小土堆pytorch--torchvision中的数据集的使用dataloader的使用
torchvision中的数据集的使用&dataloader的使用
- 一级目录
- 二级目录
- 三级目录
- 1 torchvision 中的数据集的使用
- 1.1 对与CIFAR - 10数据集的介绍
- 1.2 数据集加载代码
- 1.3 使用transform加载代码
- 2 DataLoader的使用
- 2.1 DataLoader的作用
- 1. 数据读取
- 2. 数据预处理
- 3. 批量处理
- 4. 并行加载
- 5. 数据打乱
- 6. 数据持久化(部分场景 )
- 7. 提供迭代器接口
- 2.2 常用参数讲解
- 2.3 代码
一级目录
二级目录
三级目录
1 torchvision 中的数据集的使用
1.1 对与CIFAR - 10数据集的介绍
数据规模:
总样本数:60,000 张彩色图像
训练集:50,000 张(每个类别 5,000 张)
测试集:10,000 张(每个类别 1,000 张)
图像尺寸:32×32 像素,RGB 三通道
类别:共 10 个互斥类别,涵盖常见物体:
0: 飞机 (airplane)
1: 汽车 (automobile)
2: 鸟类 (bird)
3: 猫 (cat)
4: 鹿 (deer)
5: 狗 (dog)
6: 青蛙 (frog)
7: 马 (horse)
8: 船 (ship)
9: 卡车 (truck)
数据特点
小尺寸图像:32×32 的低分辨率使得模型训练相对高效,适合快速验证算法。
多类别分类:10 个类别覆盖不同物体,挑战性适中,适合初学者入门。
平衡性:每个类别样本数量相等,避免类别不平衡问题。
现实场景:图像来自真实世界,但经过裁剪和简化,降低了背景复杂度。
典型应用
图像分类模型评估:如卷积神经网络(CNN)、Transformer 等架构的基础测试。
算法对比:研究人员常用 CIFAR - 10 比较不同模型的性能(如 ResNet、VGG 等)。
教学与实践:高校和在线课程中常用作深度学习入门案例。
模型预训练:部分研究将 CIFAR - 10 作为预训练任务,迁移到更复杂的任务中。
可以从pytorch官网下载所需数据集,注意要保持与图片中的版本相同(在左上角)
1.2 数据集加载代码
import torchvision
from torch.utils.tensorboard import SummaryWriter# dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])train_set = torchvision.datasets.CIFAR10(root="./das", train = True, download = True)
test_set = torchvision.datasets.CIFAR10(root="./das", train=False, download = True)print(test_set[0])
代码功能讲解
torchvision.datasets.CIFAR10(root="./das", train = True, download = True)

