通过POI实现对word基于书签的内容替换、删除、插入
一、基本概念
POI:即Apache POI, 它是一个开源的 Java 库,主要用于读取 Microsoft Office 文档(Word、Excel、PowerPoint 等),修改 或 生成 Office 文档内容,保存 为对应的二进制或 XML 格式(如 .doc、.docx、.xls、.xlsx)。
书签:作用类似于图书阅读中的实体书签(bookmark),字面上就是用来标记(记住)某一页或某一段的位置。在 Word 里,你可以给文档的某个位置(文字、段落或任意元素前后)打上一个“标记”,并为它命名,在自动化处理文档时,就相当于给程序提供了一个清晰、稳定的操作目标。(利用 Apache POI 等库,可以通过书签来定位,针对该区域执行“替换”、“删除”或“插入”操作,而不必遍历整个文档或依赖复杂的坐标。)
基础概念
Docx4j:即Docx 4j,Docx指用于Microsoft Word 2007 及以后版本使用的文件格式(基于 Office Open XML,扩展名为 .docx),4j表示 "for Java",即专为 Java 设计的库。它是用于Java 的 DOCX 文档处理库,明确其核心功能是操作现代 Word 文档格式(.docx)。
(Docx4j与POI均为Java开发者提供操作Word文档的能力,但POI适合需要同时处理 .doc 和 .docx 的旧项目,具有更活跃的 Apache 社区支持,采用Apache 2.0协议。而Docx4j 适合专注于 .docx 且需要更高级功能的场景(如 PDF 转换),采用AGPLv3协议。两者在实现原理上也不同,Docx4j 将 Word 文档的 XML 结构映射为 Java 对象(通过 JAXB),代码更直观,大文件处理可能更高效(依赖 JAXB 优化)。而POI 直接操作 XML 节点,灵活性高但代码更繁琐,大文件易内存溢出(DOM 模型))
Aspose.Words:即 Aspose 公司提供的 Word 文档处理解决方案,适合企业级复杂需求,功能强大,支持 Word 文档的完整操作(格式、图表、加密、渲染为 PDF 等),需要商业许可,并且提供更好的技术支持和稳定性。
(Aspose.Words 是商业化、功能全面的 Word 操作库,它提供类似 Word 对象模型(如 Document、Paragraph),API 更直观,适合企业级应用。而POI 是开源基础工具,适合轻量级需求或预算有限的场景。另外Aspose.Words支持 .NET/Java/Cloud API,并且官方商业技术支持)
HWPF:即"Horrible Word Processor Format",直译为“糟糕的文字处理器格式”。这个名字是 Apache POI 开发者对旧版 Microsoft Word 二进制文件格式(.doc)的一种调侃式命名,原因是.doc 格式是微软私有的二进制格式,结构复杂且未完全公开,解析和操作极其困难,在逆向工程 .doc 格式时遇到了许多挑战,因此用“Horrible”形容其开发过程。
(HWPF 是 Apache POI 项目中专门用于处理 旧版 Word 文件(.doc) 的组件,属于 POI 的早期核心模块之一(与 Excel 的 HSSF 属于同一代)。尽管 HWPF 已过时,但 POI 仍保留它,主要为了向后兼容,支持遗留系统需要读取或修改旧版 .doc 文件)
XWPF :即"XML Word Processor Format",表示它处理的是基于 Office Open XML (OOXML) 格式的文档(即 .docx 文件,本质是 ZIP 压缩的 XML 文件集合,可将 .docx 重命名为 .zip 解压,观察文件内容),关键类有XWPFDocument(表示整个 .docx 文档)、XWPFParagraph(操作段落)、XWPFRun(段落中的文本片段(控制字体、样式等))、XWPFTable(操作表格)、XWPFStyles(管理样式(如标题、正文样式))等
(XWPF 基于 POI 的 POI-OOXML 子模块实现,后者提供了对 Office Open XML 格式(2007+)的底层解析支持,它与旧版 HWPF(处理 .doc 二进制格式)并列,共同覆盖 Word 文档的全版本。)
OOXML:即Office Open XML,是 Microsoft 从 Office 2007 开始引入的基于 XML 的文档格式标准,用于替代旧的二进制格式(如 .doc、.xls)。Office Open表示表示格式的开放性(由 ECMA 和 ISO 标准化,文档结构可被第三方工具解析);XML表示文档内容以 XML 文件的形式存储,本质是一个 ZIP 压缩包(可重命名为 .zip 解压查看内部结构)。
典型 OOXML 文档结构(以 .docx 为例)解压后的文件目录如下:
word/
├── document.xml # 正文内容
├── styles.xml # 样式定义
├── header1.xml # 页眉
├── footer1.xml # 页脚
├── theme/ # 主题
└── ...
_rels/ # 文件关系定义
[Content_Types].xml # 内容类型声明
具体内容结构如下:
<pkg:package> 表示整个文档包...<pkg:part> 表示文档包包含的多个 part(部件件),例如正文、样式、关系等<pkg:part pkg:name="/word/document.xml"> 表示 Word 文档的主体内容所在的 XML 文件<pkg:xmlData> 表示XML 的实际数据内容,也就是文档的主体结构数据<w:document> Word 文档的根节点<w:body> 文档主体...多种不同的标签<w:p> 表示一个段落(paragraph)...多种不同的标签<w:pPr> 段落属性(paragraph properties)...多种不同的标签<w:lang> 语言设置<w:rFonts> 字体设置<w:ind> 段落缩进设置<w:r> 表示一个文本运行(run)...多种不同的标签<w:rPr> 文本运行的属性...多种不同的标签<w:rFonts> 字体设置<w:lang> 语言设置<w:noProof><w:t> 表示具体的文本内容<w:drawing> 表示绘图对象(如图片、形状)<wp:inline> 表示内联对象...多种不同的标签<a:graphic> 表示图形元素<a:graphicData> 表示图形数据...多种不同的标签<pic:pic> 表示图片元素<pic:nvPicPr> 表示图片非视觉属性<pic:blipFill> 表示图片填充<pic:spPr> 表示图形形状属性<wp:docPr> 表示文档属性<wp:extent> 表示对象尺寸<wp:effectExtent> 表示效果范围<wp:cNvGraphicFramePr> 表示图形框架属性<w:proofErr> 标记拼写或语法错误<w:bookmarkStart> 表示书签的起始(可任意位置但一定成对出现。大多数位于段落内,但是也跨段落出现,还可存在于表格、页眉页脚、文档主体中)<w:bookmarkEnd> 表示书签的结束(可任意位置,同w:bookmarkStart) <w:tbl> 表示一个表格<w:tblPr> 表示表格属性<w:tblGrid> 表示表格列宽定义...多个<w:tr><w:tr> 表示表格行(table row)...多个<w:tc><w:tc> 表示表格单元格(table cell)<w:tcPr> 表示单元格属性<w:tcW> 表示单元格宽度<w:p>(POI 基于 OOXML 标准实现,比如XWPF(用于操作 .docx)和 XSSF(用于操作 .xlsx)模块本质上是 OOXML 的高级 Java 封装。POI的操作层级根据是否进行了高级封装而不直接操作XML, 可以分为高级 API(推荐,比如使用 XWPFDocument、XWPFParagraph 等类,无需直接接触 XML)以及低级 API(直接操作 OOXML 的 XML 绑定类(如 CTP、CTR),适用于 POI 未封装的功能)。POI 屏蔽了 OOXML 的复杂性,开发者无需手动编写 XML,但是若需实现 POI 未支持的功能(如复杂图表),需直接操作 OOXML 或结合 OpenXML SDK实现)
二、操作步骤
1、引入依赖
<!-- 支持 新版 Office OOXML 格式(如 .docx、.xlsx),是操作 Word 书签的 核心依赖,并且poi-ooxml 的依赖链包含 poi、xmlbeans 等必要库,无需手动重复添加--><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.3</version></dependency><!-- 可选:旧版 Word 的附加支持(如图片、复杂格式) -->
<!-- <dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>5.2.3</version></dependency>-->(poi-ooxml是操作 Word 书签的 核心依赖,它包含 了XWPF(处理 .docx 文件的核心类,如 XWPFDocument),后续所有基于 .docx 的书签操作(替换、删除、插入)都依赖此模块)
2、插入word书签
2.1、替换书签的插入
书签固定的格式为replace_xxx,它主要用于替换具有一定文本格式的文本内容,需要选中一段文本后,通过在word的菜单 插入-》书签 弹窗中,输入书签名,点击添加插入replace书签
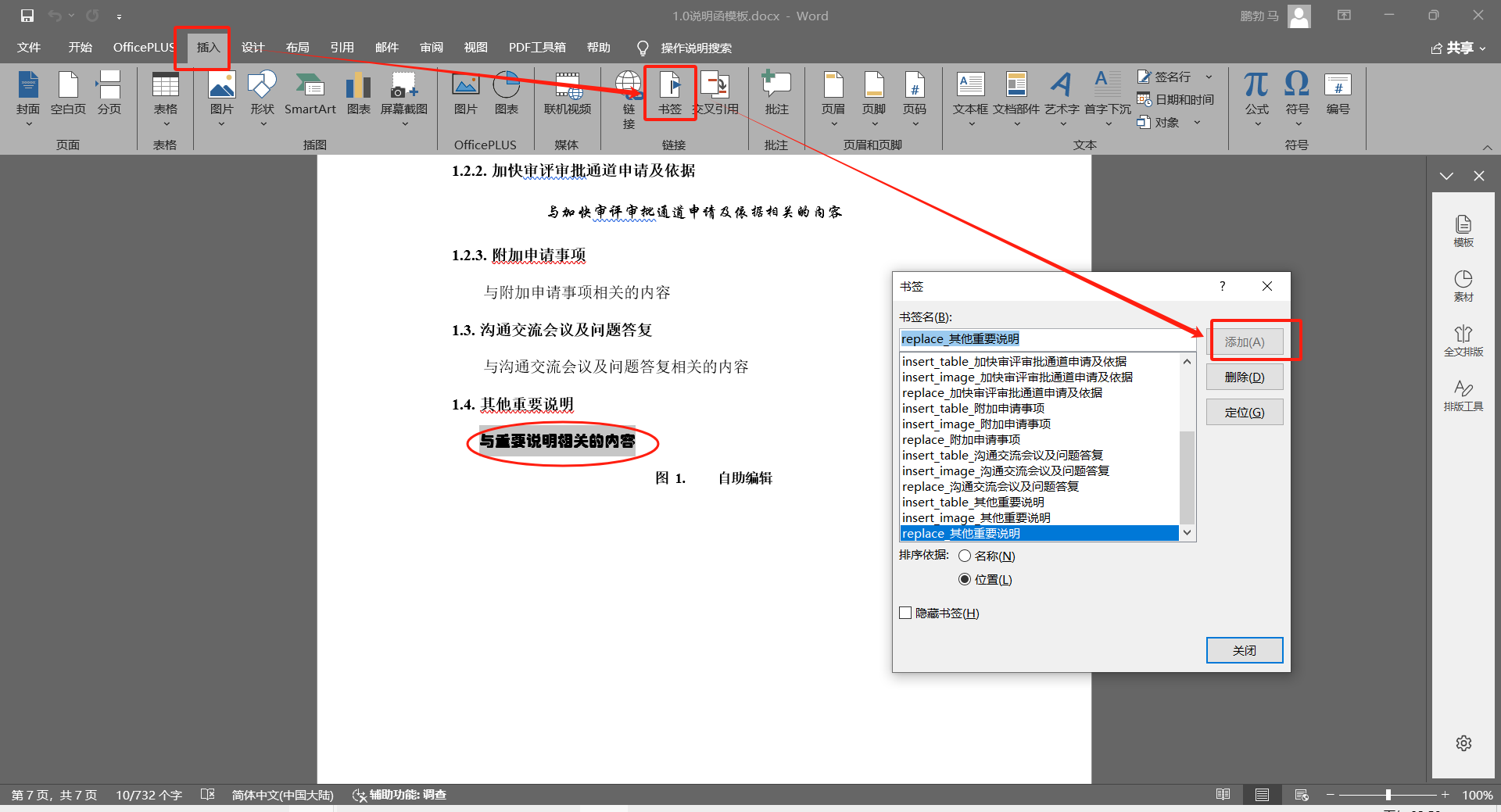
2.2、删除书签的插入
书签固定格式为delete_数字,它主要用于删除word内容,需要选择要删除的文本内容,然后在word的菜单 插入-》书签 弹窗中,输入书签名,点击添加插入delete书签
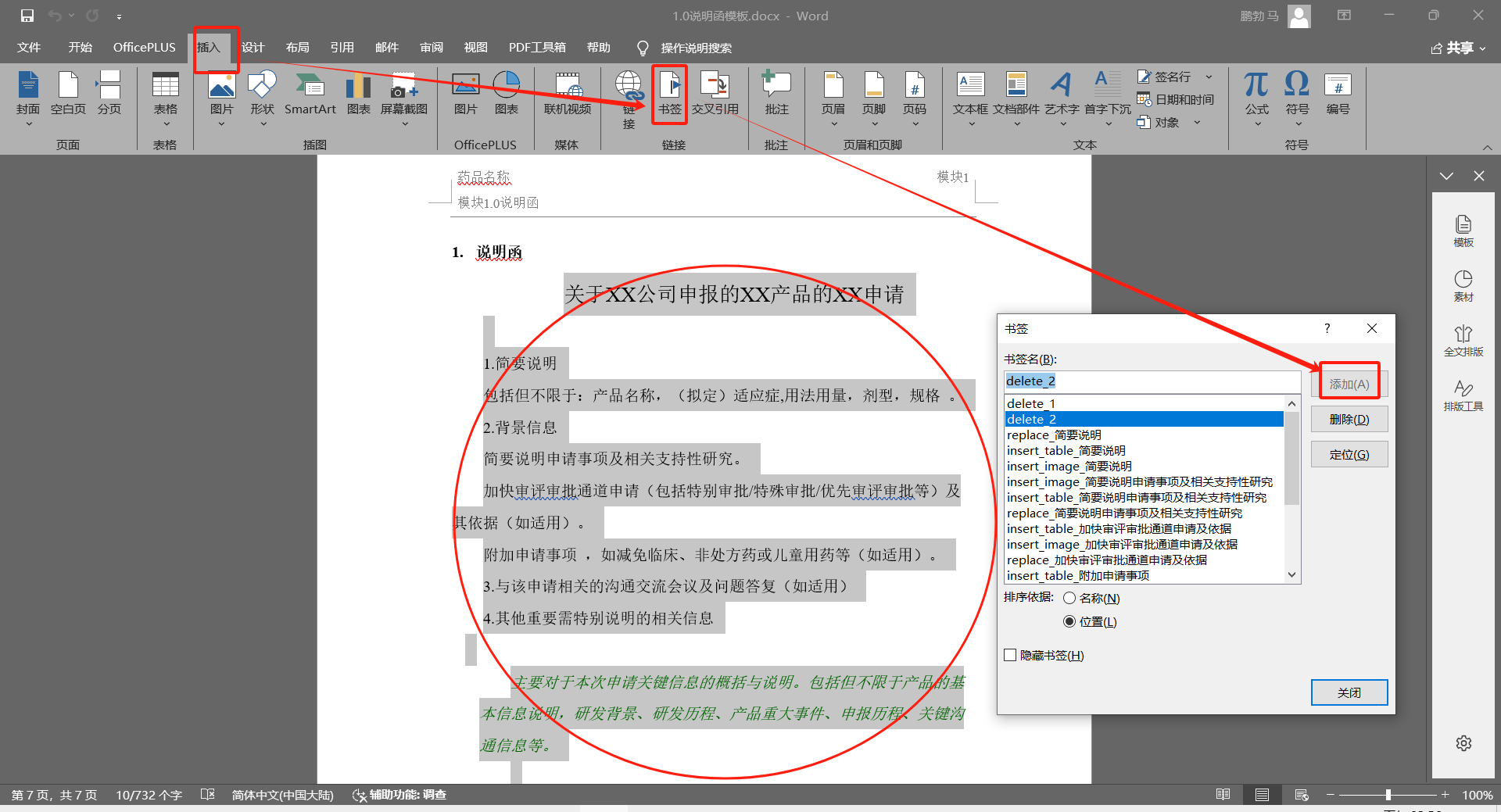
2.3、插入书签的插入
书签固定格式为insert_text_xxx、insert_image_xxx、insert_table_xxx,它主要用于插入word内容,通常对于文本会通过replace进行替换以满足文本的格式,而对于图片和表格则在代码中自定义样式插入。插入书签首先需要光标点击要插入的位置,然后直接在word的菜单 插入-》书签 弹窗中,输入书签名,点击添加插入insert书签
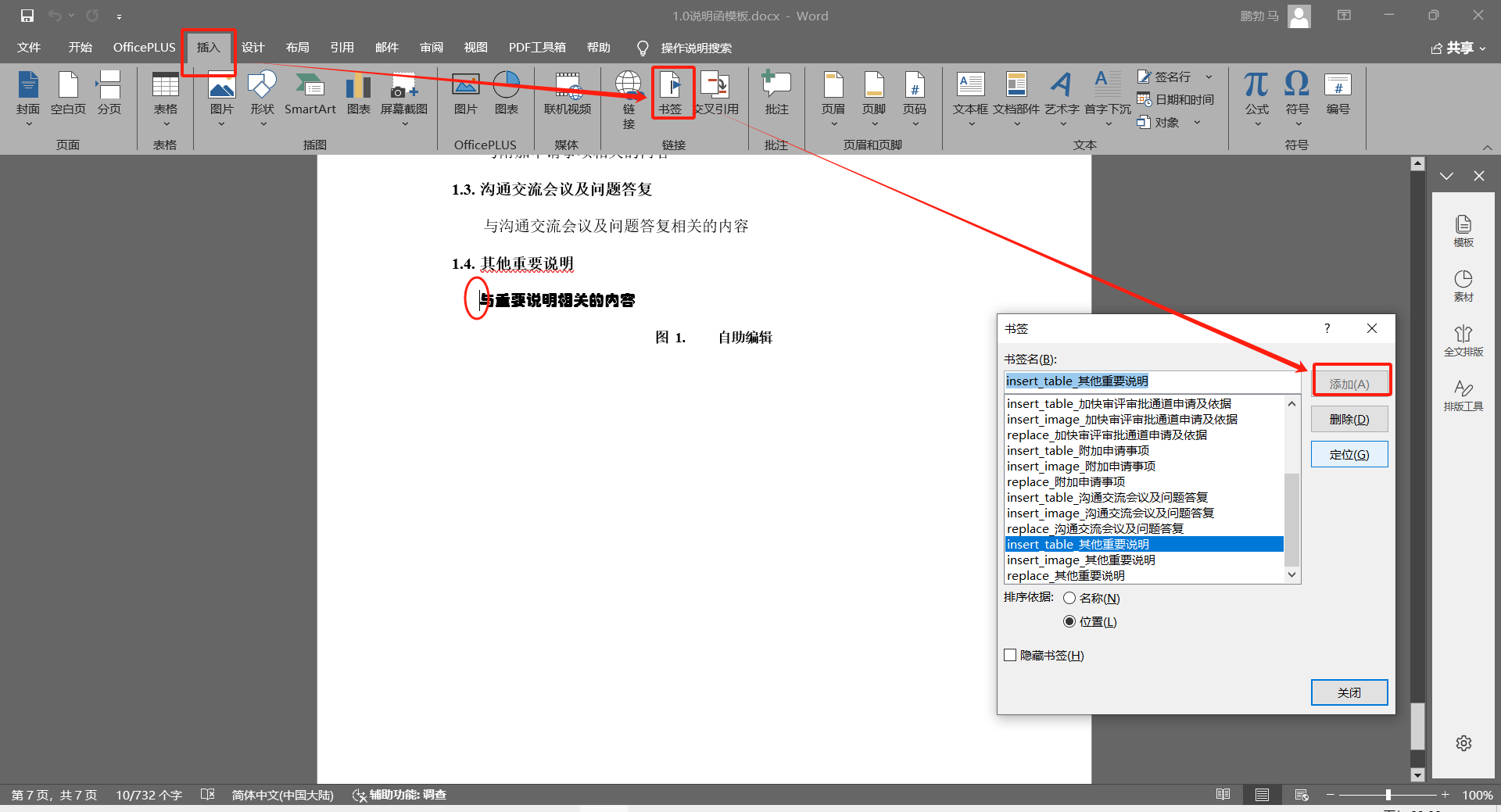
3、书签的处理
在代码中由注释可见,针对三种书签的插入有三个主要的部分,“一、replace书签的处理”部分、“二、insert书签的处理”、“三、delete书签的处理”,具体代码如下(针对OOXML中的bookmark书签,这里采用低级底层操作以真实完整获取书签位置和书签范围内的节点,因此很好的处理了一些跨段书签的情况,在多数博主相关POI操作word的文档中都未很好的考虑并处理这个问题):
