【Diffusion】在华为云ModelArts上运行MindSpore扩散模型教程
目录
一、背景与目的
二、环境搭建
三、模型原理学习
1. 类定义与初始化
2. 初始卷积层
3. 时间嵌入模块
4. 下采样模块
5. 中间模块
6. 上采样模块
7. 最终卷积层
8. 前向传播
9. 关键点总结
四、代码实现与运行
五、遇到的问题及解决方法
六、总结与展望
一、背景与目的
最近对生成模型非常感兴趣,尤其是扩散模型(Diffusion Models),它在图像生成等领域取得了显著成果。为了深入理解扩散模型的原理和实现,我选择在华为云的ModelArts平台上运行MindSpore官方提供的扩散模型教程。希望通过这次实践,能够掌握扩散模型的基本架构、训练过程以及生成图像的原理。
二、环境搭建
- 华为云ModelArts平台:注册并登录华为云账号,创建一个ModelArts项目,选择合适的计算资源(如GPU资源)。
创建一个notebook
选择好AI框架的镜像,再选择GPU模式,磁盘存储默认即可
- MindSpore框架:在ModelArts环境中安装MindSpore框架。可以通过华为云提供的镜像或手动安装MindSpore来完成。
这里我选择在镜像市场拉了一个mindspore2.0版本的镜像
- 依赖库安装:根据教程要求,安装所需的依赖库,如numpy、matplotlib、tqdm等。在ModelArts的Jupyter Notebook环境中,使用pip install命令进行安装。
三、模型原理学习
- 扩散模型概述:扩散模型是一种生成模型,通过逐步添加噪声将数据分布转换为简单分布(如高斯分布),然后通过学习逆向去噪过程生成数据样本。它包括正向扩散过程和逆向去噪过程。正向过程是将高斯噪声逐渐添加到图像中,直到变成纯噪声;逆向过程是通过神经网络从纯噪声逐渐去噪,最终生成实际图像。
- 前向过程与逆向过程:
- 前向过程:根据预定义的方差计划,在每个时间步长添加高斯噪声。使用公式q(xt ∥xt−1 )=N(xt ;1−βt xt−1 ,βt I)来实现噪声的添加。
- 逆向过程:利用神经网络学习条件概率分布pθ (xt−1 ∥xt ),通过优化目标函数(如均方误差)来训练神经网络预测噪声,从而实现去噪。
- U-Net神经网络:教程中使用U-Net作为神经网络架构,它包含编码器、解码器和瓶颈层,通过残差连接改善梯度流。U-Net能够接收带噪声的图像,并预测添加到输入中的噪声,从而实现逆向去噪。
class Unet(nn.Cell):def __init__(
self,
dim,
init_dim=None,
out_dim=None,
dim_mults=(1, 2, 4, 8),
channels=3,
with_time_emb=True,
convnext_mult=2,):super().__init__() self.channels = channels init_dim = default(init_dim, dim // 3 * 2)
self.init_conv = nn.Conv2d(channels, init_dim, 7, padding=3, pad_mode="pad", has_bias=True) dims = [init_dim, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:])) block_klass = partial(ConvNextBlock, mult=convnext_mult)if with_time_emb:
time_dim = dim * 4
self.time_mlp = nn.SequentialCell(
SinusoidalPositionEmbeddings(dim),
nn.Dense(dim, time_dim),
nn.GELU(),
nn.Dense(time_dim, time_dim),)else:
time_dim = None
self.time_mlp = None self.downs = nn.CellList([])
self.ups = nn.CellList([])
num_resolutions = len(in_out)for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1) self.downs.append(
nn.CellList([
block_klass(dim_in, dim_out, time_emb_dim=time_dim),
block_klass(dim_out, dim_out, time_emb_dim=time_dim),
Residual(PreNorm(dim_out, LinearAttention(dim_out))),
Downsample(dim_out) if not is_last else nn.Identity(),])) mid_dim = dims[-1]
self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))
self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):
is_last = ind >= (num_resolutions - 1) self.ups.append(
nn.CellList([
block_klass(dim_out * 2, dim_in, time_emb_dim=time_dim),
block_klass(dim_in, dim_in, time_emb_dim=time_dim),
Residual(PreNorm(dim_in, LinearAttention(dim_in))),
Upsample(dim_in) if not is_last else nn.Identity(),])) out_dim = default(out_dim, channels)
self.final_conv = nn.SequentialCell(
block_klass(dim, dim), nn.Conv2d(dim, out_dim, 1))def construct(self, x, time):
x = self.init_conv(x) t = self.time_mlp(time) if exists(self.time_mlp) else None h = []for block1, block2, attn, downsample in self.downs:
x = block1(x, t)
x = block2(x, t)
x = attn(x)
h.append(x) x = downsample(x) x = self.mid_block1(x, t)
x = self.mid_attn(x)
x = self.mid_block2(x, t) len_h = len(h) - 1for block1, block2, attn, upsample in self.ups:
x = ops.concat((x, h[len_h]), 1)
len_h -= 1
x = block1(x, t)
x = block2(x, t)
x = attn(x) x = upsample(x)return self.final_conv(x)
引用自Diffusion扩散模型 — MindSpore master documentation
解析:
条件 U-Net 神经网络,用于扩散模型中的逆向去噪过程。
1. 类定义与初始化
class Unet(nn.Cell):
def __init__(
self,
dim,
init_dim=None,
