ElasticSearch进阶
一、文档批量操作
1.批量获取文档数据
批量获取文档数据是通过_mget的API来实现的
(1)在URL中不指定index和type
- 请求方式:GET
- 请求地址:_mget
- 功能说明 : 可以通过ID批量获取不同index和type的数据
- 请求参数:
-
- docs : 文档数组参数
-
-
- _index : 指定index
- _type : 指定type
- _id : 指定id
- _source : 指定要查询的字段
-
GET _mget
{
"docs": [
{
"_index": "es_db",
"_type": "_doc",
"_id": 1
},
{
"_index": "es_db",
"_type": "_doc",
"_id": 2
}
]
}#响应结果如下:{"docs" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_version" : 3,"_seq_no" : 7,"_primary_term" : 1,"found" : true,"_source" : {"name" : "张三666","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "2","_version" : 1,"_seq_no" : 1,"_primary_term" : 1,"found" : true,"_source" : {"name" : "李四","sex" : 1,"age" : 28,"address" : "广州荔湾大厦","remark" : "java assistant"}}]
}(2)在URL中指定index
- 请求方式:GET
- 请求地址:/{{indexName}}/_mget
- 功能说明 : 可以通过ID批量获取不同index和type的数据
- 请求参数:
-
- docs : 文档数组参数
-
-
- _index : 指定index
- _type : 指定type
- _id : 指定id
- _source : 指定要查询的字段
-
GET /es_db/_mget
{
"docs": [
{
"_type":"_doc",
"_id": 3
},
{
"_type":"_doc",
"_id": 4
}
]
}(3)在URL中指定index和type
- 请求方式:GET
- 请求地址:/{{indexName}}/{{typeName}}/_mget
- 功能说明 : 可以通过ID批量获取不同index和type的数据
- 请求参数:
-
- docs : 文档数组参数
-
-
- _index : 指定index
- _type : 指定type
- _id : 指定id
- _source : 指定要查询的字段
-
GET /es_db/_doc/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 2
}
]
}2.批量操作文档数据
批量对文档进行写操作是通过_bulk的API来实现的
- 请求方式:POST
- 请求地址:_bulk
- 请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
-
- 第一行参数为指定操作的类型及操作的对象(index,type和id)
- 第二行参数才是操作的数据
参数类似于:
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}(1)批量创建文档create
POST _bulk
{"create":{"_index":"article", "_type":"_doc", "_id":3}}
{"id":3,"title":"aaa1","content":"aaa666","tags":["java", "面向对象"],"create_time":1554015482530}
{"create":{"_index":"article", "_type":"_doc", "_id":4}}
{"id":4,"title":"aaa2","content":"aaaNB","tags":["java", "面向对象"],"create_time":1554015482530}(2)普通创建或全量替换index
POST _bulk
{"index":{"_index":"article", "_type":"_doc", "_id":3}}
{"id":3,"title":"bbb(一)","content":"bbb666","tags":["java", "面向对象"],"create_time":1554015482530}
{"index":{"_index":"article", "_type":"_doc", "_id":4}}
{"id":4,"title":"bbb(二)","content":"bbbNB","tags":["java", "面向对象"],"create_time":1554015482530}(3)批量删除delete
POST _bulk
{"delete":{"_index":"article", "_type":"_doc", "_id":3}}
{"delete":{"_index":"article", "_type":"_doc", "_id":4}}(4)批量修改update
POST _bulk
{"update":{"_index":"article", "_type":"_doc", "_id":3}}
{"doc":{"title":"ES"}}
{"update":{"_index":"article", "_type":"_doc", "_id":4}}
{"doc":{"create_time":1554018421008}}二.DSL语言高级查询