/*** 处理书签* @param replaceBookmarkAndValue 替换书签及值* @param insertBookmarkAndValue 插入书签及值* @param deleteBookmarks 删除书签* @param tempFilePath 模板文件路径*/public void dealWithBookMark(Map<String, String> replaceBookmarkAndValue, Map<String, String> insertBookmarkAndValue,List<String> deleteBookmarks, String tempFilePath) {File file = new File(tempFilePath);try (InputStream is = Files.newInputStream(file.toPath())) {XWPFDocument docx = new XWPFDocument(is);// 一、replace书签的处理(针对文本)boolean isBookmarkEnd;Node bodyNode = docx.getDocument().getBody().getDomNode();NodeList bodyChildNodes = bodyNode.getChildNodes();List<String> replaceBookmarks = new ArrayList<>(replaceBookmarkAndValue.keySet());for (String bookmark : replaceBookmarks) {// 书签范围内完整的P标签List<Node> inBookmarkRangePNodes = new ArrayList<>();// 书签范围内除了完整的P标签之外,到结束标签为止,额外多余的P标签子节点(如果书签跨p,则从第0个子节点计算,不包含结束书签;如果书签不跨p,则包含起始书签,不包含结束书签)List<Node> inBookmarkRangeExtraPChildNodes = new ArrayList<>();isBookmarkEnd = getBookmarkSartAndEndRangeNodes(bodyChildNodes, bookmark,replaceBookmarkAndValue.get(bookmark), inBookmarkRangeExtraPChildNodes,inBookmarkRangePNodes);// 删除除第一个替换内容的<w:r 节点以外的其他所有节点if (isBookmarkEnd) {if (!CollectionUtils.isEmpty(inBookmarkRangePNodes)) {Node pNode = inBookmarkRangePNodes.get(0);NodeList pNodeChildNodes = pNode.getChildNodes();List<Node> nodes = new ArrayList<>();for (int i = 0; i < pNodeChildNodes.getLength(); i++) {Node node = pNodeChildNodes.item(i);nodes.add(node);}deleteExtraPChildNodes(bodyChildNodes, nodes);// 存在多个p时,除了第一个p,其他p全部删除if (inBookmarkRangePNodes.size() > 1) {for (int i = 1; i < inBookmarkRangePNodes.size(); i++) {Node node = inBookmarkRangePNodes.get(i);bodyNode.removeChild(node);}}// 存在p时,额外的p子内容一定是全删除的for (int i = 0; i < bodyChildNodes.getLength(); i++) {Node bodyChildNode = bodyChildNodes.item(i);for (Node pChildNode : inBookmarkRangeExtraPChildNodes) {if (pChildNode.getParentNode() == bodyChildNode) {bodyChildNode.removeChild(pChildNode);}}}} else {deleteExtraPChildNodes(bodyChildNodes, inBookmarkRangeExtraPChildNodes);}}}// 二、insert书签的处理(针对文本、图片、表格)List<String> insertBookMarks = new ArrayList<>(insertBookmarkAndValue.keySet());for (String bookmark : insertBookMarks) {for (XWPFParagraph paragraph : docx.getParagraphs()) {CTP ctp = paragraph.getCTP();List<CTBookmark> bookmarkStartList = ctp.getBookmarkStartList();if (CollectionUtils.isEmpty(bookmarkStartList)) {continue;}boolean anyMatch = bookmarkStartList.stream().map(CTBookmark::getName).anyMatch(item -> item.startsWith("insert"));if (!anyMatch) {continue;}Node paragraphNode = ctp.getDomNode();NodeList childNodes = paragraphNode.getChildNodes();for (int i = 0; i < childNodes.getLength(); i++) {if (childNodes.item(i).getNodeName().equals("w:bookmarkStart")) {String bookmarkValue = childNodes.item(i).getAttributes().getNamedItem("w:name").getNodeValue();String insertValue;int lastUnderscoreIndex = bookmark.lastIndexOf("_");// 如果书签匹配,则获取插入值(这里匹配书签的前缀部分,用于多个内容统一位置的插入,比如insert_table_简要说明_1、insert_table_简要说明_2)if (bookmark.substring(0, lastUnderscoreIndex).equals(bookmarkValue)) {insertValue = insertBookmarkAndValue.get(bookmark);} else {continue;}if (bookmarkValue.startsWith("insert")) {if (bookmarkValue.startsWith("insert_text")) {// 在书签后插入w:r标签,并插入文本内容"插入插入插入"// 创建 <w:r>Document ownerDoc = childNodes.item(i).getOwnerDocument();Element r =ownerDoc.createElementNS("http://schemas.openxmlformats" + ".org/wordprocessingml" +"/2006/main", "w:r");// 创建 <w:t>Element t =ownerDoc.createElementNS("http://schemas.openxmlformats" + ".org/wordprocessingml" +"/2006/main", "w:t");t.appendChild(ownerDoc.createTextNode(insertValue));r.appendChild(t);// 在 bookmarkStart 后插入新建的<w:r>Node insertBeforeNode = childNodes.item(i).getNextSibling();if (insertBeforeNode != null) {paragraphNode.insertBefore(r, insertBeforeNode);childNodes = paragraphNode.getChildNodes();}} else if (bookmarkValue.startsWith("insert_image")) {XWPFRun run = paragraph.createRun();InputStream picIs = Files.newInputStream(Paths.get(insertBookmarkAndValue.get(bookmark)));// 3. 向文档中添加图片数据,并且返回一个 relation id(内部处理好关系表和 media/* 文件)String filename = "图片.png";int format = XWPFDocument.PICTURE_TYPE_PNG; // 或者 PICTURE_TYPE_JPEG, etc.run.addPicture(picIs, format, filename, Units.toEMU(350), // 宽度 200pt 转换为 EMUUnits.toEMU(200) // 高度 100pt 转换为 EMU);// 在 bookmarkStart 后插入新建的<w:r>Node runNode = run.getCTR().getDomNode();Node insertBeforeNode = childNodes.item(i).getNextSibling();if (insertBeforeNode != null) {paragraphNode.insertBefore(runNode, insertBeforeNode);childNodes = paragraphNode.getChildNodes();}} else if (bookmarkValue.startsWith("insert_table")) {// 1、用Jsoup解析org.jsoup.nodes.Document htmlDoc = Jsoup.parse(insertBookmarkAndValue.get(bookmark));org.jsoup.nodes.Element htmlTable = htmlDoc.selectFirst("table");if (Objects.isNull(htmlTable)) {continue;}Elements rows = htmlTable.select("tr");// 2、计算表格尺寸(考虑 colspan)int numRows = rows.size();int maxCols = 0;for (org.jsoup.nodes.Element rowElem : rows) {int cols = 0;for (org.jsoup.nodes.Element cellElem : rowElem.select("th,td")) {int cs = cellElem.hasAttr("colspan") ? Integer.parseInt(cellElem.attr("colspan")) : 