【TF-BERT】基于张量的融合BERT多模态情感分析
不足:1. 传统跨模态transformer只能处理2种模态,所以现有方法需要分阶段融合3模态,引发信息丢失。2. 直接拼接多模态特征到BERT中,缺乏动态互补机制,无法有效整合非文本模态信息
改进方法:1. 基于张量的跨模态transformer模块,允许同时处理3个模态的交互,打破了2模态限制。2. 将TCF模块插入BERT的Transformer层,逐步融合多模态信息,即在Bert微调时动态补充非文本模态信息,避免简单拼接导致的语义干扰
abstract
(背景与问题)由于单模态情感识别在复杂的现实应用中的局限性,多模态情感分析(MSA)得到了极大的关注。传统方法通常集中于使用Transformer进行融合。然而,这些传统的方法往往达不到,因为Transformer只能同时处理两种模态,导致信息交换不足和情感数据的潜在丢失。(方法提出)针对传统跨模态Transformer模型一次只能处理两种模态的局限性,提出了一种基于张量的融合BERT模型(TF-BERT)。TF-BERT的核心是基于张量的跨模态融合(TCF)模块,该模块无缝集成到预训练的BERT语言模型中。通过将TCF模块嵌入到BERT的Transformer的多个层中,我们逐步实现了不同模态之间的动态互补。此外,我们设计了基于张量的跨模态Transformer(TCT)模块,该模块引入了一种基于张量的Transformer机制,能够同时处理三种不同的模态。这允许目标模态和其他两个源模态之间进行全面的信息交换,从而加强目标模态的表示。TCT克服了现有Crossmodal Transformer结构只能处理两个模态之间关系的局限性。(实验结果)此外,为了验证TF-BERT的有效性,我们在CMU-MOSI和CMU-MOSEI数据集上进行了广泛的实验。TF-BERT不仅在大多数指标上取得了最佳结果,而且还通过消融研究证明了其两个模块的有效性。研究结果表明,TFBERT有效地解决了以前的模型的局限性,逐步整合,并同时捕捉复杂的情感互动在所有形式。
intro
(研究背景,强调单一模态的不足,引出多模态情感分析的必要性)随着AI技术的进步和应用场景的拓展,单一模态的情感分析已不足以满足情感识别复杂多样的需求(Das & Singh,2023; Gandhi et al.,2023年)的报告。例如,仅仅依靠文本分析可能无法准确地捕捉说话者的情绪,因为语调和面部表情也起着至关重要的作用。这种情况催生了多模态情感分析(MSA)的出现,其目的是通过整合多个数据源,实现更准确、更全面的情感识别,如图1所示。例如,在智能客户服务系统中,结合文本、语音和面部表情可以更准确地评估用户的情绪。如果系统检测到用户语气中的不满意,它可以迅速调整其响应策略以提供更快或更详细的帮助。
(现有方法的缺陷)Zadeh等人(2017)的早期工作引入了一种基于张量的融合方法,计算3重笛卡尔空间以捕获模态之间的关系。近年来,随着深度学习的快速发展,研究者们不断创新融合策略,以更好地平衡不同模态之间的情感信息。Wang等人(2019)使用门控机制将音频和视频(非文本)模态转换为与文本模态相关的偏见,然后将其与文本融合。Mai等人(2021年)设计了声学和视觉LSTM来增强文本表征。Tsai等人(2019)将Transformer(Vaswani,2017)引入MSA领域,设计了用于融合不同模态的跨模态变压器。此后,交叉模态变换器得到了广泛的应用,Zhang等人(2022)利用它们来模拟人类感知系统,Huang等人(2023)利用它们来围绕文本进行融合。然而,尽管它们是有效的,但是这些跨模态变换器有一个局限性:它们的自注意结构一次只能接受两个模态作为输入,一个作为查询,另一个作为关键字和值,考虑到每次迭代只有两个模态之间的交互(Lv等人,2021年)的报告。由于多模态任务通常涉及两个以上的模态,所以当处理多模态时,这种结构限制要求交互被分阶段或分步骤地建模。这种限制可能导致信息丢失或不完整的交互,无法充分利用所有模态之间的潜在关系,从而影响情绪预测(Sun、Chen和Lin,2022)。此外,虽然Rahman等人(2020)、Zhao、Chen、Chen等人(2022)使用了预训练的来自变换器的双向编码器表示(BERT)模型(Devlin等人,2018),他们的方法只是将非文本模态与文本模态一起集成到BERT的Transformer层中,导致整个模型中多模态情感信息的集成不足。
(解决方案)针对传统的多模态Transformer无法同时处理多模态信息以及BERT中单层嵌入导致的多模态信息融合不足的问题,提出了一种基于张量的融合BERT(TFBERT)。该模型的核心组件是基于张量的跨模态融合(TCF)模块,该模块可以集成到预先训练的BERT语言模型的Transformer架构中。这允许用非文本模态表示来逐渐补充文本模态表示。具体地说,我们的框架能够在保持BERT核心结构的同时进行微调,从某个点开始将TCF嵌入每个Transformer层。TCF模块中的基于张量的跨模态Transformer(TCT)允许BERT在学习文本表示的同时嵌入非文本情感信息,逐步增强文本模态表示以充分整合多模态情感信息。TCT引入了一种基于张量的方法,在跨模态Transformer融合之前,在目标模态和两个其他源模态之间建立交互。TCT允许所有模态同时交换相关信息,补充和增强目标模态的情感信息。
最后,在CMU-MOSI和CMU-MOSEI两个数据集上测试了TF-BERT模型的性能,并通过情感预测任务对TF-BERT模型的性能进行了评估.仿真实验结果表明,TF-BERT算法优于已有的多度量方法.此外,消融研究进一步确认了TF-BERT中相应模块的有效性。
