Qwen3技术报告解读:训练秘籍公开,推理与非推理模型统一,大模型蒸馏小模型(报告详细解读)
1.简介
Qwen3 是 Qwen 模型家族的最新版本,它是一系列大型语言模型(LLMs),旨在提升性能、效率和多语言能力。基于广泛的训练,Qwen3 在推理、指令遵循、代理能力和多语言支持方面取得了突破性进展,具有以下关键特性:
- 独特支持在单一模型内无缝切换思考模式(适用于复杂逻辑推理、数学和编程)和非思考模式(适用于高效的通用对话),确保在各种场景下的最佳性能。
- 显著增强了其推理能力,在数学、代码生成和常识逻辑推理方面超越了之前的 QwQ(在思考模式下)和 Qwen2.5 指令模型(在非思考模式下)。
- 卓越的人类偏好对齐,在创意写作、角色扮演、多轮对话和指令遵循方面表现出色,提供更加自然、吸引人和沉浸式的对话体验。
- 擅长代理能力,能够在思考和非思考模式下精确集成外部工具,并在复杂的基于代理的任务中达到开源模型的领先性能。
- 支持100多种语言和方言,具有强大的多语言指令遵循和翻译能力。

权重地址(huggingface):https://huggingface.co/Qwen
权重地址(modelscope):https://modelscope.cn/organization/qwen
代码地址:https://github.com/QwenLM/Qwen3
-
-
2.架构
Qwen3系列包括6个密集模型,分别是Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B和Qwen3-32B,以及2个MoE模型,Qwen3-30B-A3B和Qwen3-235B-A22B。旗舰模型Qwen3-235B-A22B共有2350亿参数,其中220亿参数被激活。
Qwen3密集模型的架构与Qwen2.5相似,包括使用分组查询注意力、SwiGLU、旋转位置嵌入以及采用预归一化的RMSNorm。此外,作者移除了在Qwen2中使用的QKV偏置,并引入了QK-Norm到注意力机制中,以确保Qwen3的稳定训练。模型架构的关键信息见表1。
Qwen3 MoE模型与Qwen3密集模型具有相同的基础架构。模型架构的关键信息见表2。作者遵循Qwen2.5-MoE并实现了细粒度专家分割。Qwen3 MoE模型共有128个专家,每个token激活8个专家。与Qwen2.5-MoE不同,Qwen3-MoE设计中不包含共享专家。此外,作者采用了全局批量负载均衡损失,以促进专家的专门化。这些架构和训练方面的创新在下游任务中显著提升了模型性能。Qwen3模型使用了Qwen的分词器,该分词器实现了字节级字节对编码(byte-level byte-pair encoding,BBPE),词汇量为151,669。
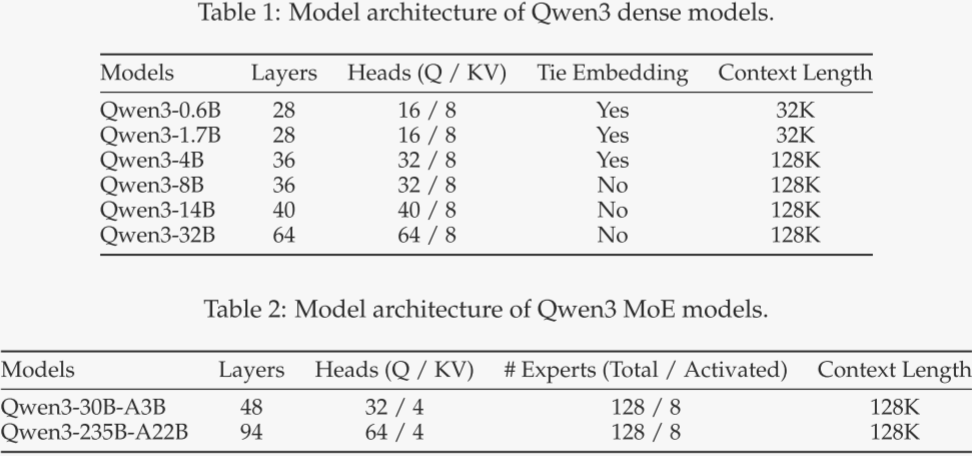
根据代码,我画出了Qwen3的模型架构,Qwen3的模型架构如下:
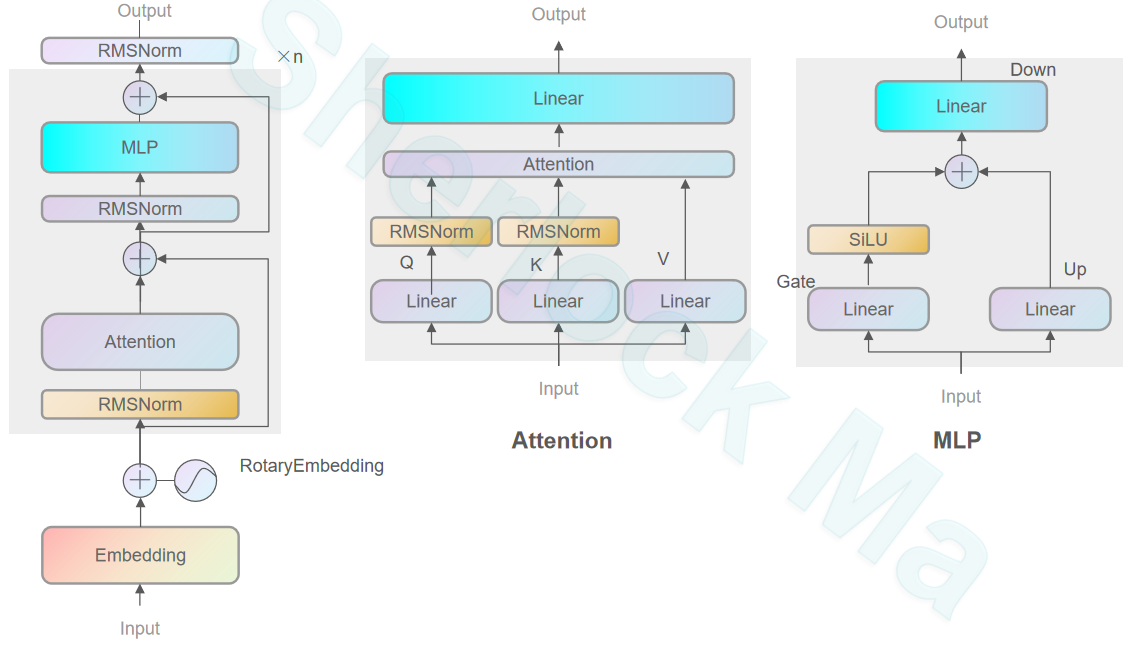
密集模型的主要区别是在QK位置做了一次归一化:
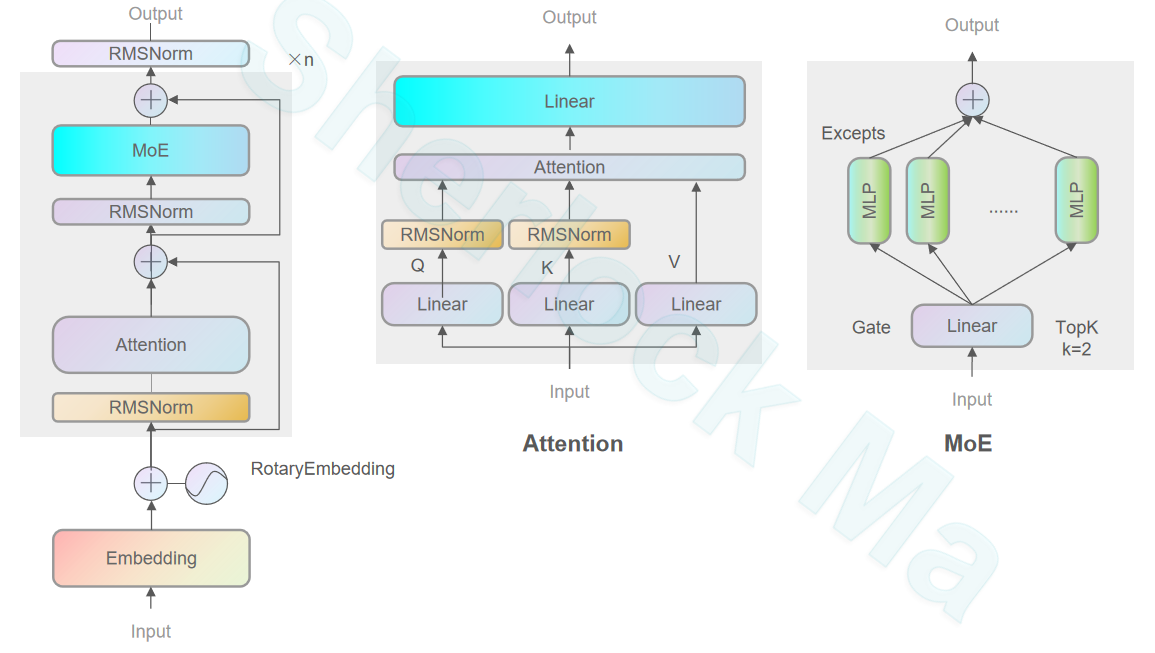
MoE模型的区别是将MLP层替换为MoE层:
-
-
3.预训练
数据
与Qwen2.5相比,作者显著扩大了训练数据的规模和多样性。具体来说,作者收集的预训练token数量是原来的两倍,覆盖的语言种类是原来的三倍。所有Qwen3模型都在一个包含119种语言和方言、总计36万亿token的庞大且多样化的数据集上进行训练。该数据集涵盖了编码、STEM(科学、技术、工程和数学)、推理任务、书籍、多语言文本和合成数据等多个领域的高质量内容。
为了进一步扩充预训练数据语料库,作者首先使用Qwen2.5-VL模型对大量类似PDF的文档进行文本识别。然后,利用Qwen2.5模型对识别出的文本进行优化,以提高其质量。通过这一两步流程,作者能够获得额外的高质量文本token,总量达数万亿。此外,作者还使用Qwen2.5、Qwen2.5-Math和Qwen2.5-Coder模型以不同格式(包括教科书、问答、指令和代码片段)合成数万亿文本token,涵盖数十个领域。最后,作者通过引入更多多语言数据和新语言,进一步扩充了预训练语料库。与Qwen2.5使用的预训练数据相比,支持的语言数量从29种大幅增加到119种,显著提升了模型的语言覆盖范围和跨语言能力。
作者开发了一个多语言数据标注系统,旨在提升训练数据的质量和多样性。该系统已应用于大规模预训练数据集,对超过30万亿token进行了标注,涵盖教育价值、领域、主题和安全性等多个维度。这些详细的标注支持更有效的数据筛选和组合。与以往在数据源或领域层面优化数据混合的研究不同,作者的方法通过在小代理模型上进行广泛的消融实验,并利用细粒度的数据标签,在实例层面优化数据混合。
预训练阶段
Qwen3模型通过三个阶段进行预训练:
- 通用阶段(S1):在第一阶段预训练中,所有Qwen3模型在超过30万亿token的数据上进行训练,序列长度为4096个token。在此阶段,模型已在语言能力和通用世界知识方面完成了充分预训练,训练数据涵盖119种语言和方言。
- 推理阶段(S2):为了进一步提升推理能力,作者通过增加STEM、编码、推理和合成数据的比例,优化了这一阶段的预训练语料库。模型在此阶段使用约5万亿高质量token进行进一步预训练,序列长度为4096个token。作者还在这一阶段加快了学习率的衰减速度。
- 长文本阶段:在最后的预训练阶段,作者收集了高质量的长文本语料库,以扩展Qwen3模型的上下文长度。所有模型在数百亿token上进行预训练,序列长度为32768个token。长文本语料库包括75%长度在16384到32768个token之间的文本,以及25%长度在4096到16384个token之间的文本。作者采用ABF技术,将RoPE的基准频率从10000提高到1000000,并引入YARN和双重块注意力机制(DCA),在推理时将序列长度容量提升了四倍。
与Qwen2.5类似,作者根据上述三个预训练阶段开发了用于预测最佳超参数(例如学习率调度器和批量大小)的缩放法则。通过大量实验,作者系统研究了模型架构、训练数据、训练阶段与最佳训练超参数之间的关系。最终,作者为每个密集模型或MoE模型设定了预测的最佳学习率和批量大小策略。
评估
作者对Qwen3系列的基础语言模型进行了全面评估。基础模型的评估主要关注其在通用知识、推理、数学、科学知识、编码和多语言能力方面的表现。预训练基础模型的评估数据集包括15个基准测试:
- 通用任务:MMLU(5-shot)、MMLU-Pro(5-shot,CoT)、MMLU-redux(5-shot)、BBH(3-shot,CoT)、SuperGPQA(5-shot,CoT)。
- 数学与STEM任务:GPQA(5-shot,CoT)、GSM8K(4-shot,CoT)、MATH(4-shot,CoT)。
