k1+k2+…+kh-2) = 1+ 2(kh-1-1)
若关键字总数少于这个值,则高度一定小于h(这写的啥啊,其实就是如果高度为h,一定大于这个值),因此 n ≥ 1+ 2(kh-1-1),得,h ≤ logk(n+1)/2 +1 = log⌈m/2⌉(n+1)/2 +1
即,含 n 个关键字的 m 阶B树,logm(n+1)≤ n ≤ log⌈m/2⌉(n+1)/2 +1
二、B树的插入删除
1.插入
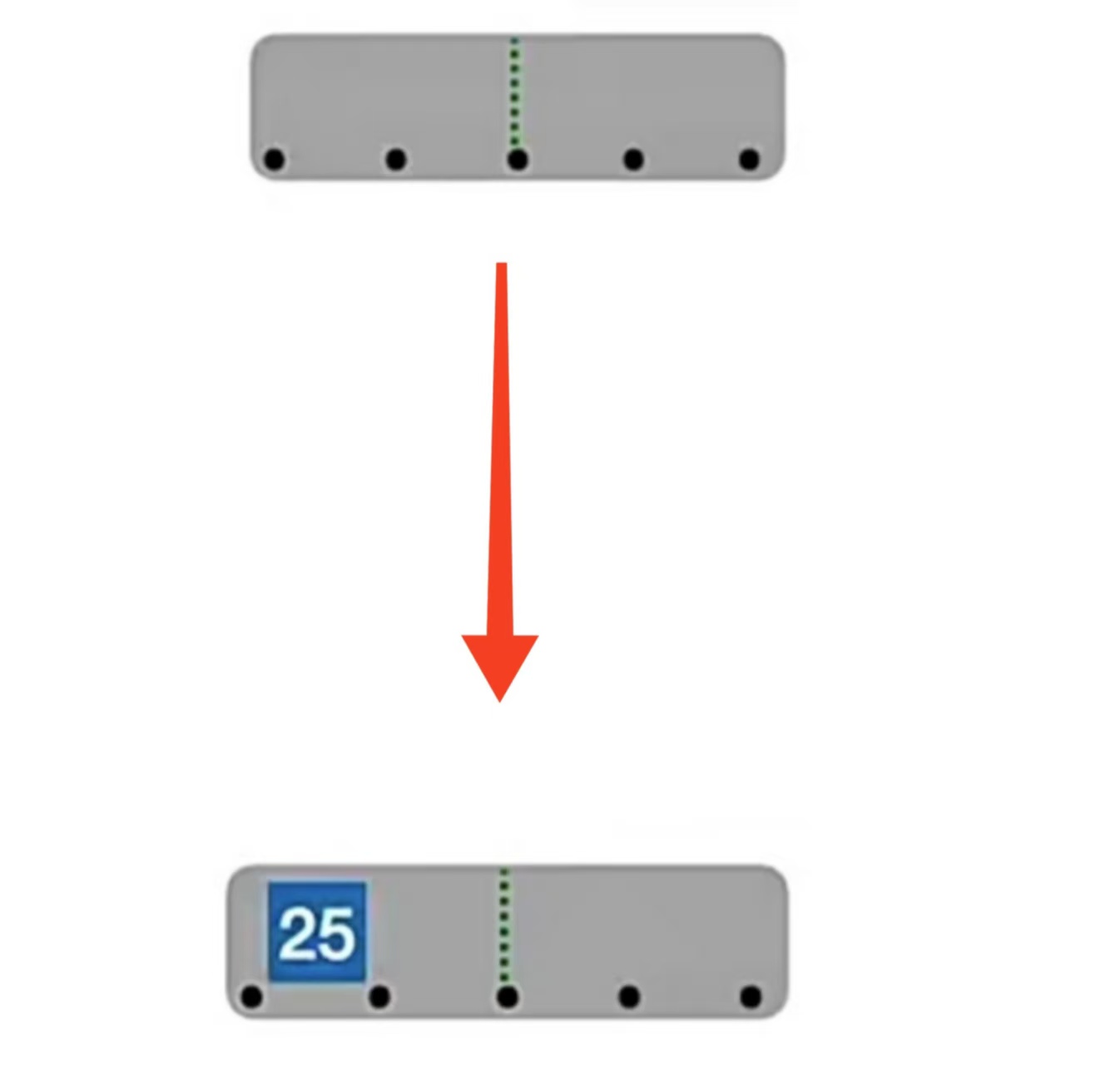
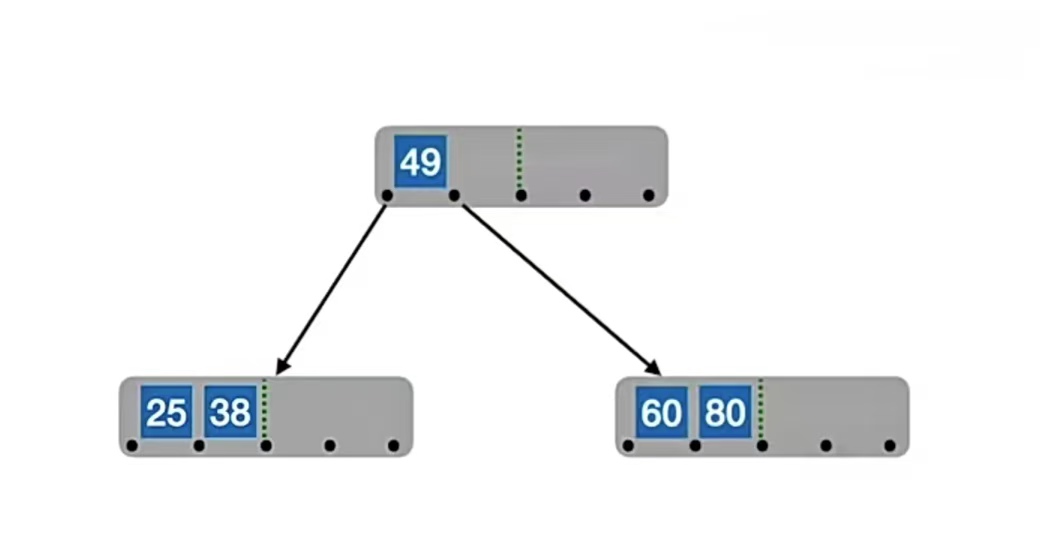
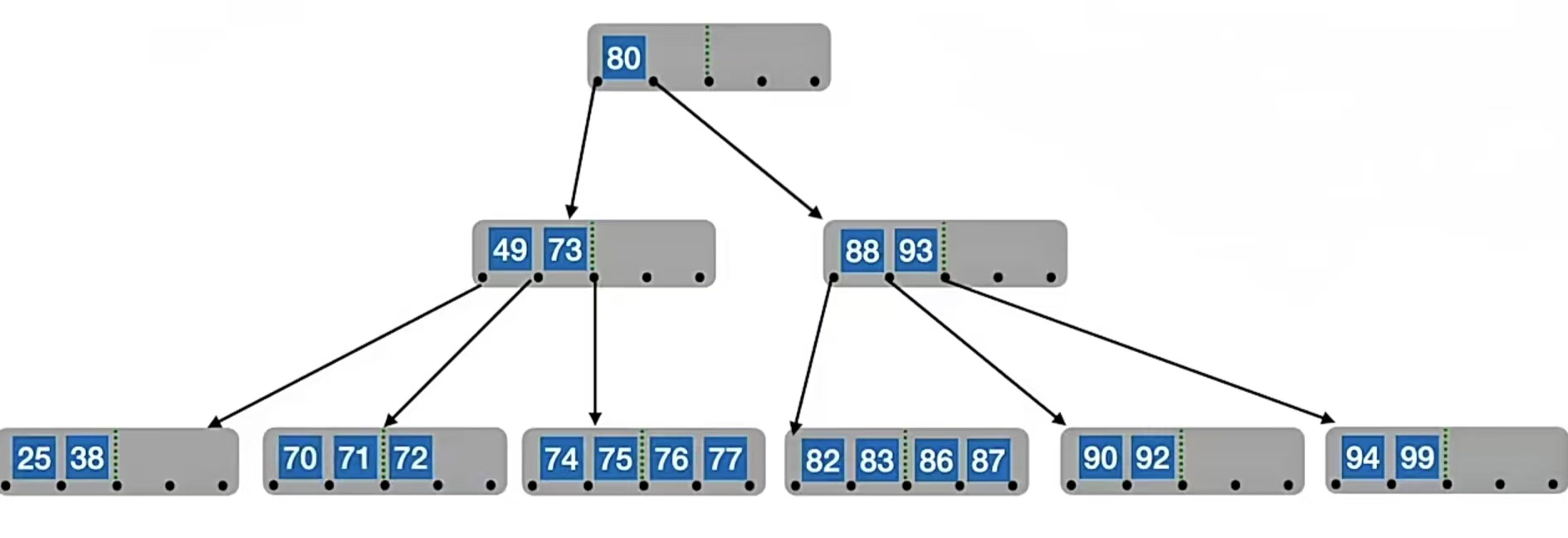
现在我们来一个一个插入5阶B树(结点关键字个数 ⌈m/2⌉-1 ≤ n ≤ m-1,即:2≤n≤4,此处省略失失败结点),用一个栗子来看看B树是怎么插入的:
首先,我们插入“25”,那么它一定是先插入到根结点上,即:
那么我们再插入“38”:

插入“49”:

插入“60”:

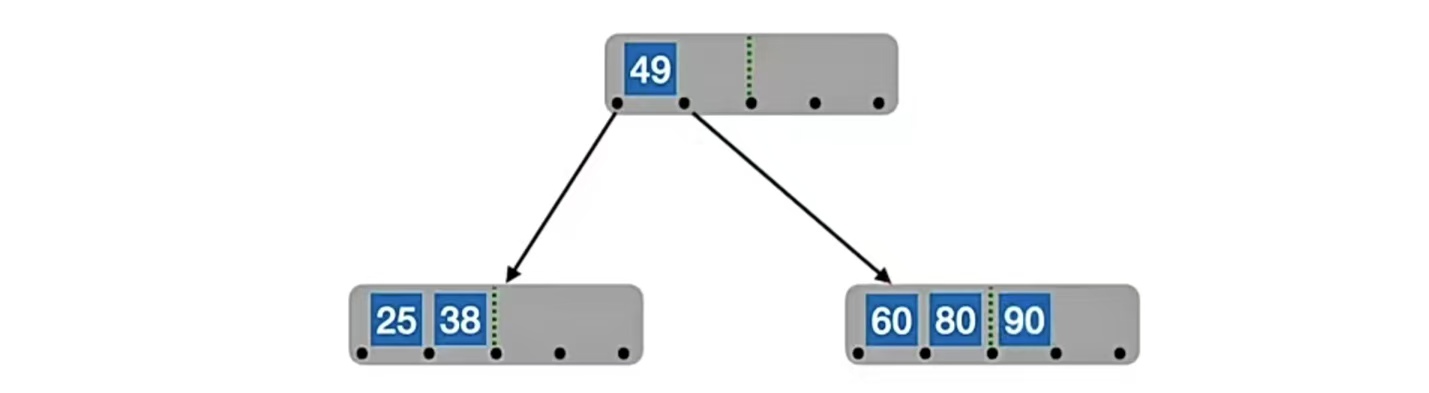
接下来,我们插入“80”,我们会发现根结点已经满了,放不下了,所以我们要“分裂”:
在插入key后,若导致原结点关键字数超过上限,则从中间位置(
⌈m/2⌉)将其中的关键字分为两部分,左部分包含的关键字放在原结点中,右部分包含的关键字放到新结点中,中间位置(⌈m/2⌉)的结点插入原结点的父结点。
那我们发现,插入“80”之后,“80”放“60”右边已经“冒了”,所以我们应该“分裂”,我们的中间位置⌈m/2⌉=⌈5/2⌉=3,也就是“49”,所以“49”左边的“25”,“38”放在原结点中,右边的“60”,“80”放在新结点中,“49”变成原结点的父结点,也就是上图那个样子。
那我们就会发现,其实根结点有位置,底下左右孩子两个结点也有位置,那我们下面如果要插入新元素,插入到哪里呢?我们有一个插入规则:
新元素一定是插入到最底层“终端结点”,用“查找”来确定插入位置。
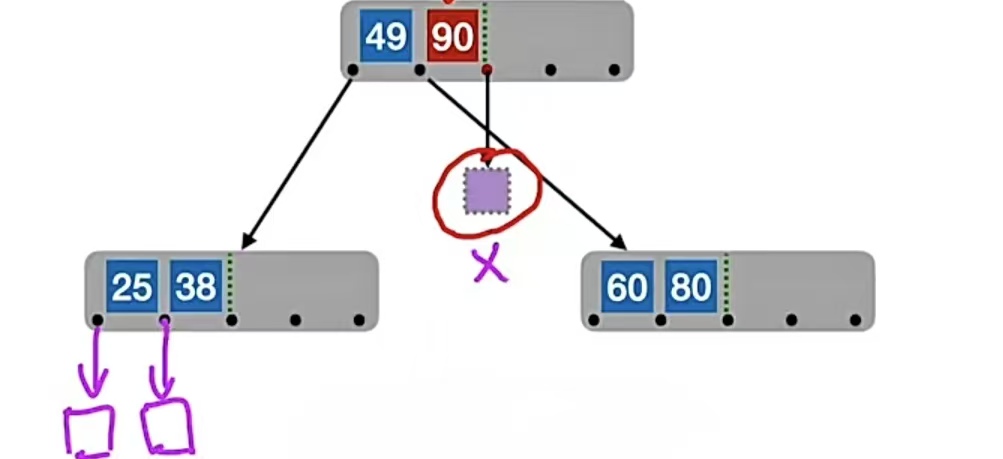
就是插入到最底层。比如现在我们要插入“90”,我们先查找它应该插入到什么位置,90>49,所以应该往右子树找;90>60,90>80,此时应该往下找,发现已经是终端结点,所以插入到“80”右边,如下:
为啥一定要插入到最底层?因为我们B树的定义就是,B树的失败结点只能出现在最下面一层,如果“90”插入到“49”旁边了,那么“90”右边指针指向的就是失败结点null,和“49”左右子树的失败结点就不是同一层了,就像下面这样:
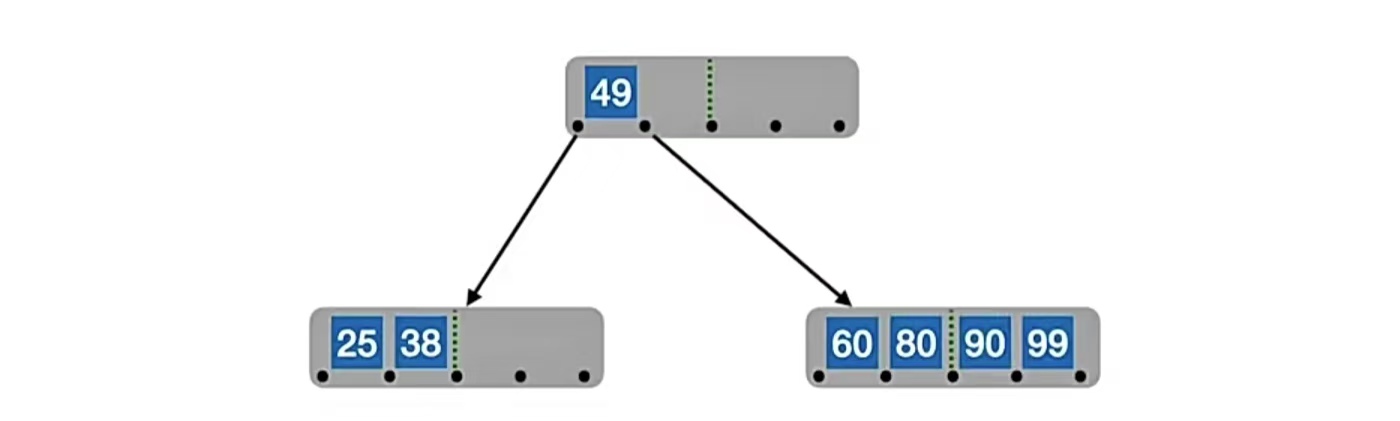
后面我们再插入“99”,还是插入到终端结点:
我们再插入“88”,查找它应该插入的位置,发现它应该插入到“49”右孩子结点中的“80”和“90”中间,即:
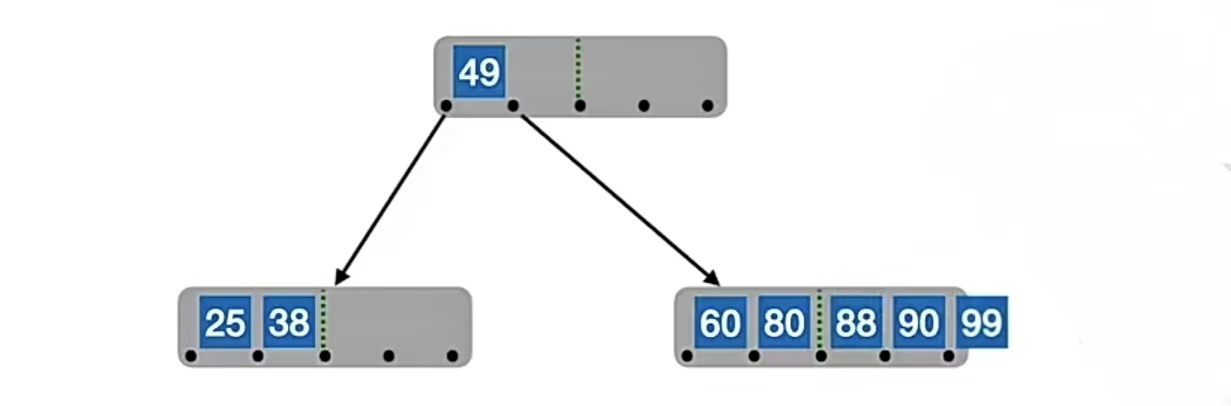
所以我们又要分裂了。我们的中间位置⌈m/2⌉=⌈5/2⌉=3,也就是“88”,所以“88”左边的“60”,“80”放在原结点中,右边的“90”,“99”放在新结点中,“88”变成原结点的父结点,但是原结点已经有父结点了,所以就放到“49”的右边,也就是这样:
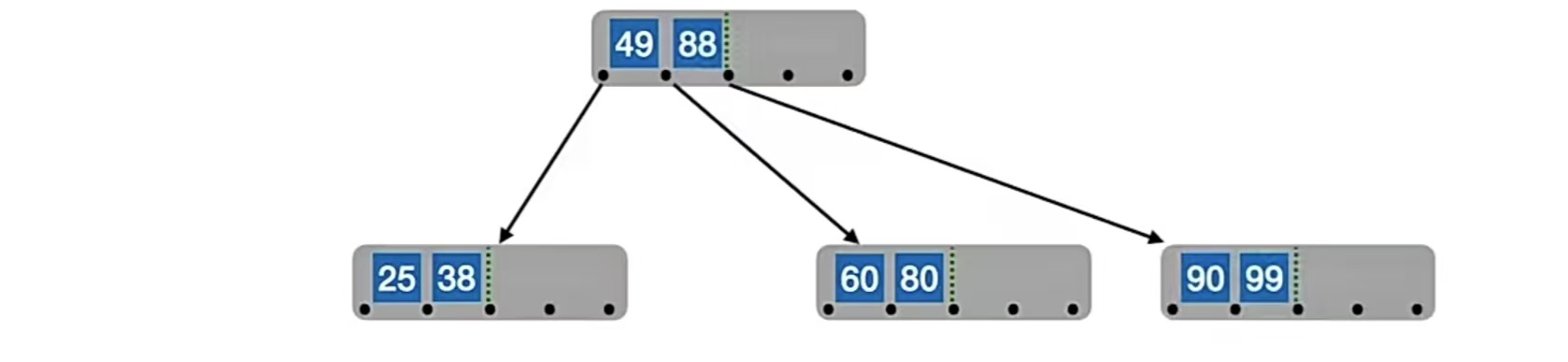
我们再插入结点“83”,49<83<88,找到它的查找位置是,49、88之间的指针指向的结点内,开始对比这个结点的数据。60<83,80<83,这个结点又是终端结点,所以插入到“80”的右边:
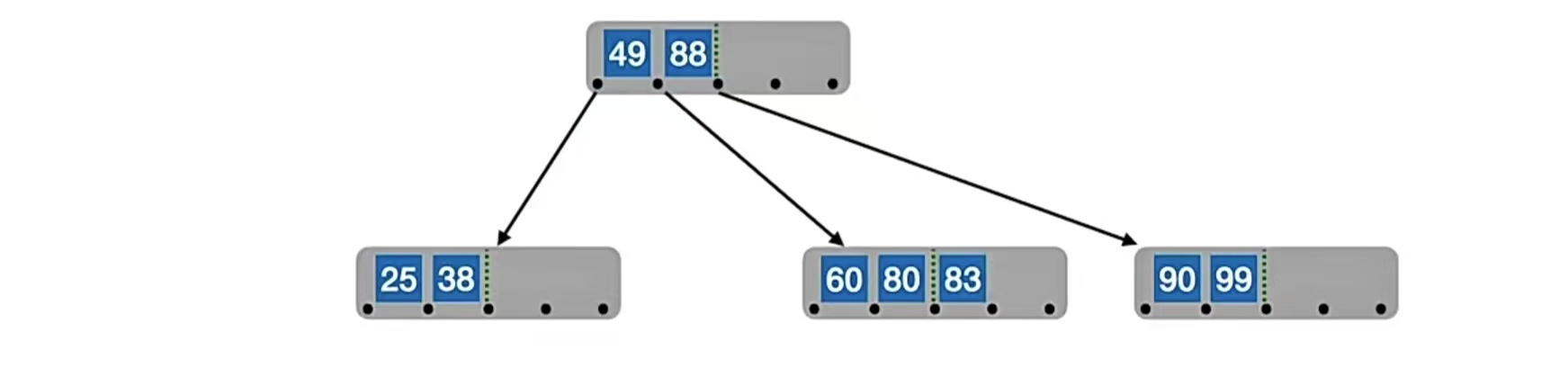
再插入“87”,同样的,找到它的插入位置,在“83”右边:
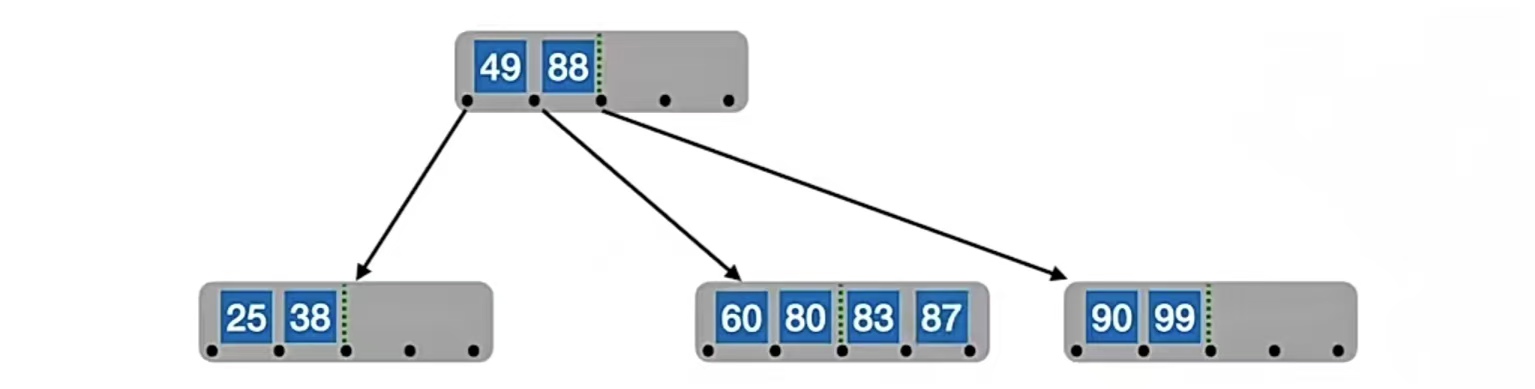
再插入结点“70”,还是按照原来的办法插入,发现又“冒了”:
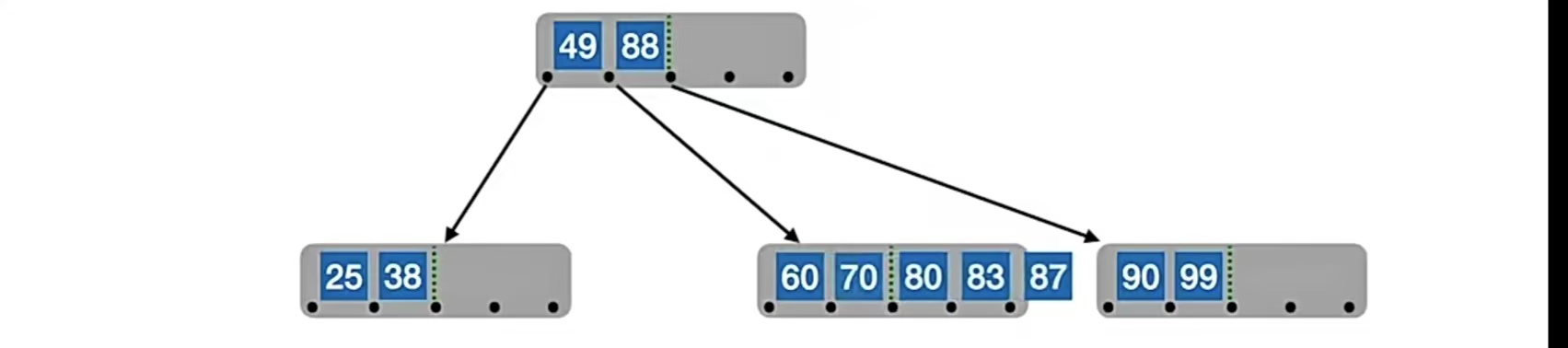
所以我们又双要分裂了。我们的中间位置⌈m/2⌉=⌈5/2⌉=3,也就是“80”,所以“80”左边的“60”,“70”放在原结点中,右边的“83”,“87”放在新结点中,“80”变成原结点的父结点,但是原结点已经有父结点了,所以就放到“49”的右边,“88”的左边,也就是这样:
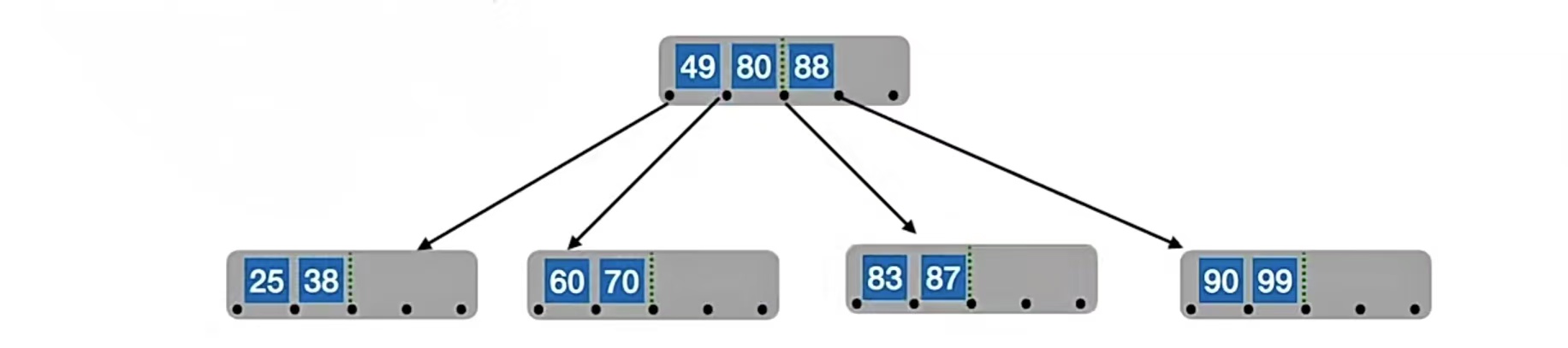
我们再插入“92”,“93”,“94”,就是这样又冒了的情况:
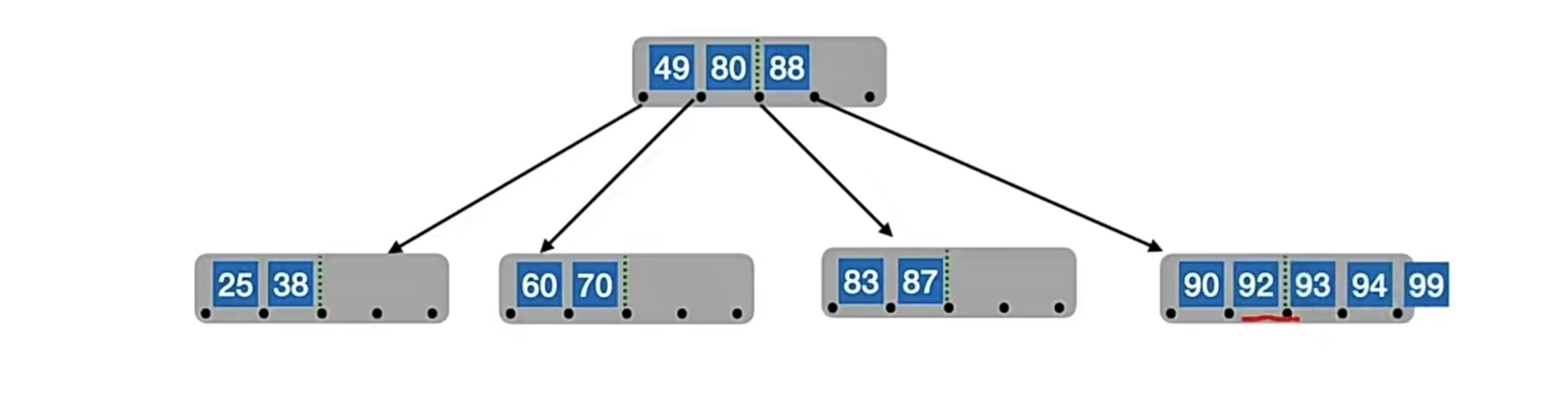
所以我们又双叒要分裂了。我们的中间位置⌈m/2⌉=⌈5/2⌉=3,也就是“93”,所以“93”左边的“90”,“92”放在原结点中,右边的“94”,“99”放在新结点中,“93”变成原结点的父结点,但是原结点已经有父结点了,所以就放到“88”的右边,也就是这样:
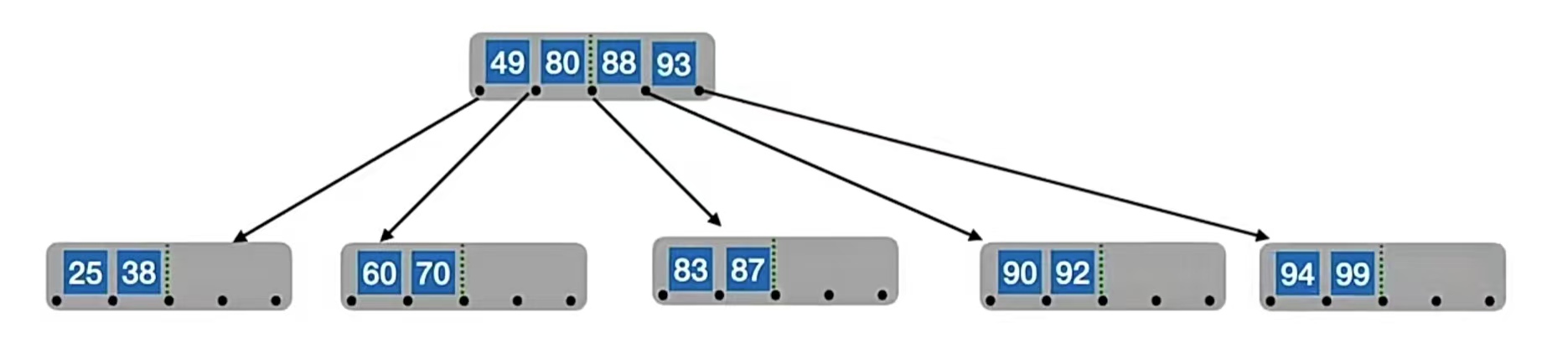
