快速排序、归并排序、计数排序
文章目录
- 前言
- 一、归并排序
- 算法逻辑
- 递归实现
- 非递归实现
- 二、快速排序
- 算法介绍
- 递归实现
- 非递归实现
- 算法的一种优化—三路划分法
- 四、计数排序
- 算法原理
- 代码实现
- 优劣分析
- 五、排序算法的性能比较
- 总结
前言
本文介绍这三种非常强大的排序算法,每种算法都有各自的特点、不同的实现方式和优化。其算法在效率和数据处理等等方面都非常的强大。
一、归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。它是将已经有序的子序列合并,得到完全有序的序列。
算法逻辑
归并排序的算法逻辑其实是很直接的,就是将待排序列不断的二分,二分至只有一个元素的子序列(视为有序),然后使有序的子序列之间有序,不断的把有序的子序列合并为有序的更大子序列,直至整个子序列有序,这就是归并的操作,像这样将两个有序序列合并为一个有序序列,称为二路归并。
归并排序的重点在于需要先二分,然后再归并,而二分之中,需要考虑序列的长度,同时如何先从二分至只剩一个元素的最小序列入手,这里我想我们应该能想到用递归去实现,当然,也有非递归的方法,只不过会用到更复杂一些的思路,并不是那么好想出来的。而归并的操作中,我们将有序序列合并,为了提高效率,可以用空间换时间,用一个新的空间接受子序列里的有效值,然后使得该空间内数据都是有序的,这样能够提高效率。
这里有一张图,可以让大家更直观的了解其原理:
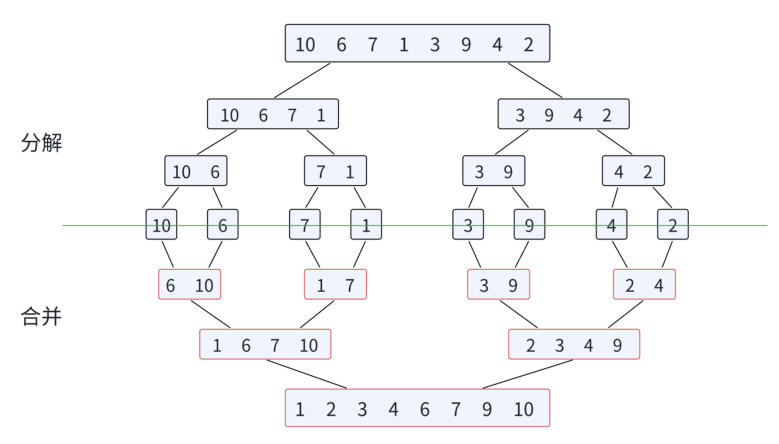
递归实现
递归是最好想的方法,这里我们直接上代码:
void _Mergesort(int* arr,int left,int right,int* tem)//参数分别是两个数组,以及子序列的左右边界
{if(left>=right)//递归的终止条件,二分划分到最小子序列{return;}int mid = (left + right)/2;//找到中间值,完成二分_Mergesort(arr,left,mid,tem);//开始递归_Mergesort(arr,mid+1,right,tem);int begin1 = left,end1 = mid;//合并两个有序序列int begin2 = mid + 1,end2 = right;int index = begin1;while(begin1 <= end1 && begin2 <= end2)//将两个有序序列合并之后,放到对应区间使有序{if(arr[begin1] < arr[begin2])tem[index++] = arr[begin1++];elsetem[index++] = arr[begin2++];}while(begin1 <= end1){tem[index++] = arr[begin1++];}while(begin2 <= end2){tem[index++] = arr[begin2++];}for(int i = left;i < right;i++)//将有序的序列导入到原数组里去{arr[i] = tem[i];}
}void Mergesort(int* arr,int n)
{int* tem = (int*)malloc(sizeof(int)*n)//开辟一个新空间,用于接收有序的合并序列_Mergesort(arr,0,n-1,tem);再用一个函数,方便完成递归free(tem);//释放动态开辟的空间tem = NULL;
}
- 时间复杂度分析
归并排序算法里出现了递归,我们首先来计算一下单次递归的时间复杂度,由于归并排序是将数组不断地二分,单次递归会对每一个子序列排序,单次的时间复杂度为O(N),而对于整个递归,我们要log2N次,转化为时间复杂度就是logN,所以整体的时间复杂度就是O(N*logN)。这也是一个相当强大的排序,当然,它的空间复杂度为O(N),这是它效率的代价,要消耗一模一样大的空间来辅助排序。
非递归实现
对于归并的二路划分,递归是一个非常好想的思路,而对于非递归的版本,我们一样是有方法的,只是这个思路比较难想到,也比较的妙。下面我就来介绍一下。
-
实现逻辑
上文有讲述过归并排序这个算法的根本逻辑,也就是二分为一个个的子序列,使得子序列有序,再合并子序列。那么上面的递归版算法使用递归也就是为了找到这一个个的子序列一一的排序合并使得序列最终有序。那么我们只需要用另一种方式找到这些子序列,从最小的开始一一排序合并即可取代递归。
既然是找序列,其实也就是找区间,我们对于子序列的排序等等操作其实都是一样的。那么可以用一个gap值代表区间的长度,然后对每一个被“划分“出来的子序列区间都进行同样排序合并操作,然后在让gap这个区间长度值每一次都乘2,得到更大一些的子序列,再合并……直到最终有序。也就是逆向的倍增区间大小,略过了二分的过程。 -
话不多说,直接上代码:
void Mergesort(int* arr,int n)
{int* tem = (int*)malloc(sizeof(int)*n);if(tem == NULL){perror("malloc fail!");exit(1);}int gap = 1;while(gap<n)//外层循环,控制子序列区间大小,二分找子序列{ //一次要完成两个数组的有序合并,一次要跳过两个子序列for(int i = 0;i < n;i += 2*gap)//内层循环,遍历整个序列,把所有的子序列都操作一边{int begin1 = i, end1 = i + gap - 1;//第一个区间int begin2 = i + gap, end2 = i + 2*gap - 1;if(bedin2 >= n)//第二个区间有可能越界:数组大小为奇数时{break;} if(end2 >= n)//第二个区间的末尾会出界,要作调整{end2 = n - 1;}int index = begin1;while(begin1 <= end1 && begin2 <= end2)//还是将两个有序序列合并之后,放到对应区间使有序{if(arr[begin1] < arr[begin2])tem[index++] = arr[begin1++];elsetem[index++] = arr[begin2++];}while(begin1 <= end1){tem[index++] = arr[begin1++];}while(begin2 <= end2){tem[index++] = arr[begin2++];}//for(int i = left;i < right;i++)//将有序的序列导入到原数组里去//{// arr[i] = tem[i];//} //这是找正确的位置 //这是区间长度memcpy(arr + i,tem + i,sizeof(int) * (end2 - i + 1));//省个事用拷贝库函数直接拷贝导入}gap *= 2;//调整区间长度,找到上一级子序列。}
}
非递归版本虽然操作不一样,但是时间复杂度还是O(N*logN),外部循环每次二倍增加,内部循环还是O(N),所以时间复杂度没变。
二、快速排序
算法介绍
快速排序是一个很有名的排序算法,被C和C++都采用为库函数中标准排序算法的底层代码,快速排序顾名思义它确实很“快”,效率很高。历史上于1962年由Hoare首先提出,是一种基于二叉树结构的交换排序算法,后续有许多大佬对这个算法有过优化,基于其根本思想有多种不同的实现方法。快速排序的根本思想是:任取待排序元素序列的中的某元素作为基准值,按照该基准值将待排序集合分割为两个子序列,每个子序列均大于或小于基准值,然后将每个子序列看作单独的序列重复该操作,直到所有元素都排列在相应位置上为止。这个算法的唯一特殊之处在于如何找基准值,快速排序有多种版本也是区别在于如何更好的取这个基准值,如最开始的Hoare版本和后来更好一些的lomuto前后指针法。但整体这个算法依旧是非常高效的算法。下面我来一一具体阐述。
递归实现
-
Hoare版本算法
- Hoare版的算法逻辑:
Hoare版的算法中利用递归实现分割子序列,而找基准值的方法是:直接取最左边的数据令为基准值,取剩下的序列的最左右的值作为一个 “指针”(看作指向这个数据的下标)从左右往中心遍历数组,对于排升序的情况:左“指针”找比基准值小的数据,右“指针”找比基准值大的数据,各自找到之后,将左右指针对应的数据作交换,两“指针”按原路线继续往下遍历,当左指针>右指针时,把基准值对应数据和右指针作交换,完成分割。接下来就是递归,重复操作直至完成排序。
- Hoare代码实现
int Findkey(int* arr,int left,int right)//额外写一个找基准值的函数,完成找基准值和分割序列的工作 {int key = left;++left;//左右两侧开始遍历while(left <= right)//开始调整序列分割{if(left<=right && arr[left] < arr[key])//还是排升序,这是在确定左右要交换的数据{left++;}if(left<=right && arr[right] > arr[key]){right--;}if(left<=right){swap(&arr[left++],&arr[right--]);//交换完之后记得继续往下遍历}swap(&arr[right],&arr[key]);//最后交换基准值完成分割} return right;//right下标才是作分割的位置 } void Quicksort(int* arr,int left,int right)//这里主函数参数不同了,要取序列左右下标值完成分割 {if(left >= right){return;}int key = Findkey(arr,left,right);//找基准值的下标Quicksort(arr,left,key - 1);//从key这里开始分割Quicksort(arr,key + 1,right); } - Hoare版的算法逻辑:
-
lomuto前后指针法
-
算法逻辑
lomuto前后指针法基于快速排序的根本思想,提出了一种新的找基准值的方法:创建前后指针,从左往右找比基准值小的进行交换(升序情况),使得比基准值小的都排在基准值的左边。比如我们创建两个“指针”,一个prev,一个cur,先找最左边的作为基准值,prev等于最左端的下标,cur初始时比prev要大一,让cur在前面“探路”找比基准值要小的数据,找到之后,先将prev加1,再将prev和cur指针对应的数据交换,然后让cur继续往前走,没有找到就往前走直到找到为止。最后就得到了分割好的两个子序列,继续递归重复这个操作,快速排序就完成了。 -
lomuto前后指针实现
void Findkey(int* arr,int left,int right) {int key = left;int prev = left + 1,cur = prev + 1;while(cur <= right){if(arr[cur] < arr[key] && ++prev != cur)//相等的话就是自己跟自己调位置,没必要{swap(&arr[prev],&arr[cur]);}cur++;}swap(&arr[key],&arr[prev]);return prev; } void Quicksort(int* arr,int left,int right) {if(left >= right){return;}int key = Findkey(arr,left,right);Quicksort(arr,left,key - 1);Quicksort(arr,key + 1,right); } -
-
时间复杂度分析
快速排序的原理是每次找基准值同时遍历对应的序列完成调整,然后是分割递归,其实这跟归并的时间复杂度计算情况有点类似,每次递归的时间复杂度是O(N),递归还是O(logN),所以时间复杂度还是O(N*logN)。
非递归实现