各个参数的作用
在torchvision.datasets.CIFAR10这行代码中各个参数的作用:
root- 作用:指定数据集下载后存储的根目录路径 。代码中
root='./das',表示将CIFAR - 10数据集存储在当前目录下名为das的文件夹中。若该文件夹不存在,会自动创建。 - 示例:若希望存储在
/data/cifar10目录,则可设置root='/data/cifar10'。
- 作用:指定数据集下载后存储的根目录路径 。代码中
train- 作用:用于区分加载训练集还是测试集。当
train = True时,加载的是CIFAR - 10数据集中的训练集(包含50000张图像 );当train = False时,加载的是测试集(包含10000张图像 )。 - 示例:若要加载测试集,可写成
test_set = torchvision.datasets.CIFAR10(root='./das', train = False)。
- 作用:用于区分加载训练集还是测试集。当
transform- 作用:对加载的图像进行一系列预处理操作 。可使用
torchvision.transforms中的各种变换函数,如将图像转换为张量(ToTensor)、归一化(Normalize)等。代码中未完整展示该参数的使用,若要对图像进行预处理,可像这样设置:transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),先把图像转成张量,再进行归一化。 - 示例:在实际应用中,常通过该参数对图像进行标准化处理,以提升模型训练效果。
- 作用:对加载的图像进行一系列预处理操作 。可使用
target_transform- 作用:对图像对应的标签(类别)进行转换操作 。例如,可以将标签从数值型转换为独热编码形式等。在一般图像分类任务中,如果不需要对标签做特殊处理,该参数可不设置。
- 示例:若要将标签转换为独热编码,可自定义一个转换函数传入该参数。
download- 作用:是一个布尔值,用于指定是否从网络下载数据集。当
download = True,且指定的root目录下不存在CIFAR - 10数据集时,会自动从网络下载数据集;download = False可以在已经将数据集下载到对应目录时候使用。 - 示例:如果已经提前下载好数据集并放在指定目录,可设置
download = True
也不会报错
- 作用:是一个布尔值,用于指定是否从网络下载数据集。当
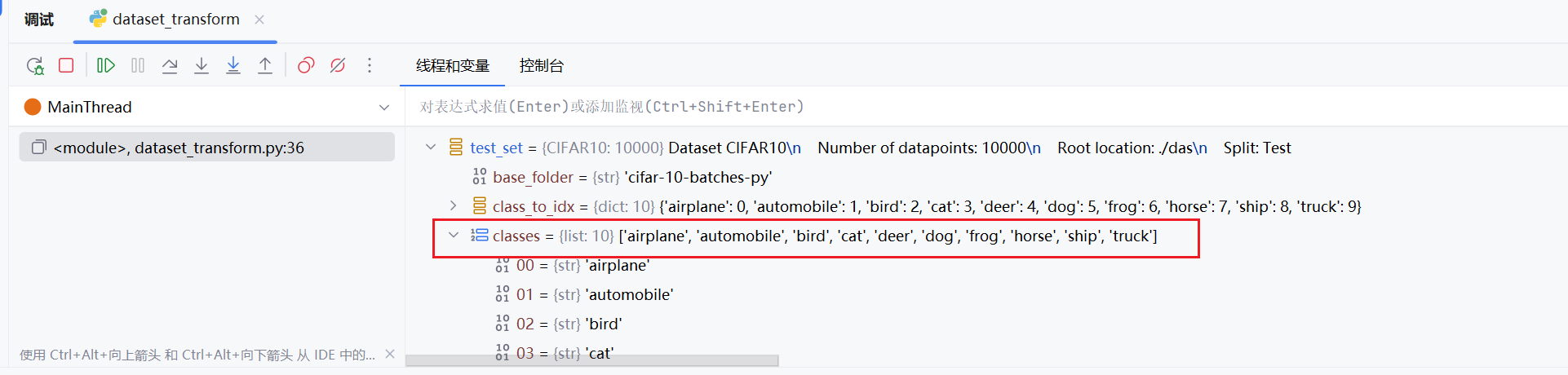
在print(test_set[0])的位置打一个断点,可以看到该数据集确实有这10给类别
print(test_set.classes)
我们也可以通过打印,由此可以看到数据集中的类别

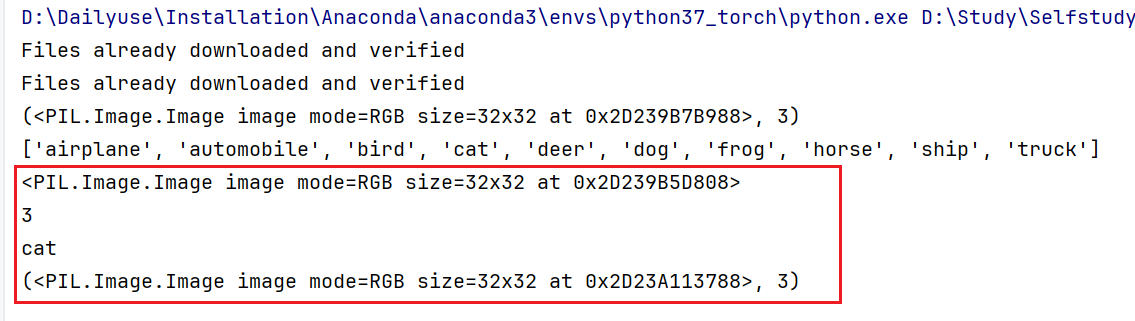
我们打印更多信息来看看
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()
print(test_set[0])
img.show()的作用是展示图片

