《100天精通Python——基础篇 2025 第19天:并发编程启蒙——理解CPU、线程与进程的那些事》
目录
- 一、计算机基础知识
- 1.1 计算机发展简史
- 1.2 计算机的分类
- 1.2.1 超级计算机(Supercomputer)
- 1.2.2 大型机(Mainframe Computer)
- 1.2.3 迷你计算机(Minicomputer)---- 普通服务器
- 1.2.4 工作站(Workstation)
- 1.2.5 微型计算机(Microcomputer)
- 1.3 计算机的体系与结构
- 1.4 计算机的层次与编程语言
- 1.5 计算机的速度单位
- 1.5.1 容量单位(Storage Units)
- 1.5.2 速度单位(运算/传输性能单位)
- 1.5.2.1 计算速度单位(FLOPS)
- 1.5.2.2 数据传输速度单位(网络带宽/IO速度)
- 1.5.2.3 CPU 速度
- 1.6 计算机的字符与编码集
- 1.7 计算机组成之CPU
- 1.8 计算机组成之存储器
- 1.9 操作系统
- 1.9.1 操作系统的发展简史(精简版)
- 1.9.2 操作系统基本功能
- 1.9.3 操作系统的用户态和内核态
- 1.10 基础概念
- 1.10.1 并行与并发
- 1.10.2 同步与异步
- 1.10.3 计算密集型与IO密集型
- 1.10.3.1 计算密集型(CPU-bound)
- 1.10.3.2 I/O 密集型(IO-bound)
- 1.10.3.3 使用 sysstat 工具分析计算密集型 vs I/O 密集型
- 二、深入探讨线程与进程
- 2.1 进程
- 2.1.1 操作系统的进程
- 2.1.2 进程的五状态模型
- 2.1.3 进程的调度方式
- 2.2 线程
- 2.2.1 操作系统的线程
- 2.2.2 线程的实现方式
- 2.2.3 进程与线程的上下文切换
- 2.3 协程(初步了解)
一、计算机基础知识
1.1 计算机发展简史
计算机五大阶段对比:
| 阶段 | 时间 | 技术基础 | 代表设备/事件 | 主要用途 | 特点关键词 |
|---|---|---|---|---|---|
| 第一代 电子管计算机 | 1940s–1950s | 电子管 | ENIAC、EDVAC | 导弹计算、科学计算 | 体积大、功耗高、无存储程序 |
| 第二代 晶体管计算机 | 1956–1964 | 晶体管 | IBM 1401、PDP-1、TX-0 | 商业应用初起、实时控制 | 更小更快、功耗低、出现编程语言 |
| 第三代 集成电路计算机 | 1964–1971 | 小规模集成电路(SSI) | IBM System/360、DEC PDP-8 | 商业计算普及、操作系统雏形 | 统一架构、多任务支持、IO增强 |
| 第四代 微处理器计算机 | 1971–至今 | 微处理器(CPU) | Intel 4004、IBM PC、Macintosh | 个人计算、教育、办公、游戏 | 单芯片处理器、个人电脑普及 |
| 第五代 智能/后冯诺依曼时代 | 21世纪至今 | 多核+AI+量子 | 量子计算机、AI芯片(TPU) | 大数据、并行处理、AI建模 | 多核协同、神经网络、量子叠加 |
💡 注: 像 IBM 7094 虽出现于集成电路早期,但它仍属于晶体管技术;而 IBM System/360 则是典型的集成电路产品,是现代操作系统和架构标准化的开端。
每一阶段稍作展开:
-
第一代:电子管时代(ENIAC、1946年)
- 技术标志:使用真空电子管作为逻辑元件
- 代表人物/机构:冯·诺依曼(提出
"存储程序计算机"结构) - 主要用途:弹道计算、天气预报、核研究(科学计算为主)
- 存在问题:体积巨大,维护困难,程序必须
"重新接线"
-
第二代:晶体管时代(1956年以后)
- 技术标志:使用晶体管替代电子管,可靠性与能效大幅提升
- 代表设备:
- IBM 1401:商业数据处理主力
- TX-0、PDP-1(林肯实验室):用于科研实验、交互式编程
- 主要用途:商用数据处理开始普及,嵌入式控制开始出现
- 重要事件:汇编语言、Fortran、COBOL 等高级语言登场
-
第三代:集成电路时代(1964年以后)
- 技术标志:集成电路(IC)让体积更小、速度更快
- 代表设备:
- IBM System/360:统一指令集 + 操作系统支持(OS/360)
- DEC PDP-8:便宜好用,广泛应用于控制系统
- 主要用途:银行系统、航空控制、大学研究机、商业计算大爆发
- 历史意义:真正意义上的
"多任务"操作系统出现
-
微处理器时代(1971年起)
- 技术标志:将 CPU 全部集成进一颗芯片(如 Intel 4004、8086)
- 代表事件/产品:
- IBM PC(1981):个人电脑革命
- Apple II、Macintosh(1984):图形界面普及
- 主要用途:进入办公桌、家庭、学校,桌面软件蓬勃发展
- 并发编程背景:早期仍以单核为主,
"多任务"为模拟并发
-
智能与多核时代(21世纪)
- 技术标志:多核、多线程、GPU/TPU 加速、量子位并行性
- 主要用途:人工智能、大数据、高性能模拟、自然语言处理等
- 代表趋势:
- CPU 核心数爆发增长(2核 → 64核+)
- 量子计算、DNA 计算、光子计算等新范式探索
1.2 计算机的分类
1.2.1 超级计算机(Supercomputer)
超级计算机是世界上性能最强大的计算机,通常具有成千上万的 CPU 核心,甚至更多的计算单元(如 GPU 加速器)。其主要特点是处理能力极强,能够执行庞大的科学计算任务。主要用途:
- 气候模拟:如气候变化预测、大气模拟等。
- 天气预报:使用复杂算法进行天气预测。
- 基因组学:基因分析和生物数据处理。
- 人工智能和深度学习:训练大型 AI 模型。
- 核试验模拟:无须实际爆炸即可模拟核爆炸的效果。
特点:
-
极高的浮点计算能力(单位如 TFlop/s 或 PFlop/s)。
单位 名称 数量级 1 GFLOP/s GigaFLOP 每秒10⁹次浮点运算(十亿次) 1 TFLOP/s TeraFLOP 每秒10¹²次(万亿次) 1 PFLOP/s PetaFLOP 每秒10¹⁵次(千万亿次) 1 EFLOP/s ExaFLOP 每秒10¹⁸次(百亿亿次) -
海量并行计算,通常由成千上万的处理单元组成。
-
高效能能耗与冷却设计。
哪些国家的超级计算机最强: 截至 2024 年,全球顶尖超级计算机排名(Top500)中领先的有:
| 排名 | 超级计算机 | 国家 | 理论峰值性能(Rpeak) |
|---|---|---|---|
| 1️⃣ | Frontier | 🇺🇸 美国 | 超过 1.1 EFLOP/s(百亿亿次) |
| 2️⃣ | Fugaku(富岳) | 🇯🇵 日本 | ~0.537 EFLOP/s |
| 3️⃣ | Lumi | 🇫🇮 芬兰(欧盟) | ~0.46 EFLOP/s |
| 🔝(隐含) | 天河、神威·太湖之光 | 🇨🇳 中国 | 未更新但性能仍在全球前列 |
截至2024年,中国在全球超级计算机领域仍保持强劲地位,拥有63台系统入选TOP500榜单,位居全球第二,仅次于美国的173台系统。中国超级计算机概况(2024年):代表性系统
- 神威·太湖之光(Sunway TaihuLight):曾于2016年登顶全球第一,拥有10,649,600个核心。
- 天河二号A(Tianhe-2A):由国防科技大学研制,曾在2013年到2016年间连续三年位居全球第一。
尽管这些系统在过去取得了显著成就,但在最新的TOP500榜单中,它们的排名有所下降。中国超级计算机排名的下滑并不意味着技术实力的下降,而是由于自2020年起,中国选择不再向TOP500组织提交最新的性能数据,导致部分新一代超算系统未被纳入榜单。天河星逸:2023年发布,采用国产处理器,峰值性能达到620 PFLOP/s,约为神威·太湖之光的5倍,显示出中国在超算领域的持续进步。天河新一代系统:在2024年Graph500榜单中,以6320.24 MTEPS/W的性能夺得大数据图计算能效榜单世界第一,体现了在图计算和能效方面的领先地位。尽管在TOP500榜单中的排名有所下降,但中国在超级计算机领域的技术实力依然强劲,特别是在自主研发和能源效率方面取得了显著成果。
假设你当前使用的个人设备如下:
| 配置 | 参数 |
|---|---|
| CPU | Intel Core i7-12700H(14核心) |
| 单核性能 | ~3.5 GHz,约 50 GFLOP/s |
| 总性能(估计) | 多核总 FLOP/s ≈ 600~800 GFLOP/s(视工作负载而定) |
与超级计算机的对比:
| 指标 | i7-12700H | Frontier 超算 |
|---|---|---|
| 理论峰值性能 | ~0.0006 TFLOP/s | ~1100 TFLOP/s(= 1.1 EFLOP/s) |
| 核心数量 | 14 核 | 超过 8 万个 CPU/GPU 芯片,总核数上千万 |
| 运算能力差距 | 百万倍以上 | 超算 = 上百万个你这颗CPU"并发运行" |
1.2.2 大型机(Mainframe Computer)
大型机是一种能够处理大量事务和数据的计算机,具有高度可靠性和可扩展性。它们通常用于需要高吞吐量和高可靠性的任务,如大规模数据处理和交易处理。主要用途:
- 银行和金融:用于大规模交易处理,ATM、证券交易等。
- 政府机构:处理庞大的公共记录、税务、国防等数据。
- 大型企业:运行 ERP 系统、客户关系管理(CRM)等。
特点:
- 高可靠性和冗余设计。
- 强大的数据处理能力,能够同时处理多个任务。
- 高吞吐量和高并发能力。
示例:IBM Z系列(如 IBM Z15、IBM zEnterprise)拓展:
- 去 IOE 运动的背景与含义: 阿里巴巴集团在2008年提出了
"去IOE"的战略,- I (IBM):IBM在企业级计算领域拥有强大的影响力,尤其是在大型机(Mainframe)领域。阿里巴巴认为,IBM的大型机(如IBM Z系列)价格昂贵,且硬件难以灵活扩展。
- O (Oracle):Oracle提供的数据库软件(如Oracle数据库)是传统企业级IT架构的重要组成部分。阿里巴巴认为,Oracle的许可证费用非常高,且不够灵活,无法满足云计算时代对弹性和低成本的需求。
- E (EMC):EMC是传统存储领域的领军企业之一。阿里巴巴认为EMC的存储设备不仅价格昂贵,而且存储架构难以满足云计算中对高效存储的需求。
- 去 IOE 运动的动机和目标: 阿里巴巴在进行去 IOE 运动时,试图实现以下目标:
- 降低成本:IBM、Oracle 和 EMC 的技术和产品价格昂贵,尤其是在传统的企业IT架构中。阿里巴巴希望通过去 IOE,减少对这些企业级产品的依赖,降低硬件和软件的投入成本。
- 提高自主研发能力:通过摆脱依赖,阿里巴巴希望能够将更多的研发资源投入到自研技术中,尤其是在数据库、大数据、云计算和存储等领域。
- 推动云计算:阿里巴巴认为云计算时代的到来,需要更加灵活、低成本、高效率的解决方案。通过自研基础设施和软件,阿里巴巴能够提供更具弹性和高效性的云计算服务。
- 去 IOE 运动与阿里云的诞生: 在去 IOE 的背景下,阿里巴巴于2009年正式成立了阿里云(Alibaba Cloud)。阿里云的成立旨在为企业提供云计算服务,特别是面向大规模数据存储、计算和分析的需求。通过自主研发技术,阿里云逐渐取代了传统的IT架构,并为大量企业提供了高效、低成本的云计算解决方案。在去 IOE 运动的推动下,阿里巴巴开始加大云计算的投入,逐步实现了云计算基础设施的自主研发。通过构建自己的技术架构,阿里云逐渐走向成熟,并成为全球领先的云计算服务提供商之一。阿里云的诞生与发展,标志着阿里巴巴从传统的电商平台转型为一家技术驱动的公司。阿里云的关键创新与进步:
- 自主研发数据库:阿里巴巴推出了自研的关系型数据库——PolarDB,它是一个兼容 MySQL 和 PostgreSQL 的分布式数据库。通过这一创新,阿里巴巴成功摆脱了对 Oracle 数据库的依赖。
- 分布式存储:阿里云研发了 OceanBase(分布式数据库)和 OSS(对象存储服务),这使得阿里巴巴在存储领域摆脱了 EMC 的垄断。
- 弹性计算服务:阿里云推出了高弹性的云计算服务,支持按需扩展,帮助企业降低基础设施建设和维护的成本。
- 大数据和人工智能:阿里云在大数据和人工智能技术方面进行了大量投资,并推出了 MaxCompute(大数据处理平台)等服务,满足了各种行业对数据处理和分析的需求。
- 去 IOE 运动的影响:
- 对行业的推动:去 IOE 运动不仅推动了阿里巴巴自研技术的快速发展,也促进了整个中国云计算行业的创新。其他云服务提供商(如腾讯云、百度云等)也开始加强自研技术,推动国内云计算市场的快速发展。
- 全球云计算竞争:通过去 IOE,阿里巴巴成功地在全球云计算市场中占据了一席之地,尤其是在中国市场,阿里云目前是最领先的云服务提供商之一。
总结: 去 IOE 运动实际上是阿里巴巴技术创新和产业升级的一个重要战略,其核心目的是实现云计算技术的自主可控,摆脱对 IBM、Oracle 和 EMC 等传统IT巨头的依赖,推动阿里云的崛起。通过这一战略,阿里巴巴不仅降低了成本,还通过自研技术为全球客户提供了更加灵活、可靠、低成本的云计算服务。这一运动对整个IT行业产生了深远影响,特别是促进了中国云计算市场的蓬勃发展,并推动了全球云计算竞争的加剧。
1.2.3 迷你计算机(Minicomputer)---- 普通服务器
迷你计算机有时也被称为普通服务器,尤其是在现代的语境下,这一类别的设备与传统的大型机有所不同,更多地体现为用于中小规模的服务器计算。为了更清晰地阐述这个概念,把迷你计算机和普通服务器做个详细对比和解释:
迷你计算机(Minicomputer): 迷你计算机是指介于大型机和微型计算机之间的中型计算机,通常用于中型企业和实验室的各种数据处理任务。它们的计算能力强于个人计算机,但不如大型机那样适合超大规模的运算。在过去,迷你计算机用于处理较复杂的数据和任务,如中型数据库、生产管理和一些较为复杂的科学计算等。在现代,迷你计算机的概念和应用逐渐与普通服务器重叠。
普通服务器(一般指现代的中型服务器): 现代的普通服务器,特别是用于企业级的服务器,通常具备中到高性能的计算能力,主要用于托管网站、数据库、文件服务、应用程序等。与迷你计算机类似,现代服务器也能处理较大规模的计算任务,并且具有更强的扩展性。
与迷你计算机的区别在于,现代服务器的硬件架构、操作系统(如 Linux、Windows Server)和虚拟化能力通常要比过去的迷你计算机更先进和灵活。现代的普通服务器支持虚拟化技术,可以容纳多个虚拟机以满足不同的计算需求。
迷你计算机(普通服务器)与其主要用途:
- 企业服务器:用于处理中小型企业的应用、数据存储和管理等。
- 数据库服务器:用于托管和管理中型规模的数据库应用。
- 虚拟化服务器:支持运行多个虚拟机,提供多样化的服务。
- 计算集群:可以用作计算集群中的一部分,用于处理并行计算任务。
特点:
- 强大的扩展性,能够根据需求扩充存储和处理能力。
- 支持虚拟化,适用于云计算和虚拟机环境。
- 高效能的数据处理能力,适合中型企业使用。
对比大型机,硬件成本较低,但仍然能够处理大规模的任务。示例:Dell PowerEdge 系列、HP ProLiant 系列、IBM System x 系列
🇨🇳 国产迷你计算机 / 普通服务器代表厂商介绍
-
浪潮(Inspur)
- 主攻方向:服务器、数据中心、云计算、AI计算平台
- 地位:浪潮是中国服务器市场的长期领先者之一,在全球服务器出货量排名前五,在中国政企市场和金融行业影响力极大。
- 产品特点:
- 支持自主可控 CPU(如鲲鹏、海光)
- 高性价比,广泛应用于政府、税务、电信、医疗等行业
- 提供整套数据中心解决方案
-
华为
- 主攻方向:智能计算、云服务器、数据中心基础设施
- 代表产品:FusionServer 系列服务器、TaiShan(鲲鹏架构)服务器
- 特点:
- 采用自主研发的鲲鹏处理器,强调
"国产自主可控" - 在国产化替代和
"去IOE"背景下崛起
- 采用自主研发的鲲鹏处理器,强调
- 在 AI、云计算、政企云场景中广泛部署
-
联想(Lenovo)
- 主攻方向:企业级服务器、工作站、边缘计算、数据中心解决方案
- 代表产品:ThinkSystem 系列服务器、ThinkStation 工作站
- 特点:
- 联想通过并购 IBM x86 服务器业务后,拥有了极为成熟的服务器产品线
- 注重全球化与稳定性,广泛应用于企业、科研院所、银行、教育等领域
- 强调节能、高性能与易维护性
现代的迷你计算机与服务器的区别: 虽然迷你计算机和现代的服务器在硬件上非常相似,但它们的定义和应用范围有所变化。如今,更多的企业采用的是标准化的、以服务器为基础的硬件架构,迷你计算机这一术语已经逐渐变得不那么常用了。
注意:"迷你计算机" ≠ 迷你机箱电脑,而是 "中型服务器" 范畴
总结: 虽然迷你计算机(Minicomputer)和现代的普通服务器在很多方面具有相似性,但它们在历史上曾有不同的背景和定位。迷你计算机现在基本可以被看作是普通服务器的前身或替代品,其应用场景和技术基础逐渐合并为现代的中型服务器和虚拟化环境。
1.2.4 工作站(Workstation)
工作站是一种高性能的个人计算机,专为处理计算密集型应用而设计,通常用于图形设计、视频编辑、3D建模等领域。它比普通桌面计算机更强大,但并不像超级计算机那样具有大量的并行处理单元。主要用途:
- 工程设计与CAD:如计算机辅助设计(CAD)、计算机辅助制造(CAM)等。
- 动画与图形设计:用于视频剪辑、3D建模和动画制作。
- 科学计算:例如物理模拟和分子建模等。
特点:
- 强大的图形处理能力,通常配备专用图形处理单元(GPU)。
- 高计算能力和内存容量,适用于高性能应用。
- 常常运行高端操作系统,如Unix或Linux。
示例:苹果 Mac Pro、HP Z 系列工作站、Dell Precision 系列
1.2.5 微型计算机(Microcomputer)
微型计算机通常是指性能相对较低的计算机,广泛应用于日常办公、娱乐以及学习中。它们通常使用单核或多核 CPU,适用于一般的计算任务。主要用途:
- 个人计算:如日常办公、文档处理、浏览网页等。
- 家庭娱乐:观看视频、游戏、音乐等。
- 教育和学习:进行编程学习、科研等。
特点:
- 适合普通消费者和中小型企业使用。
- 性能较强,但不适用于超大规模的数据处理。
- 运行桌面操作系统,如 Windows、macOS、Linux 等。
示例:苹果 MacBook 系列、Windows PC、Linux 桌面计算机、笔记本和台式机
1.3 计算机的体系与结构
现代计算机系统的底层架构,大多遵循一种经典模型:冯·诺依曼体系结构(Von Neumann Architecture)。 它的提出,标志着计算机从 "固定功能工具" 迈向了 "可编程通用设备" 的新时代。
冯·诺依曼结构诞生的背景:在 1940 年代早期,像 ENIAC 这样的计算机只能执行固定程序,这些程序往往通过硬接线、拨码开关等方式写入,修改程序需要重接电路,既繁琐又低效。为了解决程序不可灵活更换的问题,1945 年,冯·诺依曼提出了一个突破性方案——将程序和数据统一存储在计算机内存中,由处理器顺序读取执行。
这一方案被称为 "存储程序计算机",也就是后来广泛采用的 "冯·诺依曼结构"。为了实现 "通用可编程" 的目标,这一结构体系必须具备以下四种核心能力:
- 能够将程序与数据输入计算机: 即提供输入设备或机制,支持程序与数据载入
- 具有长期记忆能力: 能够存储程序、原始数据、中间结果与最终输出(即内存)
- 具备基本处理能力: 执行算术、逻辑运算及数据传输等操作(即运算器)
- 能将结果输出给用户: 通过输出设备将结果呈现给人类或其他系统
将上述能力进一步模块化,冯·诺依曼架构被标准地划分为以下五个基本单元:
| 组成部分 | 功能说明 |
|---|---|
| 存储器(Memory) | 统一存放程序与数据,实现 "可编程" |
| 运算器(ALU) | 完成加减乘除、逻辑比较等基本运算 |
| 控制器(CU) | 负责取指、译码与控制整个指令流程 |
| 输入设备(Input) | 负责将程序与数据输入计算机系统 |
| 输出设备(Output) | 将处理结果输出,供人类或其他设备使用 |
冯·诺依曼瓶颈: CPU 和 存储器速率之间的问题无法调和,CPU 处理速度快,存储设备传输速度慢,CPU 经常空转等待数据传输
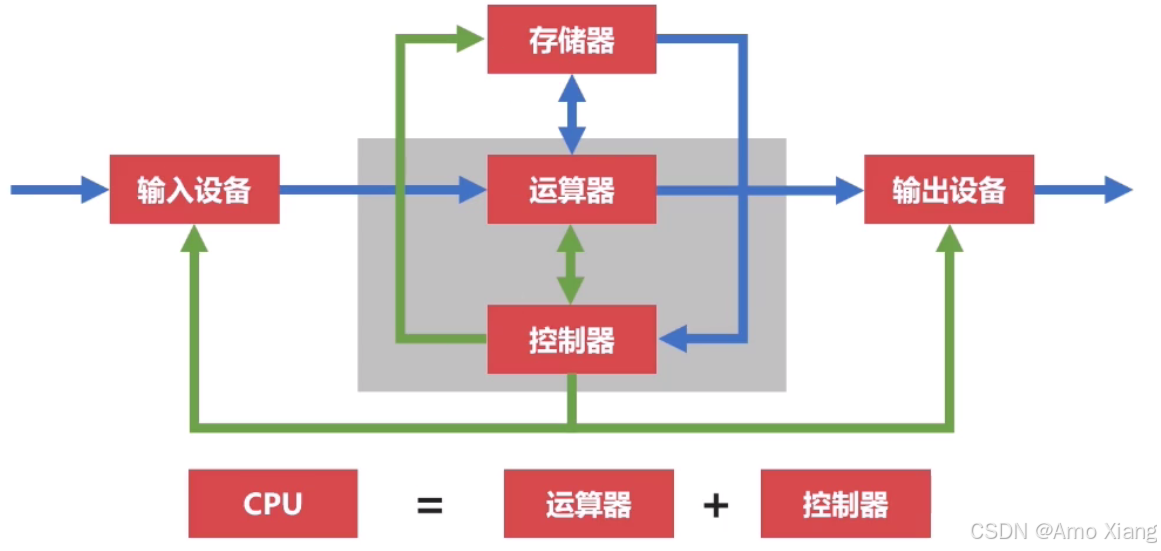
现代计算机在冯诺依曼体系结构基础上进行修改,现代计算机的结构示意图:
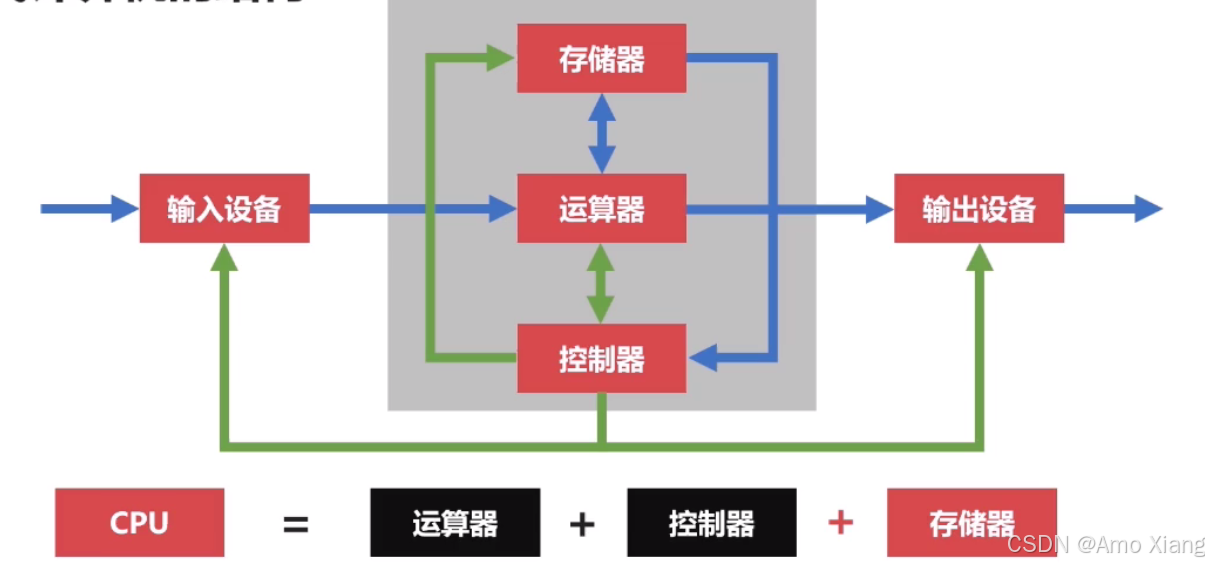
存储器从广义上去理解的话,可以理解为存储数据的介质,可以包括磁带与硬盘,但这里的存储器指的是围绕 CPU 更高速的设备,如:计算机的内存、CPU 的寄存器,现在计算机的结构可以理解为以存储器为核心。尽管冯·诺依曼结构仍是主流模型,但现代计算机在其基础上做了大量优化来提升性能:
- 引入多级缓存(L1/L2/L3):缓解 CPU 与内存间速度差
- 支持多核 CPU 与并行指令流水线:提升并发与吞吐能力
- 采用乱序执行、分支预测、超标量设计:提高单核效率
- 发展出异构计算架构:如 CPU+GPU 协作计算(SoC 等)
1.4 计算机的层次与编程语言
程序翻译与程序解释:
程序翻译:
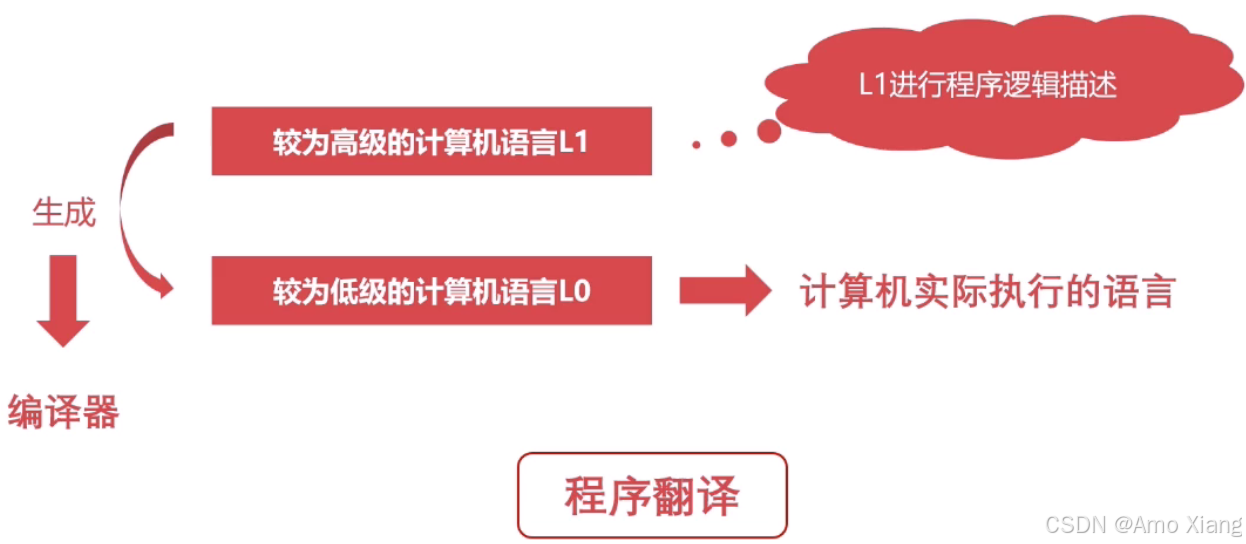
程序解释:
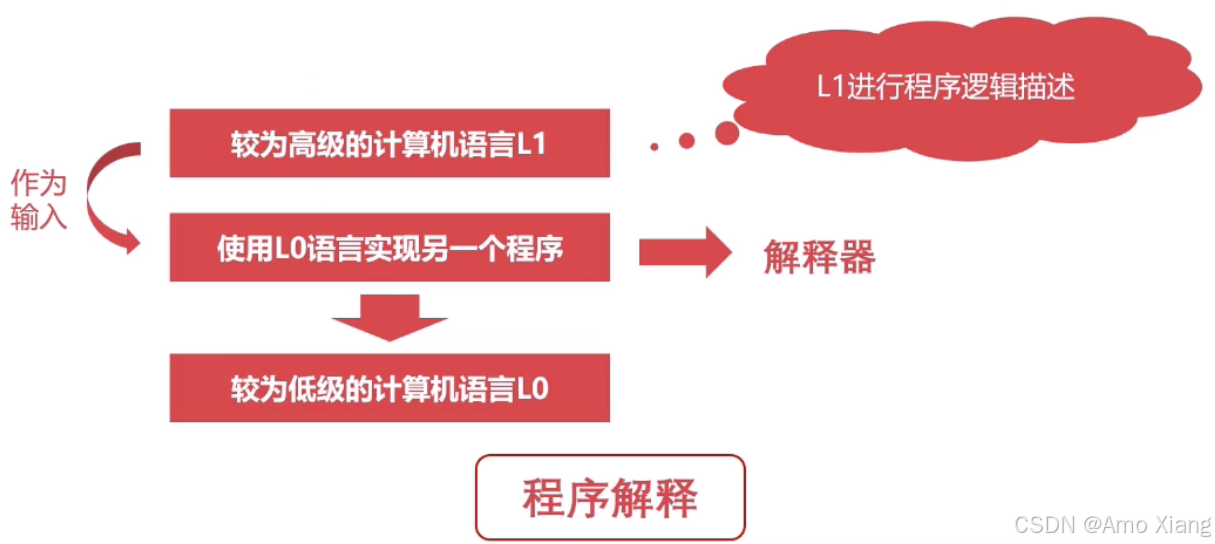
综合上图所示:计算机执行的指令都是 L0,翻译过程生成新的 L0 程序,解释过程不生成新的 L0 程序,解释过程由 L0 编写的解释器去解释 L1 程序。程序翻译:C/C++、Object-C、Golang,程序解释:Python、Php、JavaScript,程序翻译+解释:

计算机的七个层次结构(自底向上): 我们可以从 "硬件控制" 角度到 "用户应用" 角度,将计算机系统划分为如下七个层次,每一层建立在下层之上,并为上层提供抽象与接口。
| 层级 | 名称 | 简要说明 | 示例 |
|---|---|---|---|
| 第1层 | 数字逻辑层(Digital Logic) | 最底层的硬件电路,包括门电路、触发器、寄存器等 | 电路板、CPU内部结构 |
| 第2层 | 微程序/控制层(Microprogramming) | 用来控制指令执行过程的控制信号(微指令),协调硬件工作 | 控制单元的微代码 |
| 第3层 | 机器语言层(Machine Language) | 纯二进制编码的指令,是 CPU 能直接识别和执行的命令 | 如 10110000 01100001 |
| 第4层 | 汇编语言层(Assembly Language) | 用助记符代替机器码的可读性较高的语言,1:1 映射机器指令 | 如 MOV AL, 61h |
| 第5层 | 操作系统层(Operating System) | 管理硬件资源,为高级语言提供系统调用接口 | Windows、Linux、macOS |
| 第6层 | 高级语言层(High-level Languages) | 提供强大抽象能力,使程序更易写、易维护 | Python、C、Java |
| 第7层 | 应用程序层(Applications) | 最上层的软件,面向用户,解决具体问题 | Word、Photoshop、微信等 |
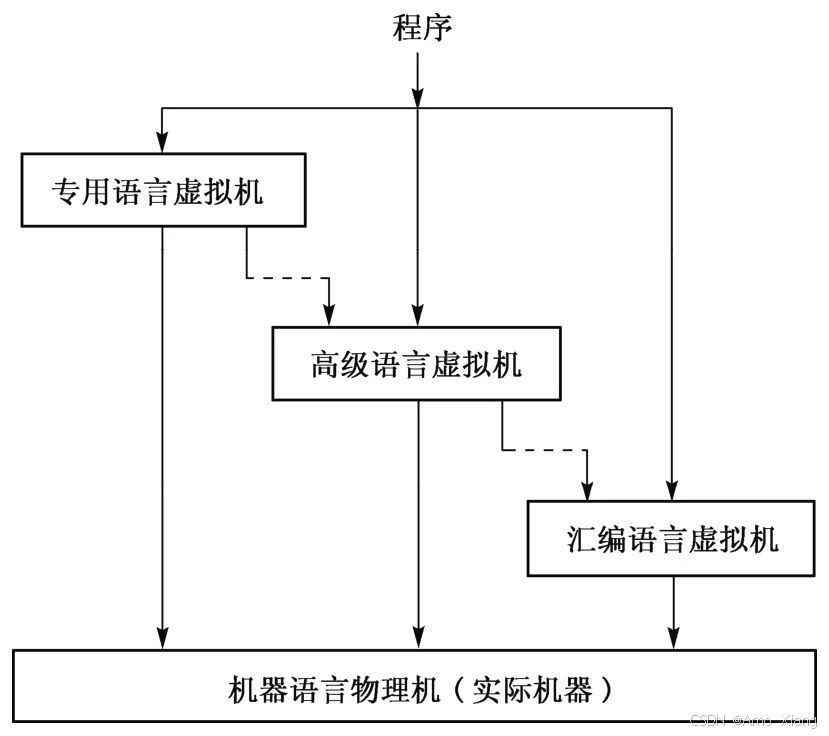
再给一个图:
1.5 计算机的速度单位
1.5.1 容量单位(Storage Units)
用于表示 存储空间的大小,如内存、硬盘、缓存等的容量。注:存储单位是2的整数次幂换算的(例如:1 KB = 2¹⁰ = 1024 B),这点不同于我们平常说的 1 千 = 1000。
| 单位 | 缩写 | 换算关系 | 举例 |
|---|---|---|---|
| 比特 | bit | 二进制最小单位,0 或 1 | 一张图像可包含百万位数据 |
| 字节 | B (Byte) | 1 B = 8 bit | 一个英文字母占1字节 |
| 千字节 | KB | 1 KB = 1024 B | 一篇普通文本文档 |
| 兆字节 | MB | 1 MB = 1024 KB | 一首MP3歌曲 ≈ 3MB |
| 千兆字节 | GB | 1 GB = 1024 MB | 一部高清电影 ≈ 2~4GB |
| 太字节 | TB | 1 TB = 1024 GB | 常见大容量机械硬盘 |
| 拍字节 | PB | 1 PB = 1024 TB | 超大数据中心使用 |
1G内存,可以存储多少字节的数据?可以存储多少比特数据?
# 字节: 1 * 1024 * 1024 * 1024
# bite: 1 * 1024 * 1024 * 1024 * 8
为什么网上买的移动硬盘500G,格式化之后就只剩465G了?
# 硬盘商一般用10进位标记容量
500 * 1000 * 1000 * 1000 / 1024 * 1024 * 1024 ≈ 465
1.5.2 速度单位(运算/传输性能单位)
用于表示 计算速度、处理能力或数据传输速度,常用于 CPU 性能、超级计算机能力、网络带宽等。
1.5.2.1 计算速度单位(FLOPS)
FLOPS:Floating Point Operations Per Second,浮点运算次数/秒,常用于衡量 CPU/GPU 或超级计算机的运算性能。
| 单位 | 含义 | 举例 |
|---|---|---|
| KFLOPS | 千次浮点运算/秒 | 早期微型计算机 |
| MFLOPS | 百万次浮点运算/秒 | 20世纪80年代 |
| GFLOPS | 十亿次浮点运算/秒 | 现代中高端笔记本CPU |
| TFLOPS | 万亿次浮点运算/秒 | 游戏主机、部分GPU |
| PFLOPS | 千万亿次浮点运算/秒 | 超级计算机级别 |
| EFLOPS | 百亿亿次浮点运算/秒 | “神威·太湖之光”级别 |
超级计算机如 "天河二号"、"神威·太湖之光" 等,峰值性能均以 PFLOPS、EFLOPS 计。
1.5.2.2 数据传输速度单位(网络带宽/IO速度)
以每秒传输的数据量来衡量,单位通常是 bit/s(注意:是 bit 而不是 byte)
| 单位 | 含义 | 示例 |
|---|---|---|
| Kbps | 千位每秒 | 拨号上网时代 |
| Mbps | 百万位每秒 | 家用宽带、WiFi速度 |
| Gbps | 十亿位每秒 | 企业级光纤、数据中心 |
| Tbps | 万亿位每秒 | 高速核心骨干网 |
为什么电信拉的100M光纤,测试峰值速度只有12M每秒?
# 网络常用单位为 Mbps
100M/s = 100Mbps = 100Mbit/s
100Mbit/s = (100/8)MB/s = 12.5MB/s
1.5.2.3 CPU 速度
CPU 的速度一般体现为 CPU 的时钟频率,CPU 的时钟频率的单位一般是赫兹(Hz),Hz 其实就是秒分之一,它是每秒钟的周期性变动重复次数的计量,并不是描述计算机领域所专有的单位。
# 处理器
# Intel(R) Core(TM) i7-10875H CPU @ 2.30GHz 2.30 GHz
主流 CPU 的时钟频率都在 2GHz 以上:
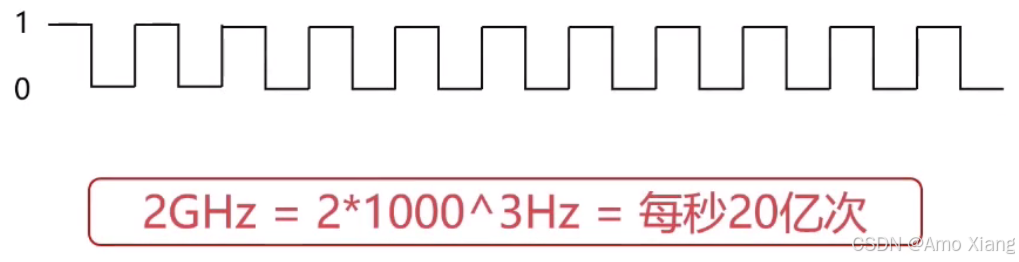
1.6 计算机的字符与编码集
参考 《C语言系统化精讲(一):编程基础》 👉 查看文章 一文的 《八、字符编码》 小节
1.7 计算机组成之CPU
赫兹(hertz,符号:Hz),常简称赫,是频率的国际单位制单位,表示每一秒周期性事件发生的次数。 赫兹是以首个用实验验证电磁波存在的科学家海因里希·赫兹命名,常用于描述正弦波、乐音、无线电通讯以及计算机时钟频率等。