我们再插入“73”,“74”,“75”,就是这样又冒了的情况:
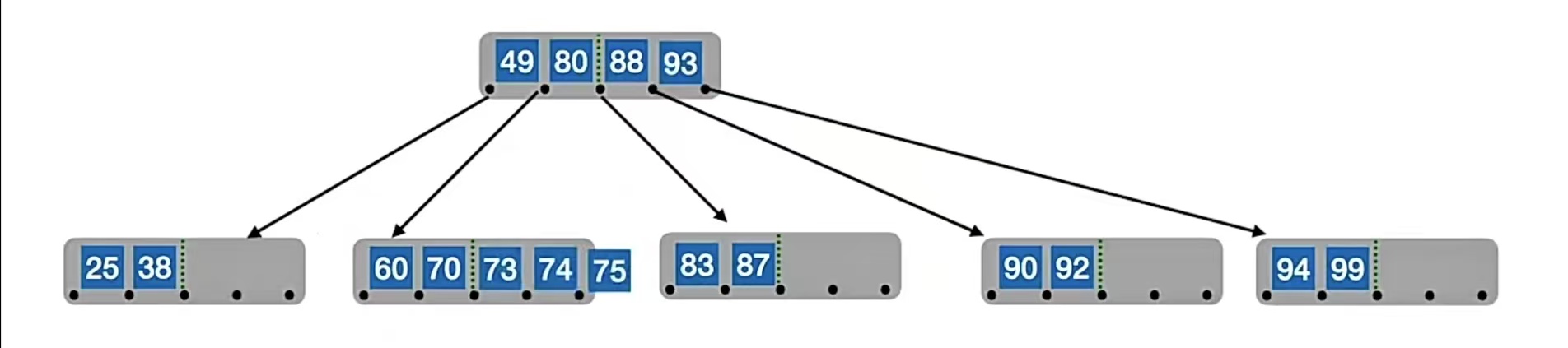
所以我们又双叒叕要分裂了。我们的中间位置⌈m/2⌉=⌈5/2⌉=3,也就是“73”,所以“73”左边的“60”,“70”放在原结点中,右边的“74”,“75”放在新结点中,“73”变成原结点的父结点,但是原结点已经有父结点了,所以就放到“49”的右边,“80”的左边,也就是这样:
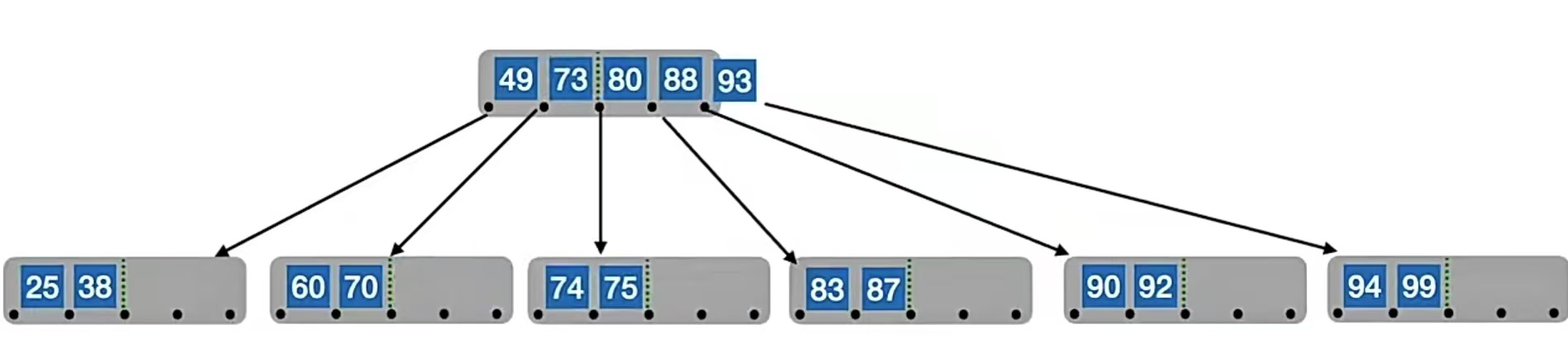
但是!!!!此时我们会发现根结点也冒了,所以我们又双叒叕又要分裂,这次分裂的是根结点。我们的中间位置⌈m/2⌉=⌈5/2⌉=3,也就是“80”,所以“80”左边的“49”,“73”放在原结点中,右边的“88”,“93”放在新结点中,“80”变成原结点的父结点,也就是这样:
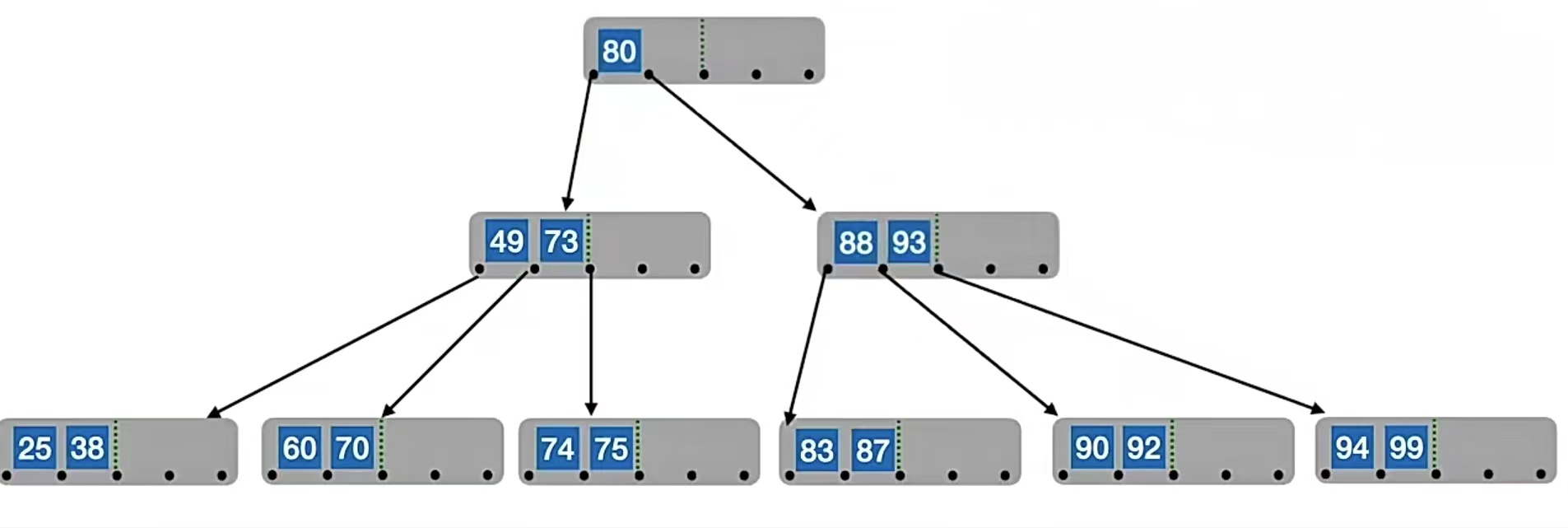
好了,经过上面的栗子,我们现在都会B树的插入了。其实就是先找,找要插到哪(注意得是终端结点),完了再看看是不是“冒了”,“冒了”就分裂,把中间位置⌈m/2⌉的元素挤到上面去。
要注意我们的核心要求:
- 对m阶B树——除根节点外,结点关键字个数 ⌈m/2⌉ - 1 ≤ m-1
- 子树0 < 关键字1 < 子树1< 关键字2 < 子树2 < ……
还有就是,新元素一定是插入到最底层“终端节点”,用“查找”来确定插入位置
在插入key后,若导致原结点关键字数超过上限,则从中间位置( ⌈m/2⌉ )将其中的关键字分为两部分,左部分包含的关键字放在原结点中,右部分包含的关键字放到新结点中,中间位置( ⌈m/2⌉ )的结点插入原结点的父结点。
若此时导致 父结点的关键字个数也超过了上限,则继续进行这种分裂操作,直至这个过程传到根结点为止,进而导致B树高度增加1。
2.删除
讲完了B树的插入,现在我们来讲B树的删除。
这是一棵水灵灵的B树:
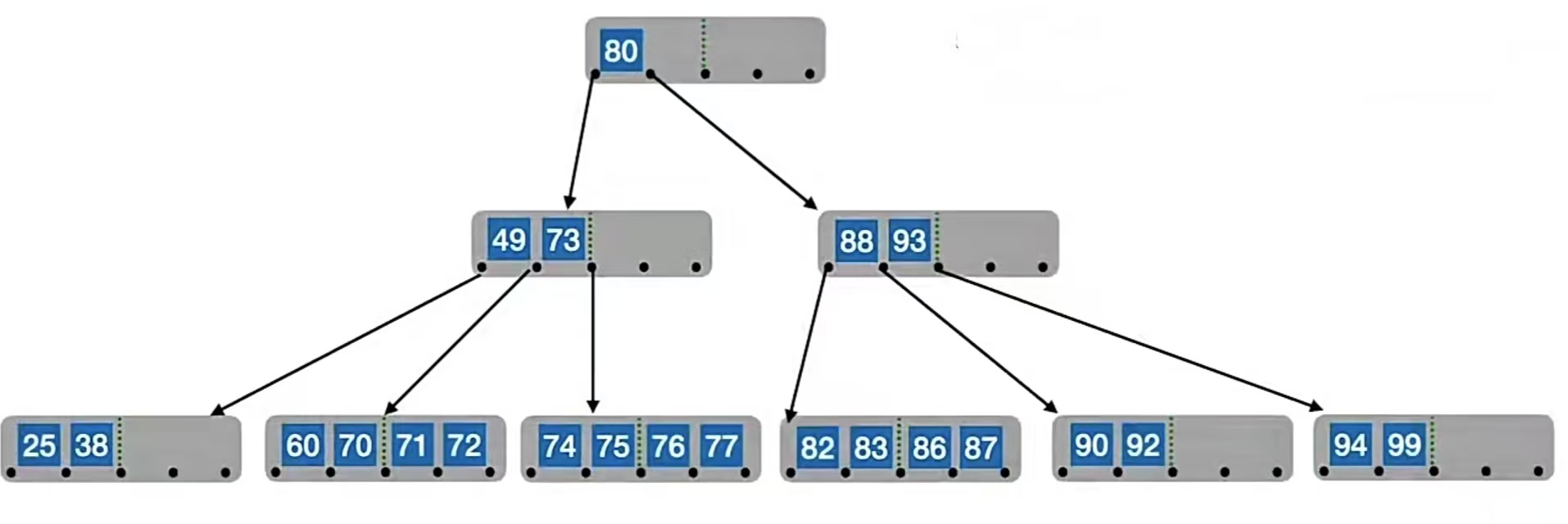
比如我们要删除“60”
若被删除关键字在
终端结点,则直接删除该关键字(要注意结点关键字个数是否低于下限 ⌈m/2⌉-1)
由于“60”在终端结点,且删除后关键字个数为3个,下限 ⌈m/2⌉-1=2,并没有低于B树的结点关键字下限,所以直接删就好了:
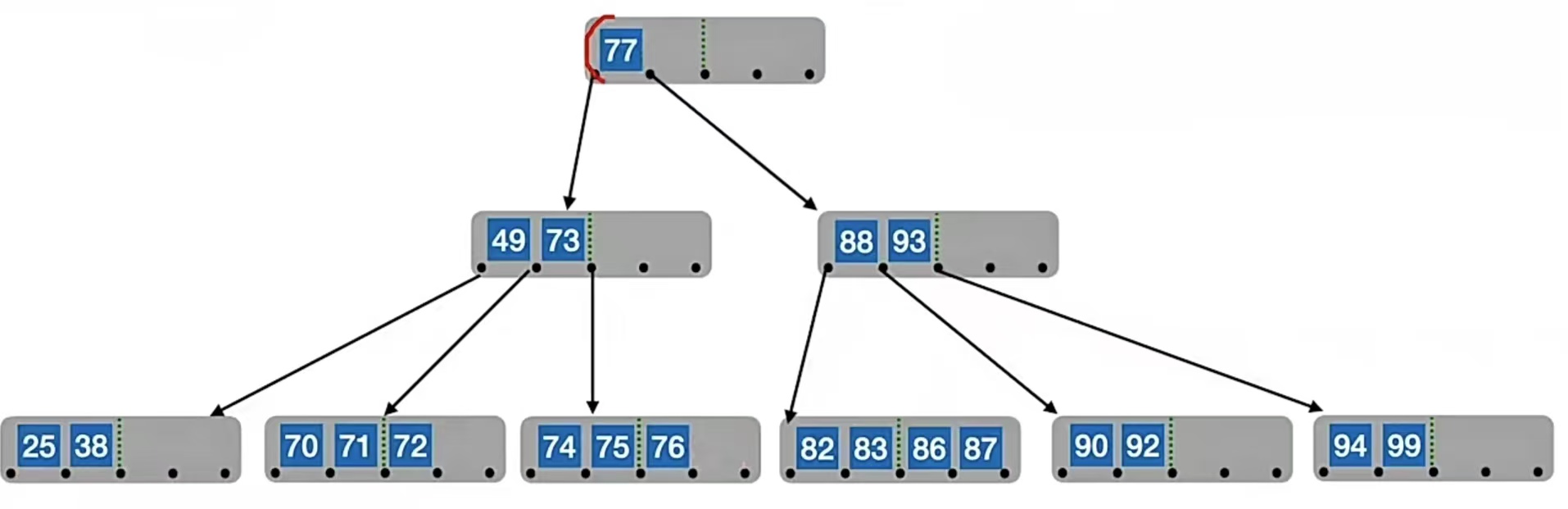
那如果我们删除的不是终端结点该怎么办,比如如果我们要删除“80”呢?其实和二叉排序树的删除一样的,都是让直接前驱/直接后继代替,然后再删,这样可以完美维持我们二叉树的左<根<右的性质:
若被删除关键字在
非终端结点,则用直接前驱或直接后继来替代被删除的关键字
直接前驱:当前关键字左侧指针所指子树中“最右下”的元素
直接后继:当前关键字右侧指针所指子树中“最左下”的元素
那我们如果用直接前驱来代替,要删除“80”,先得找“80”的直接前驱。我们找“80”左侧指针所指子树中“最右下”的元素,也就是“77”,所以我们用“77”来替代“80”,再转化为删除“77”的操作。由于“77”在终端结点,所以可以直接删,于是我们的B树就变成了这样:
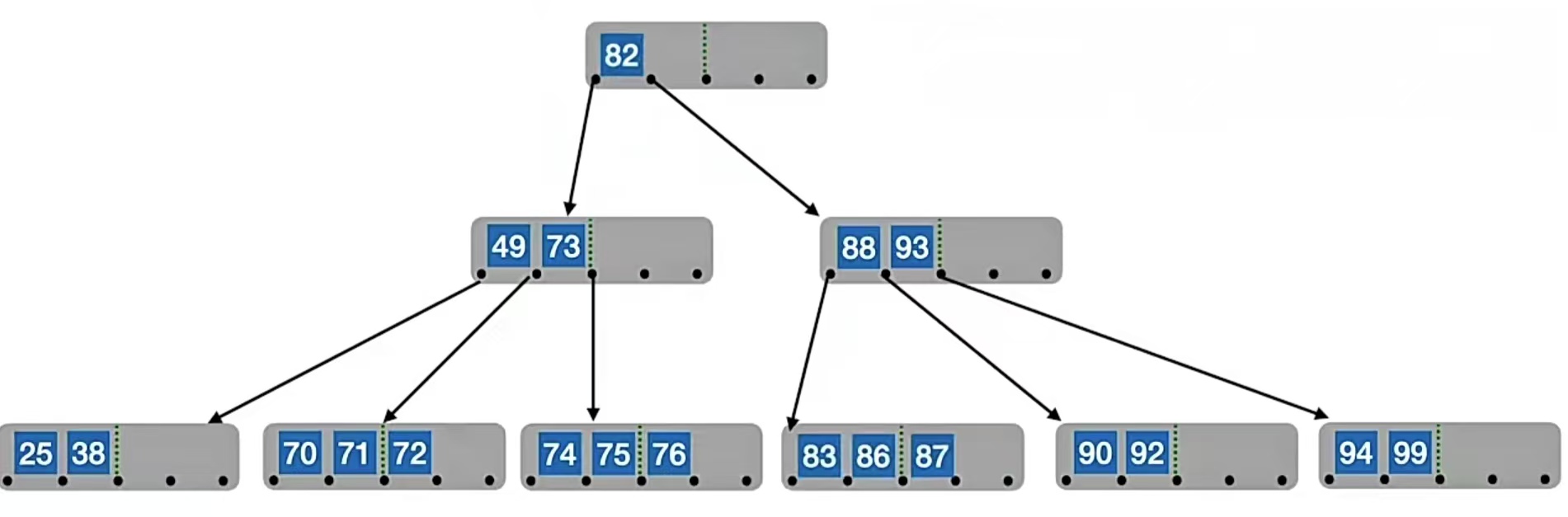
那如果我们要删除“77”呢?它也是非终端结点,这次我们用直接后继来代替。我们找“77”右侧指针所指子树中“最左下”的元素,也就是“82”,所以我们用“82”来替代“77”,再转化为删除“82”的操作。由于“82”在终端结点,所以可以直接删,于是我们的B树就变成了这样:
其实我们可以发现,对非终端结点关键字的删除,必然可以转化为对终端结点的删除操作,因为先用直接前驱/直接后继代替嘛,既然是直接前驱/直接后继,那肯定在终端结点上。
