MySQL的缓存策略
一、MySQL缓存方案用来解决什么
- 缓存用户定义的热点数据,用户直接从缓存获取热点数据,降低数据库的读写压力
- 场景分析:
- 内存访问速度是磁盘访问速度 10 万倍(数量级)
- 读的需求远远大于写的需求
- mysql 自身缓冲层跟业务无关
- mysql 作为项目主要数据库,便于统计分析
- 缓存数据库作为辅助数据库,存放热点数据
二、还有哪些方式提升 MySQL 访问性能
- 读写分离
- 是什么?:设置多个从数据库(可能分布在多个机器),写操作依然在主数据库,主数据库提供数据的主要依据。
- 解决了什么问题?:从数据库主要解决读压力。
- 原理是什么?:基于主从原理,采用异步复制,具有最终一致性(主从之间数据会有差异)。如果读操作有一致性要求,需读主数据库。
- 连接池
- 是什么?:在服务端创建多个与数据库的连接。
- 解决了什么问题?:提升数据库访问并发性能,同时复用连接资源,避免连接建立、断开及安全验证的开销。
- 原理是什么?:基于 mysql 的网络模型(select、阻塞 IO 模型)。特别地,若发送一个事务(包含多个 SQL 语句),该事务必须在一个连接中执行,即事务的对象是连接。
- 异步连接
- 是什么?:在服务端创建一个连接,针对这个连接采用非阻塞 IO。
- 解决了什么问题?:节省网络传输时间。
- 原理是什么?:使用了非阻塞 IO。
三、缓存和 MySQL 一致性状态分析
- MySQL 有,Redis 无
- 此时需将 MySQL 数据同步至 Redis,否则读取时可能多一次查询 MySQL 的操作,影响效率。
- MySQL 无,Redis 有
- 这属于脏数据情况,是不允许存在的。因为数据源头(MySQL)无此数据,而缓存(Redis)有,会导致后续读取出现错误数据,破坏数据一致性。
- 都有,数据不一致
- 典型场景如 MySQL 数据已更新,但 Redis 未同步更新。此时读取 Redis 会获取到旧数据,导致业务逻辑使用错误数据,影响系统正确性。
- 都有,数据一致
- 这是理想状态,缓存(Redis)与数据库(MySQL)数据完全一致,无论读缓存还是数据库,都能获取到正确且最新的数据,保证业务逻辑的准确性。
- 都没有
- 属于正常初始状态。首次读取时会从 MySQL 查询数据(若 MySQL 后续有写入),再将数据写入缓存,为后续读取提供加速。
四、制定用户定义热点数据的读写策略
- 读策略:
先读缓存,若缓存存在则直接返回数据;若缓存不存在,访问 MySQL 获取数据,然后将数据写入 Redis 缓存,以便后续读取直接走缓存,提升效率。 - 写策略:
- 以安全为主:
先删除 Redis 中的数据,再写 MySQL,最后将 MySQL 数据同步到 Redis。- 问题:缓存方案主要目标是提升效率,此策略为确保数据安全(避免脏数据),先删除缓存,导致下次读取需重新查询 MySQL 并同步缓存,降低了效率。
- 以效率为主:
先写缓存并设置过期时间,再写 MySQL,等待 MySQL 同步到 Redis。- 过期时间选择:需综合考虑与 MySQL 的网络传输时间、MySQL 处理时间、MySQL 同步到 Redis 的时间,确保在过期时间内,MySQL 能完成数据同步,减少脏数据存在窗口。
- 安全问题:在过期时间内(如 200ms 时间窗口),可能读到脏数据。但此策略优先保证写操作的效率,适用于对效率要求较高、对短时间脏数据容忍度较高的场景。
- 以安全为主:
五、 mysql的主从复制
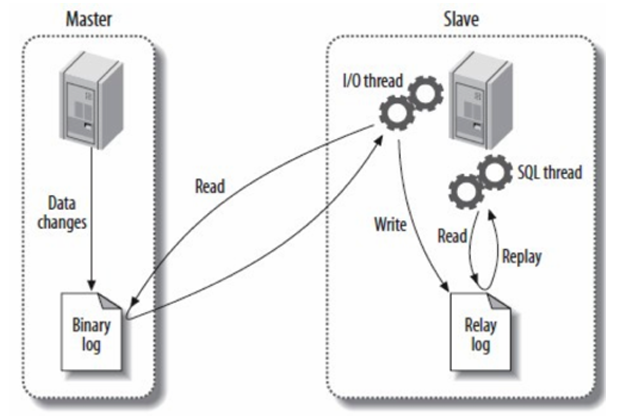
在 MySQL 主从复制机制中,主库的更新事件(如 update、insert、delete 等 DML 操作)通过 io - thread 写入到 binlog(二进制日志)中。从库会请求读取主库的 binlog,通过自身的 io - thread 将读取到的内容写入本地的 relay - log(中继日志)。接着,从库通过 sql - thread 读取 relay - log,并将其中的更新事件在从库中重放(replay)一遍,以实现数据同步。
其具体复制流程如下:
- Slave(从库)的 IO 线程连接到 Master(主库),并请求从指定日志文件的指定位置(或从最开始的日志位置)之后的日志内容。
- Master 接收到来自 Slave 的 IO 线程的请求后,负责复制的 IO 线程会根据请求信息读取日志指定位置之后的内容,返回给 Slave 的 IO 线程。返回信息除了包含日志内容外,还包括当前 Master 端的 binlog 文件名称及 binlog 的位置。
- Slave 的 IO 线程接收到信息后,将日志内容依次添加到 Slave 端的 relay - log 文件末尾,并将读取到的 Master 日志文件名和位置记录到 master - info 文件中,以便下一次读取时能明确告知 Master 从何处开始读取日志。
- Slave 的 Sql 进程检测到 relay - log 中有新增内容后,会立即解析 relay - log 的内容,使其成为在 Master 端真实执行时的可执行内容,并在从库自身执行这些操作,从而完成数据的同步复制。
六、读写分离(最终一致性)
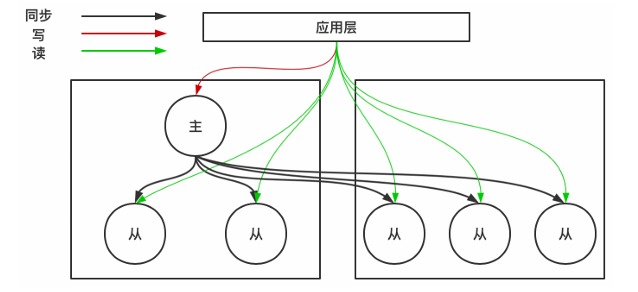
为什么需要缓冲层?
前提
读多写少,单个主节点能支撑项目数据量;数据的主要依据是 mysql。
mysql
mysql 有缓冲层,它的作用也是用来缓存热点数据,这些数据包括索引、记录等;mysql 缓冲层是从自身出发,跟具体的业务无关,这里的缓冲策略主要是 lru。
mysql 数据主要存储在磁盘当中,适合大量重要数据的存储;磁盘当中的数据一般是远大于内存当中的数据;一般业务场景关系型数据库(mysql)作为主要数据库。
缓冲层
缓存数据库可以选用 redis,memcached;它们所有数据都存储在内存当中,当然也可以将内存当中的数据持久化到磁盘当中。