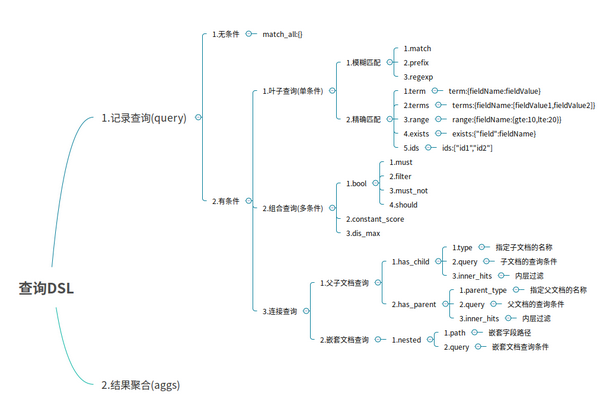
2.无查询条件
无查询条件是查询所有,默认是查询所有的,或者使用match_all表示所有
GET /es_db/_doc/_search
{
"query":{
"match_all":{}
}
}3.有查询条件
3.1 叶子条件查询(单字段查询条件)
3.1.1 模糊匹配
模糊匹配主要是针对文本类型的字段,文本类型的字段会对内容进行分词,对查询时,也会对搜索条件进行分词,然后通过倒排索引查找到匹配的数据,模糊匹配主要通过match等参数来实现
- match : 通过match关键词模糊匹配条件内容
- prefix : 前缀匹配
- regexp : 通过正则表达式来匹配数据
match的复杂用法
match条件还支持以下参数:
- query : 指定匹配的值
- operator : 匹配条件类型
-
- and : 条件分词后都要匹配
- or : 条件分词后有一个匹配即可(默认)
- minmum_should_match : 指定最小匹配的数量
3.1.2 精确匹配
- term : 单个条件相等
- terms : 单个字段属于某个值数组内的值
- range : 字段属于某个范围内的值
- exists : 某个字段的值是否存在
- ids : 通过ID批量查询
3.2 组合条件查询(多条件查询)
组合条件查询是将叶子条件查询语句进行组合而形成的一个完整的查询条件
- bool : 各条件之间有and,or或not的关系
-
- must : 各个条件都必须满足,即各条件是and的关系
- should : 各个条件有一个满足即可,即各条件是or的关系
- must_not : 不满足所有条件,即各条件是not的关系
- filter : 不计算相关度评分,它不计算_score即相关度评分,效率更高
- constant_score : 不计算相关度评分
must/filter/shoud/must_not 等的子条件是通过 term/terms/range/ids/exists/match 等叶子条件为参数的
注:以上参数,当只有一个搜索条件时,must等对应的是一个对象,当是多个条件时,对应的是一个数组
3.3 连接查询(多文档合并查询)
- 父子文档查询:parent/child
- 嵌套文档查询: nested
3.4 DSL查询语言中存在两种:查询DSL(query DSL)和过滤DSL(filter DSL)
query DSL
在查询上下文中,查询会回答这个问题——“这个文档匹不匹配这个查询,它的相关度高么?”
如何验证匹配很好理解,如何计算相关度呢?ES中索引的数据都会存储一个_score分值,分值越高就代表越匹配。另外关于某个搜索的分值计算还是很复杂的,因此也需要一定的时间。
filter DSL
在过滤器上下文中,查询会回答这个问题——“这个文档匹不匹配?”
答案很简单,是或者不是。它不会去计算任何分值,也不会关心返回的排序问题,因此效率会高一点。
过滤上下文 是在使用filter参数时候的执行环境,比如在bool查询中使用must_not或者filter
另外,经常使用过滤器,ES会自动的缓存过滤器的内容,这对于查询来说,会提高很多性能。
3.5 Query方式查询:案例
- 根据名称精确查询姓名 term, term查询不会对字段进行分词查询,会采用精确匹配
注意: 采用term精确查询, 查询字段映射类型属于为keyword.
POST /es_db/_doc/_search
{
"query": {
"term": {
"name": "admin"
}
}
}- 根据备注信息模糊查询 match, match会根据该字段的分词器,进行分词查询
POST /es_db/_doc/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"address": "广州"
}
}
}- 多字段模糊匹配查询与精准查询 multi_match
POST /es_db/_doc/_search
{
"query":{
"multi_match":{
"query":"张三",
"fields":["address","name"]
}
}
}- 未指定字段条件查询 query_string , 含 AND 与 OR 条件
POST /es_db/_doc/_search
{
"query":{
"query_string":{
"query":"广州 OR 长沙"
}
}
}- 指定字段条件查询 query_string , 含 AND 与 OR 条件
POST /es_db/_doc/_search
{
"query":{
"query_string":{
"query":"admin OR 长沙",
"fields":["name","address"]
}
}
}- 范围查询
注:json请求字符串中部分字段的含义
range:范围关键字
gte 大于等于
lte 小于等于
gt 大于
lt 小于
now 当前时间
POST /es_db/_doc/_search
{
"query" : {
"range" : {
"age" : {
"gte":25,
"lte":28
}
}
}
}- 分页、输出字段、排序综合查询
POST /es_db/_doc/_search
{
"query" : {
"range" : {
"age" : {
"gte":25,
"lte":28
}
}
},
"from": 0,
"size": 2,
"_source": ["name", "age", "book"],
"sort": {"age":"desc"}
}3.6 Filter过滤器方式查询,它的查询不会计算相关性分值,也不会对结果进行排序, 因此效率会高一点,查询的结果可以被缓存。
