三、transformers基础组件之Model
1. 什么是Model Head
- Model Head 是连接在模型后的层,通常为1个或多个全连接层
- Model Head 将模型的编码的表示结果进行映射,以解决不同类型的任务
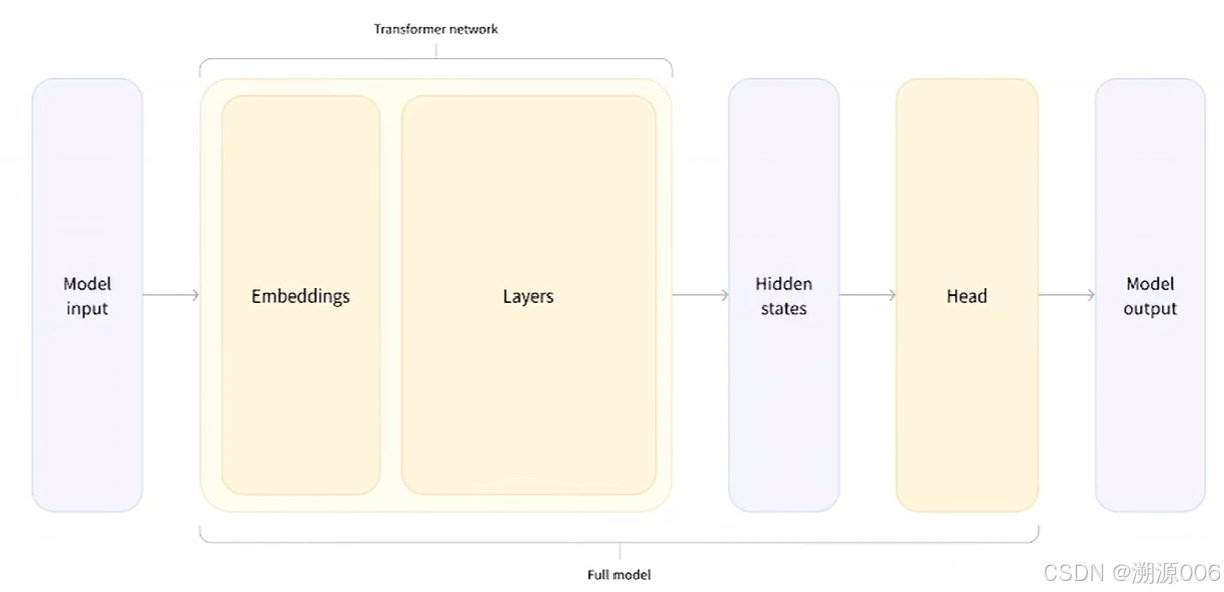
不同的任务会有不同的Model Head。
2. 模型加载
2.1 在线加载
预训练模型的加载与Tokenizer类似,我们只需要指定想要加载的模型名称即可。面对各种类型的模型,transformers也为我们提供了更加便捷的加载方式,我们无需指定具体的模型的类型,可以统一使用AutoModel进行加载。首次加载的时候会进行模型文件的下载,下载后的文件会保存在~/.cache/huggingface/transformers文件夹中。注意:可能会因为网络问题,下载失败。transformers的模型仓库中提供了丰富的模型,我们可以到模型仓库的网站中查看,直接搜索想要的模型。
from transformers import AutoConfig, AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("hfl/rbt3")
2.2 离线加载
如果在线下载失败,可以先手动从huggingface的网站下载模型文献到本地,然后再从本地加载模型。
(1)手动下载模型方式一:浏览器下载
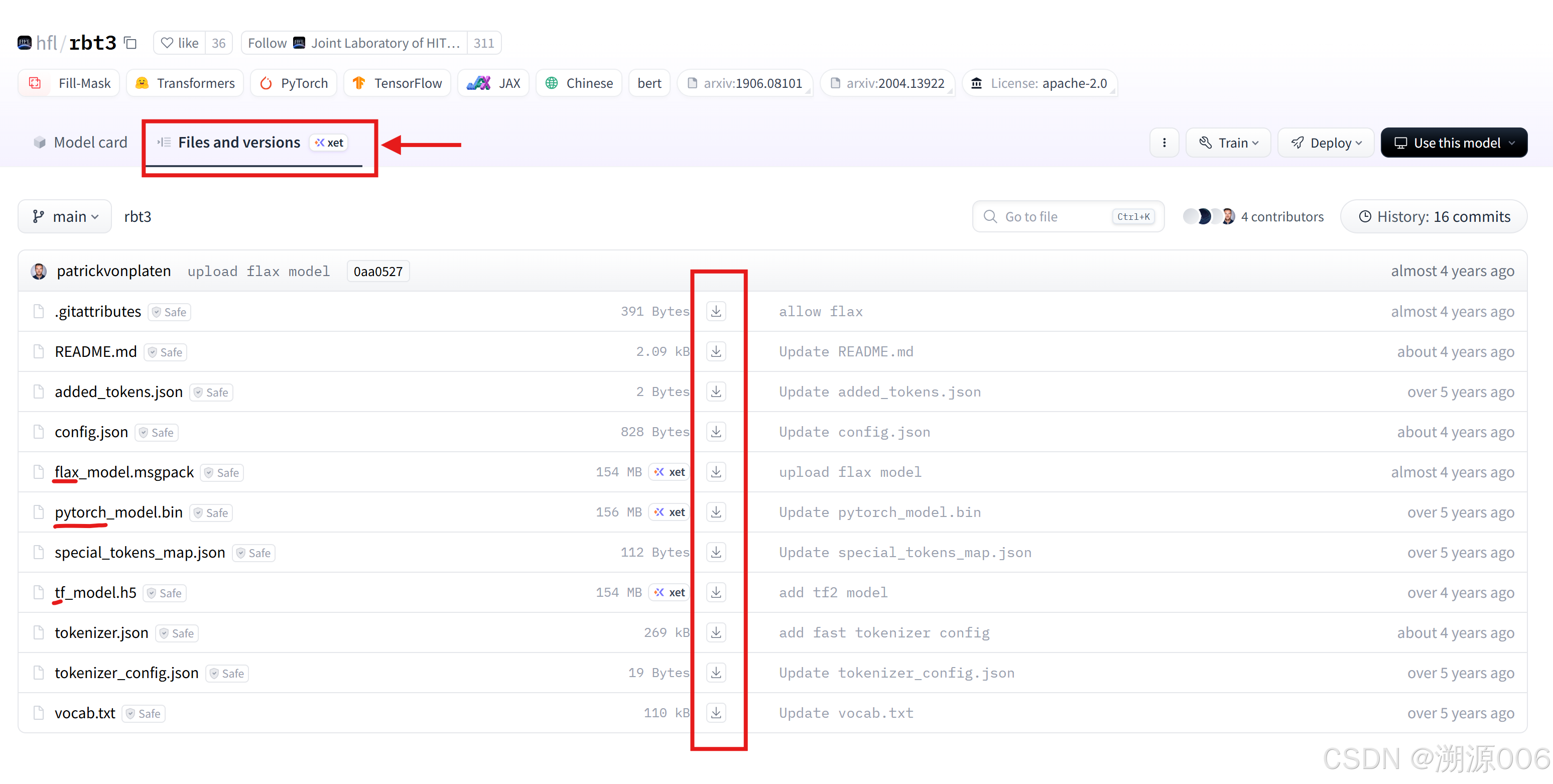
找到模型的files and versions标签页,可以点击下载按钮直接下载对应的文件。可以看到对于rbt3这个模型,三个比较大的文件,分别对应模型的不同版本,我们只需要pytorch版本。
(2)手动下载模型方式一:git clone
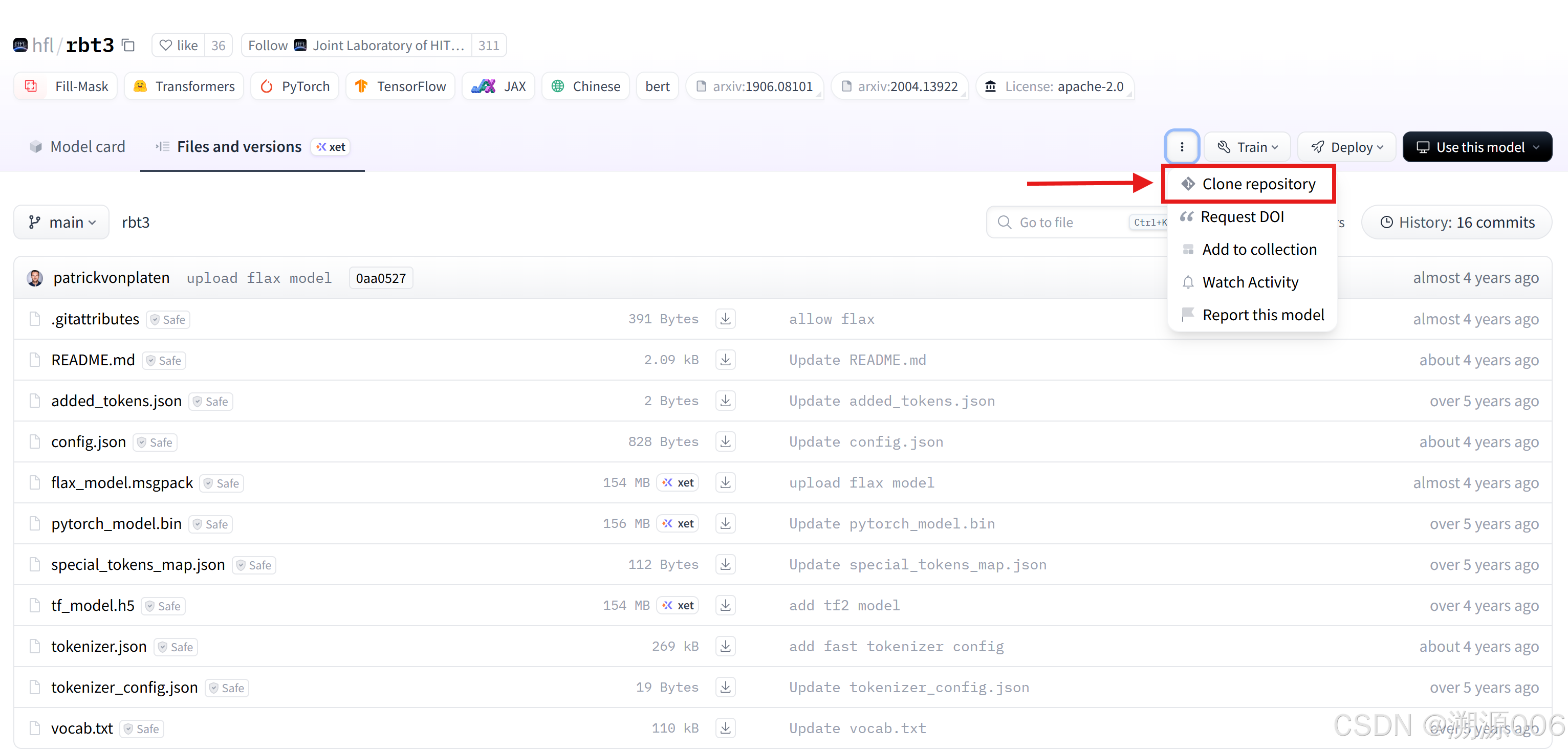
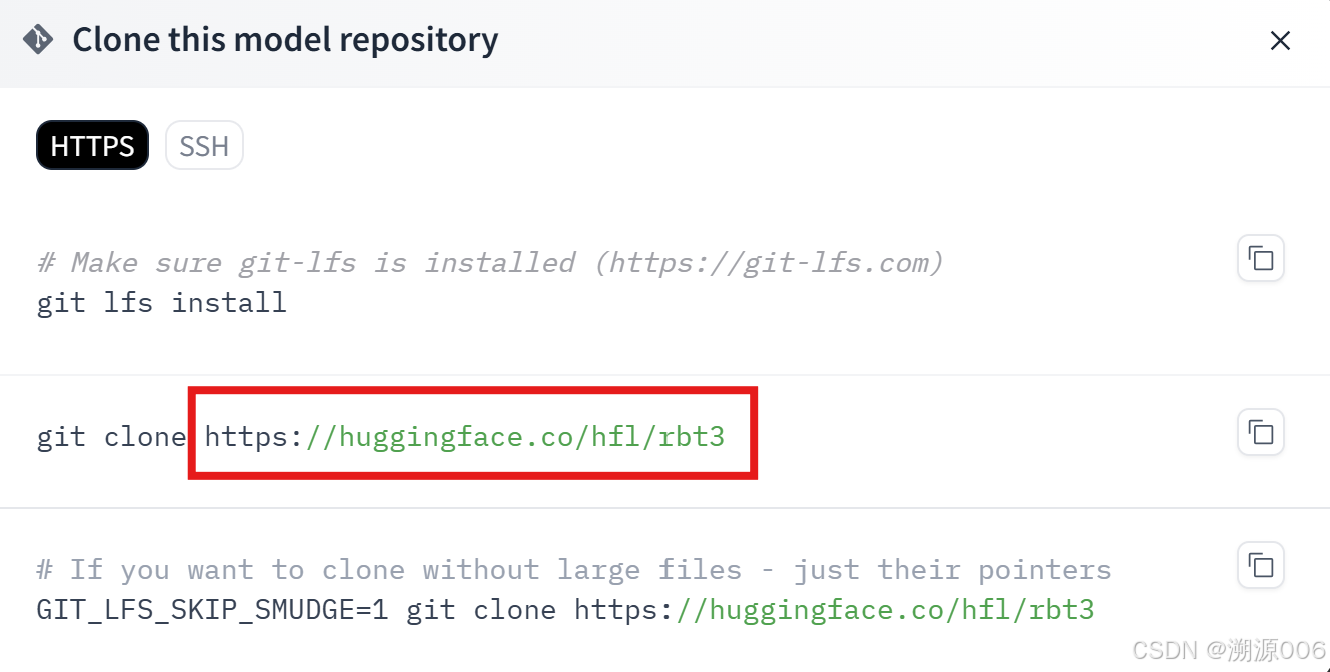
文件里可能包含其他版本的模型文件,如果只想下载pytorch版本的模型文件,如下:
# 可以使用下面命令进行下载 (只下载pytorch的权重文件)
!git lfs clone "https://huggingface.co/hfl/rbt3" --include="*.bin"
然后就可以从本地离线加载了:
# 如果在离线场景下,则需要将模型文件提前准备好,from_pretrained方法中指定本地模型存储的文件夹即可。
model = AutoModel.from_pretrained("../models/rbts")
2.3 加载模型的同时配置参数
加载的时候可以配置一些参数,有哪些参数可以加载呢?可以查看一下:
model.config
或者如下:
config = AutoConfig.from_pretrained("../models/rbts")
以上两种的结果是一样的,如下:
BertConfig {"_attn_implementation_autoset": true,"_name_or_path": "../models/rbts","architectures": ["BertForMaskedLM"],"attention_probs_dropout_prob": 0.1,"classifier_dropout": null,"directionality": "bidi","hidden_act": "gelu","hidden_dropout_prob": 0.1,"hidden_size": 768,"initializer_range": 0.02,"intermediate_size": 3072,"layer_norm_eps": 1e-12,"max_position_embeddings": 512,"model_type": "bert","num_attention_heads": 12,"num_hidden_layers": 3,"output_past": true,"pad_token_id": 0,"pooler_fc_size": 768,"pooler_num_attention_heads": 12,"pooler_num_fc_layers": 3,"pooler_size_per_head": 128,
..."transformers_version": "4.49.0","type_vocab_size": 2,"use_cache": true,"vocab_size": 21128
}
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
