《Python星球日记》 第66天:序列建模与语言模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、传统语言模型
- 1. n-gram 模型基础
- 2. n-gram 模型的局限性
- 二、RNN 在语言建模中的应用
- 1. 语言模型的基本原理
- 2. RNN 构建语言模型的优势
- 3. 实现简单的 RNN 语言模型
- 三、数据准备
- 1. 文本预处理与分词
- 2. 嵌入表示(Word Embedding)
- 四、代码练习:基于 RNN 的简单语言生成任务
- 1. 数据集准备
- 2. 模型构建
- 3. 训练与生成文本
- 4. 效果评估与改进
- 五、总结与展望
- 未来学习方向
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第65天:词向量与语言表示
大家好,欢迎来到Python星球的第66天!🪐
今天我们将探索序列建模和语言模型的fascinating世界,这是自然语言处理(NLP)领域的核心技术。从传统的n-gram模型到现代的循环神经网络(RNN)应用,我们将全面了解计算机是如何理解和生成人类语言的。
一、传统语言模型
语言模型是自然语言处理的基础,它能预测词序列的概率分布,为机器翻译、语音识别和文本生成等应用提供支持。
1. n-gram 模型基础
n-gram模型是一种基于统计的语言模型,它通过前n-1个词来预测第n个词出现的概率。具体分类:
- 一元模型(unigram):独立预测每个词,不考虑上下文
- 二元模型(bigram):基于前一个词预测当前词
- 三元模型(trigram):基于前两个词预测当前词
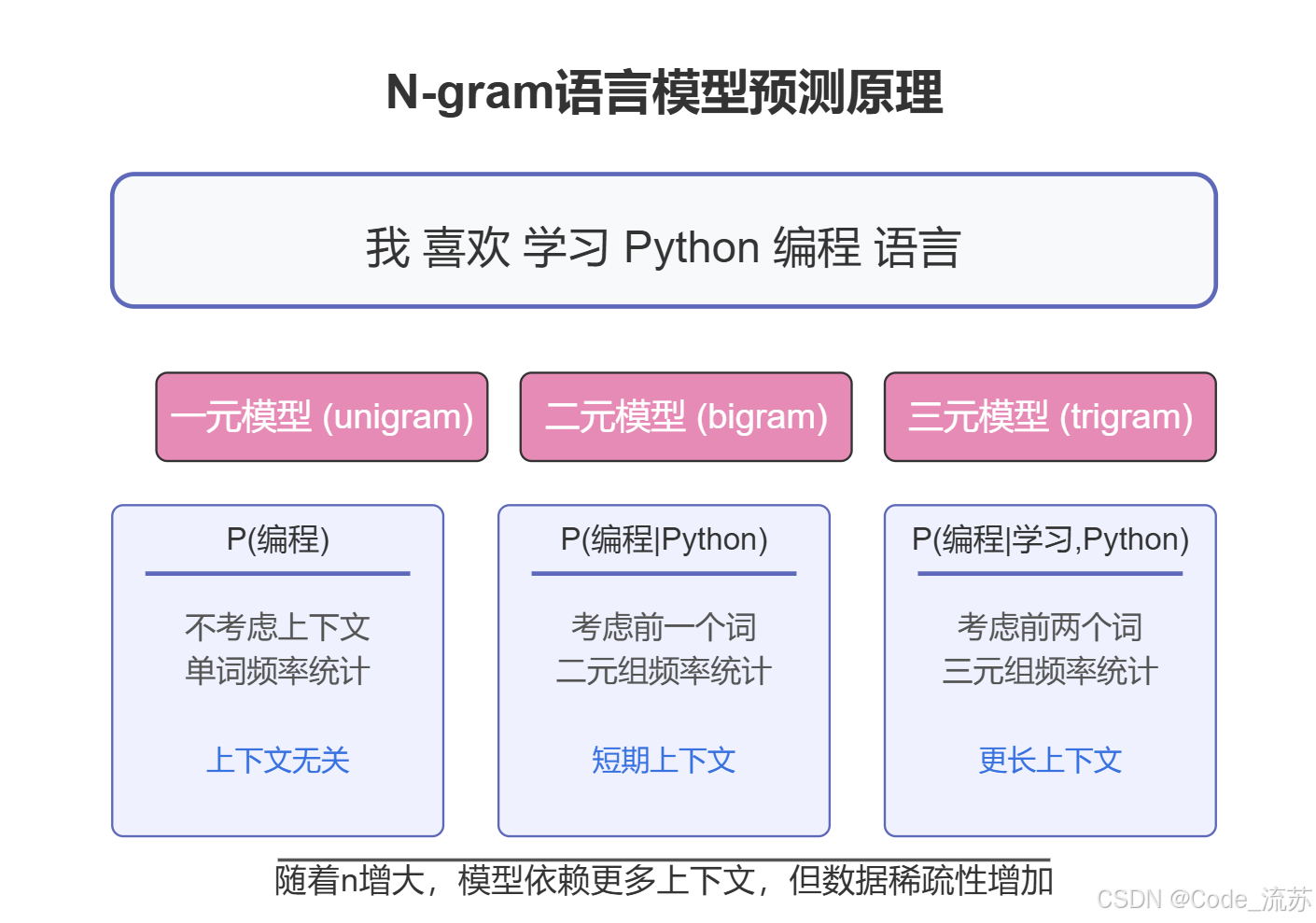
n-gram模型的核心思想可以用条件概率表示:
P(词n | 词1, 词2, ..., 词n-1) =
Count(词1, 词2, ..., 词n) / Count(词1, 词2, ..., 词n-1)
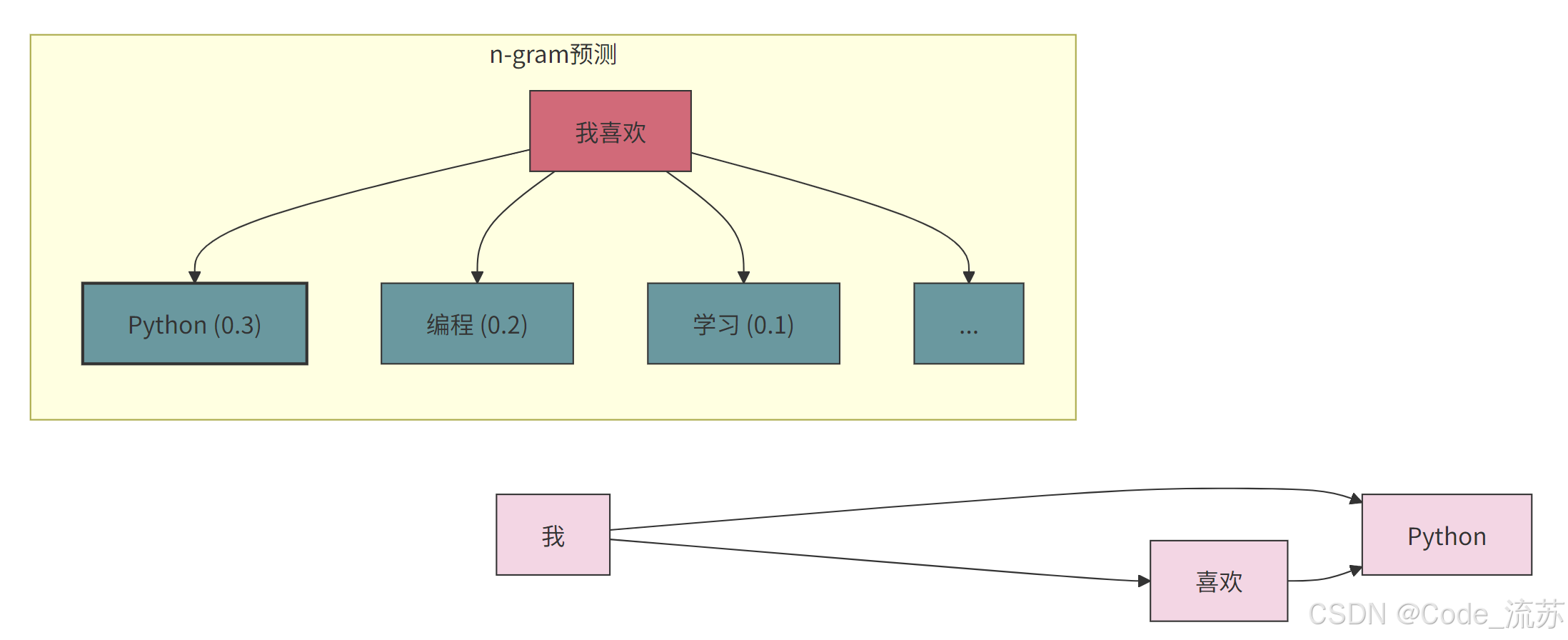
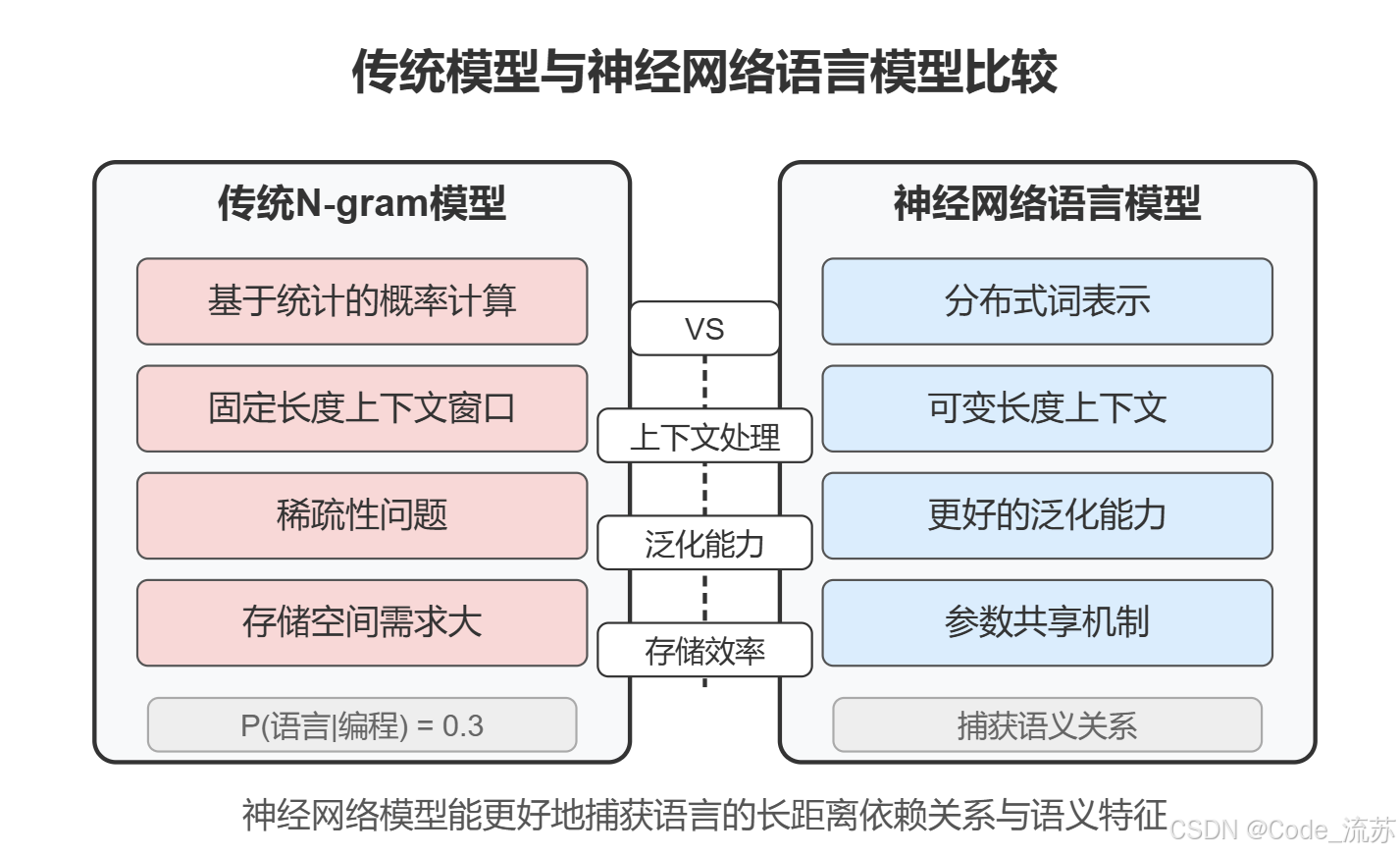
2. n-gram 模型的局限性
尽管简单实用,但n-gram模型存在几个关键限制:
-
稀疏性问题:许多有效的词序列可能在训练数据中从未出现,导致零概率问题。这通常通过平滑技术(如拉普拉斯平滑)来缓解。
-
有限上下文:n-gram模型只考虑固定数量的前序词,无法捕捉长距离依赖关系。例如,"虽然我不喜欢编程,但是我非常喜欢_____"这样的句子,如果n=3,模型就无法利用"虽然"这个重要的上下文信息。
-
内存需求:随着n的增加,可能的n-gram组合数量呈指数级增长,对存储和计算提出了极高要求。
-
缺乏语义理解:这些模型只捕捉词的统计共现关系,而不理解词的实际含义。
二、RNN 在语言建模中的应用
循环神经网络(RNN)通过维护能捕获所有先前单词信息的内部状态,解决了传统n-gram模型的许多限制。
1. 语言模型的基本原理
语言模型本质上是计算一个词序列的概率分布。给定一个词序列w₁, w₂, …, wₙ,语言模型计算:
P(w₁, w₂, ..., wₙ) = P(w₁) × P(w₂|w₁) × P(w₃|w₁,w₂) × ... × P(wₙ|w₁,...,wₙ₋₁)