总结
- 由于 mysql 的缓冲层(buffer pool)不由用户来控制,也就是不能由用户来控制缓存具体数据;
- 访问磁盘的速度比较慢,尽量获取数据从内存中获取;
- 主要解决读的性能;因为写没必要优化,必须让数据正确的落盘;如果写性能出现问题,那么请使用横向扩展集群方式来解决;
- 项目中需要存储的数据应该远大于内存的容量,同时需要进行数据统计分析,所以数据存储获取的依据应该是关系型数据库;
- 缓存数据库可以存储用户自定义的热点数据;以下的讨论都是基于热点数据的同步问题。
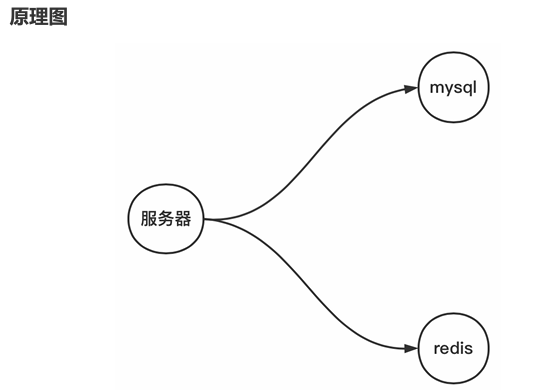
为什么有同步的问题?
没有缓冲层之前,我们对数据的读写都是基于 mysql,所以不存在同步问题;这句话也不是必然,比如读写分离就存在同步问题(数据一致性问题)。
引入缓冲层后,我们对数据的获取需要分别操作缓存数据库和 mysql,那么这个时候数据可能存在几个状态?
- mysql 有,缓存无
- mysql 无,缓存有
- 都有,但数据不一致
- 都有,数据一致
- 都没有
4 和 5 显然是没问题的,我们现在需要考虑 1、2 以及 3。
首先明确一点:我们获取数据的主要依据是 mysql,只需要将 mysql 的数据正确同步到缓存数据库就可以了;同理,缓存有,mysql 没有,这比较危险,此时我们可以认为该数据为脏数据;所以我们需要在同步策略中避免该情况发生;同时可能存在 mysql 和缓存都有数据,但是数据不一致,这种也需要在同步策略中避免。
注意:
缓存不可用,整个系统依然要保持正常工作;
mysql 不可用的话,系统停摆,停止对外提供服务。
解决数据同步问题
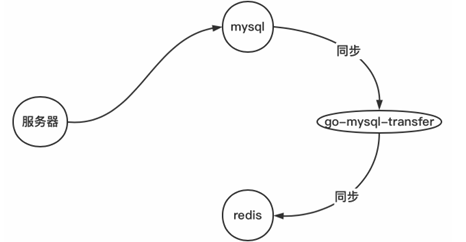
策略 1
- 读流程:先读缓存,若缓存存在,直接返回;若缓存没有,读 mysql;若 mysql 有,同步到缓存,并返回;若 mysql 没有,则返回没有。
- 写流程:先删除缓存,再写 mysql,后续数据同步交由 go - mysql - transfer 等中间件处理(将问题 3 转化成 1)。
- 先删除缓存,是为了避免其他服务读取旧数据,同时也告知系统这个数据已不是最新,建议从 mysql 获取数据。
- 但对于服务 A 而言,写入 mysql 后,接着读操作必须要能读到最新的数据。
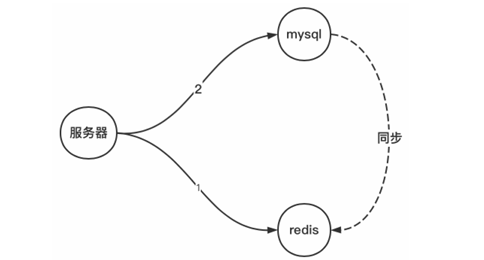
策略 2
- 读流程:先读缓存,若缓存存在,直接返回;若缓存没有,读 mysql;若 mysql 有,同步到缓存,并返回;若 mysql 没有,则返回没有。
- 写流程:先写缓存,并设置过期时间(如 200ms),再写 mysql,后续数据同步交由其他中间件处理。
- 这里设置的过期时间是预估时间,大致上是 mysql 到缓存同步的时间。
- 在写的过程中如果 mysql 停止服务,或数据没写入 mysql,则 200ms 内提供了脏数据服务,但仅仅只有 200ms 的数据错乱。
同步方案
原理图
一、环境准备
1. 系统要求
- 操作系统:Linux/Windows(推荐 Linux)。
- 依赖工具:
- MySQL:5.6+(需开启 Binlog,配置 ROW 模式)。
- Go:1.14+(用于编译源码,若使用二进制包可跳过)。
- Redis:3.0+(作为数据接收端)。
2. MySQL 配置(关键)
修改 MySQL 配置文件(
my.cnf或my.ini),开启 Binlog 并配置格式:[mysqld] log-bin=mysql-bin # 开启 Binlog binlog-format=ROW # 选择 ROW 模式(记录行级数据变更) server_id=1 # MySQL 主库 ID(需唯一,不可与 go-mysql-transfer 的 slave_id 重复) binlog_row_image=FULL # 记录完整行数据(默认即可)操作步骤:
- 重启 MySQL 使配置生效。
- 登录 MySQL,创建用于同步的用户并授权:
CREATE USER 'sync_user'@'%' IDENTIFIED BY 'sync_password'; GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'sync_user'@'%'; FLUSH PRIVILEGES;二、安装 go-mysql-transfer
1. 方式一:二进制包安装(推荐)
- 从 Gitee 仓库 下载最新二进制包。
- 解压后得到可执行文件
go-mysql-transfer(Linux 为./go-mysql-transfer,Windows 为go-mysql-transfer.exe)。2. 方式二:源码编译(适合定制需求)
- 克隆代码:
git clone https://gitee.com/mirrors/go-mysql-transfer.git cd go-mysql-transfer- 配置 Go 模块并编译:
GO111MODULE=on go env -w GOPROXY=https://goproxy.cn,direct # 设置国内代理 go build -o go-mysql-transfer三、配置文件详解(
app.yml)在项目根目录创建或修改