POST /es_db/_doc/_search
{
"query" : {
"bool" : {
"filter" : {
"term":{
"age":25
}
}
}
}
} 总结:
1. match
match:模糊匹配,需要指定字段名,但是输入会进行分词,比如"hello world"会进行拆分为hello和world,然后匹配,如果字段中包含hello或者world,或者都包含的结果都会被查询出来,也就是说match是一个部分匹配的模糊查询。查询条件相对来说比较宽松。
2. term
term: 这种查询和match在有些时候是等价的,比如我们查询单个的词hello,那么会和match查询结果一样,但是如果查询"hello world",结果就相差很大,因为这个输入不会进行分词,就是说查询的时候,是查询字段分词结果中是否有"hello world"的字样,而不是查询字段中包含"hello world"的字样。当保存数据"hello world"时,elasticsearch会对字段内容进行分词,"hello world"会被分成hello和world,不存在"hello world",因此这里的查询结果会为空。这也是term查询和match的区别。
3. match_phase
match_phase:会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样。以"hello world"为例,要求结果中必须包含hello和world,而且还要求他们是连着的,顺序也是固定的,hello that world不满足,world hello也不满足条件。
4. query_string
query_string:和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。
三.文档映射
1.ES中映射可以分为动态映射和静态映射
动态映射:
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
2 动态映射2.1 删除原创建的索引DELETE /es_db2.2 创建索引PUT /es_db2.3 创建文档(ES根据数据类型, 会自动创建映射)PUT /es_db/_doc/1 { "name": "Jack", "sex": 1, "age": 25, "book": "java入门至精通", "address": "广州小蛮腰" }2.4 获取文档映射GET /es_db/_mapping3 静态映射3.1 删除原创建的索引DELETE /es_db3.2 创建索引PUT /es_db3.3 设置文档映射PUT /es_db { "mappings":{ "properties":{ "name":{"type":"keyword","index":true,"store":true}, "sex":{"type":"integer","index":true,"store":true}, "age":{"type":"integer","index":true,"store":true}, "book":{"type":"text","index":true,"store":true}, "address":{"type":"text","index":true,"store":true} } } }3.4 根据静态映射创建文档PUT /es_db/_doc/1 { "name": "Jack", "sex": 1, "age": 25, "book": "elasticSearch入门至精通", "address": "广州车陂" }3.5 获取文档映射GET /es_db/_mapping四.核心类型(Core datatype)
字符串:string,string类型包含 text 和 keyword。
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。
keyword:该类型不能分词,可以被用来检索过滤、排序和聚合,keyword类型不可用text进行分词模糊检索。
数值型:long、integer、short、byte、double、float
日期型:date
布尔型:boolean
五.keyword 与 text 映射类型的区别
将 book 字段设置为 keyword 映射 (只能精准查询, 不能分词查询,能聚合、排序)
POST /es_db/_doc/_search
{
"query": {
"term": {
"book": "elasticSearch入门至精通"
}
}
}将 book 字段设置为 text 映射能模糊查询, 能分词查询,不能聚合、排序)
POST /es_db/_doc/_search
{
"query": {
"match": {
"book": "elasticSearch入门至精通"
}
}
}六.对已存在的mapping映射进行修改
具体方法
1)如果要推倒现有的映射, 你得重新建立一个静态索引
2)然后把之前索引里的数据导入到新的索引里
3)删除原创建的索引
4)为新索引起个别名, 为原索引名
POST _reindex
{
"source": {
"index": "db_index"
},
"dest": {
"index": "db_index_2"
}
}DELETE /db_indexPUT /db_index_2/_alias/db_index七.Elasticsearch乐观并发控制
1、悲观并发控制
这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
2、乐观并发控制
Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
