365打卡第R6周: LSTM实现糖尿病探索与预测
🍨 本文为🔗365天深度学习训练营中的学习记录博客
🍖 原作者:K同学啊

🏡 我的环境:
语言环境:Python3.10
编译器:Jupyter Lab
深度学习环境:torch==2.5.1 torchvision==0.20.1
------------------------------分割线---------------------------------
#设置GPU
import torch.nn as nn
import torch.nn.functional as F
import torchvision,torch device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(device) ![]() (数据规模很小,在普通笔记本电脑就可以流畅跑完)
(数据规模很小,在普通笔记本电脑就可以流畅跑完)
#导入数据
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
plt.rcParams['savefig.dpi'] = 500 #图片像素
plt.rcParams['figure.dpi'] = 500 #分辨率plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签import warnings
warnings.filterwarnings('ignore')DataFrame = pd.read_excel('./dia.xls')
print(DataFrame.head())print(DataFrame.shape)
# 查看是否有缺失值
print("数据缺失值------------------")
print(DataFrame.isnull().sum())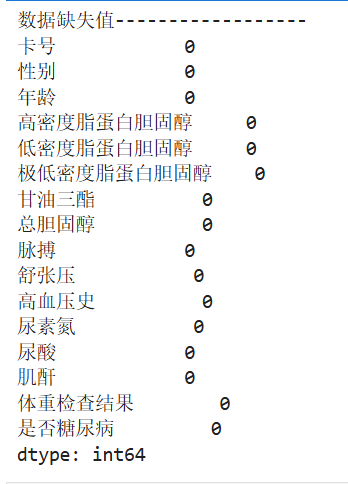
# 查看数据是否有重复值
print("数据重复值------------------")
print('数据的重复值为:'f'{DataFrame.duplicated().sum()}')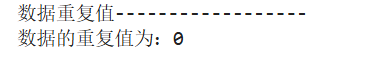
feature_map = {'年龄': '年龄','高密度脂蛋白胆固醇': '高密度脂蛋白胆固醇','低密度脂蛋白胆固醇': '低密度脂蛋白胆固醇','极低密度脂蛋白胆固醇': '极低密度脂蛋白胆固醇','甘油三酯': '甘油三酯','总胆固醇': '总胆固醇','脉搏': '脉搏','舒张压': '舒张压','高血压史': '高血压史','尿素氮': '尿素氮','尿酸': '尿酸','肌酐': '肌酐','体重检查结果': '体重检查结果'
}plt.figure(figsize=(15, 10))
for i, (col, col_name) in enumerate(feature_map.items(), 1):plt.subplot(3, 5, i)sns.boxplot(x=DataFrame['是否糖尿病'], y=DataFrame[col])plt.title(f'{col_name}的箱线图', fontsize=14)plt.ylabel('数值', fontsize=12)plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()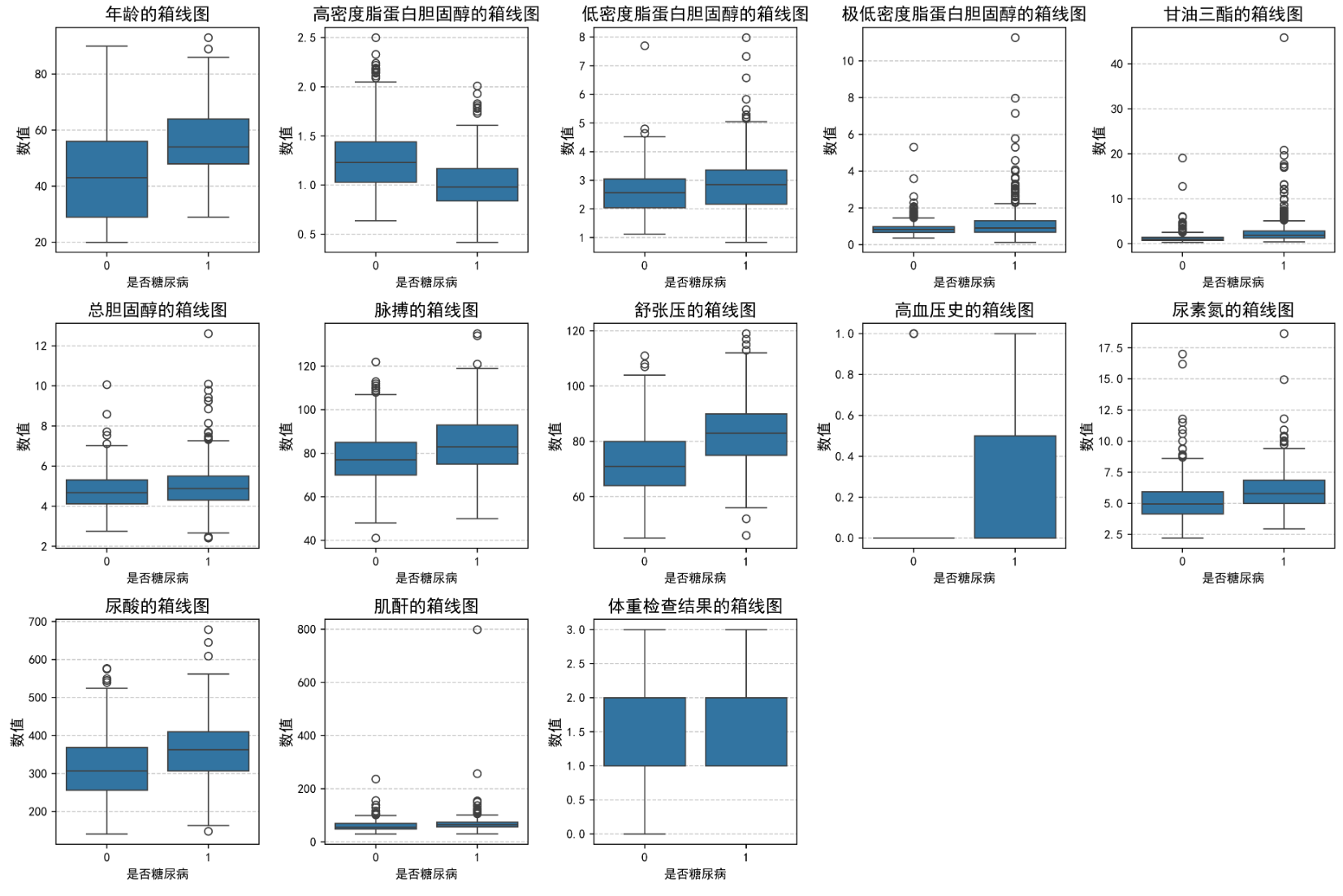
# 构建数据集
from sklearn.preprocessing import StandardScaler# '高密度脂蛋白胆固醇'字段与糖尿病负相关,故在X 中去掉该字段
X = DataFrame.drop(['卡号', '是否糖尿病', '高密度脂蛋白胆固醇'], axis=1)
y = DataFrame['是否糖尿病']# sc_X = StandardScaler()
# X = sc_X.fit_transformX = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.int64)train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2, random_state=1)train_X.shape, train_y.shape![]()
from torch.utils.data import TensorDataset, DataLoadertrain_dl = DataLoader(TensorDataset(train_X, train_y), batch_size=64, shuffle=False)