app.yml,配置 MySQL 源和 Redis 目标:# 全局配置 global:log_level: info # 日志级别(debug/info/warn/error)slave_id: 100 # 模拟从库 ID(需与 MySQL 的 server_id 不同)flush_interval: 1s # 批量写入接收端的间隔# 数据源(MySQL)配置 source:driver: mysqldsn: "sync_user:sync_password@tcp(127.0.0.1:3306)/test?charset=utf8mb4"# 注意:dsn 格式为 "用户:密码@tcp(IP:端口)/数据库?参数"table: ["user"] # 需同步的表名(支持正则,如 "user_*")binlog:start_file: "" # 起始 Binlog 文件(首次全量同步留空)start_pos: 0 # 起始位置(首次全量同步为 0)# 目标端(Redis)配置 target:- name: redisdriver: redisaddr: "127.0.0.1:6379"password: "" # 若 Redis 有密码需填写db: 0 # Redis 数据库编号# 同步规则:使用 Lua 脚本处理数据rule:type: luascript: "redis_ops.lua" # Lua 脚本路径(相对于项目根目录)四、编写 Lua 脚本(数据处理逻辑)
在项目根目录创建
redis_ops.lua,定义如何将 MySQL 数据同步到 Redis:local ops = require("redisOps") -- 加载 Redis 操作模块 local row = ops.rawRow() -- 获取当前行数据(键为列名的 table) local action = ops.rawAction() -- 获取操作类型(insert/update/delete)-- 仅处理 INSERT 事件(可根据需求扩展 UPDATE/DELETE) if action == "insert" thenlocal id = row["id"]local nick = row["nick"]local key = string.format("user:%d", id) -- 定义 Redis 键名格式-- 将字段写入 Redis 哈希结构ops.HSET(key, "id", id)ops.HSET(key, "nick", nick)ops.HSET(key, "height", row["height"])ops.HSET(key, "sex", row["sex"])ops.HSET(key, "age", row["age"])ops.EXPIRE(key, 86400) -- 设置过期时间(1 天,可选) end-- 处理 UPDATE 事件(示例) -- if action == "update" then -- local old_row = ops.oldRow() -- 获取更新前的数据 -- -- 对比新旧数据,仅更新变化的字段 -- end-- 处理 DELETE 事件(示例) -- if action == "delete" then -- local key = string.format("user:%d", row["id"]) -- ops.DEL(key) -- 删除 Redis 中的键 -- end五、启动同步流程
1. 全量数据初始化(首次同步)
# Linux/macOS ./go-mysql-transfer -stock# Windows go-mysql-transfer.exe -stock
- 作用:将 MySQL 现有数据全量导入 Redis,避免增量同步时漏数据。
- 提示:全量同步期间会锁定表(可选参数
-lock-table=false可关闭锁表,但可能导致数据不一致)。2. 增量数据同步(全量后执行)
获取 MySQL 当前 Binlog 位置:
mysql> SHOW MASTER STATUS;返回结果类似:
+------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000003 | 154 | test | | +------------------+----------+--------------+------------------+记录下
File和Position(如mysql-bin.000003和154)。启动增量同步:
# Linux/macOS ./go-mysql-transfer -config app.yml -position mysql-bin.000003 154# Windows go-mysql-transfer.exe -config app.yml -position mysql-bin.000003 154
-config:指定配置文件路径(默认app.yml)。-position:指定增量同步的起始 Binlog 文件和位置。六、演示验证
1. 创建测试表并插入数据
-- 登录 MySQL mysql -u root -p-- 创建数据库和表 CREATE DATABASE IF NOT EXISTS test; USE test;DROP TABLE IF EXISTS `user`; CREATE TABLE `user` (`id` BIGINT PRIMARY KEY,`nick` VARCHAR(100),`height` INT8,`sex` VARCHAR(1),`age` INT8 ) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- 插入测试数据 INSERT INTO `user` VALUES (10001, 'mark', 180, '1', 30); UPDATE `user` SET `age` = 31 WHERE id = 10001;2. 验证 Redis 数据同步
- 打开另一个终端,连接 Redis:
redis-cli -h 127.0.0.1 -p 6379- 查看同步后的数据:
# 查看所有键 KEYS "user:*"# 获取具体键的哈希值 HGETALL user:10001预期输出:
1) "id" 2) "10001" 3) "nick" 4) "mark" 5) "height" 6) "180" 7) "sex" 8) "1" 9) "age"- "31"