语言模型训练的目标是最大化训练语料库中观察到的文本概率,从而学习语言的模式和结构。
2. RNN 构建语言模型的优势
RNN相比n-gram模型具有以下几个显著优势:
- 可变长度上下文:理论上RNN可以捕获任意长度的依赖关系,不局限于固定的n。
- 参数共享:在每个时间步应用相同的权重,使模型更高效。
- 分布式表示:RNN使用密集的词向量(嵌入),能捕获词之间的语义关系。
- 更好的泛化能力:神经模型能更有效地泛化到未见过的模式。
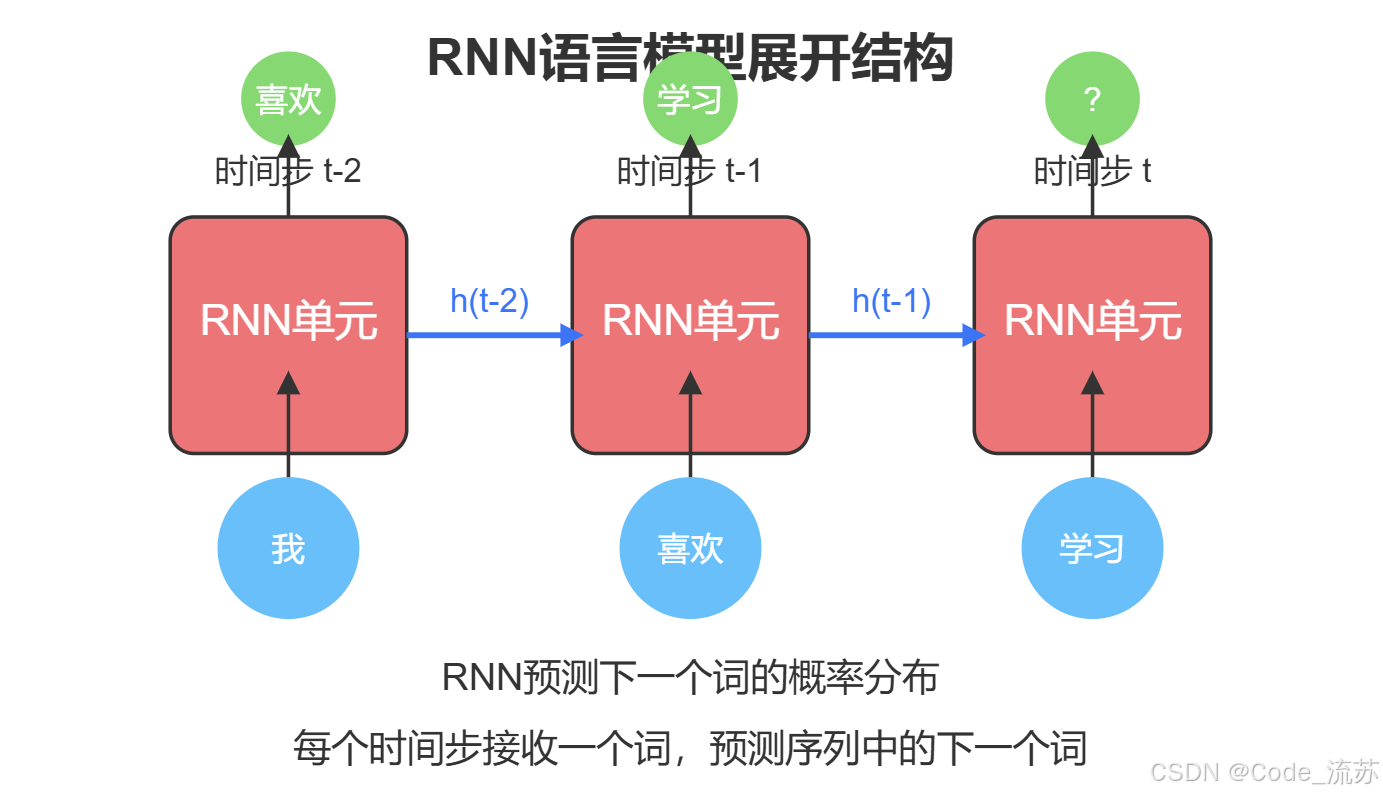
3. 实现简单的 RNN 语言模型
基于RNN的语言模型通常遵循以下工作流程:
- 接收词序列作为输入
- 一个词一个词地处理,不断更新隐藏状态
- 在每一步预测下一个词的概率分布
模型架构通常包括:
- 嵌入层:将词索引转换为向量表示
- 一个或多个RNN层:可以是简单RNN、LSTM或GRU
- 线性层:将输出投影到词汇表大小
- Softmax函数:将输出转换为概率
三、数据准备
准备高质量的数据是训练有效语言模型的关键环节。
1. 文本预处理与分词
文本预处理通常包括以下步骤:
- 清洗文本:移除特殊字符、处理大小写、标准化格式等
- 分词(tokenization):将文本分割成词或子词单元
- 构建词汇表:为每个标记分配唯一索引
- 转换为索引序列:将文本转换为数字序列
对于语言建模任务,输入和目标序列是通过移位创建的:如果输入是[w₁, w₂, …, wₙ₋₁],那么目标就是[w₂, w₃, …, wₙ]。这样模型就能学习预测序列中的下一个词。
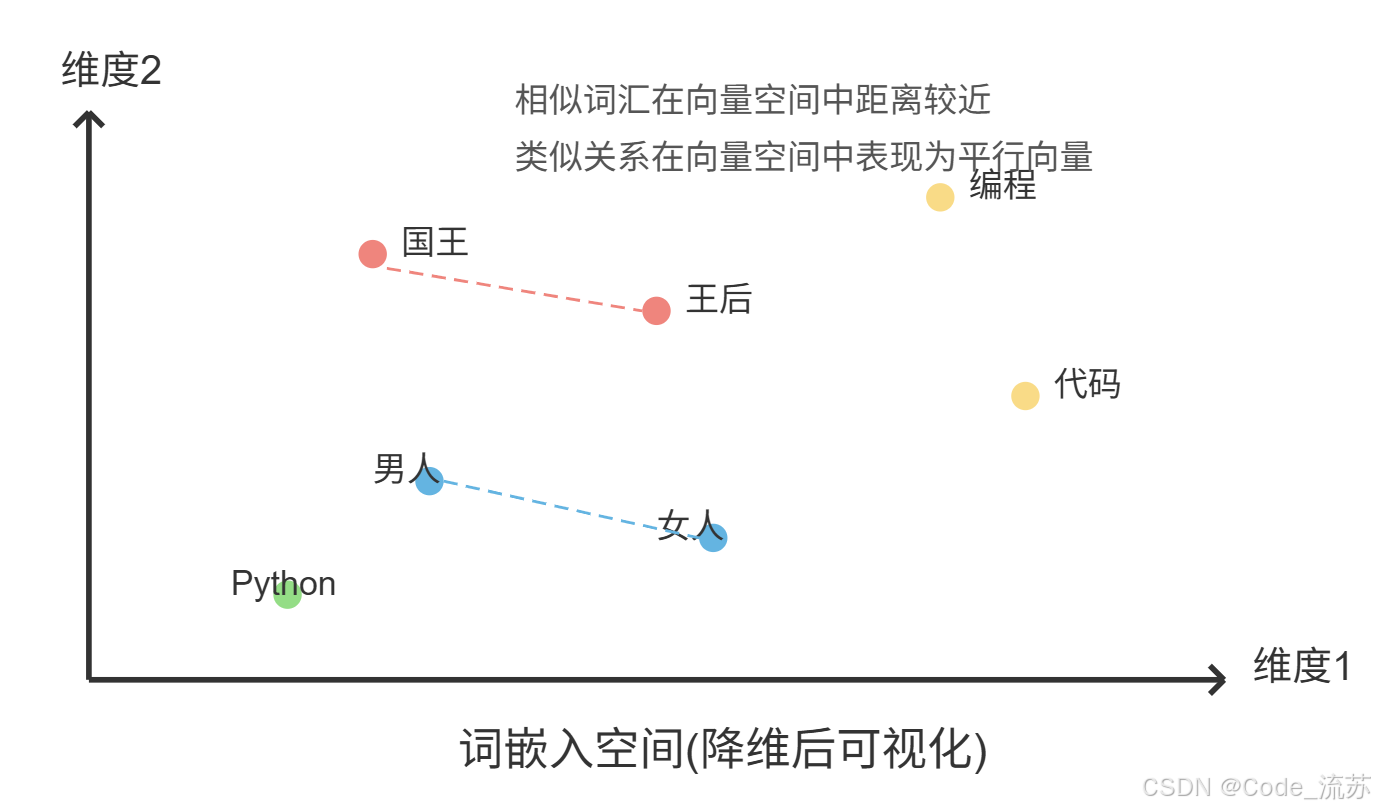
2. 嵌入表示(Word Embedding)
词嵌入是将离散的词转换为连续向量表示的过程,这些向量能捕获词之间的语义关系。常见的嵌入方法包括:
- 独热编码(One-hot encoding):简单但缺乏语义信息,每个词是一个只有一个1,其余都是0的稀疏向量
- Word2Vec:基于词共现创建的嵌入,包括Skip-gram和CBOW两种模型
- GloVe:结合全局矩阵分解与局部上下文的嵌入方法
- FastText:融合了子词信息的嵌入
- 上下文嵌入:来自BERT、GPT等模型的动态词表示
词嵌入帮助语言模型理解词之间的关系,例如"王"与"王后"的关系类似于"男人"与"女人"的关系,这大大提升了模型的泛化能力。
四、代码练习:基于 RNN 的简单语言生成任务
下面我们来实现一个基于字符级别的RNN语言模型,并使用它生成文本。我们将使用PyTorch框架完成这个任务。
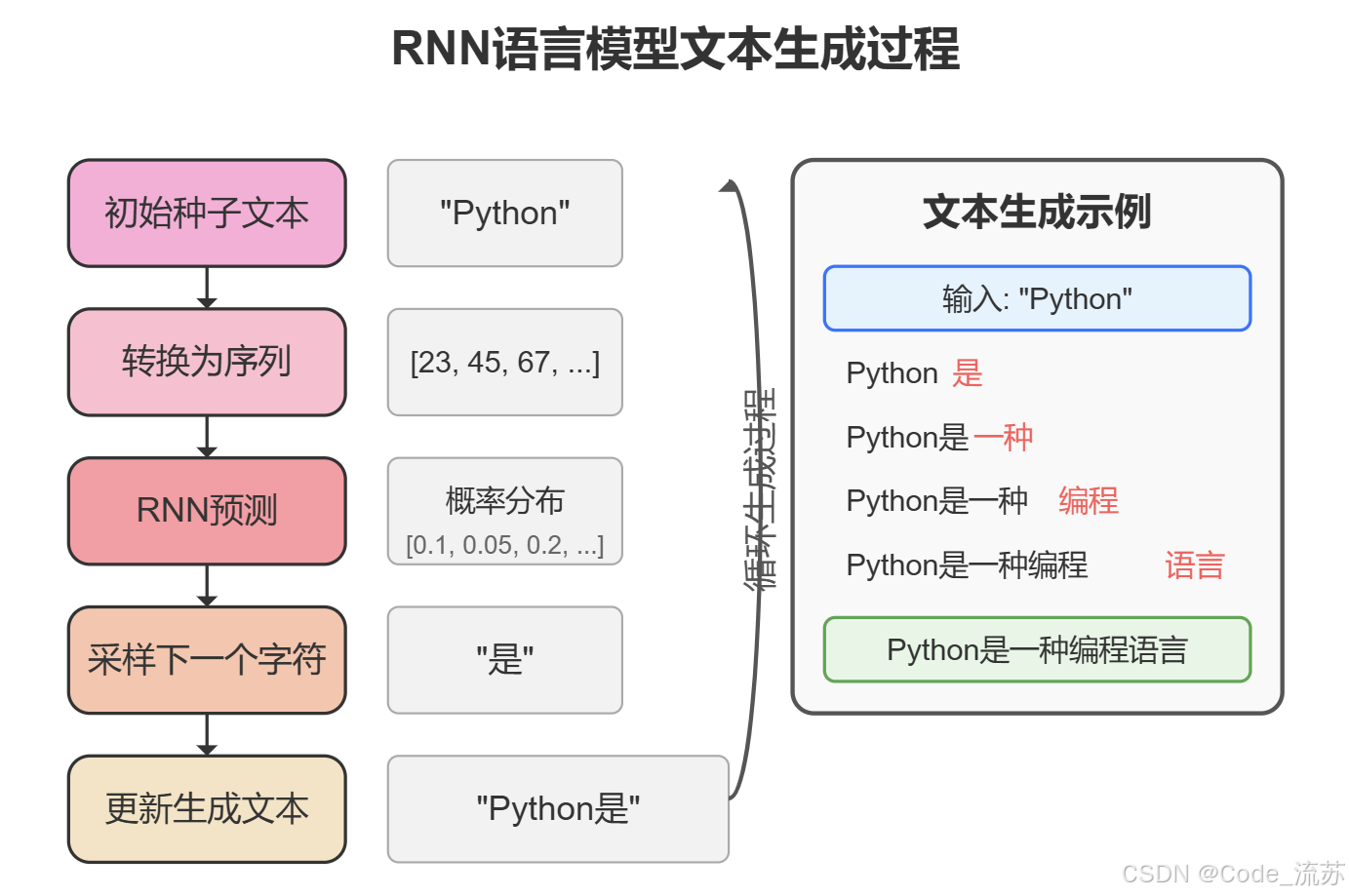
1. 数据集准备
首先,我们需要准备数据:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 示例文本(实际应用中可以使用更大的语料库)
text = """
Python是一种编程语言,让你能够快速工作并更有效地集成系统。
Python功能强大且快速,与其他语言配合良好,可在各处运行,并且使用友好。
Python可以用于Web开发、数据分析、人工智能和科学计算等多个领域。
"""# 创建字符到索引的映射和索引到字符的映射
chars = sorted(list(set(text)))
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
