7 个正则化算法完整总结
哈喽!我是我不是小upper~之前和大家聊过各类算法的优缺点,还有回归算法的总结,今天咱们来深入聊聊正则化算法!这可是解决机器学习里 “过拟合” 难题的关键技术 —— 想象一下,模型就像个死记硬背的学生,把训练题的答案全背下来了,但遇到新题目就傻眼,这就是过拟合。正则化就像给模型请了个 “家教”,教会它 “举一反三”,而不是死记硬背~
为什么需要正则化?
当模型在训练数据上表现得 “过于优秀”,甚至能记住所有噪音时,就会陷入过拟合。这时候,它在新数据上的表现会暴跌。正则化的核心思路很简单:给模型的 “学习能力” 设个限制,通过在损失函数里加一个 “惩罚项”,让模型参数不能随心所欲地变大,从而降低复杂度,提升泛化能力。
先来简单介绍一下7种正则化方法
1. L1 正则化(Lasso 回归)
- 原理:在损失函数中加入模型参数的绝对值之和作为惩罚项(公式:
)。
- 效果:
- 强制让部分参数变成 0,就像给特征做 “断舍离”,自动筛选出重要特征(比如 100 个特征里,可能只剩 10 个非零参数)。
- 适合特征多但冗余大的场景,比如基因数据、文本分类,能直接简化模型结构。
- 缺点:参数更新时可能不够平滑,极端情况下容易漏掉一些相关特征。
2. L2 正则化(Ridge 回归)
- 原理:惩罚项是参数的平方和(公式:
)。
- 效果:
- 让所有参数都趋近于 0,但不会完全为 0,就像给参数 “瘦身”,避免某个特征 “一家独大”。
- 对异常值更鲁棒,比如房价预测中,个别极端高价样本不会让模型过度倾斜。
- 应用:线性回归、神经网络中最常用的 “标配” 正则化,简单有效。
3. 弹性网络正则化(Elastic Net)
- 原理:L1 和 L2 的 “混血儿”,惩罚项是两者的加权和(公式:
)。
- 效果:
- 结合了 L1 的特征选择能力和 L2 的稳定性,比如当多个特征高度相关时(如股票价格的不同指标),L1 可能随机选一个,而弹性网络会保留多个。
- 适合特征间有复杂关联的数据集,比如金融数据、生物医学数据。
4. Dropout 正则化(神经网络专属)
- 原理:在训练过程中,随机 “丢弃” 一部分神经元(让其输出为 0),就像让模型 “闭目养神”,每次只用部分神经元学习。
- 效果:
- 迫使模型不能依赖任何一个神经元,增强泛化能力,就像学生用不同的知识点组合解题,而不是死记某一种思路。
- 计算成本低,不需要修改损失函数,在 CNN、Transformer 等网络中广泛使用。
- 注意:测试时所有神经元都正常工作,但会按比例缩放输出,保证结果无偏。
5. 贝叶斯 Ridge 和 Lasso 回归
- 原理:从贝叶斯视角看,正则化等价于给参数添加先验分布。
- 贝叶斯 Ridge:假设参数服从高斯分布(对应 L2 正则化),认为参数值越小越合理。
- 贝叶斯 Lasso:假设参数服从拉普拉斯分布(对应 L1 正则化),更容易产生稀疏解。
- 效果:不仅能正则化,还能给出参数的不确定性估计(比如 “这个特征的影响有 95% 的概率在 0.1-0.3 之间”),适合需要概率输出的场景(如医疗诊断)。
6. 早停法(Early Stopping)
- 原理:训练时监控验证集误差,当误差不再下降时提前终止训练,避免模型在训练集上 “钻牛角尖”。
- 效果:
- 简单粗暴的 “止损” 策略,不需要修改模型结构,计算成本低。
- 尤其适合深度学习,比如训练神经网络时,防止过拟合的同时节省算力。
- 注意:需要预留验证集,且终止时机需要调参(比如连续 10 轮误差上升就停)。
7. 数据增强(Data Augmentation)
- 原理:通过人工扩展训练数据(如图像旋转、文本同义词替换),让模型接触更多 “新样本”,被迫学习更通用的特征。
- 效果:
- 从源头解决数据不足的问题,比如图像分类中,翻转、裁剪图片能让模型学会 “不变性”(猫不管怎么转都是猫)。
- 对小数据集效果显著,比如用 1 万张照片通过增强变成 10 万张,提升模型鲁棒性。
- 应用:CV(计算机视觉)、NLP(自然语言处理)领域的 “必选技能”,如 ResNet 用数据增强提升 ImageNet 准确率。
咱今天要探究的是这7各部分,大家请看:
-
L1 正则化
-
L2 正则化
-
弹性网络正则化
-
Dropout 正则化
-
贝叶斯Ridge和Lasso回归
-
早停法
-
数据增强
1、L1 正则化(Lasso 正则化)
L1 正则化(又称 Lasso 正则化)是机器学习中控制模型复杂度、防止过拟合的重要技术。它的核心思想是在模型原有的损失函数中加入一个惩罚项,通过约束模型参数的大小,迫使模型优先选择简单的参数组合,从而提升模型在新数据上的泛化能力。
核心原理与公式
L1 正则化通过向损失函数中添加L1 范数项(即模型参数的绝对值之和)来实现约束。以线性回归为例,其完整的损失函数表达式为:

-
各符号含义:
- (
:第 i 个样本的真实值;
:模型对第 i 个样本的预测值(
);
:第 j 个特征的权重(参数);
:正则化超参数,用于控制惩罚项的强度(
- m:特征数量。
- (
-
关键作用:
- 稀疏性诱导:L1 正则化项中的绝对值运算会使部分参数 \(w_j\) 被强制压缩至 0,从而实现特征选择—— 自动剔除无关或冗余的特征,仅保留对目标最具影响的特征。
- 模型简化:参数稀疏化意味着模型仅依赖少数关键特征,复杂度降低,过拟合风险随之减小。
优化特性与求解方法
-
非光滑性带来的挑战: 由于 L1 正则化项包含绝对值(如
),损失函数在
处不可导,传统的梯度下降法无法直接使用。因此,L1 正则化模型通常采用以下优化方法:
- 坐标下降法:逐维更新参数,每次固定其他维度,仅优化当前维度的参数,直至收敛。
- 近端梯度下降法:在梯度下降过程中引入近端算子,处理非光滑的正则化项。
-
稀疏性的几何解释: 在二维参数空间中(假设模型仅有两个特征
和
),L1 正则化项的约束形状为菱形。当损失函数的等高线与菱形边界相切时,切点往往出现在坐标轴上(即
或
),从而迫使其中一个参数为 0,实现稀疏性。
Python 实现与案例解析
以下通过 Python 代码演示 L1 正则化在简单线性回归中的应用,并结合可视化分析其效果。
代码步骤解析
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso# 1. 生成示例数据
np.random.seed(42) # 固定随机种子,确保结果可复现
X = np.linspace(-5, 5, num=100).reshape(-1, 1) # 生成100个一维特征数据
y = 2 * X + np.random.normal(0, 1, size=(100, 1)) # 真实模型为y=2X+噪声# 2. 创建Lasso模型并训练
lasso = Lasso(alpha=0.1) # alpha对应正则化强度λ,值越大,参数越易稀疏化
lasso.fit(X, y) # 拟合数据# 3. 可视化拟合结果与正则化效应
fig, ax = plt.subplots(figsize=(8, 5))# 绘制原始数据与拟合线
ax.scatter(X, y, color="blue", label="原始数据点")
ax.plot(X, lasso.predict(X), color="red", linewidth=2, label="L1正则化拟合线")# 绘制L1正则化项的等高线图(展示参数约束效果)
beta_0 = np.linspace(-10, 10, 100) # 假设截距β0的取值范围
beta_1 = np.linspace(-10, 10, 100) # 假设权重β1的取值范围
B0, B1 = np.meshgrid(beta_0, beta_1) # 生成网格点
Z = np.zeros_like(B0)# 计算每个网格点对应的L1正则化项值(|β0| + |β1|)
for i in range(len(beta_0)):for j in range(len(beta_1)):Z[i, j] = np.abs(B0[i, j]) + np.abs(B1[i, j]) # L1范数=绝对值之和# 绘制等高线(代表正则化项的大小,层级越多,惩罚越严格)
ax.contour(B0, B1, Z, levels=20, colors="black", alpha=0.5, linestyles='dashed')# 添加坐标轴标签与标题
ax.set_xlabel("截距 β0", fontsize=12)
ax.set_ylabel("权重 β1", fontsize=12)
ax.set_title("L1正则化的等高线约束与拟合效果", fontsize=14)
ax.legend()
plt.show()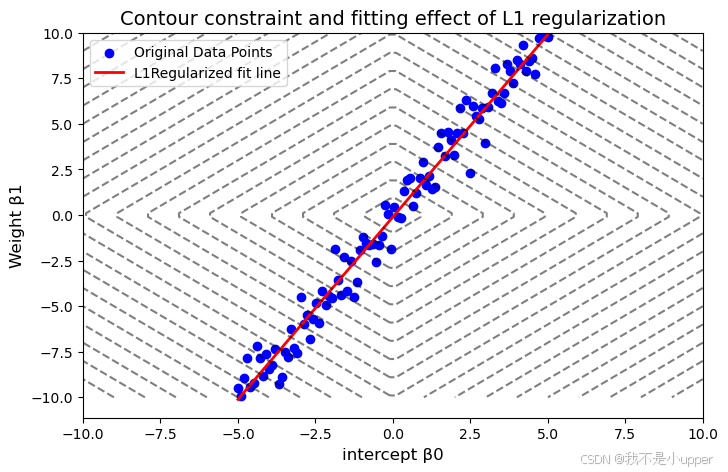
上述可视化结果解读
-
数据与拟合线: 蓝色散点为带噪声的原始数据,红色直线为 L1 正则化后的拟合结果。由于 L1 正则化的约束,模型参数被简化,拟合线不会过度贴近噪声点,体现出抗过拟合能力。
-
等高线图的意义:
- 黑色虚线为 L1 正则化项的等高线,每一条线上的点对应相同的正则化项值(如最内层菱形对应
,外层对应更大的值)。
- 损失函数的等高线(未显式绘制)与菱形等高线的切点即为最优参数解。从图中可见,切点可能位于坐标轴上(如 β0=0) 或 β1=0),直观展示了 L1 正则化如何通过几何约束迫使参数稀疏化。
- 黑色虚线为 L1 正则化项的等高线,每一条线上的点对应相同的正则化项值(如最内层菱形对应
适用场景与注意事项
-
适用场景:
- 特征数量远大于样本量(如基因表达数据、文本数据),需通过稀疏性筛选关键特征。
- 模型需要具备可解释性(仅保留少数非零参数,便于理解特征重要性)。
-
调参建议:
- 通过交叉验证(Cross-Validation)选择最优
- 若特征间存在强相关性,L1 正则化可能随机选择其中一个特征,此时可考虑弹性网络(Elastic Net)等结合 L1/L2 的正则化方法。
- 通过交叉验证(Cross-Validation)选择最优
通过 L1 正则化,模型在拟合能力与复杂度之间取得平衡,尤其在特征选择和模型解释性方面表现突出,是机器学习中处理高维数据的重要工具。
2、L2 正则化(岭正则化)
L2 正则化,也被称为岭正则化,是机器学习中控制模型复杂度、防止过拟合的重要技术。它的核心思想是通过向模型的损失函数中添加L2 范数项(即模型参数的平方和),迫使模型的权重参数尽可能缩小,从而让模型的预测结果更加平滑、泛化能力更强。
核心原理与公式
假设我们的基础损失函数是均方误差(MSE),用于衡量模型预测值与真实值的差异。引入 L2 正则化后,完整的损失函数表达式为:
- 第一部分:
是均方误差损失,衡量模型对训练数据的拟合程度(n为样本数,
- 第二部分:
是 L2 正则化项,由所有特征权重的平方和乘以正则化强度参数
关键作用:
- 通过惩罚较大的权重,L2 正则化迫使模型避免过度依赖任何单一特征,从而降低过拟合风险。
优化过程的两大特点
-
可导性与优化算法兼容性 由于正则化项包含平方运算(
),整个损失函数是连续可导的。这意味着我们可以使用常见的梯度下降、牛顿法等优化算法求解损失函数的最小值。以梯度下降为例,权重的更新公式为:
其中
是学习率,
是第i个样本的第j个特征值。可以看到,正则化项的梯度为
,会促使权重
-
权重收缩与模型平滑 L2 正则化不会让权重完全变为 0(这是与 L1 正则化的重要区别),但会将所有权重调整到较小的数值,使模型对输入特征的变化不敏感,从而产生更平滑的预测结果。例如,在多项式回归中,高次项的权重会被显著缩小,避免模型拟合训练数据中的噪声。
案例:用 Python 实现 L2 正则化
下面通过一个简单的线性回归案例,演示 L2 正则化的效果,并通过等高线图直观展示正则化项对权重的约束。
代码解析:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge# 生成示例数据(线性关系+随机噪声)
np.random.seed(42) # 固定随机种子,确保结果可复现
X = np.linspace(-5, 5, num=100).reshape(-1, 1) # 生成100个样本,特征X为一维数据
y = 2 * X + np.random.normal(0, 1, size=(100, 1)) # 真实模型为y=2X+噪声# 创建Ridge模型(L2正则化)
ridge = Ridge(alpha=0.1) # alpha对应公式中的λ,控制正则化强度
ridge.fit(X, y) # 拟合数据# 绘制数据点与拟合线
fig, ax = plt.subplots()
ax.scatter(X, y, color="blue", label="Data") # 原始数据点
ax.plot(X, ridge.predict(X), color="red", linewidth=2, label="L2 Regularization") # 拟合曲线
ax.set_xlabel("X")
ax.set_ylabel("y")
ax.set_title("L2正则化拟合结果")
ax.legend()# 绘制L2正则化项的等高线图(展示权重空间的惩罚效果)
beta_0 = np.linspace(-10, 10, 100) # 假设截距β0的取值范围
beta_1 = np.linspace(-10, 10, 100) # 权重β1的取值范围
B0, B1 = np.meshgrid(beta_0, beta_1) # 生成网格点
Z = np.zeros_like(B0)# 计算每个网格点对应的L2正则化项值(β0² + β1²)
for i in range(len(beta_0)):for j in range(len(beta_1)):Z[i, j] = beta_0[i]**2 + beta_1[j]**2 # 假设截距β0也参与正则化(实际Ridge默认对权重β1正则化)# 绘制等高线(越内层的等高线,正则化项值越小,权重越接近0)
ax.contour(B0, B1, Z, levels=20, colors="black", alpha=0.5)
ax.set_title("L2正则化项等高线图")
plt.show()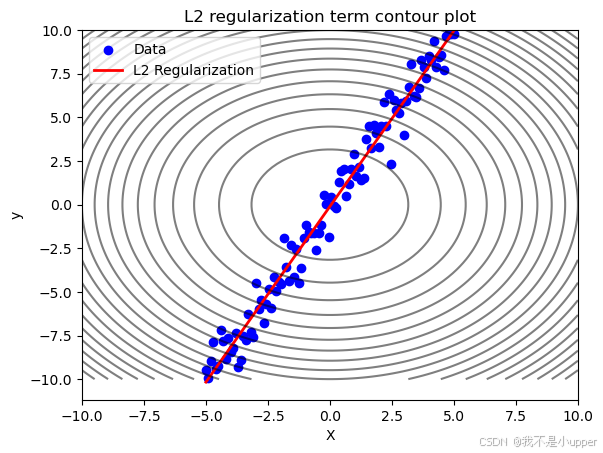
结果解读:
- 拟合曲线:红色曲线是经过 L2 正则化的线性模型,较好地捕捉了数据的整体趋势(接近真实模型
),避免了过拟合噪声。
- 等高线图:黑色等高线表示正则化项
的值,中心(权重接近 0)的值最小。模型在优化时,需要同时最小化原始损失和正则化项,因此权重会被 “拉向” 等高线的中心区域,即趋向较小的值。
L2 正则化通过惩罚权重的平方和,迫使模型参数保持较小值,从而降低复杂度、提升泛化能力。它适用于大多数线性模型(如线性回归、逻辑回归)和神经网络,是机器学习中最常用的正则化方法之一。实际应用中,可通过交叉验证调整的取值,平衡模型的偏差与方差。
3、弹性网络正则化(Elastic Net 正则化)
弹性网络正则化是一种专门为线性回归模型设计的正则化方法,它巧妙地融合了 L1 正则化和 L2 正则化的核心优势,就像是把两种 “武器” 的特点合二为一,让模型在处理复杂数据时更加灵活高效。
核心思想与应用场景
在实际数据中,经常会遇到两种棘手的问题:
- 特征数量庞大:比如基因测序数据可能包含上万个特征,但其中很多特征与目标无关,需要筛选出真正重要的特征(类似 L1 正则化的 “特征选择” 能力)。
- 特征间多重共线性:例如房价预测中,“房屋面积” 和 “房间数量” 可能高度相关,此时 L1 正则化可能会随机剔除其中一个特征,而保留另一个,但实际上两者可能都对房价有影响(L2 正则化更擅长处理这种相关性)。
弹性网络正则化正是为解决这类问题而生。它通过同时引入 L1 范数(绝对值之和)和 L2 范数(平方和)作为正则化项,既能像 L1 一样筛选特征(让部分系数变为 0),又能像 L2 一样保持系数的平滑性(避免极端值),尤其适合处理高维数据和特征间存在强相关性的场景。
损失函数与公式解析
弹性网络正则化的损失函数公式为:\(\text{Loss} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 + \alpha \left( \rho \sum_{j=1}^{m} |w_j| + (1-\rho) \sum_{j=1}^{m} w_j^2 \right)\)
- 各部分含义:
- 第一部分是均方误差(MSE),衡量模型预测值 \(\hat{y}_i\) 与真实值 \(y_i\) 的差异。
- 第二部分是正则化项,由两部分组成:
- \(\rho \sum|w_j|\):L1 范数项(\(\rho\) 是 L1 范数的比例参数)。
- \((1-\rho) \sum w_j^2\):L2 范数项。
- \(\alpha\):正则化强度参数,控制对模型复杂度的惩罚力度(\(\alpha\) 越大,模型越简单)。
- 参数关系:
- 当 \(\rho = 0\) 时,正则化项只剩 L2 范数,模型退化为岭回归(Ridge Regression)。
- 当 \(\rho = 1\) 时,正则化项只剩 L1 范数,模型退化为Lasso 回归。
- 当 \(0 < \rho < 1\) 时,模型同时具备 L1 和 L2 正则化的特性,比如:
- 特征选择:部分特征的系数会被压缩至 0(类似 L1)。
- 处理共线性:对高度相关的特征,系数会被均匀压缩(类似 L2),避免随机剔除重要特征。
Python 实现与案例解析
下面通过一个简单的回归案例,演示弹性网络正则化的应用过程:
代码步骤解析
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import ElasticNet# 1. 生成带噪声的线性数据
np.random.seed(42) # 固定随机种子,确保结果可复现
n_samples = 100 # 样本数量
X = np.linspace(-3, 3, n_samples) # 特征X:在-3到3之间均匀生成100个点
y = 0.5 * X + np.random.normal(scale=0.5, size=n_samples) # 真实模型:y=0.5X + 噪声# 2. 创建并训练弹性网络模型
enet = ElasticNet(alpha=0.5, l1_ratio=0.7) # alpha=正则化强度,l1_ratio=ρ参数(L1占比70%)
enet.fit(X.reshape(-1, 1), y) # 输入需为二维数组,reshape(-1,1)将X转为100×1的矩阵# 3. 绘制结果
plt.scatter(X, y, color='b', label='Original data') # 原始数据点
plt.plot(X, enet.predict(X.reshape(-1, 1)), color='r', linewidth=2, label='Elastic Net') # 模型拟合曲线
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.title('Elastic Net Regression')
plt.show()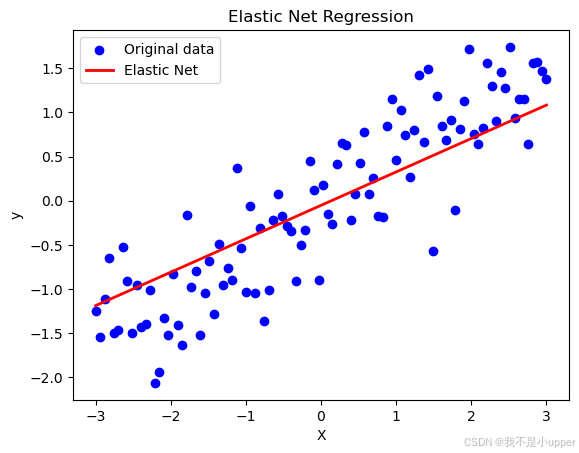
关键参数说明
- alpha=0.5:正则化强度适中,若 alpha 过大,模型可能过于平滑(欠拟合);若过小,正则化效果不明显。
- l1_ratio=0.7:L1 范数占正则化项的 70%,L2 范数占 30%,此时模型会尝试将部分特征系数置零,同时保留共线性特征的影响。
结果解读
- 图中蓝色散点是带噪声的原始数据,红色曲线是弹性网络模型的拟合结果。
- 尽管数据中存在噪声,但模型通过正则化抑制了过拟合,较好地捕捉了 X 和 y 之间的线性关系(接近真实模型 y=0.5X)。
实际应用建议
- 参数调优:
- 通过交叉验证(如 GridSearchCV)同时调整
alpha和l1_ratio,找到最优组合。 - 若数据特征间存在共线性,优先尝试
l1_ratio在 0.3-0.7 之间的值。
- 通过交叉验证(如 GridSearchCV)同时调整
- 特征预处理:
- 对数据进行标准化(如使用 StandardScaler),确保不同量纲的特征在正则化中被公平对待。
- 适用场景:
- 医学数据分析(特征多且可能存在共线性,如基因表达数据)。
- 金融建模(如股票收益率预测,特征间常高度相关)。
弹性网络正则化通过结合 L1 和 L2 的优势,在特征选择和处理共线性之间找到了平衡,是线性回归中应对复杂数据的有效工具。
4、Dropout 正则化(用于神经网络)
Dropout 正则化是神经网络中一种简单有效的防过拟合技术,特别适用于隐藏层较多的复杂模型。它的核心思路是在训练过程中,通过随机 “丢弃” 部分神经元的输出,打破神经元之间的固定依赖关系,迫使模型学习更鲁棒、更通用的特征表达。
原理与数学表达
在神经网络的训练阶段,Dropout 的具体操作如下:
-
随机丢弃神经元:对于每一层神经元,按照预设的概率 p(称为丢弃率)随机决定是否保留该神经元的输出。
- 引入二进制随机变量
(取值为 0 或 1),若
,则第 j 个神经元的输出被置为 0(即 “丢弃”);若
,则保留输出。
- 每个神经元的丢弃是独立随机的,例如当 p = 0.5 时,每层约有一半的神经元会被随机丢弃。
- 引入二进制随机变量
-
前向传播与反向传播:
- 被丢弃的神经元在本次迭代中不参与前向传播,其连接权重也不参与反向传播的梯度更新。
- 这相当于在每次训练时,模型的结构都是一个 “精简版” 的子网络,不同迭代中丢弃的神经元不同,从而形成多个子网络的集成效果。
-
损失函数与训练目标: 在带有 Dropout 的神经网络中,损失函数仍基于原始任务目标(如回归的均方误差、分类的交叉熵),但模型参数
的优化需考虑随机丢弃的影响。损失函数形式为:
其中:
- m 是训练样本数量,
是第 i 个输入样本,
是具体的损失函数(如均方误差
或交叉熵)。
- m 是训练样本数量,
-
测试阶段的补偿机制: 在测试或推理时,为保持训练与测试阶段的输出期望一致,需要将所有神经元的输出乘以训练阶段的保留概率 1 - p。例如,若训练时丢弃率为 p = 0.5,则测试时每个神经元的输出需乘以 0.5。这一步通常由框架自动实现(如 TensorFlow 会在模型导出时自动处理)。
代码实现与详细过程
以下通过一个简单的回归任务,演示如何在 TensorFlow 中使用 Dropout 正则化:
1. 生成带噪声的样本数据
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf# 生成一些样本数据
np.random.seed(42)
n_samples = 100
X = np.linspace(-3, 3, n_samples)
y = 0.5 * X + np.random.normal(scale=0.5, size=n_samples)- 数据分布:输入 X 是区间 [-3, 3] 内的均匀分布,输出 y 是线性函数 y = 0.5X 叠加标准差为 0.5 的噪声,模拟真实场景中的不完美数据。
2. 构建含 Dropout 的神经网络模型
model = tf.keras.models.Sequential([tf.keras.layers.Dense(16, activation='relu', input_shape=(1,)), # 第1层:16个神经元,ReLU激活tf.keras.layers.Dropout(0.5), # Dropout层:丢弃率50%tf.keras.layers.Dense(1) # 输出层:1个神经元(回归任务)
])- 网络结构:
- 输入层:接收形状为
的单特征数据。
- 隐藏层:16 个神经元,使用 ReLU 激活函数引入非线性。
