从InfluxDB到StarRocks:Grab实现Spark监控平台10倍性能提升

Grab 是东南亚领先的超级应用,业务涵盖外卖配送、出行服务和数字金融,覆盖东南亚八个国家的 800 多个城市,每天为数百万用户提供一站式服务,包括点餐、购物、寄送包裹、打车、在线支付等。
为了优化 Spark 监控性能,Grab 将其 Spark 可观测平台 Iris 的核心存储迁移至 StarRocks,实现了显著的性能提升。新架构统一了原本分散在 Grafana 和 Superset 的实时与历史数据分析,减少了多平台切换的复杂性。得益于 StarRocks 的高性能查询引擎,复杂分析的响应速度提升 10 倍以上,物化视图和动态分区机制有效降低运维成本。此外,直接从 Kafka 摄取数据简化了数据管道架构,使资源使用效率提升 40%。
作者:
Huong Vuong, Senior Software Engineer, Grab
Hai Nam Cao, Data Platform Engineer, Grab
一、Iris——Grab 的 Spark 可观测性平台介绍
(一)Iris 的作用
Iris 是 Grab 开发的定制化 Spark 作业可观测性工具,在作业级别收集和分析指标与元数据,深入洞察 Spark 集群的资源使用、性能和查询模式,提供实时性能指标,解决了传统监控工具仅在 EC2 实例级别提供指标的局限,使用户能按需访问 Spark 性能数据,助力更快决策和更高效的资源管理。
(二)Iris 面临的挑战
随着业务发展,Iris 暴露出一些问题:
-
分散的用户体验与访问控制:可观测性数据分散在 Grafana(实时)和 Superset(历史),用户需切换平台获取完整视角,且 Grafana 对非技术用户不友好,权限控制粒度粗。
-
运营开销:离线分析数据管道复杂,涉及多次跳转和转换。
-
数据管理:管理 InfluxDB 中的实时数据与数据湖中的离线数据存在困难,处理字符串类型元数据时问题尤为突出。
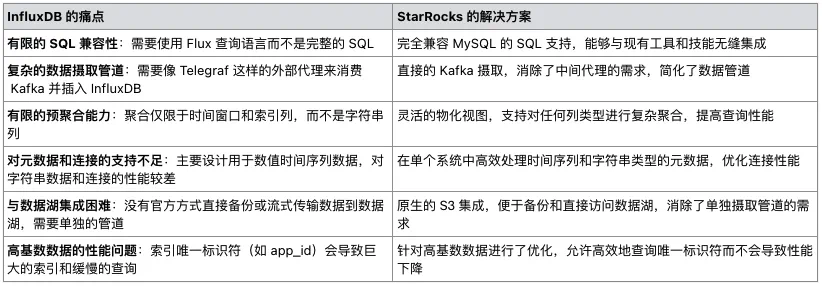
二、系统架构概览
(一)架构调整
为解决上述问题,Grab 对架构进行重大调整,从 Telegraf/InfluxDB/Grafana(TIG)堆栈转向以 StarRocks 为核心的架构。新架构包括以下关键组件:
(图1. 集成了 StarRocks 的新 Iris 架构)
-
StarRocks 数据库:替代 InfluxDB,存储实时和历史数据,支持复杂查询。
-
直接 Kafka 摄入:StarRocks 直接从 Kafka 获取数据,摆脱对 Telegraf 的依赖。
-
定制 web 应用(Iris UI):取代 Grafana 仪表板,提供集中、灵活的界面和自定义 API。
-
Superset 集成:继续保留并连接 StarRocks,提供实时数据访问,与自定义 Web 应用保持一致。
-
简化的离线数据处理:StarRocks 直接定期备份到 S3,简化了之前复杂的数据湖管道。
(二)关键改进
新架构带来诸多改进:
-
统一的数据存储:实时和历史数据统一存储,便于管理和查询。
-
简化的数据流:减少数据传输环节,降低延迟和故障点。
-
灵活的可视化:自定义 Web 应用提供符合用户角色需求的直观界面。
-
一致的实时访问:保证自定义应用和 Superset 之间数据一致性。
-
简化的备份和数据湖集成:支持直接备份至 S3,简化数据湖集成流程。
三、数据模型与数据摄取
(一)使用场景
Iris 可观测性系统主要针对 “集群观测” 场景,涵盖临时使用(团队用户共享预创建集群)和作业执行(每次提交作业创建新集群)两种情况。
(二)关键设计要点与表结构
针对每个集群,捕获元数据和指标,主要包含集群元数据、集群 Worker 指标、集群 Spark 指标三类表:
-
集群元数据:记录集群相关的各类元数据信息,如报告日期、平台、Worker UUID、集群 ID、作业 ID 等。
-
集群 Worker 指标:存储 Worker 的 CPU 核心数、内存、堆使用字节数等指标数据。
-
集群 Spark 指标:包含 Spark 应用的各种运行指标,如记录读写数量、字节读写量、任务数量等。
(三)从 Kafka 摄取数据至 StarRocks
利用 StarRocks 的 Routine Load 功能从 Kafka 导入数据,如为集群工作节点指标创建 routine load 作业,持续从指定 Kafka 主题摄取数据并进行 JSON 解析。StarRocks 提供内置工具监控例行加载任务,可通过特定查询查看加载状态。
四、统一系统处理实时与历史数据
新的 Iris 系统采用 StarRocks 高效管理实时和历史数据,并通过以下三个关键特性实现:
1.实时数据摄取
-
利用 StarRocks 的 Routine Load,实现从 Kafka 近乎实时的数据摄取。
-
多个加载任务并行消费不同分区的 topic,使数据在采集后的几秒内即可进入 Iris 表。
-
这一快速摄取能力确保监控信息的时效性,让用户能够随时掌握 Spark 作业的最新状态。
2.历史数据存储与分析
-
StarRocks 作为持久化存储,保存元数据和作业指标,并设置数据存活时间(TTL)超过 30 天。
-
这使我们能够直接在 StarRocks 中分析过去 30 天的作业运行情况,查询速度远超基于数据湖的离线分析。
3.物化视图优化查询性能
-
我们在 StarRocks 中创建了物化视图,用于预计算和聚合每次作业运行的数据。
-
这些视图整合元数据、工作节点指标和 Spark 指标,生成即用型的摘要数据。
-
这样,在 UI 中访问作业运行概览时,无需执行复杂的 Join 操作,提高 SQL 查询和 API 请求的响应速度。
这一架构相比以 InfluxDB 为基础的旧系统有显著提升:
-
作为时序数据库,InfluxDB 不擅长处理复杂查询和 Join 操作,导致查询性能受限。
-
InfluxDB 不支持物化视图,难以创建预计算的作业运行摘要 (job-run summary)。
-
过去,我们需要借助 Spark 和 Presto 在数据湖中查询过去 30 天的作业运行情况,速度远不及直接查询 StarRocks。
五、查询性能与优化
(一)物化视图
-
核心特性:StarRocks 支持同步(SYNC)和异步(ASYNC)物化视图,Grab 主要使用 ASYNC 视图,因其支持多表 Join,对作业运行摘要至关重要。可灵活配置视图刷新方式,如即时刷新或按时间间隔刷新。
-
分区 TTL:通过设置分区存活时间(Partition TTL),通常为 33 天,控制历史数据存储量,保证物化视图高性能,避免过多占用存储空间,同时确保快速访问近期历史数据。
-
选择性分区刷新:允许仅刷新物化视图特定分区,降低维护视图最新状态的计算开销,尤其适用于大型历史数据集。
(二)分区策略
表按日期分区,便于高效裁剪历史数据,查询近期作业或特定时间范围数据时,排除无关分区,减少扫描数据量,加快查询速度。
(三)动态分区策略
利用 StarRocks 的动态分区功能,新数据到达时自动创建分区,数据过期时自动删除旧分区,无需人工干预即可维持最佳查询性能。可通过特定 SQL 命令检查表的分区状态,对于超过 30 天的数据,使用每日定时任务备份至 Amazon S3,之后映射到数据湖表,不影响核心可观测性系统性能。
(四)数据副本机制
StarRocks 采用多节点数据复制策略,该设计在容错能力和查询性能两方面都至关重要。这一策略支持并行查询执行,从而加快数据检索速度。特别是在前端查询场景中,低延迟对用户体验至关重要。这种方法与其他分布式数据库系统(如 Cassandra、DynamoDB 以及 MySQL 的主从架构)中的最佳实践一致。