(1)提出了TF-BERT并设计了TCT模块,克服了传统的跨模态变换器一次只能处理两种模态的局限性。TCT模块使跨模态Transformer能够同时处理多个模态,促进目标模态与其他模态之间的全面信息交换。这种增强显著地改善了目标模态的情感特征表示。
(2)我们设计了TCF模块,它可以集成到预训练的BERT语言模型的Transformer架构中。通过在每个Transformer层中嵌入TCF模块,逐步实现了文本模态和非文本模态的互补,增强了多模态情感信息的融合和表达能力。
(3)实验结果表明:所提出的图像修复算法性能优于多种现有算法.
本文的其余部分组织如下:第二节回顾了有关单峰和MSA的工作。第3节详细描述了我们提出的方法,包括TF-BERT模型的总体架构以及TCF和TCT模块的设计。第4节讨论了在两个不同数据集上进行的实验细节。第五部分给出了实验结果沿着进行了深入的分析。最后,第六章对全文进行了总结和展望。
related works
multimodal sentiment analysis
结构框架:从单模态到多模态,按技术迭代的步伐递进
- 单模态情感分析:
- 肯定成就:引用近期文献(Darwich et al., 2020; Hamed et al., 2023)说明单模态方法的应用价值。
- 批判局限性:指出其无法捕捉情感复杂性(Geetha et al., 2024),引出多模态融合的必要性。
- 多模态融合早期方法:
- 经典模型:Zadeh等(2017)的张量融合网络(计算复杂度高)。
- 改进方向:Sun等(2022)的CubeMLP(降低复杂度)、Miao等(2024)的低秩张量融合(增强信息捕获)。
- 深度学习时代:
- RNN/LSTM局限:序列处理瓶颈(Hou et al., 2024)与长程依赖问题。
- Transformer崛起:并行处理优势(Xiao et al., 2023)及在MSA中的应用(MULT、MISA、Self-MM等)。
- 现有Transformer方法的不足:
- 两模态交互限制:Tsai等(2019)、Wang等(2023)仅支持双模态交互,导致信息不完整。
- BERT融合不足:现有工作(Rahman et al., 2020; Zhao et al., 2022)仅单层嵌入非文本模态,未能充分整合多模态信息。
- 本文解决方案:
- 提出TCT模块:同时处理三模态交互,克服两模态限制。
- TCF模块嵌入BERT:逐层渐进融合,增强多模态表征。
单模态情感分析侧重于从单一模态(如文本、音频或视频)中提取情感信息。这些年来,该领域已经取得了实质性的进步,并且已经在各种实际情况下得到了广泛的应用(Darwich等人,2020年; Hamed等人,2023年; Sukawai和Omar,2020年; Wang等人,2022年)的报告。然而,尽管取得了这些成就,但依赖单一模态往往无法捕捉到人类情感的全部复杂性和多维性(Geetha等人,2024年)的报告。单模态方法在表现情感丰富性和多样性方面的局限性(Hazmoune和Bougamouza,2024; Lian等人,2023年)促使研究人员探索多模态融合。这导致了MSA的出现,与单峰方法相比,MSA提供了具有改进的准确性、鲁棒性和泛化性的增强的情感识别。在MSA中,来自不同模态(如文本、音频和视频)的数据被集成到一个模型中,以更全面地捕获情感特征。随着深度学习技术的发展,MSA已经成为一个重要的研究热点。
最初,Zadeh等人(2017年)提出了张量融合网络,该网络需要计算三重笛卡尔积,导致计算复杂度较高。Sun,Wang,et al.(2022)介绍了CubeMLP,它通过在三个MLP单元中使用仿射变换来降低张量融合网络的计算复杂度。Miao等人(2024)通过将低秩张量融合与Mish激活函数相结合来捕获模态之间的相互作用,从而增强了MSA模型的信息捕获能力。随着深度学习的发展,研究人员开始探索在神经网络中整合多模态信息的更有效方法。传统的深度学习方法依赖于RNN和LSTM网络来处理来自不同模态的信息。Mai等人(2021)开发了声学和视觉LSTM,以建立声学和视觉增强的模态相互作用。Huddar等人(2021)提出使用基于注意力的双向LSTM从话语中提取关键的上下文信息。然而,由于LSTM的序列性质,这些模型难以并行处理序列数据,增加了计算复杂性(Hou、Saad和Omar,2024)。此外,长序列输入可能会导致信息丢失,从而限制模型探索长期依赖关系的能力。
为了解决这些问题,近年来Transformer模型已逐渐引入MSA领域(Sun等人,2023; Wang等人,2024年; Zong等人,2023年)的报告。Transformer建立在多头注意力机制的基础上,以其强大的并行处理和全局聚合能力而闻名(Xiao等人,2023),有效地解决了序列内的长期依赖性(Xiao等人,2024年)的报告。Hazarika等人(2020年)提出了MISA模型,该模型在使用Transformer融合特定模态和共享特征之前对其进行分解。为了保留特定模态的信息,Yu等人(2021年)引入了Self-MM,而Hwang和Kim(2023年)提出了SUGRM,两者都使用自我监督来生成用于单模态情感预测任务的多模态标签,然后通过Transformer进行级联和融合。为了更好地捕捉多模态数据之间的错位,Tsai等人(2019)率先提出了MULT,修改了Transformer结构,以捕捉两种不同模态之间的情感信息和长期依赖性。Wang等人(2023)进一步提出了文本增强Transformer融合网络,修改了跨模态Transformer结构,以通过将文本信息集成到非文本模态中进行增强来充分利用文本信息。Huang et al.(2023)介绍了TeFNA,该方法使用跨模态注意力逐渐对齐和融合非文本和文本表征。为了进一步增强每种模态的表示,Hou,Omar,et al.(2024)提出了TCHFN,在跨模态Transformer中使用目标模态作为键和值,使用源模态作为查询。Hu等人(2024)提出了一种基于转换器的多模态增强网络,该网络通过融合共享信息周围的模态、结合自适应对比学习和多任务学习来增强性能,从而改善MSA。