3、再以创建一个文档为例 ES老版本PUT /db_index/_doc/1 { "name": "Jack", "sex": 1, "age": 25, "book": "Spring Boot 入门到精通", "remark": "hello world" }4、实现_version乐观锁更新文档PUT /db_index/_doc/1?version=1 { "name": "Jack", "sex": 1, "age": 25, "book": "Spring Boot 入门到精通", "remark": "hello world" }5、ES新版本(7.x)不使用version进行并发版本控制 if_seq_no=版本值&if_primary_term=文档位置_seq_no:文档版本号,作用同_version_primary_term:文档所在位置POST /es_sc/_search DELETE /es_sc POST /es_sc/_doc/1 { "id": 1, "name": "aaa", "desc": "aaa", "create_date": "2021-02-24" } POST /es_sc/_update/1 { "doc": { "name": "bbb" } } POST /es_sc/_update/1/?if_seq_no=1&if_primary_term=1 { "doc": { "name": "bbb" } } POST /es_sc/_update/1/?if_seq_no=1&if_primary_term=1 { "doc": { "name": "ccc" } }八.ES集群环境搭建
1.将安装包分发到其他服务器上面2.修改elasticsearch.yml
node1.baiqi.cn 服务器使用baiqi用户来修改配置文件
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/datacd /usr/local/es/elasticsearch-7.6.1/configrm -rf elasticsearch.ymlvim elasticsearch.yml
cluster.name: baiqi-es
node.name: node1.baiqi.cn
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: node1.baiqi.cn
http.port: 9200
discovery.seed_hosts: ["IP1", "IP2", "IP3"]
cluster.initial_master_nodes: ["节点1名称", "节点2名称", "节点3名称"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"3.修改jvm.option
修改jvm.option配置文件,调整jvm堆内存大小
node1.baiqi.cn使用baiqi用户执行以下命令调整jvm堆内存大小,每个人根据自己服务器的内存大小来进行调整。
cd /usr/local/es/elasticsearch-7.6.1/config
vim jvm.options
-Xms2g
-Xmx2g4.node2与node3修改es配置文件
node2.baiqi.cn与node3.baiqi.cn也需要修改es配置文件
node2.baiqi.cn使用baiqi用户执行以下命令修改es配置文件
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/datacd /usr/local/es/elasticsearch-7.6.1/configvim elasticsearch.yml
cluster.name: baiqi-es
node.name: node2.baiqi.cn
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: node2.baiqi.cn
http.port: 9200
discovery.seed_hosts: ["IP1", "IP2", "IP3"]
cluster.initial_master_nodes: ["节点1名称", "节点2名称", "节点3名称"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"node3.baiqi.cn使用baiqi用户执行以下命令修改配置文件
mkdir -p /usr/local/es/elasticsearch-7.6.1/log
mkdir -p /usr/local/es/elasticsearch-7.6.1/datacd /usr/local/es/elasticsearch-7.6.1/configvim elasticsearch.yml
cluster.name: baiqi-es
node.name: node3.baiqi.cn
path.data: /usr/local/es/elasticsearch-7.6.1/data
path.logs: /usr/local/es/elasticsearch-7.6.1/log
network.host: node3.baiqi.cn
http.port: 9200
discovery.seed_hosts: ["IP1", "IP2", "IP3"]
cluster.initial_master_nodes: ["节点1名称", "节点2名称", "节点3名称"]
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
http.cors.enabled: true
http.cors.allow-origin: "*"
查看集群状态:
GET _cat/nodes?v
GET _cat/health?v相关文章:

ElasticSearch进阶
一、文档批量操作 1.批量获取文档数据 批量获取文档数据是通过_mget的API来实现的 (1)在URL中不指定index和type 请求方式:GET请求地址:_mget功能说明 : 可以通过ID批量获取不同index和type的数据请求参数: docs : 文档数组参…...

0基础 | L298N电机驱动模块 | 使用指南
引言 在嵌入式系统开发中,电机驱动是一个常见且重要的功能。L298N是一款高电压、大电流电机驱动芯片,广泛应用于各种电机控制场景,如直流电机的正反转、调速,以及步进电机的驱动等。本文将详细介绍如何使用51单片机来控制L298N电…...

Synchronized与锁升级
一、面试题 1)谈谈你对Synchronized的理解 2)Sychronized的锁升级你聊聊 3)Synchronized实现原理,monitor对象什么时候生成的?知道monitor的monitorenter和monitorexit这两个是怎么保证同步的嘛&#…...

MNIST DDP 分布式数据并行
Distributed Data Parallel 转自我的个人博客:https://shar-pen.github.io/2025/05/04/torch-distributed-series/3.MNIST_DDP/ The difference between DistributedDataParallel and DataParallel is: DistributedDataParallel uses multiprocessing where a proc…...

语音合成之十三 中文文本归一化在现代语音合成系统中的应用与实践
中文文本归一化在现代语音合成系统中的应用与实践 引言理解中文文本归一化(TN)3 主流LLM驱动的TTS系统及其对中文文本归一化的需求分析A. SparkTTS(基于Qwen2.5)与文本归一化B. CosyVoice(基于Qwen)与文本归…...

9.1.领域驱动设计
目录 一、领域驱动设计核心哲学 战略设计与战术设计的分野 • 战略设计:限界上下文(Bounded Context)与上下文映射(Context Mapping) • 战术设计:实体、值对象、聚合根、领域服务的构建原则 统一语言&am…...

如何配置光猫+路由器实现外网IP访问内部网络?
文章目录 前言一、网络拓扑理解二、准备工作三、光猫配置3.1 光猫工作模式3.2 光猫端口转发配置(路由模式时) 四、路由器配置4.1 路由器WAN口配置4.2 端口转发配置4.3 动态DNS配置(可选) 五、防火墙设置六、测试配置七、安全注意事…...

C++题题题题题题题题题踢踢踢
后缀表达式求值 #include<bits/stdc.h> #include<algorithm> using namespace std; string a[100]; string b[100]; stack<string> op; int la0,lb0; int main(){while(true){cin>>a[la];if(a[la]".") break;la;}for(int i0;i<la;i){if(…...
)
M. Moving Both Hands(反向图+Dijkstra)
Problem - 1725M - Codeforces 题目大意:给你一个有向图,起始点在1,问起始点分别与另外n-1个 点相遇的最短时间,无法相遇输出-1。 思路:反向建图,第一层建原图,第二层建反向图,两层…...

11、参数化三维产品设计组件 - /设计与仿真组件/parametric-3d-product-design
76个工业组件库示例汇总 参数化三维产品设计组件 (注塑模具与公差分析) 概述 这是一个交互式的 Web 组件,旨在演示简单的三维零件(如带凸台的方块)的参数化设计过程,并结合注塑模具设计(如开模动画)与公…...

智能座舱开发工程师面试题
一、基础知识类 简述智能座舱的核心组成部分及其功能 要求从硬件(如显示屏、传感器、控制器)和软件(操作系统、中间件、应用程序)层面展开,阐述各部分如何协同实现座舱的智能化体验。 对比 Android Automotive、QNX…...

【连载14】基础智能体的进展与挑战综述-多智能体系统设计
基础智能体的进展与挑战综述 从类脑智能到具备可进化性、协作性和安全性的系统 【翻译团队】刘军(liujunbupt.edu.cn) 钱雨欣玥 冯梓哲 李正博 李冠谕 朱宇晗 张霄天 孙大壮 黄若溪 在基于大语言模型的多智能体系统(LLM-MAS)中,合作目标和合…...

06.three官方示例+编辑器+AI快速学习webgl_animation_skinning_additive_blending
本实例主要讲解内容 这个Three.js示例展示了**骨骼动画(Skinning)和变形动画(Morphing)**的结合应用。通过加载一个机器人模型,演示了如何同时控制角色的肢体动作和面部表情,实现更加丰富的角色动画效果。 核心技术包括: 多动画混合与淡入…...

【Java学习日记36】:javabeen学生系统
ideal快捷键...