但是你以为我们B树的删除就这样讲完结束了吗?no no no,别忘了我们之前说的,要注意结点关键字个数是否低于下限 ⌈m/2⌉-1,所以肯定会有删完了之后结点关键字个数低于下限 ⌈m/2⌉-1的情况。
比如我们要删除“38”,直接删不做任何操作就会变成下面这样:
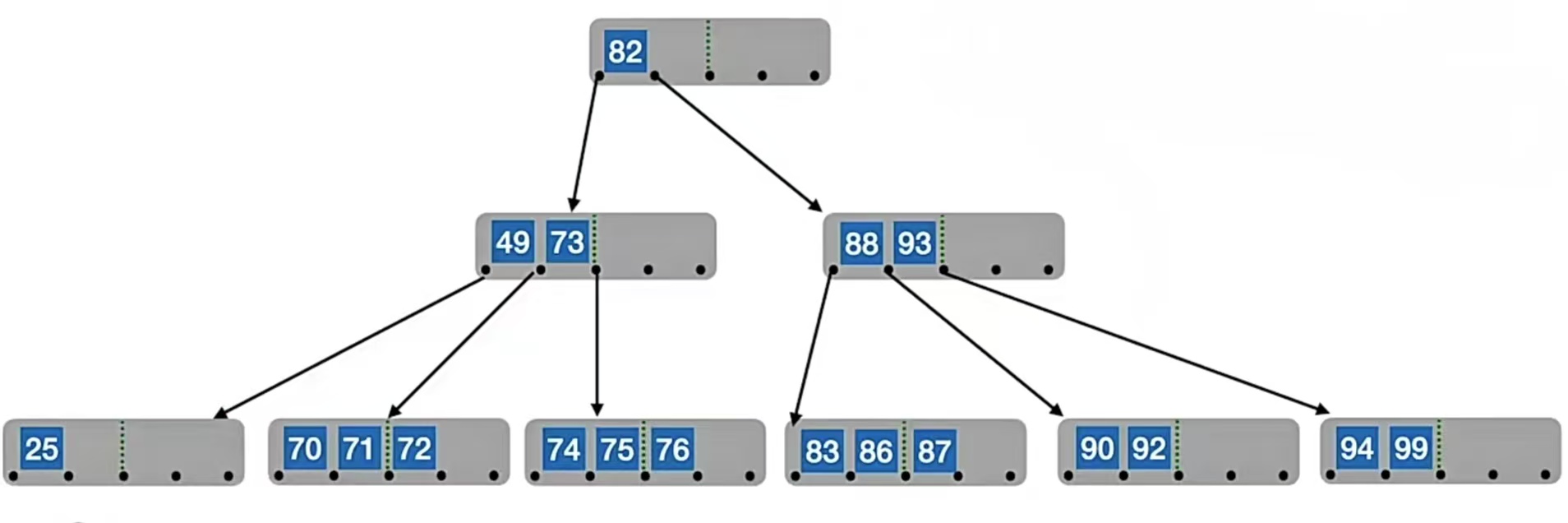
此时就会发现最左下那个结点中的关键字只有1个,个数低于下限 ⌈m/2⌉-1=2了。
我们个数不够最低下限,怎么办?遇到事情不要慌,先发个朋友圈(bushi,不够的话没关系,问别人借一个就够了:
兄弟够借。若被删除关键字所在结点删除前的关键字个数低于下限,且与此结点右(或左)兄弟结点的关键字个数还很宽裕,则需要调整该结点、右(或左)兄弟结点及其双亲结点(父子换位法)
比如我们刚刚删除“38”后,最左下的那个结点不够了,我们看到它的右兄弟还很宽裕(右结点有3个元素,就算被借走一个,那它还有2个元素,仍然满足个数不低于下限 ⌈m/2⌉-1=2),就敲开了他的门……于是把“70”给借走,则右结点就剩“71”和“72”了,我们原本的那个结点就变成了“25”和“70”:
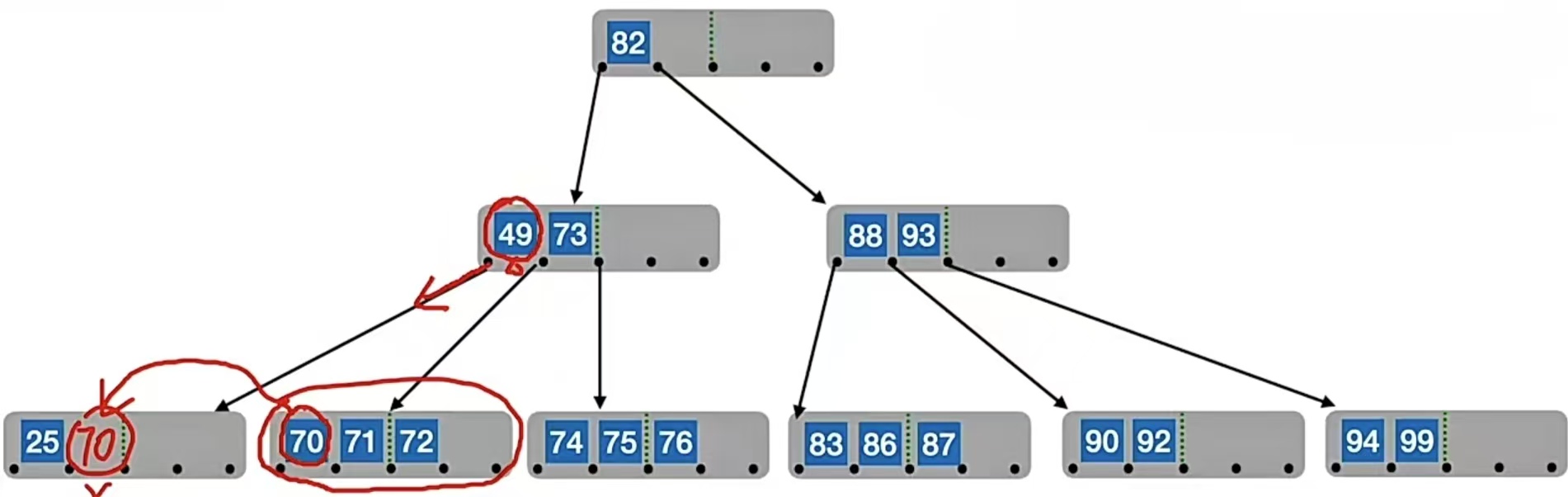
但是!!!这样是不是违反了我们二叉排序树的特性,因为它们的父结点中49<70,所以就破坏了二叉排序树,所以我们要把“49”和“70”调换,即:
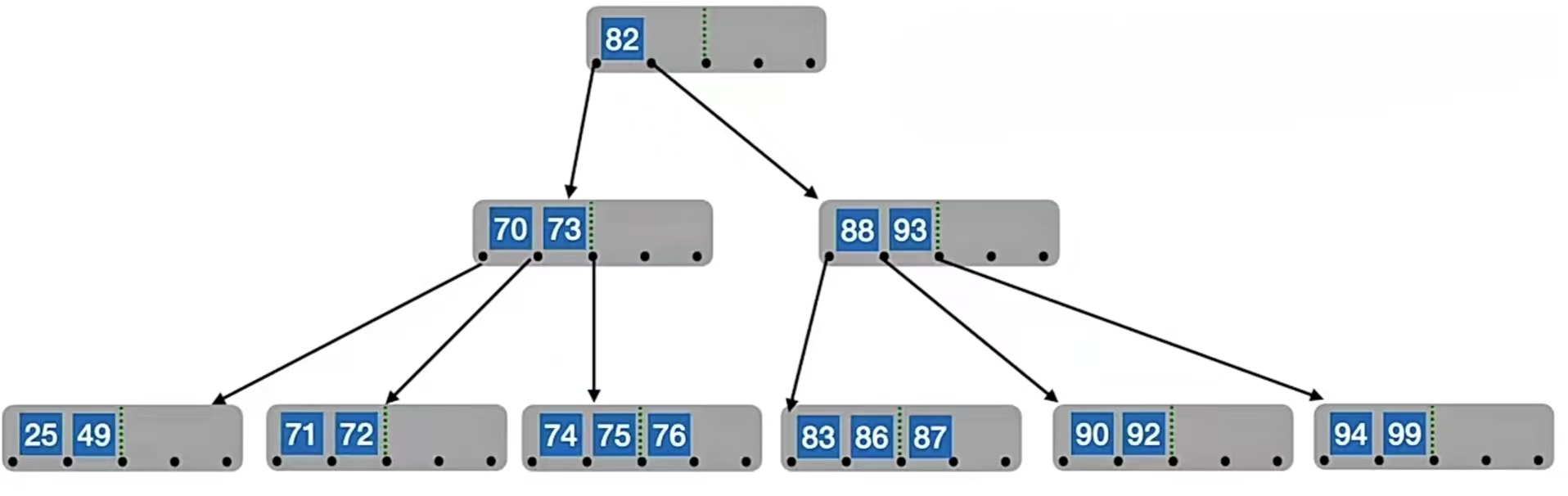
你有没有发现,其实借来的变成了“49”,也就是我们删除后不够的那个结点的直接后继……
说白了,就是当
右兄弟很宽裕时,用当前结点的后继、后继的后继来填补空缺;
当左兄弟很宽裕时,用当前结点的前驱、前驱的前驱来填补空缺即可。
啥意思呢?举个栗子就明白了。
比如我们删除“90”,删除后如下:
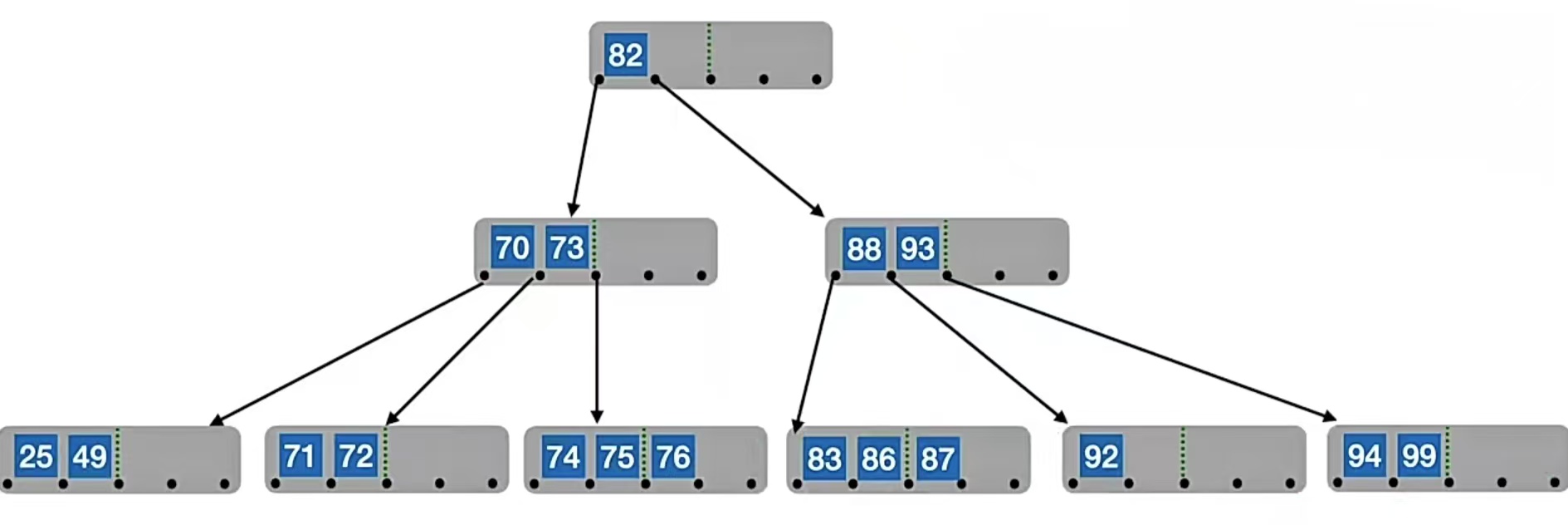
我们发现被删除元素的那个结点中的关键字只有1个,个数低于下限 ⌈m/2⌉-1=2了,右兄弟不够借,左兄弟够借(左兄弟有3个元素,就算被借走一个,那它还有2个元素,仍然满足个数不低于下限 ⌈m/2⌉-1=2),所以我们用前驱、前驱的前驱来填补空缺,前驱为“88”,前驱的前驱为“87”,所以把“88”放到被删除的那个结点里面,“87”放到前驱结点里面,即:
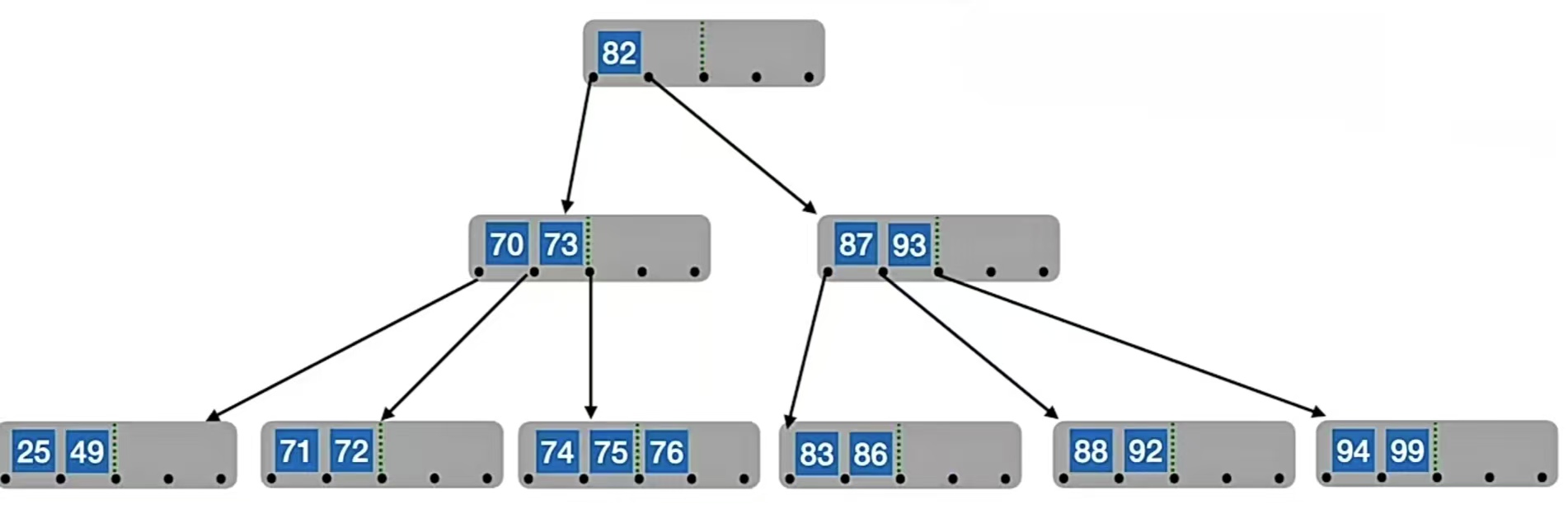
本质:要永远保证 子树0<关键字1<子树1<关键字2<子树2……
再来个“不够借”的例子,比如我们要删除“49”,删除之后:
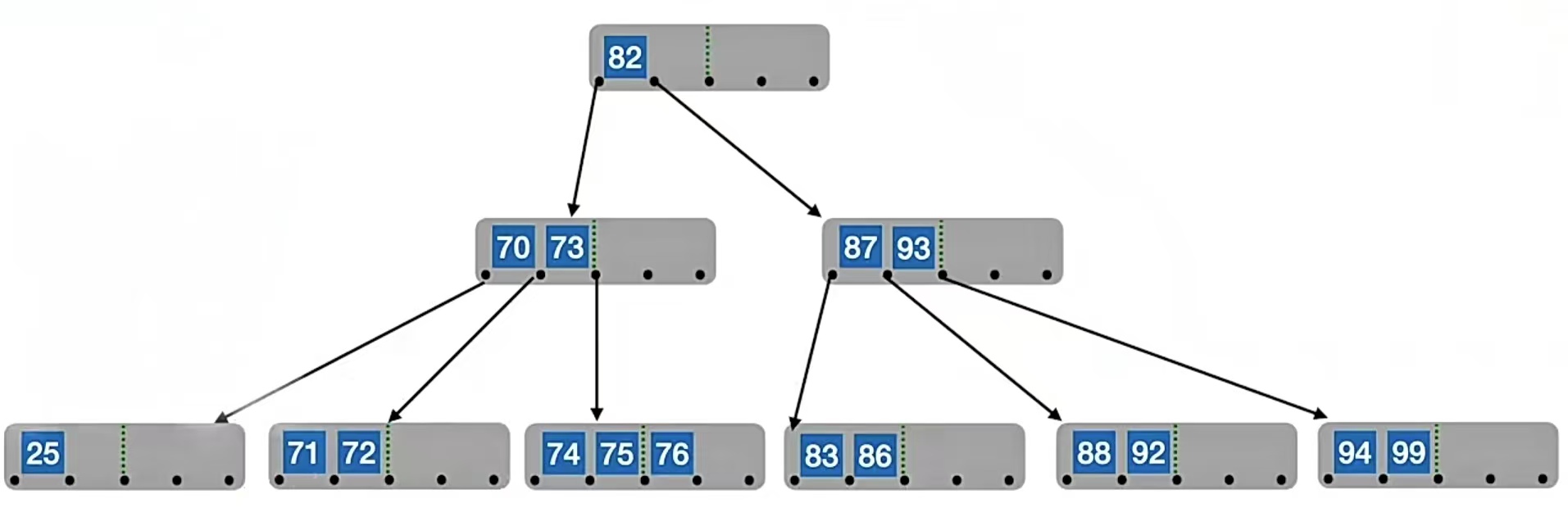
我们最左下那个结点中的关键字只有1个,个数低于下限 ⌈m/2⌉-1=2了。此时我们虽然内心很想借,但是也得别人借才行,别人自己都已经是最低下限了(右兄弟只有2个元素,要是被借走一个,那它就只剩1个元素了,就不满足个数不低于下限 ⌈m/2⌉-1=2了),你借了别人怎么办……所以这就是兄弟不够借的情况:
兄弟不够借。若被删除关键字所在结点删除前的关键字个数低于下限,且此时与该结点相邻的左、右兄弟结点的关键字个数均= ⌈m/2⌉-1,则将关键字删除后
与左(或右)兄弟结点及双亲结点中的关键字进行合并
什么意思呢?我们的兄弟不够借,那合二为一好了,大家一起就不怕了,所以将关键字删除之后和兄弟合并。光合并兄弟可不行,因为被删除结点和兄弟结点头上的指针是不一样的(分别在父节点一个关键字的左右两侧),现在要合成一个了,头上的指针肯定也是一个,所以就把父结点中的关键字拉下水,一起合并,即把“25”和“71”、“72”合并,再把“70”合并进去:
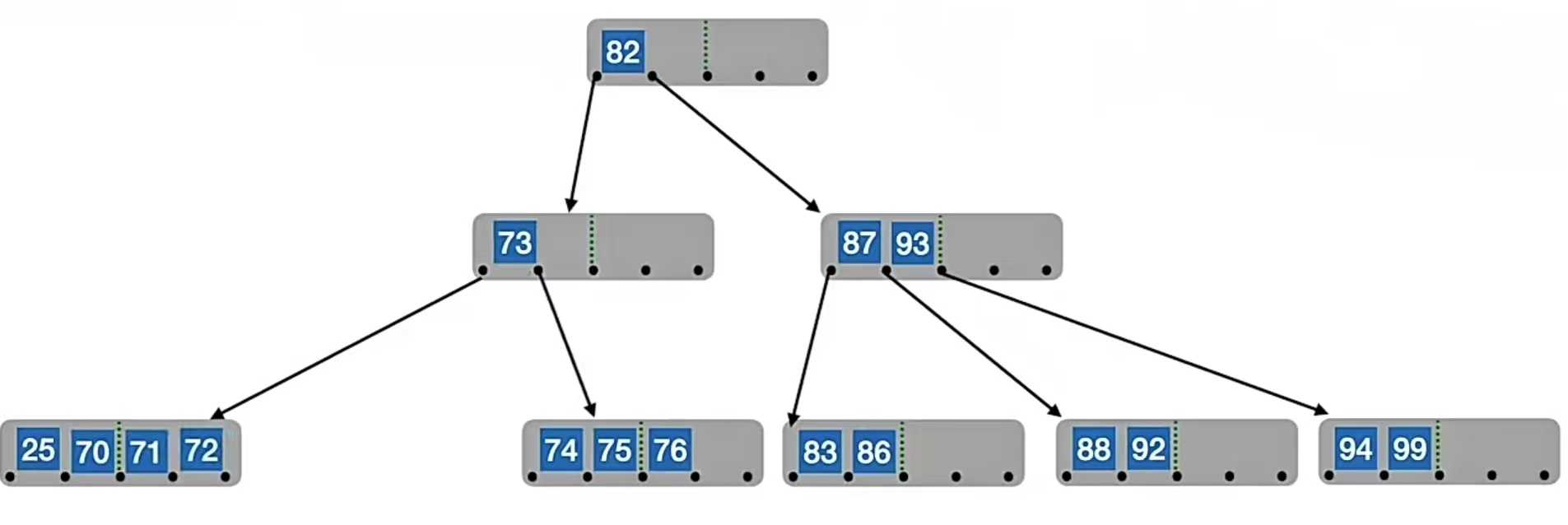
但是!!!!你有没有发现!!!这个时候它们的父结点里面关键字只有1个,个数低于下限 ⌈m/2⌉-1=2了。怎么办?没关系,别急,我们借一个就好了。不够借?也没关系,我们再再合并就好了。还记得我们怎么合并的吗?先和右兄弟合并,再把父结点中夹着的关键字拉下来一起合并,也就是把“73”和“87”、“93”合并,再把“82”合并进去:
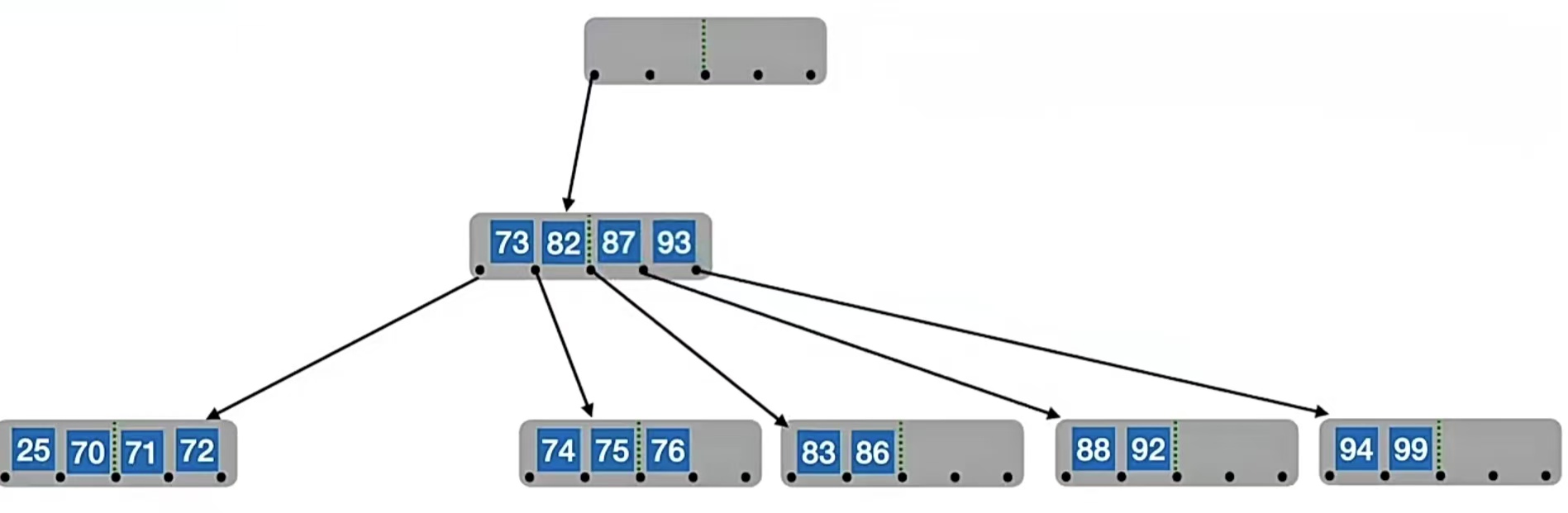
我们发现根节点关键字个数变为0了!怎么办?直接删除根结点,根结点中的元素被拉下来合并,那现在的合并的结点就变成根结点得了:
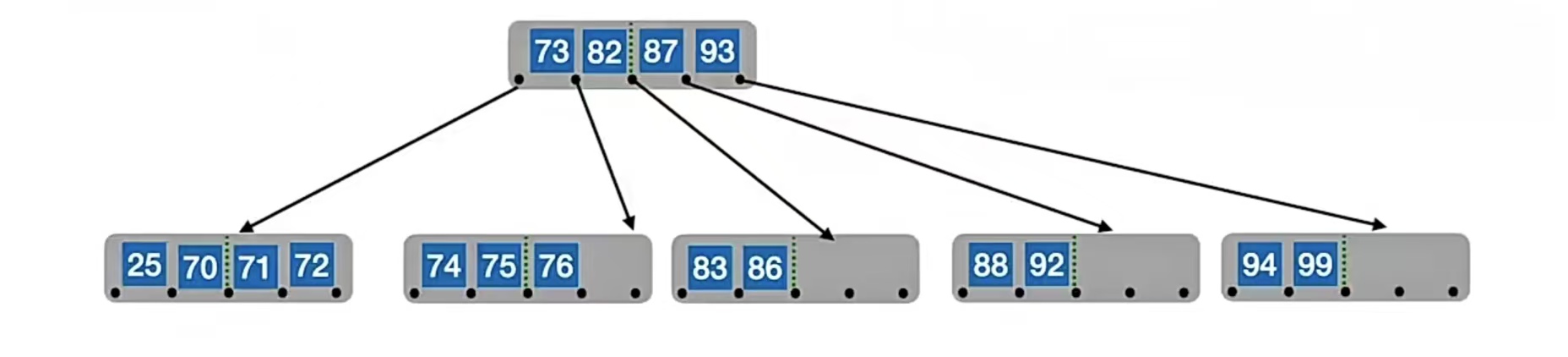
即在合并过程中,双亲结点中的关键字个数会减1。若其双亲结点是根结点且关键字个数减少至0(根结点关键字个数为1时,有2棵子树),则直接将根结点删除,合并后的新结点成为根;
若双亲结点不是根结点,且关键字个数减少到 ⌈m/2⌉-2,则又要与它自己的兄弟结点进行调整或合并操作,并重复上述步骤,直至符合B树的要求为止。
三、B+树
1.B+树
说完了B树,我们说说B+树。我们先来看一棵4阶B+树:
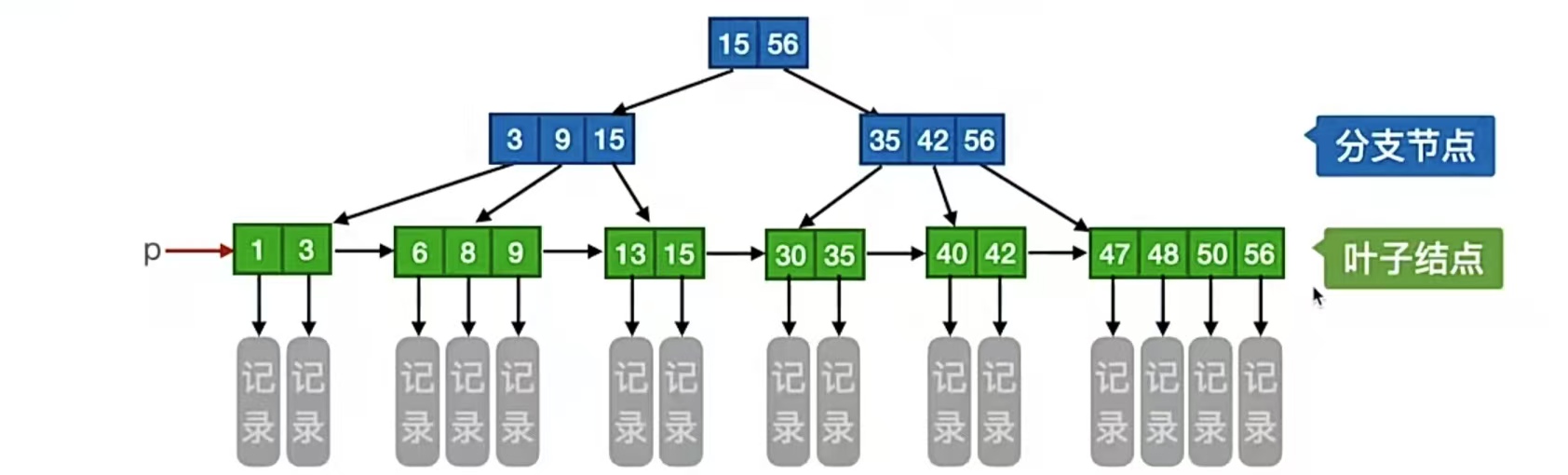
和B树还是很不一样呀。我们可以观察到,B+树中父节点保存的是子树中最大的那个元素,这是不是有点眼熟?分块查找是吧,块间有序,块内无序的那个分块查找,还记得吗?来回顾一下:
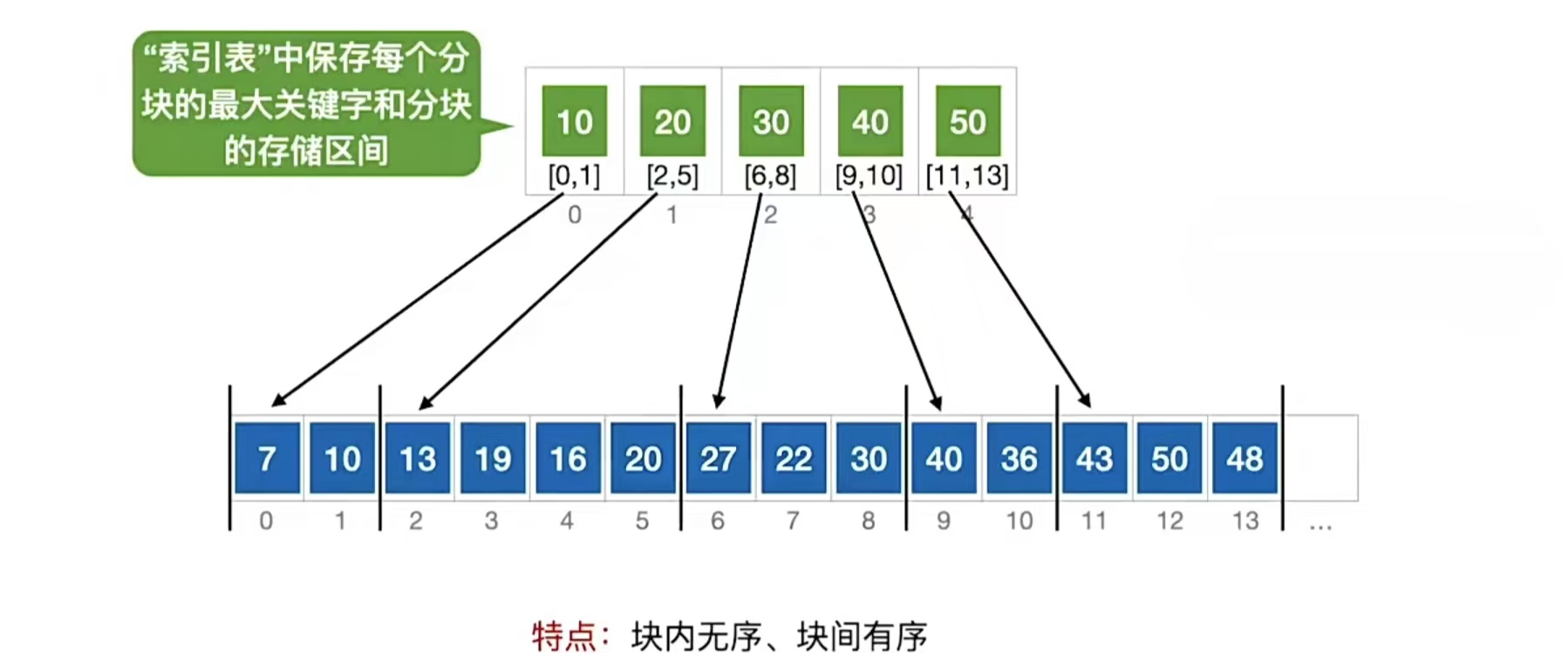
我们会发现,B+树和分块查找很像。但是也不是很像,因为分块查找没有那么多层,B+树有很多层。那么B+树的定义是什么呢?
一棵m阶的B+树需满足下列条件:
- 每个分支结点最多有m棵子树(孩子结点);
非叶根结点至少有两棵子树,其他每个分支结点至少有 ⌈m/2⌉ 棵子树;结点的子树个数与关键字个数相等;- 所有
叶结点包含全部关键字及相应记录的指针,叶结点中将关键字按大小顺序排列,并且相邻叶结点按大小顺序互相连接起来; - 所有
分支结点中仅包含它的各个子结点中关键字的最大值及指向其子结点的指针。
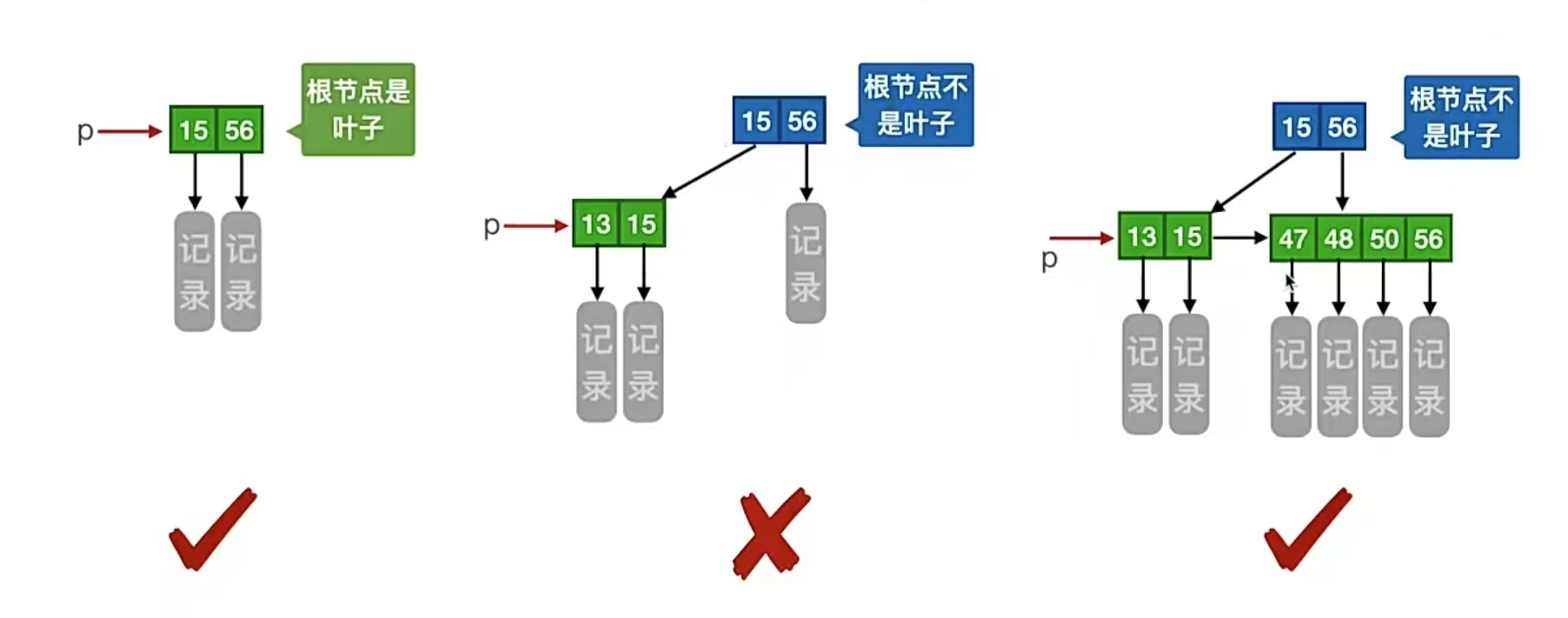
我们仍然一条一条看。首先第1条很容易理解,毕竟m阶B+树,所以每个分支结点子树个数得不超过m;那么第2条呢?非叶根结点至少有两棵子树,非叶根节点就是 根节点不是叶子结点的情况,当根节点不是叶子结点(即至少有2层)的时候,至少有2棵子树(其实就是追求平衡),其他的时候每个分支结点至少有 ⌈m/2⌉ 棵子树。(其他时候不包括根节点是叶子结点的时候,比如3阶B+树中, ⌈m/2⌉ =2,根节点是叶子结点的时候,允许只有1个关键字,我觉得这里强调根节点非叶子结点的时候至少2个子树是为了强调平衡,不要因为概念去钻牛角尖。)
举个栗子,看下面的是不是B+树。左1只有1个根节点,根节点下方没有其他结点了,所以根节点是叶子结点,没有要求,是B+树;左2根节点不是叶子结点,所以它应该至少有2棵子树,但它只有1棵,所以不是B+树;右1根节点不是叶子结点,所以它也应该至少有2棵子树,它满足,其他每个分支结点至少有 ⌈m/2⌉ =2棵子树,所以是4阶B+树。
第3条,结点的子树个数与关键字个数相等,其实我们看那个4阶B+树就可以看出来,这和B树不一样,B树是在关键字的左右两边冒出来指针,我们的B+树是直接在关键字底下冒出来指针,这条主要说这个的。
第4条,很显然了这就,我们看这个4阶B+树的图,里面所有叶结点包含全部关键字及相应记录的指针,叶结点中将关键字按大小顺序排列,并且相邻叶结点按大小顺序互相连接起来(这说明它支持顺序查找),这个没什么说的。
第5条,我们看图就会发现,除了p指针指向的绿色的结点,其他上面层里面的关键字都是绿色层出现过的,且指向它们的那个结点存放的是它们中的最大值,所以所有分支结中仅包含它的各个子结点中关键字的最大值及指向其子结点的指针。
2.B+树的查找
B+树中,无论查找成功与否,最终一定都要走到最下面一层结点
因为B+树上面层的都是最底下一层的重复数据,就算查找成功,也得到最下面一层才能看记录,查找失败也得到最下面那一层才知道(因为存放的是最下面一层的结点最大值,得到最下面那一层才知道到底有没有)。