尽管这些基于transformer的跨模态方法的性能有了显著的改进,但它们的能力受到限制,一次只能处理两个相应的模态。这种约束阻碍了模型同时捕获多个模态之间复杂交互的能力,导致信息集成不足,处理复杂性增加,以及潜在的信息不一致,最终影响全局情感表示的准确性。为了克服这些限制,Lv等人(2021)引入了渐进式模态强化模型,该模型包含一个消息模块来存储多模态信息,增强了每种模态,同时允许在所有模态之间进行同时交互。然而,模态交互的消息模块的引入可能导致信息冗余。Sun,Chen和Lin(2022)调整了Transformer框架,以便在每个融合过程中同时捕获所有模态的互补信息。然而,这种方法导致相对较高的空间复杂度。Huang等人(2024)提出了一种模态绑定学习框架,该框架将细粒度卷积模块集成到Transformer架构中,以促进三种模态之间的有效交互。尽管其有效性,融合过程仍然相对复杂。为了应对这些挑战,我们设计了TCT,以同时建立所有模式之间的互动。在通过TCT增强每种模式之后,它构成了TCF的基础。此外,由于预训练的语言模型BERT在多个下游任务中表现出出色的性能,并具有强大的迁移学习能力,因此可以对其进行微调以适应MSA任务,从而显着提高模型性能,同时节省训练资源,并能够构建更简单,更高效的融合网络。Kim和Park(2023)提出了All-Modalities-in-One BERT模型,该模型通过两个多模态预训练任务使BERT适应MSA。Rahman等人(2020)提出了MAG-BERT,它通过多模态适应门将非文本模态集成到文本模态中。Zhao,Chen,Liu和Tang(2022)介绍了共享私有记忆网络,它在通过BERT学习文本表示的同时,结合了非文本模态的共享和私有特征。Zhao,Chen,Chen,et al.(2022)还提出了HMAI-BERT,它将记忆网络集成到BERT的主干中,以对齐和融合非文本模态。Wang等人(2022)介绍了CENet,它以自我监督的方式生成非文本词典,并采用转换策略来减少文本和非文本表示之间的分布差异,然后与BERT融合。然而,这些模型仅将非文本模态嵌入到BERT内的单个Transformer层中以与文本模态融合,从而导致整个模型中的多模态信息的集成不足。为了解决这个问题,我们提出了TF-BERT,其目的是将TCF从BERT中的特定层嵌入到每个Transformer层中,逐步增强和融合所有模态表示。
method
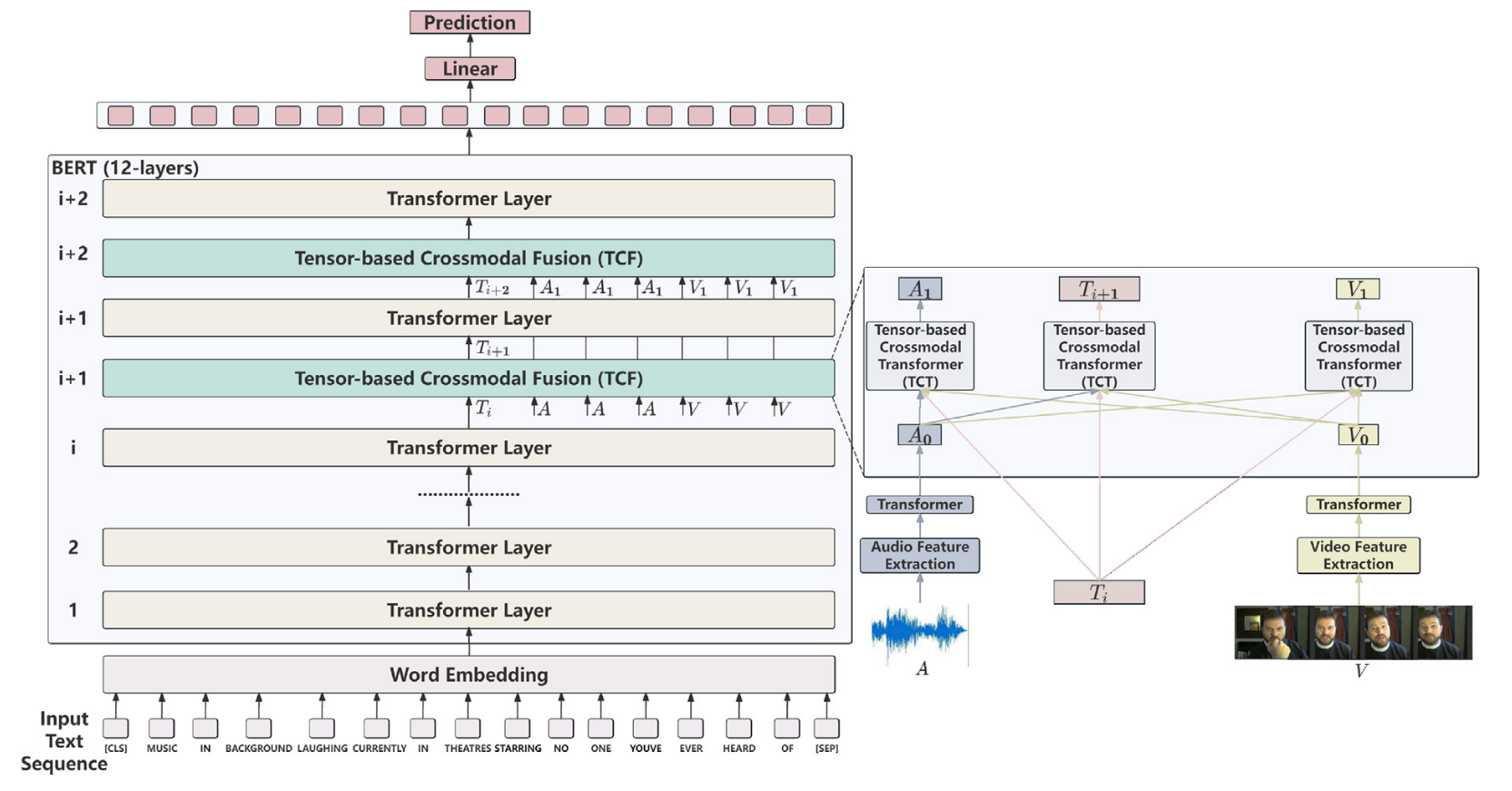
在本节中,我们将详细解释TF-BERT的整体架构及其关键组件,如图2所示。具体来说,第3.1节介绍了任务定义。第3.2节简要概述了整个模型。第3.3节介绍BERT模型。第3.4节描述了TCF模块,第3.5节讨论了TCT模块。
task definition
overall architecture
TF-BERT的结构如图2所示。
-
文本模态处理:
- 文本模态数据通过词嵌入转换为向量形式,输入BERT的Transformer层。
- 这些层捕获文本中不同位置之间的复杂上下文依赖关系。
- 经过前 i 个Transformer层处理后,文本表示在语义上更加丰富。
-
TCF模块嵌入:
- 从第 (i+1) 个Transformer层开始,TCF模块被嵌入BERT中。
- 该模块通过多模态交互增强各模态的表示:
- 第 (i+1) 个Transformer层处理增强后的文本表示。
- 非文本模态(如音频、视觉)的表示经第 (i+1) 个TCF模块增强后,与处理后的文本表示一同输入第 (i+2) 个TCF模块,进行进一步强化。
- 第 (i+2) 个Transformer层将多模态情感信息充分整合到文本表示中。
-
基于张量的跨模态交互:
- TCF模块内使用基于张量的方法,从两个源模态(如音频、视觉)中捕获情感信息。
- 跨模态Transformer利用这些信息增强目标模态(如文本),实现目标模态与两个源模态之间的情感信息交换。
-
输出与预测:
- TF-BERT最终输出的文本表示富含多模态情感信息。
- 通过线性层(Linear)进行情感预测。
基于BERT的多层嵌入
在TF-BERT模型中,BERT起着核心作用。BERT最初由Google开发,是一种专门为自然语言处理任务设计的深度学习模型,需要进行微调以适应多模态任务。BERT包括12个Transformer层,并使用双向训练方法,这意味着它在处理文本时会考虑前后上下文,从而捕获更丰富的语义关系。
BERT首先通过两个主要任务在大规模无监督文本数据上进行预训练:Masked Language Modeling和Next Sentence Prediction。在这个预训练阶段,BERT学习语言表征,包括与情感相关的信息。它非常适合集成到多模态任务中,可以进行微调以有效地融合多模态情感信息。
BERT首先通过两个主要任务进行大规模预训练:掩码语言建模(Masked Language Modeling)和下一句预测(Next Sentence Prediction)。在此预训练阶段,BERT学习语言表示(包括情感相关信息),因此非常适合集成到多模态任务中,通过微调实现多模态情感信息的有效融合。