可能还不是很全,可以通过如下方式选择参数:
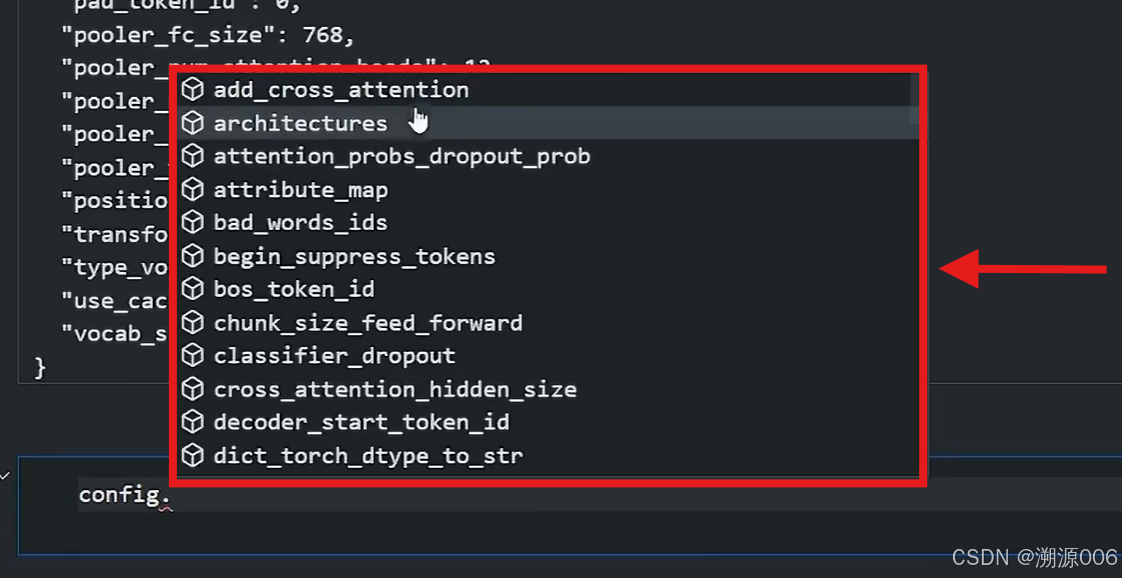
这些参数在哪里呢?首先可以查看config变量属于哪个类.上面的例子属于BertConfig类,进入这个类
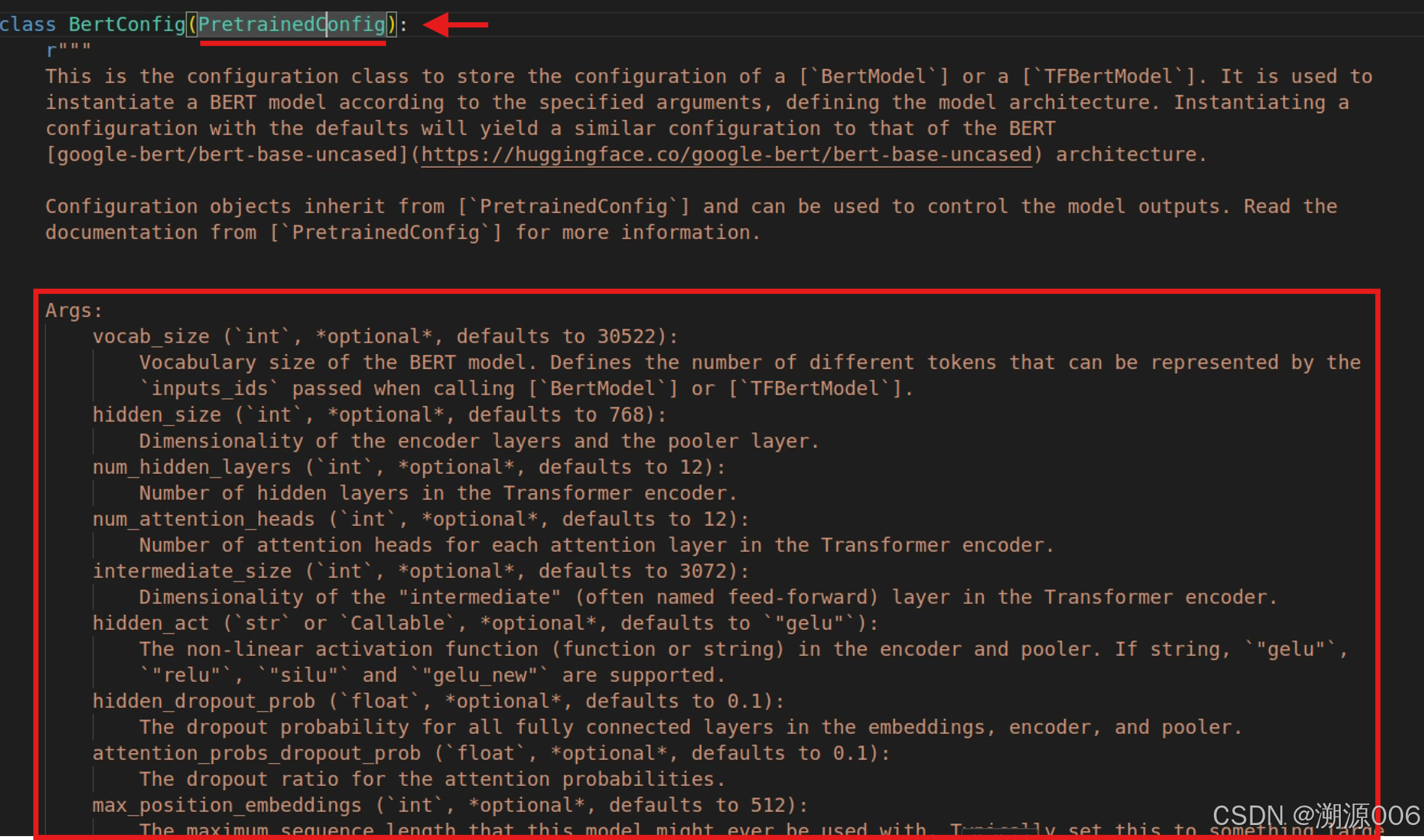
参数还不全,在进入他的父类:
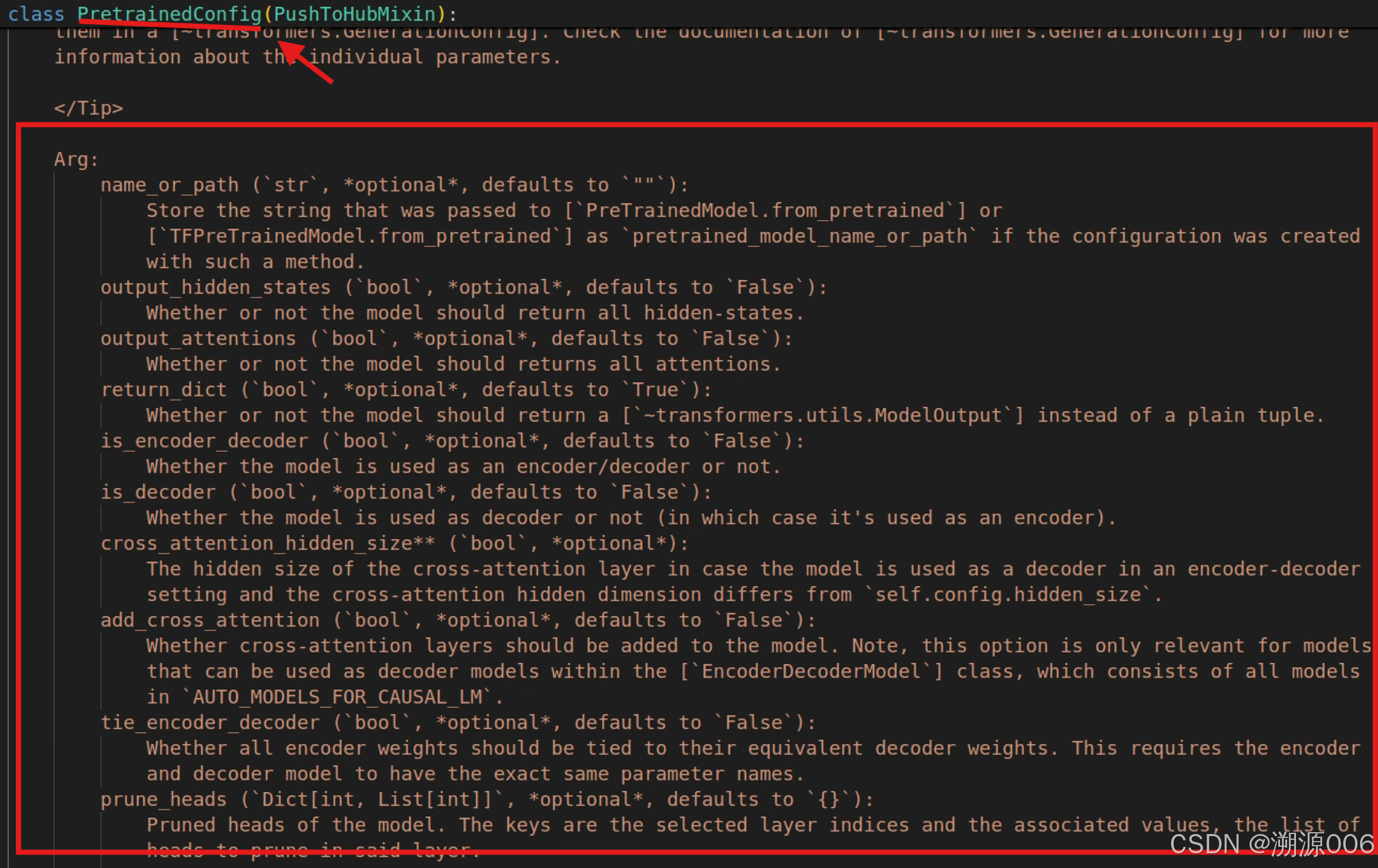
可以看到更多的参数。
3. 模型的调用
3.1 准备(tokenize)
sen = "弱小的我也有大梦想!"
tokenizer = AutoTokenizer.from_pretrained("../models/rbts")
inputs1 = tokenizer(sen)
输出如下:
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 8013, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
返回的每个值是lisst,如果是增加一个参数 return_tensors="pt",让返回pytorch tensors,如下
inputs = tokenizer(sen, return_tensors="pt")
则输出如下:
{'input_ids': tensor([[ 101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 8013, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
分词的时候加上return_tensors="pt"就把list变为pytorch tensor,可以直接输入模型。
3.2 不带Model Head的模型调用(只得到编码结果)
# 数据经过Tokenizer处理后可以便可以直接输入到模型中,得到模型编码
model = AutoModel.from_pretrained(model_path, output_attentions=True)
output = model(**inputs)
返回:
BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=tensor([[[ 0.6804, 0.6664, 0.7170, ..., -0.4102, 0.7839, -0.0262],[-0.7378, -0.2748, 0.5034, ..., -0.1359, -0.4331, -0.5874],[-0.0212, 0.5642, 0.1032, ..., -0.3617, 0.4646, -0.4747],...,[ 0.0853, 0.6679, -0.1757, ..., -0.0942, 0.4664, 0.2925],[ 0.3336, 0.3224, -0.3355, ..., -0.3262, 0.2532, -0.2507],[ 0.6761, 0.6688, 0.7154, ..., -0.4083, 0.7824, -0.0224]]],grad_fn=<NativeLayerNormBackward0>),
pooler_output=tensor([[-1.2646e-01, -9.8619e-01, -1.0000e+00, -9.8325e-01, 8.0238e-01,...,6.7307e-03, 9.9942e-01, -1.8233e-01]], grad_fn=<TanhBackward0>), hidden_states=None,
past_key_values=None,
attentions=(tensor([[[[4.7840e-01, 3.7087e-04, 1.6194e-04, ..., 1.4241e-04,4.1823e-04, 5.1813e-01],...[7.1003e-02, 1.5132e-03, 7.3035e-04, ..., 2.2069e-02,3.9020e-01, 5.0058e-01]]]], grad_fn=<SoftmaxBackward0>), tensor([[[[4.3653e-01, 1.2017e-02, 5.9486e-03, ..., 6.0889e-03,6.2510e-02, 4.1911e-01], ...,[1.7047e-01, 3.6989e-02, 2.3646e-02, ..., 4.6833e-02,2.5233e-01, 1.6721e-01]]]], grad_fn=<SoftmaxBackward0>)), cross_attentions=None)因为设置了output_attentions=True,所以输出的attentions有具体数值,否则为None。
