Hadoop 1.x设计理念解析
一、背景
有人可能会好奇,为什么要学一个二十年前的东西呢?
Hadoop 1.x虽然是二十年前的,但hadoop生态系统中的一些组件如今还在广泛使用,如hdfs和yarn,当今流行spark和flink都依赖这些组件
通过学习它们的历史设计,首先可以让我们对它们的了解更加深刻,通过了解软件的演变的过程也能对我们改进自有的系统做启发
二、整体架构
网上偷了一张图:

三、组件详解
3.1 JobTracker与TaskTracker
JobTracker:
全局资源管理和作业调度(如任务分配、故障恢复),单点运行,负载过重时易成为性能瓶颈
TaskTrackers:
执行具体的 Map 和 Reduce 任务,通过心跳向 JobTracker 汇报状态
每个节点预分配固定数量的 Map Slot 和 Reduce Slot(用户在配置TaskTracker时会把slot写在配置里,表明机器能运行的map任务和reduce任务个数)
Map任务:
Map任务数量由输入文件的分片数决定,默认为128M大小一片
Map 任务从 HDFS 读取输入分片(优先本地副本)
Map 任务处理完成后,生成的中间键值对(Key-Value pairs)会先写入运行该 Map 任务的节点的本地磁盘(而非 HDFS)
每个 Map 任务的中间数据按 Reduce 任务的分区(Partition)划分,生成多个文件(例如 part-00000, part-00001)。
Reduce任务:
任务数量由用户设置
JobTracker 在 Map 阶段完成后,分配 Reduce Slot 给 Reduce 任务。
数据拉取:Reduce 任务从各个节点的 Map 输出中拉取数据(可能跨节点,产生网络传输)。
最终输出:Reduce 任务处理完成后,结果写入 HDFS(每个 Reduce 任务生成一个输出文件)。
Q:JobTracker 收集所有节点的资源信息(如 CPU、内存、磁盘),形成集群资源的统一视图。收集这些信息的作用是什么呢?用户不是已经划分好slot了么
-
节点状态检测:通过心跳机制,JobTracker 可实时感知节点的存活状态(如宕机、网络断开)。如果某个 TaskTracker 长时间未发送心跳,JobTracker 会将其标记为失效,并将该节点上的任务重新调度到其他节点。
-
资源超负载预警:虽然 Slot 是静态分配的,但节点的实际资源(如 CPU、内存、磁盘)可能因任务负载过高而成为瓶颈。例如:
-
若某个节点的 CPU 利用率长期接近 100%,即使有空闲 Slot,新分配的任务也可能因资源竞争而执行缓慢。
-
JobTracker 可通过资源监控发现此类问题,并在调度时尽量避免向该节点分配新任务。
-
Q:什么是资源管理,什么是任务调度,两者怎样配合的?