1;cols += cs;}maxCols = Math.max(maxCols, cols);}// 3、临时在文档末尾创建一个 numRows x maxCols 的表格XWPFTable table = docx.createTable(numRows, maxCols);// 4、遍历行和列,填数据,处理行列合并Map<List<Integer>, String> cellAndText = new HashMap<>();for (int r = 0; r < numRows; r++) {XWPFTableRow tableRow = table.getRow(r);int cols = 0;int mergeEndCols = 0;boolean isMergeCols = false;List<Integer> removeCellIndex = new ArrayList<>();for (int c = 0; c < maxCols; c++) {XWPFTableCell cell = tableRow.getCell(c);if (cell != null) {// 如果已经被行合并填过,则跳过if (cellAndText.containsKey(Arrays.asList(r, c))) {CTTcPr tcPr2 = cell.getCTTc().isSetTcPr() ? cell.getCTTc().getTcPr() : cell.getCTTc().addNewTcPr();tcPr2.addNewVMerge().setVal(STMerge.CONTINUE);continue;}// 如果处于前置的列合并范围,则删除然后跳过if (isMergeCols && c < mergeEndCols) {removeCellIndex.add(c);continue;}// 读取的HTML表格数据Elements selects = rows.get(r).select("th,td");org.jsoup.nodes.Element element = selects.get(cols);cols++;// 设置填充内容水平居中cell.setVerticalAlignment(XWPFTableCell.XWPFVertAlign.CENTER);XWPFParagraph para = cell.getParagraphs().get(0);para.setAlignment(ParagraphAlignment.CENTER);XWPFRun run = para.createRun();run.setText(element.text());// 处理列合并CTTcPr tcPr = cell.getCTTc().isSetTcPr() ? cell.getCTTc().getTcPr() : cell.getCTTc().addNewTcPr();CTTblWidth tcW = tcPr.isSetTcW() ? tcPr.getTcW() : tcPr.addNewTcW();// 设置列宽度if (r == 0) {Elements colgroup = htmlTable.select("colgroup");if (!colgroup.isEmpty()) {String width = colgroup.select("col").get(c).attr("style");if (width.contains("%")) {int widthPercent = Integer.parseInt(width.replace("%", "").replace("width:", "").replace(" ", ""));tcW.setW(BigInteger.valueOf((long) PAGE_WIDTH_TWIPS / 100 * widthPercent));tcW.setType(STTblWidth.DXA);}} else {tcW.setW(BigInteger.valueOf(PAGE_WIDTH_TWIPS / maxCols));tcW.setType(STTblWidth.DXA);}}if (element.hasAttr("colspan")) {int colspan = Integer.parseInt(element.attr("colspan"));mergeEndCols = c + colspan;tcPr.addNewGridSpan().setVal(BigInteger.valueOf(colspan));isMergeCols = true;} else {mergeEndCols++;isMergeCols = false;}// 处理行合并if (element.hasAttr("rowspan")) {int rowspan = Integer.parseInt(element.attr("rowspan"));tcPr.addNewVMerge().setVal(STMerge.RESTART);int nextRowNum = r + rowspan - 1;List<Integer> cellLocation = Arrays.asList(nextRowNum, c);String nextCellText = element.text();cellAndText.put(cellLocation, nextCellText);}}}// 删除被行合并的单元格(列合并是由不同行的同列单元格的<w:vMerge w:val="restart"/> <w:vMerge/>控制)removeCellIndex = removeCellIndex.stream().sorted().collect(Collectors.toList());Collections.reverse(removeCellIndex);removeCellIndex.forEach(tableRow::removeCell);}// 5、把表格插到书签所在段落的兄弟节点中(而非段落内)CTTbl ctTbl = table.getCTTbl();Node tblNode = ctTbl.getDomNode();// paragraphNode 是 <w:p>,其父是 <w:body>Node insertBefore = paragraphNode.getNextSibling();if (insertBefore != null) {bodyNode.insertBefore(tblNode, insertBefore);} else {bodyNode.appendChild(tblNode);}}}}}}}// 三、delete书签的处理(适用所有内容)// 如果没有传入删除书签,则删除所有删除书签的内容if(CollectionUtils.isEmpty(deleteBookmarks)){deleteBookmarks = new ArrayList<>();NodeList childNodes = bodyNode.getChildNodes();for (int i = 0; i < childNodes.getLength(); i++) {Node childNode = childNodes.item(i);String nodeName = childNode.getNodeName();if (nodeName.equals("w:bookmarkStart")) {String nodeValue = childNode.getAttributes().getNamedItem("w:name").getNodeValue();if (nodeValue.startsWith("delete")) {deleteBookmarks.add(nodeValue);}}NodeList childNodes1 = childNode.getChildNodes();for (int j = 0; j < childNodes1.getLength(); j++) {Node childNode1 = childNodes1.item(j);String nodeName1 = childNode1.getNodeName();if (nodeName1.equals("w:bookmarkStart")) {String nodeValue = childNode1.getAttributes().getNamedItem("w:name").getNodeValue();if (nodeValue.startsWith("delete")) {deleteBookmarks.add(nodeValue);}}}}}for (String bookmark : deleteBookmarks) {// 书签范围内完整的P标签List<Node> inBookmarkRangePNodes = new ArrayList<>();// 书签范围内除了完整的P标签之外,到结束标签为止,额外多余的P标签子节点(如果书签跨p,则从第0个子节点计算,不包含结束书签;如果书签不跨p,则包含起始书签,不包含结束书签)List<Node> inBookmarkRangeExtraPChildNodes = new ArrayList<>();isBookmarkEnd = getBookmarkSartAndEndRangeNodes(bodyChildNodes, bookmark,replaceBookmarkAndValue.get(bookmark), inBookmarkRangeExtraPChildNodes,inBookmarkRangePNodes);// 待其他书签操作结束后,再进行删除操作(特别注意,书签最好独立分开打,不要存在需要同时处理的内容)if (isBookmarkEnd) {// body删除p节点for (Node node : inBookmarkRangePNodes) {bodyNode.removeChild(node);}// p删除子节点(无需移除段落样式,其他书签【可能是标题链接】)for (int i = 0; i < bodyChildNodes.getLength(); i++) {Node bodyChildNode = bodyChildNodes.item(i);for (Node pChildNode : inBookmarkRangeExtraPChildNodes) {if (pChildNode.getParentNode() == bodyChildNode && !pChildNode.getNodeName().equals("w:pPr") && !pChildNode.getNodeName().equals("w:bookmarkStart")) {bodyChildNode.removeChild(pChildNode);}}}}}// 保存文件try (OutputStream os = Files.newOutputStream(Paths.get(DOWNLOAD_FILE_PATH))) {docx.write(os);}docx.close();log.info("处理文档成功");} catch (Exception e) {log.error("处理文档异常", e);}}/*** 在书签范围内的额外的p子节点中,除了替换的第一个内容以外,删除书签之间的其他内容* @param bodyChildNodes body的子节点* @param inBookmarkRangeExtraPChildNodes 书签范围内的额外的p子节点*/private void deleteExtraPChildNodes(NodeList bodyChildNodes, List<Node> inBookmarkRangeExtraPChildNodes) {// 1、收集待删除的节点(特别注意,待删除的节点必须首先通过集合匹配收集,然后再循环删除.