test_dl = DataLoader(TensorDataset(test_X, test_y), batch_size=64, shuffle=False)# 定义模型
class model_lstm(nn.Module):def __init__(self):super(model_lstm, self).__init__()self.lstm0 = nn.LSTM(input_size=13, hidden_size=200,num_layers=1, batch_first=True)self.lstm1 = nn.LSTM(input_size=200, hidden_size=200,num_layers=1, batch_first=True)self.fc0 = nn.Linear(200, 2) # 输出 2 类def forward(self, x):# 如果 x 是 2D 的,转换为 3D 张量,假设 seq_len=1if x.dim() == 2:x = x.unsqueeze(1) # [batch_size, 1, input_size]# LSTM 处理数据out, (h_n, c_n) = self.lstm0(x) # 第一层 LSTM# 使用第二个 LSTM,并传递隐藏状态out, (h_n, c_n) = self.lstm1(out, (h_n, c_n)) # 第二层 LSTM# 获取最后一个时间步的输出out = out[:, -1, :] # 选择序列的最后一个时间步的输出out = self.fc0(out) # [batch_size, 2]return outmodel = model_lstm().to(device)
print(model)
# 训练模型def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小num_batches = len(dataloader) # 批次数目train_loss, train_acc = 0, 0 # 初始化训练损失和正确率model.train() # 设置模型为训练模式for X, y in dataloader: # 获取数据和标签# 如果 X 是 2D 的,调整为 3Dif X.dim() == 2:X = X.unsqueeze(1) # [batch_size, 1, input_size],即假设 seq_len=1X, y = X.to(device), y.to(device) # 将数据移动到设备# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距# 反向传播optimizer.zero_grad() # 清除上一步的梯度loss.backward() # 反向传播optimizer.step() # 更新权重# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= size # 平均准确率train_loss /= num_batches # 平均损失return train_acc, train_lossdef test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_lossloss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
epochs = 50
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = opt.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f},Lr:{:.2E}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))print("=" * 20, 'Done', "=" * 20)
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率from datetime import datetime
current_time = datetime.now()epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()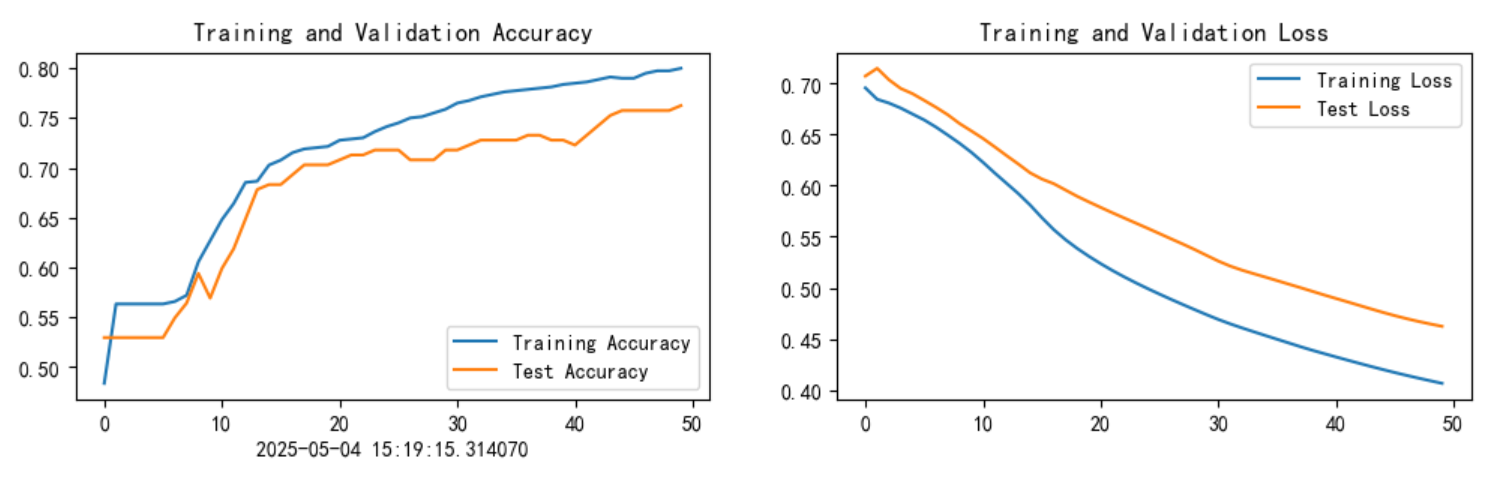
--------------小结和改进思路(顺便把R7周的任务一起完成)---------------------
针对前述代码,主要在下面几个方面进行改进:
- 性能提升:通过双向LSTM和Dropout增强特征提取能力,标准化和类别权重缓解数据问题。
- 防止过拟合:在全连接层前添加BatchNorm提高泛化性。
- 训练稳定性:学习率调度器和训练集启用shuffle随机打乱数据使训练更稳定。
通过上述优化,模型在保持LSTM核心结构的同时,能够更有效地处理表格数据并提升预测性能,最终训练集和测试集分别提高了5个百分点。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import f1_score, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns# 环境设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device![]()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
torch.manual_seed(42) # 打印随机seed使随机分配可重复![]()
# 数据加载与预处理
def load_data():df = pd.read_excel('./dia.xls')# 数据清洗print("缺失值:", df.isnull().sum().sum())print("重复值:", df.duplicated().sum())df = df.drop_duplicates().reset_index(drop=True)# 特征工程X = df.drop(['卡号', '是否糖尿病', '高密度脂蛋白胆固醇'], axis=1)y = df['是否糖尿病']# 处理类别不平衡class_counts = y.value_counts().valuesclass_weights = torch.tensor([1/count for count in class_counts], dtype=torch.float32).to(device)# 数据标准化(先分割后标准化)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)# 转换为TensorX_train = torch.tensor(X_train, dtype=torch.float32).to(device)X_test = torch.tensor(X_test, dtype=torch.float32).to(device)y_train = torch.tensor(y_train.values, dtype=torch.long).to(device)y_test = torch.tensor(y_test.values, dtype=torch.long).to(device)return X_train, X_test, y_train, y_test, class_weights# 双向LSTM模型
class BiLSTM(nn.Module):def __init__(self, input_size=12, hidden_size=100, num_layers=2):super().__init__()self.lstm = nn.LSTM(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers,bidirectional=True,batch_first=True,dropout=0.3 if num_layers>1 else 0)self.bn = nn.BatchNorm1d(hidden_size*2)self.dropout = nn.Dropout(0.5)self.fc = nn.Linear(hidden_size*2, 2)def forward(self, x):if x.dim() == 2:x = x.unsqueeze(1)out, _ = self.lstm(x)out = out[:, -1, :] # 取最后时间步out = self.bn(out)out = self.dropout(out)return self.fc(out)# 训练与验证函数
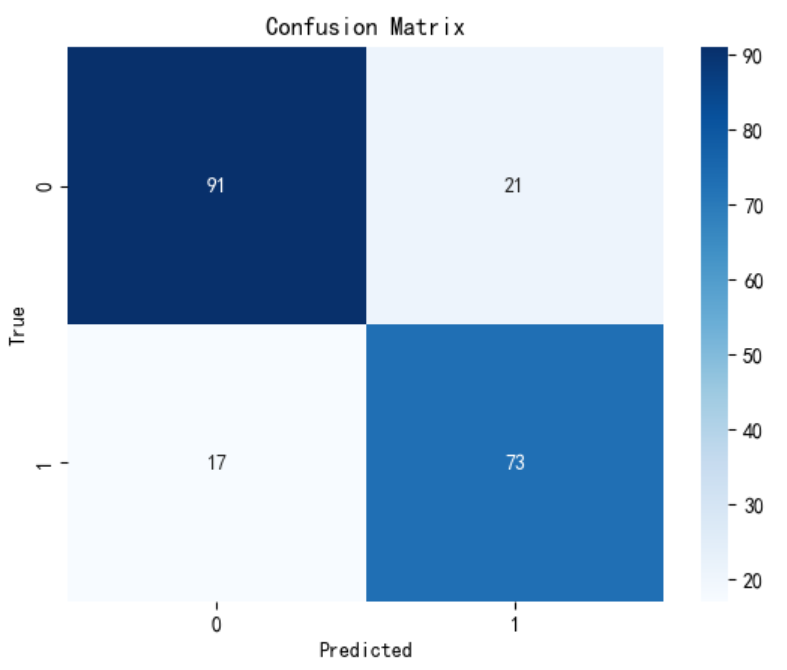