基于张量的交叉模态Transformer
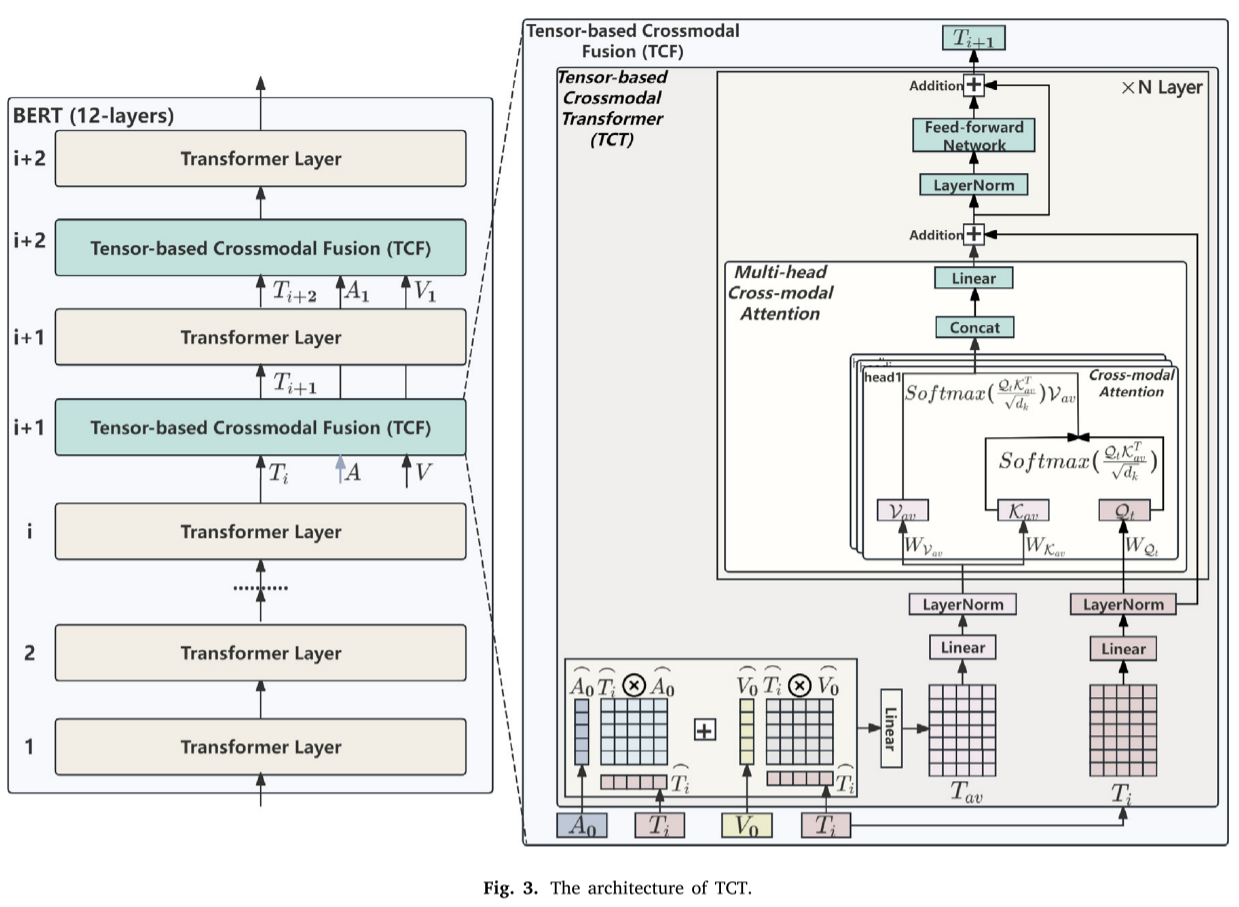
为了在跨模态Transformer中同时考虑来自所有模态的情感信息,我们设计了TCT模块,如图3所示。以文本模态的第(i+1)层TCT模块为例,具体步骤如下:


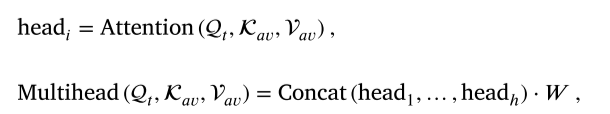
其中,k表示多头交叉模态注意机制中的头的数量,k表示多头交叉模态注意机制的最终线性变换中使用的权重系数。
最后,经过多头跨模态注意机制处理的表征经过LayerNorm层和前馈层,增强文本表征的稳定性,最终得到的结果是LayerNorm+1。
training loss

相关文章:

【TF-BERT】基于张量的融合BERT多模态情感分析
不足:1. 传统跨模态transformer只能处理2种模态,所以现有方法需要分阶段融合3模态,引发信息丢失。2. 直接拼接多模态特征到BERT中,缺乏动态互补机制,无法有效整合非文本模态信息 改进方法:1. 基于张量的跨模…...
)
SONiC-OTN代码详解(具体内容待续)
SONiC-OTN代码详解 (具体内容待续) 基于AI的源代码解析工具的产生使得代码阅读和解析变得越来越高效和简洁,计划通过这样的工具对SONiC在OTN领域的应用做一个全自动的解析,大部分内容会基于AI工具的自动解析结果。这样做的目的是…...

牛客周赛90 C题- Tk的构造数组 题解
原题链接 https://ac.nowcoder.com/acm/contest/107500/C 题目描述 解题思路 数组a是不可以动的,所以我们可以把a[i]*b[i]*i分成两组,分别为a[i]*i以及b[i] 然后策略就很明显了,让更大的b[i]匹配更大的a[i]*i 详细实现见代码。 代码&am…...

[ML]通过50个Python案例了解深度学习和神经网络
通过50个Python案例了解深度学习和神经网络 摘要:机器学习 (Machine Learning, ML)、深度学习 (Deep Learning, DL) 和神经网络 (Neural Networks, NN) 是人工智能领域的核心技术。Python 是学习和实践这些技术的首选语言,因为它提供了丰富的库(如 scikit-learn、Te…...

vue3 - keepAlive缓存组件
在Vue 3中,<keep-alive>组件用于缓存动态组件或路由组件的状态,避免重复渲染,提升性能。 我们新建两个组件,在每一个组件里面写一个input,在默认情况下当组件切换的时候,数据会被清空,但…...
)
自由学习记录(58)
Why you were able to complete the SpringBoot MyBatisPlus task smoothly: Clear logic flow: Database → Entity → Service → Controller → API → JSON response. Errors are explicit, results are verifiable — you know what’s broken and what’s fixed. Sta…...