.Net HttpClient 使用请求数据
HttpClient 使用请求数据 0、初始化及全局设置 //初始化:必须先执行一次 #!import ./ini.ipynb1、使用url 传参 参数放在Url里,形如:http://www.baidu.com?namezhangsan&age18, GET、Head请求用的比较多。优点是简单、方便࿰…...

详解 Java 并发编程 synchronized 关键字
synchronized 关键字的作用 synchronized 是 Java 中用于实现线程同步的关键字,主要用于解决多线程环境下的资源竞争问题。它可以修饰方法或代码块,确保同一时间只有一个线程可以执行被修饰的代码,从而避免数据不一致的问题。 synchronized…...

《Go小技巧易错点100例》第三十二篇
本期分享: 1.sync.Map的原理和使用方式 2.实现有序的Map sync.Map的原理和使用方式 sync.Map的底层结构是通过读写分离和无锁读设计实现高并发安全: 1)双存储结构: 包含原子化的 read(只读缓存,无锁快…...

时序约束高级进阶使用详解四:Set_False_Path
目录 一、背景 二、Set_False_Path 2.1 Set_false_path常用场景 2.2 Set_false_path的优势 2.3 Set_false_path设置项 2.4 细节区分 三、工程示例 3.1 工程代码 3.2 时序约束如下 3.3 时序报告 3.4 常规场景 3.4.1 设计代码 3.4.2 约束场景 3.4.3 约束对象总结…...
20250428 - 20250511)
每日定投40刀BTC(16)20250428 - 20250511
定投 坚持 《恒道》 长河九曲本微流,岱岳摩云起累丘。 铁杵十年销作刃,寒窗五鼓淬成钩。已谙蜀栈盘空险,更蓄湘竹带泪遒。 莫问枯荣何日证,星霜满鬓亦从头。...

C# 高效处理海量数据:解决嵌套并行的性能陷阱
C# 高效处理海量数据:解决嵌套并行的性能陷阱 问题场景 假设我们需要在 10万条ID 和 1万个目录路径 中,快速找到所有满足以下条件的路径: 路径本身包含ID字符串该路径的子目录中也包含同名ID 初始代码采用Parallel.ForEach嵌套Task.Run&am…...
】线程安全问题)
【Java EE初阶 --- 多线程(初阶)】线程安全问题
乐观学习,乐观生活,才能不断前进啊!!! 我的主页:optimistic_chen 我的专栏:c语言 ,Java 欢迎大家访问~ 创作不易,大佬们点赞鼓励下吧~ 文章目录 线程不安全的原因根本原因…...

从InfluxDB到StarRocks:Grab实现Spark监控平台10倍性能提升
Grab 是东南亚领先的超级应用,业务涵盖外卖配送、出行服务和数字金融,覆盖东南亚八个国家的 800 多个城市,每天为数百万用户提供一站式服务,包括点餐、购物、寄送包裹、打车、在线支付等。 为了优化 Spark 监控性能,Gr…...

《Redis应用实例》学习笔记,第一章:缓存文本数据
前言 最近在学习《Redis应用实例》,这本书并没有讲任何底层,而是聚焦实战用法,梳理了 32 种 Redis 的常见用法。我的笔记在 Github 上,用 Jupyter 记录,会有更好的阅读体验,作者的源码在这里:h…...

Redis 缓存
缓存介绍 Redis 最主要三个用途: 1)存储数据(内存数据库) 2)消息队列 3)缓存 对于硬件的访问速度,通常有以下情况: CPU 寄存器 > 内存 > 硬盘 > 网络 缓存的核心…...

Apache Flink 与 Flink CDC:概念、联系、区别及版本演进解析
Apache Flink 与 Flink CDC:概念、联系、区别及版本演进解析 在实时数据处理和流式计算领域,Apache Flink 已成为行业标杆。而 Flink CDC(Change Data Capture) 作为其生态中的重要组件,为数据库的实时变更捕获提供了强大的能力。 本文将从以下几个方面进行深入讲解: 什…...
:常见缓存 概念、问题、现象 及 预防问题)
缓存(4):常见缓存 概念、问题、现象 及 预防问题
常见缓存概念 缓存特征: 命中率、最大元素、清空策略 命中率:命中率返回正确结果数/请求缓存次数 它是衡量缓存有效性的重要指标。命中率越高,表明缓存的使用率越高。 最大元素(最大空间):缓存中可以存放的最大元素的…...
)
实战项目6(09)
目录 任务场景一 【r1配置】 【r2配置】 【r3配置】 任务场景二 【r1配置】 【r2配置】 【r3配置】 任务场景三 【r1配置】 【r2配置】 【r3配置】 任务场景一 按照下图完成网络拓扑搭建和配置 任务要求:在…...