vocab_size = len(chars)print(f"词汇表大小: {vocab_size}")
print(f"前10个字符: {chars[:10]}")# 准备序列
seq_length = 20 # 序列长度
x_data = [] # 输入序列
y_data = [] # 目标(下一个字符)for i in range(0, len(text) - seq_length):# 输入是长度为seq_length的序列x_data.append([char_to_idx[c] for c in text[i:i+seq_length]])# 目标是序列后面的下一个字符y_data.append(char_to_idx[text[i+seq_length]])# 转换为PyTorch张量
x_tensor = torch.tensor(x_data, dtype=torch.long)
y_tensor = torch.tensor(y_data, dtype=torch.long)# 创建DataLoader
from torch.utils.data import TensorDataset, DataLoader
dataset = TensorDataset(x_tensor, y_tensor)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
这段代码首先定义了一个小型文本语料库,然后创建了字符和索引之间的映射。接着,我们将文本划分为多个输入序列和对应的目标(每个序列后面的下一个字符)。最后,我们创建了PyTorch的DataLoader用于批量训练。
2. 模型构建
现在,我们构建RNN语言模型:
class CharRNN(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, n_layers=1):super(CharRNN, self).__init__()# 定义网络层self.embedding = nn.Embedding(vocab_size, embedding_dim) # 嵌入层self.rnn = nn.LSTM(embedding_dim, hidden_dim, n_layers, batch_first=True) # LSTM层self.fc = nn.Linear(hidden_dim, vocab_size) # 全连接层def forward(self, x):# x的形状: (batch_size, seq_length)embeds = self.embedding(x) # (batch_size, seq_length, embedding_dim)rnn_out, _ = self.rnn(embeds) # (batch_size, seq_length, hidden_dim)# 我们只需要最后一个时间步的输出来预测下一个字符output = self.fc(rnn_out[:, -1, :]) # (batch_size, vocab_size)return output# 初始化模型
embedding_dim = 64 # 嵌入维度
hidden_dim = 128 # 隐藏层维度
model = CharRNN(vocab_size, embedding_dim, hidden_dim, n_layers=1)# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