比如我们要在上面那个4阶B+树中查找“9”,先看根节点,9<15,所以在“15”指向的那个结点里面找。3<9,9=9,所以在“9”指向的那个结点里面找。6<9,8<9,9=9,查找成功,9指向的“记录”就是我们要找到内容。(当然也可以p指针顺序查找。)
那B树的查找呢?也是必须落到最下面那一层吗?no no no,我们的B树不一样,查找成功,可能停在任意一层,比如下面这张图:
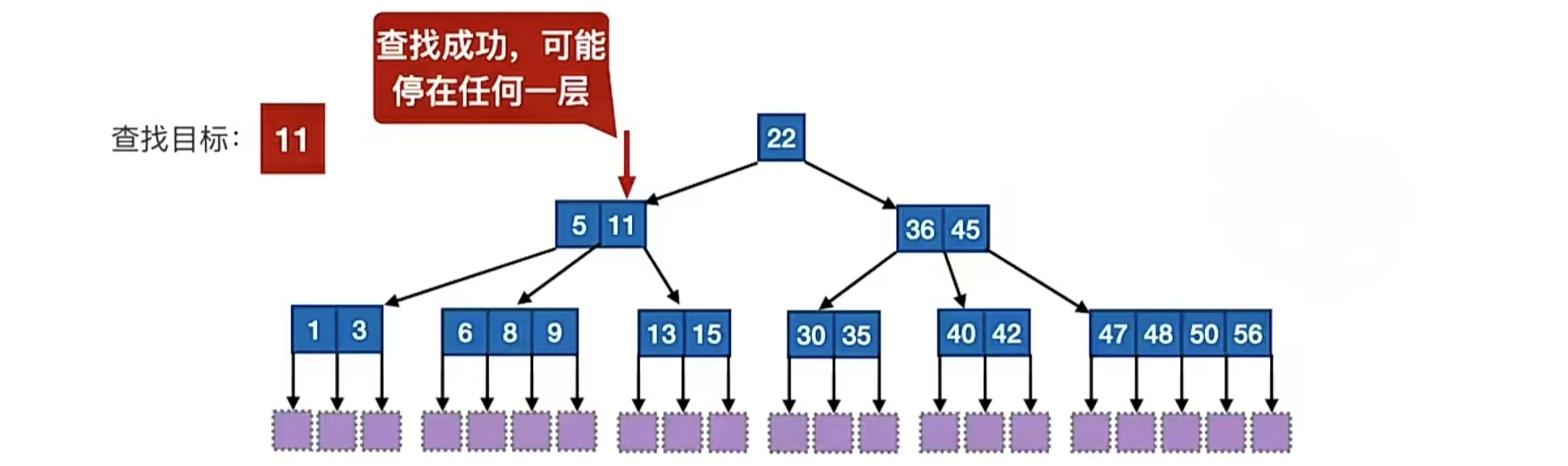
查找失败才落到叶子结点上。
3.B树和B+树的区别
-
B树结点中n个关键字对应n+1棵子树,B+树结点中的n个关键字对应n棵子树;
-
B树根结点中的关键字数 n ∈ [1,m-1],其他结点的关键字数 n ∈ [ ⌈m/2⌉,m-1];B+树根结点中的关键字数 n ∈ [1,m],其他结点的关键字数 n ∈ [ ⌈m/2⌉,m](都是最多m个分支)
-
B树中,各结点中包含的关键字是不重复的;在B+树中,叶结点包含全部关键字,非叶结点中出现过的关键字也会出现在叶结点中(叶结点是指绿色的那个最下面层的哈)
-
B树的结点中都包含了关键字对应的记录的存储地址;在B+树中,叶结点包含信息,所有非叶结点仅起索引作用,非叶结点中的每个索引项只含有对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址
- 其实就是B树中非叶结点是有信息的,B+树中非叶结点是没信息的。
在B+树中,非叶结点不含有该关键字对应记录的存储地址,可以使一个磁盘块能包含更多个关键字,使得B+树的阶更大,树高更矮,读磁盘数更少,查找更快。
为啥读磁盘数更少?因为我们B+树每个结点都存放在各个磁盘块里,每次拿数据都要把磁盘块读到内存中,这个操作很耗时,当我们非叶结点不存其他东西,只存索引,那就可以放更多索引,树高就变得更矮,往下找的时候需要读的磁盘数(层数)就更少,这样就快了。
典型应用:关系型数据库的“索引”(如MySQL)
回顾小总结一下:
| m阶B树 | m阶B+树 | |
|---|---|---|
| 类比 | 二叉查找树的进化 ——> m叉查找树 | 分块查找的进化——>多级分块查找 |
| 关键字与分叉 | n 个关键字对应 n+1 个分叉(子树) | n个关键字对应n个分叉 |
| 结点包含的信息 | 所有结点中都包含记录的信息 | 只有最下层叶子结点才包含记录的信息(可使树更矮) |
| 查找方式 | 不支持顺序查找。查找成功时,可能停在任何一层结点,查找速度“不稳定” | 支持顺序查找。查找成功或失败都会到达最下一层结点,查找速度“稳定” |
| m阶B树 、m阶B+树 | |
|---|---|
| 相同点 | 除根节点外,最少 ⌈m/2⌉ 个分叉(确保结点不要太“空”);任何一个结点的子树都要一样高(确保“绝对平衡”) |
总结
B树的插入其实就是先找,找要插到哪(注意得是终端结点),完了再看看是不是“冒了”,“冒了”就分裂,把中间位置⌈m/2⌉的元素挤到上面去,挤到上面去还“冒了”就继续分裂;B树的删除就是看满不满足结点关键字个数不低于下限 ⌈m/2⌉-1,如果不满足,那就问兄弟借;如果够借,就用前驱,前驱的前驱(或后继,后继的后继)填补,如果不够借,就和兄弟合并,再把父结点中左右指针合并的那个元素拉下来。
B+树和B树的区别主要是B树是关键字左右开叉,B+树关键字就直接出叉;还有就是B+树中最底下一层包含所有关键字,其他上面层全是重复的,B树就不这样,每个关键字都不重复;B树中非叶结点有信息,B+树非叶结点只起索引作用。
相关文章:
-B树和B+树)
数据结构第七章(四)-B树和B+树
数据结构第七章(四) B树和B树一、B树1.B树2.B树的高度 二、B树的插入删除1.插入2.删除 三、B树1.B树2.B树的查找3.B树和B树的区别 总结 B树和B树 还记得我们的二叉排序树BST吗?比如就是下面这个: 结构体也就关键字和左右指针&…...