- 编码任务:EvalPlus(0-shot)(包括HumanEval、MBPP、Humaneval+、MBPP+的平均值)、MultiPL-E(0-shot)(支持Python、C++、JAVA、PHP、TypeScript、C#、Bash、JavaScript)、MBPP-3shot、CRUXEval中的CRUX-O(1-shot)。
- 多语言任务:MGSM(8-shot,CoT)、MMMLU(5-shot)、INCLUDE(5-shot)。
在基础模型的基线比较中,作者将Qwen3系列基础模型与Qwen2.5基础模型以及其他领先的开源基础模型进行了对比,包括DeepSeek-V3 Base、Gemma-3、Llama-3和Llama-4系列基础模型。对比主要基于模型的参数规模。所有模型都使用相同的评估流程和广泛使用的评估设置,以确保公平比较。
基于整体评估结果,作者总结了Qwen3基础模型的一些关键结论:
-
与之前开源的最先进密集模型和MoE基础模型(例如DeepSeekV3 Base、Llama-4-Maverick Base和Qwen2.5-72B-Base)相比,Qwen3-235B-A22B-Base在大多数任务中表现更优,尽管其总参数量或激活参数量显著更少。
-
对于Qwen3 MoE基础模型,实验结果表明:
-
使用相同的预训练数据,Qwen3 MoE基础模型仅需1/5的激活参数即可达到与Qwen3密集基础模型相似的性能。
-
由于Qwen3 MoE架构的改进、训练token规模的扩大以及更先进的训练策略,Qwen3 MoE基础模型在激活参数量少于1/2且总参数量更少的情况下,能够超越Qwen2.5 MoE基础模型。
-
即使激活参数量仅为Qwen2.5密集基础模型的1/10,Qwen3 MoE基础模型也能达到相当的性能,这在推理和训练成本方面为作者带来了显著优势。
-
-
Qwen3密集基础模型的整体性能在更高参数规模下与Qwen2.5基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base分别与Qwen2.5-3B/7B/14B/32B/72B-Base表现出相当的性能。特别是在STEM、编码和推理基准测试中,Qwen3密集基础模型的性能甚至在更高参数规模下超越了Qwen2.5基础模型。
Qwen3-235B-A22B-Base
作者将Qwen3-235B-A22B-Base与之前类似规模的MoE模型Qwen2.5-Plus-Base以及其他领先的开源基础模型进行了对比,包括Llama-4-Maverick、Qwen2.5-72B-Base和DeepSeek-V3 Base。从表3的结果来看,Qwen3-235B-A22B-Base模型在大多数评估基准测试中均取得了最高性能分数。作者进一步将Qwen3-235B-A22B-Base与其他基线模型分别进行对比,以进行详细分析:
-
与最近开源的Llama-4-Maverick-Base模型相比,尽管后者的参数量约为Qwen3-235B-A22B-Base的两倍,但Qwen3-235B-A22B-Base在大多数基准测试中表现更优。
-
与之前的最先进开源模型DeepSeek-V3-Base相比,Qwen3-235B-A22B-Base在15项评估基准测试中的14项上表现更佳。其总参数量仅为DeepSeek-V3-Base的约1/3,激活参数量为2/3,这充分体现了模型的强大性能和成本效益。
-
与作者之前类似规模的MoE模型Qwen2.5-Plus相比,Qwen3-235B-A22B-Base以更少的参数量和激活参数量显著超越了前者,这表明Qwen3在预训练数据、训练策略和模型架构方面的显著优势。
-
与作者之前推出的旗舰开源密集模型Qwen2.5-72B-Base相比,Qwen3-235B-A22B-Base在所有基准测试中均表现更优,且激活参数量不到前者的1/3。同时,由于模型架构的优势,Qwen3-235B-A22B-Base在每万亿token的推理成本和训练成本上远低于Qwen2.5-72B-Base。
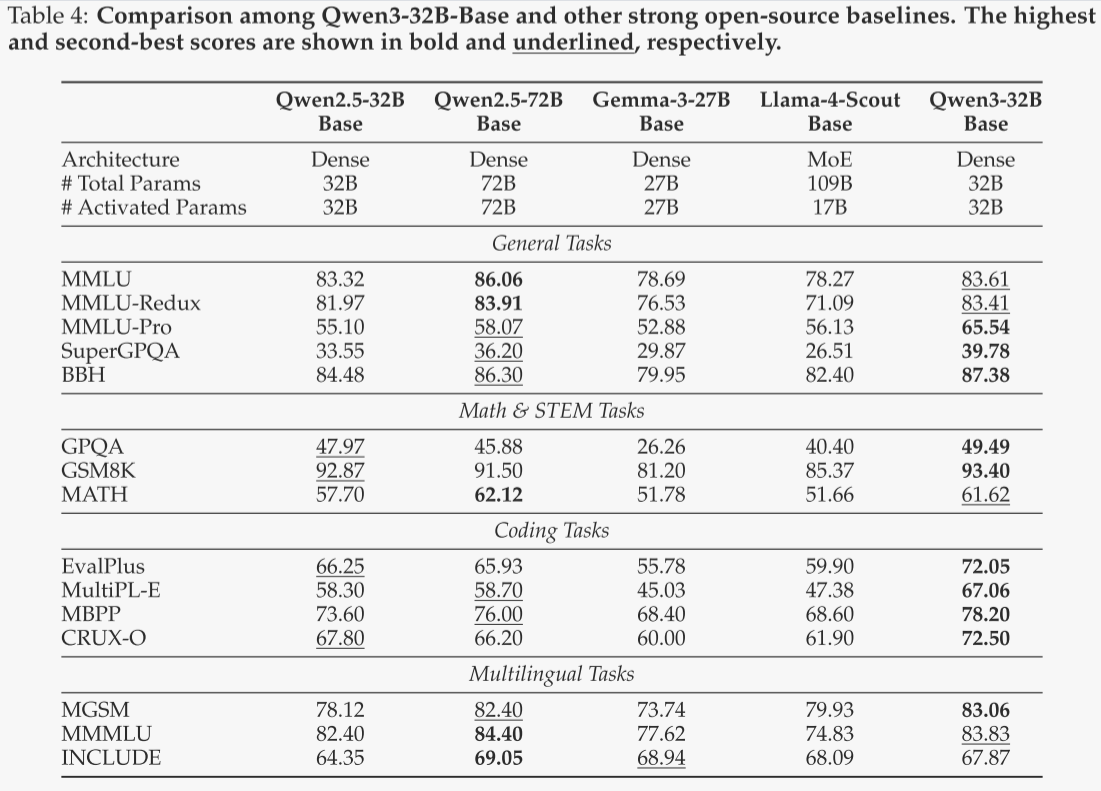
Qwen3-32B-Base
Qwen3-32B-Base是Qwen3系列中最大的密集模型。作者将其与类似规模的基线模型进行了对比,包括Gemma-3-27B和Qwen2.5-32B。此外,作者还引入了两个强大的基线模型:最近开源的MoE模型Llama4-Scout,其参数量是Qwen3-32B-Base的三倍,但激活参数量仅为一半;以及作者之前推出的旗舰开源密集模型Qwen2.5-72B-Base,其参数量是Qwen3-32B-Base的两倍多。结果如表4所示,支持以下三个关键结论:
-
与类似规模的模型相比,Qwen3-32B-Base在大多数基准测试中表现优于Qwen2.5-32B-Base和Gemma-3-27B Base。值得注意的是,Qwen3-32B-Base在MMLU-Pro上取得了65.54分,在SuperGPQA上取得了39.78分,显著优于其前身Qwen2.5-32B-Base。此外,Qwen3-32B-Base在编码基准测试中的得分也显著高于所有基线模型。
-
令人意外的是,Qwen3-32B-Base与Qwen2.5-72B-Base相比表现出了很强的竞争力。尽管Qwen3-32B-Base的参数量不到Qwen2.5-72B-Base的一半,但在15项评估基准测试中的10项上表现更优。在编码、数学和推理基准测试中,Qwen3-32B-Base具有显著优势。
-
与Llama-4-Scout-Base相比,Qwen3-32B-Base在所有15项基准测试中均显著优于前者。尽管其参数量仅为Llama-4-Scout-Base的三分之一,但激活参数量是后者的两倍。
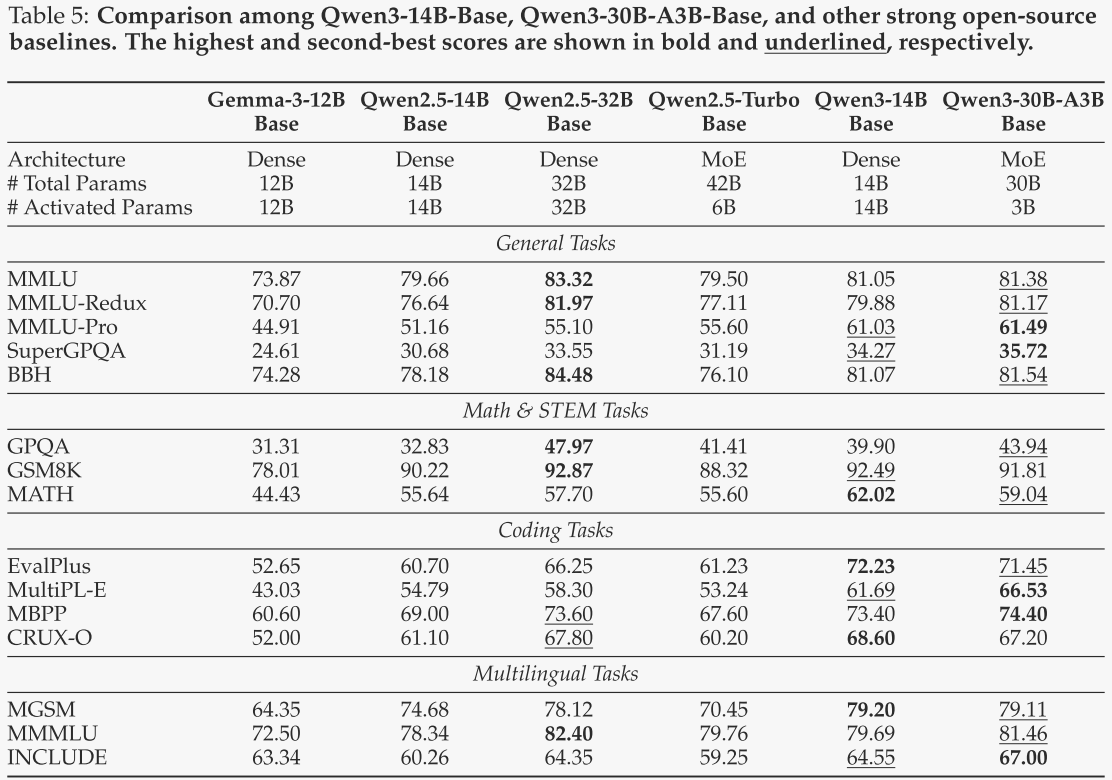
Qwen3-14B-Base 与 Qwen3-30B-A3B-Base
作者对Qwen3-14B-Base和Qwen3-30B-A3B-Base进行了评估,并将其与类似规模的基线模型进行了对比,包括Gemma-3-12B Base和Qwen2.5-14B Base。同样,作者还引入了两个强大的基线模型:(1)Qwen2.5-Turbo,其拥有420亿参数和60亿激活参数。需要注意的是,其激活参数量是Qwen3-30B-A3B-Base的两倍。(2)Qwen2.5-32B-Base,其激活参数量是Qwen3-30B-A3B的11倍,且超过Qwen3-14B的两倍。结果如表5所示,可以得出以下结论:(1)与类似规模的模型相比,Qwen3-14B-Base在所有15项基准测试中均显著优于Qwen2.5-14B-Base和Gemma-3-12B-Base。(2)同样,Qwen3-14B-Base在参数量不到一半的情况下,与Qwen2.5-32B-Base相比也表现出极具竞争力的结果。(3)仅使用1/5的激活非嵌入参数,Qwen3-30B-A3B在所有任务中均显著优于Qwen2.5-14B-Base,并且与Qwen3-14B-Base和Qwen2.5-32B-Base表现相当,这为作者在推理和训练成本方面带来了显著优势。
