论文学习_A Survey of Binary Code Similarity
摘要:二进制代码相似性方法的主要目的是比较两个或多个二进制代码片段,以识别它们之间的相似性与差异(研究背景)。由于在许多实际场景中源代码往往不可获取,因此具备比较二进制代码的能力显得尤为重要,例如在补丁分析、漏洞搜索以及恶意软件检测与分析等领域都有广泛应用(研究意义)。过去二十年中,研究人员提出了大量与二进制代码相似性相关的方法,但这一研究方向尚未经过系统性的梳理与分析(现存问题)。为此,有研究首次对该领域进行了全面的综述。文章分析了61种代表性的方法,并从四个维度对它们进行了系统化整理:一是这些方法所支持的具体应用;二是各自的技术特点;三是它们的实现方式;四是所采用的评估基准和方法。除此之外,该综述还讨论了这一研究领域的起源与发展历程,并指出了当前所面临的挑战与未来的发展方向。
引言
二进制代码相似性方法主要用于比较两个或多个二进制代码片段,例如基本块、函数甚至整个程序,以识别它们之间的相似性和差异。在源代码不可用的情况下,比较二进制代码显得尤为关键,这种情况常见于商业现成软件(COTS)、遗留系统以及恶意软件分析中。实际上,二进制代码相似性在多个现实应用中都扮演着核心角色,比如漏洞搜索、恶意软件聚类、恶意软件检测、恶意软件家族演化分析、补丁生成与分析、跨版本迁移信息、以及软件盗版检测等。这些应用在过去的研究中都有广泛探讨和实践,涵盖了多个方向,体现了该技术的广泛价值和应用潜力。BCSD的定义及意义
识别二进制代码的相似性是一项具有挑战性的任务,原因在于编译过程会导致大量程序语义信息的丢失,比如函数名、变量名、源代码注释以及数据结构的定义等。此外,即使源代码本身没有任何修改,只要重新编译,生成的二进制代码也可能发生变化。这种变化往往是由于编译过程中引入的一些间接改动造成的。例如,更换编译器、调整编译优化选项、或者改变目标操作系统和CPU架构,都可能导致最终生成的二进制代码在结构和内容上出现明显差异。更复杂的是,源代码或生成的二进制文件还可能经过混淆处理,使得原始逻辑被进一步隐藏,从而加大了识别相似性的难度。BCSD过程中存在的挑战
鉴于其广泛的应用价值以及面临的诸多挑战,在过去二十年中,研究人员提出了大量关于二进制代码相似性的研究方法。然而,令人遗憾的是,至今尚未有针对该领域的系统性综述。此前的一些综述主要关注的是与该领域相关但又有所区别的方向,比如打包工具中的二进制代码混淆技术、二进制代码类型推断,以及动态恶意软件分析方法等。这些研究方向与二进制代码相似性存在一定关联——例如在处理混淆问题时需要用到相似性分析,类型推断也可能借助相似的二进制分析平台,而恶意软件往往也是相似性检测的重要对象。但从已有综述所涵盖的论文范围来看,它们与本文所分析的研究工作并无重叠,足以说明二进制代码相似性是一个相对独立的研究方向。另有一些综述探讨的是更广义的二进制数据相似性检测问题,例如基于哈希的相似搜索,或针对数值型与二进制特征向量的相似性度量方法。但与这些综述不同,本文聚焦于能够对比二进制代码的研究方法,也就是说,关注那些能够对可执行字节流进行反汇编分析的方法。创新性声明,聚焦基于反汇编的BCSD方法
这篇论文首次对二进制代码相似性研究进行了全面的综述。作者通过系统性的筛选流程,从计算机科学多个领域——包括计算机安全、软件工程、编程语言以及机器学习等——所发表的上百篇论文中,最终确定了61种具有代表性的二进制代码相似性方法。在此基础上,文章从四个关键维度对这些方法进行了系统化分类:(1)它们所支持的具体应用场景;(2)各自方法的核心特征;(3)这些方法是如何实现的;以及(4)用于评估这些方法的基准和评价体系。此外,文章还对二进制代码相似性这一研究方向的起源与发展范围进行了探讨,梳理了其在过去二十年的演进过程,并分析了当前所面临的挑战与未来可能的发展方向。研究内容概述,从四个关键维度对BCSD进行分类
论文结构方面,论文的组织安排如下:第二节将介绍二进制代码相似性的基本概念和背景;第三节说明本综述的研究范围及所采用的文献筛选流程;第四节总结了二进制代码相似性在实际中的应用场景;第五节回顾了该领域在过去二十年中的发展演变;第六节对所选取的61种方法的核心特征进行了系统化整理;第七节聚焦于这些方法的实现细节;第八节则分析了它们的评估方式。最后,第九节讨论了未来的研究方向,第十节对全文进行了总结。
基础知识
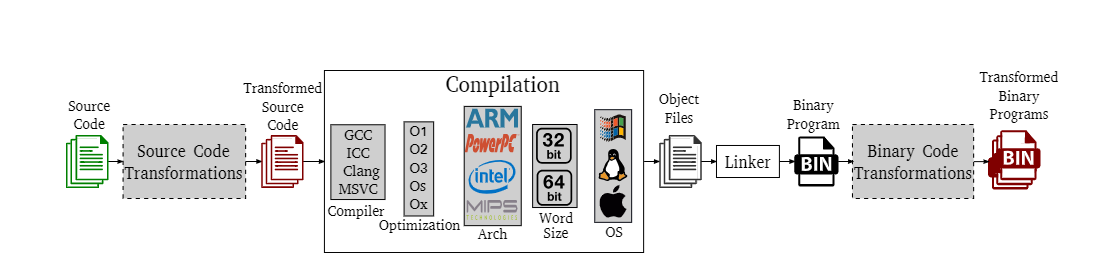
编译过程:所谓二进制代码,指的是由编译过程生成、可以被 CPU 直接执行的机器码。通常情况下,标准的编译过程以程序的源代码文件作为输入,利用特定的编译器和优化等级,并针对特定的平台(即指定的架构、字长和操作系统)进行编译,生成目标文件。接着,这些目标文件会被链接为最终的二进制程序,可能是一个独立可执行文件,也可能是一个库文件。标准编译过程