out_dim=None,
dim_mults=(1, 2, 4, 8),
channels=3,
with_time_emb=True,
convnext_mult=2,
):
super().__init__()
- Unet 类:继承自 MindSpore 的 nn.Cell,表示这是一个神经网络模块。
- 参数说明:
- dim:基础维度,用于控制网络中卷积层的通道数。
- init_dim:初始卷积层的输出通道数,默认为 dim // 3 * 2。
- out_dim:最终输出的通道数,默认为输入图像的通道数(channels)。
- dim_mults:一个元组,表示每个分辨率级别上的通道数放大倍数。例如 (1, 2, 4, 8) 表示在四个级别上,通道数分别为 dim、2*dim、4*dim、8*dim。
- channels:输入图像的通道数,默认为 3(RGB 图像)。
- with_time_emb:是否使用时间嵌入(time embedding),用于将时间步长信息编码到网络中。
- convnext_mult:ConvNeXT 块中的扩展倍数,默认为 2。
2. 初始卷积层
self.channels = channelsinit_dim = default(init_dim, dim // 3 * 2)
self.init_conv = nn.Conv2d(channels, init_dim, 7, padding=3, pad_mode="pad", has_bias=True)
- self.channels:保存输入图像的通道数。
- init_dim:计算初始卷积层的输出通道数。如果 init_dim 未指定,则默认为 dim // 3 * 2。
- self.init_conv:定义一个卷积层,将输入图像的通道数从 channels 转换为 init_dim。卷积核大小为 7×7,填充为 3,以保持图像的空间尺寸。
3. 时间嵌入模块
if with_time_emb:
time_dim = dim * 4
self.time_mlp = nn.SequentialCell(
SinusoidalPositionEmbeddings(dim),
nn.Dense(dim, time_dim),
nn.GELU(),
nn.Dense(time_dim, time_dim),
)
else:
time_dim = None
self.time_mlp = None
- with_time_emb:如果为 True,则启用时间嵌入模块。
- time_dim:时间嵌入的维度,设置为 dim * 4。
- self.time_mlp:定义一个时间嵌入模块,包含以下部分:
- SinusoidalPositionEmbeddings(dim):使用正弦位置嵌入将时间步长编码为高维向量。
- nn.Dense(dim, time_dim):将嵌入向量的维度从 dim 扩展到 time_dim。
- nn.GELU():应用 GELU 激活函数。
- nn.Dense(time_dim, time_dim):再次将维度扩展到 time_dim。
- 如果 with_time_emb 为 False,则时间嵌入模块为空。
4. 下采样模块
self.downs = nn.CellList([])
self.ups = nn.CellList([])
num_resolutions = len(in_out)for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1) self.downs.append(
nn.CellList(
[
block_klass(dim_in, dim_out, time_emb_dim=time_dim),
block_klass(dim_out, dim_out, time_emb_dim=time_dim),
Residual(PreNorm(dim_out, LinearAttention(dim_out))),
Downsample(dim_out) if not is_last else nn.Identity(),
]
)
)
- self.downs:一个 CellList,用于存储所有下采样模块。
- in_out:一个列表,包含每个分辨率级别上的输入和输出通道数。
- 循环:对每个分辨率级别,构建一个下采样模块,包含以下部分:
- 两个 ConvNeXT 块:用于特征提取,每个块的输入通道数为 dim_in,输出通道数为 dim_out。
- 一个 LinearAttention 块:用于注意力机制,提升特征的表达能力。
- 一个下采样操作:如果当前级别不是最后一个级别,则使用 Downsample 操作进行下采样;否则,使用 nn.Identity(即不进行下采样)。
5. 中间模块
mid_dim = dims[-1]
self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))
self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
- mid_dim:中间模块的通道数,等于最后一个下采样模块的输出通道数。
- self.mid_block1 和 self.mid_block2:两个 ConvNeXT 块,用于进一步提取特征。
- self.mid_attn:一个注意力模块,用于增强特征的表达能力。
6. 上采样模块
for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):
is_last = ind >= (num_resolutions - 1) self.ups.append(
nn.CellList([
block_klass(dim_out * 2, dim_in, time_emb_dim=time_dim),
block_klass(dim_in, dim_in, time_emb_dim=time_dim),
Residual(PreNorm(dim_in, LinearAttention(dim_in))),
Upsample(dim_in) if not is_last else nn.Identity(),]))
- self.ups:一个 CellList,用于存储所有上采样模块。
- reversed(in_out[1:]):从倒数第二个级别开始,逆序遍历分辨率级别。
- 循环:对每个分辨率级别,构建一个上采样模块,包含以下部分:
- 两个 ConvNeXT 块:用于特征提取,第一个块的输入通道数为 dim_out * 2(因为会拼接来自下采样模块的特征),输出通道数为 dim_in。
- 一个 LinearAttention 块:用于注意力机制。
- 一个上采样操作:如果当前级别不是最后一个级别,则使用 Upsample 操作进行上采样;否则,使用 nn.Identity。
7. 最终卷积层
out_dim = default(out_dim, channels)
self.final_conv = nn.SequentialCell(
block_klass(dim, dim), nn.Conv2d(dim, out_dim, 1)
)
- out_dim:最终输出的通道数,默认为输入图像的通道数。
- self.final_conv:定义一个最终卷积层,包含以下部分:
- 一个 ConvNeXT 块:用于最后的特征提取。
- 一个卷积层:将通道数从 dim 转换为 out_dim,卷积核大小为 1×1。
8. 前向传播
def construct(self, x, time):