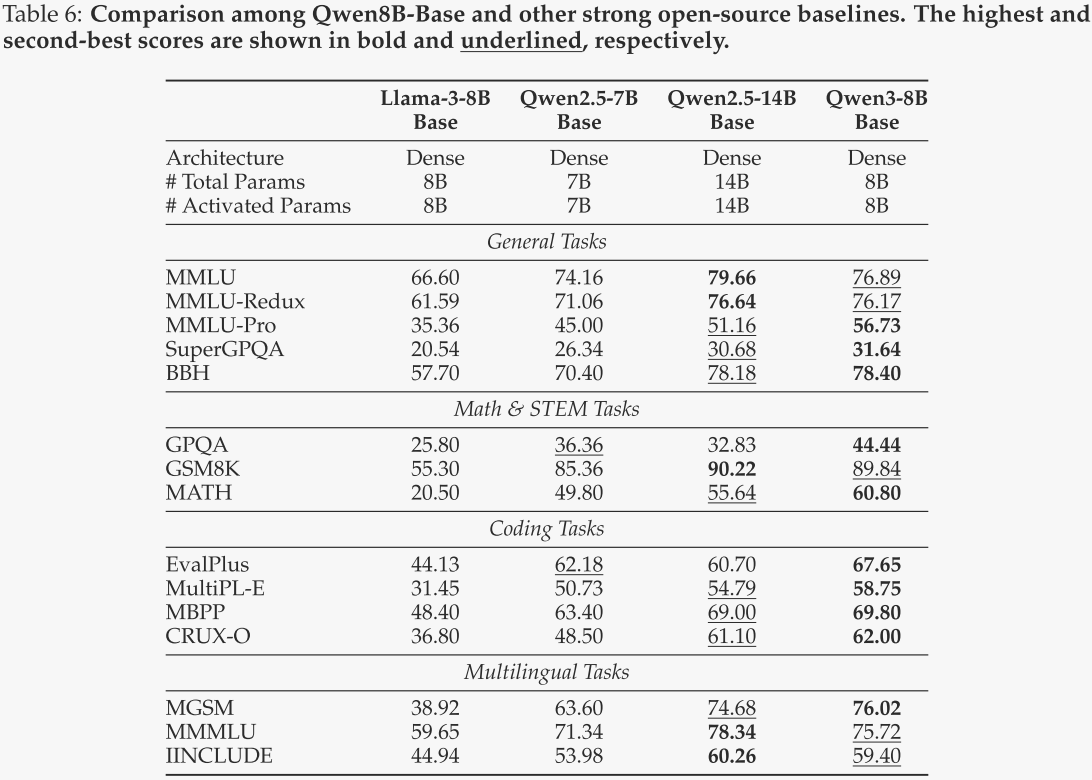
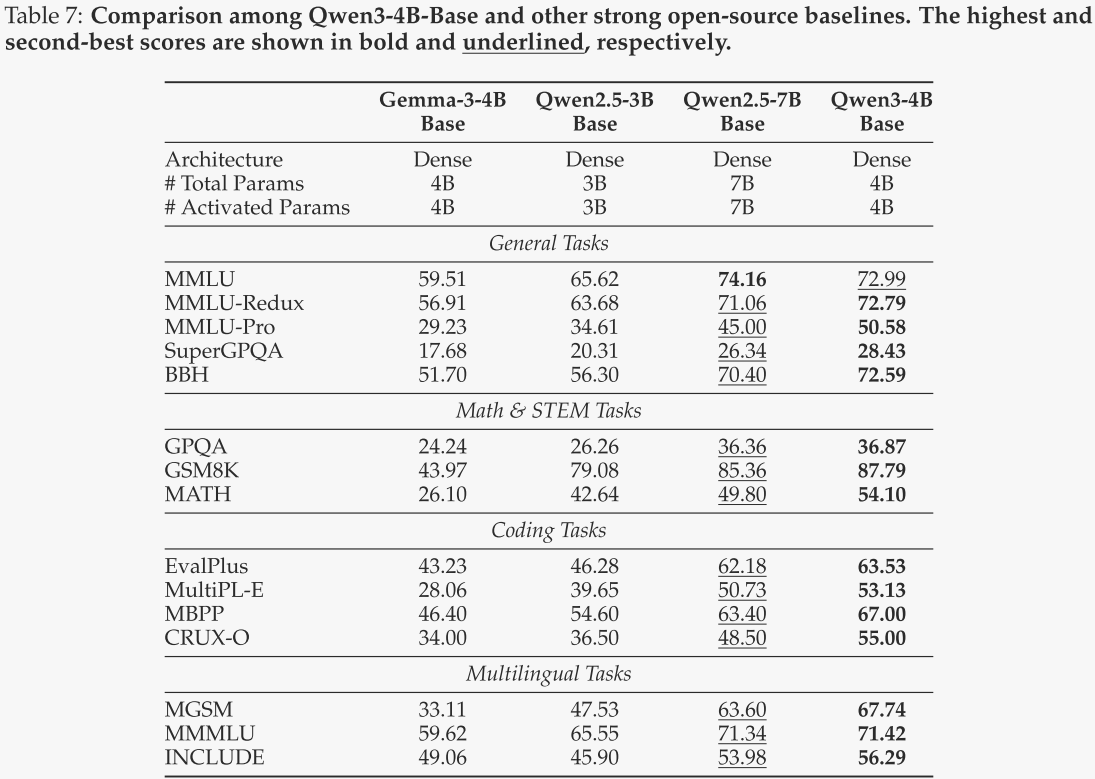
Qwen3-8B / 4B / 1.7B / 0.6B-Base
对于边缘侧模型,作者将类似规模的Qwen2.5、Llama-3和Gemma-3基础模型作为基线进行对比。结果分别见表6、表7和表8。所有Qwen3 8B / 4B / 1.7B / 0.6B-Base模型在几乎所有基准测试中均保持了强劲的性能。值得注意的是,Qwen3-8B / 4B / 1.7B-Base模型在超过一半的基准测试中甚至超越了更大规模的Qwen2.5-14B / 7B / 3B Base模型,尤其是在STEM相关和编码基准测试中,这反映了Qwen3模型的显著改进。
-
-
4.后训练
Qwen3的后训练流程是基于两个核心目标战略性设计的:(1)思维控制:这涉及整合两种不同的模式,即“非思考”模式和“思考”模式,为用户提供灵活性,让他们可以选择模型是否参与推理,并通过为思考过程指定token预算来控制思考的深度。(2)强到弱的蒸馏:其目标是为轻量级模型简化和优化后训练流程。通过利用大规模模型的知识,作者大幅减少了构建小规模模型所需的计算成本和开发工作。
如图1所示,Qwen3系列中的旗舰模型遵循一个复杂的四阶段训练过程。前两个阶段专注于发展模型的“思考”能力,接下来的两个阶段则旨在将强大的“非思考”功能整合到模型中。初步实验表明,直接将教师模型的输出logits蒸馏到轻量级学生模型中,可以在保持对推理过程的精细控制的同时有效提升其性能。这种方法消除了为每个小规模模型单独执行完整的四阶段训练过程的必要性。它不仅带来了更好的即时性能(如更高的Pass@1分数所示),还提升了模型的探索能力(如改进的Pass@64结果所反映)。此外,它以更高的训练效率实现了这些收益,仅需四阶段训练方法的1/10的GPU小时数。
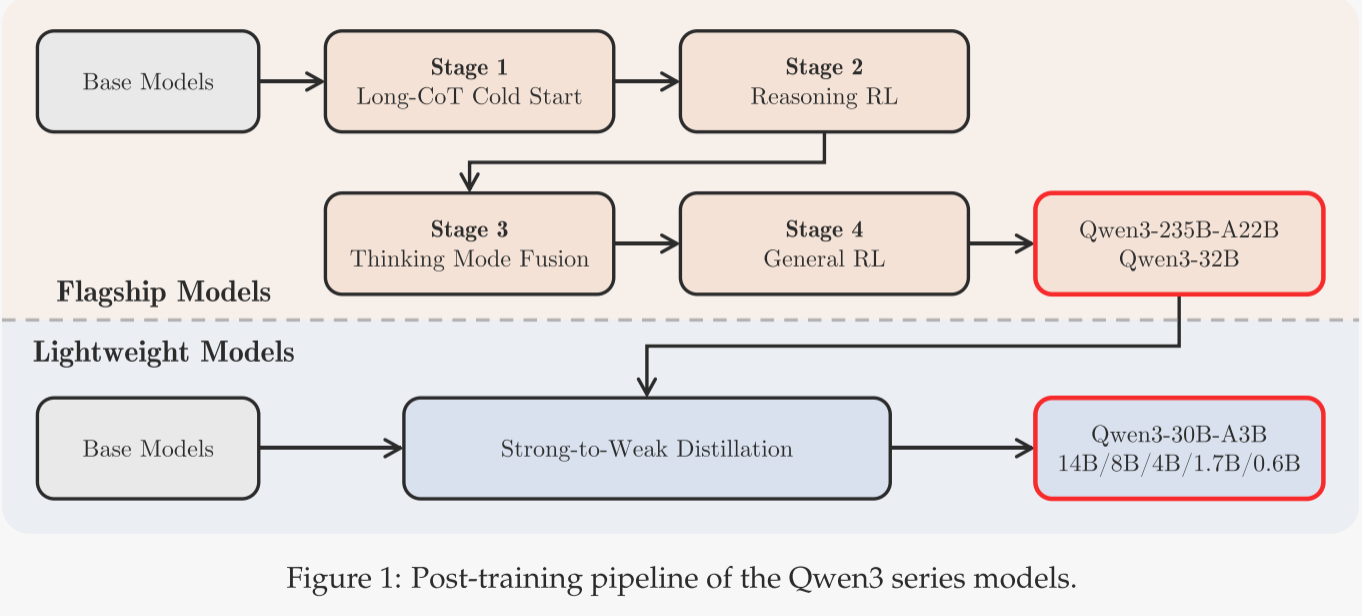 在接下来的部分中,作者将介绍四阶段训练过程,并详细解释强到弱的蒸馏方法。
在接下来的部分中,作者将介绍四阶段训练过程,并详细解释强到弱的蒸馏方法。
-
长思维链冷启动
作者首先整理了一个涵盖广泛类别的综合性数据集,包括数学、代码、逻辑推理和通用STEM问题。数据集中的每个问题都配有经过验证的参考答案或基于代码的测试用例。这个数据集是长链推理(long-CoT)训练“冷启动”阶段的基础。数据集的构建涉及严格的两阶段过滤过程:查询过滤和响应过滤。
在查询过滤阶段,作者使用Qwen2.5-72B-Instruct来识别并移除那些不易验证的查询。这包括包含多个子问题的查询,或者要求进行通用文本生成的查询。此外,作者还排除了Qwen2.5-72B-Instruct能够在不使用链式推理的情况下正确回答的查询。这有助于防止模型依赖于表面猜测,并确保只有需要更深层次推理的复杂问题被包含在内。此外,作者还使用Qwen2.5-72B-Instruct为每个查询标注领域,以保持数据集中各领域的平衡分布。
在保留一个验证查询集之后,作者使用QwQ-32B为每个剩余的查询生成N个候选响应。当QwQ-32B无法持续生成正确解决方案时,人工标注者会手动评估响应的准确性。对于通过率(Pass@N)为正的查询,进一步应用严格的过滤标准,以移除以下类型的响应:(1)得出错误最终答案的;(2)包含大量重复内容的;(3)明显缺乏充分推理的猜测性回答;(4)推理过程与总结内容不一致的;(5)涉及不当的语言混用或风格突变的;(6)被认为与潜在验证集项目过于相似的。
随后,作者从经过筛选和优化的数据集中精心挑选一个子集,用于推理模式的初始冷启动训练。这一阶段的目标是在不过分强调即时推理性能的情况下,为模型灌输基础推理模式。这种方法确保了模型的潜力不会受到限制,从而在后续的强化学习(RL)阶段能够拥有更大的灵活性和提升空间。为了有效实现这一目标,最好在这一准备阶段尽量减少训练样本数量和训练步骤。
-
推理强化学习
在推理强化学习(Reasoning RL)阶段使用的查询-验证器对必须满足以下四个标准:(1)它们未在冷启动阶段使用过;(2)它们对冷启动模型是可学习的;(3)它们尽可能具有挑战性;(4)它们覆盖广泛的子领域。作者最终收集了总共3995个查询-验证器对,并使用GRPO来更新模型参数。作者观察到,使用较大的批量大小和每个查询的高次数rollout,以及采用离策略训练来提高样本效率,对训练过程是有益的。作者还通过控制模型的熵使其稳步增加或保持稳定,解决了如何平衡探索与利用的问题,这对于维持稳定的训练至关重要。因此,在整个强化学习过程中,作者实现了训练奖励和验证性能的一致提升,而无需对超参数进行手动干预。例如,Qwen3-235B-A22B模型的AIME'24分数在总共170步的强化学习训练中从70.1提高到85.1。
-
思维模式融合
思维模式融合阶段的目标是将“非思考”能力整合到之前开发的“思考”模型中。这种方法允许开发者管理和控制推理行为,同时降低了为思考和非思考任务部署独立模型的成本和复杂性。为了实现这一目标,作者在推理强化学习(Reasoning RL)模型上进行了持续的监督微调(SFT),并设计了聊天模板以融合这两种模式。此外,作者发现能够熟练处理这两种模式的模型在不同的思考预算下表现一致良好。
SFT数据构建
SFT数据集结合了“思考”和“非思考”数据。为了确保第2阶段模型的性能不会因额外的SFT而受损,“思考”数据是通过使用第2阶段模型对第1阶段查询进行拒绝采样生成的。而“非思考”数据则经过精心策划,涵盖多种任务,包括编码、数学、指令遵循、多语言任务、创意写作、问答和角色扮演。此外,作者使用自动生成的检查清单来评估“非思考”数据的响应质量。为了提升低资源语言任务的性能,作者特别增加了翻译任务的比例。
聊天模板设计
为了更好地融合这两种模式,并使用户能够动态切换模型的思考过程,作者为Qwen3设计了聊天模板,具体如表9所示。对于“思考”模式和“非思考”模式的样本,作者分别在用户查询或系统消息中引入了/think和/no think标志。这使得模型能够根据用户的输入选择相应的思考模式。对于“非思考”模式样本,作者在助手的响应中保留了一个空的思考块。这种设计确保了模型内部格式的一致性,并允许开发者通过在聊天模板中添加空的思考块来防止模型进行思考行为。默认情况下,模型以“思考”模式运行,因此作者添加了一些用户查询中不包含/think标志的“思考”模式训练样本。对于更复杂的多轮对话,作者随机在用户的查询中插入多个/think和/no think标志,模型的响应遵循最后遇到的标志。

