Ensemble Alignment Subspace Adaptation Method for Cross-Scene Classification
用于跨场景分类的集成对齐子空间自适应方法
摘要:本文提出了一种用于跨场景分类的集成对齐子空间自适应(EASA)方法,它可以解决同谱异物和异谱同物的问题。该算法将集成学习的思想与域自适应(DA)算法相结合。考虑到原始数据(OD)的样本不均衡问题,通过按照一定规则对原始数据进行多次随机采样得到源数据(SD),并将其作为输入。然后,对源数据和目标数据(TD)进行几何对齐和统计对齐,构建公共子空间,进而对目标数据进行分类。最后,通过对多次分类结果进行计数并保留有效信息,对分类标签进行集成。该技术能够降低生成子空间投影的不确定性和随机性。在两个真实数据集上的实验结果表明,与传统机器学习和域自适应方法相比,该算法在准确率上有显著提升。
关键词:跨场景分类;域自适应(DA);集成学习;高光谱;迁移学习
一、引言
高光谱图像(HSI)的跨场景分类由于其高维数和少样本的问题,一直是一个挑战。当目标域需要实时处理且不能用于重新训练时,有必要仅在源域上训练模型,并直接将模型迁移到目标域。域自适应(DA)是转导迁移学习的一种情况,它可以在特征层面减少光谱偏移,并学习域不变模型,这在跨场景分类中已被证明是成功的。
通常情况下,训练集被假定与测试集具有相同的分布。然而,在实际情况中,测试环境往往差异很大,这可能会导致过拟合。因此,为了解决源数据(SD)和目标数据(TD)之间的不一致性问题,提出了基于域自适应的迁移学习技术。通过该技术,在源域上训练的目标函数被迁移到目标域,以提高预测的准确性。
最近,人们提出了几种方法来提高分类性能。Pan等人提出了一种迁移成分分析(TCA)算法,该算法将两个域的信息映射到一个高维再生核希尔伯特空间中。为了同时利用边际分布和条件分布,联合分布自适应(JDA)算法被提出。如果源数据和目标数据之间的差异很大,很难找到一个能同时实现两个数据投影的空间。投影空间受随机因素影响,如果没有选择合适的基作为空间向量,可能会出现错误分布。因此,Tzeng等人提出了深度域混淆(DDC)算法。在DDC之后,深度自适应网络(DANs)被提出用于进一步探索。DAN增加了一层自适应层和一个域混淆损失函数,使网络能够学习如何进行分类。这种方法减少了源域和目标域之间的分布差异。DAN最突出的方面体现在两个点:多层和多核。对于无监督域自适应中的分类问题,Sun和Yang提出了相关对齐(CORAL)算法,该算法使用线性变换对齐源域和目标域的二阶统计量。为了更好地利用类内特征,Wang等人提出了分层迁移学习(STL)算法。STL使用类内迁移计算每个类的最大平均差异(MMD)距离,以实现更好的变换效果。
在集成学习中,多个分类器结果的适当组合所得到的判断比任何单个分类器的判断都要好。提升算法(Boosting)和自训练聚合算法(Bagging)是主要的集成学习方法。个体学习器之间的差异被认为是分类器组合中非常重要的一个特征。集成学习已成功应用于高光谱图像分类。
当源数据和目标数据差异很大时,很难找到一个包含两个域共享特征的公共子空间。以前大多数基于特征的域自适应方法并没有明确最小化域之间的分布距离。在本文中,采用集成学习来处理源数据的输入并整合每个结果。集成对齐子空间自适应(EASA)方法能够有效地提高识别准确率。在域自适应算法中使用了判别协同对齐(DCA)算法,该算法应用约束来对齐两个子空间,在保持全局几何属性的同时,控制投影数据的几何结构相似性。计算域间MMD和类间MMD,并进行数据重建以保留判别信息。集成学习可以汇集不同维度空间的优势。