六、统一的 Web 应用程序
(一)后端
使用 Golang 构建,连接 StarRocks 数据库,查询原始表和物化视图数据,负责身份验证和权限管理,保障用户数据访问权限。
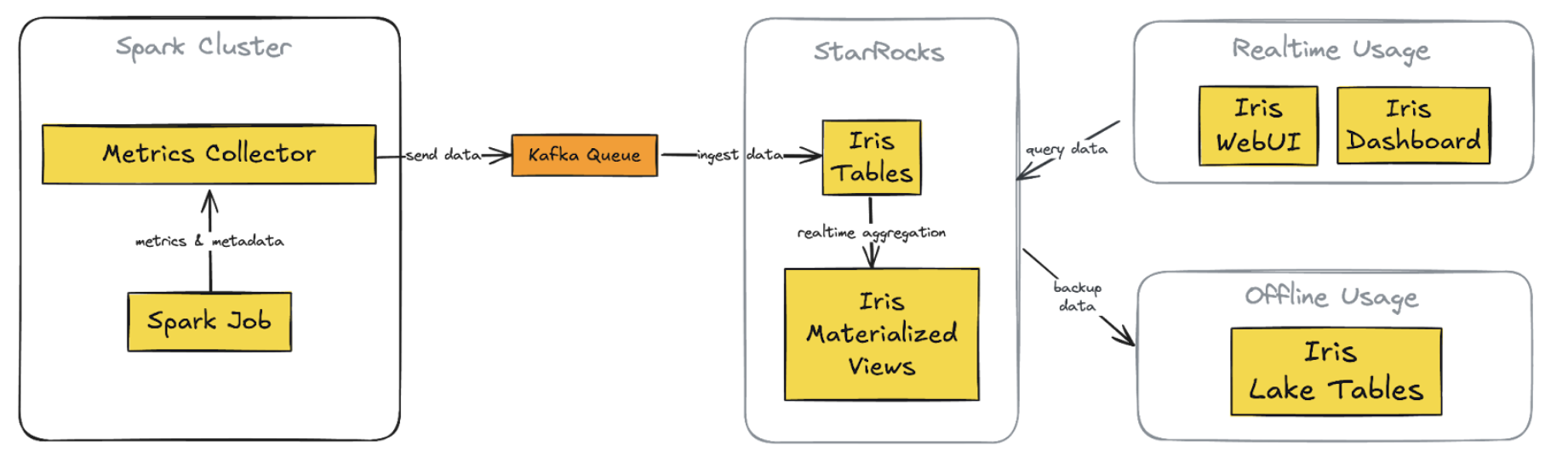
(二)前端
提供多个关键界面,如任务运行列表、任务状态、任务元数据等,任务概览页面展示关键摘要信息,帮助用户快速了解 Spark 任务运行和资源利用情况。
(图2:作业总览界面示例)
七、高级分析与洞察
(一)历史运行分析
创建物化视图聚合过去 30 天任务运行数据,包含运行次数、各类资源使用的 p95 值等指标,为分析任务趋势提供数据支持。以下为示例:
CREATE MATERIALIZED VIEW job_run_summaries_001REFRESH ASYNC EVERY(INTERVAL 1 DAY)ASselect platform,job_id,count(distinct run_id) as count_run,ceil(percentile_approx(total_instances, 0.95)) as p95_total_instances,ceil(percentile_approx(worker_instances, 0.95)) as p95_worker_instances,percentile_approx(job_hour, 0.95) as p95_job_hour,percentile_approx(machine_hour, 0.95) as p95_machine_hour,percentile_approx(cpu_hour, 0.95) as p95_cpu_hour,percentile_approx(worker_gc_hour, 0.95) as p95_worker_gc_hour,ceil(percentile_approx(driver_cpus, 0.95)) as p95_driver_cpus,ceil(percentile_approx(worker_cpus, 0.95)) as p95_worker_cpus,ceil(percentile_approx(driver_memory_gb, 0.95)) as p95_driver_memory_gb,ceil(percentile_approx(worker_memory_gb, 0.95)) as p95_worker_memory_gb,percentile_approx(driver_cpu_utilization, 0.95) as p95_driver_cpu_utilization,percentile_approx(worker_cpu_utilization, 0.95) as p95_worker_cpu_utilization,percentile_approx(driver_memory_utilization, 0.95) as p95_driver_memory_utilization,percentile_approx(worker_memory_utilization, 0.95) as p95_worker_memory_utilization,percentile_approx(total_gb_read, 0.95) as p95_gb_read,percentile_approx(total_gb_written, 0.95) as p95_gb_written,percentile_approx(total_memory_gb_spilled, 0.95) as p95_memory_gb_spilled,percentile_approx(disk_spilled_rate, 0.95) as p95_disk_spilled_ratefrom iris.job_runswhere report_date >= current_date - interval 30 daygroup by platform, job_id;(二)推荐 API