快速排序的实现是从最开始的序列开始调整分割,然后从左至右对分割出来的每个序列再次分割调整,具有一定的顺序性才能正确完成排序。递归是存在顺序的,它先递推再回归,那么如果不用递归实现,那么就可以利用栈这个数据结构,每一次将分割出来的两个序列的左右边界入栈,然后取栈顶取到要调整分割的序列边界,不断重复直到调整完成。
现在我们来实现一下这个代码,由于要使用栈这个数据结构,在C语言阶段还需要额外实现栈这个数据结构然后利用栈的各种操作来完成算法,这里作者直接默认包含了一个栈相关操作的头文件,是跟我之前那篇栈文章的实现代码,大家如果不知道可以去看看 ^ V ^
#include"Stack.h"void Quicksort(int* arr,int left,int right)
{ST st;//创建一个栈STinit(&st);STPush(&st,left);STPush(&st,right);while(!STEmpty(&st)){int end = STTop(&st);//取栈顶两次,拿到左右边界,记得先取的是右边界STPop(&st);int begin = STTop(&st);STPop(&st);int key = begin;//在[begin,end]里调整分割int prev = begin,cur = prev + 1;//用一下lomuto前后指针法while(cur <= end){if(arr[cur] < arr[key] && ++prev != cur){swap(&arr[cur],&arr[prev]);}cur++;}swap(&arr[prev],&arr[key]);key = prev;//把左右序列都入栈,注意先右后左入栈,这样就先取到左序列开始调整if(key + 1 < end)//确保有效序列{STPush(&st,key + 1);STPush(&st,end);} if(begin < key - 1){STPush(&st,begin);STPush(&st,key - 1);}}STDestroy(&st)
}
算法的一种优化—三路划分法
-
快速排序算法性能的探讨
快速排序效率的关键影响因素就是key这个基准值,每一趟排序之后,key对于序列的分割如果是基本二分居中,那么效率将会最大化,当然实际中的情况并不太可能每次都二分居中,但有偏差性能也都是可控的,基本没什么波动。但如果是每次都取到最大最小值,那么排序就将变成双层循环,性能快速的退化到O(N^2),这是很可怕的,另一种情况是数据中存在大量的和基准值相等的数据,那么也相当的影响效率,这里用一种优化算法来处理也就是三路划分法。 -
算法思想:
为了让相同值不再影响,我们把相同值放在中间,然后再次划分左右两边的子序列。也就是这里的快速排序不再是仅仅划分两个子序列,而是将数据划分成三个部分。首先基准值key还是默认取最左侧值,类似lomuto前后指针法,定义left变量指向区间最左边,right变量指向区间最右边,cur初始指向left+1的位置。遇到比基准值小的和left交换,left和cur均++,遇到比基准值大的就与right交换,同时仅需right-1(因为cur值从左往右遍历),遇到和基准值相等的就直接让cur往前走。直至完成排序。 -
代码实现
void Quicksort(int* arr,int n)
{if (left >= right) {return;}int begin = left;int end = right;int randi = left + (rand() % (right - left + 1));//随机选值作为基准值,减少取到极值的可能性Swap(&arr[left], &arr[randi]);int key = arr[left];int cur = left + 1;while (cur <= right){if (arr[cur] < key){Swap(&arr[cur], &arr[left]);cur++;left++;}else if (arr[cur] > key){Swap(&arr[cur], &arr[right]);right--;}else{cur++;}}Quicksort(arr, begin, left - 1);Quicksort(arr, right + 1, end);
}
- 三路划分法对于数据重复的情况下效率依旧可以保持,但是对于其他情况还是一般,总体来说还是只是算法的一种优化,能够应对特殊的情况。但是快速排序依旧不能够完全的凭借本身的算法面对所有问题,所以在C++中,库虽然采用了快速排序作为标准排序算法,但当快速排序的递归进程过深(即时间复杂度快速升高,性能退化)的时候会自动的转向堆排序完成排序任务。当然,现实情况中肯定不会时刻都在处理特殊情况,它毋庸置疑还是一个非常强大的排序算法。
四、计数排序
前面文章讲解了归并排序和快速排序以及他们的几种实现代码,包括本文的前一篇文章也讲解了其他四种排序,这七种排序算法其实在更大的范围内可以归为同一类,称为比较排序,因为他们都是通过值的比较来完成排序的。而接下来这种排序算法则不同,它是非比较排序。那么接下来我们就来了解一下计数排序。
算法原理
计数排序又称为鸽巢原理,是哈希直接定址法的变形应用。它只有两步基本操作:
1)统计相同元素出现的个数,
2)根据统计的结果将序列回收到原来的序列中。
当然这是比较官方的话语,我们展开来讲:
首先我们直到,数组有下标,有序。那么我们就来利用这个下标:我们找出待排序序列的最大值,开一段空间,要开到下标有最大值为止,然后将数据化为下标,在数组里统计存储下标(数据)出现的次数,然后将所有数据按照出现的次数从左到右按顺序存入到原序列里,这样就完成了排序。这是典型的以空间换时间的操作(毕竟相比于现在的空间资源,效率还是更宝贵一些)
基本原理讲完了,但是这里有个问题还需要解决:首先,我们以空间换时间是效率的来源,那么我们到底要开多大的空间是一个问题,假如我们就取最大值作为空间大小,然后像内存要一个这么大的空间,万一数据都非常大而且都非常紧凑呢?难道前面那些没有用的空间就这么浪费了吗?我们有丰富的空间资源但是也不是这么浪费的。所以,我们可以同时找最小值,这样我们就确定了数据范围,只需要max - min + 1这么大的空间就足以胜任排序工作,这就使得空间利用率也达到最大,最后导入数据的时候也只需要加上min值就得到了原数据。