def train_epoch(model, loader, criterion, optimizer):model.train()total_loss, correct = 0, 0for X, y in loader:X = X.unsqueeze(1) if X.dim()==2 else Xoptimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()total_loss += loss.item()correct += (outputs.argmax(1) == y).sum().item()return correct/len(loader.dataset), total_loss/len(loader)def evaluate(model, loader, criterion):model.eval()total_loss, correct = 0, 0all_preds, all_labels = [], []with torch.no_grad():for X, y in loader:X = X.unsqueeze(1) if X.dim()==2 else Xoutputs = model(X)loss = criterion(outputs, y)total_loss += loss.item()correct += (outputs.argmax(1) == y).sum().item()all_preds.extend(outputs.argmax(1).cpu().numpy())all_labels.extend(y.cpu().numpy())f1 = f1_score(all_labels, all_preds)cm = confusion_matrix(all_labels, all_preds)return correct/len(loader.dataset), total_loss/len(loader), f1, cmprint(model)
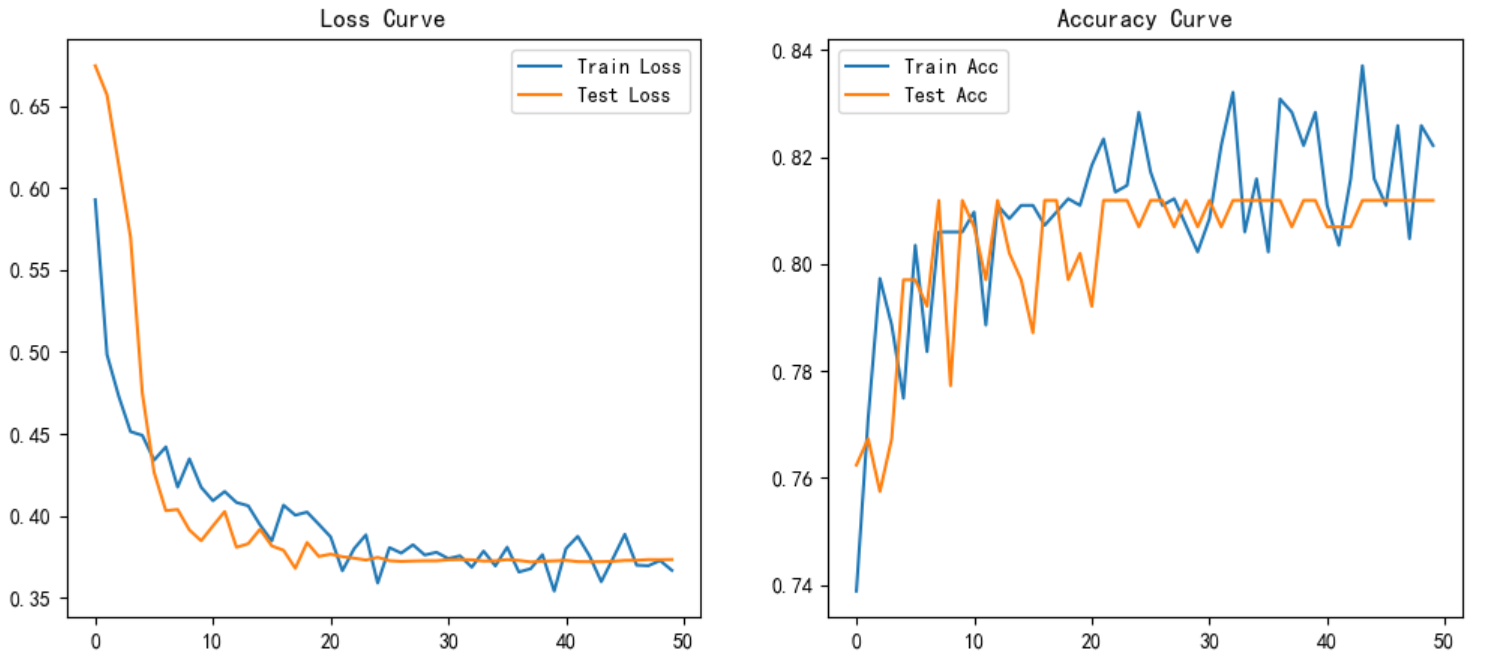
# 数据准备X_train, X_test, y_train, y_test, class_weights = load_data()train_dataset = TensorDataset(X_train, y_train)test_dataset = TensorDataset(X_test, y_test)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=64)# 模型初始化model = BiLSTM(input_size=13).to(device)criterion = nn.CrossEntropyLoss(weight=class_weights)optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-4)scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=3)# 训练循环best_f1 = 0train_losses, test_losses = [], []train_accs, test_accs = [], []for epoch in range(50):train_acc, train_loss = train_epoch(model, train_loader, criterion, optimizer)test_acc, test_loss, f1, cm = evaluate(model, test_loader, criterion)# 学习率调整scheduler.step(test_loss)# 记录指标train_losses.append(train_loss)test_losses.append(test_loss)train_accs.append(train_acc)test_accs.append(test_acc)# 打印信息print(f"Epoch {epoch+1:02d} | "f"Train Acc: {train_acc:.2%} | Test Acc: {test_acc:.2%} | "f"F1: {f1:.4f} | LR: {optimizer.param_groups[0]['lr']:.2e}")# 可视化plt.figure(figsize=(12,5))plt.subplot(1,2,1)plt.plot(train_losses, label='Train Loss')plt.plot(test_losses, label='Test Loss')plt.legend()plt.title("Loss Curve")plt.subplot(1,2,2)plt.plot(train_accs, label='Train Acc')plt.plot(test_accs, label='Test Acc')plt.legend()plt.title("Accuracy Curve")plt.show()
相关文章:

365打卡第R6周: LSTM实现糖尿病探索与预测
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 🏡 我的环境: 语言环境:Python3.10 编译器:Jupyter Lab 深度学习环境:torch2.5.1 torchvision0…...

新能源实验室电磁兼容设计优化方案论述
摘要:本文旨在进行新能源核心部件/系统测试实验室电磁兼容情况设计及优化方案进行论述,通过系统化梳理实验室的主流设备仪器,试验搭建典型方案。识别不同设备的电磁兼容现状,实验室基于设备布局常见设计方案不足点,故障…...

计算机图形学中的深度学习
文章目录 零、前言0.课程考核1.课程大纲2.前置知识3.教材4.课程大纲5.相关课程 Relevant Courses 一、计算机图形学1.本章学习目标2.图形学的应用3.SIG Graph papers 二、基本图形生成算法1.本章学习目标2.图形API3.OpenGL(1)什么是OpenGL(2)OpenGL 的基本组件:顶点…...

RockyLinux9.3-24小时制
在 RockyLinux 9.3 中,默认时间格式为 12 小时制,调整为 24 小时制 案例一:在 RockyLinux 9.3 中,默认时间格式为 12 小时制,调整为 24 小时制案例二:时间显示英文调整为中文endl 案例一:在 Roc…...
_csdn)
25.2linux中外置RTC芯片的PCF8563实验(测试)_csdn
1、硬件原理图分析 知道了这些引脚我们还是按照老习惯! 配置镜像和设备树文件! 2、修改设备树 2.1、添加或者查找 PCF8563 所使用的 IO 的 pinmux 配置 打开stm32mp15-pincrtl.dtsi 文件,查找节点I2C4: 也就是中断引脚并不需要配置pinctrl…...

高性能 WEB 服务器 Nginx:多虚拟主机实现!
Nginx 配置多虚拟主机实现 多虚拟主机是指在一台 Nginx 服务器上配置多个网站 在 Nginx 中,多虚拟主机有三种实现方式: 基于IP地址实现多虚拟主机 基于端口号实现多虚拟主机 基于域名实现多虚拟主机 1 基于域名实现多虚拟主机 在 Nginx 中配置多个…...

C++ 的类型排序
0.前言 在 C 中,我编写了一个 tuple-like 模板,这个模板能容纳任意多且可重复的类型: template<typename... Ts> struct TypeList {};// usage: using List1 TypeList<int, double, char, double>; using List2 TypeList<…...

[计算机网络]拓扑结构
拓扑结构一般会在计网教材或课程的第一章计网的分类那里接触到,但实际上计网的拓扑结构并不只是第一章提到的总线型、星型、树型、网状、混合型那几种类型那么简单,学完了后面的数链层以后对拓扑结构会有新的体会,所以特别单独总结成一篇博客…...

C#方法返回值全解析:从基础语法到实战技巧
摘要:方法返回值是C#编程的核心概念之一。本文将带你彻底掌握返回值声明、void方法特性,以及如何通过返回值实现优雅的流程控制(文末附完整示例代码)。 返回值的基础法则 类型声明原则 有返回值:必须在方法名前声明…...