短信侠 - 自建手机短信转发到电脑上并无感识别复制验证码,和找手机输验证码说再见!
自建手机短信转发到电脑上并无感识别复制验证码 一、前言 项目开发语言:本项目使用PythonRedisC#开发 你是否也遇到过这样的场景: 正在电脑上操作某个网站,需要输入短信验证码手机不在身边,或者在打字时来回切换设备很麻烦验证码…...

课程10. 聚类问题
课程10. 聚类问题 聚类此类表述的难点K 均值法让我们推广到几个集群的情况如果我们选择其他起始近似值会怎样? 结论在 sklearn 中的实现 如何处理已发现的问题?层次聚类Lance-Williams 算法Lance-Williams 公式在Scipy中实现 示例DBSCANDBSCAN 算法 聚类…...

深度学习中的数据增强:提升食物图像分类模型性能的关键策略
深度学习中的数据增强:提升食物图像分类模型性能的关键策略 在深度学习领域,数据是模型训练的基石,数据的数量和质量直接影响着模型的性能表现。然而,在实际项目中,获取大量高质量的数据往往面临诸多困难,…...

QT设计权限管理系统
Qt能够简单实现系统的权限设计 首先我们需要一个登陆界面 例如这样 然后一级权限,可以看到所有的内容,不设置菜单栏的隐藏。 然后其他权限,根据登陆者的身份进行菜单栏不同的展示。 菜单栏的隐藏代码如下: ui->actionuser-…...

从上帝视角看文件操作
1.为什么使用文件? 如果没有文件,我们写的程序中的数据是存储在电脑的内存中,当程序退出时,内存被回收后,数据就丢失了,等下次运行程序,是无法看到上次程序的数据的。(比如我们在程序中写通讯录时,联系人的相关数据都是放在内存中的,当程序退出时,这些数据也会随之消…...

【51单片机6位数码管显示时间与秒表】2022-5-8
缘由数码管 keil proteus 为什么出现这种情况呢?-编程语言-CSDN问答 #include "reg52.h" unsigned char code smgduan[]{0x3f,0x06,0x5b,0x4f,0x66,0x6d,0x7d,0x07,0x7f,0x6f,0x77,0x7c,0x39,0x5e,0x79,0x71,0,64}; //共阴0~F消隐减号 unsigned char cod…...

从头训练小模型: 4 lora 微调
1. LoRA (Low-Rank Adaptation) LoRA是一种高效的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,原理是通过低秩分解的方式对预训练模型进行微调。 相比于全参数微调(Full Fine-Tuning),LoRA…...

前端开发,文件在镜像服务器上不存在问题:Downloading binary from...Cannot download...
问题与处理策略 问题描述 在 Vue 项目中,执行 npm i 下载依赖时,报如下错误 Downloading binary from https://npm.taobao.org/mirrors/node-sass//v4.14.1/win32-x64-72_binding.node Cannot download "https://npm.taobao.org/mirrors/node-sa…...

Debezium Binlog协议与事件转换详解
Debezium Binlog协议与事件转换详解 1. MySQL Binlog通信机制 1.1 连接建立流程 #mermaid-svg-eE88YFqcTG9kUWaZ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-eE88YFqcTG9kUWaZ .error-icon{fill:#552222;}#mer…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】4.1 日期时间标准化(时区转换/格式统一)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL数据分析实战:数据清洗之日期时间标准化(时区转换/格式统一)4.1 日期时间标准化:从混乱到有序4.1.1 数据乱象&…...
)
基于Hive + Spark离线数仓大数据实战项目(视频+课件+代码+资料+笔记)
精品推荐:基于Hive Spark离线数仓大数据实战项目,共23节课,供学习参考。 项目介绍项目中 docker 使用项目环境搭建项目数仓分层项目业务分析sqoop 数据采集python 数据采集项目 ODS 层创建DWD 层构建DWS 层构建项目回顾(一&…...

【深入浅出MySQL】之数据类型介绍
【深入浅出MySQL】之数据类型介绍 MySQL中常见的数据类型一览为什么需要如此多的数据类型数值类型BIT(M)类型INT类型TINYINT类型BIGINT类型浮点数类型float类型DECIMAL(M,D)类型区别总结 字符串类型CHAR类型VARCHAR(M)类型 日期和时间类型enum和set类型 …...
从入门到登峰-嵌入式Tracker定位算法全景之旅 Part 4 |IMU 死算与校正:惯性导航在资源受限环境的落地
Part 4 |IMU 死算与校正:惯性导航在资源受限环境的落地 本章聚焦 ESP32-S3 平台上如何利用 LSM6DS3 IMU 实现 死算(Dead Reckoning),并结合 零速更新(ZUPT) 或 磁力计辅助 进行 漂移校正,最终通过 EKF/UKF 融合提升定位精度。 一、传感器简介与校准 LSM6DS3 主要参数 加速…...

【iOS】 方法交换
【iOS】 方法交换 method-swizzling 文章目录 【iOS】 方法交换 method-swizzling前言什么是method-swizzling相关API方法交换的风险在load方法中保证只加载一次要在当前类的方法中进行交换如果方法依赖于cmd 方法交换的应用 前言 之前看过有关于消息转发的内容,这里我们可以简…...