如何利用 Python 获取京东商品 SKU 信息接口详细说明
在电商领域,SKU(Stock Keeping Unit,库存进出计量的基本单元)信息是商品管理的核心数据之一。它不仅包含了商品的规格、价格、库存等关键信息,还直接影响到库存管理、价格策略和市场分析等多个方面。京东作为国内知名的…...

【机器学习】第二章模型的评估与选择
A.关键概念 2.1 经验误差和过拟合 经验误差与泛化误差:学习器在训练集上的误差为经验误差,在新样本上的误差为泛化误差 过拟合:学习器训练过度后,把训练样本自身的一些特点当作所有潜在样本具有一般性质,使得泛化性能…...

[PMIC]PMIC重要知识点总结
PMIC重要知识点总结 摘要:PMIC (Power Management Integrated Circuit) 是现代电子设备中至关重要的组件,负责电源管理,包括电压调节、电源转换、电池管理和功耗优化等。PMIC 中的数字部分主要涉及控制逻辑、状态机、寄存器配置、通信接口&am…...

LVGL- Calendar 日历控件
1 日历控件 1.1 日历背景 lv_calendar 是 LVGL(Light and Versatile Graphics Library)提供的标准 GUI 控件之一,用于显示日历视图。它支持用户查看某年某月的完整日历,还可以实现点击日期、标记日期、导航月份等操作。这个控件…...