最后一层的输出就是:last_hidden_state,他的维度如下:
output.last_hidden_state.size() # (batch_size, sequence_length, hidden_size)
#torch.Size([1, 12, 768])
3.3 带Model Head的模型调用
- 仅仅使用预训练模型本身,是无法对下游任务进行训练的。
- 想要实现对下游任务的训练,我们需要加载transformers包中的扩展模型(预训练模型+任务头模块)。
- transformers包中提供了多种的任务头。
| NLP任务 | 任务头 |
|---|---|
| 文本分类 | SequenceClassification |
| 文本匹配 | SequenceClassification |
| 阅读理解(抽取式问答) | QuestionAnswering |
| 掩码语言模型 | MaskedLM |
| 文本生成 | CausalLM |
| 命名实体识别 | TokenClassification |
| 文本摘要 | Seq2SeqLM |
| 机器翻译 | Seq2SeqLM |
| 生成式问答 | Seq2SeqLM |
在代码上,就是我们不再导入AutoModel,而是导入AutoModelFor+任务头名称。 | |
| 假设我们要做文本分类任务,那么则应该导入AutoModelForSequenceClassification。 | |
| 这里需要注意,并不是每个模型都具备上述的全部任务头。预训练模型具体支持哪些任务头,需要到官网或者源码中进行查看。 |
from transformers import AutoModelForSequenceClassification
clz_model = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=10)
clz_model(**inputs)
输出结果如下:
SequenceClassifierOutput(
loss=None,
logits=tensor([[-0.1776, 0.2208, -0.5060, -0.3938, -0.5837, 1.0171, -0.2616, 0.0495, 0.1728, 0.3047]],
grad_fn=<AddmmBackward0>),
hidden_states=None,
attentions=None
)
logits的元素个数与num_labels保持一致。
3.4 带model head 与不带model head的的对比
(1) 加载方式不同
不带model head的模型用AutoModel.from_pretrained加载模型
model = AutoModel.from_pretrained(model_path, output_attentions=True)
带model head的模型用 AutoModelForSequenceClassification.from_pretrained加载模型
clz_model = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=10)
(2) 模型的不同
不带model head的模型:
BertModel((embeddings): BertEmbeddings((word_embeddings): Embedding(21128, 768, padding_idx=0)(position_embeddings): Embedding(512, 768)(token_type_embeddings): Embedding(2, 768)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(encoder): BertEncoder((layer): ModuleList((0-2): 3 x