### **七、常见问题与解决** 1. **Binlog 格式错误**: - 确保 MySQL 的 `binlog-format=ROW`,并重启 MySQL。 2. **权限不足**: - 检查同步用户是否拥有 `REPLICATION SLAVE` 权限。 3. **连接超时**: - 检查 MySQL 和 Redis 的 IP/端口是否可达,防火墙是否放行。 4. **数据不同步**: - 查看 go-mysql-transfer 日志,确认是否有解析错误或网络问题。 - 重新执行全量同步 `./go-mysql-transfer -stock` 后再启动增量同步。 通过以上步骤,可实现 MySQL 与 Redis 的实时增量同步,有效提升读性能并保证数据最终一致性。
七、缓存出现的问题
一、缓存穿透(Cache Penetration)
问题描述
当客户端频繁请求在缓存(Redis)和数据库(MySQL)中均不存在的数据时,每次请求都会绕过缓存直接访问数据库。若这类请求量极大,会导致数据库压力骤增,甚至崩溃。
典型场景:
- 恶意攻击:黑客利用随机生成的非法 Key 发起大量请求,试图压垮数据库。
- 业务逻辑漏洞:用户输入非法参数(如负数 ID),导致系统查询不存在的数据。
核心成因
- 缓存层未对无效 Key 进行拦截,导致所有请求直达数据库。
- 数据库无法快速识别并拒绝无效请求,需消耗资源执行查询。
解决方案
1. 缓存空值标记
- 原理:
当数据库查询结果为 “无数据” 时,在缓存中记录该 Key 对应的空值(如null),并设置较短的过期时间(如 5 分钟)。
- 后续请求先查缓存,若为空值标记,则直接返回 “无数据”,不再查询数据库。
- 优缺点:
- ✅ 简单直接,无需额外组件,快速拦截重复无效请求。
- ❌ 可能存储大量无效 Key,占用缓存空间(可通过定期清理缓解)。
2. 布隆过滤器(Bloom Filter)
- 原理:
- 提前将数据库中存在的 Key 存入一个布隆过滤器(一种概率型数据结构)。
- 客户端请求前,先通过布隆过滤器校验 Key 是否存在:
- 若过滤器判定 “不存在”,则直接拒绝请求,不查询数据库。
- 若判定 “存在”,再访问缓存和数据库(可能存在误判,但概率极低)。
- 优缺点:
- ✅ 高效过滤无效请求,内存占用远低于缓存空值,适合海量 Key 场景。
- ❌ 不支持删除操作,且存在极小概率的误判(需合理设计过滤器参数)。
二、缓存击穿(Cache Breakdown)
问题描述
热点数据的缓存突然失效(如过期时间到达),此时大量并发请求同时访问数据库,导致数据库瞬间压力激增,可能引发服务降级或崩溃。
典型场景:
- 秒杀活动:某个商品的缓存过期,数万用户同时查询库存,击穿缓存。
- 周期性更新:如首页推荐数据每天凌晨 1 点统一过期,导致同一时间大量请求涌至数据库。
核心成因
- 热点数据访问量极高,缓存失效瞬间失去拦截作用。
- 数据库单节点处理能力有限,无法应对突发流量峰值。
解决方案
1. 分布式锁(Distributed Lock)
- 原理:
- 当缓存失效时,通过分布式锁(如 Redis 的
SET NX命令)确保同一时间只有一个请求能访问数据库。- 该请求查询数据库并更新缓存后,释放锁,其他请求再重试。
- 执行流程:
- 请求尝试获取锁(如
lock:key)。- 成功获取锁的请求查询数据库,更新缓存。
- 释放锁,其他请求重试时发现缓存已更新,直接读取缓存。
- 优缺点:
- ✅ 有效避免并发查询数据库,确保缓存原子性更新。
- ❌ 引入锁机制,可能增加请求延迟,需处理锁超时和死锁问题。
2. 热点数据永不过期
- 原理:
- 对访问量极高的热点数据不设置过期时间,避免因过期导致击穿。
- 通过后台异步任务(如定时任务)主动更新缓存,确保数据实时性。
- 适用场景:
- 数据更新频率较低,且允许短时间内存在不一致(如商品详情页)。
三、缓存雪崩(Cache Avalanche)
问题描述
大量缓存项在同一时间段内集中失效或缓存服务整体不可用,导致海量请求直接涌至数据库,造成数据库负载过高,甚至引发系统级故障。
典型场景:
- 缓存集群宕机:如 Redis 单节点故障且未配置高可用,导致所有缓存失效。
- 批量缓存过期:如电商首页 10 万商品缓存均设置为 24 小时过期,每天凌晨同时失效。
核心成因
- 缓存层可用性不足(如单点故障)或过期时间设计不合理(集中失效)。
- 数据库无法承受突发的流量峰值。
解决方案
1. 缓存高可用架构
- 实现方式:
- 采用 Redis 集群(Cluster)或哨兵模式(Sentinel),确保缓存层无单点故障。
- 即使部分节点宕机,其他节点仍可提供服务,避免全量缓存失效。
- 效果:提升缓存层的可靠性,防止因缓存宕机导致的雪崩。
2. 随机化过期时间
- 原理:
- 为缓存设置随机化的过期时间(如基础时间 ±30% 波动),避免大量 Key 同时失效。
- 例:基础过期时间为 3600 秒(1 小时),实际设置为 3000~4200 秒之间的随机值。
- 效果:将缓存失效的时间点分散到更长的时间段内,降低数据库压力峰值。
3. 缓存预热与持久化
- 缓存预热:
- 系统启动前,提前将热数据加载到缓存中(如通过全量同步工具
go-mysql-transfer)。- 避免启动后因缓存为空导致请求直达数据库。
- 持久化机制:
- 开启 Redis 持久化(RDB/AOF),确保重启后能快速从磁盘恢复数据。
- 若重启时间较短,依赖持久化文件恢复缓存;若时间较长,提前手动预热热数据。
总结:异常场景应对核心思路
问题类型 核心风险 解决方案关键点 缓存穿透 无效请求压垮数据库 拦截无效 Key(空值缓存、布隆过滤器) 缓存击穿 热点数据失效引发并发压力 控制并发访问(分布式锁)、避免失效(永不过期) 缓存雪崩 大量缓存失效或服务宕机 高可用架构、分散失效时间、预热与持久化
0voice · GitHub
相关文章:

MySQL的缓存策略
一、MySQL缓存方案用来解决什么 缓存用户定义的热点数据,用户直接从缓存获取热点数据,降低数据库的读写压力场景分析: 内存访问速度是磁盘访问速度 10 万倍(数量级)读的需求远远大于写的需求mysql 自身缓冲层跟业务无…...

ubuntu22.04卸载vscode
方法 1:通过 Snap 卸载 VSCode 如果你是通过 Snap 安装的 VSCode(Ubuntu 22.04 默认推荐方式),按照以下步骤卸载: 检查是否通过 Snap 安装: bash snap list | grep code如果输出显示 code,说明…...

主流数据库排查与优化速查手册
主流数据库排查与优化速查手册(优化版) 一、连接失败 1.1 统一排查流程 #mermaid-svg-IIyarbd8VatJFN14 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-IIyarbd8VatJFN14 .error-icon{fill:…...

MySQL 数据库优化:InnoDB 存储引擎深度解析:架构、调优与最佳实践
InnoDB 是 MySQL 的默认存储引擎,因其支持事务、行级锁和崩溃恢复等特性,广泛应用于高并发、数据一致性要求高的场景。本文将从 InnoDB 的核心架构、调优策略、监控诊断、高级特性 到 备份恢复 进行系统性分析,并结合代码示例与实战案例,帮助开发者全面掌握其应用与优化技巧…...
[AI算法] LLM训练-构建transformers custom model
文章目录 1. 继承与实现基础结构2. 支持 DeepSpeed 和 Accelerate 的注意事项a. 模型输出格式b. 设备管理c. 分布式训练兼容性d. DeepSpeed 特定优化 3. 训练脚本集成建议4. 测试与调试建议 在使用 Hugging Face 的 transformers 库时,若要自定义一个继承自 PreTrai…...