- Dropout 层:在隐藏层之后,以 50% 的概率随机丢弃神经元输出,防止隐藏层过度依赖某些特定神经元。
- 输出层:单神经元,直接输出连续值(适用于回归任务)。
- 输入层:接收形状为
3. 编译与训练模型
model.compile(optimizer='adam', loss='mean_squared_error') # 使用均方误差损失和Adam优化器
model.fit(X, y, epochs=50, batch_size=16, verbose=0) # 训练50轮,批量大小16- 优化目标:最小化预测值与真实值的均方误差(MSE)。
- Dropout 的作用:在每轮训练中,隐藏层的 16 个神经元会随机保留 8 个(丢弃率 50%),迫使模型学习更鲁棒的特征组合,避免过拟合噪声。
4. 可视化结果
import matplotlib.pyplot as plt
plt.scatter(X, y, color='b', label='Original data') # 绘制原始数据点
plt.plot(X, model.predict(X), color='r', linewidth=2, label='Dropout Regularization') # 绘制拟合曲线
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.title('Neural Network with Dropout Regularization')
plt.show()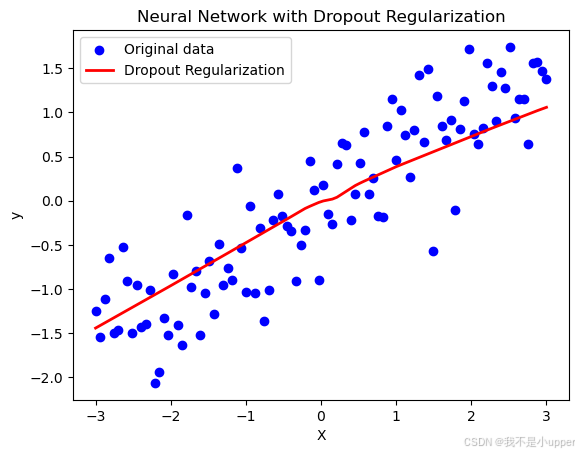
- 结果解读:
- 蓝色散点为带噪声的原始数据,红色曲线为模型预测值。
- 由于 Dropout 的正则化作用,模型未过度拟合噪声,而是学习到了数据的整体线性趋势(接近真实函数 y = 0.5X),体现了泛化能力的提升。
关键要点总结
- 丢弃率 p 的选择:通常在
之间,过大可能导致模型欠拟合(神经元丢弃过多,信息丢失严重),过小则正则化效果不足。
- 适用场景:Dropout 对全连接层效果显著,在卷积神经网络(CNN)或 Transformer 中也常作为标配组件,但需结合层特性调整丢弃率(如 CNN 中丢弃率可更低,因卷积层本身具有稀疏性)。
- 与其他正则化的结合:可与 L2 正则化、早停法等结合使用,进一步提升模型性能。
通过 Dropout,神经网络在训练中通过 “随机瘦身” 强制学习更通用的特征,有效缓解了过拟合问题,是深度学习中简单且高效的正则化手段。
5、贝叶斯 Ridge 和 Lasso 回归
贝叶斯 Ridge 回归与贝叶斯 Lasso 回归是基于贝叶斯统计理论的回归模型,它们在经典线性回归的基础上引入概率视角,不仅能拟合数据,还能通过参数的概率分布刻画模型的不确定性。以下从原理、公式、特点及代码实现展开说明。
贝叶斯 Ridge 回归
核心思想: 贝叶斯 Ridge 回归通过在损失函数中加入L2 正则化项(即权重向量的平方和)控制模型复杂度,同时将模型权重参数视为随机变量,利用贝叶斯推断估计参数的概率分布,而非单一确定值。这种方法不仅能缓解过拟合,还能给出预测结果的置信区间,体现模型对预测的 “不确定性判断”。
目标函数:
- n:样本数量;
:第i个样本的特征向量;
:模型权重向量;
:L2 范数的平方(权重平方和);
贝叶斯推断过程:
- 先验分布:假设权重
,其中
是先验方差,体现对 “权重应较小” 的先验知识。
- 似然函数:在给定
为均值的高斯分布,即:
,其中
是噪声方差。
- 后验分布:根据贝叶斯定理,结合先验和似然得到权重的后验分布
,其中
是权重的点估计,
是协方差矩阵,描述参数的不确定性。
- 预测分布:对新样本
,预测值
的分布为:
,包含数据噪声和参数不确定性。
特点:
- 优点:能处理不同类型数据和噪声,通过后验分布提供预测的置信区间,适合需要不确定性评估的场景(如医疗诊断、金融风险分析)。
- 缺点:需进行概率推断(如马尔可夫链蒙特卡罗采样),计算复杂度高于传统 Ridge 回归。
贝叶斯 Lasso 回归
核心思想: 与贝叶斯 Ridge 回归类似,但将正则化项改为L1 范数(权重绝对值之和),对应权重参数的先验分布为拉普拉斯分布。L1 范数的特性使模型倾向于将部分权重置零,从而实现特征选择,即自动识别对预测无关的特征并剔除。
目标函数:
:L1 范数(权重绝对值之和);
- 其他符号含义与贝叶斯 Ridge 回归一致。
贝叶斯推断过程:
- 先验分布:权重
,该分布在零点附近概率密度较高,促使权重向零收缩,甚至精确为零。
- 后验分布:通过贝叶斯定理结合拉普拉斯先验和高斯似然,后验分布倾向于产生稀疏解(大量权重为零),从而筛选出关键特征。
特点:
- 优点:自动进行特征选择,适合高维数据(如基因表达数据、文本数据),模型解释性更强(仅保留非零权重的特征)。
- 缺点:计算复杂度高,需高效算法(如变分贝叶斯推断)求解后验分布。
Python 代码实现(贝叶斯 Ridge 回归)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import BayesianRidge# 生成示例数据集(一维线性关系+噪声)
np.random.seed(42) # 固定随机种子确保可复现
X = np.random.rand(100, 1) * 10 # 生成100个0-10之间的随机特征值
y = 2 * X[:, 0] + np.random.randn(100) # 真实模型为y=2x+噪声(噪声服从标准正态分布)# 创建贝叶斯Ridge回归模型对象
model = BayesianRidge() # 采用默认超参数,自动估计正则化参数和噪声方差# 拟合模型(基于训练数据学习权重参数)
model.fit(X, y)# 生成用于预测的新样本点(0到10之间均匀分布的100个点)
x_new = np.linspace(0, 10, 100).reshape(-1, 1)# 预测新样本点的输出值及标准差(return_std=True返回预测标准差)
y_pred, y_std = model.predict(x_new, return_std=True)# 绘制原始数据、拟合曲线及置信区间
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(X, y, color='blue', label='原始数据', alpha=0.6) # 绘制散点图展示原始数据分布
ax.plot(x_new, y_pred, color='red', label='拟合曲线', linewidth=2) # 绘制模型拟合的线性曲线
ax.fill_between(x_new.flatten(), # x轴坐标(展平为一维数组)y_pred - y_std, # 置信区间下界(预测值减去标准差)y_pred + y_std, # 置信区间上界(预测值加上标准差)color='pink', alpha=0.3, label='95%置信区间'
) # 填充区域表示预测的不确定性范围ax.set_xlabel('特征X', fontsize=12)
ax.set_ylabel('目标y', fontsize=12)
ax.set_title('贝叶斯Ridge回归拟合效果', fontsize=14)
ax.legend()
plt.show()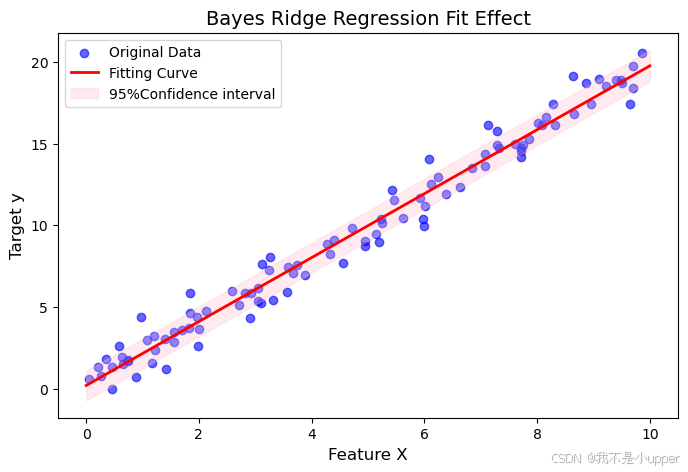
代码解析:
- 数据生成:通过
np.random.rand生成特征X,真实模型为(
为高斯噪声),模拟线性回归场景。
- 模型初始化:
BayesianRidge默认使用经验贝叶斯方法(Empirical Bayes)自动估计超参数(如正则化强度、噪声方差),无需手动调参。 - 拟合与预测:
model.fit学习权重参数,model.predict返回预测均值()和标准差(
),后者反映预测的不确定性(标准差越小,预测越可靠)。
- 结果可视化:
- 蓝色散点为原始数据,红色曲线为模型拟合的均值预测。
- 粉色阴影区域为预测值的置信区间(均值 ± 标准差),体现模型对不同x值的预测不确定性(如数据稀疏区域的置信区间更宽)。
6、早停法(Early Stopping)
早停法是一种直观且有效的防止模型过拟合的正则化技术,核心思想是在模型训练过程中实时监控其在验证集上的表现,避免模型对训练数据过度拟合。它不需要修改损失函数或模型结构,而是通过控制训练的终止时机来平衡模型的偏差与方差。
早停法的核心步骤
- 数据划分:将原始数据集划分为训练集和验证集。训练集用于模型参数更新,验证集用于评估模型在未见过数据上的泛化能力。
- 初始化模型:设定模型的初始参数(如神经网络的权重)。
- 迭代训练与监控:
- 在每一轮训练迭代中,使用训练集更新模型参数,并计算训练误差(衡量模型对训练数据的拟合程度)。
- 每轮迭代后,立即用验证集计算验证误差(衡量模型的泛化能力)。
- 终止条件判断:当验证误差连续多轮不再下降(或开始上升)时,停止训练,并保留此时的模型参数作为最终结果。
关键公式与原理
早停法的核心是通过监控验证误差来找到模型的最佳训练平衡点。假设损失函数为均方误差(MSE),则:
- 训练误差:
其中,
为训练样本数,
为模型在训练集上的预测值。
- 验证误差:
其中,
为验证样本数,
为模型在验证集上的预测值。
目标:在训练过程中,当验证误差从下降转为上升时(即出现过拟合迹象),及时终止训练,选择验证误差最小的模型参数。
Python 实现与代码解析