本文的主要贡献总结如下:
- 通过集成多个结果,可以解决寻找包含共享特征子空间的困难。
- 针对高光谱多维投影在低纬度产生判别信息损失的现象,利用约束进行全局信息保留。
- 该方法通过对原始数据进行多次随机重复采样,优化高光谱跨场景分类的效果,提高数据利用率。
二、方法论
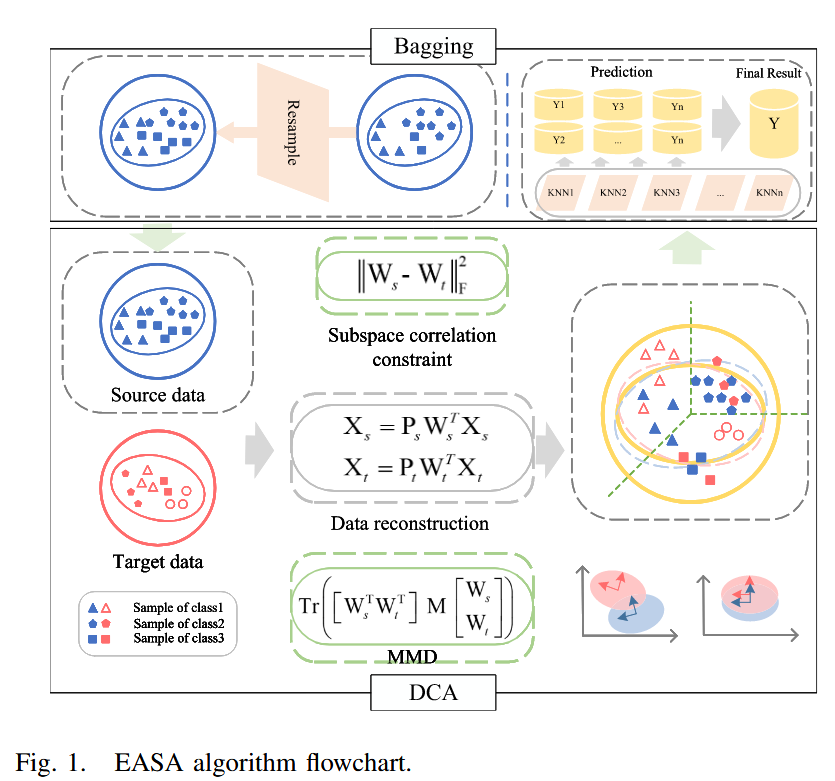
(A)判别协同对齐
DCA算法之前通过以下目标函数进行两个域投影的学习:
[min {W{s}, W_{t}}\left| W_{s}^{T} X_{s}-W_{t}^{T} X_{t}\right| {F}^{2}+\lambda{1}\left| W_{s}-W_{t}\right| {F}^{2}]
其中,(\lambda{1})是控制子空间对齐的正则化参数,(w_{s}) 、(W_{t} \in d ×k)分别是源子空间和目标子空间。k是子空间的维数。(w_{s}) 、(w_{s})可以通过公式(1)进行优化。
为了确保在低维子空间中对齐样本的判别信息不丢失,公式(1)中引入的数据重建公式为:
[\begin{aligned} & min {W{s}, W_{t}, P_{s}, P_{t}}\left| X_{s}-P_{s} W_{s}^{T} X_{s}\right| {F}^{2}+\left| X{t}-P_{t} W_{t}^{T} X_{t}\right| {F}^{2} \ &+\lambda{1}\left| W_{s}-W_{t}\right| {F}^{2} \ & s.t. P{s}^{T} P_{s}=I, P_{t}^{T} P_{t}=I . \end{aligned}]
(P_{s}) 、(P_{t} \in \mathbb{R}^{d ×k})是两个正交重建矩阵。此时,即使源数据和目标数据的光谱偏移很大,也能很好地完成重建。
MMD是迁移学习中应用最广泛的损失函数,尤其是在域自适应中。此外,MMD主要用于衡量两个不同但相关的随机变量分布之间的距离。其基本定义公式为:
[MMD[F, p, q]:=sup {f \in F}\left(E{p}[f(x)]-E_{q}[f(y)]\right)]
其中,f是映射关系,F是映射空间。
在DCA算法中,域间MMD(公式4)和类间MMD(公式5)被用作数据对齐的判别标准:
[M\left(X_{s}, X_{t}\right)=\left| \frac{1}{n_{s}} \sum_{i=1}^{n_{s}} W_{s}^{T} x_{i}-\frac{1}{n_{t}} \sum_{j=1}^{n_{t}} W_{t}^{T} x_{j}\right| {F}^{2}]
[C\left(X{s}, X_{t}\right)=\sum_{l=1}^{c}\left| \frac{1}{n_{s}^{l}} \sum_{i=1}{n_{s}{t}} W_{s}^{T} x_{i}-\frac{1}{n_{t}^{l}} \sum_{j=1}{n_{t}{t}} W_{t}^{T} x_{j}\right| _{F}^{2}]
分布位移优化项可以通过以下公式得到:
[min {W} Tr\left(W^{T} X M X^{T} W\right)]
在这个公式中,w是子空间矩阵,x是数据矩阵。M是一个线性变换。上述公式得出DCA的目标函数,可以表示为:
[\begin{aligned} min {W{s}, W{t}, P_{s}, P_{s}, P_{t}} & \left| X_{s}-P_{s} W_{s}^{T} X_{s}\right| {F}^{2}+\left| X{t}-P_{t} W_{t}^{T} X_{t}\right| {F}^{2} \ & +\lambda{1}\left| W_{s}-W_{t}\right| {F}^{2}+\lambda{2} min {W} Tr\left(W^{T} X M X^{T} W\right) \ s.t. & P{s}^{T} P_{s}=I, P_{t}^{T} P_{t}=I \end{aligned}]
其中,(\lambda_{2})是一个正则化参数,用于调整分布对齐的权重。经过对(w_{s}) 、(w_{s})的几次迭代计算后,使用对齐后的源样本训练KNN分类器,然后对目标数据进行分类。
(B)自训练聚合算法(Bagging)
Bagging算法在多次采样后得到一个包含N个序列的数据集。首先,从样本中随机抽取一个样本放入选取序列中,然后将该样本放回原始数据集,这样该样本在下次采样时仍能被选中。通过这种方式,经过m次随机采样操作后,可以得到一个包含m个样本的采样序列。原始数据集中的一些样本会出现多次,而有些样本则不会出现。
学习集由({(y_{n}, x_{n})})组成,(n = 1,2, …, N) ,其中x是输入,y是标签。使用这个数据集生成一个分类器(\varphi(x, L)),它可以预测y的结果。假设序列({L_{k}})由N个与c分布相同的独立集合组成。与单个集合训练的分类器相比,由这个序列训练的分类器具有更高的准确率。当没有复合数据集只有单个学习集c时,可以通过重复提取样本(\varphi(x, L{(B)}))生成({L{(B)}}) ,并形成一个投票(\varphi_{B}) 。对于类别数量差异较大的样本,Bagging算法表现出色。
(C)集成对齐子空间自适应
本文提出的EASA算法可以应用于样本不均衡的训练数据。数据不均衡会导致分类边界偏向较弱的类别,使样本更容易获得强标签。在数据层面使用重采样方法来平衡标记样本的数量,一种是构建弱类别样本以增加弱类别样本的数量(过采样),另一种是减少强类别样本的数量(欠采样)。在本算法中,选择随机重采样来获取采样后的源数据。
算法1 EASA算法
- 输入:源数据(X_s),目标数据(X_t),源标签(L_s),(\lambda_1),(\lambda_2),k,iter。
- 初始化:矩阵(W_s)、(W_t)赋随机值。
- 计算m的值。
- 当未达到最大迭代次数iter时:
- 为每个类别提取m个数据。
- 用KNN算法初始化(L_t)。
- 当未收敛或未达到最大迭代次数iter时:
- 计算重建矩阵(P_s)、(P_t),更新(W_s)、(W_t)。
- 用KNN算法预测(L_t)。
- 结束内循环。
- 集成每次的预测结果得到(Y)。
- 结束外循环。
- 输出:(Y)。
对原始数据进行多次随机放回采样,使每个类别获得相同数量的m个样本,并确保每次采样过程中获得的样本总数保持不变。每次采样结束时,得到一个用于训练的源数据集。假设学习集(L = {S_{1}, S_{2}, …, S_{n}})包含(II)个类别,(S_{max }) 、(S_{min })分别是数量最多和最少的类别,m的取值为:
[m=min \left(S_{max }, \frac{6}{5} S_{min }\right)]
每个数据集都有一个相应的分类器。整合多个分类器的结果,出现次数最多的数值即为最终答案。算法流程图如图1所示。