如果在匹配过程中直接删除,则会影响循环的集合的元素,导致删除异常)List<Node> toRemoveNodes = new ArrayList<>();for (int i = 0; i < bodyChildNodes.getLength(); i++) {Node bodyChildNode = bodyChildNodes.item(i);NodeList childNodes = bodyChildNode.getChildNodes();boolean findtarget = false;for (int j = 0; j < childNodes.getLength(); j++) {Node childNode = childNodes.item(j);for (Node pChildNode : inBookmarkRangeExtraPChildNodes) {if (pChildNode == childNode) {// 第一个找到的wr即替换的内容,不做删除if (childNode.getNodeName().equals("w:r")) {if(findtarget){toRemoveNodes.add(childNode);}findtarget = true;}}}}// 只有额外p子节点时,在某个p匹配到后,则无需循环其他p节点了if (findtarget) {break;}}// 2、循环删除多余节点for (int i = 0; i < bodyChildNodes.getLength(); i++) {Node bodyChildNode = bodyChildNodes.item(i);for (Node toRemoveNode : toRemoveNodes) {if (toRemoveNode.getParentNode() == bodyChildNode) {bodyChildNode.removeChild(toRemoveNode);}}}}/*** 获取书签范围内完整的P标签,和到结束标签为止额外多余的P标签子节点* @param bodyChildNodes body节点的子节点* @param bookmark 目标书签名* @param bookmarkValue 待替换的内容(当书签为replace时)* @param inBookmarkRangeExtraPChildNodes 额外p标签子节点(如果书签跨p,则从第0个子节点计算,不包含结束书签;如果书签不跨p,则包含起始书签,不包含结束书签)* @param inBookmarkRangePNodes 书签范围内完整的P标签* @return 书签结束标签是否已找到*/private boolean getBookmarkSartAndEndRangeNodes(NodeList bodyChildNodes, String bookmark, String bookmarkValue,List<Node> inBookmarkRangeExtraPChildNodes, List<Node> inBookmarkRangePNodes) {boolean isBookmarkEnd;boolean startRevord = false;isBookmarkEnd = false;Node startPNode = null;int continueIndex = 0;String bookmarkStartId = "";boolean hasReplace = false;for (int j = 0; j < bodyChildNodes.getLength(); j++) {Node bodyChildNode = bodyChildNodes.item(j);if (!startRevord) {if (bodyChildNode.getNodeName().equals("w:bookmarkStart")) {String bookmarkName = bodyChildNode.getAttributes().getNamedItem("w:name").getNodeValue();if (bookmark.equals(bookmarkName)) {bookmarkStartId = bodyChildNode.getAttributes().getNamedItem("w:id").getNodeValue();}String bookmarkStartId1 = bodyChildNode.getAttributes().getNamedItem("w:id").getNodeValue();if (bookmarkStartId.equals(bookmarkStartId1)) {startRevord = true;startPNode = bodyChildNode;}} else if (bodyChildNode.getNodeName().equals("w:p")) {NodeList pChildNodes = bodyChildNode.getChildNodes();for (int k = 0; k < pChildNodes.getLength(); k++) {Node pChildNode = pChildNodes.item(k);if (pChildNode.getNodeName().equals("w:bookmarkStart")) {String bookmarkName = pChildNode.getAttributes().getNamedItem("w:name").getNodeValue();if (bookmark.equals(bookmarkName)) {bookmarkStartId = pChildNode.getAttributes().getNamedItem("w:id").getNodeValue();}String bookmarkStartId1 = pChildNode.getAttributes().getNamedItem("w:id").getNodeValue();if (bookmarkStartId.equals(bookmarkStartId1)) {startRevord = true;startPNode = bodyChildNode;continueIndex = k;break;}}}}}if (startRevord) {// 如果与标志开始的p属于同一p,则接着坐标处理,否则新p从头处理if (bodyChildNode.getNodeName().equals("w:p")) {NodeList pChildNodes = bodyChildNode.getChildNodes();int k = 0;if (bodyChildNode == startPNode) {k = continueIndex;}for (int x = k; x < pChildNodes.getLength(); x++) {Node pChildNode = pChildNodes.item(x);// 替换书签的赋值处理,只做一次替换if(!hasReplace){if (pChildNode.getNodeName().equals("w:r")) {NodeList rChildNodes = pChildNode.getChildNodes();for (int z = 0; z < rChildNodes.getLength(); z++) {if (rChildNodes.item(z).getNodeName().equals("w:t")) {rChildNodes.item(z).getChildNodes().item(0).setNodeValue(bookmarkValue);hasReplace = true;}}}}if (pChildNode.getNodeName().equals("w:bookmarkEnd")) {String bookmarkEndId = pChildNode.getAttributes().getNamedItem("w:id").getNodeValue();if (bookmarkStartId.equals(bookmarkEndId)) {isBookmarkEnd = true;break;}}inBookmarkRangeExtraPChildNodes.add(pChildNode);}} else if (bodyChildNode.getNodeName().equals("w:bookmarkEnd")) {String bookmarkEndId = bodyChildNode.getAttributes().getNamedItem("w:id").getNodeValue();if (bookmarkStartId.equals(bookmarkEndId)) {isBookmarkEnd = true;}}// 如果当前P段落内不存在结束书签,则清空子节点保存,并且删除节点集合增加当前P段落节点if (!isBookmarkEnd) {inBookmarkRangeExtraPChildNodes.clear();inBookmarkRangePNodes.add(bodyChildNode);}}if (isBookmarkEnd) {break;}}return isBookmarkEnd;}总结
通过POI处理书签进行内容的增删改,实际就是基于OOXML结构,通过POI进行高级或低级操作,以识别书签标签并进行内容的处理
三、额外补充
1、结合AI的落地应用
可以通过低代码开发平台创建工作流任务,通过 AI 模型根据不同的业务提纲(章节大纲、关键点清单)批量生成文案、数据分析结论、图表解读等“内容片段”。每个生成单元都可以看作是一段需要插入到模板中的内容、并且带有自己书签标识。然后维护一个标准化的 Word 模板,里面预先放置好按结构划分的书签,占位符既标记“标题”“正文”“表格”“图片”所处的位置,也约定了样式(字体、段落、缩进)。将上述对书签的处理发布为接口工具,在工作流中以供调用,最终生成word文档。但是需要注意模型生成内容具有不稳定性并且可能存在幻觉,因此可能需要增加人工校验环节以提高准确性,另外生成内容基本是md格式的内容,如果包含表格,需要使用HTML的表格才能保留行列合并,如果工作流平台是dify且生成内容包含图片,在书签的处理代码中需要根据图片url结合dify存储位置获取真实的图片流进行插入。
工作流的核心思路是,提取提纲及描述,然后根据提纲检索根据描述筛选,最终再进行数据结构整合,然后调用书签处理工具生成word
相关文章:

通过POI实现对word基于书签的内容替换、删除、插入
一、基本概念 POI:即Apache POI, 它是一个开源的 Java 库,主要用于读取 Microsoft Office 文档(Word、Excel、PowerPoint 等),修改 或 生成 Office 文档内容,保存 为对应的二进制或 XML 格式&a…...

git进行版本控制时遇到Push cannot contain secrets的解决方法
git进行版本控制,push遇到Push cannot contain secrets的解决方法 最近在项目开发过程中,我遇到了一个让我头疼不已的问题。 问题的出现 一开始,我的项目远程仓库连接的是 Gitee,在开发过程中一切都很顺利,我也习惯…...

Java GUI 开发之旅:Swing 组件与布局管理的实战探索
在编程的世界里,图形用户界面(GUI)设计一直是提升用户体验的关键环节。Java 的 Swing 库为我们提供了强大的工具来构建跨平台的 GUI 应用。今天,我将通过一次实验,分享如何使用 Java Swing 开发一个功能丰富的 GUI 应用…...
 机器人环境和环境数据)
OpenVLA (2) 机器人环境和环境数据
文章目录 前言1 BridgeData V21.1 概述1.2 硬件环境 2 数据集2.1 场景与结构2.2 数据结构2.2.1 images02.2.2 obs_dict.pkl2.2.3 policy_out.pkl 前言 按照笔者之前的行业经验, 数据集的整理是非常重要的, 因此笔者这里增加原文中出现的几个数据集和环境的学习 1 BridgeData V…...