x = self.init_conv(x) t = self.time_mlp(time) if exists(self.time_mlp) else None h = [] for block1, block2, attn, downsample in self.downs:
x = block1(x, t)
x = block2(x, t)
x = attn(x)
h.append(x) x = downsample(x) x = self.mid_block1(x, t)
x = self.mid_attn(x)
x = self.mid_block2(x, t) len_h = len(h) - 1
for block1, block2, attn, upsample in self.ups:
x = ops.concat((x, h[len_h]), 1)
len_h -= 1
x = block1(x, t)
x = block2(x, t)
x = attn(x) x = upsample(x)
return self.final_conv(x)
- 输入:
- x:输入图像。
- time:时间步长信息。
- 前向传播过程:
- 初始卷积:通过 self.init_conv 将输入图像的通道数从 channels 转换为 init_dim。
- 时间嵌入:如果启用时间嵌入模块,则将时间步长信息通过 self.time_mlp 转换为高维向量。
- 下采样:依次通过每个下采样模块,提取特征并逐步降低图像的空间分辨率。将每个下采样模块的输出特征保存到列表 h 中。
- 中间模块:通过中间模块的两个 ConvNeXT 块和注意力模块,进一步提取特征。
- 上采样:逆序通过每个上采样模块,逐步恢复图像的空间分辨率。在每个上采样模块中,将当前特征与之前保存的特征进行拼接,然后通过两个 ConvNeXT 块和注意力模块进行特征提取。
- 最终卷积:通过最终卷积层,将通道数从 dim 转换为 out_dim,得到最终的输出。
9. 关键点总结
- U-Net 结构:网络采用 U-Net 结构,包含下采样模块、中间模块和上采样模块。下采样模块逐步降低图像分辨率,提取高层特征;上采样模块逐步恢复图像分辨率,生成最终输出。
- 时间嵌入:通过正弦位置嵌入将时间步长信息编码到网络中,使网络能够根据不同的时间步长进行去噪。
- 注意力机制:在下采样和上采样模块中引入注意力机制,增强特征的表达能力。
- 特征拼接:在上采样过程中,将当前特征与之前保存的特征进行拼接,保留更多的细节信息,有助于生成更高质量的图像。
这个 U-Net 网络是扩散模型中的核心部分,通过学习逆向去噪过程,能够从纯噪声逐步生成实际图像。
四、代码实现与运行
- 数据准备:使用Fashion-MNIST数据集进行训练。通过mindspore.dataset模块加载数据集,并进行预处理,包括随机水平翻转、标准化等操作,将图像值缩放到[−1,1]范围内。
- 模型构建:根据教程提供的代码,构建扩散模型的各个模块,包括位置嵌入模块、ResNet/ConvNeXT块、Attention模块、组归一化模块以及条件U-Net网络。特别注意U-Net网络的结构和参数配置,确保其能够正确接收输入并输出预测噪声。
- 正向扩散过程实现:定义正向扩散过程的函数q_sample,根据时间步长和噪声计划,将噪声添加到输入图像中。通过可视化不同时间步长下的噪声图像,观察噪声逐渐增加的过程。
- 训练过程:
- 定义损失函数p_losses,计算真实噪声和预测噪声之间的均方误差,并结合权重进行优化。
- 使用Adam优化器进行训练,设置动态学习率(如余弦衰减学习率)。在训练过程中,随机采样时间步长和噪声水平,优化神经网络的参数。
- 训练过程中,定期打印损失值,观察模型的收敛情况。同时,可以使用采样函数sample在训练过程中生成图像样本,观察模型生成能力的变化。
import timeepochs = 10iterator = dataset.create_tuple_iterator(num_epochs=epochs)
for epoch in range(epochs):
begin_time = time.time()
for step, batch in enumerate(iterator):
unet_model.set_train()
batch_size = batch[0].shape[0]
t = randint(0, timesteps, (batch_size,), dtype=ms.int32)
noise = randn_like(batch[0])
loss = train_step(batch[0], t, noise) if step % 500 == 0:
print(" epoch: ", epoch, " step: ", step, " Loss: ", loss)
end_time = time.time()
times = end_time - begin_time
print("training time:", times, "s")
# 展示随机采样效果
unet_model.set_train(False)
samples = sample(unet_model, image_size=image_size, batch_size=64, channels=channels)
plt.imshow(samples[-1][5].reshape(image_size, image_size, channels), cmap="gray")
print("Training Success!")
代码来源:Diffusion扩散模型 — MindSpore master documentation
一共训练了10轮
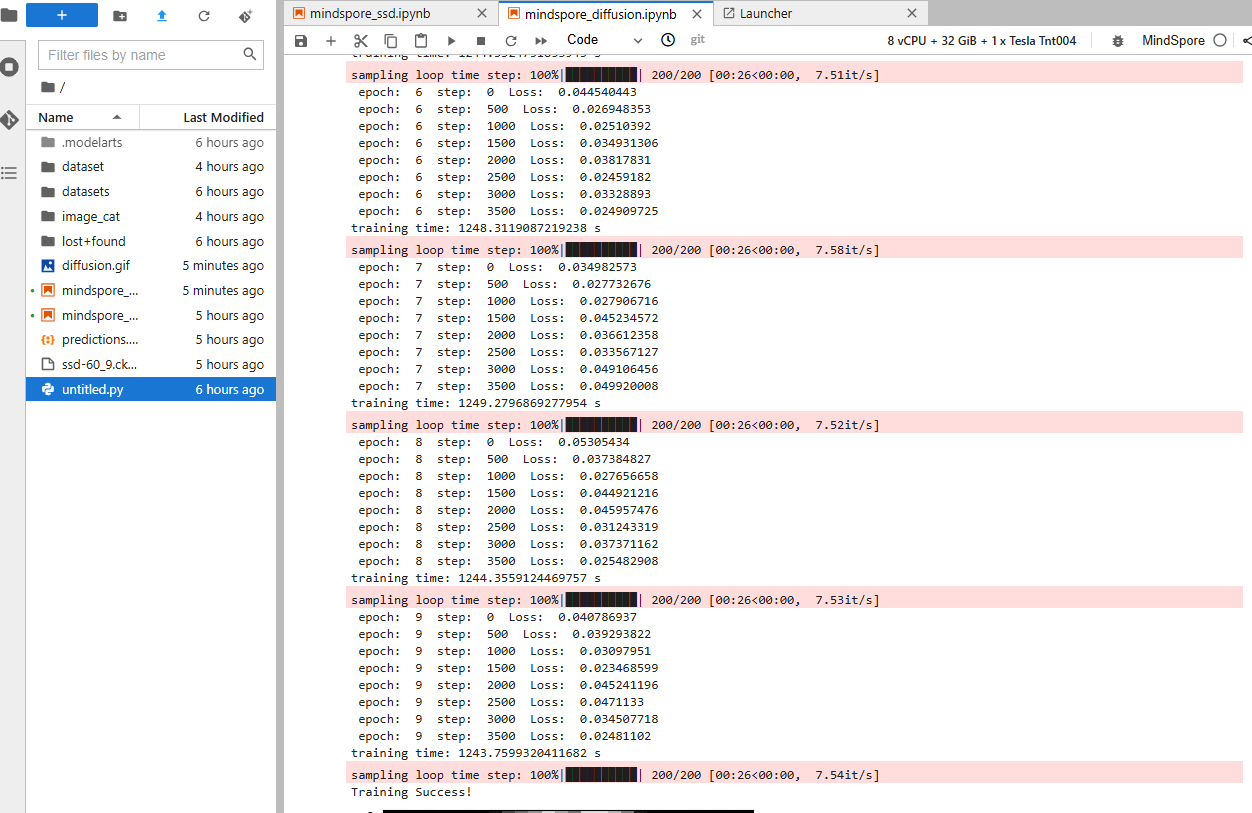
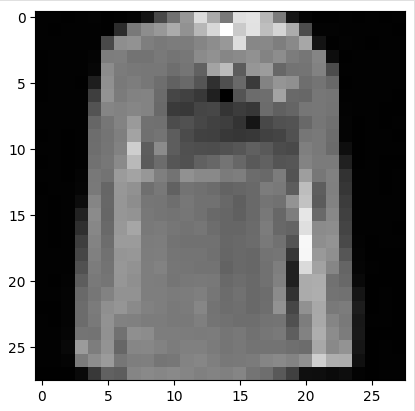
- 采样与生成:训练完成后,使用采样函数sample从模型中生成图像。通过逐步去噪,从纯噪声生成最终的图像样本。可以展示生成的图像样本,观察模型的生成效果。
生成的效果有些欠佳,可能是随机采样的原因,也可能是模型一些过拟合,需要进一步调整参数
五、遇到的问题及解决方法
- 环境配置问题:在ModelArts环境中安装MindSpore和依赖库时,可能会遇到版本兼容性问题。解决方法是仔细检查MindSpore和依赖库的版本要求,确保安装的版本相互兼容。可以通过查阅官方文档或社区论坛获取帮助。
- 训练时间过长:由于扩散模型需要多次正向传递来生成图像,训练过程可能相对较长。解决方法是合理配置计算资源,选择合适的GPU资源加速训练。同时,可以尝试减少训练数据集的大小或调整训练参数(如学习率、批次大小等),以缩短训练时间。
- 生成效果不佳:在训练过程中,可能会发现生成的图像样本质量不高或存在噪声。解决方法是仔细检查模型的结构和训练参数,确保模型能够正确学习逆向去噪过程。可以尝试调整网络结构、增加训练数据量、优化损失函数等方法来提高生成效果。
六、总结与展望
通过在华为云ModelArts上运行MindSpore扩散模型教程,我对扩散模型的原理和实现有了更深入的理解。扩散模型通过正向扩散和逆向去噪过程,能够生成具有一定质量的图像样本。在实践中,我掌握了MindSpore框架的基本使用方法,以及如何构建和训练扩散模型。同时,我也意识到扩散模型在生成效果和训练效率方面还存在一些挑战,如生成图像的多样性不足、训练时间较长等。
未来,我计划进一步探索扩散模型的改进方法,如引入更复杂的网络结构、优化训练策略等,以提高生成图像的质量和多样性。此外,我还想尝试将扩散模型应用于其他领域,如音频生成、视频生成等,探索其在不同领域的应用潜力。同时,我也会关注扩散模型的最新研究进展,学习和借鉴新的技术和方法,不断提升自己的技术水平。
相关文章:

【Diffusion】在华为云ModelArts上运行MindSpore扩散模型教程
目录 一、背景与目的 二、环境搭建 三、模型原理学习 1. 类定义与初始化 2. 初始卷积层 3. 时间嵌入模块 4. 下采样模块 5. 中间模块 6. 上采样模块 7. 最终卷积层 8. 前向传播 9. 关键点总结 四、代码实现与运行 五、遇到的问题及解决方法 六、总结与展望 一、…...

跟我学c++高级篇——模板元编程之十三处理逻辑
一、元编程处理逻辑 无论在普通编程还是在元编程中,逻辑的处理,都是一个编程开始的必然经过。开发者对普通编程中的逻辑处理一般都非常清楚,不外乎条件谈判和循环处理。而条件判断常见的基本就是if语句(switch如果不考虑效率等情…...
详解)
组合模式(Composite Pattern)详解
文章目录 1. 什么是组合模式?2. 为什么需要组合模式?3. 组合模式的核心概念4. 组合模式的结构5. 组合模式的基本实现5.1 基础示例:文件系统5.2 透明组合模式 vs 安全组合模式5.2.1 透明组合模式5.2.2 安全组合模式5.3 实例:公司组织结构5.4 实例:GUI组件树6. Java中组合模…...

最长字符串 / STL+BFS
题目 代码 #include <bits/stdc.h> using namespace std;int main() {map<vector<int>, vector<string>> a;set<vector<int>> c;vector<int> initial(26, 0);c.insert(initial);ifstream infile("words.txt");string s;w…...

