解锁Python TDD:从理论到实战的高效编程之道(9/10)
引言
在 Python 开发的广袤天地中,确保代码质量与稳定性是每位开发者的核心追求。测试驱动开发(TDD,Test-Driven Development)作为一种强大的开发理念与实践方法,正逐渐成为 Python 开发者不可或缺的工具。TDD 强调在编写功能代码之前先编写测试代码,这种看似逆向的流程,却蕴含着提升代码质量、增强代码可维护性以及加速开发进程的巨大能量。它如同为开发者配备了一位严谨的 “质量卫士”,从开发的源头开始,就为代码的正确性与健壮性保驾护航。无论是小型项目的敏捷开发,还是大型企业级应用的复杂构建,TDD 都能发挥关键作用,帮助开发者高效地创建出高质量的 Python 代码。接下来,让我们一同深入探索 Python 测试驱动开发的实践奥秘。

一、TDD 是什么
(一)TDD 定义
测试驱动开发(Test-Driven Development,TDD)是一种软件开发方法论 ,与传统的先编写功能代码,再进行测试的流程截然不同。在 TDD 中,开发者需要首先根据需求编写测试代码,这些测试代码就像是一份详细的功能说明书,精确地定义了即将编写的功能代码需要实现的具体行为和预期结果。只有当测试代码编写完成并且运行结果为失败(因为此时功能代码尚未编写)时,才开始编写功能代码。编写功能代码的过程就是不断让之前失败的测试变为成功的过程,当测试通过后,就意味着功能代码满足了预先设定的需求。
(二)TDD 基本原理
TDD 的核心是 “红 - 绿 - 重构” 循环,这一循环过程严谨且富有逻辑。
- 红(Red):此阶段专注于编写测试代码。开发者依据功能需求,精心构造出一个个测试用例,这些测试用例涵盖了正常输入、边界条件以及异常情况等多种场景。由于此时功能代码尚未实现,所以运行这些测试用例时,必然会得到失败的结果,这就如同亮起的红灯,提醒开发者功能代码的缺失。
- 绿(Green):在得到失败的测试结果后,开发者开始编写功能代码。编写功能代码的目标非常明确,就是让之前失败的测试能够通过。在这个过程中,只需要编写满足测试通过的最少量代码即可,无需过度设计或添加不必要的功能,就像朝着绿灯的方向前进,尽快达成测试通过的目标。
- 重构(Refactor):当测试通过后,并不意味着开发工作的结束。此时,开发者需要回过头来审视已编写的代码,从代码结构、可读性、可维护性以及性能优化等多个角度对代码进行重构。通过重构,去除代码中的冗余部分,优化算法和数据结构,提高代码的质量,使代码更加简洁、高效且易于理解和维护 。重构完成后,再次运行测试用例,确保重构后的代码仍然能够通过所有测试,保证功能的正确性。
(三)TDD 的优势
- 提高代码质量:由于在编写功能代码之前就已经明确了测试用例,这促使开发者在设计和编写代码时,充分考虑代码的可测试性、模块化以及低耦合性。通过不断地 “红 - 绿 - 重构” 循环,及时发现并解决代码中的潜在问题,从而确保最终的代码质量更高,缺陷更少。
- 增强代码可维护性:TDD 编写的代码通常具有良好的结构和清晰的逻辑,每个功能模块都有对应的测试用例进行验证。这使得后续的维护工作变得更加容易,当需要对代码进行修改或扩展时,开发者可以通过运行测试用例快速验证修改是否影响了原有功能,降低了维护成本和风险。
- 减少后期修复成本:在开发过程的早期阶段,通过测试用例就能发现并解决问题,避免了问题在项目后期才被发现。后期修复问题往往需要花费更多的时间和精力,因为随着项目的推进,代码量不断增加,系统复杂度也越来越高,问题的排查和修复难度会大幅上升。而 TDD 能够将问题消灭在萌芽状态,有效减少了后期修复成本。
- 促进团队协作:清晰明确的测试用例为团队成员之间的沟通和协作提供了共同的基础。无论是开发人员、测试人员还是产品经理,都可以通过测试用例来理解功能需求和代码实现,减少了因理解不一致而产生的沟通障碍,提高了团队协作效率 。
- 加速开发进程(长期视角):虽然在项目初期,TDD 可能会因为需要编写测试代码而花费更多的时间,但从项目的整个生命周期来看,由于减少了后期调试和修复问题的时间,总体上能够提高开发效率。并且,完善的测试用例还为后续的功能扩展和迭代提供了有力的支持,使得开发过程更加流畅和高效。

二、Python TDD 开发流程
(一)编写测试用例
在 Python 中,有两个常用的测试框架:unittest和pytest。unittest是 Python 内置的标准测试框架,而pytest则是一个功能强大、灵活且易于使用的第三方测试框架,它在社区中广受欢迎,拥有丰富的插件生态系统 。
- 使用unittest编写测试用例:
import unittestdef add(a, b):return a + bclass TestAddFunction(unittest.TestCase):def test_add(self):result = add(2, 3)self.assertEqual(result, 5)if __name__ == '__main__':unittest.main()
在上述示例中,首先定义了一个简单的加法函数add。然后创建了一个测试类TestAddFunction,该类继承自unittest.TestCase。在测试类中定义了一个测试方法test_add,方法名必须以test_开头,这样unittest框架才能识别它是一个测试方法。在test_add方法中,调用add函数并传入参数 2 和 3,将返回结果存储在result变量中。最后使用self.assertEqual断言来验证result是否等于预期值 5。如果相等,测试通过;否则,测试失败 。
2.使用pytest编写测试用例:
def add(a, b):return a + bdef test_add():result = add(2, 3)assert result == 5
使用pytest编写测试用例更加简洁。只需定义一个以test_开头的函数即可,不需要创建类。在test_add函数中,同样调用add函数并进行断言。pytest使用 Python 内置的assert语句进行断言,非常直观和方便。
(二)运行测试
- 运行unittest测试用例:
可以直接在命令行中运行unittest测试用例。假设上述unittest测试代码保存在test_unittest.py文件中,在命令行中执行:
python -m unittest test_unittest.py如果测试用例通过,会输出类似如下信息:
.
----------------------------------------------------------------------
Ran 1 test in 0.000sOK如果测试用例失败,会详细输出失败的原因,例如:
F
======================================================================
FAIL: test_add (test_unittest.TestAddFunction)
----------------------------------------------------------------------
Traceback (most recent call last):File "test_unittest.py", line 9, in test_addself.assertEqual(result, 6)
AssertionError: 5 != 6----------------------------------------------------------------------
Ran 1 test in 0.000sFAILED (failures=1)从失败信息中可以清晰地看到测试方法名、断言失败的位置以及实际值和预期值的差异,方便开发者定位问题。
2.运行pytest测试用例:
假设pytest测试代码保存在test_pytest.py文件中,在命令行中直接执行:
pytest test_pytest.pypytest的输出结果也非常清晰明了。如果测试通过,会显示绿色的PASSED:
============================= test session starts ==============================platform win32 -- Python 3.8.5, pytest-6.2.5, py-1.11.0, pluggy-1.0.0rootdir: C:\Users\your_pathcollected 1 itemtest_pytest.py . [100%]============================== 1 passed in 0.01s ==============================如果测试失败,会显示红色的FAILED,并详细展示失败的断言信息:
============================= test session starts ==============================
platform win32 -- Python 3.8.5, pytest-6.2.5, py-1.11.0, pluggy-1.0.0
rootdir: C:\Users\your_path
collected 1 item
test_pytest.py F [100%]
=================================== FAILURES ===================================
_______________________________ test_add ______________________________________
def test_add():
result = add(2, 3)
> assert result == 6
E assert 5 == 6
test_pytest.py:5: AssertionError
=========================== short test summary info ============================
FAILED test_pytest.py::test_add - assert 5 == 6
======================== 1 failed in 0.01s =========================
当测试失败时,仔细分析错误信息是关键。首先,定位到失败的测试方法,查看断言中实际值和预期值的差异。然后,检查被测试函数的实现逻辑,看是否存在错误。同时,还要注意测试环境、输入参数等因素,确保这些都符合预期,以便准确找到问题根源并进行修复。
(三)编写实现代码
在编写测试用例并运行测试得到失败结果后,就需要编写实现代码,使测试用例能够通过。以上述的加法函数测试为例,假设最初的add函数实现有误:
def add(a, b):return a - b运行测试用例时,会因为实际返回值与预期值不一致而失败。此时,根据测试需求修改add函数的实现:
def add(a, b):return a + b再次运行测试用例,测试将通过,因为函数的实现已经满足了测试用例中定义的功能需求。在编写实现代码时,要紧密围绕测试用例的要求,确保代码能够正确处理各种输入情况,包括正常输入、边界值和异常输入等 。例如,对于加法函数,不仅要测试两个正数相加,还要测试负数相加、零与其他数相加等情况,以保证函数的正确性和健壮性。
(四)重构代码
重构是指在不改变代码外部行为的前提下,对代码的内部结构进行优化和改进,以提高代码的可读性、可维护性、可扩展性和性能等。重构是 TDD 开发流程中不可或缺的一环,它能够使代码更加优雅、高效,并且易于理解和修改。
例如,假设有如下计算三角形面积的代码:
def calculate_triangle_area(base, height):result = base * height / 2print(f"三角形面积是: {result}")return result
这个函数虽然能够正确计算三角形面积,但存在一些问题。首先,函数既进行了计算又进行了打印操作,违反了单一职责原则,使得函数的功能不够纯粹,不利于代码的复用和维护。可以对其进行重构:
def calculate_triangle_area(base, height):return base * height / 2def print_triangle_area(base, height):area = calculate_triangle_area(base, height)print(f"三角形面积是: {area}")
重构后的代码将计算和打印功能分离,calculate_triangle_area函数只负责计算三角形面积并返回结果,print_triangle_area函数负责打印面积。这样代码结构更加清晰,每个函数的职责单一,提高了代码的可读性和可维护性。当需要修改计算逻辑或者打印方式时,只需要在相应的函数中进行修改,不会影响到其他部分的代码。同时,calculate_triangle_area函数也更方便在其他地方复用。在重构代码后,一定要重新运行测试用例,确保重构后的代码没有引入新的问题,仍然能够通过所有测试,保证功能的正确性 。