二进制代码相似性方法通常涉及一个扩展版的编译过程。相比标准的编译流程,它额外包含了两个可选步骤:源代码变换和二进制代码变换。这两类变换通常都是语义保持的,即不会改变程序的实际功能,最常见的用途是混淆处理,用于阻碍对发布程序的逆向工程分析。源代码变换发生在编译之前,因此其输入和输出都是源代码。这类变换与目标平台无关,但可能依赖于所使用的编程语言。相比之下,二进制代码变换发生在编译之后,其输入和输出均为二进制代码。这类变换不依赖于源语言,但可能会针对特定的平台架构或操作系统进行调整。扩展编译过程,新增源码转换和二进制代码转换
混淆是一种恶意软件中常见的关键步骤,但它同样也可以应用于合法程序,例如用于保护知识产权。目前已经有现成的混淆工具可供使用,包括基于源代码变换的工具以及基于二进制代码变换的工具。其中,打包是一种广泛被恶意软件采用的二进制代码变换技术。一旦恶意软件家族发布了一个新版本,其作者通常会对生成的可执行文件进行打包,以隐藏其实际功能,从而绕过商业恶意软件检测系统。打包过程以一个可执行文件为输入,输出另一个功能相同的可执行文件,但其原始代码已被隐藏(例如以数据形式加密,并在运行时再解密还原)。而且,这一过程往往会对同一个输入文件重复多次,从而生成多个外观不同的变体,即所谓的“多态变种”,尽管它们在本质上源于完全相同的源代码,但在恶意软件检测系统看来却彼此不同。如今,大多数恶意软件在发布时都会经过打包处理,而且很多恶意软件还使用定制的打包器,这使得通用的解包工具往往无法应对。二进制代码变换技术广泛应用于恶意软件
在二进制代码相似性分析中,一个主要难点在于:即便源代码相同,编译过程也可能生成截然不同的二进制表示。正如图2所示,通过修改任意一个编译环节(编译器、优化级别、指令架构等),可以生成与原始源代码在语义上等价但形式上不同的二进制程序。其中一些变换可能仅仅是标准编译流程的结果。例如,为了提高程序效率,可能需要调整编译器的优化级别,或者直接更换编译器,这些变化都会在源代码不变的前提下显著改变最终的二进制代码。此外,如果更换了目标平台,比如从一个架构迁移到使用不同指令集的另一架构,那么生成的二进制代码在结构上可能会有巨大差异。再进一步,开发者甚至可能故意施加混淆手段(基于源码转换的混淆、基于二进制代码转换的混淆),生成多个在语义上等价但在形式上多样化的多态变种程序。这些变种通常都保持了原始源代码所定义的功能。在这种背景下,理想的二进制相似性分析方法应具备识别那些经历了不同变换但本质上源于同一份源代码的二进制程序的能力。而这种能力的关键就在于方法的“鲁棒性”——即它能在多大程度上应对编译和混淆带来的变化,仍能准确检测出代码之间的相似性。BCSD任务的主要挑战
不同类型:二进制代码的比较类型主要包括,identical(完全相同)、equivalent(语义相同) 和 similar(语义相似)三种类型。具体来说:(1)若两段二进制代码在语法上完全一致,即表示方式(如十六进制字节串、反汇编指令序列、控制流图等)相同,则视为 identical,可通过哈希值快速判断;但这种方法无法识别因编译时间戳等微小差异导致的语法变化。(2)若两段代码在功能上完全一致,即实现相同语义,尽管语法和结构可能不同,则视为 equivalent,例如 mov %eax,$0 与 xor %eax,%eax。判断是否 equivalent 理论上是不可判定的,在实践中也仅适用于小范围代码。(3)similar 是一种更宽松的关系,两段代码在语法、结构或语义层面上具有部分相似性即可。语法相似性检测最轻量,但对细微变换如寄存器替换、指令重排极为敏感;结构相似性基于图(如控制流图)表示,具有一定容错性,但易受结构性改动影响;语义相似性最具鲁棒性,能识别语法与结构变换下的功能一致性,但计算代价极高。总体而言,方法越偏向语义层面,鲁棒性越强,计算成本也越高。similar是最常用的比较类型,这种方法具有较好的鲁棒性但计算成本高