1Hz=1次/秒,1000Hz=1000次/秒
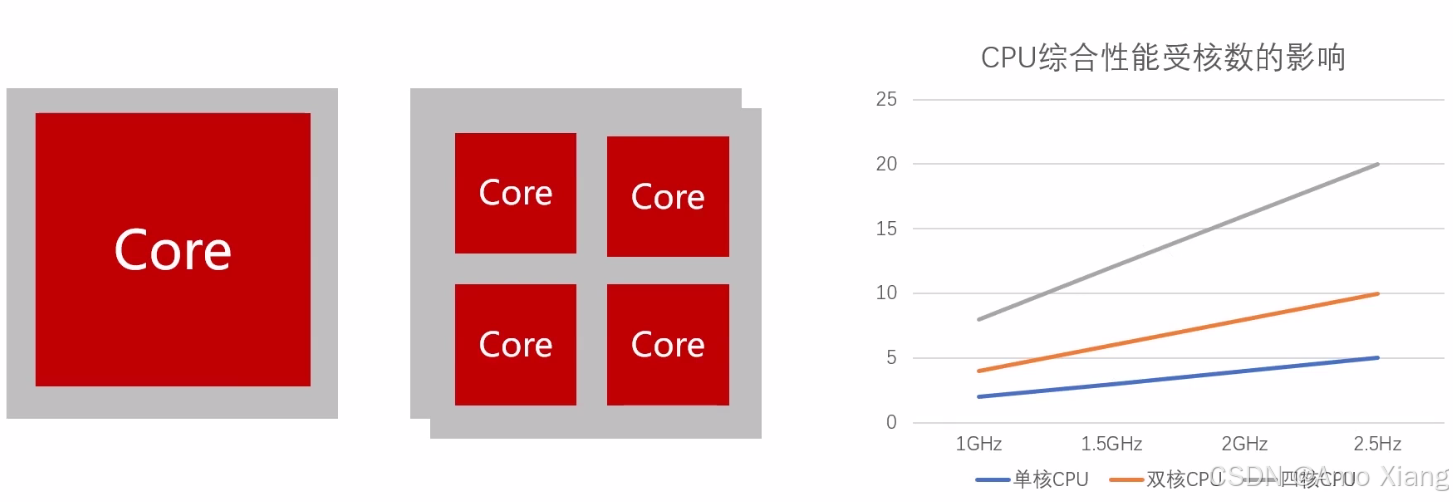
单核 CPU,性能:

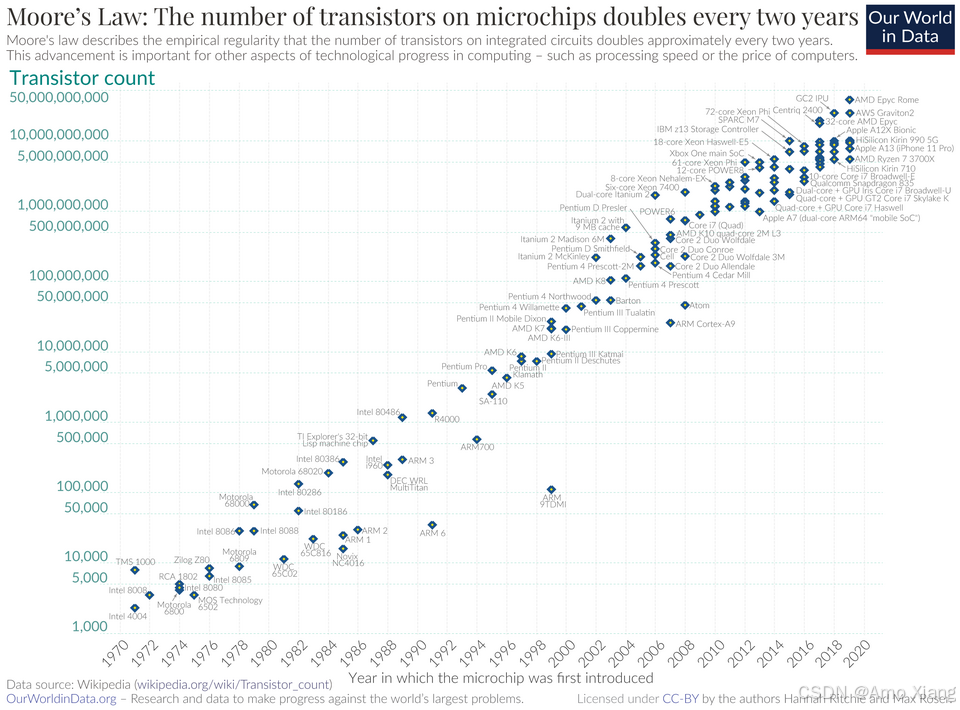
摩尔定律,价格不变时,集成电路元器件数目,约每隔 18~24 个月翻一倍。
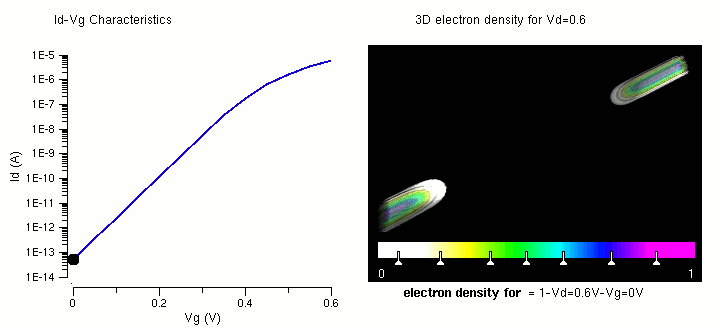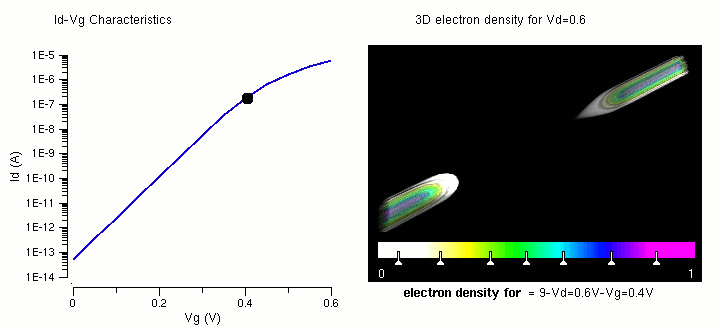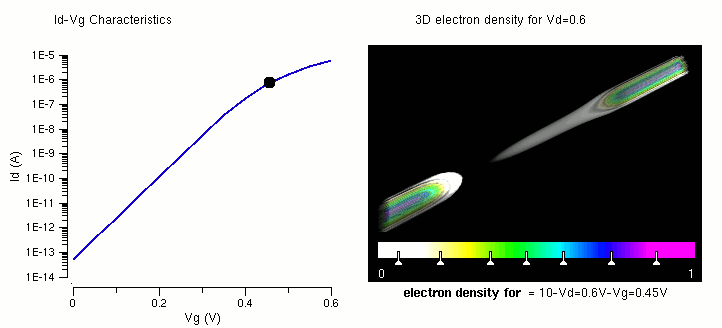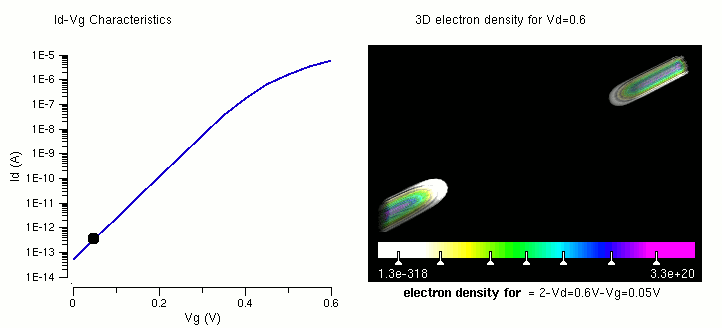
多核 CPU,性能:

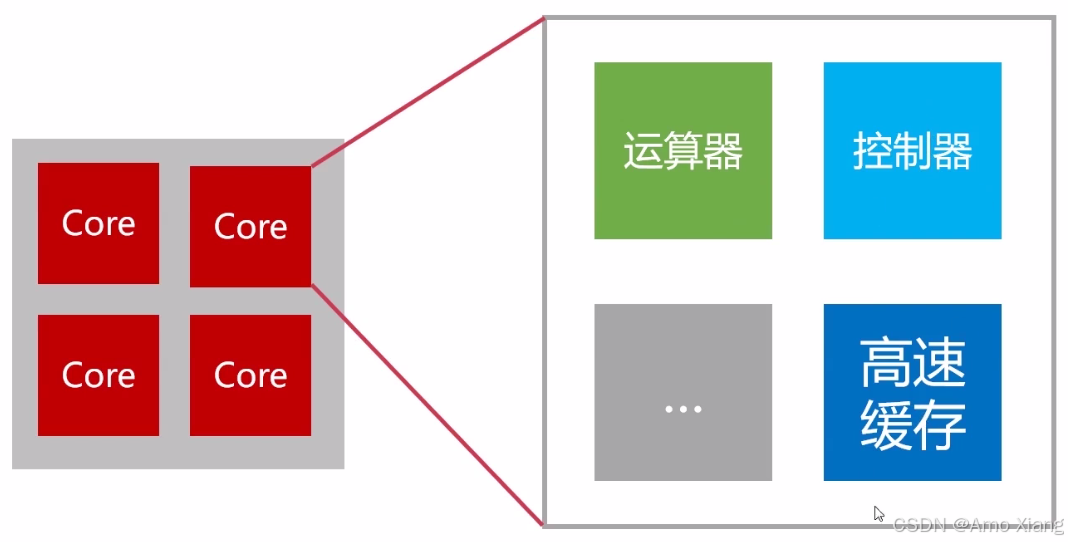
控制器: 协调和控制计算机运行的。包括:程序计数器、指令译码器、时序发生器、各种寄存器
运算器: 用来进行数据运算加工的。包括:数据缓冲器、通用寄存器、ALU、状态寄存器
总的来说,CPU 的功能:
- 控制程序的顺序运行
- 产生完成每条指令所需的控制指令
- 对各种操作加以时间上的控制
- 对数据进行算术运算和逻辑加工
1.8 计算机组成之存储器
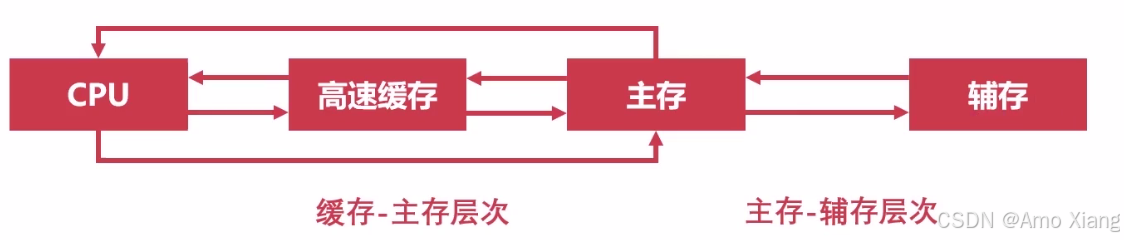
在计算机系统中,存储器负责保存程序、数据以及中间或最终的计算结果,是连接 CPU 与外部世界的数据通道核心。由于不同存储设备在速度、容量、价格上差异显著,因此计算机采用了分层设计的存储体系,以达到性能与成本的平衡。