代码实现
原理明白了,那么就来实践一下代码:
void Countsort(int* arr,int n)
{int max = arr[0],min = arr[0];//第一次遍历数组,找最值for(int i = 1;i < n;i++){if(arr[i] < min){min = arr[i];}if(arr[i] > max){max = arr[i];}}int size = max - min + 1;//计算数据范围确定空间大小(后续计算时间复杂度也会用到)int* tem = (int*)malloc(sizeof(int)*size);//开辟空间统计数据if(tem == NULL){perror("malloc fail!");exit(1);}memset(tem,0,sizeof(int)*size);//将数组初始化为0,便于统计次数for(int i = 0;i < n;i++)//遍历原数组,统计次数{tem[arr[i] - min]++;//数据作为下标,让次数增长}int index = 0;//导入数据的一个下标表示for(int i = 0;i < size; i++){while(tem[i]--){arr[intdex++] = i + min;//导入原数据}}
}
优劣分析
-
优势
计数排序用到了一个非常精妙的思想,了解了算法之后可以说完全没有难度,代码的实现相信是非常简单易懂的。从时间复杂度的角度来分析,计数排序的几个循环均为单层循环,最后的双层循环本质就是遍历一边原数组导入排序完毕的数据,所以本质还是单层循环,但次数为size。那么区别仅在于这个size的值,也就是总体的时间复杂度为O(N+size)。那么如果size的值相对较小,则计数排序将获得 非常接近于O(N) 的时间复杂度,这是一个非常恐怖的效率!又超越了前面几个强大算法一个档次! -
劣势
- 虽然计数排序的时间复杂度较高,但是确实是空间换时间换来的,不可避免会存在较大一些的空间损耗,这就是其中一个劣势之处,甚至有可能造成很大的空间资源浪费,虽然我们做出过改进尽可能优化了空间利用率,但数据的不同还是会造成这样的结果,比如最大值和最小值相差很大但是数据分布不均匀的情况,这一定会使得大量的空间只能被浪费。
- 同样的,计数排序的利用数组下标的思想很精妙,但这也成了它的局限性,上文推导过时间复杂度为O(N+size),我们知道在size 较小时,可以达到O(N),那么反过头来,size很大呢? 和空间大小挂钩即和数据本身有关这就带来了不确定和局限性,使得计数排序并不能适用于所有场景。不过在整数、范围相对较小、数据分布较密集时,它依旧拥有极高的效率,而对于浮点数、范围极大、稀疏分布或负数较多的情况应避免使用,可能会出现无法使用或效率下降(不如堆排序等)的情况。
五、排序算法的性能比较
作者在近两篇文章中讲述了七种排序算法,这里作者想额外的呈现一些东西,我来实现一个小的代码直观的比较一下几个算法的效率对比,比较的代码原码我直接放在下面,这里我是利用随机数生成,生成了八个一模一样的随机整形数组,数据量为100000个,范围也在100000以内,我还额外的添加了一个冒泡排序算法(时间复杂度为O(N^2))来作一个对比。我将八种算法在我的电脑VS2022上运行,结果是每个排序所用时间值,单位是毫秒(ms)
这里是计算时间的代码:
#include<"time.h">
/.../
void TestOP()
{srand(time(NULL));const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);int* a8 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];a7[i] = a1[i];a8[i] = a1[i];}int begin1 = clock();Insertsort(a1, N);int end1 = clock();int begin2 = clock();Shellsort(a2, N);int end2 = clock();int begin3 = clock();Selectsort(a3, N);int end3 = clock();int begin4 = clock();Heapsort(a4, N);int end4 = clock();int begin5 = clock();QuickSort(a5, 0, N - 1);int end5 = clock();int begin6 = clock();Mergesort(a6, N);int end6 = clock();int begin7 = clock();BubbleSort(a7, N);int end7 = clock();int begin8 = clock();Countsort(a8, N);int end8 = clock();printf("插入排序:%d\n", end1 - begin1);printf("希尔排序:%d\n", end2 - begin2);printf("选择排序:%d\n", end3 - begin3);printf("堆排序:%d\n", end4 - begin4);printf("快速排序:%d\n", end5 - begin5);printf("归并排序:%d\n", end6 - begin6);printf("冒泡排序:%d\n", end7 - begin7);printf("计数排序:%d\n", end8 - begin8);free(a1);free(a2);free(a3);free(a4);free(a5);free(a6);free(a7);free(a8);
}
我连续运行了三次,结果如下:



这个数据似乎刚好比较符合计数排序的要求,无论怎么样都是小于等于1ms,秒杀全场。而标准的O(N^2)的冒泡排序则稳定20秒左右,效率的差距可见一斑。
总结
本文讲解了三个排序算法,也总结了几大排序算法的效率性能,希望能让大家了解什么是一个好的排序算法以及一个好的算法。
相关文章:

快速排序、归并排序、计数排序
文章目录 前言一、归并排序算法逻辑递归实现非递归实现 二、快速排序算法介绍递归实现非递归实现算法的一种优化—三路划分法 四、计数排序算法原理代码实现优劣分析 五、排序算法的性能比较总结 前言 本文介绍这三种非常强大的排序算法,每种算法都有各自的特点、不…...

python语言与地理处理note 2025/05/11
1. 函数定义必须要在调用之前 (1)正确示例: def test():print("what a wonderful world!")test() (2)错误示例: test() def test():print("what a wonderful world!") 会报错&…...

贪心算法:最小生成树
假设无向图为: A-B:1 A-C:3 B-C:1 B-D:4 C-D:1 C-E:5 D-E:6 一、使用Prim算法: public class Prim {//声明了两个静态常量,用于辅助 Prim 算法的实现private static final int V 5;//点数private static final int INF Integer.MA…...

免费 OCR 识别 + 批量处理!PDF 工具 提升办公效率
各位办公小能手们!今天给你们介绍一款超厉害的软件——PDF工具V2.2!我跟你们说,这玩意儿就像是PDF界的超级英雄,专门搞定PDF文件的编辑、转换、压缩这些事儿。 先说说它的核心功能哈。基础文档管理方面,它能把好几个PD…...
)
尼康VR镜头防抖模式NORMAL和ACTIVE的区别(私人笔记)
1. NORMAL 模式(常规模式) 适用场景:一般手持拍摄,比如人像、静物、风景或缓慢平移镜头(如水平追拍)等。工作特性: 补偿手抖引起的小幅度震动(比如手持时自然的不稳)&am…...

在scala中sparkSQL读入csv文件
以下是 Scala 中使用 Spark SQL 读取 CSV 文件的核心步骤和代码示例(纯文本): 1. 创建 SparkSession scala import org.apache.spark.sql.SparkSession val spark SparkSession.builder() .appName("Spark SQL Read CSV") …...

swift flask python ipad当电脑键盘 实现osu x键和z键 长按逻辑有问题 quart 11毫秒
键盘不行我5星都打不过,磁轴不在身边 127.0.0.1不行要用192.168哪个地址 from flask import Flask from pynput.keyboard import Controller from threading import Threadapp Flask(__name__) keyboard Controller()# 按下按键 app.route("/press_down/<…...

浅论3DGS溅射模型在VR眼镜上的应用
摆烂仙君小课堂开课了,本期将介绍如何手搓VR眼镜,并将随手拍的电影变成3D视频。 一、3DGS模型介绍 3D 高斯模型是基于高斯函数构建的用于描述三维空间中数据分布概率的模型,高斯函数在数学和物理领域有着广泛应用,其在 3D 情境下…...