修复笔记:SkyReels-V2 项目中的 torch.cuda.amp.autocast 警告和错误
#工作记录 一、问题描述 在运行项目时,出现以下警告和错误: FutureWarning: torch.cuda.amp.autocast(args...) is deprecated. Please use torch.amp.autocast(cuda, args...) instead.with torch.cuda.amp.autocast(dtypepipe.transformer.dtype), …...

【TF-BERT】基于张量的融合BERT多模态情感分析
不足:1. 传统跨模态transformer只能处理2种模态,所以现有方法需要分阶段融合3模态,引发信息丢失。2. 直接拼接多模态特征到BERT中,缺乏动态互补机制,无法有效整合非文本模态信息 改进方法:1. 基于张量的跨模…...
)
SONiC-OTN代码详解(具体内容待续)
SONiC-OTN代码详解 (具体内容待续) 基于AI的源代码解析工具的产生使得代码阅读和解析变得越来越高效和简洁,计划通过这样的工具对SONiC在OTN领域的应用做一个全自动的解析,大部分内容会基于AI工具的自动解析结果。这样做的目的是…...

牛客周赛90 C题- Tk的构造数组 题解
原题链接 https://ac.nowcoder.com/acm/contest/107500/C 题目描述 解题思路 数组a是不可以动的,所以我们可以把a[i]*b[i]*i分成两组,分别为a[i]*i以及b[i] 然后策略就很明显了,让更大的b[i]匹配更大的a[i]*i 详细实现见代码。 代码&am…...

[ML]通过50个Python案例了解深度学习和神经网络
通过50个Python案例了解深度学习和神经网络 摘要:机器学习 (Machine Learning, ML)、深度学习 (Deep Learning, DL) 和神经网络 (Neural Networks, NN) 是人工智能领域的核心技术。Python 是学习和实践这些技术的首选语言,因为它提供了丰富的库(如 scikit-learn、Te…...

vue3 - keepAlive缓存组件
在Vue 3中,<keep-alive>组件用于缓存动态组件或路由组件的状态,避免重复渲染,提升性能。 我们新建两个组件,在每一个组件里面写一个input,在默认情况下当组件切换的时候,数据会被清空,但…...
)
自由学习记录(58)
Why you were able to complete the SpringBoot MyBatisPlus task smoothly: Clear logic flow: Database → Entity → Service → Controller → API → JSON response. Errors are explicit, results are verifiable — you know what’s broken and what’s fixed. Sta…...

短信侠 - 自建手机短信转发到电脑上并无感识别复制验证码,和找手机输验证码说再见!
自建手机短信转发到电脑上并无感识别复制验证码 一、前言 项目开发语言:本项目使用PythonRedisC#开发 你是否也遇到过这样的场景: 正在电脑上操作某个网站,需要输入短信验证码手机不在身边,或者在打字时来回切换设备很麻烦验证码…...

课程10. 聚类问题
课程10. 聚类问题 聚类此类表述的难点K 均值法让我们推广到几个集群的情况如果我们选择其他起始近似值会怎样? 结论在 sklearn 中的实现 如何处理已发现的问题?层次聚类Lance-Williams 算法Lance-Williams 公式在Scipy中实现 示例DBSCANDBSCAN 算法 聚类…...

深度学习中的数据增强:提升食物图像分类模型性能的关键策略
深度学习中的数据增强:提升食物图像分类模型性能的关键策略 在深度学习领域,数据是模型训练的基石,数据的数量和质量直接影响着模型的性能表现。然而,在实际项目中,获取大量高质量的数据往往面临诸多困难,…...

QT设计权限管理系统
Qt能够简单实现系统的权限设计 首先我们需要一个登陆界面 例如这样 然后一级权限,可以看到所有的内容,不设置菜单栏的隐藏。 然后其他权限,根据登陆者的身份进行菜单栏不同的展示。 菜单栏的隐藏代码如下: ui->actionuser-…...

从上帝视角看文件操作
1.为什么使用文件? 如果没有文件,我们写的程序中的数据是存储在电脑的内存中,当程序退出时,内存被回收后,数据就丢失了,等下次运行程序,是无法看到上次程序的数据的。(比如我们在程序中写通讯录时,联系人的相关数据都是放在内存中的,当程序退出时,这些数据也会随之消…...

【51单片机6位数码管显示时间与秒表】2022-5-8
缘由数码管 keil proteus 为什么出现这种情况呢?-编程语言-CSDN问答 #include "reg52.h" unsigned char code smgduan[]{0x3f,0x06,0x5b,0x4f,0x66,0x6d,0x7d,0x07,0x7f,0x6f,0x77,0x7c,0x39,0x5e,0x79,0x71,0,64}; //共阴0~F消隐减号 unsigned char cod…...

从头训练小模型: 4 lora 微调
1. LoRA (Low-Rank Adaptation) LoRA是一种高效的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,原理是通过低秩分解的方式对预训练模型进行微调。 相比于全参数微调(Full Fine-Tuning),LoRA…...