思考预算
思维模式融合的另一个优势是,一旦模型学会了在“非思考”和“思考”模式下做出响应,它自然就具备了处理中间情况的能力——即基于不完整的思考生成响应。这种能力为实现对模型思考过程的预算控制奠定了基础。具体来说,当模型的思考长度达到用户定义的阈值时,作者手动停止思考过程,并插入停止思考指令:“考虑到用户的时间限制,我必须根据目前的思考直接给出解决方案。
</think>
在插入此指令后,模型将根据其到目前为止的推理结果生成最终响应。值得注意的是,这种能力并非通过显式训练获得,而是思维模式融合自然产生的结果。
-
通用强化学习
通用强化学习(General RL)阶段的目标是在多样化场景中广泛提升模型的能力和稳定性。为此,作者建立了一个复杂的奖励系统,涵盖超过20个不同任务,每个任务都有定制化的评分标准。这些任务专门针对以下核心能力的提升:
-
指令遵循:这一能力确保模型能够准确解读并遵循用户指令,包括与内容、格式、长度以及结构化输出使用相关的具体要求,从而提供符合用户期望的响应。
-
格式遵循:除了明确的指令外,作者还期望模型遵守特定的格式约定。例如,它应通过切换思考和非思考模式来适当地响应/think和/no think标志,并始终使用指定的标记(例如<think>和</think>)在最终输出中分隔思考部分和响应部分。
-
偏好对齐:对于开放式查询,偏好对齐专注于提升模型的有用性、参与度和风格,最终提供更自然、更令人满意的用户体验。
-
代理能力:这涉及训练模型通过指定接口正确调用工具。在强化学习的rollout过程中,模型被允许与真实环境执行反馈进行完整的多轮交互循环,从而提升其在长期决策任务中的表现和稳定性。
-
特定场景的能力:在更专业的场景中,作者设计了针对特定上下文的任务。例如,在检索增强生成(RAG)任务中,作者引入奖励信号以引导模型生成准确且符合上下文的响应,从而最小化幻觉风险。
为了为上述任务提供反馈,作者使用了三种不同的奖励类型:
-
基于规则的奖励:基于规则的奖励在推理强化学习阶段得到了广泛使用,也适用于指令遵循和格式遵循等通用任务。精心设计的基于规则的奖励可以高精度地评估模型输出的正确性,防止出现奖励劫持等问题。
-
基于模型的奖励(带参考答案):在此方法中,作者为每个查询提供参考答案,并提示Qwen2.5-72B-Instruct根据参考答案对模型的响应进行评分。这种方法可以更灵活地处理多样化任务,而无需严格遵循格式,避免了仅依赖基于规则的奖励时可能出现的假阴性问题。
-
基于模型的奖励(无参考答案):利用人类偏好数据,作者训练了一个奖励模型,为模型响应分配标量分数。这种方法不依赖参考答案,能够处理更广泛的查询,同时有效提升模型的参与度和有用性。
强到弱蒸馏
强到弱蒸馏(Strong-to-Weak Distillation)流程是专门为优化轻量级模型而设计的,涵盖了5个密集模型(Qwen3-0.6B、1.7B、4B、8B和14B)以及一个MoE模型(Qwen3-30B-A3B)。这种方法在提升模型性能的同时,有效地赋予了模型强大的模式切换能力。蒸馏过程分为两个主要阶段:
-
离策略蒸馏(Off-policy Distillation):在这一初始阶段,作者将教师模型在/think和/no think两种模式下生成的输出结合起来进行响应蒸馏。这有助于轻量级学生模型发展基本的推理技能以及在不同思考模式之间切换的能力,为下一阶段的在线策略训练奠定了坚实基础。
-
在线策略蒸馏(On-policy Distillation):在此阶段,学生模型生成在线策略序列以进行微调。具体来说,采样提示后,学生模型会在/think或/no think模式下生成响应。然后,通过将学生模型的logits与教师模型(Qwen3-32B或Qwen3-235B-A22B)的logits对齐,以最小化KL散度的方式对模型进行微调。
-
后训练评估
为了全面评估指令微调模型的质量,作者采用了自动基准测试来评估模型在思考模式和非思考模式下的性能。这些基准测试分为以下几个维度:
-
通用任务:作者使用了包括MMLU-Redux、GPQA-Diamond、C-Eval和LiveBench在内的基准测试。对于GPQA-Diamond,作者对每个查询进行10次采样,并报告平均准确率。
-
对齐任务:为了评估模型与人类偏好的对齐程度,作者使用了一系列专门的基准测试。对于指令遵循性能,作者报告了IFEval的严格提示准确率。为了评估模型在一般主题上与人类偏好的对齐程度,作者使用了Arena-Hard和AlignBench v1.1。对于写作任务,作者依赖Creative Writing V3和WritingBench来评估模型的熟练度和创造力。
-
数学与文本推理:为了评估数学和逻辑推理能力,作者使用了包括MATH-500、AIME'24和AIME'25在内的高级数学基准测试,以及包括ZebraLogic和AutoLogi在内的文本推理任务。对于AIME问题,每年的题目包括第一部分和第二部分,共计30道题。对于每道题,作者进行64次采样,并将平均准确率作为最终得分。
-
代理与编码:为了测试模型在编码和基于代理的任务中的熟练度,作者使用了BFCL v3、LiveCodeBench和CodeElo的Codeforces评分。对于BFCL,所有Qwen3模型都使用FC格式进行评估,并使用yarn将模型部署到64k的上下文长度进行多轮评估。对于LiveCodeBench,在非思考模式下,作者使用官方推荐的提示;在思考模式下,作者调整提示模板,允许模型更自由地思考,移除了“你只能返回程序”的限制。为了评估模型与竞赛编程专家之间的性能差距,作者使用CodeForces计算Elo评分。在作者的基准测试中,每个问题通过生成多达八次独立的推理尝试来解决。
-
多语言任务:为了评估多语言能力,作者评估了四种任务:指令遵循、知识、数学和逻辑推理。指令遵循使用Multi-IF进行评估,重点关注8种关键语言。知识评估包括两种类型:通过INCLUDE评估的区域知识,涵盖44种语言,以及通过MMMLU评估的一般知识,涵盖14种语言,但不包括未优化的约鲁巴语;对于这两个基准测试,作者仅采样原始数据的10%,以提高评估效率。数学任务使用MT-AIME2024,涵盖55种语言,以及PolyMath,涵盖18种语言。逻辑推理使用MlogiQA进行评估,涵盖10种语言。