基于趋势分析结果构建推荐 API,提供优化建议,如调整资源分配、识别潜在瓶颈或修改调度策略,以优化成本和性能。
(三)前端集成
我们的 API 生成的推荐结果已集成到 Iris 前端。用户可以在任务概览或详情页面直接查看这些建议,从而获得可执行的优化指导,提升 Spark 任务的效率。
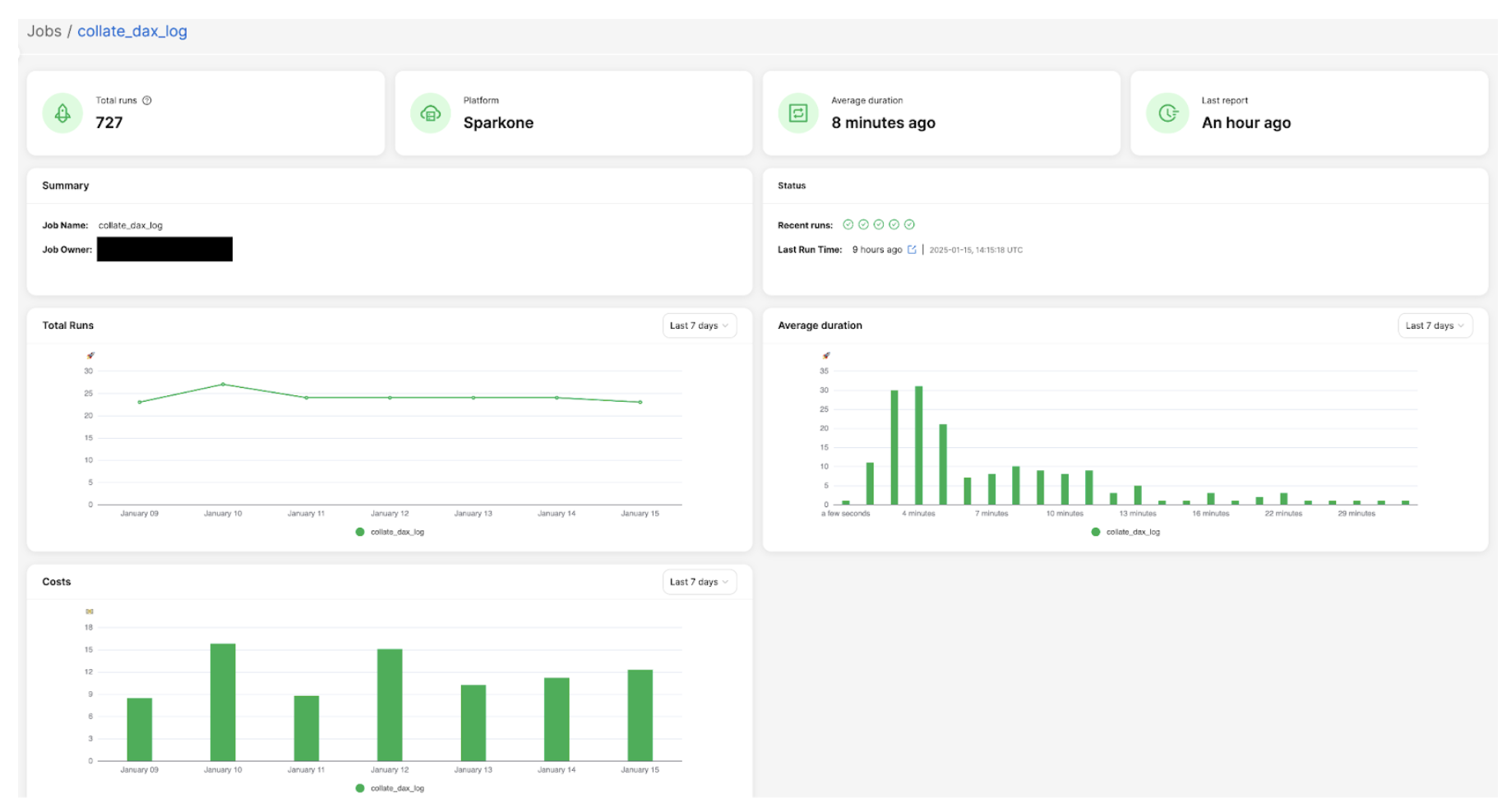
以下是一个示例:如果某个任务的资源利用率长期低于 25%,系统会建议将工作节点的规模缩小一半,以降低成本。
(图3:资源利用率较低的作业示例)
(四)Slackbot 集成
为了让这些洞察更加便捷可用,我们将推荐系统集成到了 SpellVault(Grab 的生成式 AI 平台)应用中。这样,用户可以直接在 Slack 上与推荐系统交互,无需频繁访问 Iris Web 界面,也能随时获取任务性能信息和优化建议。
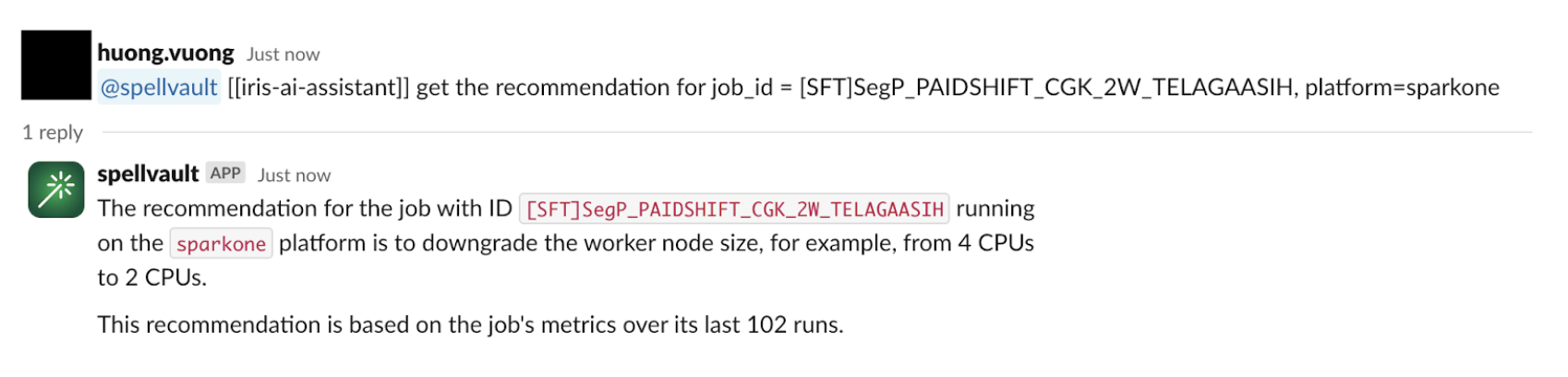
(图 4. SpellVault 集成示例)
八、迁移与推广
(一)迁移策略
-
将实时 CPU/内存监控图表从 Grafana 完全迁移到新的 Iris UI。
-
迁移完成后,将弃用 Grafana 仪表盘。
-
继续保留 Superset 以支持平台指标和特定的 BI 需求。
(二)用户引导与反馈
-
Iris 已部署在 One DE 应用中,集中化管理数据工程工具的访问。
-
UI 中的反馈按钮使用户可以轻松提交意见和建议。
九、经验总结与未来规划
以 StarRocks 为核心开发的 Iris Web 应用,为 Grab 的 Spark 观测能力带来革命性提升,实现作业级别的成本分摊机制。未来,Grab 期待在高级分析和机器学习驱动的洞察方面取得突破,推动数据工程发展。
(一)经验总结
-
统一数据存储:使用 StarRocks 作为实时和历史数据的单一数据源,显著提升了查询性能并优化了系统架构。
-
物化视图:利用 StarRocks 的物化视图进行预聚合,大幅加快了 UI 端的查询响应速度。
-
动态分区:实施动态分区机制,随着数据量增长自动管理数据保留,保持最佳性能。
-
直接 Kafka 摄取:StarRocks 直接从 Kafka 获取数据,简化了数据管道,降低了延迟和复杂性。
-
灵活的数据模型:相比之前基于时间序列的 InfluxDB,StarRocks 的关系型数据模型支持更复杂的查询,同时简化了元数据管理。
(二)未来规划
-
增强推荐系统:扩展推荐功能,提供更深入的优化建议,例如识别潜在瓶颈,并推荐 Spark 任务的最佳配置,以提升运行效率并降低成本。
-
高级分析:利用完整的 Spark 任务指标数据,深入分析任务性能和资源使用情况。
-
集成扩展:加强 Iris 与其他内部工具和平台的集成,提高用户采用率,确保数据工程生态系统的无缝体验。
-
机器学习集成:探索将机器学习模型应用于 Spark 任务的预测性分析,以优化性能。
-
可扩展性优化:持续优化系统,以支持不断增长的数据量和用户负载。
-
用户体验提升:基于用户反馈持续改进 Iris UI/UX,使其更加直观和信息丰富。
为提升可读性,本文对技术细节进行了精简,如需查看完整 SQL 示例及实现细节,请参阅原文:https://engineering.grab.com/building-a-spark-observability
相关文章:

从InfluxDB到StarRocks:Grab实现Spark监控平台10倍性能提升
Grab 是东南亚领先的超级应用,业务涵盖外卖配送、出行服务和数字金融,覆盖东南亚八个国家的 800 多个城市,每天为数百万用户提供一站式服务,包括点餐、购物、寄送包裹、打车、在线支付等。 为了优化 Spark 监控性能,Gr…...

《Redis应用实例》学习笔记,第一章:缓存文本数据
前言 最近在学习《Redis应用实例》,这本书并没有讲任何底层,而是聚焦实战用法,梳理了 32 种 Redis 的常见用法。我的笔记在 Github 上,用 Jupyter 记录,会有更好的阅读体验,作者的源码在这里:h…...

Redis 缓存
缓存介绍 Redis 最主要三个用途: 1)存储数据(内存数据库) 2)消息队列 3)缓存 对于硬件的访问速度,通常有以下情况: CPU 寄存器 > 内存 > 硬盘 > 网络 缓存的核心…...

Apache Flink 与 Flink CDC:概念、联系、区别及版本演进解析
Apache Flink 与 Flink CDC:概念、联系、区别及版本演进解析 在实时数据处理和流式计算领域,Apache Flink 已成为行业标杆。而 Flink CDC(Change Data Capture) 作为其生态中的重要组件,为数据库的实时变更捕获提供了强大的能力。 本文将从以下几个方面进行深入讲解: 什…...
:常见缓存 概念、问题、现象 及 预防问题)
缓存(4):常见缓存 概念、问题、现象 及 预防问题
常见缓存概念 缓存特征: 命中率、最大元素、清空策略 命中率:命中率返回正确结果数/请求缓存次数 它是衡量缓存有效性的重要指标。命中率越高,表明缓存的使用率越高。 最大元素(最大空间):缓存中可以存放的最大元素的…...
)
实战项目6(09)
目录 任务场景一 【r1配置】 【r2配置】 【r3配置】 任务场景二 【r1配置】 【r2配置】 【r3配置】 任务场景三 【r1配置】 【r2配置】 【r3配置】 任务场景一 按照下图完成网络拓扑搭建和配置 任务要求:在…...

MySQL 数据库故障排查指南
MySQL 数据库故障排查指南 本指南旨在帮助您识别和解决常见的 MySQL 数据库故障。我们将从问题识别开始,逐步深入到具体的故障类型和排查步骤。 1. 问题识别与信息收集 在开始排查之前,首先需要清晰地了解问题的现象和范围。 故障现象: 数…...