1.3 使用transform加载代码
import torchvision
from torch.utils.tensorboard import SummaryWriterdataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])train_set = torchvision.datasets.CIFAR10(root="./das", train = True,transform=dataset_transform, download = True)
test_set = torchvision.datasets.CIFAR10(root="./das", train=False,transform=dataset_transform, download = True)# print(test_set[0])
# print(test_set.classes)
#
# img, target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
# print(test_set[0])writer = SummaryWriter("p10")
for i in range(10):img, target = test_set[i]writer.add_image("test_set3",img, i)writer.close()
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
这是将PIL的数据类型转换成ToTensor的数据类型
我们运行代码之后可以再打开tensorboard就可以看到一下结果

2 DataLoader的使用
2.1 DataLoader的作用
在深度学习框架(如PyTorch )中,DataLoader 是用于数据加载的重要工具,主要有以下作用:
1. 数据读取
负责从存储介质(如硬盘 )中读取原始数据,数据可以是图片、文本、音频等多种格式,这些数据通常存储在文件或数据库中。比如读取CIFAR - 10图像数据集用于图像分类任务。
2. 数据预处理
读取数据后,能对数据进行一系列预处理操作,包括但不限于:
- 归一化:将数据的值映射到特定范围,如把图像像素值归一化到[0, 1]或[-1, 1] ,使模型训练更稳定。
- 标准化:按照均值为0、方差为1的标准对数据进行变换,加快模型收敛速度。
- 数据增强:通过旋转、缩放、裁剪、颜色变换等方式扩充数据样本,增加数据多样性,提升模型泛化能力,在图像领域应用广泛。
- 编码转换:例如将文本数据转换为数值编码,方便模型处理。
3. 批量处理
受内存限制,无法一次性将大规模数据集全部加载到内存中,DataLoader 将数据划分成多个小批次(batch),每个批次包含一定数量的样本,模型每次训练处理一个批次数据,有效利用内存,提高训练效率 。比如设置batch_size=32 ,则每次从数据集中取出32个样本组成一个批次供模型训练。
4. 并行加载
借助多线程或多进程,可并行地从多个文件或数据源中加载数据,充分利用计算机多核资源,大幅提升数据加载速度,尤其在处理大型数据集时优势明显 。通过设置num_workers参数指定加载数据的线程或进程数量。
5. 数据打乱
在每个训练周期(epoch)开始时,可通过设置相关参数(如PyTorch中DataLoader 的shuffle=True )打乱数据顺序,使模型在训练过程中学习到数据的不同模式,避免过拟合 。
6. 数据持久化(部分场景 )
有时为加快后续训练时的数据加载速度,会将预处理后的数据保存到磁盘(如HDF5文件 ),后续训练可直接加载预处理后的数据,无需重复预处理 。
7. 提供迭代器接口
DataLoader 是可迭代对象,提供迭代器接口,在模型训练循环中能通过简单的循环方便地访问每个批次的数据,与模型训练循环紧密集成,保证数据及时、连续地供给模型进行训练 。例如在PyTorch中可通过for batch in dataloader 遍历DataLoader 获取每个批次数据。
2.2 常用参数讲解
以PyTorch中的DataLoader为例,其常用参数如下:
dataset- 类型:
torch.utils.data.Dataset子类实例 - 作用:指定从哪个数据集对象加载数据,是必须传入的参数 。比如使用
torchvision.datasets加载的CIFAR - 10数据集,或是自定义的继承自torch.utils.data.Dataset的数据集类实例 。
- 类型:
batch_size- 类型:
int - 作用:确定每个批次中数据样本的数量 。默认值为1。例如设置
batch_size = 32,模型每次训练就会处理32个样本。一般根据内存大小和数据集规模调整,过小会使CPU、GPU空闲时间增多,过大可能导致内存不足,常见取值为2的幂次方 。
- 类型:
shuffle- 类型:
bool - 作用:决定是否在每个训练周期(epoch)开始时打乱数据集样本顺序 。默认值为
False。设置为True可避免模型学习到数据的固定顺序模式,降低过拟合风险,提升模型泛化能力 。
- 类型:
num_workers- 类型:
int - 作用:指定用于数据加载的子进程数量 。默认值为0,即使用主进程加载数据 。设置为大于0的值,能利用多个子进程并行加载数据,加快数据读取速度,尤其适合大型数据集。但在Windows系统中,多进程机制可能不稳定,常建议设为0来规避问题 。常用取值范围是0 - 8 。
- 类型:
drop_last- 类型:
bool - 作用:当数据集大小不能被
batch_size整除时,控制是否丢弃最后一个不完整的批次 。默认值为False。若设为True,会舍弃最后一个不足batch_size的批次,保证每个批次大小一致,避免训练时因批次大小差异导致的不稳定;设为False则会保留最后不完整批次 。
- 类型:
sampler- 类型:实现了
__iter__()方法的对象,常为torch.utils.data.Sampler子类 - 作用:定义从数据集中抽取样本的策略 。若指定了该参数,
shuffle参数将被忽略 。比如可以使用SubsetRandomSampler实现从数据集中按特定索引子集随机抽样 。
- 类型:实现了
batch_sampler- 类型:类似
sampler,但返回一批次的索引 - 作用:与
sampler功能相似,不过它一次返回一个批次的索引,而非单个样本索引 。不能与batch_size、shuffle和sampler同时使用 。
- 类型:类似
collate_fn- 类型:函数
- 作用:可选参数,用于指定如何将多个数据样本整理成一个批次 。比如处理不同长度的序列数据时,可自定义
collate_fn函数实现特殊的整理逻辑 。
pin_memory- 类型:
bool - 作用:设置是否将数据保存在CUDA支持的固定内存中 。默认值为
False。设为True时,可避免在显存和内存之间重复传输数据,提升数据读取和使用速度,但仅在使用CUDA时生效 。
- 类型:
2.3 代码
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./ds", train = False, transform=torchvision.transforms.ToTensor())
#专门加载测试集
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0,drop_last=False)# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)writer = SummaryWriter("dataloader")
for epoch in range(2):step = 0for data in test_loader:imgs, targets = data# print(imgs.shape)# print(targets)writer.add_images("Epoch: {}".format(epoch), imgs, step)step = step + 1writer.close()
注意:
1.对于dataloader(batch_size=64), 相当于把其中的img0-63 & target0-63 都进行打包作为dataloader中的一个返回
我们来验证一下
img, target = test_data[0]
print(img.shape)
print(target)for data in test_loader:imgs, targets = dataprint(imgs.shape)print(targets)