速度、容量、价格往往是我们在选择存储器时所要考虑的三个因素。对于我们而言肯定是希望读写速度快、存储容量大、价格低,容量 + 价格 ⇒ 位价:每比特位价格。存储器的层次结构(Memory Hierarchy):从 "越靠近CPU越快越贵容量小" 到 "越靠近硬盘越慢越便宜容量大":
| 层级 | 存储类型 | 速度 | 容量 | 成本 | 示例 |
|---|---|---|---|---|---|
| 1️⃣ | 寄存器(Register) | 极快 | 极小(几十B) | 极高 | CPU内部 |
| 2️⃣ | 高速缓存(Cache) | 很快 | 小(KB~MB) | 高 | L1、L2、L3 Cache |
| 3️⃣ | 主存(内存) | 中等 | 中(GB) | 中 | DDR4/DDR5 内存条 |
| 4️⃣ | 辅助存储(外存) | 较慢 | 大(TB) | 低 | SSD/HDD 硬盘 |
| 5️⃣ | 远程存储/云盘 | 最慢 | 极大(PB) | 最低 | 云存储、分布式存储 |
为什么需要分层? 因为:
- 性能与成本无法兼得:越快的存储越贵
- 需要用小容量、速度快的上层存储去缓解下层存储速度慢的问题
- 利用局部性原理:CPU 访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中
- 缓存-主存层次,局部性原理,在 CPU 与主存之间增加一层速度快(容量小)的 Cache,解决主存速度不足的问题;主存-辅存层次,局部性原理,主存之外增加辅助存储器(磁盘、SD卡、U盘等),解决主存容量不足的问题
1.9 操作系统
1.9.1 操作系统的发展简史(精简版)
操作系统(Operating System, OS)作为连接用户与硬件之间的桥梁,其发展过程紧密伴随计算机硬件与软件技术的演进。大致可分为以下几个阶段:
-
无操作系统时代(1940s–1950s)
- 代表机器:ENIAC、EDSAC 等第一代电子管计算机
- 特征:
- 程序通过穿孔卡或纸带输入,人工加载与控制 运行
- 没有
"操作系统"的概念,程序与硬件高度耦合 - 一次只能运行一个程序,完全手工操作
- 资源利用率低
-
批处理操作系统(Batch Processing OS, 1950s–1960s)
- 代表事件:IBM 1401、IBM 7094 等大型机引入批处理技术
- 特征:
- 用户将多个任务(作业)打包提交,由系统批量顺序处理
- 引入了作业调度、输入输出管理
- 减少了 CPU 空闲时间
-
多道程序系统(Multiprogramming OS, 1960s)
- 关键概念:同时将多个程序装入内存,交替执行
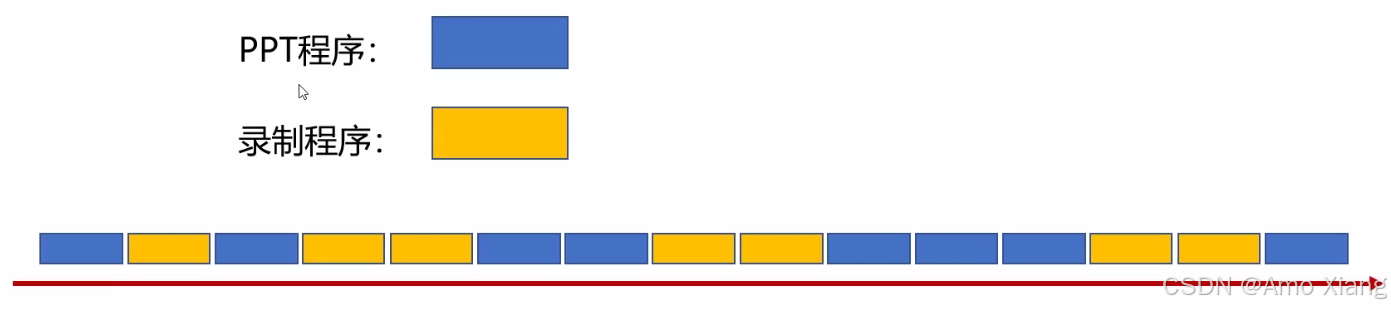
- 技术引入:
- CPU 调度、内存管理、进程管理等现代操作系统核心机制初步形成
- 提升了资源利用率
- 代表产品:IBM System/360 系统支持多道程序设计
- 关键概念:同时将多个程序装入内存,交替执行
-
分时操作系统(Time-Sharing OS, 1970s)
- 目标:让多个用户“看起来”同时使用一台计算机
- 技术要点:
- 引入时间片轮转、上下文切换
- 每个用户分得一小段 CPU 时间,增强交互性
- 代表项目:CTSS、MULTICS(Unix 前身)
-
实时操作系统(Real-Time OS, 并行出现)
- 面向场景:工业控制、嵌入式系统、航天航空
- 特征:
- 对响应时间要求极高,必须在严格时间内完成任务
-
微型机时代与通用OS(1980s–1990s)
- 标志性事件:
- UNIX 的广泛传播,衍生出 BSD、Linux 等分支
- 微软推出 MS-DOS、Windows 系列
- Apple 推出经典 Mac OS
- 特征:
- 操作系统走入个人计算机
- 图形用户界面(GUI) 成为主流
- 标志性事件:
-
现代操作系统(2000s–至今)
- 主流系统:Windows、macOS、Linux、Android、iOS
- 特征:
- 强化多线程、虚拟化、分布式、云计算支持
- 强调并发处理、资源隔离、安全性、实时性能
- 移动设备操作系统快速发展
1.9.2 操作系统基本功能
操作系统(Operating System,OS)是管理计算机硬件与软件资源的核心系统软件,其主要作用是为用户和应用程序提供一个高效、稳定、抽象的运行环境。操作系统的基本功能主要包括以下几个方面:
-
进程管理(Process Management)
- 管理程序的运行和调度(即
"进程"与"线程") - 分配与回收 CPU 时间
- 实现多任务并发、进程切换、死锁处理等
- 是并发编程的基础核心之一。ps:你在 Python 中使用的 threading、multiprocessing 都是通过操作系统提供的线程/进程能力实现的。
- 管理程序的运行和调度(即
-
内存管理(Memory Management)
- 管理内存的分配与回收
- 支持虚拟内存机制,保证各进程地址空间隔离
- 提供内存映射、分页、分段等策略,提升运行效率与安全性
-
文件系统管理(File System Management)
- 提供文件和目录的存储、访问、读写与权限控制
- 提供统一的文件接口(如 Python 的 open())
- 实现磁盘空间的管理与优化
-
设备管理(Device Management)
- 统一管理外部输入输出设备(硬盘、打印机、显卡等)
- 通过 驱动程序(Driver) 与硬件进行通信
- 屏蔽硬件差异,提供标准设备接口
-
用户接口与控制(User Interface & Control)
- 提供命令行界面(CLI)如 Windows 下的 cmd 窗口或图形界面(GUI)如:手机屏幕操作、计算机显示器+键盘、鼠标等
- 接收用户指令,反馈运行状态
- 提供系统调用(System Call)接口供应用程序访问系统资源,如:创建进程、打开文件、网络发送等
-
安全性与访问控制(Security & Protection)
- 控制资源访问权限,防止非法操作
- 实现用户身份验证、权限管理、多用户隔离
- 防御系统崩溃和攻击行为
-
拓展功能(现代 OS):
- 网络协议栈支持(如 TCP/IP)
- 虚拟化与容器(如 Docker)
- 多核调度与并行计算支持
- 能源管理、热插拔支持、模块化服务管理
操作系统基本功能小结:
# 1.操作系统统一管理着计算机资源
# 2.操作系统实现了对计算机资源的抽象
# 3.操作系统提供了用户与计算机之间的接口
1.9.3 操作系统的用户态和内核态
Linux 设计的哲学:
-
对不同的操作赋予不同的执行等级 ---- 特权
-
与系统相关的一些特别关键的操作必须由最高特权的程序来完成
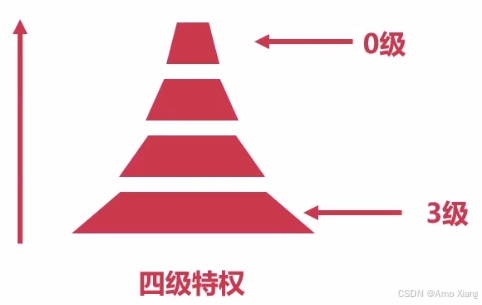
现代操作系统采用了分层保护机制,将程序运行的权限划分为两个等级:
| 属性/维度 | 🧑 用户态(User Mode) | 🛡️ 内核态(Kernel Mode) |
|---|---|---|
| 权限等级 | 权限受限(非特权级,通常为 Ring 3) | 权限最高(特权级,通常为 Ring 0) |
| 运行对象 | 应用程序(如 Python、浏览器、游戏等) | 操作系统内核、驱动、硬件控制程序 |
| 典型存在的内容 | 用户代码、用户数据、标准库、栈、堆等 | 内核代码、内核数据结构、设备驱动、中断处理程序、系统调用接口 |
| 是否可访问硬件 | ❌ 不可直接访问(只能通过系统调用间接访问) | ✅ 可直接控制硬件和资源,如磁盘、内存、网络 |
| 地址空间 | 与内核地址空间隔离,只能访问用户空间的内存 | 可访问整个系统内存,包括所有用户进程空间与设备地址 |
| 运行稳定性 | 程序出错不会影响系统整体 | 若出错,可能导致系统崩溃(如蓝屏、死机) |
| 操作系统角色 | 被服务方(运行于用户态) | 服务提供者(运行于内核态) |
| 切换方式 | 通过系统调用、中断、异常转入内核态 | 完成处理后再切回用户态 |
| 性能特点 | 高效率(执行无权限控制限制) | 切换成本高(陷入与返回涉及上下文保存与恢复) |
| 示例函数/行为 | open(), read(), print(),GUI绘图等 | 内存管理、进程调度、中断处理、文件系统操作、网络协议栈等 |
| 开发者接触方式 | 常见语言编写的用户程序(Python、Java、C++等) | 仅系统程序员/内核开发者会直接编写(如Linux内核模块) |
为什么要区分用户态与内核态? 主要是为了系统安全性与稳定性:
- 防止普通程序(如 Python 脚本)直接操作硬件,造成系统崩溃
- 通过受控接口(如系统调用)向内核请求服务,保障权限隔离
- 提高操作系统对多进程/线程的调度控制能力
如何从用户态切换到内核态? 用户程序要访问硬件资源(如文件、网络、内存)时,必须通过系统调用(System Call),让操作系统帮忙执行。
用户态程序(如 Python 脚本): 打开文件 → 调用 open() 函数↓ 触发系统调用(进入内核态)
内核态: 执行具体文件打开操作 → 分配资源↓ 完成后返回用户态
继续运行程序
# 这个切换称为 "陷入(Trap)"操作,通常代价较高,因此系统设计中会尽量减少频繁切换
# 除了系统调用,异常中断、外围设备中断也会切换
拓展: Intel Meltdown 是 2018 年初公开披露的一个严重的硬件级漏洞,它利用了现代 CPU 在执行 "推测执行(speculative execution)" 过程中存在的安全缺陷,允许低权限的用户进程访问原本只能由操作系统内核访问的敏感信息。Meltdown 可以让普通程序读取内核的内存数据,这意味着你可以不经授权偷看到密码、密钥、甚至其他进程的数据。利用点: 推测执行 + 缓存侧信道。现代 CPU 会为了提速,提前执行一些指令,哪怕程序路径还没被确认(称为推测执行)。虽然这些指令会在判断错误时被 "撤销",但它们造成的缓存行为却不会被撤销。攻击者就可以通过缓存侧信道(cache side-channel)技术推断出本不该看到的数据。内核与用户的隔离被破坏: 正常情况下,用户态程序访问内核态内存时会抛出异常。但 Meltdown 能通过如下步骤绕过这种限制:
- 访问内核内存地址(这本应抛异常);
- 利用推测执行,CPU 在异常发生前执行了后续指令;
- 这些后续指令读取内核内存中的值,并通过特定方式(如加载特定数组)将值泄露到缓存;
- 攻击者随后通过精确的缓存时间测量(Flush+Reload 技术)获取数据。
受影响处理器:
- 大多数 Intel CPU(2006 年后);
- 少部分 ARM 架构处理器;
- AMD 处理器 大多数不受影响(结构差异)。
- 操作系统层面:所有主流操作系统(Windows、Linux、macOS)都需紧急打补丁防止信息泄露。
应对方式:
- KPTI(Kernel Page Table Isolation):分离内核和用户页表,防止用户程序访问内核空间的虚拟地址。
- 硬件修复:Intel 后续 CPU 在硬件层面做了防护设计(如 Cascade Lake、Ice Lake 等系列)。
- 性能影响:KPTI 补丁导致系统调用与上下文切换的性能下降,尤其在频繁 I/O 的服务端场景中较明显。
补充:
| 概念 | 简要说明 |
|---|---|
| 推测执行 | CPU 提前执行分支路径以提升速度,但结果可能被撤销 |
| 缓存侧信道攻击 | 通过分析 CPU 缓存行为(如访问延迟)推断敏感信息 |
| Flush+Reload | 一种经典的缓存探测技术,判断数据是否在缓存中 |
| KPTI | Linux 提出的隔离内核空间的补丁,全名 “Kernel Page Table Isolation” |
小结: Meltdown 本质是硬件实现中 "安全性换性能" 的副作用;它突破了用户态与内核态的隔离墙,是现代 CPU 架构中一个严重设计缺陷;虽已修复,但它开启了对 "硬件层安全性" 的广泛重视,之后爆发的 Spectre、Foreshadow 等漏洞也是延伸。
1.10 基础概念
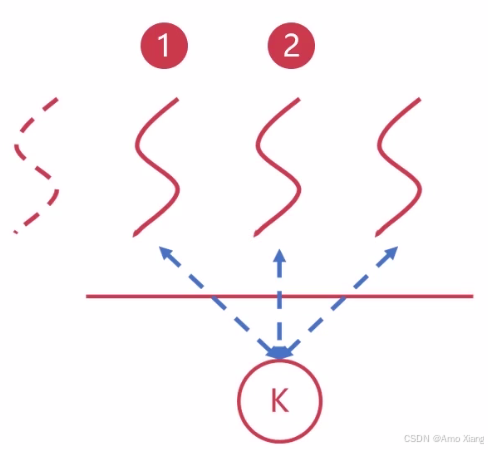
1.10.1 并行与并发
这两个词经常一起出现,看似相似,其实在计算机领域各有不同含义。