突发,苹果发布下一代 CarPlay Ultra
汽车的平均换代周期一般都超过5年,对于老旧燃油车而言,苹果的 Carplay 是黑暗中的明灯,是延续使用寿命的利器。 因为你可能不需要冰箱彩电大沙发,但一定需要大屏车载导航、倒车影像、车载听歌。如果原车不具备这个功能࿰…...

git克隆github项目到本地的三种方式
本文旨在使用git工具将别人发布在github上的项目保存到本地 1.安装git,创建github账户,并使用ssh关联自己的github账号和git,具体教程可以参照下面两篇文章: Github入门教程,适合新手学习(非常详细&#…...

Excel MCP: 自动读取、提炼、分析Excel数据并生成可视化图表和分析报告
最近,一款Excel MCP Server的开源工具火了,看起来功能很强大,咱们今天来一探究竟。 基础环境 最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个&…...

香港 GPU 服务器优势及使用场景解析
在快速发展的科技领域,数据处理和复杂计算已成为众多行业的支柱,GPU 服务器的重要性不容小觑。GPU 服务器是内部集成一个或多个 GPU的物理服务器,用于执行每个用例所需的任务。而香港 GPU 服务器,是指部署在中国香港数据中心、配备…...

Go语言交替打印问题及多种实现方法
Go语言交替打印问题及多种实现方法 在并发编程中,多个线程(或 goroutine)交替执行任务是一个经典问题。本文将以 Go 语言为例,介绍如何实现多个 goroutine 交替打印数字的功能,并展示几种不同的实现方法。 Go 语言相关…...

Grafana分布统计:Heatmap面板
Heatmap是是Grafana v4.3版本以后新添加的可视化面板,通过热图可以直观的查看样本的分布情况。在Grafana v5.1版本中Heatmap完善了对Prometheus的支持。这部分,将介绍如何使用HeatmapPanel实现对Prometheus监控指标的可视化。 使用Heatmap可视化Histogr…...

rk3576 gstreamer opencv
安装gstreamer rk3588使用gstreamer推流_rk3588 gstreamer-CSDN博客 rk3588使用gstreamer推流_rk3588 gstreamer-CSDN博客 Installing on Linux sudo apt-get install libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgstreamer-plugins-bad1.0-dev gstreamer1.0-pl…...

用户现场不支持路由映射,如何快速将安防监控EasyCVR视频汇聚平台映射到公网?
一、方案背景 随着数字化安防与智能交通管理发展,视频监控远程管理需求激增。EasyCVR作为专业视频融合平台,具备多协议接入等核心功能,是智能监控的重要工具。但实际部署中,当EasyCVR处于内网且路由器无法进行端口映射时&#…...

棋牌室台球室快速接入美团团购接口
北极星平台从2024年12月份开始慢慢关闭,现在很多开发者反馈北极星token已经不能刷新了,全部迁移到美团团购综合平台。 申请这个平台要求很高 1、保证金费用要15万起步 2、平台必须是二级等保和安全产品 ,一个二级等保费用10万起步 所以很多…...
)
Qwen3技术报告解读:训练秘籍公开,推理与非推理模型统一,大模型蒸馏小模型(报告详细解读)
1.简介 Qwen3 是 Qwen 模型家族的最新版本,它是一系列大型语言模型(LLMs),旨在提升性能、效率和多语言能力。基于广泛的训练,Qwen3 在推理、指令遵循、代理能力和多语言支持方面取得了突破性进展,具有以下…...

entity线段材质设置
在cesium中,我们可以改变其entity线段材质,这里以直线为例. 首先我们先创建一条直线 const redLine viewer.entities.add({polyline: {positions: Cesium.Cartesian3.fromDegreesArray([-75,35,-125,35,]),width: 5,material:material, 保存后可看到在地图上创建了一条线段…...

Word图片格式调整与转换工具
软件介绍 本文介绍的这款工具主要用于辅助Word文档处理。 图片排版功能 经常和Word打交道的人或许都有这样的困扰:插入的图片大小各异,排列也参差不齐。若不加以调整,遇到要求严格的领导,可能会让人颇为头疼。 而这款工具能够统…...

小刚说C语言刷题—1700请输出所有的2位数中,含有数字2的整数
1.题目描述 请输出所有的 2 位数中,含有数字 2 的整数有哪些,每行 1个,按照由小到大输出。 比如: 12、20、21、22、23… 都是含有数字 2的整数。 输入 无 输出 按题意要求由小到大输出符合条件的整数,每行 1 个。…...