可以看到返回的一组(batch_size)中确实是64张图片
再加入tensorboard相关代码,进行展示
img, target = test_data[0]
print(img.shape)
print(target)writer = SummaryWriter("dataloader")
for epoch in range(2):step = 0for data in test_loader:imgs, targets = dataprint(imgs.shape)print(targets)writer.add_images("Epoch: {}".format(epoch), imgs, step)step = step + 1writer.close()运行结果

2.注意epoch的作用是:外层循环遍历 2 个训练轮次(epoch),这在实际应用中用于训练多轮,并查看结果
相关文章:

小土堆pytorch--torchvision中的数据集的使用dataloader的使用
torchvision中的数据集的使用&dataloader的使用 一级目录二级目录三级目录 1 torchvision 中的数据集的使用1.1 对与CIFAR - 10数据集的介绍1.2 数据集加载代码1.3 使用transform加载代码 2 DataLoader的使用2.1 DataLoader的作用1. 数据读取2. 数据预处理3. 批量处理4. 并…...
)
【RabbitMQ】 RabbitMQ高级特性(一)
文章目录 一、消息确认1.1、消息确认机制1.2、手动确认方法1.2.1、AcknowledgeMode.NONE1.2.2、AcknowledgeMode.AUTO1.3.3、AcknowledgeMode.MANUAL 二、持久性2.1、 交换机持久化2.2、队列持久化2.3、消息持久化 三、发送方确认3.1、confirm确认模式3.2、return退回模式3.3、…...

优化理赔数据同步机制:从4小时延迟降至15分钟
优化理赔数据同步机制:从4小时延迟降至15分钟 1. 分析当前同步瓶颈 首先诊断当前同步延迟原因: -- 检查主从复制状态(在主库执行) SHOW MASTER STATUS; SHOW SLAVE HOSTS;-- 在从库执行检查复制延迟 SHOW SLAVE STATUS\G -- 关…...

lampiao靶场渗透
lampiao https://www.vulnhub.com/entry/lampiao-1,249/ 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶场IP192.168.23.245 3,对靶机进行端…...