不同粒度:二进制代码的比较粒度主要包括,指令级、基本块级、函数级以及整个程序级。为了在较粗粒度上进行比较,一些方法会先在较细粒度上进行分析,然后将结果进行聚合,例如评估两个程序是否相似,可以通过计算它们之间相同函数的比例来判断。通过结合不同粒度的比较可以构建递进式BCSD系统,例如函数级相似→函数区域级相似→程序级相似
不同输入:二进制代码的输入形式主要包括,一对一(One-to-One, OO)、一对多(One-to-Many, OM)和多对多(Many-to-Many, MM)。其中,OO方法通常用于二进制差异分析,即比较程序的两个版本,识别新增、删除或修改的函数,常以函数为粒度进行比对,构建旧版本与新版本函数之间的映射关系。OM方法主要用于二进制代码搜索,即将一个查询代码片段与大量目标片段进行比较,返回前k个最相似的结果。MM方法不区分源与目标代码,而是将所有输入代码视为平等,彼此进行全面比较,通常用于聚类分析,即将相似的代码片段归为一组,形成“簇”。固件中同源漏洞检测对应OM方法,固件中二进制作为目标二进制,漏洞函数作为候选二进制
技术演进
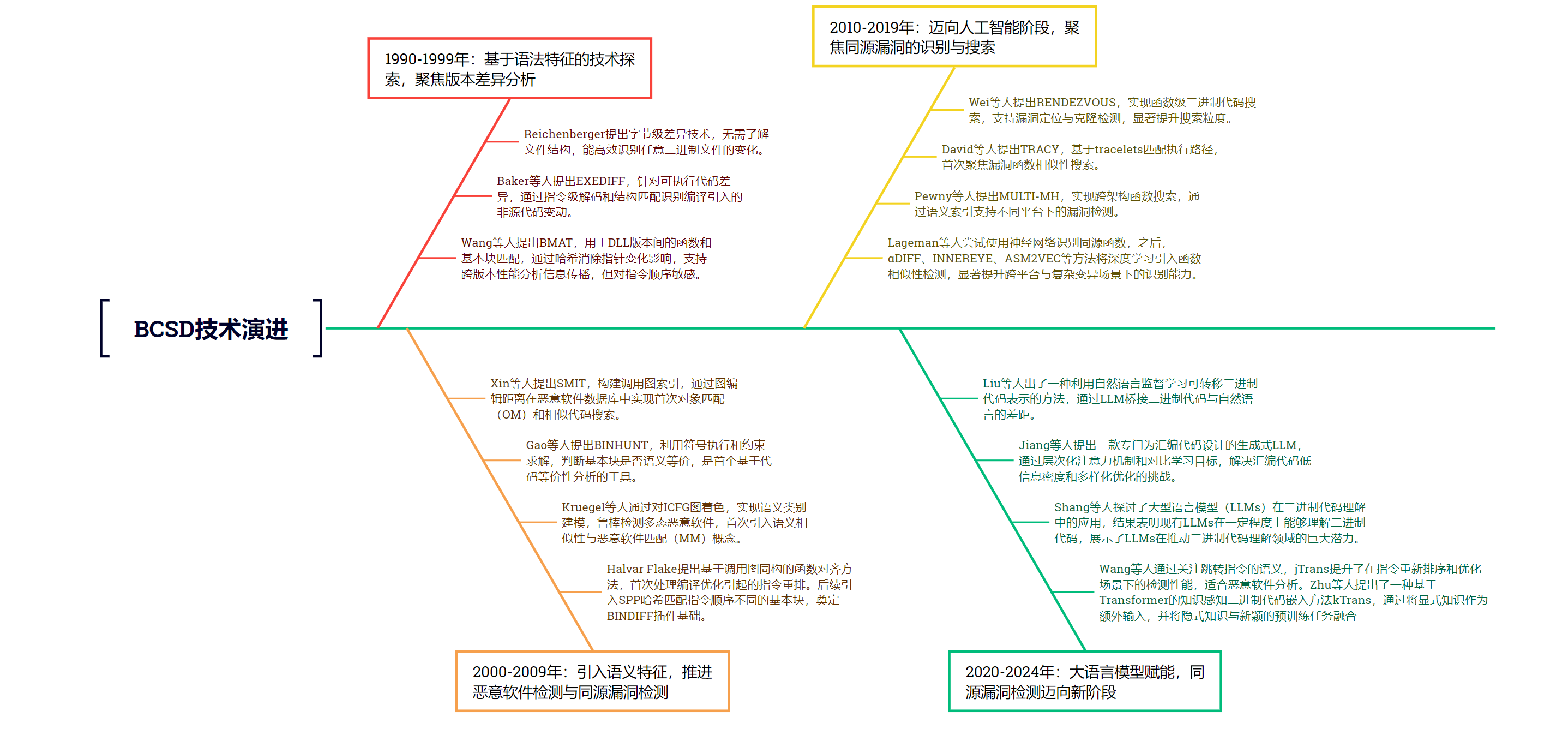
起步阶段(1990-1999年):二进制代码相似性技术的起源可追溯至对同一程序的两个连续(或相近)版本生成补丁(或差异)内容的需求。早在20世纪70年代,文本差异比较工具就已出现,其中较为著名的 UNIX diff 工具于1974年发布,并被集成至早期的源代码版本管理系统中,如 SCCS(1975年)与 RCS(1985年)。随着低带宽通信网络(如无线网络)的兴起以及部分设备资源受限,通过传输小型补丁以替代完整文件更新,成为提升版本更新效率的重要手段。1991年,Reichenberger 提出了一种可针对任意二进制文件生成补丁的差异比较技术。该方法无需了解文件结构,直接在字节层面进行比较,区别于传统文本 diff 工具采用的行级粒度。其核心优势在于能够高效识别仅存在于更新版本中的新增字节序列,并将其纳入补丁内容。随后,多个基于字节级操作的二进制补丁工具相继出现,如 RTPATCH、BDIFF95 与 XDELTA,均具备支持任意文件类型比较的能力。1999年,Baker 等人提出了首个专注于可执行代码差异压缩的研究成果,并开发了名为 EXEDIFF 的原型工具,专用于 DEC Alpha 架构的可执行文件补丁生成。他们指出,在两个版本的可执行文件中,大量差异来自编译过程所引入的“次级变化”,如寄存器分配差异、指令偏移变化等,并非源代码的直接改动。为减少补丁体积,EXEDIFF 试图在补丁应用阶段重建这些变化,从而避免冗余数据的传输。该工具通过反汇编原始字节为指令,利用代码结构特性进行比对,被视为最早关注二进制代码相似性的系统性技术探索。同年,Wang 等人提出了 BMAT 工具,用于对齐不同版本的 Windows DLL 文件,进而将旧版本中已分析的性能信息迁移至新版本,以降低重复分析成本。BMAT 是首个支持函数与基本块级别比较的工具,其核心方法包括先匹配函数,再在匹配函数对中寻找相似基本块,并通过哈希技术比较代码块内容。为应对由于指针变动引起的差异,其哈希过程剔除了重定位信息,但仍对代码块的顺序敏感。