三、Python TDD 实践案例
(一)简单函数开发
以实现一个简单的加法函数为例,完整演示 TDD 开发过程。假设我们要开发一个用于计算两个整数相加的函数add。
- 编写测试用例:使用pytest框架编写测试用例。创建一个名为test_add.py的文件,内容如下:
def test_add():from my_math import addresult = add(3, 5)assert result == 8
在这个测试用例中,从my_math模块导入add函数(此时my_math模块尚未创建),调用add函数并传入 3 和 5,然后使用assert断言验证返回结果是否等于 8。由于my_math模块和add函数都不存在,运行这个测试用例肯定会失败 。
2. 运行测试:在命令行中执行pytest test_add.py,得到如下测试结果:
============================= test session starts ==============================
platform win32 -- Python 3.8.5, pytest-6.2.5, py-1.11.0, pluggy-1.0.0
rootdir: C:\Users\your_path
collected 1 item
test_add.py F [100%]
=================================== FAILURES ===================================
_______________________________ test_add ______________________________________
def test_add():
from my_math import add
> result = add(3, 5)
E ModuleNotFoundError: No module named'my_math'
test_add.py:3: ModuleNotFoundError
=========================== short test summary info ============================
FAILED test_add.py::test_add - ModuleNotFoundError: No module named'my_math'
======================== 1 failed in 0.01s =========================
从失败信息中可以清楚地看到,由于找不到my_math模块而导致测试失败,这正是我们预期的结果,因为功能代码还未编写。
3. 编写实现代码:创建my_math.py文件,编写add函数的实现代码:
def add(a, b):return a + b
这个实现非常简单,就是将两个输入参数相加并返回结果。
4. 再次运行测试:再次在命令行中执行pytest test_add.py,此时测试结果如下:
============================= test session starts ==============================platform win32 -- Python 3.8.5, pytest-6.2.5, py-1.11.0, pluggy-1.0.0rootdir: C:\Users\your_pathcollected 1 itemtest_add.py. [100%]============================== 1 passed in 0.01s ==============================测试通过,说明add函数的实现满足了测试用例的要求。
5. 重构代码(可选):对于这个简单的加法函数,目前的实现已经很简洁明了,暂时不需要重构。但在实际开发中,如果后续发现代码存在可优化的地方,比如性能问题或者代码结构不够清晰等,可以随时进行重构。重构完成后,一定要再次运行测试用例,确保重构后的代码仍然能够通过测试,保证功能的正确性。
(二)复杂项目开发
介绍在一个小型 Python 项目中如何应用 TDD,展示项目架构和测试策略。假设我们正在开发一个简单的用户管理系统,该系统具有用户注册、登录和查询用户信息的功能。
1.项目架构:采用分层架构设计,将项目分为以下几个层次:
- 数据访问层(DAO,Data Access Object):负责与数据库进行交互,执行数据库的增删改查操作。使用SQLAlchemy库来实现数据库操作。
- 业务逻辑层(BLL,Business Logic Layer):处理业务逻辑,例如用户注册时的密码加密、登录时的用户验证等。
- 接口层(API Layer):提供外部访问的接口,例如使用Flask框架搭建 Web API,接收用户的请求并返回响应。
2.测试策略:
- 单元测试:针对每个层次的函数和方法进行单元测试,使用pytest框架。在单元测试中,重点测试各个功能的核心逻辑,确保每个函数和方法的正确性。例如,对于数据访问层的函数,测试其对数据库操作的准确性;对于业务逻辑层的函数,测试其业务逻辑的正确性。
- 集成测试:测试不同层次之间的交互,确保各个层次能够正确协作。例如,测试接口层接收到请求后,能否正确调用业务逻辑层的方法,以及业务逻辑层能否正确调用数据访问层的方法。使用Flask - Testing库来进行集成测试,它是Flask框架的测试扩展,方便对Flask应用进行测试。
- 测试覆盖率:使用coverage.py工具来测量测试覆盖率,确保测试用例能够覆盖大部分代码。尽量使测试覆盖率达到较高水平,例如 80% 以上,但也要注意不要为了追求覆盖率而编写无意义的测试用例。
3.具体实现与测试过程:
- 数据访问层:创建user_dao.py文件,实现用户数据的数据库操作。
from sqlalchemy import create_engine, Column, Integer, String from sqlalchemy.orm import sessionmaker, declarative_baseBase = declarative_base()class User(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True, autoincrement=True)username = Column(String(50), unique=True, nullable=False)password = Column(String(100), nullable=False)class UserDAO:def __init__(self, db_url):self.engine = create_engine(db_url)self.Session = sessionmaker(bind=self.engine)def create_user(self, user):session = self.Session()try:session.add(user)session.commit()except Exception as e:session.rollback()raise efinally:session.close()def get_user_by_username(self, username):session = self.Session()try:user = session.query(User).filter(User.username == username).first()return userexcept Exception as e:raise efinally:session.close()
编写测试用例test_user_dao.py:
import pytest
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from user_dao import User, UserDAO# 创建测试数据库
TEST_DB_URL ='sqlite:///:memory:'
engine = create_engine(TEST_DB_URL)
Session = sessionmaker(bind=engine)@pytest.fixture
def user_dao():Base.metadata.create_all(engine)yield UserDAO(TEST_DB_URL)Base.metadata.drop_all(engine)def test_create_user(user_dao):new_user = User(username='testuser', password='testpassword')user_dao.create_user(new_user)user = user_dao.get_user_by_username('testuser')assert user is not Noneassert user.username == 'testuser'
在这个测试用例中,使用pytest.fixture创建了一个user_dao对象,并在测试前创建数据库表,测试后删除数据库表。test_create_user测试方法验证了create_user和get_user_by_username方法的正确性。
- 业务逻辑层:创建user_bll.py文件,实现业务逻辑。
import hashlib
from user_dao import User, UserDAOclass UserBLL:def __init__(self, user_dao):self.user_dao = user_daodef register_user(self, username, password):hashed_password = hashlib.sha256(password.encode()).hexdigest()new_user = User(username=username, password=hashed_password)self.user_dao.create_user(new_user)def login_user(self, username, password):user = self.user_dao.get_user_by_username(username)if user:hashed_password = hashlib.sha256(password.encode()).hexdigest()return user.password == hashed_passwordreturn False
编写测试用例test_user_bll.py:
import pytest
from user_dao import UserDAO
from user_bll import UserBLL# 创建测试数据库
TEST_DB_URL ='sqlite:///:memory:'@pytest.fixture
def user_dao():from sqlalchemy import create_enginefrom sqlalchemy.orm import sessionmakerfrom user_dao import Baseengine = create_engine(TEST_DB_URL)Base.metadata.create_all(engine)session = sessionmaker(bind=engine)yield UserDAO(TEST_DB_URL)Base.metadata.drop_all(engine)@pytest.fixture
def user_bll(user_dao):return UserBLL(user_dao)def test_register_user(user_bll):user_bll.register_user('testuser', 'testpassword')from user_dao import Userfrom sqlalchemy.orm import sessionmakerfrom sqlalchemy import create_engineengine = create_engine(TEST_DB_URL)Session = sessionmaker(bind=engine)session = Session()user = session.query(User).filter(User.username == 'testuser').first()assert user is not Nonedef test_login_user(user_bll):user_bll.register_user('testuser', 'testpassword')assert user_bll.login_user('testuser', 'testpassword')assert not user_bll.login_user('testuser', 'wrongpassword')
在这个测试用例中,通过pytest.fixture创建了user_dao和user_bll对象,test_register_user测试方法验证了用户注册功能,test_login_user测试方法验证了用户登录功能。
- 接口层:创建app.py文件,使用Flask框架搭建 Web API。
from flask import Flask, jsonify, request
from user_bll import UserBLL
from user_dao import UserDAOapp = Flask(__name__)
user_dao = UserDAO('sqlite:///users.db')
user_bll = UserBLL(user_dao)@app.route('/register', methods=['POST'])
def register():data = request.get_json()username = data.get('username')password = data.get('password')if not username or not password:return jsonify({'message': 'Username and password are required'}), 400try:user_bll.register_user(username, password)return jsonify({'message': 'User registered successfully'}), 201except Exception as e:return jsonify({'message': 'Registration failed', 'error': str(e)}), 500@app.route('/login', methods=['POST'])
def login():data = request.get_json()username = data.get('username')password = data.get('password')if not username or not password:return jsonify({'message': 'Username and password are required'}), 400if user_bll.login_user(username, password):return jsonify({'message': 'Login successful'}), 200else:return jsonify({'message': 'Login failed'}), 401
编写集成测试用例test_app.py:
from flask.testing import FlaskClient
from app import appdef test_register(client: FlaskClient):data = {'username': 'testuser', 'password': 'testpassword'}response = client.post('/register', json=data)assert response.status_code == 201assert response.json['message'] == 'User registered successfully'def test_login(client: FlaskClient):# 先注册用户register_data = {'username': 'testuser', 'password': 'testpassword'}client.post('/register', json=register_data)# 登录用户login_data = {'username': 'testuser', 'password': 'testpassword'}response = client.post('/login', json=login_data)assert response.status_code == 200assert response.json['message'] == 'Login successful'
在这个集成测试用例中,使用Flask - Testing提供的FlaskClient来模拟 HTTP 请求,测试接口层的注册和登录功能。通过以上步骤,展示了在一个小型 Python 项目中如何应用 TDD,从项目架构设计到各个层次的实现与测试,确保了项目的质量和稳定性 。在实际开发中,还可以根据项目的具体需求和规模,进一步完善测试策略和测试用例,例如添加更多的异常处理测试、性能测试等。
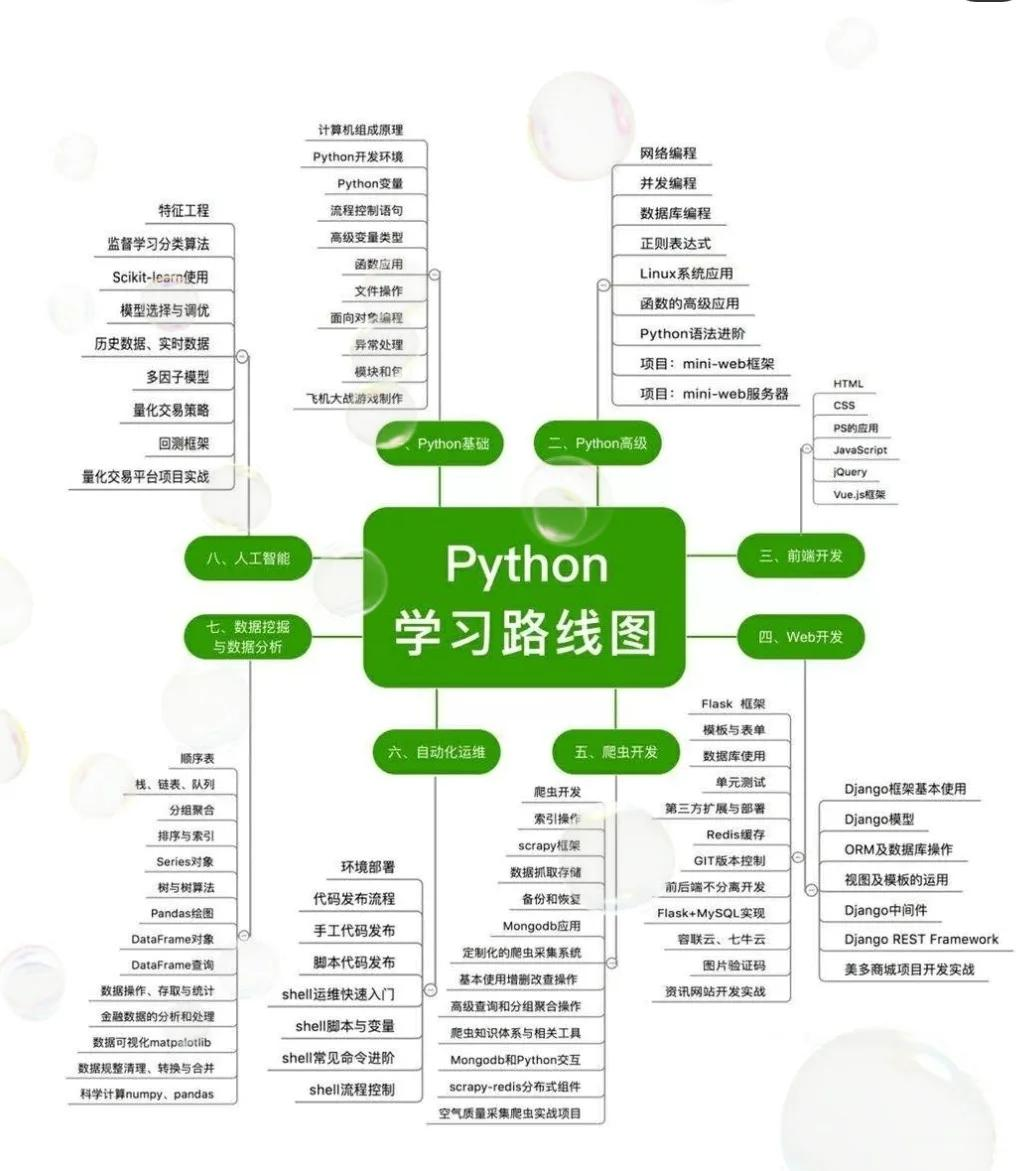
四、Python TDD 工具与框架
(一)unittest
unittest是 Python 内置的标准测试框架,它提供了一整套用于编写和运行测试的工具和类。unittest基于 Java 的 JUnit 框架,具有清晰的结构和丰富的功能,非常适合 Python 项目的单元测试。
- 基本用法:
-
- 测试用例:编写测试用例时,需要创建一个继承自unittest.TestCase的类,然后在这个类中定义以test_开头的方法,这些方法就是具体的测试用例。例如:
import unittestdef add(a, b):return a + bclass TestAddFunction(unittest.TestCase):def test_add(self):result = add(2, 3)self.assertEqual(result, 5)if __name__ == '__main__':unittest.main()
在上述代码中,TestAddFunction类继承自unittest.TestCase,test_add方法是一个测试用例,用于测试add函数的正确性。
- 测试套件:测试套件是多个测试用例的集合,可以将相关的测试用例组织在一起,方便管理和运行。使用unittest.TestSuite类来创建测试套件,通过addTest方法将测试用例添加到测试套件中。例如:
import unittestdef add(a, b):return a + bclass TestAddFunction(unittest.TestCase):def test_add(self):result = add(2, 3)self.assertEqual(result, 5)class TestAnotherFunction(unittest.TestCase):def test_something_else(self):self.assertEqual(1 + 1, 2)suite = unittest.TestSuite()
suite.addTest(TestAddFunction('test_add'))
suite.addTest(TestAnotherFunction('test_something_else'))runner = unittest.TextTestRunner()
runner.run(suite)
在这个例子中,创建了一个测试套件suite,并将TestAddFunction类中的test_add方法和TestAnotherFunction类中的test_something_else方法添加到测试套件中。然后使用unittest.TextTestRunner类来运行测试套件,TextTestRunner会在控制台上输出测试结果。
- 测试运行器:unittest提供了多种测试运行器,其中unittest.TextTestRunner是最常用的一种,它以文本形式输出测试结果。除了TextTestRunner,还有unittest.TestResult类用于收集测试结果,以及unittest.TestLoader类用于加载测试用例等。例如,可以使用TestLoader的discover方法自动发现指定目录下的所有测试用例并添加到测试套件中:
import unittestsuite = unittest.TestLoader().discover('.', pattern='test_*.py')
runner = unittest.TextTestRunner()
runner.run(suite)
上述代码会在当前目录下搜索所有以test_开头的 Python 文件,并将其中的测试用例加载到测试套件中,然后运行这些测试用例。
2.断言方法:unittest.TestCase类提供了丰富的断言方法,用于验证测试结果是否符合预期。常用的断言方法如下:
-
- assertEqual(a, b):断言a等于b,如果不相等则测试失败。例如:self.assertEqual(add(2, 3), 5)。
-
- assertNotEqual(a, b):断言a不等于b,如果相等则测试失败。
-
- assertTrue(x):断言x为True,如果x为False则测试失败。例如:self.assertTrue(5 > 3)。
-
- assertFalse(x):断言x为False,如果x为True则测试失败。
-
- assertIsNone(x):断言x为None,如果x不为None则测试失败。
-
- assertIsNotNone(x):断言x不为None,如果x为None则测试失败。
-
- assertIn(a, b):断言a在b中,例如a是列表b中的一个元素,或者a是字符串b的子串等,如果a不在b中则测试失败。例如:self.assertIn(3, [1, 2, 3])。
-
- assertNotIn(a, b):断言a不在b中,如果a在b中则测试失败。
3.测试组织方式:
- setUp和tearDown方法:在每个测试方法执行之前,setUp方法会被自动调用,用于初始化测试环境,例如创建数据库连接、初始化对象等。在每个测试方法执行之后,tearDown方法会被自动调用,用于清理测试环境,例如关闭数据库连接、释放资源等。例如:
import unittestclass TestDatabase(unittest.TestCase):def setUp(self):# 模拟创建数据库连接self.connection = create_database_connection()def tearDown(self):# 模拟关闭数据库连接self.connection.close()def test_query(self):cursor = self.connection.cursor()cursor.execute('SELECT * FROM users')results = cursor.fetchall()self.assertEqual(len(results), 10)
- setUpClass和tearDownClass方法:这两个方法是类方法,在测试类中的所有测试方法执行之前,setUpClass方法会被调用一次,用于进行类级别的初始化操作,例如创建共享资源。在测试类中的所有测试方法执行之后,tearDownClass方法会被调用一次,用于清理类级别的资源。需要注意的是,setUpClass和tearDownClass方法必须使用@classmethod装饰器进行修饰。例如:
import unittestclass TestMathFunctions(unittest.TestCase):@classmethoddef setUpClass(cls):# 模拟加载数学计算所需的配置文件cls.config = load_config()@classmethoddef tearDownClass(cls):# 模拟清理配置文件资源cls.config = Nonedef test_sqrt(self):result = sqrt(self.config['number'])self.assertEqual(result, 2)
(二)pytest
pytest是一个功能强大、灵活且易于使用的第三方测试框架,在 Python 社区中广受欢迎。它具有简洁的语法、丰富的插件生态系统和强大的功能,非常适合各种类型的测试,包括单元测试、集成测试和功能测试等。
- 简洁语法:pytest的语法非常简洁,使用普通的 Python 函数和assert语句即可编写测试用例,不需要创建复杂的测试类和继承特定的类。例如:
def add(a, b):return a + bdef test_add():result = add(2, 3)assert result == 5
上述代码中,test_add函数就是一个简单的测试用例,使用assert语句来验证add函数的返回结果是否符合预期。
2.丰富插件:pytest拥有丰富的插件生态系统,可以通过安装插件来扩展其功能。以下是一些常用的插件:
-
- pytest - cov:用于测量测试覆盖率,它可以生成详细的报告,显示哪些代码行被测试覆盖,哪些没有被覆盖,帮助开发者找出未测试的代码部分,从而提高测试的全面性。例如,在命令行中使用pytest --cov=your_module可以查看your_module模块的测试覆盖率。
-
- pytest - html:生成美观的 HTML 测试报告,报告中包含测试用例的执行结果、运行时间、失败原因等详细信息,方便查看和分析测试结果。使用时,在命令行中执行pytest --html=report.html即可生成 HTML 测试报告。
-
- pytest - xdist:支持分布式测试和并行测试,它可以将测试用例分发到多个 CPU 核心或多台机器上并行执行,大大缩短测试执行时间,提高测试效率。例如,在命令行中使用pytest -n 4可以指定使用 4 个 CPU 核心并行执行测试。
-
- pytest - mock:用于创建和使用模拟对象,在测试中可以使用它来替换真实的对象,以便更好地控制测试环境和测试条件,隔离被测试代码与外部依赖,使测试更加独立和可靠。例如,使用pytest - mock可以轻松地模拟函数调用、对象方法等。
3.参数化测试:pytest提供了强大的参数化测试功能,使用@pytest.mark.parametrize装饰器可以对同一个测试函数使用不同的参数组合进行多次测试,减少重复的测试代码。例如:
import pytestdef add(a, b):return a + b@pytest.mark.parametrize("a, b, expected", [(2, 3, 5),(-1, 1, 0),(0, 0, 0)
])
def test_add_parametrized(a, b, expected):result = add(a, b)assert result == expected
在上述代码中,test_add_parametrized函数使用了@pytest.mark.parametrize装饰器,定义了三组参数(2, 3, 5)、(-1, 1, 0)和(0, 0, 0),pytest会自动使用这三组参数分别调用test_add_parametrized函数进行测试,相当于执行了三个独立的测试用例。
4.测试发现与执行:pytest会自动发现当前目录及其子目录下所有以test_开头或_test结尾的 Python 文件,并执行其中以test_开头的函数和类中以test_开头的方法。在命令行中直接执行pytest命令即可运行所有发现的测试用例。也可以通过命令行参数指定要运行的特定测试文件、测试类或测试方法,例如:
- pytest test_module.py:运行test_module.py文件中的所有测试用例。
- pytest test_class.py::TestClass:运行test_class.py文件中TestClass类的所有测试方法。
- pytest test_class.py::TestClass::test_method:运行test_class.py文件中TestClass类的test_method测试方法。
此外,还可以使用-v参数增加输出信息的详细程度,使用-k参数通过关键字指定要运行的测试用例,例如pytest -k "add and test"表示运行所有包含add和test关键字的测试用例 。通过这些灵活的测试发现与执行方式,开发者可以根据项目需求方便地组织和运行测试。
五、TDD 实践中的常见问题与解决方法
(一)测试覆盖率问题
测试覆盖率是衡量测试用例对代码覆盖程度的重要指标,它反映了代码中被测试执行到的部分所占的比例。常见的测试覆盖率类型包括语句覆盖率、分支覆盖率、函数 / 方法覆盖率和条件覆盖率等。语句覆盖率度量被执行的代码语句数与总语句数的比例;分支覆盖率度量测试用例执行的分支(如if语句)与所有可能分支的比例;函数 / 方法覆盖率度量测试覆盖的函数或方法数与总函数或方法数的比例;条件覆盖率度量测试覆盖的条件判断(如布尔表达式中的子条件)与总条件数的比例。
在 Python 中,有多种工具可以测量测试覆盖率,其中coverage.py是一个广泛使用的工具。它不仅支持测量各种类型的测试覆盖率,还能生成详细的报告,清晰地展示哪些代码行被测试覆盖,哪些未被覆盖,帮助开发者快速定位未测试的代码区域。例如,假设我们有一个简单的 Python 模块example.py:
def add(a, b):return a + bdef subtract(a, b):if a > b:return a - belse:return b - a
然后编写测试用例test_example.py:
import unittest
from example import add, subtractclass TestExample(unittest.TestCase):def test_add(self):self.assertEqual(add(2, 3), 5)def test_subtract(self):self.assertEqual(subtract(5, 3), 2)if __name__ == '__main__':unittest.main()
使用coverage.py测量测试覆盖率,在命令行中执行:
coverage run -m unittest test_example.py
coverage report运行结果如下:
Name Stmts Miss Cover
---------------------------------
example.py 7 2 71%
test_example.py 10 0 100%
---------------------------------
TOTAL 17 2 88%从报告中可以看出,example.py模块的语句覆盖率为 71%,有 2 条语句未被测试覆盖,这 2 条语句位于subtract函数的else分支中。通过这样的报告,开发者可以针对性地编写测试用例,覆盖未测试的代码部分,提高测试覆盖率。
提高测试覆盖率的方法有很多。首先,要确保测试用例覆盖所有的代码分支,对于包含if - else、for、while等控制结构的代码,要编写不同条件下的测试用例,使每个分支都能被执行到。其次,关注边界条件和异常情况的测试,例如函数参数的边界值、空值、异常输入等情况,这些情况往往容易被忽略,但却是保证代码健壮性的关键。此外,合理使用参数化测试,通过不同的参数组合对同一个函数进行多次测试,可以覆盖更多的代码逻辑。最后,定期审查测试覆盖率报告,分析未覆盖的代码部分,找出原因并补充相应的测试用例,持续提高测试覆盖率。
(二)测试与代码分离
测试代码与实现代码分离是 TDD 实践中的一个重要原则。将测试代码与实现代码放在不同的文件或目录中,能够使项目结构更加清晰,便于管理和维护。测试代码只专注于验证实现代码的正确性,不依赖于实现代码的内部细节,这样当实现代码发生变化时,只要其外部行为不变,测试代码就无需修改,提高了测试代码的稳定性和可维护性。同时,清晰的代码结构也方便团队成员理解和协作,新成员能够更容易地找到测试代码和实现代码,快速了解项目的测试情况和功能实现。
实现测试与代码分离的方法有多种。一种常见的做法是在项目目录结构中创建一个专门的tests目录,用于存放所有的测试代码。在tests目录下,可以根据模块或功能进一步细分目录,例如为每个主要模块创建一个对应的测试子目录。以一个简单的 Python 项目为例,项目目录结构可以如下:
my_project/
├── my_module/
│ ├── __init__.py
│ ├── module1.py
│ └── module2.py
├── tests/
│ ├── __init__.py
│ ├── test_module1.py
│ └── test_module2.py
└── setup.py在这个结构中,my_module目录存放实现代码,tests目录存放测试代码,test_module1.py和test_module2.py分别用于测试module1.py和module2.py。
在编写测试代码时,要遵循一些最佳实践。尽量避免在测试代码中直接依赖实现代码的内部变量或私有方法,而是通过公共接口来调用实现代码,这样可以降低测试代码与实现代码之间的耦合度。例如,假设module1.py中有一个类MyClass,包含一个公共方法public_method和一个私有方法_private_method:
class MyClass:def _private_method(self):return "This is a private method"def public_method(self):result = self._private_method()return result.upper()
在test_module1.py中进行测试时,应该只测试public_method,而不是直接调用_private_method:
from my_module.module1 import MyClassdef test_public_method():my_obj = MyClass()result = my_obj.public_method()assert result == "THIS IS A PRIVATE METHOD"
这样,当_private_method的实现发生变化时,只要public_method的外部行为不变,测试代码就无需修改,保证了测试代码的稳定性和可维护性。
(三)处理测试中的依赖
在测试过程中,常常会遇到外部依赖,如数据库、网络服务等。这些外部依赖可能会带来一些问题,例如测试环境的不一致性、测试速度慢以及测试的不稳定性等。如果测试依赖于真实的数据库或网络服务,那么在不同的测试环境中,这些依赖的状态和数据可能不同,导致测试结果不可靠。同时,与真实的外部服务交互往往需要花费一定的时间,会延长测试的执行时间,降低开发效率。此外,网络波动、服务故障等因素也会使测试变得不稳定,增加调试的难度。
为了解决这些问题,可以采用多种方法来处理测试中的外部依赖。使用模拟对象(Mock Objects)是一种常用的方式,它可以在测试中替代真实的外部依赖,使测试更加独立和可控。在 Python 中,unittest.mock模块提供了强大的模拟对象功能。例如,假设我们有一个函数fetch_data,它通过网络请求从某个 API 获取数据:
import requestsdef fetch_data():response = requests.get('https://example.com/api/data')return response.json()
在测试fetch_data函数时,可以使用unittest.mock来模拟requests.get的行为,避免实际的网络请求:
from unittest.mock import patch
import unittestdef fetch_data():response = requests.get('https://example.com/api/data')return response.json()class TestFetchData(unittest.TestCase):@patch('__main__.requests.get')def test_fetch_data(self, mock_get):mock_response = mock_get.return_valuemock_response.json.return_value = {'key': 'value'}result = fetch_data()self.assertEqual(result, {'key': 'value'})mock_get.assert_called_once_with('https://example.com/api/data')if __name__ == '__main__':unittest.main()
在这个测试用例中,使用@patch('__main__.requests.get')装饰器来模拟requests.get函数。通过设置mock_response.json.return_value来定义模拟响应的内容,这样在测试中就不会实际发送网络请求,而是使用模拟的数据,使测试更加快速和可靠。
对于数据库依赖,可以使用内存数据库或测试专用的数据库实例。例如,在使用SQLAlchemy进行数据库操作的项目中,可以使用sqlite:///:memory:创建一个内存数据库来进行测试,这样每次测试都在一个全新的、独立的数据库环境中进行,不会影响到真实的数据库,并且测试速度非常快。另外,在测试前准备好测试数据,并在测试后清理数据,确保每次测试的环境一致,避免数据干扰导致的测试结果不准确。通过这些方法,可以有效地处理测试中的外部依赖,提高测试的质量和效率。