视频抽帧并保存blob
视频抽帧 /*** description 获取文件中的每一帧* param { File } file* param { Number } time 每一帧的时间间隔(单位:秒)* param { Boolean } isUseInterval 是否使用间隔 为false只会获取这一帧* returns { Map }* example await captureFrame({ file, 20 }) > M…...

opencloudos 安装 mosquitto
更新系统并安装依赖 sudo dnf update -y sudo dnf install -y epel-release # 若需要 EPEL 额外仓库 sudo dnf install -y gcc-c cmake openssl-devel c-ares-devel libuuid-devel libwebsockets-devel安装 Mosquitto 通过默认仓库安装(推荐) sudo dn…...

STM32CubeMX使用SG90舵机角度0-180°
1. 配置步骤 1.1 硬件连接 舵机信号线 → STM32的PWM输出引脚(如 PA2,对应定时器 TIM2_CH3)。 电源和地 → 外接5V电源(确保共地)。 1.2 定时器配置(以TIM2为例) 在STM32CubeMX中࿱…...

【Umi】项目初始化配置和用户权限
app.tsx import { RunTimeLayoutConfig } from umijs/max; import { history, RequestConfig } from umi; import { getCurrentUser } from ./services/auth; import { message } from antd;// 获取用户信息 export async function getInitialState(): Promise<{currentUse…...

使用哈希表封装myunordered_set和myunordered_map
文章目录 使用哈希表封装myunordered_set和myunordered_map实现出复用哈希表框架,并支持insert支持迭代器的实现constKey不能被修改unordered_map支持[ ]结语 我们今天又见面啦,给生活加点impetus!!开启今天的编程之路!…...

光学变焦和数字变倍模块不同点概述!
一、光学变焦与数字变倍模块的不同点 1. 物理基础 光学变焦:通过调整镜头组中镜片的物理位置改变焦距,实现无损放大。例如,上海墨扬的MF-STAR吊舱采用30倍光学变焦镜头,焦距范围6~180mm,等效焦距可达997mm。 数字…...

Spring MVC 中请求处理流程及核心组件解析
在 Spring MVC 中,请求从客户端发送到服务器后,需要经过一系列组件的处理才能最终到达具体的 Controller 方法。这个过程涉及多个核心组件和复杂的映射机制,下面详细解析其工作流程: 1. 核心组件与请求流程 Spring MVC 的请求处…...

《100天精通Python——基础篇 2025 第19天:并发编程启蒙——理解CPU、线程与进程的那些事》
目录 一、计算机基础知识1.1 计算机发展简史1.2 计算机的分类1.2.1 超级计算机(Supercomputer)1.2.2 大型机(Mainframe Computer)1.2.3 迷你计算机(Minicomputer)---- 普通服务器1.2.4 工作站(W…...

<PLC><视觉><机器人>基于海康威视视觉检测和UR机械臂,如何实现N点标定?
前言 本系列是关于PLC相关的博文,包括PLC编程、PLC与上位机通讯、PLC与下位驱动、仪器仪表等通讯、PLC指令解析等相关内容。 PLC品牌包括但不限于西门子、三菱等国外品牌,汇川、信捷等国内品牌。 除了PLC为主要内容外,相关设备如触摸屏(HMI)、交换机等工控产品,如果有…...

FC7300 WDG MCAL 配置引导
在WDG模块中,用户需要选择GPT资源,因此在配置WDG组件之前,需要先选择GPT通道。WDG包含三个组件,每一个组件对应不同的硬件。 Wdg:对应WDOG0Wdg_174_Instance1:对应WDOG1Wdg_174_Instance2:对应WDOG2一、WDG 组件 1. General Wdg Disable Allowed:是否允许在WDG运行过程…...

Leaflet 自定义瓦片地图与 PHP 大图切图算法 解决大图没办法在浏览器显示的问题
为什么使用leaflet 使用 Leaflet 来加载大图片(尤其是通过瓦片化的方式)是一种高效的解决方案,主要原因如下: 1. 性能优化 减少内存占用:直接加载大图片会占用大量内存,可能导致浏览器崩溃或性能下降。瓦片…...

MySQL——十、InnoDB引擎
MVCC 当前读: 读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。 -- 当前读 select ... lock in share mode(共享锁) select ... for update update insert delete (排他锁)快照读:…...
无法调用,直接卡死,应如何解决)
import pywinauto后tkinter.filedialog.askdirectory()无法调用,直接卡死,应如何解决
诸神缄默不语-个人技术博文与视频目录 具体情况就是我需要用pywinauto进行一些软件的自动化操作,同时需要将整个代码功能用tkinter的可视化界面来展示,在调用filedialog.askdirectory()的时候代码直接不运行了,加载不出来。我一开始还以为是…...

display:grid网格布局属性说明
网格父级 :display:grid(块级网格)/ inline-grid(行内网格) 注意:当设置网格布局,column、float、clear、vertical-align的属性是无效的。 HTML: <ul class"ls02 f18 mt50 sysmt30&…...

初识——QT
QT安装方法 一、项目创建流程 创建项目 入口:通过Qt Creator的欢迎页面或菜单栏(文件→新建项目)创建新项目。 项目类型:选择「Qt Widgets Application」。 路径要求:项目路径需为纯英文且不含特殊字符。 构建系统…...