每个生成的子空间投影都有一定的随机性,这可能会导致训练生成的分类器存在一定偏差。此外,在降维步骤中可能会丢失少量信息。本文提出的算法可以更好地解决源 - 目标样本不均衡的问题,并且具有更强的鲁棒性。
三、实验结果与讨论
(A)实验数据与评估方法
准备了休斯顿(Houston)和HyRANK数据集进行实验。使用总体准确率(OA)、类别特异性准确率(CA)和Kappa系数来评估每种算法的性能。
- 休斯顿数据集包含2013年和2018年休斯顿地区的高光谱信息。2013年的数据包含144个波段、2.5米分辨率的15种特征类型;2018年的数据包含48个波段、1米分辨率的20种特征类型。在本实验中,选择了7种类型进行分类测试,将2013年的数据作为源数据,2018年的数据作为目标数据。使用的数据数量和类别如表1所示。假彩色图像和真实地图如图2所示。
- HyRANK数据集由Hyperion传感器获取。选择Dioni地区数据作为源数据,Loukia地区数据作为目标数据,选取12个常见类别和176个光谱波段进行测试。使用的数据数量和类别如表2所示。假彩色图像和真实地图如图3所示。
(B)实验参数设置
实验中考虑以下参数:DCA中的正则化参数(\lambda_{1}) 、(\lambda_{2}),子空间的维度k,Bagging中的迭代次数iter,以及每次从样本中采样的数量n。
(\lambda_{1}) 、(\lambda_{2})的取值范围是{ (1 e-4) , (1 e-3) , (1 e-2) 1 (1 e-1) , (1 e-0) , (5 e+0) , (1 e+1) , 1e 2, 5e 2 }。在图4中,休斯顿数据适合(1 e+2)和(1 e-1) ,HyRANK数据适合(1e+2)和(1 e+2) 。
通过多次实验发现,准确率随着iter的增加而提高。考虑到时间成本,将iter设置为200。对原始数据的每个类别进行相同数量的采样可以减少样本不均衡的影响。k适合设置为20。根据随机重采样算法,休斯顿数据集的m值为198,HyRANK数据集的m值为188,对源数据进行均衡化处理。
使用KNN、TCA、CORAL、MEDA和DCA作为对比算法。TCA中的维度参数设置为20,lambda设置为10,gamma设置为0.5,并使用线性核函数。整个过程在MATLAB中实现。
(C)结果展示与分析
表3和表4给出了上述方法在两个目标场景上的类别特异性分类性能,并报告了平均精度和标准差。
EASA使用KNN进行标签初始化和最终预测。与KNN的结果相比,EASA不受源数据样本不均衡问题的影响,对小样本量类别的分类仍然准确。此外,与TCA、CORAL、MEDA等算法相比,EASA减少了由光谱偏移和空间偏移带来的分类错误。
集成学习的原理使EASA不仅在重复实验的结果中表现稳定,而且与DCA算法相比,能够成功识别子空间类别分布边缘的一些点。在两次实验中,DCA都存在无法识别的类别,休斯顿数据集中的第4类,HyRANK数据集中的第2、4和5类都无法识别。由DCA改进而来的EASA仍然存在这个问题。然而,与MEDA相比,EASA能够识别的类别数量有了很大提高。
四、结论
本文针对跨场景情况下的高光谱图像分类问题,提出了EASA方法。首先,对源数据进行重采样,使每种类型的样本数据数量相同,以减少样本不均衡的干扰。使用域自适应算法DCA对源数据和目标数据进行子空间投影,在保留原始信息的同时,对源域和目标域应用重建约束。最后,利用投票分类器的思想,对源数据多次随机采样分类得到的目标数据分类信息进行统计,获取不同投影子空间携带的特征信息。在休斯顿和HyRANK数据集上的测试结果验证了EASA比以往算法表现更优。
相关文章:

Ensemble Alignment Subspace Adaptation Method for Cross-Scene Classification
用于跨场景分类的集成对齐子空间自适应方法 摘要:本文提出了一种用于跨场景分类的集成对齐子空间自适应(EASA)方法,它可以解决同谱异物和异谱同物的问题。该算法将集成学习的思想与域自适应(DA)算法相结合…...

AFFS2 的 `yaffs_ext_tags` 数据结构详解
YAFFS2 的 yaffs_ext_tags 数据结构详解 yaffs_ext_tags 是 YAFFS2 文件系统中用于 管理 NAND 闪存页的元数据 的核心结构体,存储在 NAND 的 OOB(Out-Of-Band)区域。它记录了数据块的归属、状态、校验信息等关键元数据,是 YAFFS2…...

CSS经典布局之圣杯布局和双飞翼布局
目标: 中间自适应,两边定宽,并且三栏布局在一行展示。 圣杯布局 实现方法: 通过float搭建布局margin使三列布局到一行上relative相对定位调整位置; 给外部容器添加padding,通过相对定位调整左右两列的…...

超声波传感器模块
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 文章目录 1.HC-SR04介绍2.HC-SR04原理介绍2.1原理概述3.2原理详解 4驱动代码编写4.1写前思考4.2硬件连线 5.总结hcsr04.hhcsr04.c 1.HC-SR04介绍 超声波传感器有很多种类的型号:HC-SR04、UC-025、…...

使用scp命令拷贝hadoop100中文件到其他虚拟机中
以下是使用 scp 命令将 hadoop100 主机中的文件拷贝到其他虚拟机的操作步骤(假设其他主机名为 hadoop101 、 hadoop102 ,系统为 Linux): 1. 基本语法 bash scp [选项] 源文件路径 目标主机用户名目标主机IP:目标路径 - 选…...

Linux基础 -- 用户态Generic Netlink库高性能接收与回调框架
用户态Generic Netlink库高性能接收与回调框架 一、概述 在 Linux 系统中,Netlink 是用户态与内核态通信的强大机制。libnl 是一个专为简化 Netlink 编程而设计的库,提供了接收和处理 Netlink 消息的高级接口。libnl-genl 是其通用 Netlink (Generic N…...

java中的Optional
在 Java 8 中,Optional 是一个用于处理可能为 null 的值的容器类,旨在减少空指针异常(NullPointerException)并提升代码的可读性。以下是 Optional 的核心用法和最佳实践: 1. 创建 Optional 对象 1.1 常规创建方式 Op…...

原型和原型链
原型(Prototype) 和 原型链(Prototype Chain) 是 JavaScript 中非常重要的概念,它们是 JavaScript 实现继承和共享属性和方法的核心机制。理解原型和原型链可以帮助你更好地掌握 JavaScript 的面向对象编程(…...
)
解锁Python TDD:从理论到实战的高效编程之道(9/10)
引言 在 Python 开发的广袤天地中,确保代码质量与稳定性是每位开发者的核心追求。测试驱动开发(TDD,Test-Driven Development)作为一种强大的开发理念与实践方法,正逐渐成为 Python 开发者不可或缺的工具。TDD 强调在…...
:STM32F103开发环境搭建)
OpenMCU(七):STM32F103开发环境搭建
概述 本文主要讲述了使用Keil软件搭建STM32F103嵌入式开发环境的步骤,主要面向想从事嵌入式行业的入门同学,如果下面的讲述过程中有不对的地方,欢迎大家给我留言。 本文主要讲述了Keil 5.43的安装教程,主要用于学习交流…...

六、Hive 分桶
作者:IvanCodes 日期:2025年5月13日 专栏:Hive教程 在 Hive 中,除了常见的分区(Partitioning),分桶(Bucketing)是另一种重要且有效的数据组织和性能优化手段。它允许我们…...
:指标监控、数据管理、DSL 语句执行)
INFINI Console 纳管 Elasticsearch 9(一):指标监控、数据管理、DSL 语句执行
Elasticsearch v9.0 版本最近已发布,而 INFINI Console 作为一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台,是否支持最新的 Elasticsearch v9.0 集群管理呢?本文以 INFINI Console v1.29.2 为例,从指标监控、数…...

ansible进阶版01
ansible进阶版01 欢迎使用Markdown编辑器最佳实践保持简单 保持井然有序(有组织的)经常测试 git工作原理 chapter 2编写ymal格式的主机清单 欢迎使用Markdown编辑器 最佳实践 保持简单 使用yaml的原生语法使用自带模块尽量使用专用模块,不…...

python文件打包成exe文件
✅ 一、安装 PyInstaller 打开cmd,输入以下代码 pip install pyinstaller✅ 二、打包指令 比如说你有如下的文件需要打包。 首先复制你的文件所在目录,比如我的是C:\Users\Administrator\Desktop\BearingSearchSystem 在cmd中切换到该目录来…...