PostgreSQL 的 ANALYZE 命令
PostgreSQL 的 ANALYZE 命令 ANALYZE 是 PostgreSQL 中用于收集数据库对象统计信息的关键命令,这些统计信息对于查询优化器生成高效执行计划至关重要。 一 ANALYZE 命令 1.1 基本语法 ANALYZE [ ( option [, ...] ) ] [ table_and_columns [, ...] ] ANALYZE [ …...

初识 iOS 开发中的证书固定
引言 在移动应用安全领域,HTTPS/TLS 是数据传输的第一道防线,但仅依赖系统默认的证书验证仍有被中间人(MITM)攻击的风险。Certificate Pinning(证书固定)通过将客户端信任“钉”在指定的服务器证书或公钥上…...
)
2025 年如何使用 Pycharm、Vscode 进行树莓派 Respberry Pi Pico 编程开发详细教程(更新中)
micropython 概述 micropython 官方网站:https://www.micropython.org/ 安装 Micropython 支持固件 树莓派 Pico 安装 Micropython 支持固件 下载地址:https://www.raspberrypi.com/documentation/microcontrollers/ 选择 MicroPython 下载 RPI_PIC…...
完整讲解与实战应用)
设计模式每日硬核训练 Day 17:中介者模式(Mediator Pattern)完整讲解与实战应用
🔄 回顾 Day 16:责任链模式小结 在 Day 16 中,我们学习了责任链模式(Chain of Responsibility Pattern): 将请求沿链传递,节点可选择处理或传递下一节点。实现了请求发送者与多个处理者的解耦…...
)
文章记单词 | 第63篇(六级)
一,单词释义 vegetable [ˈvedʒtəbl] n. 蔬菜;植物人;生活单调乏味的人;adj. 蔬菜的;植物的faint [feɪnt] adj. 模糊的;微弱的;虚弱的;v. 昏倒,昏厥;n. 昏…...

ES类的索引轮换
通过以下请求方法创建一个名为 “tiered-storage-policy” 的 ISM policy: PUT _plugins/_ism/policies/tiered-storage-policy {"policy": {"description": "Changes replica count and deletes.","schema_version": 1,…...

小白机器人假想:分布式关节控制——机器人运动的未来模式?
引言 在机器人技术快速发展的今天,控制架构的创新往往能带来突破性进展。作为一名机器人爱好者,我最近思考了一个大胆的设想:如果机器人的每个关节都配备独立的动作存储器和处理器,并通过高速光纤网络与中央"驱动总脑"…...

LangChain4j +DeepSeek大模型应用开发——9 优化硅谷小鹿
1.预约业务的实现 这部分我们实现硅谷小鹿的查询订单、预约订单、取消订单的功能 创建MySQL数据库表 CREATE DATABASE xiaolu; USE xiaolu; -- 创建预约表 appointment CREATE TABLE appointment (id BIGINT NOT NULL AUTO_INCREMENT COMMENT 主键ID,自增, -- 主…...

Oracle VirtualBox 在 macOS 上的详细安装步骤
Oracle VirtualBox 在 macOS 上的详细安装步骤 一、准备工作1. 系统要求2. 下载安装包二、安装 VirtualBox1. 挂载安装镜像2. 运行安装程序3. 处理安全限制(仅限首次安装)三、安装扩展包(增强功能)四、配置第一个虚拟机1. 创建新虚拟机2. 分配内存3. 创建虚拟硬盘4. 加载系…...

Day110 | 灵神 | 二叉树 | 根到叶路径上的不足节点
Day110 | 灵神 | 二叉树 | 根到叶路径上的不足节点 1080.根到叶路径上的不足节点 1080. 根到叶路径上的不足节点 - 力扣(LeetCode) 思路: 笔者一开始没看懂,只能通过部分的例子,原因是把路径和小于limit的都给删了…...

超详细讲解C语言转义字符\a \b \r \t \? \n等等
转义字符 C语言有一组字符很特殊,叫做转义字符,顾名思义,改变原来的意思的字符。 1 \? ??)是一个三字母词,在以前的编译器它会被编译为] (??会被编译为[ 因此在以前输入(are you ok ??)就会被编译为are you ok ] 解决这个…...

TensorFlow 多卡训练 tf多卡训练
目录 export TF_GPU_ALLOCATORcuda_malloc_async 🔧 具体作用 优势 🧩 依赖条件 ✅ 设置方式(Linux/macOS) export TF_GPU_ALLOCATORcuda_malloc_async 是设置 TensorFlow 使用 CUDA 异步内存分配器 的环境变量。这个设置可…...

数据结构--树状数组
树状数组(Fenwick Tree) 概述 树状数组是一种用于高效处理动态数组中前缀和查询的数据结构。它能够在 O ( l o g n ) O(log n) O(logn) 时间复杂度内完成以下操作: 更新数组中的元素O(logn)查询数组前缀和O(logn) 数组: O(1)…...

如何使用python保存字典
在Python中,可以通过多种方式将字典(dict)保存到文件中,并能够随时读取恢复。以下是几种常见的方法: 1. 使用 json 模块(推荐) 适用场景:需要人类可读的文件格式,且数据不…...