BertLayer((attention): BertAttention((self): BertSdpaSelfAttention((query): Linear(in_features=768, out_features=768, bias=True)(key): Linear(in_features=768, out_features=768, bias=True)(value): Linear(in_features=768, out_features=768, bias=True)(dropout): Dropout(p=0.1, inplace=False))(output): BertSelfOutput((dense): Linear(in_features=768, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))(intermediate): BertIntermediate((dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation())(output): BertOutput((dense): Linear(in_features=3072, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))))(pooler): BertPooler((dense): Linear(in_features=768, out_features=768, bias=True)(activation): Tanh())
)
带model head的模型:
BertForSequenceClassification((bert): BertModel((embeddings): BertEmbeddings((word_embeddings): Embedding(21128, 768, padding_idx=0)(position_embeddings): Embedding(512, 768)(token_type_embeddings): Embedding(2, 768)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(encoder): BertEncoder((layer): ModuleList((0-2): 3 x BertLayer((attention): BertAttention((self): BertSdpaSelfAttention((query): Linear(in_features=768, out_features=768, bias=True)(key): Linear(in_features=768, out_features=768, bias=True)(value): Linear(in_features=768, out_features=768, bias=True)(dropout): Dropout(p=0.1, inplace=False))(output): BertSelfOutput((dense): Linear(in_features=768, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))(intermediate): BertIntermediate((dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation())(output): BertOutput((dense): Linear(in_features=3072, out_features=768, bias=True)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)))))(pooler): BertPooler((dense): Linear(in_features=768, out_features=768, bias=True)(activation): Tanh()))(dropout): Dropout(p=0.1, inplace=False)(classifier): Linear(in_features=768, out_features=10, bias=True)
)
可以看到带model head的模型就是在不带model head的模型加了最后的:
(dropout): Dropout(p=0.1, inplace=False)(classifier): Linear(in_features=768, out_features=10, bias=True)
3.5 一个例子:基于pytorch和model进行情感分类训练
任务类型:文本分类
使用模型:hfl/rbt3
数据集地址:https://github.com/SophonPlus/ChineseNlpCorpus
数据集:
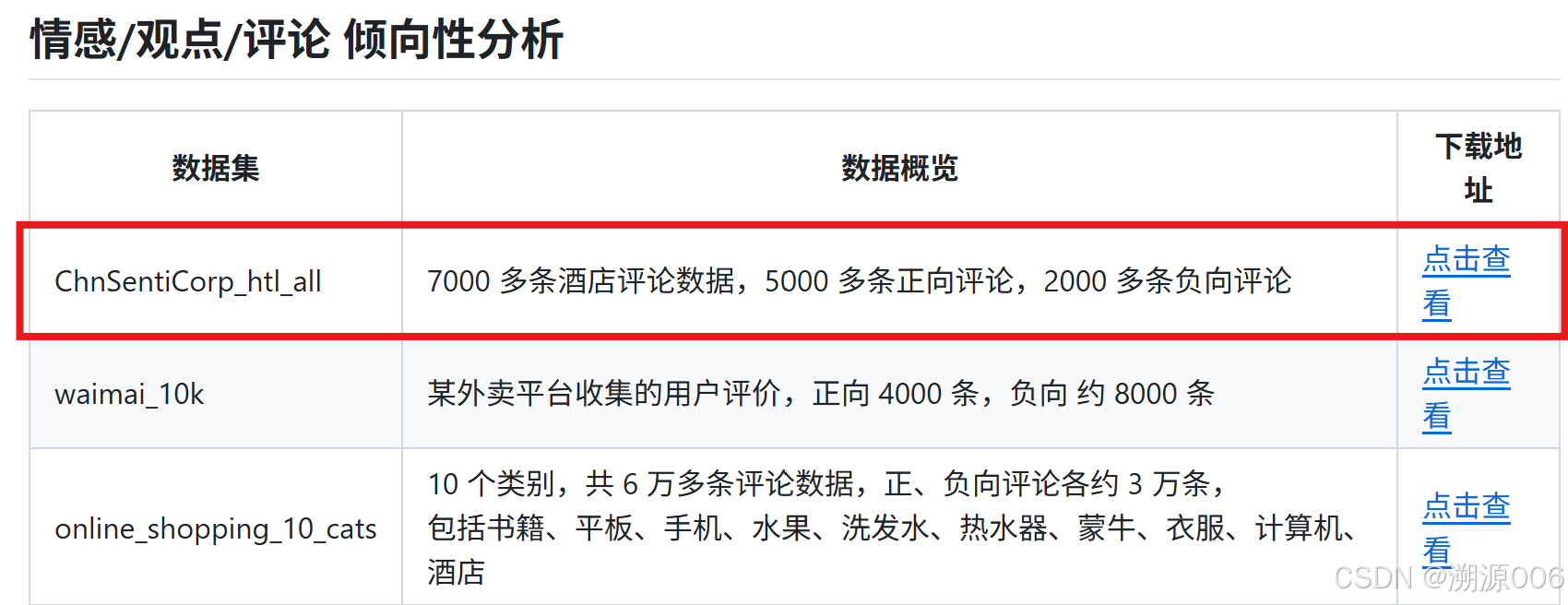
大概看一下数据集的样子:

包含两列:第一列是类别,好评是1,差评是0.
3.5.1 加载数据
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from torch.utils.data import Dataset
import pandas as pdimport warnings
warnings.filterwarnings("ignore")class MyDataset(Dataset):def __init__(self) -> None:super().__init__()self.data = pd.read_csv("./ChnSentiCorp_htl_all.csv")self.data = self.data.dropna()def __getitem__(self, index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]def __len__(self):return len(self.data)
读取数据,展示前5条:
dataset = MyDataset()
for i in range(5):print(dataset[i])
打印如下:
('距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦.建议用别的路线.房间较为简单.', 1)
('商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!', 1)
('早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。房间本身很好。', 1)
('宾馆在小街道上,不大好找,但还好北京热心同胞很多~宾馆设施跟介绍的差不多,房间很小,确实挺小,但加上低价位因素,还是无超所值的;环境不错,就在小胡同内,安静整洁,暖气好足-_-||。。。呵还有一大优势就是从宾馆出发,步行不到十分钟就可以到梅兰芳故居等等,京味小胡同,北海距离好近呢。总之,不错。推荐给节约消费的自助游朋友~比较划算,附近特色小吃很多~', 1)
('CBD中心,周围没什么店铺,说5星有点勉强.不知道为什么卫生间没有电吹风', 1)
3.5.2 创建Dataloader
from torch.utils.data import random_split
import torch
from torch.utils.data import DataLoader# 划分训练集及验证集
trainset, validset = random_split(dataset, lengths=[0.9, 0.1])# 离线加载模型
model_path = '/root/autodl-fs/models/rbt3'
tokenizer = AutoTokenizer.from_pretrained(model_path)# 对一批数据进行词元化,并且填充到相同的长度
def collate_func(batch):texts, labels = [], []for item in batch:texts.append(item[0])labels.append(item[1])inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt")###所有样本对齐到128这个长度inputs["labels"] = torch.tensor(labels)return inputstrainloader = DataLoader(trainset, batch_size=32, shuffle=True, collate_fn=collate_func)
validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=collate_func)
next(enumerate(validloader))[1]
这里有一个重要的方法:collate_func,用于对数据进行处理。需要作为参数传入DataLoader。collate_func的输入是__getitem__方法的输出。
{'input_ids': tensor([[ 101, 2769, 812, ..., 0, 0, 0],[ 101, 6983, 2421, ..., 0, 0, 0],[ 101, 6392, 3177, ..., 0, 0, 0],...,[ 101, 3302, 1218, ..., 0, 0, 0],[ 101, 2600, 860, ..., 752, 2141, 102],[ 101, 1765, 4415, ..., 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],
...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 0, 0, 0],...,[1, 1, 1, ..., 0, 0, 0],[1, 1, 1, ..., 1, 1, 1],[1, 1, 1, ..., 0, 0, 0]]), 'labels': tensor([1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1,1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1])}3.5.3 创建模型及优化器
from torch.optim import Adam# 创建到Model Head的模型
model = AutoModelForSequenceClassification.from_pretrained(model_path)if torch.cuda.is_available():model = model.cuda() #把model放GPU上# 创建优化器
optimizer = Adam(model.parameters(), lr=2e-5)
3.5.4 训练及评估
# 自定义评估 评估指标accuracy
def evaluate():model.eval() ##开启评估模式acc_num = 0with torch.inference_mode():for batch in validloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}output = model(**batch)pred = torch.argmax(output.logits, dim=-1)acc_num += (pred.long() == batch["labels"].long()).float().sum()return acc_num / len(validset)# 自定义训练
def train(epoch=3, log_step=100):global_step = 0for ep in range(epoch):model.train() #开启model的trian模式for batch in trainloader: #从trainloader取数据if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}##把数据放gpu上optimizer.zero_grad() ##梯度归零output = model(**batch) ##前向计算,输出是包含loss的output.loss.backward() ##反向传播optimizer.step() ##梯度更新if global_step % log_step == 0: ##打印日志print(f"ep: {ep}, global_step: {global_step}, loss: {output.loss.item()}")global_step += 1acc = evaluate() ##评估性能print(f"ep: {ep}, acc: {acc}")3.5.5 模型训练
train()
ep: 0, global_step: 0, loss: 0.7741488814353943
ep: 0, global_step: 100, loss: 0.38942962884902954
ep: 0, global_step: 200, loss: 0.1997242420911789
ep: 0, acc: 0.8801546096801758ep: 1, global_step: 300, loss: 0.16735711693763733
ep: 1, global_step: 400, loss: 0.39419108629226685
ep: 1, acc: 0.8969072103500366ep: 2, global_step: 500, loss: 0.20464470982551575
ep: 2, global_step: 600, loss: 0.4124392569065094
ep: 2, acc: 0.8917525410652161
3.5.6 模型预测
(1)手动写所有过程:
sen = "我觉得这家酒店不错,饭很好吃!"
id2_label = {0: "差评!", 1: "好评!"}
model.eval()
with torch.inference_mode():inputs = tokenizer(sen, return_tensors="pt")inputs = {k: v.cuda() for k, v in inputs.items()}##数据放gpu上logits = model(**inputs).logits##前向计算得到logitspred = torch.argmax(logits, dim=-1)print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}")
输入:我觉得这家酒店不错,饭很好吃!
模型预测结果:好评!
(2)pipline的方法:
from transformers import pipeline# 使用pipeline进行预测
model.config.id2label = id2_label###设置一下id2label
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)pipe('我这家饭店饭很贵,菜很贵,不喜欢吃')
[{'label': '差评!', 'score': 0.5992199182510376}]
参考:
【1】【手把手带你实战HuggingFace Transformers-入门篇】基础组件之Model(上)基本使用_哔哩哔哩_bilibili
【2】Transformers基本组件(一)快速入门Pipeline、Tokenizer、Model_transformers.pipeline-CSDN博客
相关文章:
三、transformers基础组件之Model
1. 什么是Model Head Model Head 是连接在模型后的层,通常为1个或多个全连接层Model Head 将模型的编码的表示结果进行映射,以解决不同类型的任务 不同的任务会有不同的Model Head。 2. 模型加载 2.1 在线加载 预训练模型的加载与Tokenizer类似,我们只需要指定想…...