ubuntu安装google chrome
更新系统 sudo apt update安装依赖 sudo apt install curl software-properties-common apt-transport-https ca-certificates -y导入 GPG key curl -fSsL https://dl.google.com/linux/linux_signing_key.pub | gpg --dearmor | sudo tee /usr/share/keyrings/google-chrom…...

如何开发专业小模型
在专业领域场景下,通过针对性优化大模型的词汇表、分词器和模型结构,确实可以实现参数规模的显著缩减而不损失专业能力。这种优化思路与嵌入式设备的字库剪裁有相似性,但需要结合大模型的特性进行系统性设计。以下从技术可行性、实现方法和潜…...

EXO 可以将 Mac M4 和 Mac Air 连接起来,并通过 Ollama 运行 DeepSeek 模型
EXO 可以将 Mac M4 和 Mac Air 连接起来,并通过 Ollama 运行 DeepSeek 模型。以下是具体实现方法: 1. EXO 的分布式计算能力 EXO 是一个支持 分布式 AI 计算 的开源框架,能够将多台 Mac 设备(如 M4 和 Mac Air)组合成…...

Git Worktree 使用
新入职了一家公司,发现不同项目用的使用一个 git 仓库管理。不久之后我看到这篇文章。 Git 的设计部分是为了支持实验。一旦你确定你的工作被安全地跟踪,并且存在安全的状态,以便在出现严重错误时可以恢复,你就不会害怕尝试新…...

【Linux网络】内网穿透
内网穿透 基本概念 内网穿透(Port Forwarding/NAT穿透) 是一种网络技术,主要用于解决处于 内网(局域网)中的设备无法直接被公网访问 的问题。 1. 核心原理 内网与公网的隔离:家庭、企业等局域网内的设备…...

反射机制动态解析
代码解释与注释 package com.xie.javase.reflect;import java.lang.reflect.Field; import java.lang.reflect.Modifier;public class ReflectTest01 {public static void main(String[] args) throws ClassNotFoundException {// 1. 获取java.util.HashMap类的Class对象Class…...

10 分钟打造一款超级马里奥小游戏,重拾20 年前的乐趣
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 你好,我是悟空。 前言 小时候看到村里的大朋友家里都有一款 FC 游戏机,然后旁边还放…...

鸿蒙ArkUI体验:Hexo博客客户端开发心得
最近部门也在跟进鸿蒙平台的业务开发,自己主要是做 Android 开发,主要使用 Kotlin/Java 语言。,需要对新的开发平台和开发模式进行学习,在业余时间开了个项目练手,做了个基于 Hexo 博客内容开发的App。鸿蒙主要使用Ark…...
?)
人工智能100问☞第25问:什么是循环神经网络(RNN)?
目录 一、通俗解释 二、专业解析 三、权威参考 循环神经网络(RNN)是一种通过“记忆”序列中历史信息来处理时序数据的神经网络,可捕捉前后数据的关联性,擅长处理语言、语音等序列化任务。 一、通俗解释 想象你在和朋友聊天,每说一句话都会根据之前的对话内容调整语气…...
】Zuul路由访问映射规则配置及使用(含源代码)(十二))
【springcloud学习(dalston.sr1)】Zuul路由访问映射规则配置及使用(含源代码)(十二)
该系列项目整体介绍及源代码请参照前面写的一篇文章【springcloud学习(dalston.sr1)】项目整体介绍(含源代码)(一) springcloud学习(dalston.sr1)系统文章汇总如下: 【springcloud学习(dalston…...

STM32IIC协议基础及Cube配置
STM32IIC协议基础及Cube配置 一,IC协议简介1,核心特点2,应用场景 二,IC协议基础概念1,总线结构2,主从架构3,设备寻址4,起始和停止条件5,数据传输6,应答机制 三…...

Python异常模块和包
异常 当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”, 也就是我们常说的BUG 例如:以r方式打开一个不存在的文件。 f open(‘python1.txt’,‘r’,encoding‘utf-8’) 当我们…...

每日算法刷题Day9 5.17:leetcode定长滑动窗口3道题,用时1h
9. 1652.拆炸弹(简单,学习) 1652. 拆炸弹 - 力扣(LeetCode) 思想 为了获得正确的密码,你需要替换掉每一个数字。所有数字会 同时 被替换。 如果 k > 0 ,将第 i 个数字用 接下来 k 个数字之和替换。如果 k < 0…...

题单:递归求和
宣布一个重要的事情,我的洛谷有个号叫 题目描述 给一个数组 a:a[0],a[1],...,a[n−1]a:a[0],a[1],...,a[n−1] 请用递归的方式出数组的所有数之和。 提示:递推方程 f(x)f(x−1)a[x]f(x)f(x−1)a[x]; 输入格式 第一行一个正整数 n (n≤100)n (n≤100)…...
手动实现 Transformer 模型
本文使用 Pytorch 库手动实现了传统 Transformer 模型中的多头自注意力机制、残差连接和层归一化、前馈层、编码器、解码器等子模块,进而实现了对 Transformer 模型的构建。 """ Title: 解析 Transformer Time: 2025/5/10 Author: Michael Jie &quo…...

【鸿蒙开发避坑】使用全局状态变量控制动画时,动画异常甚至动画方向与预期相反的原因分析以及解决方案
【鸿蒙开发避坑】使用全局状态变量控制动画,动画异常甚至动画方向相反的原因分析以及解决方案 一、问题复现1、问题描述2、问题示意图 二、原因深度解析1、查看文档2、调试3、原因总结:(1)第一次进入播放页面功能一切正常的原因&a…...

天拓四方锂电池卷绕机 PLC 物联网解决方案
近年来,锂电制造行业作为新能源领域的核心支柱产业,呈现出迅猛发展的态势,市场需求持续高涨。在此背景下,行业内对产品质量、生产效率以及成本控制等方面提出了更为严苛的要求。锂电制造流程涵盖混料、涂布、辊压、分切、制片、卷…...

RFID系统:技术解析与应用全景
一、技术架构与运行逻辑 RFID(Radio Frequency Identification)系统通过无线电波实现非接触式数据交互,其核心由三部分组成: 电子标签(Tag): 无源标签:依赖读写器电磁场供电&…...

hbuilderX 安装Prettier格式化代码
一、打开插件安装 搜索输入:Prettier 安装后,重启hbuilderX ,再按AltShiftF 没安装Prettier格式化: import {saveFlow,getTemplate } from "../../api/flowTemplate.js"; 安装Prettier格式化后: import …...

Python-92:最大乘积区间问题
问题描述 小R手上有一个长度为 n 的数组 (n > 0),数组中的元素分别来自集合 [0, 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024]。小R想从这个数组中选取一段连续的区间,得到可能的最大乘积。 你需要帮助小R找到最大乘积的区间,并输出这…...
--多点触控)
Compose笔记(二十三)--多点触控
这一节主要了解一下Compose中多点触控,在Jetpack Compose 中,多点触控处理需要结合Modifier和手势API来实现,一般通过组合 pointerInput、TransformableState 和 TransformModifier 来创建支持缩放、旋转和平移的组件。 一、 API 1. Pointer…...

2025.05.17淘天机考笔试真题第一题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 01. 魔法棋盘构造 问题描述 LYA 正在设计一款魔法棋盘游戏。游戏棋盘由 2 n 2 \times n...

python的漫画网站管理系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核…...
:结构化编程)
系统架构设计(十):结构化编程
定义 结构化编程是一种遵循清晰逻辑结构、避免使用 goto 的编程方法。它强调使用有限的三种基本控制结构来组织程序,提高程序的可读性、可维护性和可测试性。 它是现代程序设计的基础,被广泛应用于命令式语言(如 C、Pascal、Java࿰…...
:数据流图)
系统架构设计(七):数据流图
定义 数据流图(Data Flow Diagram, DFD)是一种用于表示信息系统数据流转及处理过程的图形工具。 它反映系统功能及数据之间的关系,是结构化分析与设计的重要工具。 主要符号 符号说明描述举例方框外部实体(源或终点)…...

BrepGen中的几何特征组装与文件保存详解 deepwiki occwl OCC包装库
有这种好东西我怎么不知道 AutodeskAILab/occwl: Lightweight Pythonic wrapper around pythonocc 组装几何特征以创建B-rep模型 保存为STEP和STL文件细说 Fast 快速 Searched across samxuxiang/BrepGen Ill explain how BrepGen assembles geometric features to create B-r…...
篇二:阅读与注释 QAction,给出源代码)
QT6 源(105)篇二:阅读与注释 QAction,给出源代码
(5)本源代码来自于头文件 qaction . h : #ifndef QACTION_H #define QACTION_H#include <QtGui/qtguiglobal.h> #if QT_CONFIG(shortcut) # include <QtGui/qkeysequence.h> #endif #include <QtGui/qicon.h> #include &…...

复旦微FMQL调试笔记:PS网口
引言 FPGA,全程现场可编程门阵列,是指一切通过软件手段更改、配置器件内部连接结构和逻辑单元,完成既定设计功能的数字集成电路。换个简单通俗的介绍方式,就好比一个全能的运动员,FPGA就是这么神奇的可以通过设定而实…...

SpringBoot启动流程深入分析
文章目录 背景启动流程listeners.starting先获取运行监听器获取SpringApplicationRunListener的实例监听器接口从spring.factories中加载数据,这里有本地缓存监听启动发布starting事件 prepareEnvironment准备环境获取或创建环境配置环境 createApplicationContext创…...

Linux - 2.系统命令
1.帮助命令 1.help [root@localhost /]# cp --help1.查看命令的信息和参数2.只能显示shell内部的命令信息3.help命令第一部分是概述,第二部分是参数详解,第三部分是说明和注意 # 使用语法 Usage: cp [OPTION]... [-T] SOURCE DESTor: cp [OPTION]... SOURCE... DIRECTORYor:…...
单选题解析)
CSP 2024 提高级第一轮(CSP-S 2024)单选题解析
单选题解析 第 1 题 在 Linux 系统中,如果你想显示当前工作目录的路径,应该使用哪个命令?(A) A. pwd B. cd C. ls D. echo 解析:Linux 系统中,pwd命令可以显示当前工作目录的路径。pwd&#x…...

JavaScript运算符
在JavaScript开发中,运算符是编程的基础工具。它们用于执行各种操作,从简单的数学计算到复杂的逻辑判断。本文将深入探讨JavaScript中的各种运算符,包括算术运算符、比较运算符、布尔运算符、位运算符以及其他一些特殊运算符。 一、算术运算…...

无线信道的噪声与干扰
目录 1. 无线信道(wireless channel)与电磁波 2.1 电磁波的传输(无线信道传输) 2.2 视线(line of sight)传播与天线高度 2. 信道的数学模型 2.1 调制信道模型 2.1.1 加性噪声/加性干扰 2.1.2 乘性噪声/乘性干扰 2.1.3 随参信道/恒参信道 2.2 编码信道模型 2.3 小结 …...
)
计算机视觉与深度学习 | Python实现EMD-CNN-LSTM时间序列预测(完整源码、数据、公式)
EMD-CNN-LSTM 1. 环境准备2. 数据生成(示例数据)3. EMD分解4. 数据预处理5. CNN-LSTM模型定义6. 模型训练7. 预测与重构8. 性能评估核心公式说明1. 经验模态分解(EMD)2. CNN-LSTM混合模型参数调优建议扩展方向典型输出示例以下是使用Python实现EMD-CNN-LSTM时间序列预测的完…...

基于Yolov8+PyQT的老人摔倒识别系统源码
概述 随着人工智能技术的普及,计算机视觉在安防领域的应用日益广泛。幽络源本次分享的基于Yolov8PyQT的老人摔倒识别系统,正是针对独居老人安全监护的实用解决方案。该系统通过深度学习算法实时检测人体姿态,精准识别站立、摔倒中等…...
)
【网络入侵检测】基于Suricata源码分析运行模式(Runmode)
【作者主页】只道当时是寻常 【专栏介绍】Suricata入侵检测。专注网络、主机安全,欢迎关注与评论。 1. 概要 👋 在 Suricata 中抽象出线程、线程模块和队列三个概念:线程类似进程,可多线程并行执行操作;监听、解码、检…...

深入解析:java.sql.SQLException: No operations allowed after statement closed 报错
在 Java 应用程序开发过程中,尤其是涉及数据库交互时,开发者常常会遇到各种各样的异常。其中,java.sql.SQLException: No operations allowed after statement closed是一个较为常见且容易令人困惑的错误。本文将深入剖析这一报错,…...

ARM-Linux 完全入门
1.准备部分 1.1 虚拟机安装 准备VMware软件、ubuntu系统镜像安装过程 VMware安装 破解(自己百度破解码,多试几个网址,会有能用的)Ubuntu安装 配置联网 桥接 虚拟机Ubuntu系统必须能连接到外网,不然不能更新软件安装…...

前端二进制数据指南:从 ArrayBuffer 到高级流处理
前端开发中,二进制数据是处理文件、图像、音视频、网络通信等场景的基础。以下是核心概念和用途的通俗解释: 前端二进制数据介绍 1. 什么是前端二进制数据? 指计算机原始的 0 和 1 格式的数据(比如一张图片的底层代码ÿ…...

深入理解构造函数,析构函数
目录 1.引言 2.构造函数 1.概念 2.特性 3.析构函数 1.概念 2.特性 1.引言 如果一个类中什么都没有,叫作空类. class A {}; 那么我们这个类中真的是什么都没有吗?其实不是,如果我们类当中上面都不写.编译器会生成6个默认的成员函数。 默认成员函数:用户没有显…...

数值分析知识重构
数值分析知识重构 一 Question 请构造一下数值分析中的误差概念以及每一个具体数值方法的误差是如何估计的? 二 Question 已知 n 1 n1 n1个数据点 ( x i , y i ) , i 0 , 1 , ⋯ , n (x_i,y_i),i0,1,\cdots,n (xi,yi),i0,1,⋯,n,请使用多种方法建立数据之间…...

全端同步!ZKmall开源商城如何用B2B2C模板让消费者跨设备购物体验无缝衔接?
在数字化浪潮席卷下,消费者的购物行为不再局限于单一设备。早晨用手机小程序浏览商品,中午在 PC 端对比参数,晚上通过平板下单,跨设备购物已成常态。然而,设备间数据不同步、操作体验割裂等问题,严重影响购…...

Redis Sentinel如何实现高可用?
Redis Sentinel 通过以下核心机制实现高可用: 1. 监控(Monitoring) Sentinel 集群会持续监控主节点(Master)和从节点(Slave)的状态: 定期发送 PING 命令检测节点是否存活…...

环形缓冲区 ring buffer 概述
环形缓冲区 ring buffer 概述 1. 简介 环形缓冲区(ring buffer),是一种用于表示一个固定尺寸、头尾相连的缓冲区的数据结构,适合缓存数据流。也称作环形缓冲区(circular buffer),环形队列&…...

Spring源码之解决循环依赖 三级缓存
目录 三级缓存核心原理 循环依赖的解决过程 1. Bean A创建过程中提前曝光工厂 2. Bean B创建时发现依赖A,从缓存获取 3. Bean A继续完成初始化 三级缓存的作用总结 二级缓存为何不够解决缓存依赖? 三级缓存如何解决? 为什么不直接在…...