我们的模型包含三个主要部分:
- 嵌入层:将字符索引转换为密集向量
- LSTM层:处理序列并捕获上下文依赖关系
- 全连接层:将LSTM的输出映射到词汇表大小,预测下一个字符的概率
3. 训练与生成文本
接下来,我们训练模型并使用它生成文本:
# 训练模型
epochs = 100
for epoch in range(epochs):total_loss = 0for x_batch, y_batch in loader:# 前向传播output = model(x_batch)loss = criterion(output, y_batch)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()if (epoch+1) % 10 == 0:print(f'Epoch {epoch+1}, Loss: {total_loss/len(loader):.4f}')# 文本生成函数
def generate_text(model, start_string, length=100):# 将起始字符串转换为索引chars_idx = [char_to_idx[c] for c in start_string]# 生成文本generated_text = start_stringmodel.eval() # 设置为评估模式with torch.no_grad():for _ in range(length):# 准备输入# 如果序列不够长,就用当前所有的字符if len(chars_idx) < seq_length:x = torch.tensor([chars_idx + [0] * (seq_length - len(chars_idx))])else:# 否则就取最后seq_length个字符x = torch.tensor([chars_idx[-seq_length:]])# 前向传播output = model(x)# 获取预测的字符(采用贪婪解码策略)_, predicted = torch.max(output, 1)predicted_idx = predicted.item()# 添加到生成文本generated_text += idx_to_char[predicted_idx]chars_idx.append(predicted_idx)return generated_text# 从"Python"开始生成文本
generated = generate_text(model, "Python")
print(generated)
这段代码完成了两个主要任务:
- 模型训练:在准备好的数据上迭代学习,通过最小化交叉熵损失来优化模型参数
- 文本生成:从给定的起始字符串开始,逐步预测下一个字符,生成连贯的文本
4. 效果评估与改进
我们的简单模型可能存在一些局限性。以下是几种改进方法:
-
使用更多数据:更大、更多样化的语料库能产生更好的语言模型。小规模语料库往往导致模型过拟合,生成的文本缺乏多样性。
-
更复杂的架构:
- 使用LSTM或GRU替代简单RNN,以解决梯度消失问题,捕获更长的依赖关系
- 增加更多层以进行层次化特征提取
- 实现注意力机制,让模型更好地关注相关上下文
-
超参数调优:
- 尝试不同的嵌入维度