React状态管理-对state进行保留和重置
相同位置的相同组件会使得 state 被保留下来 当你勾选或清空复选框的时候,计数器 state 并没有被重置。不管 isFancy 是 true 还是 false,根组件 App 返回的 div 的第一个子组件都是 <Counter />: 你可能以为当你勾选复选框的时候 st…...

嵌入式STM32学习——外部中断EXTI与NVIC的基础练习⭐
按键控制LED灯 按键控制LED的开发流程: 第一步:使能功能复用时钟 第二布,配置复用寄存器 第三步,配置中断屏蔽寄存器 固件库按键控制LED灯 外部中断EXTI结构体:typedef struct{uint32_t EXTI_Line; …...

git merge和git rebase
git merge和git rebase 在Git中merge和rebase都是git在管理整合分支的两种主要工具,但是他们的工作方式、提交历史影响和使用场景不同。 git merge 定义 将两个分支的提交历史合并,创建一个新的合并提交(merge commit)ÿ…...

我的MCP相关配置记录
1.VSCode的Cline中的MCP {"mcpServers": {"github.com/modelcontextprotocol/servers/tree/main/src/github": {"autoApprove": [],"disabled": false,"timeout": 60,"command": "cmd","args&quo…...

浅聊一下数据库的索引优化
背景 这里的索引说的是关系数据库(MSSQL)中的索引。 本篇不是纯技术性的内容,只是聊一次性能调优的经历,包含到一些粗浅的实现和验证手段,所以,大神忽略即可。 额…对了,笔者对数据库的优化手段…...

如何创建maven项目
1.IDEA 中创建 Maven 项目 步骤一:点击 File -> New -> Project,在弹出的窗口左侧选择 Maven,点击 Next: 步骤二:填写项目的 GroupId、ArtifactId、Version 等信息(这些对应 pom.xml 中的关键配置&am…...

LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
一、引言 在自然语言处理领域,大规模预训练语言模型(LLMs)展现出强大的语言理解和生成能力。然而,将这些模型适配到多个下游任务时,传统微调方法面临诸多挑战。LoRA(Low-Rank Adaptation of Large Language Models)作为一种创新的微调技术,旨在解决这些问题,为大语言…...

Conda在powershell终端中无法使用conda activate命令
主要有以下原因: Windows PowerShell安全策略:默认情况下,PowerShell的执行策略设置为"Restricted",这会阻止运行脚本,包括conda的初始化脚本。调用方式不同:在PowerShell中,需要使用…...

MySQL索引底层数据结构与算法
1、索引的数据结构 1.1、二叉树 1.2、红黑树(二叉平衡树) 1.3、hash表 对key进行一次hash计算就可以定位出数据存储的位置 问题:hash冲突问题、仅满足和in的查找,不支持范围查找 1.4、B-tree 1.5、B tree 非叶子节点不存储data&…...

GOOSE 控制块参数gocbRef及goID有大小写要求
在 IEC 61850 标准中,GOOSE 控制块参数gocbRef和goID的大小写是严格区分的。这一结论基于以下多维度分析: 一、标准协议与配置文件的强制性 XML 语法的刚性约束 GOOSE 控制块的配置信息通过 SCL(Substation Configuration Languageÿ…...

重庆医科大学附属第二医院外科楼外挡墙自动化监测
1.项目概述 重庆医科大学附属第二医院,重医附二院,是集医疗、教学、科研、预防保健为一体的国家三级甲等综合医院。前身为始建于1892年的“重庆宽仁医院”。医院现有开放床位 1380张,年门诊量超过百万人次,年收治住院病人4.5万人…...

3.4 数字特征
本章系统讲解随机变量的数字特征理论,涵盖期望、方差、协方差与相关系数的核心计算与性质。以下从四个核心考点系统梳理知识体系: 考点一:期望(数学期望) 1. 离散型随机变量的数学期望 一维情形: E ( X …...

servlet-api
本次内容总结 1、再次学习Servlet的初始化方法 2、学习Servlet中的ServletContext和<context-param> 3、什么是业务层 4、IOC 5、过滤器 7、TransActionManager、ThreadLocal、OpenSessionInViewFilter 1、再次学习Servlet的初始化方法 1)Servlet生命周期&…...

NLTK进行文本分类和词性标注
《python ⾃然语⾔处理实战》学习笔记 NLTK 下载依赖 !pip install nltkimport nltk nltk.download(punkt_tab)分词(tokenize) from nltk.tokenize import word_tokenize from nltk.text import Textinput_str """Twinkle, twinkle, little star, How I won…...
 电机驱动的本质分析以及与磁相关的使用场景)
电机控制储备知识学习(一) 电机驱动的本质分析以及与磁相关的使用场景
目录 电机控制储备知识学习(一)一、电机驱动的本质分析以及与磁相关的使用场景1)电机为什么能够旋转2)电磁原理的学习重要性 二、电磁学理论知识1)磁场基础知识2)反电动势的公式推导 附学习参考网址欢迎大家…...