力扣-78.子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 class Solution {List<List<Integer>> res new ArrayList<>();List<I…...

python中字符串的操作
1. 字符串创建 使用单引号、双引号或三引号创建字符串三引号适用于多行字符串,且可以自由包含单双引号原始字符串使用r前缀,如r’Hello\nWorld’会原样输出\n 2. 基本操作 拼接:使用运算符或join()方法复制:使用*运算符…...

《Elasticsearch 源码解析与优化实战》笔记
术语 思维导图 基础和环境 1-2 主要流程 3-10 内部模块 11-17 优化和诊断 18-22 资料 https://elasticsearchbook.com/...
)
华为网路设备学习-22(路由器OSPF-LSA及特殊详解)
一、基本概念 OSPF协议的基本概念 OSPF是一种内部网关协议(IGP),主要用于在自治系统(AS)内部使路由器获得远端网络的路由信息。OSPF是一种链路状态路由协议,不直接传递路由表,而是通过交换链路…...
)
多线程(四)
目录 一 . 单例模式 (1)什么是设计模式? (2)饿汉模式 (3)懒汉模式 二 . 指令重排序 今天咱们继续讲解多线程的相关内容 一 . 单例模式 (1)什么是设计模式&am…...

【设计模式】- 结构型模式
代理模式 给目标对象提供一个代理以控制对该对象的访问。外界如果需要访问目标对象,需要去访问代理对象。 分类: 静态代理:代理类在编译时期生成动态代理:代理类在java运行时生成 JDK代理CGLib代理 【主要角色】: 抽…...
时,报错type xxx is not json serializable错误原因及解决方案)
python报错:使用json.dumps()时,报错type xxx is not json serializable错误原因及解决方案
文章目录 一、错误原因分析二、解决方案1. **自定义对象序列化方法一:使用default参数定义转换逻辑方法二:继承JSONEncoder类统一处理 2. **处理特殊数据类型场景一:datetime或numpy类型场景二:bytes类型 3. **处理复杂数据结构 三…...

Vue3中实现轮播图
目录 1. 轮播图介绍 2. 实现轮播图 2.1 准备工作 1、准备至少三张图片,并将图片文件名改为数字123 2、搭好HTML的标签 3、写好按钮和图片标签 编辑 2.2 单向绑定图片 2.3 在按钮里使用方法 2.4 运行代码 3. 完整代码 1. 轮播图介绍 首先,什么是…...

flutter缓存网络视频到本地,可离线观看
记录一下解决问题的过程,希望自己以后可以参考看看,解决更多的问题。 需求:flutter 缓存网络视频文件,可离线观看。 解决: 1,flutter APP视频播放组件调整; 2,找到视频播放组件&a…...

2025年Ai写PPT工具推荐,这5款Ai工具可以一键生成专业PPT
上个月给客户做产品宣讲时,我对着空白 PPT 页面熬到凌晨一点,光是调整文字排版就改了十几版,最后还是被吐槽 "内容零散没重点"。后来同事分享了几款 ai 写 PPT 工具,试完发现简直打开了新世界的大门 —— 不用手动写大纲…...

【深度学习】#11 优化算法
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 目录 深度学习中的优化挑战局部极小值鞍点梯度消失 凸性凸集凸函数 梯度下降一维梯度下降学习率局部极小值 多元梯度下降 随机梯度下降随机梯度更新动态学习率…...

数学复习笔记 13
前言 继续做线性相关的练习题,然后做矩阵的例题,还有矩阵的练习题。 646 A 明显是错的。因为假设系数全部是零,就不是线性相关了。要限制系数不全是零,才可以是线性相关。 B 这个说法好像没啥问题。系数全为零肯定线性组合的结…...

AI预测3D新模型百十个定位预测+胆码预测+去和尾2025年5月16日第79弹
从今天开始,咱们还是暂时基于旧的模型进行预测,好了,废话不多说,按照老办法,重点8-9码定位,配合三胆下1或下2,杀1-2个和尾,再杀6-8个和值,可以做到100-300注左右。 (1)定…...

阳台光伏+储能:安科瑞智能计量仪表来助力
随着可再生能源的普及和家庭储能需求的增长,阳台光伏储能系统逐渐成为家庭能源管理的新趋势。如何精准计量储能系统的发电量、用电量及电网交互数据,成为优化能源利用效率的关键。安科瑞计量仪表凭借高精度、多功能及智能化特性,为家庭阳台储…...

Unable to determine the device handle for GPU 0000:1A:00.0: Unknown Error
Unable to determine the device handle for GPU 0000:1A:00.0: Unknown Error 省流:我遇到这个问题重置bios设置就好了 这个错误信息表明系统无法识别或访问GPU(0000:1A:00.0),通常与CUDA、驱动程序或硬件相关。以下是可能的原…...

多态性标记设计
1.确定区间 2.获取该区间内的序列,如果只有一个位置,可以前后扩100bp 使用ncbi primer blast进行引物设计(https://blast.ncbi.nlm.nih.gov/Blast.cgi)...

Jenkins 最佳实践
1. 在Jenkins中避免调度过载 过载Jenkins以同时运行多个作业可能导致资源竞争、构建速度变慢和系统性能问题。分配作业启动时间可以防止瓶颈,并确保更顺畅的执行。如何实现? 在Cron表达式中使用H:引入抖动(jitter)&a…...