发展阶段(2000-2009年):本阶段,二进制代码相似性研究逐步从语法层面拓展至语义层面,应用范围也从传统的版本差异比较(One-to-One,OO)扩展至多对多的代码聚类(Many-to-Many,MM)与代码搜索(One-to-Many,OM),并逐渐应用于恶意代码分析等领域。2004年,Thomas Dullien(亦称 Halvar Flake)提出了一种基于图的二进制差异分析方法。其核心思想是通过启发式方法构造调用图同构,以比对不同版本中函数的结构,这是首个能够应对编译器优化带来的指令重排序问题的技术。其后续工作进一步将比对粒度细化至函数内部基本块,并提出 Small Primes Product(SPP)哈希方法,即便在指令顺序变更的情况下也可识别相似基本块。这些成果共同奠定了后续广泛使用的 IDA 插件 BINDIFF 的基础。2005年,Kruegel 等人提出了图染色技术,以检测多态恶意软件变种,首次实现语义级相似性检测及 MM 比较方法。他们将具备相似功能的指令划分为14个语义类别,并以此对跨过程控制流图(ICFG)进行染色,从而增强了该方法在面对语法混淆(如垃圾指令插入、指令替换与重排序)时的鲁棒性。2008年,Gao 等人提出 BINHUNT,首次尝试检测不同版本程序间的语义差异,并引入符号执行与约束求解相结合的方法,以判断两个基本块是否实现相同的功能,开启了代码等价性检测的研究方向。2009年,Xin 等人提出 SMIT 方法,用于从大量样本中搜索相似的恶意软件,这是首个针对 OM 场景的代码搜索方法。其主要通过构建恶意软件的调用图索引数据库,并借助图编辑距离算法查找结构相似样本,为恶意代码分析提供了新的技术路径。
繁荣阶段(2010-2019年):随着研究的不断深入,二进制代码相似性技术逐步向代码搜索领域倾斜,尤其自2015年起,跨架构代码搜索成为研究热点(已有十余种相关方法提出),而机器学习的引入则进一步拓展了研究边界。2013年,Wei 等人提出 RENDEZVOUS,这是一个函数级别的二进制代码搜索引擎,可根据查询函数的二进制代码,在代码库中检索语法与结构相似的其他函数。与此前基于完整程序比对的方案(如 SMIT)不同,RENDEZVOUS 将粒度缩小至函数级,推动了代码克隆检测与漏洞搜索等新应用场景的发展。事实上,漏洞搜索已成为该方向的核心应用。2014年,David 等人提出 TRACY,这是首个专注于漏洞搜索的二进制代码搜索方法。TRACY 引入了 “tracelet” 概念,即控制流图中的一段可执行路径,用以识别与已知漏洞函数相似的其他函数,为漏洞迁移分析提供了有效手段。2015年,Pewny 等人提出 MULTI-MH,开创性地实现了跨架构二进制代码搜索。该方法通过建立函数输入输出语义的索引,使其能够在已知某一架构(如 x86)函数实现的情况下,识别其在另一架构(如 MIPS)上的对应实现。伴随着嵌入式系统的广泛部署,跨架构代码搜索迅速成为研究前沿。2016年,Lageman 等人首次训练神经网络模型以判定两个函数是否源于同一源代码,实现了深度学习在该领域的初步探索。随后几年,基于深度学习的研究快速发展,如 αDIFF(2018)、INNEREYE(2019)与 ASM2VEC(2019)等方法陆续提出,进一步提升了代码相似性识别的自动化与智能化水平。