- 调整隐藏层大小
- 尝试不同学习率和批量大小
- 加入正则化手段,如Dropout
-
评估指标:
- 困惑度(Perplexity):语言模型的标准评估指标,计算公式为2的交叉熵损失次方
- BLEU分数:用于比较生成文本与参考文本的相似度
- 人工评估:对生成文本的质量、连贯性和多样性进行主观评价
实际生产环境中,还可以考虑使用更高级的技术:
# 使用温度采样提高生成文本的多样性
def generate_with_temperature(model, start_string, length=100, temperature=0.8):chars_idx = [char_to_idx[c] for c in start_string]generated_text = start_stringmodel.eval()with torch.no_grad():for _ in range(length):if len(chars_idx) < seq_length:x = torch.tensor([chars_idx + [0] * (seq_length - len(chars_idx))])else:x = torch.tensor([chars_idx[-seq_length:]])# 获取原始logitslogits = model(x)# 应用温度logits = logits / temperature# 转换为概率分布probs = torch.softmax(logits, dim=1)# 从概率分布中采样predicted_idx = torch.multinomial(probs, 1).item()generated_text += idx_to_char[predicted_idx]chars_idx.append(predicted_idx)return generated_text
通过调整温度参数,我们可以控制生成文本的随机性:温度越低,生成的文本越确定性;温度越高,生成的文本则越多样化但可能变得不连贯。
五、总结与展望
在本文中,我们深入探讨了序列建模和语言模型:
- 我们从传统的n-gram模型出发,了解了它们的工作原理和局限性。
- 我们学习了RNN如何解决这些局限性,构建更强大的语言模型。
- 我们探讨了数据准备,包括分词和词嵌入的重要性。
- 我们实现了一个简单的字符级RNN语言模型,并用它生成文本。
语言建模技术在不断快速发展。现代方法如基于Transformer的模型(如GPT、BERT)已经在很大程度上取代了基于RNN的方法,提供更好的性能和捕获长距离依赖关系的能力。随着您继续Python和机器学习之旅,探索这些高级模型将是自然的下一步。
未来学习方向
- Transformer架构:深入了解自注意力机制和Transformer架构
- 预训练语言模型:研究如何使用和微调GPT、BERT等模型
- 多模态模型:探索文本与图像、音频等其他模态结合的模型
- 强化学习:学习如何通过人类反馈训练语言模型(RLHF)
语言模型的应用几乎无处不在——从智能助手到内容生成,从代码补全到语言翻译。掌握这些技术将使您在AI时代拥有宝贵的技能!
希望这篇文章对您理解序列建模和语言模型有所帮助。明天,我们将继续我们的Python星球之旅,探索更多令人兴奋的领域!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:

《Python星球日记》 第66天:序列建模与语言模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、传统语言模型1. n-gram 模型基础2. n-gram 模型的局限性 二、RNN 在语言建模…...

CRM和SCRM有什么区别
CRM(客户关系管理)与SCRM(社会化客户关系管理)的主要区别在于沟通方式、客户互动、数据来源和客户参与度。CRM更侧重企业对客户信息的管理与内部流程优化,而SCRM强调客户主动参与,通过社交媒体等平台加强互…...

破解 Qt QProcess 在 Release 模式下的“卡死”之谜
在使用 Qt 的 QProcess 以调用外部 ffmpeg/ffprobe 进行音视频处理时,常见的工作流程是: gatherParams:通过 ffprobe 同步获取媒体文件的参数(分辨率、采样率、声道数、码率等)。 reencode:逐个文件调用 f…...

重学安卓14/15自由窗口freeform企业实战bug-学员作业
背景: 在aosp14版本及以后版本上,安卓的自由窗口部分的工具栏部分都有了较大的更新 工具栏这部分已经移到了SystemUI进程的WMShell进行统一的管理。 但是近来有学员朋友在对自由窗口进行相关的拖拽操作时候,有遇到这个工具栏相关的一个bug&…...

【layout组件 与 路由镶嵌】vue3 后台管理系统
前言 很多同学在第一次搭建后台管理系统时,会遇到一个问题,layout组件该放哪里?如何使用?路由又该如何设计? 这边会讲一下我的思考过程和最后的结果,大家可以参考一下,希望大家看完能有所收获。…...

【PXIE301-211】基于PXIE总线的16路并行LVDS数据采集、1路光纤数据收发处理平台
板卡概述 PXIE301-211是一款基于PXIE总线架构的16路并行LVDS数据采集、1路光纤收发处理平台,该板卡采用Xilinx的高性能Kintex 7系列FPGA XC7K325T作为实时处理器,实现各个接口之间的互联。板载1组64位的DDR3 SDRAM用作数据缓存。板卡具有1个FMC…...

linux-进程信号的产生
Linux中的进程信号(signal)是一种用于进程间通信或向进程传递异步事件通知的机制。信号是一种软中断,用于通知进程某个事件的发生,如错误、终止请求、计时器到期等。 1. 信号的基本概念 - 信号(Signal)&am…...

基于 Nexus 在 Dockerfile 配置 yum, conda, pip 仓库的方法和参考
在 Nexus 配置代理仓库的方法,可参考 pypi 的配置博客:https://hellogitlab.com/CI/docker/create_your_nexus_2 更多代理格式,参考官方文档,如 pypi:https://help.sonatype.com/en/pypi-repositories.html 配置 yum…...

精品可编辑PPT | 全面风险管理信息系统项目建设风控一体化标准方案
这份文档是一份全面风险管理信息系统项目建设风控一体化标准方案,涵盖了业务架构、功能方案、系统技术架构设计、项目实施及服务等多个方面的详细内容。方案旨在通过信息化手段提升企业全面风险管理工作水平,促进风险管理落地和内部控制规范化࿰…...

Redis集群安装
Redis集群安装 1.集群介绍 首先要了解,Redis的高可用机制。 2个master节点,挂掉1个,1不过半,则集群宕机,不可用,容错率为0;3个master节点,挂掉1个,2>1,…...

下载知网外文文献全文的方法
知网和一些外文数据库机构是合作关系,因知网没有订购外文文献全文,所以可以搜到外文文献但不能下载全文,基本提供的都是外文文献摘要。本文就实例演示一下获取知网外文文献全文的方法步骤。 例如下面这篇知网外文文献,该文献被收…...