六、总结与展望
(一)TDD 实践总结
测试驱动开发(TDD)在 Python 开发中展现出了独特的价值和强大的优势。通过严格遵循 “红 - 绿 - 重构” 的开发循环,TDD 从根本上改变了软件开发的思维模式和流程。在 Python 项目中,无论是简单的函数开发,还是复杂的项目架构搭建,TDD 都能发挥关键作用。它就像一位严谨的质量守护者,确保每一行代码都经过精心设计和严格验证,从而显著提高了代码质量,减少了潜在的缺陷和错误。
在实践 TDD 的过程中,合理选择测试框架是关键的一步。Python 的unittest作为内置的标准测试框架,具有清晰的结构和丰富的功能,为开发者提供了一套完整的测试工具和类,适合初学者和对测试框架功能需求较为基础的项目。而pytest则凭借其简洁的语法、强大的功能和丰富的插件生态系统,成为了众多 Python 开发者的首选,尤其在处理复杂项目和需要高度定制化测试功能时,pytest的优势更加明显。
测试覆盖率是衡量测试质量的重要指标,通过使用coverage.py等工具,开发者能够准确了解测试用例对代码的覆盖程度,从而有针对性地优化测试用例,确保代码的每一个逻辑分支都得到充分测试。同时,保持测试代码与实现代码的分离,不仅有助于提高代码的可维护性和可扩展性,还能使项目结构更加清晰,便于团队成员之间的协作和沟通。此外,有效处理测试中的依赖关系,如使用模拟对象(Mock Objects)替代真实的外部依赖,能够使测试更加独立、可靠,避免因外部因素导致的测试不稳定和不可控。
(二)未来发展趋势
随着 Python 在各个领域的广泛应用,TDD 在 Python 开发领域的重要性将日益凸显。未来,TDD 有望与持续集成 / 持续部署(CI/CD)流程更加紧密地融合,实现自动化的测试和部署,进一步提高软件开发的效率和质量。在人工智能和大数据等新兴领域,Python 作为主要的编程语言,TDD 将为这些复杂系统的开发提供坚实的保障,确保模型的准确性和稳定性。同时,随着测试技术的不断发展,新的测试工具和方法将不断涌现,为 TDD 的实践带来更多的便利和创新。
对于广大 Python 开发者来说,持续学习和实践 TDD 是提升自身技术能力和代码质量的重要途径。通过不断地在项目中应用 TDD,积累经验,开发者能够更好地理解需求,设计出更加健壮、可维护的代码。同时,关注 TDD 领域的最新动态和技术发展,积极探索新的测试工具和方法,将有助于开发者在快速变化的技术环境中保持竞争力,为 Python 项目的成功开发贡献更多的价值。