新阶段(2020-2025年):在2020至2024年间,大语言模型(LLMs)的快速发展为同源漏洞检测带来了新的契机。2022年,Wang等人通过关注跳转指令的语义特征,提出了jTrans方法,在指令重新排序和优化场景下显著提升了恶意软件分析中的检测性能。Zhu等人则提出了一种基于Transformer架构的知识感知二进制代码嵌入方法kTrans,通过引入显式知识作为额外输入,并融合隐式知识与创新的预训练任务,增强了模型的表达能力。2024年,Shang等人深入研究了LLMs在二进制代码理解中的应用,实验证明当前的LLMs已具备一定的代码理解能力,展现出在该领域的巨大潜力。Jiang等人进一步提出了一款面向汇编代码的生成式LLM,通过引入层次化注意力机制与对比学习目标,有效应对了汇编代码信息密度低和多样性优化的难题。与此同时,Liu等人提出了一种利用自然语言监督学习的可迁移二进制代码表示方法,利用LLM桥接了二进制代码与自然语言之间的语义鸿沟,推动了跨模态理解的发展。
通过应用区分
同源漏洞搜索:二进制代码相似性分析最常见的应用之一是在庞大的目标二进制代码库中定位已知漏洞对应的代码片段。由于代码重用在软件开发中极为普遍,某段存在漏洞的代码往往会被多个程序复用,甚至在同一个程序的不同部分出现多次。因此,一旦确认某段代码存在漏洞,就有必要进一步识别在其他程序或代码位置中可能复用了该段代码的相似代码,以发现潜在的相同或类似漏洞。这类方法通常以一段已知存在漏洞的二进制代码作为查询输入,在大型代码库中搜索与之结构或语义相似的代码片段。该问题的一个变体是跨平台漏洞搜索,即当目标代码在不同平台(如 x86、ARM、MIPS)上编译时,仍需识别出其与查询代码的相似性。
恶意软件检测:二进制代码相似性技术也广泛应用于恶意软件的识别与溯源。在检测过程中,通过将待检测的可执行文件与已知恶意样本进行相似性比对,可以判断其是否为某一恶意软件家族的变种。若相似度较高,往往意味着该样本可能具有相似的恶意行为。此外,该技术还可用于恶意软件的聚类任务,即将结构或功能上相近的样本划分为同一家族,每个家族代表某种恶意软件的不同版本或变种形式,包括加壳、混淆等手段生成的变体。基于聚类结果,还可进一步开展恶意软件谱系分析:在确定多个样本属于同一源程序后,构建其版本演化图,图中节点代表不同版本,边则描述版本之间的继承或演进关系。这类分析在恶意软件研究中尤为重要,因为多数恶意样本缺乏明确的版本标识,难以直接追踪其演化路径。
版本差异分析:二进制代码相似性技术也广泛应用于版本差异分析,该分析通过比对程序的两个连续或相近版本,识别新版本中被修改或修复的代码区域。这在专有软件中尤其重要,因为其补丁内容通常未被公开。通过差异分析,不仅可以提取精简的二进制补丁以实现高效更新,还能识别安全修复的具体内容,甚至有可能反推出旧版本中可被利用的漏洞。此外,由于相邻版本之间代码结构高度相似,先前版本中获得的分析结果(如性能分析数据或恶意软件逆向分析成果)也可以迁移至新版本,避免重复工作,从而提高分析效率。
软件盗用检测:二进制代码相似性还可用于识别是否存在未授权的代码重用行为,例如原始程序的源代码被窃取、二进制代码被复用、专利算法被未授权实现,或是违反许可证协议(如将 GPL 代码嵌入商业软件)等情况。早期对此类侵权行为的检测方法包括“软件出生印记”技术,即提取程序固有功能特征的签名。但在这里,更关注的是基于代码本身内容的相似性检测方法,而不是基于签名的方式。
相关文章:

论文学习_A Survey of Binary Code Similarity
摘要:二进制代码相似性方法的主要目的是比较两个或多个二进制代码片段,以识别它们之间的相似性与差异(研究背景)。由于在许多实际场景中源代码往往不可获取,因此具备比较二进制代码的能力显得尤为重要,例如…...

python标准库--sys - 系统相关功能在算法比赛的应用
目录 1. 快速输入输出 2. 调整递归深度限制 1. 快速输入输出 算法比赛中,大量数据的读写可能成为瓶颈。sys.stdin和sys.stdout比内置的input()和print()效率更高。 import sys# 读取多行输入(每行一个整数) n int(sys.stdin.readline()) …...

运算放大器相关的电路
1运算放大器介绍 解释:运算放大器本质就是一个放大倍数很大的元件,就如上图公式所示 Vp和Vn相差很小但是放大后输出还是会很大。 运算放大器不止上面的三个引脚,他需要独立供电; 如图比较器: 解释:Vp&…...

进程和线程
目录 1. 基本定义 2. 核心区别 3. 优缺点对比 进程和线程是操作系统中用于实现并发执行的两个核心概念,它们既有相似之处,又有明显的区别。下面从多个维度对它们进行对比分析: 1. 基本定义 进程(Process) 进程是程…...
深度解析:理论、技术与应用全景)
生成对抗网络(GAN)深度解析:理论、技术与应用全景
生成对抗网络(Generative Adversarial Networks,GAN)作为深度学习领域的重要突破,通过对抗训练框架实现了强大的生成能力。本文从理论起源、数学建模、网络架构、工程实现到行业应用,系统拆解GAN的核心机制,涵盖基础理…...

Java面试全记录:Spring Cloud+Kafka+Redis实战解析
Java面试全记录:Spring CloudKafkaRedis实战解析 人物设定 姓名:张伟(随机生成唯一姓名) 年龄:28岁 学历:硕士 工作年限:5年 工作内容: 基于Spring Cloud搭建微服务架构使用Kafka…...

人脸识别deepface相关笔记
人脸识别deepface相关笔记 项目地址项目结构 项目地址 https://github.com/serengil/deepface.git 项目结构...

量子加密通信:守护信息安全的未来之盾
摘要 在数字化时代,信息安全成为全球关注的焦点。传统加密技术面临着被量子计算破解的风险,而量子加密通信作为一种基于量子力学原理的新型加密技术,提供了理论上无条件安全的通信保障。本文将详细介绍量子加密通信的基本原理、技术实现、应用…...
三、transformers基础组件之Model
1. 什么是Model Head Model Head 是连接在模型后的层,通常为1个或多个全连接层Model Head 将模型的编码的表示结果进行映射,以解决不同类型的任务 不同的任务会有不同的Model Head。 2. 模型加载 2.1 在线加载 预训练模型的加载与Tokenizer类似,我们只需要指定想…...

【语法】C++的多态
目录 虚函数的重写: 虚函数 重写(覆盖) 虚函数重写的两个例外: 协变: 析构函数的重写: 练习: final和override关键字 抽象类 接口继承和实现继承 虚函数重写的原理: 打印虚函数表: …...

WebGIS开发新突破:揭秘未来地理信息系统的神秘面纱
你有没有想过,未来的地理信息系统(GIS)会是什么样子?是像电影里那样,一块透明屏幕就能呈现整个城市的实时动态?还是像《钢铁侠》中那样,一个手势就能操控全球地图? 其实,…...

JVM类加载
JVM类加载 1. 类的生命周期(类加载过程)类加载的五个阶段: 2. 类加载器的分类3. 双亲委派模型4. 类的卸载与热加载5.类加载器命名空间隔离 1. 类的生命周期(类加载过程) 类加载的五个阶段: 加载ÿ…...

AD开启交叉选择功能,只选中器件,不选中网络、焊盘
AD开启交叉选择功能,只选中器件,不选中网络、焊盘。 一、打开首选项 二、打开System→Navigationg,配置如下。 三、最后点击OK即可。...

机器学习——集成学习基础
一、鸢尾花数据训练模型 1. 使用鸢尾花数据分别训练集成模型:AdaBoost模型,Gradient Boosting模型 2. 对别两个集成模型的准确率以及报告 3. 两个模型的预测结果进行可视化 需要进行降维处理,两个图像显示在同一个坐标系中 代码展示&…...

C++匿名函数
C 中的匿名函数(Lambda 表达式)是 C11 引入的一项重要特性,它允许你在需要的地方定义一个临时的、无名的函数对象,使代码更加简洁和灵活。 1. 基本语法 Lambda 表达式的基本结构: [capture list](parameter list) -…...

互联网大厂Java面试实战:Spring Boot到微服务的技术问答解析
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通 😁 2. 毕业设计专栏,毕业季咱们不慌忙,几百款毕业设计等你选。 ❤️ 3. Python爬虫专栏…...

神经网络是如何工作的
人工智能最核心的技术之一,就是神经网络(Neural Networks)。但很多初学者会觉得它是个黑盒:为什么神经网络能识别图片、翻译语言,甚至生成文章? 本文用图解最小代码实现的方式,带你深入理解&am…...
:核心功能层)
Kubernetes控制平面组件:Kubelet详解(二):核心功能层
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

【android bluetooth 框架分析 02】【Module详解 13】【CounterMetrics 模块介绍】
1. CounterMetrics 介绍 CounterMetrics 模块代码很少, 我简单介绍一下。 // system/gd/metrics/counter_metrics.cc #define LOG_TAG "BluetoothCounterMetrics"#include "metrics/counter_metrics.h"#include "common/bind.h" #i…...

Matlab自学笔记五十四:符号数学工具箱和符号运算、符号求解、绘图
1.什么是符号数学工具箱? 符号数学工具箱是Matlab针对符号对象的运算功能,它引入了一种特殊的数据类型 - 符号对象; 该数据类型包括符号数字,符号变量,符号表达式和符号函数,还包含符号矩阵,以…...