人脸识别系统中的隐私与数据权利保障
首席数据官高鹏律师创作 如今人脸识别技术以其高效、便捷的特性广泛应用于各个领域,从安防监控到移动支付,从门禁系统到社交媒体。然而,这项技术在为我们的生活带来诸多便利的同时,也引发了一系列关于隐私与数据权利的深刻担忧。…...

电脑关机再开机会换IP吗?深入解析分配机制
在日常使用电脑时,许多用户可能会好奇:关机后再开机,IP地址会不会变化? 这个问题看似简单,但实际上涉及多个因素。本文将详细解析电脑IP地址的变化机制,帮助大家理解其中的原理,并提供相关的…...

经典中的经典-比特币白皮书中文版
AI是一切假的集合,如果任凭AI如此聪明下去,所有的人都将被AI愚弄与股掌之间,那么能限制AI的只有区块链这个让一切数据都无处遁形的真神,而比特币作为区块链的鼻祖,开创了公开账本的先河,当互联网上所有的信…...

Spring事务失效的全面剖析
文章目录 1. Spring事务基础1.1 什么是Spring事务1.2 Spring事务的实现原理1.3 `@Transactional`注解的主要属性1.4 使用Spring事务的简单示例2. Spring事务失效的常见场景及解决方案2.1 方法不是public的问题描述问题示例解决方案技术原理解释2.2 自调用问题(同一个类中的方法…...
)
本地的ip实现https访问-OpenSSL安装+ssl正式的生成(Windows 系统)
1.下载OpenSSL软件 网站地址:Win32/Win64 OpenSSL Installer for Windows - Shining Light Productions 安装: 一直点击下一步就可以了 2.设置环境变量 在开始菜单右键「此电脑」→「属性」→「高级系统设置」→「环境变量」 在Path 中添加一个: xxxx\OpenSSL-…...

【go】binary包,大小端理解,read,write使用,自实现TCP封包拆包案例
binary.LittleEndian 是 Go 语言 encoding/binary 包中的一个常量,用于指定字节序(Byte Order)。字节序是指多字节数据在内存中存储的顺序,有两种主要方式: 小端序(Little Endian):…...

[万字]qqbot开发记录,部署真寻bot+自编插件
这是我成功部署真寻bot以及实现一个自己编写的插件(连接deepseek回复内容)的详细记录,几乎每一步都有截图。 正文: 我想玩玩qqbot。为了避免重复造轮子,首先选一个github的高星项目作为基础吧。 看了一眼感觉真寻bot不…...

国内USB IP商业解决方案新选择:硬件USB Server
在数字化办公日益普及的今天,USB OVER NETWORK技术,即USB IP技术,为企业带来了前所未有的便捷与高效。作为这一领域的佼佼者,朝天椒USB Server以其卓越的性能和贴心的设计,正逐步成为众多中国企业的首选USB IP商业解决…...

百度导航广告“焊死”东鹏特饮:商业底线失守,用户安全成隐忧
近日,百度地图因导航时植入“广告”的问题登上社交媒体热搜,并引发广泛争议。 截图自微博 导航途中出现“焊死”在路面的广告 安全隐患引争议 多位网友发帖称,在使用百度地图导航时,导航界面中的公路路面上出现了“累了困了喝东…...

yolo11n-obb训练rknn模型
必备: 准备一台ubuntu22的服务器或者虚拟机(x86_64) 1、数据集标注: 1)推荐使用X-AnyLabeling标注工具 2)标注选【旋转框】 3)可选AI标注,再手动补充,提高标注速度 …...

GNU Screen 曝多漏洞:本地提权与终端劫持风险浮现
SUSE安全团队全面审计发现,广泛使用的终端复用工具GNU Screen存在一系列严重漏洞,包括可导致本地提权至root权限的缺陷。这些问题同时影响最新的Screen 5.0.0版本和更普遍部署的Screen 4.9.x版本,具体影响范围取决于发行版配置。 尽管GNU Sc…...
)
无人机避障——如何利用MinumSnap进行对速度、加速度进行优化的轨迹生成(附C++python代码)
🔥轨迹规划领域的 “YYDS”——minimum snap!作为基于优化的二次规划经典,它是无人机、自动驾驶轨迹规划论文必引的 “开山之作”。从优化目标函数到变量曲线表达,各路大神疯狂 “魔改”,衍生出无数创新方案。 &#…...