C++ stl中的set、multiset、map、multimap的相关函数用法
文章目录 序列式容器和关联式容器树形结构和哈希结构树形结构哈希结构 键值对setset的相关介绍set定义方式set相关成员函数multiset mapmap的相关介绍map定义方式map的相关操作1.map的插入2.map的查找3.map的删除 序列式容器和关联式容器 CSTL中包含了序列式容器和关联式容器&…...

普通IT的股票交易成长史--20250511 美元与美股强相关性
声明:本文章的内容非原创。参考了yt博主Andy Lee的观点,为了加深自己的学习印象才做的复盘,不构成投资建议。感谢他的无私奉献! 送给自己的话: 仓位就是生命,绝对不能满仓!!&#x…...
:架构风格总结)
系统架构设计(四):架构风格总结
黑板 概念 黑板体系架构是一种用于求解复杂问题的软件架构风格,尤其适合知识密集型、推理驱动、数据不确定性大的场景。 它模拟了人类专家协同解决问题的方式,通过一个共享的“黑板”协同多个模块(专家)逐步构建解决方案。 组…...

ElasticSearch进阶
一、文档批量操作 1.批量获取文档数据 批量获取文档数据是通过_mget的API来实现的 (1)在URL中不指定index和type 请求方式:GET请求地址:_mget功能说明 : 可以通过ID批量获取不同index和type的数据请求参数: docs : 文档数组参…...