云计算中的虚拟化:成本节省、可扩展性与灾难恢复的完美结合
云计算中虚拟化的 4 大优势 1. 成本效益 从本质上讲,虚拟化最大限度地减少了硬件蔓延。团队可以将多个虚拟机整合到单个物理主机上,而不是为每个工作负载部署单独的服务器。这大大减少了前期硬件投资和持续维护。 结果如何?更低的功耗、更低…...

jenkins built-in节点如何删除
1 概述 在 Jenkins 中,默认的 “Built-In” 节点(即主节点/master)无法直接删除,因为它是 Jenkins 的核心组件。它的存在,有时会造成困扰,因为部分作业调度到其上,由于 “Built-In” 节点的环境…...

QSS样式表的选择器
一个最简单的样式设置格式如下 QWidget {background-color: black; }将样式应用到对应的控件 QWidget* w new QWidget; w->setStyleSheet("QWidget {background-color: black;}");样式表中控件的设置有多种方式 通用选择器 /*匹配所有控件*/ *{}类型选择器 …...

Python多环境管理指南
Python/UV 多环境管理指南 在Python开发中,管理多个项目环境是一个常见需求。以下是使用Python内置工具和UV(一种新兴的Python包管理器)进行多环境管理的方法。 1. 使用Python内置venv管理多环境 创建虚拟环境 python -m venv /path/to/y…...

Java从入门到精通 - 数组
数组 此笔记参考黑马教程,仅学习使用,如有侵权,联系必删 文章目录 数组1. 认识数组2. 数组的定义和访问2.1 静态初始化数组2.1.1 数组的访问2.1.1 定义代码实现总结 2.1.2 数组的遍历2.1.2.1 定义代码演示总结 案例代码实现 2.2 动态初始化…...
( 下 ))
《Vuejs 设计与实现》第 4 章(响应式系统)( 下 )
目录 4.6 避免无限递归循环 4.7 调度执行 4.8 计算属性 computed 与 lazy 4.9 watch 的实现原理 4.10 立即执行的 watch 与回调执行时机 4.11 过期副作用与竞态问题 总结 4.6 避免无限递归循环 在实现完善响应式系统时,需要注意避免无限递归循环。以以下代码…...

在 Windows 上为 Intel UHD Graphics 编译 OpenCL 程序
如果您使用的是 Intel UHD Graphics 集成显卡,以下是完整的 OpenCL 开发环境配置指南: 1. 准备工作 确认硬件支持 首先确认您的 Intel UHD Graphics 支持 OpenCL: 大多数第6代及以后的 Intel Core 处理器(Skylake 及更新架构)都支持 OpenCL 2.1+ 运行 clinfo 工具可以查…...

C++自学笔记 makefile
本博客参考南科大于仕琪教授的讲解视频和这位同学的学习笔记: 参考博客 感谢两位的分享。 makefile 的作用 用于组织大型项目的编译,是一个一键编译项目的脚本文件。 本博客通过四个版本的makefile逐步说明makefile的使用 使用说明 四个演示文件 …...

【PDF】使用Adobe Acrobat dc添加水印和加密
【PDF】使用Adobe Acrobat dc添加水印和加密 文章目录 [TOC](文章目录) 前言一、添加保护加密口令二、添加水印三、实验四、参考文章总结 实验工具: 1.Adobe Acrobat dc 前言 提示:以下是本篇文章正文内容,下面案例可供参考 一、添加保护加…...

客服系统重构详细计划
# 客服系统重构详细计划 ## 第一阶段:系统分析与准备工作 ### 1. 代码审查和分析 (1-2周) - 全面分析现有代码结构 - 识别代码中的问题和瓶颈 - 理解当前系统的业务逻辑 - 确定可重用的组件 - 制作系统功能清单 ### 2. 技术栈升级准备 (1周) - 升级PHP版本到7…...