2025 3D工业相机选型及推荐
3D工业相机是专门为工业应用设计的三维视觉采集设备,能够获取物体的三维空间信息,在智能制造、质量检测、机器人引导等领域有广泛应用。 一、主要类型 1.结构光3D相机 通过投射特定光斑或条纹图案并分析变形来重建三维形状 典型代表:双目结构…...
项目,后端接口报401-账号未登录解决方案)
芋道(yudao-cloud)项目,后端接口报401-账号未登录解决方案
一、需求 最近公司有新的业务需求,调研了一下,决定使用芋道(yudao-cloud)框架,于是从github(https://github.com/YunaiV/yudao-cloud)上克隆项目,选用的是jdk17版本的。根据项目启动手册&#…...

动态域名服务ddns怎么设置?如何使用路由器动态域名解析让外网访问内网?
设置路由器的动态域名解析(DDNS),通常需先选择支持 DDNS 的路由器和提供 DDNS 服务的平台,然后在路由器管理界面中找到 DDNS 相关设置选项,填入在服务平台注册的账号信息,完成配置后保存设置并等待生效。 …...

论文《Collaboration-Aware Graph Convolutional Network for Recommender Systems》阅读
论文《Collaboration-Aware Graph Convolutional Network for Recommender Systems》阅读 论文概况Introduction and MotivationMethodologyLightGCN 传播形式CIRCAGCNImplementation Experiments 论文概况 论文《Collaboration-Aware Graph Convolutional Network for Recomm…...

Codis集群搭建和集成使用的详细步骤示例
以下是Codis集群搭建和集成使用的详细步骤示例: 环境准备 安装Go语言环境 下载并安装适配操作系统的Go语言版本。配置环境变量GOROOT和GOPATH。 安装ZooKeeper 下载ZooKeeper压缩包,解压并进入目录。复制conf/zoo_sample.cfg为conf/zoo.cfg。启动ZooKe…...

利用比较预言机处理模糊的偏好数据
论文标题 ComPO:Preference Alignment via Comparison Oracles 论文地址 https://arxiv.org/pdf/2505.05465 模型地址 https://huggingface.co/ComparisonPO 作者背景 哥伦比亚大学,纽约大学,达摩院 动机 DPO算法直接利用标注好的数据来做偏好对…...

《数据库原理》部分习题解析
《数据库原理》部分习题解析 1. 课本pg196.第1题。 (1)函数依赖 若对关系模式 R(U) 的任何可能的关系 r,对于任意两个元组 t₁ 和 t₂,若 t₁[X] t₂[X],则必须有 t₁[Y] t₂[Y],则称属性集 Y 函数依赖…...

【HCIA】浮动路由
前言 我们通常会在出口路由器配置静态路由去规定流量进入互联网默认应该去往哪里。那么,如果有两个运营商的路由器都能为我们提供上网服务,我们应该如何配置默认路由呢?浮动路由又是怎么一回事呢? 文章目录 前言1. 网络拓扑图2. …...

基于机器学习的卫星钟差预测方法研究HPSO-BP
摘要 本文研究了三种机器学习方法(BP神经网络、随机森林和支持向量机)在卫星钟差预测中的应用。通过处理GPS和GRACE卫星的钟差数据,构建了时间序列预测模型,并比较了不同方法的预测性能。实验结果表明,优化后的BP神经…...

机器学习中分类模型的常用评价指标
评价指标是针对模型性能优劣的一个定量指标。 一种评价指标只能反映模型一部分性能,如果选择的评价指标不合理,那么可能会得出错误的结论,故而应该针对具体的数据、模型选取不同的的评价指标。 本文将详细介绍机器学习分类任务的常用评价指…...

AI 检测原创论文:技术迷思与教育本质的悖论思考
当高校将 AI 写作检测工具作为学术诚信的 "电子判官",一场由技术理性引发的教育异化正在悄然上演。GPT-4 检测工具将人类创作的论文误判为 AI 生成的概率高达 23%(斯坦福大学 2024 年研究数据),这种 "以 AI 制 AI&…...

langchain学习
无门槛免费申请OpenAI ChatGPT API搭建自己的ChatGPT聊天工具 https://nuowa.net/872 基本概念 LangChain 能解决大模型的两个痛点,包括模型接口复杂、输入长度受限离不开自己精心设计的模块。根据LangChain 的最新文档,目前在 LangChain 中一共有六大…...