MySQL 数据库故障排查指南
MySQL 数据库故障排查指南 本指南旨在帮助您识别和解决常见的 MySQL 数据库故障。我们将从问题识别开始,逐步深入到具体的故障类型和排查步骤。 1. 问题识别与信息收集 在开始排查之前,首先需要清晰地了解问题的现象和范围。 故障现象: 数…...

MacOS Python3安装
python一般在Mac上会自带,但是大多都是python2。 python2和python3并不存在上下版本兼容的情况,所以python2和python3可以同时安装在一台设备上,并且python3的一些语法和python2并不互通。 所以在Mac电脑上即使有自带python,想要使…...

锁相放大技术:从噪声中提取微弱信号的利器
锁相放大技术:从噪声中提取微弱信号的利器 一、什么是锁相放大? 锁相放大(Lock-in Amplification)是一种用于检测微弱信号的技术,它能够从强噪声背景中提取出我们感兴趣的特定信号。想象一下在嘈杂的派对上听清某个人…...

机器学习总结
1.BN【batch normalization】 https://zhuanlan.zhihu.com/p/93643523 减少 2.L1L2正则化 l1:稀疏 l2:权重减小 3.泛化误差 训练误差计算了训练集的误差,而泛化误差是计算全集的误差。 4.dropout 训练过程中神经元p的概率失活 一文彻底搞懂深度学习&#x…...

基于神经网络的无源雷达测向系统仿真实现
基于神经网络的无源雷达测向系统仿真实现 项目概述 本项目实现了基于卷积神经网络(CNN)的无源雷达方向到达角(DOA)估计系统。通过深度学习方法,系统能够从接收到的雷达信号中准确估计出信号源的方向,适用于单目标和多目标场景。相比传统的DOA估计算法&…...

《用MATLAB玩转游戏开发》Flappy Bird:小鸟飞行大战MATLAB趣味实现
《用MATLAB玩转游戏开发:从零开始打造你的数字乐园》基础篇(2D图形交互)-Flappy Bird:小鸟飞行大战MATLAB趣味实现 文章目录 《用MATLAB玩转游戏开发:从零开始打造你的数字乐园》基础篇(2D图形交互…...

【C/C++】跟我一起学_C++同步机制效率对比与优化策略
文章目录 C同步机制效率对比与优化策略1 效率对比2 核心同步机制详解与适用场景3 性能优化建议4 场景对比表5 总结 C同步机制效率对比与优化策略 多线程编程中,同步机制的选择直接影响程序性能与资源利用率。 主流同步方式: 互斥锁原子操作读写锁条件变量无锁数据…...

linux 三剑客命令学习
grep Grep 是一个命令行工具,用于在文本文件中搜索打印匹配指定模式的行。它的名称来自于 “Global Regular Expression Print”(全局正则表达式打印),它最初是由 Unix 系统上的一种工具实现的。Grep 工具在 Linux 和其他类 Unix…...

【js基础笔记] - 包含es6 类的使用
文章目录 js基础js 预解析js变量提升 DOM相关知识节点选择器获取属性节点创建节点插入节点替换节点克隆节点获取节点属性获取元素尺寸获取元素偏移量标准的dom事件流阻止事件传播阻止默认行为事件委托 正则表达式js复杂类型元字符 - 基本元字符元字符 - 边界符元字符 - 限定符元…...
》PDF下载)
《Linux命令行大全(第2版)》PDF下载
内容简介 本书对Linux命令行进行详细的介绍,全书内容包括4个部分,第一部分由Shell的介绍开启命令行基础知识的学习之旅;第二部分讲述配置文件的编辑,如何通过命令行控制计算机;第三部分探讨常见的任务与必备工具&…...
)
补补表面粗糙度的相关知识(一)
表面粗糙度,或简称粗糙度,是指表面不光滑的特性。这个在机械加工行业内可以说是绝绝的必备知识之一,但往往也是最容易被忽略的,因为往往天天接触的反而不怎么关心,或者没有真正的去认真学习掌握。对于像我一样…...