基于VSCode + PlatformIO平台的ESP8266的DS1302实时时钟
基于ESP8266的DS1302实时时钟系统开发 一、项目概述 本实验通过ESP8266开发板实现: DS1302实时时钟模块的驱动系统时间同步与维护串口实时时间显示RTC模块状态监控 硬件组成: NodeMCU ESP8266开发板DS1302实时时钟模块CR2032纽扣电池(备…...

Flink 系列之十四 - Data Stream API的自定义数据类型
之前做过数据平台,对于实时数据采集,使用了Flink。现在想想,在数据开发平台中,Flink的身影几乎无处不在,由于之前是边用边学,总体有点混乱,借此空隙,整理一下Flink的内容,…...

【数据结构】线性表
目录 1.1 线性表的概念 1.1.1 线性表的抽象数据类型 1.1.2 线性表的存储结构 1.1.3 线性表运算分类 1.2 顺序表 1.2.1 顺序表的类定义 1.2.2 顺序表的运算实现 1. 顺序表的检索 2. 顺序表的插入 3. 顺序表的删除 1.3 链表 1.3.1 单链表 1. 链表的检索 2. 链表的插…...

大疆卓驭嵌入式面经及参考答案
FreeRTOS 有哪 5 种内存管理方式? heap_1.c:这种方式简单地在编译时分配一块固定大小的内存,在整个运行期间不会进行内存的动态分配和释放。它适用于那些对内存使用需求非常明确且固定,不需要动态分配内存的场景,优点是…...

【网络】:传输层协议 —— UDP、TCP协议
目录 UDP协议 UDP协议的核心特点 UDP协议格式 UDP的缓冲区 基于UDP的应用层协议 TCP协议 TCP协议的核心特点 TCP协议格式 确认应答机制 连接管理机制 三次握手 四次挥手 流量控制 滑动窗口 拥塞控制 基于字节流 粘包和拆包 可靠性和性能保障 基于TCP的应用层…...
)
每日c/c++题 备战蓝桥杯(洛谷P1115 最大子段和)
洛谷P1115 最大子段和 题解 题目描述 最大子段和是一道经典的动态规划问题。题目要求:给定一个包含n个整数的序列,找出其中和最大的连续子序列,并输出该最大和。若所有数均为负数,则取最大的那个数。 输入格式: 第…...
)
Python与矢量网络分析仪3671E:通道插损自动化校准(Vscode)
一、背景介绍 DUT集成了多个可调衰减的射频通道,可调衰减由高精度DAC和VVA构成,使用中电思仪的3671E矢量网络分析仪测试DUT的S参数,并自动化调整VVA的控制电压,以自动化获取指定衰减值对应的控制电平。 二、前期准备 Python环境&…...
:总览与引导)
设计模式系列(1):总览与引导
目录 前言 设计模式简介 UML与设计模式 术语解释 UML工具与PlantUML 面向对象设计原则(SOLID等) 设计模式分类与典型场景 设计模式的价值 学习与实践建议 常见面试题 推荐阅读 1. 前言 本篇为设计模式系列的第一篇,定位为总览和引导,旨在为后续各专题打下基础,帮助大家…...

Day21打卡—常见降维算法
知识点回顾: LDA线性判别PCA主成分分析t-sne降维 作业: 自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题,群里的同学互相学习下。可以考虑对比下在某些特定数据集上t-sne的可视化和pca可…...
? —— 机器学习 =》 深度学习 =》 新型技术)
什么是人工智能(Artificial Intelligence,AI)? —— 机器学习 =》 深度学习 =》 新型技术
文章目录 什么是人工智能(Artificial Intelligence,AI)? —— 关系:AI >> ML >> DL一、机器学习(Machine Learning,ML)1、历史2、类型(1)监督学习…...

iVX 平台技术解析:图形化与组件化的融合创新
一、图形化逻辑编程:用流程图替代代码的革命 iVX 的核心突破在于可视化逻辑表达—— 开发者通过拖拽 “逻辑块”(如条件判断、循环控制、数据操作等)来搭建应用逻辑,彻底摒弃传统代码的字符输入模式。这种 “所见即所得” 的开发…...

【Diffusion】在华为云ModelArts上运行MindSpore扩散模型教程
目录 一、背景与目的 二、环境搭建 三、模型原理学习 1. 类定义与初始化 2. 初始卷积层 3. 时间嵌入模块 4. 下采样模块 5. 中间模块 6. 上采样模块 7. 最终卷积层 8. 前向传播 9. 关键点总结 四、代码实现与运行 五、遇到的问题及解决方法 六、总结与展望 一、…...