解决IDEA无法运行git的问题
之前git一直没有问题,今天打开就提示我安装git,自然用git去提交新项目也会遇到问题。 我出现问题的原因是:git路径缺失 文件->设置->git 发现git的路径为空,按照实际位置填写即可...

基于Qt6 + MuPDF在 Arm IMX6ULL运行的PDF浏览器——MuPDF Adapter文档
项目地址:总项目Charliechen114514/CCIMXDesktop: This is a Qt Written Desktop with base GUI Utilities 本子项目地址:CCIMXDesktop/extern_app/pdfReader at main Charliechen114514/CCIMXDesktop 前言 这个部分说的是Mupdf_adaper下的文档的工…...

Ubuntu20.04 搭建Kubernetes 1.28版本集群
环境依赖 以下操作,无特殊说明,所有节点都需要执行 安装 ssh 服务安装 openssh-server复制代码 sudo apt-get install openssh-server修改配置文件复制代码 vim /etc/ssh/sshd_config找到配置项 复制代码 LoginGraceTime 120 PermitRootLogin prohibit-password StrictModes…...

操作系统和数据库账号密码的安全管理、使用,安当SMS凭据管理系统
引言:密码管理困局下的破局之道 在数字化转型的深水区,企业正面临前所未有的密码管理挑战。某跨国制造企业因数据库密码泄露导致核心工艺参数外泄,某三甲医院因运维账号滥用引发百万级医疗数据泄露事件,这些真实案例揭示着传统密…...
)
Java设计模式之代理模式:从入门到精通(保姆级教程)
1. 代理模式概述 代理模式(Proxy Pattern)是一种结构型设计模式,它为其他对象提供一种代理以控制对这个对象的访问。代理对象在客户端和目标对象之间起到中介作用,可以在不改变目标对象代码的情况下增加额外的功能。 1.1 专业概念解释 代理模式:为其他对象提供一种代理…...

单片机-STM32部分:13-1、蜂鸣器
飞书文档https://x509p6c8to.feishu.cn/wiki/V8rpwIlYIiEuXLkUljTcXWiKnSc 一、应用场景 大部分的电子产品、家电(风扇、空调、电水壶)都会有蜂鸣器,用于提示设备的工作状态 二、原理 蜂鸣器是一种将电信号转换为声音信号的器件࿰…...

JVM——方法内联
引入 在现代软件开发中,性能优化始终是一个关键课题。随着硬件架构的不断演进,CPU的主频提升逐渐放缓,而软件复杂度却持续增加,这使得编译器优化技术的重要性日益凸显。方法内联(Method Inlining)作为编译…...

C++类成员
一、内联函数(Inline Functions) 作用 解决频繁调用小函数时的栈内存消耗问题,通过将函数代码直接插入调用点,避免压栈/出栈开销。 定义形式 inline 返回类型 函数名(参数列表) { ... }• 隐式声明:类内直接定义的成员…...

SpringBoot校园失物招领信息平台
SpringBoot校园失物招领信息平台 文章目录 SpringBoot校园失物招领信息平台1、技术栈2、项目说明2.1、登录注册2.2、管理员端截图2.3、用户端截图 3、核心代码实现3.1、前端首页3.2、前端招领广场3.3、后端业务处理 1、技术栈 本项目采用前后端分离的架构,前端和后…...

代码随想录算法训练营第三十八天
LeetCode题目: 1143. 最长公共子序列1035. 不相交的线53. 最大子数组和392. 判断子序列2094. 找出 3 位偶数(每日一题) 其他: 今日总结 往期打卡 1143. 最长公共子序列 跳转: 1143. 最长公共子序列 学习: 代码随想录公开讲解 问题: 给定两个字符串 text1 和 text2࿰…...

Nginx stream模块是连接级别的负载均衡
在Nginx的stream模块中,upstream的权重配置实现的是连接级别的负载均衡,这和http模块不同。 当客户端发起一个新的TCP连接时,Nginx根据各upstream的权重值选择其中一个upstream建立连接,之后该连接上的所有数据传输都由这个upstre…...

贝叶斯算法
贝叶斯算法是一类基于贝叶斯定理的机器学习算法,它们在分类任务中表现出色,尤其在处理具有不确定性和 probabilistic 关系的数据时具有独特优势。本文将深入探讨贝叶斯算法的核心原理、主要类型以及实际应用案例,带你领略贝叶斯算法在概率推理…...

计算机网络:CPU与时钟的关系
在计算机中,CPU(中央处理器)与时钟的关系是核心且密不可分的。时钟信号是驱动CPU运行的“心跳”,决定了计算机执行指令的节奏和协调性。以下是两者的关键关系及作用: 1. 时钟信号:CPU的“节拍器” 时钟频率(Clock Speed) CPU的时钟频率(如3.5 GHz)表示每秒的时钟周期…...

java中强引用、软应用、弱应用、虚引用
在Java中,引用类型决定了对象的生命周期和垃圾回收的时机。Java提供了四种不同的引用类型:强引用、软引用、弱引用和虚引用。每种引用类型的行为和用途不同,了解这些差异对优化内存管理和垃圾回收非常重要。 1. 强引用(Strong Re…...

分析红黑树工程实用的特点
🧭 本节目标 理解红黑树在工程中的优劣势对比红黑树与其他数据结构(AVL 树、跳表、哈希表等)分析红黑树为何成为内核级应用(如 Linux CFS、内存管理)首选总结红黑树工程上的典型使用建议 一、红黑树工程级使用的主要特…...
)
C/C++ 内存管理深度解析:从内存分布到实践应用(malloc和new,free和delete的对比与使用,定位 new )
一、引言:理解内存管理的核心价值 在系统级编程领域,内存管理是决定程序性能、稳定性和安全性的关键因素。C/C 作为底层开发的主流语言,赋予开发者直接操作内存的能力,却也要求开发者深入理解内存布局与生命周期管理。本文将从内…...

如何使用主机名在 CMD 中查找 IP 地址?
在网络中,每个系统都有一个由几位数字组成的唯一标识,称为 IP 地址。然而,记住它们可能是一项艰巨的任务,尤其是当系统数量众多时。例如,互联网上运行的每个网站都有一个 IP 地址,以便其他系统在需要时可以调用它们,但你认为记住我们访问的每个网站的长串数字是可行的吗…...