相关文章推荐:
1、Python详细安装教程(大妈看了都会)
2、02-pycharm详细安装教程(大妈看了都会)
3、如何系统地自学Python?
4、Alibaba Cloud Linux 3.2104 LTS 64位 怎么安装python3.10.12和pip3.10
5、职场新技能:Python数据分析,你掌握了吗?
6、Python爬虫图片:从入门到精通
串联文章:
1、Python小白的蜕变之旅:从环境搭建到代码规范(1/10)
2、Python面向对象编程实战:从类定义到高级特性的进阶之旅(2/10)
3、Python 异常处理与文件 IO 操作:构建健壮的数据处理体系(3/10)
4、从0到1:用Lask/Django框架搭建个人博客系统(4/10)
5、Python 数据分析与可视化:开启数据洞察之旅(5/10)
6、Python 自动化脚本开发秘籍:从入门到实战进阶(6/10)
7、Python并发编程:开启性能优化的大门(7/10)
8、从0到1:Python机器学习实战全攻略(8/10)
相关文章:
)
解锁Python TDD:从理论到实战的高效编程之道(9/10)
引言 在 Python 开发的广袤天地中,确保代码质量与稳定性是每位开发者的核心追求。测试驱动开发(TDD,Test-Driven Development)作为一种强大的开发理念与实践方法,正逐渐成为 Python 开发者不可或缺的工具。TDD 强调在…...
:STM32F103开发环境搭建)
OpenMCU(七):STM32F103开发环境搭建
概述 本文主要讲述了使用Keil软件搭建STM32F103嵌入式开发环境的步骤,主要面向想从事嵌入式行业的入门同学,如果下面的讲述过程中有不对的地方,欢迎大家给我留言。 本文主要讲述了Keil 5.43的安装教程,主要用于学习交流…...