MacOS Python3安装
python一般在Mac上会自带,但是大多都是python2。 python2和python3并不存在上下版本兼容的情况,所以python2和python3可以同时安装在一台设备上,并且python3的一些语法和python2并不互通。 所以在Mac电脑上即使有自带python,想要使…...

锁相放大技术:从噪声中提取微弱信号的利器
锁相放大技术:从噪声中提取微弱信号的利器 一、什么是锁相放大? 锁相放大(Lock-in Amplification)是一种用于检测微弱信号的技术,它能够从强噪声背景中提取出我们感兴趣的特定信号。想象一下在嘈杂的派对上听清某个人…...

机器学习总结
1.BN【batch normalization】 https://zhuanlan.zhihu.com/p/93643523 减少 2.L1L2正则化 l1:稀疏 l2:权重减小 3.泛化误差 训练误差计算了训练集的误差,而泛化误差是计算全集的误差。 4.dropout 训练过程中神经元p的概率失活 一文彻底搞懂深度学习&#x…...

基于神经网络的无源雷达测向系统仿真实现
基于神经网络的无源雷达测向系统仿真实现 项目概述 本项目实现了基于卷积神经网络(CNN)的无源雷达方向到达角(DOA)估计系统。通过深度学习方法,系统能够从接收到的雷达信号中准确估计出信号源的方向,适用于单目标和多目标场景。相比传统的DOA估计算法&…...

《用MATLAB玩转游戏开发》Flappy Bird:小鸟飞行大战MATLAB趣味实现
《用MATLAB玩转游戏开发:从零开始打造你的数字乐园》基础篇(2D图形交互)-Flappy Bird:小鸟飞行大战MATLAB趣味实现 文章目录 《用MATLAB玩转游戏开发:从零开始打造你的数字乐园》基础篇(2D图形交互…...

【C/C++】跟我一起学_C++同步机制效率对比与优化策略
文章目录 C同步机制效率对比与优化策略1 效率对比2 核心同步机制详解与适用场景3 性能优化建议4 场景对比表5 总结 C同步机制效率对比与优化策略 多线程编程中,同步机制的选择直接影响程序性能与资源利用率。 主流同步方式: 互斥锁原子操作读写锁条件变量无锁数据…...

linux 三剑客命令学习
grep Grep 是一个命令行工具,用于在文本文件中搜索打印匹配指定模式的行。它的名称来自于 “Global Regular Expression Print”(全局正则表达式打印),它最初是由 Unix 系统上的一种工具实现的。Grep 工具在 Linux 和其他类 Unix…...

【js基础笔记] - 包含es6 类的使用
文章目录 js基础js 预解析js变量提升 DOM相关知识节点选择器获取属性节点创建节点插入节点替换节点克隆节点获取节点属性获取元素尺寸获取元素偏移量标准的dom事件流阻止事件传播阻止默认行为事件委托 正则表达式js复杂类型元字符 - 基本元字符元字符 - 边界符元字符 - 限定符元…...
》PDF下载)
《Linux命令行大全(第2版)》PDF下载
内容简介 本书对Linux命令行进行详细的介绍,全书内容包括4个部分,第一部分由Shell的介绍开启命令行基础知识的学习之旅;第二部分讲述配置文件的编辑,如何通过命令行控制计算机;第三部分探讨常见的任务与必备工具&…...
)
补补表面粗糙度的相关知识(一)
表面粗糙度,或简称粗糙度,是指表面不光滑的特性。这个在机械加工行业内可以说是绝绝的必备知识之一,但往往也是最容易被忽略的,因为往往天天接触的反而不怎么关心,或者没有真正的去认真学习掌握。对于像我一样…...

Python实用工具:pdf转doc
该工具只能使用在英文目录下,且无法转换出图片,以及文本特殊格式。 下载依赖项 pip install PyPDF2 升级依赖项 pip install PyPDF2 --upgrade 查看库版本 python -c "import PyPDF2; print(PyPDF2.__version__)" 下载第二个依赖项 pip i…...

基于Dify实现对Excel的数据分析
在dify部署完成后,大家就可以基于此进行各种应用场景建设,目前dify支持聊天助手(包括对话工作流)、工作流、agent等模式的场景建设,我们在日常工作中经常会遇到各种各样的数据清洗、格式转换处理、数据统计成图等数据分…...

Win全兼容!五五 Excel Word 转 PDF 工具解决多场景转换难题
各位办公小能手们!今天给你们介绍一款超牛的工具——五五Excel Word批量转PDF工具V5.5版。这玩意儿专注搞批量格式转换,能把Excel(.xls/.xlsx)和Word(.doc/.docx)文档唰唰地变成PDF格式。 先说说它的核心功…...

java加强 -Collection集合
集合是一种容器,类似于数组,但集合的大小可变,开发中也非常常用。Collection代表单列集合,每个元素(数据)只包含1个值。Collection集合分为两类,List集合与set集合。 特点 List系列集合&#…...