以下是一个基于线性回归的早停法示例,通过逐步增加训练样本量模拟迭代过程,并直观展示误差变化:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression# 生成示例数据(线性关系+随机噪声)
np.random.seed(42) # 固定随机种子确保可复现
X = np.linspace(-5, 5, num=100).reshape(-1, 1) # 特征数据(100个样本,单维度)
y = 2 * X + np.random.normal(0, 1, size=(100, 1)) # 真实标签:y=2X+噪声# 划分训练集(80样本)和验证集(20样本)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42
)# 初始化线性回归模型
model = LinearRegression()# 存储每轮迭代的训练误差和验证误差
train_errors = []
val_errors = []# 模拟迭代训练:逐步增加训练样本量(从1到80样本)
for i in range(1, len(X_train) + 1):# 使用前i个样本训练模型model.fit(X_train[:i], y_train[:i])# 计算训练误差:仅用已训练的i个样本预测y_train_pred = model.predict(X_train[:i])train_error = np.mean((y_train_pred - y_train[:i]) ** 2)train_errors.append(train_error)# 计算验证误差:用整个验证集预测y_val_pred = model.predict(X_val)val_error = np.mean((y_val_pred - y_val) ** 2)val_errors.append(val_error)# 绘制误差曲线
fig, ax = plt.subplots(figsize=(8, 4))
ax.plot(train_errors, label="训练误差", linestyle="-", color="blue")
ax.plot(val_errors, label="验证误差", linestyle="-", color="orange")
# 找到验证误差最小的位置(早停点)
best_epoch = np.argmin(val_errors)
ax.axvline(x=best_epoch, linestyle="--", color="red", label=f"早停点(第{best_epoch+1}轮)"
) # +1是因为索引从0开始
ax.set_xlabel("训练轮数(样本量递增)")
ax.set_ylabel("均方误差(MSE)")
ax.set_title("早停法效果可视化")
ax.legend()
plt.grid(True)
plt.show()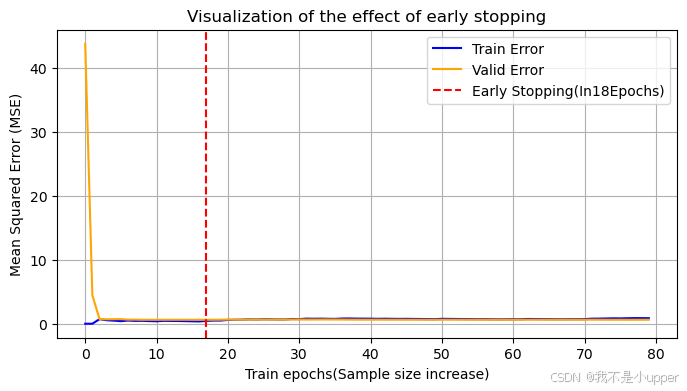
代码详解与可视化分析
- 数据生成:创建一维特征X和线性标签y=2X+噪声,模拟真实场景中的数据分布。
- 数据划分:将数据按 8:2 划分为训练集和验证集,验证集用于监控泛化能力。
- 迭代训练:
- 从 1 个样本开始,逐步增加到 80 个样本(每轮多训练 1 个样本),模拟模型从简单到复杂的过程。
- 每轮训练后,同时计算训练误差(仅用已训练的样本评估)和验证误差(用独立验证集评估)。
- 可视化结果:
- 训练误差:随训练样本增加持续下降(模型对训练数据拟合越来越好)。
- 验证误差:先下降后上升(当模型开始过拟合时,验证误差回升)。
- 早停点:验证误差最小的位置(图中红色虚线),此时模型在泛化能力和拟合能力间达到平衡。
早停法的优缺点
- 优点:
- 无需修改模型结构或超参数,实现简单。
- 计算成本低,尤其适合深度学习中避免过度训练。
- 缺点:
- 需预留验证集,可能减少训练数据量。
- 终止时机依赖经验(如连续多少轮误差上升才停),需调参。
早停法通过 “监控 - 止损” 的逻辑,为模型训练提供了一种动态平衡的解决方案,是实际应用中防止过拟合的常用技术之一。
7、数据增强
数据增强是一种通过扩充和变换训练数据来提升模型泛化能力的正则化技术。其核心逻辑是:当模型见过的数据越多、越多样,就越不容易被训练集中的特定噪声或局部模式 “带偏”,从而在新数据上表现得更稳健。
数据增强的核心步骤
-
随机变换操作:
对原始训练数据应用各类随机变换,常见的包括:- 几何变换:旋转(如将图像顺时针旋转 30 度)、平移(将图像向左移动 10 像素)、缩放(将图像放大 1.2 倍)、裁剪(随机截取图像的一部分)等。
- 像素变换:调整亮度(调暗 20%)、对比度(增强对比度)、添加高斯噪声(模拟图像模糊)等。
- 空间变换:在自然语言处理中,可随机替换同义词(如将 “高兴” 换成 “开心”)、打乱句子顺序等。
-
扩充数据集:
将变换后的样本与原始数据合并,形成更大的训练集。例如,原始数据有 1000 张图片,经过 5 种变换后,可扩充为 6000 张图片(原始 + 5 倍变换数据)。 -
模型训练:
使用增强后的数据集训练模型,让模型在学习过程中接触更多样化的输入模式,从而提升对不同场景的适应能力。
数据增强的目标
通过增加数据的多样性,迫使模型学习更本质的特征,而非记忆训练集中的表面规律。例如:
- 在图像分类中,对猫的图像进行旋转、缩放等变换后,模型需要学会 “无论猫怎么摆姿势都是猫”,而不是记住某个特定角度的猫。
- 在语音识别中,对音频添加背景噪声,模型需学会从嘈杂环境中提取关键语音特征。
代码示例解析
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.linear_model import LogisticRegression# 生成示例数据集(月亮形状的二分类数据)
np.random.seed(42) # 固定随机种子确保结果可复现
X, y = make_moons(n_samples=200, noise=0.1) # 生成200个带噪声的样本# 创建逻辑回归模型
model = LogisticRegression()# 绘制原始数据分布(两类样本呈月牙状分布)
fig, ax = plt.subplots()
ax.scatter(X[:, 0], X[:, 1], c=y, cmap="bwr", edgecolors='k')
ax.set_xlabel("X1")
ax.set_ylabel("X2")
ax.set_title("Original Data Distribution")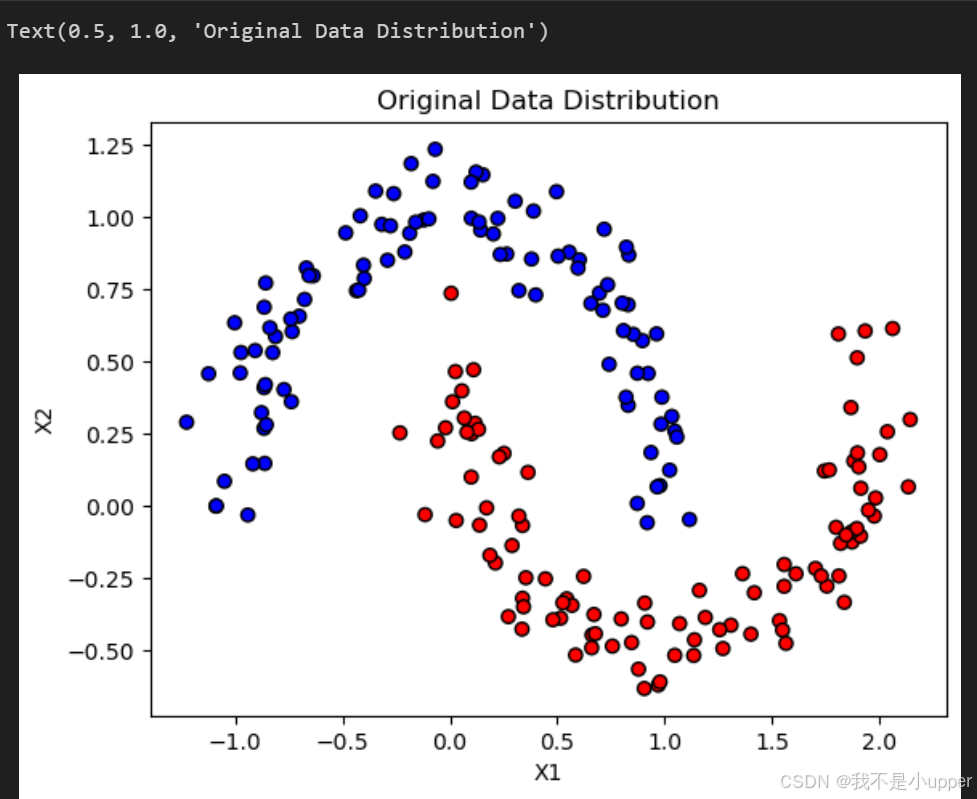
数据增强过程:
n_transforms = 50 # 生成50倍增强数据
augmented_X = []
augmented_y = []
for i in range(n_transforms):# 对原始数据添加随机高斯扰动(噪声均值0,标准差0.05)transformed_X = X + np.random.normal(0, 0.05, size=X.shape)augmented_X.append(transformed_X)augmented_y.append(y) # 标签与原始数据一致# 合并原始数据与增强数据
augmented_X = np.concatenate(augmented_X, axis=0) # 纵向拼接,shape从(200,2)变为(200*50,2)
augmented_y = np.concatenate(augmented_y, axis=0)可视化增强后的数据:
fig, ax = plt.subplots()
ax.scatter(augmented_X[:, 0], augmented_X[:, 1], c=augmented_y, cmap="bwr", edgecolors='k')
ax.set_xlabel("X1")
ax.set_ylabel("X2")
ax.set_title("Data Distribution after Augmentation")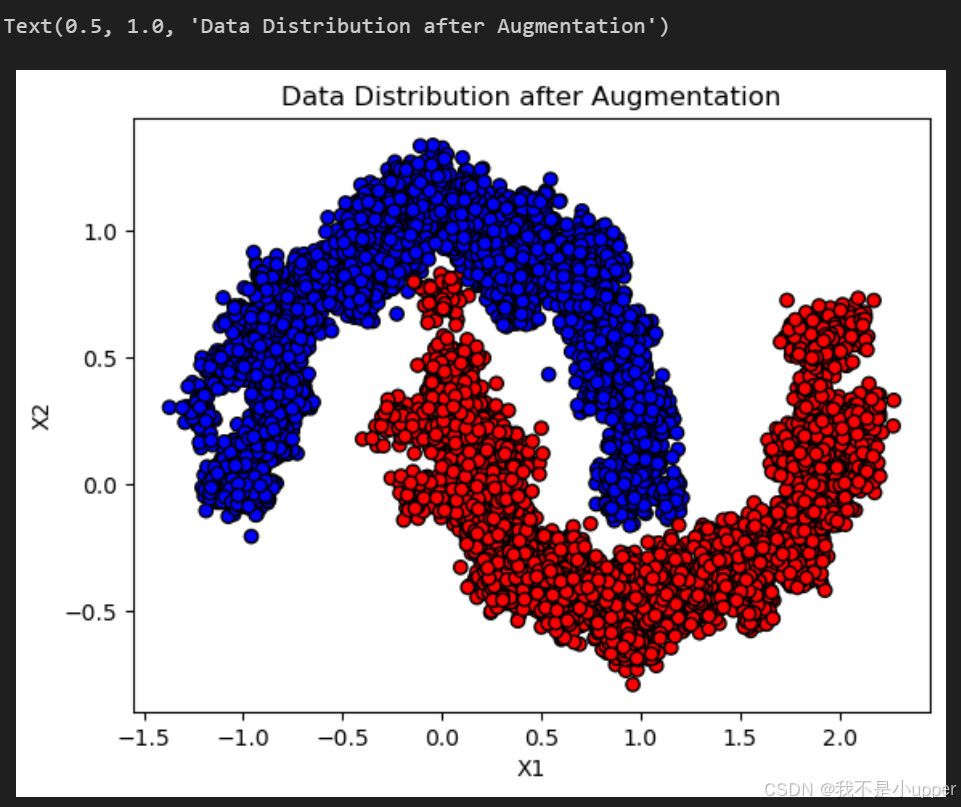
- 变化:原始数据集中的每个样本(如某个月牙点)周围生成了许多 “近邻点”(通过高斯噪声扰动),数据集的密度显著增加,覆盖了更广泛的空间区域。
模型训练与决策边界绘制:
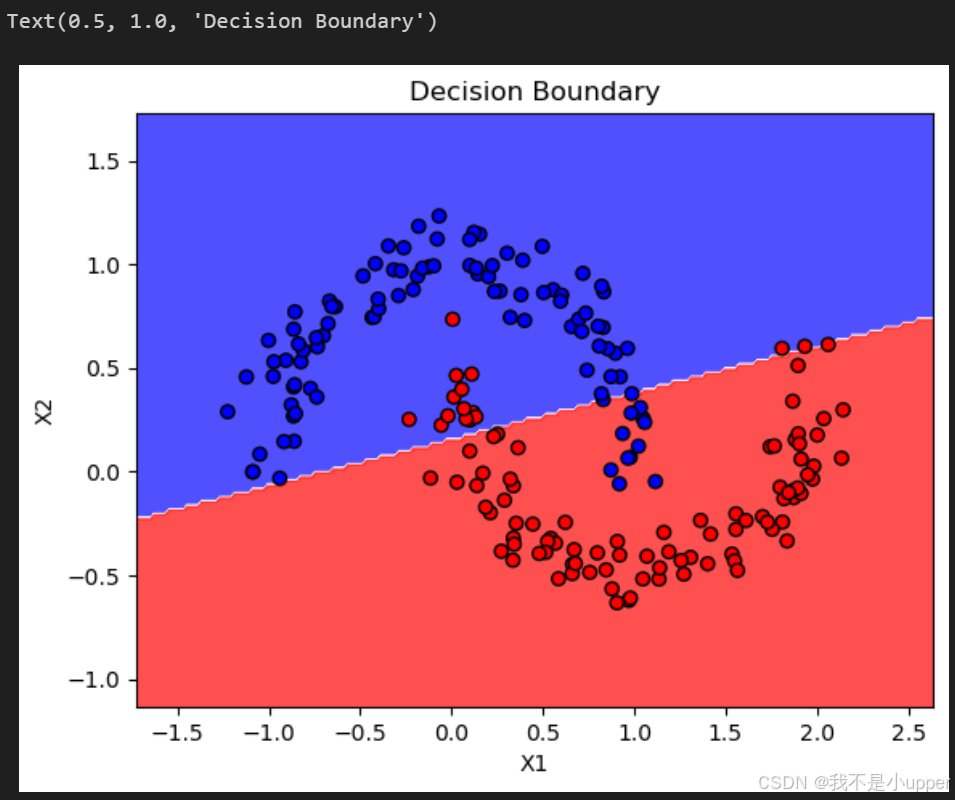
- 结果分析:
- 增强前:模型可能因训练数据有限,决策边界过度拟合原始月牙的局部形状。
- 增强后:数据点分布更密集,模型学到的决策边界更平滑,能更好地泛化到未见过的新样本(如原始数据点周围的区域)。
关键要点
-
无显式公式但有统计规律:
数据增强没有统一的数学公式,但其本质是对数据分布进行平滑扩展—— 通过随机变换生成符合原始数据分布规律的新样本(如高斯扰动保持数据的局部相关性)。 -
任务特异性:
- 图像领域:常用旋转、裁剪、颜色抖动等变换。
- 文本领域:常用同义词替换、句子截断、段落打乱等。
- 时序数据(如股票价格):常用时间平移、幅度缩放等。
-
平衡多样性与真实性:
变换需合理(如不能将猫的图像旋转 180 度后标签仍标为 “猫”),确保增强数据与原始数据属于同一分布,避免引入误导性样本。
通过数据增强,模型能在不增加真实数据采集成本的前提下,“虚拟” 扩充数据集,是应对小数据过拟合问题的核心技术之一。
最后
今天介绍了7个机器学习中正则化算法的总结,以及不同情况使用的情况。
喜欢的朋友可以收藏、点赞、转发起来!
相关文章:

7 个正则化算法完整总结
哈喽!我是我不是小upper~之前和大家聊过各类算法的优缺点,还有回归算法的总结,今天咱们来深入聊聊正则化算法!这可是解决机器学习里 “过拟合” 难题的关键技术 —— 想象一下,模型就像个死记硬背的学生&am…...
)
lesson03-简单回归案例(理论+代码)
一、梯度下降 二、 线性方程怎么样? 三、有噪音吗? 四、让我们看一个列子 五、如何优化 启发式搜索 学习进度 六、线性回归、逻辑回归、分类 总结、 简单线性回归是一种统计方法,用于确定两个变量之间的关系。具体来说,它试图…...

Linux系统篇——文件描述符FD
🧠 Linux 文件描述符(File Descriptor)详解与学习指南 一、什么是文件描述符(fd) 在 Linux 中,一切皆文件(everything is a file),包括普通文件、目录、套接字ÿ…...
安装与问题解决指南)
C++ Kafka客户端(cppkafka)安装与问题解决指南
一、cppkafka简介 cppkafka是一个现代C的Apache Kafka客户端库,它是对librdkafka的高级封装,旨在简化使用librdkafka的过程,同时保持最小的性能开销。 #mermaid-svg-qDUFSYLBf8cKkvdw {font-family:"trebuchet ms",verdana,arial,…...