Matlab 模糊控制平行侧边自动泊车
1、内容简介 Matlab 233-模糊控制平行侧边自动泊车 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

新书速览|纯血鸿蒙HarmonyOS NEXT原生开发之旅
《纯血鸿蒙HarmonyOS NEXT原生开发之旅》 本书内容 《纯血鸿蒙HarmonyOS NEXT原生开发之旅》全面系统地介绍了基于HarmonyOS NEXT系统进行原生应用开发的实用技巧。全书共12章,内容涵盖从基础工具使用到高级功能实现的各个方面。第1章详细介绍了开发环境的搭建、Ar…...
数据类型讲解)
tinyint(3)数据类型讲解
TINYINT(3) 是数据库中用于定义字段数据类型的一种写法,常见于 MySQL 等数据库系统。下面来详细了解其含义和作用: 数据类型本质 TINYINT 属于整数类型,在不同的数据库系统中,它所占用的存储空间和表示范围通常是固定的。以 MyS…...

manjaro系统详解
1. Manjaro 概述 Manjaro 是一款基于 Arch Linux 的滚动更新发行版,以 用户友好、易用性 和 硬件兼容性 为核心设计理念。它继承了 Arch 的灵活性和软件丰富性,同时通过图形化工具和稳定的更新策略降低了使用门槛,适合从新手到高级用户的广泛…...

# 实时英文 OCR 文字识别:从摄像头到 PyQt5 界面的实现
实时英文 OCR 文字识别:从摄像头到 PyQt5 界面的实现 引言 在数字化时代,文字识别技术(OCR)在众多领域中发挥着重要作用。无论是文档扫描、车牌识别还是实时视频流中的文字提取,OCR 技术都能提供高效且准确的解决方案…...

9.3.云原生架构模式
目录 一、云原生架构核心概念 云原生定义与核心原则 • 四大核心要素:容器化、微服务、DevOps、持续交付 • 核心原则:弹性、可观测性、自动化、不可变基础设施 云原生技术矩阵 • 容器与编排:Docker、Kubernetes、CRI-O • 服务治理&#…...

现代化水库运行管理矩阵平台如何建设?
政策背景 2023年8月24日,水利部发布的水利部关于加快构建现代化水库运行管理矩阵的指导意见中指出,在全面推进水库工程标准化管理的基础上,强化数字赋能,加快构建以推进全覆盖、全要素、全天候、全周期“四全”管理,完…...

木马查杀引擎—关键流程图
记录下近日研究的木马查杀引擎,将关键的实现流程图画下来 PHP AST通道实现 木马查杀调用逻辑 模型训练流程...

基于libevent的异步事件驱动型线程池实现
----------------------| IFoxThread | ← 抽象线程接口|----------------------|| dispatch() || start() || stop() || ... |----------^-----------|--------------------|----------------------| …...

ArcGIS+InVEST+RUSLE:水土流失模拟与流域管理的高效解决方案;水土保持专题地图制作
在全球生态与环境面临严峻挑战的当下,水土流失问题已然成为制约可持续发展的重要因素之一。水土流失不仅影响土地资源的可持续利用,还对生态环境、农业生产以及区域经济发展带来深远影响。因此,科学、精准地模拟与评估水土流失状况࿰…...

#S4U2SELF#S4U2Proxy#CVE-2021-42278/42287
#S4U2SELF Win08创建普通用户 s4u2 xwj456 可以看到普通用户是没用委托属性的 Win08手动赋予委托服务属性 setspn -A wsw/wsw.com s4u2 Win10身份验证 s4u2 xwj456 AS请求 两个勾 两个勾和include-pac记得按上(蓝色) ,发包之前把wiresh…...

利用基于LLM的概念提取和FakeCTI数据集提升网络威胁情报对抗虚假信息活动的能力
摘要 虚假新闻和虚假信息宣传活动的迅速蔓延对公众信任、政治稳定和网络安全构成了重大威胁。传统的网络威胁情报(CTI)方法依赖于域名和社交媒体账号等低级指标,很容易被频繁修改其在线基础设施的对手规避。为了解决这些局限性,我…...
)
uniapp|实现手机通讯录、首字母快捷导航功能、多端兼容(H5、微信小程序、APP)
基于uniapp实现带首字母快捷导航的通讯录功能,通过拼音转换库实现汉字姓名首字母提取与分类,结合uniapp的scroll-view组件与pageScrollTo API完成滚动定位交互,并引入uni-indexed-list插件优化索引栏性能。 目录 核心功能实现动态索引栏生成联系人列表渲染滚动定位联动性…...

使用PhpStudy搭建Web测试服务器
一、安装PhpStudy 从以下目录下载PhpStudy安装文件 Windows版phpstudy下载 - 小皮面板(phpstudy) (xp.cn) 安装成功之后打开如下界面 点击启动Apache 查看网站地址 在浏览器中输入localhost:88,出现如下页面就ok了 二、与Unity交互 1.配置下载文件路径,点击…...