BGP实验练习1
需求: 要求五台路由器的环回地址均可以相互访问 需求分析: 1.图中存在五个路由器 AR1、AR2、AR3、AR4、AR5,分属不同自治系统(AS),AR1 在 AS 100,AR2 - AR4 在 AS 200,AR5 在 AS …...

Nginx location静态文件映射配置
遇到问题? 以下这个Nginx的配置,愿意为访问https://abc.com会指向一个动态网站,访问https://abc.com/tongsongzj时会访问静态网站,但是配置之后(注意看后面那个location /tongsongzj/静态文件映射的配置)&…...

四、Hive DDL表定义、数据类型、SerDe 与分隔符核心
在理解了 Hive 数据库的基本操作后,本篇笔记将深入到数据存储的核心单元——表 (Table) 的定义和管理。掌握如何创建表、选择合适的数据类型、以及配置数据的读写方式 (特别是 SerDe 和分隔符),是高效使用 Hive 的关键。 一、创建表 (CREATE TABLE)&…...

每日脚本 5.11 - 进制转换和ascii字符
前置知识 python中各个进制的开头 二进制 : 0b 八进制 : 0o 十六进制 : 0x 进制转换函数 : bin() 转为2进制 oct() 转换为八进制的函数 hex() 转换为16进制的函数 ascii码和字符之间的转换 : chr(97) 码转为字符 …...

cookie和session的区别
一、基本概念 1. Cookie 定义:Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据(通常小于4KB),浏览器会在后续请求中自动携带该数据。作用:用于跟踪用户状态(如登录状态)、记…...

Kotlin Multiplatform--03:项目实战
Kotlin Multiplatform--03:项目实战 引言配置iOS开发环境配置项目环境运行程序 引言 本章将会带领读者进行项目实战,了解如何从零开始编译一个能同时在Android和iOS运行的App。开发环境一般来说需要使用Macbook,笔者没试过Windows是否能开发。…...

图形学、人机交互、VR/AR领域文献速读【持续更新中...】
(1)笔者在时间有限的情况下,想要多积累一些自身课题之外的新文献、新知识,所以开了这一篇文章。 (2)想通过将文献喂给大模型,并向大模型提问的方式来快速理解文献的重要信息(如基础i…...

opencascade.js stp vite 调试笔记
Hello, World! | OpenCascade.js cnpm install opencascade.js cnpm install vite-plugin-wasm --save-dev 当你不知道文件写哪的时候trae还是有点用的 ‘’‘ import { defineConfig } from vite; import wasm from vite-plugin-wasm; import rollupWasm from rollup/plugi…...

openharmony系统移植之gpu mesa3d适配
openharmony系统移植之gpu mesa3d适配 文章目录 openharmony系统移植之gpu mesa3d适配1. 环境说明2. gpu内核panfrost驱动2.1 使能panfrost驱动2.2 panfrost dts配置 3. buildroot下测试gpu驱动3.1 buildroot配置编译 4. ohos下mesa3d适配4.1 ohos下mesa3d编译调试4.1.2 编译4.…...

Java开发经验——阿里巴巴编码规范经验总结2
摘要 这篇文章是关于Java开发中阿里巴巴编码规范的经验总结。它强调了避免使用Apache BeanUtils进行属性复制,因为它效率低下且类型转换不安全。推荐使用Spring BeanUtils、Hutool BeanUtil、MapStruct或手动赋值等替代方案。文章还指出不应在视图模板中加入复杂逻…...

Linux中常见开发工具简单介绍
目录 apt/yum 介绍 常用命令 install remove list vim 介绍 常用模式 命令模式 插入模式 批量操作 底行模式 模式替换图 vim的配置文件 gcc/g 介绍 处理过程 预处理 编译 汇编 链接 库 静态库 动态库(共享库) make/Makefile …...

深入理解深度Q网络DQN:基于python从零实现
DQN是什么玩意儿? 深度Q网络(DQN)是深度强化学习领域里一个超厉害的算法。它把Q学习和深度神经网络巧妙地结合在了一起,专门用来搞定那些状态空间维度特别高、特别复杂的难题。它展示了用函数近似来学习价值函数的超能力…...

使用lldb看看Rust的HashMap
目录 前言 正文 读取桶的状态 获取键值对 键值对的指针地址 此时,读取数据 读取索引4的键值对 多添加几个键值对 使用i32作为键,&str作为值 使用i32作为键,String作为值 前言 前面使用ldb看了看不同的类型,这篇再使用…...

Vue3简易版购物车的实现。
文章目录 一、话不多说,直接上代码? 一、话不多说,直接上代码? <template><div><input type"text" placeholder"请输入内容" v-model"keywords"><button click"addGood…...