六、Hive 分桶
作者:IvanCodes 日期:2025年5月13日 专栏:Hive教程 在 Hive 中,除了常见的分区(Partitioning),分桶(Bucketing)是另一种重要且有效的数据组织和性能优化手段。它允许我们…...
:指标监控、数据管理、DSL 语句执行)
INFINI Console 纳管 Elasticsearch 9(一):指标监控、数据管理、DSL 语句执行
Elasticsearch v9.0 版本最近已发布,而 INFINI Console 作为一款开源的非常轻量级的多集群、跨版本的搜索基础设施统一管控平台,是否支持最新的 Elasticsearch v9.0 集群管理呢?本文以 INFINI Console v1.29.2 为例,从指标监控、数…...

ansible进阶版01
ansible进阶版01 欢迎使用Markdown编辑器最佳实践保持简单 保持井然有序(有组织的)经常测试 git工作原理 chapter 2编写ymal格式的主机清单 欢迎使用Markdown编辑器 最佳实践 保持简单 使用yaml的原生语法使用自带模块尽量使用专用模块,不…...

python文件打包成exe文件
✅ 一、安装 PyInstaller 打开cmd,输入以下代码 pip install pyinstaller✅ 二、打包指令 比如说你有如下的文件需要打包。 首先复制你的文件所在目录,比如我的是C:\Users\Administrator\Desktop\BearingSearchSystem 在cmd中切换到该目录来…...

人脸识别系统中的隐私与数据权利保障
首席数据官高鹏律师创作 如今人脸识别技术以其高效、便捷的特性广泛应用于各个领域,从安防监控到移动支付,从门禁系统到社交媒体。然而,这项技术在为我们的生活带来诸多便利的同时,也引发了一系列关于隐私与数据权利的深刻担忧。…...