跟我学c++高级篇——模板元编程之十三处理逻辑
一、元编程处理逻辑 无论在普通编程还是在元编程中,逻辑的处理,都是一个编程开始的必然经过。开发者对普通编程中的逻辑处理一般都非常清楚,不外乎条件谈判和循环处理。而条件判断常见的基本就是if语句(switch如果不考虑效率等情…...
详解)
组合模式(Composite Pattern)详解
文章目录 1. 什么是组合模式?2. 为什么需要组合模式?3. 组合模式的核心概念4. 组合模式的结构5. 组合模式的基本实现5.1 基础示例:文件系统5.2 透明组合模式 vs 安全组合模式5.2.1 透明组合模式5.2.2 安全组合模式5.3 实例:公司组织结构5.4 实例:GUI组件树6. Java中组合模…...

最长字符串 / STL+BFS
题目 代码 #include <bits/stdc.h> using namespace std;int main() {map<vector<int>, vector<string>> a;set<vector<int>> c;vector<int> initial(26, 0);c.insert(initial);ifstream infile("words.txt");string s;w…...

C++ stl中的set、multiset、map、multimap的相关函数用法
文章目录 序列式容器和关联式容器树形结构和哈希结构树形结构哈希结构 键值对setset的相关介绍set定义方式set相关成员函数multiset mapmap的相关介绍map定义方式map的相关操作1.map的插入2.map的查找3.map的删除 序列式容器和关联式容器 CSTL中包含了序列式容器和关联式容器&…...

普通IT的股票交易成长史--20250511 美元与美股强相关性
声明:本文章的内容非原创。参考了yt博主Andy Lee的观点,为了加深自己的学习印象才做的复盘,不构成投资建议。感谢他的无私奉献! 送给自己的话: 仓位就是生命,绝对不能满仓!!&#x…...
:架构风格总结)
系统架构设计(四):架构风格总结
黑板 概念 黑板体系架构是一种用于求解复杂问题的软件架构风格,尤其适合知识密集型、推理驱动、数据不确定性大的场景。 它模拟了人类专家协同解决问题的方式,通过一个共享的“黑板”协同多个模块(专家)逐步构建解决方案。 组…...

ElasticSearch进阶
一、文档批量操作 1.批量获取文档数据 批量获取文档数据是通过_mget的API来实现的 (1)在URL中不指定index和type 请求方式:GET请求地址:_mget功能说明 : 可以通过ID批量获取不同index和type的数据请求参数: docs : 文档数组参…...

0基础 | L298N电机驱动模块 | 使用指南
引言 在嵌入式系统开发中,电机驱动是一个常见且重要的功能。L298N是一款高电压、大电流电机驱动芯片,广泛应用于各种电机控制场景,如直流电机的正反转、调速,以及步进电机的驱动等。本文将详细介绍如何使用51单片机来控制L298N电…...

Synchronized与锁升级
一、面试题 1)谈谈你对Synchronized的理解 2)Sychronized的锁升级你聊聊 3)Synchronized实现原理,monitor对象什么时候生成的?知道monitor的monitorenter和monitorexit这两个是怎么保证同步的嘛&#…...

MNIST DDP 分布式数据并行
Distributed Data Parallel 转自我的个人博客:https://shar-pen.github.io/2025/05/04/torch-distributed-series/3.MNIST_DDP/ The difference between DistributedDataParallel and DataParallel is: DistributedDataParallel uses multiprocessing where a proc…...

语音合成之十三 中文文本归一化在现代语音合成系统中的应用与实践
中文文本归一化在现代语音合成系统中的应用与实践 引言理解中文文本归一化(TN)3 主流LLM驱动的TTS系统及其对中文文本归一化的需求分析A. SparkTTS(基于Qwen2.5)与文本归一化B. CosyVoice(基于Qwen)与文本归…...

9.1.领域驱动设计
目录 一、领域驱动设计核心哲学 战略设计与战术设计的分野 • 战略设计:限界上下文(Bounded Context)与上下文映射(Context Mapping) • 战术设计:实体、值对象、聚合根、领域服务的构建原则 统一语言&am…...