华三路由器单臂路由配置
目录 1.实验目的1.1 掌握华三路由器单臂路由配置方法2.1 路由器连接交换机,交换机划分多个 VLAN,不同 VLAN 的 PC 通过路由器实现通信 配置步骤与命令解析1.配置交换机2.配置路由器验证配置3.1 配置交换机 VLAN3.1.1 创建 VLAN3.1.2 配置端口所属 VLAN3.…...

一键转换上百文件 Word 批量转 PDF 软件批量工具
各位办公族们,你们有没有被手动把Word一个个转成PDF给折腾得欲哭无泪过啊?我之前就因为这事忙得晕头转向,眼睛都快看瞎了!不过呢,后来我发现了专门为咱提升办公效率设计的Word批量转PDF软件,那简直就是办公…...

矫平机:工业精密矫正的全维度解析
作为现代制造业的核心设备之一,矫平机通过消除材料残余应力、提升平整度,持续推动着汽车、航空航天、新能源等领域的质量升级。本文基于最新行业动态与技术突破,从原理革新到智能化实践展开深度解析。 一、核心原理:力学与智能的深…...
 2-3 GB/T 22240—2020《信息安全技术 网络安全等级保护定级指南》-2020-04-28发布【现行】)
网络安全-等级保护(等保) 2-3 GB/T 22240—2020《信息安全技术 网络安全等级保护定级指南》-2020-04-28发布【现行】
################################################################################ 在开始等级保护安全建设前,第一步需要知道要保护的是什么,要保护到什么程度,所以在开始等级保护中介绍的第一个标准是《定级指南》,其中明确了…...

GNSS数据自动化下载系统的设计与实现
摘要 本文详细介绍了三种不同设计的GNSS数据自动化下载系统,分别针对IGS观测数据、GRACE-FO Level-1B数据以及通过代理服务器获取数据的需求场景。系统采用Python实现,具备断点续传、完整性校验、异常处理和进度显示等核心功能。实验结果表明࿰…...

c语言第一个小游戏:贪吃蛇小游戏06
实现贪吃蛇四方向的风骚走位 实现代码 #include <curses.h> #include <stdlib.h> struct snake{ int hang; int lie; struct snake *next; }; struct snake *head; struct snake *tail; int key; int dir; //全局变量 #define UP 1 //这个是宏定义&a…...

人工智能_大模型数据标注主要做什么_拉框_人工智能训练师_数据标准师介绍---人工智能工作笔记0244
随着大模型的快速发展,数据标注迅速成为比较热门的工作,那么 数据标注,具体干什么呢? 因为现在人工智能在某个领域如果理解,或者识别的越精准,那么 就需要越高质量的数据, 就是因为,模型的训练,大多还是有监督深度学习.给他足够高质量的数据才行有好的效果. 可以看到在AI领…...

工业4G路由器IR5000公交站台物联网应用解决方案
随着城市化进程的加速,公共交通是智慧城市的重要枢纽。城市公共交通由无数的公交站台作作为节点组合而成,其智能化升级成为提升城市出行效率与服务质量的关键。传统公交站台信息发布滞后、缺乏实时性,难以满足乘客对公交信息快速获取的需求&a…...

文件操作: File 类的用法和 InputStream, OutputStream 的用法
目录 1. File 概述 1.1 File的属性 1.2 File的构造方法 1.3 File的方法 2. 文件的基本操作 2.1 InputStream 2.2 OutputStream 2.3.字符流读取(Reader) 2.4 字符流写(Writer) 1. File 概述 Java 中通过 java.io.File 类来对⼀个文件…...

SQL 中 INSTR 函数简介及 截取地址应用
一、基本语法与参数解析 语法: INSTR(string1, string2 [, start_position [, nth_occurrence]]) 参数说明: a.string1:源字符串(必选)。 b.string2:需查找的子字符串&am…...

Oracle SYSTEM/UNDO表空间损坏的处理思路
Oracle SYSTEM/UNDO表空间损坏是比较棘手的故障,通常会导致数据库异常宕机进而无法打开数据库。数据库的打开故障处理起来相对比较麻烦,读者可以参考本书第5章进一步了解该类故障的处理过程。如果数据库没有备份,通常需要设置官方不推荐的隐含…...

【HarmonyOs鸿蒙】七种传参方式
一、页面间导航传参 使用场景:页面跳转时传递参数 实现方式:通过router模块的push方法传递参数 // 页面A传参 import router from ohos.router;router.pushUrl({url: pages/PageB,params: { id: 123, name: HarmonyOS } });// 页面B接收参数 Entry Co…...

微信小程序 密码框改为text后不可见,需要点击一下
这个问题是做项目的时候碰到的。 密码框常规写法: <view class"inputBox"><view class"input-container"><input type"{{inputType}}" placeholder"请输入密码" data-id"passwordValue" bindin…...