电脑关机再开机会换IP吗?深入解析分配机制
在日常使用电脑时,许多用户可能会好奇:关机后再开机,IP地址会不会变化? 这个问题看似简单,但实际上涉及多个因素。本文将详细解析电脑IP地址的变化机制,帮助大家理解其中的原理,并提供相关的…...

经典中的经典-比特币白皮书中文版
AI是一切假的集合,如果任凭AI如此聪明下去,所有的人都将被AI愚弄与股掌之间,那么能限制AI的只有区块链这个让一切数据都无处遁形的真神,而比特币作为区块链的鼻祖,开创了公开账本的先河,当互联网上所有的信…...

Spring事务失效的全面剖析
文章目录 1. Spring事务基础1.1 什么是Spring事务1.2 Spring事务的实现原理1.3 `@Transactional`注解的主要属性1.4 使用Spring事务的简单示例2. Spring事务失效的常见场景及解决方案2.1 方法不是public的问题描述问题示例解决方案技术原理解释2.2 自调用问题(同一个类中的方法…...
)
本地的ip实现https访问-OpenSSL安装+ssl正式的生成(Windows 系统)
1.下载OpenSSL软件 网站地址:Win32/Win64 OpenSSL Installer for Windows - Shining Light Productions 安装: 一直点击下一步就可以了 2.设置环境变量 在开始菜单右键「此电脑」→「属性」→「高级系统设置」→「环境变量」 在Path 中添加一个: xxxx\OpenSSL-…...

【go】binary包,大小端理解,read,write使用,自实现TCP封包拆包案例
binary.LittleEndian 是 Go 语言 encoding/binary 包中的一个常量,用于指定字节序(Byte Order)。字节序是指多字节数据在内存中存储的顺序,有两种主要方式: 小端序(Little Endian):…...

[万字]qqbot开发记录,部署真寻bot+自编插件
这是我成功部署真寻bot以及实现一个自己编写的插件(连接deepseek回复内容)的详细记录,几乎每一步都有截图。 正文: 我想玩玩qqbot。为了避免重复造轮子,首先选一个github的高星项目作为基础吧。 看了一眼感觉真寻bot不…...

国内USB IP商业解决方案新选择:硬件USB Server
在数字化办公日益普及的今天,USB OVER NETWORK技术,即USB IP技术,为企业带来了前所未有的便捷与高效。作为这一领域的佼佼者,朝天椒USB Server以其卓越的性能和贴心的设计,正逐步成为众多中国企业的首选USB IP商业解决…...

百度导航广告“焊死”东鹏特饮:商业底线失守,用户安全成隐忧
近日,百度地图因导航时植入“广告”的问题登上社交媒体热搜,并引发广泛争议。 截图自微博 导航途中出现“焊死”在路面的广告 安全隐患引争议 多位网友发帖称,在使用百度地图导航时,导航界面中的公路路面上出现了“累了困了喝东…...

yolo11n-obb训练rknn模型
必备: 准备一台ubuntu22的服务器或者虚拟机(x86_64) 1、数据集标注: 1)推荐使用X-AnyLabeling标注工具 2)标注选【旋转框】 3)可选AI标注,再手动补充,提高标注速度 …...

GNU Screen 曝多漏洞:本地提权与终端劫持风险浮现
SUSE安全团队全面审计发现,广泛使用的终端复用工具GNU Screen存在一系列严重漏洞,包括可导致本地提权至root权限的缺陷。这些问题同时影响最新的Screen 5.0.0版本和更普遍部署的Screen 4.9.x版本,具体影响范围取决于发行版配置。 尽管GNU Sc…...
)
无人机避障——如何利用MinumSnap进行对速度、加速度进行优化的轨迹生成(附C++python代码)
🔥轨迹规划领域的 “YYDS”——minimum snap!作为基于优化的二次规划经典,它是无人机、自动驾驶轨迹规划论文必引的 “开山之作”。从优化目标函数到变量曲线表达,各路大神疯狂 “魔改”,衍生出无数创新方案。 &#…...

2025 3D工业相机选型及推荐
3D工业相机是专门为工业应用设计的三维视觉采集设备,能够获取物体的三维空间信息,在智能制造、质量检测、机器人引导等领域有广泛应用。 一、主要类型 1.结构光3D相机 通过投射特定光斑或条纹图案并分析变形来重建三维形状 典型代表:双目结构…...
项目,后端接口报401-账号未登录解决方案)
芋道(yudao-cloud)项目,后端接口报401-账号未登录解决方案
一、需求 最近公司有新的业务需求,调研了一下,决定使用芋道(yudao-cloud)框架,于是从github(https://github.com/YunaiV/yudao-cloud)上克隆项目,选用的是jdk17版本的。根据项目启动手册&#…...

动态域名服务ddns怎么设置?如何使用路由器动态域名解析让外网访问内网?
设置路由器的动态域名解析(DDNS),通常需先选择支持 DDNS 的路由器和提供 DDNS 服务的平台,然后在路由器管理界面中找到 DDNS 相关设置选项,填入在服务平台注册的账号信息,完成配置后保存设置并等待生效。 …...

论文《Collaboration-Aware Graph Convolutional Network for Recommender Systems》阅读
论文《Collaboration-Aware Graph Convolutional Network for Recommender Systems》阅读 论文概况Introduction and MotivationMethodologyLightGCN 传播形式CIRCAGCNImplementation Experiments 论文概况 论文《Collaboration-Aware Graph Convolutional Network for Recomm…...

Codis集群搭建和集成使用的详细步骤示例
以下是Codis集群搭建和集成使用的详细步骤示例: 环境准备 安装Go语言环境 下载并安装适配操作系统的Go语言版本。配置环境变量GOROOT和GOPATH。 安装ZooKeeper 下载ZooKeeper压缩包,解压并进入目录。复制conf/zoo_sample.cfg为conf/zoo.cfg。启动ZooKe…...

利用比较预言机处理模糊的偏好数据
论文标题 ComPO:Preference Alignment via Comparison Oracles 论文地址 https://arxiv.org/pdf/2505.05465 模型地址 https://huggingface.co/ComparisonPO 作者背景 哥伦比亚大学,纽约大学,达摩院 动机 DPO算法直接利用标注好的数据来做偏好对…...

《数据库原理》部分习题解析
《数据库原理》部分习题解析 1. 课本pg196.第1题。 (1)函数依赖 若对关系模式 R(U) 的任何可能的关系 r,对于任意两个元组 t₁ 和 t₂,若 t₁[X] t₂[X],则必须有 t₁[Y] t₂[Y],则称属性集 Y 函数依赖…...

【HCIA】浮动路由
前言 我们通常会在出口路由器配置静态路由去规定流量进入互联网默认应该去往哪里。那么,如果有两个运营商的路由器都能为我们提供上网服务,我们应该如何配置默认路由呢?浮动路由又是怎么一回事呢? 文章目录 前言1. 网络拓扑图2. …...

基于机器学习的卫星钟差预测方法研究HPSO-BP
摘要 本文研究了三种机器学习方法(BP神经网络、随机森林和支持向量机)在卫星钟差预测中的应用。通过处理GPS和GRACE卫星的钟差数据,构建了时间序列预测模型,并比较了不同方法的预测性能。实验结果表明,优化后的BP神经…...

机器学习中分类模型的常用评价指标
评价指标是针对模型性能优劣的一个定量指标。 一种评价指标只能反映模型一部分性能,如果选择的评价指标不合理,那么可能会得出错误的结论,故而应该针对具体的数据、模型选取不同的的评价指标。 本文将详细介绍机器学习分类任务的常用评价指…...