-
资源管理阶段:
-
JobTracker 通过心跳收集各节点的 Slot 状态和负载信息。
-
维护全局资源池(如可用 Map Slot=6,Reduce Slot=3)。
-
-
作业提交与调度阶段:
-
用户提交作业后,JobTracker 根据资源池状态拆分任务。
-
调度器选择最优节点分配任务(例如优先本地节点)。
-
-
任务执行与反馈:
-
TaskTracker 执行任务并向 JobTracker 发送进度报告。
-
若任务失败,JobTracker 从资源池中重新分配 Slot。
-
3.2 HDFS
架构:
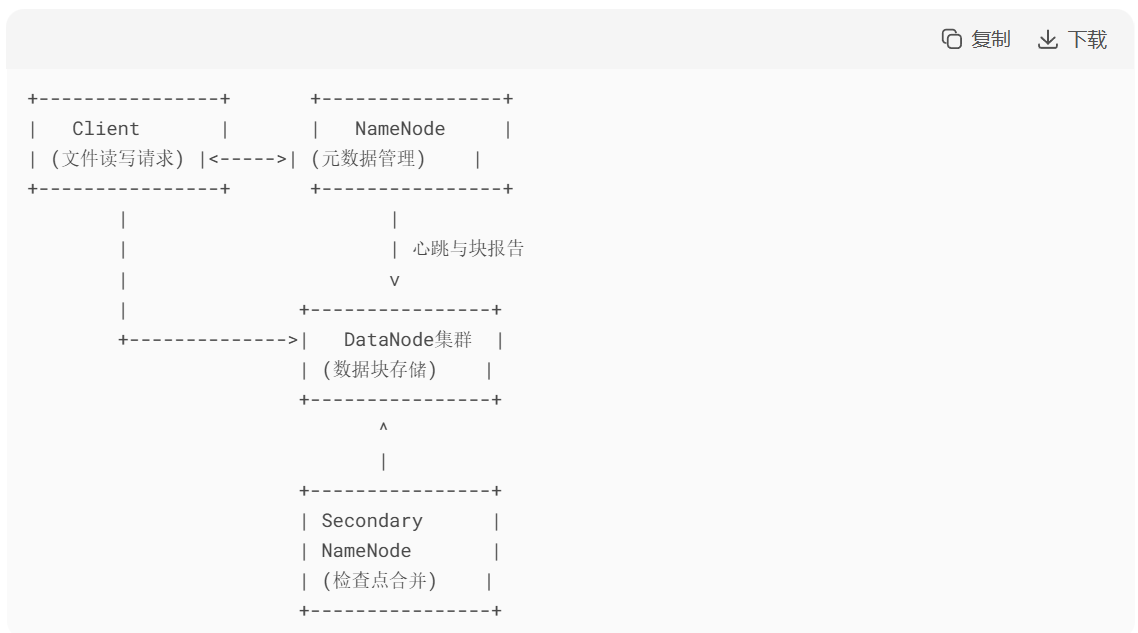
架构组件说明:
1. NameNode(主节点)
-
角色:HDFS 的“大脑”,负责管理文件系统的元数据。
-
功能:
-
维护文件系统的目录树结构(文件名、路径、权限等)。
-
记录每个文件的块(Block)分布信息(如块 ID、副本位置)。
-
响应客户端对元数据的查询(如读文件时返回块的位置)。
-
-
存储机制:
-
元数据存储在内存中(快速访问),并通过两个文件持久化:
-
fsimage:元数据的完整快照。 -
edits:记录所有元数据变更的日志文件(如创建、删除文件)。
-
-
单点故障风险:NameNode 是单点,故障会导致整个 HDFS 不可用。
-
2. DataNode(从节点)
-
角色:实际存储数据块的节点。
-
功能:
-
存储数据块(默认 64MB/块,可配置),每个块有多个副本(默认 3 副本)。
-
定期向 NameNode 发送心跳信号(每 3 秒一次)和块报告(每 1 小时一次)。
-
直接处理客户端的数据读写请求。
-
-
容错机制:
-
若 DataNode 宕机(超过 10 分钟无心跳),NameNode 会标记其存储的块为失效,并触发副本重新复制。
-
3. Secondary NameNode(辅助节点)
-
角色:辅助 NameNode 合并元数据,不是热备份!
-
功能:
-
定期从 NameNode 下载
fsimage和edits文件,合并生成新的fsimage(称为检查点机制)。 -
合并后的
fsimage推送给 NameNode,替换旧的fsimage,并清空edits文件。
-
-
关键点:
-
合并周期由
fs.checkpoint.period(默认 1 小时)和fs.checkpoint.size(默认 64MB)控制。 -
若 NameNode 故障,需手动恢复:用 Secondary NameNode 的
fsimage启动新 NameNode,但会丢失最后一次合并后的操作记录。
-
HDFS 文件读写流程:
-
客户端请求:Client 向 NameNode 申请写入文件。
-
元数据分配:NameNode 检查权限后,分配可写入的 DataNode 列表(按机架感知策略)。
-
流水线写入:
-
Client 将文件切分为块,依次传输给第一个 DataNode。
-
第一个 DataNode 接收数据后,转发给第二个 DataNode,依此类推,形成流水线。
-
-
确认完成:所有副本写入成功后,NameNode 更新元数据。
读取文件流程
-
客户端请求:Client 向 NameNode 查询文件元数据(块的位置)。
-
返回块位置:NameNode 返回包含块副本的 DataNode 列表(按网络拓扑就近选择)。
-
并行读取:Client 直接从最近的 DataNode 并行读取数据块,合并后返回完整文件
四、计算流程
(1) Map 任务执行
-
输入读取:
-
Map 任务从 HDFS 读取输入分片(优先本地副本)。
-
-
中间数据写入:
-
Map 任务的输出按 Reduce 分区(Partition)写入本地磁盘(非 HDFS)。
-
例如,若有 3 个 Reduce 任务,每个 Map 任务生成 3 个中间文件(