0基础 | L298N电机驱动模块 | 使用指南
引言 在嵌入式系统开发中,电机驱动是一个常见且重要的功能。L298N是一款高电压、大电流电机驱动芯片,广泛应用于各种电机控制场景,如直流电机的正反转、调速,以及步进电机的驱动等。本文将详细介绍如何使用51单片机来控制L298N电…...

Synchronized与锁升级
一、面试题 1)谈谈你对Synchronized的理解 2)Sychronized的锁升级你聊聊 3)Synchronized实现原理,monitor对象什么时候生成的?知道monitor的monitorenter和monitorexit这两个是怎么保证同步的嘛&#…...

MNIST DDP 分布式数据并行
Distributed Data Parallel 转自我的个人博客:https://shar-pen.github.io/2025/05/04/torch-distributed-series/3.MNIST_DDP/ The difference between DistributedDataParallel and DataParallel is: DistributedDataParallel uses multiprocessing where a proc…...

语音合成之十三 中文文本归一化在现代语音合成系统中的应用与实践
中文文本归一化在现代语音合成系统中的应用与实践 引言理解中文文本归一化(TN)3 主流LLM驱动的TTS系统及其对中文文本归一化的需求分析A. SparkTTS(基于Qwen2.5)与文本归一化B. CosyVoice(基于Qwen)与文本归…...

9.1.领域驱动设计
目录 一、领域驱动设计核心哲学 战略设计与战术设计的分野 • 战略设计:限界上下文(Bounded Context)与上下文映射(Context Mapping) • 战术设计:实体、值对象、聚合根、领域服务的构建原则 统一语言&am…...

如何配置光猫+路由器实现外网IP访问内部网络?
文章目录 前言一、网络拓扑理解二、准备工作三、光猫配置3.1 光猫工作模式3.2 光猫端口转发配置(路由模式时) 四、路由器配置4.1 路由器WAN口配置4.2 端口转发配置4.3 动态DNS配置(可选) 五、防火墙设置六、测试配置七、安全注意事…...

C++题题题题题题题题题踢踢踢
后缀表达式求值 #include<bits/stdc.h> #include<algorithm> using namespace std; string a[100]; string b[100]; stack<string> op; int la0,lb0; int main(){while(true){cin>>a[la];if(a[la]".") break;la;}for(int i0;i<la;i){if(…...
)
M. Moving Both Hands(反向图+Dijkstra)
Problem - 1725M - Codeforces 题目大意:给你一个有向图,起始点在1,问起始点分别与另外n-1个 点相遇的最短时间,无法相遇输出-1。 思路:反向建图,第一层建原图,第二层建反向图,两层…...

11、参数化三维产品设计组件 - /设计与仿真组件/parametric-3d-product-design
76个工业组件库示例汇总 参数化三维产品设计组件 (注塑模具与公差分析) 概述 这是一个交互式的 Web 组件,旨在演示简单的三维零件(如带凸台的方块)的参数化设计过程,并结合注塑模具设计(如开模动画)与公…...

智能座舱开发工程师面试题
一、基础知识类 简述智能座舱的核心组成部分及其功能 要求从硬件(如显示屏、传感器、控制器)和软件(操作系统、中间件、应用程序)层面展开,阐述各部分如何协同实现座舱的智能化体验。 对比 Android Automotive、QNX…...

【连载14】基础智能体的进展与挑战综述-多智能体系统设计
基础智能体的进展与挑战综述 从类脑智能到具备可进化性、协作性和安全性的系统 【翻译团队】刘军(liujunbupt.edu.cn) 钱雨欣玥 冯梓哲 李正博 李冠谕 朱宇晗 张霄天 孙大壮 黄若溪 在基于大语言模型的多智能体系统(LLM-MAS)中,合作目标和合…...

06.three官方示例+编辑器+AI快速学习webgl_animation_skinning_additive_blending
本实例主要讲解内容 这个Three.js示例展示了**骨骼动画(Skinning)和变形动画(Morphing)**的结合应用。通过加载一个机器人模型,演示了如何同时控制角色的肢体动作和面部表情,实现更加丰富的角色动画效果。 核心技术包括: 多动画混合与淡入…...

【Java学习日记36】:javabeen学生系统
ideal快捷键...

.Net HttpClient 使用请求数据
HttpClient 使用请求数据 0、初始化及全局设置 //初始化:必须先执行一次 #!import ./ini.ipynb1、使用url 传参 参数放在Url里,形如:http://www.baidu.com?namezhangsan&age18, GET、Head请求用的比较多。优点是简单、方便࿰…...

详解 Java 并发编程 synchronized 关键字
synchronized 关键字的作用 synchronized 是 Java 中用于实现线程同步的关键字,主要用于解决多线程环境下的资源竞争问题。它可以修饰方法或代码块,确保同一时间只有一个线程可以执行被修饰的代码,从而避免数据不一致的问题。 synchronized…...