并发(Concurrency): 逻辑上的同时进行。多个任务在同一时间段交替执行,但不一定真正同时进行。就像你一个人炒菜、看剧、回复微信 —— 看起来这些事都在 "同时" 进行,但你其实是在不断切换注意力。并发的重点是:切换执行。应用场景:
- 单核 CPU 通过任务切换实现多个任务
"并行运行"的效果。 - Web 服务同时处理多个客户端请求(异步编程场景常见)。
并行(Parallelism): 物理上的同时进行。多个任务在同一时刻真正地同时运行,依赖多个处理器核心支持。比如两个人同时在厨房,一个做饭、一个洗菜,这是真正的同时进行。并行的重点是:同时执行。应用场景:
- 多核 CPU 执行多线程程序,各线程分配到不同 CPU 核上。
- 科学计算、图像渲染等需要高计算量任务。
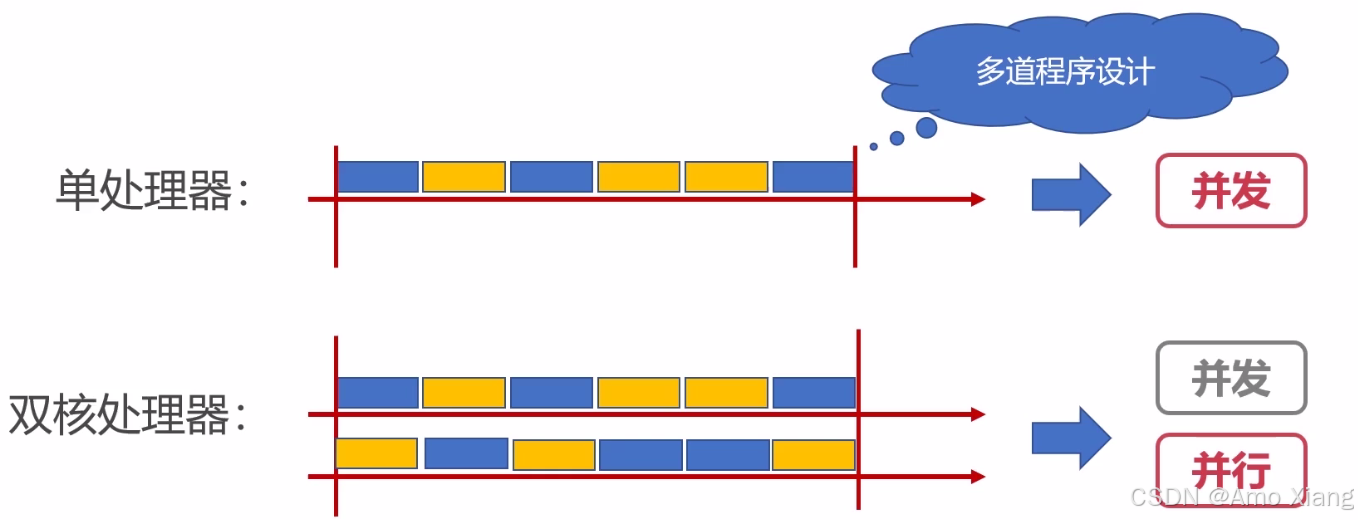
这张图非常直观地说明了 并发(Concurrency)与并行(Parallelism) 的本质区别:
-
单处理器(单核CPU):虽然系统中有多个任务(蓝色和黄色块分别代表两个任务),但由于只有一个核心,它在某一时刻只能执行一个任务。通过时间片轮转的方式快速切换任务,让用户感觉多个任务
"同时"执行。实际上是"交替执行"→ 这是并发(Concurrency)。 -
双核处理器(多处理器):有两个物理核心,系统可以真正同时执行两个任务。蓝色任务与黄色任务各在线程或进程中独立运行。所以这里既有
"多个任务在时间上交错"→ 并发;又有"多个任务在空间上同时执行(由多个物理资源并行完成任务)"→ 并行。
小结:并行是指两个或多个事件可以在 "同一时刻" 发生,并发是指两个或多个事件可以在 "同一个时间间隔" 发生。在传统的并发系统中,不论事件是 "在同一时刻真正同时发生",还是 "在某段时间内交替执行",都被统一称为 "并发系统"。
1.10.2 同步与异步
这两个概念描述的是:任务之间的等待与执行关系,尤其是在程序调用过程中的 "谁等谁"。
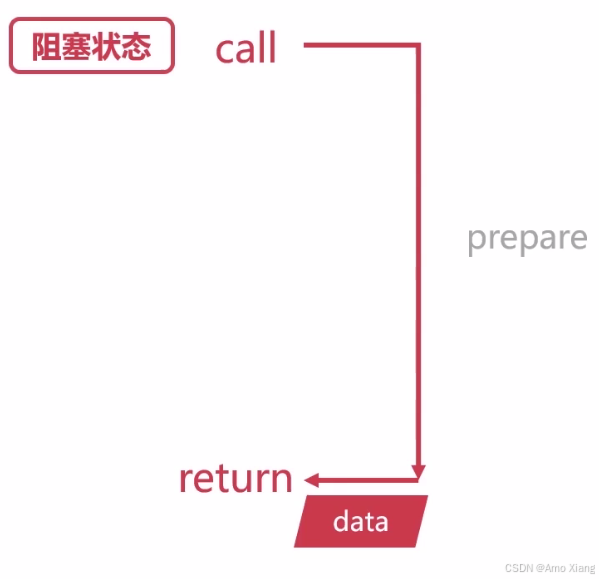
同步(Synchronous)—— 你等我做完。发出一个请求后,必须等待其完成后才能继续做下一件事。类比生活:你去餐馆点餐,必须等厨师做好菜、端上桌后你才能吃,期间你啥都不能干。程序中,调用方必须等待结果返回,整个线程阻塞在原地。
异步(Asynchronous)—— 你先忙,我回头看结果。发出请求后,不用等结果,可以先做别的事,等任务完成了再来处理结果。类比生活:你点了外卖,转头继续打游戏,外卖送到后响铃通知你。程序中,调用方不会阻塞,可以继续执行其他任务,等结果准备好后再处理。
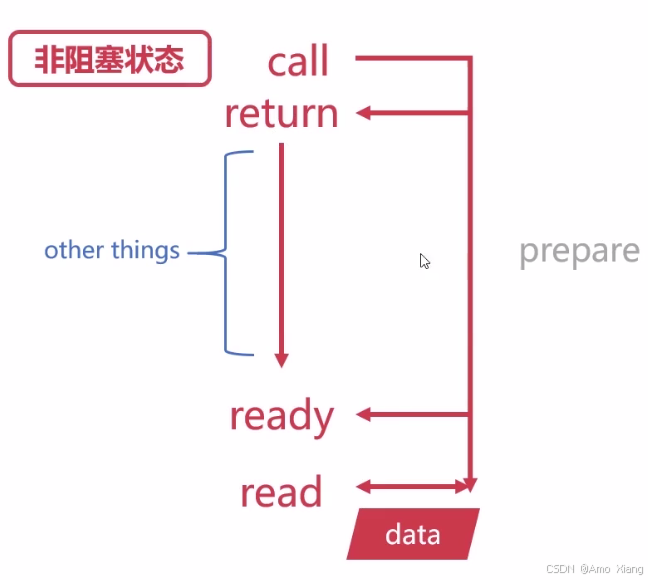
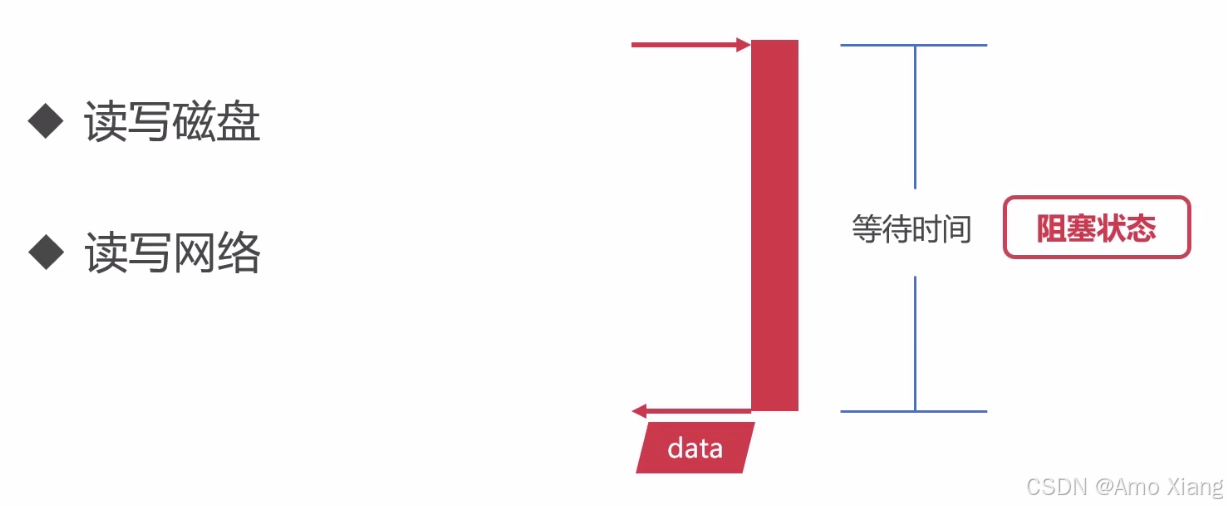
读写磁盘、读写网络(同步):
读取数据(异步):
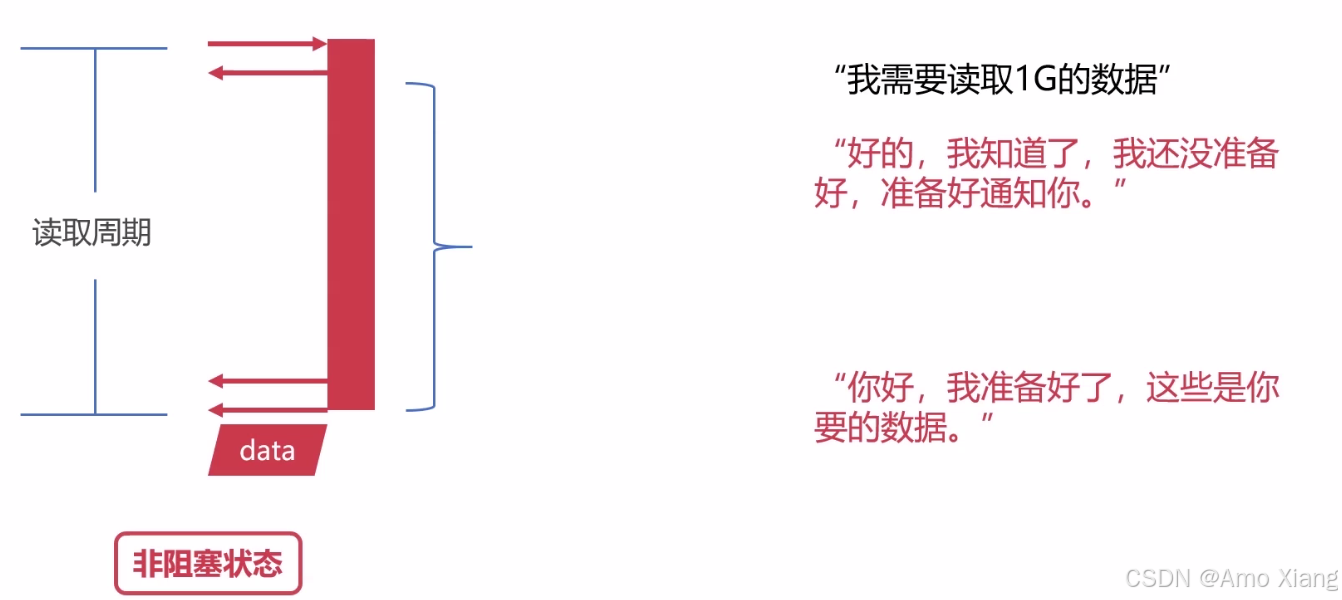
异步是如何实现的?也就是说这个通知是怎么样去完成的,这个是后面我们要学习的内容了(协程),我们后面的编程模型里面重点来看这个异步,这个协程是怎么实现的,这里面涉及比较多的操作系统实践以及 IO 多路复用,信号等等的一些知识,这个问题留到后面来具体的去解决,这里先卖一个关子。同步和异步强调的是 "消息通信机制",阻塞和非阻塞强调的是 "程序在等待调用结果时的状态"。
现实类比:同步 vs 异步 vs 并发 vs 并行
| 类别 | 类比场景 |
|---|---|
| 同步 | 排队买票,每人必须等前面人买完 |
| 异步 | 网络购票,下单后等短信通知 |
| 并发 | 一个柜员轮流为多个顾客服务 |
| 并行 | 多个柜员同时服务多个顾客(并行窗口) |
1.10.3 计算密集型与IO密集型
1.10.3.1 计算密集型(CPU-bound)
程序主要消耗 CPU 的计算资源,几乎不涉及磁盘、网络等慢速设备。特点:
- CPU 使用率非常高,基本没有等待。
- 程序大部分时间都在执行计算(如数学运算、逻辑判断)。
- 在 Python 中,受 GIL 限制,适合使用多进程提升性能。
常见场景:
- 图像处理、视频渲染
- 大数据计算
- 加解密算法
- 科学模拟与建模
示例代码(判断素数个数):
def is_prime(n):for i in range(2, n):if n % i == 0:return Falsereturn Truedef count_primes(limit):count = 0for i in range(2, limit):if is_prime(i):count += 1return countcount_primes(100000)
1.10.3.2 I/O 密集型(IO-bound)
程序大部分时间在等待外部资源的响应,比如文件、网络、数据库等。特点:
- CPU 等待 I/O 响应,利用率低。
- 并发执行多个 I/O 操作可显著提升效率。
- 在 Python 中适合使用 多线程或协程(异步)。
常见场景:
- 网络请求(如爬虫)
- 文件读写
- 数据库查询
- Web 后端处理请求
1.10.3.3 使用 sysstat 工具分析计算密集型 vs I/O 密集型
安装 sysstat 工具包(如未安装):
sudo apt install sysstat # Debian/Ubuntu
sudo yum install sysstat # CentOS/RHEL# 检查是否安装成功
sar -h
sar -u: 查看 CPU 使用情况。举例:sar -u 1 5,每 1 秒采样一次,共采样 5 次。常见输出字段:
| 字段 | 含义 |
|---|---|
%user | 用户空间占用的 CPU 百分比(运行应用程序) |
%nice | 用户进程(niced)所占用 CPU 百分比 |
%system | 内核(系统调用)占用的 CPU 百分比 |
%iowait | 等待 I/O 操作的时间比例 |
%steal | 被其他虚拟机偷走的 CPU 时间(虚拟化环境中常见) |
%idle | 空闲 CPU 百分比(未用于处理任务) |
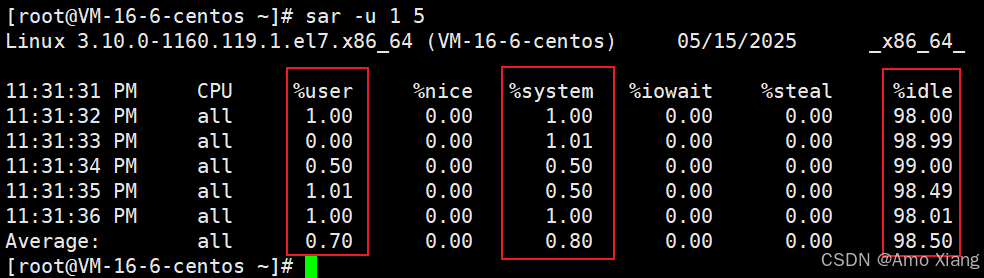
用途举例:%user 高 → 程序计算密集,%iowait 高 → 程序 I/O 密集,%idle 高 → 系统很空闲。测试 《1.10.3.1 计算密集型(CPU-bound)》 小节的 《示例代码(判断素数个数)》,执行程序前:
执行程序后:
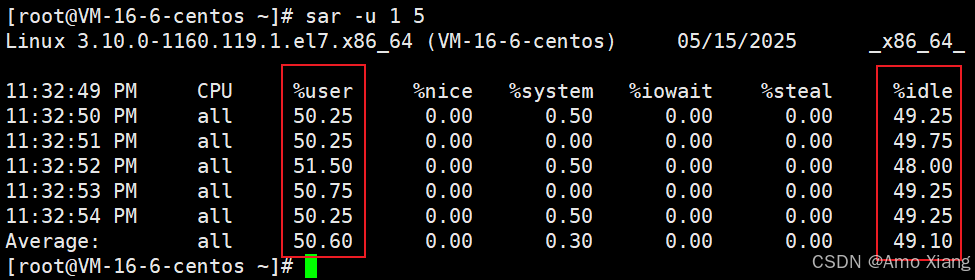
对比程序执行前后,看出该程序属于计算密集型。
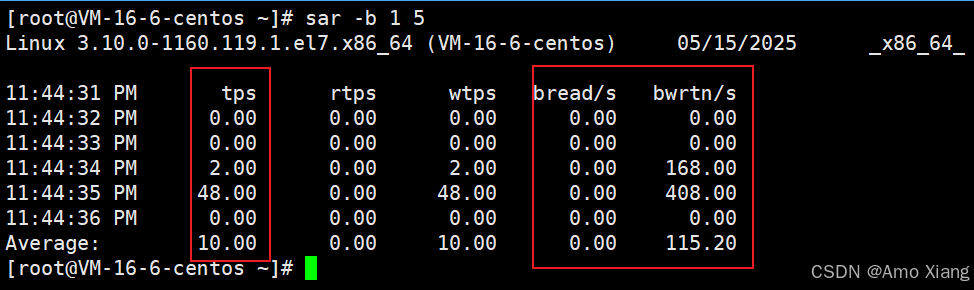
sar -b:查看块设备 I/O 状况(即磁盘读写)。 举例:sar -b 1 5,每 1 秒采样一次,共采样 5 次。常见输出字段:
| 字段 | 含义 |
|---|---|
tps | 每秒传输次数(读+写请求总和) |
rtps | 每秒读请求数(Read Transfers Per Second) |
wtps | 每秒写请求数(Write Transfers Per Second) |
bread/s | 每秒从块设备读取的数据(单位:块) |
bwrtn/s | 每秒向块设备写入的数据(单位:块) |
用途举例:tps 很高 → 系统磁盘 I/O 活跃,bread/s、bwrtn/s 高 → 读写频繁 → 可能是 I/O 密集型程序。执行程序前:
示例:I/O 密集型 Python 程序(模拟大量磁盘读写)
# -*- coding: utf-8 -*-
# @Time : 2025-05-15 23:42
# @Author : AmoXiang
# @File : io_intensive.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import os
import timedef generate_large_file(filename, size_mb):"""生成指定大小的文件(单位:MB)"""with open(filename, 'wb') as f:f.write(os.urandom(size_mb * 1024 * 1024))def read_file_repeatedly(filename, repeat):"""重复读取文件以制造磁盘读压力"""for _ in range(repeat):with open(filename, 'rb') as f:while f.read(1024 * 1024): # 每次读取1MBpassdef io_intensive_task():filename = "test_io_file.dat"file_size_mb = 200 # 创建一个 2000MB 的文件repeat_times = 20 # 重复读取文件20次print(f"正在生成 {file_size_mb}MB 文件...")generate_large_file(filename, file_size_mb)print("开始进行大量文件读取...")start = time.time()read_file_repeatedly(filename, repeat_times)end = time.time()print(f"读取完成,耗时 {end - start:.2f} 秒。")os.remove(filename)print("清理完毕。")if __name__ == "__main__":io_intensive_task()
检测结果:
[root@VM-16-6-centos ~]# sar -b 1 10
Linux 3.10.0-1160.119.1.el7.x86_64 (VM-16-6-centos) 05/15/2025 _x86_64_ (2 CPU)11:56:32 PM tps rtps wtps bread/s bwrtn/s
11:56:33 PM 0.00 0.00 0.00 0.00 0.00
11:56:34 PM 0.00 0.00 0.00 0.00 0.00
11:56:35 PM 0.00 0.00 0.00 0.00 0.00
11:56:36 PM 0.00 0.00 0.00 0.00 0.00
11:56:37 PM 51.00 0.00 51.00 0.00 928.00
11:56:38 PM 777.00 0.00 777.00 0.00 726192.00
11:56:39 PM 557.00 3.00 554.00 64.00 531352.00
11:56:40 PM 570.00 13.00 557.00 920.00 532624.00
11:56:41 PM 588.00 37.00 551.00 4448.00 531344.00
11:56:42 PM 568.00 11.00 557.00 240.00 533616.00
Average: 311.10 6.40 304.70 567.20 285605.60
[root@VM-16-6-centos ~]# sar -u 1 5
Linux 3.10.0-1160.119.1.el7.x86_64 (VM-16-6-centos) 05/15/2025 _x86_64_ (2 CPU)11:56:45 PM CPU %user %nice %system %iowait %steal %idle
11:56:46 PM all 1.01 0.00 7.58 43.43 0.00 47.98
11:56:47 PM all 1.01 0.00 7.54 45.73 0.00 45.73
11:56:48 PM all 1.01 0.00 19.19 33.84 0.00 45.96
11:56:49 PM all 3.05 0.00 54.82 3.05 0.00 39.09
11:56:50 PM all 0.50 0.00 50.25 0.00 0.00 49.25
Average: all 1.31 0.00 27.85 25.23 0.00 45.61
对比程序执行前后,看出该程序属于 IO 密集型。
二、深入探讨线程与进程
2.1 进程
2.1.1 操作系统的进程
为什么操作系统需要进程? 在早期的计算机系统中,计算资源是由整个程序独占的。一个程序执行完之后,才能开始另一个程序。这种串行的方式效率极低,浪费资源。为了解决这个问题,操作系统引入了 "进程(Process)" 的概念,用于实现多道程序设计:即多个程序看起来 "同时" 运行,提高系统资源利用率和响应能力。什么是进程(Process)? 进程是程序的一次执行过程,是操作系统进行资源分配和调度的基本单位。它具有独立的地址空间,并包含程序代码、数据、堆栈和一些状态信息(如程序计数器、寄存器内容等)。程序是静态的代码,进程是动态的执行实体。 Windows 下的进程:
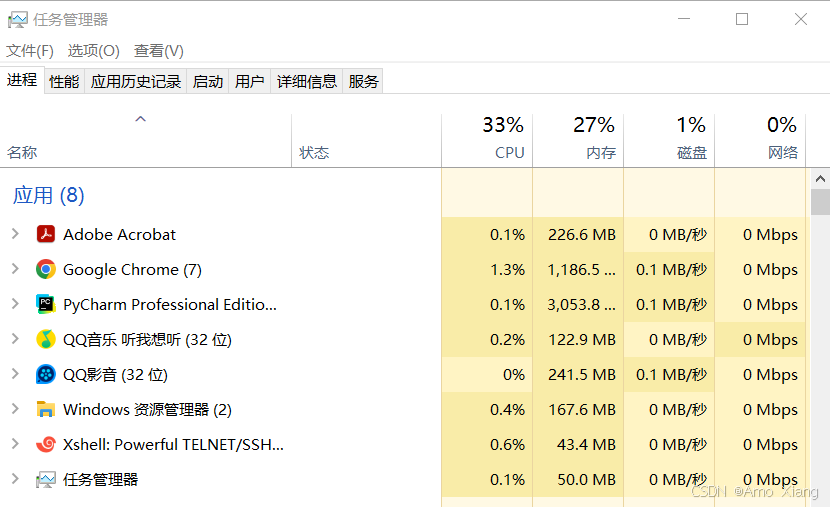
可以看到进程是要使用资源的,比如 CPU、内存、磁盘、网络。进程的作用:
| 功能 | 说明 |
|---|---|
| 资源隔离 | 每个进程拥有独立的内存空间、打开的文件等,防止互相干扰,提高系统稳定性和安全性 |
| 调度单位 | 进程是 CPU 调度的基本单位,操作系统通过调度进程实现 "并发" 执行。 |
| 程序运行载体 | 程序本身是静态代码,只有作为进程被操作系统调度后才具有 "动态运行能力"。进程作为程序独立运行的载体保障程序正常执行 |
| 支持多任务 | 每个任务都可以由一个或多个进程完成,实现多任务并发执行 |
进程的形态:

虚拟地址空间(Virtual Address Space): 每个进程都运行在自己的虚拟地址空间中,这是操作系统为每个进程构造的一个独立的、统一的地址环境。典型的 32 位进程虚拟地址空间划分(简化):
+---------------------------+ 0xFFFFFFFF
| 内核空间 | <-- 内核态访问
| 内核代码 / 栈 / 数据等 |
| …………………… |
| 用户态不可访问 |
+---------------------------+ 0xC0000000
| 用户空间 | <-- 用户态访问
| 栈区(Stack) |
| 堆区(Heap) |
| BSS、数据段、代码段 |
+---------------------------+ 0x00000000
用户态视角(User Mode): 用户态是程序正常运行时的状态,程序在用户态下通过 "进程" 形式存在。用户程序不能直接操作硬件(如磁盘、网卡),必须通过 "系统调用" 进入内核。用户只看到 "进程" 的逻辑概念:如运行中、挂起、等待状态。
+-----------------+ 高地址
| 栈区 Stack | --> 函数调用相关信息、局部变量、返回地址等
+-----------------+
| 堆区 Heap | --> 动态分配的内存(malloc/new)
+-----------------+
| BSS 段(未初始化的全局/静态变量)|
+-----------------+
| 数据段(已初始化的全局/静态变量)|
+-----------------+
| 代码段(Text) | --> 程序的机器指令(只读)
+-----------------+ 低地址
各部分说明:
| 区域 | 功能描述 |
|---|---|
| 代码段(Text) | 存储程序的可执行指令,通常是只读的 |
| 数据段(Data) | 存储已初始化的全局变量和静态变量 |
| BSS段 | 存储未初始化的全局变量和静态变量,系统在运行时会将其清零 |
| 堆区(Heap) | 用于动态内存分配,大小可变,程序员手动分配和释放(如malloc、free) |
| 栈区(Stack) | 用于函数调用时保存临时数据(如返回地址、参数、局部变量等),由系统自动管理,向下增长 |
内核态视角(Kernel Mode): 内核态是操作系统特权级最高的状态,操作系统通过 PCB(进程控制块) 来管理每个进程。PCB 是内核中用于描述进程的结构体,包含该进程的所有 "管理信息"。内核态中进程的内容(主要指 PCB 包含的内容):
┌─────────────────────────────┐
│ Process ID (PID) │
├─────────────────────────────┤
│ Process State │
├─────────────────────────────┤
│ Program Counter (PC) │
├─────────────────────────────┤
│ CPU Registers (R1~Rn) │
├─────────────────────────────┤
│ Priority / Scheduling │
├─────────────────────────────┤
│ Memory Management Info │
├─────────────────────────────┤
│ I/O & File Descriptors │
├─────────────────────────────┤
│ Parent / Child Pointers │
└─────────────────────────────┘
即:
| 类别 | 描述 |
|---|---|
| 进程标识信息 | 进程 ID(PID)、父进程 ID(PPID)、用户 ID(UID)等 |
| 处理器状态信息(上下文) | 程序计数器 PC、通用寄存器、程序状态字 PSW |
| 进程状态 | 就绪、运行、等待、终止等 |
| 调度和优先级信息 | 进程优先级、调度策略、时间片等 |
| 内存管理信息 | 页面表、段表、内存映射区、代码/数据段起止地址等 |
| 资源管理信息 | 打开文件列表、I/O 设备、信号量、管道、消息队列等 |
| 会计信息(统计信息) | CPU 时间、内存使用量、创建时间、终止时间等 |
用户态(User Mode)与内核态(Kernel Mode):
| 状态 | 权限 | 描述 |
|---|---|---|
| 用户态 | 受限(不能访问内核资源) | 正常用户程序运行时所处的状态 |
| 内核态 | 高权限(可访问全部资源) | 执行系统调用、中断处理时所处的状态 |
状态切换场景:
- 系统调用:如 read()、write(),用户态 → 内核态。
- 中断/异常处理:发生硬件中断时自动进入内核态。
- 进程调度:上下文切换由内核在内核态中进行。
在废话一下,为什么要分用户空间与内核空间?
| 原因 | 解释 |
|---|---|
| 安全性 | 防止用户程序破坏操作系统或访问敏感资源。 |
| 稳定性 | 用户进程崩溃不会影响整个系统运行。 |
| 隔离性 | 每个进程拥有独立用户空间,避免互相干扰。 |
| 权限控制 | 实现最小权限原则,提升系统安全和可靠性。 |
进程的形态小结:
- 用于描述和控制进程运行的通用数据结构
- 记录进程当前状态和控制进程运行的全部信息
- PCB 使得进程可以能够独立的运行
2.1.2 进程的五状态模型
进程在生命周期中会随着资源申请、调度、等待等状态的变化,在五种状态之间切换:
① 创建(New): 进程正在被创建,尚未被操作系统接纳投入调度队列。此时系统会初始化进程控制块(PCB),分配资源(如内存、PID)。分配 PCB ⇒ 插入就绪队列,创建进程时拥有 PCB 但其他资源尚未就绪的状态称为创建状态,操作系统提供 fork 函数接口创建进程。
② 就绪(Ready): 进程已经完成创建,等待操作系统调度器将它分配到 CPU 上运行。就绪进程可能很多,通常存放在 就绪队列 中,等待轮到它执行。即当进程被分配到除 CPU 以外所有必要的资源后,只要再获得 CPU 的使用权,就可以立即运行,其他资源都准备好,只差 CPU 资源的状态为就绪状态。

③ 运行(Running): 进程正在被 CPU 执行,此时它获得了 CPU 的控制权。在单核 CPU 中,同一时间只有一个进程处于 "运行态";多核 CPU 则可有多个运行进程。
④ 阻塞(Blocked)/ 等待(Waiting): 进程因等待某些事件(如 I/O、信号量)而暂时不能继续执行。例如读取磁盘、等待键盘输入,进程就会从运行态 → 阻塞态。即进程因某种原因如:其他设备未就绪而无法继续执行,从而放弃 CPU 的状态称为阻塞状态。

⑤ 终止(Terminated)/ 完成(Exit): 进程运行完毕或发生错误、被操作系统或用户强制终止后,进入此状态。操作系统会清理该进程占用的资源,销毁其 PCB。系统清理 ⇒ PCB 归还,即进程结束由系统清理或者归还 PCB 的状态称为终止状态。
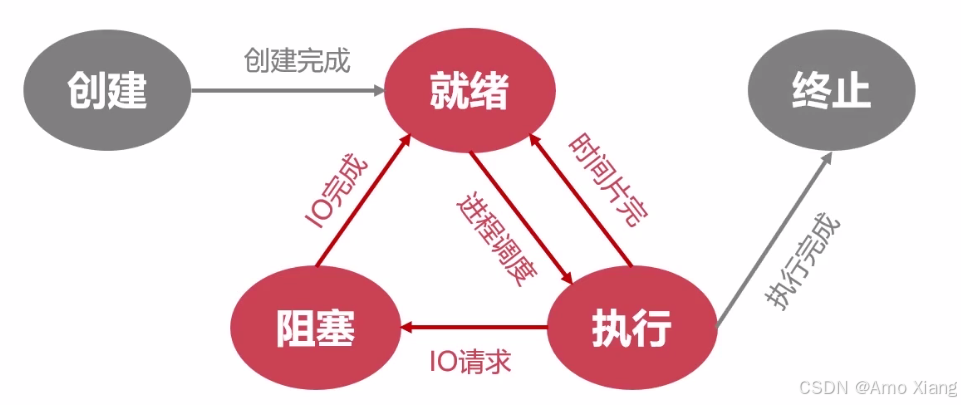
2.1.3 进程的调度方式
进程的优先级是有差异的,CPU 资源如何公平分配?即进程的调度方式,也称为调度算法,进程调度前提:多道程序设计、CPU 资源有限。
什么是抢占 vs 非抢占? 非抢占式调度(Non-preemptive Scheduling): 一旦某个进程获得了 CPU 就一直执行下去,直到它主动释放 CPU(运行结束或阻塞)。其他进程无法中途抢走 CPU。
| 算法名 | 简介 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 先来先服务(FCFS,First-Come First-Served) | 按进程到达时间顺序调度 | 简单易实现 | 对长任务不友好,平均等待时间长 | 批处理系统 |
| 最短作业优先(SJF,Shortest Job First) | 选择服务时间最短的进程执行 | 维护的就绪队列始终规模较小,平均等待时间最短,提高系统吞吐量 | 不知道确切执行时间,易饿死长任务 | 预测精度高的任务场景 |
| 最高响应比优先(HRRN,Hight Response Ratio Next) | 选择响应比最高的进程(考虑等待+服务时间) 响应比 = (等待时间 + 服务时间) / 服务时间 | 综合公平与效率,不饿死长作业 | 实现略复杂,需要计算响应比 | 批处理系统、调度公平性高的系统 |
| 优先级调度(静态) | 按事先设定的优先级调度 | 实现简单 | 容易导致低优先级任务饥饿 | 管理类系统 |
抢占式调度(Preemptive Scheduling): 操作系统可以在任何时刻中断当前进程,将 CPU 分配给其他更高优先级或等待时间更长的进程。如时间片轮转、优先级调度等。进程拥有优先级 ⇒ 优先级作为调度的参考
| 算法名 | 简介 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 短进程优先抢占式(Preemptive SJF)/最短剩余时间优先(SRTF) | 当前进程剩余时间比新进程长则被抢占 | 理论上等待时间最短 | 高开销,难以预估服务时间 | 实时计算负载环境 |
| 优先级调度(动态) | 按动态优先级调度,高优先级可抢占低优先级进程 | 控制灵活,可实现实时响应 | 饥饿问题,需老化机制 | 实时系统 |
| 时间片轮转(Round Robin) | 给每个进程分配一个时间片,轮流执行 | 公平性高,响应快 | 时间片太小切换频繁;太大则像FCFS | 多任务系统,交互系统 |
| 多级反馈队列调度(MFQ) | 综合使用多个优先级队列,执行完未完成任务逐步降低优先级,结合RR与优先级 | 灵活适配各种类型任务 | 实现复杂 | 操作系统常用调度策略(如Linux) |
2.2 线程
2.2.1 操作系统的线程
什么是线程(Thread)? 线程(Thread)是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。一个进程至少有一个线程(主线程),也可以创建多个线程来并发执行任务。