【语法】C++的多态
目录 虚函数的重写: 虚函数 重写(覆盖) 虚函数重写的两个例外: 协变: 析构函数的重写: 练习: final和override关键字 抽象类 接口继承和实现继承 虚函数重写的原理: 打印虚函数表: …...

WebGIS开发新突破:揭秘未来地理信息系统的神秘面纱
你有没有想过,未来的地理信息系统(GIS)会是什么样子?是像电影里那样,一块透明屏幕就能呈现整个城市的实时动态?还是像《钢铁侠》中那样,一个手势就能操控全球地图? 其实,…...

JVM类加载
JVM类加载 1. 类的生命周期(类加载过程)类加载的五个阶段: 2. 类加载器的分类3. 双亲委派模型4. 类的卸载与热加载5.类加载器命名空间隔离 1. 类的生命周期(类加载过程) 类加载的五个阶段: 加载ÿ…...

AD开启交叉选择功能,只选中器件,不选中网络、焊盘
AD开启交叉选择功能,只选中器件,不选中网络、焊盘。 一、打开首选项 二、打开System→Navigationg,配置如下。 三、最后点击OK即可。...

机器学习——集成学习基础
一、鸢尾花数据训练模型 1. 使用鸢尾花数据分别训练集成模型:AdaBoost模型,Gradient Boosting模型 2. 对别两个集成模型的准确率以及报告 3. 两个模型的预测结果进行可视化 需要进行降维处理,两个图像显示在同一个坐标系中 代码展示&…...