对于所有处于思考模式下的Qwen3模型,作者采用了0.6的采样温度、0.95的top-p值和20的top-k值。此外,在Creative Writing v3和WritingBench任务中,作者应用了1.5的存在惩罚,以鼓励生成更多样化的内容。对于处于非思考模式下的Qwen3模型,作者将采样超参数设置为温度=0.7、top-p=0.8、top-k=20和存在惩罚=1.5。对于思考模式和非思考模式,作者将最大输出长度均设置为32,768个token,但在AIME'24和AIME'25任务中,作者将该长度扩展到38,912个token,以提供足够的思考空间。
-
从评估结果中,作者总结了最终确定的Qwen3模型的几个关键结论:
-
作者的旗舰模型Qwen3-235B-A22B在思考模式和非思考模式下均展现出开源模型中顶尖的整体性能,超越了诸如DeepSeek-R1和DeepSeek-V3等强大的基线模型。Qwen3-235B-A22B与闭源的领先模型(如OpenAI-o1、Gemini2.5-Pro和GPT-4o)也极具竞争力,展现了其深刻的推理能力和全面的通用能力。
-
作者的旗舰密集模型Qwen3-32B在大多数基准测试中超越了作者之前最强的推理模型QwQ-32B,并且与闭源的OpenAI-o3mini表现相当,显示出其强大的推理能力。Qwen3-32B在非思考模式下也表现出色,超越了作者之前旗舰的非推理密集模型Qwen2.5-72B-Instruct。
-
作者的轻量级模型,包括Qwen3-30B-A3B、Qwen3-14B以及其他较小的密集模型,其性能一致优于参数量相近或更大的开源模型,证明了作者强到弱蒸馏方法的成功。
Qwen3-235B-A22B
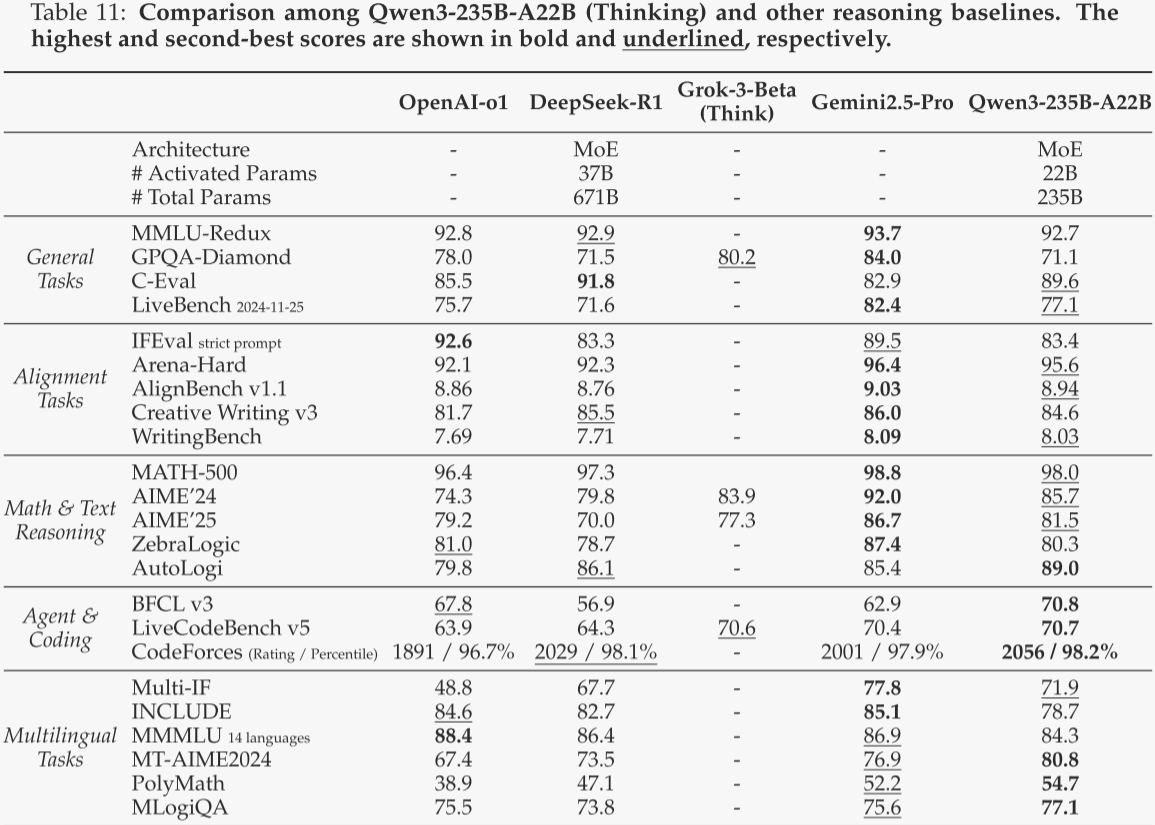
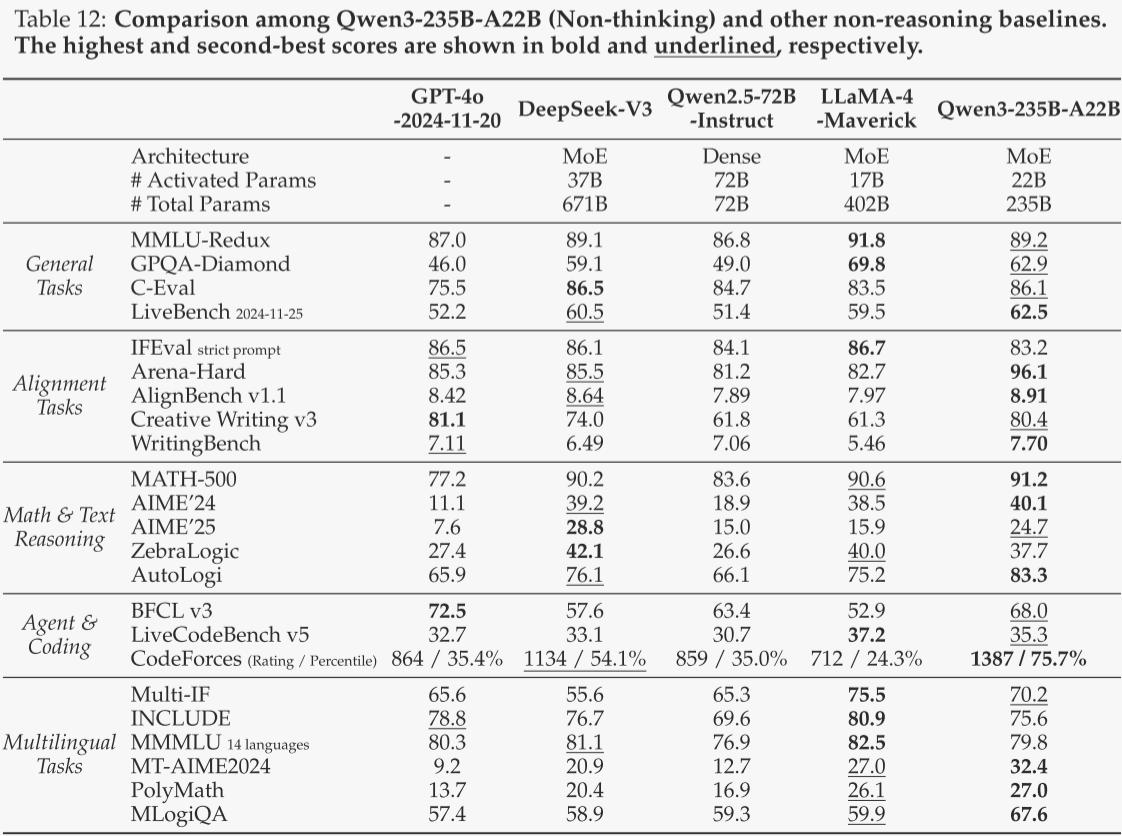
对于作者的旗舰模型Qwen3-235B-A22B,作者将其与领先的推理和非推理模型进行了对比。在思考模式下,作者将OpenAI-o1、DeepSeek-R1、Grok-3-Beta(Think)和Gemini2.5-Pro作为推理任务的基线模型。在非思考模式下,作者将GPT-4o-2024-11-20、DeepSeek-V3、Qwen2.5-72B-Instruct和LLaMA-4-Maverick作为非推理任务的基线模型。评估结果分别见表11和表12。
-
从表11可以看出,尽管Qwen3-235B-A22B(思考模式)仅激活了60%的参数,总参数量仅为35%,但它在23项基准测试中的17项上超越了DeepSeek-R1,尤其是在需要推理的任务(例如数学、代理和编码)上表现出色,展现了Qwen3-235B-A22B在开源模型中顶尖的推理能力。此外,Qwen3-235B-A22B(思考模式)与闭源的OpenAI-o1、Grok-3-Beta(Think)和Gemini2.5-Pro相比也极具竞争力,显著缩小了开源模型与闭源模型在推理能力上的差距。
-
从表12可以看出,Qwen3-235B-A22B(非思考模式)超越了其他领先的开源模型,包括DeepSeek-V3、LLaMA-4-Maverick和作者之前的旗舰模型Qwen2.5-72B-Instruct,并且在23项基准测试中的18项上超过了闭源的GPT-4o-2024-11-20。这表明即使在没有经过刻意思考过程增强的情况下,该模型本身也具备强大的能力。
Qwen3-32B
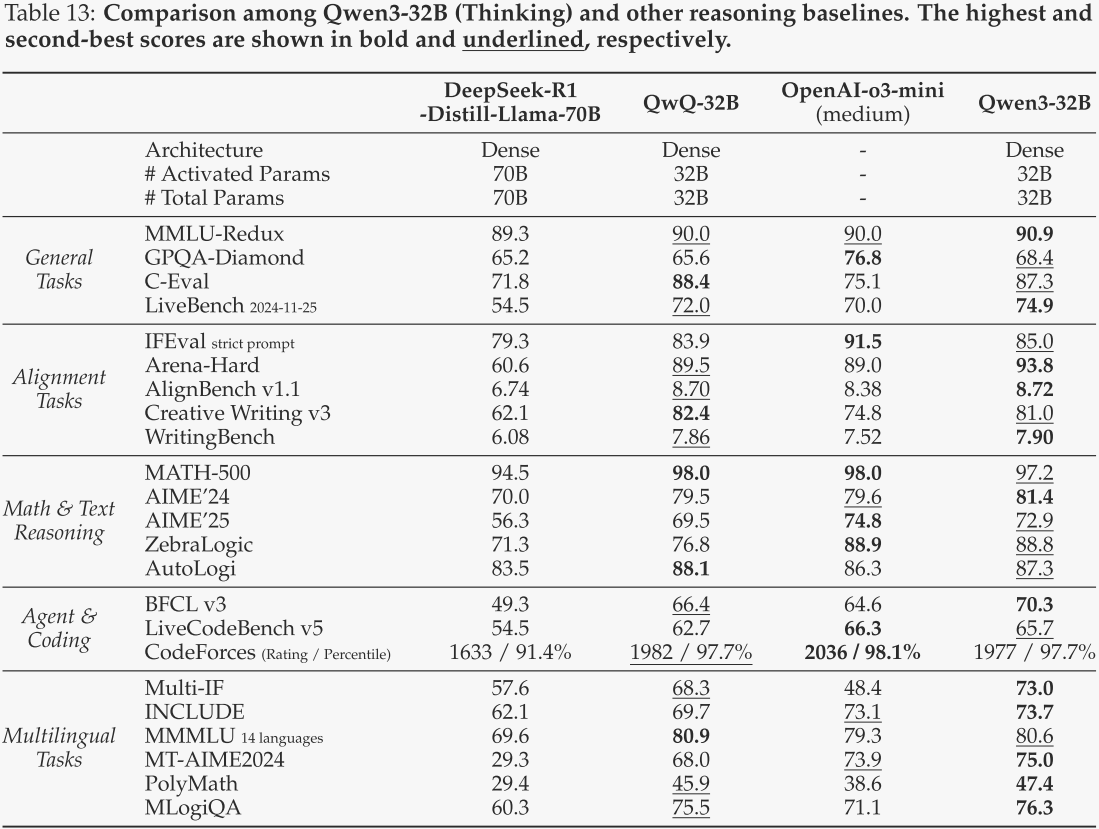
对于作者的旗舰密集模型Qwen3-32B,在思考模式下,作者将其与DeepSeek-R1-Distill-Llama-70B、OpenAI-o3-mini(medium)以及作者之前最强的推理模型QwQ-32B进行了对比。在非思考模式下,作者将其与GPT-4o-mini-2024-07-18、LLaMA-4-Scout以及作者之前的旗舰模型Qwen2.5-72B-Instruct进行了对比。评估结果分别见表13和表14。
-
从表13可以看出,Qwen3-32B(思考模式)在23项基准测试中的17项上超越了QwQ-32B,成为32B参数规模下新的顶尖推理模型。此外,Qwen3-32B(思考模式)在对齐能力和多语言性能方面也与闭源的OpenAI-o3-mini(medium)形成了有力竞争。
-
从表14可以看出,Qwen3-32B(非思考模式)在几乎所有基准测试中都展现出了优于所有基线模型的性能。特别是Qwen3-32B(非思考模式)在通用任务上与Qwen2.5-72B-Instruct表现相当,同时在对齐、多语言和与推理相关的任务上具有显著优势,再次证明了Qwen3相较于作者之前的Qwen2.5系列模型的显著改进。
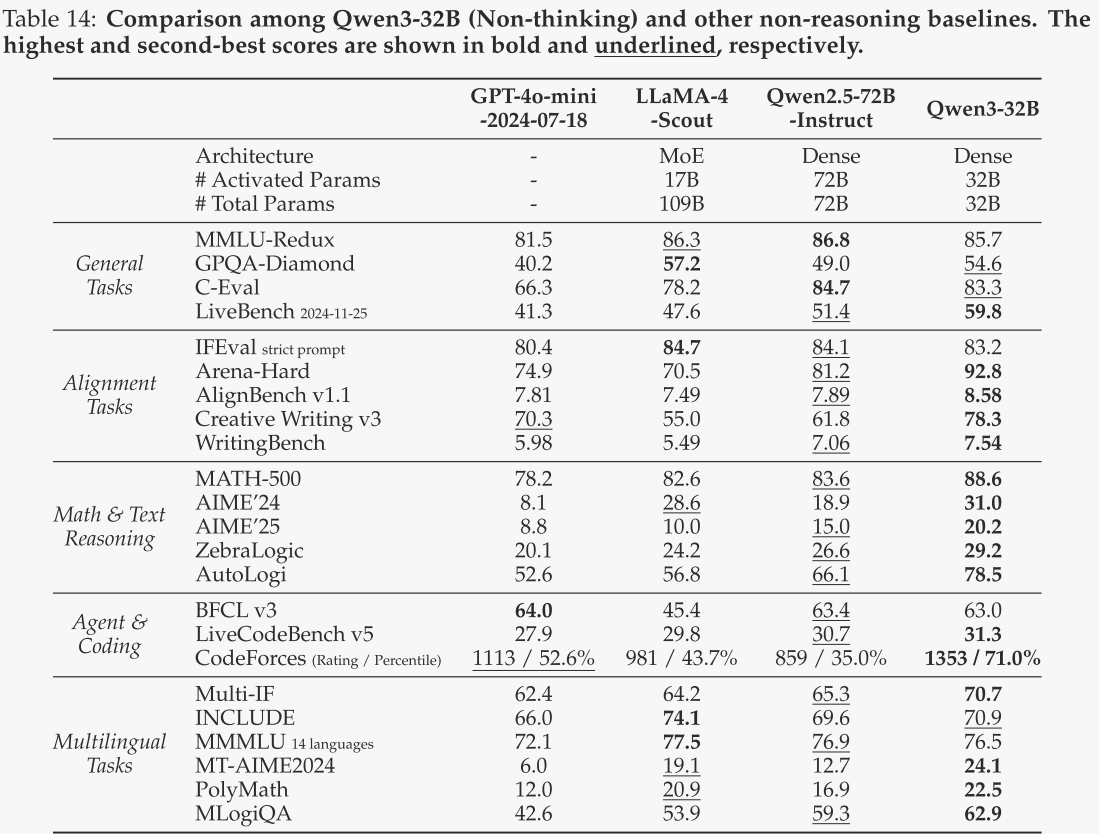 Qwen3-30B-A3B 与 Qwen3-14B
Qwen3-30B-A3B 与 Qwen3-14B
对于Qwen3-30B-A3B和Qwen3-14B,在思考模式下,作者将其与DeepSeek-R1-Distill-Qwen-32B和QwQ-32B进行了对比;在非思考模式下,作者将其与Phi-4、Gemma-3-27B-IT和Qwen2.5-32B-Instruct进行了对比。评估结果分别见表15和表16。
-
从表15可以看出,Qwen3-30B-A3B和Qwen3-14B(思考模式)均展现出与QwQ-32B相当的竞争力,尤其是在与推理相关的基准测试中。值得注意的是,Qwen3-30B-A3B在模型规模更小、激活参数量不到1/10的情况下,实现了与QwQ-32B相当的性能,这充分证明了作者的强到弱蒸馏方法在赋予轻量级模型深刻推理能力方面的有效性。
-
从表16可以看出,Qwen3-30B-A3B和Qwen3-14B(非思考模式)在大多数基准测试中均超越了非推理基线模型。它们以更少的激活参数和总参数量,显著优于作者之前的Qwen2.5-32B-Instruct模型,实现了更高效且更具成本效益的性能表现。
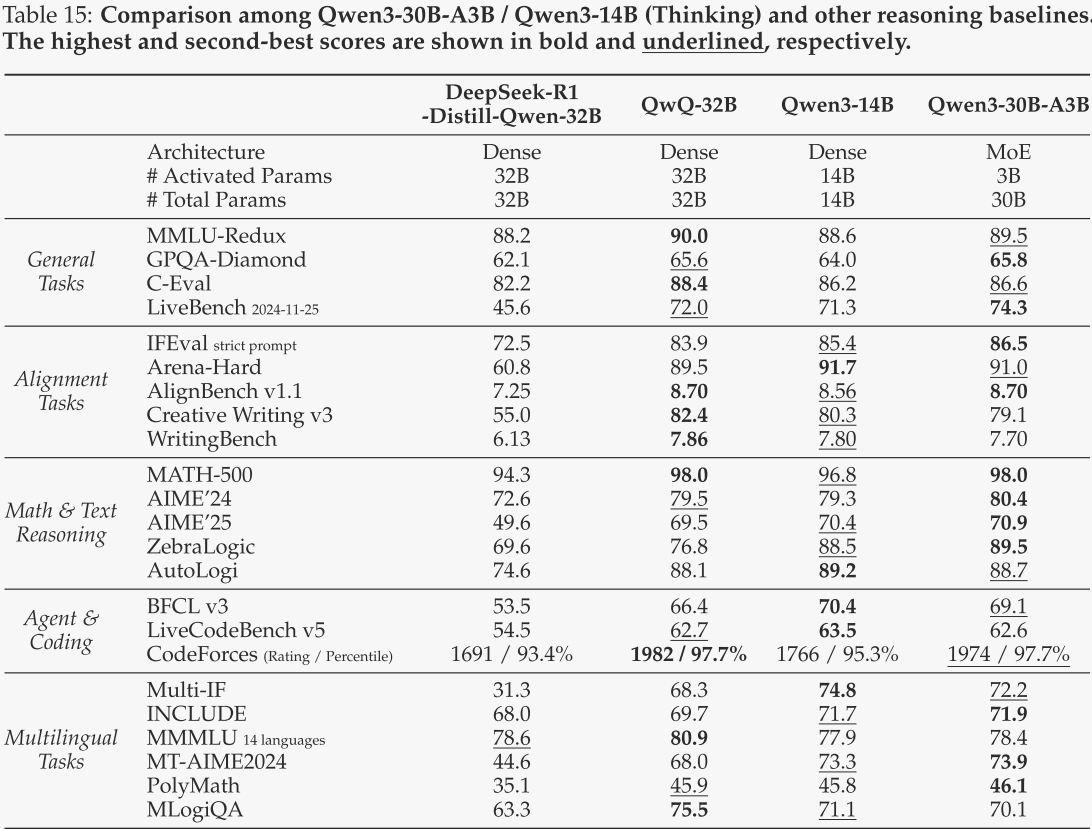
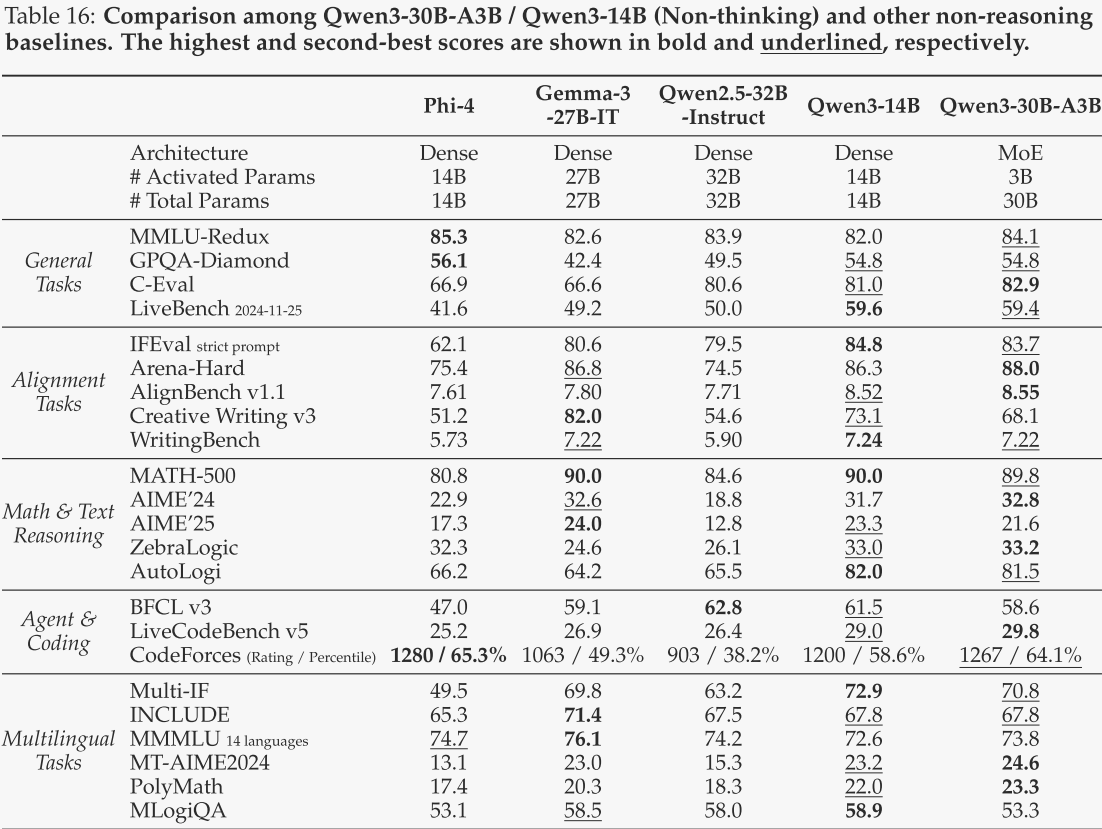
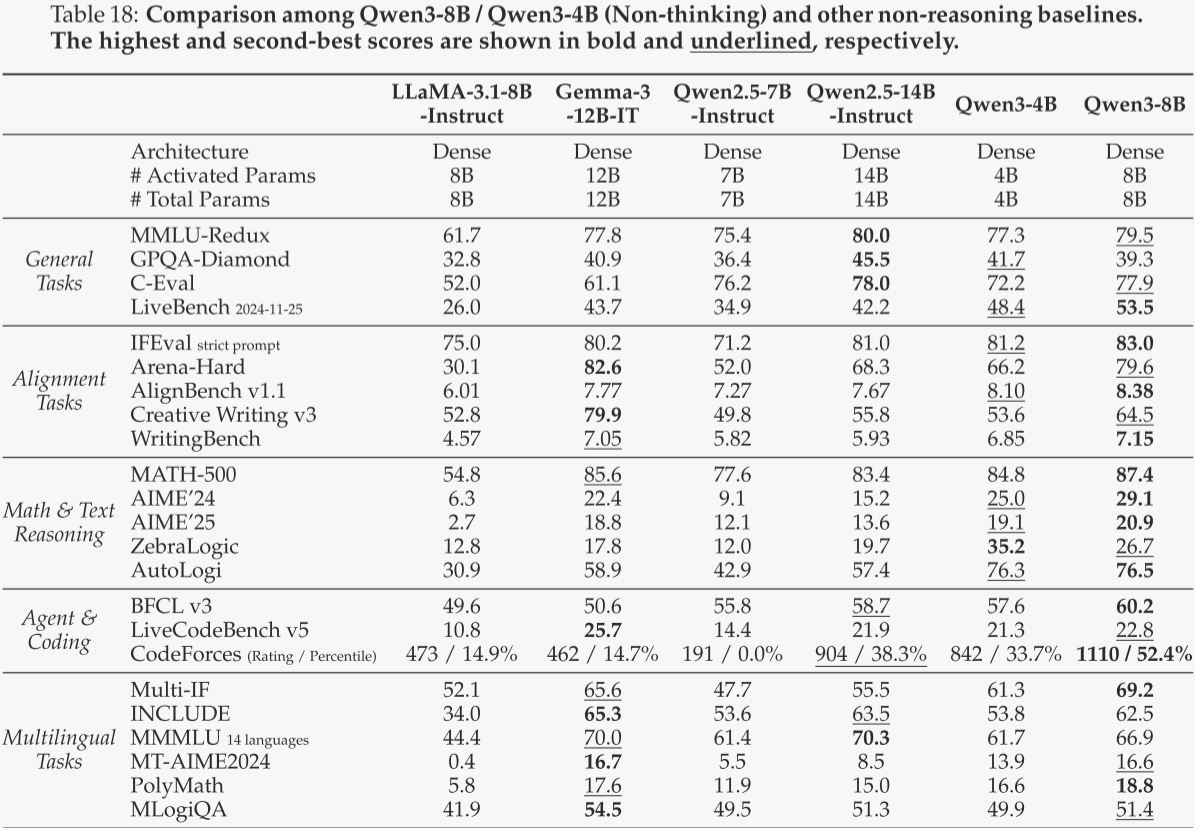