AI 检测原创论文:技术迷思与教育本质的悖论思考
当高校将 AI 写作检测工具作为学术诚信的 "电子判官",一场由技术理性引发的教育异化正在悄然上演。GPT-4 检测工具将人类创作的论文误判为 AI 生成的概率高达 23%(斯坦福大学 2024 年研究数据),这种 "以 AI 制 AI&…...

langchain学习
无门槛免费申请OpenAI ChatGPT API搭建自己的ChatGPT聊天工具 https://nuowa.net/872 基本概念 LangChain 能解决大模型的两个痛点,包括模型接口复杂、输入长度受限离不开自己精心设计的模块。根据LangChain 的最新文档,目前在 LangChain 中一共有六大…...

蓝桥杯 10. 全球变暖
全球变暖 原题目链接 题目描述 你有一张某海域 N x N 像素的照片: . 表示海洋# 表示陆地 例如如下所示: ....... .##.... .##.... ....##. ..####. ...###. .......在照片中,“上下左右”四个方向上连在一起的一片陆地组成一座岛屿。例…...

OpenTiny icons——超轻量的CSS图标库,引领图标库新风向
我们非常高兴地宣布 opentiny/icons 正式发布啦! 源码:https://github.com/opentiny/icons(欢迎 Star ⭐) 官网:https://opentiny.github.io/icons/ 图标预览:https://opentiny.github.io/icons/brow…...

python使用OpenCV 库将视频拆解为帧并保存为图片
python使用OpenCV 库将视频拆解为帧并保存为图片 import cv2 import osdef video_to_frames(video_path, output_folder, frame_prefixframe_, interval1, target_sizeNone, grayscaleFalse):"""将视频拆分为帧并保存为图片参数:video_path (str): 视频文件路径…...

[论文阅读]ControlNET: A Firewall for RAG-based LLM System
ControlNET: A Firewall for RAG-based LLM System [2504.09593] ControlNET: A Firewall for RAG-based LLM System RAG存在数据泄露风险和数据投毒风险。相关研究探索了提示注入和投毒攻击,但是在控制出入查询流以减轻威胁方面存在不足 文章提出一种ai防火墙CO…...

机器学习 --- 数据集
机器学习 — 数据集 文章目录 机器学习 --- 数据集一,sklearn数据集介绍二,sklearn现实世界数据集介绍三,sklearn加载数据集3.1 加载鸢尾花数据集3.2 加载糖尿病数据集3.3 加载葡萄酒数据集 四,sklearn获取现实世界数据集五&#…...

在Ubuntu服务器上部署Label Studio
一、拉取镜像 docker pull heartexlabs/label-studio:latest 二、启动容器 (回到用户目录,例:输入pwd,显示 /home/<user>) docker run -d --name label-studio -it -p 8081:8080 -v $(pwd)/mydata:/label-st…...

机器学习07-归一化与标准化
归一化与标准化 一、基本概念 归一化(Normalization) 定义:将数据缩放到一个固定的区间,通常是[0,1]或[-1,1],以消除不同特征之间的量纲影响和数值范围差异。公式:对于数据 ( x ),归一化后的值…...

用vue和go实现登录加密
前端使用CryptoJS默认加密方法: var pass CryptoJS.AES.encrypt(formData.password, key.value).toString()使用 CryptoJS.AES.encrypt() 时不指定加密模式和参数时,CryptoJS 默认会执行以下操作 var encrypted CryptoJS.AES.encrypt("明文&quo…...

服务器制造业中,L2、L6、L10等表示什么意思
在服务器制造业中,L2、L6、L10等是用于描述服务器生产流程集成度的分级体系,从基础零件到完整机架系统共分为L1-L12共12个等级。不同等级对应不同的生产环节和交付形态,以下是核心级别的具体含义: L2(Level 2…...

mysql8常用sql语句
查询结果带行号 -- 表名为 mi_user, 假设包含列 id ,address SELECT ROW_NUMBER() OVER (ORDER BY id) AS row_num, t.id, t.address FROM mi_user t ; SELECT ROW_NUMBER() OVER ( ) AS row_num, t.id, t.address FROM mi_user t ; 更新某列数…...

多模态RAG与LlamaIndex——1.deepresearch调研
摘要 关键点: 多模态RAG技术通过结合文本、图像、表格和视频等多种数据类型,扩展了传统RAG(检索增强生成)的功能。LlamaIndex是一个开源框架,支持多模态RAG,提供处理文本和图像的模型、嵌入和索引功能。研…...

汽车工厂数字孪生实时监控技术从数据采集到三维驱动实现
在工业智能制造推动下,数字孪生技术正成为制造业数字化转型的核心驱动力。今天详细介绍数字孪生实时监控技术在汽车工厂中的应用,重点解析从数据采集到三维驱动实现的全流程技术架构,并展示其在提升生产效率、降低成本和优化决策方面的显著价…...

深度解码双重订阅用户:高价值流量池的掘金指南
在流量红利消退的当下,内容平台与电商平台的竞争已进入白热化阶段。数据显示,2023年全球用户平均每日切换应用频次超过200次,但仅有3%的用户愿意为多个平台持续付费。这3%的群体——“双重订阅用户”,正成为商业价值最高的流量金矿…...

MATLAB Simulink在Autosar和非Autosar工程下的开发流程
软件开发有两种方法:自上而下和自下而上。自上而下就是从整体出发去设计各个模块和模块间的接口,要求架构设计人员对产品功能非常清楚;自下而上就是从一个一个模块出发去设计,进而组成一个整体。自下而上可能会带来冗余代码过多和…...

使用DevEco Studio性能分析工具高效解决鸿蒙原生应用内存问题
目录 一、内存问题的识别与初步判断 1.1 内存问题的常见表现 1.2 使用 DevEco Profiler 的实时监控功能 1.2.1 打开 Profiler 工具 1.2.2 监控内存变化 1.2.3 判断内存异常 1.2.4 示例代码:模拟内存泄漏 二、内存问题的定界与定位 2.1 使用 Snapshot/Allocation 模板分…...

AI视频生成工具开发与搭建:从技术到应用的全方位指南
随着AI技术的飞速发展,视频创作的门槛被大幅降低。无论是个人用户还是企业开发者,都能通过AI工具实现照片转动态、视频爆改创意、小程序开发等多样化需求。本文将从技术开发、工具应用及行业趋势三个维度,深度解析AI视频生成的核心技术与实践…...

【android bluetooth 框架分析 02】【Module详解 7】【VendorSpecificEventManager 模块介绍】
1. 背景 我们在 gd_shim_module 介绍章节中,看到 我们将 VendorSpecificEventManager 模块加入到了 modules 中。 // system/main/shim/stack.cc modules.add<hci::VendorSpecificEventManager>();在 ModuleRegistry::Start 函数中我们对 加入的所有 module…...

Docker环境下的Apache NiFi安装实践踩坑记录
引言:由于最近用到数据同步,故打算采用中间件工具来做数据同步,谁知第一步部署Apache NiFi环境就耽搁了好久,其中遇到一些问题,故记录下来部署成功记录 问题1:HTTPS访问 HTTP ERROR 400 Invalid SNI问题2:…...

flutter Stream 有哪两种订阅模式。
Flutter 中的 Stream 有两种订阅模式: 单订阅模式 (Single Subscription) 只能有一个订阅者(listen 只能调用一次),后续调用会抛出异常。数据仅在订阅后开始传递,适用于点对点通信场景(如文件读取流…...

删除购物车中一个商品
一. 删除购物车中一个商品 删除商品时我们要考虑一个问题,当商品数量等于1时,删除商品就直接将其从数据库中删除即可。但是当数量大于1时,删除商品就是让商品数量-1。因此我们在删除一个商品时首先要判断该商品在购物车中的数量。 Controlle…...