C++匿名函数
C 中的匿名函数(Lambda 表达式)是 C11 引入的一项重要特性,它允许你在需要的地方定义一个临时的、无名的函数对象,使代码更加简洁和灵活。 1. 基本语法 Lambda 表达式的基本结构: [capture list](parameter list) -…...

互联网大厂Java面试实战:Spring Boot到微服务的技术问答解析
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通 😁 2. 毕业设计专栏,毕业季咱们不慌忙,几百款毕业设计等你选。 ❤️ 3. Python爬虫专栏…...

神经网络是如何工作的
人工智能最核心的技术之一,就是神经网络(Neural Networks)。但很多初学者会觉得它是个黑盒:为什么神经网络能识别图片、翻译语言,甚至生成文章? 本文用图解最小代码实现的方式,带你深入理解&am…...
:核心功能层)
Kubernetes控制平面组件:Kubelet详解(二):核心功能层
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

【android bluetooth 框架分析 02】【Module详解 13】【CounterMetrics 模块介绍】
1. CounterMetrics 介绍 CounterMetrics 模块代码很少, 我简单介绍一下。 // system/gd/metrics/counter_metrics.cc #define LOG_TAG "BluetoothCounterMetrics"#include "metrics/counter_metrics.h"#include "common/bind.h" #i…...

Matlab自学笔记五十四:符号数学工具箱和符号运算、符号求解、绘图
1.什么是符号数学工具箱? 符号数学工具箱是Matlab针对符号对象的运算功能,它引入了一种特殊的数据类型 - 符号对象; 该数据类型包括符号数字,符号变量,符号表达式和符号函数,还包含符号矩阵,以…...

Matlab 模糊控制平行侧边自动泊车
1、内容简介 Matlab 233-模糊控制平行侧边自动泊车 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

新书速览|纯血鸿蒙HarmonyOS NEXT原生开发之旅
《纯血鸿蒙HarmonyOS NEXT原生开发之旅》 本书内容 《纯血鸿蒙HarmonyOS NEXT原生开发之旅》全面系统地介绍了基于HarmonyOS NEXT系统进行原生应用开发的实用技巧。全书共12章,内容涵盖从基础工具使用到高级功能实现的各个方面。第1章详细介绍了开发环境的搭建、Ar…...
数据类型讲解)
tinyint(3)数据类型讲解
TINYINT(3) 是数据库中用于定义字段数据类型的一种写法,常见于 MySQL 等数据库系统。下面来详细了解其含义和作用: 数据类型本质 TINYINT 属于整数类型,在不同的数据库系统中,它所占用的存储空间和表示范围通常是固定的。以 MyS…...

manjaro系统详解
1. Manjaro 概述 Manjaro 是一款基于 Arch Linux 的滚动更新发行版,以 用户友好、易用性 和 硬件兼容性 为核心设计理念。它继承了 Arch 的灵活性和软件丰富性,同时通过图形化工具和稳定的更新策略降低了使用门槛,适合从新手到高级用户的广泛…...

# 实时英文 OCR 文字识别:从摄像头到 PyQt5 界面的实现
实时英文 OCR 文字识别:从摄像头到 PyQt5 界面的实现 引言 在数字化时代,文字识别技术(OCR)在众多领域中发挥着重要作用。无论是文档扫描、车牌识别还是实时视频流中的文字提取,OCR 技术都能提供高效且准确的解决方案…...

9.3.云原生架构模式
目录 一、云原生架构核心概念 云原生定义与核心原则 • 四大核心要素:容器化、微服务、DevOps、持续交付 • 核心原则:弹性、可观测性、自动化、不可变基础设施 云原生技术矩阵 • 容器与编排:Docker、Kubernetes、CRI-O • 服务治理&#…...

现代化水库运行管理矩阵平台如何建设?
政策背景 2023年8月24日,水利部发布的水利部关于加快构建现代化水库运行管理矩阵的指导意见中指出,在全面推进水库工程标准化管理的基础上,强化数字赋能,加快构建以推进全覆盖、全要素、全天候、全周期“四全”管理,完…...

木马查杀引擎—关键流程图
记录下近日研究的木马查杀引擎,将关键的实现流程图画下来 PHP AST通道实现 木马查杀调用逻辑 模型训练流程...

基于libevent的异步事件驱动型线程池实现
----------------------| IFoxThread | ← 抽象线程接口|----------------------|| dispatch() || start() || stop() || ... |----------^-----------|--------------------|----------------------| …...

ArcGIS+InVEST+RUSLE:水土流失模拟与流域管理的高效解决方案;水土保持专题地图制作
在全球生态与环境面临严峻挑战的当下,水土流失问题已然成为制约可持续发展的重要因素之一。水土流失不仅影响土地资源的可持续利用,还对生态环境、农业生产以及区域经济发展带来深远影响。因此,科学、精准地模拟与评估水土流失状况࿰…...

#S4U2SELF#S4U2Proxy#CVE-2021-42278/42287
#S4U2SELF Win08创建普通用户 s4u2 xwj456 可以看到普通用户是没用委托属性的 Win08手动赋予委托服务属性 setspn -A wsw/wsw.com s4u2 Win10身份验证 s4u2 xwj456 AS请求 两个勾 两个勾和include-pac记得按上(蓝色) ,发包之前把wiresh…...

利用基于LLM的概念提取和FakeCTI数据集提升网络威胁情报对抗虚假信息活动的能力
摘要 虚假新闻和虚假信息宣传活动的迅速蔓延对公众信任、政治稳定和网络安全构成了重大威胁。传统的网络威胁情报(CTI)方法依赖于域名和社交媒体账号等低级指标,很容易被频繁修改其在线基础设施的对手规避。为了解决这些局限性,我…...
)
uniapp|实现手机通讯录、首字母快捷导航功能、多端兼容(H5、微信小程序、APP)
基于uniapp实现带首字母快捷导航的通讯录功能,通过拼音转换库实现汉字姓名首字母提取与分类,结合uniapp的scroll-view组件与pageScrollTo API完成滚动定位交互,并引入uni-indexed-list插件优化索引栏性能。 目录 核心功能实现动态索引栏生成联系人列表渲染滚动定位联动性…...

使用PhpStudy搭建Web测试服务器
一、安装PhpStudy 从以下目录下载PhpStudy安装文件 Windows版phpstudy下载 - 小皮面板(phpstudy) (xp.cn) 安装成功之后打开如下界面 点击启动Apache 查看网站地址 在浏览器中输入localhost:88,出现如下页面就ok了 二、与Unity交互 1.配置下载文件路径,点击…...

Qt/C++面试【速通笔记九】—视图框架机制
在Qt中,QGraphicsView和QGraphicsScene是用于构建二维图形界面的核心组件。它们的设计使得开发者能够高效地管理和渲染图形项,支持丰富的用户交互,例如缩放、旋转、平移等。 1. QGraphicsScene和QGraphicsView的基本概念 QGraphicsScene QG…...

react-diff-viewer 如何实现语法高亮
前言 react-diff-viewer 是一个很好的 diff 展示库,但是也有一些坑点和不完善的地方,本文旨在描述如何在这个库中实现自定义语法高亮。 Syntax highlighting is a bit tricky when combined with diff. Here, React Diff Viewer provides a simple rend…...