MySQL的缓存策略
一、MySQL缓存方案用来解决什么 缓存用户定义的热点数据,用户直接从缓存获取热点数据,降低数据库的读写压力场景分析: 内存访问速度是磁盘访问速度 10 万倍(数量级)读的需求远远大于写的需求mysql 自身缓冲层跟业务无…...

ubuntu22.04卸载vscode
方法 1:通过 Snap 卸载 VSCode 如果你是通过 Snap 安装的 VSCode(Ubuntu 22.04 默认推荐方式),按照以下步骤卸载: 检查是否通过 Snap 安装: bash snap list | grep code如果输出显示 code,说明…...

主流数据库排查与优化速查手册
主流数据库排查与优化速查手册(优化版) 一、连接失败 1.1 统一排查流程 #mermaid-svg-IIyarbd8VatJFN14 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-IIyarbd8VatJFN14 .error-icon{fill:…...

MySQL 数据库优化:InnoDB 存储引擎深度解析:架构、调优与最佳实践
InnoDB 是 MySQL 的默认存储引擎,因其支持事务、行级锁和崩溃恢复等特性,广泛应用于高并发、数据一致性要求高的场景。本文将从 InnoDB 的核心架构、调优策略、监控诊断、高级特性 到 备份恢复 进行系统性分析,并结合代码示例与实战案例,帮助开发者全面掌握其应用与优化技巧…...
[AI算法] LLM训练-构建transformers custom model
文章目录 1. 继承与实现基础结构2. 支持 DeepSpeed 和 Accelerate 的注意事项a. 模型输出格式b. 设备管理c. 分布式训练兼容性d. DeepSpeed 特定优化 3. 训练脚本集成建议4. 测试与调试建议 在使用 Hugging Face 的 transformers 库时,若要自定义一个继承自 PreTrai…...

突发,苹果发布下一代 CarPlay Ultra
汽车的平均换代周期一般都超过5年,对于老旧燃油车而言,苹果的 Carplay 是黑暗中的明灯,是延续使用寿命的利器。 因为你可能不需要冰箱彩电大沙发,但一定需要大屏车载导航、倒车影像、车载听歌。如果原车不具备这个功能࿰…...

git克隆github项目到本地的三种方式
本文旨在使用git工具将别人发布在github上的项目保存到本地 1.安装git,创建github账户,并使用ssh关联自己的github账号和git,具体教程可以参照下面两篇文章: Github入门教程,适合新手学习(非常详细&#…...

Excel MCP: 自动读取、提炼、分析Excel数据并生成可视化图表和分析报告
最近,一款Excel MCP Server的开源工具火了,看起来功能很强大,咱们今天来一探究竟。 基础环境 最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个&…...

香港 GPU 服务器优势及使用场景解析
在快速发展的科技领域,数据处理和复杂计算已成为众多行业的支柱,GPU 服务器的重要性不容小觑。GPU 服务器是内部集成一个或多个 GPU的物理服务器,用于执行每个用例所需的任务。而香港 GPU 服务器,是指部署在中国香港数据中心、配备…...

Go语言交替打印问题及多种实现方法
Go语言交替打印问题及多种实现方法 在并发编程中,多个线程(或 goroutine)交替执行任务是一个经典问题。本文将以 Go 语言为例,介绍如何实现多个 goroutine 交替打印数字的功能,并展示几种不同的实现方法。 Go 语言相关…...

Grafana分布统计:Heatmap面板
Heatmap是是Grafana v4.3版本以后新添加的可视化面板,通过热图可以直观的查看样本的分布情况。在Grafana v5.1版本中Heatmap完善了对Prometheus的支持。这部分,将介绍如何使用HeatmapPanel实现对Prometheus监控指标的可视化。 使用Heatmap可视化Histogr…...

rk3576 gstreamer opencv
安装gstreamer rk3588使用gstreamer推流_rk3588 gstreamer-CSDN博客 rk3588使用gstreamer推流_rk3588 gstreamer-CSDN博客 Installing on Linux sudo apt-get install libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgstreamer-plugins-bad1.0-dev gstreamer1.0-pl…...

用户现场不支持路由映射,如何快速将安防监控EasyCVR视频汇聚平台映射到公网?
一、方案背景 随着数字化安防与智能交通管理发展,视频监控远程管理需求激增。EasyCVR作为专业视频融合平台,具备多协议接入等核心功能,是智能监控的重要工具。但实际部署中,当EasyCVR处于内网且路由器无法进行端口映射时&#…...

棋牌室台球室快速接入美团团购接口
北极星平台从2024年12月份开始慢慢关闭,现在很多开发者反馈北极星token已经不能刷新了,全部迁移到美团团购综合平台。 申请这个平台要求很高 1、保证金费用要15万起步 2、平台必须是二级等保和安全产品 ,一个二级等保费用10万起步 所以很多…...
)
Qwen3技术报告解读:训练秘籍公开,推理与非推理模型统一,大模型蒸馏小模型(报告详细解读)
1.简介 Qwen3 是 Qwen 模型家族的最新版本,它是一系列大型语言模型(LLMs),旨在提升性能、效率和多语言能力。基于广泛的训练,Qwen3 在推理、指令遵循、代理能力和多语言支持方面取得了突破性进展,具有以下…...

entity线段材质设置
在cesium中,我们可以改变其entity线段材质,这里以直线为例. 首先我们先创建一条直线 const redLine viewer.entities.add({polyline: {positions: Cesium.Cartesian3.fromDegreesArray([-75,35,-125,35,]),width: 5,material:material, 保存后可看到在地图上创建了一条线段…...

Word图片格式调整与转换工具
软件介绍 本文介绍的这款工具主要用于辅助Word文档处理。 图片排版功能 经常和Word打交道的人或许都有这样的困扰:插入的图片大小各异,排列也参差不齐。若不加以调整,遇到要求严格的领导,可能会让人颇为头疼。 而这款工具能够统…...

小刚说C语言刷题—1700请输出所有的2位数中,含有数字2的整数
1.题目描述 请输出所有的 2 位数中,含有数字 2 的整数有哪些,每行 1个,按照由小到大输出。 比如: 12、20、21、22、23… 都是含有数字 2的整数。 输入 无 输出 按题意要求由小到大输出符合条件的整数,每行 1 个。…...

视频抽帧并保存blob
视频抽帧 /*** description 获取文件中的每一帧* param { File } file* param { Number } time 每一帧的时间间隔(单位:秒)* param { Boolean } isUseInterval 是否使用间隔 为false只会获取这一帧* returns { Map }* example await captureFrame({ file, 20 }) > M…...

opencloudos 安装 mosquitto
更新系统并安装依赖 sudo dnf update -y sudo dnf install -y epel-release # 若需要 EPEL 额外仓库 sudo dnf install -y gcc-c cmake openssl-devel c-ares-devel libuuid-devel libwebsockets-devel安装 Mosquitto 通过默认仓库安装(推荐) sudo dn…...