解读RTOS:第二篇 · 线程/任务管理与调度策略
1. 引言 在 RTOS 中,线程(Task)是最基本的执行单元,它封装了应用功能、资源使用和优先级属性。任务管理与调度策略决定了系统在多任务场景下的响应速度、资源分配效率与实时性保证。理解并掌握任务创建、状态转换、优先级设计和调度算法,是 RTOS 应用开发的核心内容。 2…...

linux下minio的进程管理脚本
准备工作: 参考链接: Deploy MinIO: Single-Node Single-Drive — MinIO Object Storage for Linux 下载: wget https://dl.min.io/server/minio/release/linux-amd64/minio kill-app.sh #!/bin/bash # 文件名: kill-app.sh…...

论文学习_A Survey of Binary Code Similarity
摘要:二进制代码相似性方法的主要目的是比较两个或多个二进制代码片段,以识别它们之间的相似性与差异(研究背景)。由于在许多实际场景中源代码往往不可获取,因此具备比较二进制代码的能力显得尤为重要,例如…...

python标准库--sys - 系统相关功能在算法比赛的应用
目录 1. 快速输入输出 2. 调整递归深度限制 1. 快速输入输出 算法比赛中,大量数据的读写可能成为瓶颈。sys.stdin和sys.stdout比内置的input()和print()效率更高。 import sys# 读取多行输入(每行一个整数) n int(sys.stdin.readline()) …...

运算放大器相关的电路
1运算放大器介绍 解释:运算放大器本质就是一个放大倍数很大的元件,就如上图公式所示 Vp和Vn相差很小但是放大后输出还是会很大。 运算放大器不止上面的三个引脚,他需要独立供电; 如图比较器: 解释:Vp&…...

进程和线程
目录 1. 基本定义 2. 核心区别 3. 优缺点对比 进程和线程是操作系统中用于实现并发执行的两个核心概念,它们既有相似之处,又有明显的区别。下面从多个维度对它们进行对比分析: 1. 基本定义 进程(Process) 进程是程…...
深度解析:理论、技术与应用全景)
生成对抗网络(GAN)深度解析:理论、技术与应用全景
生成对抗网络(Generative Adversarial Networks,GAN)作为深度学习领域的重要突破,通过对抗训练框架实现了强大的生成能力。本文从理论起源、数学建模、网络架构、工程实现到行业应用,系统拆解GAN的核心机制,涵盖基础理…...

Java面试全记录:Spring Cloud+Kafka+Redis实战解析
Java面试全记录:Spring CloudKafkaRedis实战解析 人物设定 姓名:张伟(随机生成唯一姓名) 年龄:28岁 学历:硕士 工作年限:5年 工作内容: 基于Spring Cloud搭建微服务架构使用Kafka…...

人脸识别deepface相关笔记
人脸识别deepface相关笔记 项目地址项目结构 项目地址 https://github.com/serengil/deepface.git 项目结构...

量子加密通信:守护信息安全的未来之盾
摘要 在数字化时代,信息安全成为全球关注的焦点。传统加密技术面临着被量子计算破解的风险,而量子加密通信作为一种基于量子力学原理的新型加密技术,提供了理论上无条件安全的通信保障。本文将详细介绍量子加密通信的基本原理、技术实现、应用…...
三、transformers基础组件之Model
1. 什么是Model Head Model Head 是连接在模型后的层,通常为1个或多个全连接层Model Head 将模型的编码的表示结果进行映射,以解决不同类型的任务 不同的任务会有不同的Model Head。 2. 模型加载 2.1 在线加载 预训练模型的加载与Tokenizer类似,我们只需要指定想…...

【语法】C++的多态
目录 虚函数的重写: 虚函数 重写(覆盖) 虚函数重写的两个例外: 协变: 析构函数的重写: 练习: final和override关键字 抽象类 接口继承和实现继承 虚函数重写的原理: 打印虚函数表: …...

WebGIS开发新突破:揭秘未来地理信息系统的神秘面纱
你有没有想过,未来的地理信息系统(GIS)会是什么样子?是像电影里那样,一块透明屏幕就能呈现整个城市的实时动态?还是像《钢铁侠》中那样,一个手势就能操控全球地图? 其实,…...

JVM类加载
JVM类加载 1. 类的生命周期(类加载过程)类加载的五个阶段: 2. 类加载器的分类3. 双亲委派模型4. 类的卸载与热加载5.类加载器命名空间隔离 1. 类的生命周期(类加载过程) 类加载的五个阶段: 加载ÿ…...

AD开启交叉选择功能,只选中器件,不选中网络、焊盘
AD开启交叉选择功能,只选中器件,不选中网络、焊盘。 一、打开首选项 二、打开System→Navigationg,配置如下。 三、最后点击OK即可。...

机器学习——集成学习基础
一、鸢尾花数据训练模型 1. 使用鸢尾花数据分别训练集成模型:AdaBoost模型,Gradient Boosting模型 2. 对别两个集成模型的准确率以及报告 3. 两个模型的预测结果进行可视化 需要进行降维处理,两个图像显示在同一个坐标系中 代码展示&…...

C++匿名函数
C 中的匿名函数(Lambda 表达式)是 C11 引入的一项重要特性,它允许你在需要的地方定义一个临时的、无名的函数对象,使代码更加简洁和灵活。 1. 基本语法 Lambda 表达式的基本结构: [capture list](parameter list) -…...

互联网大厂Java面试实战:Spring Boot到微服务的技术问答解析
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通 😁 2. 毕业设计专栏,毕业季咱们不慌忙,几百款毕业设计等你选。 ❤️ 3. Python爬虫专栏…...

神经网络是如何工作的
人工智能最核心的技术之一,就是神经网络(Neural Networks)。但很多初学者会觉得它是个黑盒:为什么神经网络能识别图片、翻译语言,甚至生成文章? 本文用图解最小代码实现的方式,带你深入理解&am…...
:核心功能层)
Kubernetes控制平面组件:Kubelet详解(二):核心功能层
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

【android bluetooth 框架分析 02】【Module详解 13】【CounterMetrics 模块介绍】
1. CounterMetrics 介绍 CounterMetrics 模块代码很少, 我简单介绍一下。 // system/gd/metrics/counter_metrics.cc #define LOG_TAG "BluetoothCounterMetrics"#include "metrics/counter_metrics.h"#include "common/bind.h" #i…...

Matlab自学笔记五十四:符号数学工具箱和符号运算、符号求解、绘图
1.什么是符号数学工具箱? 符号数学工具箱是Matlab针对符号对象的运算功能,它引入了一种特殊的数据类型 - 符号对象; 该数据类型包括符号数字,符号变量,符号表达式和符号函数,还包含符号矩阵,以…...