《Go小技巧易错点100例》第三十二篇
本期分享: 1.sync.Map的原理和使用方式 2.实现有序的Map sync.Map的原理和使用方式 sync.Map的底层结构是通过读写分离和无锁读设计实现高并发安全: 1)双存储结构: 包含原子化的 read(只读缓存,无锁快…...

时序约束高级进阶使用详解四:Set_False_Path
目录 一、背景 二、Set_False_Path 2.1 Set_false_path常用场景 2.2 Set_false_path的优势 2.3 Set_false_path设置项 2.4 细节区分 三、工程示例 3.1 工程代码 3.2 时序约束如下 3.3 时序报告 3.4 常规场景 3.4.1 设计代码 3.4.2 约束场景 3.4.3 约束对象总结…...
20250428 - 20250511)
每日定投40刀BTC(16)20250428 - 20250511
定投 坚持 《恒道》 长河九曲本微流,岱岳摩云起累丘。 铁杵十年销作刃,寒窗五鼓淬成钩。已谙蜀栈盘空险,更蓄湘竹带泪遒。 莫问枯荣何日证,星霜满鬓亦从头。...

C# 高效处理海量数据:解决嵌套并行的性能陷阱
C# 高效处理海量数据:解决嵌套并行的性能陷阱 问题场景 假设我们需要在 10万条ID 和 1万个目录路径 中,快速找到所有满足以下条件的路径: 路径本身包含ID字符串该路径的子目录中也包含同名ID 初始代码采用Parallel.ForEach嵌套Task.Run&am…...
】线程安全问题)
【Java EE初阶 --- 多线程(初阶)】线程安全问题
乐观学习,乐观生活,才能不断前进啊!!! 我的主页:optimistic_chen 我的专栏:c语言 ,Java 欢迎大家访问~ 创作不易,大佬们点赞鼓励下吧~ 文章目录 线程不安全的原因根本原因…...

从InfluxDB到StarRocks:Grab实现Spark监控平台10倍性能提升
Grab 是东南亚领先的超级应用,业务涵盖外卖配送、出行服务和数字金融,覆盖东南亚八个国家的 800 多个城市,每天为数百万用户提供一站式服务,包括点餐、购物、寄送包裹、打车、在线支付等。 为了优化 Spark 监控性能,Gr…...

《Redis应用实例》学习笔记,第一章:缓存文本数据
前言 最近在学习《Redis应用实例》,这本书并没有讲任何底层,而是聚焦实战用法,梳理了 32 种 Redis 的常见用法。我的笔记在 Github 上,用 Jupyter 记录,会有更好的阅读体验,作者的源码在这里:h…...

Redis 缓存
缓存介绍 Redis 最主要三个用途: 1)存储数据(内存数据库) 2)消息队列 3)缓存 对于硬件的访问速度,通常有以下情况: CPU 寄存器 > 内存 > 硬盘 > 网络 缓存的核心…...

Apache Flink 与 Flink CDC:概念、联系、区别及版本演进解析
Apache Flink 与 Flink CDC:概念、联系、区别及版本演进解析 在实时数据处理和流式计算领域,Apache Flink 已成为行业标杆。而 Flink CDC(Change Data Capture) 作为其生态中的重要组件,为数据库的实时变更捕获提供了强大的能力。 本文将从以下几个方面进行深入讲解: 什…...
:常见缓存 概念、问题、现象 及 预防问题)
缓存(4):常见缓存 概念、问题、现象 及 预防问题
常见缓存概念 缓存特征: 命中率、最大元素、清空策略 命中率:命中率返回正确结果数/请求缓存次数 它是衡量缓存有效性的重要指标。命中率越高,表明缓存的使用率越高。 最大元素(最大空间):缓存中可以存放的最大元素的…...
)
实战项目6(09)
目录 任务场景一 【r1配置】 【r2配置】 【r3配置】 任务场景二 【r1配置】 【r2配置】 【r3配置】 任务场景三 【r1配置】 【r2配置】 【r3配置】 任务场景一 按照下图完成网络拓扑搭建和配置 任务要求:在…...

MySQL 数据库故障排查指南
MySQL 数据库故障排查指南 本指南旨在帮助您识别和解决常见的 MySQL 数据库故障。我们将从问题识别开始,逐步深入到具体的故障类型和排查步骤。 1. 问题识别与信息收集 在开始排查之前,首先需要清晰地了解问题的现象和范围。 故障现象: 数…...

MacOS Python3安装
python一般在Mac上会自带,但是大多都是python2。 python2和python3并不存在上下版本兼容的情况,所以python2和python3可以同时安装在一台设备上,并且python3的一些语法和python2并不互通。 所以在Mac电脑上即使有自带python,想要使…...