STM32CubeMX使用SG90舵机角度0-180°
1. 配置步骤 1.1 硬件连接 舵机信号线 → STM32的PWM输出引脚(如 PA2,对应定时器 TIM2_CH3)。 电源和地 → 外接5V电源(确保共地)。 1.2 定时器配置(以TIM2为例) 在STM32CubeMX中࿱…...

【Umi】项目初始化配置和用户权限
app.tsx import { RunTimeLayoutConfig } from umijs/max; import { history, RequestConfig } from umi; import { getCurrentUser } from ./services/auth; import { message } from antd;// 获取用户信息 export async function getInitialState(): Promise<{currentUse…...

使用哈希表封装myunordered_set和myunordered_map
文章目录 使用哈希表封装myunordered_set和myunordered_map实现出复用哈希表框架,并支持insert支持迭代器的实现constKey不能被修改unordered_map支持[ ]结语 我们今天又见面啦,给生活加点impetus!!开启今天的编程之路!…...

光学变焦和数字变倍模块不同点概述!
一、光学变焦与数字变倍模块的不同点 1. 物理基础 光学变焦:通过调整镜头组中镜片的物理位置改变焦距,实现无损放大。例如,上海墨扬的MF-STAR吊舱采用30倍光学变焦镜头,焦距范围6~180mm,等效焦距可达997mm。 数字…...

Spring MVC 中请求处理流程及核心组件解析
在 Spring MVC 中,请求从客户端发送到服务器后,需要经过一系列组件的处理才能最终到达具体的 Controller 方法。这个过程涉及多个核心组件和复杂的映射机制,下面详细解析其工作流程: 1. 核心组件与请求流程 Spring MVC 的请求处…...

《100天精通Python——基础篇 2025 第19天:并发编程启蒙——理解CPU、线程与进程的那些事》
目录 一、计算机基础知识1.1 计算机发展简史1.2 计算机的分类1.2.1 超级计算机(Supercomputer)1.2.2 大型机(Mainframe Computer)1.2.3 迷你计算机(Minicomputer)---- 普通服务器1.2.4 工作站(W…...

<PLC><视觉><机器人>基于海康威视视觉检测和UR机械臂,如何实现N点标定?
前言 本系列是关于PLC相关的博文,包括PLC编程、PLC与上位机通讯、PLC与下位驱动、仪器仪表等通讯、PLC指令解析等相关内容。 PLC品牌包括但不限于西门子、三菱等国外品牌,汇川、信捷等国内品牌。 除了PLC为主要内容外,相关设备如触摸屏(HMI)、交换机等工控产品,如果有…...

FC7300 WDG MCAL 配置引导
在WDG模块中,用户需要选择GPT资源,因此在配置WDG组件之前,需要先选择GPT通道。WDG包含三个组件,每一个组件对应不同的硬件。 Wdg:对应WDOG0Wdg_174_Instance1:对应WDOG1Wdg_174_Instance2:对应WDOG2一、WDG 组件 1. General Wdg Disable Allowed:是否允许在WDG运行过程…...

Leaflet 自定义瓦片地图与 PHP 大图切图算法 解决大图没办法在浏览器显示的问题
为什么使用leaflet 使用 Leaflet 来加载大图片(尤其是通过瓦片化的方式)是一种高效的解决方案,主要原因如下: 1. 性能优化 减少内存占用:直接加载大图片会占用大量内存,可能导致浏览器崩溃或性能下降。瓦片…...

MySQL——十、InnoDB引擎
MVCC 当前读: 读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。 -- 当前读 select ... lock in share mode(共享锁) select ... for update update insert delete (排他锁)快照读:…...
无法调用,直接卡死,应如何解决)
import pywinauto后tkinter.filedialog.askdirectory()无法调用,直接卡死,应如何解决
诸神缄默不语-个人技术博文与视频目录 具体情况就是我需要用pywinauto进行一些软件的自动化操作,同时需要将整个代码功能用tkinter的可视化界面来展示,在调用filedialog.askdirectory()的时候代码直接不运行了,加载不出来。我一开始还以为是…...

display:grid网格布局属性说明
网格父级 :display:grid(块级网格)/ inline-grid(行内网格) 注意:当设置网格布局,column、float、clear、vertical-align的属性是无效的。 HTML: <ul class"ls02 f18 mt50 sysmt30&…...

初识——QT
QT安装方法 一、项目创建流程 创建项目 入口:通过Qt Creator的欢迎页面或菜单栏(文件→新建项目)创建新项目。 项目类型:选择「Qt Widgets Application」。 路径要求:项目路径需为纯英文且不含特殊字符。 构建系统…...

力扣-78.子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 class Solution {List<List<Integer>> res new ArrayList<>();List<I…...

python中字符串的操作
1. 字符串创建 使用单引号、双引号或三引号创建字符串三引号适用于多行字符串,且可以自由包含单双引号原始字符串使用r前缀,如r’Hello\nWorld’会原样输出\n 2. 基本操作 拼接:使用运算符或join()方法复制:使用*运算符…...

《Elasticsearch 源码解析与优化实战》笔记
术语 思维导图 基础和环境 1-2 主要流程 3-10 内部模块 11-17 优化和诊断 18-22 资料 https://elasticsearchbook.com/...
)
华为网路设备学习-22(路由器OSPF-LSA及特殊详解)
一、基本概念 OSPF协议的基本概念 OSPF是一种内部网关协议(IGP),主要用于在自治系统(AS)内部使路由器获得远端网络的路由信息。OSPF是一种链路状态路由协议,不直接传递路由表,而是通过交换链路…...
)
多线程(四)
目录 一 . 单例模式 (1)什么是设计模式? (2)饿汉模式 (3)懒汉模式 二 . 指令重排序 今天咱们继续讲解多线程的相关内容 一 . 单例模式 (1)什么是设计模式&am…...

【设计模式】- 结构型模式
代理模式 给目标对象提供一个代理以控制对该对象的访问。外界如果需要访问目标对象,需要去访问代理对象。 分类: 静态代理:代理类在编译时期生成动态代理:代理类在java运行时生成 JDK代理CGLib代理 【主要角色】: 抽…...
时,报错type xxx is not json serializable错误原因及解决方案)
python报错:使用json.dumps()时,报错type xxx is not json serializable错误原因及解决方案
文章目录 一、错误原因分析二、解决方案1. **自定义对象序列化方法一:使用default参数定义转换逻辑方法二:继承JSONEncoder类统一处理 2. **处理特殊数据类型场景一:datetime或numpy类型场景二:bytes类型 3. **处理复杂数据结构 三…...

Vue3中实现轮播图
目录 1. 轮播图介绍 2. 实现轮播图 2.1 准备工作 1、准备至少三张图片,并将图片文件名改为数字123 2、搭好HTML的标签 3、写好按钮和图片标签 编辑 2.2 单向绑定图片 2.3 在按钮里使用方法 2.4 运行代码 3. 完整代码 1. 轮播图介绍 首先,什么是…...

flutter缓存网络视频到本地,可离线观看
记录一下解决问题的过程,希望自己以后可以参考看看,解决更多的问题。 需求:flutter 缓存网络视频文件,可离线观看。 解决: 1,flutter APP视频播放组件调整; 2,找到视频播放组件&a…...

2025年Ai写PPT工具推荐,这5款Ai工具可以一键生成专业PPT
上个月给客户做产品宣讲时,我对着空白 PPT 页面熬到凌晨一点,光是调整文字排版就改了十几版,最后还是被吐槽 "内容零散没重点"。后来同事分享了几款 ai 写 PPT 工具,试完发现简直打开了新世界的大门 —— 不用手动写大纲…...

【深度学习】#11 优化算法
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 目录 深度学习中的优化挑战局部极小值鞍点梯度消失 凸性凸集凸函数 梯度下降一维梯度下降学习率局部极小值 多元梯度下降 随机梯度下降随机梯度更新动态学习率…...

数学复习笔记 13
前言 继续做线性相关的练习题,然后做矩阵的例题,还有矩阵的练习题。 646 A 明显是错的。因为假设系数全部是零,就不是线性相关了。要限制系数不全是零,才可以是线性相关。 B 这个说法好像没啥问题。系数全为零肯定线性组合的结…...

AI预测3D新模型百十个定位预测+胆码预测+去和尾2025年5月16日第79弹
从今天开始,咱们还是暂时基于旧的模型进行预测,好了,废话不多说,按照老办法,重点8-9码定位,配合三胆下1或下2,杀1-2个和尾,再杀6-8个和值,可以做到100-300注左右。 (1)定…...