比亚迪全栈自研生态的底层逻辑
比亚迪全栈自研生态的底层逻辑:汽车工程师必须理解的闭环技术革命 引言:当技术壁垒成为护城河 2023年比亚迪销量突破302万辆的震撼数据背后,隐藏着一个更值得工程师深思的事实:其全栈自研体系覆盖了新能源汽车83%的核心零部件。这…...
)
[Java实战]Spring Boot 快速配置 HTTPS 并实现 HTTP 自动跳转(八)
[Java实战]Spring Boot 快速配置 HTTPS 并实现 HTTP 自动跳转(八) 引言 在当今网络安全威胁日益严峻的背景下,为 Web 应用启用 HTTPS 已成为基本要求。Spring Boot 提供了简单高效的方式集成 HTTPS 支持,无论是开发环境测试还是生产环境部署࿰…...

5.1.1 WPF中Command使用介绍
WPF 的命令系统是一种强大的输入处理机制,它比传统的事件处理更加灵活和可重用,特别适合 MVVM (Model, View, ViewModel)模式开发。 一、命令系统核心概念 1.命令系统基本元素: 命令(Command): 即ICommand类,使用最多的是RoutedCommand,也可以自己继承ICommand使用自定…...
桥梁模式)
设计模式简述(十九)桥梁模式
桥梁模式 描述基本组件使用 描述 桥梁模式是一种相对简单的模式,通常以组合替代继承的方式实现。 从设计原则来讲,可以说是单一职责的一种体现。 将原本在一个类中的功能,按更细的粒度拆分到不同的类中,然后各自独立发展。 基本…...

常用设计模式
一、什么是设计模式 设计模式(Design Pattern)是一套被反复使用、多数人知晓的、经过分类编目的代码设计经验总结,旨在解决面向对象设计中反复出现的问题,提升代码的可重用性、可理解性和可靠性。以下从多个维度详细讲解ÿ…...

20242817-李臻-课下作业:Qt和Sqlite
实验内容 阅读附件内容,编译运行附件中第一章,第三章的例子。 实验过程 第一章 t1实践 #include <QApplication> #include <QWidget> #include <QPushButton> #include <QVBoxLayout>int main(int argc, char *argv[]) {QA…...

嵌入式机器学习平台Edge Impulse图像分类 – 快速入门
陈拓 2025/05/08-2025/05/11 1. 简介 官方网址 https://edgeimpulse.com/ 适用于任何边缘设备的人工智能: Gateways - 网关 Sensors & Cameras - 传感器和摄像头 Docker Containers - Docker容器 MCUs, NPUs, CPUs, GPUs 构建数据集、训练模型并优化库以…...

JavaWeb, Spring, Spring Boot
出现时间 JavaWeb - Spring - Spring Boot 一、JavaWeb 的发展历程 Servlet 和 JSP: Servlet:1997 年首次发布,用于处理 HTTP 请求和响应。 JSP:1999 年首次发布,用于动态生成 HTML 页面。 特点:提供了基…...

upload-labs靶场通关详解:第五关
一、分析源代码 $is_upload false; $msg null; if (isset($_POST[submit])) {if (file_exists(UPLOAD_PATH)) {$deny_ext array(".php",".php5",".php4",".php3",".php2",".html",".htm",".ph…...

【问题】Watt加速github访问速度:好用[特殊字符]
前言 GitHub 是全球知名的代码托管平台,主要用于软件开发,提供 Git 仓库托管、协作工具等功能,经常要用到,但是国内用户常因网络问题难以稳定访问 。 Watt Toolkit(原名 Steam)是由江苏蒸汽凡星科技有限公…...

GitHub打开缓慢甚至失败的解决办法
在C:\Windows\System32\drivers\etc的hosts中增加如下内容: 20.205.243.166 github.com 199.59.149.236 github.global.ssl.fastly.net185.199.109.153 http://assets-cdn.github.com 185.199.108.153 http://assets-cdn.github.com 185.199.110.153 http://asset…...
数字签名和数字证书)
【25软考网工】第六章(3)数字签名和数字证书
博客主页:christine-rr-CSDN博客 专栏主页:软考中级网络工程师笔记 大家好,我是christine-rr !目前《软考中级网络工程师》专栏已经更新二十多篇文章了,每篇笔记都包含详细的知识点,希望能帮助到你!…...

Android Native 函数 Hook 技术介绍
版权归作者所有,如有转发,请注明文章出处:https://cyrus-studio.github.io/blog/ 前言 Android Native 函数 Hook 技术是一种在应用运行时拦截或替换系统或自身函数行为的手段,常见实现包括 PLT Hook、Inline Hook。 PLT Hook 和…...

代码随想录算法训练营第60期第三十二天打卡
大家好,今天是我们贪心算法章节的第三阶段,前面我们讲过的几道题不知道大家理解的情况如何,还是那句话,贪心算法没有固定的套路与模板,一道题一个思路,我们要多思考这样慢慢地我就就可以水到渠成。今天我们…...

Problem C: 异常1
1.题目描述 检测年龄,其中若为负数或大于等于200岁皆为异常,请将下列代码补充完整。 // 你的代码将被嵌入这里 class Main{ public static void main(String[] args){ Person p1new Person("John",80); Person p2new Pers…...