part-m-00000,part-m-00001,part-m-00002)。
-
(2) Shuffle 阶段
-
Reduce 任务启动:
-
JobTracker 在所有 Map 任务完成后,分配 Reduce Slot。
-
-
数据拉取(Fetch):
-
每个 Reduce 任务通过 HTTP 请求从所有 TaskTracker 的本地磁盘拉取属于自己分区的数据。
-
流程:
-
Reduce 任务向 JobTracker 获取已完成的 Map 任务列表。
-
根据 Map 任务输出的元数据(存储位置),直接连接对应 TaskTracker 拉取数据。
-
-
-
归并与排序:
-
Reduce 任务将拉取的中间数据合并并排序,形成最终的输入键值对。
-
(3) Reduce 任务执行
-
处理与输出:
-
Reduce 任务处理排序后的数据,结果写入 HDFS(每个 Reduce 任务生成一个输出文件,如
part-r-00000)。
-
单个作业仅支持 1 次 Map 阶段 → 1 次 Shuffle/Sort 阶段 → 1 次 Reduce 阶段。
若需要实现 Map → Reduce → Map → Reduce 的流程,可通过:
-
作业1:
Map1 → Reduce1,输出结果到路径output1。 -
作业2:读取
output1作为输入,执行Map2 → Reduce2,输出结果到output2。
// 创建作业1(Map1 → Reduce1)
JobConf job1 = new JobConf(conf, Job1.class);
FileInputFormat.addInputPath(job1, new Path(input));
FileOutputFormat.setOutputPath(job1, new Path(output1));// 创建作业2(Map2 → Reduce2),依赖作业1完成
JobConf job2 = new JobConf(conf, Job2.class);
FileInputFormat.addInputPath(job2, new Path(output1));
FileOutputFormat.setOutputPath(job2, new Path(output2));// 定义作业依赖
ControlledJob controlledJob1 = new ControlledJob(job1);
ControlledJob controlledJob2 = new ControlledJob(job2);
controlledJob2.addDependingJob(controlledJob1);// 提交作业链
JobControl jobControl = new JobControl("multi-job-chain");
jobControl.addJob(controlledJob1);
jobControl.addJob(controlledJob2);
jobControl.run();Q:在Hadoop 1.x中,假如有多个job提交,作业调度的优先级是怎样的?
默认调度器:FIFO(先进先出):
1. 优先级规则
-
按提交顺序执行:作业严格按照提交的先后顺序分配资源。
-
任务级并行:若集群有空闲资源(Map/Reduce Slot),后续作业的任务可以与前一个作业的任务并行执行,但整体作业的优先级仍按提交顺序。
-
资源独占性:若先提交的作业占满所有 Slot,后续作业需等待资源释放。
2. 示例场景
-
集群资源:总共有 4 个 Map Slot 和 2 个 Reduce Slot。
-
提交作业:
-
Job1:需要 6 个 Map 任务 和 2 个 Reduce 任务。
-
Job2:需要 3 个 Map 任务 和 1 个 Reduce 任务。
-
执行流程:
-
Map 阶段:
-