Python实用工具:pdf转doc
该工具只能使用在英文目录下,且无法转换出图片,以及文本特殊格式。 下载依赖项 pip install PyPDF2 升级依赖项 pip install PyPDF2 --upgrade 查看库版本 python -c "import PyPDF2; print(PyPDF2.__version__)" 下载第二个依赖项 pip i…...

基于Dify实现对Excel的数据分析
在dify部署完成后,大家就可以基于此进行各种应用场景建设,目前dify支持聊天助手(包括对话工作流)、工作流、agent等模式的场景建设,我们在日常工作中经常会遇到各种各样的数据清洗、格式转换处理、数据统计成图等数据分…...

Win全兼容!五五 Excel Word 转 PDF 工具解决多场景转换难题
各位办公小能手们!今天给你们介绍一款超牛的工具——五五Excel Word批量转PDF工具V5.5版。这玩意儿专注搞批量格式转换,能把Excel(.xls/.xlsx)和Word(.doc/.docx)文档唰唰地变成PDF格式。 先说说它的核心功…...

java加强 -Collection集合
集合是一种容器,类似于数组,但集合的大小可变,开发中也非常常用。Collection代表单列集合,每个元素(数据)只包含1个值。Collection集合分为两类,List集合与set集合。 特点 List系列集合&#…...

BGP实验练习1
需求: 要求五台路由器的环回地址均可以相互访问 需求分析: 1.图中存在五个路由器 AR1、AR2、AR3、AR4、AR5,分属不同自治系统(AS),AR1 在 AS 100,AR2 - AR4 在 AS 200,AR5 在 AS …...

Nginx location静态文件映射配置
遇到问题? 以下这个Nginx的配置,愿意为访问https://abc.com会指向一个动态网站,访问https://abc.com/tongsongzj时会访问静态网站,但是配置之后(注意看后面那个location /tongsongzj/静态文件映射的配置)&…...

四、Hive DDL表定义、数据类型、SerDe 与分隔符核心
在理解了 Hive 数据库的基本操作后,本篇笔记将深入到数据存储的核心单元——表 (Table) 的定义和管理。掌握如何创建表、选择合适的数据类型、以及配置数据的读写方式 (特别是 SerDe 和分隔符),是高效使用 Hive 的关键。 一、创建表 (CREATE TABLE)&…...

每日脚本 5.11 - 进制转换和ascii字符
前置知识 python中各个进制的开头 二进制 : 0b 八进制 : 0o 十六进制 : 0x 进制转换函数 : bin() 转为2进制 oct() 转换为八进制的函数 hex() 转换为16进制的函数 ascii码和字符之间的转换 : chr(97) 码转为字符 …...

cookie和session的区别
一、基本概念 1. Cookie 定义:Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据(通常小于4KB),浏览器会在后续请求中自动携带该数据。作用:用于跟踪用户状态(如登录状态)、记…...

Kotlin Multiplatform--03:项目实战
Kotlin Multiplatform--03:项目实战 引言配置iOS开发环境配置项目环境运行程序 引言 本章将会带领读者进行项目实战,了解如何从零开始编译一个能同时在Android和iOS运行的App。开发环境一般来说需要使用Macbook,笔者没试过Windows是否能开发。…...

图形学、人机交互、VR/AR领域文献速读【持续更新中...】
(1)笔者在时间有限的情况下,想要多积累一些自身课题之外的新文献、新知识,所以开了这一篇文章。 (2)想通过将文献喂给大模型,并向大模型提问的方式来快速理解文献的重要信息(如基础i…...

opencascade.js stp vite 调试笔记
Hello, World! | OpenCascade.js cnpm install opencascade.js cnpm install vite-plugin-wasm --save-dev 当你不知道文件写哪的时候trae还是有点用的 ‘’‘ import { defineConfig } from vite; import wasm from vite-plugin-wasm; import rollupWasm from rollup/plugi…...