【Ansible】基于windows主机,采用NTLM+HTTPS 认证部署
我们现在准备Linux centos7(Ansible控制机)和Windows(客户机)环境下的详细部署步骤: 一、Windows客户机配置 1. 准备SSL证书 1.1 生成自签名证书(测试用) 以管理员身份打开PowerShell&#…...
)
React19源码系列之 API(react-dom)
API之 preconnect preconnect – React 中文文档 preconnect 函数向浏览器提供一个提示,告诉它应该打开到给定服务器的连接。如果浏览器选择这样做,则可以加快从该服务器加载资源的速度。 preconnect(href) 一、使用例子 import { preconnect } fro…...

鸿蒙Next开发 获取APP缓存大小和清除缓存
1. 鸿蒙Next开发 获取APP缓存大小和清除缓存 1.1. 介绍 1.1.1. 文件系统分类 在最新的Core File Kit套件中,按文件所有者的不同。分为如下三类: (1)应用文件:文件所有者为应用,包括应用安装文件、应用…...
Python脚本 - 随笔)
PNG转ico图标(支持圆角矩形/方形+透明背景)Python脚本 - 随笔
摘要 在网站开发或应用程序设计中,常需将高品质PNG图像转换为ICO格式图标。本文提供一份基于Pillow库实现的,能够完美保留透明背景且支持导出圆角矩形/方形图标的格式转换脚本。 源码示例 圆角方形 from PIL import Image, ImageDraw, ImageOpsdef c…...