Python实例题:Django搭建简易博客
目录 Python实例题 题目 1. 创建 Django 项目和应用 2. 配置项目 3. 设计模型 blog_app templates blog_app post_list.html admin.py models.py urls.py views.py blog_project urls.py 代码解释 models.py: admin.py: urls.py&…...

Kotlin 异步初始化值
在一个类初始化的时候或者方法执行的时候,总有一些值是需要的但是不是立即需要的,并且在需要的时候需要阻塞流程来等待值的计算,这时候异步的形式创建这个值是毋庸置疑最好的选择。 为了更好的创建值需要使用 Kotlin 的协程来创建࿰…...

扩展:React 项目执行 yarn eject 后的 config 目录结构详解
扩展:React 项目执行 yarn eject 后的 config 目录结构详解 什么是 yarn eject?React 项目执行 yarn eject 后的 config 目录结构详解📁 config 目录结构各文件作用详解env.jsgetHttpsConfig.jsmodules.jspaths.jswebpack.config.jswebpackDe…...
Java学习-5.8(总结,springboot))
(自用)Java学习-5.8(总结,springboot)
一、MySQL 数据库 表关系 一对一、一对多、多对多关系设计外键约束与级联操作 DML 操作 INSERT INTO table VALUES(...) DELETE FROM table WHERE... UPDATE table SET colval WHERE...DQL 查询 基础查询:SELECT * FROM table WHERE...聚合函数:COUNT()…...

cursor 如何在项目内自动创建规则
在对话框内 / Generate。cursor rules 就会自动根据项目进行创建规则 文档来自:https://www.kdocs.cn/l/cp5GpLHAWc0p...

C++ 迭代器
1.用途: 像我们之前学习的容器map,vector等,如果需要遍历该怎么做呢?这些容器大部分对下标式遍历,无法像数组灵活使用,也包括增删改查,因为它们的特性,所以需要一种其他的方法。 那么迭代器就…...

基于微信小程序的城市特色旅游推荐应用的设计与实现
💗博主介绍💗:✌在职Java研发工程师、专注于程序设计、源码分享、技术交流、专注于Java技术领域和毕业设计✌ 温馨提示:文末有 CSDN 平台官方提供的老师 Wechat / QQ 名片 :) Java精品实战案例《700套》 2025最新毕业设计选题推荐…...

最大m子段和
问题描述解题思路伪代码代码实现复杂度分析 问题描述 给定一个有n(n>0)个整数的序列,要求其m个互不相交的子段,使得这m个子段和最大。 输入:整数序列{nums},m。 输出:最大m子段和。 对于m1的情况,即求最…...

4.MySQL全量、增量备份与恢复
1.数据备份的重要性 在企业中数据的价值至关重要,数据保障了企业业务的正常运行。因此,数据的安全性及数据的可靠性是运维的重中之重,任何数据的丢失都可能对企业产生严重的后果。通常情况下造成数据丢失的原因有如下几种: a.程…...

每日算法刷题Day4 5.12:leetcode数组4道题,用时1h
7. 704.二分查找 704. 二分查找 - 力扣(LeetCode) 思想 二分模版题 代码 c: class Solution { public:int search(vector<int>& nums, int target) {int nnums.size();int left0,rightn-1;int res-1;while(left<right){int midleft((…...

Day 15
目录 1.chika和蜜柑1.1 解析1.2 代码 2.对称之美2.1 解析2.2 代码 3.添加字符3.1 解析3.2 代码 1.chika和蜜柑 chika和蜜柑 TopK、堆、排序 1.1 解析 1.2 代码 #include <iostream> #include <vector> #include <algorithm> using namespace std; struct …...
为例)
脑机接口重点产品发展路径分析:以四川省脑机接口及人机交互产业攻坚突破行动计划(2025-2030年)为例
引言 随着人工智能和生物技术的飞速发展,脑机接口技术作为连接人类大脑与智能设备的桥梁,正在成为全球科技竞争的新焦点。2025年5月12日,四川省经济和信息化厅等8部门联合印发了《四川省脑机接口及人机交互产业攻坚突破行动计划(2025-2030年)》,为四川省在这一前沿领域的…...

leetcode 18. 四数之和
题目描述 和leetcode 15. 三数之和用同样的方法。有两个注意点。 一是剪枝的逻辑 这是和15. 三数之和 - 力扣(LeetCode)问题不同的地方。 无法通过这种情况: 二是整数溢出 最终答案 class Solution { public:vector<vector<int>…...

CentOS部署Collabora Online
1.安装Docker CentOS7安装Docker(超详细)-CSDN博客 2.拉取镜像 docker pull collabora/code:latest 3. 启动容器(直接暴露HTTP端口) docker run -d --name collabora -p 9980:9980 -e "usernameadmin" -e "password123456" -e …...

《Spring Boot 4.0新特性深度解析》
Spring Boot 4.0的发布标志着Java生态向云原生与开发效能革命的全面迈进。作为企业级应用开发的事实标准框架,此次升级在运行时性能、云原生支持、开发者体验及生态兼容性四大维度实现突破性创新。本文深度解析其核心技术特性,涵盖GraalVM原生镜像支持、…...
—— 环境配置与视频解封装)
FFmpeg 与 C++ 构建音视频处理全链路实战(一)—— 环境配置与视频解封装
在数字媒体的浩瀚宇宙中,FFmpeg 就像一艘功能强大的星际战舰,承载着处理音视频数据的重任。而 C 作为一门高效、灵活的编程语言,犹如一位技艺精湛的星际工程师,能够精准操控 FFmpeg 战舰,完成各类复杂的音视频处理任务…...
 的主要区别是什么?)
什么是 NoSQL 数据库?它与关系型数据库 (RDBMS) 的主要区别是什么?
我们来详细分析一下 NoSQL 数据库与关系型数据库 (RDBMS) 的主要区别。 什么是 NoSQL 数据库? NoSQL (通常指 “Not Only SQL” 而不仅仅是 “No SQL”) 是一类数据库管理系统的总称。它们的设计目标是解决传统关系型数据库 (RDBMS) 在某些场景下的局限性…...

AI需求分析话术 | DeepSeek R1
运行环境:jupyter notebook (python 3.12.7) Dash 场景: 收集了小程序的问题点和优化建议,一键AI分析,快速排优先级 指令话术: 对收集的小程序问题点和建议,做需求分析并总结形成报告,报告结构…...

【Redis】键值对数据库实现
目录 1、背景2、五种基本数据类型对应底层实现3、redis数据结构 1、背景 redis是一个(key-value)键值对数据库,其中value可以是五大基本数据类型:string、list、hash、set、zset,这五大基本数据类型对应着不同的底层结…...
)
MySQL 8.0 OCP 英文题库解析(三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题16~25 试题16:…...

互联网大厂Java求职面试:优惠券服务架构设计与AI增强实践-1
互联网大厂Java求职面试:优惠券服务架构设计与AI增强实践-1 在一间简洁明亮的会议室里,郑薪苦正面对着一位技术总监级别的面试官,这位面试官拥有超过十年的大型互联网企业经验,以技术全面性与落地能力著称。 第一轮面试…...

object的常用方法
在面向对象编程中,Object 类是所有类的根类,它提供了一些基本的方法,这些方法可以被所有对象继承和使用。以下是一些在 Java 中 Object 类的常用方法,以及它们的作用和使用示例: 1. equals(Object obj) 作用ÿ…...