Gatsby知识框架
一、Gatsby 基础概念 1. 核心特性 基于React的静态站点生成器:使用React构建,输出静态HTML/CSS/JS GraphQL数据层:统一的数据查询接口 丰富的插件系统:超过2000个官方和社区插件 高性能优化:自动代码分割、预加载、…...

TCP协议十大核心特性深度解析:构建可靠传输的基石
TCP(传输控制协议)作为互联网的"交通指挥官",承载着全球80%以上的网络流量。本文将深入解析TCP协议的十大核心特性,通过原理剖析、流程图解和实战案例,揭示其如何实现高效可靠的数据传输。 一、面向连接的可…...

【架构】RUP统一软件过程:企业级软件开发的全面指南
一、RUP概述 RUP(Rational Unified Process,统一软件过程)是由Rational Software公司(后被IBM收购)开发的一种迭代式软件开发过程框架。它结合了传统瀑布模型的系统性和敏捷方法的灵活性,为中大型软件项目提供了全面的开发方法论。 RUP不仅仅是一种过程…...

基于智能家居项目 实现DHT11驱动源代码
DHT11 温湿度传感器的数据读取一般分为 四个步骤,下面详细介绍每个步骤的具体内容: 步骤一:主机发送起始信号 主机(如 MCU)主动向 DHT11 发送开始信号,方式为: 将数据线拉低 至少 18ms&…...

小程序的内置组件
一、Text文本组件 1.Text组件解析 Text组件用于显示文本, 类似于span标签, 是行内元素 user-select属性决定文本内容是否可以让用户选中 space有三个取值(了解) decode是否解码(了解) decode可以解析的有 < > & '    二、Butto…...

T-BOX硬件方案深度解析:STM32与SD NAND Flash存储的完美搭配
在智能网联汽车快速发展的当下,车载 T-BOX(Telematics Box)作为车辆与云端互联的核心枢纽,其性能和可靠性直接决定了用户体验的上限。米客方德(MK)推出的基于 STM32H7RX 主控芯片与 MKDV4GIL-AST࿰…...

hadoop3.x单机部署
jdk hadoop3.x需要jdk8以上的版本 hadoop3.x 从官网下载对应的tar.gz文件 配置环境变量 vim /etc/profile# 需要替换为自己的安装地址!!! export JAVA_HOME/usr/lib/jvm/java-1.8.0-openjdk-amd64 export PATH$PATH:$JAVA_HOME/bin expo…...

Hadoop的目录结构和组成
Hadoop 目录结构 bin 目录:包含了 Hadoop 的各种命令行工具,如hadoop、hdfs等,用于启动和管理 Hadoop 集群,以及执行各种数据处理任务。etc 目录:存放 Hadoop 的配置文件,包括core-site.xml、hdfs-site.xm…...

深度剖析 RTX 4090 GPU 算力租赁:从技术优势到生态价值的全维度解析
一、引言:当算力成为数字经济的 "新石油" 在 AI 大模型训练成本突破千万美元大关、元宇宙场景渲染需求呈指数级增长的 2025 年,算力已然成为驱动技术创新的核心生产要素。NVIDIA RTX 4090 显卡作为消费级 GPU 的性能天花板,正通…...

基于MATLAB的生物量数据拟合模型研究
一、研究背景 在现代科学研究与工程实践的广泛领域中,数据拟合扮演着举足轻重的角色。从物理学中对复杂物理现象的建模,到生物学里对生物生长规律的探究,数据拟合已成为揭示数据内在规律、构建有效数学模型的关键技术手段。其核心要义在于&am…...

VSCode设置SSH免密登录
引言 2025年05月13日20:21:14 原来一直用的PyCharn来完成代码在远程服务器上的运行,但是PyCharm时不时同步代码会有问题。因此,尝试用VSCode来完成代码SSH远程运行。由于VSCode每次进行SSH连接的时候都要手动输入密码,为了解决这个问题在本…...

微信小程序的开发及问题解决
HttpClient 测试例子 SpringBootTest public class HttpClientTest {/*** 测试通过httpclient发送get方式的请求*/Testpublic void testGET() throws IOException {//创建httpclient对象CloseableHttpClient httpClient HttpClients.createDefault();//创建请求对象HttpGet ht…...
)
vscode百宝箱工具插件(devtools)
vscode百宝箱插件是一款结合JSON格式化, 正则表达式测试等工具为一体的插件, 直接嵌入到vscode里面, 省去了上网去找相应的工具 一、插件名称:devtools(TraesureBox) 目前插件上传到vscode插件市场, 搜索 devtools 看…...

3.5 统计初步
本章系统阐述统计推断理论基础,涵盖大数定律、抽样分布、参数估计与假设检验等核心内容。以下从六个核心考点系统梳理知识体系: 考点一:大数定律与中心极限定理 1. 大数定律 切比雪夫不等式: 设随机变量 X X X 的数学期望 E (…...