Job1 的 4 个 Map 任务立即占用所有 Map Slot 并行执行。
-
当 Job1 的任意 Map 任务完成并释放 Slot 后,Job1 的第 5、6 个 Map 任务继续占用空闲 Slot。
-
Job2 的 Map 任务必须等待 Job1 的所有 Map 任务完成后才能开始执行(因为 FIFO 默认按作业顺序调度)。
-
-
Reduce 阶段:
-
Job1 的 2 个 Reduce 任务占用所有 Reduce Slot 并行执行。
-
Job2 的 Reduce 任务需等待 Job1 的 Reduce 任务完成后才能执行。
-
结果:
-
Job1 完全独占资源,Job2 必须等待 Job1 全部完成后才能启动。
容量调度器(Capacity Scheduler):
1. 优先级规则
-
队列划分:集群资源划分为多个队列(如
prod和dev),每个队列分配固定容量(如 70% 和 30%)。 -
队列内 FIFO:每个队列内的作业按提交顺序执行。
-
队列间并行:不同队列的作业可以并行执行,共享集群资源,但受队列容量限制。
2. 示例场景
-
队列配置:
-
prod队列:分配 70% 资源(即 3 个 Map Slot 和 1 个 Reduce Slot)。 -
dev队列:分配 30% 资源(即 1 个 Map Slot 和 1 个 Reduce Slot)。
-
-
提交作业:
-
Job1 提交到
prod队列,需要 4 个 Map 任务 和 1 个 Reduce 任务。 -
Job2 提交到
dev队列,需要 2 个 Map 任务 和 1 个 Reduce 任务。
-
执行流程:
-
Map 阶段:
-
Job1 的 3 个 Map 任务立即占用
prod队列的 3 个 Map Slot。 -
Job2 的 1 个 Map 任务占用
dev队列的 1 个 Map Slot。 -
Job1 的第 4 个 Map 任务需等待
prod队列的 Slot 释放。 -
Job2 的第 2 个 Map 任务需等待
dev队列的 Slot 释放。
-
-
Reduce 阶段:
-
Job1 的 Reduce 任务占用
prod队列的 1 个 Reduce Slot。 -
Job2 的 Reduce 任务占用
dev队列的 1 个 Reduce Slot。
-
结果:
-
prod和dev队列的作业并行执行,但每个队列内的作业按 FIFO 顺序运行。
公平调度器(Fair Scheduler):
1. 优先级规则
-
公平共享:资源按时间片轮转动态分配给所有作业,确保每个作业都能获得均等资源。
-
最小资源保证:可为特定作业或用户组设置最小资源配额。
-
任务级抢占:长时间未获得资源的作业可抢占其他作业的资源。
2. 示例场景
-
集群资源:4 个 Map Slot 和 2 个 Reduce Slot。
-
提交作业:
-
Job1(大作业):需要 8 个 Map 任务和 2 个 Reduce 任务。
-
Job2(小作业):需要 2 个 Map 任务和 1 个 Reduce 任务。
-
执行流程:
-
初始阶段:
-
Job1 提交后,立即占用所有 4 个 Map Slot 并行执行。
-
-
Job2 提交后:
-
公平调度器将空闲 Slot 动态分配给 Job2。例如:
-
Job1 释放 2 个 Map Slot 后,Job2 的 2 个 Map 任务开始执行。
-
-
Reduce 阶段同理,Job2 可能抢占部分 Reduce Slot。
-
-
最终结果:
-
Job2 快速完成,Job1 逐步占用剩余资源。
-
五、架构不足
-
单点故障:NameNode 和 JobTracker 均为单点。
-
扩展性差:集群规模上限约 4000 节点,JobTracker 负载过高。
-
资源僵化:静态 Slot 分配导致资源浪费。
-
仅支持 MapReduce:无法适配多样化的计算框架
相关文章:

Hadoop 1.x设计理念解析
一、背景 有人可能会好奇,为什么要学一个二十年前的东西呢? Hadoop 1.x虽然是二十年前的,但hadoop生态系统中的一些组件如今还在广泛使用,如hdfs和yarn,当今流行spark和flink都依赖这些组件 通过学习它们的历史设计…...

缓存与数据库的高效读写流程解析
目录 前言1 读取数据的流程1.1 检查缓存是否命中1.2 从数据库读取数据1.3 更新缓存1.4 返回数据 2 写入数据的流程2.1 更新数据库2.2 更新或删除缓存2.3 缓存失效 3 缓存与数据库的一致性问题3.1 写穿(Write-through)策略3.2 写回(Write-back…...

Linux中的粘滞位和开发工具和文本编辑器vim
1.粘滞位的使用的背景: 当几个普通用户需要文件共享操作时,他们就需要在同一个目录下进行操作,那么就诞生一个问题,由谁来创建这个公共的目录文件?假设是由其中的一个普通用户来创建一个默认的目录文件,这就…...

冯诺依曼结构与哈佛架构深度解析
一、冯诺依曼结构(Von Neumann Architecture) 1.1 核心定义 由约翰冯诺依曼提出,程序指令与数据共享同一存储空间和总线,通过分时复用实现存取。 存储器总带宽 指令带宽 数据带宽 即:B_mem f_clk W_data f_…...

如何提升个人情商?
引言 提升个人情商(EQ)是一个持续的自我修炼过程,涉及自我认知、情绪管理、人际沟通等多个方面。以下是一些具体且可实践的方法,帮助你逐步提升情商: 一、提升自我觉察能力 1. 记录情绪日记 每天回顾自己的情绪…...

JSON Web Token 默认密钥 身份验证安全性分析 dubbo-admin JWT硬编码身份验证绕过
引言 在web开发中,对于用户认证的问题,有很多的解决方案。其中传统的认证方式:基于session的用户身份验证便是可采用的一种。 基于session的用户身份验证验证过程: 用户在用进行验证之后,服务器保存用户信息返回sess…...
通常支持多通道输出,常见配置为3个独立通道)
K230的ISP(图像信号处理器)通常支持多通道输出,常见配置为3个独立通道
也就是一个摄像头可以拍摄三种配置的图片,这样就可以调用三种: img_try sensor.snapshot(chnCAM_CHN_ID_0) img_try2 sensor.snapshot(chnCAM_CHN_ID_1) img_try3 sensor.snapshot(chnCAM_CHN_ID_2) 这样可以一图多用 eg: # 初始化并配…...

工程师 - 小米汽车尾部主动扩散器
关于小米SU7 Ultra的主动尾部扩散器,其设计初衷是为了平衡日常驾驶的节能需求与运动驾驶的操控性能。这一装置位于车辆尾部下方,具备自动调节功能,能够根据车速在0和32之间切换,同时也支持手动调整。 32度打开状态: 0度…...

Linux watch 命令使用详解
简介 watch 命令会以固定间隔(默认每 2 秒)重复运行给定命令,并在终端上显示其输出。它非常适合监控不断变化的输出,例如磁盘使用情况、内存使用情况、文件更改、服务状态等。 基础语法 watch [options] command常用选项 -n, -…...

RabbitMQ-基础
RabbitMQ-基础 文章目录 RabbitMQ-基础1.同步调用2.异步调用3.技术选型4.安装RabbitMQ(官方网址)https://www.rabbitmq.com/5.快速入门5.1收发消息5.1.1交换机5.1.2队列5.1.3绑定关系5.1.4发送消息 5.2数据隔离5.2.1用户管理5.2.2virtual host 6.Java客户端操作RabbitMQ6.1快速…...

第九周作业
安全专题笔记 1、文件上传 (1) 服务端白名单绕过 %00截断绕过要求虚拟机中搭建实验环境,分别实现GET、POST方法的绕过 前提条件: 1 php的版本需要在5.4以下 2 magic_quotes_gpc需要设置为off 启动phpstudy,前往php-ini将magic_quotes_gpc…...
题解)
AtCoder Beginner Contest 404 C-G(无F)题解
C. Cycle Graph? 题意 给你一个 N N N 个顶点 M M M 条边的简单(无重边、自环)无向图,第 i i i 条边连接节点 A i A_i Ai 和 B i B_i Bi,判断这个图是不是一个环。 思路 首先一个图是环,要满足点数等于边…...
)
Python----机器学习(模型评估:准确率、损失函数值、精确度、召回率、F1分数、混淆矩阵、ROC曲线和AUC值、Top-k精度)
一、模型评估 1. 准确率(Accuracy):这是最基本的评估指标之一,表示模型在测试集上正确 分类样本的比例。对于分类任务而言,准确率是衡量模型性能的直观标准。 2. 损失函数值(Loss)࿱…...

开上“Python跑的车”——自动驾驶数据可视化的落地之道
开上“Python跑的车”——自动驾驶数据可视化的落地之道 一、自动驾驶离不开“看得见”的智能 在智能汽车时代,自动驾驶已然不是“炫技”标签,而是一场技术实力的全面拉锯战。而在这场战役中,有一个极其关键但常被忽略的领域,叫做: 数据可视化(Data Visualization)。 为…...