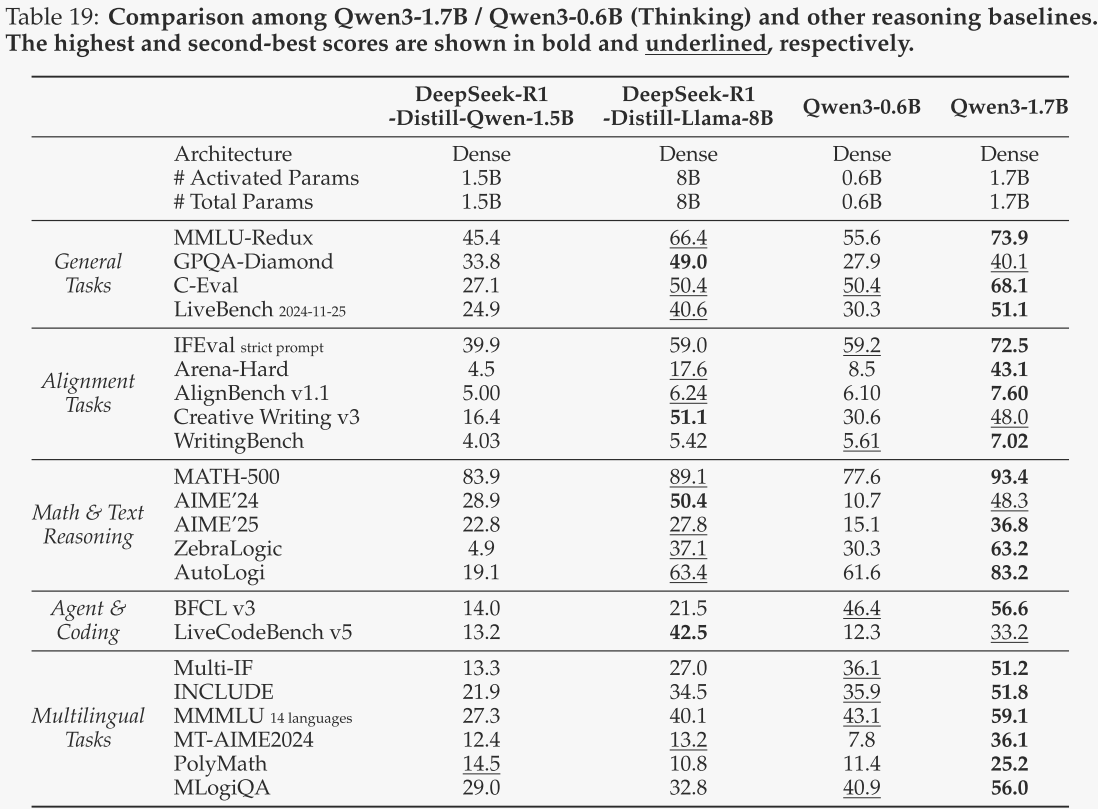
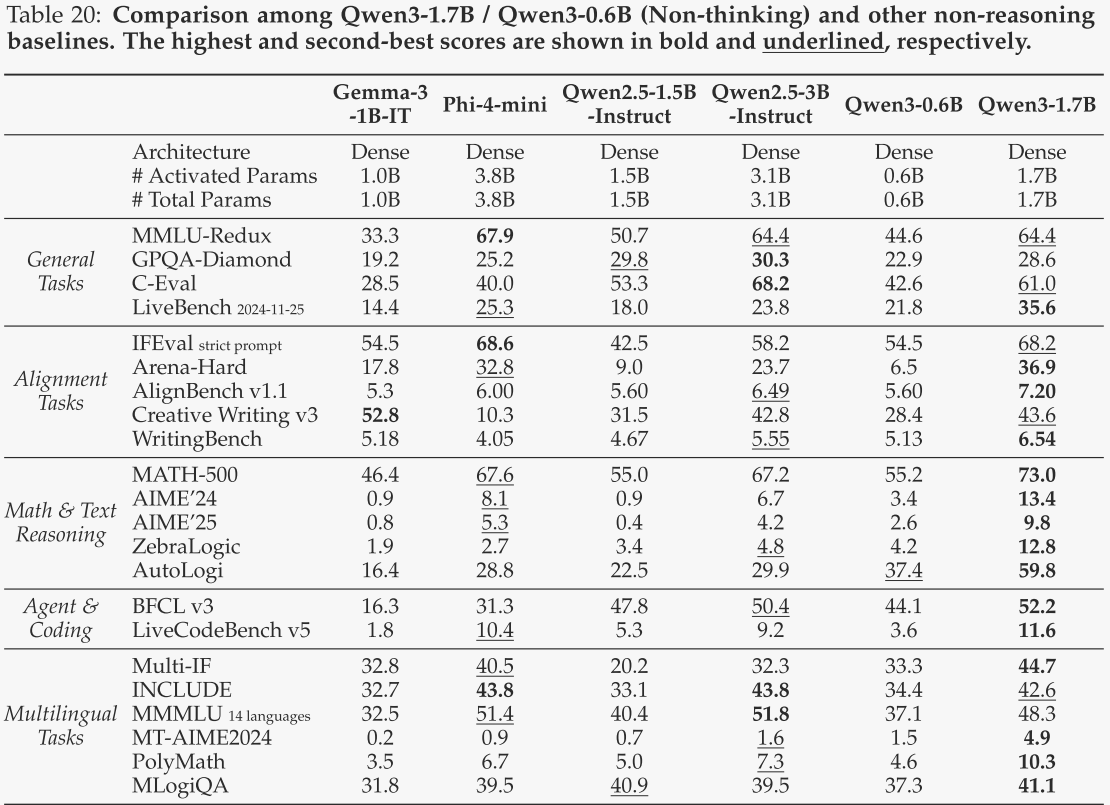
Qwen3-8B / 4B / 1.7B / 0.6B
对于Qwen3-8B和Qwen3-4B,在思考模式下,作者将其与DeepSeek-R1-Distill-Qwen-14B和DeepSeek-R1-Distill-Qwen-32B进行了对比;在非思考模式下,作者将其与LLaMA-3.1-8B-Instruct、Gemma-3-12B-IT、Qwen2.5-7B-Instruct和Qwen2.5-14B-Instruct进行了对比。对于Qwen3-1.7B和Qwen3-0.6B,在思考模式下,作者将其与DeepSeek-R1-Distill-Qwen-1.5B和DeepSeek-R1-Distill-Llama-8B进行了对比;在非思考模式下,作者将其与Gemma-3-1B-IT、Phi-4-mini、Qwen2.5-1.5B-Instruct和Qwen2.5-3B-Instruct进行了对比。Qwen3-8B和Qwen3-4B的评估结果分别见表17和表18,Qwen3-1.7B和Qwen3-0.6B的评估结果分别见表19和表20。
总体而言,这些边缘侧模型展现了令人印象深刻的性能,在思考模式或非思考模式下,即使在参数量更少的情况下,也超越了包括作者之前的Qwen2.5模型在内的基线模型。这些结果再次证明了作者强到弱蒸馏方法的有效性,使得作者能够以显著减少的成本和工作量构建轻量级的Qwen3模型。
-
讨论
思考预算的有效性
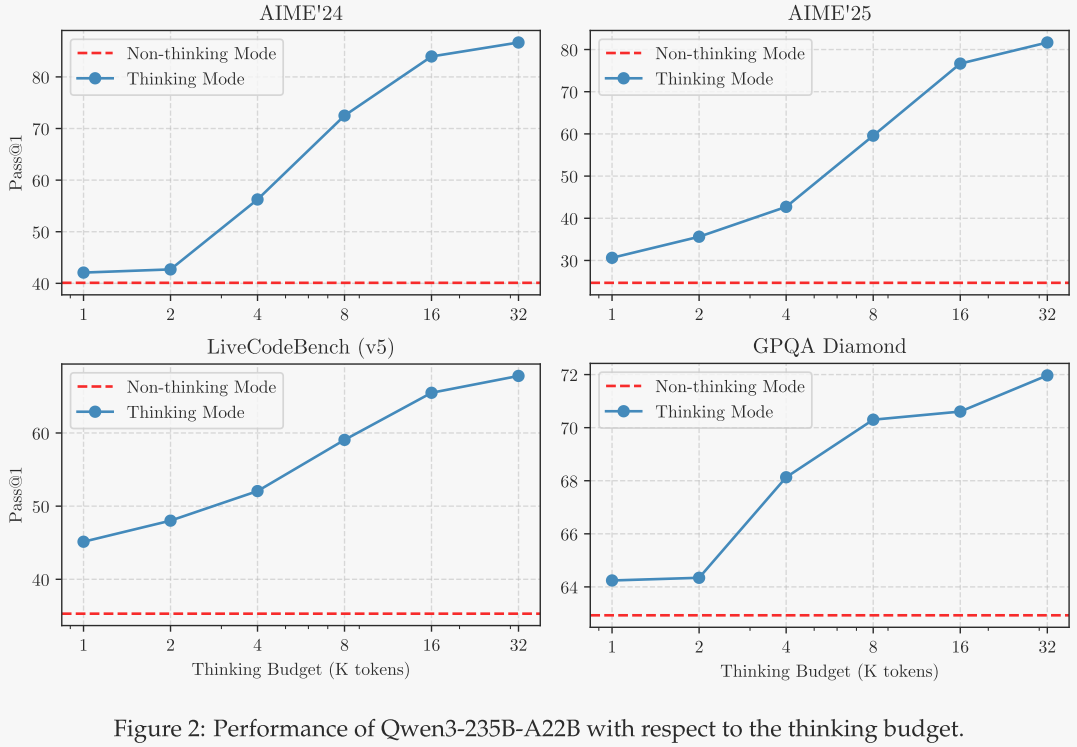
为了验证Qwen3能够通过增加思考预算来提升其智能水平,作者在数学、编码和STEM领域的四个基准测试中调整了分配的思考预算。结果如图2所示,Qwen3展现出与其分配的思考预算相关联的可扩展且平稳的性能提升。此外,作者观察到,如果进一步将输出长度扩展到超过32K,模型的性能预计在未来会进一步提高。这一探索将作为未来的工作。
在线策略蒸馏的有效性和效率
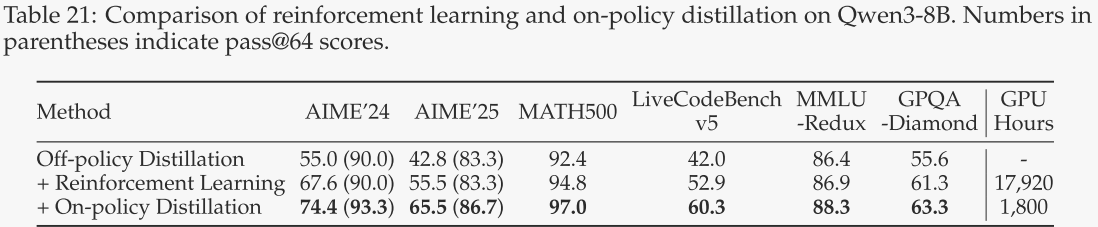
作者通过比较经过蒸馏与直接进行强化学习后的性能和计算成本(以GPU小时数衡量)来评估在线策略蒸馏的有效性和效率,两者均从相同的离策略蒸馏8B检查点开始。为简化起见,作者仅关注与数学和编码相关的查询。结果总结在表21中,显示蒸馏在性能上显著优于强化学习,同时仅需大约1/10的GPU小时数。此外,从教师模型的logits进行蒸馏使学生模型能够扩展其探索空间并增强其推理潜力,这在蒸馏后与初始检查点相比,在AIME'24和AIME'25基准测试中改进的pass@64分数中得到了证明。相比之下,强化学习并未导致pass@64分数的任何提升。这些观察结果突显了利用更强的教师模型指导学生模型学习的优势。
思考模式融合与通用强化学习的效果
为了评估后训练阶段中思考模式融合和通用强化学习(RL)的有效性,作者对Qwen-32B模型的不同阶段进行了评估。除了前面提到的数据集外,作者还引入了一些内部基准测试来监控其他能力。这些基准测试包括:
-
CounterFactQA:包含反事实问题,模型需要识别这些问题并非事实,并避免生成幻觉性的回答。
-
LengthCtrl:包含有长度要求的创意写作任务;最终得分基于生成内容长度与目标长度的差异。
-
ThinkFollow:涉及多轮对话,其中随机插入/think和/no think标志,以测试模型是否能够根据用户查询正确切换思考模式。
-
ToolUse:评估模型在单轮、多轮和多步骤工具调用过程中的稳定性。得分包括意图识别的准确性、格式准确性和工具调用过程中的参数准确性。
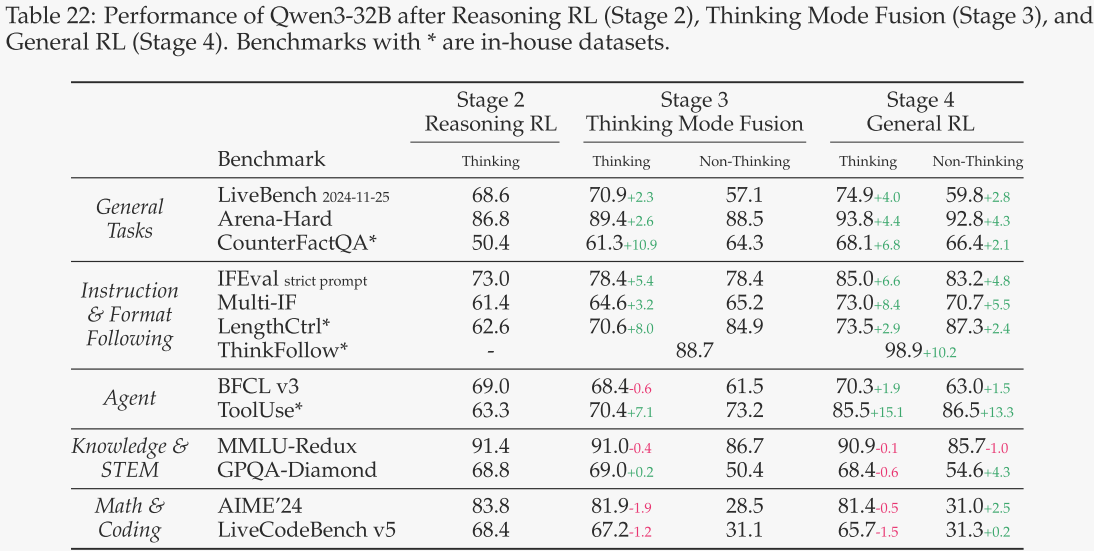 结果如表22所示,可以得出以下结论:
结果如表22所示,可以得出以下结论:
-
第3阶段:将非思考模式整合到已经具备思考能力的模型中(经过前两个阶段的训练)。ThinkFollow基准测试的得分为88.7,表明模型已经初步具备在不同模式之间切换的能力,尽管偶尔仍会出错。第3阶段还增强了模型在思考模式下的通用能力和指令遵循能力,CounterFactQA得分提高了10.9分,LengthCtrl得分提高了8.0分。
-
第4阶段:进一步加强了模型在思考和非思考模式下的通用能力、指令遵循能力和代理能力。值得注意的是,ThinkFollow得分提高到98.9,确保了模式切换的准确性。
-
对特定任务的影响:对于知识、STEM、数学和编码任务,思考模式融合和通用强化学习并未带来显著提升。相反,在AIME'24和LiveCodeBench等更具挑战性的任务中,经过这两个训练阶段后,模型在思考模式下的表现实际上有所下降。作者推测这种性能下降是由于模型在更广泛的通用任务上进行了训练,这可能削弱了其处理复杂问题的专项能力。在开发Qwen3时,作者选择接受这种性能权衡,以增强模型的整体通用性。
-
-
5.总结
在本技术报告中,作者介绍了Qwen3,这是Qwen系列的最新版本。Qwen3具备思考模式和非思考模式,使用户能够动态管理用于复杂思考任务的token数量。该模型在包含36万亿token的庞大语料库上进行了预训练,能够理解和生成119种语言和方言的文本。通过一系列全面的评估,Qwen3在预训练和后训练模型的标准基准测试中均展现出强劲的性能,涵盖编码生成、数学、推理和代理等任务。
在未来的研究中,作者将重点关注以下几个关键领域。作者将继续扩大预训练规模,使用质量更高、内容更丰富的数据。同时,作者将致力于改进模型架构和训练方法,以实现有效的压缩以及扩展到极长上下文等目标。此外,作者计划增加用于强化学习的计算资源,特别关注从环境反馈中学习的基于代理的强化学习系统。这将使作者能够构建能够应对需要推理时间扩展的复杂任务的代理。
相关文章:
)
Qwen3技术报告解读:训练秘籍公开,推理与非推理模型统一,大模型蒸馏小模型(报告详细解读)
1.简介 Qwen3 是 Qwen 模型家族的最新版本,它是一系列大型语言模型(LLMs),旨在提升性能、效率和多语言能力。基于广泛的训练,Qwen3 在推理、指令遵循、代理能力和多语言支持方面取得了突破性进展,具有以下…...