-
一个进程 = 至少一个线程
-
多线程共享进程的资源(如内存空间、文件描述符)
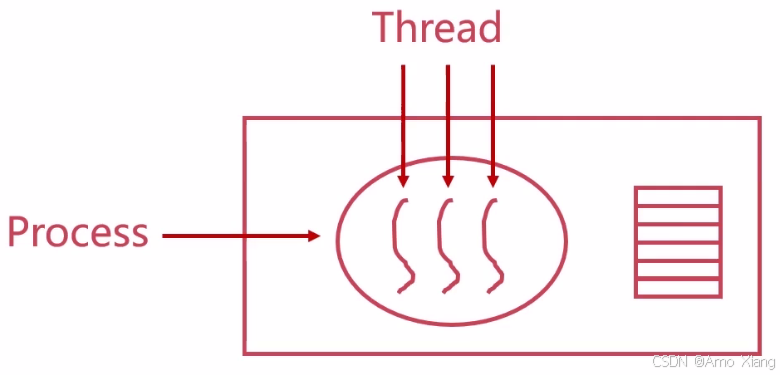
为什么需要线程? 线程是为了解决进程开销大、并发效率低的问题(提高系统内程序并发执行的程度):
多线程可提升程序响应速度(如 UI 界面不卡顿)
利于资源共享与通信(如共享内存数据结构)
更适合处理 I/O 密集型任务(如下载、数据库查询)
线程控制块 TCB(Thread Control Block): TCB 是用于管理线程的控制块,记录一个线程的运行状态和上下文,是线程调度、管理的基础。⚠️ 注意:多个线程可以共享一个进程的 PCB,因为线程是进程内的最小执行单元,共享资源。TCB 主要内容:
| 类别 | 说明 |
|---|---|
| 线程标识信息 | 线程 ID(TID)、所属进程 ID(PID) |
| 线程状态 | 就绪、运行、等待、终止等 |
| 寄存器状态 | 程序计数器、堆栈指针、工作寄存器 |
| 栈信息 | 每个线程有自己独立的栈空间 |
| 调度信息 | 优先级、时间片、线程调度队列指针等 |
| 信号或事件管理 | 阻塞状态下等待的信号、互斥量等 |
PCB 与 TCB 的关系:
+---------------------+ +--------------------+
| PCB(进程) |<----------| 多个 TCB(线程) |
+---------------------+ +--------------------+
| PID、状态、资源信息 | | TID、堆栈、寄存器等 |
| 内存空间(共享) |<--------->| 局部栈(私有) |
+---------------------+ +--------------------+
线程与进程的对比:
| 特征 | 进程(Process) | 线程(Thread) |
|---|---|---|
| 定义 | 系统资源分配的基本单位 | CPU调度的基本单位 |
| 是否独立 | 相互独立 | 同一进程内共享资源 |
| 拥有地址空间 | ✅ 每个进程有独立空间 | ❌ 同一进程内线程共享地址空间 |
| 创建开销 | 大 | 小 |
| 切换开销 | 大(切换需上下文完整切换) | 小(部分共享) |
| 通信方式 | 通常使用 IPC(如管道、消息队列) | 共享内存通信,更高效 |
2.2.2 线程的实现方式
线程的实现方式主要有三种类型:用户级线程(User-Level Thread, ULT)、内核级线程(Kernel-Level Thread, KLT)、混合线程(Hybrid Thread)。下面我们来详细讲解它们的结构、特点、优缺点及适用场景。
用户级线程(ULT): 线程由用户空间的线程库管理(如 pthread、green thread 等)。操作系统内核并不感知线程的存在,只管理进程。特点:
| 特征 | 说明 |
|---|---|
| 切换开销 | ✅ 线程切换非常快,不涉及内核态 |
| 并发能力 | ❌ 一个进程中多个线程 共享一个内核线程,多核 CPU 下无法并行 |
| 系统调用阻塞 | ❌ 一个线程阻塞会导致整个进程阻塞 |
| 灵活性 | ✅ 应用程序可自定义调度算法 |
优点: 切换代价小,可在不支持线程的操作系统上实现。缺点: 多线程不是真正的并行,一旦线程阻塞,整个进程都会阻塞。
内核级线程(KLT): 线程完全由操作系统内核管理,线程的创建、调度、同步、销毁等都在内核完成。每个用户线程都有一个对应的内核线程。特点:
| 特征 | 说明 |
|---|---|
| 切换开销 | ❌ 线程切换涉及用户态/内核态切换,开销较大 |
| 并发能力 | ✅ 多线程可同时在多个 CPU 上并行执行 |
| 系统调用阻塞 | ✅ 某线程阻塞不会影响其他线程 |
| 调度方式 | 由操作系统统一调度,较为公平、稳定 |
优点: 真正的并发执行,系统级调度更高效,线程阻塞不会影响全局。缺点: 切换开销大,创建和销毁成本高。
混合线程 / 组合线程(Hybrid Threading): 结合用户级线程和内核级线程的优点。每个用户线程绑定在一个或多个内核线程上,通常采用 M:N 模型(M个用户线程映射到N个内核线程)。实现示例:Solaris 线程库、Windows 线程池、GNU Portable Threads(Pth)+ LWP(轻量级进程)。特点:
| 特征 | 说明 |
|---|---|
| 并发性 | ✅ 支持多核并行执行 |
| 调度方式 | ✅ 用户级调度灵活 + 内核级调度支持并行 |
| 开销 | ✅ 相对折中,不如ULT快,但比KLT灵活 |
优点: 兼顾了 ULT 和 KLT 的优势,更灵活的调度策略。缺点: 实现复杂,不同系统实现细节差异大。
总结对比表:
| 特性 / 类型 | 用户级线程(ULT) | 内核级线程(KLT) | 混合线程(Hybrid) |
|---|---|---|---|
| 是否依赖内核支持 | 否 | 是 | 是 |
| 切换开销 | 最小 | 最大 | 中等 |
| 并发能力 | 无 | 有 | 有 |
| 阻塞影响 | 整个进程 | 不影响其他线程 | 不影响其他线程 |
| 实现复杂度 | 简单 | 中等 | 复杂 |
| 调度机制 | 用户态 | 内核态 | 双重调度 |
线程模型分类:
| 模型 | 描述 |
|---|---|
| 1:1 模型 | 每个用户线程对应一个内核线程。真实并发,受限于内核调度。 |
| M:1 模型 | 多个用户线程映射到一个内核线程。线程由用户态调度,内核不感知。 |
| M:N 模型 | 多个用户线程映射到多个内核线程。较为灵活,但实现复杂。 |
常见语言线程模型对比:
| 编程语言 | 默认线程模型 | 实现方式/线程库 | 是否支持真实并发 | 模型说明 |
|---|---|---|---|---|
| C/C++ | 1:1 | POSIX Threads(pthreads) | ✅ | 使用 OS 提供的内核线程 |
| Java | 1:1 | Java Threads(映射到 native threads) | ✅ | Java 的线程由 JVM 调用本地线程库(如 pthread) |
| Python(CPython) | 1:1(但限制) | threading 模块 + GIL | ❌ | 存在 GIL,全局解释器锁限制多线程并发,仅适合 I/O 密集型 |
| Go | M:N | Goroutines + 调度器(GMP 模型) | ✅ | 用户级线程,由 Go runtime 管理调度 |
| Rust | 1:1 / M:N | 默认使用 OS 线程;支持 async(协程)模型 | ✅ | 低层支持原生线程,也可基于 async 实现 M:N |
| Erlang | M:N | Erlang 轻量级进程(绿色线程) | ✅ | 数以千计并发线程,由 Erlang VM 调度 |
| Node.js | M:1 | 单线程事件循环 + worker threads | ❌ | 主线程为单线程,I/O 异步调度 |
| Kotlin(协程) | M:N | 协程(Coroutines)调度到多个线程上 | ✅ | 灵活,适合并发结构清晰的应用 |
拓展与延伸:
- CPython 的线程问题。虽然 Python 使用 1:1 模型,但由于 GIL(全局解释器锁-----后续文章会详细讲解 Python GIL)的存在:多线程无法并行执行 Python 字节码。所以 Python 的 threading 适合 I/O 密集型任务,非 计算密集型。可使用 multiprocessing 模块来实现真正并行。
- Go 的 GMP 模型。G(Goroutine) → M(Machine/内核线程) → P(Processor)Go runtime 实现了用户态调度器,支持数万个协程运行在少量线程上。
- Java 虚拟机(JVM)线程。每个 Thread 映射为一个系统线程,由 JVM 使用系统调用调度。优点是简洁、并发支持强,缺点是线程创建和销毁成本较高。
- Erlang 与 Actor 模型。Erlang 不使用传统线程,而是
"轻量级进程",由 VM 完全调度。极其轻量,适合高并发场景(如电信、消息服务器)。
总结表格:
| 模型 | 语言/平台示例 | 是否真实并发 | 特点 |
|---|---|---|---|
| 1:1 | C/C++ (pthreads), Java, Rust(默认) | ✅ | 每个线程由 OS 管理,开销大,易于编程 |
| M:1 | 旧版 Python Greenlet、Node.js 主线程 | ❌ | 用户态调度,不能多核并行 |
| M:N | Go, Erlang, Kotlin 协程, Rust async | ✅ | 高效并发,调度复杂 |
2.2.3 进程与线程的上下文切换
上下文切换是指: CPU 在多个任务(进程/线程)之间切换执行时,保存当前任务的状态,并恢复另一个任务状态的过程。
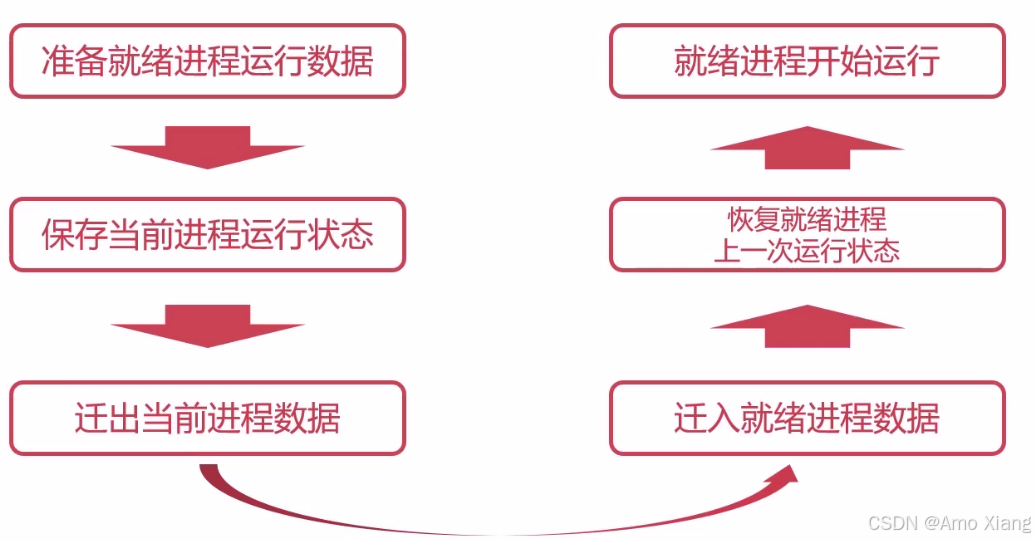
进程上下文切换(Process Context Switch),涉及内容:
- CPU 寄存器内容(程序计数器 PC、通用寄存器)
- 内存管理相关信息(页表)
- 系统资源描述符(文件描述符、I/O 状态等)
- 地址空间的切换(用户空间)
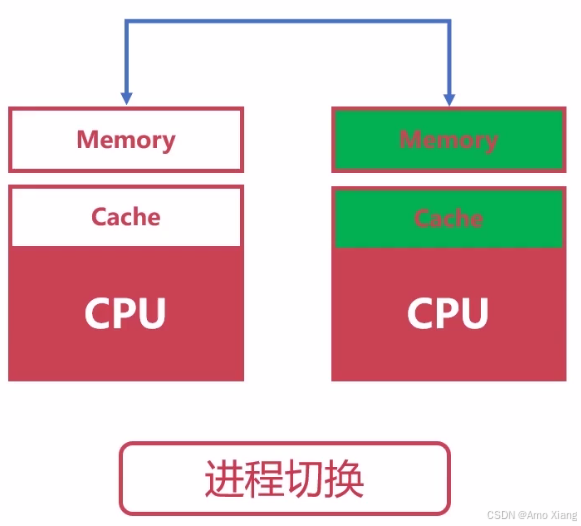
成本较高,因为:需要切换整个虚拟地址空间(MMU 切换页表),缓存(如 CPU cache、TLB)失效,频繁切换可能导致性能下降("上下文切换抖动")
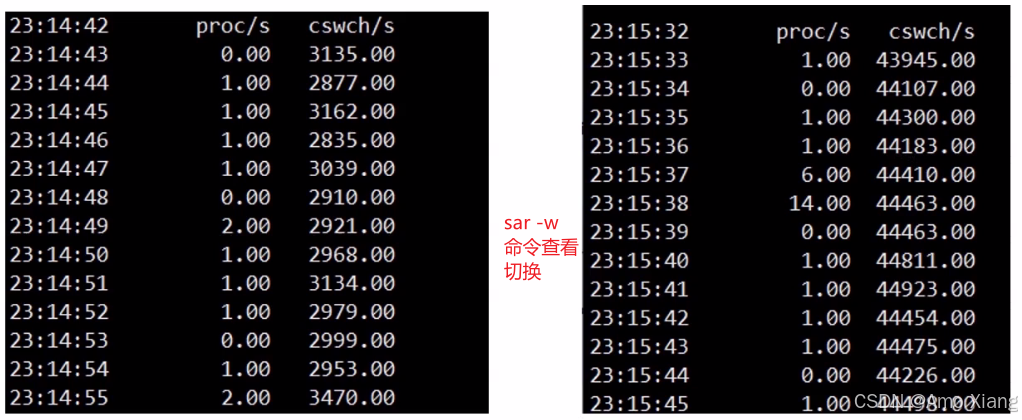
从上图估算切换时间: 2us ~ 5us ⇒ 5us * 40000/1000/8 = 25ms(8核16G)

线程上下文切换(Thread Context Switch): 线程属于进程,多个线程共享:进程的地址空间,打开的文件、全局变量等资源。切换内容:CPU 寄存器、程序计数器、栈指针(因为每个线程有自己的栈),成本较低,不需要切换地址空间,共享资源开销小,切换速度快于进程切换。
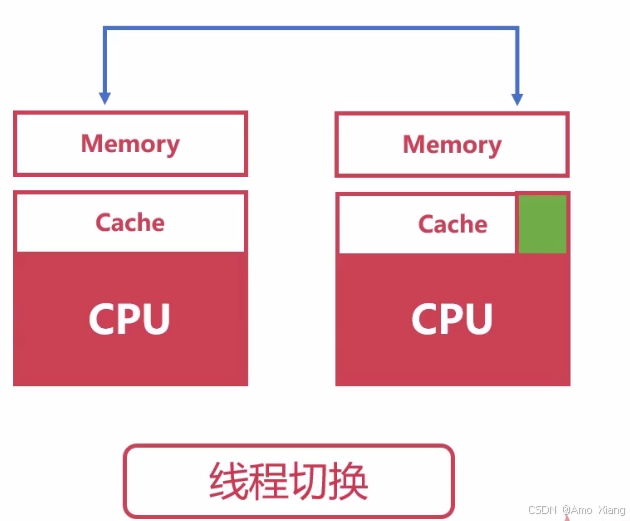
进程 vs 线程 上下文切换对比:
| 对比项 | 进程上下文切换 | 线程上下文切换 |
|---|---|---|
| 是否切换地址空间 | ✅ 是 | ❌ 否(线程共享同一地址空间) |
| 切换粒度 | 粗粒度(整个任务) | 细粒度(任务中的子任务) |
| 切换成本 | 较高(涉及更多寄存器和页表切换) | 较低(寄存器和栈切换) |
| 场景适用 | 独立任务(如数据库、Web服务) | 高并发任务(如网络服务、爬虫) |
实际示意图:
CPU 执行任务时间线(简化): 进程切换:
[进程A执行] → 保存状态 → 切换地址空间 → [进程B执行]线程切换(同一进程):
[线程A执行] → 保存状态 → 切换栈和寄存器 → [线程B执行]
2.3 协程(初步了解)
协程(Coroutine)是一种轻量级的用户态线程,是并发编程模型中的一种核心工具,尤其在 高并发、高IO等待 的场景下表现出色。下面我们来探索协程的本质、原理、优势与使用场景。协程也叫微线程、协作式线程、纤程。

协程的本质是 "协作式调度",协程 ≠ 线程,它的关键在于:协程是由程序主动让出控制权的函数级 "并发单元",通过协作完成切换。不像线程依赖系统调度器,协程是在用户态调度,不涉及内核参与。
协程与线程的对比:
| 特性 | 协程(Coroutine) | 线程(Thread) |
|---|---|---|
| 是否由操作系统管理 | ❌ 否(用户态调度) | ✅ 是(内核态调度) |
| 切换成本 | 极低(仅栈和程序计数器切换) | 较高(涉及上下文切换与地址空间) |
| 并发方式 | 伪并发(单线程内协作) | 真并发(多核同时执行) |
| 是否需要锁 | ❌ 一般不需要(单线程避免竞态) | ✅ 多线程共享资源需加锁 |
| 场景适合 | 高 IO 密集型 | 高计算密集型、多核并行 |
协程的原理与实现机制(后续文章会用代码体现): 协程的核心特征在于:
- 挂起与恢复。协程可以:在某个点 挂起自己(主动让出执行权),被 恢复执行,从挂起点继续,这一点通常通过 保存栈帧、程序计数器 来实现。
- 调度器管理(非抢占式)。协程的调度:不依赖操作系统调度器,通常通过事件循环(Event Loop)或任务队列实现
协程的 "轻量级" 体现在哪?
- 几万个协程常驻内存,远比线程/进程节省资源
- 切换速度快(微秒级)
- 没有线程上下文切换的巨大成本
- 没有锁的问题(协程天生串行执行)
现代编程语言对协程的支持:
| 语言 | 协程支持方式 | 示例库或框架 |
|---|---|---|
| Python | 原生支持(async/await) | asyncio、trio |
| Go | 原生协程(goroutine) | goroutine + channel |
| JavaScript | 异步函数(async/await) | Promise + Event Loop |
| Kotlin | 原生协程 | kotlinx.coroutines |
| Rust | 借助 async runtime | tokio、async-std |
协程适合解决什么问题?
- 网络爬虫、高并发 HTTP 请求
- 高 IO 等待场景,如数据库访问、文件读写
- Web 服务(如 FastAPI)
- 游戏逻辑控制、UI 编程(避免卡顿)
协程的局限:
- 单线程运行,不能利用多核并行
- 计算密集任务会阻塞整个协程调度器
- 协程栈小,但写错容易造成难以调试的 bug
小结: 协程是一种 "用户级线程",通过主动让出控制权,实现高效、低成本的并发执行,非常适合 IO 密集型任务。
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习Python语言的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!
相关文章:

《100天精通Python——基础篇 2025 第19天:并发编程启蒙——理解CPU、线程与进程的那些事》
目录 一、计算机基础知识1.1 计算机发展简史1.2 计算机的分类1.2.1 超级计算机(Supercomputer)1.2.2 大型机(Mainframe Computer)1.2.3 迷你计算机(Minicomputer)---- 普通服务器1.2.4 工作站(W…...