C和指针——预处理
预处理是编译前的过程,主要对define,include以及一些编译器定义的内容进行替换 #define的本质就是替换 1、例子 #define FOREVER for(;;) 2、例子 #define TEMPD "1231231231\ 123123123" \\如果太长了,可以用\换行 3、例子——可…...

windows python ta-lib安装
https://github.com/TA-Lib/ta-lib/releases windows安装ta-lib指令 pip install --no-cache-dir https://github.com/cgohlke/talib-build/releases/download/v0.6.3/ta_lib-0.6.3-cp310-cp310-win_amd64.whl...

机器学习+多目标优化的算法如何设计?
一、核心问题与设计思路 机器学习(ML)与多目标优化(MOO)的结合旨在解决两类核心问题: 利用ML提升MOO算法的性能:通过机器学习模型预测解的质量、优化搜索方向或加速收敛;利用MOO优化ML模型的多…...

爬虫管理平台-最新版本发布
TaskPyro 是什么? TaskPyro 是一个轻量级的 Python 任务调度平台,专注于提供简单易用的任务管理和爬虫调度解决方案。它能够帮助您轻松管理和调度 Python 任务,特别适合需要定时执行的爬虫任务和数据处理任务。 官方文档:https:/…...

SpringCloud教程 — 无废话从0到1逐步学习
目录 什么是微服务? 微服务与单体架构的区别 微服务主要用法概念 远程调用 服务注册/发现&注册中心 配置中心 服务熔断&服务降级 1)服务熔断 2)服务降级 API 网关 环境准备 Nacos OpenFeign Gateway Sentinel Sea…...
)
Webug4.0通关笔记12- 第17关 文件上传之前端拦截(3种方法)
目录 一、文件上传前端拦截原理 二、第17关 文件上传(前端拦截) 1.打开靶场 2.构造php脚本 3.源码分析 (1)js源码 (2)服务器源码 (3)总结 4.渗透实战 (1)禁用js法 &#…...

使用synchronized关键字同步Java线程
问题 在Java多线程编程中,你需要保护某些数据,防止多个线程同时访问导致数据不一致或程序错误。 解决方案 在需要保护的方法或代码段上使用synchronized关键字。 讨论 synchronized关键字是Java提供的同步机制,用于确保在同一时刻只有一…...

从头训练小模型: 2 监督微调SFT
简介 从头训练小模型是我个人对大语言模型(LLM)学习中的重要部分。 通过对一个小规模模型的最小化复现实践,我不仅能够深入理解模型训练的基本流程,还可以系统地学习其中的核心原理和实际运行机制。这种实践性的学习方法让我能够直观地感受模型训练的每…...

【QT】QT中http协议和json数据的解析-http获取天气预报
QT中http协议和json数据的解析 1.http协议的原理2.QT中http协议的通信流程2.1 方法步骤 3.使用http协议(通过http下载图片和获取天气预报信息)3.1 http下载网络上的图片(下载小文件)3.1.1 示例代码3.1.2 现象 3.2 获取网络上天气预报3.2.1 免费的天气预报…...

PiscTrace针对YOLO深度适配:从v8到v12
一、YOLO简介:目标检测的核心技术 YOLO(You Only Look Once)是近年来最为流行的目标检测模型,凭借其实时性与高精度,广泛应用于自动驾驶、视频监控、安防检测等多个领域。YOLO系列模型自v1问世以来,经过不…...

前端面试每日三题 - Day 24
这是我为准备前端/全栈开发工程师面试整理的第24天每日三题练习,涵盖了: JavaScript 中的 Promise.all()、Promise.race() 和 Promise.allSettled() 的实际应用和性能差异React 中的 Concurrent Rendering 和 useTransition API如何设计一个高并发的在线…...

正态分布习题集 · 题目篇
正态分布习题集 题目篇 全面覆盖单变量正态、多变量正态、参数估计、假设检验、变换以及应用,共 20 题,从基础到进阶。完成后请移步《答案与解析篇》。 1. 基础定义与性质(5题) 1.1 密度函数 写出正态分布 N ( μ , σ 2 ) N(…...
-动画、材质)
Three.js在vue中的使用(二)-动画、材质
一、Three.js 动画原理与实现 1. 基本原理 Three.js 的动画系统基于 关键帧(Keyframe) 和 时间轴(AnimationClip) 实现: THREE.AnimationMixer:管理多个动画片段的播放器THREE.AnimationClip:…...

【办公类-99-04】20250504闵豆统计表excle转PDF,合并PDF、添加中文字体页眉+边框下划线
需求说明 督导检查,各条线都要收集资料。 今天去加班,遇到家教主任,她让我用保教主任的彩色打印机打印这套活跃度表格。(2023学年上学期下学期-2024学年上学期,就是202309-202504) 每个excle都是内容在A4一…...

ES类迁移方法
快照(s3 file FS)跨集群迁移es-dumpremote-reindexLogstash Elasticsearch 迁移方法 Elasticsearch 迁移是将数据、索引和配置从一个 Elasticsearch 集群转移到另一个集群的过程。以下是几种常见的迁移方法: 1. 快照和恢复 (Snapshot and Restore) 这是最推荐的…...

智能合约部署之全国职业院校技能大赛“区块链技术应用”赛项—“航班延误险案例”
智能合约部署之全国职业院校技能大赛“区块链技术应用”赛项—“航班延误险案例” 1.启动虚拟机上的区块链 (1)打开VMware虚拟机,在桌面中点击右键,选择Open Terminal打开命令行窗口。 (2)使用"cd geth_local/"命令,切换至区块链根目录,输入下面的命令启动…...