『大模型笔记』Langchain作者Harrison Chase专访:环境智能体与全新智能体收件箱
Langchain作者Harrison Chase专访:环境智能体与全新智能体收件箱 文章目录 摘要访谈内容什么环境智能体为什么要探索环境智能体怎么让人类能更方便地和环境智能体互动参考文献摘要 LangChain 的 CEO Harrison Chase 提出了_“环境智能体”(Ambient Agents)的概念,这是一种…...
GPT( Generative Pre-trained Transformer )模型:基于Transformer
GPT是由openAI开发的一款基于Transformer架构的预训练语言模型,拥有强大的生成能力和多任务处理能力,推动了自然语言处理(NLP)的快速发展。 一 GPT发展历程 1.1 GPT-1(2018年) 是首个基于Transformer架构…...

游戏引擎学习第275天:将旋转和剪切传递给渲染器
回顾并为今天的内容定下基调 我们认为在实现通用动画系统之前,先学习如何手写动画逻辑是非常有价值的。虽然加载和播放预设动画是合理的做法,尤其是在团队中有美术人员使用工具制作动画的情况下更是如此,但手动编写动画代码能让我们更深入理…...

conda 输出指定python环境的库 输出为 yaml文件
conda 输出指定python环境的库 输出为 yaml文件。 有时为了项目部署,需要匹配之前的python环境,需要输出对应的python依赖库。 假设你的目标环境名为 myenv,运行以下命令: conda env export -n myenv > myenv_environment.ym…...

ES6 语法
扩展运算符 … 口诀:三个点,打散数组,逐个放进去 例子: let arr [1, 2];let more [3, 4];arr.push(...more); // arr 变成 [1, 2, 3, 4]解构赋值 口诀:左边是变量,右边是值,一一对应 例子&…...
)
BFS算法篇——打开智慧之门,BFS算法在拓扑排序中的诗意探索(下)
文章目录 引言一、课程表1.1 题目链接:https://leetcode.cn/problems/course-schedule/description/1.2 题目分析:1.3 思路讲解:1.4 代码实现: 二、课程表||2.1 题目链接:https://leetcode.cn/problems/course-schedul…...

While语句数数字
import java.util.Scanner;public class Hello {public static void main(String[] args) {Scanner in new Scanner(System.in);int number in.nextInt();int count 0;while( number > 0 ){number number / 10;count count 1;}System.out.println(count);} }...

G1JVM内存分配机制详解
为什么堆内存不是预期的3G? 当您设置-XX:MaxRAMPercentage75时,JVM并不会简单地将容器内存(4G)的75%全部分配给堆,原因如下: 计算基准差异: 百分比是应用于"可用物理内存"而非"容器总内存" &q…...

“端 - 边 - 云”三级智能协同平台的理论建构与技术实现
摘要 随着低空经济与智能制造的深度融合,传统集中式云计算架构在实时性、隐私保护和资源效率上的瓶颈日益凸显。本文提出“端 - 边 - 云”三级智能协同平台架构,以“时空 - 资源 - 服务”三维协同理论为核心,构建覆盖终端感知、边缘计算、云端…...

【UAP】《Empirical Upper Bound in Object Detection and More》
Borji A, Iranmanesh S M. Empirical upper bound in object detection and more[J]. arXiv preprint arXiv:1911.12451, 2019. arXiv-2019 文章目录 1、Background and Motivation2、Related Work3、Advantages / Contributions4、Experimental Setup4.1、Benchmarks Dataset…...
介绍)
Web Service及其实现技术(SOAP、REST、XML-RPC)介绍
一.概述 1.Web Service(Web 服务) Web Service 由万维网联盟 (W3C) 定义为一种软件系统,旨在支持通过网络进行可互操作的计算机间交互。 广义概念:基于 Web 技术(如 HTTP 协议)的跨平台、跨语言通信机制…...

基于Spring Boot+Layui构建企业级电子招投标系统实战指南
一、引言:重塑招投标管理新范式 在数字经济浪潮下,传统招投标模式面临效率低、透明度不足、流程冗长等痛点。本文将以Spring Boot技术生态为核心,融合Mybatis持久层框架、Redis高性能缓存及Layui前端解决方案,构建一个覆盖招标代理…...

【嵌入式】记一次解决VScode+PlatformIO安装卡死的经历
PlatformIO 是开源的物联网开发生态系统。提供跨平台的代码构建器、集成开发环境(IDE),兼容 Arduino,ESP8266和mbed等。 开源库地址:https://github.com/platformio 在 VScode 中配置 PlatformIO 插件,记录…...

抗量子计算攻击的数据安全体系构建:从理论突破到工程实践
在“端 - 边 - 云”三级智能协同理论中,端 - 边、边 - 云之间要进行数据传输,网络的安全尤为重要,为了实现系统总体的安全可控,将构建安全网络。 可先了解我的前文:“端 - 边 - 云”三级智能协同平台的理论建构与技术实…...

【FMMT】基于模糊多模态变压器模型的个性化情感分析
遇到很难的文献看不懂,不应该感到气馁,应该激动,因为外审估计也看不太懂,那么学明白了可以吓唬他 缺陷一:输入依赖性与上下文建模不足 缺陷描述: 传统自注意力机制缺乏因果关系,难以捕捉序列历史背景多模态数据间的复杂依赖关系未被充分建模CNN/RNN类模型在…...
)
力扣Hot100(Java版本)
1. 哈希 1.1 两数之和 题目描述: 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同…...

Stream流简介、常用方法
Stream流的三类方法 获取Stream流 创建一条流水线,并把数据放到流水线上准备进行操作 中间方法 流水线上的操作一次操作完毕之后,还可以继续进行其他操作 终结方法 一个Stream流只能有一个终结方法是流水线上的最后一个操作 生成Stream流的方式 Collec…...

C# 集成 FastDFS 完整指南
1. 环境准备 (1) 安装 FastDFS 服务端 部署 Tracker 和 Storage 节点,确保服务正常运行。 配置 tracker_server 地址(如 192.168.1.100:22122)。 (2) 添加 NuGet 包 通过 NuGet 安装 FastDFS 客户端库: Install-Pack…...

重构门店网络:从“打补丁“到“造地基“的跨越
您是否遇到过这样的窘境? 新店开张要等一周,就为装根网线; 偏远地区门店三天两头断网,顾客排长队却结不了账; 总部想看实时数据,结果收到一堆乱码报错; 总部ERP系统升级,2000家门…...

TI的ADS1291代替芯片LH001-99
血管疾病严重威胁人类生命健康安全,随着人口老龄化进程的加快和社会压力等因素的增加,患病率正呈现逐年上升趋势,并且越来越年轻化。然而,心血管疾病大多由器官器质性病变引起,一旦患病很难完全康复,需要进…...