前端开发,文件在镜像服务器上不存在问题:Downloading binary from...Cannot download...
问题与处理策略 问题描述 在 Vue 项目中,执行 npm i 下载依赖时,报如下错误 Downloading binary from https://npm.taobao.org/mirrors/node-sass//v4.14.1/win32-x64-72_binding.node Cannot download "https://npm.taobao.org/mirrors/node-sa…...

Debezium Binlog协议与事件转换详解
Debezium Binlog协议与事件转换详解 1. MySQL Binlog通信机制 1.1 连接建立流程 #mermaid-svg-eE88YFqcTG9kUWaZ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-eE88YFqcTG9kUWaZ .error-icon{fill:#552222;}#mer…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】4.1 日期时间标准化(时区转换/格式统一)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL数据分析实战:数据清洗之日期时间标准化(时区转换/格式统一)4.1 日期时间标准化:从混乱到有序4.1.1 数据乱象&…...
)
基于Hive + Spark离线数仓大数据实战项目(视频+课件+代码+资料+笔记)
精品推荐:基于Hive Spark离线数仓大数据实战项目,共23节课,供学习参考。 项目介绍项目中 docker 使用项目环境搭建项目数仓分层项目业务分析sqoop 数据采集python 数据采集项目 ODS 层创建DWD 层构建DWS 层构建项目回顾(一&…...

【深入浅出MySQL】之数据类型介绍
【深入浅出MySQL】之数据类型介绍 MySQL中常见的数据类型一览为什么需要如此多的数据类型数值类型BIT(M)类型INT类型TINYINT类型BIGINT类型浮点数类型float类型DECIMAL(M,D)类型区别总结 字符串类型CHAR类型VARCHAR(M)类型 日期和时间类型enum和set类型 …...
从入门到登峰-嵌入式Tracker定位算法全景之旅 Part 4 |IMU 死算与校正:惯性导航在资源受限环境的落地
Part 4 |IMU 死算与校正:惯性导航在资源受限环境的落地 本章聚焦 ESP32-S3 平台上如何利用 LSM6DS3 IMU 实现 死算(Dead Reckoning),并结合 零速更新(ZUPT) 或 磁力计辅助 进行 漂移校正,最终通过 EKF/UKF 融合提升定位精度。 一、传感器简介与校准 LSM6DS3 主要参数 加速…...

【iOS】 方法交换
【iOS】 方法交换 method-swizzling 文章目录 【iOS】 方法交换 method-swizzling前言什么是method-swizzling相关API方法交换的风险在load方法中保证只加载一次要在当前类的方法中进行交换如果方法依赖于cmd 方法交换的应用 前言 之前看过有关于消息转发的内容,这里我们可以简…...

PostgreSQL 的 ANALYZE 命令
PostgreSQL 的 ANALYZE 命令 ANALYZE 是 PostgreSQL 中用于收集数据库对象统计信息的关键命令,这些统计信息对于查询优化器生成高效执行计划至关重要。 一 ANALYZE 命令 1.1 基本语法 ANALYZE [ ( option [, ...] ) ] [ table_and_columns [, ...] ] ANALYZE [ …...

初识 iOS 开发中的证书固定
引言 在移动应用安全领域,HTTPS/TLS 是数据传输的第一道防线,但仅依赖系统默认的证书验证仍有被中间人(MITM)攻击的风险。Certificate Pinning(证书固定)通过将客户端信任“钉”在指定的服务器证书或公钥上…...
)
2025 年如何使用 Pycharm、Vscode 进行树莓派 Respberry Pi Pico 编程开发详细教程(更新中)
micropython 概述 micropython 官方网站:https://www.micropython.org/ 安装 Micropython 支持固件 树莓派 Pico 安装 Micropython 支持固件 下载地址:https://www.raspberrypi.com/documentation/microcontrollers/ 选择 MicroPython 下载 RPI_PIC…...
完整讲解与实战应用)
设计模式每日硬核训练 Day 17:中介者模式(Mediator Pattern)完整讲解与实战应用
🔄 回顾 Day 16:责任链模式小结 在 Day 16 中,我们学习了责任链模式(Chain of Responsibility Pattern): 将请求沿链传递,节点可选择处理或传递下一节点。实现了请求发送者与多个处理者的解耦…...
)
文章记单词 | 第63篇(六级)
一,单词释义 vegetable [ˈvedʒtəbl] n. 蔬菜;植物人;生活单调乏味的人;adj. 蔬菜的;植物的faint [feɪnt] adj. 模糊的;微弱的;虚弱的;v. 昏倒,昏厥;n. 昏…...

ES类的索引轮换
通过以下请求方法创建一个名为 “tiered-storage-policy” 的 ISM policy: PUT _plugins/_ism/policies/tiered-storage-policy {"policy": {"description": "Changes replica count and deletes.","schema_version": 1,…...