Linux内核gcov修改为模块
Linux内核gcov修改为模块 Gcov 是 GNU 项目开发的代码覆盖率分析工具,与 GCC 编译器深度集成,用于统计程序运行时代码的执行情况,帮助开发者评估测试用例的完整性和代码质量。 Gcov工作原理 1. 编译插桩 编译时需添加 -fprofile-arcs -…...

【安装配置教程】linux部署AList记录
之前朋友安利给自己AList,这个工具可以很方便的管理个人的网盘内容,可以随时上传下载拉取,于是心血来潮自己部署并记录一下。 一、拉取下载脚本 在AList官网,找到安装下面的一键脚本 curl -fsSL "https://alist.nn.ci/v3.sh…...

题解:AT_abc245_e [ABC245E] Wrapping Chocolate
我绝对不会告诉你我打比赛时没做出来这道题。 题目简化:给定每个巧克力和盒子的长宽,已知每个盒子只能放一块巧克力,并且必须保证巧克力能放下,求是否所有巧克力都能放入。 思路:贪心、二分、排序、STL。 首先看到这…...
)
Linux 入门:操作系统进程详解(上)
目录 一.冯诺依曼体系结构 一). 软件运行前为什么要先加载?程序运行之前在哪里? 二).理解数据流动 二.操作系统OS(Operator System) 一).概念 二).设计OS的目的 三).如何理解操作系统…...

5.7/Q1,GBD数据库最新文章解读
文章题目:Global, regional, and national burden and trends of rheumatoid arthritis among the elderly population: an analysis based on the 2021 Global Burden of Disease study DOI:10.3389/fimmu.2025.1547763 中文标题:全球、区域…...

[pdf,epub]292页《分析模式》漫谈合集01-59提供下载
《分析模式》漫谈合集01-59的pdf、epub文件提供下载,地址: umlchina.com/url/ap.html,或查看本账号的CSDN资源。 已排版成适合手机阅读,pdf的排版更好一些。...

Spring MVC的工作流程, DispatcherServlet 的工作流程
Spring MVC 是一种基于Java的模型-视图-控制器(MVC)Web框架,它通过清晰的角色划分简化了Web应用开发。下面是Spring MVC的工作流程以及DispatcherServlet的具体工作流程。 Spring MVC 工作流程 请求到达:客户端发起一个HTTP请求…...

【Godot】使用 Shader 实现可配置圆角效果
文章目录 效果预览实现原理完整Shader代码关键参数详解1. 半径参数(radius)2. 角开关参数(hide_*)数学原理圆形区域判定公式坐标映射性能优化使用示例编辑器操作代码控制进阶技巧1. 添加抗锯齿2. 外发光效果3. 动画效果常见问题解决方案问题1:圆角边缘锯齿问题2:圆形变形…...
)
【翻译、转载】MCP 提示 (Prompts)
原文地址:https://modelcontextprotocol.io/docs/concepts/prompts#python 提示 (Prompts) 创建可重用的提示模板和工作流 提示 (Prompts) 使服务器能够定义可重用的提示模板和工作流,客户端可以轻松地将其呈现给用户和 LLM。它们提供了一种强大的方式来…...

论快乐的学习和学习的快乐
目录 一、背景二、过程1.快乐的学习:理念与实践快乐学习的理念溯源快乐学习在教育实践中的体现 2.学习的快乐:内涵与价值学习的快乐的多维内涵学习的快乐对个人成长的价值 3.快乐的学习与学习的快乐的相互关系快乐的学习是学习快乐的重要前提学习的快乐是…...

Git 命令
参考文献: Git 教程 | 菜鸟教程Git 使用教程:最详细、最正宗手把手教学(万字长文)git忽略某个目录或文件不上传 文章目录 工作原理基本命令配置使用 其他命令日志分支回退标签 忽略指定文件远程仓库 工作原理 Git 是由 Linus To…...

365打卡第R6周: LSTM实现糖尿病探索与预测
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 🏡 我的环境: 语言环境:Python3.10 编译器:Jupyter Lab 深度学习环境:torch2.5.1 torchvision0…...

新能源实验室电磁兼容设计优化方案论述
摘要:本文旨在进行新能源核心部件/系统测试实验室电磁兼容情况设计及优化方案进行论述,通过系统化梳理实验室的主流设备仪器,试验搭建典型方案。识别不同设备的电磁兼容现状,实验室基于设备布局常见设计方案不足点,故障…...