entity线段材质设置
在cesium中,我们可以改变其entity线段材质,这里以直线为例. 首先我们先创建一条直线 const redLine viewer.entities.add({polyline: {positions: Cesium.Cartesian3.fromDegreesArray([-75,35,-125,35,]),width: 5,material:material, 保存后可看到在地图上创建了一条线段…...

Word图片格式调整与转换工具
软件介绍 本文介绍的这款工具主要用于辅助Word文档处理。 图片排版功能 经常和Word打交道的人或许都有这样的困扰:插入的图片大小各异,排列也参差不齐。若不加以调整,遇到要求严格的领导,可能会让人颇为头疼。 而这款工具能够统…...

小刚说C语言刷题—1700请输出所有的2位数中,含有数字2的整数
1.题目描述 请输出所有的 2 位数中,含有数字 2 的整数有哪些,每行 1个,按照由小到大输出。 比如: 12、20、21、22、23… 都是含有数字 2的整数。 输入 无 输出 按题意要求由小到大输出符合条件的整数,每行 1 个。…...

视频抽帧并保存blob
视频抽帧 /*** description 获取文件中的每一帧* param { File } file* param { Number } time 每一帧的时间间隔(单位:秒)* param { Boolean } isUseInterval 是否使用间隔 为false只会获取这一帧* returns { Map }* example await captureFrame({ file, 20 }) > M…...

opencloudos 安装 mosquitto
更新系统并安装依赖 sudo dnf update -y sudo dnf install -y epel-release # 若需要 EPEL 额外仓库 sudo dnf install -y gcc-c cmake openssl-devel c-ares-devel libuuid-devel libwebsockets-devel安装 Mosquitto 通过默认仓库安装(推荐) sudo dn…...

STM32CubeMX使用SG90舵机角度0-180°
1. 配置步骤 1.1 硬件连接 舵机信号线 → STM32的PWM输出引脚(如 PA2,对应定时器 TIM2_CH3)。 电源和地 → 外接5V电源(确保共地)。 1.2 定时器配置(以TIM2为例) 在STM32CubeMX中࿱…...

【Umi】项目初始化配置和用户权限
app.tsx import { RunTimeLayoutConfig } from umijs/max; import { history, RequestConfig } from umi; import { getCurrentUser } from ./services/auth; import { message } from antd;// 获取用户信息 export async function getInitialState(): Promise<{currentUse…...

使用哈希表封装myunordered_set和myunordered_map
文章目录 使用哈希表封装myunordered_set和myunordered_map实现出复用哈希表框架,并支持insert支持迭代器的实现constKey不能被修改unordered_map支持[ ]结语 我们今天又见面啦,给生活加点impetus!!开启今天的编程之路!…...

光学变焦和数字变倍模块不同点概述!
一、光学变焦与数字变倍模块的不同点 1. 物理基础 光学变焦:通过调整镜头组中镜片的物理位置改变焦距,实现无损放大。例如,上海墨扬的MF-STAR吊舱采用30倍光学变焦镜头,焦距范围6~180mm,等效焦距可达997mm。 数字…...