如何配置光猫+路由器实现外网IP访问内部网络?
文章目录 前言一、网络拓扑理解二、准备工作三、光猫配置3.1 光猫工作模式3.2 光猫端口转发配置(路由模式时) 四、路由器配置4.1 路由器WAN口配置4.2 端口转发配置4.3 动态DNS配置(可选) 五、防火墙设置六、测试配置七、安全注意事…...

C++题题题题题题题题题踢踢踢
后缀表达式求值 #include<bits/stdc.h> #include<algorithm> using namespace std; string a[100]; string b[100]; stack<string> op; int la0,lb0; int main(){while(true){cin>>a[la];if(a[la]".") break;la;}for(int i0;i<la;i){if(…...
)
M. Moving Both Hands(反向图+Dijkstra)
Problem - 1725M - Codeforces 题目大意:给你一个有向图,起始点在1,问起始点分别与另外n-1个 点相遇的最短时间,无法相遇输出-1。 思路:反向建图,第一层建原图,第二层建反向图,两层…...

11、参数化三维产品设计组件 - /设计与仿真组件/parametric-3d-product-design
76个工业组件库示例汇总 参数化三维产品设计组件 (注塑模具与公差分析) 概述 这是一个交互式的 Web 组件,旨在演示简单的三维零件(如带凸台的方块)的参数化设计过程,并结合注塑模具设计(如开模动画)与公…...

智能座舱开发工程师面试题
一、基础知识类 简述智能座舱的核心组成部分及其功能 要求从硬件(如显示屏、传感器、控制器)和软件(操作系统、中间件、应用程序)层面展开,阐述各部分如何协同实现座舱的智能化体验。 对比 Android Automotive、QNX…...

【连载14】基础智能体的进展与挑战综述-多智能体系统设计
基础智能体的进展与挑战综述 从类脑智能到具备可进化性、协作性和安全性的系统 【翻译团队】刘军(liujunbupt.edu.cn) 钱雨欣玥 冯梓哲 李正博 李冠谕 朱宇晗 张霄天 孙大壮 黄若溪 在基于大语言模型的多智能体系统(LLM-MAS)中,合作目标和合…...

06.three官方示例+编辑器+AI快速学习webgl_animation_skinning_additive_blending
本实例主要讲解内容 这个Three.js示例展示了**骨骼动画(Skinning)和变形动画(Morphing)**的结合应用。通过加载一个机器人模型,演示了如何同时控制角色的肢体动作和面部表情,实现更加丰富的角色动画效果。 核心技术包括: 多动画混合与淡入…...

【Java学习日记36】:javabeen学生系统
ideal快捷键...

.Net HttpClient 使用请求数据
HttpClient 使用请求数据 0、初始化及全局设置 //初始化:必须先执行一次 #!import ./ini.ipynb1、使用url 传参 参数放在Url里,形如:http://www.baidu.com?namezhangsan&age18, GET、Head请求用的比较多。优点是简单、方便࿰…...

详解 Java 并发编程 synchronized 关键字
synchronized 关键字的作用 synchronized 是 Java 中用于实现线程同步的关键字,主要用于解决多线程环境下的资源竞争问题。它可以修饰方法或代码块,确保同一时间只有一个线程可以执行被修饰的代码,从而避免数据不一致的问题。 synchronized…...

《Go小技巧易错点100例》第三十二篇
本期分享: 1.sync.Map的原理和使用方式 2.实现有序的Map sync.Map的原理和使用方式 sync.Map的底层结构是通过读写分离和无锁读设计实现高并发安全: 1)双存储结构: 包含原子化的 read(只读缓存,无锁快…...

时序约束高级进阶使用详解四:Set_False_Path
目录 一、背景 二、Set_False_Path 2.1 Set_false_path常用场景 2.2 Set_false_path的优势 2.3 Set_false_path设置项 2.4 细节区分 三、工程示例 3.1 工程代码 3.2 时序约束如下 3.3 时序报告 3.4 常规场景 3.4.1 设计代码 3.4.2 约束场景 3.4.3 约束对象总结…...