计算机图形学中的深度学习
文章目录 零、前言0.课程考核1.课程大纲2.前置知识3.教材4.课程大纲5.相关课程 Relevant Courses 一、计算机图形学1.本章学习目标2.图形学的应用3.SIG Graph papers 二、基本图形生成算法1.本章学习目标2.图形API3.OpenGL(1)什么是OpenGL(2)OpenGL 的基本组件:顶点…...

RockyLinux9.3-24小时制
在 RockyLinux 9.3 中,默认时间格式为 12 小时制,调整为 24 小时制 案例一:在 RockyLinux 9.3 中,默认时间格式为 12 小时制,调整为 24 小时制案例二:时间显示英文调整为中文endl 案例一:在 Roc…...
_csdn)
25.2linux中外置RTC芯片的PCF8563实验(测试)_csdn
1、硬件原理图分析 知道了这些引脚我们还是按照老习惯! 配置镜像和设备树文件! 2、修改设备树 2.1、添加或者查找 PCF8563 所使用的 IO 的 pinmux 配置 打开stm32mp15-pincrtl.dtsi 文件,查找节点I2C4: 也就是中断引脚并不需要配置pinctrl…...

高性能 WEB 服务器 Nginx:多虚拟主机实现!
Nginx 配置多虚拟主机实现 多虚拟主机是指在一台 Nginx 服务器上配置多个网站 在 Nginx 中,多虚拟主机有三种实现方式: 基于IP地址实现多虚拟主机 基于端口号实现多虚拟主机 基于域名实现多虚拟主机 1 基于域名实现多虚拟主机 在 Nginx 中配置多个…...

C++ 的类型排序
0.前言 在 C 中,我编写了一个 tuple-like 模板,这个模板能容纳任意多且可重复的类型: template<typename... Ts> struct TypeList {};// usage: using List1 TypeList<int, double, char, double>; using List2 TypeList<…...

[计算机网络]拓扑结构
拓扑结构一般会在计网教材或课程的第一章计网的分类那里接触到,但实际上计网的拓扑结构并不只是第一章提到的总线型、星型、树型、网状、混合型那几种类型那么简单,学完了后面的数链层以后对拓扑结构会有新的体会,所以特别单独总结成一篇博客…...

C#方法返回值全解析:从基础语法到实战技巧
摘要:方法返回值是C#编程的核心概念之一。本文将带你彻底掌握返回值声明、void方法特性,以及如何通过返回值实现优雅的流程控制(文末附完整示例代码)。 返回值的基础法则 类型声明原则 有返回值:必须在方法名前声明…...

修复笔记:SkyReels-V2 项目中的 torch.cuda.amp.autocast 警告和错误
#工作记录 一、问题描述 在运行项目时,出现以下警告和错误: FutureWarning: torch.cuda.amp.autocast(args...) is deprecated. Please use torch.amp.autocast(cuda, args...) instead.with torch.cuda.amp.autocast(dtypepipe.transformer.dtype), …...

【TF-BERT】基于张量的融合BERT多模态情感分析
不足:1. 传统跨模态transformer只能处理2种模态,所以现有方法需要分阶段融合3模态,引发信息丢失。2. 直接拼接多模态特征到BERT中,缺乏动态互补机制,无法有效整合非文本模态信息 改进方法:1. 基于张量的跨模…...
)
SONiC-OTN代码详解(具体内容待续)
SONiC-OTN代码详解 (具体内容待续) 基于AI的源代码解析工具的产生使得代码阅读和解析变得越来越高效和简洁,计划通过这样的工具对SONiC在OTN领域的应用做一个全自动的解析,大部分内容会基于AI工具的自动解析结果。这样做的目的是…...

牛客周赛90 C题- Tk的构造数组 题解
原题链接 https://ac.nowcoder.com/acm/contest/107500/C 题目描述 解题思路 数组a是不可以动的,所以我们可以把a[i]*b[i]*i分成两组,分别为a[i]*i以及b[i] 然后策略就很明显了,让更大的b[i]匹配更大的a[i]*i 详细实现见代码。 代码&am…...