Spring MVC 中请求处理流程及核心组件解析
在 Spring MVC 中,请求从客户端发送到服务器后,需要经过一系列组件的处理才能最终到达具体的 Controller 方法。这个过程涉及多个核心组件和复杂的映射机制,下面详细解析其工作流程: 1. 核心组件与请求流程 Spring MVC 的请求处…...

《100天精通Python——基础篇 2025 第19天:并发编程启蒙——理解CPU、线程与进程的那些事》
目录 一、计算机基础知识1.1 计算机发展简史1.2 计算机的分类1.2.1 超级计算机(Supercomputer)1.2.2 大型机(Mainframe Computer)1.2.3 迷你计算机(Minicomputer)---- 普通服务器1.2.4 工作站(W…...

<PLC><视觉><机器人>基于海康威视视觉检测和UR机械臂,如何实现N点标定?
前言 本系列是关于PLC相关的博文,包括PLC编程、PLC与上位机通讯、PLC与下位驱动、仪器仪表等通讯、PLC指令解析等相关内容。 PLC品牌包括但不限于西门子、三菱等国外品牌,汇川、信捷等国内品牌。 除了PLC为主要内容外,相关设备如触摸屏(HMI)、交换机等工控产品,如果有…...

FC7300 WDG MCAL 配置引导
在WDG模块中,用户需要选择GPT资源,因此在配置WDG组件之前,需要先选择GPT通道。WDG包含三个组件,每一个组件对应不同的硬件。 Wdg:对应WDOG0Wdg_174_Instance1:对应WDOG1Wdg_174_Instance2:对应WDOG2一、WDG 组件 1. General Wdg Disable Allowed:是否允许在WDG运行过程…...

Leaflet 自定义瓦片地图与 PHP 大图切图算法 解决大图没办法在浏览器显示的问题
为什么使用leaflet 使用 Leaflet 来加载大图片(尤其是通过瓦片化的方式)是一种高效的解决方案,主要原因如下: 1. 性能优化 减少内存占用:直接加载大图片会占用大量内存,可能导致浏览器崩溃或性能下降。瓦片…...

MySQL——十、InnoDB引擎
MVCC 当前读: 读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。 -- 当前读 select ... lock in share mode(共享锁) select ... for update update insert delete (排他锁)快照读:…...
无法调用,直接卡死,应如何解决)
import pywinauto后tkinter.filedialog.askdirectory()无法调用,直接卡死,应如何解决
诸神缄默不语-个人技术博文与视频目录 具体情况就是我需要用pywinauto进行一些软件的自动化操作,同时需要将整个代码功能用tkinter的可视化界面来展示,在调用filedialog.askdirectory()的时候代码直接不运行了,加载不出来。我一开始还以为是…...

display:grid网格布局属性说明
网格父级 :display:grid(块级网格)/ inline-grid(行内网格) 注意:当设置网格布局,column、float、clear、vertical-align的属性是无效的。 HTML: <ul class"ls02 f18 mt50 sysmt30&…...

初识——QT
QT安装方法 一、项目创建流程 创建项目 入口:通过Qt Creator的欢迎页面或菜单栏(文件→新建项目)创建新项目。 项目类型:选择「Qt Widgets Application」。 路径要求:项目路径需为纯英文且不含特殊字符。 构建系统…...

力扣-78.子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 class Solution {List<List<Integer>> res new ArrayList<>();List<I…...

python中字符串的操作
1. 字符串创建 使用单引号、双引号或三引号创建字符串三引号适用于多行字符串,且可以自由包含单双引号原始字符串使用r前缀,如r’Hello\nWorld’会原样输出\n 2. 基本操作 拼接:使用运算符或join()方法复制:使用*运算符…...

《Elasticsearch 源码解析与优化实战》笔记
术语 思维导图 基础和环境 1-2 主要流程 3-10 内部模块 11-17 优化和诊断 18-22 资料 https://elasticsearchbook.com/...
)
华为网路设备学习-22(路由器OSPF-LSA及特殊详解)
一、基本概念 OSPF协议的基本概念 OSPF是一种内部网关协议(IGP),主要用于在自治系统(AS)内部使路由器获得远端网络的路由信息。OSPF是一种链路状态路由协议,不直接传递路由表,而是通过交换链路…...
)
多线程(四)
目录 一 . 单例模式 (1)什么是设计模式? (2)饿汉模式 (3)懒汉模式 二 . 指令重排序 今天咱们继续讲解多线程的相关内容 一 . 单例模式 (1)什么是设计模式&am…...

【设计模式】- 结构型模式
代理模式 给目标对象提供一个代理以控制对该对象的访问。外界如果需要访问目标对象,需要去访问代理对象。 分类: 静态代理:代理类在编译时期生成动态代理:代理类在java运行时生成 JDK代理CGLib代理 【主要角色】: 抽…...
时,报错type xxx is not json serializable错误原因及解决方案)
python报错:使用json.dumps()时,报错type xxx is not json serializable错误原因及解决方案
文章目录 一、错误原因分析二、解决方案1. **自定义对象序列化方法一:使用default参数定义转换逻辑方法二:继承JSONEncoder类统一处理 2. **处理特殊数据类型场景一:datetime或numpy类型场景二:bytes类型 3. **处理复杂数据结构 三…...

Vue3中实现轮播图
目录 1. 轮播图介绍 2. 实现轮播图 2.1 准备工作 1、准备至少三张图片,并将图片文件名改为数字123 2、搭好HTML的标签 3、写好按钮和图片标签 编辑 2.2 单向绑定图片 2.3 在按钮里使用方法 2.4 运行代码 3. 完整代码 1. 轮播图介绍 首先,什么是…...

flutter缓存网络视频到本地,可离线观看
记录一下解决问题的过程,希望自己以后可以参考看看,解决更多的问题。 需求:flutter 缓存网络视频文件,可离线观看。 解决: 1,flutter APP视频播放组件调整; 2,找到视频播放组件&a…...

2025年Ai写PPT工具推荐,这5款Ai工具可以一键生成专业PPT
上个月给客户做产品宣讲时,我对着空白 PPT 页面熬到凌晨一点,光是调整文字排版就改了十几版,最后还是被吐槽 "内容零散没重点"。后来同事分享了几款 ai 写 PPT 工具,试完发现简直打开了新世界的大门 —— 不用手动写大纲…...

【深度学习】#11 优化算法
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 目录 深度学习中的优化挑战局部极小值鞍点梯度消失 凸性凸集凸函数 梯度下降一维梯度下降学习率局部极小值 多元梯度下降 随机梯度下降随机梯度更新动态学习率…...

数学复习笔记 13
前言 继续做线性相关的练习题,然后做矩阵的例题,还有矩阵的练习题。 646 A 明显是错的。因为假设系数全部是零,就不是线性相关了。要限制系数不全是零,才可以是线性相关。 B 这个说法好像没啥问题。系数全为零肯定线性组合的结…...

AI预测3D新模型百十个定位预测+胆码预测+去和尾2025年5月16日第79弹
从今天开始,咱们还是暂时基于旧的模型进行预测,好了,废话不多说,按照老办法,重点8-9码定位,配合三胆下1或下2,杀1-2个和尾,再杀6-8个和值,可以做到100-300注左右。 (1)定…...

阳台光伏+储能:安科瑞智能计量仪表来助力
随着可再生能源的普及和家庭储能需求的增长,阳台光伏储能系统逐渐成为家庭能源管理的新趋势。如何精准计量储能系统的发电量、用电量及电网交互数据,成为优化能源利用效率的关键。安科瑞计量仪表凭借高精度、多功能及智能化特性,为家庭阳台储…...

Unable to determine the device handle for GPU 0000:1A:00.0: Unknown Error
Unable to determine the device handle for GPU 0000:1A:00.0: Unknown Error 省流:我遇到这个问题重置bios设置就好了 这个错误信息表明系统无法识别或访问GPU(0000:1A:00.0),通常与CUDA、驱动程序或硬件相关。以下是可能的原…...

多态性标记设计
1.确定区间 2.获取该区间内的序列,如果只有一个位置,可以前后扩100bp 使用ncbi primer blast进行引物设计(https://blast.ncbi.nlm.nih.gov/Blast.cgi)...

Jenkins 最佳实践
1. 在Jenkins中避免调度过载 过载Jenkins以同时运行多个作业可能导致资源竞争、构建速度变慢和系统性能问题。分配作业启动时间可以防止瓶颈,并确保更顺畅的执行。如何实现? 在Cron表达式中使用H:引入抖动(jitter)&a…...

如何查询Ubuntu系统中最大的几个目录以G单位显示大小,从大到小排列?
环境: Ubuntu 20,04 问题描述: 如何查询系统中最大的几个目录以G单位显示大小,从大到小排列? 解决方案: 想查看整个系统(单一文件系统内)最大的20个目录,结果按大小从大到小排序…...

深入浅出拆分学习,图神经网络拆分学习,混合联邦学习
深入浅出解析拆分学习(Split Learning)、图神经网络拆分学习(Split Learning for Graph Neural Networks)以及混合联邦学习(Hybrid Federated Learning),这三者都体现了在分布式数据环境下进行机…...

DDD领域驱动介绍
📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、(架构篇)清华大学出版社签约作家、Java领域优质创作者、CSDN博客专家、…...

ubuntu22鼠键失灵恢复记录笔记chatgpt解决
ChatGPT 说: 你提到“Ubuntu 22 鼠键失灵”,这个问题可能涉及以下几方面: 🧭 先确认问题 是鼠标问题还是键盘问题,还是触控板? “鼠键”一般理解为“鼠标键”,请确认你是指鼠标左键/右键失灵&a…...
)
在服务器上安装AlphaFold2遇到的问题(1)
犯了错误,轻信deepseek,误将cuDNN8.9.7删掉 [rootlocalhost ~]# cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2 #define CUDNN_MAJOR 8 #define CUDNN_MINOR 9 #define CUDNN_PATCHLEVEL 7 -- #define CUDNN_VERSION (CUDNN_MA…...

ch10 题目参考思路
ch10 - 最小生成树 有线通讯网 知识点:Prim 算法思路: 该题要求对 n 座城市铺设 n - 1 条光缆,并要求所有城市连通,那本质上是一棵树,又要求铺设光缆的费用最低,即要求选取的 n - 1 条光缆的长度最小&…...

Hudi、Iceberg 、 Paimon 数据湖选型对比
Hudi、Iceberg 和 Paimon 是当前数据湖领域的三大主流开源框架,均致力于解决数据湖场景下的增量更新、事务支持、元数据管理、流批统一等核心问题,但设计理念和适用场景存在差异。以下从技术特性、适用场景和选型建议三方面对比分析: 一、核心技术特性对比 维度HudiIceberg…...
:小行星轨迹预测思路)
2025认证杯数学建模第二阶段A题完整论文(代码齐全):小行星轨迹预测思路
2025认证杯数学建模第二阶段A题完整论文(代码齐全):小行星轨迹预测思路,详细内容见文末名片 第二阶段问题 1 分析 问题起源与相关性:为了更全面地评估近地小行星对地球的潜在威胁,需要对其轨道进行长期预测。三个月内的观测数据为…...

信息安全基础知识
信息系统 信息系统能进行(数据)的采集、传输、存储、加工,使用和维护的计算机应用系统 例如:办公自动化、CRM/ERP、HRM、12306火车订票系统等。 信息安全 信息安全是指保护信息系统中的计算机硬件、软件、数据不因偶然或者恶意…...

UE RPG游戏开发练手 第二十六课 普通攻击1
UE RPG游戏开发练手 第二十六课 普通攻击1 1.定义攻击的InputTag MyGameplayTags.h代码 RPGGAMETEST_API UE_DECLARE_GAMEPLAY_TAG_EXTERN(InputTag_LightAttack_Axe);MyGameplayTag.cpp代码 UE_DEFINE_GAMEPLAY_TAG(InputTag_LightAttack_Axe, "InputTag.LightAttack.Ax…...

SAP ABAP 程序中归档数据读取方式
上一篇文章记录了字段目录,归档信息结构,这篇文章记录如何通过字段目录,归档信息结构,归档对象读取归档数据。未归档数据是从数据库表直接抽取,本样例是通过归档读取方式复写sql。 发布时间:2025.05.16 示…...

每周资讯 | 腾讯Q1财报:国内游戏业务收入同比增长24%;Tripledot 8亿美元收购AppLovin游戏业务
内容速览: 广州“服务贸易和数字贸易22条”助推游戏产业发展Tripledot Studios 8亿美元收购AppLovin游戏业务苹果紧急申请暂停执行AppStore新规4月中国手游出海收入下载榜,点点互动《Kingshot》收入激增 腾讯Q1财报:国内游戏业务收入同比增长…...
)
iOS SwiftUI的具体运用实例(SwiftUI库的运用)
最近接触到一个 SwiftUI的第三方框架,它非常的好用。以下是 具体运用实例,结合其核心功能与开发场景,分多个维度进行详细解析: 一、基础 UI 组件开发 登录界面 SwiftUI 的 VStack、TextField 和 Button 可快速构建用户登录表单。例…...

杰理ac696配置sd卡随机播放
#define FCYCLE_LIST 0 // 列表循环(按顺序播放文件列表) #define FCYCLE_ALL 1 // 全部循环(播放完所有文件后重新开始) #define FCYCLE_ONE 2 // 单曲循环(重复播放当前文件) #define …...