小白机器人假想:分布式关节控制——机器人运动的未来模式?
引言 在机器人技术快速发展的今天,控制架构的创新往往能带来突破性进展。作为一名机器人爱好者,我最近思考了一个大胆的设想:如果机器人的每个关节都配备独立的动作存储器和处理器,并通过高速光纤网络与中央"驱动总脑"…...

LangChain4j +DeepSeek大模型应用开发——9 优化硅谷小鹿
1.预约业务的实现 这部分我们实现硅谷小鹿的查询订单、预约订单、取消订单的功能 创建MySQL数据库表 CREATE DATABASE xiaolu; USE xiaolu; -- 创建预约表 appointment CREATE TABLE appointment (id BIGINT NOT NULL AUTO_INCREMENT COMMENT 主键ID,自增, -- 主…...

Oracle VirtualBox 在 macOS 上的详细安装步骤
Oracle VirtualBox 在 macOS 上的详细安装步骤 一、准备工作1. 系统要求2. 下载安装包二、安装 VirtualBox1. 挂载安装镜像2. 运行安装程序3. 处理安全限制(仅限首次安装)三、安装扩展包(增强功能)四、配置第一个虚拟机1. 创建新虚拟机2. 分配内存3. 创建虚拟硬盘4. 加载系…...

Day110 | 灵神 | 二叉树 | 根到叶路径上的不足节点
Day110 | 灵神 | 二叉树 | 根到叶路径上的不足节点 1080.根到叶路径上的不足节点 1080. 根到叶路径上的不足节点 - 力扣(LeetCode) 思路: 笔者一开始没看懂,只能通过部分的例子,原因是把路径和小于limit的都给删了…...

超详细讲解C语言转义字符\a \b \r \t \? \n等等
转义字符 C语言有一组字符很特殊,叫做转义字符,顾名思义,改变原来的意思的字符。 1 \? ??)是一个三字母词,在以前的编译器它会被编译为] (??会被编译为[ 因此在以前输入(are you ok ??)就会被编译为are you ok ] 解决这个…...

TensorFlow 多卡训练 tf多卡训练
目录 export TF_GPU_ALLOCATORcuda_malloc_async 🔧 具体作用 优势 🧩 依赖条件 ✅ 设置方式(Linux/macOS) export TF_GPU_ALLOCATORcuda_malloc_async 是设置 TensorFlow 使用 CUDA 异步内存分配器 的环境变量。这个设置可…...

数据结构--树状数组
树状数组(Fenwick Tree) 概述 树状数组是一种用于高效处理动态数组中前缀和查询的数据结构。它能够在 O ( l o g n ) O(log n) O(logn) 时间复杂度内完成以下操作: 更新数组中的元素O(logn)查询数组前缀和O(logn) 数组: O(1)…...

如何使用python保存字典
在Python中,可以通过多种方式将字典(dict)保存到文件中,并能够随时读取恢复。以下是几种常见的方法: 1. 使用 json 模块(推荐) 适用场景:需要人类可读的文件格式,且数据不…...

C和指针——预处理
预处理是编译前的过程,主要对define,include以及一些编译器定义的内容进行替换 #define的本质就是替换 1、例子 #define FOREVER for(;;) 2、例子 #define TEMPD "1231231231\ 123123123" \\如果太长了,可以用\换行 3、例子——可…...

windows python ta-lib安装
https://github.com/TA-Lib/ta-lib/releases windows安装ta-lib指令 pip install --no-cache-dir https://github.com/cgohlke/talib-build/releases/download/v0.6.3/ta_lib-0.6.3-cp310-cp310-win_amd64.whl...

机器学习+多目标优化的算法如何设计?
一、核心问题与设计思路 机器学习(ML)与多目标优化(MOO)的结合旨在解决两类核心问题: 利用ML提升MOO算法的性能:通过机器学习模型预测解的质量、优化搜索方向或加速收敛;利用MOO优化ML模型的多…...

爬虫管理平台-最新版本发布
TaskPyro 是什么? TaskPyro 是一个轻量级的 Python 任务调度平台,专注于提供简单易用的任务管理和爬虫调度解决方案。它能够帮助您轻松管理和调度 Python 任务,特别适合需要定时执行的爬虫任务和数据处理任务。 官方文档:https:/…...

SpringCloud教程 — 无废话从0到1逐步学习
目录 什么是微服务? 微服务与单体架构的区别 微服务主要用法概念 远程调用 服务注册/发现&注册中心 配置中心 服务熔断&服务降级 1)服务熔断 2)服务降级 API 网关 环境准备 Nacos OpenFeign Gateway Sentinel Sea…...
)
Webug4.0通关笔记12- 第17关 文件上传之前端拦截(3种方法)
目录 一、文件上传前端拦截原理 二、第17关 文件上传(前端拦截) 1.打开靶场 2.构造php脚本 3.源码分析 (1)js源码 (2)服务器源码 (3)总结 4.渗透实战 (1)禁用js法 &#…...