[ML]通过50个Python案例了解深度学习和神经网络
通过50个Python案例了解深度学习和神经网络 摘要:机器学习 (Machine Learning, ML)、深度学习 (Deep Learning, DL) 和神经网络 (Neural Networks, NN) 是人工智能领域的核心技术。Python 是学习和实践这些技术的首选语言,因为它提供了丰富的库(如 scikit-learn、Te…...

vue3 - keepAlive缓存组件
在Vue 3中,<keep-alive>组件用于缓存动态组件或路由组件的状态,避免重复渲染,提升性能。 我们新建两个组件,在每一个组件里面写一个input,在默认情况下当组件切换的时候,数据会被清空,但…...
)
自由学习记录(58)
Why you were able to complete the SpringBoot MyBatisPlus task smoothly: Clear logic flow: Database → Entity → Service → Controller → API → JSON response. Errors are explicit, results are verifiable — you know what’s broken and what’s fixed. Sta…...

短信侠 - 自建手机短信转发到电脑上并无感识别复制验证码,和找手机输验证码说再见!
自建手机短信转发到电脑上并无感识别复制验证码 一、前言 项目开发语言:本项目使用PythonRedisC#开发 你是否也遇到过这样的场景: 正在电脑上操作某个网站,需要输入短信验证码手机不在身边,或者在打字时来回切换设备很麻烦验证码…...

课程10. 聚类问题
课程10. 聚类问题 聚类此类表述的难点K 均值法让我们推广到几个集群的情况如果我们选择其他起始近似值会怎样? 结论在 sklearn 中的实现 如何处理已发现的问题?层次聚类Lance-Williams 算法Lance-Williams 公式在Scipy中实现 示例DBSCANDBSCAN 算法 聚类…...

深度学习中的数据增强:提升食物图像分类模型性能的关键策略
深度学习中的数据增强:提升食物图像分类模型性能的关键策略 在深度学习领域,数据是模型训练的基石,数据的数量和质量直接影响着模型的性能表现。然而,在实际项目中,获取大量高质量的数据往往面临诸多困难,…...

QT设计权限管理系统
Qt能够简单实现系统的权限设计 首先我们需要一个登陆界面 例如这样 然后一级权限,可以看到所有的内容,不设置菜单栏的隐藏。 然后其他权限,根据登陆者的身份进行菜单栏不同的展示。 菜单栏的隐藏代码如下: ui->actionuser-…...

从上帝视角看文件操作
1.为什么使用文件? 如果没有文件,我们写的程序中的数据是存储在电脑的内存中,当程序退出时,内存被回收后,数据就丢失了,等下次运行程序,是无法看到上次程序的数据的。(比如我们在程序中写通讯录时,联系人的相关数据都是放在内存中的,当程序退出时,这些数据也会随之消…...

【51单片机6位数码管显示时间与秒表】2022-5-8
缘由数码管 keil proteus 为什么出现这种情况呢?-编程语言-CSDN问答 #include "reg52.h" unsigned char code smgduan[]{0x3f,0x06,0x5b,0x4f,0x66,0x6d,0x7d,0x07,0x7f,0x6f,0x77,0x7c,0x39,0x5e,0x79,0x71,0,64}; //共阴0~F消隐减号 unsigned char cod…...

从头训练小模型: 4 lora 微调
1. LoRA (Low-Rank Adaptation) LoRA是一种高效的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,原理是通过低秩分解的方式对预训练模型进行微调。 相比于全参数微调(Full Fine-Tuning),LoRA…...

前端开发,文件在镜像服务器上不存在问题:Downloading binary from...Cannot download...
问题与处理策略 问题描述 在 Vue 项目中,执行 npm i 下载依赖时,报如下错误 Downloading binary from https://npm.taobao.org/mirrors/node-sass//v4.14.1/win32-x64-72_binding.node Cannot download "https://npm.taobao.org/mirrors/node-sa…...

Debezium Binlog协议与事件转换详解
Debezium Binlog协议与事件转换详解 1. MySQL Binlog通信机制 1.1 连接建立流程 #mermaid-svg-eE88YFqcTG9kUWaZ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-eE88YFqcTG9kUWaZ .error-icon{fill:#552222;}#mer…...