Qt/C++面试【速通笔记九】—视图框架机制
在Qt中,QGraphicsView和QGraphicsScene是用于构建二维图形界面的核心组件。它们的设计使得开发者能够高效地管理和渲染图形项,支持丰富的用户交互,例如缩放、旋转、平移等。 1. QGraphicsScene和QGraphicsView的基本概念 QGraphicsScene QG…...

react-diff-viewer 如何实现语法高亮
前言 react-diff-viewer 是一个很好的 diff 展示库,但是也有一些坑点和不完善的地方,本文旨在描述如何在这个库中实现自定义语法高亮。 Syntax highlighting is a bit tricky when combined with diff. Here, React Diff Viewer provides a simple rend…...

Python实例题:Django搭建简易博客
目录 Python实例题 题目 1. 创建 Django 项目和应用 2. 配置项目 3. 设计模型 blog_app templates blog_app post_list.html admin.py models.py urls.py views.py blog_project urls.py 代码解释 models.py: admin.py: urls.py&…...

Kotlin 异步初始化值
在一个类初始化的时候或者方法执行的时候,总有一些值是需要的但是不是立即需要的,并且在需要的时候需要阻塞流程来等待值的计算,这时候异步的形式创建这个值是毋庸置疑最好的选择。 为了更好的创建值需要使用 Kotlin 的协程来创建࿰…...

扩展:React 项目执行 yarn eject 后的 config 目录结构详解
扩展:React 项目执行 yarn eject 后的 config 目录结构详解 什么是 yarn eject?React 项目执行 yarn eject 后的 config 目录结构详解📁 config 目录结构各文件作用详解env.jsgetHttpsConfig.jsmodules.jspaths.jswebpack.config.jswebpackDe…...
Java学习-5.8(总结,springboot))
(自用)Java学习-5.8(总结,springboot)
一、MySQL 数据库 表关系 一对一、一对多、多对多关系设计外键约束与级联操作 DML 操作 INSERT INTO table VALUES(...) DELETE FROM table WHERE... UPDATE table SET colval WHERE...DQL 查询 基础查询:SELECT * FROM table WHERE...聚合函数:COUNT()…...

cursor 如何在项目内自动创建规则
在对话框内 / Generate。cursor rules 就会自动根据项目进行创建规则 文档来自:https://www.kdocs.cn/l/cp5GpLHAWc0p...

C++ 迭代器
1.用途: 像我们之前学习的容器map,vector等,如果需要遍历该怎么做呢?这些容器大部分对下标式遍历,无法像数组灵活使用,也包括增删改查,因为它们的特性,所以需要一种其他的方法。 那么迭代器就…...

基于微信小程序的城市特色旅游推荐应用的设计与实现
💗博主介绍💗:✌在职Java研发工程师、专注于程序设计、源码分享、技术交流、专注于Java技术领域和毕业设计✌ 温馨提示:文末有 CSDN 平台官方提供的老师 Wechat / QQ 名片 :) Java精品实战案例《700套》 2025最新毕业设计选题推荐…...

最大m子段和
问题描述解题思路伪代码代码实现复杂度分析 问题描述 给定一个有n(n>0)个整数的序列,要求其m个互不相交的子段,使得这m个子段和最大。 输入:整数序列{nums},m。 输出:最大m子段和。 对于m1的情况,即求最…...

4.MySQL全量、增量备份与恢复
1.数据备份的重要性 在企业中数据的价值至关重要,数据保障了企业业务的正常运行。因此,数据的安全性及数据的可靠性是运维的重中之重,任何数据的丢失都可能对企业产生严重的后果。通常情况下造成数据丢失的原因有如下几种: a.程…...

每日算法刷题Day4 5.12:leetcode数组4道题,用时1h
7. 704.二分查找 704. 二分查找 - 力扣(LeetCode) 思想 二分模版题 代码 c: class Solution { public:int search(vector<int>& nums, int target) {int nnums.size();int left0,rightn-1;int res-1;while(left<right){int midleft((…...

Day 15
目录 1.chika和蜜柑1.1 解析1.2 代码 2.对称之美2.1 解析2.2 代码 3.添加字符3.1 解析3.2 代码 1.chika和蜜柑 chika和蜜柑 TopK、堆、排序 1.1 解析 1.2 代码 #include <iostream> #include <vector> #include <algorithm> using namespace std; struct …...
为例)
脑机接口重点产品发展路径分析:以四川省脑机接口及人机交互产业攻坚突破行动计划(2025-2030年)为例
引言 随着人工智能和生物技术的飞速发展,脑机接口技术作为连接人类大脑与智能设备的桥梁,正在成为全球科技竞争的新焦点。2025年5月12日,四川省经济和信息化厅等8部门联合印发了《四川省脑机接口及人机交互产业攻坚突破行动计划(2025-2030年)》,为四川省在这一前沿领域的…...

leetcode 18. 四数之和
题目描述 和leetcode 15. 三数之和用同样的方法。有两个注意点。 一是剪枝的逻辑 这是和15. 三数之和 - 力扣(LeetCode)问题不同的地方。 无法通过这种情况: 二是整数溢出 最终答案 class Solution { public:vector<vector<int>…...

CentOS部署Collabora Online
1.安装Docker CentOS7安装Docker(超详细)-CSDN博客 2.拉取镜像 docker pull collabora/code:latest 3. 启动容器(直接暴露HTTP端口) docker run -d --name collabora -p 9980:9980 -e "usernameadmin" -e "password123456" -e …...