蓝桥杯 10. 全球变暖
全球变暖 原题目链接 题目描述 你有一张某海域 N x N 像素的照片: . 表示海洋# 表示陆地 例如如下所示: ....... .##.... .##.... ....##. ..####. ...###. .......在照片中,“上下左右”四个方向上连在一起的一片陆地组成一座岛屿。例…...

OpenTiny icons——超轻量的CSS图标库,引领图标库新风向
我们非常高兴地宣布 opentiny/icons 正式发布啦! 源码:https://github.com/opentiny/icons(欢迎 Star ⭐) 官网:https://opentiny.github.io/icons/ 图标预览:https://opentiny.github.io/icons/brow…...

python使用OpenCV 库将视频拆解为帧并保存为图片
python使用OpenCV 库将视频拆解为帧并保存为图片 import cv2 import osdef video_to_frames(video_path, output_folder, frame_prefixframe_, interval1, target_sizeNone, grayscaleFalse):"""将视频拆分为帧并保存为图片参数:video_path (str): 视频文件路径…...

[论文阅读]ControlNET: A Firewall for RAG-based LLM System
ControlNET: A Firewall for RAG-based LLM System [2504.09593] ControlNET: A Firewall for RAG-based LLM System RAG存在数据泄露风险和数据投毒风险。相关研究探索了提示注入和投毒攻击,但是在控制出入查询流以减轻威胁方面存在不足 文章提出一种ai防火墙CO…...

机器学习 --- 数据集
机器学习 — 数据集 文章目录 机器学习 --- 数据集一,sklearn数据集介绍二,sklearn现实世界数据集介绍三,sklearn加载数据集3.1 加载鸢尾花数据集3.2 加载糖尿病数据集3.3 加载葡萄酒数据集 四,sklearn获取现实世界数据集五&#…...

在Ubuntu服务器上部署Label Studio
一、拉取镜像 docker pull heartexlabs/label-studio:latest 二、启动容器 (回到用户目录,例:输入pwd,显示 /home/<user>) docker run -d --name label-studio -it -p 8081:8080 -v $(pwd)/mydata:/label-st…...

机器学习07-归一化与标准化
归一化与标准化 一、基本概念 归一化(Normalization) 定义:将数据缩放到一个固定的区间,通常是[0,1]或[-1,1],以消除不同特征之间的量纲影响和数值范围差异。公式:对于数据 ( x ),归一化后的值…...

用vue和go实现登录加密
前端使用CryptoJS默认加密方法: var pass CryptoJS.AES.encrypt(formData.password, key.value).toString()使用 CryptoJS.AES.encrypt() 时不指定加密模式和参数时,CryptoJS 默认会执行以下操作 var encrypted CryptoJS.AES.encrypt("明文&quo…...

服务器制造业中,L2、L6、L10等表示什么意思
在服务器制造业中,L2、L6、L10等是用于描述服务器生产流程集成度的分级体系,从基础零件到完整机架系统共分为L1-L12共12个等级。不同等级对应不同的生产环节和交付形态,以下是核心级别的具体含义: L2(Level 2…...

mysql8常用sql语句
查询结果带行号 -- 表名为 mi_user, 假设包含列 id ,address SELECT ROW_NUMBER() OVER (ORDER BY id) AS row_num, t.id, t.address FROM mi_user t ; SELECT ROW_NUMBER() OVER ( ) AS row_num, t.id, t.address FROM mi_user t ; 更新某列数…...

多模态RAG与LlamaIndex——1.deepresearch调研
摘要 关键点: 多模态RAG技术通过结合文本、图像、表格和视频等多种数据类型,扩展了传统RAG(检索增强生成)的功能。LlamaIndex是一个开源框架,支持多模态RAG,提供处理文本和图像的模型、嵌入和索引功能。研…...

汽车工厂数字孪生实时监控技术从数据采集到三维驱动实现
在工业智能制造推动下,数字孪生技术正成为制造业数字化转型的核心驱动力。今天详细介绍数字孪生实时监控技术在汽车工厂中的应用,重点解析从数据采集到三维驱动实现的全流程技术架构,并展示其在提升生产效率、降低成本和优化决策方面的显著价…...