<PLC><视觉><机器人>基于海康威视视觉检测和UR机械臂,如何实现N点标定?
前言 本系列是关于PLC相关的博文,包括PLC编程、PLC与上位机通讯、PLC与下位驱动、仪器仪表等通讯、PLC指令解析等相关内容。 PLC品牌包括但不限于西门子、三菱等国外品牌,汇川、信捷等国内品牌。 除了PLC为主要内容外,相关设备如触摸屏(HMI)、交换机等工控产品,如果有…...

FC7300 WDG MCAL 配置引导
在WDG模块中,用户需要选择GPT资源,因此在配置WDG组件之前,需要先选择GPT通道。WDG包含三个组件,每一个组件对应不同的硬件。 Wdg:对应WDOG0Wdg_174_Instance1:对应WDOG1Wdg_174_Instance2:对应WDOG2一、WDG 组件 1. General Wdg Disable Allowed:是否允许在WDG运行过程…...

Leaflet 自定义瓦片地图与 PHP 大图切图算法 解决大图没办法在浏览器显示的问题
为什么使用leaflet 使用 Leaflet 来加载大图片(尤其是通过瓦片化的方式)是一种高效的解决方案,主要原因如下: 1. 性能优化 减少内存占用:直接加载大图片会占用大量内存,可能导致浏览器崩溃或性能下降。瓦片…...

MySQL——十、InnoDB引擎
MVCC 当前读: 读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。 -- 当前读 select ... lock in share mode(共享锁) select ... for update update insert delete (排他锁)快照读:…...
无法调用,直接卡死,应如何解决)
import pywinauto后tkinter.filedialog.askdirectory()无法调用,直接卡死,应如何解决
诸神缄默不语-个人技术博文与视频目录 具体情况就是我需要用pywinauto进行一些软件的自动化操作,同时需要将整个代码功能用tkinter的可视化界面来展示,在调用filedialog.askdirectory()的时候代码直接不运行了,加载不出来。我一开始还以为是…...

display:grid网格布局属性说明
网格父级 :display:grid(块级网格)/ inline-grid(行内网格) 注意:当设置网格布局,column、float、clear、vertical-align的属性是无效的。 HTML: <ul class"ls02 f18 mt50 sysmt30&…...

初识——QT
QT安装方法 一、项目创建流程 创建项目 入口:通过Qt Creator的欢迎页面或菜单栏(文件→新建项目)创建新项目。 项目类型:选择「Qt Widgets Application」。 路径要求:项目路径需为纯英文且不含特殊字符。 构建系统…...

力扣-78.子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 class Solution {List<List<Integer>> res new ArrayList<>();List<I…...

python中字符串的操作
1. 字符串创建 使用单引号、双引号或三引号创建字符串三引号适用于多行字符串,且可以自由包含单双引号原始字符串使用r前缀,如r’Hello\nWorld’会原样输出\n 2. 基本操作 拼接:使用运算符或join()方法复制:使用*运算符…...

《Elasticsearch 源码解析与优化实战》笔记
术语 思维导图 基础和环境 1-2 主要流程 3-10 内部模块 11-17 优化和诊断 18-22 资料 https://elasticsearchbook.com/...
)
华为网路设备学习-22(路由器OSPF-LSA及特殊详解)
一、基本概念 OSPF协议的基本概念 OSPF是一种内部网关协议(IGP),主要用于在自治系统(AS)内部使路由器获得远端网络的路由信息。OSPF是一种链路状态路由协议,不直接传递路由表,而是通过交换链路…...
)
多线程(四)
目录 一 . 单例模式 (1)什么是设计模式? (2)饿汉模式 (3)懒汉模式 二 . 指令重排序 今天咱们继续讲解多线程的相关内容 一 . 单例模式 (1)什么是设计模式&am…...

【设计模式】- 结构型模式
代理模式 给目标对象提供一个代理以控制对该对象的访问。外界如果需要访问目标对象,需要去访问代理对象。 分类: 静态代理:代理类在编译时期生成动态代理:代理类在java运行时生成 JDK代理CGLib代理 【主要角色】: 抽…...
时,报错type xxx is not json serializable错误原因及解决方案)
python报错:使用json.dumps()时,报错type xxx is not json serializable错误原因及解决方案
文章目录 一、错误原因分析二、解决方案1. **自定义对象序列化方法一:使用default参数定义转换逻辑方法二:继承JSONEncoder类统一处理 2. **处理特殊数据类型场景一:datetime或numpy类型场景二:bytes类型 3. **处理复杂数据结构 三…...

Vue3中实现轮播图
目录 1. 轮播图介绍 2. 实现轮播图 2.1 准备工作 1、准备至少三张图片,并将图片文件名改为数字123 2、搭好HTML的标签 3、写好按钮和图片标签 编辑 2.2 单向绑定图片 2.3 在按钮里使用方法 2.4 运行代码 3. 完整代码 1. 轮播图介绍 首先,什么是…...

flutter缓存网络视频到本地,可离线观看
记录一下解决问题的过程,希望自己以后可以参考看看,解决更多的问题。 需求:flutter 缓存网络视频文件,可离线观看。 解决: 1,flutter APP视频播放组件调整; 2,找到视频播放组件&a…...

2025年Ai写PPT工具推荐,这5款Ai工具可以一键生成专业PPT
上个月给客户做产品宣讲时,我对着空白 PPT 页面熬到凌晨一点,光是调整文字排版就改了十几版,最后还是被吐槽 "内容零散没重点"。后来同事分享了几款 ai 写 PPT 工具,试完发现简直打开了新世界的大门 —— 不用手动写大纲…...

【深度学习】#11 优化算法
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 目录 深度学习中的优化挑战局部极小值鞍点梯度消失 凸性凸集凸函数 梯度下降一维梯度下降学习率局部极小值 多元梯度下降 随机梯度下降随机梯度更新动态学习率…...

数学复习笔记 13
前言 继续做线性相关的练习题,然后做矩阵的例题,还有矩阵的练习题。 646 A 明显是错的。因为假设系数全部是零,就不是线性相关了。要限制系数不全是零,才可以是线性相关。 B 这个说法好像没啥问题。系数全为零肯定线性组合的结…...

AI预测3D新模型百十个定位预测+胆码预测+去和尾2025年5月16日第79弹
从今天开始,咱们还是暂时基于旧的模型进行预测,好了,废话不多说,按照老办法,重点8-9码定位,配合三胆下1或下2,杀1-2个和尾,再杀6-8个和值,可以做到100-300注左右。 (1)定…...

阳台光伏+储能:安科瑞智能计量仪表来助力
随着可再生能源的普及和家庭储能需求的增长,阳台光伏储能系统逐渐成为家庭能源管理的新趋势。如何精准计量储能系统的发电量、用电量及电网交互数据,成为优化能源利用效率的关键。安科瑞计量仪表凭借高精度、多功能及智能化特性,为家庭阳台储…...

Unable to determine the device handle for GPU 0000:1A:00.0: Unknown Error
Unable to determine the device handle for GPU 0000:1A:00.0: Unknown Error 省流:我遇到这个问题重置bios设置就好了 这个错误信息表明系统无法识别或访问GPU(0000:1A:00.0),通常与CUDA、驱动程序或硬件相关。以下是可能的原…...

多态性标记设计
1.确定区间 2.获取该区间内的序列,如果只有一个位置,可以前后扩100bp 使用ncbi primer blast进行引物设计(https://blast.ncbi.nlm.nih.gov/Blast.cgi)...

Jenkins 最佳实践
1. 在Jenkins中避免调度过载 过载Jenkins以同时运行多个作业可能导致资源竞争、构建速度变慢和系统性能问题。分配作业启动时间可以防止瓶颈,并确保更顺畅的执行。如何实现? 在Cron表达式中使用H:引入抖动(jitter)&a…...

如何查询Ubuntu系统中最大的几个目录以G单位显示大小,从大到小排列?
环境: Ubuntu 20,04 问题描述: 如何查询系统中最大的几个目录以G单位显示大小,从大到小排列? 解决方案: 想查看整个系统(单一文件系统内)最大的20个目录,结果按大小从大到小排序…...

深入浅出拆分学习,图神经网络拆分学习,混合联邦学习
深入浅出解析拆分学习(Split Learning)、图神经网络拆分学习(Split Learning for Graph Neural Networks)以及混合联邦学习(Hybrid Federated Learning),这三者都体现了在分布式数据环境下进行机…...

DDD领域驱动介绍
📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、(架构篇)清华大学出版社签约作家、Java领域优质创作者、CSDN博客专家、…...

ubuntu22鼠键失灵恢复记录笔记chatgpt解决
ChatGPT 说: 你提到“Ubuntu 22 鼠键失灵”,这个问题可能涉及以下几方面: 🧭 先确认问题 是鼠标问题还是键盘问题,还是触控板? “鼠键”一般理解为“鼠标键”,请确认你是指鼠标左键/右键失灵&a…...
)
在服务器上安装AlphaFold2遇到的问题(1)
犯了错误,轻信deepseek,误将cuDNN8.9.7删掉 [rootlocalhost ~]# cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 #define CUDNN_MAJOR 8 #define CUDNN_MINOR 9 #define CUDNN_PATCHLEVEL 7 -- #define CUDNN_VERSION (CUDNN_MA…...

ch10 题目参考思路
ch10 - 最小生成树 有线通讯网 知识点:Prim 算法思路: 该题要求对 n 座城市铺设 n - 1 条光缆,并要求所有城市连通,那本质上是一棵树,又要求铺设光缆的费用最低,即要求选取的 n - 1 条光缆的长度最小&…...

Hudi、Iceberg 、 Paimon 数据湖选型对比
Hudi、Iceberg 和 Paimon 是当前数据湖领域的三大主流开源框架,均致力于解决数据湖场景下的增量更新、事务支持、元数据管理、流批统一等核心问题,但设计理念和适用场景存在差异。以下从技术特性、适用场景和选型建议三方面对比分析: 一、核心技术特性对比 维度HudiIceberg…...
:小行星轨迹预测思路)
2025认证杯数学建模第二阶段A题完整论文(代码齐全):小行星轨迹预测思路
2025认证杯数学建模第二阶段A题完整论文(代码齐全):小行星轨迹预测思路,详细内容见文末名片 第二阶段问题 1 分析 问题起源与相关性:为了更全面地评估近地小行星对地球的潜在威胁,需要对其轨道进行长期预测。三个月内的观测数据为…...

信息安全基础知识
信息系统 信息系统能进行(数据)的采集、传输、存储、加工,使用和维护的计算机应用系统 例如:办公自动化、CRM/ERP、HRM、12306火车订票系统等。 信息安全 信息安全是指保护信息系统中的计算机硬件、软件、数据不因偶然或者恶意…...

UE RPG游戏开发练手 第二十六课 普通攻击1
UE RPG游戏开发练手 第二十六课 普通攻击1 1.定义攻击的InputTag MyGameplayTags.h代码 RPGGAMETEST_API UE_DECLARE_GAMEPLAY_TAG_EXTERN(InputTag_LightAttack_Axe);MyGameplayTag.cpp代码 UE_DEFINE_GAMEPLAY_TAG(InputTag_LightAttack_Axe, "InputTag.LightAttack.Ax…...

SAP ABAP 程序中归档数据读取方式
上一篇文章记录了字段目录,归档信息结构,这篇文章记录如何通过字段目录,归档信息结构,归档对象读取归档数据。未归档数据是从数据库表直接抽取,本样例是通过归档读取方式复写sql。 发布时间:2025.05.16 示…...

每周资讯 | 腾讯Q1财报:国内游戏业务收入同比增长24%;Tripledot 8亿美元收购AppLovin游戏业务
内容速览: 广州“服务贸易和数字贸易22条”助推游戏产业发展Tripledot Studios 8亿美元收购AppLovin游戏业务苹果紧急申请暂停执行AppStore新规4月中国手游出海收入下载榜,点点互动《Kingshot》收入激增 腾讯Q1财报:国内游戏业务收入同比增长…...
)
iOS SwiftUI的具体运用实例(SwiftUI库的运用)
最近接触到一个 SwiftUI的第三方框架,它非常的好用。以下是 具体运用实例,结合其核心功能与开发场景,分多个维度进行详细解析: 一、基础 UI 组件开发 登录界面 SwiftUI 的 VStack、TextField 和 Button 可快速构建用户登录表单。例…...

杰理ac696配置sd卡随机播放
#define FCYCLE_LIST 0 // 列表循环(按顺序播放文件列表) #define FCYCLE_ALL 1 // 全部循环(播放完所有文件后重新开始) #define FCYCLE_ONE 2 // 单曲循环(重复播放当前文件) #define …...

MCP协议的核心机制和交互过程
MCP的核心是JSON-RPC 2.0 MCP使用了 JSON-RPC 2.0 作为client和server端的消息传输。JSON-RPC 2.0是一个用JSON编码的轻量级远程过程调用协议。它的优越性如下: 易读,易调试与编程语言无关,环境无关技术成熟,规范清晰且应用广泛JSON-NPC 2.0定义了request、response、noti…...

论信息系统项目的范围管理
论信息系统项目的范围管理 前言一、规划范围管理,收集需求二、定义范围三、创建工作分解结构四、确认范围五、控制范围 前言 为了应对烟草零售客户数量大幅度增长所带来的问题,切实履行控烟履约的相关要求,同时也为了响应国务院“放管服”政策…...

米勒电容补偿的理解
米勒电容补偿是使运放放大器稳定的重要手法,可以使两级运放的两个极点分离,从而可以得到更好的相位裕度。 Miller 电容补偿的本质是增加一条通路流电流,流电流才是miller效应的本质。给定一个相同的输入,Miller 电容吃掉的电流比…...
)
力扣654题:最大二叉树(递归)
小学生一枚,自学信奥中,没参加培训机构,所以命名不规范、代码不优美是在所难免的,欢迎指正。 标签: 二叉树、递归 语言: C 题目: 给定一个不重复的整数数组 nums 。最大二叉树可以用下面的算…...

Go语言实现生产者-消费者问题的多种方法
Go语言实现生产者-消费者问题的多种方法 生产者-消费者问题是并发编程中的经典问题,涉及多个生产者生成数据,多个消费者消费数据,二者通过缓冲区(队列)进行协调,保证数据的正确传递和同步。本文将从简单到…...
)
深度学习驱动下的目标检测技术:原理、算法与应用创新(二)
三、主流深度学习目标检测算法剖析 3.1 R - CNN 系列算法 3.1.1 R - CNN 算法详解 R - CNN(Region - based Convolutional Neural Networks)是将卷积神经网络(CNN)应用于目标检测领域的开创性算法,其在目标检测发展历…...

提权脚本Powerup命令备忘单
1. 获取与加载 从 GitHub 下载:(New-Object Net.WebClient).DownloadFile("https://raw.githubusercontent.com/PowerShellMafia/PowerSploit/master/Privesc/PowerUp.ps1", "C:\Temp\PowerUp.ps1")本地加载:Import-Module .\Power…...
 在无线接入网络 (RAN) 中的变革性作用)
人工智能 (AI) 在无线接入网络 (RAN) 中的变革性作用
随着电信行业向更智能、更高效的系统迈进,将 AI 集成到 RAN 中已不再是可有可无,而是至关重要。 随着 6G 时代的到来,人工智能 (AI) 有望降低运营成本,并带来更大的盈利机会。AI-RAN 正处于这一变革的前沿,在 RAN 环境…...

从硬件角度理解“Linux下一切皆文件“,详解用户级缓冲区
目录 前言 一、从硬件角度理解"Linux下一切皆文件" 从理解硬件是种“文件”到其他系统资源的抽象 二、缓冲区 1.缓冲区介绍 2.缓冲区的刷新策略 3.用户级缓冲区 这个用户级缓冲区在哪呢? 解释关于fork再加重定向“>”后数据会打印两份的原因 4.内核缓冲…...

Python-感知机以及实现感知机
感知机定义 如果有一个算法,具有1个或者多个入参,但是返回值要么是0,要么是1,那么这个算法就叫做感知机,也就是说,感知机是个算法 感知机有什么用 感知机是用来表示可能性的大小的,我们可以认…...

根据台账批量制作个人表
1. 前期材料准备 1)要有 人员总的信息台账 2)要有 个人明白卡模板 2. 开始操作 1)打开 人员总的信息台账,选择所需要的数据模块; 2)点击插入,选择数据透视表,按流程操作&…...