锁相放大技术:从噪声中提取微弱信号的利器
锁相放大技术:从噪声中提取微弱信号的利器 一、什么是锁相放大? 锁相放大(Lock-in Amplification)是一种用于检测微弱信号的技术,它能够从强噪声背景中提取出我们感兴趣的特定信号。想象一下在嘈杂的派对上听清某个人…...

机器学习总结
1.BN【batch normalization】 https://zhuanlan.zhihu.com/p/93643523 减少 2.L1L2正则化 l1:稀疏 l2:权重减小 3.泛化误差 训练误差计算了训练集的误差,而泛化误差是计算全集的误差。 4.dropout 训练过程中神经元p的概率失活 一文彻底搞懂深度学习&#x…...

基于神经网络的无源雷达测向系统仿真实现
基于神经网络的无源雷达测向系统仿真实现 项目概述 本项目实现了基于卷积神经网络(CNN)的无源雷达方向到达角(DOA)估计系统。通过深度学习方法,系统能够从接收到的雷达信号中准确估计出信号源的方向,适用于单目标和多目标场景。相比传统的DOA估计算法&…...

《用MATLAB玩转游戏开发》Flappy Bird:小鸟飞行大战MATLAB趣味实现
《用MATLAB玩转游戏开发:从零开始打造你的数字乐园》基础篇(2D图形交互)-Flappy Bird:小鸟飞行大战MATLAB趣味实现 文章目录 《用MATLAB玩转游戏开发:从零开始打造你的数字乐园》基础篇(2D图形交互…...

【C/C++】跟我一起学_C++同步机制效率对比与优化策略
文章目录 C同步机制效率对比与优化策略1 效率对比2 核心同步机制详解与适用场景3 性能优化建议4 场景对比表5 总结 C同步机制效率对比与优化策略 多线程编程中,同步机制的选择直接影响程序性能与资源利用率。 主流同步方式: 互斥锁原子操作读写锁条件变量无锁数据…...

linux 三剑客命令学习
grep Grep 是一个命令行工具,用于在文本文件中搜索打印匹配指定模式的行。它的名称来自于 “Global Regular Expression Print”(全局正则表达式打印),它最初是由 Unix 系统上的一种工具实现的。Grep 工具在 Linux 和其他类 Unix…...

【js基础笔记] - 包含es6 类的使用
文章目录 js基础js 预解析js变量提升 DOM相关知识节点选择器获取属性节点创建节点插入节点替换节点克隆节点获取节点属性获取元素尺寸获取元素偏移量标准的dom事件流阻止事件传播阻止默认行为事件委托 正则表达式js复杂类型元字符 - 基本元字符元字符 - 边界符元字符 - 限定符元…...
》PDF下载)
《Linux命令行大全(第2版)》PDF下载
内容简介 本书对Linux命令行进行详细的介绍,全书内容包括4个部分,第一部分由Shell的介绍开启命令行基础知识的学习之旅;第二部分讲述配置文件的编辑,如何通过命令行控制计算机;第三部分探讨常见的任务与必备工具&…...
)
补补表面粗糙度的相关知识(一)
表面粗糙度,或简称粗糙度,是指表面不光滑的特性。这个在机械加工行业内可以说是绝绝的必备知识之一,但往往也是最容易被忽略的,因为往往天天接触的反而不怎么关心,或者没有真正的去认真学习掌握。对于像我一样…...

Python实用工具:pdf转doc
该工具只能使用在英文目录下,且无法转换出图片,以及文本特殊格式。 下载依赖项 pip install PyPDF2 升级依赖项 pip install PyPDF2 --upgrade 查看库版本 python -c "import PyPDF2; print(PyPDF2.__version__)" 下载第二个依赖项 pip i…...

基于Dify实现对Excel的数据分析
在dify部署完成后,大家就可以基于此进行各种应用场景建设,目前dify支持聊天助手(包括对话工作流)、工作流、agent等模式的场景建设,我们在日常工作中经常会遇到各种各样的数据清洗、格式转换处理、数据统计成图等数据分…...

Win全兼容!五五 Excel Word 转 PDF 工具解决多场景转换难题
各位办公小能手们!今天给你们介绍一款超牛的工具——五五Excel Word批量转PDF工具V5.5版。这玩意儿专注搞批量格式转换,能把Excel(.xls/.xlsx)和Word(.doc/.docx)文档唰唰地变成PDF格式。 先说说它的核心功…...

java加强 -Collection集合
集合是一种容器,类似于数组,但集合的大小可变,开发中也非常常用。Collection代表单列集合,每个元素(数据)只包含1个值。Collection集合分为两类,List集合与set集合。 特点 List系列集合&#…...

BGP实验练习1
需求: 要求五台路由器的环回地址均可以相互访问 需求分析: 1.图中存在五个路由器 AR1、AR2、AR3、AR4、AR5,分属不同自治系统(AS),AR1 在 AS 100,AR2 - AR4 在 AS 200,AR5 在 AS …...