NPOI 操作 Word 文档
管理 NuGet 程序包 # word操作 NPOI# 图片操作 SkiaSharp Controller代码 using Microsoft.AspNetCore.Mvc; using NPOI.Util; using NPOI.XWPF.Model; using NPOI.XWPF.UserModel; using SkiaSharp;namespace WebApplication2.Controllers {[Route("api/Npoi/[action]…...

css3基于伸缩盒模型生成一个小案例
css3基于伸缩模型生成一个小案例 在前面学习了尚硅谷天禹老师的css3内容后,基于伸缩盒模型做的一个小案例,里面使用了 flex 布局,以及主轴切换,以及主轴平分等特性,分为使用css3 伸缩盒模型方式,已经传统的…...

精简大语言模型:用于定制语言模型的自适应知识蒸馏
Streamlining LLMs: Adaptive Knowledge Distillation for Tailored Language Models 发表:NAACL 2025 机构:德国人工智能研究中心 Abstract 诸如 GPT-4 和 LLaMA-3 等大型语言模型(LLMs)在多个行业展现出变革性的潜力…...

Rollup入门与进阶:为现代Web应用构建超小的打包文件
我们常常面临Webpack复杂配置或是Babel转译后的冗余代码,结果导致最终的包体积居高不下加载速度也变得异常缓慢,而在众多打包工具中Rollup作为一个轻量且高效的选择,正悄然改变着这一切,本文将带你深入了解这个令人惊艳的打包工具…...
)
博客系统技术需求文档(基于 Flask)
以下内容是AI基于要求生成的技术文档,仅供参考~ 🧱 一、系统架构设计概览 层级 内容 前端层 HTML Jinja2 模板引擎,集成 Markdown 编辑器、代码高亮 后端层 Flask 框架,RESTful 风格,Jinja2 渲染 数据库 SQLi…...

快速排序、归并排序、计数排序
文章目录 前言一、归并排序算法逻辑递归实现非递归实现 二、快速排序算法介绍递归实现非递归实现算法的一种优化—三路划分法 四、计数排序算法原理代码实现优劣分析 五、排序算法的性能比较总结 前言 本文介绍这三种非常强大的排序算法,每种算法都有各自的特点、不…...

python语言与地理处理note 2025/05/11
1. 函数定义必须要在调用之前 (1)正确示例: def test():print("what a wonderful world!")test() (2)错误示例: test() def test():print("what a wonderful world!") 会报错&…...

贪心算法:最小生成树
假设无向图为: A-B:1 A-C:3 B-C:1 B-D:4 C-D:1 C-E:5 D-E:6 一、使用Prim算法: public class Prim {//声明了两个静态常量,用于辅助 Prim 算法的实现private static final int V 5;//点数private static final int INF Integer.MA…...

免费 OCR 识别 + 批量处理!PDF 工具 提升办公效率
各位办公小能手们!今天给你们介绍一款超厉害的软件——PDF工具V2.2!我跟你们说,这玩意儿就像是PDF界的超级英雄,专门搞定PDF文件的编辑、转换、压缩这些事儿。 先说说它的核心功能哈。基础文档管理方面,它能把好几个PD…...
)
尼康VR镜头防抖模式NORMAL和ACTIVE的区别(私人笔记)
1. NORMAL 模式(常规模式) 适用场景:一般手持拍摄,比如人像、静物、风景或缓慢平移镜头(如水平追拍)等。工作特性: 补偿手抖引起的小幅度震动(比如手持时自然的不稳)&am…...

在scala中sparkSQL读入csv文件
以下是 Scala 中使用 Spark SQL 读取 CSV 文件的核心步骤和代码示例(纯文本): 1. 创建 SparkSession scala import org.apache.spark.sql.SparkSession val spark SparkSession.builder() .appName("Spark SQL Read CSV") …...

swift flask python ipad当电脑键盘 实现osu x键和z键 长按逻辑有问题 quart 11毫秒
键盘不行我5星都打不过,磁轴不在身边 127.0.0.1不行要用192.168哪个地址 from flask import Flask from pynput.keyboard import Controller from threading import Threadapp Flask(__name__) keyboard Controller()# 按下按键 app.route("/press_down/<…...

浅论3DGS溅射模型在VR眼镜上的应用
摆烂仙君小课堂开课了,本期将介绍如何手搓VR眼镜,并将随手拍的电影变成3D视频。 一、3DGS模型介绍 3D 高斯模型是基于高斯函数构建的用于描述三维空间中数据分布概率的模型,高斯函数在数学和物理领域有着广泛应用,其在 3D 情境下…...

React状态管理-对state进行保留和重置
相同位置的相同组件会使得 state 被保留下来 当你勾选或清空复选框的时候,计数器 state 并没有被重置。不管 isFancy 是 true 还是 false,根组件 App 返回的 div 的第一个子组件都是 <Counter />: 你可能以为当你勾选复选框的时候 st…...

嵌入式STM32学习——外部中断EXTI与NVIC的基础练习⭐
按键控制LED灯 按键控制LED的开发流程: 第一步:使能功能复用时钟 第二布,配置复用寄存器 第三步,配置中断屏蔽寄存器 固件库按键控制LED灯 外部中断EXTI结构体:typedef struct{uint32_t EXTI_Line; …...

git merge和git rebase
git merge和git rebase 在Git中merge和rebase都是git在管理整合分支的两种主要工具,但是他们的工作方式、提交历史影响和使用场景不同。 git merge 定义 将两个分支的提交历史合并,创建一个新的合并提交(merge commit)ÿ…...

我的MCP相关配置记录
1.VSCode的Cline中的MCP {"mcpServers": {"github.com/modelcontextprotocol/servers/tree/main/src/github": {"autoApprove": [],"disabled": false,"timeout": 60,"command": "cmd","args&quo…...

浅聊一下数据库的索引优化
背景 这里的索引说的是关系数据库(MSSQL)中的索引。 本篇不是纯技术性的内容,只是聊一次性能调优的经历,包含到一些粗浅的实现和验证手段,所以,大神忽略即可。 额…对了,笔者对数据库的优化手段…...

如何创建maven项目
1.IDEA 中创建 Maven 项目 步骤一:点击 File -> New -> Project,在弹出的窗口左侧选择 Maven,点击 Next: 步骤二:填写项目的 GroupId、ArtifactId、Version 等信息(这些对应 pom.xml 中的关键配置&am…...

LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
一、引言 在自然语言处理领域,大规模预训练语言模型(LLMs)展现出强大的语言理解和生成能力。然而,将这些模型适配到多个下游任务时,传统微调方法面临诸多挑战。LoRA(Low-Rank Adaptation of Large Language Models)作为一种创新的微调技术,旨在解决这些问题,为大语言…...

Conda在powershell终端中无法使用conda activate命令
主要有以下原因: Windows PowerShell安全策略:默认情况下,PowerShell的执行策略设置为"Restricted",这会阻止运行脚本,包括conda的初始化脚本。调用方式不同:在PowerShell中,需要使用…...

MySQL索引底层数据结构与算法
1、索引的数据结构 1.1、二叉树 1.2、红黑树(二叉平衡树) 1.3、hash表 对key进行一次hash计算就可以定位出数据存储的位置 问题:hash冲突问题、仅满足和in的查找,不支持范围查找 1.4、B-tree 1.5、B tree 非叶子节点不存储data&…...